
Superando as limitações do aprendizado de máquina (Parte 1): carência de métricas compatíveis

Infelizmente, os perigos de seguir cegamente as "melhores práticas" comprometem silenciosamente outras ferramentas das quais dependemos em nossas estratégias de trading, e os profissionais não devem pensar que esse problema seja exclusivo dos indicadores técnicos.
Nesta série de artigos, examinaremos problemas críticos que os traders algorítmicos enfrentam diariamente, causados justamente por recomendações e práticas destinadas a protegê-los ao usar modelos de aprendizado de máquina. Em resumo, se os modelos de aprendizado de máquina implantados diariamente na nuvem MQL5 conhecerem os fatos apresentados nesta discussão antes dos profissionais responsáveis, os problemas serão inevitáveis. Os investidores podem descobrir rapidamente que estão expostos a um risco maior do que esperavam.
Para ser franco, esses problemas não recebem atenção suficiente nem mesmo nos principais livros de aprendizado estatístico do mundo. O ponto central da nossa discussão é uma verdade simples que todo profissional da nossa comunidade deve conhecer:
"É possível demonstrar analiticamente que a primeira derivada de métricas euclidianas de dispersão, como RMSE, MAE ou MSE, pode ser solucionada usando a média da variável-alvo".
Quem já conhece esse fato e suas consequências não precisa continuar a leitura.
No entanto, é justamente aos profissionais que não entendem o que isso significa que eu preciso transmitir este artigo com urgência. Em resumo, as métricas de regressão que usamos para construir nossos modelos não são adequadas para modelar os retornos dos ativos.
Neste artigo, você aprenderá como isso acontece, quais perigos isso representa para você e quais mudanças pode implementar para começar a usar esse princípio como uma bússola para filtrar mercados, tendo à sua disposição centenas de mercados potenciais nos quais pode operar.
Os profissionais que desejam obter demonstrações mais aprofundadas podem consultar materiais da Universidade Harvard que discute as limitações de métricas como RMSE. Em particular, o artigo de Harvard apresenta uma demonstração analítica de que a média amostral minimiza o erro quadrático médio. O leitor pode acessar o artigo pelo link aqui.
Outras instituições, como a Social Science Research Network (SSRN), mantêm uma base de artigos publicados e revisados por pares de diversas áreas, incluindo o artigo relevante para a nossa discussão, que investiga funções de perda alternativas para substituir a raiz do erro quadrático médio (RMSE) em tarefas de precificação de ativos. O artigo que selecionei para o leitor examina uma série de outros trabalhos nessa área, apresenta uma breve revisão da literatura atual e, em seguida, demonstra uma nova abordagem. O leitor pode encontrar esse artigo facilmente aqui.
Experimento mental (todos precisam entender isso)
Imagine que você está participando de uma competição semelhante a uma loteria. Você e outras 99 pessoas são escolhidos aleatoriamente para disputar um prêmio acumulado de 1 000 000 de dólares. As regras são simples: você precisa adivinhar a altura dos outros 99 participantes. O vencedor será quem tiver o menor erro total nas 99 tentativas.
Agora vem a parte inesperada: neste exemplo, imagine que a altura média de uma pessoa no mundo seja de 1,1 metro. Se você simplesmente usar a estimativa de 1,1 metro para todos, poderá de fato ganhar o jackpot, mesmo que cada previsão esteja tecnicamente errada. E por quê? Porque, em um ambiente ruidoso e incerto, estimar o valor médio tende a gerar o menor erro total.
O paralelo no trading
O objetivo desse experimento mental foi mostrar ao leitor, de forma clara, exatamente como a maioria dos modelos de aprendizado de máquina é selecionada para uso nos mercados financeiros.
Por exemplo, suponha que você esteja criando um modelo para prever os retornos do índice S&P 500. Um modelo que sempre prevê a média histórica do índice, cerca de 7% ao ano, pode, na prática, superar modelos mais complexos se for avaliado por métricas como RMSE, MAE ou MSE. Mas é aqui que está a armadilha: esse modelo não aprendeu nada de útil. Suas previsões simplesmente se concentravam em torno da média estatística. E, pior ainda, as métricas e os procedimentos de validação em que você confiava acabavam recompensando esse comportamento.
Nota para iniciantes: RMSE (raiz do erro quadrático médio) é uma métrica usada para avaliar a qualidade de modelos de aprendizado de máquina treinados para prever variáveis-alvo reais e relevantes.
Ela penaliza grandes desvios, mas não leva em conta o motivo pelo qual o modelo errou. No entanto, lembre-se de que alguns desses desvios pelos quais o modelo é penalizado, na verdade, geravam lucro.
Assim, um modelo que sempre prevê o retorno médio, mesmo sem ter qualquer compreensão do mercado, pode parecer excelente no papel quando avaliado pela RMSE. Infelizmente, isso nos permite criar modelos matematicamente fundamentados, mas inúteis na prática.
O que realmente acontece
Os dados financeiros são ruidosos. Não conseguimos observar variáveis essenciais, como a verdadeira relação global entre oferta e demanda, o sentimento dos investidores ou a profundidade do livro de ofertas no nível institucional. Assim, para minimizar o erro, seu modelo fará a escolha mais lógica do ponto de vista estatístico: prever o valor médio.
E o leitor precisa entender que, do ponto de vista matemático, essa é uma prática razoável. Prever o valor médio minimiza os erros de regressão mais comuns. Mas a essência do trading não está em minimizar o erro estatístico, e sim em tomar decisões lucrativas sob incerteza. E essa diferença importa. Em nossa comunidade, esse comportamento pode ser comparado ao overfitting, mas os estatísticos que desenvolveram esses modelos não enxergavam as coisas da mesma forma que nós.
Seria ingênuo acreditar que esse problema é exclusivo dos modelos de regressão. Em tarefas de classificação, um modelo pode minimizar erros simplesmente prevendo sempre a classe mais frequente na amostra de treinamento. E, se por acaso a classe majoritária do conjunto de treinamento corresponder à classe majoritária de toda a população, acredito que o profissional conseguirá perceber rapidamente como o modelo pode facilmente aparentar competência.
Reward hacking: quando os modelos vencem trapaceando
Esse fenômeno é chamado de "reward hacking": o modelo atinge o nível de desempenho desejado aprendendo um comportamento indesejado. No caso do trading, o reward hacking leva os profissionais a escolher um modelo que parece profissional, mas que, na realidade, apenas joga o jogo das médias, funcionando como um castelo de cartas estatístico. Você pensa que ele aprendeu alguma coisa, mas, na verdade, ele fez o equivalente estatístico da afirmação "a altura de todas as pessoas é 1,1 metro". E a RMSE aceita isso todas as vezes, sem questionar.
Evidências reais
Agora que nossa motivação está clara, vamos deixar as alegorias de lado e analisar dados reais de mercado. Usando a MetaTrader 5 Python API, acessei 333 mercados da minha corretora. Filtramos os mercados que tinham dados históricos reais de pelo menos quatro anos. Esse filtro reduziu nossa amostra para 119 mercados.
Em seguida, construímos dois modelos para cada mercado:
- Modelo de referência: sempre prevê o retorno médio de 10 dias.
- Modelo preditivo: tenta aprender padrões e prever retornos futuros.
Nossos resultados
Em 91,6% dos mercados testados, a vitória ficou com o modelo de referência. Em outras palavras, o modelo que sempre prevê o retorno médio histórico de 10 dias apresentou erro menor ao longo de um período de 4 anos em 91% dos casos! Como os profissionais verão em breve, mesmo quando testamos redes neurais mais profundas, a melhora foi insignificante.
Então, o profissional deve seguir as "melhores práticas" de aprendizado de máquina e sempre escolher o modelo que apresenta o menor erro, lembrando ao mesmo tempo se o modelo está apenas prevendo o retorno médio?
Nota para iniciantes: isso não significa que o aprendizado de máquina não possa ajudar você. Significa que você deve ter extremo cuidado ao definir o que é "bom desempenho" no contexto do seu trading. Sem esse cuidado, é razoável esperar que você possa escolher, sem perceber, um modelo recompensado por prever o retorno médio do mercado.
E agora, o que fazer?
A conclusão é evidente: as métricas de avaliação de modelos que usamos atualmente, RMSE, MSE e MAE, não foram projetadas para trading. Elas surgiram na estatística, na medicina e em outras ciências naturais, onde prever a média faz sentido. Mas, em nossa comunidade de trading algorítmico, prever o retorno médio às vezes pode ser ainda pior do que não ter previsão alguma; em alguns casos, a ausência completa de IA pode até ser mais segura. Mas uma IA sem compreensão jamais será segura!
Precisamos de frameworks de avaliação que recompensem habilidades úteis, e não métricas estatísticas superficiais. Precisamos de métricas que levem em conta lucros e perdas. Além disso, precisamos de protocolos de treinamento que penalizem a "ancoragem" ao valor médio, procedimentos que incentivem o modelo a alinhar-se aos objetivos da nossa comunidade sem perder de vista a realidade prática do trading. É exatamente disso que trata esta série: um conjunto único de desafios que não são gerados diretamente pelo mercado. Em vez disso, elas decorrem das próprias ferramentas que queremos usar e raramente são discutidas em outros artigos, em livros acadêmicos de aprendizado estatístico ou mesmo nos debates da nossa comunidade.
Os profissionais precisam conhecer bem esses fatos para sua própria segurança. Infelizmente, o conhecimento básico sobre essas limitações não é amplamente conhecido nem acessível para todos os participantes da nossa comunidade. Todos os dias, profissionais repetem sem hesitar práticas estatísticas bastante perigosas.
Começamos
Vamos ver se há alguma utilidade no que discutimos até agora. Carregamos nossas bibliotecas padrão.
import pandas as pd import numpy as np import matplotlib.pyplot as plt import MetaTrader5 as mt5 import multiprocessing as mp
Definimos até que ponto no futuro queremos prever.
HORIZON = 10Carregamos o terminal MetaTrader 5 para poder obter dados reais de mercado.
if(not mt5.initialize()): print("Failed to load MT5")
Obtemos a lista completa de todos os símbolos disponíveis.
symbols = mt5.symbols_get()
Extraímos apenas os nomes dos símbolos.
symbols[0].name
symbol_names = []
for i in range(len(symbols)):
symbol_names.append(symbols[i].name)Agora nos preparamos para verificar se conseguimos superar um modelo que sempre prevê o retorno médio.
from sklearn.linear_model import Ridge from sklearn.model_selection import TimeSeriesSplit,cross_val_score
Criamos um divisor para validação de séries temporais.
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON)Precisamos de um método que retorne nossos níveis de erro ao prever o retorno médio do mercado e nossos níveis de erro ao tentar prever o retorno futuro do mercado.
def null_test(name): data_amount = 365 * 4 f_data = pd.DataFrame(mt5.copy_rates_from_pos(name,mt5.TIMEFRAME_D1,0,data_amount)) if(f_data.shape[0] < data_amount): print(f"{symbol_names[i]} did not have enough data!") return(None) f_data['time'] =pd.to_datetime(f_data['time'],unit='s') f_data['target'] = f_data['close'].shift(-HORIZON) - f_data['close'] f_data.dropna(inplace=True) model = Ridge() res = [] res.append(np.mean(np.abs(cross_val_score(model,f_data.loc[:,['open']] * 0,f_data['target'],cv=tscv)))) res.append(np.mean(np.abs(cross_val_score(model,f_data.loc[:,['open','high','low','close']],f_data['target'],cv=tscv)))) return(res)
Agora executamos o teste em todos os mercados disponíveis.
res = pd.DataFrame(columns=['Mean Forecast','Direct Forecast'],index=symbol_names) for i in range(len(symbol_names)): test_score = null_test(symbol_names[i]) if(test_score is None): print(f"{symbol_names[i]} does not have enough data!") res.iloc[i,:] = [np.nan,np.nan] continue res.iloc[i,0] = test_score[0] res.iloc[i,1] = test_score[1] print(f"{i/len(symbol_names)}% complete.") res['Score'] = ((res.iloc[:,1] / res.iloc[:,0])) res.to_csv("Deriv Null Model Test.csv")
Concluído 0,06606606606606606%.
Concluído 0,06906906906906907%.
Concluído 0,07207207207207207%.
...
O índice RSI de tendência de baixa do GBPUSD não tinha dados suficientes!
O índice RSI de tendência de baixa do GBPUSD não tem dados suficientes!
De todos os mercados disponíveis, quantos conseguimos analisar?
#How many markets did we manage to investigate? test = pd.read_csv("Null Model Test.csv") print(f"{(test.dropna().shape[0] / test.shape[0]) * 100}% of Markets Were Evaluated")
35,73573573573574% dos mercados foram avaliados
Agora vamos agrupar nossos 119 mercados com base na pontuação atribuída a cada mercado. A pontuação será a razão entre nosso erro ao prever os retornos do mercado e nosso erro ao prever constantemente o retorno médio. Resultados abaixo de 1 são impressionantes, pois significam que superamos o modelo que sempre prevê o retorno médio. Por outro lado, valores acima de 1 confirmam nossa motivação para realizar este exercício à luz do que discutimos na introdução deste artigo.
Nota para iniciantes: o método de avaliação que descrevemos brevemente não é algo novo na área de aprendizado de máquina. Trata-se de uma métrica amplamente conhecida como R-quadrado. O R-quadrado mostra qual parcela da variância da variável-alvo explicamos com o modelo proposto. Não estamos usando a fórmula exata do r-quadrado com a qual você talvez esteja familiarizado por seus próprios estudos independentes.
Primeiro, vamos agrupar todos os mercados em que obtivemos um valor de indicador menor que 1.
res.loc[res['Score'] < 1]
| Nome do mercado | Previsão da média | Previsão direta | Indicador |
|---|---|---|---|
| AUDCAD | 0.022793 | 0.018566 | 0.814532 |
| EURCAD | 0.037192 | 0.027209 | 0.731587 |
| NZDCAD | 0.019124 | 0.015117 | 0.790466 |
| USDCNH | 0.125586 | 0.112814 | 0.898297 |
Em que percentual de todos os mercados que testamos conseguimos superar, ao longo de 4 anos, o modelo que sempre prevê o retorno médio do mercado? Aproximadamente 8%.
res.loc[res['Score'] < 1].shape[0] / res.shape[0]
0.08403361344537816
Assim, isso também significa que, ao longo de 4 anos, não conseguimos superar o modelo que sempre prevê o retorno médio em aproximadamente 91,6% de todos os mercados testados.
res.loc[res['Score'] > 1].shape[0] / res.shape[0]
0.9159663865546218
Neste ponto, alguns leitores podem pensar: "O autor usou modelos lineares simples, mas, se tivéssemos dedicado mais tempo e criado modelos mais flexíveis, sempre conseguiríamos superar o modelo que prevê o retorno médio. Isso não faz sentido". Isso é parcialmente verdadeiro. Vamos construir uma rede neural profunda para o EURUSD que supere o modelo que prevê o retorno médio do mercado.
Primeiro, precisaremos de um script MQL5 para coletar informações detalhadas de mercado sobre a cotação do EURUSD. Vamos registrar a variação de cada um dos quatro níveis de preço, bem como a variação deles em relação uns aos outros.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| File name | //+------------------------------------------------------------------+ string file_name = Symbol() + " IID Candlestick Recognition.csv"; //+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input int size = 3000; input int HORIZON = 10; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","Delta Open","Delta High","Delta Low","Delta Close","O - H","O - L","O - C","H - L","H - C","L - C"); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON
Agora arraste seu script para o gráfico para obter dados históricos de mercado e, depois disso, poderemos começar.
#Read in market data HORIZON = 10 data = pd.read_csv('EURUSD IID Candlestick Recognition.csv') #Label the data data['Null'] = 0 data['Target'] = data['Close'].shift(-HORIZON) - data['Close'] #Drop the last HORIZON rows of data data = data.iloc[:-HORIZON,:] data
Os leitores que acreditam que redes neurais profundas e modelos complexos resolverão a dificuldade de superar o modelo que prevê o retorno médio do mercado ficarão chocados ao ler o que vem a seguir neste artigo.
Antes de implementar seus modelos usando seu próprio capital, recomendo que você repita este experimento com sua corretora. Agora vamos carregar as ferramentas do scikit-learn para comparar o desempenho da nossa rede neural profunda com o do nosso modelo linear simples.
#Load our models from sklearn.neural_network import MLPRegressor from sklearn.linear_model import Ridge from sklearn.model_selection import TimeSeriesSplit,train_test_split,cross_val_score
Vamos dividir os dados.
#Split the data into half train,test = train_test_split(data,test_size=0.5,shuffle=False)
Criamos um objeto para validação de séries temporais.
#Create a time series validation object tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON)
Ajuste o modelo que sempre prevê o retorno médio do mercado. O erro associado à previsão constante da média é chamado de "soma total dos quadrados" (TSS). A TSS é uma referência crítica de erro em aprendizado de máquina; ela nos dá uma referência de orientação.
#Fit the model predicting the mean on the train set null_model = Ridge() null_model.fit(train[['Null']],train['Target']) tss = np.mean(np.abs(cross_val_score(null_model,test[['Null']],test['Target'],cv=tscv,scoring='neg_mean_absolute_error'))) tss
np.float64(0.011172426520738554)
Definimos nossas entradas e a variável-alvo.
X = data.iloc[:,4:-2].columns y = 'Target'
Configure sua rede neural profunda. Incentivo o leitor a ajustar livremente essa rede neural como preferir para ver se ela tem o que é necessário para superar a média.
#Let us now try to outperform the null model model = MLPRegressor(activation='logistic',solver='lbfgs',random_state=0,shuffle=False,hidden_layer_sizes=(len(X),200,50),max_iter=1000,early_stopping=False) model.fit(train.loc[:,X],train['Target']) rss = np.mean(np.abs(cross_val_score(model,test.loc[:,X],test['Target'],cv=tscv,scoring='neg_mean_absolute_error'))) print(f"Test Passed: {rss < tss} || New R-Squared Metric {rss/tss}") res = [] res.append(rss) res.append(tss) sns.barplot(res,color='black') plt.axhline(tss,color='red',linestyle=':') plt.grid() plt.ylabel("RMSE") plt.xticks([0,1],['Deep Neural Network','Null Model']) plt.title("Our Deep Neural Network vs The Null Model") plt.show()
Depois de muitos ajustes, refinamentos e otimizações, consegui superar o modelo que prevê o retorno médio usando uma rede neural profunda. No entanto, vamos examinar com mais detalhes o que está acontecendo aqui.

Fig. 1: Superar o modelo que prevê o retorno médio do mercado não é uma tarefa fácil
Vamos visualizar as melhorias trazidas pela nossa rede neural profunda. Primeiro, vou criar uma grade para avaliarmos a distribuição dos retornos do mercado no conjunto de teste, bem como a distribuição dos retornos previstos pelo nosso modelo. Vamos salvar os retornos previstos pelo modelo para o conjunto de teste.
predictions = model.predict(test.loc[:,X])
Começaremos marcando o retorno médio do mercado observado no conjunto de treinamento como uma linha vermelha tracejada no centro do diagrama.
plt.title("Visualizing Our Improvements")
plt.plot()
plt.grid()
plt.xlabel("Return")
plt.axvline(train['Target'].mean(),color='red',linestyle=':')
legend = ['Train Mean']
plt.legend(legend)
Fig. 2: Visualização do retorno médio do mercado com base no conjunto de treinamento
Agora vamos sobrepor a previsão do modelo para o conjunto de teste ao retorno médio do conjunto de treinamento. Como o leitor pode ver, as previsões do modelo estão distribuídas em torno da média do conjunto de treinamento. No entanto, o problema fica evidente quando finalmente sobrepomos a distribuição real observada no mercado, representada pelo gráfico preto abaixo.
plt.title("Visualizing Our Improvements") plt.plot() plt.grid() plt.xlabel("Return") plt.axvline(train['Target'].mean(),color='red',linestyle=':') sns.histplot(predictions,color='blue') legend = ['Train Mean','Model Predictions'] plt.legend(legend)
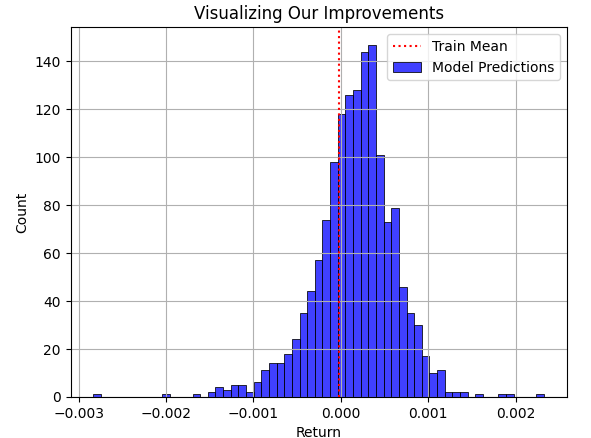
Fig. 3: Visualização das previsões do nosso modelo em relação ao retorno médio observado pelo modelo no conjunto de treinamento
A área azul das previsões feitas pelo nosso modelo parece razoável na Fig. 3, mas, quando finalmente observamos a distribuição real do mercado na Fig. 4, fica evidente que esse modelo não é adequado para esse problema. O modelo não consegue capturar toda a amplitude da distribuição real do mercado, onde alguns dos maiores lucros e prejuízos ficam fora do alcance do nosso modelo. Infelizmente, a RMSE frequentemente direcionará os profissionais a escolher modelos desse tipo se essa métrica não for devidamente compreendida, tratada com o devido cuidado e interpretada por um profissional responsável. Usar um modelo assim no trading real terá consequências catastróficas para sua operação em tempo real.
plt.title("Visualizing Our Improvements") plt.plot() plt.grid() plt.xlabel("Return") plt.axvline(train['Target'].mean(),color='red',linestyle=':') sns.histplot(test['Target'],color='black') sns.histplot(predictions,color='blue') legend = ['Train Mean','Test Distribution','Model Prediction'] plt.legend(legend)
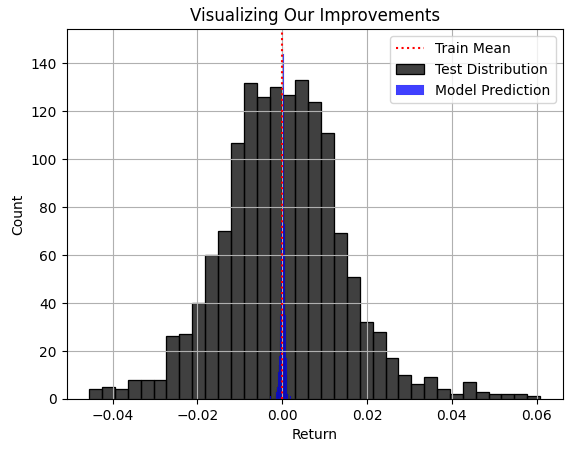
Fig. 4: Visualização da distribuição das previsões dos nossos modelos em relação à distribuição real do mercado
Nossa solução proposta
Neste ponto, demonstramos ao leitor que métricas como a RMSE podem ser facilmente otimizadas sempre prevendo o retorno médio do mercado, e também demonstramos por que isso é problemático, já que a RMSE muitas vezes pode nos dizer que um modelo inútil como esse é o melhor que conseguimos fazer. Expressamos a necessidade evidente de procedimentos e novos métodos que claramente:
- Testem a compreensão real do mercado.
- Entendam a diferença entre lucro e prejuízo.
- Inibam o comportamento de "ancoragem" à média.
Gostaria de propor uma arquitetura de modelo única, que poderia servir como uma possível solução para o leitor considerar. Chamo essa estratégia de "Modelos de Alternância Dinâmica de Regimes", ou, abreviadamente, DRS. Em uma discussão separada sobre configurações de alta probabilidade, observamos que modelar o lucro/prejuízo gerado por uma estratégia de trading pode ser mais simples do que tentar prever diretamente o comportamento do mercado. Os leitores que ainda não leram esse artigo podem acessá-lo pelo link aqui.
Agora continuaremos usando essa observação de uma forma interessante. Desenvolveremos dois modelos idênticos para modelar versões opostas de uma mesma estratégia de trading. Um modelo sempre assume que o mercado está em estado de seguimento de tendência, enquanto o outro sempre assume que o mercado está em estado de reversão à média. Cada modelo será treinado separadamente e não terá nenhuma informação nem meios para coordenar suas previsões com o outro modelo.
O leitor deve lembrar que a hipótese do mercado eficiente ensina aos investidores que comprar e vender volumes iguais do mesmo ativo permite ao investidor hedgear completamente seus riscos e, se ambas as posições forem abertas e fechadas simultaneamente, o lucro total será igual a 0, desconsiderando eventuais custos de transação. Portanto, devemos esperar que nossos modelos estejam sempre alinhados a esse fato. Na prática, podemos verificar se nossos modelos respeitam essa verdade. Modelos que não respeitam essa verdade não têm compreensão real do mercado.
Assim, podemos abandonar a necessidade de depender de métricas como a RMSE e começar a verificar se nosso modelo DRS demonstra compreensão desse princípio que estrutura o mercado. É aqui que entra em jogo nosso teste de compreensão real do mercado. Se ambos os nossos modelos realmente entendem a realidade prática do trading, então a soma de suas previsões deve ser sempre igual a 0, a qualquer momento. Treinaremos nossos modelos no conjunto de treinamento e depois os testaremos fora da amostra para ver se a soma das previsões dos modelos é sempre igual a 0, mesmo quando os modelos não forem suficientemente exigidos.
Lembremos que as previsões dos modelos não são coordenadas de forma alguma. Os modelos são treinados separadamente e não têm nenhuma informação um sobre o outro. Assim, se os modelos não estiverem "hackeando" as métricas de erro desejadas, mas realmente aprendendo a estrutura básica do mercado, eles provarão que chegaram às suas previsões de maneira ética se a soma das previsões de ambos os modelos for igual a 0.
Apenas um desses modelos pode esperar uma recompensa positiva em qualquer momento. Se a soma das previsões dos nossos modelos não for igual a 0, então talvez haja no modelo um viés direcional incorporado de forma não intencional, violando a hipótese do mercado eficiente. Caso contrário, no melhor cenário, conseguiremos alternar dinamicamente entre esses dois estados de mercado com um nível de confiança que não tínhamos no passado. Apenas um modelo pode esperar lucro positivo em qualquer momento, e nossa filosofia de trading se baseia em considerar que o modelo corresponde ao estado oculto em que o mercado se encontra naquele momento. E isso pode ser mais valioso para nós do que valores baixos da RMSE.
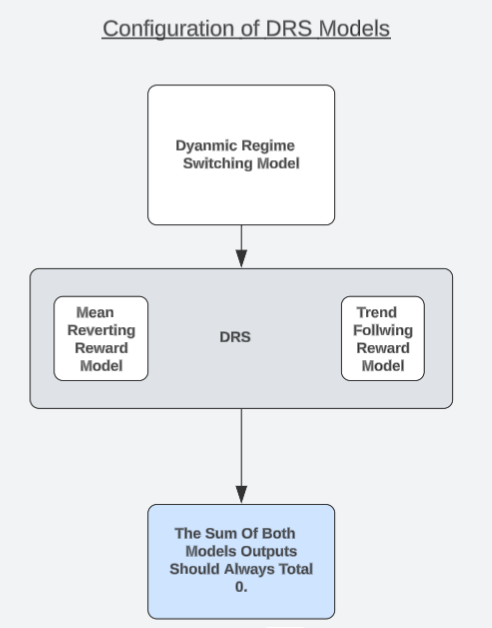
Fig. 5: Compreensão da arquitetura geral dos nossos modelos DRS
Obtendo dados do nosso terminal
Para obter os melhores resultados, nossos dados devem ser o mais detalhados possível. Por isso, acompanhamos os valores atuais dos nossos indicadores técnicos e níveis de preço, bem como a variação que ocorre simultaneamente na dinâmica do mercado.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- Define our moving average indicator #define MA_PERIOD 5 //--- Moving Average Period #define MA_TYPE MODE_SMA //--- Type of moving average we have #define HORIZON 10 //--- Our handlers for our indicators int ma_handle; //--- Data structures to store the readings from our indicators double ma_reading[]; //--- File name string file_name = Symbol() + " DRS Modelling.csv"; //--- Amount of data requested input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { int fetch = size + (HORIZON * 2); //---Setup our technical indicators ma_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","Delta O","Delta H","Delta Low","Delta Close","SMA 5","Delta SMA 5"); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,(i + HORIZON)), ma_reading[i], ma_reading[i] - ma_reading[(i + HORIZON)] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Começamos
Para começar, vamos importar nossas bibliotecas padrão.
#Load our libraries import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns
Agora podemos ler os dados que gravamos anteriormente no CSV.
#Read in the data data = pd.read_csv("/content/drive/MyDrive/Colab Data/Financial Data/FX/EUR USD/DRS Modelling/EURUSD DRS Modelling.csv") data
Ao criar nosso script em MQL5, definimos uma previsão 10 passos à frente. Precisamos manter essa informação.
#Recall that in our MQL5 Script our forecast horizon was 10 HORIZON = 10 #Calculate the returns generated by the market data['Return'] = data['Close'].shift(-HORIZON) - data['Close'] #Drop the last horizon rows data = data.iloc[:-HORIZON,:]
Agora vamos rotular os dados. Lembremos que teremos 2 rótulos: um sempre assume que o mercado continuará se movendo em tendência, enquanto o outro sempre assume que o mercado está preso em um regime de reversão à média.
#Now let us define the signals being generated by the moving average, in the DRS framework there are always at least n signals depending on the n states the market could be in #Our simple DRS model assumes only 2 states #First we will define the actions you should take assuming the market is in a trending state #Therefore if price crosses above the moving average, buy. Otherwise, sell. data['Trend Action'] = 0 data.loc[data['Close'] > data['SMA 5'], 'Trend Action'] = 1 data.loc[data['Close'] < data['SMA 5'], 'Trend Action'] = -1 #Now calculate the returns generated by the strategy data['Trend Profit'] = data['Trend Action'] * data['Return']
Depois de rotular as ações de acompanhamento de tendência, insira as ações de reversão à média.
#Now we will repeat the procedure assuming the market was mean reverting data['Mean Reverting Action'] = 0 data.loc[data['Close'] > data['SMA 5'], 'Mean Reverting Action'] = -1 data.loc[data['Close'] < data['SMA 5'], 'Mean Reverting Action'] = 1 #Now calculate the returns generated by the strategy data['Mean Reverting Profit'] = data['Mean Reverting Action'] * data['Return']
Ao rotular os dados dessa forma, esperamos que o computador identifique as condições em que cada estratégia perde dinheiro e quando devemos dar atenção a cada estratégia. Se construirmos um gráfico do valor acumulado da variável-alvo, veremos claramente que, no período selecionado dos nossos dados, o mercado EURUSD passou mais tempo em regime de reversão à média do que em regime de acompanhamento de tendência. No entanto, observe que há impulsos repentinos em ambas as linhas. Acredito que esses impulsos podem corresponder a mudanças repentinas de regime no mercado.
#If we plot our cumulative profit sums, we can see the profit and losses aren't evenly distributed between the two states plt.plot(data['Trend Profit'].cumsum(),color='black') plt.plot(data['Mean Reverting Profit'].cumsum(),color='red') #The mean reverting strategy appears to have been making outsized profits with respect to the trending stratetefgy #However, closer inspection reveals, that both strategies are profitable, but never at the same time! #The profit profiles of both strategies show abrupt shocks, when the opposite strategy become more profitable. plt.legend(['Trend Profit','Mean Reverting Profit']) plt.xlabel('Time') plt.ylabel('Profit/Loss') plt.title('A DRS Model Visualizes The Market As Being in 2 Possible States') plt.grid() plt.axhline(0,color='black',linestyle=':')
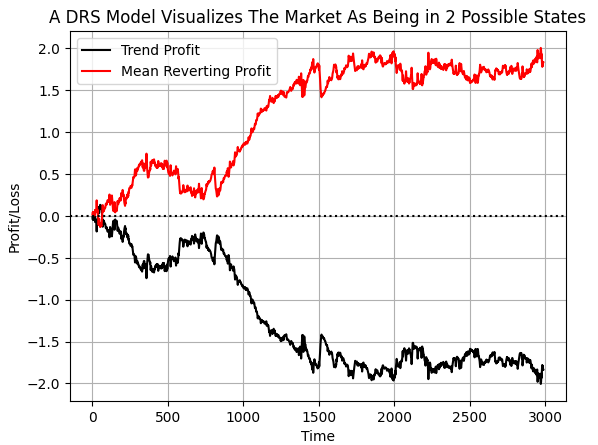
Fig. 6: Visualização da distribuição dos lucros nas duas estratégias opostas
Defina suas entradas e a variável-alvo.
#Let's define the inputs and target X = data.iloc[:,1:-5].columns y = ['Trend Profit','Mean Reverting Profit']
Vamos escolher nossas ferramentas para modelar o mercado.
#Import the modelling tools from sklearn.model_selection import train_test_split,TimeSeriesSplit from sklearn.ensemble import RandomForestRegressor
Vamos dividir os dados duas vezes. Assim, teremos um conjunto de treinamento, um conjunto de validação e um conjunto final de teste.
#Split the data train , test = train_test_split(data,test_size=0.5,shuffle=False) f_train , f_validation = train_test_split(train,test_size=0.5,shuffle=False)
Agora vamos preparar nossos 2 modelos. Lembremos que ambos os modelos nos darão duas perspectivas sobre o mercado, mas suas previsões não devem ser coordenadas de nenhuma forma.
#The trend model trend_model = RandomForestRegressor() #The mean reverting model mean_model = RandomForestRegressor()
Vamos treinar nossos modelos.
trend_model.fit(f_train.loc[:,X],f_train.loc[:,y[0]]) mean_model.fit(f_train.loc[:,X],f_train.loc[:,y[1]])
Verificação da confiabilidade dos nossos modelos. Registraremos as previsões de ambos os modelos sobre os valores que suas variáveis-alvo assumirão no conjunto de teste. Lembremos que os modelos não aprendem a mesma variável-alvo. Cada modelo aprendeu de forma independente sua própria variável-alvo e buscou reduzir seu erro de forma independente do outro modelo.
pred_1 = trend_model.predict(f_validation.loc[:,X]) pred_2 = mean_model.predict(f_validation.loc[:,X])
O conjunto de validação está fora da amostra para nossos modelos. Na prática, estamos submetendo os modelos a um teste de estresse usando dados ainda não vistos pelos modelos, para ver se nossos modelos se comportarão de maneira ética sob estresse significativo.
Nosso teste se baseia na soma das previsões de ambos os modelos. Se o valor máximo da soma das previsões dos modelos for igual a 0,0, então nossos modelos passaram no teste. Isso porque o par de modelos, em essência, está alinhado à hipótese do mercado eficiente, segundo a qual, ao seguir ambos os modelos simultaneamente, o investidor não ganhará nada. Pretendemos seguir apenas um modelo por vez. Por isso, alternaremos dinamicamente entre regimes. Em outras palavras, nossa estratégia tem a capacidade de alternar entre abordagens sem intervenção humana.
test_result = pred_1 + pred_2 print(f" Test Passed: {np.linalg.norm(test_result,ord=2) == 0.0}")
O pacote NumPy contém muitos módulos úteis, como o módulo de álgebra linear que usamos acima. A função de norma que chamamos simplesmente retorna uma medida do tamanho do vetor, que pode assumir formas diferentes conforme a norma escolhida, dependendo de como o método é chamado. Logicamente, isso é o mesmo que verificar manualmente o conteúdo do array para garantir que todos os números no array sejam iguais a 0. Observe: eu cortei a saída do array, mas o leitor pode ter certeza de que todos os valores são iguais a 0.
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
Quando construímos o gráfico do lucro real gerado pela estratégia de acompanhamento de tendência e o comparamos com as previsões feitas pelo modelo de acompanhamento de tendência, percebemos que, salvo algumas grandes oscilações de lucratividade, por exemplo, durante o intervalo entre 600 e 700 dias, quando o mercado EURUSD oscilou com volatilidade significativa, nosso modelo conseguiu acompanhar os ganhos restantes de magnitude normal.
plt.plot(f_validation.loc[:,y[0]],color='black') plt.plot(pred_1,color='red',linestyle=':') plt.legend(['Actual Profit','Predicted Profit']) plt.grid() plt.ylabel('Loss / Profit') plt.xlabel('Out Of Sample Days') plt.title('Visualizing Our Model Performance Out Of Sample on the EURUSD 10 Day Return')
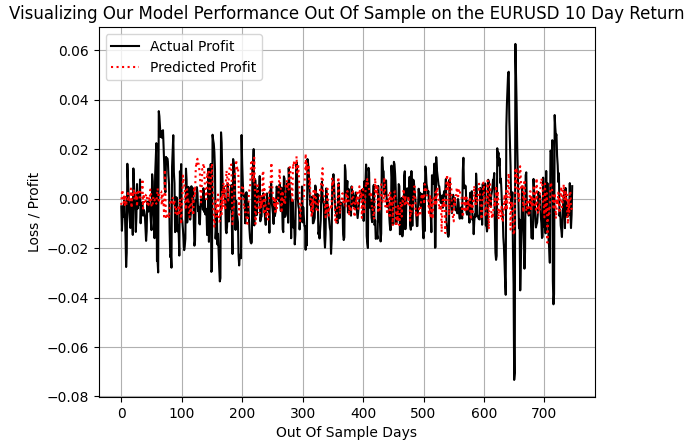
Fig. 7: Nosso modelo DRS não conseguiu capturar a verdadeira volatilidade do mercado
Agora estamos prontos para exportar nossos modelos de aprendizado de máquina para o formato ONNX e começar a expandir nossos aplicativos de trading em novas direções. ONNX é a sigla de Open Neural Network Exchange e permite criar e implantar modelos de aprendizado de máquina usando um conjunto de APIs amplamente usadas. Essa ampla adoção permite que diferentes linguagens de programação trabalhem com o mesmo modelo ONNX. Lembremos que um modelo ONNX é simplesmente uma representação do seu modelo de aprendizado de máquina. Se você ainda não tiver instalado as bibliotecas skl2onnx e ONNX, comece instalando-as.
!pip install skl2onnx onnx
Agora vamos carregar as bibliotecas necessárias para exportar os modelos.
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Defina a forma de entrada e saída dos seus modelos ONNX.
eurusd_drs_shape = [("float_input",FloatTensorType([1,len(X)]))] eurusd_drs_output_shape = [("float_output",FloatTensorType([1,1]))]
Vamos preparar os protótipos ONNX do seu modelo DRS.
trend_drs_model_proto = convert_sklearn(trend_model,initial_types=eurusd_drs_shape,final_types=eurusd_drs_output_shape,target_opset=12) mean_drs_model_proto = convert_sklearn(mean_model,initial_types=eurusd_drs_shape,final_types=eurusd_drs_output_shape,target_opset=12)
Vamos salvar os modelos.
onnx.save(trend_drs_model_proto,"EURUSD RF D1 T LBFGSB DRS.onnx") onnx.save(mean_drs_model_proto,"EURUSD RF D1 M LBFGSB DRS.onnx")
Parabéns, você construiu sua primeira arquitetura de modelo DRS. Agora vamos nos preparar para o backtesting dos modelos e ver se há diferença, além de verificar se conseguimos substituir de forma significativa a raiz do erro quadrático médio (RMSE) do nosso processo de desenvolvimento.
Começamos no MQL5
Para começar, definiremos as constantes do sistema que são importantes para nossa atividade de trading.
//+------------------------------------------------------------------+ //| EURUSD DRS.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define HORIZON 10 #define MA_PERIOD 5 #define MA_SHIFT 0 #define MA_MODE MODE_SMA #define TRADING_VOLUME SymbolInfoDouble(Symbol(),SYMBOL_VOLUME_MIN)
Agora podemos carregar nossos recursos do sistema.
//+------------------------------------------------------------------+ //| System dependencies | //+------------------------------------------------------------------+ #resource "\\Files\\DRS\\EURUSD RF D1 T DRS.onnx" as uchar onnx_proto[] //Our Trend Model #resource "\\Files\\DRS\\EURUSD RF D1 M DRS.onnx" as uchar onnx_proto_2[] //Our Mean Reverting Mode
Vamos carregar a biblioteca de trading.
//+------------------------------------------------------------------+ //| System libraries | //+------------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
Também precisaremos de variáveis para nossos indicadores técnicos.
//+------------------------------------------------------------------+ //| Technical Indicators | //+------------------------------------------------------------------+ int ma_o_handle,ma_c_handle,atr_handle; double ma_o[],ma_c[],atr[]; double bid,ask; int holding_period;
Vamos definir as variáveis globais.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model,onnx_model_2;
No carregamento inicial do nosso aplicativo, chamaremos o método responsável por carregar nossos indicadores técnicos e modelos ONNX.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!setup()) return(INIT_FAILED); //--- return(INIT_SUCCEEDED); }
Quando não estivermos mais usando o aplicativo, limparemos os recursos de que não precisamos mais.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- release(); }
Por fim, ao receber níveis de preço atualizados, buscaremos oportunidades de trading ou gerenciaremos as posições abertas.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- static datetime time_stamp; datetime current_time = iTime(Symbol(),PERIOD_D1,0); if(time_stamp != current_time) { time_stamp = current_time; update_variables(); if(PositionsTotal() == 0) { find_setup(); } else if(PositionsTotal() > 0) { manage_setup(); } } } //+------------------------------------------------------------------+
Esta é a implementação da função que escrevemos para configurar todo o sistema.
//+------------------------------------------------------------------+ //| Attempt To Setup Our System Variables | //+------------------------------------------------------------------+ bool setup(void) { atr_handle = iATR(Symbol(),PERIOD_CURRENT,14); ma_c_handle = iMA(Symbol(),PERIOD_CURRENT,MA_PERIOD,MA_SHIFT,MA_MODE,PRICE_CLOSE); ma_o_handle = iMA(Symbol(),PERIOD_CURRENT,MA_PERIOD,MA_SHIFT,MA_MODE,PRICE_OPEN); holding_period = 0; onnx_model = OnnxCreateFromBuffer(onnx_proto,ONNX_DEFAULT); onnx_model_2 = OnnxCreateFromBuffer(onnx_proto_2,ONNX_DEFAULT); if(onnx_model == INVALID_HANDLE) { Comment("Failed to load Trend DRS model"); return(false); } if(onnx_model_2 == INVALID_HANDLE) { Comment("Failed to load Mean Reverting DRS model"); return(false); } ulong input_shape[] = {1,10}; ulong output_shape[] = {1,1}; if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Comment("Failed to set Trend DRS Model input shape"); return(false); } if(!OnnxSetInputShape(onnx_model_2,0,input_shape)) { Comment("Failed to set Mean Reverting DRS Model input shape"); return(false); } if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Comment("Failed to set Trend DRS Model output shape"); return(false); } if(!OnnxSetOutputShape(onnx_model_2,0,output_shape)) { Comment("Failed to set Mean Reverting DRS Model output shape"); return(false); } return(true); }
Ao desinicializar o sistema, liberaremos manualmente os indicadores e modelos ONNX que não usamos mais.
//+------------------------------------------------------------------+ //| Free up system resources | //+------------------------------------------------------------------+ void release(void) { IndicatorRelease(ma_c_handle); IndicatorRelease(ma_o_handle); OnnxRelease(onnx_model); OnnxRelease(onnx_model_2); }
Atualizamos as variáveis do sistema sempre que novas informações de preço chegam.
//+------------------------------------------------------------------+ //| Update our system variables | //+------------------------------------------------------------------+ void update_variables(void) { bid = SymbolInfoDouble(Symbol(),SYMBOL_BID); ask = SymbolInfoDouble(Symbol(),SYMBOL_ASK); CopyBuffer(ma_c_handle,0,1,(HORIZON*2),ma_c); CopyBuffer(ma_o_handle,0,1,(HORIZON*2),ma_o); CopyBuffer(atr_handle,0,0,1,atr); ArraySetAsSeries(ma_c,true); ArraySetAsSeries(ma_o,true); }
Gerencie as operações abertas basicamente fazendo a contagem do horizonte de 10 dias dos nossos retornos.
//+------------------------------------------------------------------+ //| Manage The Trade We Have Open | //+------------------------------------------------------------------+ void manage_setup(void) { if((PositionsTotal() > 0) && (holding_period < (HORIZON-1))) holding_period +=1; else if((PositionsTotal() > 0) && (holding_period == (HORIZON - 1))) Trade.PositionClose(Symbol()); }
Encontre um setup de trading obtendo informações detalhadas sobre o estado atual do mercado e passando-as para o nosso modelo. Nossa estratégia se baseia no uso de médias móveis como indicadores do sentimento dos investidores. Quando as médias móveis emitem sinais de venda, assumimos que a maioria dos investidores pretende abrir uma posição short, mas acreditamos que, no mercado de câmbio, a maioria costuma estar errada.
//+------------------------------------------------------------------+ //| Find A Trading Oppurtunity For Our Strategy | //+------------------------------------------------------------------+ void find_setup(void) { vectorf model_inputs = vectorf::Zeros(10); vectorf model_outputs = vectorf::Zeros(1); vectorf model_2_outputs = vectorf::Zeros(1); holding_period = 0; int i = 0; model_inputs[0] = (float) iOpen(Symbol(),PERIOD_CURRENT,0); model_inputs[1] = (float) iHigh(Symbol(),PERIOD_CURRENT,0); model_inputs[2] = (float) iLow(Symbol(),PERIOD_CURRENT,0); model_inputs[3] = (float) iClose(Symbol(),PERIOD_CURRENT,0); model_inputs[4] = (float)(iOpen(Symbol(),PERIOD_CURRENT,0) - iOpen(Symbol(),PERIOD_CURRENT,HORIZON)); model_inputs[5] = (float)(iHigh(Symbol(),PERIOD_CURRENT,0) - iHigh(Symbol(),PERIOD_CURRENT,HORIZON)); model_inputs[6] = (float)(iLow(Symbol(),PERIOD_CURRENT,0) - iLow(Symbol(),PERIOD_CURRENT,HORIZON)); model_inputs[7] = (float)(iClose(Symbol(),PERIOD_CURRENT,0) - iClose(Symbol(),PERIOD_CURRENT,HORIZON)); model_inputs[8] = (float) ma_c[0]; model_inputs[9] = (float)(ma_c[0] - ma_c[HORIZON]); if(!OnnxRun(onnx_model,ONNX_DEFAULT,model_inputs,model_outputs)) { Comment("Failed to run the ONNX model correctly."); } if(!OnnxRun(onnx_model_2,ONNX_DEFAULT,model_inputs,model_2_outputs)) { Comment("Failed to run the ONNX model correctly."); } if(model_outputs[0] > 0) { if(ma_c[0] < ma_o[0]) { if(iClose(Symbol(),PERIOD_CURRENT,0) > ma_c[0]) Trade.Buy(TRADING_VOLUME,Symbol(),ask,0,0,""); } else if(ma_c[0] > ma_o[0]) { if(iClose(Symbol(),PERIOD_CURRENT,0) < ma_c[0]) Trade.Sell(TRADING_VOLUME,Symbol(),bid,0,0,""); } } else if(model_2_outputs[0] > 0) { if(ma_c[0] < ma_o[0]) { if(iClose(Symbol(),PERIOD_CURRENT,0) < ma_c[0]) Trade.Buy(TRADING_VOLUME,Symbol(),ask,0,0,""); } if(ma_c[0] > ma_o[0]) { if(iClose(Symbol(),PERIOD_CURRENT,0) > ma_c[0]) Trade.Sell(TRADING_VOLUME,Symbol(),bid,0,0,""); } } Comment("0: ",model_outputs[0],"1: ",model_2_outputs[0]); }
Vamos remover a definição das constantes do sistema.
//+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON #undef MA_MODE #undef MA_PERIOD #undef MA_SHIFT #undef TRADING_VOLUME //+------------------------------------------------------------------+
Primeiro, precisamos escolher as datas do nosso backtest. Lembremos que sempre escolhemos datas fora do conjunto de treinamento do modelo para obter uma estimativa confiável de quão bem o modelo pode funcionar no futuro.
Fig. 8: Certifique-se de escolher datas fora do conjunto de treinamento do modelo
Normalmente, queremos fazer um teste de estresse do nosso modelo, por isso escolhemos "Random delay" e "Every tick based on real ticks" para testar nossa estratégia em condições de mercado realistas e difíceis.
Fig. 9: O uso de "Every tick based on real ticks" é a opção de modelagem mais realista que podemos escolher para testar nossa arquitetura DRS sob estresse
Abaixo, apresentamos um relatório detalhado de desempenho da nossa nova estratégia DRS. É interessante perceber que conseguimos substituir a RMSE pela DRS e ainda assim obter uma estratégia lucrativa, embora esta tenha sido nossa primeira tentativa de substituir a RMSE de maneira formal no nosso processo de construção do modelo.
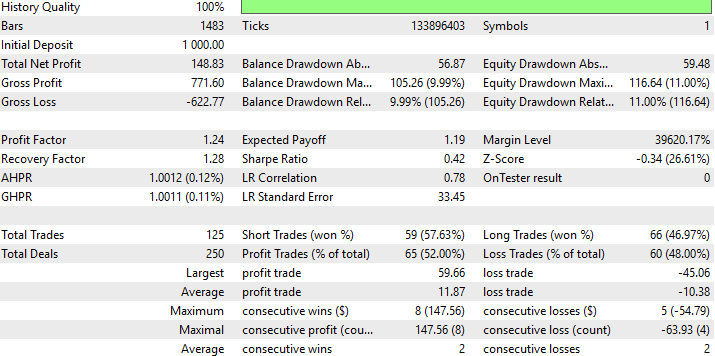
Fig. 10: Resultados detalhados de desempenho da nossa estratégia em dados que ela não tinha visto antes
Ao observar a curva de equity obtida pela nossa estratégia, é possível ver os problemas causados pela incapacidade do nosso modelo DRS de antecipar a volatilidade do mercado, como discutimos anteriormente. Isso faz nossa estratégia oscilar entre períodos lucrativos e períodos de prejuízo. No entanto, nossa estratégia demonstra capacidade de se recuperar e manter uma trajetória adequada, que é exatamente o que buscamos.
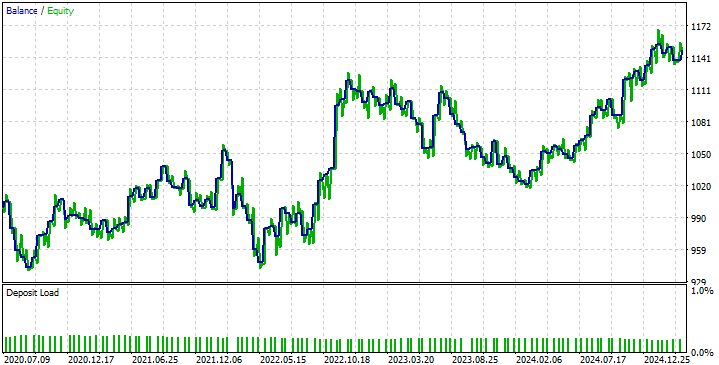
Fig. 11: Curva de equity obtida pela nossa nova estratégia de trading
Conclusão
Depois de ler este artigo, os leitores que não conheciam as limitações dessas métricas sairão mais preparados do que eram antes da leitura. Conhecer as limitações das suas ferramentas é tão importante quanto conhecer seus pontos fortes. Os métodos de otimização que usamos para criar IA podem ficar "presos" ao tentar resolver problemas especialmente difíceis. E, quando os profissionais usam essas ferramentas para modelar retornos de ativos, precisam ter plena consciência de que seus modelos podem apresentar uma tendência a ficar presos no retorno médio do mercado.
O leitor também adquiriu conhecimento prático e agora entende as vantagens de filtrar mercados com base em quão bem uma estratégia consegue superar o modelo que prevê o retorno médio nesse mercado, pois isso implica que o mercado apresenta sinais de ineficiência que o profissional deve explorar.
Ao filtrar mercados com base em quão bem o profissional consegue superar a média, o leitor aprendeu a evitar a interpretação acrítica da RMSE como uma métrica autônoma e, em vez disso, a sempre considerar a RMSE em relação à TSS. O leitor obteve uma compreensão prática das limitações que essas métricas impõem à prática cotidiana, algo incomum na maioria das literatura sobre esse tema ou nos trabalhos de pesquisa referenciados aqui.
E, por fim, se o leitor pretendia em breve implantar um modelo de aprendizado de máquina para operar com seu próprio capital, mas não conhecia essas limitações, eu recomendaria que ele primeiro repetisse o exercício que demonstrei neste artigo, para ter certeza de que não está prestes a dar um tiro no próprio pé sem perceber. A RMSE permite que nossos modelos trapaceiem nos testes, mas tenho certeza de que os leitores que chegaram até aqui não serão enganados tão facilmente pelas limitações da IA.
| Nome do arquivo | Descrição do arquivo |
|---|---|
| DRS Models.mq5 | Script MQL5 que criamos para extrair os dados detalhados de mercado necessários para construir nosso modelo DRS. |
| Dynamic_Regime_Switching_Models_(DRS_Modelling).ipynb | Notebook Jupyter que criamos para projetar nosso modelo DRS. |
| EURUSD DRS.mq5 | Nosso EA EURUSD, que usou nosso modelo DRS. |
| EURUSD RF D1 T DRS.onnx | O modelo DRS de acompanhamento de tendência sempre assume que o mercado está em regime de acompanhamento de tendência. |
| EURUSD RF D1 M DRS.onnx | O modelo DRS de reversão à média sempre assume que o mercado está em regime de reversão à média. |
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/17906
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Desenvolvimento de um sistema personalizado de detecção do regime de mercado em MQL5 (Parte 1): Indicador
Desenvolvimento de um sistema personalizado de detecção do regime de mercado em MQL5 (Parte 1): Indicador
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
"No entanto, nossa estratégia demonstra a capacidade de se recuperar e permanecer no caminho certo, que é exatamente o que buscamos."
Sempre achei que o que se deve buscar é que uma estratégia gere lucros :)
"No entanto, nossa estratégia mostra a capacidade de se recuperar e permanecer no caminho certo, que é exatamente o que estamos buscando."
Sempre achei que você deve se esforçar para que uma estratégia traga lucros :)
Obrigado pelo artigo, @Gamuchirai Zororo Ndawana
Concordo com @Maxim Dmitrievsky que o objetivo final é a lucratividade. A ideia de "recuperar e manter-se no caminho certo" faz sentido como controle de robustez e rebaixamento, mas não substitui o lucro.
Sugestão prática: teste walk-forward, custos e derrapagem, perda assimétrica ou quantil ou objetivos baseados em utilidade e penalização do volume de negócios para evitar o mean hugging. (Consideração pragmática: alinhe a perda com a forma como você ganha dinheiro).
Citado: Sim, de fato, mas infelizmente ainda não temos métricas padronizadas de aprendizado de máquina que estejam cientes da diferença entre lucro e prejuízo.
Resposta: As colunas de lucros e perdas só existirão se o seu produto testado ou o mercado plano for tão bom quanto o mercado a termo que você está usando em relação ao portfólio subsequente ou à cesta de índices que seguirá essa linha de ordem.
Existem alguns índices e ETFs recém-fundados que estão sendo lançados, ou que são produzidos cada vez mais, para esse uso pretendido, e que produzirão esses resultados, margens de lucro, como o índice dowjones 30, bem como muitos outros índices que foram criados para esse uso pretendido. Peter Matty
Obrigado pelo artigo, @Gamuchirai Zororo Ndawana
Concordo com @Maxim Dmitrievsky que o objetivo final é a lucratividade. A ideia de se recuperar e permanecer no caminho certo faz sentido para a robustez e o controle do drawdown, mas não substitui o lucro.
Às vezes, eu me pergunto se as ferramentas de tradução com as quais contamos podem não captar a mensagem original. Sua resposta oferece muito mais pontos de discussão do que o que eu entendi da mensagem original de @Maxim Dmitrievsky .
Obrigado por apontar esses descuidos na tendência de olhar para frente (recursos com i + HORIZON), esses são os piores bugs que odeio, eles exigem um novo teste completo. Mas, desta vez, com mais cuidado.
Você também forneceu um feedback valioso sobre as medidas de validação usadas para validar modelos na prática. Preciso aprender mais sobre Calmar e Sortino para desenvolver uma opinião sobre eles, obrigado por isso.
Concordo com você que os dois termos são antissimétricos por design, e o teste é que os modelos devem permanecer antissimétricos, qualquer desvio dessa expectativa é reprovado no teste. Se um ou ambos os modelos tiverem uma tendência inaceitável, suas previsões não permanecerão antissimétricas como esperamos.
Entretanto, a noção de lucro é apenas uma ilustração simples que dei para destacar o problema. Nenhuma das métricas que temos hoje nos informa quando o mean hugging está acontecendo. Nenhuma das publicações sobre aprendizado estatístico nos diz por que está ocorrendo o mean hugging. Infelizmente, isso está acontecendo devido às práticas recomendadas que seguimos, e essa é apenas uma das muitas maneiras pelas quais desejo iniciar mais conversas sobre os perigos das práticas recomendadas.
Esse artigo foi mais um pedido de ajuda, para que nos reuníssemos e criássemos novos protocolos desde o início. Novos padrões. Novos objetivos nos quais nossos otimizadores trabalhem diretamente e que sejam adaptados aos nossos interesses.