
Прогнозирование временных рядов с использованием нейронных сетей LSTM: Нормализация цены и токенизация времени
Введение
Изучая применение нейронных сетей при разработке торговых стратегий, я посмотрел несколько видеороликов на YouTube. Большинство из них начинались с очень базового уровня, например, с программирования на Python - использования строк, массивов, ООП и прочих основ. К тому времени, как преподаватель доходил до сути курса — нейронных сетей и машинного обучения, — я уже понимал, что он просто объяснит, как использовать определенную библиотеку или предварительно обученную модель, не объясняя, как они работают. После долгих поисков я наконец наткнулся на видеоролики Andrej Karpathy, которые оказались весьма познавательными. В частности, его видеоролик "Let's build GPT: from scratch, in code, spelled out" (создаем GPT: с нуля, с кодом, с деталями) позволил мне увидеть, как можно связать простые математические концепции с кодом и оживить почти человеческий интеллект всего с помощью нескольких сотен строк кода. Видео открыло для меня мир нейронных сетей относительно интуитивно понятным и практичным способом, позволив мне ощутить их силу на собственном опыте. Объединив базовые знания, полученные на его видеоканале, с сотнями запросов ChatGPT (чтобы понять, как они работают, как их писать на Python и т. д.), мне удалось разработать методологию использования нейронных сетей для составления прогнозов и создания советников. В этой статье я хотел бы не только задокументировать этот путь, но и показать, чему я научился, а также то, как можно использовать простую нейронную сеть, такую как LSTM (long short-term memory, долгая краткосрочная память), для составления рыночных прогнозов.
Обзор LSTM
Когда я начал искать информацию в Интернете, я наткнулся на несколько статей, описывающих использование LSTM для прогнозирования временных рядов. В частности, я нашел пост в блоге Кристофера Олаха (Christopher Olah) "Understanding LSTM Networks" (О сетях LSTM). В своем блоге Олах объясняет структуру и функции LSTM, сравнивает их со стандартными рекуррентными нейронными сетями (RNN, recurrent neural network) и обсуждает различные варианты LSTM, например, с глазковыми соединениями (peephole connections) или управляемыми рекуррентными нейронами (gated recurrent units, GRU). В заключение Олах подчеркивает значительное влияние LSTM на применение RNN и указывает на потенциальные будущие усовершенствования, такие как механизмы внимания.
По сути, традиционные нейронные сети испытывают трудности с задачами, требующими контекста из предыдущих входных данных, из-за отсутствия у них памяти. RNN решают эту проблему с помощью циклов, которые позволяют информации сохраняться, но они по-прежнему сталкиваются с трудностями, связанными с долгосрочными зависимостями. Например, предсказание следующего слова в предложении, где релевантный контекст находится на много слов назад, может быть сложной задачей для стандартных RNN. Сети LSTM - это разновидность RNN, разработанная для лучшей обработки долгосрочных зависимостей, отсутствующих в RNN.
LSTM-сети решают эту проблему, используя более сложную архитектуру, которая включает состояние ячейки и три типа ворот - входные (input), забывания (forget) и выходные (output), которые регулируют поток информации. Такая конструкция позволяет LSTM-сетям запоминать информацию в течение длительного времени, что делает их весьма эффективными для таких задач, как моделирование языка, распознавание речи и создание подписей к изображениям. Мне было интересно узнать, могут ли LSTM-сети помочь предсказать сегодняшнее ценовое движение на основе предыдущего в дни с аналогичным ценовым движением, учитывая что они обладают естественной способностью запоминать информацию в течение более длительных периодов времени. Я наткнулся на полезную статью Эдриана Тэма (Adrian Tam) "LSTM for Time Series Prediction in PyTorch" (применение LSTM для прогнозирования временных рядов в PyTorch), которая прояснила для меня математическую и программную стороны вопроса благодаря практическому примеру. Я почувствовал себя достаточно уверенно, чтобы взяться за задачу и применить полученные знания в попытке предсказать будущее движение цены для любой заданной валютной пары.
Токенизация и нормализация
Я разработал метод токенизации времени в течение определенного дня и нормализации цены для определенного периода времени в течение дня для обучения нейронной сети. Затем я нашел способ использовать обученную нейронную сеть для составления прогнозов и, наконец, денормализовать прогноз, чтобы получить прогноз будущей цены. Этот подход был вдохновлен видеороликом о ChatGPT, упомянутом во введении. Аналогичная стратегия используется большими языковыми моделями (large language models, LLM) для преобразования текстовых строк в числовые и векторные представления с целью обучения нейронных сетей обработке языка и генерации ответов. В моем случае, при работе с ценой, я хотел, чтобы входные данные в нейронной сети были регулярно связаны с максимумом или минимумом данного дня. Стратегия нормализации и токенизации, которую я использовал, приведена в скрипте ниже и кратко выглядит так:
Токенизация времени
-
Преобразование в секунды: Скрипт берет столбец времени (в формате datetime) и преобразует его в общее количество секунд, прошедших с начала дня. Этот расчет включает часы, минуты и секунды.
-
Нормализация к доле дня: Полученное количество секунд затем делится на общее количество секунд в сутках (86 400). Полученный time_token представляет время как часть дня. Например, полдень будет составлять 0,5 или 50% завершенного дня.
Ежедневная нормализация повторяющихся максимумов/минимумов цены
-
Группировка по дате: Данные сгруппированы по столбцу даты, чтобы гарантировать, что нормализация происходит независимо для каждого торгового дня.
-
Расчет повторяющегося (rolling) максимума/минимума:
- Для каждой группы (дня), скрипт вычисляет растущий максимум (rolling_high) и растущий минимум (rolling_low) максимальной и минимальной цен соответственно. Это означает, что повторяющийся максимум/минимум увеличивается/уменьшается только по мере поступления новых данных в течение дня.
-
Нормализация:
- Цены открытия, максимума, минимума и закрытия нормализуются с использованием формулы: normalized_price = (price - rolling_low) / (rolling_high - rolling_low)
- Это масштабирует каждую цену в диапазоне от 0 до 1 относительно самой высокой и самой низкой цены, зафиксированной на данный момент в этот день.
- Нормализация выполняется ежедневно, что гарантирует регистрацию ценовых взаимоотношений в течение каждого дня и исключает влияние на нормализацию колебаний цен в течение нескольких дней.
-
Обработка нечисловых значений (NaN): значения NaN могут возникать в начале дня до установления повторяющегося максимума/минимума. Я рассмотрел три разных подхода к решению этой проблемы. Первый заключался в их удалении, второй — в предварительном заполнении, а третий — в замене их нулями. После долгих испытаний и трудностей с их удалением я решил заменить их нулями, поскольку в конечном итоге моя цель — преобразовать процесс в конвейер обработки данных в формате ONNX (Open Neural Network Exchange), который можно использовать напрямую с MQL5 для прогнозирования без копирования кода. Я пришел к выводу, что ONNX относительно негибок в плане форм входных и выходных данных, а отбрасывание значений NaN изменяет форму выходного вектора, что приводит к непредвиденным ошибкам при использовании ONNX в MQL. Я попытался использовать метод предварительного заполнения (forward filling), чтобы также заменить NaN, но это метод Pandas/NumPy, и его неудобно переводить в Torch, библиотеку, которую я в основном использовал для преобразования своей модели нейронной сети в ONNX. В конце концов я решил просто заменить NaN нулями. Похоже, это сработало лучше всего, позволив мне обойти проблему форм переменных, создать конвейер для всей обработки данных и реализовать его в MQL через ONNX, тем самым оптимизировав весь процесс получения прогноза в MQL.
В целом нормализация выполняется ежедневно, что гарантирует регистрацию ценовых взаимоотношений в течение каждого дня и исключает влияние на нормализацию колебаний цен в течение нескольких дней. Это позволяет выравнивать цены по одинаковой шкале, предотвращая смещение модели в сторону характеристик с большими величинами. Это также помогает адаптироваться к меняющейся волатильности в течение каждого дня.
Приведенный ниже код помогает визуализировать описанный выше процесс. Код можно найти в приложенном zip-файле в папке "Visualizing the Normalization and Tokenization Process" (визуализация нормализации и токенизации). Файл называется "visualizing.py"
import torch import torch.nn as nn import numpy as np import pandas as pd from sklearn.preprocessing import MinMaxScaler import MetaTrader5 as mt5 import matplotlib.pyplot as plt import joblib # Connect to MetaTrader 5 if not mt5.initialize(): print("Initialize failed") mt5.shutdown() # Load market data symbol = "EURUSD" timeframe = mt5.TIMEFRAME_M15 rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 96) # Note: 96 represents 1 day or 15*96= 1440 minutes of data (there are 1440 minutes in a day) mt5.shutdown() # Convert to DataFrame data = pd.DataFrame(rates) data['time'] = pd.to_datetime(data['time'], unit='s') data.set_index('time', inplace=True) # Tokenize time data['time_token'] = (data.index.hour * 3600 + data.index.minute * 60 + data.index.second) / 86400 # Normalize prices on a rolling basis resetting at the start of each day def normalize_daily_rolling(data): data['date'] = data.index.date data['rolling_high'] = data.groupby('date')['high'].transform(lambda x: x.expanding(min_periods=1).max()) data['rolling_low'] = data.groupby('date')['low'].transform(lambda x: x.expanding(min_periods=1).min()) data['norm_open'] = (data['open'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_high'] = (data['high'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_low'] = (data['low'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_close'] = (data['close'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) # Replace NaNs with zeros data.fillna(0, inplace=True) return data # Visualize the price before normalization plt.figure(figsize=(15, 10)) plt.subplot(3, 1, 1) data['close'].plot() plt.title('Close Prices') plt.xlabel('Time') plt.ylabel('Price') data = normalize_daily_rolling(data) # Check for NaNs in the data if data.isnull().values.any(): print("Data contains NaNs") print(data.isnull().sum()) # Drop unnecessary columns data = data[['time_token', 'norm_open', 'norm_high', 'norm_low', 'norm_close']] # Visualize the normalized price plt.subplot(3, 1, 2) data['norm_close'].plot() plt.title('Normalized Close Prices') plt.xlabel('Time') plt.ylabel('Normalized Price') # Visualize Time After Tokenization plt.subplot(3, 1, 3) data['time_token'].plot() plt.title('Time Token') plt.xlabel('Time') plt.ylabel('Time Token') plt.tight_layout() plt.show()
Если вы запустите приведенный выше код, вы увидите предложенный мной подход в действии. На графике ниже представлены цены за весь торговый день 12.06.2024, переходящий в 13.06.2024. В этот день были опубликованы данные по индексу потребительских цен (Consumer Price Index, CPI) и состоялось заседание ФРС — два важных новостных события в один день, что случается относительно редко. Вы можете видеть, что маркер времени сбрасывается в конце каждого дня и линейно увеличивается в течение дня. Цена также сбрасывается, но это немного сложнее увидеть на графиках. Каждый раз, когда формируется новый максимум, значение нормализованных цен закрытия становится равным 1. Когда формируется новый минимум, значение нормализованных цен закрытия становится равным 0.

Краткое описание этапов обучения и проверки
Приведенный ниже код обучает модель LSTM для прогнозирования цен, уделяя особое внимание валютной паре EURUSD. Пользователь может изменить EURUSD на любую другую пару, с которой он хочет работать.
Подготовка данных
- Извлечение данных: Подключиться к платформе MetaTrader 5 для получения исторических данных о ценах (максимум, минимум, открытие, закрытие) для EURUSD M15. Опять же, вы можете выбрать любой предпочитаемый вами таймфрейм.
- Предварительная обработка данных:
- Преобразовать данные в Pandas DataFrame, установить временную метку в качестве индекса.
- Создать функцию time_token для представления времени как части суток.
- Нормализовать цены в течение каждого дня на основе повторяющихся максимумов/минимумов для учета ежедневных колебаний.
- Обработать отсутствующие значения (NAN), заменяя их нулями.
- Удалить ненужные столбцы, такие как тиковые объемы, реальный объем и спред.
- Создание последовательностей: Структурирует данные в последовательности из 60 временных шагов, где каждая последовательность становится входными данными (X), а следующая цена закрытия — целью (y).
- Разделение данных: Разделить последовательности на обучающий (80%) и тестовый (20%) наборы.
- Преобразование в тензоры: Преобразовать данные в тензоры PyTorch для совместимости моделей.
Определение и обучение модели
- Определение LSTM-модели: Создать класс для LSTM-модели:
- Слой LSTM, который обрабатывает данные последовательности.
- Линейный слой, который создает окончательный прогноз.
- Внутренние переменные состояния для LSTM.
- Настройка обучения:
- Определить среднеквадратичную ошибку (Mean Squared Error, MSE) как функцию потерь, которую необходимо минимизировать.
- Использовать оптимизатор Adam для корректировки весов модели.
- Установить случайное начальное число для воспроизводимости.
- Тренировка модели:
- Выполнить более 100 итераций (полных проходов по обучающим данным).
- Для каждой последовательности в обучающем наборе:
- Сбросить скрытое состояние LSTM.
- Пропустить последовательность через модель для получения прогноза.
- Рассчитать среднеквадратичную потерю между прогнозируемым и истинным значением.
- Обратное распространение для обновления весов модели.
- Выводить потери каждые 10 эпох.
- Сохранение модели: Сохранить параметры обученной модели. Файл сохраняется под именем lstm_model.pth в той же папке, которая использовалась для запуска файла LSTM_model_training.py. Также необходимо преобразовать модель в формат ONNX для использования напрямую с MQL5. ONNX-файл называется lstm_model.onnx. Примечание: форма вектора, необходимая для прогнозирования, - seq_length, 1, input_size. Это 60, 1, 5, что указывает на то, что требуются 60 предыдущих баров 15-минутных данных в качестве 1 пакета с 5 значениями (time_token, norm_open, norm_high, norm_low и norm_close), все из которых находятся в диапазоне от 0 до 1. Мы воспользуемся этими данными далее в статье для создания конвейера обработки данных в ONNX для использования с нашей моделью.
Оценка
- Генерация прогнозов:
- Перевести модель в режим оценки.
- Пройтись по последовательностям в тестовом наборе и сгенерировать прогнозы.
- Визуализация результатов:
- Показать истинные и прогнозируемые нормализованные цены.
- Рассчитать и показать процентное изменение цен как для истинных, так и для прогнозируемых значений.
Выбор параметров модели:
- Большая часть этого кода написана с целью поиска внутридневных тенденций. Однако его можно легко адаптировать к другим временным интервалам, например, недельным, месячным и т. д. Единственной проблемой для меня была доступность данных. В противном случае я мог бы расширить код, включив в него и некоторые другие временные рамки.
- Я решил работать с 15-минутным таймфреймом, поскольку мог получить около 80 000 баров данных для загрузки в свою нейронную сеть. Это примерно 3 года торговых данных (исключая выходные), которых оказалось вполне достаточно для построения хорошей нейронной сети LSTM, которая пытается предсказать внутридневное ценовое движение.
- Общей основой модели являются следующие пять параметров: time_token, norm_open, norm_high, norm_low и norm_close. Поэтому input_size = 5. Я решил проигнорировать еще три параметра: тиковые объемы, реальные объемы и спред. Я исключил тиковые объемы, поскольку не смог найти достаточно надежный источник данных, чтобы гарантировать их достоверность. Я исключил реальные объемы, так как у моего брокера они отсутствуют и всегда отображаются как нулевые. Наконец, я исключил спред, поскольку данные были получены с демо-счета, поэтому они не соответствуют спредам брокера на реальном счете.
- Количество скрытых слоев было выбрано равным 100. Это произвольное значение, которое я выбрал и которое, как мне показалось, работает хорошо.
- output_size = 1, поскольку эта модель разработана таким образом, что нас интересует только прогноз для следующего 15-минутного бара.
- Я выделил 80% на обучение и 20% на тестирование. Это также произвольный выбор. Некоторые люди предпочитают соотношение 50:50, другие — 70:30. Я не был уверен, поэтому решил использовать соотношение 80:20.
- Я выбрал начальное значение (seed) равным 42. Моей главной целью было добиться некоторой воспроизводимости результатов от одного испытания к другому. Поэтому я указал начальное значение, чтобы иметь возможность сравнивать результаты на равной основе, если я решу поиграться с какими-либо параметрами в будущем.
- Я выбрал значение скорости обучения равным 0,001. Это опять же произвольный выбор. Пользователь может свободно устанавливать скорость обучения по своему усмотрению.
- Я выбрал длину последовательности (seq_length) равной 60. По сути, это количество баров "контекста", необходимое модели LSTM для прогнозирования следующего бара. Это также был произвольный выбор. 60 * 15 минут = 900 минут или 15 часов. Это довольно много времени для получения контекста и возможности предсказать один 15-минутный бар. У меня нет веских оснований для выбора этого значения. Однако модель гибкая, и пользователи могут изменять эти значения по своему усмотрению.
- Время обучения: 100 эпох было выбрано потому, что для запуска модели с 80 000 баров на моем компьютере потребовалось бы около 8 часов. Для обучения я использовал центральный процессор. Во время написания статьи я внес несколько усовершенствований в свой код и мне пришлось перезапускать модель несколько раз. Так что 8 часов - это то время, которое я мог позволить себе на тренировку модели.
import torch import torch.nn as nn import numpy as np import pandas as pd import MetaTrader5 as mt5 import matplotlib.pyplot as plt import torch.onnx import torch.nn.functional as F # Connect to MetaTrader 5 if not mt5.initialize(): print("Initialize failed") mt5.shutdown() # Load market data symbol = "EURUSD" timeframe = mt5.TIMEFRAME_M15 rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 80000) mt5.shutdown() # Convert to DataFrame data = pd.DataFrame(rates) data['time'] = pd.to_datetime(data['time'], unit='s') data.set_index('time', inplace=True) # Tokenize time data['time_token'] = (data.index.hour * 3600 + data.index.minute * 60 + data.index.second) / 86400 # Normalize prices on a rolling basis resetting at the start of each day def normalize_daily_rolling(data): data['date'] = data.index.date data['rolling_high'] = data.groupby('date')['high'].transform(lambda x: x.expanding(min_periods=1).max()) data['rolling_low'] = data.groupby('date')['low'].transform(lambda x: x.expanding(min_periods=1).min()) data['norm_open'] = (data['open'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_high'] = (data['high'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_low'] = (data['low'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_close'] = (data['close'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) # Replace NaNs with zeros data.fillna(0, inplace=True) return data data = normalize_daily_rolling(data) # Check for NaNs in the data if data.isnull().values.any(): print("Data contains NaNs") print(data.isnull().sum()) # Drop unnecessary columns data = data[['time_token', 'norm_open', 'norm_high', 'norm_low', 'norm_close']] # Create sequences def create_sequences(data, seq_length): xs, ys = [], [] for i in range(len(data) - seq_length): x = data.iloc[i:(i + seq_length)].values y = data.iloc[i + seq_length]['norm_close'] xs.append(x) ys.append(y) return np.array(xs), np.array(ys) seq_length = 60 X, y = create_sequences(data, seq_length) # Split data split = int(len(X) * 0.8) X_train, X_test = X[:split], X[split:] y_train, y_test = y[:split], y[split:] # Convert to tensors X_train = torch.tensor(X_train, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32) X_test = torch.tensor(X_test, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.float32) # Set the seed for reproducibility seed_value = 42 torch.manual_seed(seed_value) # Define LSTM model class class LSTMModel(nn.Module): def __init__(self, input_size, hidden_layer_size, output_size): super(LSTMModel, self).__init__() self.hidden_layer_size = hidden_layer_size self.lstm = nn.LSTM(input_size, hidden_layer_size) self.linear = nn.Linear(hidden_layer_size, output_size) def forward(self, input_seq): h0 = torch.zeros(1, input_seq.size(1), self.hidden_layer_size).to(input_seq.device) c0 = torch.zeros(1, input_seq.size(1), self.hidden_layer_size).to(input_seq.device) lstm_out, _ = self.lstm(input_seq, (h0, c0)) predictions = self.linear(lstm_out.view(input_seq.size(0), -1)) return predictions[-1] print(f"Seed value used: {seed_value}") input_size = 5 # time_token, norm_open, norm_high, norm_low, norm_close hidden_layer_size = 100 output_size = 1 model = LSTMModel(input_size, hidden_layer_size, output_size) #model = torch.compile(model) loss_function = nn.MSELoss() optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # Training epochs = 100 for epoch in range(epochs + 1): for seq, labels in zip(X_train, y_train): optimizer.zero_grad() y_pred = model(seq.unsqueeze(1)) # Ensure both are tensors of shape [1] y_pred = y_pred.view(-1) labels = labels.view(-1) single_loss = loss_function(y_pred, labels) # Print intermediate values to debug NaN loss if torch.isnan(single_loss): print(f'Epoch {epoch} NaN loss detected') print('Sequence:', seq) print('Prediction:', y_pred) print('Label:', labels) single_loss.backward() optimizer.step() if epoch % 10 == 0 or epoch == epochs: # Include the final epoch print(f'Epoch {epoch} loss: {single_loss.item()}') # Save the model's state dictionary torch.save(model.state_dict(), 'lstm_model.pth') # Convert the model to ONNX format model.eval() dummy_input = torch.randn(seq_length, 1, input_size, dtype=torch.float32) onnx_model_path = "lstm_model.onnx" torch.onnx.export(model, dummy_input, onnx_model_path, input_names=['input'], output_names=['output'], dynamic_axes={'input': {0: 'sequence'}, 'output': {0: 'sequence'}}, opset_version=11) print(f"Model has been converted to ONNX format and saved to {onnx_model_path}") # Predictions model.eval() predictions = [] for seq in X_test: with torch.no_grad(): predictions.append(model(seq.unsqueeze(1)).item()) # Evaluate the model plt.plot(y_test.numpy(), label='True Prices (Normalized)') plt.plot(predictions, label='Predicted Prices (Normalized)') plt.legend() plt.show() # Calculate percent changes with a small value added to the denominator to prevent divide by zero error true_prices = y_test.numpy() predicted_prices = np.array(predictions) true_pct_change = np.diff(true_prices) / (true_prices[:-1] + 1e-10) predicted_pct_change = np.diff(predicted_prices) / (predicted_prices[:-1] + 1e-10) # Plot the true and predicted prices plt.figure(figsize=(12, 6)) plt.subplot(2, 1, 1) plt.plot(true_prices, label='True Prices (Normalized)') plt.plot(predicted_prices, label='Predicted Prices (Normalized)') plt.legend() plt.title('True vs Predicted Prices (Normalized)') # Plot the percent change plt.subplot(2, 1, 2) plt.plot(true_pct_change, label='True Percent Change') plt.plot(predicted_pct_change, label='Predicted Percent Change') plt.legend() plt.title('True vs Predicted Percent Change') plt.tight_layout() plt.show()
Результаты оценки модели
Время обучения составило около 8 часов на 100 эпох. Модель не обучалась с использованием графического процессора. Я использовал свой собственный ПК — игровую машину возрастом 4 года со следующими характеристиками: AMD Ryzen 5 4600H с графикой Radeon Graphics 3.00 GHz и установленной оперативной памятью объемом 64 ГБ.
Начальное значение и потери среднеквадратической ошибки для каждых 10 эпох выводятся на консоль.
- Seed value used: 42
- Epoch 0 loss: 0.01435865368694067
- Epoch 10 loss: 0.014593781903386116
- Epoch 20 loss: 0.02026239037513733
- Epoch 30 loss: 0.017134636640548706
- Epoch 40 loss: 0.017405137419700623
- Epoch 50 loss: 0.004391830414533615
- Epoch 60 loss: 0.0210900716483593
- Epoch 70 loss: 0.008576949127018452
- Epoch 80 loss: 0.019675739109516144
- Epoch 90 loss: 0.008747504092752934
- Epoch 100 loss: 0.033280737698078156
В конце обучения я получил предупреждение, показанное ниже. Предупреждение предлагает указать модель другим способом. Повозившись с предупреждением, я в конце концов решил игнорировать его, поскольку последовательности в пакете не будут иметь разной длины.

Дополнительно генерируются следующие графики:
 цены")
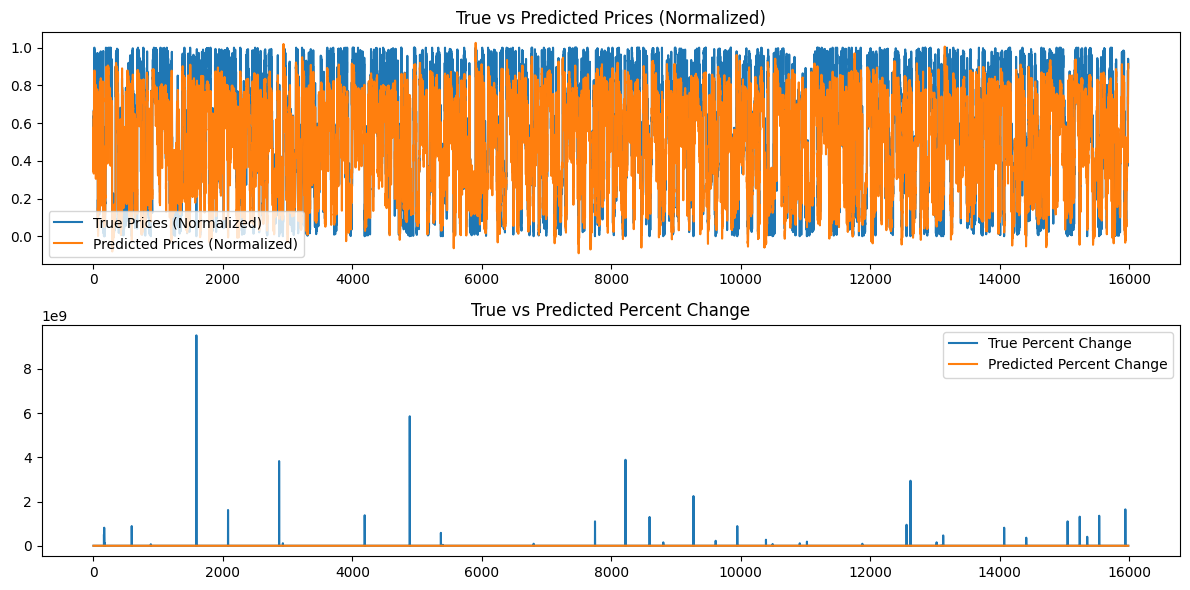
Анализ результатов модели
Потери эпох для начального значения 42, по-видимому, уменьшаются неравномерно. Поскольку они не являются монотонными, возможно, модель могла бы выиграть от дальнейшего обучения. В качестве альтернативы пользователь может рассмотреть возможность предоставления другого начального значения или использования случайного начального значения, автоматически сгенерированного библиотекой Torch в Python, и вывода этого значения с помощью команды torch.seed(). Кроме того, производительность модели может также улучшиться, если увеличить объем доступных данных, однако при этом пользователь может столкнуться с дополнительными вычислительными затратами, связанными с более длительным временем обучения и большими требованиями к аппаратной памяти.
Созданные графики представляют собой попытку обобщить более 16000 баров 15-минутных данных. Графическая система, которую я использовал, не очень эффективна, поскольку большая часть данных становится сжатой и ее трудно оценить. Эти графики являются более "глобальными" представлениями всего прошедшего обучения. В таком виде они не представляют никакой ценности. Я включил их для справки, поскольку я обучал модель и на меньших наборах данных. Там они оказались полезными, а вот для 80 000 баров - нет. Мы рассмотрим эту проблему в следующем разделе, когда попытаемся сделать прогнозы на основе нашей сгенерированной модели, а данные будут представлять собой "локальное" представление, то есть ежедневное изменение цены. В следующем разделе мы создадим непрерывный прогноз на основе нашей модели, используя длину нашей последовательности 60 и добавив еще 100 баров (всего 160 баров 15-минутных данных), а также непрерывный прогноз от бара 100 до 0, а затем представим его на графике, который, возможно, будет более наглядным.
Прогнозирование с помощью обученной модели (с использованием Python)
Для создания скрипта прогнозирования в идеале нам следует использовать последние 60 значений из данных EURUSD на 15-минутном таймфрейме, чтобы сделать прогноз с использованием сохраненной модели LSTM. Однако я посчитал, что будет лучше получить повторяющийся прогноз вместе с графиком на Python, чтобы я мог быстро проверить модель перед ее использованием. Ниже приведены основные особенности скрипта прогнозирования для Python. Краткое содержание скрипта приведено ниже:
-
Определение модели LSTM: Скрипт определяет структуру модели LSTM. Модель состоит из слоя LSTM, за которым следует линейный слой. Это идентично тому, что мы использовали для обучения модели в приведенном выше скрипте обучения.
-
Подготовка данных:
- Подключение к MetaTrader 5 для получения последних 160 баров (15-минутные интервалы) данных по EURUSD. Хотя для составления прогноза нам нужно всего 60 баров 15-минутных данных, для составления прогноза мы возьмем 160 баров и сравним последние 100 прогнозов. Это даст нам некоторое представление о базовой тенденции прогнозируемых и фактических значений.
- Данные преобразуются в pandas DataFrame и нормализуются с использованием того же метода повторяющейся нормализации, который использовался во время обучения.
- Токенизация времени применяется для преобразования времени в число.
-
Загрузка модели:
- Загрузка обученной модели LSTM (из lstm_model.pth).
-
Оценка:
- Скрипт выполняет итерацию по последним 100 шагам данных.
- На каждом шаге в качестве входных данных используются 60 предыдущих баров, а затем модель используется для прогнозирования нормализованной цены закрытия.
- Истинные и прогнозируемые цены сохраняются для сравнения.
-
Следующий прогноз:
- Делается прогноз для следующего шага с использованием последних 60 баров.
- Рассчитывается процентное изменение для этого прогноза.
- Прогноз отображается в виде красной точки на графике.
-
Визуализация:
- Создаются два графика:
- Истинные и прогнозируемые (нормализованные) цены с выделенным прогнозом.
- Истинное и прогнозируемое процентное изменение цены с выделенным прогнозом.
- Для лучшей визуализации значения по оси Y ограничены 100%.
- Создаются два графика:
Приведенный ниже код можно найти в файле LSTM_model_prediction.py, который находится в корне архива LSTM_Files.zip, прикрепленного к статье.
import torch import torch.nn as nn import numpy as np import pandas as pd import MetaTrader5 as mt5 import matplotlib.pyplot as plt # Define LSTM model class (same as during training) class LSTMModel(nn.Module): def __init__(self, input_size, hidden_layer_size, output_size): super(LSTMModel, self).__init__() self.hidden_layer_size = hidden_layer_size self.lstm = nn.LSTM(input_size, hidden_layer_size) self.linear = nn.Linear(hidden_layer_size, output_size) self.hidden_cell = (torch.zeros(1, 1, self.hidden_layer_size), torch.zeros(1, 1, self.hidden_layer_size)) def forward(self, input_seq): lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq), 1, -1), self.hidden_cell) predictions = self.linear(lstm_out.view(len(input_seq), -1)) return predictions[-1] # Normalize prices on a rolling basis resetting at the start of each day def normalize_daily_rolling(data): data['date'] = data.index.date data['rolling_high'] = data.groupby('date')['high'].transform(lambda x: x.expanding(min_periods=1).max()) data['rolling_low'] = data.groupby('date')['low'].transform(lambda x: x.expanding(min_periods=1).min()) data['norm_open'] = (data['open'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_high'] = (data['high'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_low'] = (data['low'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_close'] = (data['close'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) # Replace NaNs with zeros data.fillna(0, inplace=True) return data[['norm_open', 'norm_high', 'norm_low', 'norm_close']] # Load the saved model input_size = 5 # time_token, norm_open, norm_high, norm_low, norm_close hidden_layer_size = 100 output_size = 1 model = LSTMModel(input_size, hidden_layer_size, output_size) model.load_state_dict(torch.load('lstm_model.pth')) model.eval() # Connect to MetaTrader 5 if not mt5.initialize(): print("Initialize failed") mt5.shutdown() # Load the latest 160 bars of market data symbol = "EURUSD" timeframe = mt5.TIMEFRAME_M15 bars = 160 # 60 for sequence length + 100 for evaluation steps rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, bars) mt5.shutdown() # Convert to DataFrame data = pd.DataFrame(rates) data['time'] = pd.to_datetime(data['time'], unit='s') data.set_index('time', inplace=True) # Normalize the new data data[['norm_open', 'norm_high', 'norm_low', 'norm_close']] = normalize_daily_rolling(data) # Tokenize time data['time_token'] = (data.index.hour * 3600 + data.index.minute * 60 + data.index.second) / 86400 # Drop unnecessary columns data = data[['time_token', 'norm_open', 'norm_high', 'norm_low', 'norm_close']] # Fetch the last 100 sequences for evaluation seq_length = 60 evaluation_steps = 100 # Initialize lists for storing evaluation results all_true_prices = [] all_predicted_prices = [] model.eval() for step in range(evaluation_steps, 0, -1): # Get the sequence ending at 'step' seq = data.values[-step-seq_length:-step] seq = torch.tensor(seq, dtype=torch.float32) # Make prediction with torch.no_grad(): model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size), torch.zeros(1, 1, model.hidden_layer_size)) prediction = model(seq).item() all_true_prices.append(data['norm_close'].values[-step]) all_predicted_prices.append(prediction) # Calculate percent changes and convert to percentages true_pct_change = (np.diff(all_true_prices) / np.array(all_true_prices[:-1])) * 100 predicted_pct_change = (np.diff(all_predicted_prices) / np.array(all_predicted_prices[:-1])) * 100 # Make next prediction next_seq = data.values[-seq_length:] next_seq = torch.tensor(next_seq, dtype=torch.float32) with torch.no_grad(): model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size), torch.zeros(1, 1, model.hidden_layer_size)) next_prediction = model(next_seq).item() # Calculate percent change for the next prediction next_true_price = data['norm_close'].values[-1] next_price_pct_change = ((next_prediction - all_predicted_prices[-1]) / all_predicted_prices[-1]) * 100 print(f"Next predicted close price (normalized): {next_prediction}") print(f"Percent change for the next prediction based on normalized price: {next_price_pct_change:.5f}%") print("All Predicted Prices: ", all_predicted_prices) # Plot the evaluation results with capped y-axis plt.figure(figsize=(12, 8)) plt.subplot(2, 1, 1) plt.plot(all_true_prices, label='True Prices (Normalized)') plt.plot(all_predicted_prices, label='Predicted Prices (Normalized)') plt.scatter(len(all_true_prices), next_prediction, color='red', label='Next Prediction') plt.legend() plt.title('True vs Predicted Prices (Normalized, Last 100 Steps)') plt.ylim(min(min(all_true_prices), min(all_predicted_prices))-0.1, max(max(all_true_prices), max(all_predicted_prices))+0.1) plt.subplot(2, 1, 2) plt.plot(true_pct_change, label='True Percent Change') plt.plot(predicted_pct_change, label='Predicted Percent Change') plt.scatter(len(true_pct_change), next_price_pct_change, color='red', label='Next Prediction') plt.legend() plt.title('True vs Predicted Price Percent Change (Last 100 Steps)') plt.ylabel('Percent Change (%)') plt.ylim(-100, 100) # Cap the y-axis at -100% to 100% plt.tight_layout() plt.show()
Ниже представлены данные, выведенные в консоли, и полученные графики. Прогноз был создан в самом начале дня 14.06.2024 (приблизительное время брокера 00:45 UTC + 3)
Данные в консоли:
Следующая прогнозируемая цена закрытия (нормализованная): 0.9003118872642517
Процентное изменение для следующего прогноза на основе нормализованной цены: 73.64274%
All Predicted Prices: [0.6229779124259949, 0.6659790277481079, 0.6223553419113159, 0.5994003415107727, 0.565409243106842, 0.5767043232917786, 0.5080181360244751, 0.5245669484138489, 0.6399291753768921, 0.5184902548789978, 0.6269711256027222, 0.6532717943191528, 0.7470211386680603, 0.6783792972564697, 0.6942530870437622, 0.6399927139282227, 0.5649009943008423, 0.6392825841903687, 0.6454082727432251, 0.4829435348510742, 0.5231367349624634, 0.17141318321228027, 0.3651347756385803, 0.2568517327308655, 0.41483253240585327, 0.43905267119407654, 0.40459558367729187, 0.25486069917678833, 0.3488359749317169, 0.41225481033325195, 0.13895493745803833, 0.21675345301628113, 0.04991495609283447, 0.28392884135246277, 0.17570143938064575, 0.34913408756256104, 0.17591500282287598, 0.33855849504470825, 0.43142321705818176, 0.5618296265602112, 0.0774659514427185, 0.13539350032806396, 0.4843936562538147, 0.5048894882202148, 0.8364744186401367, 0.782444417476654, 0.7968958616256714, 0.7907949686050415, 0.5655181407928467, 0.6196668744087219, 0.7133172750473022, 0.5095566511154175, 0.3565239906311035, 0.2686333656311035, 0.3386841118335724, 0.5644893646240234, 0.23622554540634155, 0.3433009088039398, 0.3493557274341583, 0.2939424216747284, 0.08992069959640503, 0.33946871757507324, 0.20876094698905945, 0.4227801263332367, 0.4044940173625946, 0.654332160949707, 0.49300187826156616, 0.6266812086105347, 0.807404637336731, 0.5183461904525757, 0.46170246601104736, 0.24424996972084045, 0.3224128782749176, 0.5156376957893372, 0.06813174486160278, 0.1865384578704834, 0.15443122386932373, 0.300825834274292, 0.28375834226608276, 0.4036571979522705, 0.015333771705627441, 0.09899216890335083, 0.16346102952957153, 0.27330827713012695, 0.2869266867637634, 0.21237093210220337, 0.35913240909576416, 0.4736405313014984, 0.3459511995315552, 0.47014304995536804, 0.3305799663066864, 0.47306257486343384, 0.4134630858898163, 0.4199170768260956, 0.5666837692260742, 0.46681761741638184, 0.35662856698036194, 0.3547590374946594, 0.5447400808334351, 0.5184851884841919]

Анализ результатов прогнозирования
Выходные данные консоли составляют 0,9003118872642517, что указывает на то, что следующее движение цены, скорее всего, составит 0,9 от текущего дневного диапазона, который находится примерно между 1,07402 и 1,07336 или ~8 пунктов. Этого изменения цены может оказаться недостаточно, что вполне объяснимо, поскольку на момент написания статьи (14.06.2024) торговые операции длились всего около 45 минут. Однако модель прогнозирует, что цена закроется вблизи верхней границы текущего дневного диапазона.
Следующая строка: Процентное изменение для следующего прогноза на основе нормализованной цены: 73,64274%. Это говорит о том, что следующее изменение цены, скорее всего, будет примерно на 74% выше предыдущей цены, что в контексте дневного диапазона в 8 пунктов может не обеспечить достаточного количества пунктов для размещения сделки.
Вместо того чтобы работать с числами и дробями, пользователь может рассмотреть возможность добавления линии, которая берет дневную разницу (максимум - минимум) и умножает ее на нормализованную прогнозируемую цену закрытия, чтобы получить фактическое ожидаемое значение в пунктах. Мы не только сделаем это, когда преобразуем наш скрипт в MQL, но и получим точный прогноз цены.
Как мы можем видеть выше, на консоль также выводится список из 100 прогнозов. Мы можем использовать эти значения для проверки, особенно когда перейдем на MQL5 и начнем использовать скрипт там.
Наконец, мы также получаем график из библиотеки Matplotlib в Python, который дает нам набор из последних 100 прогнозов, отображает их в виде графика и сравнивает с фактическими изменениями цен закрытия на нормализованной основе (шкала от 0 до 1). Красная точка показывает следующую наиболее вероятную цену на нормализованной основе, давая нам представление о возможном следующем направлении цены. Судя по данным за этот конкретный день, наш прогноз, по-видимому, отстает от рынка, что указывает на то, что прогнозируемые результаты могут не соответствовать фактическому поведению цены за день. В такой день осторожному трейдеру следует подумать о том, чтобы остаться в стороне и не торговать, поскольку модель не дает точных прогнозов. Это не обязательно означает, что прогнозы модели неверны для всего набора данных, поэтому повторное обучение может не потребоваться.
Переход с Python на ONNX и использование обученной модели напрямую с MQL5
Создание конвейера обработки данных
Идея создания конвейера обработки данных для меня заключалась в том, чтобы не дублировать код нормализации и токенизации, созданный мной на Python. Мне не хотелось переписывать этот код на MQL. Поэтому я решил преобразовать скрипт в конвейер данных, преобразовать его в ONNX и использовать ONNX напрямую для обработки данных в MQL. Мне потребовалось несколько дней, чтобы разобраться в необходимом коде, поскольку у меня не было опыта создания конвейеров обработки данных. Причина моих трудностей в том, что Python относительно гибок в отношении типов данных. Но при переходе на ONNX нужно быть гораздо более конкретным. По пути я столкнулся с многочисленными ошибками. Поэтому, когда всё наконец-то получилось, я вздохнул с облегчением. Вот краткое описание работы скрипта:
Как я уже отмечал ранее, предварительная обработка состоит из двух важнейших этапов:
-
Токенизация времени: Преобразует необработанное время суток (например, 15:45) в дробное значение от 0 до 1, представляющее прошедшую часть 24-часового дня.
-
Ежедневная повторяющаяся нормализация: Каждый дент стандартизирует данные о ценах (открытие, максимум, минимум, закрытие). Вычисляет повторяющиеся минимальные и максимальные цены в течение каждого дня и нормализует цены относительно этих значений. Такая нормализация помогает в обучении модели, гарантируя единообразие масштаба ценовых данных.
Компоненты:
-
TimeTokenizer (Custom Transformer): Класс обрабатывает токенизацию времени. Он извлекает столбец времени из входного тензора, преобразует его в дробное представление дня, а затем объединяет с другими ценовыми данными.
-
DailyRollingNormalizer (Custom Transformer): Класс выполняет ежедневную повторяющуюся нормализацию. Он перебирает ценовые данные, отслеживая скользящие максимумы и минимумы за каждый день. Затем цены нормализуются с использованием этих динамических значений. Он также включает шаг по замене любых потенциальных значений NaN, которые могут возникнуть в ходе вычислений.
-
ReplaceNaNs (Custom Transformer): Заменяет все значения NaN из расчета нулями.
-
Pipeline (nn.Sequential): Объединяет три вышеупомянутых пользовательских преобразователя в последовательный рабочий процесс. Входные данные проходят TimeTokenizer, затем - DailyRollingNormalizer и наконец - ReplaceNaNs.
-
Соединение с MetaTrader 5: Скрипт устанавливает соединение с MetaTrader 5 для получения исторических данных о ценах EURUSD.
Исполнение:
-
Загрузка данных: Скрипт извлекает 160 баров (точек ценовых данных) из MetaTrader 5 для пары EURUSD на 15-минутном таймфрейме.
-
Преобразование данных: Необработанные данные преобразуются в тензор PyTorch для дальнейшей обработки.
-
Обработка конвейера: Тензор передается через определенный конвейер, применяя шаги токенизации времени и ежедневной повторяющейся нормализации.
-
Экспорт ONNX: Окончательные предварительно обработанные данные выводятся на консоль для отображения результатов до и после обработки. Кроме того, весь конвейер предварительной обработки экспортируется в файл ONNX. ONNX — это открытый формат, позволяющий легко переносить модели машинного обучения между различными фреймворками и средами, обеспечивая более широкую совместимость при развертывании и использовании моделей.
Ключевые моменты:
- Модульность: Использование специальных трансформаторов делает код модульным и пригодным для повторного использования. Каждый трансформер реализует определенный этап предварительной обработки.
- PyTorch: Скрипт использует PyTorch, популярный фреймворк глубокого обучения, для тензорных операций и управления моделями.
- Экспорт ONNX: Экспорт в ONNX обеспечивает возможность бесшовной интеграции этапов предварительной обработки с различными платформами или инструментами, на которых развернута обученная модель.
import torch import torch.nn as nn import pandas as pd import MetaTrader5 as mt5 # Custom Transformer for tokenizing time class TimeTokenizer(nn.Module): def forward(self, X): time_column = X[:, 0] # Assuming 'time' is the first column time_token = (time_column % 86400) / 86400 time_token = time_token.unsqueeze(1) # Add a dimension to match the input shape return torch.cat((time_token, X[:, 1:]), dim=1) # Concatenate the time token with the rest of the input # Custom Transformer for daily rolling normalization class DailyRollingNormalizer(nn.Module): def forward(self, X): time_tokens = X[:, 0] # Assuming 'time_token' is the first column price_columns = X[:, 1:] # Assuming 'open', 'high', 'low', 'close' are the remaining columns normalized_price_columns = torch.zeros_like(price_columns) rolling_max = price_columns.clone() rolling_min = price_columns.clone() for i in range(1, price_columns.shape[0]): reset_mask = (time_tokens[i] < time_tokens[i-1]).float() rolling_max[i] = reset_mask * price_columns[i] + (1 - reset_mask) * torch.maximum(rolling_max[i-1], price_columns[i]) rolling_min[i] = reset_mask * price_columns[i] + (1 - reset_mask) * torch.minimum(rolling_min[i-1], price_columns[i]) denominator = rolling_max[i] - rolling_min[i] normalized_price_columns[i] = (price_columns[i] - rolling_min[i]) / denominator time_tokens = time_tokens.unsqueeze(1) # Assuming 'time_token' is the first column return torch.cat((time_tokens, normalized_price_columns), dim=1) class ReplaceNaNs(nn.Module): def forward(self, X): X[torch.isnan(X)] = 0 X[X != X] = 0 # replace negative NaNs with 0 return X # Connect to MetaTrader 5 if not mt5.initialize(): print("Initialize failed") mt5.shutdown() # Load market data (reduced sample size for demonstration) symbol = "EURUSD" timeframe = mt5.TIMEFRAME_M15 rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 160) #intialize with maximum number of bars allowed by your broker mt5.shutdown() # Convert to DataFrame and keep only 'time', 'open', 'high', 'low', 'close' columns data = pd.DataFrame(rates)[['time', 'open', 'high', 'low', 'close']] # Convert the DataFrame to a PyTorch tensor data_tensor = torch.tensor(data.values, dtype=torch.float32) # Create the updated pipeline pipeline = nn.Sequential( TimeTokenizer(), DailyRollingNormalizer(), ReplaceNaNs() ) # Print the data before processing print('Data Before Processing\n', data[:100]) # Process the data processed_data = pipeline(data_tensor) print('Data After Processing\n', processed_data[:100]) # Export the pipeline to ONNX format dummy_input = torch.randn(len(data), len(data.columns)) torch.onnx.export(pipeline, dummy_input, "data_processing_pipeline.onnx", input_names=["input"], output_names=["output"])
Код выводит данные до и после обработки на консоль. Вы можете запустить скрипт, чтобы увидеть результаты самостоятельно. Кроме того, на выходе создается файл: data_processing_pipeline.onnx. Для проверки формы, используемой этой моделью ONNX, я создал следующий скрипт:
Он находится в папке ONNX Data Pipeline в файле shape_check.py. Файл расположен в прикрепленном архиве LSTM_Files.zip.
import onnx
model = onnx.load("data_processing_pipeline.onnx")
onnx.checker.check_model(model)
for input in model.graph.input:
print(f'Input name: {input.name}')
print(f'Input type: {input.type}')
for dim in input.type.tensor_type.shape.dim:
print(dim.dim_value) Результат:
- 160
- 5
Таким образом, форма, требуемая нашей моделью, составляет 160 15-минутных баров и 5 значений (значение времени как целое число UNIX, открытие, максимум, минимум, закрытие). После обработки данных мы получаем нормализованные данные time_token, norm_open, norm_high, norm_low и norm_close.
Для проверки обработки данных в MQL я также разработал специальный скрипт LSTM Data Pipeline.mq5, расположенный в корневой папке прикрепленного zip-файла. Он позволяет убедиться, что данные преобразуются так, как и предполагалось изначально. Скрипт можно найти ниже. Основные характеристики можно обобщить следующим образом:
-
Инициализация (OnInit):
- Загружаем модель ONNX из двоичных данных (data_processing_pipeline.onnx), встроенных в качестве ресурса. Помните, что модель ONNX хранится в папке LSTM, которая в свою очередь находится в папке Experts, как показано ниже.
- Затем настраиваем входные и выходные формы модели на основе нашего кода ONNX. LSTM Data Pipeline Test.ex5 следует сохранить в папке Experts, поскольку мы используем путь, указанный ниже. Если вы хотите сохранить файл каким-либо другим способом, измените эту строку для правильной работы кода.
-
#resource "\\LSTM\\data_processing_pipeline.onnx" as uchar ExtModel[]

-
Обработка тиковых данных (OnTick):
- Функция активируется при каждом обновлении ценового тика.
- Ждет, пока сформируется следующий бар (в данном случае 15-минутная свеча).
- Вызывает функцию ProcessData для обработки данных и прогнозирования.
-
Обработка данных (ProcessData):
- Извлекает последние SAMPLE_SIZE (в данном случае 160) баров данных по EURUSD M15.
- Извлекает из полученных данных время, цену открытия, максимума, минимума и закрытия.
- Нормализует компонент времени, чтобы он представлял часть дня (от 0 до 1).
- Подготавливает входные данные для модели ONNX в виде одномерного вектора.
- Выполняет модель ONNX (OnnxRun) с подготовленным входным вектором.
- Получает обработанные выходные данные из модели.
- Отображает обработанные данные, включая временной токен и нормализованные цены.
//+------------------------------------------------------------------+ //| ONNX Test | //| Copyright 2023 | //| Your Name Here | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Your Name Here" #property link "https://www.mql5.com" #property version "1.00" static vectorf ExtOutputData(1); vectorf output_data(1); #include <Trade\Trade.mqh> CTrade trade; #resource "\\LSTM\\data_processing_pipeline.onnx" as uchar ExtModel[] #define SAMPLE_SIZE 160 // Adjusted to match the model's expected input size long ExtHandle=INVALID_HANDLE; datetime ExtNextBar=0; // Expert Advisor initialization int OnInit() { // Load the ONNX model ExtHandle = OnnxCreateFromBuffer(ExtModel, ONNX_DEFAULT); if (ExtHandle == INVALID_HANDLE) { Print("Error creating model OnnxCreateFromBuffer ", GetLastError()); return(INIT_FAILED); } // Set input shape const long input_shape[] = {SAMPLE_SIZE, 5}; // Adjust based on your model's input dimensions if (!OnnxSetInputShape(ExtHandle, ONNX_DEFAULT, input_shape)) { Print("Error setting the input shape OnnxSetInputShape ", GetLastError()); return(INIT_FAILED); } // Set output shape const long output_shape[] = {SAMPLE_SIZE, 5}; // Adjust based on your model's output dimensions if (!OnnxSetOutputShape(ExtHandle, 0, output_shape)) { Print("Error setting the output shape OnnxSetOutputShape ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } // Expert Advisor deinitialization void OnDeinit(const int reason) { if (ExtHandle != INVALID_HANDLE) { OnnxRelease(ExtHandle); ExtHandle = INVALID_HANDLE; } } // Process the tick function void OnTick() { if (TimeCurrent() < ExtNextBar) return; ExtNextBar = TimeCurrent(); ExtNextBar -= ExtNextBar % PeriodSeconds(); ExtNextBar += PeriodSeconds(); // Fetch new data and run the ONNX model if (!ProcessData()) { Print("Error processing data"); return; } } // Function to process data using the ONNX model bool ProcessData() { MqlRates rates[SAMPLE_SIZE]; int copied = CopyRates(_Symbol, PERIOD_M15, 1, SAMPLE_SIZE, rates); if (copied != SAMPLE_SIZE) { Print("Failed to copy the expected number of rates. Expected: ", SAMPLE_SIZE, ", Copied: ", copied); return false; } else if(copied == SAMPLE_SIZE) { Print("Successfully copied the expected number of rates. Expected: ", SAMPLE_SIZE, ", Copied: ", copied); } double min_time = rates[0].time; double max_time = rates[0].time; for (int i = 1; i < copied; i++) { if (rates[i].time < min_time) min_time = rates[i].time; if (rates[i].time > max_time) max_time = rates[i].time; } float input_data[SAMPLE_SIZE * 5]; int count; for (int i = 0; i < copied; i++) { count++; // Normalize time to be between 0 and 1 within a day input_data[i * 5 + 0] = (float)((rates[i].time)); // normalized time input_data[i * 5 + 1] = (float)rates[i].open; // open input_data[i * 5 + 2] = (float)rates[i].high; // high input_data[i * 5 + 3] = (float)rates[i].low; // low input_data[i * 5 + 4] = (float)rates[i].close; // close } Print("Count of copied after for loop: ", count); // Resize input vector to match the copied data size vectorf input_vector; input_vector.Resize(copied * 5); for (int i = 0; i < copied * 5; i++) { input_vector[i] = input_data[i]; } vectorf output_vector; output_vector.Resize(copied * 5); if (!OnnxRun(ExtHandle, ONNX_NO_CONVERSION, input_vector, output_vector)) { Print("Error running the ONNX model: ", GetLastError()); return false; } // Process the output data as needed for (int i = 0; i < copied; i++) { float time_token = output_vector[i * 5 + 0]; float norm_open = output_vector[i * 5 + 1]; float norm_high = output_vector[i * 5 + 2]; float norm_low = output_vector[i * 5 + 3]; float norm_close = output_vector[i * 5 + 4]; // Print the processed data PrintFormat("Time Token: %f, Norm Open: %f, Norm High: %f, Norm Low: %f, Norm Close: %f", time_token, norm_open, norm_high, norm_low, norm_close); } return true; }
Скрипт проверяет, работает ли конвейер данных так, как ожидалось.

Чтобы еще раз проверить вывод, приведенный выше, я создал дополнительный скрипт на Python под названием LSTM Data Pipeline Test.py, которые выдает почти такие же результаты. Этот скрипт также включен в прикрепленный zip-файл (в папке ONNX Data Pipeline).
import torch import onnx import onnxruntime as ort import MetaTrader5 as mt5 import pandas as pd import numpy as np # Load the ONNX model onnx_model = onnx.load("data_processing_pipeline.onnx") onnx.checker.check_model(onnx_model) # Initialize MT5 and fetch new data if not mt5.initialize(): print("Initialize failed") mt5.shutdown() symbol = "EURUSD" timeframe = mt5.TIMEFRAME_M15 rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 160) mt5.shutdown() # Convert the new data to a DataFrame data = pd.DataFrame(rates)[['time', 'open', 'high', 'low', 'close']] data_tensor = torch.tensor(data.values, dtype=torch.float32) # Prepare the input for ONNX input_data = data_tensor.numpy() # Run the ONNX model ort_session = ort.InferenceSession("data_processing_pipeline.onnx") input_name = ort_session.get_inputs()[0].name output_name = ort_session.get_outputs()[0].name processed_data = ort_session.run([output_name], {input_name: input_data})[0] # Convert the output back to DataFrame for easy viewing processed_df = pd.DataFrame(processed_data, columns=['time_token', 'norm_open', 'norm_high', 'norm_low', 'norm_close']) print('Processed Data') print(processed_df)
Результаты работы скрипта приведены ниже. Формат и форма выходных данных соответствуют тому, что мы видели в выходных данных MQL выше.

Использование обученной модели для прогнозирования в MQL
В этом разделе я наконец хочу объединить разные части этой статьи — обработку данных и прогнозирование — в один скрипт, который позволяет пользователю получить прогноз после обучения своей модели. Давайте кратко рассмотрим, что необходимо для получения прогноза на MQL и создания советника:
- Обучение модели с помощью LSTM_model_training.py. Вы можете настраивать параметры по своему усмотрению. Запуск этого файла создаст lstm_model.onnx.
- Копирование файла lstm_model.onnx, который является результатом работы LSTM_model_training.py, в папку MQL Experts внутри подпапки LSTM
- Создание конвейера обработки данных путем запуска LSTM Data Pipeline.py. Файл находится внутри папки ONNX Data Pipeline Folder в прикрепленном zip-архиве.
- Запуск файла создаст файл ONNX для обработки данных. Скопируйте data_processing_pipeline.onnx в папку MQL Experts внутри подпапки LSTM.
- Сохранение приведенного ниже скрипта в основной папке Experts и присоединение его к 15-минутному графику EURUSD для получения прогноза:
//+------------------------------------------------------------------+ //| ONNX Test | //| Copyright 2023 | //| Your Name Here | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Your Name Here" #property link "https://www.mql5.com" #property version "1.00" static vectorf ExtOutputData(1); vectorf output_data(1); #include <Trade\Trade.mqh> //#include <Chart\Chart.mqh> CTrade trade; #resource "\\LSTM\\data_processing_pipeline.onnx" as uchar DataProcessingModel[] #resource "\\LSTM\\lstm_model.onnx" as uchar PredictionModel[] #define SAMPLE_SIZE_DATA 160 // Adjusted to match the model's expected input size #define SAMPLE_SIZE_PRED 60 long DataProcessingHandle = INVALID_HANDLE; long PredictionHandle = INVALID_HANDLE; datetime ExtNextBar = 0; // Expert Advisor initialization int OnInit() { // Load the data processing ONNX model DataProcessingHandle = OnnxCreateFromBuffer(DataProcessingModel, ONNX_DEFAULT); if (DataProcessingHandle == INVALID_HANDLE) { Print("Error creating data processing model OnnxCreateFromBuffer ", GetLastError()); return(INIT_FAILED); } // Set input shape for data processing model const long input_shape[] = {SAMPLE_SIZE_DATA, 5}; // Adjust based on your model's input dimensions if (!OnnxSetInputShape(DataProcessingHandle, ONNX_DEFAULT, input_shape)) { Print("Error setting the input shape OnnxSetInputShape for data processing model ", GetLastError()); return(INIT_FAILED); } // Set output shape for data processing model const long output_shape[] = {SAMPLE_SIZE_DATA, 5}; // Adjust based on your model's output dimensions if (!OnnxSetOutputShape(DataProcessingHandle, 0, output_shape)) { Print("Error setting the output shape OnnxSetOutputShape for data processing model ", GetLastError()); return(INIT_FAILED); } // Load the prediction ONNX model PredictionHandle = OnnxCreateFromBuffer(PredictionModel, ONNX_DEFAULT); if (PredictionHandle == INVALID_HANDLE) { Print("Error creating prediction model OnnxCreateFromBuffer ", GetLastError()); return(INIT_FAILED); } // Set input shape for prediction model const long prediction_input_shape[] = {SAMPLE_SIZE_PRED, 1, 5}; // Adjust based on your model's input dimensions if (!OnnxSetInputShape(PredictionHandle, ONNX_DEFAULT, prediction_input_shape)) { Print("Error setting the input shape OnnxSetInputShape for prediction model ", GetLastError()); return(INIT_FAILED); } // Set output shape for prediction model const long prediction_output_shape[] = {1}; // Adjust based on your model's output dimensions if (!OnnxSetOutputShape(PredictionHandle, 0, prediction_output_shape)) { Print("Error setting the output shape OnnxSetOutputShape for prediction model ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } // Expert Advisor deinitialization void OnDeinit(const int reason) { if (DataProcessingHandle != INVALID_HANDLE) { OnnxRelease(DataProcessingHandle); DataProcessingHandle = INVALID_HANDLE; } if (PredictionHandle != INVALID_HANDLE) { OnnxRelease(PredictionHandle); PredictionHandle = INVALID_HANDLE; } } // Process the tick function void OnTick() { if (TimeCurrent() < ExtNextBar) return; ExtNextBar = TimeCurrent(); ExtNextBar -= ExtNextBar % PeriodSeconds(); ExtNextBar += PeriodSeconds(); // Fetch new data and run the data processing ONNX model vectorf input_data = ProcessData(DataProcessingHandle); if (input_data.Size() == 0) { Print("Error processing data"); return; } // Make predictions using the prediction ONNX model double predictions[SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED + 1]; for (int i = 0; i < SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED + 1; i++) { double prediction = MakePrediction(input_data, PredictionHandle, i, SAMPLE_SIZE_PRED); //if (prediction < 0) //{ // Print("Error making prediction"); // return; //} // Print the prediction //PrintFormat("Predicted close price (index %d): %f", i, prediction); double min_price = iLow(Symbol(), PERIOD_D1, 0); //price is relative to the day's price therefore we use low of day for min price double max_price = iHigh(Symbol(), PERIOD_D1, 0); //high of day for max price double price = prediction * (max_price - min_price) + min_price; predictions[i] = price; PrintFormat("Predicted close price (index %d): %f", i, predictions[i]); } // Get the actual prices for the last 60 bars double actual_prices[SAMPLE_SIZE_PRED]; for (int i = 0; i < SAMPLE_SIZE_PRED; i++) { actual_prices[i] = iClose(Symbol(), PERIOD_M15, SAMPLE_SIZE_PRED - i); Print(actual_prices[i]); } // Create a label object to display the predicted and actual prices string label_text = "Predicted | Actual\n"; for (int i = 0; i < SAMPLE_SIZE_PRED; i++) { label_text += StringFormat("%.5f | %.5f\n", predictions[i], actual_prices[i]); } label_text += StringFormat("Next prediction: %.5f", predictions[SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED]); Print(label_text); //int label_handle = ObjectCreate(OBJ_LABEL, 0, 0, 0); //ObjectSetText(label_handle, label_text, 12, clrWhite, clrBlack, ALIGN_LEFT); //ObjectMove(label_handle, 0, ChartHeight() - 20, ChartWidth(), 20); } // Function to process data using the data processing ONNX model vectorf ProcessData(long data_processing_handle) { MqlRates rates[SAMPLE_SIZE_DATA]; vectorf blank_vector; int copied = CopyRates(_Symbol, PERIOD_M15, 1, SAMPLE_SIZE_DATA, rates); if (copied != SAMPLE_SIZE_DATA) { Print("Failed to copy the expected number of rates. Expected: ", SAMPLE_SIZE_DATA, ", Copied: ", copied); return blank_vector; } float input_data[SAMPLE_SIZE_DATA * 5]; for (int i = 0; i < copied; i++) { // Normalize time to be between 0 and 1 within a day input_data[i * 5 + 0] = (float)((rates[i].time)); // normalized time input_data[i * 5 + 1] = (float)rates[i].open; // open input_data[i * 5 + 2] = (float)rates[i].high; // high input_data[i * 5 + 3] = (float)rates[i].low; // low input_data[i * 5 + 4] = (float)rates[i].close; // close } vectorf input_vector; input_vector.Resize(copied * 5); for (int i = 0; i < copied * 5; i++) { input_vector[i] = input_data[i]; } vectorf output_vector; output_vector.Resize(copied * 5); if (!OnnxRun(data_processing_handle, ONNX_NO_CONVERSION, input_vector, output_vector)) { Print("Error running the data processing ONNX model: ", GetLastError()); return blank_vector; } return output_vector; } // Function to make predictions using the prediction ONNX model double MakePrediction(const vectorf& input_data, long prediction_handle, int start_index, int size) { vectorf input_subset; input_subset.Resize(size * 5); for (int i = 0; i < size * 5; i++) { input_subset[i] = input_data[start_index * 5 + i]; } vectorf output_vector; output_vector.Resize(1); if (!OnnxRun(prediction_handle, ONNX_NO_CONVERSION, input_subset, output_vector)) { Print("Error running the prediction ONNX model: ", GetLastError()); return -1.0; } // Extract the normalized close price from the output data double norm_close = output_vector[0]; return norm_close; }
Если вы используете структуру папок, отличную от той, что я описал в этой статье, отредактируйте следующие строки кода, изменив пути к файлам.
#resource "\\LSTM\\data_processing_pipeline.onnx" as uchar DataProcessingModel[] #resource "\\LSTM\\lstm_model.onnx" as uchar PredictionModel[]
Для наглядности рассмотрим, как работает скрипт. Он работает с EURUSD на 15-минутном таймфрейме.
-
Модель предварительной обработки данных: Модель (data_processing_pipeline.onnx) решает такие задачи, как токенизация времени (преобразование времени в числовое представление) и нормализация данных о ценах, подготавливая их для использования с нашей обученной моделью LSTM.
-
Модель прогнозирования: Эта модель (lstm_model.onnx) сеть модели LSTM (долговременной краткосрочной памяти), обученную анализировать предыдущие 60 баров 15-минутного ценового движения, чтобы дать нам прогноз следующей вероятной цены закрытия.
Функционал:
-
Инициализация (OnInit):
- Загружает обе модели ONNX (предварительную обработку данных и прогнозирование) из встроенных ресурсов.
- Настраивает входные и выходные формы для обеих моделей на основе их требований.
-
Обработка тиковых данных (OnTick):
- Функция срабатывает при каждом новом изменении цены.
- Она ждет, пока сформируется следующий 15-минутный бар (свеча).
- Вызывает функцию ProcessData для предварительной обработки данных.
- Выполняет итерацию предварительно обработанных данных, генерируя прогнозы цен с помощью функции MakePrediction.
- Преобразует нормализованные прогнозы обратно в фактические значения цен. ПРИМЕЧАНИЕ: В MQL мы теперь используем следующие строки кода для прогнозирования. Эти строки кода преобразуют полученный нами прогноз, который был нормализован относительно дневного максимума и минимума в диапазоне от 0 до 1, обратно в фактическую целевую цену.
-
double min_price = iLow(Symbol(), PERIOD_D1, 0); //price is relative to the day's price therefore we use low of day for min price double max_price = iHigh(Symbol(), PERIOD_D1, 0); //high of day for max price double price = prediction * (max_price - min_price) + min_price;
- Распечатывает прогнозируемые и фактические цены закрытия для сравнения. Значения можно просмотреть на вкладке "Журнал".
- Форматирует строку с прогнозируемой и фактической информацией о цене.
- Примечание: Закомментированный раздел кода, по-видимому, предназначен для создания метки на графике для отображения прогнозов и фактических значений. Это упрощает оценку эффективности модели в реальном времени. Но я пока не доделал код, поскольку все еще думаю, как лучше использовать прогнозы — как индикатор или как советник.
-
Обработка данных (ProcessData):
- Функция извлекает последние 160 баров данных EURUSD M15.
- Подготавливает входные данные для модели обработки данных (время, открытие, максимум, минимум, закрытие).
- Выполняет модель обработки данных для нормализации и токенизации входных данных.
-
Прогноз (MakePrediction):
- В качестве входных данных принимается подмножество предварительно обработанных данных (последовательность из 60 точек данных).
- Функция запускает модель прогнозирования для получения нормализованной прогнозируемой цены закрытия на постоянной основе.
- Отображает прогноз на вкладке "Эксперты".
Ниже приведен формат вывода:

Как видим, на выходе мы получаем несколько разных вещей. Сначала указываются прогнозируемые и фактические значения в строках над Next Prediction (следующий прогноз) в формате "прогнозируемое | фактическое значение" согласно строкам кода выше.
for (int i = 0; i < SAMPLE_SIZE_PRED; i++) { label_text += StringFormat("%.5f | %.5f\n", predictions[i], actual_prices[i]); }
Строка "Next prediction: 1.07333" взята из следующих строк кода выше:
label_text += StringFormat("Next prediction: %.5f", predictions[SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED]); Print(label_text);
Применение обученных моделей: создание советников
Создание советника
Подход, который я использовал для преобразования прогноза в советник, вдохновлен статьей Евгения Коштенко "Python, ONNX и MetaTrader 5: Создаем модель RandomForest с предварительной обработкой данных RobustScaler и PolynomialFeatures". Это относительно простой советник для усвоения основ. Конечно, пользователи могут расширить подход, который я описал ниже, включив дополнительные параметры, такие как скользящие стоп-лоссы, или объединить прогнозы нейронной сети LSTM с другими инструментами, которые они уже используют при разработке своих советников.
Мы используем общую структуру для обработки данных и составления прогноза, как мы делали выше. Однако в советнике мы используем следующие дополнительные модификации:
-
Определение сигнала (DetermineSignal):
- Сравнивает последнюю прогнозируемую цену закрытия с текущей ценой закрытия и спредом для определения торгового сигнала.
- Рассматривает небольшой порог разброса для фильтрации шумных сигналов.
-
Управление сделками (CheckForOpen, CheckForClose):
- CheckForOpen: если нет открытых позиций и получен сигнал на покупку или продажу, открывается новая позиция с настроенным размером лота, стоп-лоссом и тейк-профитом.
- CheckForClose: если позиция открыта и получен сигнал в противоположном направлении, закрывает позицию. Это произойдет только в том случае, если InpUseStops равен False из-за следующих строк в коде:
// Check position closing conditions void CheckForClose(void) { if (InpUseStops) return; //...rest of code }В противном случае, если InpUseStops равен true, позиция будет закрыта только при срабатывании стоп-лосса или тейк-профита. Полный код советника со всеми реализованными функциями можно найти в корневой папке внутри приложенного файла LSTM_Files.zip. Файл называется LSTM_Simple_EA.mq5
//+------------------------------------------------------------------+ //| ONNX Test | //| Copyright 2023 | //| Your Name Here | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Your Name Here" #property link "https://www.mql5.com" #property version "1.00" static vectorf ExtOutputData(1); vectorf output_data(1); #include <Trade\Trade.mqh> CTrade trade; input double InpLots = 1.0; // Lot volume to open a position input bool InpUseStops = true; // Trade with stop orders input int InpTakeProfit = 500; // Take Profit level input int InpStopLoss = 500; // Stop Loss level #resource "\\LSTM\\data_processing_pipeline.onnx" as uchar DataProcessingModel[] #resource "\\LSTM\\lstm_model.onnx" as uchar PredictionModel[] #define SAMPLE_SIZE_DATA 160 // Adjusted to match the model's expected input size #define SAMPLE_SIZE_PRED 60 long DataProcessingHandle = INVALID_HANDLE; long PredictionHandle = INVALID_HANDLE; datetime ExtNextBar = 0; int ExtPredictedClass = -1; #define PRICE_UP 1 #define PRICE_SAME 2 #define PRICE_DOWN 0 // Expert Advisor initialization int OnInit() { // Load the data processing ONNX model DataProcessingHandle = OnnxCreateFromBuffer(DataProcessingModel, ONNX_DEFAULT); if (DataProcessingHandle == INVALID_HANDLE) { Print("Error creating data processing model OnnxCreateFromBuffer ", GetLastError()); return(INIT_FAILED); } // Set input shape for data processing model const long input_shape[] = {SAMPLE_SIZE_DATA, 5}; // Adjust based on your model's input dimensions if (!OnnxSetInputShape(DataProcessingHandle, ONNX_DEFAULT, input_shape)) { Print("Error setting the input shape OnnxSetInputShape for data processing model ", GetLastError()); return(INIT_FAILED); } // Set output shape for data processing model const long output_shape[] = {SAMPLE_SIZE_DATA, 5}; // Adjust based on your model's output dimensions if (!OnnxSetOutputShape(DataProcessingHandle, 0, output_shape)) { Print("Error setting the output shape OnnxSetOutputShape for data processing model ", GetLastError()); return(INIT_FAILED); } // Load the prediction ONNX model PredictionHandle = OnnxCreateFromBuffer(PredictionModel, ONNX_DEFAULT); if (PredictionHandle == INVALID_HANDLE) { Print("Error creating prediction model OnnxCreateFromBuffer ", GetLastError()); return(INIT_FAILED); } // Set input shape for prediction model const long prediction_input_shape[] = {SAMPLE_SIZE_PRED, 1, 5}; // Adjust based on your model's input dimensions if (!OnnxSetInputShape(PredictionHandle, ONNX_DEFAULT, prediction_input_shape)) { Print("Error setting the input shape OnnxSetInputShape for prediction model ", GetLastError()); return(INIT_FAILED); } // Set output shape for prediction model const long prediction_output_shape[] = {1}; // Adjust based on your model's output dimensions if (!OnnxSetOutputShape(PredictionHandle, 0, prediction_output_shape)) { Print("Error setting the output shape OnnxSetOutputShape for prediction model ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } // Expert Advisor deinitialization void OnDeinit(const int reason) { if (DataProcessingHandle != INVALID_HANDLE) { OnnxRelease(DataProcessingHandle); DataProcessingHandle = INVALID_HANDLE; } if (PredictionHandle != INVALID_HANDLE) { OnnxRelease(PredictionHandle); PredictionHandle = INVALID_HANDLE; } } // Process the tick function void OnTick() { if (TimeCurrent() < ExtNextBar) return; ExtNextBar = TimeCurrent(); ExtNextBar -= ExtNextBar % PeriodSeconds(); ExtNextBar += PeriodSeconds(); // Fetch new data and run the data processing ONNX model vectorf input_data = ProcessData(DataProcessingHandle); if (input_data.Size() == 0) { Print("Error processing data"); return; } // Make predictions using the prediction ONNX model double predictions[SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED + 1]; for (int i = 0; i < SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED + 1; i++) { double prediction = MakePrediction(input_data, PredictionHandle, i, SAMPLE_SIZE_PRED); double min_price = iLow(Symbol(), PERIOD_D1, 0); // price is relative to the day's price therefore we use low of day for min price double max_price = iHigh(Symbol(), PERIOD_D1, 0); // high of day for max price double price = prediction * (max_price - min_price) + min_price; predictions[i] = price; PrintFormat("Predicted close price (index %d): %f", i, predictions[i]); } // Determine the trading signal DetermineSignal(predictions); // Execute trades based on the signal if (ExtPredictedClass >= 0) if (PositionSelect(_Symbol)) CheckForClose(); else CheckForOpen(); } // Function to determine the trading signal void DetermineSignal(double &predictions[]) { double spread = GetSpreadInPips(_Symbol); double predicted = predictions[SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED]; // Use the last prediction for decision making if (spread < 0.000005 && predicted > iClose(Symbol(), PERIOD_M15, 1)) { ExtPredictedClass = PRICE_UP; } else if (spread < 0.000005 && predicted < iClose(Symbol(), PERIOD_M15, 1)) { ExtPredictedClass = PRICE_DOWN; } else { ExtPredictedClass = PRICE_SAME; } } // Check position opening conditions void CheckForOpen(void) { ENUM_ORDER_TYPE signal = WRONG_VALUE; if (ExtPredictedClass == PRICE_DOWN) signal = ORDER_TYPE_SELL; else if (ExtPredictedClass == PRICE_UP) signal = ORDER_TYPE_BUY; if (signal != WRONG_VALUE && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { double price, sl = 0, tp = 0; double bid = SymbolInfoDouble(_Symbol, SYMBOL_BID); double ask = SymbolInfoDouble(_Symbol, SYMBOL_ASK); if (signal == ORDER_TYPE_SELL) { price = bid; if (InpUseStops) { sl = NormalizeDouble(bid + InpStopLoss * _Point, _Digits); tp = NormalizeDouble(ask - InpTakeProfit * _Point, _Digits); } } else { price = ask; if (InpUseStops) { sl = NormalizeDouble(ask - InpStopLoss * _Point, _Digits); tp = NormalizeDouble(bid + InpTakeProfit * _Point, _Digits); } } trade.PositionOpen(_Symbol, signal, InpLots, price, sl, tp); } } // Check position closing conditions void CheckForClose(void) { if (InpUseStops) return; bool tsignal = false; long type = PositionGetInteger(POSITION_TYPE); if (type == POSITION_TYPE_BUY && ExtPredictedClass == PRICE_DOWN) tsignal = true; if (type == POSITION_TYPE_SELL && ExtPredictedClass == PRICE_UP) tsignal = true; if (tsignal && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { trade.PositionClose(_Symbol, 3); CheckForOpen(); } } // Function to get the current spread double GetSpreadInPips(string symbol) { double spreadPoints = SymbolInfoInteger(symbol, SYMBOL_SPREAD); double spreadPips = spreadPoints * _Point / _Digits; return spreadPips; } // Function to process data using the data processing ONNX model vectorf ProcessData(long data_processing_handle) { MqlRates rates[SAMPLE_SIZE_DATA]; vectorf blank_vector; int copied = CopyRates(_Symbol, PERIOD_M15, 1, SAMPLE_SIZE_DATA, rates); if (copied != SAMPLE_SIZE_DATA) { Print("Failed to copy the expected number of rates. Expected: ", SAMPLE_SIZE_DATA, ", Copied: ", copied); return blank_vector; } float input_data[SAMPLE_SIZE_DATA * 5]; for (int i = 0; i < copied; i++) { // Normalize time to be between 0 and 1 within a day input_data[i * 5 + 0] = (float)((rates[i].time)); // normalized time input_data[i * 5 + 1] = (float)rates[i].open; // open input_data[i * 5 + 2] = (float)rates[i].high; // high input_data[i * 5 + 3] = (float)rates[i].low; // low input_data[i * 5 + 4] = (float)rates[i].close; // close } vectorf input_vector; input_vector.Resize(copied * 5); for (int i = 0; i < copied * 5; i++) { input_vector[i] = input_data[i]; } vectorf output_vector; output_vector.Resize(copied * 5); if (!OnnxRun(data_processing_handle, ONNX_NO_CONVERSION, input_vector, output_vector)) { Print("Error running the data processing ONNX model: ", GetLastError()); return blank_vector; } return output_vector; } // Function to make predictions using the prediction ONNX model double MakePrediction(const vectorf& input_data, long prediction_handle, int start_index, int size) { vectorf input_subset; input_subset.Resize(size * 5); for (int i = 0; i < size * 5; i++) { input_subset[i] = input_data[start_index * 5 + i]; } vectorf output_vector; output_vector.Resize(1); if (!OnnxRun(prediction_handle, ONNX_NO_CONVERSION, input_subset, output_vector)) { Print("Error running the prediction ONNX model: ", GetLastError()); return -1.0; } // Extract the normalized close price from the output data double norm_close = output_vector[0]; return norm_close; }
Тестирование советников
После создания советника я запустил оптимизатор со следующими настройками:

Я получил следующие параметры оптимизации менее чем за 1 час. Я показываю только первый полученный результат в демонстрационных целях. Я не завершил полный цикл оптимизации, поскольку просто хотел проиллюстрировать, насколько хорошо работают прогнозы даже при небольшой оптимизации и относительно простом советнике, представленном выше:

Результаты за период тестирования с указанными настройками можно увидеть ниже. Полный отчет о тестировании на истории также прилагается в виде zip-файла для дальнейшего изучения.

Заключение
В этой статье я поделился своим полным опытом перехода от перевода данных из MetaTrader в Python к созданию советника с использованием обученной нейронной сети LSTM, которую можно использовать в MQL. Попутно я описал токенизацию времени, нормализацию цены, проверку данных и получение прогнозов с использованием Python и MQL. Мне пришлось внести более 200 правок в этот текст, поскольку, узнавая что-то новое, я включал это в статью. Я рассчитываю, что читатели смогут использовать мою работу и быстро освоить мощные нейронные сети, доступные в Python, и реализовать их в MQL с помощью ONNX. Вы можете использовать конвейеры обработки данных для преобразования данных нужным вам способом и реализовать этот функционал в своих MQL-скриптах с использованием ONNX. Надеюсь, статья вам понравится. С нетерпением жду вопросов и рекомендаций.
Примечания:
- LSTM_Files.zip включает файл requirements.txt с необходимыми пакетами Python. Используйте команду pip install -r requirements.txt в своем терминале. Это приведет к установке всех пакетов, перечисленных в файле requirements.txt.
- Если вы внимательно изучите код, то заметите, что масштабирование основано на максимуме и минимуме текущего дня, тогда как массив прогнозов может также содержать данные предыдущего дня, поскольку он использует 60 непрерывных прогнозов, которые могут перекрываться с предыдущим днем, особенно во время азиатской сессии.
for (int i = 0; i < SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED + 1; i++) { double prediction = MakePrediction(input_data, PredictionHandle, i, SAMPLE_SIZE_PRED); double min_price = iLow(Symbol(), PERIOD_D1, 0); // price is relative to the day's price therefore we use low of day for min price double max_price = iHigh(Symbol(), PERIOD_D1, 0); // high of day for max price double price = prediction * (max_price - min_price) + min_price; predictions[i] = price; PrintFormat("Predicted close price (index %d): %f", i, predictions[i]); }
Таким образом, было бы точнее использовать цену предыдущего дня для части прогноза, чтобы получить фактические прогнозируемые цены.
double min_price = iLow(Symbol(), PERIOD_D1, 1 ); // previous day's low double max_price = iHigh(Symbol(), PERIOD_D1, 1 ); // previous day's high
- Даже приведенный выше код не очень точен, поскольку для получения точного прогноза вам придется учитывать повторяющиеся максимумы и минимумы вплоть до определенной точки дня.
- Я оставил все как есть, потому что моей целью было преобразовать код в советник, который в первую очередь будет делать будущие прогнозы на основе самых последних токенизированных значений на текущий день. Это делается в data_processing_pipeline.onnx. При разработке индикатора следует рассмотреть возможность использования повторяющихся диапазонов максимума/минимума предыдущего дня для масштабирования прошлых прогнозов, которые перекрываются предыдущим днем. Возможно, логично было бы создать зеркальный вариант data_processing_pipeline.onnx, которая делает то же самое в обратном порядке.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/15063
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования