
Redes neurais no trading: uma visão unificada sobre espaço e tempo (Extralonger)

Introdução
A previsão da dinâmica de sistemas complexos é tradicionalmente uma das tarefas centrais da análise de dados. A qualidade e a profundidade das previsões determinam não apenas o interesse acadêmico dos pesquisadores, mas também resultados bastante práticos: otimização de fluxos, redução de custos e gestão de riscos. Esse problema se manifesta de forma especialmente clara em duas áreas que, à primeira vista, parecem distantes entre si: os sistemas inteligentes de transporte e os mercados financeiros. À primeira vista, estradas com fluxos de veículos e bolsas com fluxos de ordens têm pouco em comum. No entanto, uma análise mais atenta revela uma profunda semelhança estrutural.
Nos estudos de transporte, os dados são representados como uma rede em que os nós correspondem a estações de monitoramento, enquanto as arestas refletem suas inter-relações. No mundo financeiro, ativos, bolsas, corretoras e plataformas de negociação cumprem papel semelhante, pois por esses elementos circulam continuamente informação e capital. Se, em uma rede viária, o sinal é o tráfego de veículos, nos sistemas financeiros esse sinal é composto por preços, volumes, liquidez e pelo comportamento dos participantes do mercado. Em ambos os casos, é preciso estudar dados históricos, identificar padrões na dinâmica espaço-temporal e gerar previsões.
As abordagens tradicionais para resolver esse tipo de problema se baseavam na análise separada dos componentes espacial e temporal. Nos estudos de transporte, isso significava analisar as séries temporais de tráfego separadamente da topologia da rede viária. Em finanças, métodos análogos se concentravam ora na dinâmica temporal das séries de preços, ora nas correlações estruturais entre ativos. Essa separação entre espaço e tempo gera limitações importantes: os algoritmos se tornam excessivamente custosos em termos de recursos, enquanto sua capacidade de previsão de longo prazo diminui drasticamente.
A principal dificuldade está no fato de que o processamento dos atributos temporais exige iterações repetidas sobre as relações espaciais. Ao mesmo tempo, a análise das dependências estruturais entre nós exige múltiplas passagens pelo eixo temporal. Como resultado, a complexidade computacional aumenta em uma ordem de grandeza em comparação com tarefas estritamente de previsão de séries temporais. Somando-se a isso o crescimento acelerado dos volumes de dados característicos dos sistemas de transporte e dos mercados financeiros, torna-se evidente que, sem uma abordagem fundamentalmente nova, é praticamente impossível avançar além de um horizonte de algumas horas ou de alguns passos.
Uma forma de resolver esse problema foi proposta pelos autores do artigo "Extralonger: "Toward a Unified Perspective of Spatial-Temporal Factors for Extra-Long-Term Traffic Forecasting". Os autores se inspiram nas ideias de Albert Einstein sobre a inseparabilidade entre espaço e tempo, defendendo que os fatores espaciais e temporais devem ser considerados em conjunto e ao mesmo tempo. Essa ideia se materializa no conceito de Unified Spatial-Temporal Representation, ou representação espaço-temporal unificada, que elimina a necessidade de separar artificialmente os dados em componentes temporais e espaciais. A informação espacial é incorporada a cada passo temporal, enquanto a informação temporal é incorporada a cada nó da rede.
Nos sistemas de transporte, essa abordagem permitiu, pela primeira vez, ampliar o horizonte de previsão das habituais 2 a 4 horas para uma semana inteira. Para os mercados financeiros, o potencial é ainda mais impressionante. Imagine um modelo capaz não apenas de reagir a impulsos de curto prazo, mas também de construir previsões coerentes em horizontes relevantes para o trading estratégico, a gestão de riscos e o planejamento de investimentos. Em um ambiente no qual até mesmo uma pequena vantagem na compreensão da dinâmica futura dos preços pode levar a resultados financeiros significativos, a possibilidade de prever com base em uma representação espaço-temporal unificada abre horizontes fundamentalmente novos.
Além disso, a unificação entre espaço e tempo reduz radicalmente os custos computacionais. Se, na formulação clássica, a complexidade dos algoritmos crescia rapidamente e, na prática, restringia os pesquisadores a horizontes curtos, o Extralonger demonstra uma redução da complexidade em uma ordem de grandeza. Isso significa algoritmos mais rápidos e a possibilidade de aplicá-los em condições reais, nas quais a velocidade de resposta e a eficiência no uso dos recursos são essenciais. Como resultado, o treinamento dos modelos é acelerado em centenas de vezes, enquanto o consumo de memória cai para níveis que tornam viável a previsão de longo prazo mesmo em uma infraestrutura limitada.
Para os mercados financeiros, esse ponto tem importância especial. Afinal, o mercado não é apenas um enorme conjunto de dados históricos, mas também um fluxo contínuo de novos sinais que precisam ser processados em tempo real. As arquiteturas tradicionais muitas vezes esbarravam justamente nessa etapa. A complexidade excessiva dificultava lidar com tarefas de planejamento de horizonte longo, obrigando a sacrificar velocidade, confiabilidade ou ambas. O framework Extralonger demonstra que esse tipo de compromisso já não é obrigatório.
Algoritmo Extralonger
A maioria dos modelos de previsão existentes se baseia na chamada representação clássica dos dados.
![]()
em que T é o comprimento da janela temporal, N é o número de nós da rede, C é o número de atributos originais, e D é a dimensionalidade do espaço de atributos transformado.
Na prática, isso significa que projetamos primeiro os dados linearmente em um espaço de dimensionalidade fixa e, em seguida, módulos específicos extraem informações temporais e espaciais.
A arquitetura clássica geralmente inclui dois tipos de módulos, temporal e espacial. que podem ser combinados em diferentes ordens: analisar primeiro o tempo e depois o espaço. ou tentar processar as duas dimensões simultaneamente. No entanto, na prática, qualquer uma dessas separações apresentava a mesma limitação: o processamento dos atributos ao longo de um eixo exigia múltiplas iterações pelo outro. Como resultado, a complexidade computacional crescia rapidamente. Por exemplo, nos mecanismos de autoatenção, ela alcançava a ordem de O(NT2 + TN2), com aumento semelhante no consumo de memória. Para os mercados financeiros, isso significa que a previsão em horizontes longos se torna extremamente custosa em termos de recursos. Grandes volumes de cotações históricas e de inter-relações entre instrumentos simplesmente sobrecarregam o sistema.
Tentativas de contornar essas limitações já foram feitas anteriormente, inclusive com o uso de modelos convolucionais (CNN). Nesse caso, os dados eram processados como uma imagem, em que um eixo corresponde ao tempo e o outro, ao conjunto de nós. Essa abordagem de fato permite considerar espaço e tempo simultaneamente, mas também possui limitações. A janela convolucional não permite abranger a imagem completa, mas apenas regiões locais. Além disso, a complexidade do algoritmo, nesse caso, era expressa como O(k2TN), em que k é o tamanho do kernel de convolução, o que ainda restringia a possibilidade de ampliar o horizonte.
O framework Extralonger muda radicalmente esse cenário ao introduzir a Unified Spatial-Temporal Representation, ou representação espaço-temporal unificada. A essência da ideia é simples: espaço e tempo não são separados, mas descritos de forma unificada. Para isso, comprimimos primeiro a representação original X∈RT×N×C na dimensão dos atributos e, em seguida, aplicamos duas projeções lineares: uma ao longo do espaço e outra ao longo do tempo. Como resultado, obtemos dois conjuntos de representações:
- Et ∈ RT×D, em que cada passo temporal contém informações sobre todos os nós da rede,
- Es ∈ RN×D, em que cada nó acumula dados de todos os passos temporais.
Assim, cada observação passa a carregar uma visão espaço-temporal completa, e não apenas um recorte local. Essa é a diferença fundamental: enquanto a representação clássica se apoiava em atributos isolados, a nova representação oferece uma visão integral.
Essa abordagem traz de imediato várias vantagens fundamentais. Em primeiro lugar, reduz a complexidade. Ao eliminar iterações redundantes, o modelo passa a processar as dependências temporais e espaciais em conjunto, e a complexidade do algoritmo cai para O(T2 + N2). Isso permite construir previsões dezenas e centenas de passos à frente sem esbarrar no limite dos recursos computacionais.
Em segundo lugar, a agregação simultânea. Enquanto os métodos clássicos eram obrigados a avançar ao longo de um eixo, incorporando gradualmente informações do outro, o Extralonger permite que cada nó esteja conectado de imediato a todos os demais em qualquer passo temporal. Consequentemente, o algoritmo é capaz de considerar simultaneamente a interação entre diferentes instrumentos e sua dinâmica ao longo do tempo, algo extremamente importante para a análise abrangente de correlações e relações intermercados.
Por fim, em terceiro lugar, temos o campo receptivo completo. Ao usar autoatenção dentro de uma representação unificada, o Extralonger garante a conexão de cada nó com qualquer outro nó em todos os instantes de tempo. Isso dá ao modelo a capacidade de capturar as dependências mais longas, desde ciclos diários e semanais até padrões mais complexos, associados, por exemplo, à sazonalidade do mercado acionário ou a fases de tendência que se estendem por vários dias. Em comparação, em modelos RNN, de atenção ou Transformers clássicos, a agregação ocorre por dimensões separadas, enquanto as CNN ficam limitadas a um campo receptivo local.
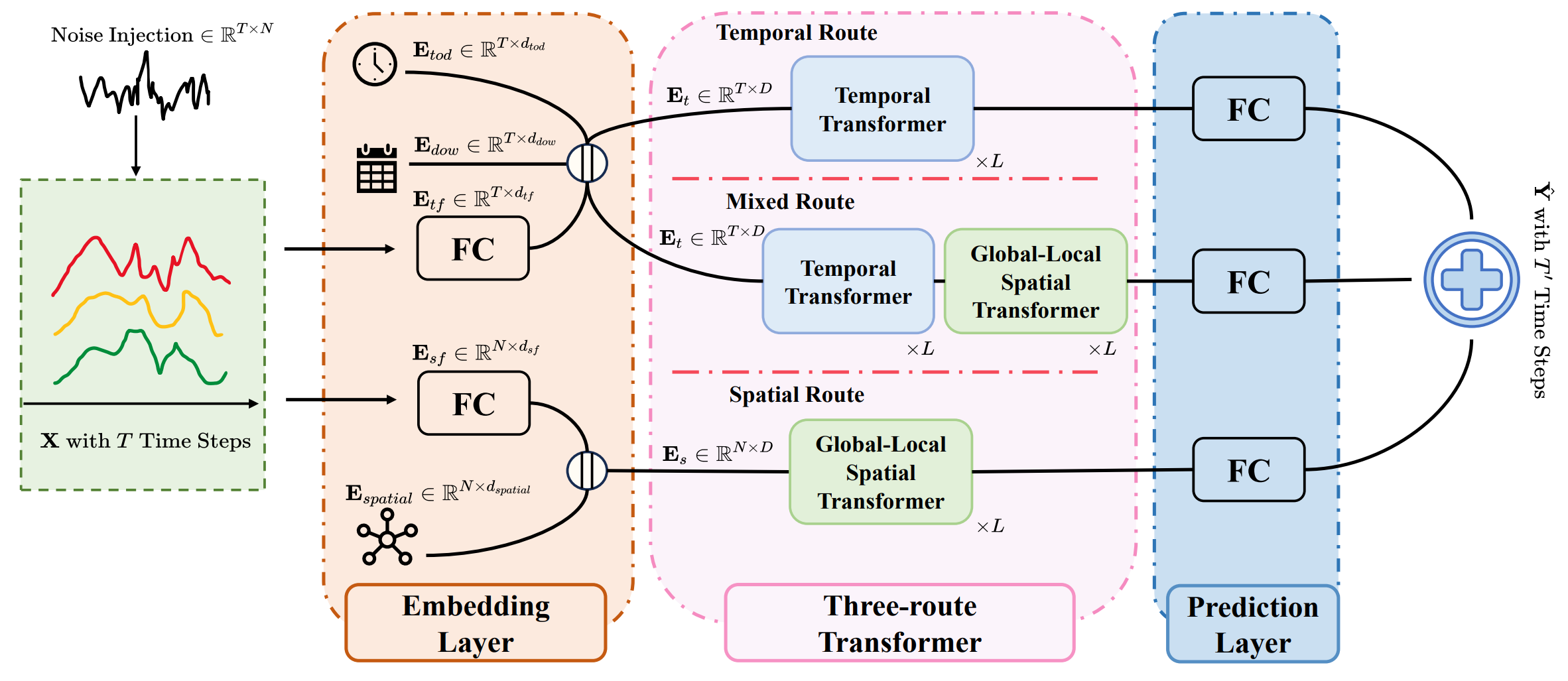
A arquitetura do Extralonger é composta por três componentes principais:
- camada de embedding (embedding layer),
- módulo Transformer de três rotas (three-route Transformer),
- camada de previsão (prediction layer).
A camada de embedding transforma os dados originais em uma representação interna que inclui dois elementos centrais: a representação espacial Es e a representação temporal Et. A particularidade da arquitetura está no fato de que os dados já passam por um pré-processamento na entrada. Um ruído treinável é introduzido no array de dados originais X, o que ajuda a aumentar a robustez do modelo às oscilações ruidosas do mercado.
Em seguida, aplicamos duas camadas lineares totalmente conectadas: uma gera os atributos temporais Etf∈RT×dtf, enquanto a outra forma os atributos espaciais Esf∈RN×dsf.
Para capturar a ciclicidade característica dos processos reais, a arquitetura do Extralonger incorpora embeddings de periodicidade treináveis. No eixo temporal, ela usa o embedding timestamp-of-day Etod∈RT×d_tod, que reflete o ciclo diário, e o embedding day-of-week Edow∈RT×d_dow, que modela a sazonalidade semanal. De modo análogo, na dimensão espacial, introduz um embedding treinável Espatial∈RN×d_spatial, permitindo capturar padrões espaciais persistentes.
Obtemos as representações finais pela concatenação desses embeddings:
- representação temporal Et = Etf ‖ Etod ‖ Edow ∈ RT×D,
- representação espacial Es = Esf ‖ Espatial ∈ RN×D.
Assim, ainda na etapa de formação dos atributos, o modelo já incorpora ciclos fundamentais e relações espaciais. Para os mercados financeiros, isso é especialmente valioso: oscilações diárias de liquidez, ritmos semanais de atividade, correlações entre instrumentos e ambientes de negociação passam a ser refletidos diretamente na estrutura dos dados.
O núcleo do sistema é o Transformer de três rotas, no qual três caminhos operam em paralelo: temporal, espacial e misto. Graças ao uso da representação espaço-temporal unificada, as três rotas conseguem considerar ao mesmo tempo a estrutura temporal e a estrutura espacial dos dados. Ao mesmo tempo, cada rota enfatiza sua própria função. O caminho puramente temporal e o caminho misto usam um codificador Transformer padrão, enquanto a rota espacial e a rota mista recebem um módulo especial: o Global-Local Spatial Transformer, que permite capturar com eficiência tanto relações locais quanto globais.
Diferentemente do mecanismo padrão de autoatenção, em que todos os nós da rede são processados da mesma forma e sem levar em conta sua estrutura real, o Global-Local Spatial Transformer foi criado especificamente para explorar as características topológicas do sistema analisado. No problema de transporte, essa estrutura é a rede viária, na qual algumas estações estão conectadas diretamente, enquanto outras se relacionam apenas de forma indireta. No mundo financeiro, uma estrutura análoga aparece na forma de um grafo de ativos: alguns ativos apresentam forte correlação entre si, enquanto outros estão conectados apenas por tendências globais de mercado.
O Transformer tradicional trata todas as conexões como equivalentes. Isso permite capturar a visão geral, mas, ao mesmo tempo, dilui as particularidades locais. Por outro lado, modelos que se concentram exclusivamente nas conexões locais conseguem capturar bem os detalhes, mas perdem a capacidade de enxergar dependências de longo alcance. É exatamente aqui que surge a necessidade de equilíbrio, isto é, de considerar simultaneamente padrões globais e locais.
O módulo GLST implementa essa ideia diretamente, combinando dois mecanismos de atenção: global e local. Na primeira etapa, a partir da representação espacial Es, construímos as matrizes Query, Key e Value. Com base nelas, calculamos os pesos de atenção global.
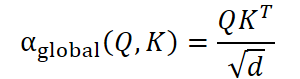
Essa matriz reflete a força das inter-relações entre todos os nós de uma só vez. No contexto financeiro, isso pode ser entendido como uma matriz de correlações cruzadas entre instrumentos.
Em seguida, entra em cena a atenção local. Para formá-la, usamos a matriz de adjacência A, que define a estrutura das conexões reais. Em tarefas de transporte, A codifica as conexões viárias. Já em finanças, essa matriz pode assumir a forma de um grafo de correlações persistentes ou de uma rede de influências mútuas entre instrumentos. A aplicação de A restringe a atenção apenas aos nós vizinhos, criando a componente local.
![]()
em que ⊙ representa o produto elemento a elemento.
Assim, a parte global captura dependências amplas, enquanto a parte local mantém o foco nas conexões mais próximas e relevantes.
As duas matrizes passam pela normalização SoftMax e são combinadas em uma única expressão.
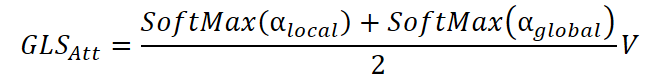
O resultado é uma agregação equilibrada, na qual cada nó recebe simultaneamente informações sobre todo o sistema e sobre suas conexões mais próximas.
Depois disso, seguindo a lógica do Transformer clássico, aplica-se uma camada de normalização, conexões residuais (conexões de salto) e uma rede Feed-Forward. Essas etapas formam a representação espacial atualizada final Ês.
É importante destacar que, para os mercados financeiros, esse módulo é especialmente natural. As correlações entre ativos mudam ao longo do tempo, e as conexões entre instrumentos podem ser persistentes ou dinâmicas. O uso da atenção global-local dá flexibilidade ao modelo: ele pode se ajustar à estrutura atual do mercado, distinguir dependências sólidas de relações temporárias e, portanto, gerar uma previsão mais confiável.
Como resultado, o Global-Local Spatial Transformer se torna uma espécie de ponte entre os níveis micro e macro da análise. No nível micro, ele acompanha os sinais locais do mercado e as inter-relações de curto prazo. No nível macro, captura tendências globais e correlações de longo prazo. A fusão dessas duas perspectivas torna o modelo poderoso do ponto de vista teórico e aplicável ao trading real, no qual é justamente a combinação entre detalhes e contexto global que determina o sucesso das estratégias.
Depois que o Transformer de três rotas conclui o processamento dos dados e forma as representações espaço-temporais, vem a etapa final: a previsão. Essa etapa transforma embeddings abstratos em valores previstos concretos para o horizonte de planejamento definido.
Para isso, usamos projeções lineares que levam os tensores de saída do espaço oculto de volta ao formato das previsões. Como a formulação do problema no Extralonger é assimétrica (T → T′), ou seja, o comprimento da janela histórica T e o comprimento do intervalo de previsão T′ não coincidem, precisamos projetar explicitamente as saídas do Transformer para a dimensionalidade T′. Em outras palavras, a partir de um fragmento histórico de comprimento fixo, obtemos uma previsão para um horizonte mais longo ou mais curto, algo especialmente importante para os mercados financeiros, nos quais o tamanho da janela pode se adaptar à estratégia.
Depois da projeção, o modelo combina os resultados das três rotas: temporal, espacial e mista. Aqui, os autores do framework não usam aprendizado automático dos pesos, mas uma combinação definida previamente, isto é, um ajuste manual dos coeficientes de ponderação. Essa abordagem permite regular explicitamente a contribuição de cada rota para a previsão final: é possível, por exemplo, reforçar o papel da componente temporal em mercados com tendências bem marcadas ou, ao contrário, enfatizar as dependências espaciais quando a estrutura de correlações entre ativos for mais importante.
Em conjunto, a arquitetura proposta transforma o Extralonger em uma ferramenta poderosa, na qual cada módulo reforça o outro. A rota temporal captura a dinâmica de longo prazo de cotações e volumes, a rota espacial captura as interdependências entre ativos e mercados, e a rota mista combina os dois aspectos, criando uma percepção integrada do cenário de mercado.
A visualização do framework Extralonger apresentada pelos autores é mostrada abaixo.
Implementação com MQL5
Depois de examinar os aspectos teóricos do framework Extralonger, passamos à parte prática deste artigo, na qual tentaremos recriar com MQL5 uma possível implementação dos algoritmos do framework. A principal vantagem da arquitetura proposta pelos autores está em sua modularidade. Cada componente pode ser isolado, testado e, se necessário, substituído ou aprimorado. Isso é especialmente valioso para sistemas de trading, nos quais a flexibilidade e a capacidade de adaptação às particularidades de mercados específicos são essenciais. No nosso caso, também seguiremos um desenvolvimento por etapas, módulo por módulo, aproveitando ao máximo o conjunto de objetos desenvolvido anteriormente para evitar duplicação de funcionalidades.
Como observado na parte teórica, o processamento dos dados originais começa com a adição de ruído treinável. É importante destacar que, aqui, ruído não significa a componente aleatória tradicional gerado por geradores de números pseudoaleatórios. Pelo contrário, trata-se de uma matriz de parâmetros treináveis que funciona como um viés adicional. Em outras palavras, não é uma distorção caótica, mas uma expansão direcionada do espaço de atributos, permitindo que o modelo capture dependências ocultas que não são evidentes nos dados originais.
Se traçarmos uma analogia com arquiteturas clássicas, essa camada desempenha uma função semelhante à da codificação posicional treinável em modelos Transformer. Nos modelos Transformer, ela permite que o modelo diferencie as posições em uma sequência temporal; neste caso, acrescenta a possibilidade de deslocar os dados em uma direção favorável à extração posterior de padrões. É justamente essa característica que torna a abordagem especialmente valiosa para os mercados financeiros: esses deslocamentos podem, na prática, codificar padrões sazonais persistentes ou correlações fracas que não aparecem de forma explícita nas séries de preços.
Na nossa biblioteca, já existe o objeto CNeuronLearnabledPE, que implementa uma funcionalidade semelhante. Sua finalidade é adicionar um deslocamento posicional treinável aos dados originais e, no contexto da implementação do framework Extralonger, ele se encaixa perfeitamente como ruído treinável. Em essência, podemos usar uma solução pronta, já validada em vários experimentos, sem a necessidade de criar um novo componente.
Essa escolha economiza esforço e também garante estabilidade, já que o objeto foi testado em experimentos anteriores.
Depois da adição do deslocamento treinável, vem a formação das projeções nos eixos temporal e espacial. Na descrição teórica do framework Extralonger, isso é feito por meio de duas camadas totalmente conectadas que, operando em paralelo, criam dois conjuntos de embeddings.
Na nossa implementação, podemos atribuir essa etapa aos objetos da camada convolucional CNeuronConvOCL. Essa escolha é natural e conveniente, pois as operações convolucionais já se consolidaram como uma ferramenta universal para transformar arrays originais. Elas permitem controlar facilmente o número de canais de entrada e saída, definindo o tamanho do kernel. Consequentemente, podemos implementar a formação das projeções temporais e espaciais como duas camadas convolucionais paralelas: a primeira opera ao longo do eixo temporal e gera Et, enquanto a segunda atua no eixo dos nós e gera Es. Isso corresponde plenamente à ideia dos autores do Extralonger e, ao mesmo tempo, preserva a uniformidade da nossa implementação.
Adição dos embeddings espaciais
Em seguida, vem a etapa de adição dos embeddings espaciais e temporais. À primeira vista, aqui não há grandes dificuldades. Já lidamos com operações semelhantes antes. A criação do embedding espacial em uma estrutura de dados fixa é semelhante à etapa anterior, com a adição de ruído treinável. A diferença é que, nessa etapa, não somamos tensores, mas os concatenamos, combinando informações de diferentes fontes. O novo objeto CNeuronSpatialEmbedding implementa essa lógica, herda a funcionalidade básica de CNeuronBaseOCL e a estende para as nossas tarefas.
class CNeuronSpatialEmbedding : public CNeuronBaseOCL { protected: uint iWindow; uint iUnits; uint iEmbeddingDim; CParams cEmbedding; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSpatialEmbedding(void) {}; ~CNeuronSpatialEmbedding(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint embed_dim, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronSpatialEmbedding; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; };
O método de inicialização Init define a arquitetura do neurônio. Nele, especificamos seus principais parâmetros: o número de sequências unitárias, o tamanho de cada uma delas e a dimensionalidade do embedding.
bool CNeuronSpatialEmbedding::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint embed_dim, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, (window + embed_dim)*units, optimization_type, batch)) return false; activation = None;
Dentro do método, chamamos primeiro a inicialização da classe-pai do neurônio com suporte a OpenCL. Em seguida, calculamos a dimensionalidade do tensor de resultados como a soma do comprimento da representação da sequência unitária com a dimensionalidade do embedding, multiplicada pelo número dessas sequências. Se a inicialização básica falhar, o método encerra corretamente a execução, retornando um sinal de erro.
Em seguida, o neurônio configura a função de ativação, embora, para o próprio neurônio, ela ainda não seja usada.
Depois disso, inicializamos o objeto responsável pela geração dos embeddings. Aqui, já usamos a tangente hiperbólica TANH como função de ativação, que introduz não linearidade e limita os valores ao intervalo [-1, 1]. Isso ajuda o modelo a gerar representações mais estáveis dos padrões de mercado e evita que valores extremos tenham influência excessiva sobre o treinamento.
if(!cEmbedding.Init(0, 0, OpenCL, embed_dim * units, optimization, iBatch)) return false; cEmbedding.SetActivationFunction(TANH); //--- iUnits = units; iWindow = window; iEmbeddingDim = embed_dim; //--- return true; }
Em seguida, os parâmetros do neurônio são salvos para as operações posteriores de propagação para frente e propagação reversa.
Como resultado, o método Init conecta a teoria à prática de forma fluida. O neurônio fica totalmente pronto para processar dados, concatenar embeddings e transmitir informações estruturadas adiante. Isso cria uma base confiável para construir modelos de trading capazes de analisar sinais de mercado em diferentes horizontes temporais e identificar dependências ocultas importantes para a tomada de decisões de negociação fundamentadas.
O método feedForward implementa o algoritmo de propagação para frente dos dados pelo neurônio, das entradas para as saídas. No contexto financeiro, isso lembra o modo como um trader analisa sequencialmente os dados históricos e forma uma representação integrada da situação atual do mercado.
Verificamos primeiro a validade do ponteiro recebido para o neurônio anterior NeuronOCL. Se ele não existir, o método retorna false imediatamente. Isso é importante, pois, sem os dados originais, a propagação para frente é impossível, assim como é impossível tomar decisões sem cotações de mercado.
bool CNeuronSpatialEmbedding::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Em seguida, se o neurônio estiver em modo de treinamento (bTrain=true), chamamos a propagação para frente do objeto cEmbedding. Nessa etapa, formamos os embeddings espaciais, que codificam as principais dependências do mercado no campo receptivo selecionado. Se essa operação falhar, o método retorna false para sinalizar um problema na criação dos embeddings.
if(bTrain) if(!cEmbedding.FeedForward()) return false;
Observe que executamos a operação apenas durante o treinamento. Afinal, nesse caso, os embeddings não dependem dos dados originais, mas apenas codificam as posições das sequências. Consequentemente, em produção, os valores permanecem fixos, e eliminamos operações desnecessárias, o que permite aumentar a velocidade de tomada de decisão.
Depois de gerados os embeddings, vem a etapa central: a concatenação dos dados originais com os embeddings. O método Concat combina as saídas do neurônio anterior e do embedding em um único tensor Output, levando em conta o tamanho da representação de cada sequência unitária e a dimensionalidade do embedding.
if(!Concat(NeuronOCL.getOutput(), cEmbedding.getOutput(), Output, iWindow, iEmbeddingDim, iUnits)) return false; //--- return true; }
Por fim, quando todas as operações terminam com sucesso, o método retorna true, sinalizando que o neurônio executou corretamente a propagação para frente e que o tensor de resultados está pronto para seguir para a próxima camada do modelo.
Como se pode notar, o algoritmo do método de propagação para frente é bastante simples e estruturado de forma linear. Ele verifica sequencialmente os dados de entrada, gera os embeddings espaciais e os concatena com as saídas da camada anterior, criando um tensor pronto para seguir adiante. Os métodos de propagação reversa seguem uma lógica análoga, repetindo a mesma estrutura, mas na direção oposta. Graças a essa estrutura clara e sequencial, ambos os métodos são fáceis de compreender e permitem concentrar a atenção nas principais particularidades do funcionamento do neurônio com séries temporais de dados financeiros.
Para um estudo mais aprofundado, recomenda-se examinar por conta própria a implementação da propagação reversa. O código completo da classe CNeuronSpatialEmbedding e de todos os seus métodos está disponível no anexo, permitindo acompanhar o funcionamento do neurônio desde a inicialização até a geração dos embeddings e a transmissão das informações para o modelo.
Embedding temporal
Com os embeddings temporais, a situação é um pouco mais complexa. Em primeiro lugar, há vários deles, e cada um codifica diferentes ciclos temporais. Os autores do framework propõem usar dois níveis: intradiário e intrassemanal. Esse tipo de problema já nos é familiar pelos experimentos anteriores com o codificador temporal do framework HimNet, em que também formávamos embeddings de séries temporais. Naquele caso, eram usados blocos recorrentes, e a cada passo o tensor dos dados originais recebia apenas os embeddings do estado analisado.
Agora, o problema é um pouco mais complexo. Em cada passagem, o neurônio analisa uma sequência temporal inteira, e cada passo temporal dessa sequência deve receber seus próprios embeddings. Isso lembra a atividade de um trader que não observa apenas o preço ou o indicador atual, mas avalia simultaneamente toda a série de sinais históricos para identificar ciclos e padrões ocultos.
Naturalmente, vamos aproveitar as soluções já desenvolvidas no HimNet, mas adaptá-las à nova arquitetura, em que formamos os embeddings temporais para todos os passos da sequência ao mesmo tempo. Isso permite que o modelo capture a dinâmica do mercado com mais precisão e responda de maneira mais adequada às suas mudanças.
Começamos a implementar os embeddings temporais no programa OpenCL, onde criamos o kernel ConcatByLabel. Esse kernel concatena os dados originais com vários níveis de embeddings. No nosso caso, são dois embeddings temporais, correspondentes aos ciclos intradiário e intrassemanal. No contexto financeiro, isso lembra a análise simultânea de vários horizontes temporais: oscilações de curto prazo e ciclos mais longos influenciam a previsão, e o modelo deve considerar todos eles.
O kernel usa uma grade tridimensional de identificadores globais: row_id, col_id e buffer_id. Isso nos permite processar simultaneamente as linhas e colunas do tensor original, além de escolher com qual buffer estamos trabalhando: os dados originais ou um dos embeddings.
__kernel void ConcatByLabel(__global const float* data, __global const float* label, __global const float* embedding1, __global const float* embedding2, __global float *output, const int dimension_data, const int dimension_emb1, const int dimension_emb2, const int frame1, const int frame2, const int period1, const int period2 ) { const size_t row_id = get_global_id(0); const size_t col_id = get_global_id(1); const size_t buffer_id = get_global_id(2); const size_t total_rows = get_global_size(0); const size_t total_cols = get_global_size(1); const size_t total_buffers = get_global_size(2);
O kernel atribui primeiro identificadores globais a cada fluxo de execução:
- row_id: índice da linha, corresponde à marca de tempo ou ao passo da série temporal;
- col_id: índice da coluna, corresponde a uma variável ou atributo específico;
- buffer_id: seleciona o buffer com o qual esse fluxo de execução trabalha: dados originais, primeiro embedding ou segundo embedding.
As dimensões globais do espaço de tarefas definem a grade geral de fluxos. Aqui, é importante entender que total_buffers determina quantos conjuntos diferentes de dados estamos concatenando. Esse valor define a dimensionalidade final do vetor de saída.
__global const float *buffer; int dimension_in, dimension_out; int shift_in, shift_out; //--- switch(total_buffers) { case 1: dimension_out = dimension_data; break; case 2: dimension_out = dimension_data + dimension_emb1; break; case 3: dimension_out = dimension_data + dimension_emb1 + dimension_emb2; break; default: return; }
Se houver mais de três buffers, o kernel simplesmente encerra a execução, evitando o uso incorreto do kernel.
O passo seguinte é escolher o buffer específico e calcular os deslocamentos para leitura e gravação dos dados.
switch(buffer_id) { case 0: buffer = data; dimension_in = dimension_data; shift_in = RCtoFlat(row_id, col_id, total_rows, dimension_in, 0); shift_out = RCtoFlat(row_id, col_id, total_rows, dimension_out, 0); break; case 1: buffer = embedding1; dimension_in = dimension_emb1; shift_in = ((int)IsNaNOrInf(label[row_id] / frame1, 0)) % period1; shift_in = RCtoFlat(shift_in, col_id, period1, dimension_in, 0); shift_out = RCtoFlat(row_id, dimension_data + col_id, total_rows, dimension_out, 0); break; case 2: buffer = embedding2; dimension_in = dimension_emb2; shift_in = ((int)IsNaNOrInf(label[row_id] / frame2, 0)) % period2; shift_in = RCtoFlat(shift_in, col_id, period2, dimension_in, 0); shift_out = RCtoFlat(row_id, dimension_data + dimension_emb1 + col_id, total_rows, dimension_out, 0); break; }
Para os dados originais, calculamos shift_in e shift_out diretamente pela função RCtoFlat, que transforma os índices bidimensionais de linha e coluna em um índice linear do buffer global.
Para os embeddings, shift_in depende do valor da marca de tempo de cada passo da sequência label[row_id], dividido pelo período (frame1 ou frame2). Isso permite selecionar ciclicamente o embedding correspondente a uma fase específica do ciclo temporal, algo especialmente importante para dados financeiros com padrões intradiários e intrassemanais recorrentes.
Depois da preparação, gravamos os dados correspondentes no buffer de resultados.
if(col_id < dimension_in) output[shift_out] = IsNaNOrInf(buffer[shift_in], 0); }
Aqui, vale observar que pressupomos o uso de dimensionalidades diferentes para os dados originais e para os embeddings. Ao enfileirar o kernel para execução, usamos o parâmetro máximo. Por isso, antes de executar as operações de acesso aos buffers, verificamos se o índice da coluna corresponde ao buffer utilizado. Além disso, limpamos os dados de valores incorretos (NaN ou Inf), para não comprometer os cálculos posteriores.
Como resultado, o kernel gera um tensor completamente concatenado, que leva em conta todos os embeddings definidos e os dados originais. Cada passo temporal recebe seu próprio conjunto de embeddings, permitindo que o modelo capture toda a dinâmica do mercado simultaneamente, incluindo flutuações de curto prazo e ciclos mais longos, melhorando a qualidade das previsões e a robustez dos modelos de trading.
Depois de construir o algoritmo de propagação para frente, o próximo passo natural é implementar a retropropagação do erro. Se a propagação para frente gera os embeddings e os combina com os dados originais, a propagação reversa responde pela correção dos pesos e pela melhoria da qualidade da representação das informações. No contexto financeiro, isso se parece com a rotina de um trader que, ao avaliar as consequências de decisões passadas, ajusta a estratégia para o próximo passo. Os erros de previsão nos passos temporais anteriores permitem que o modelo ajuste os embeddings para refletir melhor a dinâmica do mercado.
Nesse caso, realizamos a retropropagação entre os dados originais e os embeddings correspondentes. O kernel ConcatByLabelGrad implementa essa lógica. Em essência, trata-se da etapa em que a rede propaga os erros de volta para cada componente, permitindo corrigir os pesos e melhorar a previsão.
__kernel void ConcatByLabelGrad(__global float* data_gr, __global const float* label, __global float* embedding1_gr, __global float* embedding2_gr, __global float *output_gr, const int dimension_data, const int dimension_emb1, const int dimension_emb2, const int frame1, const int frame2, const int period1, const int period2, const int units ) { const size_t row_id = get_global_id(0); const size_t col_id = get_global_id(1); const size_t buffer_id = get_global_id(2); const size_t total_rows = get_global_size(0); const size_t total_cols = get_global_size(1); const size_t total_buffers = get_global_size(2); //--- __global float *buffer; int dimension_in, dimension_out; int shift_in, shift_out, shift_col; int period, frame, rows;
No início, identificamos cada fluxo de execução no espaço tridimensional de tarefas. Isso permite que cada fluxo de execução processe uma combinação específica de passo temporal, atributo e buffer.
Em seguida, determinamos a dimensionalidade final do tensor de resultados, neste caso, dos gradientes do erro.
switch(total_buffers) { case 1: dimension_out = dimension_data; break; case 2: dimension_out = dimension_data + dimension_emb1; break; case 3: dimension_out = dimension_data + dimension_emb1 + dimension_emb2; break; default: return; }
Acredito que você tenha notado a repetição de operações do kernel de propagação para frente. No entanto, a partir daqui surgem as diferenças. Se o buffer processado for o dos dados originais (buffer_id == 0), os gradientes são simplesmente copiados diretamente do buffer de gradientes do erro no nível dos resultados. Depois disso, encerramos a execução do kernel.
switch(buffer_id) { case 0: if(col_id < dimension_data && row_id<units) { shift_in = RCtoFlat(row_id, col_id, total_rows, dimension_in, 0); shift_out = RCtoFlat(row_id, col_id, total_rows, dimension_out, 0); data_gr[shift_in] = IsNaNOrInf(output_gr[shift_out], 0); } return;
Já no caso dos embeddings (buffer_id == 1 ou 2), o algoritmo é um pouco mais complexo. Aqui, definimos o período e o deslocamento com que os gradientes serão coletados.
case 1: rows = period1; buffer = embedding1_gr; dimension_in = dimension_emb1; shift_in = RCtoFlat(row_id, col_id, period1, dimension_in, 0); shift_col = dimension_data; period = period1; frame = frame1; break; case 2: rows = period2; buffer = embedding2_gr; dimension_in = dimension_emb2; shift_in = RCtoFlat(row_id, col_id, period2, dimension_in, 0); shift_col = dimension_data + dimension_emb1; period = period2; frame = frame2; break; }
Em seguida, verificamos se o fluxo atual está dentro das dimensões do embedding correspondente, considerando a dimensionalidade da representação e a periodicidade dos dados. Só depois disso implementamos um laço que percorre todos os passos temporais do tensor de gradientes do erro no nível dos resultados e acumula a contribuição do erro para cada embedding.
if(row_id >= rows || col_id >= dimension_in) return; float grad = 0; for(uint r = 0; r < total_rows; r ++) { int row = ((int)IsNaNOrInf(label[r] / frame, 0)) % period; if(row != row_id) continue; shift_out = RCtoFlat(r, shift_col + col_id, total_rows, dimension_out, 0); grad += IsNaNOrInf(output_gr[shift_out], 0); } buffer[shift_in] = IsNaNOrInf(grad, 0); }
No corpo do laço, calculamos a qual objeto de periodicidade o passo atual pertence, para acumular os gradientes na posição de fase correspondente do ciclo temporal. Somente quando o valor obtido corresponde ao elemento analisado é que somamos os erros provenientes do tensor de resultados.
Gravamos o gradiente do erro acumulado no buffer global de gradientes do embedding correspondente. Também limpamos o resultado obtido de valores inválidos ou não finitos (NaN ou Inf).
Como resultado, o kernel ConcatByLabelGrad distribui cuidadosamente os erros entre os dados originais e os embeddings, garantindo a atualização correta dos pesos em todos os níveis da sequência temporal. Isso permite que o modelo se adapte aos ciclos complexos das séries temporais financeiras, melhorando a precisão das previsões e a robustez ao ruído.
Avançamos bastante, e o artigo já está bastante denso. Sugiro fazer uma pequena pausa para que as informações se assentem e possam ser assimiladas com tranquilidade. Continuaremos a implementação iniciada e a examinaremos em detalhes no próximo artigo.
Conclusão
Neste artigo, conhecemos o framework Extralonger, que integra fatores espaciais e temporais em um único modelo para previsão de séries temporais. Essa abordagem permite reduzir significativamente a complexidade computacional e os requisitos de memória em comparação com os métodos clássicos. Com isso, amplia os horizontes de previsão para escalas recordes.
O valor especial da abordagem está em fornecer seu próprio embedding a cada elemento da sequência temporal, permitindo que o modelo considere simultaneamente oscilações de curto prazo e padrões de longo prazo. Esse princípio pode ser adaptado para resolver diferentes tarefas nas quais as interações entre fatores espaciais e temporais são importantes, dos mercados financeiros ao planejamento da infraestrutura urbana ou à previsão das condições meteorológicas.
O Extralonger abre um novo caminho para a construção de modelos de previsão eficientes com base em dados espaço-temporais, combinando alta precisão, economia de recursos e escalabilidade para horizontes longos.
Referências
- Extralonger: Toward a Unified Perspective of Spatial-Temporal Factors for Extra-Long-Term Traffic Forecasting
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Study.mq5 | Expert Advisor | EA para treinamento offline de modelos |
| 2 | StudyOnline.mq5 | Expert Advisor | EA para treinamento online de modelos |
| 3 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema e da arquitetura dos modelos |
| 5 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de uma rede neural |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/19494
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Caminhe em novos trilhos: Personalize indicadores no MQL5
Caminhe em novos trilhos: Personalize indicadores no MQL5
 Está chegando o novo MetaTrader 5 e MQL5
Está chegando o novo MetaTrader 5 e MQL5
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso