Discussing the article: "Using PatchTST Machine Learning Algorithm for Predicting Next 24 Hours of Price Action"
Hi, can you explain better what those bars are that I see in MT5? ok they have two colors green and red but what do they indicate? Thanks
The green and the red bars are generated from this code snippet:
ObjectSetInteger(0, obj_name, OBJPROP_COLOR, close > open ? clrGreen : clrRed);
So green means that model thinks that close will be higher than open (much like a green bar on a candle stick chart), in the future at that time. Red means close will be lower than open for that hour in the future.
Like for example, I trained the model for a few other pairs yesterday. I used the indicator that I show in the chart but the ONNX model was trained for USDJPY and AUDUSD. I caught a 15R trade this morning based on the model's prediction for USDJPY. I wasn't even watching the charts really while all this happened. I just took the trade in the afternoon after completing the training and let the position run overnight (I paid the swap). In my experience, so far, what I have been able to discern is that you can generally trust the direction that the model is predicting. Also note any patterns you may see, so for example, more consecutive red bars on the chart would indicate that the model thinks price will go down. More green bars would indicate that model thinks the price will go up.
As you can see, I also lost about 1R for AUDUSD based on the model prediction, so it's not perfect. You still have to use your other skills like supply and demand zones for setting SL and TP, macro fundamentals, positing sizing, and risk management etc. In my opinion, using trained PatchTST models will give you a lot more precision and confidence in placing those trades at the right hour of the day or in the right session at least (Asia, London, or NY). The screenshot below is from a prop-firm evaluation that I am working on at the moment.
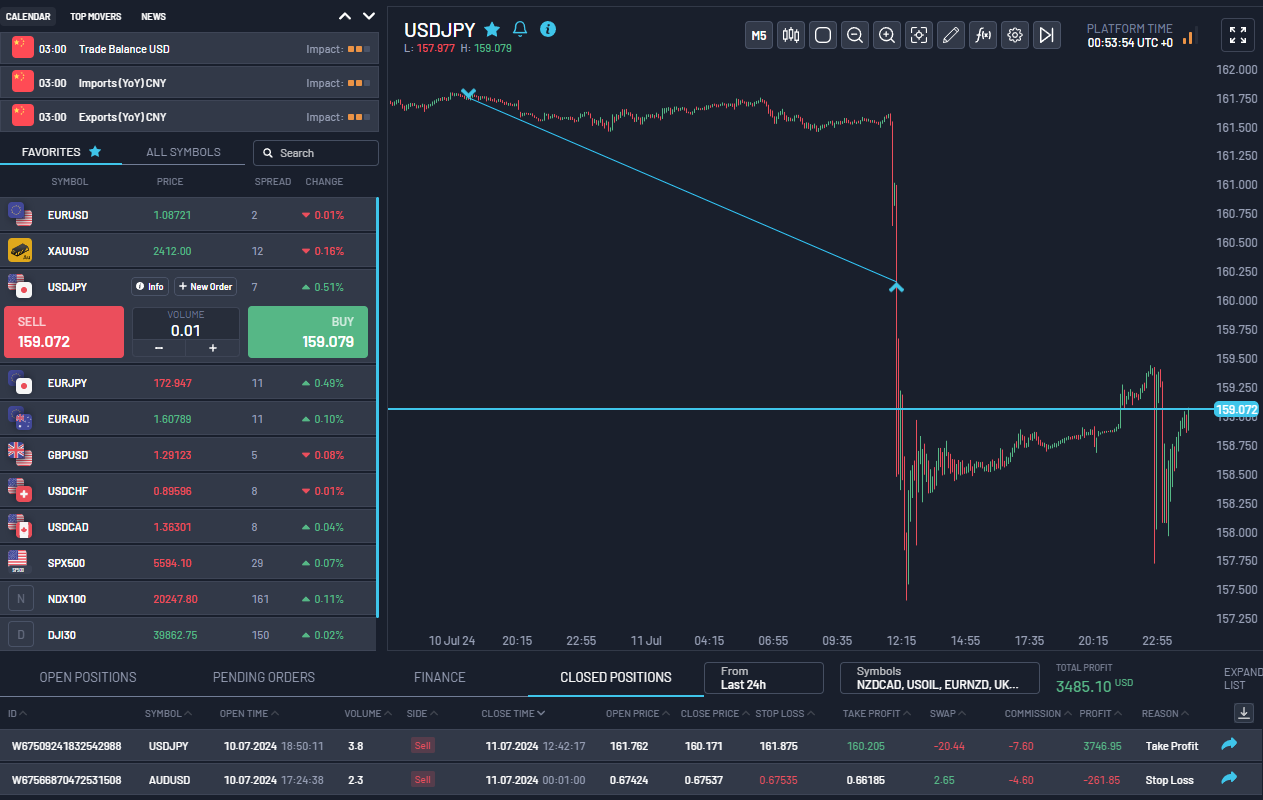
Hello this is amazing work!
Thank you for your interest and thoughtful comments on the ML trading algorithm! I'm glad you found the idea interesting. Let me address your points one by one:
- LSTM vs. PatchTST Performance:
- I found PatchTST to be more accurate in predicting trends.
- LSTM seemed to perform better during consolidations.
- Overall, PatchTST had a slightly better win rate in my tests.
- Training Period and Timeframes:
- I've experimented with training on different timeframes.
- The 1-hour timeframe seems to work best in my experience.
- I haven't specifically tried training over just a one-month period, as longer historical data tends to yield more robust models.
- Combining Models and Timeframes:
- Your idea of combining models on different timeframes (e.g., H1 and M15) is interesting.
- There's a trade-off to consider: using shorter timeframes requires more data points and increases training time exponentially.
- For example, using a 15-minute timeframe would need 4 times as many bars as the 1-hour timeframe for equivalent training, also increasing the prediction horizon by a factor of 4.
- Scalper Strategy on M1:
- Your suggestion of creating a scalper on the M1 timeframe, using predictions as a filter, is creative.
- The idea of using 7/10 green bars for buying and 5-6/10 for ranging is a good starting point for a strategy.
- This approach could potentially reduce false signals and improve entry timing.
- Current Work and Future Directions:
- I'm currently working on a 3-tiered approach: a) One model predicting price action over a 1-week timeframe b) Another model for the 1-day timeframe c) A third model for the 5-minute timeframe
- These are all different models, tailored to their specific timeframes.
- The goal is to create a more comprehensive trading system that considers multiple time horizons.
- Additional Considerations:
- Combining predictions from multiple timeframes and models can indeed enhance overall strategy performance.
- However, it's crucial to manage complexity and avoid overfitting.
- Backtesting and forward testing on out-of-sample data are essential to validate the effectiveness of any combined approach.
Thank you again for sharing your ideas. They've given me some new perspectives to consider in my ongoing work. If you have any more thoughts or questions, feel free to ask!
# Step 11: Train the model for epoch in range(num_epochs): model.train() total_loss = 0 for batch_X, batch_y in train_loader: optimizer.zero_grad() batch_X = batch_X.to(device) batch_y = batch_y.to(device) outputs = model(batch_X) outputs = outputs[:, -pred_length:, :4] loss = loss_fn(outputs, batch_y) loss.backward() optimizer.step() total_loss += loss.item() print(f"Epoch {epoch+1}/{num_epochs}, Loss: {total_loss/len(train_loader):.10f}")
RuntimeError: permute(sparse_coo): number of dimensions in the tensor input does not match the length of the desired ordering of dimensions i.e. input.dim() = 3 is not equal to len(dims) = 4
Check out the new article: Using PatchTST Machine Learning Algorithm for Predicting Next 24 Hours of Price Action.
Author: Shashank Rai
Thanks for publishing such a fascinating article. I'm experienced with python, but haven't dabbled much with AI models.
If I want to train on M1 data rather than H1 would this be a reasonable change to the training script? Thanks.
seq_length = 10080 # 1 week of M1 data pred_length = 30 # Predict next 30 minutes
All numerical series are calculated on a regular calculator. If you want, you can enter everything in Excel, or write an MT inducer.
The PatchTST algorithm is indeed more complex than basic numerical calculations, but that's by design. While you could use Excel or simpler tools for basic calculations, neural networks like PatchTST can capture complex patterns in market data that might not be apparent with simpler analysis methods. The model's strength lies in its ability to learn these patterns automatically from historical data.
Thanks for publishing such a fascinating article. I'm experienced with python, but haven't dabbled much with AI models.
If I want to train on M1 data rather than H1 would this be a reasonable change to the training script? Thanks.
Thank you for your interest! Yes, those changes to the parameters would work in principle, but there are a few important considerations when switching to M1 data:
1. Data Volume: Training with 10080 minutes (1 week) of M1 data means handling significantly more data points than with H1. This will:
- Increase training time substantially
- Require more memory
- Potentially need GPU acceleration for efficient training
2. Model Architecture Adjustments: In Step 8 of model training and Step 4 of prediction code, you might want to adjust other parameters to accommodate the larger input sequence:
class Config: def __init__(self): self.patch_len = 120 # Consider larger patch sizes for M1 data self.stride = 120 # Adjust stride accordingly self.d_model = 128 # Might need larger model capacity3. Prediction Quality: While you'll get more granular predictions, be aware that M1 data typically contains more noise. You might want to experiment with different sequence lengths and prediction windows to find the optimal balance.
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
Check out the new article: Using PatchTST Machine Learning Algorithm for Predicting Next 24 Hours of Price Action.
In this article, we apply a relatively complex neural network algorithm released in 2023 called PatchTST for predicting the price action for the next 24 hours. We will use the official repository, make slight modifications, train a model for EURUSD, and apply it to making future predictions both in Python and MQL5.
I first encountered an algorithm called PatchTST when I started to dig into the AI advancements associated with time series predictions on Huggingface.co. As anyone who has worked with large language models (LLMs) would know, the invention of transformers has been a game changer for developing tools for natural language, image, and video processing. But what about time series? Is it something that's just left behind? Or is most of the research simply behind closed doors? It turns out there are many newer models that apply transformers successfully for predicting time series. In this article, we will look at one such implementation.
What's impressive about PatchTST is how quick it is to train a model and how easy it is to use the trained model with MQL. I admit openly that I am new to the concept of neural networks. But going through this process and tackling the implementation of PatchTST outlined in this article for MQL5, I felt like I took a giant leap forward in my learning and understanding of how these complex neural networks are developed, troubleshot, trained, and used. It is like taking a child, who is barely learning to walk, and putting him on a professional soccer team, expecting him to score the winning goal in the World Cup final.
Author: Shashank Rai