
Redes neurais em trading: Desvendando os componentes estruturais da série (SCNN)

Introdução
A previsão de séries temporais multivariadas é uma tarefa fundamental em machine learning. É justamente por essa perspectiva que se analisa uma ampla variedade de aplicações práticas: da estimativa de demanda e previsões de tráfego ao reconhecimento do comportamento dos participantes do mercado e dos movimentos das cotações. No setor financeiro, isso é especialmente relevante, pois praticamente qualquer ativo, seja uma ação, uma moeda ou uma commodity, representa uma série temporal complexa com muitos fatores inter-relacionados: volumes, preços, indicadores, dados macroeconômicos, sinais comportamentais e assim por diante.
A principal dificuldade dessas previsões está em capturar padrões espaço-temporais. Os aspectos espaciais se manifestam nas particularidades do ambiente externo: diferenças de liquidez, sessões de negociação e atividade regional. Já os padrões temporais estão ligados aos ritmos dos próprios mercados: ciclos de negociação, choques de notícias e periodicidade dos dados macroeconômicos. Na prática, as séries financeiras distam muito de ser estacionárias. Elas estão sujeitas a mudanças bruscas, mudanças na distribuição e transições complexas entre fases: tendências, lateralização, pânico e euforia. Além disso, as dependências de autocorrelação são instáveis: o que funciona hoje pode deixar de ter qualquer validade amanhã.
Métodos modernos baseados em redes neurais, como transformers, redes recorrentes e arquiteturas convolucionais, não exigem a hipótese de estacionariedade e já comprovaram sua eficácia em tarefas de previsão de curto prazo. No entanto, no mercado real, eles geralmente demonstram robustez apenas diante de padrões conhecidos. Ao se depararem com deslocamentos repentinos, seja um colapso da liquidez ou uma mudança no padrão de comportamento dos participantes, sua precisão cai drasticamente. Além disso, esses modelos continuam sendo, em essência, caixas pretas com alta carga computacional e interpretabilidade limitada.
Nesse contexto, a ideia de decomposição de séries temporais vem atraindo cada vez mais atenção, isto é, a separação das séries em tendência, sazonalidade e oscilações residuais. Essa abordagem permite simplificar a estrutura da tarefa, aumentar a adaptabilidade do modelo e deixar mais claro em que a previsão se baseia. Em alguns casos, mesmo modelos lineares simples que usam decomposição superam redes neurais complexas em precisão e estabilidade.
No entanto, é preciso reconhecer que esses métodos também têm limitações. Muitos deles se concentram exclusivamente nos componentes de longo prazo e sazonais, ignorando segmentos de curta duração ou voláteis, nos quais se concentram justamente os principais sinais de mercado. Além disso, o processamento isolado dos componentes sem troca de informações entre eles dificulta a captura de interações de alto nível e não lineares. O uso de parâmetros estáticos mostra-se ineficiente diante da dinâmica das dependências de autocorrelação, já que as configurações ideais do modelo precisam se ajustar dinamicamente ao estado atual do mercado.
Para superar essas dificuldades, no trabalho "Disentangling Structured Components: Towards Adaptive, Interpretable and Scalable Time Series Forecasting", foi apresentada uma nova arquitetura: Structured Component Neural Network (SCNN). Trata-se da primeira rede neural desse tipo, inteiramente construída sobre a decomposição estrutural de séries temporais. A ideia central da SCNN é decompor estrategicamente os dados em vários componentes heterogêneos: não apenas tendências de longo prazo e oscilações sazonais, mas também segmentos voláteis que mudam rapidamente. Cada grupo é processado por uma sub-rede especializada, ajustada à sua própria dinâmica. Com essa abordagem, o modelo se torna mais sensível às mudanças nas condições de mercado, enquanto seu funcionamento fica mais claro e transparente.
O diferencial da SCNN está no fato de que a decomposição e a montagem são integradas à própria estrutura da rede neural, em vez de ficarem restritas apenas às etapas de entrada e saída. Essa arquitetura permite não só decompor os dados em profundidade, mas também identificar interações complexas entre os componentes, incluindo relações cruzadas e dependências latentes. Além disso, cada módulo da rede é estruturado em um esquema de duas ramificações: uma ramificação adapta dinamicamente os parâmetros do modelo às condições atuais do mercado, enquanto a segunda usa esses parâmetros para processar atributos ocultos. Em essência, o modelo se reconfigura em tempo real, ajustando-se à estrutura atual da autocorrelação.
Para aumentar ainda mais a robustez e a capacidade de generalização da SCNN, os autores do framework integraram um mecanismo especial de regularização estrutural. Isso ajuda o modelo a concentrar a atenção nos componentes da série temporal menos sujeitos a ruído e distorções. Desse modo, mesmo em um ambiente de mercado instável, no qual alguns padrões rapidamente perdem validade e outros surgem de repente, a SCNN mantém alta precisão e confiabilidade.
A confirmação vem dos resultados de uma ampla validação experimental conduzida pelos autores do framework em três datasets independentes. A SCNN demonstrou consistentemente superioridade em relação aos concorrentes, especialmente em condições de mudanças bruscas na distribuição e anomalias nos dados. O mais importante é que tudo isso é alcançado com uma carga computacional razoável, o que torna o modelo aplicável tanto a cálculos locais quanto à integração em sistemas de trading.
Algoritmo SCNN
Em seu trabalho, os autores do framework SCNN partem da hipótese de que a série temporal é formada em etapas, de perturbações aleatórias a estruturas de mercado complexas.
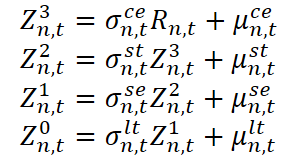
Aqui, Z⁰n,t é o valor inicial da série temporal observada (por exemplo, o preço ou o volume de uma operação), enquanto Zⁱn,t, para i = 1, 2, 3, são representações intermediárias em diferentes níveis da estrutura Rn,t é a componente residual, que inclui ruídos ou outliers inesperados. Cada estágio inclui tanto um coeficiente multiplicativo σ, que reflete a influência de escala, quanto um deslocamento aditivo µ, correspondente a ajustes absolutos.
Para entender intuitivamente essa construção, vamos recorrer a uma analogia com a análise de dados de mercado. Imagine a dinâmica do preço de um ativo. O componente de longo prazo reflete deslocamentos fundamentais. Pode ser a influência das taxas de juros ou mudanças estruturais na economia. O componente sazonal corresponde a padrões recorrentes associados a divulgação de resultados trimestrais, períodos fiscais ou hábitos de grandes participantes do mercado. O componente de curto prazo captura oscilações locais provocadas, por exemplo, pela divulgação de notícias, pelo aumento da atividade de negociação ou por uma escassez temporária de liquidez. A camada coevolutiva modela eventos de mercado síncronos, por exemplo, quando várias ações de um mesmo setor reagem a uma mesma notícia macroeconômica. O componente residual corresponde a ruído branco ou valores atípicos provocados, por exemplo, por ordens isoladas de grande volume ou erros de cotação.
É importante entender que, em condições reais de mercado, as fronteiras entre essas camadas são bastante fluidas. Por exemplo, um aumento brusco no volume negociado de determinada ação pode, a princípio, ser percebido como um valor atípico, mas, se persistir, já se torna uma tendência de curto prazo. E, se persistir por semanas, com o tempo passa a fazer parte da estrutura de longo prazo. Essa evolução dos padrões exige dos modelos flexibilidade e capacidade de adaptação à estrutura mutável dos dados.
Nessa estrutura, cada componente exerce tanto um efeito multiplicativo quanto um efeito aditivo. O efeito multiplicativo permite modelar variações proporcionais. O efeito aditivo, por sua vez, reflete deslocamentos constantes, como o impacto persistente de dividendos corporativos ou de taxas sazonais que não dependem do nível atual do preço. É justamente a combinação desses dois efeitos que permite modelar os dados de mercado da forma mais realista possível. Afinal, em alguns casos, o fator decisivo é a mudança relativa; em outros, é a magnitude absoluta.
O componente de longo prazo serve para identificar padrões estruturais estáveis da série temporal, como o crescimento sustentado dos volumes de negociação ou a expansão da atividade de mercado em meio a um ciclo de alta econômica. Por padrão recorrente, entendemos não apenas uma sequência cronológica, mas especificamente a forma da distribuição dos dados agregados, sem estar atrelada a pontos temporais específicos. Assim, a estrutura de longo prazo é definida pelo perfil estatístico dos dados coletados ao longo de um período extenso, que abrange vários ciclos de sazonalidade.
A ideia é simples: ao combinar observações de diferentes períodos sazonais, é possível suavizar as oscilações de curto prazo e obter uma estimativa mais limpa e com baixo nível de ruído das tendências estáveis. Essa abordagem permite evitar o sobreajuste a anomalias temporais, como picos pontuais de volume ou correções breves, e concentrar-se na dinâmica fundamental do mercado.
Para implementar essa abordagem, utiliza-se uma janela deslizante com comprimento ∆, que permite selecionar dinamicamente as observações em cada passo de tempo. Em seguida, são calculados dois parâmetros estatísticos centrais: a média (ou centro da distribuição) e o desvio padrão (que caracteriza a escala das oscilações). Ambos os parâmetros são usados em conjunto para construir uma representação do componente de longo prazo. Depois disso, cada novo segmento analisado é normalizado: subtrai-se dele a média de longo prazo, e o resultado é dividido pelo desvio padrão. Isso coloca todos os segmentos em uma escala comum, removendo deslocamentos de longo prazo e preparando os dados para a próxima etapa da decomposição.
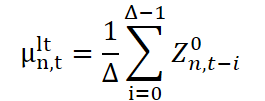
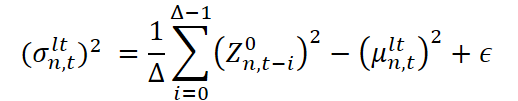
Aqui, μˡᵗn,t e σˡᵗn,t são, respectivamente, a média de longo prazo e a escala (desvio padrão), obtidas a partir dos dados da janela ∆. Já Z¹n,t é o valor normalizado, sem o componente de longo prazo, que é passado para o próximo nível de processamento, no qual a sazonalidade será isolada.
Essa etapa pode ser interpretada como uma representação alinhada do mercado, na qual as tendências estruturais estáveis já foram consideradas. Isso é especialmente importante na previsão financeira, em que estratégias de curto prazo (por exemplo, intraday) precisam de dados limpos de deslocamentos de longo prazo para identificar oportunidades locais sem distorções causadas por tendências globais.
O componente sazonal é responsável por identificar padrões cíclicos recorrentes da série temporal. No contexto dos mercados financeiros, esses padrões podem ser, por exemplo, picos intraday de atividade de negociação: surtos pela manhã, calmaria no horário do almoço, aceleração no fim do dia antes do encerramento da sessão. Também pode haver ciclicidade semanal: queda da volatilidade na sexta-feira ou aumento dos volumes às segundas-feiras, bem como efeitos sazonais trimestrais e anuais associados a divulgações de resultados ou publicações macroeconômicas.
Parte-se do pressuposto de que o comprimento do ciclo sazonal permanece constante ao longo do tempo. Trata-se de uma hipótese simplificada, mas prática. Ainda assim, para cenários com comprimento de ciclo variável, os autores do framework propõem integrar uma estimativa automática da sazonalidade usando FFT (transformada rápida de Fourier).
Do ponto de vista técnico, a extração do componente sazonal segue uma lógica semelhante à normalização de longo prazo, mas com uma diferença importante: utiliza-se uma janela esparsa (dilated window), cujo passo corresponde ao comprimento do ciclo. Seja τ o tamanho da janela, e m o coeficiente de esparsidade (na prática, o comprimento do ciclo). Isso permite percorrer os dados em intervalos correspondentes à estrutura sazonal.
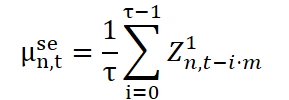
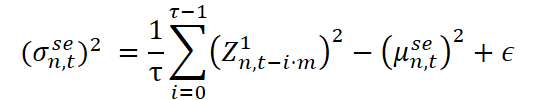
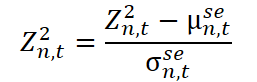
Aqui, Z²n,t são os dados normalizados, limpos da sazonalidade, que são transmitidos à próxima etapa de processamento.
O componente de curto prazo é responsável por capturar desvios locais e irregulares que não são explicados nem por tendências de longo prazo nem por padrões sazonais. Nas condições do mercado financeiro, esses efeitos podem ser causados por uma reação repentina a uma notícia inesperada, falhas técnicas, surtos especulativos de liquidez ou uma mudança brusca no sentimento dos traders em meio à volatilidade. Trata-se de uma espécie de pulsação do mercado, que reflete sua sensibilidade a estímulos externos em intervalos de tempo muito curtos.
Ao contrário da normalização de longo prazo, aqui é usada uma pequena janela de suavização para evitar a suavização excessiva das oscilações de curta duração. Seja δ o comprimento dessa janela. Com base nela, são calculadas as características estatísticas padrão: o centro e a escala da amostra; depois, os dados são normalizados.
O valor obtido Z³n,t constitui uma representação intermediária, depurada das flutuações de curta duração, e é encaminhado adiante, para a etapa final de normalização.
No entanto, esse componente tem suas próprias limitações. Em primeiro lugar, ele não consegue reagir instantaneamente a mudanças repentinas e bruscas, pois o modelo apresenta comportamento inercial. Em segundo lugar, se a mudança durar apenas dois ou três passos de tempo, ela pode passar despercebida, especialmente em condições de alta dispersão. Isso lembra uma situação de mercado em que a volatilidade de curta duração em uma ação pode ser ignorada pelo sistema como um todo se seu sinal se diluir no ruído agregado.
Para suavizar esse efeito e aumentar a sensibilidade do modelo a sinais de curto prazo, a SCNN prevê o uso de séries temporais coevolutivas (co-evolving). Ou seja, se for observado um desvio em um instrumento, o modelo verifica sinais síncronos em outros ativos, como instrumentos derivativos, índices ou volumes. Assim, o componente de curto prazo se torna não apenas reativo, mas também contextual, o que é especialmente importante em condições de trading de alta frequência e algorítmico.
O componente coevolutivo ocupa um lugar especial na estrutura geral do modelo. Ao contrário dos três componentes anteriores, que analisam o comportamento de cada série temporal de forma isolada, essa parte do modelo se apoia em correlações espaciais e permite capturar mudanças instantâneas que se manifestam de forma síncrona em várias séries temporais. Se duas ou mais séries temporais demonstram dinâmica semelhante nos mesmos instantes de tempo, isso indica, com alta probabilidade, a presença de um processo gerador comum. Nesse caso, é possível estimá-lo agregando as observações correspondentes.
No entanto, para implementar essa abordagem, é necessário resolver uma tarefa central: determinar exatamente quais séries participam desse processo conjunto. Isso equivale a medir a correlação entre as séries temporais. Aqui há duas abordagens possíveis: fixar previamente a matriz de correlações com base em conhecimento de especialistas ou treiná-la diretamente a partir dos dados. Os autores do framework escolheram o segundo caminho, mais flexível e universal, especialmente quando não há informação a priori sobre a estrutura dos dados.
Para cada par de séries temporais n e n', é calculado um coeficiente de atenção individual, que depois é normalizado por meio da função SoftMax. Isso garante que a soma dos pesos para cada série seja igual a 1.
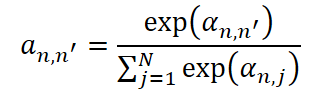
Usando esses pesos, calculamos os parâmetros do componente coevolutivo. Primeiro, calcula-se a média, que reflete a centragem local levando em conta as relações entre as séries.
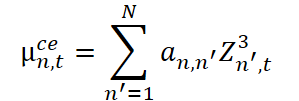
Em seguida, estima-se a escala (desvio padrão) com a adição da constante estabilizadora ϵ.
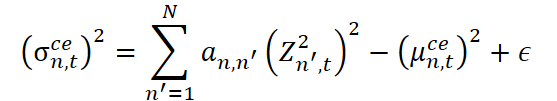
Com base nisso, forma-se o resíduo normalizado.
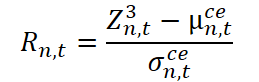
Esse resíduo Rn,t representa a parte do sinal que não é explicada por nenhum dos componentes já isolados. Ele reflete a incerteza residual, o ruído estrutural ou desvios específicos e não formalizáveis de uma série específica em relação à dinâmica geral.
Quando se trabalha com um grande número de séries temporais, é possível aumentar ainda mais a escalabilidade do modelo. Para isso, propõe-se usar um módulo de treinamento da matriz de adjacência, que permite ajustar com flexibilidade a arquitetura de atenção e otimizar os cálculos.
Na etapa final, todas as representações intermediárias são combinadas em um único vetor de features.
![]()
Em paralelo, forma-se um vetor auxiliar de parâmetros de normalização.
![]()
Assim, a série temporal deixa de ser apenas um conjunto de números fixados no tempo. Ela se transforma em uma representação de múltiplos componentes, em que cada parte corresponde a um tipo específico de dinâmica: tendência estrutural, oscilações sazonais recorrentes, flutuações locais de curta duração ou mudanças coletivas síncronas. Isso permite analisar os dados com mais precisão, construir modelos interpretáveis e desenvolver algoritmos de previsão robustos.
Como cada componente apresenta sua própria dinâmica em graus diferentes de previsibilidade, surge a necessidade natural de modelar seu comportamento separadamente. Isso é especialmente relevante na previsão de curto prazo, quando os componentes de longo prazo e sazonais, em geral, mantêm comportamento estável e mudam segundo padrões bastante regulares. Nessas condições, eles podem continuar a ser extrapolados diretamente, sem a necessidade de introduzir parâmetros adicionais ou modelos mais complexos.
Assim, para o componente de longo prazo, aplica-se a técnica mais simples: assume-se que seus valores permanecem inalterados ao longo de todo o horizonte de previsão. Ou seja, se as estimativas atuais dos parâmetros desse componente são conhecidas, basta copiá-las para o futuro.
O componente sazonal, por sua vez, se apoia na periodicidade e exige uma abordagem um pouco mais refinada. Como a ciclicidade se mantém, reutilizamos os valores dos parâmetros de instantes de tempo anteriores que estão na mesma fase do ciclo que o ponto a ser previsto. Em outras palavras, os valores do componente sazonal para o momento t+i são obtidos no momento t-m+i, em que m é o comprimento do ciclo.
Esse método preserva o ritmo sazonal e permite extrapolar o comportamento do componente com alta precisão, sem carga computacional adicional para o modelo.
Ao contrário do componente de longo prazo e do componente sazonal, o componente de curto prazo, as dependências coevolutivas e as representações residuais têm uma estocasticidade muito maior. Sua dinâmica é significativamente menos regular, o que torna impossível usar heurísticas fixas ou leis de extrapolação rigidamente definidas. Por isso, para cada um desses três componentes, os autores do framework aplicam um modelo parametrizado baseado em autorregressão, o que permite capturar suas oscilações complexas e imprevisíveis.
Para cada instante de tempo i do horizonte de previsão, os valores dos componentes correspondentes são calculados com base nos δ valores anteriores, por meio de um modelo linear com pesos treináveis. O procedimento de extrapolação é o mesmo para os componentes de curto prazo, componente coevolutivo e componente residual, e é expresso da seguinte forma:
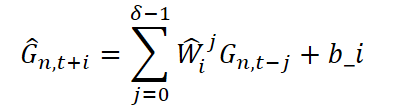
em que G ∈ {Zˡn,t+i, μstn,t+i, σstn,t+i,μcen,t+i, σcen,t+i} são os parâmetros extrapolados correspondentes aos diferentes componentes; Ŵji ∈ Rdz · dz são matrizes de pesos treináveis, que refletem a contribuição dos valores passados; bi é o viés (bias), também treinável.
Após a extrapolação, todos os componentes são combinados em dois vetores:
- Ĥn, t+i é o agregado de parâmetros estatísticos;
- Źn, t+i é o conjunto das representações normalizadas.
Para modelar a interação entre esses dois conjuntos de features, aplica-se uma operação de multiplicação pareada (produto elemento a elemento) de duas projeções lineares, cada uma formada com base em uma matriz de parâmetros treinável.
![]()
Assim, forma-se a representação final da previsão, que sintetiza todos os aspectos estatisticamente significativos do processo analisado.
Implementação em MQL5
Após a análise detalhada dos fundamentos teóricos do framework SCNN, passamos à sua implementação prática. Nesta seção, será apresentada uma das versões funcionais de implementação das ideias centrais do modelo em nível aplicado com MQL5. Vamos demonstrar como implementar a decomposição da série temporal em componentes estruturais e construir a parte preditiva do modelo, preservando sua interpretabilidade e modularidade. Essa abordagem abre caminho para a criação de estratégias de trading claras, flexíveis e adaptativas baseadas em arquiteturas neurais complexas.
Na primeira etapa da implementação do framework SCNN, vamos nos concentrar na construção do bloco básico: o algoritmo de extração das características estatísticas e de normalização dos dados de entrada por intervalos de tempo fixos. Essa etapa desempenha um papel central na decomposição da série temporal, pois é justamente nela que são formados os componentes de longo prazo e de curto prazo, que servirão de base para toda a previsão posterior.
O algoritmo é implementado como o kernel OpenCL PeriodNorm, responsável por calcular as características estatísticas e normalizar os dados dentro de janelas deslizantes da série temporal. A implementação baseia-se na ideia de processamento paralelo, em que os dados de todas as variáveis e janelas temporais são processados simultaneamente.
__kernel void PeriodNorm(__global const float* inputs, __global float2* mean_stdevs, __global float* outputs, const int total_inputs ) { const size_t i = get_global_id(0); const size_t p = get_local_id(1); const size_t v = get_global_id(2); const size_t windows = get_global_size(0); const size_t period = get_local_size(1); const size_t variable = get_global_size(2);
A função recebe o array de entrada inputs, além dos arrays usados para registrar os valores normalizados outputs e os parâmetros estatísticos calculados (médias e desvios padrão) mean_stdevs. Também é passado o parâmetro total_inputs, que define o comprimento da série temporal para uma variável.
A configuração dos fluxos de operações é tridimensional: a primeira coordenada corresponde ao número da janela (segmento temporal), a segunda à posição dentro da janela, e a terceira ao índice da variável. Assim, cada fluxo fica responsável por um elemento específico da série dentro de uma janela e para uma variável específicas.
Primeiro, são calculados os índices necessários para acessar corretamente os dados na memória. A variável shift_i define a posição do ponto atual em relação ao início da série temporal, shift_v define o deslocamento no eixo das variáveis, e shift_ms define a posição no array de estatísticas.
__local float Temp[LOCAL_ARRAY_SIZE]; const int shift_i = i * period + p; const int shift_v = v * total_inputs; const int shift_ms = v * windows + i;
Depois disso, o valor da série temporal é extraído do array original com uma verificação de valores inválidos: se forem encontrados NaN ou valores infinitos, eles são substituídos por zero.
//--- float val = 0; if((shift_i) < total_inputs) val = IsNaNOrInf(inputs[shift_v + shift_i], 0);
A próxima etapa é o cálculo da média dentro da janela atual. Para isso, usa-se a função auxiliar LocalSum, que permite somar os valores processados pelos work-items do grupo local, o que melhora significativamente o desempenho.
float mean = IsNaNOrInf(LocalSum(val, 1, Temp) / period, 0); val -= mean; BarrierLoc;
A média obtida é então subtraída da observação atual e, com base nisso, o desvio padrão é calculado como a raiz da média dos quadrados dos desvios. Todas as etapas contam com verificações internas de estabilidade numérica para evitar divisão por zero e acúmulo de erros.
float stdev = LocaSum(val * val, 1, Temp) / period; stdev = IsNaNOrInf(sqrt(stdev), 1);
Os resultados são salvos de duas formas: primeiro, as estatísticas de cada par janela-variável são registradas no array mean_stdevs; segundo, os valores normalizados são retornados no array outputs.
mean_stdevs[shift_ms] = (float2)(mean, stdev); if((shift_i) < total_inputs) outputs[shift_v + shift_i] = IsNaNOrInf(val / stdev, 0); }
A normalização é executada pela fórmula clássica da padronização Z, usando como fator de escala o desvio padrão calculado dinamicamente.
O kernel foi escrito de modo a escalar facilmente: é possível alterar o tamanho da janela, o número de variáveis ou a profundidade temporal da série sem alterar a lógica. Em particular, quando o comprimento da janela aumenta, a normalização se torna sensível a tendências de longo prazo e pode ser usada para extrair a tendência. Por outro lado, a redução da janela permite capturar com mais precisão desvios de curto prazo e anomalias.
Para implementar o modelo com um ciclo completo de treinamento, incluindo a retropropagação do erro, precisamos permitir a propagação do gradiente das saídas da arquitetura neural para suas entradas. Embora o kernel PeriodNorm não tenha parâmetros treináveis (todos os cálculos são estritamente estatísticos e baseados na série de entrada), os gradientes devem ser calculados se a normalização for executada como parte do grafo computacional. Por isso, complementamos a arquitetura com um segundo kernel, o PeriodNormGrad.
__kernel void PeriodNormGrad(__global const float* inputs, __global float* inputs_gr, __global const float2* mean_stdevs, __global const float2* mean_stdevs_gr, __global const float* outputs, __global const float* outputs_gr, const int total_inputs ) { const size_t i = get_global_id(0); const size_t p = get_local_id(1); const size_t v = get_global_id(2); const size_t windows = get_global_size(0); const size_t period = get_local_size(1); const size_t variable = get_global_size(2);
Ao contrário dos blocos clássicos com parâmetros treináveis, o algoritmo implementado no kernel PeriodNormGrad é voltado para a retropropagação correta do erro por uma camada que, por si só, não contém neurônios nem pesos. Antes de tudo, no kernel, configura-se o acesso específico a cada janela temporal da série para cada variável. Os índices são calculados da mesma forma que na propagação para frente:
- i, número da janela,
- p, posição dentro da janela,
- v, número da variável.
Depois de obter esses índices, extraímos todos os dados necessários: o valor original (inp), sua versão normalizada (out), o gradiente do erro em relação ao valor normalizado (out_gr), bem como a média e o desvio padrão previamente calculados na janela (mean_stdev) e seus respectivos gradientes (mean_stdev_gr), que podem ser obtidos adicionalmente em caso de reutilização múltipla desses valores. Em particular, o framework SCNN prevê seu uso para a extrapolação dos dados. Todos os valores passam por uma verificação de validade: NaN e valores infinitos são eliminados para não contaminar os cálculos.
__local float Temp[LOCAL_ARRAY_SIZE]; const int shift_i = i * period + p; const int shift_v = v * total_inputs; const int shift_ms = v * windows + i; //--- float inp = 0; float inp_gr = 0; float out = 0; float out_gr = 0; const float2 mean_stdev = means_stdevs[shift_ms]; const float2 mean_stdev_gr = means_stdevs_gr[shift_ms]; if((shift_i) < total_inputs) { inp = IsNaNOrInf(inputs[shift_v + shift_i], 0); out = IsNaNOrInf(outputs[shift_v + shift_i], 0); out_gr = IsNaNOrInf(outputs_gr[shift_v + shift_i], 0); }
Agora vem a parte mais interessante. Para entender o quanto cada valor original influenciou o erro final do modelo, precisamos calcular como o erro muda se esse valor for ligeiramente alterado. Em estatística, a normalização é feita pela subtração da média e pela divisão pelo desvio padrão. Portanto, qualquer mudança na entrada afetará tanto o numerador (o desvio em relação à média) quanto o denominador (o tamanho da dispersão dentro da janela). Por isso, é necessário calcular os gradientes em relação aos dois parâmetros: a média e o desvio padrão.
float mean_gr = LocalSum(out_gr, 1, Temp) / period + IsNaNOrInf(mean_stdev.x, 0); BarrierLoc; float stdev_gr = out * LocalSum(IsNaNOrInf(out * out_gr, 0), 1, Temp) / period + IsNaNOrInf(mean_stdev.y, 0);
Para isso, primeiro calcula-se a soma de todos os gradientes no nível dos resultados da camada, em out_gr na janela atual e se calcula sua média. Esse é justamente a contribuição para o gradiente em relação à média (mean_gr). Observe que aqui não estamos simplesmente propagando o gradiente diretamente: levamos em conta como a mudança da média afeta os valores normalizados em toda a janela.
Em seguida, o cálculo do gradiente em relação ao desvio padrão (stdev_gr) é um pouco mais complexo: aqui usamos o produto do valor médio pelo respectivo gradiente do erro, depois calculamos a média desse produto e, assim, obtemos a sensibilidade do erro à dispersão dos dados.
Agora, com esses dois gradientes, podemos passar ao cálculo do resultado principal: o gradiente em relação à própria entrada. Combinamos o gradiente vindo de out_gr com as derivadas em relação à média e ao desvio padrão. A fórmula final é balanceada e permite refletir com precisão a contribuição de cada valor de entrada para o erro geral do modelo, levando em conta sua posição na janela e sua influência sobre as características estatísticas agregadas.
inp_gr = (out_gr - mean_gr - stdev_gr) / IsNaNOrInf(mean_stdev.y, 1); //--- if((shift_i) < total_inputs) inpurs_gr[shift_v + shift_i] = IsNaNOrInf(inp_gr, 0); }
No final, como de costume, o valor obtido é gravado de volta no array de gradientes em relação à entrada (inputs_gr). Tudo é feito respeitando os limites: se o índice atual ficar fora dos limites do array, nenhuma operação é executada.
Assim, PeriodNormGrad não é apenas uma implementação meramente formal dos gradientes, mas uma importante ponte funcional entre a estatística clássica e os métodos modernos de treinamento de modelos. Ele permite que operações estatísticas participem plenamente do grafo computacional e do treinamento, propagando corretamente a informação do erro até o ponto em que ele surgiu.
No programa principal, criaremos uma classe especializada CNeuronPeriodNorm, destinada a encapsular a lógica de operação com os kernels OpenCL de normalização por períodos, tanto para a propagação para frente quanto para a propagação reversa. Ela herda da classe base CNeuronBaseOCL, o que indica seu pertencimento à hierarquia de componentes do modelo computacional. A estrutura do novo objeto é apresentada abaixo.
class CNeuronPeriodNorm : public CNeuronBaseOCL { protected: uint iPeriod; uint iVariables; uint iCount; CNeuronBaseOCL cMeanSTDevs; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return true; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronPeriodNorm(void) : iPeriod(-1), iVariables(1) {}; ~CNeuronPeriodNorm(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units_count, uint period, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual int Type(void) override const { return defNeuronPeriodNorm; } virtual void SetOpenCL(COpenCLMy *obj) override; //--- CNeuronBaseOCL* GetMeanSTDevs(void) { return cMeanSTDevs.AsObject(); } virtual uint GetPeriod(void) const { return iPeriod; } virtual uint GetVariables(void) const { return iVariables; } virtual uint GetUnits(void) const { return iCount; } };
Os campos internos da classe refletem os principais parâmetros de configuração. Em particular, a variável iPeriod define o comprimento da janela dentro da qual ocorre o processamento estatístico: cálculo da média e do desvio padrão. O parâmetro iVariables define o número de variáveis (ou features) processadas, enquanto iCount define o número de janelas independentes para cada sequência individual.
Além disso, a classe contém o objeto cMeanSTDevs, que representa um buffer intermediário no qual são armazenados os valores de médias e desvios padrão calculados na etapa de propagação para frente. Esse buffer também participa da propagação reversa dos gradientes, como foi implementado no kernel PeriodNormGrad.
O método Init funciona como um inicializador: ele recebe todos os parâmetros e, com base neles, prepara as estruturas internas e associa o objeto aos recursos OpenCL necessários.
Os métodos de propagação para frente e propagação reversa, em essência, funcionam como wrappers auxiliares. Sua tarefa não é recalcular os dados manualmente, mas preparar os recursos necessários para colocar corretamente os kernels OpenCL correspondentes na fila de execução.
Observe a função GetMeanSTDevs: ela fornece acesso ao buffer com as estatísticas calculadas, que pode ser usado por outros componentes do modelo, por exemplo, para visualização ou processamento posterior.
Assim, a classe CNeuronPeriodNorm representa um componente totalmente autônomo e flexível, que não apenas executa a normalização, mas também garante a integração adequada à estrutura do modelo computacional com suporte a treinamento. Tudo segue rigorosamente os padrões arquiteturais dos frameworks de redes neurais, mas preservando a lógica clara característica de sistemas com gerenciamento manual da computação, como MQL5 + OpenCL.
O código completo dessa classe, incluindo seus métodos, é apresentado em anexo para consulta e estudo.
Hoje realizamos um trabalho sério e produtivo. O material ficou bastante denso e exige tempo para assimilação. É um bom momento para fazer uma breve pausa, recuperar o fôlego e, com energia renovada, continuar no próximo artigo.
Conclusão
Neste artigo, conhecemos os aspectos teóricos do framework SCNN, que propõe uma abordagem original e conceitualmente consistente para a decomposição de séries temporais em componentes interpretáveis: de longo prazo, sazonal, de curto prazo e residual. Essa estrutura permite não apenas aumentar a precisão da previsão, mas também melhora significativamente a transparência do modelo, tornando seu comportamento mais previsível e adaptável às mudanças nas condições de mercado.
Dá-se ênfase especial à diferença na natureza da dinâmica de cada componente, o que determina o uso de métodos especializados de interpolação: para os componentes de longo prazo e sazonal, aplicam-se padrões recorrentes simples, enquanto as oscilações de curto prazo e residuais são modeladas por estruturas autorregressivas treináveis.
Na parte prática do artigo, começamos a implementar nossa própria visão das abordagens propostas e construímos um dos elementos básicos do modelo: o algoritmo de normalização de segmentos periódicos da série temporal. Examinamos os detalhes da implementação dos cálculos no lado do OpenCL, incluindo a propagação para frente e a propagação reversa, o que permitirá posteriormente incorporar esse mecanismo a uma arquitetura neural treinável. Esse passo se tornou um elo importante na adaptação prática do framework às tarefas de trading no ambiente MQL5.
No próximo artigo, continuaremos a desenvolver essa implementação, adicionando novos componentes do modelo e nos aproximando gradualmente de um sistema completo de análise e previsão de séries temporais com base no framework SCNN.
Referências
- Disentangling Structured Components: Towards Adaptive, Interpretable and Scalable Time Series Forecasting
- Outros artigos da série
Programas usados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Study.mq5 | EA | EA de treinamento offline de modelos |
| 2 | StudyOnline.mq5 | EA | EA de treinamento online de modelos |
| 3 | Test.mq5 | EA | EA para teste do modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura para descrever o estado do sistema e a arquitetura dos modelos |
| 5 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de uma rede neural |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/18950
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso