
Redes neurais em trading: modelo de difusão adaptativa em grafos (Conclusão)

Introdução
Hoje concluímos a implementação das abordagens propostas pelos autores do framework SAGDFN. Eles apresentaram uma das possíveis soluções para o problema mais crítico da previsão espaço-temporal: a complexidade cada vez maior do processamento de grafos grandes. Modelos tradicionais de redes neurais em grafos (GNN) sofrem com a redundância das conexões: quanto maior o número de nós, maior a probabilidade de que a informação relevante se perca em um fluxo de interações pouco significativas. Tentar processar todas as conexões indiscriminadamente leva ao crescimento quadrático da carga computacional e reduz a capacidade de generalização do modelo. Os autores do SAGDFN propuseram romper esse ciclo, concentrando-se apenas nas conexões realmente relevantes e eliminando o excesso ainda nas etapas iniciais do processamento dos dados.
O módulo Significant Neighbors Sampling (SNS) foi a primeira peça dessa arquitetura. Sua função é selecionar, para cada nó, um conjunto de vizinhos significativos que concentram o maior valor preditivo. Na abordagem clássica, os modelos em grafos usam todos os vizinhos indiscriminadamente ou ficam rigidamente limitados a uma estrutura fixa. SNS vai além: ele monta dinamicamente o conjunto de conexões, analisando tanto os candidatos mais próximos pela métrica de similaridade quanto elementos escolhidos aleatoriamente para preservar a diversificação. Isso não apenas reduz a dimensionalidade do grafo, mas também diminui o risco de sobreajuste, pois o modelo não fica preso a uma estrutura predefinida e aprende a construir de forma adaptativa o mapa de importância das conexões.
Depois que o esqueleto do grafo é montado, entra em cena o Sparse Spatial Multi-Head Attention (SSMHA), um mecanismo adaptativo de atenção que trabalha com a estrutura esparsa obtida na etapa anterior. Esse módulo exerce duas funções centrais ao mesmo tempo: redistribui os coeficientes de atenção entre os vizinhos e permite que cada nó considere diferentes aspectos do contexto por meio da atenção multicabeça. Diferentemente do SoftMax clássico, em que a soma de todos os pesos é sempre estritamente normalizada, no SAGDFN foi usado o α-Entmax, que permite zerar de forma mais rigorosa as conexões não essenciais. Quando α=1, essa função se reduz ao SoftMax comum; quando α=2, aproxima-se do Sparse-SoftMax, em que os elementos pouco relevantes são efetivamente excluídos dos cálculos. Isso dá flexibilidade ao modelo. Ele pode permanecer sensível a sinais fracos quando isso for importante. e, ao mesmo tempo, concentrar-se nos nós realmente significativos quando a densidade do grafo se torna excessiva.
Um elemento igualmente importante é o OneStepFastGConv, uma convolução em grafos otimizada que transforma os atributos espaciais em uma única etapa, evitando cascatas redundantes de operações. Em vez de aplicar sequencialmente várias camadas, cada uma responsável por uma pequena transformação, aqui usamos uma agregação em etapa única, o que acelera o treinamento e reduz os requisitos de memória. Essa abordagem é especialmente importante para tarefas em tempo real, nas quais cada milissegundo de processamento dos dados conta.
A operação conjunta desses módulos lembra uma orquestra bem coordenada: o SNS seleciona os músicos principais, o SSMHA distribui os papéis e as ênfases entre eles, e o FastGConv transforma essa cacofonia de sinais em uma melodia coerente de previsão. Além disso, todos os elementos foram concebidos desde o início para serem escaláveis, ou seja, capazes de operar de forma eficiente tanto com grafos relativamente compactos quanto com grandes estruturas, contendo milhares de nós e milhões de conexões potenciais.
A representação do framework SAGDFN proposta pelos autores é apresentada abaixo.

Nos artigos anteriores, examinamos passo a passo os principais blocos estruturais do framework, implementando os módulos Significant Neighbors Sampling e Sparse Spatial Multi-Head Attention em MQL5 e OpenCL. Nesse desenvolvimento, não nos limitamos a repetir literalmente o algoritmo original. Pelo contrário, introduzimos uma série de otimizações importantes, voltadas a aumentar a eficiência computacional e a estabilidade do modelo. Assim, em vez da função iterativa α-Entmax, que exige recursos consideráveis por causa da busca pelo parâmetro ótimo τ, aplicamos o Sparse-SoftMax, mais leve e estável. Isso permitiu preservar o conceito de filtragem seletiva dos elementos pouco relevantes e reduzir a carga computacional. Também aprimoramos a montagem das conexões no módulo de seleção de vizinhos. Implementamos a avaliação paralela dos candidatos previamente selecionados e dos candidatos aleatórios, o que aumentou a diversidade das conexões e reduziu a probabilidade de perda de informações potencialmente úteis.
Agora que os mecanismos de construção do grafo e de distribuição dos coeficientes entre seus nós estão ajustados, chegou o momento de avançar para o próximo passo lógico: a construção do módulo OneStepFastGConv. Esse componente exerce um papel especial na arquitetura SAGDFN, pois é ele que responde pela agregação das informações espaciais e pela geração dos atributos nos quais a previsão final será baseada.
Objeto recorrente de convolução em grafos
Seguindo a linha lógica do material anterior, em que já montamos o esqueleto do grafo com o Significant Neighbors Sampling e aprendemos a distribuir cuidadosamente os coeficientes entre as conexões-chave com o Sparse Spatial Multi-Head Attention, passamos agora ao núcleo do bloco recorrente: a convolução rápida em grafos. Esta não é nossa primeira incursão no universo dos módulos recorrentes em grafos. Na HimNet, usamos o GCRU, que se mostrou muito eficiente em estruturas densas. Mas, no SAGDFN, o cenário é diferente. Trabalhamos deliberadamente com uma matriz esparsa de interdependências, e é justamente essa esparsidade que impõe outra lógica algorítmica. Para não construir sobre uma base instável, começaremos pela operação fundamental sobre a qual o OneStepFastGConv será sustentado: a multiplicação eficiente de uma matriz esparsa por uma matriz densa.
Essa etapa é essencial, pois é ela que permitirá integrar de forma eficiente a estrutura esparsa de interdependências obtida anteriormente ao contexto geral do processamento dos dados. Para isso, criamos um kernel em OpenCL, responsável por executar essa operação da forma mais simples possível, mas com foco em desempenho e economia de memória.
__kernel void SparseMatMult(__global const float *sparse_index, __global const float *sparse_data, __global const float *full, __global float *result, const int full_rows ) { const size_t sparse_row = get_global_id(0); const size_t sparse_col = get_local_id(1); const size_t full_col = get_global_id(2); const size_t sparse_rows = get_global_size(0); const size_t sparse_cols = get_local_size(1); const size_t full_cols = get_global_size(2); //--- __local float Temp[LOCAL_ARRAY_SIZE];
No início da execução, o kernel determina as coordenadas da tarefa: os índices de linha e coluna da matriz esparsa, sendo estes últimos agrupados em grupos locais, assim como o índice da coluna da matriz densa. Esses parâmetros formam uma espécie de tripla de coordenadas, que permite a cada work-item saber exatamente por qual trecho dos dados ele é responsável. Em seguida, o kernel determina os tamanhos de todas as dimensões, necessários para endereçar corretamente os elementos.
Depois disso, alocamos o array local Temp, usado para sincronização e soma dos valores intermediários no grupo de trabalho.
Na etapa seguinte, cada work-item determina o deslocamento na memória para o elemento atual da matriz esparsa e extrai o índice da linha correspondente da matriz densa.
const int shift_sparse = RCtoFlat(sparse_row, sparse_col, sparse_rows, sparse_cols, 0); const int full_row = sparse_index[shift_sparse]; const int shift_full = RCtoFlat(full_row, full_col, full_rows, full_cols, 0);
Se esse índice estiver no intervalo válido, calculamos o produto entre o coeficiente da matriz esparsa e o elemento da matriz densa. Caso contrário, usamos o valor zero, o que evita operações incorretas.
float res = (full_row >= 0 && full_row < full_rows ? IsNaNOrInf(sparse_data[shift_sparse] * full[shift_full], 0) : 0); res = LocalSum(res, 1, Temp);
O produto parcial obtido passa para o procedimento local de soma, que acumula os resultados de todos os work-items do grupo de trabalho. Assim que a soma é concluída, o primeiro work-item de cada grupo, com índice local de coluna igual a zero, grava o valor final na matriz resultante. Com isso, alcançamos um equilíbrio entre o paralelismo dos cálculos e o controle da gravação dos dados, evitando conflitos de acesso.
if(sparse_col == 0) { const int shift_result = RCtoFlat(sparse_row, full_col, sparse_rows, full_cols, 0); result[shift_result] = res; } }
Essa abordagem garante o uso eficiente dos recursos da GPU. Cada work-item executa apenas a sua parte da operação, enquanto a soma coletiva assegura a precisão e a consistência do resultado final.
Depois de implementarmos a propagação para frente e aprendermos a acumular a contribuição dos vizinhos nos atributos resultantes, o próximo passo é a propagação reversa, ou seja, a distribuição correta do gradiente do erro por todos os elementos envolvidos. O algoritmo está implementado no kernel SparseMatMultGrad, que recebe como entrada:
- índices e coeficientes da matriz esparsa,
- buffer para os gradientes desses coeficientes,
- matriz densa e seu buffer de gradientes,
- array de gradientes do resultado,
- tamanhos de todas as dimensões.
__kernel void SparseMatMultGrad(__global const float *sparse_index, __global const float *sparse_data, __global float *sparse_gr, __global const float *full, __global float *full_gr, __global const float *result_gr, const int sparse_rows, const int sparse_cols, const int full_rows, const int full_cols ) { const size_t row_id = get_global_id(0); const size_t local_id = get_local_id(1); const size_t col_id = get_global_id(2); const size_t total_rows = get_global_size(0); const size_t total_local = get_local_size(1); const size_t total_cols = get_global_size(2); //--- __local float Temp[LOCAL_ARRAY_SIZE];
No corpo do kernel, cada work-item recebe suas coordenadas no espaço de tarefas:
- row_id: linha pela qual ocorre o processamento da matriz;
- local_id: identificador local do grupo;
- col_id: coluna da matriz.
Alocamos o buffer de memória local Temp para reduções e para a troca de pequenas porções de dados entre os work-items de um mesmo grupo de trabalho. Esse é o principal instrumento de coordenação: por meio dele, os work-items trocam resultados intermediários e se sincronizam.
Aqui, vale observar que, neste kernel, teremos de distribuir os gradientes do erro entre duas matrizes de tamanhos diferentes. Os identificadores de linha e coluna servem como referência justamente para a matriz que receberá os gradientes. Para isso, na chamada do kernel pela fila de comandos, planejamos usar as dimensões máximas das duas matrizes. Os work-items excedentes são filtrados no próprio kernel.
O primeiro bloco calcula os gradientes do erro em relação aos coeficientes da matriz esparsa. Primeiro, validamos o índice: se a posição atual estiver no intervalo permitido, o work-item calcula shift_sparse, o deslocamento plano nos arrays de índices e de dados da matriz esparsa.
//--- Calce sparse gradient if(row_id < sparse_rows && col_id < sparse_cols) { float grad = 0; int shift_sparse = 0; if(local_id == 0) { shift_sparse = RCtoFlat(row_id, col_id, sparse_rows, sparse_cols, 0); Temp[0] = sparse_index[shift_sparse]; } BarrierLoc; uint full_row = (uint)Temp[0];
O work-item com local_id igual a 0 lê o índice correspondente e o grava no primeiro elemento do buffer de memória local, para que os demais work-items possam usar esse valor sem acessos globais adicionais.
Depois da barreira, todos os work-items do grupo de trabalho conhecem o índice da linha da matriz densa.
Observe que é importante verificar se o índice de linha obtido é válido. Depois que ele passa pelo bloco de validação, cada work-item percorre suas posições na dimensão de atributos e acumula a contribuição do elemento.
if(full_row < (uint)full_rows) for(int i = local_id; i < full_cols; i += total_local) { int shift_result = RCtoFlat(row_id, i, sparse_rows, full_cols, 0); int shift_full = RCtoFlat(full_row, i, full_rows, full_cols, 0); grad += IsNaNOrInf(result_gr[shift_result] * full[shift_full], 0); }
Esse é um acúmulo escalar clássico por atributos: tomamos o gradiente do resultado para cada atributo e o multiplicamos pelo valor da célula correspondente da matriz densa, somando ao longo de todos os atributos.
Depois que a varredura local é concluída, executamos uma redução pelos work-items do grupo de trabalho para obter a contribuição total dessa par (row_id, col_id).
grad = LocalSum(grad, 1, Temp); if(local_id == 0) sparse_gr[shift_sparse] = grad; }
E apenas um work-item grava o resultado final do grupo de trabalho no elemento correspondente do buffer global sparse_gr.
Ao passar para a segunda grande parte, o cálculo do gradiente em relação à matriz densa, encontramos a tarefa inversa. Para cada elemento da matriz densa, é preciso acumular sua contribuição para o resultado do bloco. No entanto, aqui surge o problema da ausência de uma associação explícita com os elementos da matriz esparsa. Por isso, teremos de percorrer toda a matriz de índices da matriz esparsa em busca dos ponteiros necessários. É justamente essa tarefa que atribuiremos aos work-items do grupo local.
Primeiro, implementamos um laço para percorrer as linhas da matriz de índices dos gradientes do erro. Vale lembrar que o número de linhas no tensor dos gradientes do erro e na matriz esparsa é o mesmo.
//--- Calce full gradient if(row_id < full_rows && col_id < full_cols) { float grad = 0; for(int r = 0; r < sparse_rows; r ++) { float s = 0; for(int c = local_id; c < sparse_cols; c += total_local) { int shift_sparse = RCtoFlat(r, c, sparse_rows, sparse_cols, 0); if((int)sparse_index[shift_sparse] == (int)row_id) { s = sparse_data[shift_sparse]; break; } }
No laço, tentamos encontrar, entre os índices da matriz esparsa, um ponteiro para a linha atual da matriz densa. Para manter o paralelismo eficiente, cada work-item do grupo local percorre apenas uma parte das colunas da matriz esparsa e, ao encontrar a primeira correspondência, lê o coeficiente de atenção e interrompe a busca.
Vale lembrar que, durante a seleção dos vizinhos mais próximos, incorporamos um mecanismo de exclusão de duplicatas. Por isso, não esperamos que a mesma conexão apareça mais de uma vez em cada linha da matriz esparsa.
Em seguida, com LocalSum, reunimos as informações sobre os coeficientes de atenção de todos os work-items do grupo de trabalho.
s = LocalSum(s, 1, Temp); if(s != 0 && local_id == 0) { int shift_result = RCtoFlat(r, col_id, sparse_rows, full_cols, 0); grad += IsNaNOrInf(s * result_gr[shift_result], 0); } }
Se a soma for diferente de zero, o primeiro work-item do grupo de trabalho multiplica o coeficiente obtido pelo valor do elemento correspondente no buffer de gradientes do erro do bloco e acumula o resultado na variável grad.
Depois que todas as iterações do sistema de laços são concluídas e o gradiente total do erro é acumulado a partir de todos os elementos dependentes, o primeiro work-item do grupo de trabalho grava o valor acumulado no buffer global full_gr.
if(local_id == 0) { int shift_full = RCtoFlat(row_id, col_id, full_rows, full_cols, 0); full_gr[shift_full] = grad; } } }
Após concluir a preparação, passamos à implementação prática do bloco recorrente OneStepFastGConv no programa principal. Aqui, implementamos as abordagens propostas na classe CNeuronFastGConv, concebida como um contêiner compacto para todos os buffers intermediários e para a lógica do módulo. A estrutura da classe é apresentada abaixo.
class CNeuronFastGConv : public CNeuronBaseOCL { protected: CNeuronBaseOCL cInpAndHidden; CNeuronBaseOCL cNormAttention; CNeuronBaseOCL cInvDiag; CNeuronBaseOCL cAX; CNeuronBaseOCL cAXplusX; CNeuronBaseOCL cNormAXplusX; CNeuronConvOCL cZ_R; CNeuronBaseOCL cZ; CNeuronBaseOCL cR; CNeuronBaseOCL cCandidate; CNeuronConvOCL cHC; //--- virtual bool RandomWalk(CBufferFloat* data, CBufferFloat* normal, CBufferFloat* inv_diag, const int rows, const int cols ); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return false; }; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None ) override { return false; } //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronFastGConv(void) {}; ~CNeuronFastGConv(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint sparse_dimension, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool FeedForward(CNeuronBaseOCL *SourceData, CNeuronSNSMHAttention *SparseAttent); virtual bool CalcInputGradients(CNeuronBaseOCL *SourceData, CNeuronSNSMHAttention *SparseAttent); //--- virtual int Type(void) const { return defNeuronFastGConv; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; //--- virtual uint GetCount(void) const { return (uint)cInvDiag.Neurons(); } virtual uint GetSparseDimension(void) const { return (uint)cNormAttention.Neurons() / GetCount(); } virtual uint GetWindow(void) const { return (uint)Neurons() / GetCount(); } };
Na estrutura da nova classe, vemos uma quantidade bastante grande de objetos internos. No entanto, todos eles são declarados estaticamente, o que nos permite manter vazios o construtor e o destrutor da classe. Toda a lógica de configuração da arquitetura do objeto foi transferida para o método de inicialização Init.
bool CNeuronFastGConv::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint sparse_dimension, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, units * window, optimization_type, batch)) return false; activation = None;
A primeira linha do método passa o controle para a classe pai. Trata-se da vinculação básica da camada ao contexto OpenCL e da criação de todas as interfaces herdadas necessárias para o funcionamento do módulo no modelo. Se essa inicialização falhar, o restante do método deixa de fazer sentido; por isso, retornamos false imediatamente. Essa saída antecipada protege contra erros posteriores e alocações desnecessárias.
Logo depois, desativamos explicitamente a função de ativação. Isso é lógico: o próprio bloco controla as ativações em seus componentes, com sigmoides para os gates e tanh para os candidatos, de modo que uma ativação externa geral não é necessária aqui.
Em seguida, vem a inicialização dos componentes internos. O primeiro objeto é destinado à concatenação do estado oculto anterior com os dados de entrada.
int index = 0; if(!cInpAndHidden.Init(0, index, OpenCL, 2 * units * window, optimization, iBatch)) return false;
Na linha seguinte, criamos cNormAttention. Esse é o espaço para armazenar a matriz slim de atenção As após a normalização. Ela receberá os pesos do módulo Sparse Attention.
index++; if(!cNormAttention.Init(0, index, OpenCL, units * sparse_dimension, optimization, iBatch)) return false; index++; if(!cInvDiag.Init(0, index, OpenCL, units, optimization, iBatch)) return false;
Passamos para cInvDiag, um vetor de inversos da diagonal, que multiplicará as linhas do resultado da difusão durante a normalização.
Em seguida, criamos cAX. Esse buffer armazena o resultado da SpMM. Seu tamanho é definido a partir de cInpAndHidden, o que garante compatibilidade dimensional com as etapas seguintes.
index++; if(!cAX.Init(0, index, OpenCL, cInpAndHidden.Neurons(), optimization, iBatch)) return false; index++; if(!cAXplusX.Init(0, index, OpenCL, cInpAndHidden.Neurons(), optimization, iBatch)) return false; index++; if(!cNormAXplusX.Init(0, index, OpenCL, cInpAndHidden.Neurons(), optimization, iBatch)) return false;
Depois de cAX, vem cAXplusX, o buffer para a soma AX + X. Aqui, salvamos explicitamente o resultado intermediário antes de aplicar a inversão da diagonal. Esse buffer explícito facilita a depuração e dá controle sobre a ordem das operações.
Em seguida, criamos cNormAXplusX, o tensor normalizado final (D+I)-1(AX + X). Ele é passado adiante para o bloco semelhante a GRU. Sem ele, a mecânica dos update gates se rompe; portanto, a verificação aqui também é crítica.
Depois, inicializamos cZ_R. Trata-se de uma camada convolucional compacta, que formará simultaneamente os logits dos gates Z e R. Como função de ativação, usamos aqui a sigmoide. Essa solução é simples e confiável: os gates permanecem sempre no intervalo [0,1].
index++; if(!cZ_R.Init(0, index, OpenCL, 2 * window, 2 * window, 2 * window, units, 1, optimization, iBatch)) return false; cZ_R.SetActivationFunction(SIGMOID); index++; if(!cZ.Init(0, index, OpenCL, window * units, optimization, iBatch)) return false; index++; if(!cR.Init(0, index, OpenCL, window * units, optimization, iBatch)) return false;
Os dois buffers seguintes, cZ e cR, são criados para separar os valores dos gates. A presença de buffers separados simplifica a lógica passo a passo de atualização do estado oculto.
A inicialização de cCandidate cria o buffer para a entrada concatenada intermediária do bloco de candidatos.
index++; if(!cCandidate.Init(0, index, OpenCL, 2 * window * units, optimization, iBatch)) return false; index++; if(!cHC.Init(0, index, OpenCL, 2 * window, 2 * window, window, units, 1, optimization, iBatch)) return false; cHC.SetActivationFunction(TANH); //--- return true; }
O bloco cHC corresponde ao cálculo propriamente dito do Candidate Hidden State. Usar TANH como função de ativação nesse bloco é um padrão que mantém os candidatos limitados e estáveis em escala.
Quando todas as chamadas do método Init são executadas com sucesso, retornamos true no final, sinalizando que a camada foi configurada e está pronta para operação.
Passamos então da inicialização para a execução. Agora que tudo está alocado e configurado, o método FeedForward representa o fluxo vivo dos dados pelo OneStepFastGConv.
bool CNeuronFastGConv::FeedForward(CNeuronBaseOCL *SourceData, CNeuronSNSMHAttention *SparseAttent) { if(!SourceData || !SparseAttent) return false; //--- const uint units = GetCount(); const uint window = GetWindow(); const uint sparse = GetSparseDimension();
Primeiro, o método verifica as entradas e a validade dos ponteiros recebidos para os objetos dos dados de entrada. Essa é uma proteção simples, mas necessária: sem uma fonte de dados ou sem o módulo de atenção esparsa, não é possível continuar. Essa saída antecipada evita falhas não controladas e fornece um diagnóstico previsível.
Em seguida, extraímos os parâmetros de configuração da camada. É muito conveniente manter essas variáveis localmente: ler esses valores por meio dos métodos da classe em um laço quente é mais lento e menos claro.
A linha seguinte executa RandomWalk. Trata-se do pré-processamento da matriz de atenção. RandomWalk coleta estatísticas por linha da matriz slim e executa uma normalização suave. Depois disso, grava cNormAttention (N×M) e cInvDiag (N), os inversos das diagonais para a normalização subsequente. Aqui, é importante notar que RandomWalk opera em modo paralelo na GPU, somando cuidadosamente ao longo de M e retornando inv_diag estáveis. Se essa etapa falhar, é melhor interromper a execução, pois todas as normalizações seguintes dependem dela.
if(!RandomWalk(SparseAttent.getOutput(), cNormAttention.getOutput(), cInvDiag.getOutput(), window, sparse)) return false; if(!SwapOutputs()) return false; if(!Concat(SourceData.getOutput(), PrevOutput, cInpAndHidden.getOutput(), window, window, units)) return false;
Depois disso, executamos SwapOutputs. Esse é um mecanismo interno da camada que troca os ponteiros entre a saída anterior e a saída atual, funcionando como um buffer rotativo. O swap garante que PrevOutput contenha Ht-1, enquanto o Output atual fica livre para gravação.
Em seguida, montamos a entrada para SpMM/GRU. Aqui ocorre a concatenação ao longo da dimensão de canais: para cada linha, formamos um vetor que combina o fragmento observado atual Xt e o estado oculto anterior Ht-1.
Após concluir a preparação, executamos a operação central: a multiplicação da matriz esparsa de atenção pela matriz densa previamente preparada, formada pela concatenação dos dados de entrada com o estado oculto.
if(!SparseMatMul(SparseAttent.GetIndexes(), cNormAttention.getOutput(), cInpAndHidden.getOutput(), cAX.getOutput(), units, sparse, units, 2 * window)) return false; if(!SumAndNormilize(cAX.getOutput(), cInpAndHidden.getOutput(), cAXplusX.getOutput(), 2 * window, false, 0, 0, 0, 1)) return false;
Depois, é feita a soma com Self-Loop. Aqui somamos AX + X.
O próximo passo é aplicar a normalização diagonal.
if(!DiagMatMul(cInvDiag.getOutput(), cAXplusX.getOutput(), cNormAXplusX.getOutput(), units, 2 * window, 1, None)) return false;
Trata-se de uma multiplicação simples, canal a canal, das linhas pelo inv_diag calculado previamente.
Em seguida, calculamos os logits dos gates. A camada convolucional cZ_R recebe os atributos agregados normalizados e retorna um vetor de dimensão 2×hidden, com os logits para Z e R. Como a ativação SIGMOID foi configurada na etapa de inicialização, o resultado dessa operação fica no intervalo [0,1].
if(!cZ_R.FeedForward(cNormAXplusX.AsObject())) return false; if(!DeConcat(cZ.getOutput(), cR.getOutput(), cZ_R.getOutput(), window, window, units)) return false;
Depois, separamos os logits obtidos em buffers individuais.
Logo em seguida, vem a multiplicação elemento a elemento do Reset gate pelo estado oculto anterior. Aqui, formamos R⊙Ht-1. O resultado é usado adiante como uma versão modificada do estado oculto para a geração dos candidatos.
if(!ElementMult(cR.getOutput(), PrevOutput, cR.getPrevOutput())) return false;
Em seguida, formamos a entrada dos candidatos, concatenando R⊙Ht-1 com o Xt atual.
if(!Concat(SourceData.getOutput(), cR.getPrevOutput(), cCandidate.getOutput(), window, window, units)) return false; if(!cHC.FeedForward(cCandidate.AsObject())) return false; if(!GateElementMult(PrevOutput, cHC.getOutput(), cZ.getOutput(), Output)) return false; //--- return true; }
A chamada do método de propagação para frente da camada convolucional cHC executa a transformação não linear e aplica tanh, retornando o estado oculto candidato. Por fim, a composição final gera o novo estado oculto.
Da descrição da propagação para frente, passamos à etapa reversa: agora precisamos entender como os gradientes se propagam por todos os elos do OneStepFastGConv. Essa lógica está implementada no método CalcInputGradients.
bool CNeuronFastGConv::CalcInputGradients(CNeuronBaseOCL *SourceData, CNeuronSNSMHAttention *SparseAttent) { if(!SourceData || !SparseAttent) return false; //--- const uint units = GetCount(); const uint window = GetWindow(); const uint sparse = GetSparseDimension();
Logo no início, o método se protege: se não houver ponteiros válidos para os objetos de dados de entrada, não há nada a executar. Nesse caso, encerramos corretamente a operação com o resultado false. É uma verificação simples, mas necessária: é melhor interromper a passagem de treinamento em uma etapa inicial do que encontrar NaNs difíceis de explicar mais adiante.
Em seguida, extraímos os parâmetros de configuração. Esses números definem a forma de todos os tensores de gradiente e são necessários para o endereçamento correto.
A primeira chamada real é GateElementMultGrad. Ela desfaz a composição final Ht = Z⊙Ht-1+(1−Z)⊙H̃.
if(!GateElementMultGrad(PrevOutput, cInpAndHidden.getGradient(), cHC.getOutput(), cHC.getGradient(), cZ.getOutput(), cZ.getGradient(), Gradient, None, cHC.Activation(), cZ_R.Activation())) return false;
A função calcula três coisas ao mesmo tempo: o gradiente em relação a H̃, os candidatos, em relação a Z, o Update gate, e em relação a Ht-1, o estado oculto anterior, decompondo o gradiente total em seus componentes.
Depois disso, propagamos o gradiente do erro pela camada convolucional que forma os candidatos.
if(!cCandidate.CalcHiddenGradients(cHC.AsObject())) return false; if(!DeConcat(SourceData.getGradient(), cR.getPrevOutput(), cCandidate.getGradient(), window, window, units)) return false;
Em seguida, separamos os gradientes obtidos em duas partes: a influência dos dados de entrada e a de R⊙Ht-1.
Depois, ElementMultGrad distribui a contribuição do Reset gate e do estado oculto anterior.
if(!ElementMultGrad(cR.getOutput(), cR.getGradient(), PrevOutput, cInpAndHidden.getGradient(), cR.getPrevOutput(), cZ_R.Activation(), None)) return false;
O próximo passo é reagrupar os gradientes locais Z e R em um vetor plano de logits, que passamos para cZ_R na propagação reversa da camada.
if(!Concat(cZ.getGradient(), cR.getGradient(), cZ_R.getGradient(), window, window, units)) return false; if(!cNormAXplusX.CalcHiddenGradients(cZ_R.AsObject())) return false; if(!DiagMatMulGrad(cInvDiag.getOutput(), cInvDiag.getGradient(), cAXplusX.getOutput(), cAX.getGradient(), cNormAXplusX.getGradient(), units, 2 * window, 1)) return false; if(!SparseMatMulGrad(SparseAttent.GetIndexes(), cNormAttention.getOutput(), cNormAttention.getGradient(), cInpAndHidden.getOutput(), cInpAndHidden.getGradient(), cAX.getGradient(), units, sparse, units, 2 * window)) return false;
Em seguida, executamos a propagação reversa pela camada convolucional que forma os logits dos gates. Como resultado, obtemos o gradiente em relação a cNormAXplusX, isto é, em relação à entrada agregada normalizada.
Depois, vem uma sequência de iterações para distribuir os gradientes do erro entre o tensor concatenado dos dados de entrada e os coeficientes de atenção normalizados. Primeiro, propagamos o gradiente pela normalização diagonal. Em seguida, desfazemos a SpMM e distribuímos os gradientes entre os coeficientes de atenção normalizados e os atributos concatenados.
É importante observar que, depois da execução de SparseMatMulGrad, precisamos somar o gradiente do erro do tensor concatenado de atributos vindo de dois fluxos de informação.
if(!SumAndNormilize(cAX.getGradient(), cInpAndHidden.getGradient(), cInpAndHidden.getGradient(), 2 * window, false, 0, 0, 0, 1)) return false;
Em seguida, precisamos reagrupar os gradientes do erro no nível dos dados de entrada. Aqui, vale lembrar que usamos os dados de entrada em dois fluxos de informação: na concatenação primária dos atributos e na concatenação do tensor para os candidatos. Já propagamos o gradiente do erro pelo segundo fluxo de informação. Agora, precisamos extrair os valores desse segundo fluxo e somá-los aos valores obtidos anteriormente.
if(!DeConcat(cAXplusX.getGradient(), cAXplusX.getPrevOutput(), cInpAndHidden.getGradient(), window, window, units)) return false; if(!SumAndNormilize(SourceData.getGradient(), cAXplusX.getGradient(), SourceData.getGradient(), window, false, 0, 0, 0, 1)) return false; if(SourceData.Activation() != None) if(!DeActivation(SourceData.getOutput(), SourceData.getGradient(), SourceData.getGradient(), SourceData.Activation())) return false;
Também não podemos esquecer de verificar se há uma função de ativação aplicada ao tensor dos dados de entrada. Se necessário, corrigimos os valores obtidos pela sua derivada.
O último passo relevante é transferir o gradiente do erro da matriz de atenção normalizada cNormAttention para seu estado inicial SparseAttent. Na propagação para frente, aplicamos a normalização; agora, propagamos os gradientes por essa etapa diagonal até a forma esperada pelo módulo SparseAttent.
if(!DiagMatMul(cInvDiag.getOutput(), cNormAttention.getGradient(), SparseAttent.getGradient(), units, sparse, 1, None)) return false; //--- return true; }
No final, o método retorna true, indicando que todos os gradientes percorreram corretamente o caminho reverso e foram acumulados nas entradas e nos parâmetros internos correspondentes.
Com isso, concluímos a análise dos algoritmos de implementação dos métodos da classe CNeuronFastGConv. O código completo desse objeto e de todos os seus métodos é apresentado no anexo.
Objeto SAGDFN de alto nível
Depois de construir o objeto de um bloco recorrente, passamos ao nível superior: o wrapper que conecta o codificador e o decodificador em um único sistema. A classe CNeuronSAGDFN não é apenas um contêiner: ela estrutura o fluxo de dados, controla o uso compartilhado da mesma matriz slim de adjacência e garante a consistência das transformações temporais e espaciais em todo o modelo.
class CNeuronSAGDFN : public CNeuronTransposeOCL { protected: CNeuronTransposeOCL cTranspose; CLayer cEmbedding; CNeuronSNSMHAttention cAttention; CLayer cGCRU; CLayer cProjection; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSAGDFN(void) {}; ~CNeuronSAGDFN(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint time_steps, uint variables, uint embedding_dim, uint emb_layers, uint sparse_dimension, uint heads, float sparse, uint gcru_layers, uint forecast, uint forec_layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronSAGDFN; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override {}; };
Ao implementar a lógica da classe CNeuronSAGDFN, é importante observar que o framework SAGDFN se baseia na identificação de dependências espaciais-chave, analisando correlações entre sequências unitárias de uma série temporal multimodal. Nós, porém, normalmente trabalhamos com sequências temporais. Por isso, no objeto, implementamos a transposição do tensor dos dados de entrada e a transposição inversa do tensor de resultados.
Para executar a primeira operação, declaramos o objeto interno correspondente; já a última operação será executada por meio da classe pai CNeuronTransposeOCL. Essa solução simplifica a preparação dos dados antes de passá-los para o módulo e facilita a integração do modelo ao pipeline existente.
Além disso, previmos a possibilidade de alterar dinamicamente a arquitetura do objeto. Para isso, foram incluídos três arrays dinâmicos:
- cEmbedding: mini-modelo que gera embeddings de tamanho definido a partir dos dados de entrada;
- cGCRU: conjunto sequencial de GCRU (Graph-Convolutional Recurrent Unit), que agrega uma sequência de blocos OneStepFastGConv;
- cProjection: bloco de projeção que, no decodificador, transforma as representações ocultas em previsões-alvo.
Essa abordagem permite aumentar de forma flexível a profundidade da pilha recorrente e experimentar diferentes números de passos de difusão. O CNeuronSAGDFN conecta a transposição das entradas, o embedding, o Attention compartilhado e a pilha GCRU em uma única arquitetura Codificador-Decodificador. Ele gerencia a reutilização da mesma matriz slim de adjacência ao longo de toda a pilha, garante a compatibilidade dos formatos de dados e atua como o orquestrador central durante o treinamento.
A construção direta da arquitetura do novo objeto é feita no método Init.
bool CNeuronSAGDFN::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint time_steps, uint variables, uint embedding_dim, uint emb_layers, uint sparse_dimension, uint heads, float sparse, uint gcru_layers, uint forecast, uint forec_layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(emb_layers <= 0 || gcru_layers <= 0 || forec_layers <= 0) return false;
No corpo do método, primeiro é executada uma validação simples dos parâmetros recebidos: se o número de camadas de qualquer um dos blocos for igual a zero, a inicialização é interrompida imediatamente. É uma verificação direta e útil: melhor rejeitar os dados de entrada do que continuar montando uma estrutura incorreta.
Em seguida, o controle é passado para o método homônimo da classe pai, que define a forma geral do neurônio e reserva os recursos básicos. Se essa etapa falhar, também retornamos false de forma segura, pois todo o restante depende de um contexto básico correto.
if(!CNeuronTransposeOCL::Init(numOutputs, myIndex, open_cl, variables, forecast, optimization_type, batch)) return false;
Depois, inicializamos o objeto de transposição do tensor dos dados de entrada para o formato esperado.
uint index = 0; if(!cTranspose.Init(0, index, OpenCL, time_steps, variables, optimization, iBatch)) return false;
Em seguida, começamos a montar o mini-modelo de embedding. Limpamos o contêiner e vinculamos o contexto OpenCL. O primeiro bloco convolucional ajusta a dimensionalidade dos dados ao nível definido. Adicionamos esse bloco ao contêiner cEmbedding e atribuímos a ele SoftPlus como função de ativação.
//--- Embedding cEmbedding.Clear(); cEmbedding.SetOpenCL(OpenCL); index++; CNeuronConvOCL *conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, index, OpenCL, time_steps, time_steps, embedding_dim, variables, 1, optimization, iBatch) || !cEmbedding.Add(conv)) { DeleteObj(conv); return false; } conv.SetActivationFunction(SoftPlus); for(uint i = 1; i < emb_layers; i++) { index++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, index, OpenCL, embedding_dim, embedding_dim, embedding_dim, variables, 1, optimization, iBatch) || !cEmbedding.Add(conv)) { DeleteObj(conv); return false; } conv.SetActivationFunction(SoftPlus); }
Depois, no laço por emb_layers, adicionamos camadas convolucionais adicionais com ativação SoftPlus. Isso cria uma pilha profunda de embedding com a mesma largura de canais.
Após as convoluções, adicionamos BatchNorm, um objeto separado que normaliza a saída da última camada convolucional.
CNeuronBatchNormOCL *norm = new CNeuronBatchNormOCL(); index++; if(!norm || !norm.Init(0, index, OpenCL, conv.Neurons(), iBatch, optimization) || !cEmbedding.Add(norm)) { DeleteObj(norm); return false; } norm.SetActivationFunction(None);
Em seguida, preparamos os blocos GCRU. Limpamos o contêiner cGCRU, vinculamos OpenCL e inicializamos imediatamente cAttention.
//--- GCRUs cGCRU.Clear(); cGCRU.SetOpenCL(OpenCL); index++; if(!cAttention.Init(0, index, OpenCL, variables, embedding_dim, heads, sparse_dimension, sparse, optimization, iBatch)) return false;
Observe que cAttention é inicializado antes da criação dos objetos gcru. Isso é intencional e correto, porque todos os GCRU lerão a mesma matriz slim de adjacência. Se a inicialização de attention falhar, interrompemos a execução e sinalizamos o problema.
Depois, no laço, criamos o número necessário de CNeuronFastGConv. Se algum gcru não for criado, nós o excluímos e retornamos false. Assim, é formada a pilha de blocos recorrentes em grafos, e todos eles operarão em conjunto sobre a matriz criada por cAttention.
CNeuronFastGConv *gcru = NULL; for(uint i = 0; i < gcru_layers; i++) { index++; gcru = new CNeuronFastGConv(); if(!gcru || !gcru.Init(0, index, OpenCL, variables, embedding_dim, sparse_dimension, optimization, iBatch) || !cGCRU.Add(gcru)) { DeleteObj(gcru); return false; } }
Depois disso, construímos o bloco de projeção cProjection. A primeira camada convolucional transforma os dados da dimensionalidade do embedding para o espaço de previsão forecast de cada variável.
//--- Forecast cProjection.Clear(); cProjection.SetOpenCL(OpenCL); index++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, index, OpenCL, embedding_dim, embedding_dim, forecast, variables, 1, optimization, iBatch) || !cProjection.Add(conv)) { DeleteObj(conv); return false; } conv.SetActivationFunction(SoftPlus); for(uint i = 1; i < forec_layers; i++) { index++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, index, OpenCL, forecast, forecast, forecast, variables, 1, optimization, iBatch) || !cProjection.Add(conv)) { DeleteObj(conv); return false; } conv.SetActivationFunction(SoftPlus); } norm = new CNeuronBatchNormOCL(); index++; if(!norm || !norm.Init(0, index, OpenCL, conv.Neurons(), iBatch, optimization) || !cProjection.Add(norm)) { DeleteObj(norm); return false; } norm.SetActivationFunction(None); //--- return true; }
Em seguida, no laço, adicionamos camadas convolucionais adicionais. No final do mini-modelo, adicionamos BatchNorm sem ativação externa, como fizemos na pilha de embeddings. Se todas as inclusões forem concluídas com sucesso, Init retorna true, e a arquitetura está montada.
Passando naturalmente da estrutura das camadas para sua execução, vamos percorrer o método feedForward e ver o que acontece em runtime: quais buffers são movimentados, quais verificações evitam falhas e onde estão os pontos mais sensíveis.
bool CNeuronSAGDFN::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cTranspose.FeedForward(NeuronOCL)) return false;
O método começa pela transposição dos dados de entrada. Esse é o momento em que passamos da representação da série temporal multimodal para um conjunto de sequências unitárias. Se a operação falhar, o restante do pipeline deixa de fazer sentido, então saímos de forma segura.
Depois disso, criamos variáveis locais com ponteiros para os objetos internos. É uma operação simples, mas essencial, que permite reutilizar o mesmo bloco de código com objetos diferentes.
CNeuronBaseOCL *inputs = cTranspose.AsObject();
CNeuronBaseOCL *current = NULL;
Primeiro, executamos o embedding. Iteramos por todos os componentes do contêiner cEmbedding em um laço. A cada iteração, obtemos a próxima camada na variável current e chamamos de forma segura seu método de propagação para frente. Isso significa que cada elo do embedding transforma sequencialmente os dados de entrada e entrega o resultado ao próximo.
//--- Embedding for(int i = 0; i < cEmbedding.Total(); i++) { current = cEmbedding[i]; if(!current || !current.FeedForward(inputs)) return false; inputs = current; }
Após a execução bem-sucedida, alteramos o ponteiro na variável inputs, ou seja, transferimos o papel de dados de entrada para o resultado recém-obtido. Em seguida, passamos para a próxima iteração do laço.
No final, depois que todas as iterações do laço são concluídas, o ponteiro na variável inputs referencia a última camada do embedding: a representação densa pronta da janela temporal analisada.
Próxima etapa: a pilha GCRU. Primeiro, formamos a matriz slim As, com índices e coeficientes, com base nas representações atuais. Se attention falhar, é melhor interromper a execução e não prosseguir.
//--- GCRUs if(!cAttention.FeedForward(inputs)) return false; CNeuronFastGConv *gcru = NULL; for(int i = 0; i < cGCRU.Total(); i++) { gcru = cGCRU[i]; if(!gcru || !gcru.FeedForward(inputs, cAttention.AsObject())) return false; inputs = gcru; }
Depois, no laço sobre o contêiner cGCRU, pegamos cada elemento em sequência e executamos seu método de propagação para frente.
Observe que, neste caso, são passados dois argumentos: o tensor atual e uma referência ao objeto attention, de onde o GCRU obterá os índices e coeficientes de As. Depois de cada etapa bem-sucedida, atualizamos novamente o ponteiro na variável local dos dados de entrada e passamos para a próxima iteração.
Como resultado, a pilha GCRU opera sequencialmente: cada bloco lê a mesma matriz slim, mas a aplica ao seu próprio estado e retorna uma representação oculta atualizada.
Quando a pilha de blocos recorrentes termina sua execução, passamos ao bloco de projeção da previsão. O laço sobre o contêiner cProjection repete a mesma lógica: pegamos a próxima camada de projeção e chamamos seu método de propagação para frente, atualizando em seguida o ponteiro para o objeto dos dados de entrada.
//--- Forecast for(int i = 0; i < cProjection.Total(); i++) { current = cProjection[i]; if(!current || !current.FeedForward(inputs)) return false; inputs = current; } //--- result return CNeuronTransposeOCL::feedforward(inputs); }
Conceitualmente, isso transforma a representação oculta na forma final da previsão para cada variável.
Por fim, retornamos os dados ao formato original por meio da classe pai. Trata-se da transposição inversa: agora as previsões voltam ao formato esperado pelo restante do sistema. Se a última etapa for bem-sucedida, o método retornará true, e toda a cadeia da propagação para frente será concluída corretamente.
O método feedForward é implementado de forma linear e transparente: os dados passam pela transposição, depois pela pilha de embedding, recebem a matriz slim de atenção compartilhada, são processados sequencialmente pelos blocos GCRU, projetados na previsão e retornados ao formato original. Esse fluxo é fácil de depurar e expandir, desde que se mantenha o cuidado com os ponteiros e com a eficiência das transformações intermediárias.
Os métodos de propagação reversa são construídos de forma análoga. Portanto, proponho não nos determos em sua análise detalhada. O código completo da classe CNeuronSAGDFN e de todos os seus métodos é apresentado no anexo e está disponível para estudo independente.
Testes
O treinamento do modelo lembra uma expedição bem planejada: antes de sair para o mar aberto do mercado real, treinamos com cuidado no porto tranquilo do histórico. Essa primeira etapa, offline, foi construída com dados do par de moedas EURUSD no timeframe H1 ao longo de todo o ano de 2024, um período rico em contrastes. Nele houve águas calmas, quase espelhadas, de mercados laterais, tempestades de movimentos tendenciais bruscos e rajadas inesperadas de volatilidade provocada por notícias. Essa variedade de cenários de mercado permitiu que o modelo desenvolvesse uma navegação mais robusta, aprendendo a reconhecer tanto padrões comuns quanto formações raras do movimento dos preços, sem perder a orientação mesmo em condições difíceis.
Quando essa preparação foi concluída, chegou o momento de sair da doca de treinamento e testar a embarcação nas correntes do mercado real. A segunda etapa, o ajuste online, foi realizada em condições operacionais no testador de estratégias do MetaTrader 5. Nela, os dados chegavam sequencialmente, vela a vela, e o modelo aprendia não apenas a analisar informações em fluxo, mas também a preservar a estabilidade nos redemoinhos do ruído, nos baixios instáveis da baixa liquidez e durante rajadas inesperadas de notícias. Essa etapa cumpriu o papel de um ajuste fino: não quebrou a estrutura já construída, mas ajudou a poli-la para a realidade, aumentando a adaptabilidade e reduzindo o risco de sobreajuste.
A verificação final foi um verdadeiro batismo de fogo. Usamos dados de janeiro de 2025, completamente novos, não utilizados nos experimentos anteriores, e carregamos todos os parâmetros previamente obtidos sem qualquer alteração. Esse foi um ponto fundamental: sem ajuste aos dados de teste, sem correções adicionais, apenas um teste limpo, capaz de refletir a real capacidade de generalização do modelo.
Os resultados dos testes são apresentados abaixo.
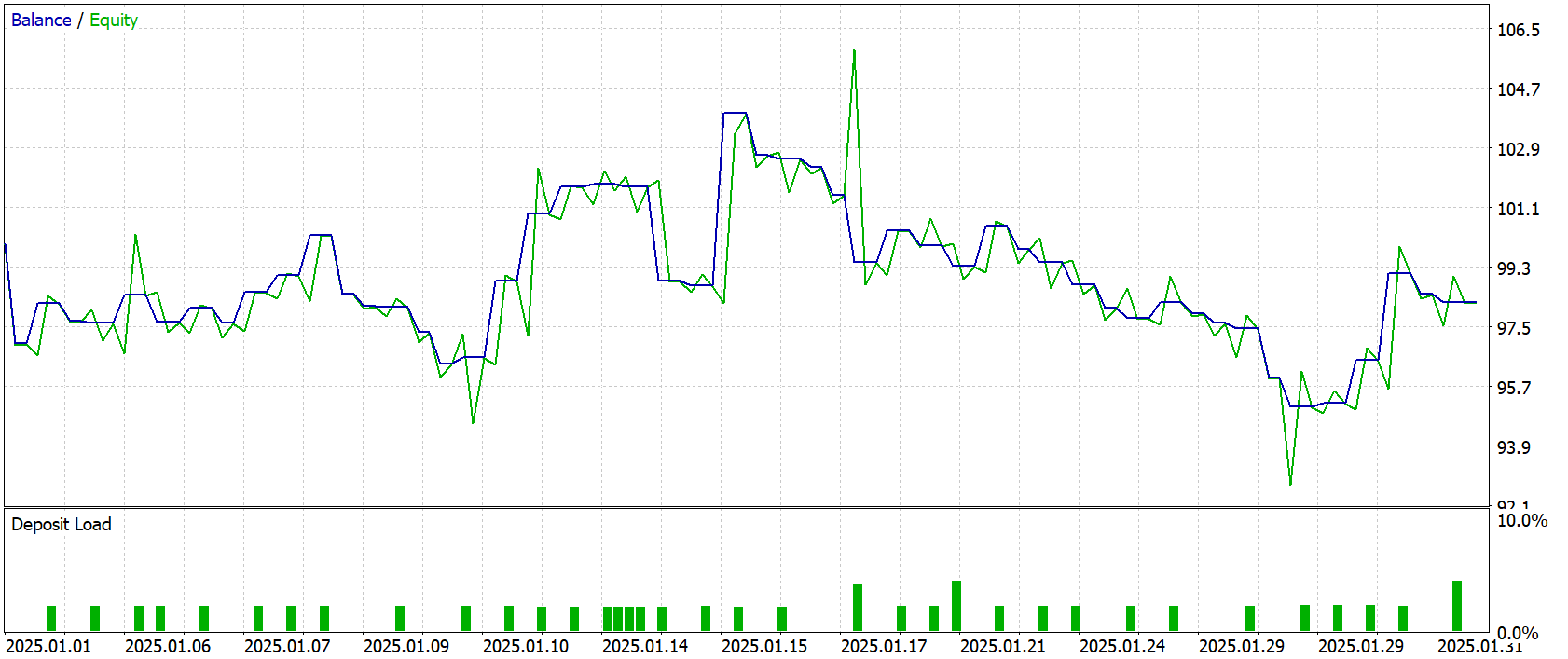
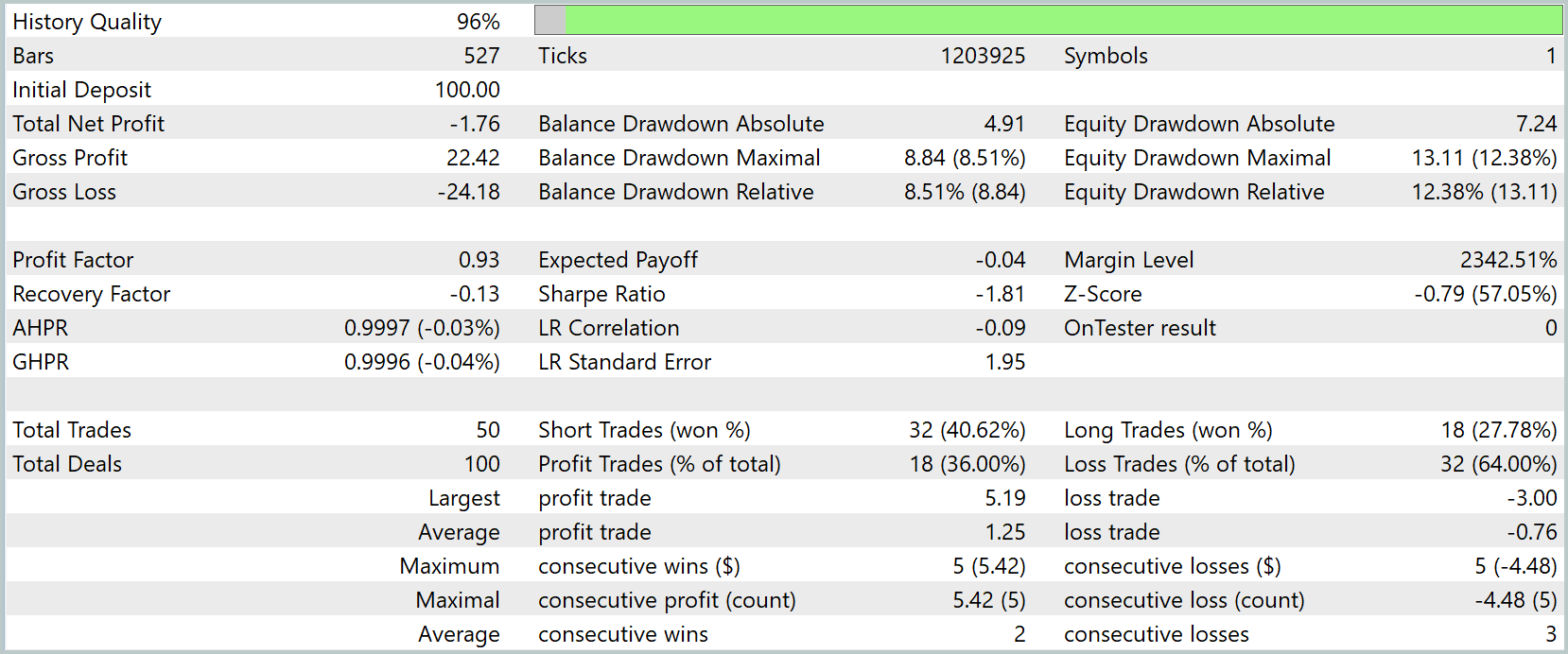
Os resultados dos testes mostraram que o modelo se comportou de forma contida e bastante previsível. Ainda assim, a rentabilidade final foi negativa: -1,76 USD sobre um depósito inicial de 100,0 USD. O lucro total foi de 22,42 USD, mas as perdas o superaram, chegando a 24,18 USD. Isso também se refletiu nas principais métricas: o fator de lucro ficou em 0,93, indicando uma leve predominância de operações perdedoras. O fator de recuperação também entrou em território negativo, alcançando -0,13.
Pela distribuição das operações, vemos que o modelo abriu 50 ordens, das quais 32 foram posições vendidas, com taxa de acerto de cerca de 40%, enquanto as operações compradas foram apenas 18, com sucesso pouco abaixo de 28%. Houve 18 operações lucrativas, ou seja, 36% do total, enquanto o prejuízo foi registrado em 32 operações. A maior sequência de lucro foi relativamente modesta: cinco operações consecutivas, que geraram um ganho de cerca de 5,42 USD. A sequência de perdas também chegou a cinco operações, com rebaixamento de -4,48 USD.
O gráfico de balanço e equity mostra que a estratégia se comportou de forma ondulada, com períodos de crescimento moderado seguidos por quedas, sem colapsos bruscos, mas também sem uma tendência ascendente sustentável. Depois da adaptação inicial, houve uma alta de curto prazo que, no entanto, não se consolidou, e o balanço foi deslizando gradualmente para a região negativa, oscilando em torno do nível inicial até o fim do período de teste. Isso indica que o algoritmo ainda não obteve uma vantagem consistente no intervalo analisado, mas também não apresentou falhas catastróficas: o rebaixamento permaneceu dentro de 8,5% no balanço e cerca de 12% na equity.
De modo geral, os resultados dos testes podem ser caracterizados como intermediários e indicam que o modelo exige ajustes adicionais e, possivelmente, a ampliação da amostra de treinamento para melhorar sua capacidade de generalização. Ele não tende a rebaixamentos agressivos, mas ainda não demonstra lucro estável, o que torna seu comportamento mais conservador e cauteloso do que arriscado.
Conclusão
Ao final do trabalho realizado, podemos constatar que os testes permitiram avaliar objetivamente o estado atual da abordagem desenvolvida e identificar seus pontos fortes e fracos. O modelo demonstrou resistência a oscilações bruscas do mercado e um nível moderado de rebaixamento, mantendo o controle dos riscos mesmo em cenários desfavoráveis. No entanto, a rentabilidade final ainda permanece negativa, e a relação entre operações lucrativas e perdedoras indica a necessidade de uma otimização adicional dos parâmetros e, provavelmente, da ampliação do volume de dados de treinamento.
Esses resultados não representam uma derrota. Pelo contrário, delimitam as fronteiras da implementação atual e indicam os caminhos para o desenvolvimento posterior. Os próximos passos devem se concentrar no aprimoramento do mecanismo de tomada de decisão, no reforço da filtragem de ruído e no aumento da precisão da previsão em condições de mercado volátil. Assim, o framework apresentado já demonstra uma base operacional robusta, mas seu potencial ainda foi explorado apenas parcialmente, deixando espaço para melhorias futuras e para a adaptação prática a tarefas reais de trading.
Referências
- SAGDFN: A Scalable Adaptive Graph Diffusion Forecasting Network for Multivariate Time Series Forecasting
- Outros artigos da série
Programas usados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Study.mq5 | Expert Advisor | EA de treinamento offline de modelos |
| 2 | StudyOnline.mq5 | Expert Advisor | EA de treinamento online de modelos |
| 3 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema e da arquitetura dos modelos |
| 5 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de redes neurais |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca do código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/19425
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso