
Superando las limitaciones del aprendizaje automático (Parte 1): Falta de métricas interoperables

Lamentablemente, los peligros de seguir ciegamente las «mejores prácticas» corrompen silenciosamente otras herramientas en las que confiamos en nuestras estrategias comerciales, por lo que los profesionales no deben pensar que este problema es exclusivo de los indicadores técnicos.
En esta serie de artículos, exploraremos los problemas críticos a los que se enfrentan a diario los operadores algorítmicos, según las propias directrices y prácticas destinadas a garantizar su seguridad al utilizar modelos de aprendizaje automático. En resumen, si los modelos de aprendizaje automático que se implementan a diario en la nube MQL5 siguen siendo conscientes de los hechos presentados en este debate, por delante de los profesionales responsables, los problemas son inminentes. Los inversores pueden verse rápidamente expuestos a más riesgos de los que habían previsto.
Sinceramente, estos problemas no se tratan con suficiente profundidad, ni siquiera en los libros más importantes del mundo sobre aprendizaje estadístico. El tema de nuestro debate es una simple verdad que todos los profesionales de nuestra comunidad deberían conocer:
«Se puede demostrar analíticamente que la primera derivada de las métricas de dispersión euclidiana, como RMSE, MAE o MSE, se puede resolver mediante la media del objetivo».
Los profesionales que ya conocen este hecho y sus implicaciones no necesitan seguir leyendo a partir de este punto.
Sin embargo, es precisamente a aquellos profesionales que no comprenden lo que esto significa a quienes necesito llegar urgentemente a través de este artículo. En resumen, las métricas de regresión que utilizamos para construir nuestros modelos no son adecuadas para modelar los rendimientos de los activos.
Este artículo le explicará cómo ocurre esto, los peligros que supone para usted y los cambios que puede implementar para empezar a utilizar este principio como brújula para filtrar los mercados, dada la posibilidad de elegir entre cientos de mercados potenciales en los que podría operar.
Los profesionales que deseen obtener pruebas más sólidas pueden consultar la bibliografía de la Universidad de Harvard, donde se analizan las limitaciones de métricas como el RMSE. En concreto, el artículo de Harvard ofrece una prueba analítica de que la media de la muestra minimiza el RMSE. El lector puede encontrar el artículo, enlazado, aquí.
Otras instituciones, como la Red de Investigación en Ciencias Sociales (Social Science Research Network, SSRN), mantienen una revista de artículos publicados y revisados por pares de diversos ámbitos, entre los que se incluye un artículo útil para nuestro debate, en el que se exploran funciones de pérdida alternativas para sustituir el RMSE en las tareas de valoración de activos. El artículo que he seleccionado para el lector revisa otros artículos en este campo y ofrece un resumen de la bibliografía actual antes de presentar un enfoque novedoso. Este artículo está disponible para el lector, aquí.
Un experimento mental (todo el mundo debería entenderlo)
Imagina que estás en una competición tipo lotería. Tú y otras 99 personas habéis sido seleccionados al azar para jugar por un bote de 1.000.000 $. Las reglas son sencillas: debes adivinar la estatura de los otros 99 participantes. El ganador es la persona con el menor error total en sus 99 intentos.
Ahora, aquí está el giro: para este ejemplo, imagina que la altura media global de los seres humanos es de 1,1 metros. Si simplemente adivinas 1,1 metros para todos, podrías ganar el premio gordo, aunque técnicamente todas las predicciones sean incorrectas. ¿Por qué? Porque en entornos ruidosos e inciertos, adivinar el promedio tiende a producir el error general más pequeño.
El paralelo comercial
Este experimento mental tuvo como objetivo dramatizar para el lector exactamente cómo se seleccionan la mayoría de los modelos de aprendizaje automático para su uso en los mercados financieros.
Por ejemplo, supongamos que está construyendo un modelo para pronosticar el rendimiento del S&P 500. Un modelo que siempre predice el promedio histórico del índice, aproximadamente un 7% anual, podría en realidad superar a modelos más complejos cuando se juzga por métricas como RMSE, MAE o MSE. Pero aquí está la trampa: ese modelo no aprendió nada útil. Simplemente se agrupó alrededor de la media estadística. Y lo que es peor, las métricas y los procedimientos de validación en los que confiaba lo recompensaron por hacerlo.
Nota para principiantes: El RMSE (error cuadrático medio) es una «unidad» que se utiliza para evaluar la calidad de los modelos de aprendizaje automático que aprenden a pronosticar objetivos con valores reales.
Castiga las grandes desviaciones pero no le importa por qué el modelo cometió el error, pero recuerda que algunas de estas desviaciones por las que se castiga al modelo en realidad fueron ganancias.
Por lo tanto, un modelo que siempre predice el promedio (incluso si no tiene conocimiento del mercado) puede verse muy bien en el papel cuando se lo juzga con RMSE. Desafortunadamente esto nos permite crear modelos que son matemáticamente sólidos, pero prácticamente inútiles.
¿Qué está pasando realmente?
Los datos financieros son ruidosos. No podemos observar variables clave como la verdadera oferta y demanda global, el sentimiento de los inversores o la profundidad de la cartera de pedidos institucionales. Entonces, para minimizar el error, su modelo hará lo más lógico estadísticamente: predecir el promedio.
Y el lector debe entender que, matemáticamente, es una buena práctica. Predecir la media minimiza los errores de regresión más comunes. Pero el trading no consiste en minimizar el error estadístico, sino en tomar decisiones rentables en condiciones de incertidumbre. Y esa distinción importa. En nuestra comunidad, tal conducta es comparable al sobreajuste, pero los estadísticos que construyeron estos modelos no vieron las cosas del mismo modo que nosotros.
Sería ingenuo pensar que este problema es exclusivo de los modelos de regresión. En las tareas de clasificación, un modelo puede minimizar los errores simplemente prediciendo siempre la clase más común en la muestra de entrenamiento. Y si la clase más grande en el conjunto de entrenamiento corresponde a la clase más grande de toda la población, creo que el profesional puede ver rápidamente cómo un modelo puede fingir fácilmente su habilidad.
Reward Hacking: Cuando los modelos ganan haciendo trampa
Este fenómeno se llama Reward Hacking: cuando un modelo alcanza niveles de rendimiento deseables al aprender un comportamiento indeseable. En el caso del trading, la piratería de recompensas (Reward Hacking) da como resultado que los profesionales elijan un modelo que parece hábil, pero en realidad el modelo simplemente está jugando un juego de promedios, un castillo de naipes estadístico. Crees que ha aprendido algo, pero en realidad ha hecho el equivalente estadístico de decir "todos miden 1,1 metros". Y RMSE lo acepta siempre, sin cuestionarlo.
Evidencia real
Ahora que nuestra motivación está clara, dejemos de usar la alegoría y, en cambio, consideremos datos del mercado del mundo real. Usando la API Python de MetaTrader 5, accedí a 333 mercados desde mi bróker. Filtramos los mercados con al menos cuatro años de datos históricos del mundo real. Este filtro redujo nuestro universo de mercados a 119.
Luego construimos dos modelos para cada mercado:
- Modelo de control: Siempre predice el rendimiento promedio de 10 días.
- Modelo de previsión: Intenta aprender y predecir rendimientos futuros.
Nuestros resultados
En el 91,6% de los mercados que probamos, el modelo de control ganó. Es decir, ¡el modelo que siempre predice el retorno promedio histórico de 10 días produjo un error menor durante 4 años, el 91% del tiempo! Como el profesional verá pronto, incluso cuando probamos redes neuronales más profundas, la mejora fue insignificante.
Por lo tanto, ¿debería el profesional obedecer las "mejores prácticas" del aprendizaje automático y elegir siempre el modelo que produzca el menor error y, recuerde, el modelo siempre predice el rendimiento promedio?
Nota para principiantes: Esto no significa que el aprendizaje automático no pueda funcionar para usted. Esto significa que debes ser extremadamente cauteloso acerca de cómo debe definirse el “buen desempeño” en tu contexto comercial. Si no tiene cuidado, sería razonable esperar que, sin saberlo, seleccione un modelo que sea recompensado por predecir el rendimiento promedio del mercado.
¿Y ahora qué?
La conclusión es clara: las métricas de evaluación que utilizamos actualmente (RMSE, MSE, MAE) no están diseñadas para el trading. Nacieron en la estadística, la medicina y otras ciencias naturales donde predecir la media tiene sentido. Pero en nuestra comunidad de trading algorítmico, predecir el retorno promedio podría ser a veces incluso peor que no tener ninguna predicción; no tener IA en absoluto a veces es más seguro. ¡Pero la IA sin comprensión nunca está segura!
Necesitamos marcos de evaluación que recompensen las habilidades útiles, no métricas de cooperación estadística. Necesitamos métricas que entiendan ganancias y pérdidas. Además, necesitamos protocolos de capacitación que penalicen el abrazo cruel, procedimientos que animen al modelo a reflejar los valores de nuestra comunidad mientras aprende las realidades del trading. Y en eso se centra esta serie. Un conjunto único de problemas, que no son generados directamente por el mercado. Más bien, surgen de las mismas herramientas que deseamos emplear y rara vez se analizan en otros artículos, libros de aprendizaje estadístico académico o incluso en nuestras propias discusiones comunitarias.
Los profesionales deben estar bien informados sobre estos hechos, por su propia seguridad. Lamentablemente, el conocimiento básico de estas limitaciones no es un conocimiento común que todos los miembros de nuestra comunidad tengan a su alcance. Los profesionales cotidianos repiten sin dudarlo prácticas estadísticas muy peligrosas.
Empezando
Veamos si hay algún mérito en lo que hemos discutido hasta ahora. Cargue nuestras bibliotecas estándar.
import pandas as pd import numpy as np import matplotlib.pyplot as plt import MetaTrader5 as mt5 import multiprocessing as mp
Definir hasta qué punto en el futuro deseamos pronosticar.
HORIZON = 10Cargue la terminal MetaTrader 5 para que podamos obtener datos reales del mercado.
if(not mt5.initialize()): print("Failed to load MT5")
Obtenga una lista completa de todos los símbolos disponibles.
symbols = mt5.symbols_get()
Simplemente extraiga los nombres de los símbolos.
symbols[0].name
symbol_names = []
for i in range(len(symbols)):
symbol_names.append(symbols[i].name)Ahora, prepárense para ver si podemos superar a un modelo que siempre predice la media.
from sklearn.linear_model import Ridge from sklearn.model_selection import TimeSeriesSplit,cross_val_score
Crear un divisor de validación de series de tiempo.
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON)Necesitamos un método que nos devuelva nuestros niveles de error al predecir siempre el rendimiento promedio del mercado y nuestros niveles de error al intentar predecir el rendimiento futuro del mercado.
def null_test(name): data_amount = 365 * 4 f_data = pd.DataFrame(mt5.copy_rates_from_pos(name,mt5.TIMEFRAME_D1,0,data_amount)) if(f_data.shape[0] < data_amount): print(f"{symbol_names[i]} did not have enough data!") return(None) f_data['time'] =pd.to_datetime(f_data['time'],unit='s') f_data['target'] = f_data['close'].shift(-HORIZON) - f_data['close'] f_data.dropna(inplace=True) model = Ridge() res = [] res.append(np.mean(np.abs(cross_val_score(model,f_data.loc[:,['open']] * 0,f_data['target'],cv=tscv)))) res.append(np.mean(np.abs(cross_val_score(model,f_data.loc[:,['open','high','low','close']],f_data['target'],cv=tscv)))) return(res)
Ahora realizaremos la prueba en todos los mercados que tenemos disponibles.
res = pd.DataFrame(columns=['Mean Forecast','Direct Forecast'],index=symbol_names) for i in range(len(symbol_names)): test_score = null_test(symbol_names[i]) if(test_score is None): print(f"{symbol_names[i]} does not have enough data!") res.iloc[i,:] = [np.nan,np.nan] continue res.iloc[i,0] = test_score[0] res.iloc[i,1] = test_score[1] print(f"{i/len(symbol_names)}% complete.") res['Score'] = ((res.iloc[:,1] / res.iloc[:,0])) res.to_csv("Deriv Null Model Test.csv")
0.06606606606606606% complete.
0.06906906906906907% complete.
0.07207207207207207% complete.
...
¡El índice de tendencia bajista del GBPUSD RSI no tenía suficientes datos!
¡El índice de tendencia bajista del GBPUSD RSI no tiene suficientes datos!
De todos los mercados que teníamos disponibles, ¿cuántos mercados pudimos analizar?
#How many markets did we manage to investigate? test = pd.read_csv("Null Model Test.csv") print(f"{(test.dropna().shape[0] / test.shape[0]) * 100}% of Markets Were Evaluated")
35.73573573573574% of Markets Were Evaluated
Ahora agruparemos nuestros 119 mercados en función de una puntuación asociada a cada mercado. La puntuación será la relación entre nuestro error al predecir el mercado y nuestro error al predecir siempre el rendimiento medio. Las puntuaciones menores a 1 son impresionantes porque implican que superamos a un modelo que siempre predice el rendimiento promedio. De lo contrario, puntuaciones mayores a 1 validan nuestra motivación para realizar este ejercicio a la luz de lo que compartimos en la introducción de este artículo.
Nota para principiantes: El método de puntuación que hemos descrito brevemente no es nada nuevo dentro del aprendizaje automático. Es una métrica comúnmente conocida como r-cuadrado. Nos informa qué parte de la varianza en el objetivo estamos explicando con nuestro modelo propuesto. No utilizamos la fórmula exacta de R-cuadrado con la que quizás esté familiarizado gracias a sus estudios independientes.
Agrupemos primero todos los mercados donde obtuvimos una puntuación menor a 1.
res.loc[res['Score'] < 1]
| Nombre del mercado | Pronóstico medio | Pronóstico directo | Puntuación |
|---|---|---|---|
| AUDCAD | 0.022793 | 0.018566 | 0.814532 |
| EURCAD | 0.037192 | 0.027209 | 0.731587 |
| NZDCAD | 0.019124 | 0.015117 | 0.790466 |
| USDCNH | 0.125586 | 0.112814 | 0.898297 |
¿En qué porcentaje de todos los mercados que probamos superamos a un modelo que siempre predice el rendimiento medio del mercado, durante 4 años? Aproximadamente el 8%.
res.loc[res['Score'] < 1].shape[0] / res.shape[0]
0.08403361344537816
Por lo tanto, eso también implica que a lo largo de 4 años no podríamos superar a un modelo que siempre predice el rendimiento promedio de aproximadamente el 91,6 % de todos los mercados que probamos.
res.loc[res['Score'] > 1].shape[0] / res.shape[0]
0.9159663865546218
Ahora bien, en este punto, algunos lectores pueden estar pensando que "El autor utilizó modelos lineales simples, si nos tomáramos nuestro tiempo y construyéramos modelos más flexibles, siempre podríamos superar al modelo que predice el rendimiento promedio. "Esto es una tontería". Lo cual es en parte cierto. Construyamos una red neuronal profunda en el mercado EURUSD para superar el modelo que predice el rendimiento promedio del mercado.
Primero, necesitaremos un script MQL5 para capturar información detallada del mercado sobre el tipo de cambio EURUSD. Registraremos los crecimientos en cada uno de los cuatro niveles de precios, y también sus crecimientos entre sí.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| File name | //+------------------------------------------------------------------+ string file_name = Symbol() + " IID Candlestick Recognition.csv"; //+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input int size = 3000; input int HORIZON = 10; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","Delta Open","Delta High","Delta Low","Delta Close","O - H","O - L","O - C","H - L","H - C","L - C"); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON
Ahora arrastre y suelte su script en el gráfico para obtener datos históricos sobre el mercado y luego podremos comenzar.
#Read in market data HORIZON = 10 data = pd.read_csv('EURUSD IID Candlestick Recognition.csv') #Label the data data['Null'] = 0 data['Target'] = data['Close'].shift(-HORIZON) - data['Close'] #Drop the last HORIZON rows of data data = data.iloc[:-HORIZON,:] data
Los lectores que piensan que las redes neuronales profundas y los modelos sofisticados resolverán el problema de superar a un modelo que predice el retorno promedio del mercado, se sorprenderán al leer lo que sigue en el resto de este artículo.
Te animo a que repitas este experimento con tu broker, antes de implementar tus modelos con tu capital. Ahora carguemos las herramientas de aprendizaje de scikit para comparar el rendimiento de nuestra red neuronal profunda frente a nuestro modelo lineal simple.
#Load our models from sklearn.neural_network import MLPRegressor from sklearn.linear_model import Ridge from sklearn.model_selection import TimeSeriesSplit,train_test_split,cross_val_score
Dividir los datos.
#Split the data into half train,test = train_test_split(data,test_size=0.5,shuffle=False)
Crear un objeto de validación de series de tiempo.
#Create a time series validation object tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON)
Ajuste el modelo prediciendo siempre la rentabilidad media del mercado. El error causado por predecir siempre la media se denomina "suma total de cuadrados". El TSS es un punto de referencia de error crítico en el aprendizaje automático; nos dice dónde está el norte.
#Fit the model predicting the mean on the train set null_model = Ridge() null_model.fit(train[['Null']],train['Target']) tss = np.mean(np.abs(cross_val_score(null_model,test[['Null']],test['Target'],cv=tscv,scoring='neg_mean_absolute_error'))) tss
np.float64(0.011172426520738554)
Definir nuestras entradas y objetivos.
X = data.iloc[:,4:-2].columns y = 'Target'
Ajuste su red neuronal profunda. Animo al lector a que se sienta bienvenido a ajustar esta red neuronal como crea conveniente para ver si tiene lo necesario para superar la media.
#Let us now try to outperform the null model model = MLPRegressor(activation='logistic',solver='lbfgs',random_state=0,shuffle=False,hidden_layer_sizes=(len(X),200,50),max_iter=1000,early_stopping=False) model.fit(train.loc[:,X],train['Target']) rss = np.mean(np.abs(cross_val_score(model,test.loc[:,X],test['Target'],cv=tscv,scoring='neg_mean_absolute_error'))) print(f"Test Passed: {rss < tss} || New R-Squared Metric {rss/tss}") res = [] res.append(rss) res.append(tss) sns.barplot(res,color='black') plt.axhline(tss,color='red',linestyle=':') plt.grid() plt.ylabel("RMSE") plt.xticks([0,1],['Deep Neural Network','Null Model']) plt.title("Our Deep Neural Network vs The Null Model") plt.show()
Después de mucha configuración, ajustes y optimización, pude derrotar al modelo que predecía el retorno promedio, usando una red neuronal profunda. Sin embargo, veamos más de cerca lo que está sucediendo aquí.

Figura 1: Superar un modelo que predice el rendimiento promedio del mercado es un desafío material.
Visualicemos las mejoras que está realizando nuestra Red Neuronal Profunda. Primero, configuraré una cuadrícula para que podamos evaluar la distribución de los rendimientos del mercado en el conjunto de prueba y las distribuciones de los rendimientos que predijo nuestro modelo. Almacene los retornos que el modelo predice para el conjunto de prueba.
predictions = model.predict(test.loc[:,X])
Comenzaremos marcando primero el rendimiento promedio del mercado que observamos en el conjunto de entrenamiento como la línea punteada roja en el medio del gráfico.
plt.title("Visualizing Our Improvements")
plt.plot()
plt.grid()
plt.xlabel("Return")
plt.axvline(train['Target'].mean(),color='red',linestyle=':')
legend = ['Train Mean']
plt.legend(legend)
Figura 2: Visualización del rendimiento promedio del mercado a partir del conjunto de entrenamiento.
Ahora, superpongamos la predicción del modelo para el conjunto de prueba, sobre el rendimiento promedio del conjunto de entrenamiento. Como puede ver el lector, las predicciones del modelo se distribuyen alrededor de la media del conjunto de entrenamiento. Sin embargo, el problema se vuelve claro cuando finalmente superponemos la distribución real que siguió el mercado como un gráfico negro debajo.
plt.title("Visualizing Our Improvements") plt.plot() plt.grid() plt.xlabel("Return") plt.axvline(train['Target'].mean(),color='red',linestyle=':') sns.histplot(predictions,color='blue') legend = ['Train Mean','Model Predictions'] plt.legend(legend)
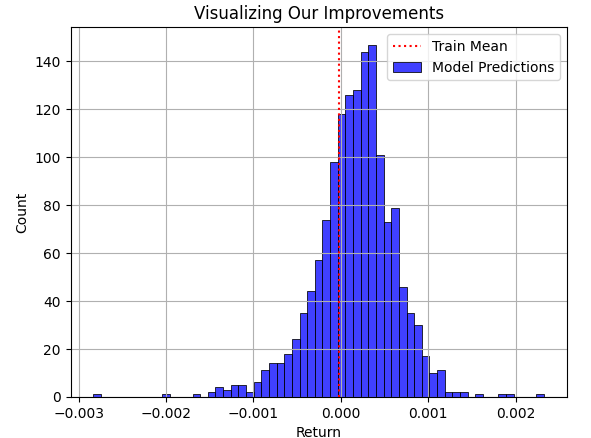
Figura 3: Visualización de las predicciones de nuestro modelo con respecto al rendimiento promedio que el modelo observó en el conjunto de entrenamiento.
La región azul de las predicciones realizadas por nuestro modelo parecía razonable en la Figura 3, pero cuando finalmente consideramos la distribución real que siguió el mercado en la Figura 4, se hace evidente que este modelo no es sólido para la tarea en cuestión. El modelo no logra capturar la amplitud de la distribución real del mercado, donde algunas de las mayores ganancias y pérdidas quedan ocultas a la percepción de nuestro modelo. Lamentablemente, RMSE frecuentemente remitirá a los profesionales a dichos modelos, si el profesional a cargo no comprende, respeta e interpreta cuidadosamente la métrica de RMSE. Utilizar un modelo así en el trading real sería catastrófico para su experiencia de trading en vivo.
plt.title("Visualizing Our Improvements") plt.plot() plt.grid() plt.xlabel("Return") plt.axvline(train['Target'].mean(),color='red',linestyle=':') sns.histplot(test['Target'],color='black') sns.histplot(predictions,color='blue') legend = ['Train Mean','Test Distribution','Model Prediction'] plt.legend(legend)
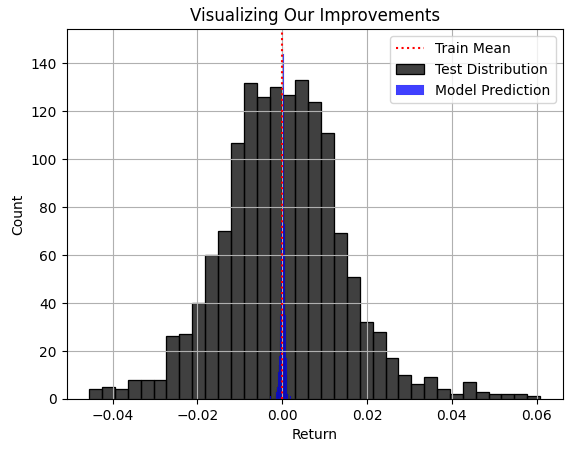
Figura 4: Visualización de la distribución de las predicciones de nuestros modelos con respecto a la distribución real del mercado.
Nuestra solución propuesta
En este punto, hemos demostrado al lector que métricas como el RMSE pueden optimizarse fácilmente prediciendo siempre el rendimiento medio del mercado, y hemos demostrado por qué esto no es atractivo, ya que el RMSE podría indicarnos con frecuencia que un modelo tan inútil es lo mejor que podemos hacer. Expresamos que, claramente, existe la necesidad de procedimientos y nuevas técnicas que explícitamente:
- Prueba tu comprensión del mercado real.
- Comprender la diferencia entre ganancias y pérdidas.
- Desaliente los comportamientos agresivos.
Me gustaría proponer una arquitectura de modelo única que podría ser una posible solución candidata que el lector puede considerar. Me refiero a la estrategia como «Modelos dinámicos de cambio de régimen» o DRS, por sus siglas en inglés. En un debate aparte sobre las configuraciones de alta probabilidad, observamos que modelar las ganancias/pérdidas generadas por una estrategia comercial puede ser más fácil que intentar pronosticar el mercado directamente. Los lectores que aún no hayan leído ese artículo pueden encontrar el enlace al mismo aquí.
Ahora procederemos a explotar esa observación de una manera interesante. Construiremos dos modelos idénticos para simular versiones opuestas de una estrategia comercial. Un modelo siempre asumirá que el mercado está en un estado de seguimiento de tendencia, mientras que el último siempre asumirá que el mercado está en un estado de reversión a la media. Cada modelo se entrenará por separado y no tendrá conciencia ni medios para coordinar sus predicciones con el otro modelo.
El lector debe recordar que la Hipótesis del Mercado Eficiente enseña a los inversores que comprar y vender los mismos volúmenes del mismo activo dejará al inversor perfectamente cubierto, y si ambas posiciones se abren y cierran simultáneamente, el beneficio total es 0, sin incluir ninguna comisión de transacción. Por lo tanto, debemos esperar que nuestros modelos siempre estén de acuerdo con este hecho. De hecho, podemos probar si nuestros modelos están de acuerdo con esta verdad; los modelos que no están de acuerdo con esta verdad no tienen una verdadera comprensión del mercado.
Por lo tanto, podemos sustituir la necesidad de confiar en métricas como RMSE probando si nuestro modelo DVM demuestra una comprensión de este principio que construye la estructura del mercado. Aquí es donde nuestra prueba de comprensión del mercado del mundo real entra en juego. Si ambos modelos comprenden verdaderamente las realidades del trading, entonces la suma de sus pronósticos debería ser siempre 0, en todo momento. Ajustaremos nuestros modelos al conjunto de entrenamiento y luego los probaremos fuera de la muestra, para ver si las predicciones del modelo siempre suman 0, incluso cuando los modelos están subestresados.
Recordemos que las predicciones de los modelos no están coordinadas de ningún modo. Los modelos se entrenan por separado y no tienen conciencia de los demás. Por lo tanto, si los modelos no están "pirateando" métricas de error deseables sino que realmente están aprendiendo la estructura subyacente del mercado, entonces demostrarán que han llegado a sus predicciones a través de una conducta ética si ambas predicciones del modelo suman 0.
Sólo uno de estos modelos puede esperar una recompensa positiva en cualquier momento. Si la suma de las predicciones de nuestro modelo no es 0, entonces los modelos pueden haber aprendido involuntariamente un sesgo direccional que viola la hipótesis del mercado eficiente. De lo contrario, en el mejor de los casos, podemos alternar dinámicamente entre estos dos estados del mercado con un nivel de confianza con el que no estábamos familiarizados en el pasado. Solo un modelo debe esperar una recompensa positiva en cualquier momento, y nuestra filosofía comercial es que creemos que ese modelo corresponde al estado oculto en el que se encuentra actualmente el mercado. Y esto podría potencialmente tener más valor para nosotros que unas lecturas RMSE bajas.
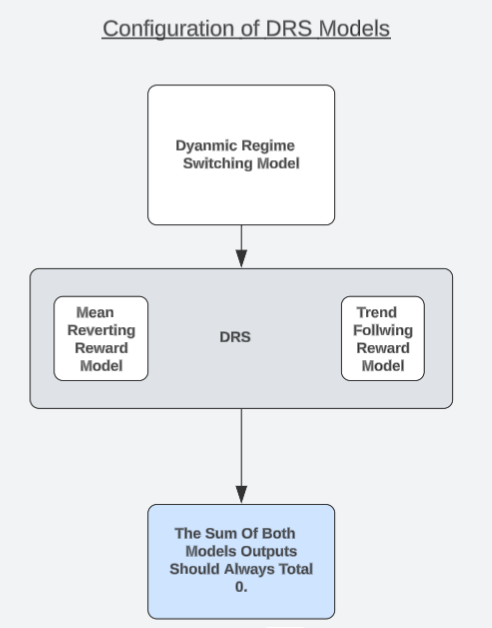
Figura 5: Comprensión de la arquitectura general de nuestros modelos DRS.
Obtención de datos desde nuestro terminal
Nuestros datos deben ser lo más detallados posible para obtener los mejores resultados. Por lo tanto, estamos realizando un seguimiento de los valores actuales de nuestros indicadores técnicos y niveles de precios, así como del crecimiento que se ha producido en estas dinámicas de mercado al mismo tiempo.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- Define our moving average indicator #define MA_PERIOD 5 //--- Moving Average Period #define MA_TYPE MODE_SMA //--- Type of moving average we have #define HORIZON 10 //--- Our handlers for our indicators int ma_handle; //--- Data structures to store the readings from our indicators double ma_reading[]; //--- File name string file_name = Symbol() + " DRS Modelling.csv"; //--- Amount of data requested input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { int fetch = size + (HORIZON * 2); //---Setup our technical indicators ma_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","Delta O","Delta H","Delta Low","Delta Close","SMA 5","Delta SMA 5"); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,(i + HORIZON)), ma_reading[i], ma_reading[i] - ma_reading[(i + HORIZON)] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Empezando
Para empezar, primero importaremos nuestras bibliotecas estándar.
#Load our libraries import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns
Ahora podemos leer los datos que escribimos anteriormente en el archivo CSV.
#Read in the data data = pd.read_csv("/content/drive/MyDrive/Colab Data/Financial Data/FX/EUR USD/DRS Modelling/EURUSD DRS Modelling.csv") data
Cuando creamos nuestro script MQL5, pronosticábamos 10 pasos hacia el futuro. Debemos mantener eso.
#Recall that in our MQL5 Script our forecast horizon was 10 HORIZON = 10 #Calculate the returns generated by the market data['Return'] = data['Close'].shift(-HORIZON) - data['Close'] #Drop the last horizon rows data = data.iloc[:-HORIZON,:]
Ahora etiqueta los datos. Recordemos que tendremos dos etiquetas, una que siempre asume que el mercado continuará con una tendencia y otra que siempre asume que el mercado se encuentra estancado en un comportamiento de reversión a la media.
#Now let us define the signals being generated by the moving average, in the DRS framework there are always at least n signals depending on the n states the market could be in #Our simple DRS model assumes only 2 states #First we will define the actions you should take assuming the market is in a trending state #Therefore if price crosses above the moving average, buy. Otherwise, sell. data['Trend Action'] = 0 data.loc[data['Close'] > data['SMA 5'], 'Trend Action'] = 1 data.loc[data['Close'] < data['SMA 5'], 'Trend Action'] = -1 #Now calculate the returns generated by the strategy data['Trend Profit'] = data['Trend Action'] * data['Return']
Después de etiquetar las acciones que siguen la tendencia, inserte las acciones de reversión a la media.
#Now we will repeat the procedure assuming the market was mean reverting data['Mean Reverting Action'] = 0 data.loc[data['Close'] > data['SMA 5'], 'Mean Reverting Action'] = -1 data.loc[data['Close'] < data['SMA 5'], 'Mean Reverting Action'] = 1 #Now calculate the returns generated by the strategy data['Mean Reverting Profit'] = data['Mean Reverting Action'] * data['Return']
Al etiquetar los datos de esta manera, esperamos que el ordenador detecte las condiciones en las que cada estrategia pierde dinero y cuándo seguir cada estrategia. Si trazamos el valor objetivo acumulativo, podemos ver claramente que, durante el periodo de tiempo seleccionado en nuestros datos, el mercado EURUSD pasó más tiempo mostrando un comportamiento de reversión a la media que siguiendo una tendencia. Sin embargo, hay que tener en cuenta que ambas líneas presentan sacudidas repentinas. Creo que estas perturbaciones pueden corresponder a cambios repentinos en el régimen del mercado.
#If we plot our cumulative profit sums, we can see the profit and losses aren't evenly distributed between the two states plt.plot(data['Trend Profit'].cumsum(),color='black') plt.plot(data['Mean Reverting Profit'].cumsum(),color='red') #The mean reverting strategy appears to have been making outsized profits with respect to the trending stratetefgy #However, closer inspection reveals, that both strategies are profitable, but never at the same time! #The profit profiles of both strategies show abrupt shocks, when the opposite strategy become more profitable. plt.legend(['Trend Profit','Mean Reverting Profit']) plt.xlabel('Time') plt.ylabel('Profit/Loss') plt.title('A DRS Model Visualizes The Market As Being in 2 Possible States') plt.grid() plt.axhline(0,color='black',linestyle=':')
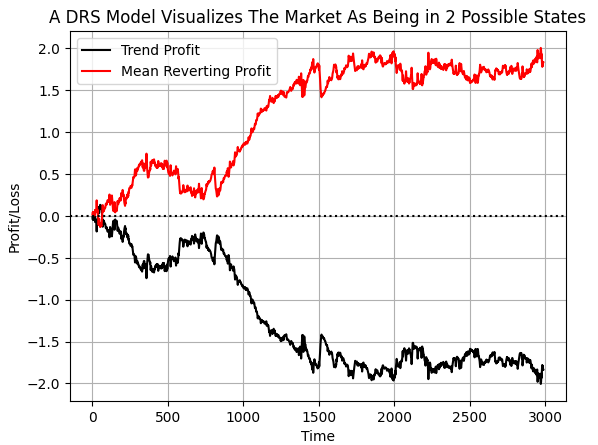
Figura 6: Visualización de la distribución de ganancias entre dos estrategias opuestas.
Define tus entradas y objetivos.
#Let's define the inputs and target X = data.iloc[:,1:-5].columns y = ['Trend Profit','Mean Reverting Profit']
Seleccione nuestras herramientas para modelar el mercado.
#Import the modelling tools from sklearn.model_selection import train_test_split,TimeSeriesSplit from sklearn.ensemble import RandomForestRegressor
Dividir los datos dos veces. De esta manera tenemos un conjunto de entrenamiento, un conjunto de validación y un conjunto de prueba final.
#Split the data train , test = train_test_split(data,test_size=0.5,shuffle=False) f_train , f_validation = train_test_split(train,test_size=0.5,shuffle=False)
Preparemos nuestros 2 modelos ahora. Recordemos que ambos modelos nos darán una doble visión del mundo, pero no deben coordinarse de ninguna manera.
#The trend model trend_model = RandomForestRegressor() #The mean reverting model mean_model = RandomForestRegressor()
Se adapta a nuestros modelos.
trend_model.fit(f_train.loc[:,X],f_train.loc[:,y[0]]) mean_model.fit(f_train.loc[:,X],f_train.loc[:,y[1]])
Probando la validez de nuestros modelos. Registraremos las predicciones de ambos modelos sobre qué valores tomarán sus objetivos en el conjunto de prueba. Recuerde, los modelos no están aprendiendo el mismo objetivo. Cada modelo aprendió independientemente su propio objetivo y trabajó para reducir su error independientemente del otro modelo.
pred_1 = trend_model.predict(f_validation.loc[:,X]) pred_2 = mean_model.predict(f_validation.loc[:,X])
El contenido del conjunto de validación está fuera de la muestra para nuestros modelos. En esencia, estamos poniendo a prueba los modelos utilizando datos que no han visto antes, para observar si nuestros modelos se comportarán de manera ética bajo estrés material.
Nuestra prueba se realiza sobre la suma de las predicciones de ambos modelos. Si el valor máximo de la suma de las predicciones del modelo es igual a 0,0, entonces nuestro modelo ha pasado nuestra prueba. Porque nuestro modelo concuerda esencialmente con la hipótesis del mercado eficiente de que al seguir ambos modelos al mismo tiempo el inversor no ganará nada. Nuestra intención es seguir sólo un modelo a la vez. Por lo tanto, cambiaremos dinámicamente entre regímenes. Es decir, nuestra estrategia, tiene la capacidad de cambiar de estrategia sin intervención humana.
test_result = pred_1 + pred_2 print(f" Test Passed: {np.linalg.norm(test_result,ord=2) == 0.0}")
El paquete numpy contiene muchas bibliotecas útiles, como el paquete de álgebra lineal que usamos anteriormente. La función norma que llamamos simplemente devuelve la suma total del contenido de un vector, o el valor más grande de un vector, dependiendo de cómo se llama el método. Lógicamente, esto es lo mismo que comprobar manualmente el contenido de la matriz por uno mismo, para asegurarse de que todos los números en la matriz sean 0. Tenga en cuenta que he truncado las salidas de la matriz, pero el lector puede estar seguro de que todas eran 0.
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
Cuando graficamos las ganancias reales obtenidas con la estrategia de seguimiento de tendencias y las comparamos con las predicciones realizadas por el modelo de seguimiento de tendencias, nos damos cuenta de que, al retener algunas oscilaciones masivas en la rentabilidad, como durante el intervalo de 600 y 700 días, cuando el mercado ERUUSD osciló con una volatilidad significativa, nuestro modelo pudo mantenerse al día con las otras ganancias de tamaño normal.
plt.plot(f_validation.loc[:,y[0]],color='black') plt.plot(pred_1,color='red',linestyle=':') plt.legend(['Actual Profit','Predicted Profit']) plt.grid() plt.ylabel('Loss / Profit') plt.xlabel('Out Of Sample Days') plt.title('Visualizing Our Model Performance Out Of Sample on the EURUSD 10 Day Return')
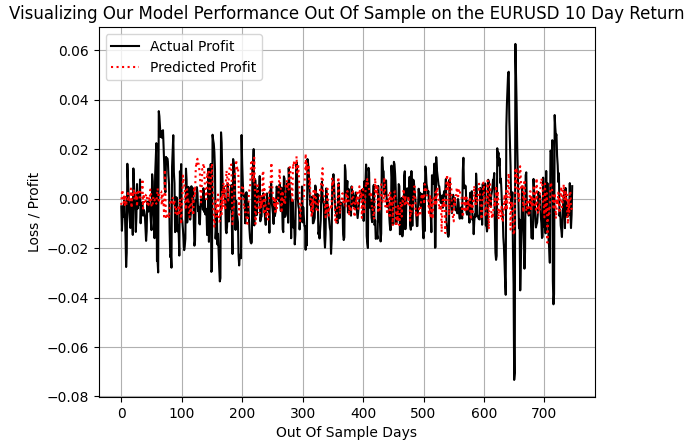
Figura 7: Nuestro modelo DRS no logró capturar la verdadera volatilidad del mercado.
Ahora estamos listos para exportar nuestros modelos de aprendizaje automático al formato ONNX y comenzar a guiar nuestras aplicaciones comerciales en nuevas direcciones. ONNX significa Open Neural Network Exchange y nos permite construir e implementar modelos de aprendizaje automático a través de un conjunto de API ampliamente adoptadas. Esta adopción generalizada permite que diferentes lenguajes de programación trabajen con el mismo modelo ONNX. Y recuerda, cada modelo ONNX es solo una representación de tu modelo de aprendizaje automático. Si aún no tiene instaladas las bibliotecas skl2onnx y ONNX, comience por instalarlas.
!pip install skl2onnx onnx
Ahora cargamos las librerías que necesitamos exportar.
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Define la forma de E/S de tus modelos ONNX.
eurusd_drs_shape = [("float_input",FloatTensorType([1,len(X)]))] eurusd_drs_output_shape = [("float_output",FloatTensorType([1,1]))]
Prepare prototipos ONNX de su modelo DRS.
trend_drs_model_proto = convert_sklearn(trend_model,initial_types=eurusd_drs_shape,final_types=eurusd_drs_output_shape,target_opset=12) mean_drs_model_proto = convert_sklearn(mean_model,initial_types=eurusd_drs_shape,final_types=eurusd_drs_output_shape,target_opset=12)
Guardar los modelos.
onnx.save(trend_drs_model_proto,"EURUSD RF D1 T LBFGSB DRS.onnx") onnx.save(mean_drs_model_proto,"EURUSD RF D1 M LBFGSB DRS.onnx")
Felicitaciones, ha creado su primera arquitectura de modelo DRS. Ahora preparémonos para realizar pruebas retrospectivas de los modelos y ver si hacen una diferencia y si pudimos sustituir de manera significativa el RMSE de nuestro proceso de diseño.
Introducción a MQL5
Para comenzar, primero definiremos las constantes del sistema que son importantes para nuestras actividades comerciales.
//+------------------------------------------------------------------+ //| EURUSD DRS.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define HORIZON 10 #define MA_PERIOD 5 #define MA_SHIFT 0 #define MA_MODE MODE_SMA #define TRADING_VOLUME SymbolInfoDouble(Symbol(),SYMBOL_VOLUME_MIN)
Ahora podemos cargar los recursos de nuestro sistema.
//+------------------------------------------------------------------+ //| System dependencies | //+------------------------------------------------------------------+ #resource "\\Files\\DRS\\EURUSD RF D1 T DRS.onnx" as uchar onnx_proto[] //Our Trend Model #resource "\\Files\\DRS\\EURUSD RF D1 M DRS.onnx" as uchar onnx_proto_2[] //Our Mean Reverting Mode
Cargue la biblioteca comercial.
//+------------------------------------------------------------------+ //| System libraries | //+------------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
También necesitaremos variables para nuestros indicadores técnicos.
//+------------------------------------------------------------------+ //| Technical Indicators | //+------------------------------------------------------------------+ int ma_o_handle,ma_c_handle,atr_handle; double ma_o[],ma_c[],atr[]; double bid,ask; int holding_period;
Especificar variables globales.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model,onnx_model_2;
Cuando nuestra aplicación se carga inicialmente, llamaremos a un método responsable de cargar nuestros indicadores técnicos y modelos ONNX.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!setup()) return(INIT_FAILED); //--- return(INIT_SUCCEEDED); }
Si no estamos usando la aplicación, limpiemos los recursos que ya no necesitamos.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- release(); }
Finalmente, cuando recibamos niveles de precios actualizados, buscaremos una oportunidad comercial o gestionaremos las posiciones abiertas que tengamos.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- static datetime time_stamp; datetime current_time = iTime(Symbol(),PERIOD_D1,0); if(time_stamp != current_time) { time_stamp = current_time; update_variables(); if(PositionsTotal() == 0) { find_setup(); } else if(PositionsTotal() > 0) { manage_setup(); } } } //+------------------------------------------------------------------+
Esta es la implementación de la función que escribimos para configurar todo el sistema.
//+------------------------------------------------------------------+ //| Attempt To Setup Our System Variables | //+------------------------------------------------------------------+ bool setup(void) { atr_handle = iATR(Symbol(),PERIOD_CURRENT,14); ma_c_handle = iMA(Symbol(),PERIOD_CURRENT,MA_PERIOD,MA_SHIFT,MA_MODE,PRICE_CLOSE); ma_o_handle = iMA(Symbol(),PERIOD_CURRENT,MA_PERIOD,MA_SHIFT,MA_MODE,PRICE_OPEN); holding_period = 0; onnx_model = OnnxCreateFromBuffer(onnx_proto,ONNX_DEFAULT); onnx_model_2 = OnnxCreateFromBuffer(onnx_proto_2,ONNX_DEFAULT); if(onnx_model == INVALID_HANDLE) { Comment("Failed to load Trend DRS model"); return(false); } if(onnx_model_2 == INVALID_HANDLE) { Comment("Failed to load Mean Reverting DRS model"); return(false); } ulong input_shape[] = {1,10}; ulong output_shape[] = {1,1}; if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Comment("Failed to set Trend DRS Model input shape"); return(false); } if(!OnnxSetInputShape(onnx_model_2,0,input_shape)) { Comment("Failed to set Mean Reverting DRS Model input shape"); return(false); } if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Comment("Failed to set Trend DRS Model output shape"); return(false); } if(!OnnxSetOutputShape(onnx_model_2,0,output_shape)) { Comment("Failed to set Mean Reverting DRS Model output shape"); return(false); } return(true); }
Cuando desinicialicemos el sistema, liberaremos manualmente los indicadores y modelos ONNX que ya no utilizamos.
//+------------------------------------------------------------------+ //| Free up system resources | //+------------------------------------------------------------------+ void release(void) { IndicatorRelease(ma_c_handle); IndicatorRelease(ma_o_handle); OnnxRelease(onnx_model); OnnxRelease(onnx_model_2); }
Actualizar las variables del sistema siempre que tengamos nueva información de precios.
//+------------------------------------------------------------------+ //| Update our system variables | //+------------------------------------------------------------------+ void update_variables(void) { bid = SymbolInfoDouble(Symbol(),SYMBOL_BID); ask = SymbolInfoDouble(Symbol(),SYMBOL_ASK); CopyBuffer(ma_c_handle,0,1,(HORIZON*2),ma_c); CopyBuffer(ma_o_handle,0,1,(HORIZON*2),ma_o); CopyBuffer(atr_handle,0,0,1,atr); ArraySetAsSeries(ma_c,true); ArraySetAsSeries(ma_o,true); }
Gestionar operaciones abiertas, básicamente realizando una cuenta regresiva hasta nuestro retorno de 10 días.
//+------------------------------------------------------------------+ //| Manage The Trade We Have Open | //+------------------------------------------------------------------+ void manage_setup(void) { if((PositionsTotal() > 0) && (holding_period < (HORIZON-1))) holding_period +=1; else if((PositionsTotal() > 0) && (holding_period == (HORIZON - 1))) Trade.PositionClose(Symbol()); }
Encuentre una configuración comercial obteniendo información detallada sobre el estado actual del mercado y alimentándola a nuestro modelo. Nuestra estrategia se basa en el uso de medias móviles como indicadores del sentimiento de los inversores. Cuando las medias móviles dan señales de venta, asumiremos que la mayoría de los inversores quieren ir en corto, pero creemos que la mayoría tiende a estar equivocada en el mercado de divisas.
//+------------------------------------------------------------------+ //| Find A Trading Oppurtunity For Our Strategy | //+------------------------------------------------------------------+ void find_setup(void) { vectorf model_inputs = vectorf::Zeros(10); vectorf model_outputs = vectorf::Zeros(1); vectorf model_2_outputs = vectorf::Zeros(1); holding_period = 0; int i = 0; model_inputs[0] = (float) iOpen(Symbol(),PERIOD_CURRENT,0); model_inputs[1] = (float) iHigh(Symbol(),PERIOD_CURRENT,0); model_inputs[2] = (float) iLow(Symbol(),PERIOD_CURRENT,0); model_inputs[3] = (float) iClose(Symbol(),PERIOD_CURRENT,0); model_inputs[4] = (float)(iOpen(Symbol(),PERIOD_CURRENT,0) - iOpen(Symbol(),PERIOD_CURRENT,HORIZON)); model_inputs[5] = (float)(iHigh(Symbol(),PERIOD_CURRENT,0) - iHigh(Symbol(),PERIOD_CURRENT,HORIZON)); model_inputs[6] = (float)(iLow(Symbol(),PERIOD_CURRENT,0) - iLow(Symbol(),PERIOD_CURRENT,HORIZON)); model_inputs[7] = (float)(iClose(Symbol(),PERIOD_CURRENT,0) - iClose(Symbol(),PERIOD_CURRENT,HORIZON)); model_inputs[8] = (float) ma_c[0]; model_inputs[9] = (float)(ma_c[0] - ma_c[HORIZON]); if(!OnnxRun(onnx_model,ONNX_DEFAULT,model_inputs,model_outputs)) { Comment("Failed to run the ONNX model correctly."); } if(!OnnxRun(onnx_model_2,ONNX_DEFAULT,model_inputs,model_2_outputs)) { Comment("Failed to run the ONNX model correctly."); } if(model_outputs[0] > 0) { if(ma_c[0] < ma_o[0]) { if(iClose(Symbol(),PERIOD_CURRENT,0) > ma_c[0]) Trade.Buy(TRADING_VOLUME,Symbol(),ask,0,0,""); } else if(ma_c[0] > ma_o[0]) { if(iClose(Symbol(),PERIOD_CURRENT,0) < ma_c[0]) Trade.Sell(TRADING_VOLUME,Symbol(),bid,0,0,""); } } else if(model_2_outputs[0] > 0) { if(ma_c[0] < ma_o[0]) { if(iClose(Symbol(),PERIOD_CURRENT,0) < ma_c[0]) Trade.Buy(TRADING_VOLUME,Symbol(),ask,0,0,""); } if(ma_c[0] > ma_o[0]) { if(iClose(Symbol(),PERIOD_CURRENT,0) > ma_c[0]) Trade.Sell(TRADING_VOLUME,Symbol(),bid,0,0,""); } } Comment("0: ",model_outputs[0],"1: ",model_2_outputs[0]); }
Indefinir constantes del sistema.
//+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON #undef MA_MODE #undef MA_PERIOD #undef MA_SHIFT #undef TRADING_VOLUME //+------------------------------------------------------------------+
Primero, seleccionaremos las fechas de nuestras pruebas retrospectivas. Recuerde que siempre elegimos fechas que están más allá del conjunto de entrenamiento del modelo para obtener una idea confiable de qué tan bien puede funcionar el modelo en el futuro.
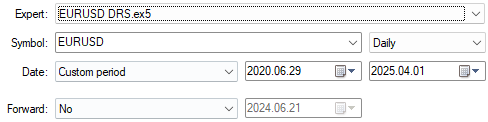
Figura 8: Asegúrese de haber seleccionado fechas que estén más allá del conjunto de entrenamiento del modelo.
Generalmente queremos poner a prueba nuestro modelo, así que seleccionamos "Retraso aleatorio" y "Cada tick basado en ticks reales" para probar nuestra estrategia en condiciones de mercado realistas y desafiantes.
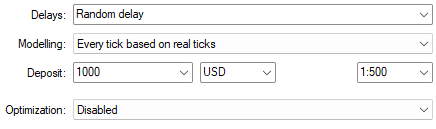
Figura 9: Usar "Cada tick basado en ticks reales" es la opción de modelado más realista que podemos seleccionar para probar nuestra arquitectura DRS.
A continuación podemos encontrar un resumen detallado del desempeño de nuestra nueva estrategia DRS. Es interesante darse cuenta de que logramos sustituir RMSE por DRS y aún así produjimos una estrategia rentable, a pesar de que este fue nuestro primer intento de sustituir RMSE en nuestro proceso de construcción de modelos de manera formal.
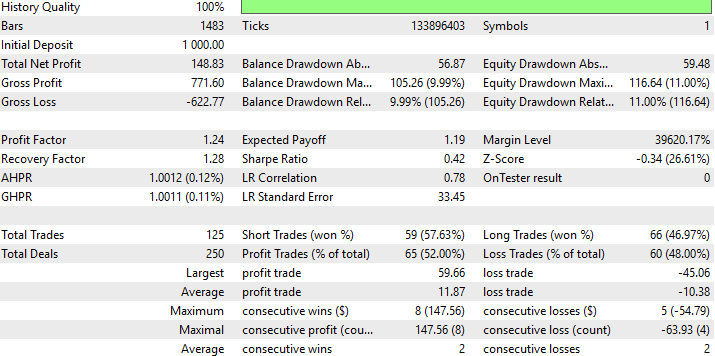
Figura 10: Resultados detallados del desempeño de nuestra estrategia con datos que no había visto antes.
Cuando observamos la curva de capital producida por nuestra estrategia, podemos empezar a ver los problemas causados por nuestro modelo DRS al no anticipar la volatilidad del mercado como comentamos anteriormente. Esto hace que nuestra estrategia oscile entre períodos rentables y períodos no rentables. Sin embargo, nuestra estrategia está demostrando capacidad para recuperarnos y mantener el rumbo, que es lo que deseamos.
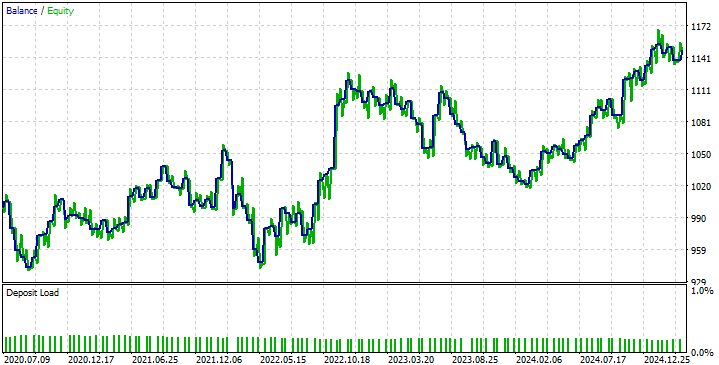
Figura 11: La curva de capital producida por nuestra nueva estrategia comercial.
Conclusión
Después de leer este artículo, los lectores que no eran conscientes de las limitaciones de estas métricas se sienten más fuertes que cuando comenzaron a leerlo. Conocer las limitaciones de tus herramientas es tan importante como conocer sus fortalezas. Los métodos de optimización que utilizamos para desarrollar IA pueden quedar “atascados” cuando intentamos resolver problemas particularmente desafiantes. Y cuando los profesionales utilizan estas herramientas para modelar el rendimiento de los activos, deben ser plenamente conscientes de que sus modelos pueden mostrar una tendencia a estancarse en el rendimiento promedio del mercado.
El lector también ha adquirido conocimientos útiles y ahora entiende los beneficios de filtrar los mercados en función de qué tan bien pueden superar a un modelo que predice el rendimiento promedio en ese mercado porque esto implica que el mercado tiene ineficiencias que el profesional debe aprovechar.
Al filtrar los mercados en función de qué tan bien el profesional puede superar la media, el lector ha aprendido a desistir de interpretar ciegamente el RMSE como una métrica independiente y, en cambio, leer el RMSE en relación con el TSS en todo momento. El lector se ha beneficiado de una comprensión práctica de las limitaciones que estas métricas imponen en su trabajo diario, una característica que no es común en la mayoría de la literatura que cubre este tema o en los artículos de investigación vinculados aquí.
Y por último, si el lector tenía la intención de implementar un modelo de aprendizaje automático para negociar su capital privado pronto, pero no estaba al tanto de estas limitaciones, entonces le advertiría que primero repitiera el ejercicio que demostré en este artículo, para estar seguro de que no estaba a punto de dispararse silenciosamente en el pie. RMSE permite que nuestros modelos hagan trampa en nuestras pruebas, pero tengo confianza en que los lectores que han leído hasta aquí no serán engañados fácilmente por las limitaciones de la IA.
| Nombre del archivo | Descripción del archivo |
|---|---|
| DRS Models.mq5 | El script MQL5 que construimos para obtener los datos de mercado detallados que necesitábamos para construir nuestro modelo DRS. |
| Dynamic_Regime_Switching_Models_(DRS_Modelling).ipynb | El notebook Jupyter que escribimos para diseñar nuestro modelo DRS. |
| EURUSD DRS.mq5 | Nuestro asesor experto EURUSD que empleó nuestro modelo DRS. |
| EURUSD RF D1 T DRS.onnx | El modelo DRS de seguimiento de tendencias siempre supone que el mercado está en tendencia. |
| EURUSD RF D1 M DRS.onnx | El modelo DRS de reversión a la media siempre supone que el mercado está en un estado de reversión a la media. |
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/17906
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Trading de arbitraje en Forex: Sistema comercial matricial para retornar al valor justo con limitación del riesgo
Trading de arbitraje en Forex: Sistema comercial matricial para retornar al valor justo con limitación del riesgo
 Redes neuronales en el trading: Pronóstico de series temporales con descomposición modal adaptativa (ACEFormer)
Redes neuronales en el trading: Pronóstico de series temporales con descomposición modal adaptativa (ACEFormer)
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
"Sin embargo, nuestra estrategia demuestra la capacidad de recuperarse y mantener el rumbo, que es exactamente lo que pretendemos".
Siempre he pensado que por lo que hay que esforzarse es porque una estrategia genere beneficios :)
"Sin embargo, nuestra estrategia muestra la capacidad de recuperarnos y mantenernos en el buen camino, que es exactamente lo que pretendemos".
Siempre he pensado que hay que esforzarse para que una estrategia aporte beneficios :)
Gracias por el artículo, @Gamuchirai Zororo Ndawana.
Estoy de acuerdo con @Maxim Dmitrievsky en que el objetivo final es la rentabilidad. La idea de "recuperar y mantener el rumbo" tiene sentido como robustez y control del drawdown, pero no sustituye a la rentabilidad.
Sugerencia práctica: prueba de walk-forward, costes y deslizamiento, pérdida asimétrica o cuantílica u objetivos basados en la utilidad, y penalizar la rotación para evitar el abrazo a la media. (Sugerencia pragmática: alinear la pérdida con la forma de ganar dinero).
Citado: Sí, en efecto, pero por desgracia aún no disponemos de métricas estandarizadas de aprendizaje automático que sean conscientes de la diferencia entre pérdidas y ganancias.
Respuesta: Las columnas de pérdidas y ganancias sólo existirán si su producto de backtesting o el mercado plano es tan bueno como el mercado a plazo que está utilizando contra la cartera subsiguiente o cesta de índice que seguirá esta línea de orden.
Hay algunos índices y ETF's recientemente fundados que están saliendo, o que son producidos sobre una base creciente, para este uso previsto, y producirán estos resultados, márgenes de beneficio tales como el índice dowjones 30 así como muchos otros índices que han sido creados para este uso previsto. Peter Matty
Gracias por el artículo, @Gamuchirai Zororo Ndawana .
Estoy de acuerdo con @Maxim Dmitrievsky en que el objetivo final es la rentabilidad. La idea de recuperar y mantener el rumbo tiene sentido por solidez y para controlar el drawdown, pero no sustituye a la rentabilidad.
A veces me pregunto si las herramientas de traducción que utilizamos no captan el mensaje original. Tu respuesta ofrece muchos más puntos de discusión que lo que yo entendí del mensaje original de @Maxim Dmitrievsky .
Gracias por señalar esos descuidos en el look ahead bias (rasgos con i + HORIZONTE), esos son los peores bugs que odio, necesitan todo un re-test. Pero esta vez con más detenimiento.
También has aportado información valiosa con las medidas de validación utilizadas para validar modelos en la práctica, el Sharpe Ratio debe ser algo así como un Gold Standard universal. Tengo que aprender más sobre Calmar y Sortino para formarme una opinión al respecto, gracias por ello.
Estoy de acuerdo contigo en que los dos términos son antisimétricos por diseño, y la prueba es que los modelos deben permanecer antisimétricos, cualquier desviación de esta expectativa, es fallar la prueba. Si uno o ambos modelos tienen un sesgo inaceptable, sus predicciones no seguirán siendo antisimétricas como esperamos.
Sin embargo, la noción de beneficio no es más que una simple ilustración que he dado para poner de relieve el problema. Ninguna de las métricas que tenemos hoy en día nos informa de cuándo se está produciendo el abrazo a la media. Ninguna de las publicaciones sobre aprendizaje estadístico nos explica por qué se produce este fenómeno. Desgraciadamente, se debe a las mejores prácticas que seguimos, y ésta es sólo una de las muchas maneras en que deseo que se inicien más conversaciones sobre los peligros de las mejores prácticas.
Este artículo era más bien un grito de ayuda, para que nos unamos y diseñemos nuevos protocolos desde cero. Nuevas normas. Nuevos objetivos en los que trabajen directamente nuestros optimizadores, que se adapten a nuestros intereses.