
Do básico ao intermediário: Filas, Listas e Árvores (II)

Introdução
No artigo anterior Do básico ao intermediário: Filas, Listas e Árvores (I), começamos a explicar sobre um dos temas que muitos iniciantes ignoram ou costumam fazer pouco caso. Já que em sua ampla maioria, não são devidamente orientados a respeito de certas implementações, ou modelos de implementações. Grande parte dos iniciantes, simplesmente imaginam que basta arregaçar as mangas e se atolar até o pescoço de livros e artigos que já conseguirão aprender programação. Mas a verdade, é que programação em si, não é algo muito complexo. Já que tudo que você de fato precisa saber, se resume em conhecer alguns comandos e a sintaxe dos mesmos.
Porém apesar de isto ser de fato verdadeiro, o principal problema enfrentado por todo iniciante é o de entender que programação é basicamente matemática. E muitas das vezes esta matemática vem sendo estudada e aplicada em diversos mecanismos amplamente discutidos em diversos livros e artigos, disponíveis de maneira pública. No entanto, mesmo isto ocorrendo, muitas das vezes, um iniciante tem dificuldades em entender por que usar, e quando usar tais mecanismos. E acaba perdendo muito tempo tentando bolar soluções que já existem, bastando para isto adaptar conceitos já existentes ao problema que está sendo analisado.
Justamente um destes conceitos, é o que começamos a ver no artigo anterior. No entanto, aquilo foi apenas uma primeira abordagem, sendo basicamente voltado a demonstrar como poderíamos implementar mecanismos de fila, lista e árvores, usando um mínimo de conhecimento geral sobre MQL5.
Mas apesar de ter dado a demonstração de filas do tipo FIFO e do tipo circular, ainda falta falar de um outro tipo de fila. Completando assim os tipos básicos que podemos implementar. É muito importante que você, meu caro leitor, procure entender os conceitos adotados aqui. Não tente decorar como o código é montado. Já que isto pode variar de caso a caso. Dependendo é claro do tipo de problema que está sendo solucionado.
Assim sendo, vamos continuar aquele mesmo assunto, iniciado no artigo anterior. E para isto, vamos a um novo tópico. Lembrando que o material visto aqui, estará intimamente ligado ao que foi mostrado no artigo anterior.
Filas, Listas e árvores (II)
Ok, muito provavelmente, se você está iniciando na programação, pode ter ficado um tanto quanto confuso sobre onde e como utilizar o que foi visto no artigo anterior. No entanto, existe uma enormidade de momentos em que saber como implementar o que foi visto e explicado ali, poderá fazer a diferença na sua vida como programador. Mas você deve ter notado que tanto a fila do tipo FIFO quanto a do tipo circular, tem em comum o fato de que os elementos serão sempre lidos na ordem em que eles foram colocados na fila. Ou seja, o elemento mais antigo é sempre o primeiro a ser lido, e por consequência o elemento mais recente na fila é sempre o último a ser lido. No entanto, muitas vezes precisamos que esta ordem seja invertida. Ou seja, queremos que o elemento mais recente seja o primeiro a ser lido, e que o elemento mais antigo na fila seja o último a ser lido.
Você pode até pensar que para fazer isto, bastaria que invertêssemos a ordem de leitura dos elementos colocados em uma fila do tipo FIFO ou do tipo circular. De fato, e em alguns casos práticos é exatamente o que acontece. Porém, toda via e, entretanto, existe um tipo de fila especialmente criada para que isto venha a ser implementado. Sem que venhamos a ter uma modificação no código já implementado. Este tipo de fila especialmente criado para inverter a ordem, é conhecido como pilha.
Uma pilha nada mais é do que o próprio nome indica. Ou seja, quando adicionamos novos elementos, não podemos remover elementos mais antigos sem antes remover os elementos mais recentes. Existe até mesmo um brinquedo que exemplifica perfeitamente o que seria uma pilha e onde ela poderia ser utilizada. Tal brinquedo é mostrado na imagem logo abaixo.

Imagem 01
Para quem desconhece este brinquedo, ele é conhecido como Torre de Hanói. Acreditem, este brinquedo já foi usado como forma de análise e comparação de CPUs no passado. Isto porque existem formas de implementar ele a fim de ter uma boa medida da velocidade de processamento. Porém, devido ao fato de que muitas CPUs começaram a ser otimizadas para fazer com que o algoritmo ficasse mais rápido do que seria de fato a velocidade real de execução da CPU. Tal modelo de comparação foi abandonado. Se desejar experimentar a forma de solução desta torre, você pode dar uma olhada no site Somatemática.
Ok, mas onde entramos nesta história toda? Bem meu caro leitor, entender como esta torre de Hanói, funciona, irá lhe ajudar a entender a lógica por trás do que seria a implementação de uma pilha. Pois a pilha em si é muito fácil de ser implementada. Mas entender onde e quando a usar, é algo que somente com a prática você irá conseguir enxergar de maneira mais rápida e sem tropeços. Para tornar a coisa mais fácil de entender, vamos pegar como base o código da fila do tipo FIFO que foi mostrado e explicado no artigo anterior. Aquele mesmo código é replicado logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> struct stFIFO 05. { 06. private: 07. //+----------------+ 08. T value[]; 09. //+----------------+ 10. public: 11. //+----------------+ 12. T Restore(void) 13. { 14. T local = NULL; 15. 16. if (value.Size() > 0) 17. { 18. local = value[0]; 19. ArrayRemove(value, 0, 1); 20. }; 21. return local; 22. }; 23. //+----------------+ 24. void Stock(T arg) 25. { 26. T local[1]; 27. local[0] = arg; 28. ArrayInsert(value, local, value.Size()); 29. } 30. //+----------------+ 31. }; 32. //+------------------------------------------------------------------+ 33. void OnStart(void) 34. { 35. stFIFO <char> fifo; 36. 37. fifo.Stock(10); 38. fifo.Stock(84); 39. fifo.Stock(-6); 40. 41. Print(fifo.Restore()); 42. Print(fifo.Restore()); 43. Print(fifo.Restore()); 44. Print(fifo.Restore()); 45. } 46. //+------------------------------------------------------------------+
Código 01
Este código 01 quando executado produz o resultado que já conhecemos e que pode ser visto na imagem abaixo.
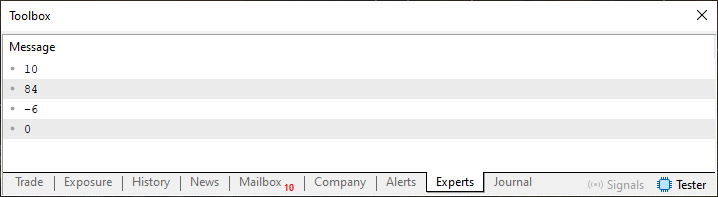
Imagem 02
Agora preste atenção. O nome das funções e procedimentos podem ser qualquer um. Porém, normalmente quando usamos uma modelagem de pilha, gostamos, como programadores, de usar certos nomes para estas funções e procedimentos que implementa a fila do tipo pilha. Assim sendo, a primeira coisa a ser feita, é mudar o código 01, para o que é visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> struct stStack 05. { 06. private: 07. //+----------------+ 08. T value[]; 09. //+----------------+ 10. public: 11. //+----------------+ 12. bool Pop(T &arg) 13. { 14. arg = NULL; 15. 16. if (value.Size() == 0) 17. return false; 18. arg = value[0]; 19. ArrayRemove(value, 0, 1); 20. return true; 21. }; 22. //+----------------+ 23. void Push(T arg) 24. { 25. T local[1]; 26. local[0] = arg; 27. ArrayInsert(value, local, value.Size()); 28. } 29. //+----------------+ 30. }; 31. //+------------------------------------------------------------------+ 32. void OnStart(void) 33. { 34. stStack <char> my; 35. 36. my.Push(10); 37. my.Push(84); 38. my.Push(-6); 39. 40. for (char info; my.Pop(info);) 41. Print(info); 42. } 43. //+------------------------------------------------------------------+
Código 02
Muito bem, agora veja que mudamos algumas coisas do código 01 para este código 02. No entanto, ainda assim continuamos implementando o que seria a fila do tipo FIFO, mesmo neste código 02. Porém ao executarmos ele o resultado será ligeiramente diferente. Como você pode notar na imagem 03, que é vista logo na sequência.
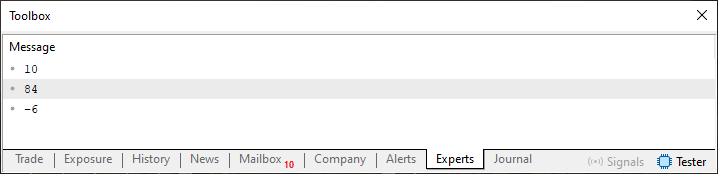
Imagem 03
Agora vem a parte interessante. Observe que a ordem em que estamos adicionando os elementos na fila, não está sendo modificada. No entanto, queremos fazer com que, os elementos colocados no topo da fila, ou seja, os últimos elementos, sejam os primeiros a serem lidos e removidos da fila. Fazendo com que a fila seja lida do elemento mais recente para o elemento mais antigo. E para com que isto venha a ocorrer, tudo que precisamos fazer é mudar o código nas linhas 18 e 19 deste que seria o código 02. Ao fazermos isto, mudamos o que seria uma fila do tipo FIFO para o que seria uma fila do tipo pilha. Note que é muito simples de mudar as coisas. E como a mudança a ser feita é em um local muito particular. Podemos desconsiderar o restante do código e focarmos apenas neste ponto específico. Então, a mudança que precisa ser feita pode ser observada no fragmento de código logo abaixo.
. . . 11. //+----------------+ 12. bool Pop(T &arg) 13. { 14. arg = NULL; 15. 16. if (value.Size() == 0) 17. return false; 18. arg = value[value.Size() - 1]; 19. ArrayRemove(value, value.Size() - 1, 1); 20. return true; 21. }; 22. //+----------------+ . . .
Fragmento 01
Mas é somente isto? Não acredito. Preciso ver o resultado da execução deste código. Ok, meu caro leitor, você pode ver isto olhando a imagem logo abaixo, que apresenta o resultado que é mostrado no terminal do MetaTrader 5.
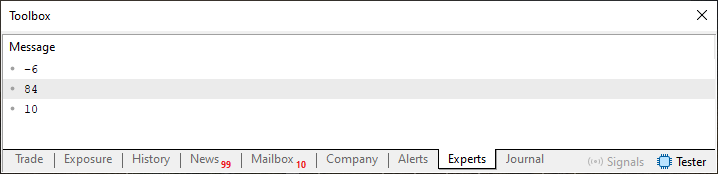
Imagem 04
Note que nesta imagem 04 temos os elementos sendo lidos na ordem inversa do que é mostrado na imagem 03. E como não mudamos nenhuma outra parte do código, apenas as linhas 18 e 19, significa que estamos lendo os elementos do mais recentemente colocado na fila, para o mais antigo. Ou seja, funciona, temos então o que seria uma fila do tipo pilha, ou mas comumente chamada de pilha.
Este procedimento que você está vendo acontecer aqui, não se restringe apenas a situações especiais. A própria CPU, usa algo muito parecido no momento em que efetuamos chamadas a procedimentos ou funções. Neste caso, a CPU, usa uma região reservada da memória como uma pilha. Se você procurar saber como aplicações são executadas a nível de CPU, irá encontrar referencias disto que acabamos de ver. Pode ser algo que venha a lhe interessar, caso você pretenda entender melhor como um computador funciona.
Mas agora fiquei com uma dúvida. Será que existe alguma implementação, e se existir, onde seria usada? Que faz uso do conceito de pilha em uma fila circular? Bem, meu caro leitor, existir pode até existir, nada impede de que isto possa vir a ocorrer. O detalhe é: Qual seria o objetivo de tal implementação. Visto que uma fila circular, em algum momento irá acabar destruindo elementos mais antigos dentro da mesma. Mas dependendo do tipo de coisa que você esteja implementando. Pode vir a ser interessante usar o conceito de pilha em uma fila circular. Mas isto vai de caso a caso. E como é algo muito específico, não vejo motivo para mostrar como implementar isto aqui. Mas acredito que você não terá dificuldades em fazer tal coisa. Devido justamente a similaridade entre uma fila do tipo FIFO e a do tipo circular. Como foi demonstrado no artigo anterior.
Agora que já falamos dos tipos básicos de filas. Chegou a hora de tornar estas mesmas filas, algo um pouco mais elaborado. E com isto, surge um novo conceito, que são as listas. Para entender o que seria uma lista, e por que elas são uma evolução das filas. Primeiro você precisa entender uma coisa, que obviamente você já deve ter notado. Quando estamos lidando com filas, NÃO PODEMOS mudar, ou melhor dizendo, não podemos informar, em que posição um dado elemento deverá ficar na fila. Este tipo de coisa NÃO É POSSIVEL. Tudo que podemos fazer é enviar o elemento, ou dado para ser colocado dentro da fila. Não podendo dizer onde ele seria colocado.
Agora preste atenção, pois isto é muito importante de ser entendido. Uma fila seria uma abstração do que seria um array. Já uma lista seria a evolução do que seria uma fila. O que em tese nos faria voltar ao que seria o conceito de array. Porém, é esta é a parte importante, quando lidamos com listas, não indicamos necessariamente um index para colocar o elemento na fila. Assim como seria feito se estivéssemos usando um array. Ao invés de fazer isto, que seria a indicação do index que o elemento deveria ocupar na fila. Fazemos algo um pouco diferente. E é neste ponto que a coisa realmente pega. Já que muitos iniciantes tem dificuldade em entender por que estamos fazendo isto ou aquilo. Já que o conceito não muda, mas a implementação em si, muda bastante, dependendo de cada caso específico. O que acaba confundindo muita gente. Ainda mais quando entramos no conceito de árvore. Mas vamos com calma. Um passo de cada vez.
Vamos começar entendendo, como podemos modificar os códigos de fila, vistos até aqui, a fim de criar o que seria uma lista. Com um detalhe: Existem dois tipos de lista. A lista singularmente encadeada e a duplamente encadeada. Sendo que a diferença entre uma e outra está no fato de como podemos navegar dentro dela. Além é claro de algumas diferenças na forma de implementar o código. Mas isto será visto com calma.
Antes de começarmos a falar sobre listas propriamente ditas. Preciso explicar rapidamente sobre uma outra coisa. A explicação será bem rápida apenas para que você entenda o que será feito. Depois iremos nos aprofundar neste assunto. O detalhe aqui, é que o MQL5 NÃO NOS PERMITE USAR PONTEIROS PARA ESTRUTURAS. Não entendo. Por que isto é um problema para nós? Bem, meu caro leitor, problema é que para se criar listas, da maneira correta, precisamos utilizar ponteiros. E qualquer que seja o motivo, aqui no MQL5 não podemos fazer isto usando estruturas.
Porém podemos fazer isto usando classes. A grosso modo, e isto falando de uma maneira bem grosseira, uma classe nada mais é do que uma estrutura. Novamente, esta não é a melhor forma de se definir e de se criar um conceito sobre classes. Classes são coisas muito mais elaboradas do que estruturas. Porém, como não quero ainda me aprofundar na explicação sobre classes. Você, neste momento, e apenas para os fins que estaremos implementando aqui. Pode sim, considerar classes como sendo estruturas. Mas fique ciente de que em breve iremos nos aprofundar a respeito do que seria de fato uma classe.
Tendo como base isto, que espero tenha ficado claro. Podemos começar a trabalhar no que seria uma lista. Para tornar as coisas o mais simples possível e ao mesmo tempo bem mais didática. Vamos começar com uma implementação bem simplificada. Esta pode ser vista logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. class stList 05. { 06. private: 07. //+----------------+ 08. int info; 09. //+----------------+ 10. public: 11. //+----------------+ 12. void Set(int arg) 13. { 14. info = arg; 15. } 16. //+----------------+ 17. int Get(void) 18. { 19. return info; 20. } 21. //+----------------+ 22. }; 23. //+------------------------------------------------------------------+ 24. void OnStart(void) 25. { 26. stList list; 27. 28. list.Set(512); 29. Print(list.Get()); 30. }; 31. //+------------------------------------------------------------------+
Código 03
Isto que pode ser visto no código 03, NÃO representa uma lista, não ainda. Mas quero que você observe o que está sendo declarado na linha quatro. Aqui a palavra reservada class, está substituindo a palavra reservada struct. Sendo assim você deve, até que o conceito de classe seja explicado, procurar pensar neste código como se ele estivesse criando uma estrutura e não uma classe. Como o resultado deste código, quando executado é algo muito simples e direto. Não vou entrar em detalhes sobre ele. Mas se o modificarmos de uma determinada maneira, podemos criar o que seria a fila do tipo pilha. Gosto de começar desta forma, assim você irá conseguir entender onde estou querendo chegar. Bem, para tornar este código 03, em uma pilha, precisamos modificar o mesmo como mostrado logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> class stList 05. { 06. private: 07. //+----------------+ 08. T info[]; 09. //+----------------+ 10. public: 11. //+----------------+ 12. void Push(T arg) 13. { 14. T loc[1]; 15. loc[0] = arg; 16. ArrayInsert(info, loc, info.Size()); 17. } 18. //+----------------+ 19. bool Pop(T &arg) 20. { 21. arg = NULL; 22. if (info.Size() == 0) 23. return false; 24. arg = value[value.Size() - 1]; 25. ArrayRemove(value, value.Size() - 1, 1); 26. 27. return true; 28. } 29. //+----------------+ 30. }; 31. //+------------------------------------------------------------------+ 32. void OnStart(void) 33. { 34. stList <char> list; 35. 36. list.Push(10); 37. list.Push(84); 38. list.Push(-6); 39. 40. for (char info; list.Pop(info);) 41. Print(info); 42. 43. }; 44. //+------------------------------------------------------------------+
Código 04
Este código 04, quando executado produzirá o mesmo resultado, visto na imagem 04. Já que aqui estamos criando algo muito parecido com o código 02, utilizando o fragmento 01, visto neste mesmo artigo. Preste atenção, ainda não criamos a lista, já que na linha oito, ainda estamos usando um array. Agora quero que você preste muita atenção a uma coisa neste código 04. Note o que estamos fazendo nas linhas 16 e 25. Justamente nestas linhas é que estamos adicionando algum elemento no array e também removendo algo do array.
Porém, e é agora que as coisas ficam interessante, e se removermos o array do sistema, o que irá acontecer? Bem, neste caso estas linhas 16 e 25 ficarão invalidadas. Já que não mais estaremos lidando com um array. No entanto se tornarmos a linha oito deste código 04 em um valor do tipo escalar, iremos voltar a situação vista no código 03. Onde não poderíamos adicionar uma sequência de valores na memória e depois os recuperar. Muito provavelmente você não entendeu o que eu acabei de dizer. Então vamos implementar estas palavras em forma de código. Isto é visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> class stList 05. { 06. private: 07. //+----------------+ 08. T info; 09. //+----------------+ 10. public: 11. //+----------------+ 12. void Push(T arg) 13. { 14. info = arg; 15. } 16. //+----------------+ 17. bool Pop(T &arg) 18. { 19. arg = info; 20. 21. return true; 22. } 23. //+----------------+ 24. }; 25. //+------------------------------------------------------------------+ 26. void OnStart(void) 27. { 28. stList <char> list; 29. 30. list.Push(10); 31. list.Push(84); 32. list.Push(-6); 33. 34. for (char info, c = 0; list.Pop(info) && c < 4; c++) 35. Print(info); 36. 37. }; 38. //+------------------------------------------------------------------+
Código 05
Agora quando este código 05 for executado teremos como resultado o que é visto na imagem abaixo.
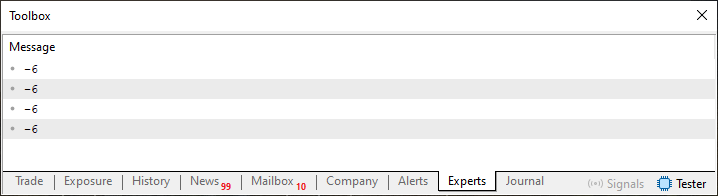
Imagem 05
Aqui no caso, foi necessário mudar a linha 34, vista no código 05, a fim de evitar um loop infinito. Mas observe o que aconteceu com o código 05. Neste caso estamos lidando com um código que já não consegue memorizar os valores que estamos informando nas linhas 30 até 32. Sendo que apenas o último valor será retornado. Você obviamente pode pensar que isto se deve ao fato de que na linha oito, do código 05, temos um escalar sendo utilizado e não mais um array. E é neste ponto em que mora o pulo do gato. E é onde a lista começa a fazer sentido.
O que precisamos fazer aqui meu caro leitor, é criar um mecanismo que venha a forçar de alguma forma, que o valor que estiver na variável da linha oito seja memorizada. Isto quando os procedimentos e funções de acesso forem utilizados. Porém, tal mecanismo NÃO DEVE USAR UM ARRAY. E então como podemos fazer isto? Bem, a resposta é vista no código logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename T> class stList 05. { 06. private: 07. //+----------------+ 08. T info; 09. stList <T> *prev; 10. //+----------------+ 11. public: 12. //+----------------+ 13. stList(void) 14. :prev(NULL) 15. {} 16. //+----------------+ 17. void Push(T arg) 18. { 19. stList <T> *loc; 20. 21. loc = new stList <T>; 22. (*loc).info = arg; 23. (*loc).prev = prev; 24. prev = loc; 25. } 26. //+----------------+ 27. bool Pop(T &arg) 28. { 29. stList <T> *loc; 30. 31. if (prev == NULL) 32. return false; 33. 34. loc = prev; 35. arg = (*loc).info; 36. prev = (*loc).prev; 37. 38. delete loc; 39. 40. return true; 41. } 42. //+----------------+ 43. }; 44. //+------------------------------------------------------------------+ 45. void OnStart(void) 46. { 47. stList <char> list; 48. 49. list.Push(10); 50. list.Push(84); 51. list.Push(-6); 52. 53. for (char info; list.Pop(info);) 54. Print(info); 55. }; 56. //+------------------------------------------------------------------+
Código 06
Isto que você está vendo no código 06 é algo muito, mas muito divertido. E ao mesmo tempo muito interessante. Já que quando este código 06 for executado, você terá o mesmo resultado visto na imagem 04. E notem que não estamos usando um array aqui. Mas então como isto é possível? A resposta é que este código 06 está criando o que é conhecida como lista encadeada simples. Mas esta lista não está sendo implementada com toda a sua capacidade. Apenas está sendo modelada de forma que você, meu caro leitor, consiga entender o que estamos fazendo aqui. Já que neste artigo basicamente tratamos do que seria uma pilha. E sendo a pilha um tipo de fila simples. Acabamos por assim dizer, criar o que seria uma lista simples. Mas com a mesma capacidade operacional que seria dada se estivéssemos programando uma fila do tipo pilha.
Agora quero que você preste atenção ao seguinte fato. Este código 06, de fato cria o mesmo resultado que seria visto se fosse utilizado o código 04. Ou até mesmo o código 02, porém com o fragmento 01 incluso no mesmo. Neste caso o código completo estará presente no anexo. Assim como este código 06.
Mas o que eu quero que você entenda, e isto pode vir a fazer toda a diferença futuramente na sua vida como programador, é que não importa como o código em si foi implementado internamente. O que importa de fato é como será a interface de acesso ao que você programou. Isto influencia enormemente a forma de se trabalhar com o código que você estará disponibilizando, assim como o tipo de resultado esperado. Note que mesmo usando uma metodologia diferente para conseguir gerar uma pilha o resultado final obtido é exatamente idêntico ao que havia sido feito anteriormente.
Ou seja, você pode vir a implementar algo que funciona internamente de uma maneira, e o usuário de seu código, jamais irá se dar conta de que tipo de mecanismo você estará de fato utilizando. Esta é a graça de se programar. Você pode criar as coisas de uma forma que para muitos irá soar como absurda. Seja por ser muito complicada, seja por ser extremamente simples. Não importa, o que realmente importa é o resultado final que será obtido.
Certo, acho que consegui captar a ideia. Mas você poderia dar uma explicação sobre como este código 06 funciona. Já que não estou conseguindo entender como ele consegue armazenar os valores e depois os restaurar conforme foi mostrado. Sem problemas, meu caro leitor. Acredito que você não tem nenhuma dúvida com relação a forma como o procedimento OnStart, presente na linha 45 funciona. Sendo que a sua principal dúvida, deve estar no fato de como, sem usarmos um array, conseguimos empilhar valores. Nos permitindo os recuperar em um momento futuro. Pois bem, para conseguir entender isto, é preciso que você entenda, ou já tenha o conhecimento sobre um outro assunto que já abordei aqui.
O assunto em questão é a recursividade. Este tema foi abordado no artigo Do básico ao intermediário: Recursividade. E por que entender este tema é importante aqui? O motivo é que quando criamos uma lista, ou a base inicial de uma lista, como está sendo feito no código 06. Estamos na verdade criando um mecanismo de recursividade. Porém este mecanismo é um pouco diferente daquele que foi abordado no artigo acima mencionado. Então preste atenção para conseguir entender o que está acontecendo aqui. Você pode notar que na linha quatro do código 06, estamos declarando um template para uma classe. Agora esqueça o fato de estarmos usando uma classe, pense nisto como sendo uma estrutura. Ok, dentro de uma estrutura de dados, podemos ter diversas informações sendo agrupadas de maneira lógica. Normalmente estas informações são referentes apenas e somente a valores que você como programador pode manipular e declarar. Este é o princípio básico.
Por conta disto temos na linha oito, o tal valor que podemos, como programadores manipular da forma que for mais conveniente. Mas, e é aqui onde a mágica começa a ocorrer. Dentro de uma estrutura de dados, também podemos adicionar um elemento extra. Ou elementos dependendo do caso. No nosso caso, este elemento extra é justamente a linha nove. Esta linha é como uma linha mágica. Que se você olhar para ele irá ver que estamos declarando um ponteiro. Mas um ponteiro que aponta para o que? Bem, este ponteiro estará apontando para uma cópia da estrutura declarando na linha quatro. Epá, agora complicou de vez. Como assim? Estamos dentro de uma estrutura que estará apontando para dentro dela mesma? Isto é não faz muito sentido. Pelo menos ao meu entender. De certa forma devo concordar com você, meu caro leitor. Quando comecei a aprender programação, tive uma certa dificuldade em entender isto que estou tentando lhe explicar.
O fato é que, quando usamos este ponteiro declarado na linha nove, dentro da estrutura. Podemos criar uma recursividade dentro da própria estrutura. Isto sem que de fato, esta recursividade afete a própria estrutura. Como muito provavelmente é a primeira vez que você está vendo isto. Tal coisa pode não fazer muito sentido. Mas ela fará quando ampliarmos a funcionalidade deste código 06 a fim de realmente criar uma lista encadeada. Mas antes de fazermos isto, é preciso que você entenda muito bem estes conceitos que estou explicando. Caso contrário, você não conseguirá assimilar o conhecimento necessário para criar seus próprios códigos.
Bem, voltando a explicação. Quando usamos o procedimento da linha 17, a fim de empilhar um elemento qualquer, veja que a primeira coisa que estaremos fazendo é declarar na linha 19, algo muito parecido com o que é visto na linha nove. Ou seja um ponteiro. Só que aqui na linha 19, este ponteiro é local e temporário. Preste muita, mais muita atenção a este detalhe, pois ele é importante. Na linha 21, alocamos memória para o tipo de estrutura que está sendo declarada no ponteiro das linhas nove e 19.
Agora vem a parte que muita gente se perde, ao tentar entender as listas. VOCÊ NÃO DEVE ARMAZENAR O NOVO ELEMENTO NA VARIAVEL DECLARADA NA LINHA OITO. Você deve armazenar o novo elemento na região da memória que acabamos de alocar. Lembre-se de que esta região, obedece exatamente ao que está declarando na estrutura que estamos alocando. Assim, agora aquela variável da linha oito, pode ser usada para armazenar o novo elemento. Porém a parte realmente importante é o que acontece na linha 23. É neste exato momento que criamos um link entre a atual posição, com a nova posição. Criando assim o que seria um array. Mas com propriedades diferentes do que seria um array. Como será visto futuramente.
Como agora estamos apontando para um elemento novo, usamos a linha 24 para atualizar o sistema, e manter assim o encadeamento entre os elementos. Um detalhe importante. A linha 14 evita que precisemos adicionar uma variável extra na própria estrutura. Como aqui estamos usando uma classe, podemos utilizar esta metodologia a fim de simplificar a própria estrutura de dados. Muito bem, então quando a estrutura é inicializada, temos inicialmente o que pode ser visto na imagem logo abaixo.

Imagem 06
Aqui a região em verde indica o conteúdo presente na variável da linha oito. Já a região em vermelho indica o valor do ponteiro declarado na linha nove. Ok, isto acontece quando a linha 47 é executada. Agora quando a linha 49 for executada, teremos uma chamada para o procedimento Push, que pode ser visto na linha 17, e que acabei de dar uma breve descrição de como funciona. Mas para tornar bem mais simples entender o real funcionamento deste procedimento Push, vamos recorrer a uma nova imagem. E está é vista logo a seguir.
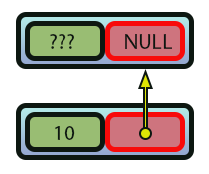
Imagem 07
Hum, não entendi. O que esta imagem 07 representa? Esta imagem 07 representa a criação da recursividade de dados. Note que agora o valor 10 foi empilhado na memória. Mas o valor da variável presente na linha nove, agora aponta para a região anterior da memória. E isto é indicado pela seta em amarelo. Depois que a linha 51 tenha sido executada, o que teremos de fato criado é visto na imagem logo abaixo.
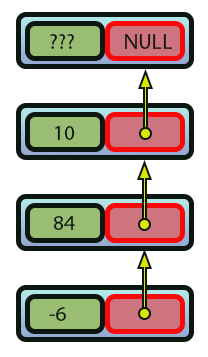
Imagem 08
Note que em todo o caso, o valor que estará sendo colocado na variável da linha nove, irá sempre apontar para a região anteriormente alocada. Criando assim o que seria um encadeamento de valores. Então, quando o laço da linha 53 vir a ser executado, teremos uma varredura deste sistema visto na imagem 08. Só que na ordem inversa. Agora veja que o teste responsável por fazer com que o laço da linha 53 seja finalizado, é executado exatamente na linha 31. Quando este teste obtiver sucesso, isto indicará que alcançamos a base inicial do que seria a lista que estaria sendo criada. Com isto podemos desempilhar os dados de maneira muito simples e fácil. Bastando fazermos uso de um mecanismo inverso ao mecanismo adotado no empilhamento.
Neste caso específico, usamos a linha 34 para acessar a região da memória que foi alocada lá na linha 21. Isto torna mais simples o código. Já que poderíamos usar uma outra forma de dizer ao compilador o que fazer. Mas como aqui o objetivo é ser didático. Decidi deixar desta maneira mesmo. Então como estamos agora apontando para a região alocada. Poderemos acessar o valor presente naquela região, usando para isto a linha 35. E usando a linha 36, fazemos com que o ponteiro atual, seja atualizado. Para finalmente na linha 38 podermos devolver a memória alocada para o sistema operacional. Completando assim o ciclo.
Considerações finais
Este artigo, merece ser muito bem estudado. Já que aqui apenas introduzi o conceito básico necessário para que possamos criar uma lista. Porém como o processo em si, da criação de uma lista pode ser um tanto quanto complicado para qualquer iniciante entender. Procurei elaborar este artigo, de forma que você tenha uma base inicial para estudar. Isto utilizando inicialmente uma fila com o objetivo de criar uma pilha, e logo depois criando a base de uma lista, fazendo uso de uma pilha também. Desta forma, fica muito mais fácil entender os conceitos básicos envolvidos na criação e implementação de listas encadeadas. Já que na prática elas são bem simples de serem implementadas. Mas entender a teoria e a forma correta de as criar, envolve entender o que está sendo explicado neste artigo.
Tentei deixar as coisas o mais simples e didáticas quanto foi possível ser feito. Acredito ter alcançado tal objetivo. De qualquer maneira, procure estudar muito bem estes códigos daqui, meu caro leitor. Pois no próximo artigo iremos nos aprofundar um pouco mais nesta questão das listas. Mas sem entender o que foi mostrado e explicado aqui, será muito difícil entender o que será visto no próximo artigo. Então bons estudos e nos vemos no próximo artigo.
| Arquivo | Descrição |
|---|---|
| Code 01 | Fila simples |
| Code 02 | Fila simples |
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Observador Connexus (Parte 8): Adicionando Request Observer (Observador de requisições)
Observador Connexus (Parte 8): Adicionando Request Observer (Observador de requisições)
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso