
От начального до среднего уровня: Struct (VI)

Введение
В предыдущей статье "От начального до среднего уровня: Struct (V)", мы показали и объяснили, как создавать простые шаблоны структур. Цель заключалась в том, чтобы перегрузить структуру для других типов данных без необходимости перепрограммировать весь структурный контекст. Хотя данная статья может быть немного сложной для понимания, мы постарались объяснить её как можно проще и практичнее. Наша цель состоит в том, чтобы каждый мог следить за темами и изучать их, чтобы на практике использовать концепции, показанные и принятые в каждой из статей.
Но, несмотря ни на что, увиденное в этой статье, является легкой частью набора концепций и информации, которые в основном направлены на то, чтобы сгруппировать под одним зонтиком широкий и разнообразный спектр действий, который может выполнять квалифицированный программист.
Материал, который мы начнем рассматривать сегодня (покажем это постепенно) призван буквально расширить то, о чем рассказали в предыдущей статье. Поэтому эту тему проходят на многих курсах по программированию и анализу данных. Так что не надейтесь увидеть всё в одной статье: потребуется огромное количество статей, чтобы рассмотреть этот вопрос как следует. И это ещё без учета объектно-ориентированного программирования.
И почему я это подчеркиваю? Причина в том, что я заметил много людей, желающих научиться использовать классы и тому подобное. Однако этим же людям не хватает базовых знаний для понимания ООП. А данные понятия рождаются только при правильном понимании структурного программирования. Чтобы понять это, нужно потратить много времени. И это то, что приходит только со временем и опытом.
Однако цель этих статей как раз в том, чтобы ускорить данный этап обучения. Таким образом, то, на что ушли бы годы, можно сделать за несколько месяцев или даже недель, в зависимости от наших усилий и бэкграунда. Поверьте, наличие бэкграунда программиста крайне необходимо для быстрого усвоения материала. Без него можно научиться создавать различные вещи, но, к сожалению, наступит момент, когда вы не сможете продвинуться дальше. Наша цель в этих статьях именно такова: показать вам, что при наличии спокойствия, терпения и целеустремленности, не имеет значения, есть ли у вас подходящий бэкграунд или нет. Любой человек может стать хорошим программистом.
Поэтому давайте начнем новую тему, так мы рассмотрим то, что сделали в предыдущей статье, и изучим некоторые детали, которые могли быть упущены. Это очень важно для понимания некоторых аспектов, которые мы проанализируем совсем скоро.
Подумаем о повседневных задачах
Одна из самых простых - поиск контакта в записной книжке. Это, конечно, очень простая и базовая задача, как поиск синонимов или значения слова в словаре. Этому может научиться и ребенок. Однако задумывались ли вы когда-нибудь о том, что было бы, если бы вы не знали, как найти контакт в записной книжке или номер телефона в телефонной книге, или как ваш веб-браузер быстро находит запрошенную вами веб-страницу? В основе всех этих задач лежит одна и та же первооснова: структуры.
Да, концепция одна и та же, но вид хранимой информации может сильно различаться. Например, в записной книжке могут быть указаны имя, адрес или номер телефона. Однако в словаре вы найдете слово, за которым следует его значение. Всё это можно организовать очень простым и практичным способом. Но, что действительно замечательно, так это реализация кода, который справляется с различными типами структуры, не требуя огромных модификаций. Существуют способы сделать это, но мы не будем заходить так далеко, - в этом нет необходимости. Наша с вами цель - показать, как можно реализовать простые вещи.
В предыдущей статье мы рассказали, как работать с очень простым типом структурного кода, в котором внутри самой структуры используются дискретные данные для различных целей. Однако данный тип решения не подходит для решения задач более широкого характера. Для вашего понимания мы создадим очень простой и понятный код, как можно увидеть ниже:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Get(const uint index) 21. { 22. return Values[index]; 23. } 24. //+----------------+ 25. }; 26. //+------------------------------------------------------------------+ 27. #define PrintX(X) Print(#X, " => ", X) 28. //+------------------------------------------------------------------+ 29. void OnStart(void) 30. { 31. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 32. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 33. 34. st_Data <double> Info_1; 35. st_Data <uint> Info_2; 36. 37. Info_1.Set(H); 38. Info_2.Set(K); 39. 40. PrintX(Info_1.Get(Info_2.Get(3))); 41. } 42. //+------------------------------------------------------------------+
Код 01
Этот двоичный код может быть очень интересным, в зависимости от того, как вы его проанализируете, даже до того, как вы поймете, что я хочу объяснить. В нем мы создаем разрывные отношения между двумя сущностями. Однако не будем торопиться, ведь концепция, которую нам предстоит понять, помогает разобраться с тем, как повседневные проблемы могут быть смоделированы таким образом, чтобы использовать очень простое и относительно полное структурное программирование.
В коде 01 мы пытаемся создать с помощью структурного программирования связь между элементами массивов K и H. Очевидно, мы могли бы сделать то же самое обычным способом. Однако, если мы создаем код структурно, то вскоре увидим, насколько проще применять его для решения других задач. Нет необходимости изменять уже созданный код.
Если вы изучали содержание статей, то вы точно знаете, какой результат генерирует этот код. И вы знаете, почему этот код генерирует именно такой результат, просто взглянув на код 01. Но для тех, кто еще не достиг этого уровня, мы покажем результат, выведенный на терминал MetaTrader 5, который можно увидеть на изображении ниже:

Изображение 01
Вопрос: почему строка 40 показывает такое значение на изображении 01? Ответ: Потому что мы используем элемент массива K для индексации элемента массива H, но это не совсем то, что мы хотели бы сделать. На самом деле, идея состоит в том, чтобы связать значение в массиве K с соответствующим значением в массиве H, но соединение не произошло так, как мы ожидали.
Чтобы было понятно, в чем здесь идея, вам нужно понять следующее: массив K будет как ключ, где каждое из значений будет индексом для доступа или знания значения массива H. Однако массив K не упорядочен, и это сделано специально, чтобы вы поняли, почему решение не всегда находится сразу.
Чтобы вы могли понять, как будут развиваться данные отношения, мы изменим код 01 на код 02.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Get(const uint index) 21. { 22. return Values[index]; 23. } 24. //+----------------+ 25. uint NumberOfElements(void) 26. { 27. return Values.Size(); 28. } 29. //+----------------+ 30. }; 31. //+------------------------------------------------------------------+ 32. void OnStart(void) 33. { 34. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 35. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 36. 37. st_Data <double> Info_1; 38. st_Data <uint> Info_2; 39. 40. Info_1.Set(H); 41. Info_2.Set(K); 42. 43. for (uint c = 0; c < Info_2.NumberOfElements(); c++) 44. PrintFormat("Index [%d] => [%.2f]", Info_2.Get(c), Info_1.Get(c)); 45. } 46. //+------------------------------------------------------------------+
Код 02
Возможно, теперь, с кодом 02, всё станет яснее. В строке 43 мы используем цикл, чтобы пройтись по всем элементам и показать, как один массив соотносится с другим. Запустив код 02, мы получим следующее:
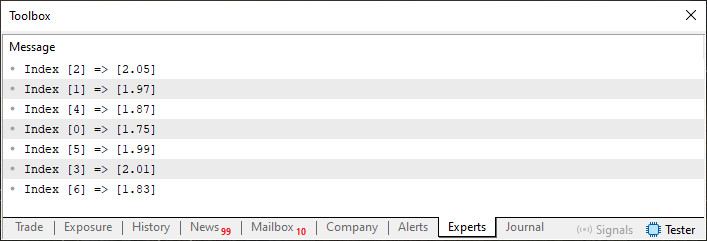
Изображение 02
Хорошо, теперь мы можем вернуться к вопросу в коде 01, поскольку, исходя из изображения 02, мы знаем, что для каждого индекса, объявленного в массиве K, есть соответствующее значение в массиве H. Поэтому, когда в коде 01 мы спрашиваем, каково значение индекса 03, мы на самом деле не имеем в виду значение, показанное на изображении 01. Это происходит, потому что, если не учитывать тот факт, что массивы расположены не по порядку, индекс 03 в массиве K будет равен нулю. Однако, попросив показать соответствующее значение, мы не укажем правильный индекс в массиве H. Я знаю, что это может показаться сложным, но вы скоро поймете, к чему я веду.
Итак, первая проблема заключается в том, что массивы расположены не по порядку, а для действительно эффективного поиска необходимо, чтобы они были отсортированы. Не забывайте, что соотношение, показанное на изображении 02, должно быть сохранено, поскольку один массив будет служить источником поиска, а другой - источником ответа.
Многие начинающие пользователи, услышав такое, сразу же придумывают решение, самым очевидным из которых является использование функции ArraySort для упорядочивания массивов или функции ArrayBsearch для поиска в самом массиве. В любом случае, для достижения цели нам необходимо изменить код 01. Это приводит к появлению такого кода:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. T Values[]; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Set(const T &arg[]) 15. { 16. ArrayFree(Values); 17. ArrayCopy(Values, arg); 18. } 19. //+----------------+ 20. T Get(const uint index) 21. { 22. return Values[index]; 23. } 24. //+----------------+ 25. T Search(const uint index) 26. { 27. return ArrayBsearch(Values, index); 28. } 29. //+----------------+ 30. }; 31. //+------------------------------------------------------------------+ 32. #define PrintX(X) Print(#X, " => ", X) 33. //+------------------------------------------------------------------+ 34. void OnStart(void) 35. { 36. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 37. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 38. 39. st_Data <double> Info_1; 40. st_Data <uint> Info_2; 41. 42. Info_1.Set(H); 43. Info_2.Set(K); 44. 45. PrintX(Info_1.Get(Info_2.Search(3))); 46. } 47. //+------------------------------------------------------------------+
Код 03
Выполнив код 03, мы наконец-то установили правильную и нужную связь. Это приведет к появлению ответа, показанного ниже:

Изображение 03
Прошу заметить, что значение, выдаваемое в качестве ответа, на самом деле соответствует, так сказать, искомому индексу в нашем списке, как это видно из соответствия между массивами K и H на изображении 02. Однако есть и более простые способы создания такого же вида связи, где мы можем работать лучше, поддерживая более тесное отношение между массивами K и H.
Одним из таких способов является использование многомерных массивов. Но многомерные массивы не очень подходят для работы с разными типами информации, поэтому для создания такого типа связи необходимо использовать другой метод. Напомним, что идея состоит в том, чтобы создать код, который содержится в структуре.
Поэтому нам нужно сделать один шаг назад, а затем два шага вперед. Цель - сделать решение более понятным. Чтобы не рассматривать это по-отдельности, давайте сменим тему.
Структуры структур
Один из моментов, который часто сбивает с толку многих новичков, - это когда мы переходим от использования концепций, которые рассматривались по отдельности, к комбинированному формату. Я знаю, что разговор об этом может показаться странным, поскольку по сути концепция осталась нетронутой. Однако, когда мы объединяем концепции и применяем их более глубоко, появляются новые возможности, которые поначалу могут быть совершенно непонятными для вас.
Чтобы объяснить это, мы изменим код 03 (рассмотренный в предыдущей теме), чтобы создать нечто простое для понимания, но в то же время позволяющее сфокусировать объяснение на нашей главной цели. Иными словами, создадим некую связь между одним набором значений и совершенно другим набором значений.
Для этого мы будем использовать код, реализованный ниже:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. struct st_Reg 07. { 08. double h_value; 09. uint k_value; 10. }Values[]; 11. }; 12. //+------------------------------------------------------------------+ 13. bool Set(st_Data &dst, const uint &arg1[], const double &arg2[]) 14. { 15. if (arg1.Size() != arg2.Size()) 16. return false; 17. 18. ArrayResize(dst.Values, arg1.Size()); 19. for (uint c = 0; c < arg1.Size(); c++) 20. { 21. dst.Values[c].k_value = arg1[c]; 22. dst.Values[c].h_value = arg2[c]; 23. } 24. 25. return true; 26. } 27. //+------------------------------------------------------------------+ 28. string Get(const st_Data &src, const uint index) 29. { 30. for (uint c = 0; c < src.Values.Size(); c++) 31. if (src.Values[c].k_value == index) 32. return DoubleToString(src.Values[c].h_value, 2); 33. 34. return "-nan"; 35. } 36. //+------------------------------------------------------------------+ 37. #define PrintX(X) Print(#X, " => ", X) 38. //+------------------------------------------------------------------+ 39. void OnStart(void) 40. { 41. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 42. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 43. 44. st_Data info; 45. 46. Set(info, K, H); 47. PrintX(Get(info, 3)); 48. } 49. //+------------------------------------------------------------------+
Код 04
Прежде, чем я начну объяснять детали того, что делает код 04, мне нужно, чтобы вы поняли следующее: то, что мы видим здесь, - это просто способ реализовать что-то с заранее определенной целью.
Ни в коем случае не считайте приведенный ниже способ единственным, так как существуют и другие, более простые и или сложные, которые включают в себя использование многомерных массивов. Это основано на том, что мы уже объяснили и показывали до этого момента.
Но есть еще лучший способ сделать это. Но об этом позже. Давайте теперь рассмотрим, что делает код 04. Для начала посмотрим на результат выполнения, чуть ниже:

Изображение 04
Какой интересный результат, не так ли? Можно подумать: когда выполняется строка 47, она делает что-то очень похожее на то, что было показано в коде 01. Однако, если посмотреть на функцию Get, присутствующую в строке 28 кода 04, то можно увидеть, что значение индекса ищется в пределах набора элементов массива K.
Но ключевой момент, представляющий реальный интерес, заключается в том, что при успешном выполнении строки 31 мы возвращаем не индекс элемента массива K, а значение того же индекса массива H, создавая тем самым связь. Теперь обратите внимание на следующее: поскольку количество элементов невелико, нам не нужно беспокоиться о времени выполнения кода.
Однако в нормальной и реальной ситуации структура, создаваемая в строке 4, должна быть каким-то образом упорядочена. Таким образом, во время поиска, который мы выполняем в строке 28, время выполнения будет самым маленьким из возможных.
Итак, возникает новая идея: как создать код, приближенный к реальности? Что ж, для этого нам нужно дать этой структуре свой собственный контекст. Именно с этого момента начинается то, что в компьютерной науке называется анализом данных.
Когда мы применяем анализ данных к нашим кодам, мы должны каким-то образом их структурировать, но идеальной структуры для всех случаев нет. В одних случаях необходимо реализовать код определенным образом, а в других - совсем иным. Поэтому каждая проблема требует соответствующего уровня знаний для получения наилучшего результата в кратчайшие сроки.
Наверное, теперь вы думаете: «Разве мы собираемся начать изучать анализ данных?» Пока нет, дорогой читатель. До этого нам предстоит рассмотреть ещё несколько вещей. Мы могли бы начать делать это в ближайшее время, но в данный момент это не так. Дело в том, что, поняв, что теперь у нас есть связь между множеством элементов в массиве K и множеством элементов в массиве H, мы можем начать думать о том, как преобразовать структуру строки 04 в контекстную структуру, которая содержит необходимые механизмы для поддержания, управления и обеспечения того, чтобы данная связь между элементами оставалась должным образом установленной.
Для этого мы сначала воспользуемся кодом 04, чтобы построить данное моделирование. Другими словами, мы пока не собираемся обобщать механизм, это позволяет компилятору создать перегрузку типов. Новый модифицированный код показан ниже:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. struct st_Reg 10. { 11. double h_value; 12. uint k_value; 13. }Values[]; 14. //+----------------+ 15. public: 16. //+----------------+ 17. bool Set(const uint &arg1[], const double &arg2[]) 18. { 19. if (arg1.Size() != arg2.Size()) 20. return false; 21. 22. ArrayResize(Values, arg1.Size()); 23. for (uint c = 0; c < arg1.Size(); c++) 24. { 25. Values[c].k_value = arg1[c]; 26. Values[c].h_value = arg2[c]; 27. } 28. 29. return true; 30. } 31. //+----------------+ 32. string Get(const uint index) 33. { 34. for (uint c = 0; c < Values.Size(); c++) 35. if (Values[c].k_value == index) 36. return DoubleToString(Values[c].h_value, 2); 37. 38. return "-nan"; 39. } 40. //+----------------+ 41. }; 42. //+------------------------------------------------------------------+ 43. #define PrintX(X) Print(#X, " => ", X) 44. //+------------------------------------------------------------------+ 45. void OnStart(void) 46. { 47. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 48. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 49. 50. st_Data info; 51. 52. info.Set(K, H); 53. PrintX(info.Get(3)); 54. } 55. //+------------------------------------------------------------------+
Код 05
А теперь будьте внимательны, чтобы не потерять нить изложения. Когда код 05 будет выполнен, мы увидим в терминале MetaTrader 5 ту же основную информацию, что и на изображении 04, но с небольшим отличием, которое можно увидеть чуть ниже:

Изображение 05
В отличие от кода 04, код 05 является структурным. Однако из-за объявления типов, которое реализовано в строках 11 и 12, мы привязаны к определенному типу данных, которые можно здесь использовать. Предположим, мы хотим или должны создать другую систему, где вместо связи числовых значений мы хотим создать связь текстовых значений, то есть строк, вместо используемых в коде 05 значений. Как мы можем это сделать, изменив как можно меньше кода 05?
Если вы не прочитали предыдущие статьи, то зря: в них объясняются некоторые детали, которые я не буду здесь повторять. Однако мы рассмотрим, как можно обобщить структуру, объявленную в строке 04, так, чтобы компилятор создал необходимую перегрузку типов, и таким образом охватить случаи, которые, очевидно, были бы невозможны.
Для простоты мы начнем с обобщения только одного базового типа - того, который определен в строке 11. Новый код показан ниже:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> 05. struct st_Data 06. { 07. //+----------------+ 08. private: 09. //+----------------+ 10. struct st_Reg 11. { 12. T h_value; 13. uint k_value; 14. }Values[]; 15. //+----------------+ 16. string ConvertToString(T arg) 17. { 18. if ((typename(T) == "double") || (typename(T) == "float")) return DoubleToString(arg, 2); 19. if (typename(T) == "string") return arg; 20. 21. return IntegerToString(arg); 22. } 23. //+----------------+ 24. public: 25. //+----------------+ 26. bool Set(const uint &arg1[], const T &arg2[]) 27. { 28. if (arg1.Size() != arg2.Size()) 29. return false; 30. 31. ArrayResize(Values, arg1.Size()); 32. for (uint c = 0; c < arg1.Size(); c++) 33. { 34. Values[c].k_value = arg1[c]; 35. Values[c].h_value = arg2[c]; 36. } 37. 38. return true; 39. } 40. //+----------------+ 41. string Get(const uint index) 42. { 43. for (uint c = 0; c < Values.Size(); c++) 44. if (Values[c].k_value == index) 45. return ConvertToString(Values[c].h_value); 46. 47. return "-nan"; 48. } 49. //+----------------+ 50. }; 51. //+------------------------------------------------------------------+ 52. #define PrintX(X) Print(#X, " => ", X) 53. //+------------------------------------------------------------------+ 54. void OnStart(void) 55. { 56. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 57. const uint K[] = {2, 1, 4, 0, 5, 3, 6}; 58. 59. st_Data <double> info; 60. 61. info.Set(K, H); 62. PrintX(info.Get(3)); 63. } 64. //+------------------------------------------------------------------+
Код 06
Теперь стало по-настоящему весело с построением кода 06. Это связано с тем, что в коде 06 мы можем начать обобщать структуру, чтобы компилятор мог выполнять перегрузку, когда это нужно. Таким образом, мы можем работать с разными видами данных, чтобы создать некий механизм поиска. Но, когда мы пытаемся скомпилировать этот код, заметно, что, в отличие от предыдущих, сообщение будет другим.
Это можно увидеть чуть ниже:

Изображение 06
Возможно, вы помните, что я упоминал о том, что есть ситуации, когда сообщения компилятора можно игнорировать, а есть - когда нельзя. Это типичный пример того, когда мы можем игнорировать предупреждения компилятора, а всё потому, что компилятор НЕ ПОНИМАЕТ, что мы делаем в строках 19 и 21, которые будут выполняться только в очень специфических случаях, а также в самой строке 18. Существует способ предотвратить отображение данных сообщений, но я покажу его в другой раз, возможно, в следующей статье, поскольку эта подходит к концу.
Итак, поскольку мы обобщаем одно из значений, нам надо сообщить компилятору, какая информация будет использоваться. Затем мы можем создать соответствующий код для этого типа данных. Для этого в строке 59 мы объявляем переменную, которая даст нам доступ к структуре. Теперь, поскольку базовый тип, объявленный в строке 56, - double, мы должны использовать совместимый или идентичный тип в объявлении в строке 59. Иначе у нас возникнут проблемы с поиском структуры данных.
«Но как такое возможно? Я не понял эту часть. Я, конечно, понимаю причину объявления в строке 59 именно благодаря объявлению в структуре. Однако я не понимаю, зачем нужно объявлять подходящий тип, как в строке 56. Если мы создаем что-то общее, то в этом нет особого смысла».
Ну что ж, поскольку объяснить это довольно сложно, я посвящу этой теме оставшуюся часть статьи, оставив значительную часть материала для следующей.
Хочу обратить ваше внимание, что в начале статьи мы использовали код, очень похожий на код 06. Но, когда мы это сделали, результат был в некотором смысле известен заранее, поскольку мы не заботились о преобразовании или возврате правильного типа данных.
Теперь подумайте о следующем: в коде 01 тип возвращаемых данных зависит от типа хранимых данных. Но, и в этом вся суть, в коде 06 всегда будет возвращаться тип данных, независимо от типа хранимых данных. В данном случае мы будем хранить данные типа double. Однако у ответа ВСЕГДА будет тип string.
Сам факт того, что это делается, приводит, так сказать, к запутыванию самой системы, поскольку данное преобразование не ожидается программистом, использующим структуру, которую мы определяем. Вы, наверное, думаете: как это возможно? Конечно, он будет знать. Но это не всегда так, ведь мы можем создавать библиотеки кода и использовать их в разное время. И когда говорим о библиотеке кода, мы не имеем в виду, что вы накапливаете много исходного кода.
Данные библиотеки обычно состоят из исполняемого кода, как, например, знаменитые DLL. В них мы не знаем, как именно работает внутренний код, у нас есть только представление о нем, поскольку мы передаем DLL значения, а она возвращает результат. Важно знать тип данных, которые мы передаем в структуру, поскольку нам может понадобиться преобразовать их к исходному типу, поскольку результатом всегда будет строка.
Хорошо. «Но разве мы не можем оставить обобщения? Другими словами, вместо того чтобы преобразовывать данные к строковому типу, если бы мы сохранили их в исходном типе, у нас не было бы этой проблемы, о которой мы говорили минуту назад. Я прав?» Да, мой друг, вы правы. Однако помните, что цель здесь обучение, а не создание кода, который можно было бы использовать в реальной ситуации.
Но даже в этом случае, поскольку я хочу дать вам возможность остановиться на мгновение и поразмыслить над некоторыми вещами, мы изменим код 06 таким образом, чтобы в коде, показанном выше, изменился только фрагмент, показанный ниже. И уже один тот факт, что мы это сделали, говорит о том, что перед нами совершенно иная ситуация, поставленная и реализованная здесь. Давайте посмотрим на измененный фрагмент:
. . . 53. //+------------------------------------------------------------------+ 54. void OnStart(void) 55. { 56. const string T = "possible loss of data due to type conversion"; 57. const uint K[] = {2, 1, 4, 0, 7, 5, 3, 6}; 58. 59. st_Data <string> info; 60. string H[]; 61. 62. StringSplit(T, ' ', H); 63. info.Set(K, H); 64. PrintX(info.Get(3)); 65. } 66. //+------------------------------------------------------------------+
Код 07
Не стоит беспокоиться, ведь в приложении вы получите доступ к кодам в полном объеме, чтобы вы могли экспериментировать и отрабатывать каждую деталь, показанную здесь. В любом случае, я хочу, чтобы вы остановились и подумали о том, что мы здесь делаем: изменив код 06 на фрагмент из кода 07, простой факт изменения типа информации, которая будет находиться в структуре, позволит нам построить вещи, которые, по мнению многих, покажутся маловероятными или труднореализуемыми.
Один совет, который поможет вам задуматься о том, что делается: в зависимости от того, как мы создадим и разместим информацию в переменной в строке 60 из кода 07, мы можем создать код, который может работать на любом языке, если, конечно, мы реализуем и разместим информацию в переменной в строке 60 соответствующим образом.
Подумайте, как это можно сделать и как это повлияет на целое поколение кода, который вы можете создать.
Заключительные идеи
В этой статье мы более глубоко изучили некоторые основы программирования и рассмотрели, как можно начать реализовывать общую кодовую базу. Цель - снизить нагрузку при программировании и использовать весь потенциал самого языка программирования, в данном случае MQL5. То, что мы показываем или объясняем здесь, мне очень долго пришлось усваивать.
Однако это было связано с тем, что в то время, как я изучал данные вещи, они как раз создавались. Сейчас почти все говорят, что ООП - самое лучшее. И да, он действительно очень хорош и полезен. Но почему? Бесполезно видеть код класса, использовать его или даже модифицировать, не понимая, почему он работает. Чтобы по-настоящему понять и научиться, нужно сначала разобраться, как языки программирования вышли на этот уровень, почему было создано ООП и почему оно так широко используется.
Понять это можно только с помощью практики и экспериментов, используя код с принципами, которые обсуждаются только в ООП, но которые, по сути, не создаются, как методы и возможности, которые предоставляет только ООП. На самом деле данные принципы зародились в структурном программировании - теме, о которой сегодня почти никто не говорит и которую мы начинаем изучать именно здесь.
Перевод с португальского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/pt/articles/15889
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования