
Redes neurais em trading: decomposição em vez de aumento de escala (SSCNN)

Introdução
A previsão de séries temporais continua sendo uma das áreas fundamentais da análise de dados, do aprendizado de máquina e da estatística. Sua importância não pode ser subestimada: das finanças e da meteorologia à infraestrutura urbana e às telecomunicações, em todas as áreas em que a dinâmica e a previsibilidade são relevantes, as séries temporais desempenham um papel central. No entanto, modelos unidimensionais clássicos, como o ARIMA, e métodos de suavização exponencial mostram-se cada vez mais limitados diante da complexidade de sistemas abertos, dinâmicos e em constante mudança.
Esse cenário começou a mudar de forma decisiva com o surgimento das técnicas de aprendizado profundo. Um avanço especialmente relevante ocorreu após a introdução da arquitetura Transformer, capaz não apenas de identificar dependências complexas par a par em sequências, mas também de extrair suas representações em múltiplos níveis. Foram justamente essas propriedades que tornaram o Transformer uma das tecnologias centrais na previsão moderna, estabelecendo um novo patamar de precisão para os modelos.
No contexto do rápido desenvolvimento dos modelos de linguagem de grande porte (LLM), o aumento da escala das redes neurais tornou-se, na prática, a linha dominante. Hoje, a imensa maioria dos modelos de ponta possui milhões de parâmetros e, no caso dos LLM pré-treinados, chega a bilhões. À primeira vista, essa expansão deveria garantir um salto qualitativo nos resultados. No entanto, ao contrário do esperado, as melhorias foram relativamente moderadas: o ganho de precisão, em termos de MSE e MAE, não ultrapassa 30%, enquanto o número de parâmetros aumenta centenas ou milhares de vezes em comparação com modelos lineares simples. Além disso, a partir do modelo PatchTST, o progresso passou a desacelerar rapidamente, e os modelos posteriores apresentaram apenas melhorias graduais e pouco significativas.
Essas observações colocam em dúvida a direção em que a área tem avançado. É evidente que a escala do modelo, por si só, não é garantia de alta qualidade. Nesse contexto, torna-se cada vez mais relevante adotar o vetor oposto: reduzir o número de parâmetros sem perder a capacidade preditiva.
No entanto, antes de propor uma solução alternativa, é importante entender por que os métodos atuais perdem desempenho quando o número de parâmetros é reduzido. A maioria das arquiteturas modernas utiliza o chamado patching, isto é, a divisão dos dados em fragmentos ao longo das dimensões temporais ou espaciais. Em conjunto com o mecanismo de atenção, essa abordagem de fato permite capturar dependências complexas. Mas ela também tem seu lado negativo. Com o patching, os identificadores temporais ou espaciais deixam de ser preservados, as relações entre observações se perdem e, consequentemente, desaparece justamente a estrutura que o modelo deveria captar.
Para compensar parcialmente essas perdas, os pesquisadores introduzem uma codificação adicional de identidades e posições temporais, ampliando o espaço latente de características. No entanto, quanto maior o número de identidades que precisam ser preservadas, maior é a dimensionalidade desse espaço e, com ela, maior também é o número de parâmetros. Como resultado, o modelo cresce de forma exponencial. Isso, por sua vez, eleva o risco de sobreajuste, especialmente nos casos em que há uma quantidade limitada de dados de treinamento, algo típico em tarefas com séries temporais.
Se o objetivo é obter não apenas um modelo eficiente, mas também parcimonioso, é necessário repensar o próprio paradigma: em vez de recriar a estrutura no espaço latente, convém preservar e usar as regularidades dos dados desde o início. Pesquisas recentes mostram que a decomposição de características (feature decomposition) pode aumentar significativamente a precisão sem exigir modelos gigantescos. No entanto, essa abordagem também tem suas limitações. Em primeiro lugar, ela é pouco aplicável a tarefas de previsão de longo prazo, especialmente quando os dados apresentam dependências espaço-temporais complexas. Além disso, há também o aspecto analítico da questão: por que e como a decomposição funciona, e por que ela é superior ao patching?
Em resposta a esses problemas, os autores do estudo "Parsimony or Capability? Decomposition Delivers Both in Long-term Time Series Forecasting" propõem uma nova abordagem: a arquitetura neural SSCNN (Selective Structured Components-based Neural Network). Esse modelo combina precisão, economia e base analítica. Diferentemente das soluções anteriores, a SSCNN é a primeira a apresentar uma análise formal das vantagens da decomposição de características em relação ao patching, justificando essa vantagem tanto em termos de eficiência quanto de compacidade do modelo. Além disso, na SSCNN, a decomposição básica é reforçada por um mecanismo de seleção: o modelo é capaz de identificar dependências importantes no nível de cada passo temporal, o que aumenta significativamente a precisão da reconstrução dos componentes estruturais e, consequentemente, a qualidade geral da previsão.
Os resultados dos testes da SSCNN em tarefas de referência, conduzidos pelos autores do framework, mostram que o modelo supera de forma consistente os métodos existentes na qualidade da previsão e, em 99% dos casos, requer menos parâmetros do que modelos como PatchTST ou iTransformer. Ainda mais impressionante: em tarefas de previsão de longo prazo, a SSCNN utiliza 87% menos parâmetros até mesmo em comparação com a DLinear, um modelo ultracompacto.
A SSCNN representa um avanço não pelo aumento da potência computacional, mas pelo uso criterioso da estrutura dos dados e pela precisão da engenharia. Essa solução mostra que o caminho para uma previsão de alta qualidade não está na quantidade, mas na compreensão.
Algoritmo SSCNN
Na tarefa de previsão multivariada de séries temporais, dadas observações históricas X = {x1, …, xN} ∈ RN*Tin, em que N é o número de variáveis e Tin é a extensão da sequência analisada, é necessário prever os valores em um intervalo futuro de comprimento Tout, denotado por X̂ ∈ RN*Tout. Os dados de entrada passam por pré-processamento com o objetivo de prever valores futuros ainda desconhecidos. Durante a previsão, forma-se uma sequência de representações intermediárias que refletem a dinâmica interna dos dados.
A arquitetura SSCNN é estruturada em dois ramos funcionalmente distintos. A ramificação superior é responsável pela inferência: ela extrai os componentes estruturais da série temporal juntamente com os resíduos correspondentes. A ramificação inferior, por sua vez, concentra-se na extrapolação, isto é, na previsão da possível evolução desses componentes ao longo do tempo.
Os componentes e resíduos obtidos são combinados em um único vetor concatenado de maior dimensionalidade, que então é usado como entrada de uma camada de regressão polinomial. Essa camada permite identificar relações complexas entre os elementos, preservando ao mesmo tempo a estrutura dos dados.
Os autores do framework SSCNN introduzem um novo mecanismo de normalização, o T-AttnNorm, baseado em atenção temporal. Ele permite isolar, passo a passo, os principais componentes da série temporal: os de longo prazo, os sazonais e os de curto prazo. Cada um desses elementos é extraído individualmente para cada variável ao longo do eixo temporal. Com isso, é formado um mapa de seleção (selection map), que reflete a dinâmica do componente de interesse.
Após extrair cada componente, o modelo o separa da representação geral da série, obtendo um sinal residual que acumula a informação que não entrou na estrutura do elemento extraído. Assim, a partir da representação inicial da série temporal H ∈ RN*Tin*d, são formadas duas representações paralelas: o componente estrutural µ ∈ RN*Tin*d e o resíduo R ∈ RN*Tin*d. O mapa de seleção I ∈ RN*Tin*Tin orienta a construção de cada componente.
![]()
![]()
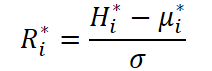
Para preservar a correção da normalização, as linhas da matriz I* são normalizadas de modo que a soma dos elementos de cada linha seja igual a 1. A diferença entre os componentes de longo prazo, os sazonais e os de curto prazo está justamente no modo como essa matriz é construída.
É importante observar que o resíduo obtido em uma etapa é fornecido como entrada ao bloco seguinte. Por exemplo, para extrair o componente sazonal, utiliza-se como entrada o resíduo remanescente após a extração do componente de longo prazo.
Após a decomposição de cada componente estrutural e do sinal residual, ambas as representações são extrapoladas para o horizonte temporal futuro por meio de um mapeamento linear definido pela matriz E ∈ RN*Tin*Tout. Assim como o mapa de atenção I*, a matriz E* também é normalizada por linha.
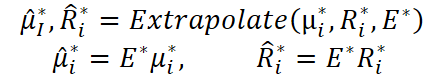
Como resultado, obtemos os componentes previstos ̂µ* e R̂* ∈ RN*Tout*d.
O componente de longo prazo do modelo serve para identificar e descrever tendências persistentes em séries temporais. Para obter uma estimativa o mais objetiva possível desse elemento, os autores do framework calculam a média dos valores coletados ao longo de vários períodos sazonais. Essa abordagem permite minimizar a influência de oscilações sazonais e de curto prazo, que exercem apenas um impacto local e podem distorcer a direção geral da dinâmica.
Os mecanismos de extração e extrapolação do componente de longo prazo são implementados por meio de matrizes simples, nas quais todos os valores são iguais: cada célula dessas matrizes recebe o valor 1/Tin. Isso significa que cada ponto temporal do passado contribui igualmente para a formação do panorama de longo prazo. Assim, nenhum trecho da série recebe prioridade. Pelo contrário, o modelo se apoia no comportamento médio global.
Os autores do framework excluíram deliberadamente o mecanismo de atenção (attention) do processamento do componente de longo prazo. A prática mostrou que, nos conjuntos de dados analisados, isso não aumenta a precisão das previsões. A atenção pode, de fato, ser útil quando a distribuição do componente muda de forma perceptível ao longo do tempo, pois nesse caso ela ajuda a reduzir o viés da estimativa. No entanto, no caso do componente de longo prazo, essa distribuição permanece estável ao longo de todo o intervalo de entrada. Portanto, o uso de attention nesse contexto não se justifica e se torna apenas uma complexidade desnecessária, sem benefício prático.
O componente sazonal do modelo é destinado a descrever oscilações regulares que se repetem com uma periodicidade definida. Sua extração se baseia na suposição de que a duração do ciclo é estável, o que simplifica a identificação dos padrões sazonais. Introduz-se então a notação c, que representa a duração de um ciclo. Nesse caso, τin indica o número de ciclos completos contidos na sequência analisada (τin • c ≤ Tin), enquanto τout representa o número mínimo de ciclos necessário para cobrir a sequência de saída (τout • c ≥ Tout). Para facilitar os cálculos posteriores, assume-se que o comprimento da entrada Tin é múltiplo de c.
Para obter uma estimativa precisa e não enviesada do componente sazonal, os autores do framework SSCNN introduzem uma matriz treinável de parâmetros Wse ∈ Rτin*τin, na qual cada célula reflete a relação entre um par de ciclos. Essa matriz é normalizada linha a linha por meio de SoftMax. Assim, ao calcular os pesos para o ciclo atual, o modelo considera a contribuição de todos os ciclos anteriores, o que permite capturar regularidades locais e globais.
O modelo constrói um mapa de seleção especial, uma espécie de filtro que permite extrair apenas os valores correspondentes às mesmas fases de diferentes ciclos. Ou seja, são comparados, por exemplo, apenas os primeiros dias de cada mês ou apenas as segundas-feiras de todas as semanas, dependendo da escala do ciclo. Isso é obtido ao considerar apenas os elementos cuja diferença entre os índices é múltipla de c, enquanto o pertencimento a um ciclo específico é determinado por meio da divisão inteira.
Na extrapolação, isto é, na previsão do componente sazonal para pontos temporais futuros, utiliza-se uma lógica semelhante. Introduz-se a matriz Ŵse ∈ Rτout*τin, que reflete as relações entre os ciclos das sequências de saída e entrada. Ela também é normalizada e forma o mapa de seleção para a extrapolação, garantindo, no futuro, a continuação lógica e consistente dos padrões sazonais já identificados.
Essa configuração permite que o modelo leve em consideração, com precisão, os padrões recorrentes dos dados, utilizando-os como âncora para as previsões, o que proporciona alta estabilidade e precisão nas previsões sazonais.
O componente de curto prazo destina-se a identificar anomalias locais e efeitos de curta duração que não se enquadram nas regularidades sazonais e de longo prazo. Diferentemente da tendência, ele é formado com base em uma janela limitada de observações δ, que determina o alcance temporal retrospectivo. Esses dados permanecem relevantes apenas no horizonte temporal imediato e apresentam diferentes graus de correlação em função das defasagens, isto é, da distância entre os pontos de observação.
É por isso que a extração do componente de curto prazo se baseia em um vetor paramétrico wst ∈ Rδ, que permite atribuir pesos diferentes aos valores dentro da janela definida. Esses pesos passam por normalização SoftMax, o que permite destacar as observações mais relevantes, preservando a estabilidade numérica do modelo. Assim, a atenção fica concentrada apenas nos valores mais recentes da série temporal, mantendo o foco nas mudanças mais próximas do ponto de previsão.
Na previsão do componente de curto prazo, a abordagem depende do alcance do horizonte temporal. Se a previsão abrange os passos mais próximos, as correlações com os valores recentes são preservadas, e utiliza-se um modelo de regressão baseado na matriz paramétrica wst ∈ Rδ*δ. No entanto, à medida que o horizonte se afasta, acumulam-se incertezas que reduzem a confiabilidade das previsões. Nesses casos, o modelo aplica o método de preenchimento com zeros (zero-padding), abrindo mão deliberadamente de parâmetros em excesso que poderiam levar ao sobreajuste.
Assim, o componente de curto prazo permanece compacto e flexível, capturando com precisão as oscilações locais sem sobrecarregar o modelo com operações computacionais e pesos desnecessários. Essa adaptabilidade é especialmente importante em condições de dados instáveis ou ruidosos, nas quais a dinâmica de curto prazo desempenha um papel central na tomada de decisões.
O componente espacial abrange os aspectos das séries temporais que não podem ser descritos pelos componentes temporais já extraídos: de longo prazo, sazonal e de curto prazo. Em outras palavras, ele reflete características temporalmente irregulares, mas espacialmente coerentes, que se manifestam de forma semelhante em várias séries ao mesmo tempo.
A extração desse componente é feita por meio de um mecanismo especial de normalização baseado em atenção espacial, o S-AttnNorm. Diferentemente da normalização temporal, aplicada ao longo do eixo do tempo, aqui o tratamento é feito a cada passo temporal, ao longo da dimensão espacial. Ou seja, em cada passo temporal, o modelo analisa simultaneamente o comportamento de todas as séries, identificando suas características comuns.
Os cálculos seguem uma lógica semelhante à da normalização temporal: para cada passo temporal, são calculados o valor médio (centroide), o desvio padrão e o resíduo. No entanto, aqui a vetorização ocorre ao longo da dimensão espacial, e não da dimensão temporal: cada passo temporal é tratado como um corte espacial.
Para identificar as relações entre as séries, especialmente aquelas que permanecem após a remoção dos principais componentes temporais, como tendência, sazonalidade e dinâmica de curto prazo, aplica-se a análise de correlação. Cada série temporal é representada como uma matriz Tin * d, que posteriormente é vetorizada. Isso permite construir a matriz de similaridade Isi ∈ RN*N, que reflete a correlação condicional entre pares de séries. Assim, o modelo passa a ser capaz de identificar grupos de séries que reagem de modo semelhante a fatores externos, apesar da instabilidade temporal dessas reações.
Concluída a decomposição dos componentes temporais e espaciais, o modelo passa para a etapa de agregação e interpretação, na qual os componentes extraídos são combinados em uma representação unificada para a previsão final. Essa etapa é implementada por meio de uma camada de regressão polinomial, um elemento central da arquitetura que permite considerar interações lineares e não lineares entre os componentes.
Na implementação proposta, os autores do framework SSCNN ampliaram significativamente a funcionalidade do módulo: às relações aditivas, ou seja, de soma, foram acrescentadas dependências multiplicativas, o que permite modelar formas mais complexas de relações entre os componentes, incluindo efeitos de segunda ordem.
![]()
![]()
O vetor Si representa a concatenação de todos os componentes obtidos anteriormente e dos resíduos correspondentes.
Essa estrutura permite que a camada não apenas some os componentes obtidos, mas também identifique suas interdependências e seus efeitos combinados, algo especialmente importante no contexto de séries temporais inter-relacionadas e de alta dimensionalidade.
O resultado do processamento de Hi é uma representação agregada, na qual todos os padrões principais já foram considerados. Essa representação é passada para a camada seguinte do modelo, a partir de uma nova iteração do bloco de longo prazo Hlt i , fechando assim o ciclo arquitetural e garantindo uma dinâmica de previsão integrada. Essa abordagem aumenta a expressividade do modelo e sua capacidade de ajuste fino a dados reais do mercado, nos quais a simples soma dos componentes muitas vezes é insuficiente.
A visualização do framework SSCNN apresentada pelos autores aparece abaixo.

Implementação em MQL5
Depois de examinar em profundidade os fundamentos teóricos do framework SSCNN, passamos à parte prática do artigo. Nesta seção, examinaremos em detalhes uma das implementações dos métodos propostos usando os recursos do ambiente MQL5. Isso nos permitirá consolidar os conceitos e demonstrar sua aplicação eficiente em condições reais do mercado financeiro.
Ao longo da parte teórica, você provavelmente já notou uma semelhança conceitual evidente entre o framework SSCNN apresentado aqui e a abordagem SCNN analisada anteriormente. Essa semelhança aparece até nos nomes dos frameworks, o que não é por acaso. Ambos os métodos se baseiam na ideia de decompor a série temporal em componentes distintos, permitindo analisar os dados de forma mais refinada e estruturada.
No entanto, a principal diferença está na própria abordagem de extração desses componentes e em sua posterior extrapolação. Enquanto a SCNN utiliza métodos mais tradicionais de decomposição e previsão, a SSCNN incorpora mecanismos adaptativos inovadores, como a decomposição seletiva de componentes estruturados e mapas de atenção específicos, o que aumenta significativamente a precisão e a eficiência da previsão.
Ainda assim, a extração do componente de longo prazo por meio de uma matriz preenchida com valores fixos idênticos reduz-se, na prática, à normalização clássica: o cálculo da média ao longo de todo o intervalo temporal. Isso simplifica a tarefa e permite usar soluções prontas e já validadas, sem a necessidade de criar algo do zero.
A situação muda, porém, quando se trata da extração de componentes mais complexos, como o sazonal e o de curto prazo. Nesse caso, são necessários muito mais esforço e ajuste fino. A extração correta desses componentes exige mecanismos adaptativos capazes de captar a periodicidade, a variabilidade e as características locais da série temporal. Isso inclui a construção de mapas de atenção específicos, a parametrização das relações entre períodos e a incorporação das correlações locais.
Passamos agora ao elemento central da implementação: a implementação e a análise do kernel de propagação para frente em OpenCL. É justamente aqui, no nível mais baixo da arquitetura computacional, que começa o processamento efetivo dos dados, que viabiliza as operações fundamentais de normalização e atenção, sem as quais não é possível obter alta precisão e estabilidade do modelo.
Essa transição é lógica e necessária. Já sabemos como é importante extrair com cuidado e de forma sequencial os componentes de longo prazo, os sazonais e os de curto prazo da série temporal. No entanto, para implementar esses conceitos de forma eficiente e escalável, é preciso contar com uma ferramenta poderosa para o processamento paralelo de grandes volumes de dados. O OpenCL é justamente uma ferramenta desse tipo, pois oferece acesso flexível e eficiente aos recursos das GPUs e CPUs modernas.
Começamos pela criação do kernel AttentNorm, o principal módulo operacional responsável pela aplicação dos mecanismos de atenção e normalização aos dados de entrada. Sua tarefa é receber os dados temporais brutos, ponderá-los com a matriz de atenção previamente calculada, calcular as médias locais e os desvios padrão e, em seguida, aplicar a padronização, levando os dados a uma forma normalizada.
Os parâmetros do kernel recebem ponteiros para os dados analisados, para os pesos de atenção, para os arrays que armazenam as médias e os desvios padrão, bem como para o buffer que grava os resultados normalizados. Além disso, também recebem constantes: o número total de elementos na sequência processada como unidade e o tamanho do segmento a ser processado.
__kernel void AttentNorm(__global const float* inputs, __global const float* attention, __global float* means, __global float* stdevs, __global float* outputs, const int total_inputs, const int segment_size ) { const size_t s = get_global_id(0); const size_t i = get_local_id(1); const size_t v = get_global_id(2); const size_t total_segments = get_global_size(0); const size_t total_local = get_local_size(1); const size_t variables = get_global_size(2);
Em seguida, dentro do kernel, obtemos os índices das threads de computação atuais nas três dimensões. A variável s indica o índice global do segmento, i representa o índice local dentro do bloco e v corresponde ao índice global da variável ou do canal. Esses valores permitem que cada thread saiba exatamente por qual trecho dos dados ela é responsável. Também são definidos o número total de segmentos, o tamanho do bloco local e a quantidade de variáveis, para garantir a distribuição correta do processamento.
Para armazenar temporariamente os resultados intermediários, é declarado o array local Temp na memória rápida do dispositivo. Em seguida, calcula-se o deslocamento, isto é, o índice no array dos dados de entrada correspondente à thread, à variável e ao segmento atuais.
__local float Temp[LOCAL_ARRAY_SIZE]; const int shift = v * total_inputs + s * segment_size + i;
No início dos cálculos, são inicializadas as variáveis para armazenar a média, o desvio padrão e o valor auxiliar, que serão acumulados gradualmente. Em seguida, é iniciado um laço no qual cada thread local processa, em sequência, os elementos do segmento com um incremento definido, garantindo paralelismo e distribuição uniforme dos cálculos. Ao mesmo tempo, verifica-se se ultrapassa os limites para evitar erros de acesso à memória.
float mean = 0, stdev = 0; float val = 0; for(uint l = 0; l < segment_size; l += total_local) { if((l + i) >= segment_size || (s * segment_size + l + i) >= total_inputs) break; float val_l = IsNaNOrInf(inputs[shift + l], 0); if(l == 0) val = val_l; float att = IsNaNOrInf(attention[v * segment_size + l + i], 0); mean += val_l * att; stdev += val_l * val_l * att; }
Em cada iteração do laço, extrai-se um valor do array de entrada considerando o deslocamento e aplica-se uma função que protege contra dados inválidos, substituindo valores não numéricos ou infinitos por zero. Na primeira iteração, o valor atual é salvo em uma variável separada para uso posterior. De forma análoga, o peso correspondente é extraído do array de pesos de atenção e também passa por uma verificação de validade.
Em seguida, acumula-se a soma dos valores ponderados para o cálculo da média, bem como da soma ponderada dos quadrados dos valores para o cálculo posterior da variância. Após a conclusão do laço, uma função de soma local reduz os valores de todas as threads locais dentro do bloco: todas as somas parciais são combinadas em um único valor, garantindo o cálculo preciso das estatísticas. Para sincronizar corretamente as threads, utiliza-se uma barreira de sincronização, assegurando que todas as threads tenham concluído seus cálculos antes que a execução prossiga.
mean = LocalSum(mean, 1, Temp); BarrierLoc; stdev = LocalSum(stdev, 1, Temp); //--- stdev -= mean * mean; stdev = IsNaNOrInf(sqrt(stdev), 1); if(stdev <= 0) stdev = 1;
Na etapa seguinte, calcula-se a variância subtraindo o quadrado da média da soma dos quadrados. Em seguida, extrai-se a raiz quadrada para obter o desvio padrão. É importante observar que, se o desvio padrão for zero, negativo ou inválido, ele é substituído por 1, evitando erros na normalização subsequente.
Na sequência, uma das threads locais grava a média e o desvio padrão calculados nos arrays de saída correspondentes, armazenando os resultados para cada segmento e variável.
if(i == 0) { int shift_ms = v * total_segments + s; means[shift_ms] = mean; stdevs[shift_ms] = stdev; }
Em seguida, é iniciado outro laço, no qual ocorre a normalização propriamente dita dos dados: subtrai-se a média de cada valor de entrada e divide-se o resultado pelo desvio padrão, com verificação obrigatória da validade do resultado. Os valores normalizados são gravados no buffer de saída, prontos para o processamento posterior.
for(uint l = 0; l < segment_size; l += total_local) { if((l + i) >= segment_size || (s * segment_size + l + i) >= total_inputs) break; if(l > 0) val = inputs[shift + l]; outputs[shift + l] = IsNaNOrInf((val - mean) / stdev, 0); } }
Esse kernel distribui a carga computacional de forma eficiente entre as threads, assegura o cálculo preciso das estatísticas considerando os pesos de atenção e normaliza corretamente os dados, algo especialmente importante ao lidar com séries temporais em tarefas de previsão e análise. Graças ao uso de memória local e sincronização, obtêm-se alto desempenho e estabilidade dos cálculos.
Além disso, é importante destacar uma das premissas centrais incorporadas à lógica de funcionamento desse kernel. Em particular, assume-se que o tamanho do grupo de trabalho local é igual ao tamanho do segmento analisado. Isso não é apenas uma igualdade formal, mas uma condição essencial que permite simplificar a lógica computacional e aumentar a eficiência da execução do código na GPU.
Quando essa condição é atendida, os laços destinados a percorrer iterativamente o segmento com incremento igual ao tamanho do grupo de trabalho local reduzem-se, na prática, a uma única iteração. Isso significa que cada thread processa exatamente um elemento de seu segmento, sem executar passagens repetidas. Essa abordagem reduz drasticamente a complexidade dos laços internos, simplifica a lógica e, o que é especialmente importante, minimiza o número de acessos à memória global.
Em vez de ler repetidamente os dados do buffer global, cada valor do segmento é salvo em uma variável privada da thread assim que possível e, em seguida, passa a ser acessado a partir do registrador. Isso já representa outro nível de desempenho: o acesso ao registrador ou à memória local é uma ordem de grandeza mais rápido do que o acesso à memória global, especialmente quando é necessário processar centenas ou milhares de segmentos paralelos em tempo real.
Assim, a proporção bem dimensionada entre o grupo de trabalho local e o segmento deixa de ser apenas um elemento de configuração e passa a atuar como um fator ativo de otimização. Ela permite explorar plenamente o potencial da aceleração por hardware, reduzindo a sobrecarga e aumentando a eficiência de todo o sistema de processamento de séries temporais.
Ainda assim, apesar de toda a elegância e eficiência da abordagem descrita, em condições reais não se pode depender exclusivamente de cenários ideais. Os recursos técnicos do hardware, infelizmente, nem sempre obedecem às nossas preferências. As plataformas de GPU diferem quanto à arquitetura, ao volume de memória disponível, às limitações de tamanho do grupo local e até às particularidades dos drivers. Tudo isso faz com que a igualdade estrita entre o tamanho do grupo de trabalho e o tamanho do segmento seja mais uma condição desejável do que garantida.
É justamente por isso que mantemos o laço no código, como um recurso para preservar a adaptabilidade e a portabilidade. Mesmo que ele seja executado apenas uma vez no caso ideal, continua sendo necessário nas situações em que o hardware não permite configurar um grupo de trabalho local com o tamanho necessário. Trata-se de uma espécie de salvaguarda: se o segmento for maior do que o grupo local disponível, o laço percorrerá o segmento por partes, de forma controlada, garantindo a correção dos cálculos em qualquer configuração de hardware.
Esse compromisso entre eficiência e flexibilidade permite preservar o desempenho quando isso é possível e, ao mesmo tempo, garantir o funcionamento correto mesmo em dispositivos menos potentes. No mundo das tarefas computacionais, assim como na vida, é sempre recomendável ter um plano B à mão, especialmente quando se lida com hardware pouco disposto a compromissos.
Concluída a descrição da propagação para frente, na qual cada elemento é normalizado com base na média e no desvio padrão de seu segmento, passamos a uma parte mais sutil e criticamente importante: o algoritmo da propagação reversa. Aqui, a simples retropropagação do erro não é suficiente. É necessário considerar que cada elemento do gradiente de saída influencia todos os elementos do segmento de entrada, pois tanto a média quanto a variância são calculadas sobre todo o conjunto de valores do segmento ao mesmo tempo. Isso impõe requisitos específicos à implementação.
Para deixar isso mais claro, vamos examinar brevemente a expressão que descreve a derivada do valor normalizado em relação à entrada.
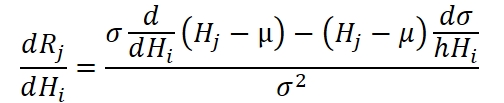
Ela contém duas parcelas: uma depende diretamente da derivada em relação ao valor de entrada, enquanto a outra depende da derivada em relação ao desvio padrão, que por sua vez depende de todos os valores do segmento. Isso significa que o cálculo do gradiente de um único elemento é impossível sem levar em conta a contribuição de todos os demais.
Formalmente, isso significa que cada gradiente de saída deve ser retroprojetado para todo o segmento, e não apenas sobre sua própria posição na entrada. Assim, para calcular corretamente o gradiente em relação a um elemento de entrada específico, é necessário percorrer todos os elementos de saída do segmento e somar suas contribuições, considerando como a média e o desvio padrão mudariam com a variação dessa entrada.
Um caso especialmente importante ocorre quando o índice do elemento de saída atual coincide com o índice do elemento de entrada para o qual estamos acumulando o gradiente. Nesse caso, a influência se propaga não apenas pela alteração das estatísticas, mas também diretamente, por meio da derivada da normalização do próprio valor. Se os índices forem diferentes, permanece apenas a influência indireta, determinada integralmente pela alteração da média e da variância.
Na implementação, isso significa que, para cada elemento de entrada, é necessário percorrer todos os gradientes de saída do segmento, acumulando a contribuição de cada um. Essa abordagem torna a estrutura do kernel mais complexa, mas permite obter uma correspondência exata com a formulação matemática. Isso é especialmente importante para que o treinamento do modelo de rede neural seja realizado de forma correta e eficiente.
Ao analisarmos o algoritmo do kernel AttentNormGrad, chegamos ao cerne do algoritmo de retropropagação do erro. É aqui que são calculados os gradientes em relação aos dados de entrada e aos coeficientes de atenção, levando em conta a dependência da saída normalizada em relação a todo o conjunto de valores do segmento.
__kernel void AttentNormGrad(__global const float* inputs, __global float* inputs_gr, __global const float* attention, __global float* attention_gr, __global const float* means, __global const float* stdevs, __global const float* means_gr, __global const float* outputs_gr, const int total_inputs, const int segment_size ) { const size_t i = get_global_id(0); // main const size_t loc = get_local_id(1); // local to sum const size_t v = get_global_id(2); // variable const size_t total_main = get_global_size(0); // total const size_t total_loc = get_local_size(1); // local dimension const size_t variables = get_global_size(2); // total variables
No início do kernel, são definidos os índices:
- i — identificador global do elemento atual,
- loc — índice local dentro do grupo de threads,
- v — número da variável com a qual estamos lidando.
__local float Temp[LOCAL_ARRAY_SIZE]; //--- Inputs gradient { const int s = i / segment_size; const int shift_in = v * total_inputs + i; const int shift_ms = v * segment_size + s; float grad = 0; if(loc == 0 && i < total_inputs) { Temp[0] = IsNaNOrInf(inputs[shift_in], 0); Temp[1] = IsNaNOrInf(means[shift_ms], 0); Temp[2] = IsNaNOrInf(stdevs[shift_ms], 1); Temp[3] = IsNaNOrInf(means_gr[shift_ms], 0); Temp[4] = IsNaNOrInf(attention[(v - s) * segment_size + i], 0); } BarrierLoc;
Em seguida, começa a primeira parte do kernel: o cálculo dos gradientes para os dados de entrada inputs. Aqui, determinamos a qual segmento pertence o elemento i, calculamos os deslocamentos necessários na memória e, se estivermos na primeira thread dentro do grupo de trabalho local (loc == 0), carregamos no buffer local os valores necessários: o próprio valor de entrada, a média, o desvio padrão, o gradiente da média e o coeficiente de atenção correspondente. Depois disso, usa-se uma barreira de sincronização, para que todas as threads aguardem o carregamento dos dados e possam trabalhar com eles com segurança.
Agora começa a etapa mais importante. Percorremos todo o segmento e analisamos a contribuição de cada saída normalizada para o gradiente do valor de entrada de interesse. Nesse processo, verificamos com atenção especial se as posições coincidem, isto é, se é o mesmo elemento para o qual calculamos o gradiente (same). Se as posições coincidirem, sua contribuição é calculada diretamente; caso contrário, apenas de forma indireta, por meio da alteração das estatísticas do segmento. Para isso, o cálculo leva em conta tanto o desvio do valor em relação à média quanto sua influência sobre o desvio padrão. Tudo isso é acumulado cuidadosamente na variável grad. Também consideramos o gradiente em relação à média, acumulado em outros fluxos de informação.
if(i < total_inputs) { float x = Temp[0]; float mean = Temp[1]; float stdev = Temp[2]; float mean_gr = Temp[3]; float att = Temp[4]; for(int l = 0; l < segment_size; l += total_loc) { if((l + loc) >= segment_size || (i * segment_size + loc + l) >= total_inputs) break; float out_gr = IsNaNOrInf(outputs_gr[v * total_inputs + s * segment_size + loc + l], 0); bool same = (i - s * segment_size) == (loc + l); float xl = x; if(!same) xl = IsNaNOrInf(inputs[v * total_inputs + s * segment_size + loc + l], 0); float dy = ((int)same - att) * (1 / stdev - (xl - mean) * att * x / pow(stdev, 3.0f)); float dmean = (same ? IsNaNOrInf(mean_gr * att, 0) : 0); grad += IsNaNOrInf(dy * out_gr + dmean, 0); } } grad = LocalSum(grad, 1, Temp); if(loc == 0 && i < total_inputs) inputs_gr[shift_in] = grad; BarrierLoc; }
Os resultados obtidos são somados localmente e gravados no buffer inputs_gr.
Concluído o cálculo dos gradientes em relação aos dados de entrada, passamos à segunda parte: o cálculo dos gradientes em relação aos coeficientes de atenção. A lógica é espelhada, mas o foco muda. Agora, para cada i, isto é, para cada elemento do segmento, percorremos todos os dados de entrada e avaliamos como a saída se altera quando o coeficiente de atenção é modificado. A estrutura permanece a mesma: cálculo do gradiente local, verificação das condições de coincidência, incorporação da contribuição decorrente da alteração do desvio padrão e da média. E, mais uma vez, soma local precisa e gravação do resultado em attention_gr.
//--- Attention gradient { float grad = 0; int shift_att = v * segment_size + i; if(i < segment_size) { float att = IsNaNOrInf(attention[shift_att], 0); for(int l = 0; l < total_inputs; l += total_loc) { if((l + loc) >= total_inputs) break; int shift_out = (l + loc) + v * total_inputs; int s = (l + loc) / segment_size; int shift_in = v * total_inputs + s * segment_size + i; float x = IsNaNOrInf(inputs[shift_in], 0); float out_gr = IsNaNOrInf(outputs_gr[shift_out], 0); float mean = means[v * segment_size + s]; float stdev = stdevs[v * segment_size + s]; float mean_gr = means_gr[v * segment_size + s]; bool same = (i - s * segment_size) == (loc + l); float xl = x; if(!same) xl = IsNaNOrInf(inputs[shift_out], 0); float dy = -x / stdev - (xl - mean) * x * x * (1 - 2 * att) / (2 * pow(stdev, 3.0f)); float dmean = IsNaNOrInf(mean_gr * x, 0); grad += IsNaNOrInf(dy * out_gr + dmean, 0); } } grad = LocalSum(grad, 1, Temp); if(loc == 0 && i < segment_size) attention_gr[shift_att] = grad; } }
Nosso kernel implementa a expressão do gradiente de acordo com a fórmula derivada anteriormente. O código como um todo não é apenas um conjunto de comandos, mas um sistema de estrutura refinada. Cada thread avalia cuidadosamente como a alteração de cada entrada individual ou coeficiente de atenção afeta as saídas de todo o grupo. Há otimização por meio de buffers locais, sincronização precisa e tratamento atento das condições de limite. É assim que se caracteriza uma verdadeira solução de engenharia: rigorosa, bem ajustada e, ao mesmo tempo, adaptável às capacidades do hardware e às particularidades da diferenciação numérica.
Analisamos em detalhes a implementação do componente central do framework SSCNN: o módulo de normalização com atenção no componente OpenCL do programa. Vimos como a teoria se transforma em um algoritmo funcional, capaz de levar em conta o peso de cada elemento e distribuir sua influência por toda a estrutura dos dados com precisão digna de uma engenharia de alto nível. Também vimos como é importante ajustar finamente a interação entre a memória local e a memória global, como é crítico levar em conta as particularidades da arquitetura do hardware e por que até mesmo uma operação de normalização formalmente simples se transforma em uma tarefa computacional completa em um ambiente paralelo.
No entanto, nosso caminho ainda não terminou. A normalização é apenas uma das partes do mecanismo multicomponente que sustenta todo o framework SSCNN. No próximo artigo, daremos continuidade ao desenvolvimento. A parte mais interessante está apenas começando.
Conclusão
Neste artigo, estudamos os aspectos teóricos do framework SSCNN, no qual se dá atenção especial à ideia de decomposição estrutural da série temporal e à extração de componentes por meio de normalização baseada no mecanismo de atenção. Os autores do framework propuseram uma arquitetura bem fundamentada, capaz de processar séries temporais de alta dimensionalidade com sobrecarga computacional mínima.
Na parte prática do artigo, examinamos em detalhes a implementação de um dos componentes-chave do framework: a camada T-AttnNorm. Dedicamos atenção especial às particularidades da propagação para frente e da propagação reversa, bem como à interação entre a memória global e a memória local. Identificamos nuances do comportamento do algoritmo em casos específicos e apresentamos comentários práticos sobre sua adaptação à arquitetura OpenCL.
Estabelecemos a base para a implementação do stack completo da SSCNN e criamos as condições necessárias para seu treinamento, confirmando a importância da acumulação precisa dos gradientes e do cálculo das derivadas. No próximo artigo, daremos continuidade a esse percurso.
Links
- Parsimony or Capability? Decomposition Delivers Both in Long-term Time Series Forecasting
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Study.mq5 | Expert Advisor | EA de treinamento offline de modelos |
| 2 | StudyOnline.mq5 | Expert Advisor | EA de treinamento online de modelos |
| 3 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 4 | Trajectory.mqh | Biblioteca de classes | Estrutura para descrever o estado do sistema e a arquitetura dos modelos |
| 5 | NeuroNet.mqh | Biblioteca de classes | Biblioteca de classes para criação de redes neurais |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/19069
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso