
Usando o Algoritmo de Aprendizado de Máquina PatchTST para Prever a Ação do Preço nas Próximas 24 Horas
Introdução
Eu encontrei pela primeira vez um algoritmo chamado PatchTST quando comecei a explorar os avanços da IA relacionados às previsões de séries temporais no Huggingface.co. Como qualquer pessoa que trabalhou com grandes modelos de linguagem (LLMs) sabe, a invenção dos transformers foi um divisor de águas para o desenvolvimento de ferramentas para processamento de linguagem natural, imagens e vídeos. Mas e quanto às séries temporais? Isso é algo que foi simplesmente deixado de lado? Ou a maior parte da pesquisa está apenas por trás de portas fechadas? Acontece que existem muitos modelos mais novos que aplicam transformers com sucesso para prever séries temporais. Neste artigo, veremos uma implementação como essa.
O que é impressionante sobre o PatchTST é quão rápido ele treina um modelo e quão fácil é usar o modelo treinado com MQL. Admito abertamente que sou novo no conceito de redes neurais. Mas ao passar por esse processo e abordar a implementação do PatchTST descrita neste artigo para MQL5, senti que dei um grande salto no meu aprendizado e na minha compreensão de como essas redes neurais complexas são desenvolvidas, depuradas, treinadas e usadas. É como pegar uma criança, que mal está aprendendo a andar, e colocá-la em um time profissional de futebol, esperando que ela marque o gol da vitória na final da Copa do Mundo.
Visão Geral do PatchTST
Após descobrir o PatchTST, comecei a olhar o artigo que explica seu design: "Uma Série Temporal Vale 64 Palavras: Previsões de Longo Prazo com Transformers". O título era interessante. Quando comecei a ler mais sobre o artigo, pensei: uau, isso parece uma estrutura fascinante - tem muitos elementos que sempre quis aprender. Então, naturalmente, quis experimentar e ver como as previsões funcionam. Aqui está o que me deixou ainda mais interessado nesse algoritmo:
- Você pode prever open, high, low e close usando o PatchTST. Com o PatchTST, senti que você poderia fornecer todos os dados conforme eles chegam - open, high, low, close e até volume. Você pode esperar que ele encontre os padrões nos dados porque todos os dados são convertidos em algo chamado "patches". Mais sobre o que são patches um pouco mais tarde neste artigo. Por enquanto, é importante saber que patches são atraentes e ajudam a melhorar as previsões.
- Requisitos mínimos de pré-processamento de dados com o PatchTST. Quando comecei a explorar mais a fundo o algoritmo, percebi que os autores usam algo chamado "RevIn", que é normalização reversa de instâncias. RevIn vem de um artigo intitulado: "REVERSIBLE INSTANCE NORMALIZATION FOR ACCURATE TIME-SERIES FORECASTING AGAINST DISTRIBUTION SHIFT". RevIn tenta resolver o problema de mudança de distribuição nas previsões de séries temporais. Como traders algorítmicos, estamos todos muito familiarizados com a sensação quando nosso EA treinado parece não prever mais o mercado e somos forçados a reotimizar e atualizar nossos parâmetros. Considere o RevIn como uma forma de fazer a mesma coisa.
- Este método basicamente pega os dados passados para ele e os normaliza usando a seguinte fórmula:
x = (x - média) / desvio
Então, quando o modelo precisa fazer uma previsão, ele desnormaliza os dados usando a propriedade oposta:
x = x * desvio + média
RevIn também tem outra propriedade chamada affine_bias. Em termos mais simples, este é um parâmetro aprendível que cuida da assimetria, curtose, etc., que pode estar presente no conjunto de dados.
x = x * affine_weight + affine_bias
A estrutura do PatchTST pode ser resumida da seguinte forma:
Dados de Entrada -> RevIn -> Decomposição da Série -> Componente de Tendência -> Backbone do PatchTST -> TSTiEncoder -> Flatten_Head -> Previsor de Tendência -> Componente Residual -> Adicionar Tendência e Residual -> Previsão Final
Entendemos que nossos dados serão extraídos usando MT5. Também discutimos como o RevIn funciona.
Aqui está como o PatchTST funciona: digamos que você pegue 80.000 barras de dados do EURUSD para o intervalo de tempo H1. Isso equivale a cerca de 13 anos de dados. Com o PatchTST, você segmenta os dados em algo chamado “patches”. Como analogia, pense nos patches como algo semelhante ao funcionamento dos Vision Transformers (ViTs) para imagens, mas adaptado para dados de séries temporais. Por exemplo, se o comprimento do patch for 16, então cada patch conterá 16 valores consecutivos de preço. Isso é como olhar pequenos pedaços da série temporal de cada vez, o que ajuda o modelo a focar em padrões locais antes de considerar o padrão global.
Em seguida, os patches incluem codificação posicional para preservar a ordem da sequência, o que ajuda o modelo a lembrar a posição de cada patch na sequência.
O transformer passa os patches normalizados e codificados por uma pilha de camadas de codificação. Cada camada de codificação contém uma camada de atenção multi-cabeça e uma camada feed-forward. A camada de atenção multi-cabeça permite que o modelo se concentre em diferentes partes da sequência de entrada, enquanto a camada feed-forward permite que o modelo aprenda transformações não-lineares complexas dos dados.
Por fim, temos os componentes de tendência e residual. O mesmo processo de patching, normalização, codificação posicional e camadas de transformer é aplicado tanto ao componente de tendência quanto ao componente residual. Depois, somamos as saídas dos componentes de tendência e residual para produzir a previsão final.
Problemas do Repositório Oficial do PatchTST
O repositório oficial do PatchTST pode ser encontrado no GitHub no seguinte link: PatchTST (ICLR 2023). Existem duas versões diferentes disponíveis - supervisionada e não supervisionada. Para este artigo, usaremos a abordagem de aprendizado supervisionado. Como sabemos, para usar qualquer modelo com MQL5, precisamos de uma forma de convertê-lo para o formato ONNX. No entanto, os autores do PatchTST não levaram isso em consideração. Tive que fazer as seguintes modificações no código base deles para fazer o modelo funcionar com MQL5:
Código Original:
class PatchTST_backbone(nn.Module): def __init__(self, c_in:int, context_window:int, target_window:int, patch_len:int, stride:int, max_seq_len:Optional[int]=1024, n_layers:int=3, d_model=128, n_heads=16, d_k:Optional[int]=None, d_v:Optional[int]=None, d_ff:int=256, norm:str='BatchNorm', attn_dropout:float=0., dropout:float=0., act:str="gelu", key_padding_mask:bool='auto', padding_var:Optional[int]=None, attn_mask:Optional[Tensor]=None, res_attention:bool=True, pre_norm:bool=False, store_attn:bool=False, pe:str='zeros', learn_pe:bool=True, fc_dropout:float=0., head_dropout = 0, padding_patch = None, pretrain_head:bool=False, head_type = 'flatten', individual = False, revin = True, affine = True, subtract_last = False, verbose:bool=False, **kwargs): super().__init__() # RevIn self.revin = revin if self.revin: self.revin_layer = RevIN(c_in, affine=affine, subtract_last=subtract_last) # Patching self.patch_len = patch_len self.stride = stride self.padding_patch = padding_patch patch_num = int((context_window - patch_len)/stride + 1) if padding_patch == 'end': # can be modified to general case self.padding_patch_layer = nn.ReplicationPad1d((0, stride)) patch_num += 1 # Backbone self.backbone = TSTiEncoder(c_in, patch_num=patch_num, patch_len=patch_len, max_seq_len=max_seq_len, n_layers=n_layers, d_model=d_model, n_heads=n_heads, d_k=d_k, d_v=d_v, d_ff=d_ff, attn_dropout=attn_dropout, dropout=dropout, act=act, key_padding_mask=key_padding_mask, padding_var=padding_var, attn_mask=attn_mask, res_attention=res_attention, pre_norm=pre_norm, store_attn=store_attn, pe=pe, learn_pe=learn_pe, verbose=verbose, **kwargs) # Head self.head_nf = d_model * patch_num self.n_vars = c_in self.pretrain_head = pretrain_head self.head_type = head_type self.individual = individual if self.pretrain_head: self.head = self.create_pretrain_head(self.head_nf, c_in, fc_dropout) # custom head passed as a partial func with all its kwargs elif head_type == 'flatten': self.head = Flatten_Head(self.individual, self.n_vars, self.head_nf, target_window, head_dropout=head_dropout) def forward(self, z): # z: [bs x nvars x seq_len] # norm if self.revin: z = z.permute(0,2,1) z = self.revin_layer(z, 'norm') z = z.permute(0,2,1) # do patching if self.padding_patch == 'end': z = self.padding_patch_layer(z) z = z.unfold(dimension=-1, size=self.patch_len, step=self.stride) # z: [bs x nvars x patch_num x patch_len] z = z.permute(0,1,3,2) # z: [bs x nvars x patch_len x patch_num] # model z = self.backbone(z) # z: [bs x nvars x d_model x patch_num] z = self.head(z) # z: [bs x nvars x target_window] # denorm if self.revin: z = z.permute(0,2,1) z = self.revin_layer(z, 'denorm') z = z.permute(0,2,1) return z
O código acima é o principal backbone. Como você pode ver, o código usa uma função chamada Unfold na linha:
z = z.unfold(dimension=-1, size=self.patch_len, step=self.stride) # z: [bs x nvars x patch_num x patch_len]
A conversão de Unfold não é suportada pelo ONNX. Você receberá um erro como:
Unsupported: ONNX export of operator Unfold, input size not accessible. Por favor, sinta-se à vontade para solicitar suporte ou enviar um pull request no GitHub do PyTorch: https://github.com/pytorch/pytorch/issues
Então, tive que substituir esta seção do código por:
# Manually unfold the input tensor batch_size, n_vars, seq_len = z.size() patches = [] for i in range(0, seq_len - self.patch_len + 1, self.stride): patches.append(z[:, :, i:i+self.patch_len])
Observe que a substituição acima é um pouco menos eficiente porque usa um loop for para treinar uma Rede Neural. As ineficiências podem se acumular ao longo de muitas épocas e com conjuntos de dados grandes. Mas isso é necessário, caso contrário, o modelo simplesmente falhará na conversão e não poderemos usá-lo com MQL5.
Abordei especificamente esse problema. Fazer isso levou o maior tempo. Depois, coloquei tudo junto em um arquivo chamado patchTST.py, que pode ser encontrado no arquivo zip anexado a este artigo. Este é o arquivo que usaremos para o treinamento do nosso modelo.
Requisitos para Trabalhar com PatchTST em Python
Nesta seção, fornecerei os requisitos para trabalhar com o PatchTST em Python. Esses requisitos podem ser resumidos abaixo:
Crie um ambiente virtual:
python -m venv myenv
Ative o ambiente virtual (Windows)
.\myenv\Scripts\activate
Instale o arquivo requirements.txt incluído no arquivo zip anexado a este artigo:
pip install -r requirements.txt
Especificamente, os requisitos para rodar este projeto são:
MetaTrader5
pandas
numpy
torch
plotly
datetime Desenvolvimento do Código de Treinamento do Modelo Passo a Passo
Para o código a seguir, você pode acompanhar comigo usando um notebook Jupyter que eu incluí no arquivo zip: PatchTST Step-By-Step.ipynb. Resumiremos os passos abaixo:
-
Importar Bibliotecas Necessárias: Importando as bibliotecas necessárias, incluindo MetaTrader 5, Pandas, Numpy, Torch e o modelo PatchTST.
# Step 1: Import necessary libraries import MetaTrader5 as mt5 import pandas as pd import numpy as np import torch from torch.utils.data import TensorDataset, DataLoader from patchTST import Model as PatchTST
-
Inicializar e Obter Dados do MetaTrader 5: A função fetch_mt5_data inicializa o MT5, obtém os dados para o símbolo fornecido, intervalo de tempo e número de barras, e retorna um dataframe com as colunas open, high, low e close.
# Step 2: Initialize and fetch data from MetaTrader 5 def fetch_mt5_data(symbol, timeframe, bars): if not mt5.initialize(): print("MT5 initialization failed") return None timeframe_dict = { 'M1': mt5.TIMEFRAME_M1, 'M5': mt5.TIMEFRAME_M5, 'M15': mt5.TIMEFRAME_M15, 'H1': mt5.TIMEFRAME_H1, 'D1': mt5.TIMEFRAME_D1 } rates = mt5.copy_rates_from_pos(symbol, timeframe_dict[timeframe], 0, bars) mt5.shutdown() df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') df.set_index('time', inplace=True) return df[['open', 'high', 'low', 'close']] # Fetch data data = fetch_mt5_data('EURUSD', 'H1', 80000)
-
Preparar Dados para Previsão Usando Janela Deslizante: A função prepare_forecasting_data cria o conjunto de dados usando uma abordagem de janela deslizante, gerando sequências de dados históricos (X) e os dados futuros correspondentes (y).
# Step 3: Prepare forecasting data using sliding window def prepare_forecasting_data(data, seq_length, pred_length): X, y = [], [] for i in range(len(data) - seq_length - pred_length): X.append(data.iloc[i:(i + seq_length)].values) y.append(data.iloc[(i + seq_length):(i + seq_length + pred_length)].values) return np.array(X), np.array(y) seq_length = 168 # 1 week of hourly data pred_length = 24 # Predict next 24 hours X, y = prepare_forecasting_data(data, seq_length, pred_length)
-
Dividir Dados em Conjuntos de Treinamento e Teste: Dividindo os dados em conjuntos de treinamento e teste, com 80% para treinamento e 20% para teste.
# Step 4: Split data into training and testing sets split = int(len(X) * 0.8) X_train, X_test = X[:split], X[split:] y_train, y_test = y[:split], y[split:]
-
Converter Dados para Tensores PyTorch: Convertendo os arrays NumPy para tensores PyTorch, que são necessários para o treinamento com PyTorch. Define uma semente manual para o torch, para reprodução dos resultados.
# Step 5: Convert data to PyTorch tensors X_train = torch.tensor(X_train, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32) X_test = torch.tensor(X_test, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.float32) torch.manual_seed(42)
-
Definir Dispositivo para Cálculo: Definindo o dispositivo para CUDA, se disponível, caso contrário, usando o CPU. Isso é essencial para aproveitar a aceleração da GPU durante o treinamento, especialmente se estiver disponível.
# Step 6: Set device for computation device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(f"Using device: {device}")
-
Criar Data Loader para Dados de Treinamento: Criando um data loader para lidar com o agrupamento e embaralhamento dos dados de treinamento.
# Step 7: Create DataLoader for training data train_dataset = TensorDataset(X_train, y_train) train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
-
Definir a Classe de Configuração para o Modelo: Definindo uma classe de configuração Config para armazenar todos os hiperparâmetros e configurações necessárias para o modelo PatchTST.
# Step 8: Define the configuration class for the model class Config: def __init__(self): self.enc_in = 4 # Adjusted for 4 columns (open, high, low, close) self.seq_len = seq_length self.pred_len = pred_length self.e_layers = 3 self.n_heads = 4 self.d_model = 64 self.d_ff = 256 self.dropout = 0.1 self.fc_dropout = 0.1 self.head_dropout = 0.1 self.individual = False self.patch_len = 24 self.stride = 24 self.padding_patch = True self.revin = True self.affine = False self.subtract_last = False self.decomposition = True self.kernel_size = 25 configs = Config()
-
Inicializar o Modelo PatchTST: Inicializando o modelo PatchTST com a configuração definida e movendo-o para o dispositivo selecionado.
# Step 9: Initialize the PatchTST model model = PatchTST( configs=configs, max_seq_len=1024, d_k=None, d_v=None, norm='BatchNorm', attn_dropout=0.1, act="gelu", key_padding_mask='auto', padding_var=None, attn_mask=None, res_attention=True, pre_norm=False, store_attn=False, pe='zeros', learn_pe=True, pretrain_head=False, head_type='flatten', verbose=False ).to(device)
-
Definir Otimizador e Função de Perda: Configurando o otimizador (Adam) e a função de perda (Erro Quadrático Médio) para treinar o modelo.
# Step 10: Define optimizer and loss function optimizer = torch.optim.Adam(model.parameters(), lr=0.001) loss_fn = torch.nn.MSELoss() num_epochs = 100
-
Treinar o Modelo: Treinando o modelo pelo número especificado de épocas. Para cada lote de dados, o modelo realiza uma passagem direta, calcula a perda, realiza uma passagem reversa para calcular os gradientes e atualiza os parâmetros do modelo.
# Step 11: Train the model for epoch in range(num_epochs): model.train() total_loss = 0 for batch_X, batch_y in train_loader: optimizer.zero_grad() batch_X = batch_X.to(device) batch_y = batch_y.to(device) outputs = model(batch_X) outputs = outputs[:, -pred_length:, :4] loss = loss_fn(outputs, batch_y) loss.backward() optimizer.step() total_loss += loss.item() print(f"Epoch {epoch+1}/{num_epochs}, Loss: {total_loss/len(train_loader):.10f}")
-
Salvar o Modelo no Formato PyTorch: Salvando o dicionário de estado do modelo treinado em um arquivo. Podemos usar este arquivo para fazer previsões diretamente no Python.
# Step 12: Save the model in PyTorch format torch.save(model.state_dict(), 'patchtst_model.pth')
-
Preparar uma Entrada Fictícia para Exportação para ONNX: Criando um tensor de entrada fictício para usar na exportação do modelo para o formato ONNX.
# Step 13: Prepare a dummy input for ONNX export dummy_input = torch.randn(1, seq_length, 4).to(device)
-
Exportar o Modelo para o Formato ONNX: Exportando o modelo treinado para o formato ONNX. Precisaremos deste arquivo para fazer previsões com MQL5.
# Step 14: Export the model to ONNX format torch.onnx.export(model, dummy_input, "patchtst_model.onnx", opset_version=13, input_names=['input'], output_names=['output'], dynamic_axes={'input': {0: 'batch_size'}, 'output': {0: 'batch_size'}}) print("Model trained and saved in PyTorch and ONNX formats.")
Resultados do Treinamento do Modelo
Aqui estão os resultados que obtive ao treinar o modelo.
Epoch 1/100, Loss: 0.0000283705 Epoch 2/100, Loss: 0.0000263274 Epoch 3/100, Loss: 0.0000256321 Epoch 4/100, Loss: 0.0000252389 Epoch 5/100, Loss: 0.0000249340 Epoch 6/100, Loss: 0.0000246715 Epoch 7/100, Loss: 0.0000244293 Epoch 8/100, Loss: 0.0000241942 Epoch 9/100, Loss: 0.0000240157 Epoch 10/100, Loss: 0.0000236776 Epoch 11/100, Loss: 0.0000233954 Epoch 12/100, Loss: 0.0000230437 Epoch 13/100, Loss: 0.0000226635 Epoch 14/100, Loss: 0.0000221875 Epoch 15/100, Loss: 0.0000216960 Epoch 16/100, Loss: 0.0000213242 Epoch 17/100, Loss: 0.0000208693 Epoch 18/100, Loss: 0.0000204956 Epoch 19/100, Loss: 0.0000200573 Epoch 20/100, Loss: 0.0000197222 Epoch 21/100, Loss: 0.0000193516 Epoch 22/100, Loss: 0.0000189223 Epoch 23/100, Loss: 0.0000186635 Epoch 24/100, Loss: 0.0000184025 Epoch 25/100, Loss: 0.0000180468 Epoch 26/100, Loss: 0.0000177854 Epoch 27/100, Loss: 0.0000174621 Epoch 28/100, Loss: 0.0000173247 Epoch 29/100, Loss: 0.0000170032 Epoch 30/100, Loss: 0.0000168594 Epoch 31/100, Loss: 0.0000166609 Epoch 32/100, Loss: 0.0000164818 Epoch 33/100, Loss: 0.0000162424 Epoch 34/100, Loss: 0.0000161265 Epoch 35/100, Loss: 0.0000159775 Epoch 36/100, Loss: 0.0000158510 Epoch 37/100, Loss: 0.0000156571 Epoch 38/100, Loss: 0.0000155327 Epoch 39/100, Loss: 0.0000154742 Epoch 40/100, Loss: 0.0000152778 Epoch 41/100, Loss: 0.0000151757 Epoch 42/100, Loss: 0.0000151083 Epoch 43/100, Loss: 0.0000150182 Epoch 44/100, Loss: 0.0000149140 Epoch 45/100, Loss: 0.0000148057 Epoch 46/100, Loss: 0.0000147672 Epoch 47/100, Loss: 0.0000146499 Epoch 48/100, Loss: 0.0000145281 Epoch 49/100, Loss: 0.0000145298 Epoch 50/100, Loss: 0.0000144795 Epoch 51/100, Loss: 0.0000143969 Epoch 52/100, Loss: 0.0000142840 Epoch 53/100, Loss: 0.0000142294 Epoch 54/100, Loss: 0.0000142159 Epoch 55/100, Loss: 0.0000140837 Epoch 56/100, Loss: 0.0000140005 Epoch 57/100, Loss: 0.0000139986 Epoch 58/100, Loss: 0.0000139122 Epoch 59/100, Loss: 0.0000139010 Epoch 60/100, Loss: 0.0000138351 Epoch 61/100, Loss: 0.0000138050 Epoch 62/100, Loss: 0.0000137636 Epoch 63/100, Loss: 0.0000136853 Epoch 64/100, Loss: 0.0000136191 Epoch 65/100, Loss: 0.0000136272 Epoch 66/100, Loss: 0.0000135552 Epoch 67/100, Loss: 0.0000135439 Epoch 68/100, Loss: 0.0000135200 Epoch 69/100, Loss: 0.0000134461 Epoch 70/100, Loss: 0.0000133950 Epoch 71/100, Loss: 0.0000133979 Epoch 72/100, Loss: 0.0000133059 Epoch 73/100, Loss: 0.0000133242 Epoch 74/100, Loss: 0.0000132816 Epoch 75/100, Loss: 0.0000132145 Epoch 76/100, Loss: 0.0000132803 Epoch 77/100, Loss: 0.0000131212 Epoch 78/100, Loss: 0.0000131809 Epoch 79/100, Loss: 0.0000131538 Epoch 80/100, Loss: 0.0000130786 Epoch 81/100, Loss: 0.0000130651 Epoch 82/100, Loss: 0.0000130255 Epoch 83/100, Loss: 0.0000129917 Epoch 84/100, Loss: 0.0000129804 Epoch 85/100, Loss: 0.0000130086 Epoch 86/100, Loss: 0.0000130156 Epoch 87/100, Loss: 0.0000129557 Epoch 88/100, Loss: 0.0000129013 Epoch 89/100, Loss: 0.0000129018 Epoch 90/100, Loss: 0.0000128864 Epoch 91/100, Loss: 0.0000128663 Epoch 92/100, Loss: 0.0000128411 Epoch 93/100, Loss: 0.0000128514 Epoch 94/100, Loss: 0.0000127915 Epoch 95/100, Loss: 0.0000127778 Epoch 96/100, Loss: 0.0000127787 Epoch 97/100, Loss: 0.0000127623 Epoch 98/100, Loss: 0.0000127452 Epoch 99/100, Loss: 0.0000127141 Epoch 100/100, Loss: 0.0000127229
Os resultados podem ser visualizados da seguinte forma:

Também obtemos a seguinte saída sem erros ou avisos, indicando que nosso modelo foi convertido com sucesso para o formato ONNX.
Modelo treinado e salvo nos formatos PyTorch e ONNX.
Gerando Previsões Usando Python Passo a Passo
Agora, vamos dar uma olhada no código de previsão:
- Etapa 1. Importar Bibliotecas Necessárias: começamos importando todas as bibliotecas necessárias.
# Import required libraries import MetaTrader5 as mt5 import pandas as pd import numpy as np import torch from datetime import datetime, timedelta import plotly.graph_objects as go from plotly.subplots import make_subplots from patchTST import Model as PatchTST
- Etapa 2. Buscar Dados do MetaTrader 5: definimos uma função para buscar dados do MetaTrader 5 e convertê-los em um DataFrame. Buscamos 168 barras anteriores porque isso é o que é necessário para obter uma previsão com nosso modelo.
# Function to fetch data from MetaTrader 5 def fetch_mt5_data(symbol, timeframe, bars): if not mt5.initialize(): print("MT5 initialization failed") return None timeframe_dict = { 'M1': mt5.TIMEFRAME_M1, 'M5': mt5.TIMEFRAME_M5, 'M15': mt5.TIMEFRAME_M15, 'H1': mt5.TIMEFRAME_H1, 'D1': mt5.TIMEFRAME_D1 } rates = mt5.copy_rates_from_pos(symbol, timeframe_dict[timeframe], 0, bars) mt5.shutdown() df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') df.set_index('time', inplace=True) return df[['open', 'high', 'low', 'close']] # Fetch the latest week of data historical_data = fetch_mt5_data('EURUSD', 'H1', 168)
- Etapa 3. Preparar Dados de Entrada: definimos uma função para preparar os dados de entrada para o modelo, pegando as últimas linhas de dados de comprimento seq_length. Ao puxar os dados, precisamos apenas das últimas 168 horas de dados de 1h para fazer previsões para as próximas 24 horas. Isso ocorre porque foi assim que treinamos o modelo.
# Function to prepare input data def prepare_input_data(data, seq_length): X = [] X.append(data.iloc[-seq_length:].values) return np.array(X) # Prepare the input data seq_length = 168 # 1 week of hourly data input_data = prepare_input_data(historical_data, seq_length)
- Etapa 4. Definir Configuração: definimos uma classe de configuração para configurar os parâmetros do modelo. Essas configurações são as mesmas que usamos para treinar o modelo.
# Define the configuration class class Config: def __init__(self): self.enc_in = 4 # Adjusted for 4 columns (open, high, low, close) self.seq_len = seq_length self.pred_len = 24 # Predict next 24 hours self.e_layers = 3 self.n_heads = 4 self.d_model = 64 self.d_ff = 256 self.dropout = 0.1 self.fc_dropout = 0.1 self.head_dropout = 0.1 self.individual = False self.patch_len = 24 self.stride = 24 self.padding_patch = True self.revin = True self.affine = False self.subtract_last = False self.decomposition = True self.kernel_size = 25 # Initialize the configuration config = Config()
- Etapa 5. Carregar o Modelo Treinado: definimos uma função para carregar o modelo PatchTST treinado. Essas são as mesmas configurações que usamos para treinar o modelo.
# Function to load the trained model def load_model(model_path, config): model = PatchTST( configs=config, max_seq_len=1024, d_k=None, d_v=None, norm='BatchNorm', attn_dropout=0.1, act="gelu", key_padding_mask='auto', padding_var=None, attn_mask=None, res_attention=True, pre_norm=False, store_attn=False, pe='zeros', learn_pe=True, pretrain_head=False, head_type='flatten', verbose=False ) model.load_state_dict(torch.load(model_path)) model.eval() return model # Load the trained model model_path = 'patchtst_model.pth' device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model = load_model(model_path, config).to(device)
- Etapa 6. Fazer Previsões: definimos uma função para fazer previsões usando o modelo carregado e os dados de entrada.
# Function to make predictions def predict(model, input_data, device): with torch.no_grad(): input_data = torch.tensor(input_data, dtype=torch.float32).to(device) output = model(input_data) return output.cpu().numpy() # Make predictions predictions = predict(model, input_data, device)
- Etapa 7. Pós-processamento e Visualização: processamos as previsões, criamos um data frame e visualizamos os dados históricos e previstos usando Plotly.
# Ensure predictions have the correct shape if predictions.shape[2] != 4: predictions = predictions[:, :, :4] # Adjust based on actual number of columns required # Check the shape of predictions print("Shape of predictions:", predictions.shape) # Create a DataFrame for predictions pred_index = pd.date_range(start=historical_data.index[-1] + pd.Timedelta(hours=1), periods=24, freq='H') pred_df = pd.DataFrame(predictions[0], columns=['open', 'high', 'low', 'close'], index=pred_index) # Combine historical data and predictions combined_df = pd.concat([historical_data, pred_df]) # Create the plot fig = make_subplots(rows=1, cols=1, shared_xaxes=True, vertical_spacing=0.03, subplot_titles=('EURUSD OHLC')) # Add historical candlestick fig.add_trace(go.Candlestick(x=historical_data.index, open=historical_data['open'], high=historical_data['high'], low=historical_data['low'], close=historical_data['close'], name='Historical')) # Add predicted candlestick fig.add_trace(go.Candlestick(x=pred_df.index, open=pred_df['open'], high=pred_df['high'], low=pred_df['low'], close=pred_df['close'], name='Predicted')) # Add a vertical line to separate historical data from predictions fig.add_vline(x=historical_data.index[-1], line_dash="dash", line_color="gray") # Update layout fig.update_layout(title='EURUSD OHLC Chart with Predictions', yaxis_title='Price', xaxis_rangeslider_visible=False) # Show the plot fig.show() # Print predictions (optional) print("Predicted prices for the next 24 hours:", predictions)
Código de Treinamento e Previsão em Python
Se você não estiver interessado em rodar o código em um notebook Jupyter, forneci alguns arquivos que você pode rodar diretamente nos anexos:
- model_training.py
- model_prediction.py
Você pode configurar o modelo como desejar e executá-lo sem usar o Jupyter.
Resultados da Previsão
Após treinar o modelo e executar o código de previsão em Python, obtive o seguinte gráfico. As previsões foram criadas por volta das 12:30 AM (CEST + 3) do dia 7/8/2024. Este é exatamente o momento da Abertura de Domingo à Noite / Segunda-feira de manhã. Podemos ver um gap no gráfico porque o EURUSD abriu com um gap. O modelo prevê que o EURUSD deverá experimentar uma tendência de alta durante a maior parte do tempo, possivelmente preenchendo esse gap. Após o gap ser preenchido, a ação do preço deverá virar para baixo perto do final do dia.

Também imprimimos o valor bruto dos resultados, que pode ser visto abaixo:
Predicted prices for the next 24 hours: [[[1.0789319 1.08056 1.0789403 1.0800443] [1.0791171 1.080738 1.0791024 1.0802013] [1.0792702 1.0807946 1.0792127 1.0802455] [1.0794896 1.0809869 1.07939 1.0804181] [1.0795166 1.0809793 1.0793561 1.0803629] [1.0796498 1.0810834 1.079427 1.0804263] [1.0798903 1.0813211 1.0795883 1.0805805] [1.0800778 1.081464 1.0796818 1.0806502] [1.0801392 1.0815498 1.0796598 1.0806476] [1.0802988 1.0817037 1.0797216 1.0807337] [1.080521 1.0819166 1.079835 1.08086 ] [1.0804708 1.0818571 1.079683 1.0807351] [1.0805807 1.0819991 1.079669 1.0807738] [1.0806456 1.0820425 1.0796478 1.0807805] [1.080733 1.0821087 1.0796758 1.0808226] [1.0807986 1.0822101 1.0796862 1.08086 ] [1.0808219 1.0821983 1.0796905 1.0808747] [1.0808604 1.082247 1.0797052 1.0808727] [1.0808146 1.082188 1.0796149 1.0807893] [1.0809066 1.0822624 1.0796828 1.0808471] [1.0809724 1.0822903 1.0797662 1.0808889] [1.0810378 1.0823163 1.0797914 1.0809084] [1.0810691 1.0823379 1.0798224 1.0809308] [1.0810966 1.0822875 1.0797993 1.0808865]]]
Levando o Modelo Pré-treinado para MQL5
Nesta seção, criaremos um precursor de um indicador que nos ajudará a visualizar a ação do preço prevista em nossos gráficos. Deliberadamente, fiz o script rudimentar e aberto, porque nossos leitores podem ter objetivos diferentes e estratégias diferentes para como usar essas redes neurais complexas. O indicador é desenvolvido no Formato de Consultor Especial do MQL5. Aqui está o script completo:
//+------------------------------------------------------------------+ //| PatchTST Predictor | //| Copyright 2024 | //+------------------------------------------------------------------+ #property copyright "Copyright 2024" #property link "https://www.mql5.com" #property version "1.00" #resource "\\PatchTST\\patchtst_model.onnx" as uchar PatchTSTModel[] #define SEQ_LENGTH 168 #define PRED_LENGTH 24 #define INPUT_FEATURES 4 long ModelHandle = INVALID_HANDLE; datetime ExtNextBar = 0; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Load the ONNX model ModelHandle = OnnxCreateFromBuffer(PatchTSTModel, ONNX_DEFAULT); if (ModelHandle == INVALID_HANDLE) { Print("Error creating ONNX model: ", GetLastError()); return(INIT_FAILED); } // Set input shape const long input_shape[] = {1, SEQ_LENGTH, INPUT_FEATURES}; if (!OnnxSetInputShape(ModelHandle, ONNX_DEFAULT, input_shape)) { Print("Error setting input shape: ", GetLastError()); return(INIT_FAILED); } // Set output shape const long output_shape[] = {1, PRED_LENGTH, INPUT_FEATURES}; if (!OnnxSetOutputShape(ModelHandle, 0, output_shape)) { Print("Error setting output shape: ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { if (ModelHandle != INVALID_HANDLE) { OnnxRelease(ModelHandle); ModelHandle = INVALID_HANDLE; } } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { if (TimeCurrent() < ExtNextBar) return; ExtNextBar = TimeCurrent(); ExtNextBar -= ExtNextBar % PeriodSeconds(); ExtNextBar += PeriodSeconds(); // Prepare input data float input_data[]; if (!PrepareInputData(input_data)) { Print("Error preparing input data"); return; } // Make prediction float predictions[]; if (!MakePrediction(input_data, predictions)) { Print("Error making prediction"); return; } // Draw hypothetical future bars DrawFutureBars(predictions); } //+------------------------------------------------------------------+ //| Prepare input data for the model | //+------------------------------------------------------------------+ bool PrepareInputData(float &input_data[]) { MqlRates rates[]; ArraySetAsSeries(rates, true); int copied = CopyRates(_Symbol, PERIOD_H1, 0, SEQ_LENGTH, rates); if (copied != SEQ_LENGTH) { Print("Failed to copy rates data. Copied: ", copied); return false; } ArrayResize(input_data, SEQ_LENGTH * INPUT_FEATURES); for (int i = 0; i < SEQ_LENGTH; i++) { input_data[i * INPUT_FEATURES + 0] = (float)rates[SEQ_LENGTH - 1 - i].open; input_data[i * INPUT_FEATURES + 1] = (float)rates[SEQ_LENGTH - 1 - i].high; input_data[i * INPUT_FEATURES + 2] = (float)rates[SEQ_LENGTH - 1 - i].low; input_data[i * INPUT_FEATURES + 3] = (float)rates[SEQ_LENGTH - 1 - i].close; } return true; } //+------------------------------------------------------------------+ //| Make prediction using the ONNX model | //+------------------------------------------------------------------+ bool MakePrediction(const float &input_data[], float &output_data[]) { ArrayResize(output_data, PRED_LENGTH * INPUT_FEATURES); if (!OnnxRun(ModelHandle, ONNX_NO_CONVERSION, input_data, output_data)) { Print("Error running ONNX model: ", GetLastError()); return false; } return true; } //+------------------------------------------------------------------+ //| Draw hypothetical future bars | //+------------------------------------------------------------------+ void DrawFutureBars(const float &predictions[]) { datetime current_time = TimeCurrent(); for (int i = 0; i < PRED_LENGTH; i++) { datetime bar_time = current_time + PeriodSeconds(PERIOD_H1) * (i + 1); double open = predictions[i * INPUT_FEATURES + 0]; double high = predictions[i * INPUT_FEATURES + 1]; double low = predictions[i * INPUT_FEATURES + 2]; double close = predictions[i * INPUT_FEATURES + 3]; string obj_name = "FutureBar_" + IntegerToString(i); ObjectCreate(0, obj_name, OBJ_RECTANGLE, 0, bar_time, low, bar_time + PeriodSeconds(PERIOD_H1), high); ObjectSetInteger(0, obj_name, OBJPROP_COLOR, close > open ? clrGreen : clrRed); ObjectSetInteger(0, obj_name, OBJPROP_FILL, true); ObjectSetInteger(0, obj_name, OBJPROP_BACK, true); } ChartRedraw(); }
Para rodar o script acima, observe como a seguinte linha está definida:
#resource "\\PatchTST\\patchtst_model.onnx" as uchar PatchTSTModel[]
Isso significa que dentro da pasta do Consultor Especial, precisaremos criar uma subpasta chamada PatchTST. Dentro da subpasta PatchTST, precisaremos salvar o arquivo ONNX do treinamento do modelo. No entanto, o EA principal será armazenado na pasta raiz.
Os parâmetros que usamos para treinar nosso modelo também estão definidos no topo do script:
#define SEQ_LENGTH 168 #define PRED_LENGTH 24 #define INPUT_FEATURES 4
No nosso caso, queremos usar 168 barras anteriores, alimentá-las no modelo ONNX e obter uma previsão para as próximas 24 barras no futuro. Temos 4 características de entrada: open, high, low e close.
Além disso, observe o seguinte código dentro da função OnTick():
if (TimeCurrent() < ExtNextBar) return; ExtNextBar = TimeCurrent(); ExtNextBar -= ExtNextBar % PeriodSeconds(); ExtNextBar += PeriodSeconds();
Como os modelos ONNX são intensivos em poder de processamento de um computador, esse código garantirá que uma nova previsão seja gerada apenas uma vez por barra. No nosso caso, como estamos trabalhando com barras horárias, as previsões serão atualizadas uma vez por hora.
Finalmente, neste código, desenharemos as barras futuras na tela, através dos recursos de desenho do MQL5:
void DrawFutureBars(const float &predictions[]) { datetime current_time = TimeCurrent(); for (int i = 0; i < PRED_LENGTH; i++) { datetime bar_time = current_time + PeriodSeconds(PERIOD_H1) * (i + 1); double open = predictions[i * INPUT_FEATURES + 0]; double high = predictions[i * INPUT_FEATURES + 1]; double low = predictions[i * INPUT_FEATURES + 2]; double close = predictions[i * INPUT_FEATURES + 3]; string obj_name = "FutureBar_" + IntegerToString(i); ObjectCreate(0, obj_name, OBJ_RECTANGLE, 0, bar_time, low, bar_time + PeriodSeconds(PERIOD_H1), high); ObjectSetInteger(0, obj_name, OBJPROP_COLOR, close > open ? clrGreen : clrRed); ObjectSetInteger(0, obj_name, OBJPROP_FILL, true); ObjectSetInteger(0, obj_name, OBJPROP_BACK, true); } ChartRedraw(); }
Após implementar este código em MQL5, compilar o modelo e colocar o EA resultante no intervalo de tempo H1, você deverá ver algumas barras adicionais no futuro em seu gráfico. No meu caso, isso se parece com o seguinte:
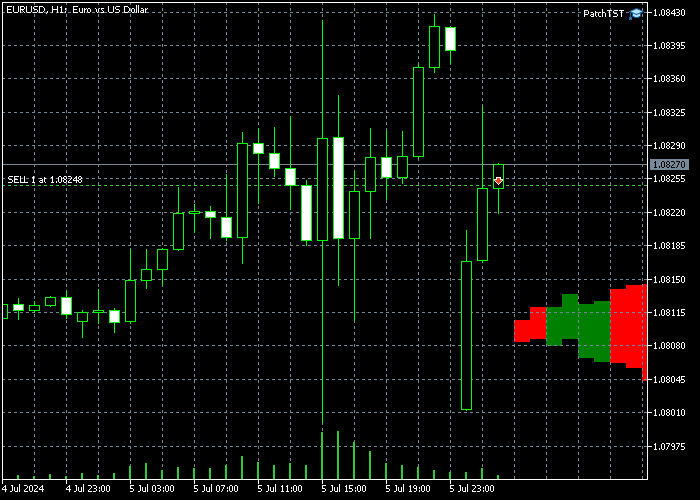
Observe que se você não vir as barras recém-desenhadas à direita, pode ser necessário clicar no botão "Shift end of chart from right border". ![]()
Conclusão
Neste artigo, tomamos uma abordagem passo a passo para treinar o modelo PatchTST, que foi introduzido em 2023. Obtemos uma visão geral de como o algoritmo PatchTST funciona. O código base teve alguns problemas relacionados à conversão para ONNX. Especificamente, o operador "Unfold" não é suportado, então resolvemos esse problema para tornar o código mais compatível com ONNX. Também mantivemos o propósito do artigo voltado para o trader, focando nos conceitos básicos do modelo, como puxar os dados, treinar o modelo e obter uma previsão para as próximas 24 horas. Depois, implementamos a previsão em MQL5, para que possamos usar o modelo completamente treinado com nossos indicadores e consultores especializados favoritos. Estou feliz em compartilhar todo o meu código com a comunidade MQL nos arquivos zip anexados. Por favor, me avise se tiver alguma dúvida ou comentário.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/15198
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Muitas vezes, percebo que os resultados previstos desse modelo não são muito consistentes com a situação real. Não fiz nenhuma alteração no código desse modelo. Você poderia me dar alguma orientação? Muito obrigado.
Obrigado por compartilhar sua experiência com o modelo. Você levantou uma questão válida sobre a consistência da previsão. O modelo PatchTST funciona melhor quando integrado a uma abordagem de negociação abrangente que considera vários fatores de mercado. Veja como eu recomendo usar as previsões do modelo de forma mais eficaz:
Algumas observações pessoais adicionais:
As previsões do modelo devem ser usadas como um componente de sua análise, e não como o único responsável pela tomada de decisões. Ao incorporar esses elementos, você pode potencialmente melhorar a consistência dos resultados de suas negociações ao usar o modelo PatchTST.
Espero que isso ajude.
Fair Value Gap (FVG) Script que mencionei (esses gaps funcionam de forma muito semelhante às zonas de oferta e demanda, em minha experiência):
Obrigado por seu interesse! Sim, essas alterações nos parâmetros funcionariam em princípio, mas há algumas considerações importantes ao mudar para os dados M1:
1. Volume de dados: Treinar com 10080 minutos (1 semana) de dados M1 significa lidar com um número significativamente maior de pontos de dados do que com H1. Isso irá:
2. Ajustes na arquitetura do modelo: Na Etapa 8 do treinamento do modelo e na Etapa 4 do código de previsão, talvez você queira ajustar outros parâmetros para acomodar a sequência de entrada maior:
3. Qualidade da previsão: Embora você obtenha previsões mais granulares, esteja ciente de que os dados M1 normalmente contêm mais ruído. Talvez você queira fazer experiências com diferentes comprimentos de sequência e janelas de previsão para encontrar o equilíbrio ideal.Obrigado pela informação. Meu computador é razoavelmente capaz, com 256 GB e 64 núcleos físicos. No entanto, ele poderia ter uma GPU melhor.
Depois de atualizar a GPU, tentarei as definições de configuração atualizadas.
Obrigado por compartilhar sua experiência com o modelo. Você levantou uma questão válida sobre a consistência das previsões. O modelo PatchTST funciona melhor quando integrado a uma abordagem de negociação abrangente que considera vários fatores de mercado. Veja como eu recomendo usar as previsões do modelo de forma mais eficaz:
Algumas observações pessoais adicionais:
As previsões do modelo devem ser usadas como um componente de sua análise, e não como o único responsável pela tomada de decisões. Ao incorporar esses elementos, você pode potencialmente melhorar a consistência dos resultados de suas negociações ao usar o modelo PatchTST.
Espero que isso ajude.
Fair Value Gap (FVG) Script que mencionei (esses gaps funcionam de forma muito semelhante às zonas de oferta e demanda, em minha experiência):
Muito obrigado por sua resposta paciente e por seu compartilhamento altruísta. Nunca vi respostas tão detalhadas e profissionais antes. Lerei seu artigo várias vezes. Esses conhecimentos são particularmente valiosos para mim. Meus melhores votos para você.
Muito obrigado. Suas palavras gentis significam muito! Entre em contato se precisar de mais ajuda!