
Do básico ao intermediário: Filas, Listas e Árvores (I)

Introdução
No artigo anterior Do básico ao intermediário: Como bolhas de sabão, foi demonstrado como poderíamos implementar um mecanismo de ordenação muito simples. Apesar de ele não ser assim tão eficiente em termos de tempo de execução. Ele em muitos casos é suficientemente adequado para uma ampla gama de casos. Onde o objetivo seria ordenar uma serie de dados a fim de tornar mais simples, tanto o nosso trabalho de interpretar tais dados, quanto também o de efetuar pesquisas simples nos mesmos.
Mas aquele tipo de mecanismo, mostrado no artigo anterior, nem sempre trabalha de fato sozinho. Na maioria das vezes, sistemas de ordenação e pesquisa, estão intimamente ligados a outros tipos de mecanismos. E neste artigo iremos abordar um destes mecanismos.
É bem verdade, que apesar de estarmos ainda focados em um conteúdo mais básico. O que será visto aqui, para alguns pode vir a ser um tipo de conteúdo que muitos consideram mais avançado. No entanto, o mesmo ainda assim está ligado as bases, ou fundamentos que todo profissional de programação precisa conhecer.
Ok, então para começar da maneira correta. Vamos iniciar um novo tópico. Lembrando que se você por ventura vier a ter alguma dificuldade no entendimento do que será mostrado aqui. Isto se tratando de elementos que não estejam sendo explicados neste artigo específico. Procure estudar os artigos anteriores. Pois neles teremos toda a base de conhecimento, necessário para o perfeito entendimento do que será visto neste artigo.
Filas, Listas e árvores (I)
Existe um tipo de material que muitos iniciantes acabam por desprezar por imaginar ser algo desnecessário ser aprendido. Ou melhor dizendo, ser corretamente assimilado e muito bem compreendido. Este material, que muitos iniciantes desprezam, tem como objetivo, justamente nos permitir uma adequada analise e estruturação de dados.
Agora preste atenção, meu caro leitor. Nada adianta você estudar como criar um Expert Advisor, ou mesmo um simples indicador. Se você não tem um correto entendimento sobre como efetuar uma análise de todos os dados que estão sendo gerados pela aplicação. Agora pare e pense um pouco. Se você conseguir entender como analisar e classificar os dados que estão chegando para sua aplicação poder trabalhar. Poderá tornar todo o trabalho de sua aplicação, mais fácil e por consequência mais rápido.
Atualmente está sendo criado um grande alvoroço em torno de aprendizagem de máquina e coisas do gênero. No entanto, mesmo sistema de inteligência artificial, entre outras coisas, nada mais são do que simples classificadores e sistemas de analise estatística de dados. Não existindo de maneira alguma, algo realmente inteligente ali. Capaz de superar a criatividade humana e a capacidade de compreensão que podemos vir a ter sobre um determinado tipo de assunto.
Ou seja, no final, mesmo que a tal inteligência artificial, ou o aprendizado de máquina, que muitos acham ser o máximo, possa parecer ser algo surpreendente. Elas não passam de meros algoritmos capazes de usar uma serie de bases que todo bom programador precisa dominar. E entender como, mas principalmente por que usar este e não aquele modelo de implementação, pode vir a fazer toda a diferença. Mas isto é algo que somente com o tempo e uma boa dose de prática e experiência e que você irá conseguir dominar. O objetivo destes artigos, não é lhe dizer quando usar este ou aquele modelo de implementação. Mas sim apresentar os modelos e mostrar como eles podem vir a ser utilizados via MQL5. Isto para que o MetaTrader 5, gere os resultados para nós.
Ok, existe uma certa sequência lógica, se é que podemos dizer, ou se quer afirmar isto, para apresentar o material que iremos ver aqui. E como quero ser o mais didático possível. Já que alguns, principalmente iniciantes, podem não entender a importância do que será visto. Vamos começar com o que seria a implementação mais simples de todas, ou seja, filas.
Uma fila, seria a princípio algo equivalente a um array. Porém, apesar desta equivalência, uma fila pode assumir diversas formas, e algumas bem diferente entre si. Tendo por consequência, objetivos completamente diferentes, dependendo de cada caso específico e de como a fila estará sendo implementada. Justamente por se parecer tanto com um array de dados. Muitas das vezes, filas são confundidas, e não é à toa, por grande parte dos iniciantes, como sendo um array. Porém, filas não são necessariamente arrays, já que o objetivo e a forma de se trabalhar com elas é muito diferente da forma e objetivo de se trabalhar com arrays, propriamente ditos.
Como as filas podem assumir certas características bem marcantes, e ao mesmo tempo bastante interessantes. Podendo inclusive ter uma implementação bem exótica, dependendo dos recursos que a linguagem nos oferece. Vamos começar com algo bem simples cujo princípio é fácil de entender. Isto porque ainda não foi explicado o conceito e funcionamento de uma classe. Porém, já foi explicado elementos suficientes, para que possamos implementar diversas coisas sem muita dificuldade. Com isto podemos escrever, ou melhor dizendo, implementar um código que é visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> struct stFIFO 05. { 06. private: 07. //+----------------+ 08. T value[]; 09. //+----------------+ 10. public: 11. //+----------------+ 12. T Restore(void) 13. { 14. T local = NULL; 15. 16. if (value.Size() > 0) 17. { 18. local = value[0]; 19. ArrayRemove(value, 0, 1); 20. }; 21. return local; 22. }; 23. //+----------------+ 24. void Stock(T arg) 25. { 26. T local[1]; 27. local[0] = arg; 28. ArrayInsert(value, local, value.Size()); 29. } 30. //+----------------+ 31. }; 32. //+------------------------------------------------------------------+ 33. void OnStart(void) 34. { 35. stFIFO <char> fifo; 36. 37. fifo.Stock(10); 38. fifo.Stock(84); 39. fifo.Stock(-6); 40. 41. Print(fifo.Restore()); 42. Print(fifo.Restore()); 43. Print(fifo.Restore()); 44. Print(fifo.Restore()); 45. } 46. //+------------------------------------------------------------------+
Código 01
Beleza, este é o no nosso primeiro passo em direção a um entendimento maior e mais amplo do que seria estas coisas, conhecida na programação como filas, listas e árvores. Agora quero que você preste atenção a alguns detalhes aqui neste código meu caro leitor. Observe que apesar de estarmos declarando um array dinâmico na linha oito. E este poder ser de qualquer tipo, como você já deve conseguir entender apenas por olhar a própria declaração da linha oito.
Este array, não deve ser pensado como sendo algo que já vimos até então. Isto por conta da função da linha doze e do procedimento da linha 24. O nome destes procedimentos e funções podem ser qualquer um. O que importa de fato e como eles funcionam. Então preste muita atenção ao que será explicado. Isto porque dependendo das funções e procedimentos envolvidos, podemos ter uma rápida mudança do que estaria sendo implementado. Podendo variar o tipo de fila, ou até mesmo, ter uma mudança drástica a ponto de no lugar de uma fila, estarmos implementando uma lista ou mesmo uma árvore.
Ok, esta é a parte fácil. se você observar o código da função Restore, que está presente na linha doze. Irá notar que quando temos algo no array declarado na linha oito. Iremos sempre armazenar a informação presente no index zero do array para depois retornar esta mesma informação ao chamador. Mas a parte realmente importante de ser observada aqui, é justamente o que a linha 19 estará fazendo. Esta linha 19, tem como objetivo, remover justamente o que seria o index zero. Mas espere um pouco. Não entendi. Se estamos sempre retornando o conteúdo presente no index zero. Ao removermos este mesmo index iremos acabar tendo uma certa inconsistência no código. Já que na próxima chamada, este index zero não irá conter nenhuma informação.
Bem, meu caro leitor, na verdade não é bem isto que irá acontecer. Como eu disse, muitos iniciantes acabam por confundir as coisas, justamente por apenas observar o código por cima. Sem de fato entender o que acontece nos bastidores. Mas garanto que em breve você irá entender isto melhor. Apenas preste atenção ao que estarei explicando.
Ok, agora sabemos que a função da linha doze irá sempre retornar o conteúdo presente no index zero do array. Mas e quanto ao procedimento da linha 24. O que ele faz? Bem, neste caso este procedimento tem como objetivo armazenar no array, as informações que vão sendo enviadas a ele. Porém estas mesmas informações irão sempre ser colocadas no final do array. Hum, não entendi. Poderia explicar isto um pouco melhor.
Sim, meu caro leitor. Acredito que você, já sabe, ou já deve entender, que um array, pode conter diversas posições de index. Iniciando em zero e indo até um valor qualquer. Quando a primeira informação é enviada para o procedimento Stock, visto na linha 24, ela será armazenada no index zero. Até aí tudo normal, já que quando estivermos usando a função Restore, iremos justamente ler o que está neste index zero. Agora vem a parte confusa, para muito iniciante. A próxima informação enviada para Stock, será armazenada no index um. Isto porque já existe uma no index zero. E a próxima no index dois, pelo mesmo motivo de se ter uma no index um, e assim por diante.
No entanto, em qualquer uma destas situações, a função Restore, ainda assim estará lendo sempre o que está no index zero. Mas aqui é onde as coisas ficam divertidas. Quando usamos a função Restore, iremos decrementar o index em uma unidade. Assim acabamos criando um tipo de fila de atendimento. Para ver isto acontecendo na prática, veja a lista de comandos presentes no procedimento OnStart, visto na linha 33. Quando as linhas 37 até 39 são executadas, teremos a criação do que seria uma fila. Exatamente na ordem em que estamos declarando as coisas. Já quando as linhas 41 até a linha 44 tem seus códigos executados, estaremos lendo o que havia sido colocado na fila. Parece um tanto quanto estranho. Mas funciona. Veja o resultado da execução na imagem logo abaixo.
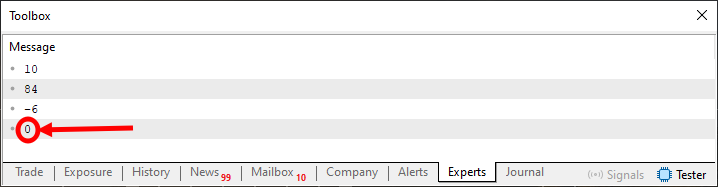
Imagem 01
Note que temos um elemento diferente sendo destacado nesta imagem 01. Este elemento é devolvido pela função Restore, justamente pelo fato de que não existe mais nenhum elemento na fila. Isto devido ao fato de que na linha 14 estamos declarando qual será o retorno, quando nenhum dado estiver armazenado no array declarado na linha oito.
É possível notar claramente o fato de que, apesar de estamos sempre olhando para o index zero, durante a função Restore. Ainda assim, conseguimos ver os dados que foram colocados na fila. Este tipo de fila, tem uma denominação especial. Ela é chamada de FIFO, ou seja primeiro a entra, primeiro a sair. Procure fazer alguns testes, a fim de entender isto melhor. Como por exemplo adicionar alguns valores na fila. Depois ler parte deles, e logo depois adicionar mais valores. Tentando assim entender como este procedimento de leitura e escrita acontece de fato.
Este tipo de fila é muito útil em diversas situações, onde precisamos que as coisas sejam analisadas em uma certa ordem e não podemos as perder de vista. Por isto é bom você procurar praticar e entender como este primeiro código funciona. Isto antes de vermos o próximo.
Neste próximo código que você poderá observar um pouco mais abaixo. Estaremos criando um outro tipo de fila, com um objetivo completamente diferente deste que vimos a pouco. Mas antes de tentar entender o que estará acontecendo no próximo código. Sugiro fortemente que você, meu caro e estimado leitor, procure dedicar um tempo para realmente entender o que foi visto no código 01 e como ele funciona. Isto para não vir a confundir o que será visto no código logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> struct stQueue 05. { 06. private: 07. //+----------------+ 08. T value[]; 09. uint c_Pos, 10. c_Max; 11. //+----------------+ 12. public: 13. //+----------------+ 14. void Init(uint arg) 15. { 16. ArrayResize(value, arg + 1); 17. c_Pos = c_Max = 0; 18. } 19. //+----------------+ 20. bool GetInfo(T &arg) 21. { 22. if (c_Pos == c_Max) 23. return false; 24. c_Pos = (c_Pos < value.Size() - 1 ? c_Pos + 1 : 0); 25. arg = value[c_Pos]; 26. 27. return true; 28. } 29. //+----------------+ 30. void Stock(const T arg) 31. { 32. c_Max = (c_Max < value.Size() - 1 ? c_Max + 1 : 0); 33. c_Pos = (c_Pos == c_Max ? (c_Pos < value.Size() - 1 ? c_Pos + 1 : 0) : c_Pos); 34. value[c_Max] = arg; 35. } 36. //+----------------+ 37. }; 38. //+------------------------------------------------------------------+ 39. void OnStart(void) 40. { 41. stQueue <char> Queue; 42. 43. Queue.Init(5); 44. 45. Queue.Stock(10); 46. Queue.Stock(84); 47. Queue.Stock(-6); 48. Queue.Stock(15); 49. Queue.Stock(-35); 50. Queue.Stock(40); 51. Queue.Stock(-35); 52. 53. for (char info; Queue.GetInfo(info);) 54. Print(info); 55. } 56. //+------------------------------------------------------------------+
Código 02
Neste código 02, estamos implementando um outro tipo de fila, que é reconhecida entre os programadores, como sendo uma fila circular. Apesar de este tipo de implementação ser mais simples de ser feita, quando se utiliza classes na sua implantação. Nada nos impede de implementar o código com os recursos já explicados em artigos passados. Apesar de que quando a implementação feita usando classe, você verá que tudo irá se tornar muito mais simples. Tanto com relação a criação, quanto na utilização da própria implementação que está sendo feita aqui. Mas isto é assunto para um outro momento. Vamos focar no que temos em mãos neste exato instante.
Agora redobre a sua atenção meu caro leitor. Pois se o código 01, lhe pareceu um tanto quanto confuso e complicado. Este código 02 irá lhe deixar ainda mais sem direção. Já que aqui estamos fazendo algo que para muitos pode parecer pura insanidade. Mas que na prática, pode vir a ser muito útil em diversos momentos. Note que parte da estrutura declarada na linha quatro, neste código 02, se parece bastante com o que foi feito no código 01. Tendo inclusive algumas partes muito parecidas. Porém o tipo de coisa que está sendo feita aqui, é muito diferente do que foi feito no código 01. E não apenas isto. Aqui neste código 02, existe a possibilidade de que algumas informações possam ser perdidas, diferente do que ocorria no código 01.
Mas espere um pouco. Como assim, temos a possibilidade de ter informações sendo perdidas? Isto não seria um problema para o código? Na verdade não, meu caro leitor. Existem situações em que de fato, é esperado, ou melhor dizendo, podemos perder informações sem que de fato tenhamos problemas com o tipo de resultado que nos será apresentado. Talvez para muitos de vocês isto possa parecer um tanto quanto estranho. Mas pense no caso das médias móveis que você utiliza no gráfico. Elas seriam de certa maneira uma fila de valores, onde os valores mais antigos são descartados. Por exemplo: Uma média móvel de 20 períodos armazena em si, 20 valores, sendo que o primeiro valor é o mais recente, e o último valor será descartado, assim que um valor mais recente entrar na fila.
Agora preste atenção, pois isto é importante. Como temos um range fixo de valores e eles vão sendo substituídos por valores mais novos. Não devemos chamar este tipo de estrutura de lista, mas sim de fila. Listas de valores tem um outro objetivo. Mas filas tem um objetivo bem singelo e prático. Não é raro confundir estes dois termos. Mas para que não tenhamos problemas de interpretação. Chamamos de filas o que está sendo mostrado aqui. Mesmo que a princípio isto lhe pareça ser uma lista de valores.
Ok, agora note que neste caso da fila circular, precisamos de uma forma de limitar o range, ou quantidade de valores presentes na fila. Isto é feito pelo procedimento mostrado na linha 14. Aqui informamos a quantidade de valores que estarão na fila. Podendo ser qualquer valor maior que zero. Com isto, na linha 16, alocamos memória suficiente para que o array dinâmico da linha oito seja construído e mantido em memória. Contudo, como estamos iniciando a nossa fila circular, precisamos também inicializar dois valores extras. Isto é feito na linha 17. Com isto temos a fila construída e pronta para receber dados ou ter dados lidos da mesma.
Agora vem a parte onde muitos, costumam ficar bastante confusos, no primeiro contanto com este tipo de modelagem. Como precisamos ler elementos da fila, implementamos a função da linha 20. Esta tem como objetivo, retornar um elemento qualquer de entro da fila. Mas qual elemento? Bem, isto depende, meu caro leitor. Para entender o motivo desta minha resposta, veja que temos na linha 22 um teste sendo feito. Caso os valores c_Pos que indica a posição atual a ser lida, seja igual a c_Max, que indica a atual posição a ser escrita. Temos zero elementos a serem retornados. Por conta disto, este teste na linha 22, pode em alguns casos retornar o valor false.
Caso isto não aconteça, significa que algum valor pode ter sido lido. Nesta situação, usamos a linha 24 para calcular a nova posição de leitura, dentro da fila. Mas por que precisamos deste cálculo? Não seria muito mais simples, apenas incrementar o valor do contador c_Pos? Na verdade não, meu caro leitor. Isto por que, estamos lidando com uma fila circular, e a não ser que esta fila venha a conter o número de elementos que podem ser representados dentro do tipo uint, realmente precisaremos ter que efetuar um ajuste como é visto na linha 24. Isto faz com que uma vez que o contador c_Pos alcance o limite superior da fila, ele volte e comece a apontar para o primeiro index dentro do array. Com isto temos a fila circular sendo criada. O restante do código é simples.
Então vamos para o procedimento visto na linha 30, pois este é responsável por fazer algo bem curioso e ao mesmo tempo bem intrigante. Observe o seguinte: Na linha 32, temos algo muito parecido com a linha 24. Apenas mudando o fato de que a variável a ser ajustada é outra. Mas o objetivo é o mesmo, promover um retrocesso ao início do array, assim que o número máximo de elementos que foram alocados na linha 16 for atingido.
Parou tudo. Agora complicou de vez. Isto por que estou percebendo que este mesmo valor c_Max é usado na linha 34 para apontar qual o index onde o valor que estamos informando será armazenado. Porém, você está me dizendo que a linha 32 estará de tempos em tempos voltando ao index zero. Então supondo que temos a capacidade de armazenar 20 elementos e venhamos a armazenar 21 elementos, ou seja um a mais que o limite que a linha 16 criou. Apenas poderemos ser um elemento? Não meu caro leitor. Iremos realmente continuar tendo a capacidade de ler 20 elementos já gravados. Porém o primeiro elemento armazenado na fila será substituído por este novo elemento que seria o elemento 21. Cara que coisa mais confusa. Não estou conseguindo entender como conseguiremos fazer isto. Tenha calma, você logo irá entender. Mas para garantir que manteremos esta capacidade de leitura dentro de toda a fila circular, é preciso que implementemos a linha 33. Esta linha é a responsável por fazer com que a fila ande sem que precisemos deslocar elemento algum dentro do array.
Perceba o seguinte: Quando c_Max for igual a c_Pos, significa que a fila está completamente cheia. Caso contrário estes valores jamais serão iguais. Devido ao fato de que a fila já está cheia, forçamos c_Pos para a próxima posição. Mas para garantir que c_Pos de fato estará apontando para a próxima posição valida dentro da fila, usamos um segundo operador ternário a fim de garantir que os limites dentro da fila circular sejam respeitados. Por isto este segundo operador ternário é exatamente igual ao que é mostrado na linha 24. Como sei que a maior parte de vocês, são iniciantes e podem ter uma certa dificuldade em entender este código 02. No anexo teremos um código ligeiramente diferente. Este é visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> struct stQueue 05. { 06. #define macro_AdjustLimit(A) (A < value.Size() - 1 ? A + 1 : 0) 07. //+----------------+ 08. private: 09. //+----------------+ 10. T value[]; 11. uint c_Pos, 12. c_Max; 13. //+----------------+ 14. public: 15. //+----------------+ 16. void Init(uint arg) 17. { 18. ArrayResize(value, arg + 1); 19. c_Pos = c_Max = 0; 20. } 21. //+----------------+ 22. bool GetInfo(T &arg) 23. { 24. if (c_Pos == c_Max) 25. return false; 26. c_Pos = macro_AdjustLimit(c_Pos); 27. arg = value[c_Pos]; 28. 29. return true; 30. } 31. //+----------------+ 32. void Stock(const T arg) 33. { 34. c_Max = macro_AdjustLimit(c_Max); 35. c_Pos = (c_Pos == c_Max ? macro_AdjustLimit(c_Pos) : c_Pos); 36. value[c_Max] = arg; 37. } 38. //+----------------+ 39. #undef macro_AdjustLimit 40. //+----------------+ 41. }; 42. //+------------------------------------------------------------------+ 43. void OnStart(void) 44. { 45. stQueue <char> Queue; 46. 47. Queue.Init(5); 48. 49. Queue.Stock(10); 50. Queue.Stock(84); 51. Queue.Stock(-6); 52. Queue.Stock(15); 53. Queue.Stock(-35); 54. Queue.Stock(40); 55. Queue.Stock(-35); 56. 57. for (char info; Queue.GetInfo(info);) 58. Print(info); 59. } 60. //+------------------------------------------------------------------+
Código 03
Este código 03, faz exatamente a mesma coisa que o código 02. Apenas temos a diferença que é a definição da macro na linha seis, neste código 03. Contudo, isto torna a mesma linha 33 vista no código 02, um tanto quanto mais simples de ser entendida. Visto que esta linha 35 no código 03, é bem mais agradável aos olhos. Apesar de ser a mesma coisa que a linha 33 do código 02.
Porém o que nos interessa de fato, é ver como esta estrutura funciona. Isto a ponto de criar e manter a tal fila circular. Para que possamos experimentar esta estrutura que cria a fila circular, usamos o que está dentro do procedimento OnStart.
Agora vamos focar a explicação no código 03. Isto a fim de acompanhar as linhas que serão informadas. A primeira coisa que fazemos é definir a própria fila. E isto é feito na linha 45. Logo depois, definimos quantos elementos estarão presentes na fila. No caso isto é feito usando a linha 47. Note que neste caso estamos definindo que serão cinco elementos NO MÁXIMO.
Agora vem a parte divertida. Que é justamente fazer uso da fila circular. Para isto usamos as linhas 49 até a linha 55. Perceba o seguinte fato, estamos com uma fila que pode conter no máximo cinco elementos. Porém, toda via e, entretanto, estamos pedindo para que sete elementos sejam colocados nesta fila. Pergunta: O que irá acontecer aqui? Resposta: Alguns elementos irão desaparecer, sendo substituídos conforme a fila anda. Mas como podemos ter certeza disto? Bem, para isto, usamos a linha 57, onde temos um laço muito intrigante à primeira vista. Porém em outro artigo, expliquei exatamente como podemos trabalhar com o comando for a fim de criar laços com objetivos bem interessantes. Este é um destes casos. Note que o próprio laço cria as condições que precisamos, a fim de que ele seja encerrado e que também seja executado. Mas a parte que nos toca e nos interessa o que a linha 58 seja executada. Pois é nela que nos permitirá ver que elementos foram descartados e quais elementos estavam na fila.
Certo, então quando executamos este código 03 ou o código 02, temos como resultado o que é visto na imagem logo abaixo.
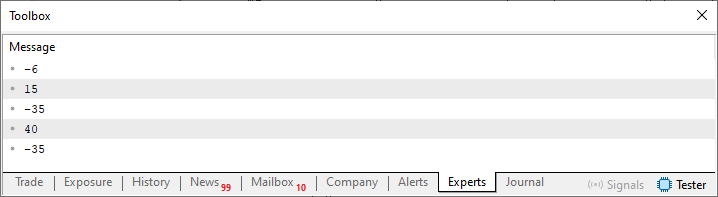
Imagem 02
Bem, aí está meu caro leitor. Mas quero que você pare um pouco e pense a respeito do que está sendo mostrado nesta imagem 02. E compare isto com o que é visto no código 03, entre as linhas 49 e 55. Você consegue entender o que está acontecendo aqui? Consegue perceber uma certa ligação entre o que foi visto no código 01, onde implementando uma fila do tipo primeiro a entrar, primeiro a sair. Com esta fila circular que está sendo implementada neste código 03? Sim. Não, ou quem sabe talvez. Bem, talvez você não esteja conseguindo perceber esta ligação. Mas existe sim uma ligação entre o que foi explicado no início deste artigo com isto que estamos vendo aqui. E a ligação é: O primeiro elemento na fila está sempre sendo o primeiro elemento a ser mostrado. Assim como o último elemento na fila, está sendo o último elemento mostrado. Porém diferente do que acontecia antes. Aqui estamos limitando o número de elementos que pode existir na fila. No caso, isto é definido na linha 47 do código 03.
Esta é a parte confusa, da qual muita gente não consegue se dar conta. Quando estamos iniciando na programação, perdemos muito tempo tentando criar ou implementar algo. No entanto, é muito pouco provável de que não exista em lugar algum, algo que implemente o que estamos tentando fazer. Agora pense no seguinte: Supondo que você esteja criando um Expert Advisor para ficar analisando uma média móvel de X períodos. Por que você precisa ficar armazenando mais que X elementos de preço? Não faz sentido. Da mesma forma, não faz sentido, ficar movendo dados de preço a fim de manter um array com X valores de preço sempre atualizado. Tudo que você precisa fazer é criar, ou implementar uma estrutura de dados como uma fila circular e pronto. A própria implementação cuidará de manter os preços sempre atualizados com praticamente nenhum trabalho de movimentação. Já que os contadores de index que estamos usando farão este trabalho para nós. O que torna o código executável muito mais rápido e fácil de manter.
Considerações finais
Neste artigo, começamos a brincar e a nos divertir com um dos temas muito pouco conhecidos por parte de programadores iniciantes. Muitas das vezes as pessoas ficam desesperadas por aprender programação, mas não procuram entender ou compreender conceitos básicos. Entender e compreender de maneira adequada tais conceitos, é ao meu ver, algo muito mais importante e necessário do que escrever códigos e mais códigos. Isto porque, o simples fato de que você tenha o conhecimento adequado de certos conceitos, pode lhe ajudar a criar códigos muito mais seguros, rápidos e fáceis de se manter.
Então meu caro leitor, procure estudar com calma e praticar o que foi visto neste artigo. Pois esta base que estou tentando passar a você, foi algo que demorei um bom tempo para conseguir assimilar. Isto devido ao fato de que, quando estudei este assunto, ninguém de fato dava muita importância para ele. Todos nos cobravam apenas resultados, independente da forma como eles eram conseguidos. Mas aqui estou lhe mostrando o caminho das pedras. Depende de você saber como trilhar este caminho. Isto a fim de tornar seu aprendizado mais suave e consistente quanto for possível de ser feito. Não tenha pressa. Estude e pratique bastante o que foi visto neste artigo. E no próximo artigo iremos continuar a falar sobre filas, listas e árvores.
| Arquivo | Descrição |
|---|---|
| Code 01 | Fila simples |
| Code 02 | Fila simples |
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso