
Do básico ao intermediário: Filas, Listas e Árvores (III)

Introdução
No artigo anterior Do básico ao intermediário: Filas, Listas e Árvores (II), foi explicado o que seria a base inicial para a construção de uma lista encadeada. No entanto, aquela base apresentada ali, naquele artigo, não está completa. Ainda falta implementar um tipo de coisa que torna as listas encadeadas, algo realmente interessante. Tanto pelo ponto de vista prático, quanto pelo ponto de vista teórico.
Mas diferente do que seria explicado, sobre listas encadeadas caso você venha a estudar este assunto em meios acadêmicos. Aqui vamos focar na parte prática da implementação e uso das mesmas. Sendo que o para um correto entendimento do que será visto neste artigo, se faz necessário que você tenha compreendido muito bem o que foi visto no artigo anterior. Além é claro, ter um bom entendimento sobre as bases e conceitos por trás de arrays. Isto por que, não é raro, muitos iniciantes confundirem o que será visto aqui, com sendo um tipo de implementação especial de arrays. Ainda mais quando passamos a usar um outro tipo de recurso, possível e presente no MQL5. Do qual ainda não falei. Mas que irei explicar em um outro momento.
Justamente para não tornar ainda mais confuso, um assunto que precisa ser muito bem esclarecido e bem compreendido. Dada a importância envolvida quando o assunto é listas e suas aplicações. De qualquer forma, vamos iniciar o que será o tópico principal deste artigo.
Filas, Listas e árvores (III)
Para começar da maneira correta. Vamos dar uma rápida passada no que foi visto no artigo anterior. Pois é muito importante que você tenha o que foi visto ali, bem fresco em sua mente. Isto para entender o que será feito logo depois. Assim, vamos pegar o que foi o código final daquele artigo. Este é visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> class stList 05. { 06. private: 07. //+----------------+ 08. T info; 09. stList <T> *prev; 10. //+----------------+ 11. public: 12. //+----------------+ 13. stList(void) 14. :prev(NULL) 15. {} 16. //+----------------+ 17. void Push(T arg) 18. { 19. stList <T> *loc; 20. 21. loc = new stList <T>; 22. (*loc).info = arg; 23. (*loc).prev = prev; 24. prev = loc; 25. } 26. //+----------------+ 27. bool Pop(T &arg) 28. { 29. stList <T> *loc; 30. 31. if (prev == NULL) 32. return false; 33. 34. loc = prev; 35. arg = (*loc).info; 36. prev = (*loc).prev; 37. 38. delete loc; 39. 40. return true; 41. } 42. //+----------------+ 43. }; 44. //+------------------------------------------------------------------+ 45. void OnStart(void) 46. { 47. stList <char> list; 48. 49. list.Push(10); 50. list.Push(84); 51. list.Push(-6); 52. 53. for (char info; list.Pop(info);) 54. Print(info); 55. }; 56. //+------------------------------------------------------------------+
Código 01
Este código 01, tem como objetivo, criar o equivalente a uma pilha. Que seria um tipo de fila onde os valores mais recentemente adicionados, seriam os primeiros a serem lidos. No entanto, diferente do que seria a implementação de uma fila. Este código 01, já não faz uso de nenhum tipo de array interno a ele. E justamente este pequeno detalhe, que faz com que esta implementação receba uma classificação diferente. Desta forma a classificação deste código 01 seria algo como sendo uma LISTA ENCADEADA. Porém, ela ainda não pode ser realmente encarada desta forma.
Isto por que ainda falta algo que uma lista encadeada é capaz de faz e este código 01, ainda não tem capacidade de efetuar. Que seria justamente a possibilidade de adicionar ou remover elementos em qualquer posição dentro da lista de elementos. Ou seja, um código que de fato implementaria uma lista encadeada, de maneira geral, nos permitiria criar um simulacro do que seria um array dinâmico. Mas sem a necessidade de utilizar operações que normalmente são necessárias em atividades de arrays dinâmicos. Algo que em muitas situações é desejável, já que a velocidade de processamento é muito superior a qualquer implementação feita com uso de arrays.
Mas espere um pouco aí. Deixe-me ver se entendi bem, o que acabei de ler. Você está me dizendo que o objetivo de uma lista encadeada é o de criar um sistema de arrays, sem que venhamos a usar um array para isto? Mas qual o sentido em se fazer isto? Para entender isto, meu caro leitor, primeiro preciso que você venha a entender uma outra coisa. Estou considerando que você tem um conhecimento mínimo sobre programação. Ou seja, que você de fato não faz ideia de como certas coisas são feitas internamente pela CPU.
Quando você usa a função de biblioteca do MQL5, chamada ArrayInsert, seu objetivo é o de inserir novos dados dentro de um array já existente. Até aí tudo certo. Porém esta função tem um pequeno detalhe: Quando inserimos novos dados no final do array já existente, os dados são simplesmente copiados para dentro do array. Algo equivalente ao de usar a função ArrayCopy.
Porém, toda via e, entretanto, quando queremos adicionar elementos no meio de um array já existente, ou no início deste mesmo array. Algo diferente acontece. Neste caso, a função ArrayInsert irá alocar um novo bloco de memória, logo depois irá copiar parte dos elementos para este novo bloco. Adicionar o que seria os novos elementos que estamos inserindo, no bloco recém alocado. Para somente depois, copiar o restante do array original, para dentro do bloco alocado. Com isto, se estivermos utilizando um array muito grande, podemos ter um tempo de execução um tanto quanto grande. Apesar de que com o atual barramento em placas mães modernas. Estes blocos que precisam ser movimentados, precisam realmente ser muito grandes para que você possa notar a diferença. Ou no mínimo, precisamos efetuar diversas inserções para que o tempo de processamento possa ser percebido.
No entanto, no começo da era dos computadores, a coisa não era tão rápida. O barramento era lento e estas movimentações, mesmo que com poucos elementos, demandava muito tempo. Assim engenheiros e acadêmicos criaram uma solução para o problema. E esta solução é justamente as listas. Agora vamos voltar a questão do código 01. Quando a lista está totalmente criada. O que iremos ter na memória é algo parecido com o que é visto logo abaixo.
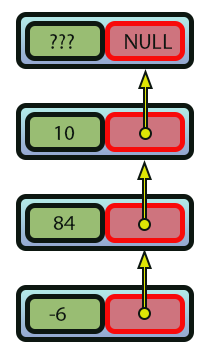
Imagem 01
A forma como chegamos neste resultado visto na imagem 01, foi explicada no artigo anterior. Porém aqui iremos dar um passo extra. Que seria justamente o de tornar a lista encadeada realmente funcional. Mas para que de fato as operações que iremos implementar venham a fazer sentido para você. Vamos primeiro entender como seria feito a mesma coisa, se estivéssemos usando um array. Ao fazermos isto, esta mesma imagem 01, será convertida em algo parecido com a imagem 02, vista logo na sequência.
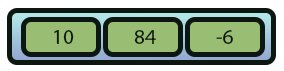
Imagem 02
Agora suponhamos que você queira adicionar um novo elemento nesta array da imagem 02. Conforme mostrado na imagem 03 logo abaixo.
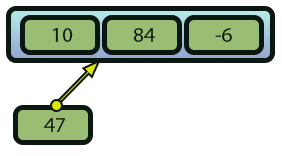
Imagem 03
Como você faria isto, sem usar a função ArrayInsert? Bem, se você entendeu a explicação dada um pouco mais acima, neste artigo. Você primeiro precisaria alocar um novo bloco de memória. Isto iria gerar o que é visto na imagem a seguir.

Imagem 04
Note que ainda não copiamos nada para este novo bloco. Apena alocamos ele na memória. O próximo passo seria o de copiar os elementos anteriores a posição onde o novo elemento será inserido. Suponde que o novo elemento será inserido no index um. A primeira cópia irá gerar o que pode ser visto logo abaixo.

Imagem 05
Ok, agora podemos inserir o novo elemento no array. E ao fazermos isto teremos o que é visto na imagem abaixo.

Imagem 06
Uma vez que a novo elemento tenha sido inserido no array final. Podemos fazer a cópia do restante dos elementos que existiam no array original. Com isto o resultado final é o que pode ser visto na imagem 07, logo abaixo.
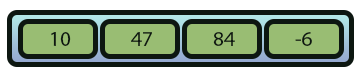
Imagem 07
Note que o passo a passo é bem simples de ser implementado, mesmo que por um iniciante em programação. Algo muito parecido acontece quando precisamos remover algum elemento de dentro do array. Só que neste caso os passos a serem feitos, será o inverso do que o mostrado aqui. Onde primeiro alocamos um bloco com menos elementos, copiamos os elementos que irão ser mantidos, pulamos os que serão removidos e finalizamos a cópia dos elementos restantes no array.
Mas vamos voltar a questão do tempo de processamento. Pense em fazer isto com um array contendo milhares de elementos. E que você precisa inserir ou remover outros milhares de elementos em posições não consecutivas, ou seja, pode ser que você insira um elemento na posição dois e o próximo lá na posição quatro e assim por diante. Neste caso, o que foi feito nas figuras acima, precisará ser feito milhares de vezes. Resultando assim em uma quantidade de movimentações consideráveis. O que no final acaba tomando muito tempo de CPU. Mesmo em um barramento moderno. No entanto, é aqui que a lista encadeada faz a sua mágica. Já que para fazer a mesma coisa vista nas imagens acima, podemos fazer em bem menos passos. Como você pode observar logo abaixo.
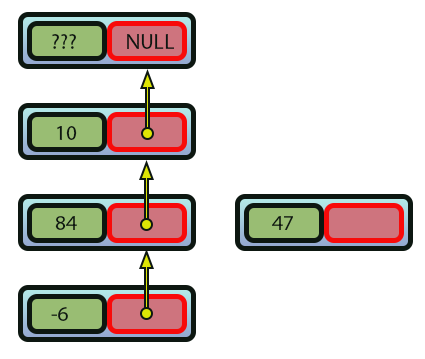
Imagem 08
Observe que esta imagem 08 é muito parecida com a imagem 01. Só que aqui temos um novo elemento que precisa ser adicionado. E este ainda não faz parte da lista encadeada. Então tudo que precisamos fazer, para adicionar este novo elemento, é dizer onde ele deverá ser adicionado. E a própria implementação irá tornar a imagem 08, na imagem 09 vista logo abaixo.
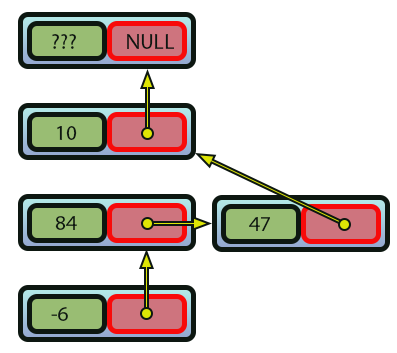
Imagem 09
Note como foi muito, mas muito mais simples adicionar um novo elemento. Assim como também é muito mais simples remover um elemento. Pois basta que venhamos a remover o link que o liga a lista, reajustando os links que mantem a lista ligada. Assim, o que seria um sistema lento, passa a ser agora um sistema muito mais rápido. Pelo simples fato de mudarmos a forma como as coisas serão feitas internamente pela implementação.
Muito bem, agora que você entendeu a ideia que existe por debaixo dos panos. Podemos ver como isto é implementado em termos de código. Sendo está a parte realmente divertida do artigo.
Ok, então vamos voltar ao que seria o código 01, visto no começo deste artigo. Só que agora iremos modificar aquele mesmo código, como mostrado logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> class stList 05. { 06. private: 07. //+----------------+ 08. T info; 09. stList <T> *prev, 10. *start; 11. //+----------------+ 12. public: 13. //+----------------+ 14. stList(void) 15. :prev(NULL), 16. start(NULL) 17. {} 18. //+----------------+ 19. void Store(T arg) 20. { 21. stList <T> *loc; 22. 23. loc = new stList <T>; 24. (*loc).info = arg; 25. (*loc).prev = prev; 26. prev = loc; 27. } 28. //+----------------+ 29. bool Restore(T &arg) 30. { 31. stList <T> *loc; 32. 33. if (prev == NULL) 34. return false; 35. 36. loc = prev; 37. arg = (*loc).info; 38. prev = (*loc).prev; 39. 40. delete loc; 41. 42. return true; 43. } 44. //+----------------+ 45. }; 46. //+------------------------------------------------------------------+ 47. void OnStart(void) 48. { 49. stList <char> list; 50. 51. list.Store(10); 52. list.Store(84); 53. list.Store(-6); 54. 55. for (char info; list.Restore(info);) 56. Print(info); 57. }; 58. //+------------------------------------------------------------------+
Código 02
Agora preste atenção meu caro leitor. Este código 02 estamos começando a implementar o que seria realmente uma lista encadeada simples. Aqui você pode usar qualquer nome para as funções e procedimentos adotados. Isto não importa. Porém, é esta é a parte importante, você precisa tomar cuidado com a forma como o código será implementado. Isto para que a lista seja criada e mantida da forma correta. Da forma como este código 02 se encontra, continuamos tendo o que seria uma pilha, implementada no formato de lista. Entender isto é importante para entender o que será visto depois.
Agora, podemos começar a implementar as funções e procedimentos aos poucos. Mas antes de fazermos isto, que tão ver o resultado da execução deste código 02. Apesar de ele já ser conhecido por aqueles que viram o artigo anterior. De qualquer forma, o resultado é visto logo abaixo.
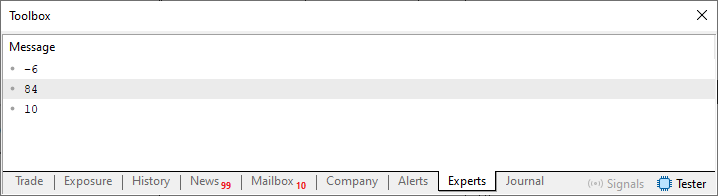
Imagem 10
Muito bem, agora vamos fazer o que será a primeira modificação deste mesmo código 02. Isto a fim de conseguir adicionar um valor no início do que será a nossa lista. Esta primeira mudança pode ser vista logo na sequência.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> class stList 05. { 06. private: 07. //+----------------+ 08. T info; 09. stList <T> *prev, 10. *start; 11. //+----------------+ 12. public: 13. //+----------------+ 14. stList(void) 15. :prev(NULL), 16. start(NULL) 17. {} 18. //+----------------+ 19. void Store(T arg, const ENUM_FILE_POSITION pos = SEEK_END) 20. { 21. stList <T> *loc; 22. 23. loc = new stList <T>; 24. switch(pos) 25. { 26. case SEEK_SET: 27. (*loc).info = arg; 28. (*loc).prev = NULL; 29. (*start).prev = loc; 30. start = loc; 31. break; 32. case SEEK_END: 33. (*loc).info = arg; 34. (*loc).prev = prev; 35. prev = loc; 36. start = (start == NULL ? loc : start); 37. break; 38. } 39. } 40. //+----------------+ 41. bool Restore(T &arg) 42. { 43. stList <T> *loc; 44. 45. if (prev == NULL) 46. return false; 47. 48. loc = prev; 49. arg = (*loc).info; 50. prev = (*loc).prev; 51. 52. delete loc; 53. 54. return true; 55. } 56. //+----------------+ 57. }; 58. //+------------------------------------------------------------------+ 59. void OnStart(void) 60. { 61. stList <char> list; 62. 63. list.Store(10); 64. list.Store(84); 65. list.Store(-6); 66. list.Store(47, SEEK_SET); 67. 68. for (char info; list.Restore(info);) 69. Print(info); 70. }; 71. //+------------------------------------------------------------------+
Código 03
Agora preste muita, mas muita atenção mesmo ao que irei explicar, meu caro leitor. Pois apesar de para mim, e para programadores com uma boa experiência, isto que está sendo feito aqui no código 03, ser muito simples de ser entendido. Para muitos de vocês, isto daqui é algo extremamente complicado. E aqui estamos apenas iniciando a implementação da lista propriamente dita. Para evitar de criar muitas coisas, estou utilizando a enumeração de posicionamento de arquivo aqui no código. Esta pode ser vista na linha 19.
Repare que existe uma diferença entre o que seria o código 02 e este código 03, justamente neste mesmo procedimento. Pois bem, este código 03, continua funcionando como se fosse uma pilha. Porém, uma pilha que pode ser construída de maneira um pouco arbitrária. Agora vamos a questão. SEEK_END irá sempre colocar as coisas partindo do final do que já esteja colocado na lista. E SEEK_SET irá sempre colocar as coisas partindo do início do que já está colocado na lista. Isto seria o mesmo princípio adotado durante manipulações de arquivos binários.
No entanto a parte confusa é justamente quando precisamos colocar algo no início da lista. Isto quando já temos uma lista previamente construída. Digo isto pelo fato de que se você observar, irá notar que a parte responsável por colocar dados no final da fila é muito parecido com o que já estava sendo feito. Porém, foi necessário adicionar a linha 36, justamente para que o ponteiro de início da lista seja corretamente atribuído. E é justamente isto que irá nos permitir adiciona depois, novos elementos no início da lista.
Pois bem, quando uma chamada ao procedimento da linha 19, tem seu segundo argumento SEEK_SET, como é o caso da linha 66. Teremos a execução do código entre as linhas 26 e 31. Ok, então vamos entender linha por linha o que está acontecendo aqui. A linha 27, armazena o valor do elemento, assim como é feito pela linha 33. Já a linha 28, garante que o valor anterior seja um NULL. Isto é importante para que o teste da linha 45 tenha sucesso caso não exista nenhum elemento na lista. Beleza, já a linha 29, faz com que o atual ponteiro para o valor anterior, aponte para o que será o novo primeiro elemento no início da lista. E para finalizar a linha 30, atribui o primeiro elemento para que ele seja corretamente apontado.
Sei que olhando assim, este tipo de coisa, aparentemente simples, pode fazer com que você abaixe a guarda. Achando fácil demais entender este código. No entanto, preciso alerta a você, meu caro leitor, que sem entender isto que está sendo feito aqui no código 03, você dificilmente irá entender o que será visto em breve. De qualquer forma, quando executado este código 03, irá produzir o seguinte resultado visto logo abaixo.
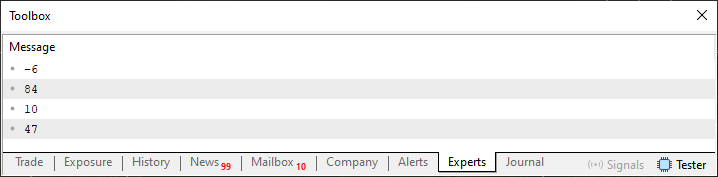
Imagem 11
Bem, mas você pode estar pensando: Será que não poderíamos colocar o conteúdo desta linha 66 antes do que seria a linha 63? Assim evitaríamos criar esta possível confusão no código. Na verdade, este não é exatamente o problema aqui, meu caro leitor. O detalhe, é que precisamos nos certificar de que o código consegue de fato adicionar elementos no que seria o início da nossa lista. Sendo este o ponto pelo qual a linha 66, se apresenta como mostrado no código 03.
Isto foi um tanto quando divertido. Mas podemos e iremos deixar as coisas ainda mais divertidas. Então vamos modificar o código 03, agora para o que seria o código 04, visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> class stList 05. { 06. private: 07. //+----------------+ 08. T info; 09. stList <T> *prev, 10. *start; 11. //+----------------+ 12. public: 13. //+----------------+ 14. stList(void) 15. :prev(NULL), 16. start(NULL) 17. {} 18. //+----------------+ 19. void Store(T arg, const ENUM_FILE_POSITION pos = SEEK_END) 20. { 21. stList <T> *loc; 22. 23. loc = new stList <T>; 24. 25. (*loc).info = arg; 26. (*loc).prev = NULL; 27. switch(pos) 28. { 29. case SEEK_SET: 30. (*loc).start = start; 31. (*start).prev = loc; 32. start = loc; 33. break; 34. case SEEK_END: 35. if (prev != NULL) (*prev).start = loc; 36. (*loc).prev = prev; 37. prev = loc; 38. start = (start == NULL ? loc : start); 39. break; 40. } 41. } 42. //+----------------+ 43. bool Restore(T &arg, const ENUM_FILE_POSITION pos = SEEK_END) 44. { 45. stList <T> *loc = NULL; 46. 47. if ((prev == NULL) || (start == NULL)) 48. return false; 49. 50. switch (pos) 51. { 52. case SEEK_SET: 53. loc = start; 54. start = (*loc).start; 55. break; 56. case SEEK_END: 57. loc = prev; 58. prev = (*loc).prev; 59. break; 60. } 61. arg = (*loc).info; 62. 63. delete loc; 64. 65. return true; 66. } 67. //+----------------+ 68. }; 69. //+------------------------------------------------------------------+ 70. void OnStart(void) 71. { 72. stList <char> list; 73. 74. list.Store(10); 75. list.Store(84); 76. list.Store(-6); 77. list.Store(47, SEEK_SET); 78. 79. for (char info; list.Restore(info, SEEK_SET);) 80. Print(info); 81. }; 82. //+------------------------------------------------------------------+
Código 04
Neste código 04, já começamos a implementar algo que à primeira vista não parecer ser o que realmente é. Então vamos dar uma relaxada e observar este código 04 com calma. Veja que agora, temos a função Restore, presente na linha 43, podendo também receber uma indicação de como a leitura deverá ser feita.
Sendo assim, neste exato momento, caímos em um tipo de questão da qual foi vista lá no artigo Do básico ao intermediário: Filas, Listas e Árvores (I) onde falamos sobre filas do tipo FIFO, e também de filas circulares. Mas aqui, por motivos de simplicidade do próprio código. Não irei entrar na questão referente a filas circulares. Vamos nos manter na questão que seja mais simples, e ao mesmo tempo interessante para compor o artigo.
Antes de entrarmos na questão da função Restore. Vamos ver o que mudou em relação ao procedimento Store. Pois apesar de parecer não ter mudado. As mudanças feitas neste procedimento, criam algo diferente do que é visto na imagem 01. Então preste atenção meu caro leitor, pois na imagem 01, tínhamos o que seria uma lista encadeada simples. Porém, este código 04, mais especificamente no procedimento Store, cria o que é conhecido como LISTA DUPLAMENTE ENCADEADA. Mas espere um pouco. No código 03 não tínhamos criado este tipo de lista dupla? Não meu caro leitor. No código 03, ainda estávamos no que seria uma lista simples. No entanto, estas poucas mudanças feitas no código 04, tornaram aquilo que era uma lista simples em uma lista dupla. Para entender isto veja a imagem abaixo, que representa uma lista duplamente encadeada.
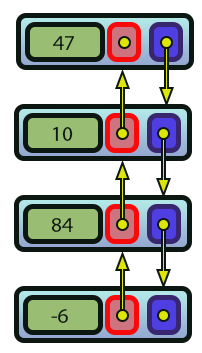
Imagem 12
Observe que neste caso da imagem 12 temos duas direções de setas. Diferente do que pode ser visto na imagem 01, onde havia apenas uma única direção de seta. É isto que nos permite distinguir entre o que seria uma lista dupla e uma lista simples.
Mas espere um pouco. Ainda não consegui entender por que o código 03 é uma lista simples e este código 04 é uma lista dupla. Poderia explicar isto melhor. Bem então vamos entender isto de maneira mais clara. Note que na linha 30 do código 04 criamos uma ligação para marcar o início de uma lista. Assim como também é feito na linha 35. Mas, da forma como estamos fazendo isto, faz com que a lista mude de comportamento. Não durante a escrita, mas sim durante o processo de leitura, que iremos ver em breve. Observe que cada elemento, ou node, como normalmente é chamado um elemento de uma lista, tem duas direções que podem ser seguidas. A primeira destas direções, nos faz seguir rumo a origem, ou primeiro elemento da lista. Já a segunda direção, faz com que venhamos a seguir rumo ao fim da lista. Como não estamos fechando a lista a fim de a tornar circular as coisas ficam limitadas a este range.
Perceba que as mudanças feitas, a fim de criar a lista dupla foram apenas estas que menciono. E isto não muda a forma de se trabalhar com o procedimento de estocagem de dados na lista. Porém isto nos permite criar uma forma bem diferente de se fazer a leitura da lista. Então vamos ver a função Restore, presente na linha 43. Claramente você logo nota que podemos dizer se a lista será lida do elemento mais antigo em direção ao mais recente, ou se será o contrário. E justamente isto que diferencia o que seria uma fila do tipo FIFO ou do tipo pilha, como foi visto nos artigos anteriores. No entanto, aqui não estamos lidando com filas, mas sim listas. Porém o conceito continua valendo.
Preste atenção agora ao fato de que o teste na linha 47, estamos verificando duas condições que tornam a lista vazia. Se a mesma não estiver vazia, passamos a parte de leitura. Como a parte onde estamos implementando SEEK_END, que seria a leitura do elemento mais recente para o elemento mais antigo, já foi bastante explorada. Vamos ao que é a novidade aqui. Ou seja SEEK_SET. Quando este método é usado, faremos a leitura do elemento mais antigo, ou seja os primeiros elementos na lista, para os mais recentes, que seriam os últimos elementos presentes na lista. Veja que para fazer isto, fazemos a leitura do elemento atual na linha 53, e logo depois ajustamos o ponteiro do atual elemento para o próximo elemento na lista. Isto é feito na linha 54. E é somente isto que precisamos fazer. Assim sendo quando o código é executado, iremos ver o que é mostrado na imagem logo abaixo.
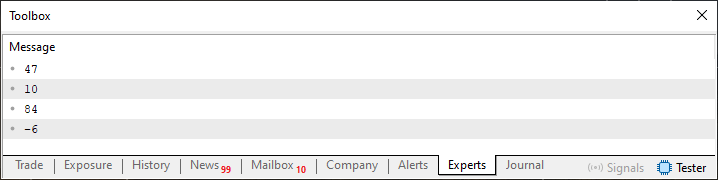
Imagem 13
Credo. Que coisa mais maluca. De fato meu caro leitor, olhando assim, talvez você possa não estar entendendo bem o que está ocorrendo. De qualquer forma, no anexo, você terá os códigos principais vistos neste artigo, para poder experimentar. Mas não deixe de experimentar os códigos intermediários que estão sendo mostrados neste artigo. Pois eles ajudarão a você entender melhor o que está ocorrendo aqui.
De qualquer forma, antes de terminar este artigo, quero mostrar uma outra coisa para você, meu caro e estimado leitor. Talvez isto lhe ajude a entender ainda melhor como esta lista duplamente encadeada está sendo criada dentro da memória.
É muito importante que você consiga entender isto, para entender o que irei explicar no próximo artigo. Já que não quero lhe bombardear com muita informação. Pois o que já temos neste artigo, é o bastante para que muitos tenham bastante coisa a ser estudada e compreendida. A parte que quero mostrar pode ser vista no código logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> class stList 05. { 06. private: 07. //+----------------+ 08. T info; 09. stList <T> *prev, 10. *start; 11. //+----------------+ 12. public: 13. //+----------------+ 14. stList(void) 15. :prev(NULL), 16. start(NULL) 17. {} 18. //+----------------+ 19. void Store(T arg, const ENUM_FILE_POSITION pos = SEEK_END) 20. { 21. stList <T> *loc; 22. 23. loc = new stList <T>; 24. 25. (*loc).info = arg; 26. (*loc).prev = NULL; 27. switch(pos) 28. { 29. case SEEK_SET: 30. (*loc).start = start; 31. (*start).prev = loc; 32. start = loc; 33. break; 34. case SEEK_END: 35. if (prev != NULL) (*prev).start = loc; 36. (*loc).prev = prev; 37. prev = loc; 38. start = (start == NULL ? loc : start); 39. break; 40. } 41. } 42. //+----------------+ 43. bool Restore(T &arg, const ENUM_FILE_POSITION pos = SEEK_END) 44. { 45. stList <T> *loc = NULL; 46. 47. if ((prev == NULL) || (start == NULL)) 48. return false; 49. 50. switch (pos) 51. { 52. case SEEK_SET: 53. loc = start; 54. start = (*loc).start; 55. break; 56. case SEEK_END: 57. loc = prev; 58. prev = (*loc).prev; 59. break; 60. } 61. arg = (*loc).info; 62. 63. delete loc; 64. 65. return true; 66. } 67. //+----------------+ 68. void Debug(void) 69. { 70. Print("===== DEBUG ====="); 71. for (stList <T> *loc = prev; loc != NULL; loc = (*loc).prev) 72. PrintFormat("0x%06X ->> 0x%06X <<- 0x%06X = [%d]",(*loc).start, loc, (*loc).prev, loc.info); 73. Print("================="); 74. } 75. //+----------------+ 76. }; 77. //+------------------------------------------------------------------+ 78. void OnStart(void) 79. { 80. stList <char> list; 81. 82. list.Store(10); 83. list.Store(84); 84. list.Store(-6); 85. list.Store(47, SEEK_SET); 86. 87. list.Debug(); 88. 89. for (char info; list.Restore(info, SEEK_SET);) 90. Print(info); 91. }; 92. //+------------------------------------------------------------------+
Código 05
Se você usar este código 05, que estará no anexo, com bastante calma e atenção irá entender como a lista é criada na prática. Isto por que, na linha 68, adicionei um procedimento, cujo objetivo seria o de mostrar a lista dentro da memória. Como aqui no MetaTrader 5, não podemos fazer certas coisas, sem entrar em outros detalhes ainda mais avançados. Este procedimento da linha 68, irá imprimir no terminal a estrutura da lista de uma forma relativamente simples de entender. Quando a linha 87 é executada, iremos chamar este procedimento da linha 68. E o resultado pode ser visto na imagem logo abaixo.
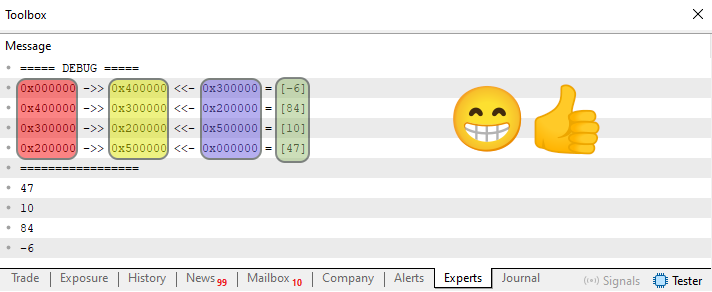
Imagem 14
Aqui temos quatro regiões sendo marcadas. E estas regiões de certa maneira, estão ligadas com o que seria a imagem 12. Note que em verde, nesta imagem 14, temos os valores presentes naquele node da lista. Em amarelo temos o endereço do node. E as regiões em vermelho e roxo? Bem, estas regiões indicam o endereço do próximo bloco e o do bloco anterior. Veja que as setas mostradas nesta imagem 14 indicam a direção de leitura que estaremos fazendo. Se a seta estiver em direção a esquerda estaremos lendo do elemento mais antigo para o mais recente. O que seria equivalente a uma leitura do tipo FIFO. Já as setas voltadas para a direita, estaremos lendo os nodes, no que seria equivalente a uma pilha. Ou seja do elemento mais recente para o mais antigo na lista.
Então basicamente é isto, meu caro leitor. Agora é estudar e praticar para realmente entender o que está acontecendo aqui, nestes códigos.
Considerações finais
Neste artigo, cujo conteúdo é bastante denso e muito complicado para grande parte dos iniciantes. Vimos na prática como implementar um modelo simples e bastante prático de uma lista encadeada. Começamos com o que seria uma implementação de lista simples e terminamos naquilo que é classificado como sendo uma lista duplamente encadeada.
Apesar do que está sendo visto aqui, possa parecer muito mais complicado do que realmente é. Gostaria que você, meu caro leitor, procura-se estudar com calma o que foi visto aqui neste artigo. Isto porque, ainda falta mostrar como implementar uma coisa neste sistema de lista. Que seria justamente o de incluir ou excluir elementos baseando-se em um valor de index. Como este tipo de coisa envolve usar algo que para muitos seria muito mais fácil e simples de entender usando arrays. Não irei mostrar neste artigo esta parte. Mesmo porque, existe um outro detalhe, que torna ainda mais confuso esta parte faltante. No entanto, este detalhe será deixado para ser explicado em um outro momento. Ao meu ver, apesar deste detalhe tornar a coisa muito mais confusa, para iniciantes. Ele torna a implementação e uso do código muito mais simples.
De qualquer forma não irei comentar isto neste primeiro momento. Mas gostaria que você fizesse um esforço, mesmo que não venha a conseguir fazer isto. Criar um mecanismo que permita inserir e excluir elementos dentro da lista. Usando para isto um valor de index. Da mesma forma que você faria se estivesse usando arrays. Para lhe ajudar a entender como fazer isto, para aqueles que querem se desafiar a fim de ver quanto já conseguiram assimilar sobre programação em MQL5, deixo a seguinte dica:
Procure modificar o procedimento da linha 68 do código 05, a fim de conseguir conhecer o ponto de exclusão e inclusão de dados na lista. Uma vez conseguido fazer isto, tente modificar de maneira adequada, o procedimento da linha 19. Isto para que ele receba um index indicando em que posição a lista será modificada. Permitindo assim, que você crie ou remova um determinado node da lista. Criando assim, algo muito parecido com o que é visto na imagem 09. Detalhe: Para uma lista duplamente encadeada, será mais simples implementar o código. Já que o código 05 cria uma lista duplamente encadeada. Mas nada lhe impede de criar uma lista encadeada simples.
Tente fazer isto, antes de ver qual será a minha proposta, para solucionar este tipo de situação. Lembrando que o código não precisa ser igual ao que irei apresentar. Mas precisa ser capaz de conseguir o mesmo tipo de efeito. Então bons estudos e que você se divirta pensando em como fazer isto. E nos vemos no próximo artigo.
| Arquivo MQ5 | Descrição |
|---|---|
| Code 01 | Lista simples |
| Code 02 | Lista simples |
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Cliente no Connexus (Parte 7): Adicionando a camada de cliente
Cliente no Connexus (Parte 7): Adicionando a camada de cliente
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso