
Redes neurais em trading: modelo de difusão adaptativa em grafos (módulo de atenção)

Introdução
No artigo anterior, conhecemos o framework SAGDFN. Discutimos os princípios centrais de seu funcionamento e destacamos seus pontos fortes. Mas, no mercado, uma arquitetura elegante no papel não basta. Estratégias frágeis e decisões excessivamente hesitantes perdem valor rapidamente. Para que o modelo seja útil, é preciso transformar a ideia em implementação e validar cada etapa com rigor.
O framework SAGDFN foi concebido desde o início como resposta a um problema antigo e ainda muito presente nos mercados financeiros: o excesso de dados e o ruído que mascara os sinais relevantes. Os métodos clássicos de análise tendiam a se perder nesse volume de informações ou a reduzi-lo por meio de filtragens grosseiras. O SAGDFN propõe outro caminho: não apenas filtrar, mas selecionar com critério. Os autores do framework mantêm apenas os vizinhos que realmente influenciam o comportamento do sistema, em linha com uma regra prática do trading: ouvir o mercado, mas separar o ruído da informação útil.
A ideia central da arquitetura é o Significant Neighbors Sampling, um sistema dinâmico de amostragem de vizinhos significativos. Imagine um antigo porto, onde a cada minuto chegam centenas de navios trazendo notícias de todos os mares. Nem todos são importantes para o seu negócio: alguns trazem apenas rumores de mercados distantes, outros carregam mercadorias que amanhã perderão valor. Em vez de tratar todas as conexões como igualmente úteis, o método seleciona as relações com maior impacto esperado sobre o comportamento do sistema. Para isso, combina avaliação determinística de importância com aleatoriedade controlada. Essa combinação evita que o modelo se prenda sempre às mesmas relações e, com isso, reduz o risco de sobreajuste.
Outro elemento igualmente importante é o mecanismo α-Entmax, responsável por controlar a distribuição da atenção. Diferentemente do SoftMax, que distribui massa por todos os elementos, o α-Entmax torna a distribuição esparsa e preserva coeficientes elevados apenas onde eles são realmente necessários. Na prática, isso ajuda o modelo a concentrar capacidade computacional nas relações com maior potencial informativo.
O SAGDFN também se distingue pelo equilíbrio entre o contexto local e o global. Ele analisa relações próximas, barras isoladas e clusters locais de negociações, mas preserva uma visão mais ampla das tendências, dos padrões acumulados e da estrutura dos fluxos de longo prazo. Assim, o modelo consegue combinar sinais de curto alcance com dependências mais extensas da série temporal.
A arquitetura do framework SAGDFN é modular e extensível, o que é especialmente valioso em condições de mercado em constante mudança. Ela não impõe uma estrutura rígida ao pesquisador. Cada bloco, seja a amostragem de vizinhos, a normalização da atenção ou a integração com fontes externas de dados, pode ser aprimorado, otimizado ou substituído.
A representação do framework SAGDFN proposta pelos autores é apresentada abaixo.
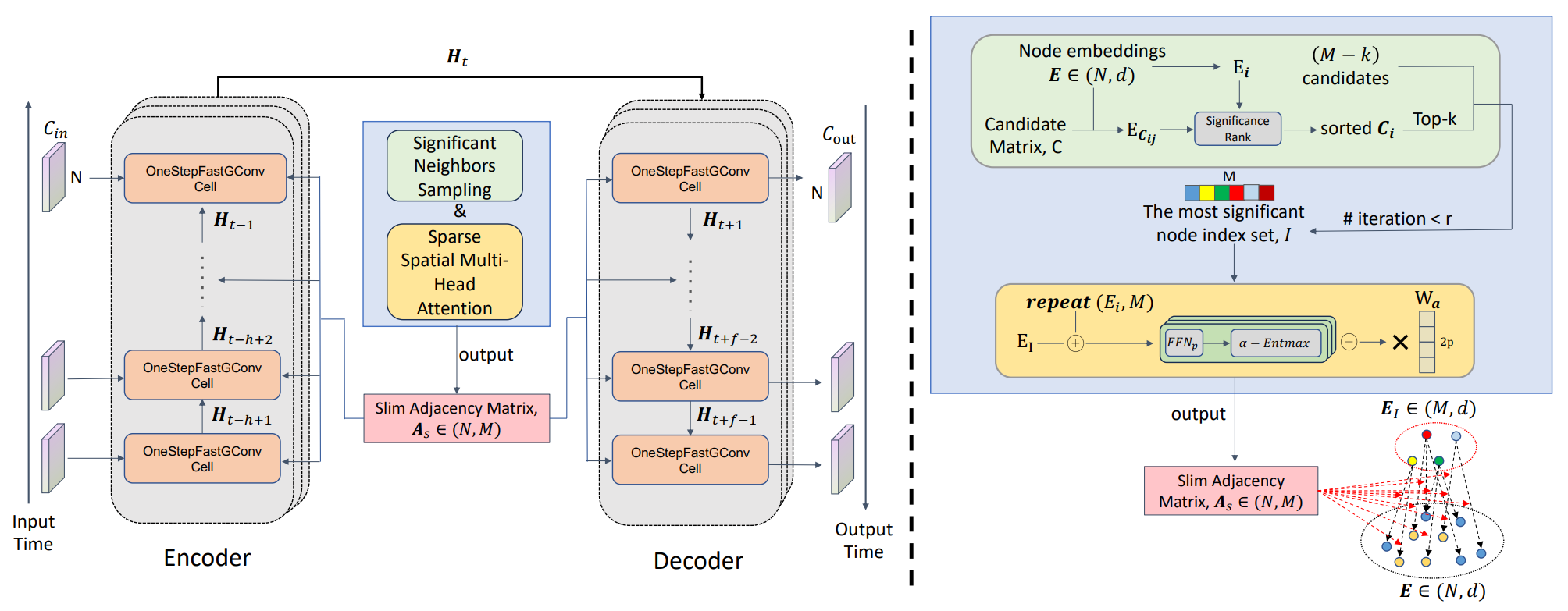
Na parte prática do artigo anterior, demos o primeiro passo importante: implementamos o algoritmo do módulo Significant Neighbors Sampling em OpenCL e definimos a base técnica da arquitetura. Aprendemos a extrair, de um grande volume de dados, as conexões realmente relevantes e encaminhá-las ao fluxo computacional subsequente sem ruído excessivo. Não foi apenas um experimento técnico, mas uma etapa essencial do futuro mecanismo de trading: sem uma amostragem bem ajustada, não há sistema de análise confiável.
Hoje, avançamos para a integração, em MQL5, da nossa própria interpretação das abordagens propostas pelos autores do framework SAGDFN.
Discussão da implementação
Depois de implementar os algoritmos do módulo Significant Neighbors Sampling, responsável por selecionar as conexões mais significativas, podemos avançar da preparação dos dados para uma análise mais profunda. Nesta etapa, começamos a desenvolver os algoritmos do módulo Sparse Spatial Multi-Head Attention, que será uma ferramenta-chave para extrair padrões estruturais dos vizinhos já selecionados.
Esse módulo funciona como um filtro inteligente: processa as informações e distribui a atenção do modelo para que ele se concentre nas relações espaciais realmente significativas, sem perder o contexto global. Ele usa atenção multicabeça, mas em uma forma esparsa, diferente da abordagem clássica. Com isso, reduz a carga computacional sem comprometer a qualidade da análise. Cada fluxo de dados passa por uma estrutura de atenção mais econômica e seletiva, na qual cada cabeça preserva as conexões mais relevantes e exerce sua própria função de filtragem.
Antes de avançar para a implementação, convém esclarecer nossa leitura dos algoritmos propostos pelos autores e os pontos que exigem atenção especial. A abordagem original é bastante intuitiva. Para construir o grafo, os autores concatenam, par a par, os embeddings de cada elemento com os embeddings de seus vizinhos mais próximos, previamente selecionados pelo módulo Significant Neighbors Sampling. Em seguida, cada par passa por um modelo totalmente conectado compacto, que gera a representação subsequente das conexões.
À primeira vista, a metodologia parece lógica e o processamento parece simples. No entanto, em uma implementação prática, especialmente com dados reais de trading e alta densidade de conexões, essa simplicidade aparente tem custo significativo. A concatenação par a par dos embeddings de cada elemento com os de seus vizinhos aumenta o volume de dados e eleva os requisitos de memória RAM. Na prática, cada par cria um novo vetor; quanto maior o número de pares, mais recursos são necessários para armazená-los e processá-los.
Além disso, usar um modelo totalmente conectado para cada par aumenta a carga computacional, pois cada par exige processamento individual. Isso amplia o tempo de execução e reduz a flexibilidade do sistema ao lidar com grafos grandes ou com recursos computacionais limitados. Portanto, apesar de parecer clara, essa solução pode se tornar um gargalo para um sistema eficiente e escalável.
A formulação original mostra que todos os pares [ei ‖ ej]$ passam pela mesma pequena rede totalmente conectada, em que ei é o embedding do nó e ej é o embedding de um de seus vizinhos selecionados. Os parâmetros dessa rede são compartilhados por todos os pares: não há vários modelos diferentes, mas o mesmo conjunto de pesos reutilizado repetidamente. É esse compartilhamento que podemos explorar para acelerar os cálculos.
Uma camada totalmente conectada é, em essência, uma transformação linear seguida de uma não linearidade. Na etapa linear, ela multiplica os componentes do vetor de entrada pelos pesos correspondentes e os soma. Se a entrada é a concatenação [ei ‖ ej] ∈ R2d, e a matriz de pesos da primeira camada é W ∈ Rh * 2d, o produto se decompõe na soma de dois termos.
![]()
em que W1 и W2 ∈ Rh * d são, respectivamente, a metade esquerda e a metade direita de W.
Essa observação algébrica simplifica o cálculo. Em vez de passar cada ei M vezes pela mesma camada, uma vez para cada vizinho, é mais racional calcular uma vez a projeção de cada nó pi = W1 ei e, separadamente, a projeção do vizinho ki = W2 ei. Assim, qualquer par (i,j), na etapa linear, é obtido diretamente como pi + kj. Depois vêm a mesma não linearidade e a próxima projeção linear da cabeça de atenção, sem aplicar repetidamente a matriz mais custosa à concatenação.
Na prática, multiplicamos antecipadamente o tensor original de embeddings E por duas matrizes de pesos e obtemos dois tensores de projeções. Essas operações são executadas uma vez por lote e são bem vetorizadas na GPU. Depois disso, para cada par nó-vizinho, basta somar as projeções correspondentes. O ganho é duplo: cada ei é multiplicado pelos pesos de consulta W1 uma única vez, independentemente de quantos vizinhos tenha; e cada ej também é multiplicado pelos pesos de chave W2 uma única vez, mesmo que apareça nas listas de dezenas de outros nós. A parte densa do processamento deixa de escalar com M.
Pelas ordens de complexidade, fica claro como o perfil de carga muda. A concatenação ingênua exige N × M multiplicações matriz-vetor de dimensionalidade h × 2d, o que resulta em O(NMhd) na primeira etapa linear. A versão refatorada realiza duas multiplicações, EW_q e EW_k, com custo O(Nhd) cada. Depois, executa apenas N × M somas de vetores h-dimensionais e uma cabeça leve, isto é, O(NMh), sem o fator d computacionalmente custoso. Quando d é grande e M também é significativo, a diferença aparece diretamente no profiler. Em termos de memória, a lógica é semelhante: em vez de armazenar N × M vetores concatenados de comprimento 2d, mantemos dois pools matriciais P e K de tamanho N × h e formamos as somas sob demanda para os pares necessários. A pressão sobre a memória diminui, e a largura de banda da ALU é usada de forma mais eficiente.
Essa mesma lógica se ajusta muito bem à nossa implementação em MQL5 + OpenCL. Para formar as projeções, podemos usar uma camada convolucional comum com 2h filtros e executá-la uma única vez por passagem, independentemente do conjunto atual de vizinhos. Isso é importante porque a lista I pode mudar de uma iteração para outra, enquanto o recálculo das projeções continua estável e barato. Em seguida, para cada par (i,j), lemos as linhas P_i e K_j, somamos elemento a elemento e aplicamos a cabeça de atenção. Onde antes havia multiplicações matriciais sobre tensores concatenados, agora restam somas vetoriais bem organizadas e uma pequena camada linear, operações ideais para vetorização ampla. Se também usarmos normalização esparsa da atenção, ela trabalhará sobre os logits obtidos e preservará o esquema de projeções preliminares.
Há também um ganho de interpretabilidade. A matriz W_q passa a atuar como projeção de consultas, enquanto W_k atua como projeção de chaves. Pelas suas linhas e ativações, é possível identificar quais componentes do embedding participam mais da formação da atenção em determinada cabeça. Para a gestão de risco, esse detalhe ajuda a explicar por que o modelo prioriza petróleo em vez de títulos em certo momento, ou por que um par de moedas se tornou subitamente o vizinho dominante para ações de tecnologia.
Outro aspecto importante é o uso da função α-Entmax. Sua principal característica é normalizar suavemente os dados de entrada e permitir o ajuste do nível de filtragem dos elementos pouco relevantes. Quando α==1, essa função equivale ao SoftMax clássico; quando α==2, aproxima-se do Sparse-SoftMax e zera de forma mais agressiva os valores não essenciais. Apesar do apelo da ideia, o algoritmo α-Entmax exige uma busca iterativa pelo parâmetro τ, o que aumenta a complexidade computacional e o tempo de execução. Na nossa implementação, priorizamos a eficiência e substituímos essa função pelo Sparse-SoftMax. Essa escolha preserva o conceito do framework, voltado à exclusão de elementos pouco relevantes da análise, ao mesmo tempo que melhora o desempenho e reduz o consumo de recursos na etapa de cálculo.
No próximo passo, vamos incorporar esse esquema ao nosso pipeline existente. A álgebra linear já simplificou a parte mais custosa; agora resta distribuir corretamente os cálculos no tempo e na memória, para que o mecanismo de atenção multicabeça opere de forma rápida, precisa e sem ruído desnecessário.
Extensão do programa OpenCL
Depois de discutirmos os princípios de arquitetura do módulo Sparse Spatial Multi-Head Attention, chegou o momento de levar esse conceito para a implementação prática. Na etapa anterior, vimos que multiplicar o tensor original uma única vez pela matriz de parâmetros economiza recursos e preserva as características centrais do algoritmo, incluindo a seleção dos vizinhos mais significativos. No contexto do OpenCL, isso é especialmente importante, pois cada operação e cada bloco de memória local precisam ser otimizados para alto desempenho.
Começamos pelo kernel de propagação para frente SparseMHScores, que calcula os coeficientes de atenção entre os elementos centrais e seus vizinhos mais significativos. O kernel foi estruturado para maximizar o paralelismo no processamento de cada elemento e, ao mesmo tempo, manter o controle sobre a esparsidade dos coeficientes.
__kernel void SparseMHScores(__global const float* data,
__global const float* indexes,
__global float* scores,
const float sparse ///< [0.0 .. 1.0) coefficient of sparse
)
{
const int main = (int)get_global_id(0);
const int slave = (int)get_local_id(1);
const int head = (int)get_global_id(2);
const int total_mains = (int)get_global_size(0);
const int total_slaves = (int)get_local_size(1);
const int total_heads = (int)get_global_size(2);
Primeiro, cada work-item global recebe o índice de seu elemento principal main e o identificador local do vizinho slave. Em paralelo, o kernel determina o identificador da cabeça de atenção atual, head, o que permite processar todas as cabeças ao mesmo tempo e criar um mapa multidimensional de correlações. Em seguida, cria o array local Temp, usado para armazenar temporariamente cálculos intermediários ao identificar os valores máximos e mínimos no bloco.
__local float Temp[LOCAL_ARRAY_SIZE];
Depois, extraímos os valores dos logits do elemento principal e de seu vizinho a partir dos arrays data. A função IsNaNOrInf garante a correção das operações subsequentes. Caso o valor seja inválido, como NaN ou Inf, ele é substituído por 0.
float value = IsNaNOrInf(data[RCtoFlat(main, head, total_mains, 2 * total_heads, 0)], 0); int slave_id = (int)indexes[RCtoFlat(main, slave, total_mains, total_slaves, 0)]; if(slave_id < total_mains && slave_id >= 0) value += IsNaNOrInf( data[RCtoFlat(slave_id, head + total_heads, total_mains, 2 * total_heads, 0)], 0);
Antes disso, obtemos o índice exato do vizinho a partir do buffer indexes e validamos esse valor. Se o vizinho estiver fora dos limites ou tiver índice negativo, ele é excluído dos cálculos. Isso mantém a consistência do processamento e evita somas incorretas.
Em seguida, o kernel executa a operação central Sparse-Softmax. Primeiro, calcula os máximos e mínimos locais por meio das funções LocalMax e LocalMin, o que permite determinar o valor de limiar threshold. Esse limiar controla a filtragem dos elementos pouco relevantes: valores abaixo dele são zerados, enquanto os elementos significativos passam pela exponencial e são normalizados pela soma de todos os elementos do bloco.
const float max_value = LocalMax(value, 1, Temp); const float min_value = LocalMin(value, 1, Temp); const float threshold = (max_value - min_value) * sparse + min_value; value = (threshold <= value ? IsNaNOrInf(exp(value - max_value), 0) : 0); const float sum = LocalSum(value, 1, Temp); value = IsNaNOrInf(value / sum, 0); //--- scores[RCtoFlat(slave, head, total_slaves, total_heads, main)] = value; }
Como resultado, obtemos um vetor de coeficientes esparsos e informativos, que codifica a importância de cada vizinho para o elemento atual. Os coeficientes calculados são gravados no array de saída scores. A função RCtoFlat converte índices multidimensionais em posições unidimensionais. Essa abordagem garante armazenamento consistente dos resultados e permite que a etapa seguinte de convolução em grafos os utilize diretamente para agregar informações.
Em conjunto, esse kernel implementa um processamento de atenção compacto, eficiente e paralelo, com distribuição precisa dos coeficientes entre os elementos e seus vizinhos significativos. Ele preserva a lógica da abordagem proposta pelos autores do framework SAGDFN, mas torna os cálculos escaláveis e adequados para uso prático em grandes séries temporais.
Depois de examinarmos em detalhes a propagação para frente e entendermos como são formados os coeficientes de atenção esparsos para cada cabeça e cada elemento, o passo natural é implementar a propagação reversa.
A propagação reversa é necessária para calcular corretamente os gradientes durante o treinamento do modelo. Ela propaga, de volta para os embeddings e parâmetros, os erros obtidos na saída e envolvidos no cálculo dos coeficientes de atenção. No contexto do OpenCL, isso exige um kernel separado, semelhante ao da propagação para frente, mas voltado ao acúmulo correto dos gradientes e ao tratamento da estrutura esparsa dos coeficientes.
Aqui, porém, alguns pontos merecem destaque. Em primeiro lugar, o logit de consulta participa simultaneamente do cálculo de todos os coeficientes de atenção. Portanto, durante a propagação reversa, ele precisa acumular os gradientes de erro vindos de todos os sinais associados, garantindo a propagação correta do erro pela rede.
Em segundo lugar, os elementos vizinhos são representados por uma estrutura semelhante a uma matriz esparsa, o que impõe restrições ao algoritmo de propagação reversa. Por isso, é preciso controlar quais elementos realmente participam dos cálculos, propagando gradientes apenas pelas conexões ativas e evitando gasto de recursos com posições vazias ou pouco relevantes.
Também é importante lembrar uma particularidade da função SoftMax: alterar um elemento afeta todo o vetor e cria interdependência entre os coeficientes. No nosso caso, os elementos que não entraram no conjunto de vizinhos selecionados recebem peso zero. Ainda assim, o gradiente de erro precisa ser propagado por toda a sequência para atualizar corretamente os parâmetros, mesmo quando alguns elementos não participaram diretamente das conexões ativas. Isso preserva a integridade e a estabilidade da retropropagação.
Para entender com mais clareza o funcionamento do kernel de propagação reversa, convém retomar a lógica do módulo Sparse Spatial Multi-Head Attention. Na propagação para frente, formamos pontuações de atenção esparsas para os vizinhos selecionados, usando índices e projeções de nós previamente calculados. Esses valores têm papel central na distribuição de informações entre os nós do grafo; por isso, a propagação correta do erro no sentido inverso é crítica para o treinamento estável do modelo.
O kernel SparseMHScoresGrad distribui os gradientes de erro para cada elemento do tensor de entrada, levando em conta a esparsidade e as particularidades do SoftMax. Em especial, alterar um logit afeta todos os elementos do vetor de atenção; portanto, até mesmo os vizinhos que não entraram no conjunto final devem receber o gradiente correto. Isso mantém a estrutura dos cálculos e a consistência da distribuição do erro.
__kernel void SparseMHScoresGrad(__global float* data_gr, __global const float* indexes, __global const float* scores, __global const float* scores_gr ) { const int main = (int)get_global_id(0); const int slave = (int)get_local_id(1); const int head = (int)get_global_id(2); const int total_mains = (int)get_global_size(0); const int total_slaves = (int)get_local_size(1); const int total_heads = (int)get_global_size(2);
A cada work-item do kernel são atribuídos três índices-chave:
- main, o nó para o qual o gradiente é calculado,
- slave, o índice local do vizinho,
- head, a cabeça de atenção.
O buffer Temp, na memória local, armazena temporariamente os valores intermediários dos gradientes dentro do bloco local de work-items, enquanto a sincronização por meio de BarrierLoc garante a consistência dos dados durante o processamento paralelo.
__local float Temp[LOCAL_ARRAY_SIZE]; const uint ls = min((uint)total_slaves, (uint)LOCAL_ARRAY_SIZE);
No primeiro bloco de cálculos, o kernel calcula os gradientes em relação ao nó analisado. Primeiro, extrai o coeficiente de atenção do vizinho atual e seu índice slave_id.
//--- Calc grad by main { float value = IsNaNOrInf(scores[RCtoFlat(slave, head, total_slaves, total_heads, main)], 0); int slave_id = (int)indexes[RCtoFlat(main, slave, total_mains, total_slaves, 0)]; const float sc_gr = IsNaNOrInf( scores_gr[RCtoFlat(slave, head, total_slaves, total_heads, main)], 0);
O gradiente grad corresponde à diferença entre o coeficiente real e o valor esperado, multiplicada pelo gradiente de erro do coeficiente de atenção sc_gr na posição atual.
float grad = 0; for(uint d = 0; d < total_slaves; d += ls) { if(slave >= d && slave < (d + ls)) Temp[slave - d] = IsNaNOrInf(sc_gr, 0); BarrierLoc; for(uint l = 0; l < min(ls, (uint)(total - d)); l++) grad += IsNaNOrInf(Temp[l] * ((float)((d + l) == slave && slave_id == main) - value), 0); BarrierLoc; }
A agregação local por meio de Temp, seguida da redução com LocalSum, viabiliza um somatório paralelo e eficiente, minimizando a latência ao trabalhar com grandes conjuntos de dados.
grad = LocalSum(grad, 1, Temp); if(slave == 0) data_gr[RCtoFlat(main, head, total_mains, 2 * total_heads, 0)] = grad; }
O resultado obtido é salvo no buffer global por apenas um work-item, evitando condições de corrida.
O segundo bloco é responsável pelo cálculo dos gradientes em relação aos vizinhos. Aqui, é importante lembrar que, em tese, cada vizinho participa do cálculo do respectivo coeficiente de atenção, ainda que nulo, para cada nó. Por isso, usamos main como índice do vizinho analisado e implementamos um laço que percorre todos os nós.
//--- Calc grad by slave { float grad = 0; for(uint d = 0; d < total_mains; d++) { float value = IsNaNOrInf(scores[RCtoFlat(slave, head, total_slaves, total_heads, d)], 0); const float sc_gr = IsNaNOrInf( scores_gr[RCtoFlat(slave, head, total_slaves, total_heads, d)], 0); int slave_id = (int)indexes[RCtoFlat(d, slave, total_mains, total_slaves, 0)];
Cada work-item verifica se o índice atual corresponde ao nó-vizinho e adiciona sua contribuição ao gradiente total. As barreiras locais e a soma por meio de Temp garantem que todos os work-items participem da agregação de forma coordenada.
float gr = IsNaNOrInf(sc_gr * ((float)(slave_id == d) - value), 0); gr = LocalSum(gr, 1, Temp); if(slave == 0) grad += gr; } if(slave == 0) data_gr[RCtoFlat(main, head + total_heads, total_mains, 2 * total_heads, 0)] = IsNaNOrInf(grad, 0); } }
Os resultados são gravados no buffer global data_gr para a atualização posterior dos parâmetros do modelo. Essa abordagem permite propagar corretamente o erro mesmo com uma estrutura de atenção esparsa, em que muitos elementos têm peso zero, sem comprometer a integridade dos cálculos.
Além disso, essa implementação aproveita os recursos paralelos da GPU. Cada work-item trabalha com um subconjunto independente de dados, enquanto a memória local e as barreiras minimizam conflitos e garantem consistência. Isso é especialmente importante no treinamento de modelos sobre grafos grandes, com milhares de nós, em que o cálculo sequencial tradicional dos gradientes seria lento demais e consumiria recursos em excesso.
De modo geral, o kernel SparseMHScoresGrad demonstra como é possível implementar com eficiência a retropropagação do erro para a atenção esparsa multicabeça, combinando precisão, preservação da esparsidade e alta eficiência computacional.
Com isso, podemos encerrar a etapa de implementação no programa OpenCL. A atenção esparsa multicabeça foi adaptada ao contexto paralelo, desde a propagação para frente, com o cálculo dos coeficientes, até a distribuição dos gradientes na propagação reversa. Garantimos uma interação correta e eficiente entre os nós e seus vizinhos, preservamos a estrutura esparsa para economizar memória e recursos computacionais e mantivemos a precisão dos gradientes para o treinamento posterior do modelo. Agora o algoritmo está pronto para ser integrado ao restante do programa MQL5.
Objeto de atenção multicabeça
Nesta etapa, integramos todos os componentes desenvolvidos anteriormente em uma estrutura unificada no programa principal. Para isso, criamos a classe CNeuronSNSMHAttention. Ela herda a funcionalidade básica da camada convolucional de CNeuronConvOCL e combina dois módulos-chave: Significant Neighbors Sampling e Sparse Spatial Multi-Head Attention. Essa classe funciona como núcleo computacional: reúne a seleção dos vizinhos significativos, a geração das projeções e o cálculo dos coeficientes de atenção, garantindo o funcionamento coeso da arquitetura.
class CNeuronSNSMHAttention : public CNeuronConvOCL { float fSparse; //--- CNeuronBaseOCL cNeighbors; CNeuronBaseOCL cRamdomCandidates; CNeuronConvOCL cProjection[2]; CNeuronBaseOCL cScores; //--- virtual bool SignificantNeighborsSampling(CNeuronBaseOCL *NeuronOCL); virtual bool SparseMHScores(void); virtual bool SparseMHScoresGrad(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSNSMHAttention(void) {}; ~CNeuronSNSMHAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint heads, uint m_units, float sparse, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronSNSMHAttention; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
A classe contém vários objetos internos, cada um deles com uma função especializada.
- cNeighbors e cRamdomCandidates processam os candidatos a vizinhos. O primeiro lida com os candidatos mais significativos, enquanto o segundo trata os candidatos aleatórios. Isso preserva a diversidade da amostra e evita que o modelo fique preso a padrões locais muito específicos dos dados.
- Os objetos cProjection geram as projeções dos embeddings originais no espaço de consultas e chaves, servindo de base para os cálculos posteriores da atenção multicabeça.
- cScores acumula os coeficientes de atenção calculados, transformando-os em uma matriz esparsa de influência, que será usada na etapa de convolução em grafos.
- O parâmetro fSparse define o coeficiente de esparsidade da atenção, permitindo controlar o equilíbrio entre a precisão preditiva e a carga computacional, especialmente ao trabalhar com grandes séries temporais.
Nesta etapa, é importante destacar que todos os objetos internos da classe CNeuronSNSMHAttention são declarados como estáticos. Com isso, o construtor e o destrutor da classe podem permanecer vazios. Essa estrutura simplifica a gestão da memória e torna a inicialização da camada mais previsível. O método Init configura a arquitetura da camada neural, combina seus elementos e define os parâmetros necessários.
bool CNeuronSNSMHAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint window, uint heads, uint m_units, float sparse, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!sparse >= 1 || sparse < 0) return false; fSparse = sparse; //--- if(!CNeuronConvOCL::Init(numOutputs, myIndex, open_cl, heads, heads, 1, units * m_units, 1, optimization_type, batch)) return false;
O método começa validando o coeficiente de esparsidade sparse. Se o valor estiver fora da faixa permitida [0, 1), a função retorna false imediatamente e evita erros posteriores de configuração. Depois disso, o parâmetro fSparse é salvo para uso nos cálculos dos coeficientes de atenção.
Em seguida, o método inicializa a classe base e define os parâmetros básicos do objeto.
Aqui vale esclarecer que, neste caso, a classe base não se limita à criação de interfaces básicas. Ela é um objeto completo do nosso modelo e executa a convolução de atenção multicabeça.
Após a inicialização básica, o método configura os objetos internos etapa por etapa. Primeiro, inicializa o módulo cNeighbors, responsável pelo processamento dos vizinhos mais significativos.
int index = 0; if(!cNeighbors.Init(0, index, OpenCL, units * m_units, optimization, iBatch)) return false; CBufferFloat* temp = cNeighbors.getOutput(); if(!temp || !temp.Random(0, (float)(units - 1))) return false;
Na etapa inicial, preenchemos o buffer de resultados do objeto com índices aleatórios de vizinhos, garantindo a diversidade da amostra.
O módulo cRamdomCandidates segue a mesma lógica e armazena candidatos aleatórios para ampliar a amostra.
index++; if(!cRamdomCandidates.Init(0, index, OpenCL, units * m_units, optimization, iBatch)) return false; temp = cRamdomCandidates.getOutput(); if(!temp || !temp.Random(0, (float)(units - 1))) return false;
Essa abordagem cria um mecanismo híbrido de seleção de vizinhos, combinando elementos significativos e aleatórios.
Em seguida, o método inicializa dois objetos do array cProjection, que geram as projeções dos embeddings originais nos espaços de consultas e chaves. O primeiro objeto recebe a função de ativação SoftPlus; o segundo, TANH. Isso cria uma transformação não linear e permite que o modelo considere interações complexas entre os elementos.
index++; if(!cProjection[0].Init(index, 0, OpenCL, window, window, 2 * heads, units, 1, optimization, iBatch)) return false; cProjection[0].SetActivationFunction(SoftPlus); index++; if(!cProjection[1].Init(index, 0, OpenCL, 2 * heads, 2 * heads, 2 * heads, units, 1, optimization, iBatch)) return false; cProjection[0].SetActivationFunction(TANH); index++; if(!cScores.Init(0, index, OpenCL, units * m_units * heads, optimization, iBatch)) return false; //--- return true; }
Por fim, o método inicializa o objeto cScores, que acumula os coeficientes de atenção esparsos e gera a matriz final de influência, usada na convolução em grafos.
De modo geral, o método Init inicializa a camada por etapas e configura corretamente todos os seus componentes. Ele atribui a cada objeto os tamanhos, as funções de ativação e os parâmetros necessários para operar em uma arquitetura integrada. Essa abordagem torna a camada flexível e escalável, permitindo adaptá-la a diferentes configurações de dados, números de cabeças de atenção e tamanhos de amostra de vizinhos, sem perder eficiência computacional nem precisão.
O método feedForward executa a propagação para frente dos dados pela arquitetura unificada do módulo e garante a interação sequencial dos componentes internos. Primeiro, chama SignificantNeighborsSampling, que gera os arrays de índices dos vizinhos significativos. Se essa etapa falhar, a função retorna false imediatamente, evita cálculos subsequentes e preserva a consistência do estado da camada.
bool CNeuronSNSMHAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!SignificantNeighborsSampling(NeuronOCL)) return false;
Após a seleção bem-sucedida dos vizinhos, a variável local inputs recebe o ponteiro para o objeto de dados originais NeuronOCL, que passa sequencialmente pelos blocos de projeção. O laço percorre cada elemento do array cProjection. Para cada elemento, chama seu método FeedForward, que aplica transformações lineares e não lineares ao tensor original e forma as projeções de consultas e chaves usadas na operação de atenção subsequente.
CNeuronBaseOCL* inputs = NeuronOCL; for(uint i = 0; i < cProjection.Size(); i++) { if(!cProjection[i].FeedForward(inputs)) return false; inputs = cProjection[i].AsObject(); }
Após o processamento de cada bloco, a entrada da etapa seguinte passa a apontar para a saída da etapa anterior, garantindo um fluxo contínuo de dados e uma transformação em cascata bem estruturada.
No passo seguinte, o método chama SparseMHScores, que calcula os coeficientes de atenção esparsos para todos os pares nó-vizinho, levando em conta o coeficiente de esparsidade fSparse.
if(!SparseMHScores()) return false; if(!CNeuronConvOCL::feedForward(cScores.AsObject())) return false; //--- return true; }
Os valores obtidos são acumulados e passados para a camada convolucional de agregação da atenção multicabeça, fornecida pela classe base. Nessa etapa, a transformação final gera os valores definitivos de saída da camada.
Todo o fluxo conduz os dados pelas etapas principais em ordem lógica: seleção dos vizinhos significativos, geração das projeções, cálculo dos coeficientes de atenção esparsos e agregação das informações. Essa organização melhora a legibilidade do código e facilita a integração de transformações ou otimizações adicionais sem comprometer a arquitetura geral. Ao final, o método retorna true, indicando que a propagação para frente foi concluída corretamente e que a camada está pronta para as etapas seguintes.
O método calcInputGradients distribui o gradiente de erro por todos os componentes internos da camada e pelos dados de entrada, garantindo a propagação reversa correta para o treinamento do modelo. Primeiro, verifica se o ponteiro para a camada anterior prevLayer é válido. Se ele estiver ausente, a função retorna false imediatamente e evita cálculos incorretos.
bool CNeuronSNSMHAttention::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
Em seguida, o método chama a versão homônima da classe base para distribuir os gradientes no nível da camada agregadora cScores.
if(!CNeuronConvOCL::calcInputGradients(cScores.AsObject())) return false; if(!SparseMHScoresGrad()) return false;
Depois disso, chama SparseMHScoresGrad, responsável por distribuir os gradientes pelos coeficientes de atenção esparsos gerados pelo módulo Sparse Spatial Multi-Head Attention. É nessa etapa que o método considera as particularidades da matriz esparsa de vizinhos e mantém a lógica operacional da arquitetura.
Em seguida, inicia-se um laço que percorre o array de projeções cProjection em ordem inversa, a partir do último bloco. Para cada projeção, o método define o objeto de entrada inputs: se não for o primeiro bloco, usa a saída do bloco anterior; caso contrário, usa prevLayer.
int total=(int)cProjection.Size(); CNeuronBaseOCL* inputs = NULL; for(int i = total-1; i >=0; i--) { inputs = (i>0 ? cProjection[i-1].AsObject() : prevLayer); if(!inputs.CalcHiddenGradients(cProjection[i].AsObject())) return false; } //--- return true; }
Para cada objeto, o método chama CalcHiddenGradients, que calcula os gradientes locais dos estados ocultos e considera todos os gradientes acumulados vindos do nível seguinte. Isso garante a propagação sequencial e correta do erro por todas as camadas intermediárias, preservando a consistência dos pesos e dos estados ocultos.
Assim, calcInputGradients executa uma propagação reversa completa pelo módulo unificado, distribuindo os gradientes pelos coeficientes de atenção esparsos e por todas as camadas de projeção. Com isso, prepara o sistema para a etapa posterior de otimização.
O método updateInputWeights atualiza sequencialmente os pesos de todos os componentes internos da camada após a distribuição dos gradientes de erro. Ele otimiza o modelo com base nos gradientes calculados e aplica as alterações a cada elemento da arquitetura.
bool CNeuronSNSMHAttention::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL* inputs = NeuronOCL; for(uint i = 0; i < cProjection.Size(); i++) { if(!cProjection[i].UpdateInputWeights(inputs)) return false; inputs = cProjection[i].AsObject(); }
Primeiro, o método declara um ponteiro local inputs para o objeto de dados de entrada, que inicialmente aponta para a camada externa NeuronOCL. Em seguida, percorre todos os blocos de projeção cProjection. Para cada bloco, chama UpdateInputWeights, que aplica os gradientes calculados aos pesos do bloco atual. Se a atualização dos pesos falhar em qualquer etapa, o método retorna false imediatamente e evita um estado inconsistente do modelo. Após a atualização bem-sucedida do bloco, o ponteiro inputs passa a apontar para a saída da projeção atual, para que o bloco seguinte a receba corretamente como entrada.
Ao final do laço, o método chama a versão homônima da classe base, que atualiza os pesos da camada agregadora de atenção multicabeça e garante a consistência entre todos os níveis do modelo. Essa etapa é essencial para manter o funcionamento correto dos coeficientes de atenção esparsos e preservar a influência de cada vizinho selecionado na previsão final.
if(!CNeuronConvOCL::updateInputWeights(cScores.AsObject())) return false; //--- return true; }
Por fim, o método retorna true, sinalizando que a otimização dos pesos foi concluída com sucesso para todos os componentes internos do módulo.
Em conjunto, o objeto CNeuronSNSMHAttention combina os algoritmos de seleção de vizinhos e atenção multicabeça em uma estrutura única, clara, escalável e flexível.
O trabalho de hoje foi intenso e produtivo. Aprofundamos a implementação dos módulos Significant Neighbors Sampling e Sparse Spatial Multi-Head Attention. Analisamos suas características de arquitetura e examinamos em detalhes os mecanismos de propagação para frente, propagação reversa e otimização dos pesos. Agora vale fazer uma pausa para assimilar o conteúdo e preparar a próxima etapa.
No próximo artigo, retomaremos o trabalho para concluir essa implementação. Também testaremos o modelo desenvolvido em dados históricos, avaliaremos sua robustez e a precisão das previsões, além de demonstrar a aplicabilidade prática da abordagem proposta em séries temporais financeiras reais.
Conclusão
Neste artigo, examinamos em detalhes a implementação prática dos módulos-chave do framework SAGDFN usando MQL5 e OpenCL. Analisamos a seleção de vizinhos significativos por meio do Significant Neighbors Sampling, a atenção esparsa multicabeça e a propagação eficiente para frente e reversa dentro de uma camada neural unificada. Demos atenção especial à otimização dos cálculos e mostramos como a reutilização dos pesos treináveis e a normalização esparsa reduzem significativamente a pressão sobre a memória e aceleram o processamento dos dados.
Como resultado, a arquitetura criada oferece, ao mesmo tempo, alta precisão das previsões e eficiência computacional, tornando o modelo adequado para trabalhar com uma grande quantidade de séries temporais.
Referências
- SAGDFN: A Scalable Adaptive Graph Diffusion Forecasting Network for Multivariate Time Series Forecasting
- Outros artigos da série
Programas usados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Study.mq5 | EA | EA para treinamento offline de modelos |
| 2 | StudyOnline.mq5 | EA | EA para treinamento online de modelos |
| 3 | Test.mq5 | EA | EA para testar o modelo |
| 4 | Trajectory.mqh | Biblioteca de classes | Estrutura de descrição do estado do sistema e da arquitetura dos modelos |
| 5 | NeuroNet.mqh | Biblioteca de classes | Biblioteca de classes para criação da rede neural |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/19370
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Caminhe em novos trilhos: Personalize indicadores no MQL5
Caminhe em novos trilhos: Personalize indicadores no MQL5
 Está chegando o novo MetaTrader 5 e MQL5
Está chegando o novo MetaTrader 5 e MQL5
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso