Инженерия признаков с Python и MQL5 (Часть IV): Распознавание свечных паттернов с помощью UMAP-регрессии

Свечные паттерны широко применяются в самых разных торговых стратегиях, в особенности в алгоритмическом трейдинге в этом сообществе. Однако наше понимание таких паттернов ограничено лишь теми свечными формациями, которые нам уже известны. На практике же может существовать множество других прибыльных свечных паттернов, о которых мы пока не знаем. Учитывая огромный объем информации, доступной по большинству современных рынков, мы уже не всегда уверены в том, что используем наиболее надежные паттерны из числа существующих.
Попробуем пойти дальше — обсудим решение, которое потенциально позволяет алгоритму выявлять новые свечные паттерны, о существовании которых мы ранее не подозревали. Предлагаемая здесь структура чем-то похожа на детскую игру, которую почти все мы знаем. Эта игра имеет разные названия, но ее принцип остается неизменным. Игрокам предлагается описать некое существительное, используя прилагательные и не используя само это существительное. Например, если заданным словом является "банан", ведущий игрок дает своим друзьям подсказки, наилучшим образом описывающие банан, такие как "желтый и изогнутый". Надеюсь, эта аналогия понятна.
Эта детская игра логически идентична задачам, которые мы будем ставить перед компьютером, чтобы выявить новые свечные паттерны, которые мы сами не могли бы обнаружить из-за высокого количества расчетов, требуемых для современных наборов данных. По аналогии с описанной игрой, где игрока просят описать банан тремя словами или менее, мы предоставим компьютеру рыночные данные, содержащие 10 столбцов, описывающих текущую свечу, а затем попросим его описать исходные рыночные данные в 8 столбцах (эмбеддингах) или менее. Этот процесс называется снижением размерности.
Существует множество известных методов снижения размерности, с которыми вы, возможно, уже знакомы, например метод главных компонент (Principal Components Analysis, PCA). Эти методы полезны тем, что направляют фокус компьютера на наиболее значимые аспекты преобразованных данных. Сегодня мы будем использовать метод Uniform Manifold Approximation And Projection (UMAP) — приближение и проекция на равномерном многообразии. Это сравнительно новый алгоритм, и, как мы увидим, он способен выявлять нелинейные зависимости в рыночных данных принципиально новым способом.
Наша цель — спроектировать и сформировать столбцы в исходном наборе данных, которые давали бы детальное описание текущей свечи. Это позволяет алгоритму UMAP преобразовывать данные, группировать схожие свечи и описывать их меньшим числом "слов" (эмбеддингов). В свою очередь, это может помочь компьютеру распознавать свечные паттерны, которые ранее были скрыты из-за их размерности, необходимой для точного описания каждой свечи.
Для проверки работы алгоритма UMAP мы обучили две идентичные статистические модели для прогнозирования доходности дневного курса по EURGBP. Первая модель обучалась на исходных рыночных данных в их первоначальном виде. В данном примере исходные рыночные данные имели 10 измерений, сформированных напрямую на рыночных данных из терминала MetaTrader 5. С помощью алгоритма UMAP нам удалось преобразовать исходные данные всего в 3 измерения, которые оказались достаточными для того, чтобы превзойти по ошибке модель, обученную на исходных данных без преобразований.
Мы не будем рассматривать реализацию алгоритма UMAP с нуля полностью на MQL5. Причина в том, что данный алгоритм достаточно сложен, и его реализация с численной устойчивостью и вычислительной эффективностью не так проста. Если вы уверены, что обладаете необходимыми знаниями в области аналитической геометрии и алгебраической топологии, вы может самостоятельно реализовать алгоритм, используя чисто язык MQL5. По этой ссылке находится оригинальная статья, подробно описывающая математическую специфику алгоритма.
Если же вы, как и я, не обладаете глубокими вычислительными навыками, здесь мы посмотрим, как можно отказаться от реализации алгоритма с нуля, используя вместо этого навыки аппроксимации функций.
Почему именно UMAP?
Существует огромное множество полезных и более известных методов снижения размерности. Поэтому, вы можете задаться вопросом: "Почему же именно метод UMAP? Действительно ли нужно изучать еще одну библиотеку?". Одним из главных преимуществ UMAP является то, что по мере увеличения размера набора данных время, необходимое библиотеке для преобразования данных, остается практически постоянным. Кроме того, алгоритм UMAP предназначен для выявления нелинейных эффектов в данных, при этом он стремится сохранить глобальную структуру исходных данных. Иными словами, алгоритм целенаправленно старается не искажать данные и не создавать вводящих в заблуждение артефактов, которые могли бы добавить дополнительный шум. А это проблема в большинстве методов снижения размерности.
Алгоритм UMAP относительно новый, а реализация, которую мы рассмотрим сегодня, построена с использованием Python и Numba. Numba — это компилятор, который преобразует код Python в машинный код. Такое сочетание Python и машинного кода обеспечивает высокую скорость и численно устойчивые вычисления даже на больших наборах данных. Данная реализация алгоритма UMAP была разработана Лиландом МакИннесом и соавторами. Библиотека была впервые опубликована в 2018 году.

Рис. 1. Лиланд МакИннес — один из ведущих авторов исследовательской статьи по UMAP и один из сопровождающих Python-библиотеки
Однако следует учитывать, что эти качества не могут быть гарантированы при использовании реализации алгоритма UMAP из другой библиотеки, отличной от рассматриваемой в данной статье. Различные реализации одного и того же алгоритма могут существенно отличаться по своим численным свойствам.
Начало работы с MQL5
Для начала мы получим количественные данные, описывающие текущую свечу. Нас интересует изменение цен Open, High, Low и Close, произошедшее за определенный период, который в данном примере называется горизонтом (horizon). Кроме того, нужно отслеживать рост от Open к High, от Open к Low и от Open к Close. Эти расчеты будем проводить для каждого из четырех ценовых потоков, доступных в терминале MetaTrader 5. В результате мы получаем в общей сложности 10 столбцов, не считая первых двух столбцов — Time и True Close. Эти 10 столбцов способны эффективно описывать любой свечной паттерн, такой как доджи или молот. Однако текущий подход не подходит для идентификации свечных паттернов, формирующихся более чем из одной свечи.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define HORIZON 24 //+------------------------------------------------------------------+ //| File name | //+------------------------------------------------------------------+ string file_name = Symbol() + " UMAP Candlestick Recognition.csv"; //+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time","True Close","Open","High","Low","Close","O - H","O - L","O - C","H - L","H - C","L - C"); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON
Анализ данных в Python
У нас двойная цель:
- Продемонстрировать преимущества использования UMAP-преобразований по сравнению с использованием ценовых данных в их исходном виде.
- Получить аппроксимацию алгоритма UMAP с использованием методов аппроксимации функций, чтобы протестировать, насколько эффективен данный алгоритм.
Мы покажем преимущества применения UMAP по сравнению с использованием исходных ценовых данных, чтобы сделать (по возможности) выгоды очевидными для читателя. После этого мы воспользуемся преобразованиями, предоставляемыми библиотекой UMAP, для обучения первой нейронной сети, которая будет оценивать UMAP-эмбеддинги заданных рыночных данных.
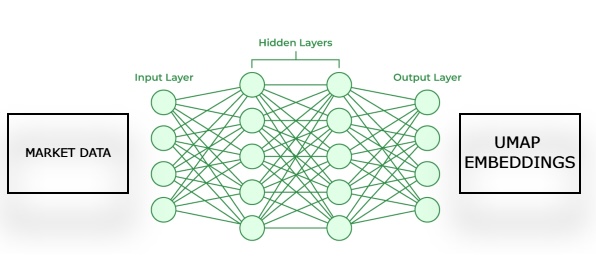
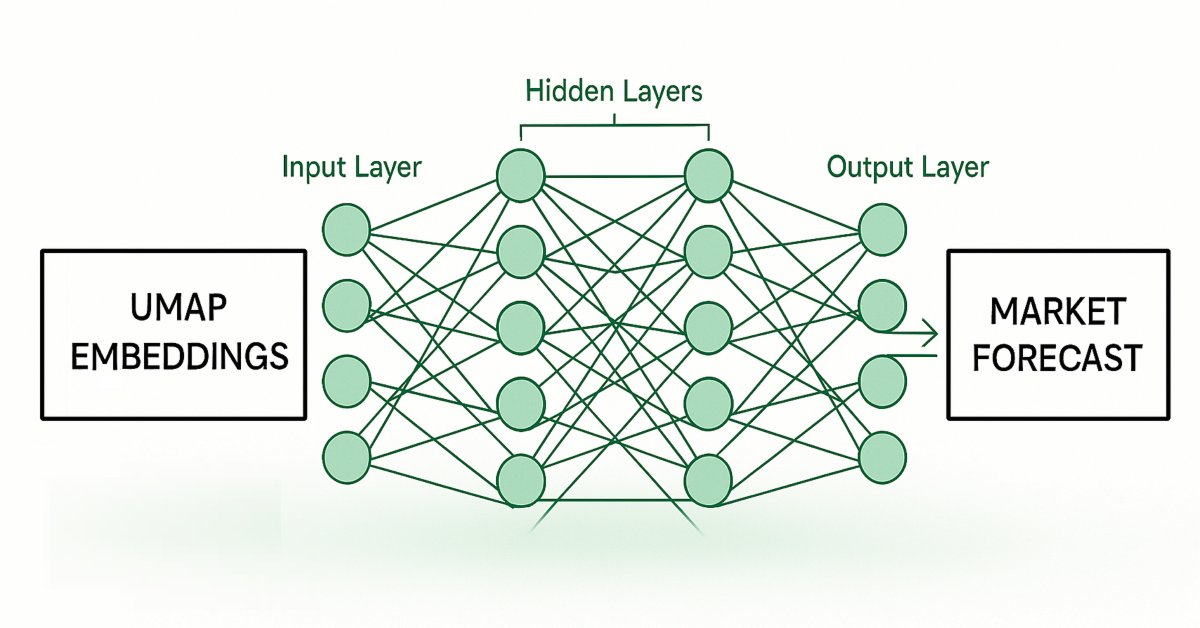
Рис. 2. Визуализация архитектуры для оценки UMAP-эмбеддингов по заданным рыночным данным
Затем мы обучим вторую модель, которая будет прогнозировать будущие движения цен на рынке, используя UMAP-эмбеддинги от первой модели. Нужно, чтобы эти две статистические модели работали в цепочке. Первая модель оценивает UMAP-эмбеддинги по рыночным данным, а вторая модель использует выход первой для прогнозирования будущей доходности рынка, на котором мы торгуем. Такая архитектура будет быстрее и, надеюсь, такой же эффективной, как и реализация алгоритма UMAP с нуля.
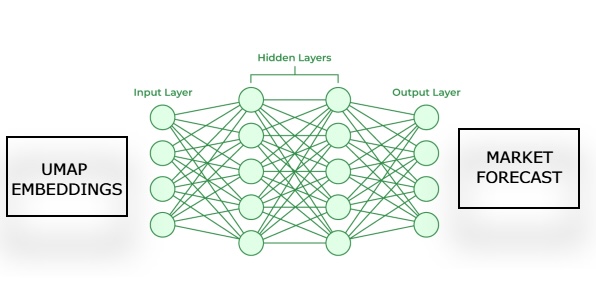
Рис. 3. Визуализация архитектуры для генерации рыночного прогноза на основе вычисленных UMAP-эмбеддингов
После рассмотрения мотивации и методологии перейдем к работе в Python. Начнем с импорта необходимых библиотек. Чтобы дальше идти по материалу, вам нудно установить библиотеку UMAP. Для этого выполните команду: pip install umap-learn.
import pandas as pd import numpy as np import matplotlib.pyplot as plt import umap import seaborn as sns
После этого следующим шагом надо загрузить рыночные данные, которые мы сгенерировали с помощью нашего MQL5-скрипта.
HORIZON = 24 data = pd.read_csv("..\EURGBP UMAP Candlestick Recognition.csv") data['Target'] = data['True Close'].shift(-HORIZON) - data['True Close'] data['Class'] = 0 data.loc[data['Target'] > 0,'Class'] = 1 data.dropna(inplace=True) data
Рыночные данные были успешно считаны, однако, если взглянуть на столбец Time, можно заметить, что CSV-файл содержит недавние рыночные данные. Удалим последние 5 лет рыночных данных из CSV-файла, чтобы провести чистое тестирование стратегии, и чтобы модель не имела доступа к информации из будущего, как при реальной работе.
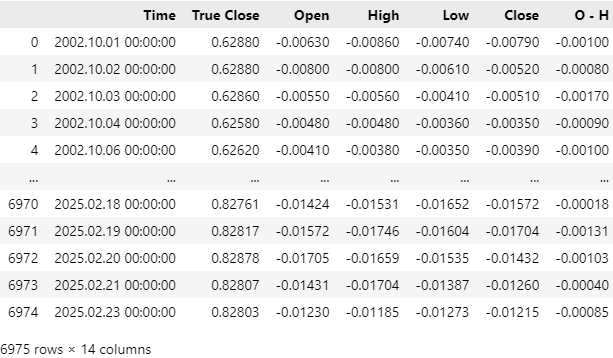
Рис. 4: Исторические рыночные данные, полученные с помощью MQL5-скрипта
Удалим последние 5 лет рыночных данных из CSV-файла. Обратите внимание, что последняя дата в CSV-файле теперь — 16 октября 2019 года. Тестирование будет выполняться с 1 января 2020 года. Такой перерыв между окончанием обучающего периода и началом тестового периода позволит точнее оценить работу стратегии.
#Delete all the data that overlaps with our back test data = data.iloc[:(-(365 * 5) + (31 * 5)),:] data
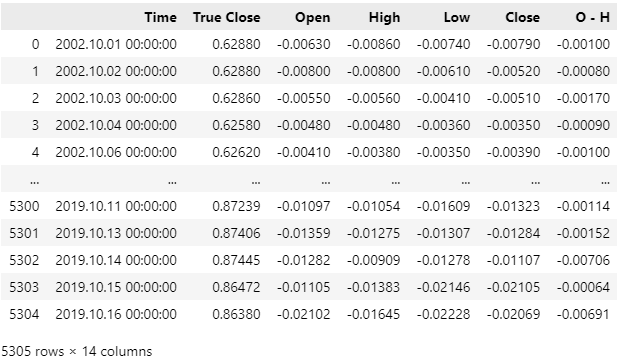
Рис. 5. Удаляем все данные, которые совпадают с периодом, который мы будем проверять на исторических данных
Визуализируем результаты созданных нами столбцов. Столбец "H - L" представляет разницу между максимальной и минимальной ценой дня. Фактически, это торговый диапазон за день. Столбец "O - C" отражает чистое изменение цены за день. Построим график рассеяния для этих двух столбцов, чтобы определить, существует ли какая-либо зависимость между дневным диапазоном и чистым изменением цены. К сожалению, эта зависимость оказалась сложной и нелинейной. Именно для работы с таким типом данных и может быть полезным метод UMAP.
sns.scatterplot(
data=data,
y='O - C',
x='H - L',
hue='Class'
)
plt.grid()
plt.title("Visualizing Our Custom Columns on EURUSD Market Data")
plt.axhline(0,color='black',linestyle='--')
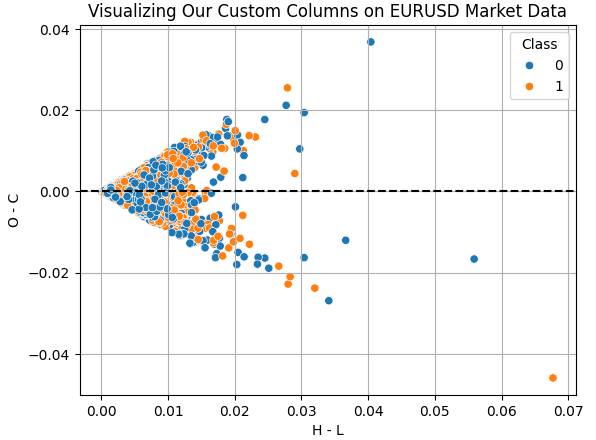
Рис. 6. Визуализация зависимости между торговым диапазоном и чистым изменением цены за тот же день
Применять UMAP-преобразования достаточно просто. Сначала необходимо создать объект UMAP. Затем мы обучаем этот объект на наших данных и получаем преобразованные данные. По умолчанию объект UMAP снижает размерность данных до двух столбцов. Вообще можно задавать любое желаемое количество столбцов. Десять столбцов, которые мы изначально получили с помощью MQL5-скрипта, свелись к двум измерениям, показанным на рис. 7.
В примере кода ниже показаны параметры настройки библиотеки UMAP:
- n_neighbors — параметр, указывающий алгоритму, какое количество точек данных он должен стараться удерживать в одном и том же локальном окружении;
- metric — метрика расстояния, используемая для оценки того, насколько "близки" друг к другу две точки и могут ли они считаться принадлежащими к одному окружению. Изменение метрики расстояния существенно меняет структуру проецированных данных.
reducer = umap.UMAP(n_neighbors=100,metric="euclidean") embedding = reducer.fit_transform(data.iloc[:,2:-2]) embedding = pd.DataFrame(embedding,columns=['X1','X2']) embedding['Class'] = data['Class'] sns.scatterplot( data=embedding, x='X1', y='X2', hue='Class' ) plt.grid() plt.title("Visualizing the effects of UMAP on our EURUSD Market Data")
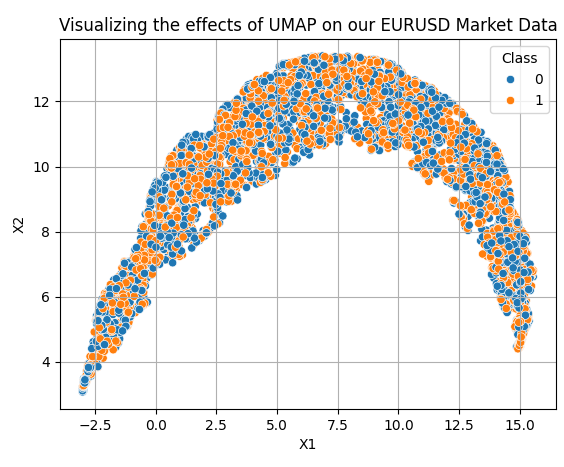
Рис. 7. Визуализация преобразованных данных после применения алгоритма UMAP
Новое представление данных не является идеальным. Тем не менее, в нем присутствуют области с преобладанием оранжевых точек и области, где больше синих. Это может облегчить статистическим моделям задачу обучения различию между двумя классами, которые мы пытаемся разделить. Хочу заметить, что здесь произвольно выбраны лишь два столбца. Я хотел дать общее представление о простоте начала работы. В действительности мы не знаем, сколько измерений необходимо для эффективного преобразования данных. Для этого выполним линейный поиск в диапазоне от 1 до 9. Следующая функция принимает параметр, задающий желаемое число измерений, и возвращает соответствующие преобразованные данные.
def return_transformed_data(n_components): HORIZON = 24 data = pd.read_csv("..\EURGBP UMAP Candlestick Recognition.csv") data['Target'] = data['True Close'].shift(-HORIZON) - data['True Close'] data.dropna(inplace=True) data = data.iloc[:(-(365 * 5) + (31 * 5)),:] reducer = umap.UMAP(n_neighbors=100,metric="euclidean",n_components=n_components,n_jobs=-1) embedding = reducer.fit_transform(data.iloc[:,2:-1]) cols = [] for i in np.arange(n_components): s = 'X' + ' ' + str(i) cols.append(s) embedding = pd.DataFrame(embedding,columns=cols) return embedding.copy()
Теперь подготовим наши модели.
from sklearn.ensemble import GradientBoostingRegressor from sklearn.model_selection import TimeSeriesSplit,cross_val_score
Определим объект разбиения временного ряда для корректной кросс-валидации временных рядов.
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON) Выполним линейный поиск, чтобы определить оптимальное число измерений, необходимое для представления исходных данных.
LEVELS = 8 res = pd.DataFrame(columns=['X'],index=np.arange(LEVELS)) for i in range(LEVELS): new_data = return_transformed_data(i+1) res.iloc[i,0] = np.mean(np.abs(cross_val_score(GradientBoostingRegressor(),new_data.iloc[:,0:],data['Target'],cv=tscv)))
Получим индекс минимума и минимальное значение.
res['X'] = pd.to_numeric(res['X'], errors='coerce') min_value = min(res.iloc[:,0]) min_index = res['X'].idxmin()
Лучшие результаты были получены при использовании 3 столбцов для представления исходных 10. Обратите внимание, что это не "лучшие 3 столбца" из исходных 10. Все 10 столбцов были преобразованы в 3 новых измерения.
plt.plot(res,color='black') plt.grid() plt.title('Finding The Optimal Number of U-MAP Components') plt.ylabel('RMSE Validation Error') plt.xlabel('Training Iteration') plt.scatter(min_index,min_value,color='red')
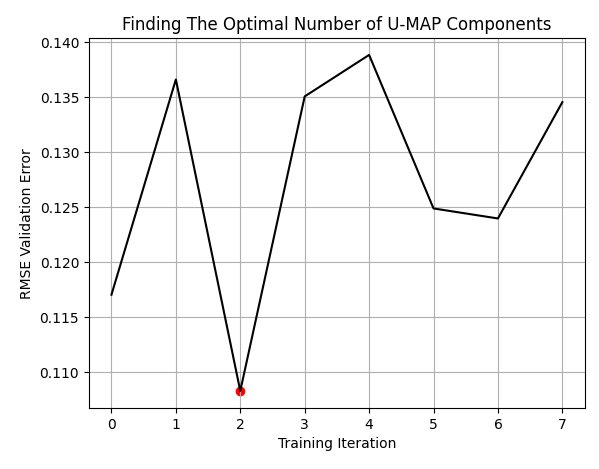
Рис. 8. Оптимальное число столбцов — 3 вместо исходных 10
Теперь зафиксируем уровни ошибки при использовании рыночных данных в их исходном виде.
classic_error = np.mean(np.abs(cross_val_score(GradientBoostingRegressor(),data.iloc[:,2:-2],data['Target'],cv=tscv)))
Далее сравним ошибку, полученную при использовании преобразованных UMAP-данных, с ошибкой при работе с рыночными данными без каких-либо преобразований. Как видите, UMAP-преобразование снизило уровень ошибки до оптимальных значений, которых невозможно было достичь при работе с исходными ценовыми данными.
results = [min(res.iloc[:,0]),classic_error] sns.barplot(results,color='black') plt.axhline(results[0],color='red',linestyle='--') plt.ylabel('RMSE Validation Error') plt.xlabel('0: UMAP Transformed Data | 1: Original OHLC Data') plt.title("UMAP Transformations Are Helping Us Reduce Our Error Rates")
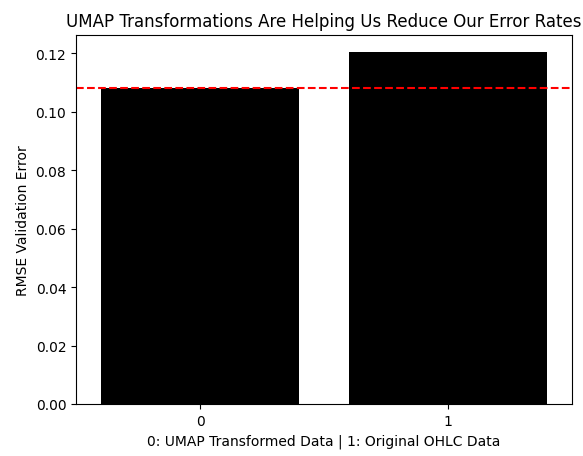
Рис. 9. UMAP-преобразование снижает уровень ошибки по сравнению с работой с исходными данными
Далее перейдем непосредственно к построению архитектуры, описанной на рис. 2 и 3. Начнем с оценки того, сколько итераций обучения требуется нашей нейронной сети для эффективного преобразования исходных рыночных данных в UMAP-эмбеддинги.
from sklearn.neural_network import MLPRegressor
Получим необходимые данные.
new_data = return_transformed_data(3) Выполним линейный поиск, чтобы изучить зависимость между ошибкой модели и количеством эпох обучения.
LEVELS = 18 NN_ERROR = pd.DataFrame(columns=['Error'],index=np.arange(LEVELS)) for i in range(LEVELS): model = MLPRegressor(hidden_layer_sizes=(data.iloc[:,2:-2].shape[1],10,5),max_iter=(2 ** i),solver='adam') NN_ERROR.iloc[i,0] = np.mean(np.abs(cross_val_score(model,new_data,data['Target'],cv=tscv)))
Отобразим результаты на графике. Лучшие результаты были получены, когда модель смогла выполнять 65 536 итераций обучения, то есть 2 в степени 16.
NN_ERROR['Error'] = pd.to_numeric(NN_ERROR['Error'], errors='coerce') min_idx = NN_ERROR.idxmin() min_value = NN_ERROR.min() plt.plot(NN_ERROR,color='black') plt.grid() plt.ylabel('5 Fold CV RMSE') plt.xlabel('Max Iterations As Powers of 2') plt.scatter(min_idx,min_value,color='red') plt.title('Minimizing The Error of Our Neural Network')
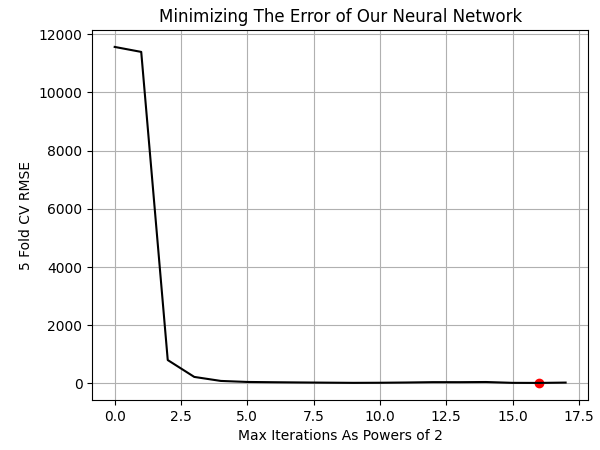
Рис. 10. Визуализация оптимального числа итераций обучения, необходимых модели для освоения UMAP-эмбеддингов
Теперь можем обучить обе модели.
#The first model will transform the given market data into its UMAP embeddings umap_transform_model = MLPRegressor(hidden_layer_sizes=(data.iloc[:,2:-2].shape[1],10,5),max_iter=int(2 ** min_idx),solver='adam') umap_transform_model.fit(data.iloc[:,2:-2],new_data) #The second model will forecast the future EURGBP returns, given UMAP embeddings forecast_model = MLPRegressor(hidden_layer_sizes=(new_data.shape[1],10,5),max_iter=int(2 ** min_idx),solver='adam') forecast_model.fit(new_data,data['Target'])
Подготовим к экспорту моделей в формат ONNX.
import onnx import netron from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Модель, отвечающая за вычисление UMAP-эмбеддингов, имеет уникальную форму входных и выходных данных. Она принимает 10 входных параметров и возвращает 3 выходных. Укажем это с помощью параметров initial_types и final_types API ONNX.
umap_transform_shape = [("float_input",FloatTensorType([1,data.iloc[:,2:-2].shape[1]]))] umap_transform_output_shape = [("float_output",FloatTensorType([new_data.shape[1],1]))]
Модель, прогнозирующая изменение цены на основе заданных UMAP-эмбеддингов, имеет более простые параметры. Она принимает 3 выходных значения из первой модели в качестве входных данных и возвращает одно.
forecast_shape = [("float_input",FloatTensorType([1,new_data.shape[1]]))]
Определим формы ввода и вывода моделей. Обратите внимание, что необходимо выполнить дополнительный шаг, чтобы указать, что первая модель выдает множество параметров, а затем задать соответствующую форму.
umap_model_proto = convert_sklearn(umap_transform_model,initial_types=umap_transform_shape,final_types=umap_transform_output_shape,target_opset=12) forecast_model_proto = convert_sklearn(forecast_model,initial_types=forecast_shape,target_opset=12)
Сохраним модели.
onnx.save(umap_model_proto,"EURGBP UMAP.onnx") onnx.save(forecast_model_proto,"EURGBP UMAP Forecast.onnx")
Начало работы в MQL5
Перейдем к написанию MQL5-кода для тестирования прибыльности UMAP-регрессии. Напомню, что на рис. 5 мы удалили все данные, начиная с 2020 года и до настоящего времени. Следовательно, бэктест должен дать честное представление о том, как наша стратегия будет работать в реальных условиях, с которыми она ранее не сталкивалась. Загрузим модели ONNX.
//+------------------------------------------------------------------+ //| UMAP Regression.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURGBP UMAP.onnx" as uchar umap_onnx_buffer[]; #resource "\\Files\\EURGBP UMAP Forecast.onnx" as uchar umap_forecast_onnx_buffer[];
Кроме того, нам потребуется несколько глобальных переменных. Поскольку стратегия является алгоритмической, их понадобится не так много.
//+------------------------------------------------------------------+ //| Global Variables | //+------------------------------------------------------------------+ long umap_onnx_model,umap_forecast_onnx_model; vectorf umap_onnx_output(3),umap_forecast_onnx_output(1); double trade_sl;
Определим хендлы и буферы индикаторов.
//+------------------------------------------------------------------+ //| Technical indicators | //+------------------------------------------------------------------+ int ma_o_handler,ma_c_handler; double ma_o[],ma_c[];
Загрузим торговую библиотеку.
//+------------------------------------------------------------------+ //| Technical indicators | //+------------------------------------------------------------------+ int ma_o_handler,ma_c_handler; double ma_o[],ma_c[];
Чтобы код оставался читабельным, я решил выделить отдельные функции под каждый обработчик событий. В результате основной код легко читается от начала до конца. Если вы захотите добавить дополнительную функциональность, рекомендую придерживаться того же принципа проектирования: оборачивать требуемую логику в отдельный метод и вызывать его из основного кода программы. Такой подход делает работу с кодом значительно более удобной, ее проще сопровождать по сравнению с альтернативой, когда сотни строк кода сосредоточены в одном обработчике событий.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!setup()) return(INIT_FAILED); //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- release(); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- update(); } //+------------------------------------------------------------------+
Функция release очищает ресурсы советника перед выгрузкой.
//+------------------------------------------------------------------+ //| Custom functions | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Free up system memory | //+------------------------------------------------------------------+ void release(void) { IndicatorRelease(ma_c_handler); IndicatorRelease(ma_o_handler); OnnxRelease(umap_onnx_model); OnnxRelease(umap_forecast_onnx_model); }
Функция setup отвечает за инициализацию ONNX-модели и нужных системных переменных. Она возвращает логическое значение false, если в процессе инициализации что-то пошло не так. В противном случае функция должна возвращать true. Формы входов и выходов ONNX-моделей даны попарно, так же, как и их вызовы.
//+------------------------------------------------------------------+ //| Setup system variables | //+------------------------------------------------------------------+ bool setup(void) { umap_onnx_model = OnnxCreateFromBuffer(umap_onnx_buffer,ONNX_DATA_TYPE_FLOAT); umap_forecast_onnx_model = OnnxCreateFromBuffer(umap_forecast_onnx_buffer,ONNX_DATA_TYPE_FLOAT); ma_c_handler = iMA(_Symbol,PERIOD_CURRENT,2,0,MODE_EMA,PRICE_CLOSE); ma_o_handler = iMA(_Symbol,PERIOD_CURRENT,2,0,MODE_EMA,PRICE_OPEN); if(umap_onnx_model == INVALID_HANDLE) { Comment("Failed to create EURGBP UMAP Transformer ONNX model"); return(false); } if(umap_forecast_onnx_model == INVALID_HANDLE) { Comment("Failed to create EURGBP UMAP Forecast ONNX model"); return(false); } ulong umap_input_shape[] = { 1 , 10 }; ulong umap_forecast_input_shape[] = { 1 , 3 }; ulong umap_output_shape[] = { 3 , 1 }; ulong umap_forecast_output_shape[] = { 1 , 1 }; if(!OnnxSetInputShape(umap_onnx_model,0,umap_input_shape)) { Comment("Failed to specify ONNX model input shape"); Print("Actual shape: ",OnnxGetInputCount(umap_onnx_model)); return(false); } if(!OnnxSetInputShape(umap_forecast_onnx_model,0,umap_forecast_input_shape)) { Comment("Failed to specify EURGBP Forecast ONNX model input shape"); Print("Actual shape: ",OnnxGetInputCount(umap_onnx_model)); return(false); } if(!OnnxSetOutputShape(umap_onnx_model,0,umap_output_shape)) { Comment("Failed to specify ONNX model output shape"); Print("Actual shape: ",OnnxGetOutputCount(umap_onnx_model)); return(false); } if(!OnnxSetOutputShape(umap_forecast_onnx_model,0,umap_forecast_output_shape)) { Comment("Failed to specify EURGBP Forecast ONNX model output shape"); Print("Actual shape: ",OnnxGetOutputCount(umap_onnx_model)); return(false); } trade_sl = 2e-2; return(true); }
Функция update помогает копирует значения индикаторов в их буферы и выполняет торговые функции один раз в день.
//+------------------------------------------------------------------+ //| Update our system variables | //+------------------------------------------------------------------+ void update(void) { static datetime time_stamp; datetime current_time = iTime(_Symbol,PERIOD_CURRENT,0); if(current_time != time_stamp) { time_stamp = current_time; CopyBuffer(ma_c_handler,0,0,1,ma_c); CopyBuffer(ma_o_handler,0,0,1,ma_o); if(PositionsTotal() == 0) { GetModelForecast(); FindSetup(); } } }
Функция forecast получает цепочку прогнозов. Первый прогноз представляет собой аппроксимацию UMAP-эмбеддингов исходных рыночных данных. Второй — наш торговый сигнал, то есть прогнозируемая доходность рынка EURGBP, полученная на основе аппроксимации его UMAP-эмбеддингов.
//+------------------------------------------------------------------+ //| Get a forecast from our models | //+------------------------------------------------------------------+ void GetModelForecast(void) { vectorf model_inputs = GetUmapModelInputs(); OnnxRun(umap_onnx_model,ONNX_DATA_TYPE_FLOAT,model_inputs,umap_onnx_output); OnnxRun(umap_forecast_onnx_model,ONNX_DATA_TYPE_FLOAT,umap_onnx_output,umap_forecast_onnx_output); Print("Model Inputs: \n",model_inputs); Print("Umap Transformer Forecast: \n",umap_onnx_output); Print("EURUSD Return UMAP Forecast: \n",umap_forecast_onnx_output); }
Прежде чем мы сможем получить прогноз от модели, необходимо подготовить ее входные данные. Напомню, что сначала мы нужно подготовить входные значения для первой модели. Данные, полученные на выходе первой модели, подадим на вход второй.
//+------------------------------------------------------------------+ //| Get our model's input data | //+------------------------------------------------------------------+ vectorf GetUmapModelInputs(void) { vectorf umap_model_inputs(10); umap_model_inputs[0] = (float)(iOpen(_Symbol,PERIOD_CURRENT,1) - iOpen(_Symbol,PERIOD_CURRENT,11)); umap_model_inputs[1] = (float)(iHigh(_Symbol,PERIOD_CURRENT,1) - iHigh(_Symbol,PERIOD_CURRENT,11)); umap_model_inputs[2] = (float)(iLow(_Symbol,PERIOD_CURRENT,1) - iLow(_Symbol,PERIOD_CURRENT,11)); umap_model_inputs[3] = (float)(iClose(_Symbol,PERIOD_CURRENT,1) - iClose(_Symbol,PERIOD_CURRENT,11)); umap_model_inputs[4] = (float)(iOpen(_Symbol,PERIOD_CURRENT,1) - iHigh(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[5] = (float)(iOpen(_Symbol,PERIOD_CURRENT,1) - iLow(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[6] = (float)(iOpen(_Symbol,PERIOD_CURRENT,1) - iClose(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[7] = (float)(iHigh(_Symbol,PERIOD_CURRENT,1) - iLow(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[8] = (float)(iHigh(_Symbol,PERIOD_CURRENT,1) - iClose(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[9] = (float)(iLow(_Symbol,PERIOD_CURRENT,1) - iClose(_Symbol,PERIOD_CURRENT,1)); return(umap_model_inputs); } //+------------------------------------------------------------------+
Напомню также, что на рис. 4 и 5 мы удалили все исторические данные, которые пересекались с датами, используемыми на рис. 11 ниже. Это позволяет увидеть, как модель будет вести себя при работе с данными вне обучающей выборки. Только так можно оценить потенциальную прибыльности стратегии.

Рис. 11. Период тестирования для оценки ансамбля моделей UMAP
Теперь определим условия, при которых будет тестироваться стратегия. Чтобы получить наиболее надежные результаты, проведем стресс-тестирование в сложных условиях, задав для тестирования случайную задержку между моментом отправки ордера и его фактическим исполнением.

Рис. 12. Смоделированные выше условия имитируют реальные торговые сценарии
В журнал тестера стратегий выводятся входные параметры наших ONNX-моделей, а цепочка UMAP-моделей формирует выходные значения. Первая модель корректно сократила 10 входных параметров, полученных из рыночных данных, до 3 параметров, которые затем использовались для получения прогноза.

Рис. 13. Выглядит корректно, все компоненты успешно взаимодействуют на внутреннем уровне
Кривая доходности демонстрирует положительную динамику, то есть модель работает. Это обнадеживает, если вспомнить, что мы лишь аппроксимировали алгоритм UMAP и его эмбеддинги.

Рис. 14. Наша стратегия на данный момент выглядит прибыльной
Рассмотрим более детально показатели эффективности стратегии. Система имеет коэффициент Шарпа 0,42 при ожидаемой доходности 7,05 — это положительные показатели. Доля прибыльных сделок составляет 64%, при общем количестве сделок 25.

Рис. 15. Детальный анализ эффективности UMAP-регрессии на истории
Среднее время удержания сделки = 1274 часа, то есть около 54 дней. Это говорит о том, что советник, вероятно, улавливает тренды на рынке, поскольку средняя продолжительность позиции такая длинная.

Рис. 16. Визуализация распределения времени жизни
Как видно по результатам тестирования, советник действительно понимает устойчивые рыночные тренды. На ниже скриншоте ниже вертикальные белые линии соответствуют периодам в 1 день. Накже на графике показаны сделки, которые советник UMAP Regression разместил во время тестирования. Первая сделка была открыта в апреле 2020 года и закрыта в следующем месяце, в мае. Следующая сделка продолжалась с конца мая до начала сентября.
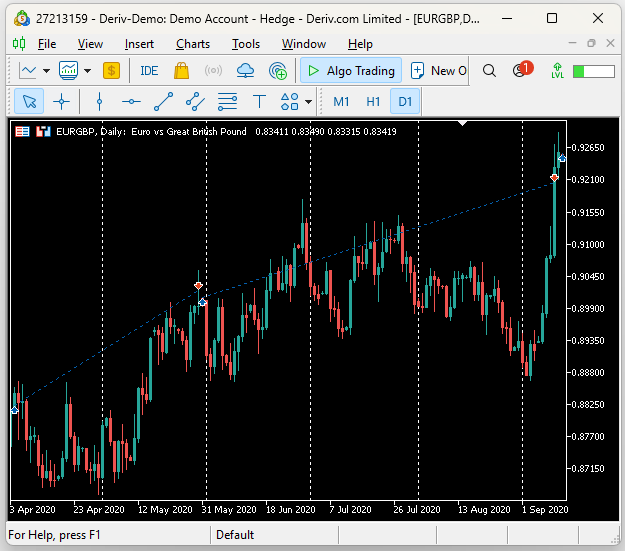
Рис. 17. Визуализация сделок, совершенных советником
Заключение
В этой статье мы поговорили о методах снижения размерности, которые призваны помочь статистической модели выявлять доминирующие рыночные признаки в имеющихся данных. Мы показали, что алгоритм UMAP способен снижать уровень ошибок статистических моделей до 40% по сравнению с идентичной моделью, обученной на исходных рыночных данных без UMAP-преобразований. Также мы представили новую архитектуру, позволяющую безопасно аппроксимировать алгоритмы, которые невозможно реализовать нативно. Надеюсь, эти знания и навыки окажутся для кого-то полезными и помогут достичь лучших результатов на рынке. | Название файла | Описание |
|---|---|
| EURGBP UMAP Forecast.onnx | Файл ONNX, который принимает на вход рассчитанные UMAP-эмбеддинги для прогнозирования EURGBP |
| EURGBP UMAP.onnx | Файл ONNX, отвечающий за обработку рыночных данных в качестве входных параметров и аппроксимацию правильных эмбеддингов |
| UMAP Candlestick Recognition.ipynb | Jupyter Notebook, который мы использовали для анализа рыночных данных из MetaTrader 5 и создания ONNX-файлов |
| UMAP Candlestick Recognition.mq5 | Скрипт MQL5 для получения рыночных данных |
| UMAP Regression.mq5 | Советник для торговли на EURGBP с использованием двухмодельной архитектуры |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/17631
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Спасибо, это действительно интересное приложение.Если вы получаете NameError: name 'FloatTensorType' is not defined, вам нужно установить или обновить onnixxmltools через !pip install onnxmltools. Мои данные получились совсем не такими, как показано здесь, мне было бы интересно узнать, как остальные справляются с этим кодом
Мне нужен советник для MT5 и использования брокера Exness.