
Использование алгоритма машинного обучения PatchTST для прогноза ценовых движений на следующие 24 часа
Введение
Впервые я столкнулся с алгоритмом под названием PatchTST, когда начал изучать достижения ИИ, связанные с прогнозами временных рядов на сайте Huggingface.co. Как известно всякому, кто работал с большими языковыми моделями (Large Language Model, LLM), изобретение трансформеров кардинально изменило правила игры в разработке инструментов для обработки естественного языка, изображений и видеоматериалов. А как насчет временных рядов? Разве о них просто забыли? Или большинство исследований просто проводят за закрытыми дверями? Оказывается, есть множество более новых моделей, успешно применяющих трансформеры для прогнозирования временных рядов. В этой статье мы рассмотрим одну из таких реализаций.
Что впечатляет в алгоритме PatchTST, так это быстрота, с которой он обучает модель, и простота использования обученной модели с MQL. Не скрою, я новичок в том, что касается теории нейросетей. Но пройдя через этот процесс и взяв на себя труд реализовать PatchTST на MQL5, как описано в этой статье, я почувствовал, что сделал огромный скачок вперед в изучении и понимании способов разработки, устранения неисправностей, обучения и использования этих сложных нейросетей. Это как взять едва научившегося ходить ребенка и отправить его в профессиональную футбольную команду, ожидая, что он забьет решающий гол в финале Чемпионата мира.
Обзор алгоритма PatchTST
Узнав о PatchTST, я стал изучать статью, объясняющую, как он устроен: "A Time Series is Worth 64 Words: Long-term Forecasting with Transformers" ("Лучше временной ряд, чем 64 слова: долгосрочное прогнозирование с помощью трансформеров"). Название было интересным. Вчитавшись, я подумал: "Ух ты, как увлекательно написано, — и здесь много элементов, о которых я всегда хотел узнать". Само собой, мне захотелось попробовать эти прогнозы на практике. Вот что еще больше заинтересовало меня в этом алгоритме:
- С помощью PatchTST можно прогнозировать цены открытия, максимумы, минимумы и цены закрытия. Благодаря PatchTST я решил, что такому алгоритму можно передавать все данные по мере их поступления — цены открытия и закрытия, максимумы и минимумы, даже объем. Можно ожидать, что он найдет закономерности в данных, так как все они преобразуются в так называемые "патчи" (сегменты). Подробнее о том, что такое собой патчи, расскажу ниже в этой статье. Пока важно только понимать, что патчи привлекательны и помогают делать более точные прогнозы.
- Минимальные требования к предварительной обработке данных в алгоритме PatchTST. Погрузившись в дальнейшее изучение этого алгоритма, я узнал, что авторы используют метод под названием RevIn (reverse instance normalization — обратимая инстантная нормализация). RevIn взят из статьи под названием: "REVERSIBLE INSTANCE NORMALIZATION FOR ACCURATE TIME-SERIES FORECASTING AGAINST DISTRIBUTION SHIFT" ("ОБРАТИМАЯ ИНСТАНТНАЯ НОРМАЛИЗАЦИЯ ДЛЯ ТОЧНОГО ПРОГНОЗИРОВАНИЯ ВРЕМЕННЫХ РЯДОВ ОТНОСИТЕЛЬНО СДВИГА РАСПРЕДЕЛЕНИЯ"). RevIn пытается решить задачу сдвига распределения при прогнозировании временных рядов. Нам, алгоритмическим трейдерам, слишком хорошо знакомо чувство, когда обученный советник перестает предсказывать рынок, и мы вынуждены заново оптимизировать и обновлять свои параметры. Считайте, что RevIn — способ сделать то же самое.
- По сути, этот метод берет переданные в него данные и нормализует их с помощью следующей формулы:
x = (x - mean) / std
Затем, когда модели нужно сделать прогноз, она выполняет денормализацию данных с помощью противоположного свойства:
x = x * std + mean
Кроме того, у RevIn есть другое свойство, которое называется affine_bias. Проще говоря, это обучаемый параметр, учитывающий асимметрию, эксцесс и прочих элементов, которые могут присутствовать в наборе данных.
x = x * affine_weight + affine_bias
Обобщить структуру PatchTST можно так:
Input Data -> RevIn -> Series Decomposition -> Trend Component -> PatchTST Backbone -> TSTiEncoder -> Flatten_Head -> Trend Forecaster -> Residual Component -> Add Trend and Residual -> Final Forecast
Мы понимаем, что данные будут извлечены с помощью MT5. Кроме того, мы обсудили, как работает RevIn.
Вот как работает PatchTST: предположим, вы извлекаете 80 000 баров данных по EURUSD на таймфрейме H1. И это данные всего за 13 лет. С помощью PatchTST вы сегментируете данные в так называемые "патчи". В качестве аналогии представьте, что патчи похожи на работу Vision Transformers (ViTs) для изображений, но адаптированы для данных временных рядов. Так, например, если длина патча 16, то в каждом патче будет 16 последовательных значений цены. Это похоже на просмотр небольших фрагментов временного ряда за раз, что помогает модели сфокусироваться на локальных закономерностях, прежде чем рассматривать глобальную.
Далее, патчи включают позиционное кодирование для сохранения порядка последовательности, благодаря чему модель лучше запоминает положение каждого патча в последовательности.
Трансформер передает нормализованные и закодированные патчи через стек слоев кодировщика. Каждый слой кодировщика содержит слой многопоточного механизма внимания и слой с прямой связью. Слой многопоточного внимания позволяет модели уделять внимание различным компонентов входной последовательности, а слой с прямой связью позволяет ей осваивать сложные нелинейные преобразования данных.
Наконец, у нас есть тренд и остаточные компоненты. Создание патчей, нормализация, позиционное кодирование и слои трансформеров применяются как к компоненту тренда, так и к остаточному компоненту. Затем сложим выходные данные компонентов тренда и остаточных компонентов, чтобы получить окончательный прогноз.
Проблемы PatchTST с официальным репозиторием
Официальный репозиторий PatchTST можно найти на сайте GitHub по ссылке: PatchTST (ICLR 2023). Доступны две различные версии — контролируемая и неконтролируемая. Для данной статьи используем подход с контролируемым обучением. Как известно, для использования любой модели с MQL5 нам нужен способ преобразовать ее в формат ONNX. Однако авторы PatchTST не приняли это во внимание. Для работы модели с MQL5 мне пришлось внести в их базовый код следующие модификации:
Оригинальный код:
class PatchTST_backbone(nn.Module): def __init__(self, c_in:int, context_window:int, target_window:int, patch_len:int, stride:int, max_seq_len:Optional[int]=1024, n_layers:int=3, d_model=128, n_heads=16, d_k:Optional[int]=None, d_v:Optional[int]=None, d_ff:int=256, norm:str='BatchNorm', attn_dropout:float=0., dropout:float=0., act:str="gelu", key_padding_mask:bool='auto', padding_var:Optional[int]=None, attn_mask:Optional[Tensor]=None, res_attention:bool=True, pre_norm:bool=False, store_attn:bool=False, pe:str='zeros', learn_pe:bool=True, fc_dropout:float=0., head_dropout = 0, padding_patch = None, pretrain_head:bool=False, head_type = 'flatten', individual = False, revin = True, affine = True, subtract_last = False, verbose:bool=False, **kwargs): super().__init__() # RevIn self.revin = revin if self.revin: self.revin_layer = RevIN(c_in, affine=affine, subtract_last=subtract_last) # Patching self.patch_len = patch_len self.stride = stride self.padding_patch = padding_patch patch_num = int((context_window - patch_len)/stride + 1) if padding_patch == 'end': # can be modified to general case self.padding_patch_layer = nn.ReplicationPad1d((0, stride)) patch_num += 1 # Backbone self.backbone = TSTiEncoder(c_in, patch_num=patch_num, patch_len=patch_len, max_seq_len=max_seq_len, n_layers=n_layers, d_model=d_model, n_heads=n_heads, d_k=d_k, d_v=d_v, d_ff=d_ff, attn_dropout=attn_dropout, dropout=dropout, act=act, key_padding_mask=key_padding_mask, padding_var=padding_var, attn_mask=attn_mask, res_attention=res_attention, pre_norm=pre_norm, store_attn=store_attn, pe=pe, learn_pe=learn_pe, verbose=verbose, **kwargs) # Head self.head_nf = d_model * patch_num self.n_vars = c_in self.pretrain_head = pretrain_head self.head_type = head_type self.individual = individual if self.pretrain_head: self.head = self.create_pretrain_head(self.head_nf, c_in, fc_dropout) # custom head passed as a partial func with all its kwargs elif head_type == 'flatten': self.head = Flatten_Head(self.individual, self.n_vars, self.head_nf, target_window, head_dropout=head_dropout) def forward(self, z): # z: [bs x nvars x seq_len] # norm if self.revin: z = z.permute(0,2,1) z = self.revin_layer(z, 'norm') z = z.permute(0,2,1) # do patching if self.padding_patch == 'end': z = self.padding_patch_layer(z) z = z.unfold(dimension=-1, size=self.patch_len, step=self.stride) # z: [bs x nvars x patch_num x patch_len] z = z.permute(0,1,3,2) # z: [bs x nvars x patch_len x patch_num] # model z = self.backbone(z) # z: [bs x nvars x d_model x patch_num] z = self.head(z) # z: [bs x nvars x target_window] # denorm if self.revin: z = z.permute(0,2,1) z = self.revin_layer(z, 'denorm') z = z.permute(0,2,1) return z
Вышеприведенный код — это основа. Как видите, код использует функцию под названием Unfold в строке:
z = z.unfold(dimension=-1, size=self.patch_len, step=self.stride) # z: [bs x nvars x patch_num x patch_len]
ONNX не поддерживает преобразование функции Unfold. Вы получите ошибку типа:
Unsupported: ONNX export of operator Unfold, input size not accessible. Не стесняйтесь обращаться за поддержкой или отправлять запрос на включение изменений на PyTorch GitHub по адресу: https://github.com/pytorch/pytorch/issues
Поэтому мне пришлось заменить этот участок кода на:
# Manually unfold the input tensor batch_size, n_vars, seq_len = z.size() patches = [] for i in range(0, seq_len - self.patch_len + 1, self.stride): patches.append(z[:, :, i:i+self.patch_len])
Обратите внимание, что вышеприведенная замена немного менее эффективна, так как пользуется циклом for для обучения нейросети. Неэффективность может копиться на протяжении многих эпох и на больших наборах данных. Но это необходимо, поскольку иначе модель просто не сможет преобразоваться и мы не сможем использовать ее с MQL5.
Я специально занялся решением этой проблемы. Это заняло больше всего времени. Затем я все собрал в файле patchTST.py, который можно найти в прикрепленном к этой статье zip-архиве. Вот файл, который мы используем для обучения своей модели.
Требования к работе с PatchTST на языке Python
В этом разделе я расскажу о требованиях к работе с PatchTST на языке Python. Их можно обобщить ниже:
Создание виртуальной среды:
python -m venv myenv
Активация виртуальной среды (Windows)
.\myenv\Scripts\activate
Установка файла requirements.txt из архива, прикрепленного к этой статье:
pip install -r requirements.txt
В частности, требования к запуску этого проекта:
MetaTrader5
pandas
numpy
torch
plotly
datetime Пошаговая разработка кода обучения модели
Для следующего кода вы можете повторить за мной, используя блокнот Jupyter, который я включил в zip-файл: PatchTST Step-By-Step.ipynb. Ниже кратко опишем шаги:
-
Импорт необходимых библиотек. Импорт нужных библиотек, в том числе MetaTrader 5, Pandas, Numpy, Torch, и модели PatchTST.
# Step 1: Import necessary libraries import MetaTrader5 as mt5 import pandas as pd import numpy as np import torch from torch.utils.data import TensorDataset, DataLoader from patchTST import Model as PatchTST
-
Инициализация и извлечение данных из MetaTrader 5. Функция fetch_mt5_data инициализирует MT5, извлекает данные для заданного символа, таймфрейма и количества баров, а затем возвращает датафрейм со столбцами для цены открытия, максимума, минимума и цены закрытия.
# Step 2: Initialize and fetch data from MetaTrader 5 def fetch_mt5_data(symbol, timeframe, bars): if not mt5.initialize(): print("MT5 initialization failed") return None timeframe_dict = { 'M1': mt5.TIMEFRAME_M1, 'M5': mt5.TIMEFRAME_M5, 'M15': mt5.TIMEFRAME_M15, 'H1': mt5.TIMEFRAME_H1, 'D1': mt5.TIMEFRAME_D1 } rates = mt5.copy_rates_from_pos(symbol, timeframe_dict[timeframe], 0, bars) mt5.shutdown() df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') df.set_index('time', inplace=True) return df[['open', 'high', 'low', 'close']] # Fetch data data = fetch_mt5_data('EURUSD', 'H1', 80000)
-
Подготовка данных прогнозирования с помощью скользящего окна. Функция prepare_forecasting_data создает набор данных с помощью метода скользящего окна, генерируя последовательности исторических данных (X) и соответствующих будущих данных (y).
# Step 3: Prepare forecasting data using sliding window def prepare_forecasting_data(data, seq_length, pred_length): X, y = [], [] for i in range(len(data) - seq_length - pred_length): X.append(data.iloc[i:(i + seq_length)].values) y.append(data.iloc[(i + seq_length):(i + seq_length + pred_length)].values) return np.array(X), np.array(y) seq_length = 168 # 1 week of hourly data pred_length = 24 # Predict next 24 hours X, y = prepare_forecasting_data(data, seq_length, pred_length)
-
Разделение данных на обучающие и тестовые. Разбиение данных на наборы — 80% для обучения и 20% для тестирования.
# Step 4: Split data into training and testing sets split = int(len(X) * 0.8) X_train, X_test = X[:split], X[split:] y_train, y_test = y[:split], y[split:]
-
Преобразование данных в тензоры PyTorch. Преобразование массивов NumPy в тензоры PyTorch, необходимые для обучения с помощью PyTorch. Устанавливает вручную начальное значение (сид) для модели torch для воспроизводимости результатов.
# Step 5: Convert data to PyTorch tensors X_train = torch.tensor(X_train, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32) X_test = torch.tensor(X_test, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.float32) torch.manual_seed(42)
-
Установка устройства для расчетов. Настройка элемента на CUDA при наличии, в противном случае использование ЦП. Это важно для применения ускорения графического процессора во время обучения, особенно если он доступен.
# Step 6: Set device for computation device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(f"Using device: {device}")
-
Создание загрузчика для обучающих данных. Создание загрузчика данных для обработки пакетирования и перемешивания обучающих данных.
# Step 7: Create DataLoader for training data train_dataset = TensorDataset(X_train, y_train) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
-
Определение класса конфигурации для модели. Определение класса Config для хранения всех гиперпараметров и настроек, необходимых для модели PatchTST.
# Step 8: Define the configuration class for the model class Config: def __init__(self): self.enc_in = 4 # Adjusted for 4 columns (open, high, low, close) self.seq_len = seq_length self.pred_len = pred_length self.e_layers = 3 self.n_heads = 4 self.d_model = 64 self.d_ff = 256 self.dropout = 0.1 self.fc_dropout = 0.1 self.head_dropout = 0.1 self.individual = False self.patch_len = 24 self.stride = 24 self.padding_patch = True self.revin = True self.affine = False self.subtract_last = False self.decomposition = True self.kernel_size = 25 configs = Config()
-
Инициализация модели PatchTST. Инициализация модели PatchTST с определенной конфигурацией и перемещение ее на выбранное устройство.
# Step 9: Initialize the PatchTST model model = PatchTST( configs=configs, max_seq_len=1024, d_k=None, d_v=None, norm='BatchNorm', attn_dropout=0.1, act="gelu", key_padding_mask='auto', padding_var=None, attn_mask=None, res_attention=True, pre_norm=False, store_attn=False, pe='zeros', learn_pe=True, pretrain_head=False, head_type='flatten', verbose=False ).to(device)
-
Описание оптимизатора и функции потерь. Настройка оптимизатора (Adam) и функции потерь (Mean Squared Error — среднеквадратическая ошибка) для обучения модели.
# Step 10: Define optimizer and loss function optimizer = torch.optim.Adam(model.parameters(), lr=0.001) loss_fn = torch.nn.MSELoss() num_epochs = 100
-
Обучение модели. Обучение модели на протяжении указанного количества эпох. Для каждого пакета данных модель выполняет прямой проход, вычисляет потери, выполняет обратный проход для расчета градиентов и обновляет параметры модели.
# Step 11: Train the model for epoch in range(num_epochs): model.train() total_loss = 0 for batch_X, batch_y in train_loader: optimizer.zero_grad() batch_X = batch_X.to(device) batch_y = batch_y.to(device) outputs = model(batch_X) outputs = outputs[:, -pred_length:, :4] loss = loss_fn(outputs, batch_y) loss.backward() optimizer.step() total_loss += loss.item() print(f"Epoch {epoch+1}/{num_epochs}, Loss: {total_loss/len(train_loader):.10f}")
-
Сохранение модели в формате PyTorch. Сохранение словаря состояний обученной модели в файл. Можем использовать этот файл для создания прогнозов непосредственно на языке Python.
# Step 12: Save the model in PyTorch format torch.save(model.state_dict(), 'patchtst_model.pth')
-
Подготовка фиктивных входных данных для экспорта ONNX. Создание фиктивного входного тензора для использования при экспорте модели в формат ONNX.
# Step 13: Prepare a dummy input for ONNX export dummy_input = torch.randn(1, seq_length, 4).to(device)
-
Экспорт модели в формат ONNX. Экспорт обученной модели в формат ONNX. Нам понадобится этот файл для прогнозирования с помощью MQL5.
# Step 14: Export the model to ONNX format torch.onnx.export(model, dummy_input, "patchtst_model.onnx", opset_version=13, input_names=['input'], output_names=['output'], dynamic_axes={'input': {0: 'batch_size'}, 'output': {0: 'batch_size'}}) print("Model trained and saved in PyTorch and ONNX formats.")
Результаты обучения модели
Вот результаты, которые я получил в результате обучения модели.
Epoch 1/100, Loss: 0.0000283705 Epoch 2/100, Loss: 0.0000263274 Epoch 3/100, Loss: 0.0000256321 Epoch 4/100, Loss: 0.0000252389 Epoch 5/100, Loss: 0.0000249340 Epoch 6/100, Loss: 0.0000246715 Epoch 7/100, Loss: 0.0000244293 Epoch 8/100, Loss: 0.0000241942 Epoch 9/100, Loss: 0.0000240157 Epoch 10/100, Loss: 0.0000236776 Epoch 11/100, Loss: 0.0000233954 Epoch 12/100, Loss: 0.0000230437 Epoch 13/100, Loss: 0.0000226635 Epoch 14/100, Loss: 0.0000221875 Epoch 15/100, Loss: 0.0000216960 Epoch 16/100, Loss: 0.0000213242 Epoch 17/100, Loss: 0.0000208693 Epoch 18/100, Loss: 0.0000204956 Epoch 19/100, Loss: 0.0000200573 Epoch 20/100, Loss: 0.0000197222 Epoch 21/100, Loss: 0.0000193516 Epoch 22/100, Loss: 0.0000189223 Epoch 23/100, Loss: 0.0000186635 Epoch 24/100, Loss: 0.0000184025 Epoch 25/100, Loss: 0.0000180468 Epoch 26/100, Loss: 0.0000177854 Epoch 27/100, Loss: 0.0000174621 Epoch 28/100, Loss: 0.0000173247 Epoch 29/100, Loss: 0.0000170032 Epoch 30/100, Loss: 0.0000168594 Epoch 31/100, Loss: 0.0000166609 Epoch 32/100, Loss: 0.0000164818 Epoch 33/100, Loss: 0.0000162424 Epoch 34/100, Loss: 0.0000161265 Epoch 35/100, Loss: 0.0000159775 Epoch 36/100, Loss: 0.0000158510 Epoch 37/100, Loss: 0.0000156571 Epoch 38/100, Loss: 0.0000155327 Epoch 39/100, Loss: 0.0000154742 Epoch 40/100, Loss: 0.0000152778 Epoch 41/100, Loss: 0.0000151757 Epoch 42/100, Loss: 0.0000151083 Epoch 43/100, Loss: 0.0000150182 Epoch 44/100, Loss: 0.0000149140 Epoch 45/100, Loss: 0.0000148057 Epoch 46/100, Loss: 0.0000147672 Epoch 47/100, Loss: 0.0000146499 Epoch 48/100, Loss: 0.0000145281 Epoch 49/100, Loss: 0.0000145298 Epoch 50/100, Loss: 0.0000144795 Epoch 51/100, Loss: 0.0000143969 Epoch 52/100, Loss: 0.0000142840 Epoch 53/100, Loss: 0.0000142294 Epoch 54/100, Loss: 0.0000142159 Epoch 55/100, Loss: 0.0000140837 Epoch 56/100, Loss: 0.0000140005 Epoch 57/100, Loss: 0.0000139986 Epoch 58/100, Loss: 0.0000139122 Epoch 59/100, Loss: 0.0000139010 Epoch 60/100, Loss: 0.0000138351 Epoch 61/100, Loss: 0.0000138050 Epoch 62/100, Loss: 0.0000137636 Epoch 63/100, Loss: 0.0000136853 Epoch 64/100, Loss: 0.0000136191 Epoch 65/100, Loss: 0.0000136272 Epoch 66/100, Loss: 0.0000135552 Epoch 67/100, Loss: 0.0000135439 Epoch 68/100, Loss: 0.0000135200 Epoch 69/100, Loss: 0.0000134461 Epoch 70/100, Loss: 0.0000133950 Epoch 71/100, Loss: 0.0000133979 Epoch 72/100, Loss: 0.0000133059 Epoch 73/100, Loss: 0.0000133242 Epoch 74/100, Loss: 0.0000132816 Epoch 75/100, Loss: 0.0000132145 Epoch 76/100, Loss: 0.0000132803 Epoch 77/100, Loss: 0.0000131212 Epoch 78/100, Loss: 0.0000131809 Epoch 79/100, Loss: 0.0000131538 Epoch 80/100, Loss: 0.0000130786 Epoch 81/100, Loss: 0.0000130651 Epoch 82/100, Loss: 0.0000130255 Epoch 83/100, Loss: 0.0000129917 Epoch 84/100, Loss: 0.0000129804 Epoch 85/100, Loss: 0.0000130086 Epoch 86/100, Loss: 0.0000130156 Epoch 87/100, Loss: 0.0000129557 Epoch 88/100, Loss: 0.0000129013 Epoch 89/100, Loss: 0.0000129018 Epoch 90/100, Loss: 0.0000128864 Epoch 91/100, Loss: 0.0000128663 Epoch 92/100, Loss: 0.0000128411 Epoch 93/100, Loss: 0.0000128514 Epoch 94/100, Loss: 0.0000127915 Epoch 95/100, Loss: 0.0000127778 Epoch 96/100, Loss: 0.0000127787 Epoch 97/100, Loss: 0.0000127623 Epoch 98/100, Loss: 0.0000127452 Epoch 99/100, Loss: 0.0000127141 Epoch 100/100, Loss: 0.0000127229
Их можно визуализировать следующим образом:

Кроме того, мы получаем следующий вывод без ошибок и предупреждений, что указывает на успешное преобразование нашей модели в формат ONNX.
Модель, обученная и сохраненная в форматах PyTorch и ONNX.
Пошаговая генерация прогнозов с помощью Python
Теперь посмотрим на код прогноза:
- Шаг 1. Импорт библиотек: начнем с импорта всех необходимых библиотек.
# Import required libraries import MetaTrader5 as mt5 import pandas as pd import numpy as np import torch from datetime import datetime, timedelta import plotly.graph_objects as go from plotly.subplots import make_subplots from patchTST import Model as PatchTST
- Шаг 2. Извлечение даннных из MetaTrader 5: определим функцию для извлечения данных из MetaTrader 5 и преобразуем их в DataFrame. Извлечем 168 предыдущих баров, потому что именно это требуется для получения прогноза с помощью нашей модели.
# Function to fetch data from MetaTrader 5 def fetch_mt5_data(symbol, timeframe, bars): if not mt5.initialize(): print("MT5 initialization failed") return None timeframe_dict = { 'M1': mt5.TIMEFRAME_M1, 'M5': mt5.TIMEFRAME_M5, 'M15': mt5.TIMEFRAME_M15, 'H1': mt5.TIMEFRAME_H1, 'D1': mt5.TIMEFRAME_D1 } rates = mt5.copy_rates_from_pos(symbol, timeframe_dict[timeframe], 0, bars) mt5.shutdown() df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') df.set_index('time', inplace=True) return df[['open', 'high', 'low', 'close']] # Fetch the latest week of data historical_data = fetch_mt5_data('EURUSD', 'H1', 168)
- Шаг 3. Подготовка входных данных: определим функцию для подготовки входных данных для модели, взяв последние строки данных seq_length. При извлечении данных нам требуются только последние 168 часов из 1-часовых данных для прогнозов на последующие 24 часа. Это потому, что мы обучили модель именно так.
# Function to prepare input data def prepare_input_data(data, seq_length): X = [] X.append(data.iloc[-seq_length:].values) return np.array(X) # Prepare the input data seq_length = 168 # 1 week of hourly data input_data = prepare_input_data(historical_data, seq_length)
- Шаг 4. Определение конфигурации: определим класс конфигурации для настройки параметров модели. Это те же настройки, что мы используем для обучения модели.
# Define the configuration class class Config: def __init__(self): self.enc_in = 4 # Adjusted for 4 columns (open, high, low, close) self.seq_len = seq_length self.pred_len = 24 # Predict next 24 hours self.e_layers = 3 self.n_heads = 4 self.d_model = 64 self.d_ff = 256 self.dropout = 0.1 self.fc_dropout = 0.1 self.head_dropout = 0.1 self.individual = False self.patch_len = 24 self.stride = 24 self.padding_patch = True self.revin = True self.affine = False self.subtract_last = False self.decomposition = True self.kernel_size = 25 # Initialize the configuration config = Config()
- Шаг 5. Загрузка обученной модели: определим функцию для загрузки обученной модели PatchTST. Это те же настройки, что мы используем для обучения модели.
# Function to load the trained model def load_model(model_path, config): model = PatchTST( configs=config, max_seq_len=1024, d_k=None, d_v=None, norm='BatchNorm', attn_dropout=0.1, act="gelu", key_padding_mask='auto', padding_var=None, attn_mask=None, res_attention=True, pre_norm=False, store_attn=False, pe='zeros', learn_pe=True, pretrain_head=False, head_type='flatten', verbose=False ) model.load_state_dict(torch.load(model_path)) model.eval() return model # Load the trained model model_path = 'patchtst_model.pth' device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model = load_model(model_path, config).to(device)
- Шаг 6. Составление прогнозов: определим функцию для составления прогнозов с помощью загруженной модели и входных данных.
# Function to make predictions def predict(model, input_data, device): with torch.no_grad(): input_data = torch.tensor(input_data, dtype=torch.float32).to(device) output = model(input_data) return output.cpu().numpy() # Make predictions predictions = predict(model, input_data, device)
- Шаг 7. Постобработка и визуализация: обрабатываем прогнозы, создаем датафреймы и визуализируем исторические и прогнозируемые данные при помощи Plotly.
# Ensure predictions have the correct shape if predictions.shape[2] != 4: predictions = predictions[:, :, :4] # Adjust based on actual number of columns required # Check the shape of predictions print("Shape of predictions:", predictions.shape) # Create a DataFrame for predictions pred_index = pd.date_range(start=historical_data.index[-1] + pd.Timedelta(hours=1), periods=24, freq='H') pred_df = pd.DataFrame(predictions[0], columns=['open', 'high', 'low', 'close'], index=pred_index) # Combine historical data and predictions combined_df = pd.concat([historical_data, pred_df]) # Create the plot fig = make_subplots(rows=1, cols=1, shared_xaxes=True, vertical_spacing=0.03, subplot_titles=('EURUSD OHLC')) # Add historical candlestick fig.add_trace(go.Candlestick(x=historical_data.index, open=historical_data['open'], high=historical_data['high'], low=historical_data['low'], close=historical_data['close'], name='Historical')) # Add predicted candlestick fig.add_trace(go.Candlestick(x=pred_df.index, open=pred_df['open'], high=pred_df['high'], low=pred_df['low'], close=pred_df['close'], name='Predicted')) # Add a vertical line to separate historical data from predictions fig.add_vline(x=historical_data.index[-1], line_dash="dash", line_color="gray") # Update layout fig.update_layout(title='EURUSD OHLC Chart with Predictions', yaxis_title='Price', xaxis_rangeslider_visible=False) # Show the plot fig.show() # Print predictions (optional) print("Predicted prices for the next 24 hours:", predictions)
Код обучения и прогнозирования на языке Python
Если вас не интересует запуск базы исходного кода в блокноте Jupyter, во вложениях я предоставил пару файлов, которые можно запустить напрямую:
- model_training.py
- model_prediction.py
Вы можете конфигурировать модель по своему усмотрению и запускать ее без использования Jupyter.
Результаты прогнозирования
После обучения модели и запуска кода прогнозирования на Python я получил следующий график. Прогнозы были созданы примерно в 00:30 (CEST+3) 8 июля 2024 года. Это как раз во время открытия в воскресенье ночью (понедельник утром). Мы видим на графике разрыв, потому что открытие EURUSD произошло с разрывом. Модель прогнозирует для EURUSD восходящий тренд для большей части заполнения этого разрыва. После заполнения разрыва движение цены должно пойти вниз ближе к концу дня.

Кроме того, мы распечатали необработанные значения результатов, которые можно видеть ниже:
Predicted prices for the next 24 hours: [[[1.0789319 1.08056 1.0789403 1.0800443] [1.0791171 1.080738 1.0791024 1.0802013] [1.0792702 1.0807946 1.0792127 1.0802455] [1.0794896 1.0809869 1.07939 1.0804181] [1.0795166 1.0809793 1.0793561 1.0803629] [1.0796498 1.0810834 1.079427 1.0804263] [1.0798903 1.0813211 1.0795883 1.0805805] [1.0800778 1.081464 1.0796818 1.0806502] [1.0801392 1.0815498 1.0796598 1.0806476] [1.0802988 1.0817037 1.0797216 1.0807337] [1.080521 1.0819166 1.079835 1.08086 ] [1.0804708 1.0818571 1.079683 1.0807351] [1.0805807 1.0819991 1.079669 1.0807738] [1.0806456 1.0820425 1.0796478 1.0807805] [1.080733 1.0821087 1.0796758 1.0808226] [1.0807986 1.0822101 1.0796862 1.08086 ] [1.0808219 1.0821983 1.0796905 1.0808747] [1.0808604 1.082247 1.0797052 1.0808727] [1.0808146 1.082188 1.0796149 1.0807893] [1.0809066 1.0822624 1.0796828 1.0808471] [1.0809724 1.0822903 1.0797662 1.0808889] [1.0810378 1.0823163 1.0797914 1.0809084] [1.0810691 1.0823379 1.0798224 1.0809308] [1.0810966 1.0822875 1.0797993 1.0808865]]]
Перенос предварительно обученной модели в MQL5
В этом разделе создадим предшественник индикатора, который поможет визуализировать прогнозируемое движение цен на наших графиках. Я намеренно сделал скрипт элементарным и расширяемым, потому что у наших читателей могут быть разные цели и разные стратегии использования этих сложных нейросетей. Индикатор разработан в формате советника на языке MQL5. Вот полный код скрипта:
//+------------------------------------------------------------------+ //| PatchTST Predictor | //| Copyright 2024 | //+------------------------------------------------------------------+ #property copyright "Copyright 2024" #property link "https://www.mql5.com" #property version "1.00" #resource "\\PatchTST\\patchtst_model.onnx" as uchar PatchTSTModel[] #define SEQ_LENGTH 168 #define PRED_LENGTH 24 #define INPUT_FEATURES 4 long ModelHandle = INVALID_HANDLE; datetime ExtNextBar = 0; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Load the ONNX model ModelHandle = OnnxCreateFromBuffer(PatchTSTModel, ONNX_DEFAULT); if (ModelHandle == INVALID_HANDLE) { Print("Error creating ONNX model: ", GetLastError()); return(INIT_FAILED); } // Set input shape const long input_shape[] = {1, SEQ_LENGTH, INPUT_FEATURES}; if (!OnnxSetInputShape(ModelHandle, ONNX_DEFAULT, input_shape)) { Print("Error setting input shape: ", GetLastError()); return(INIT_FAILED); } // Set output shape const long output_shape[] = {1, PRED_LENGTH, INPUT_FEATURES}; if (!OnnxSetOutputShape(ModelHandle, 0, output_shape)) { Print("Error setting output shape: ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { if (ModelHandle != INVALID_HANDLE) { OnnxRelease(ModelHandle); ModelHandle = INVALID_HANDLE; } } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { if (TimeCurrent() < ExtNextBar) return; ExtNextBar = TimeCurrent(); ExtNextBar -= ExtNextBar % PeriodSeconds(); ExtNextBar += PeriodSeconds(); // Prepare input data float input_data[]; if (!PrepareInputData(input_data)) { Print("Error preparing input data"); return; } // Make prediction float predictions[]; if (!MakePrediction(input_data, predictions)) { Print("Error making prediction"); return; } // Draw hypothetical future bars DrawFutureBars(predictions); } //+------------------------------------------------------------------+ //| Prepare input data for the model | //+------------------------------------------------------------------+ bool PrepareInputData(float &input_data[]) { MqlRates rates[]; ArraySetAsSeries(rates, true); int copied = CopyRates(_Symbol, PERIOD_H1, 0, SEQ_LENGTH, rates); if (copied != SEQ_LENGTH) { Print("Failed to copy rates data. Copied: ", copied); return false; } ArrayResize(input_data, SEQ_LENGTH * INPUT_FEATURES); for (int i = 0; i < SEQ_LENGTH; i++) { input_data[i * INPUT_FEATURES + 0] = (float)rates[SEQ_LENGTH - 1 - i].open; input_data[i * INPUT_FEATURES + 1] = (float)rates[SEQ_LENGTH - 1 - i].high; input_data[i * INPUT_FEATURES + 2] = (float)rates[SEQ_LENGTH - 1 - i].low; input_data[i * INPUT_FEATURES + 3] = (float)rates[SEQ_LENGTH - 1 - i].close; } return true; } //+------------------------------------------------------------------+ //| Make prediction using the ONNX model | //+------------------------------------------------------------------+ bool MakePrediction(const float &input_data[], float &output_data[]) { ArrayResize(output_data, PRED_LENGTH * INPUT_FEATURES); if (!OnnxRun(ModelHandle, ONNX_NO_CONVERSION, input_data, output_data)) { Print("Error running ONNX model: ", GetLastError()); return false; } return true; } //+------------------------------------------------------------------+ //| Draw hypothetical future bars | //+------------------------------------------------------------------+ void DrawFutureBars(const float &predictions[]) { datetime current_time = TimeCurrent(); for (int i = 0; i < PRED_LENGTH; i++) { datetime bar_time = current_time + PeriodSeconds(PERIOD_H1) * (i + 1); double open = predictions[i * INPUT_FEATURES + 0]; double high = predictions[i * INPUT_FEATURES + 1]; double low = predictions[i * INPUT_FEATURES + 2]; double close = predictions[i * INPUT_FEATURES + 3]; string obj_name = "FutureBar_" + IntegerToString(i); ObjectCreate(0, obj_name, OBJ_RECTANGLE, 0, bar_time, low, bar_time + PeriodSeconds(PERIOD_H1), high); ObjectSetInteger(0, obj_name, OBJPROP_COLOR, close > open ? clrGreen : clrRed); ObjectSetInteger(0, obj_name, OBJPROP_FILL, true); ObjectSetInteger(0, obj_name, OBJPROP_BACK, true); } ChartRedraw(); }
Для запуска этого скрипта обратите внимание на определение следующей строки:
#resource "\\PatchTST\\patchtst_model.onnx" as uchar PatchTSTModel[]
Это значит, что нам нужно будет создать внутри папки Expert Advisor подпапку с названием PatchTST. Внутри подпапки PatchTST нам нужно будет сохранить файл ONNX из обучения модели. Однако основной EA будет храниться в корневой папке.
Кроме того, в верхней части скрипта определены параметры, которые мы использовали для обучения модели:
#define SEQ_LENGTH 168 #define PRED_LENGTH 24 #define INPUT_FEATURES 4
В нашем случае нужно использовать 168 предшествующих баров, ввести их в модель ONNX и получить прогноз на следующие 24 бара в будущем. У нас 4 входных характеристики: Open, High, Low и Close.
Кроме того, обратите внимание на следующий код внутри функции OnTick():
if (TimeCurrent() < ExtNextBar) return; ExtNextBar = TimeCurrent(); ExtNextBar -= ExtNextBar % PeriodSeconds(); ExtNextBar += PeriodSeconds();
Поскольку модели ONNX требуют больших вычислительных мощностей компьютера, этот код обеспечит генерацию нового прогноза только один раз для каждого бара. В нашем случае, поскольку мы работаем с часовыми барами, прогнозы будут обновляться один раз в час.
Наконец, в этом коде будем рисовать на экране фьючерсные бары, используя функции рисования MQL5:
void DrawFutureBars(const float &predictions[]) { datetime current_time = TimeCurrent(); for (int i = 0; i < PRED_LENGTH; i++) { datetime bar_time = current_time + PeriodSeconds(PERIOD_H1) * (i + 1); double open = predictions[i * INPUT_FEATURES + 0]; double high = predictions[i * INPUT_FEATURES + 1]; double low = predictions[i * INPUT_FEATURES + 2]; double close = predictions[i * INPUT_FEATURES + 3]; string obj_name = "FutureBar_" + IntegerToString(i); ObjectCreate(0, obj_name, OBJ_RECTANGLE, 0, bar_time, low, bar_time + PeriodSeconds(PERIOD_H1), high); ObjectSetInteger(0, obj_name, OBJPROP_COLOR, close > open ? clrGreen : clrRed); ObjectSetInteger(0, obj_name, OBJPROP_FILL, true); ObjectSetInteger(0, obj_name, OBJPROP_BACK, true); } ChartRedraw(); }
После реализации этого кода на MQL5, компиляции модели и размещения полученного EA на таймфрейме H1 вы должны увидеть несколько новых баров, добавленных в будущее на графике. В моем случае это выглядит так:
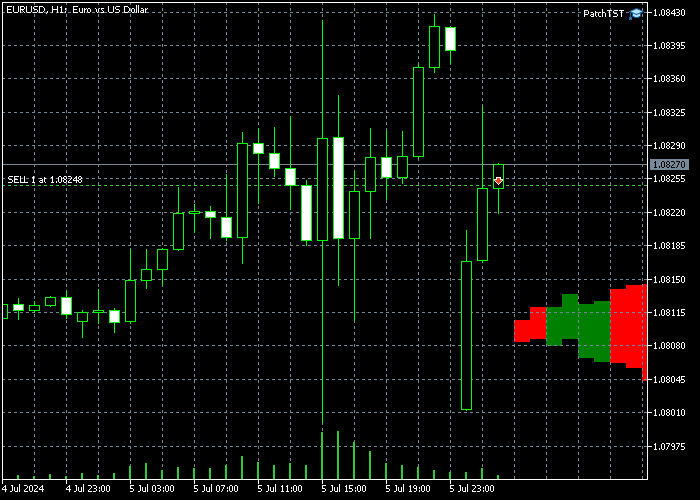
Обратите внимание: если вы не видите вновь нарисованных баров справа, вам может понадобиться щелкнуть на кнопке "Отодвинуть конец графика от правой границы" ("Shift end of chart from right border"). ![]()
Заключение
В этой статье мы применили пошаговый подход к обучению модели PatchTST, представленной в 2023 году. Получили общее представление о принципах работы алгоритма PatchTST. В базовом коде было несколько проблем, связанных с преобразованием ONNX. В частности, не поддерживается оператор "Unfold", поэтому мы решили эту проблему, адаптировав код к ONNX. Кроме того, мы сохранили ориентацию цели статьи на трейдеров, сосредоточившись на основах модели, извлечении данных, обучении модели и получении прогноза на ближайшие 24 часа. Затем мы реализовали прогнозирование на языке MQL5, чтобы иметь возможность использовать полностью обученную модель с любимыми индикаторами и советниками. Рад поделиться своим кодом в прикрепленном архивном файле с сообществом MQL. Дайте мне знать, пожалуйста, если у вас появятся вопросы или комментарии.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/15198
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
 Разработка интерактивного графического пользовательского интерфейса на MQL5 (Часть 1): Создание панели
Разработка интерактивного графического пользовательского интерфейса на MQL5 (Часть 1): Создание панели
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Я часто обнаруживаю, что предсказанные результаты этой модели не вполне соответствуют реальной ситуации. Я не вносил никаких изменений в код этой модели. Не могли бы вы дать мне какие-нибудь рекомендации? Спасибо.
Спасибо, что поделились своим опытом работы с моделью. Вы подняли важный вопрос о согласованности прогнозов. Модель PatchTST лучше всего работает, когда она интегрирована в комплексный торговый подход, учитывающий множество рыночных факторов. Вот как я рекомендую использовать прогнозы модели более эффективно:
Некоторые дополнительные личные наблюдения:
Прогнозы модели должны использоваться как один из компонентов вашего анализа, а не как единственное средство принятия решений. Приняв во внимание эти элементы, вы сможете потенциально улучшить согласованность результатов торговли при использовании модели PatchTST.
Надеюсь, это поможет.
Скрипт гэпа справедливой стоимости (FVG), о котором я упоминал (по моему опыту, эти гэпы работают очень похоже на зоны спроса и предложения):
Спасибо за интерес! Да, эти изменения параметров в принципе будут работать, но есть несколько важных соображений при переходе на данные M1:
1. Объем данных: Обучение на данных M1 длительностью 10080 минут (1 неделя) означает обработку значительно большего количества точек данных, чем в случае с H1. Это приведет к:
2. Корректировка архитектуры модели: На шаге 8 обучения модели и шаге 4 кода предсказания, возможно, потребуется настроить другие параметры, чтобы учесть большую входную последовательность:
3. Качество предсказания: Хотя вы получите более детальные предсказания, имейте в виду, что данные M1 обычно содержат больше шума. Возможно, вам захочется поэкспериментировать с различными длинами последовательностей и окнами предсказаний, чтобы найти оптимальный баланс.Спасибо за понимание. Мой компьютер достаточно мощный, с 256 ГБ и 64 физическими ядрами. Однако ему не помешал бы лучший GPU.
Как только я обновлю GPU, я попробую обновленные настройки конфигурации.
Спасибо, что поделились своим опытом работы с моделью. Вы подняли важный вопрос о согласованности прогнозов. Модель PatchTST лучше всего работает, когда она интегрирована в комплексный торговый подход, учитывающий множество рыночных факторов. Вот как я рекомендую использовать прогнозы модели более эффективно:
Некоторые дополнительные личные наблюдения:
Прогнозы модели должны использоваться как один из компонентов вашего анализа, а не как единственное средство принятия решений. Учет этих элементов позволит вам улучшить согласованность результатов торговли при использовании модели PatchTST.
Надеюсь, это поможет.
Скрипт гэпа справедливой стоимости (FVG), о котором я упоминал (по моему опыту, эти гэпы работают очень похоже на зоны спроса и предложения):
Большое спасибо за ваш терпеливый ответ и бескорыстное участие. Я никогда раньше не встречала таких подробных и профессиональных ответов. Я буду перечитывать вашу статью неоднократно. Эти знания особенно ценны для меня. С наилучшими пожеланиями.
Спасибо. Ваши добрые слова очень много значат! Пожалуйста, обращайтесь, если вам понадобится дополнительная помощь!