
Redes Generativas Adversariais (GANs) para Dados Sintéticos em Modelagem Financeira (Parte 1): Introdução às GANs e Dados Sintéticos em Modelagem Financeira

O trading algorítmico depende de dados financeiros de qualidade, mas problemas como amostras pequenas ou desbalanceadas podem prejudicar a confiabilidade do modelo. As Redes Generativas Adversariais (GANs) oferecem uma solução ao gerar dados sintéticos, aumentando a diversidade do conjunto de dados e a robustez do modelo.
As GANs, introduzidas em 2014 por Ian Goodfellow, são modelos de aprendizado de máquina que simulam distribuições de dados para criar cópias realistas, amplamente utilizadas em finanças para lidar com a escassez de dados e ruídos. Por exemplo, as GANs podem gerar sequências sintéticas de preços de ações, enriquecendo conjuntos de dados limitados para melhor generalização nos modelos. No entanto, treinar GANs exige grande poder computacional, e os dados sintéticos devem ser cuidadosamente validados quanto à relevância para evitar discrepâncias com as condições reais de mercado.
A estrutura de uma GAN
As GANs são simplesmente duas redes neurais — o Gerador e o Discriminador — que jogam um jogo adversarial: aqui está uma visão geral desses componentes.
- Gerador: Pelo termo Gerador, a intenção aqui é treinar um algoritmo para imitar dados reais. Ele trabalha com ruído aleatório como entrada e, com o tempo, tende a produzir amostras de dados mais realistas. Em termos de trading, o Gerador forneceria sequências falsas de movimento de preços ou volumes de negociação que se assemelham às sequências reais.
- Discriminador: O papel do Discriminador é decidir quais dados, dentre os estruturados e os sintetizados, são genuínos. Cada amostra de dados é então avaliada quanto à probabilidade de ser original ou sintetizada. Como resultado, no processo de treinamento, o Discriminador aumenta sua capacidade de classificar a entrada como dado real, incentivando o Gerador a avançar na geração dos dados.
Agora vamos analisar o processo Adversarial, já que é justamente esse aspecto que torna as GANs tão poderosas. Aqui está como as duas redes interagem durante o processo de treinamento:
- Etapa 1: O Gerador cria um lote de amostras de dados sintéticos a partir de ruído.
- Etapa 2: O Discriminador recebe os dados reais, bem como os dados sintéticos do Gerador. Ele atribui probabilidades, ou em outras palavras “julga” a autenticidade de cada amostra.
- Etapa 3: Nas próximas interações, com base no feedback do Discriminador, os pesos do Gerador são ajustados para gerar dados mais realistas.
- Etapa 4: O Discriminador também ajusta seus pesos para distinguir melhor os dados reais dos falsos.
Esse ciclo contínuo prossegue até que os dados sintéticos do Gerador sejam altamente precisos e não possam mais ser distinguidos pelo Discriminador dos dados reais. Nesse ponto, a GAN é considerada treinada, já que o Gerador está produzindo dados sintéticos de alta qualidade.
A perda do Gerador diminui à medida que se aproxima de gerar dados mais realistas, enquanto a perda do Discriminador varia conforme ele tenta se adaptar à saída melhorada do Gerador.
Aqui está uma estrutura simplificada de uma GAN em Python usando TensorFlow para ilustrar como o Gerador e o Discriminador interagem:
import tensorflow as tf from tensorflow.keras import layers # Define the Generator model def build_generator(): model = tf.keras.Sequential([ layers.Dense(128, activation='relu', input_shape=(100,)), layers.Dense(256, activation='relu'), layers.Dense(512, activation='relu'), layers.Dense(1, activation='tanh') # Output size to match the data shape ]) return model # Define the Discriminator model def build_discriminator(): model = tf.keras.Sequential([ layers.Dense(512, activation='relu', input_shape=(1,)), layers.Dense(256, activation='relu'), layers.Dense(128, activation='relu'), layers.Dense(1, activation='sigmoid') # Output is a probability ]) return model # Compile GAN with Generator and Discriminator generator = build_generator() discriminator = build_discriminator() # Combine the models in the adversarial network discriminator.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) gan = tf.keras.Sequential([generator, discriminator]) gan.compile(optimizer='adam', loss='binary_crossentropy')
Nesta estrutura:
O Gerador transforma ruído aleatório em dados sintéticos realistas, o Discriminador classifica a entrada como real ou falsa, e a GAN combina ambos os modelos, permitindo que aprendam iterativamente um com o outro.
Treinando uma GAN
Até agora conhecemos a estrutura de uma GAN, podemos agora passar ao treinamento de uma GAN, que é um processo interativo no qual as redes do Gerador e do Discriminador são treinadas simultaneamente, em turnos, para melhorar seu desempenho. O processo de treinamento é uma série de etapas em que cada rede atua de forma que a outra possa aprender, tornando possível oferecer resultados melhores. Agora vamos discutir as principais partes do processo de treinamento de uma GAN eficaz. O núcleo do treinamento de uma GAN é um processo alternado de duas etapas, onde cada rede é atualizada independentemente em cada ciclo:
- Etapa 1: Treinar o Discriminador.
Primeiro, o Discriminador recebe amostras reais de dados e estima a probabilidade de cada uma delas ser real, depois recebe dados sintéticos gerados pelo Gerador. Em seguida, a perda do Discriminador é determinada por sua capacidade de classificar as amostras reais e sintéticas. Seus pesos são ajustados para minimizar essa perda, melhorando sua capacidade de identificar dados reais de falsos.
- Etapa 2: Treinar o Gerador.
O Gerador gera amostras sintéticas a partir de ruído aleatório e depois as envia ao Discriminador. As previsões do Discriminador são então usadas para calcular a perda do Gerador, pois o Gerador “quer” que o Discriminador diga que ele estava gerando dados realistas. Os pesos do Gerador são ajustados para reduzir sua perda, de modo que possa gerar dados mais realistas capazes de enganar o Discriminador.
Esse processo de alternância entre as previsões é repetido inúmeras vezes, com as redes se adaptando gradualmente às mudanças uma da outra.
O código a seguir demonstra o núcleo de um loop de treinamento de uma GAN em Python usando TensorFlow:
import numpy as np import tensorflow as tf from tensorflow.keras import layers, Model from tensorflow.keras.optimizers import Adam tf.get_logger().setLevel('ERROR') # Only show errors # Generator model def create_generator(): input_layer = layers.Input(shape=(100,)) x = layers.Dense(128, activation="relu")(input_layer) x = layers.Dense(256, activation="relu")(x) x = layers.Dense(512, activation="relu")(x) output_layer = layers.Dense(784, activation="tanh")(x) model = Model(inputs=input_layer, outputs=output_layer) return model # Discriminator model def create_discriminator(): input_layer = layers.Input(shape=(784,)) x = layers.Dense(512, activation="relu")(input_layer) x = layers.Dense(256, activation="relu")(x) output_layer = layers.Dense(1, activation="sigmoid")(x) model = Model(inputs=input_layer, outputs=output_layer) return model # GAN model to combine generator and discriminator def create_gan(generator, discriminator): discriminator.trainable = False # Freeze discriminator during GAN training gan_input = layers.Input(shape=(100,)) x = generator(gan_input) gan_output = discriminator(x) gan_model = Model(inputs=gan_input, outputs=gan_output) return gan_model # Function to train the GAN def train_gan(generator, discriminator, gan, data, epochs=10000, batch_size=64): half_batch = batch_size // 2 for epoch in range(epochs): # Train Discriminator noise = np.random.normal(0, 1, (half_batch, 100)) generated_data = generator.predict(noise, verbose=0) real_data = data[np.random.randint(0, data.shape[0], half_batch)] # Train discriminator on real and fake data d_loss_real = discriminator.train_on_batch(real_data, np.ones((half_batch, 1))) d_loss_fake = discriminator.train_on_batch(generated_data, np.zeros((half_batch, 1))) d_loss = 0.5 * np.add(d_loss_real, d_loss_fake) # Train Generator noise = np.random.normal(0, 1, (batch_size, 100)) g_loss = gan.train_on_batch(noise, np.ones((batch_size, 1))) # Print progress every 100 epochs if epoch % 100 == 0: print(f"Epoch {epoch} | D Loss: {d_loss[0]:.4f} | G Loss: {g_loss[0]:.4f}") # Prepare data data = np.random.normal(0, 1, (1000, 784)) # Initialize models generator = create_generator() discriminator = create_discriminator() discriminator.compile(optimizer=Adam(), loss="binary_crossentropy", metrics=["accuracy"]) gan = create_gan(generator, discriminator) gan.compile(optimizer=Adam(), loss="binary_crossentropy") # Train GAN train_gan(generator, discriminator, gan, data, epochs=10000, batch_size=64)
Este código treina o Discriminador basicamente com dados reais do conjunto fornecido, bem como com os dados falsos/recriados pelo Gerador. Os dados reais são classificados como ‘1’, enquanto os dados gerados são classificados como ‘0’ no treinamento do Discriminador. Em seguida, o Gerador é treinado a partir do Discriminador por meio de um sistema de feedback, de forma que o Gerador crie dados semelhantes aos reais.
A partir da resposta do Discriminador, o Gerador pode aprimorar ainda mais sua capacidade de criar dados realistas. O código também imprime as perdas do Discriminador e do Gerador a cada cem épocas, conforme será discutido mais adiante. Isso constitui um meio pelo qual o progresso do treinamento da GAN pode ser avaliado e uma análise feita sobre o quão bem cada parte da GAN está desempenhando sua função em determinado momento.
GANs em Modelagem Financeira
As GANs tornaram-se bastante úteis na modelagem financeira, especialmente na geração de novos dados. Nos mercados financeiros, a falta de dados ou problemas de privacidade de dados significa que dados de alta qualidade para treinar e testar modelos preditivos são escassos. As GANs ajudam a resolver esse problema, pois produzem dados sintéticos que possuem estatísticas semelhantes aos conjuntos de dados financeiros reais.
Uma das áreas de aplicação que podemos identificar é o campo da avaliação de risco, onde as GANs podem modelar condições extremas de mercado e ajudar a realizar testes de estresse em portfólios sem usar dados históricos. Além disso, as GANs são úteis para aumentar a robustez do modelo, gerando conjuntos de treinamento diversos e evitando o overfitting. Elas também são usadas na geração de outliers, onde modelos complexos são desenvolvidos para criar conjuntos de dados sintéticos que apontam para outliers como transações fraudulentas ou anomalias de mercado.
De forma geral, o uso de GANs em modelagem financeira permite que instituições enfrentem problemas de baixa qualidade de dados, simulem eventos raros e aumentem o poder preditivo dos modelos, tornando as GANs ferramentas importantes para a análise financeira moderna e para a tomada de decisões.
Implementando uma GAN Simples em MQL5
Agora que estamos familiarizados com as GANs, vamos passar para a geração de dados sintéticos como resultado do treinamento de uma Rede Generativa Adversarial (GAN) em MQL5, que oferece uma maneira inovadora de abordar o conceito de dados sintéticos no contexto do trading. Uma GAN básica é composta por dois componentes: um Gerador, que gera dados falsos (por exemplo, tendências de preços), e um Discriminador, que determina se um ponto de dado é genuíno ou falso. É assim que podemos aplicar uma GAN simples em MQL5 para modelar preços de fechamento artificiais que imitam a dinâmica real do mercado.
- Definindo o Gerador e o Discriminador
double GenerateSyntheticPrice() { return NormalizeDouble(MathRand() / 1000.0, 5); // Simple random price } double Discriminator(double price, double threshold) { if (MathAbs(price - threshold) < 0.001) return 1; // Real return 0; // Fake }
O exemplo apresentado do uso de GANs em MQL5 mostra como é possível utilizá-las para criar dados sintéticos para modelagem e testes financeiros, expandindo assim os horizontes de melhoria dos algoritmos de trading.
Abaixo está o teste de um expert advisor em dados reais e sintéticos:
De acordo com esses resultados, os Dados Reais resultaram em lucros mais realistas, porém potencialmente menores, devido à natureza imprevisível das condições reais de mercado.
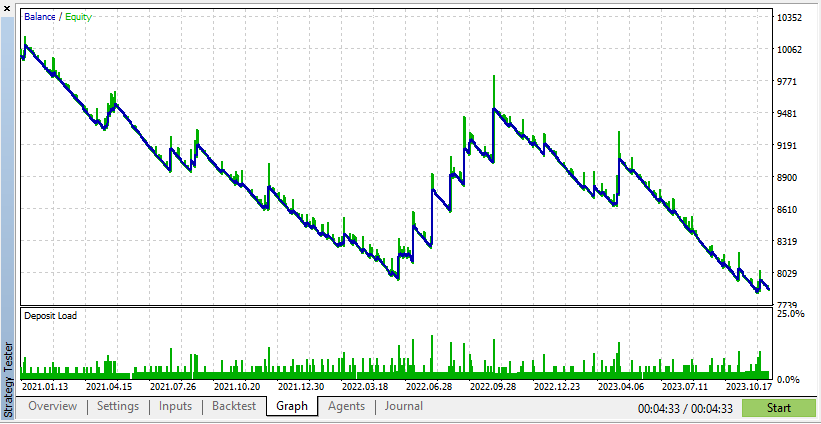
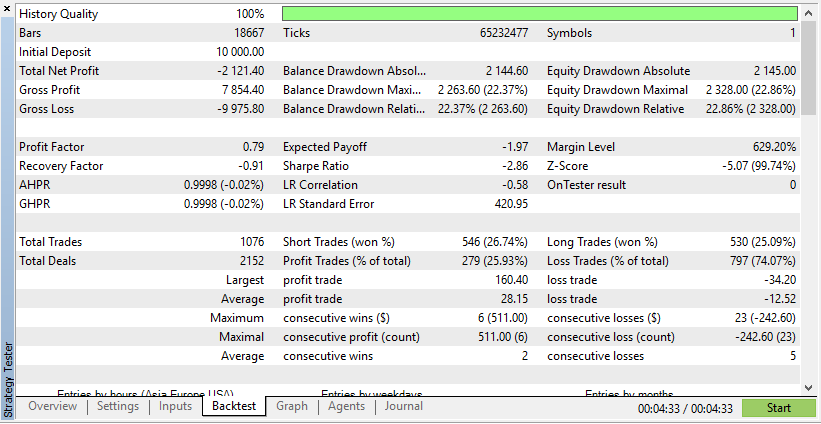
De acordo com esses resultados, os Dados Sintéticos mostraram lucros maiores se os dados forem devidos às condições ideais para o seu EA.
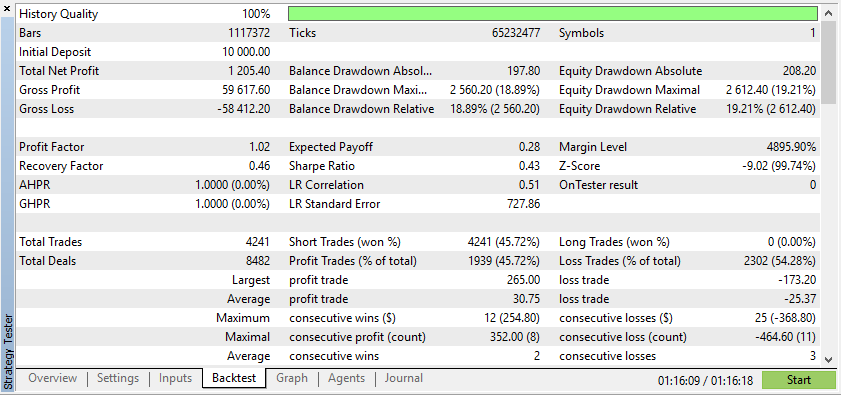
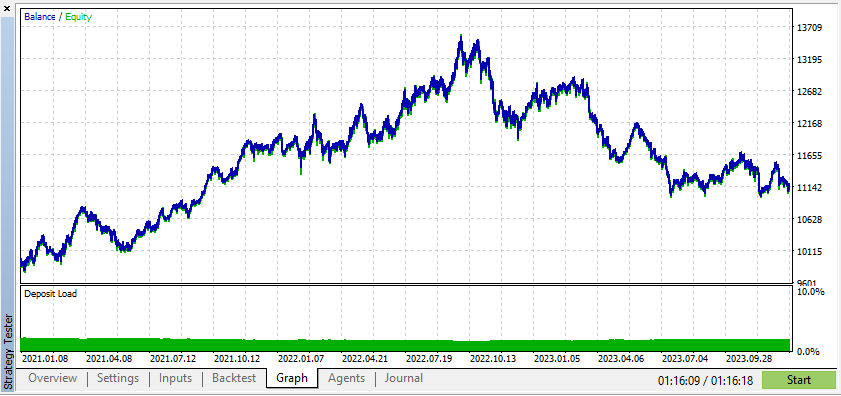
No entanto, os dados reais lhe darão uma compreensão muito mais clara de como o EA se comportará em condições reais de negociação. Confiar em dados sintéticos pode muitas vezes levar a resultados de backtest enganosos, que podem não ser reproduzíveis em um mercado real.
A percepção do treinamento de GANs é crucial, pois fornece insights sobre o processo de aprendizado e a estabilidade do modelo. Na modelagem financeira, a visualização é usada para ajudar os modeladores a entenderem se os dados sintéticos possuem o padrão correto, como os dados reais capturados pela GAN. As saídas geradas em diferentes estágios de treinamento podem ser exibidas aos desenvolvedores para detectar possíveis problemas, como colapso de modo ou baixa qualidade dos dados sintéticos. Essa avaliação é contínua, o que possibilita ao treinamento definir parâmetros adequadamente, promovendo o desempenho da GAN para gerar dados que reflitam os padrões financeiros-alvo.
Abaixo está um código de como criar um instrumento sintético baseado em 3 anos de dados de EURUSD:
import pandas as pd import numpy as np import matplotlib.pyplot as plt import os # Download data using the terminal # Replace 'your-api-key' with an actual API key from a data provider # Here, we simulate this with a placeholder for clarity api_key = "your-api-key" symbol = "EURUSD" output_csv = "EURUSD_3_years.csv" # Command to download the data from Alpha Vantage or any similar service # Example using Alpha Vantage (Daily FX data): https://www.alphavantage.co command = f"curl -o {output_csv} 'https://www.alphavantage.co/query?function=FX_DAILY&from_symbol=EUR&to_symbol=USD&outputsize=full&apikey={api_key}&datatype=csv'" os.system(command) # Read the downloaded CSV file data = pd.read_csv(output_csv) # Ensure the CSV is structured correctly for further processing # Rename columns if necessary to match yfinance format data.rename(columns={"close": "Close"}, inplace=True) # Print the first few rows to confirm print(data.head()) # Extract the 'Close' prices from the data prices = data['Close'].values # Normalize the prices for generating synthetic data min_price = prices.min() max_price = prices.max() normalized_prices = (prices - min_price) / (max_price - min_price) # Example: Generating some mock data def generate_real_data(samples=100): # Real data following a sine wave pattern time = np.linspace(0, 4 * np.pi, samples) data = np.sin(time) + np.random.normal(0, 0.1, samples) # Add some noise return time, data def generate_fake_data(generator, samples=100): # Fake data generated by the GAN noise = np.random.normal(0, 1, (samples, 1)) generated_data = generator.predict(noise).flatten() return generated_data # Mock generator function (replace with actual GAN generator model) class MockGenerator: def predict(self, noise): # Simulate GAN output with a cosine pattern (for illustration) return np.cos(np.linspace(0, 4 * np.pi, len(noise))).reshape(-1, 1) # Instantiate a mock generator for demonstration generator = MockGenerator() # Generate synthetic data: Let's use a simple random walk model as a basic example # (this is a placeholder for a more sophisticated method, like using GANs) np.random.seed(42) # Set seed for reproducibility synthetic_prices_normalized = normalized_prices[0] + np.cumsum(np.random.normal(0, 0.01, len(prices))) # Denormalize the synthetic prices back to the original scale synthetic_prices = synthetic_prices_normalized * (max_price - min_price) + min_price # Configure font sizes plt.rcParams.update({ 'font.size': 12, # General font size 'axes.titlesize': 16, # Title font size 'axes.labelsize': 14, # Axis labels font size 'legend.fontsize': 12, # Legend font size 'xtick.labelsize': 10, # X-axis tick labels font size 'ytick.labelsize': 10 # Y-axis tick labels font size }) # Plot both historical and synthetic data on the same graph plt.figure(figsize=(14, 7)) plt.plot(prices, label="Historical EURUSD", color='blue') plt.plot(synthetic_prices, label="Synthetic EURUSD", linestyle="--", color='red') plt.xlabel("Time Steps", fontsize=14) # Adjust fontsize directly if needed plt.ylabel("Price", fontsize=14) # Adjust fontsize directly if needed plt.title("Comparison of Historical and Synthetic EURUSD Data", fontsize=16) plt.legend() plt.show()
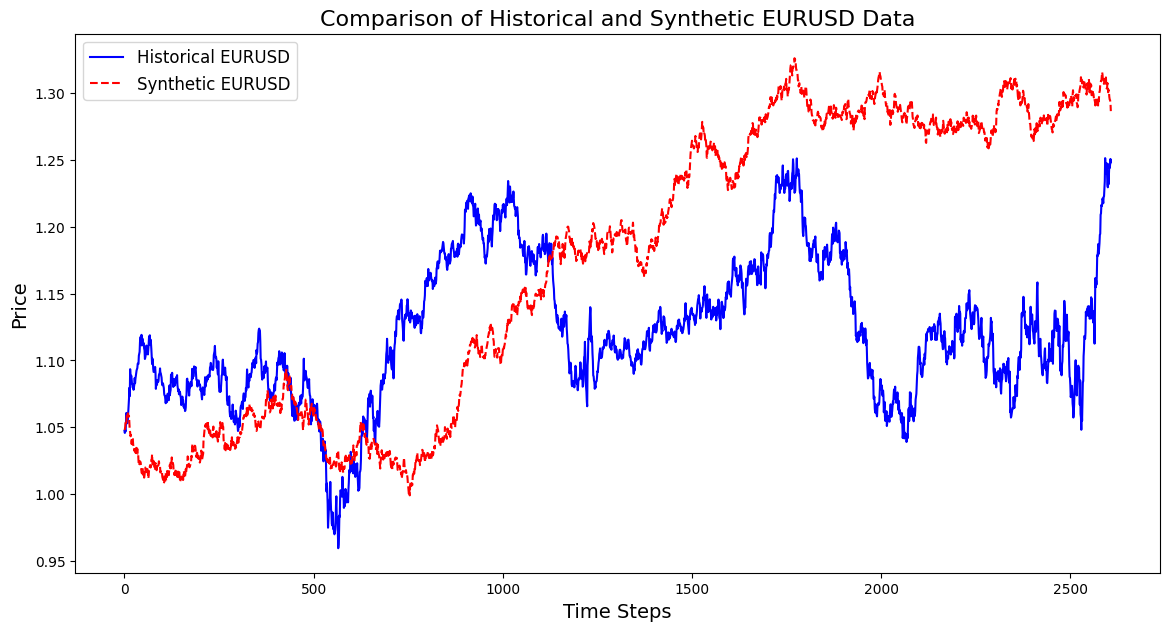
Essa visualização ajuda a acompanhar o quão de perto os dados sintéticos correspondem aos dados reais, oferecendo insights sobre o progresso da GAN e destacando áreas para possíveis melhorias durante o treinamento.
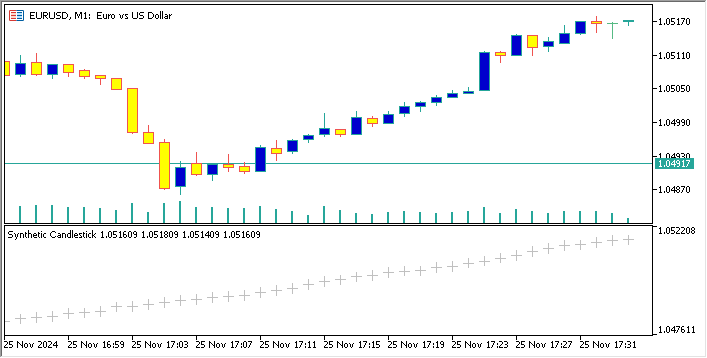
Abaixo está um código que cria um par de moedas sintético baseado em EURUSD e exibe seu gráfico de velas no gráfico do EURUSD.
//+------------------------------------------------------------------+ //| Sythetic EURUSDChart.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property indicator_separate_window // Display in a seperate window #property indicator_buffers 4 //Buffers for Open, High,Low,Close #property indicator_plots 1 //Plot a single series(candlesticks) //+------------------------------------------------------------------+ //| Indicator to generate and display synthetic currency data | //+------------------------------------------------------------------+ double openBuffer[]; double highBuffer[]; double lowBuffer[]; double closeBuffer[]; //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { //---Set buffers for synthetic data SetIndexBuffer(0, openBuffer); SetIndexBuffer(1, highBuffer); SetIndexBuffer(2, lowBuffer); SetIndexBuffer(3, closeBuffer); //---Define the plots for candle sticks IndicatorSetString(INDICATOR_SHORTNAME, "Synthetic Candlestick"); //---Set the plot type for the candlesticks PlotIndexSetInteger(0, PLOT_DRAW_TYPE, DRAW_CANDLES); //---Setcolours for the candlesticks PlotIndexSetInteger(0, PLOT_COLOR_INDEXES, clrGreen); PlotIndexSetInteger(1, PLOT_COLOR_INDEXES, clrRed); //---Set the width of the candlesticks PlotIndexSetInteger(0, PLOT_LINE_WIDTH, 2); //---Set up the data series(buffers as series arrays) ArraySetAsSeries(openBuffer, true); ArraySetAsSeries(highBuffer, true); ArraySetAsSeries(lowBuffer, true); ArraySetAsSeries(closeBuffer, true); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Custom indicator iteration function | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { //--- int start = MathMax(prev_calculated-1, 0); //start from the most recent data double price =close[rates_total-1]; // starting price MathSrand(GetTickCount()); //initialize random seed //---Generate synthetic data for thechart for(int i = start; i < rates_total; i++) { double change = (MathRand()/ 32768.0)* 0.0002 - 0.0002; //Random price change price += change ; // Update price with the random change openBuffer[i]= price; highBuffer[i]= price + 0.0002; //simulated high lowBuffer[i]= price - 0.0002; //simulated low closeBuffer[i]= price; } //--- return value of prev_calculated for next call return(rates_total); } //+------------------------------------------------------------------+
Análise de Métricas Populares para Avaliar GANs em Modelagem Financeira
Avaliar Redes Generativas Adversariais (GANs) é crucial para determinar se seus dados sintéticos replicam com precisão os dados financeiros reais. Aqui estão as principais métricas usadas para avaliação:
1. Erro Quadrático Médio (MSE)
O MSE mede a diferença média ao quadrado entre pontos de dados reais e sintéticos. Um MSE mais baixo indica que os dados sintéticos se assemelham de perto ao conjunto de dados reais, tornando-os adequados para tarefas como previsão de preços ou gestão de portfólio. Os traders podem usar o MSE para validar se os dados gerados por GAN refletem os movimentos reais do mercado. Por exemplo, um trader que utiliza uma Rede Generativa Adversarial (GAN) para gerar dados falsos de preços de ações pode medir a entropia em comparação com os preços reais registrados na história para calcular o Erro Quadrático Médio (MSE). Um MSE baixo comprova a solidez dos dados sintetizados, pois eles correspondem aos movimentos reais do mercado, permitindo seu uso no treinamento de modelos de IA para prever interações futuras de preços.
2. Distância de Fréchet Inception (FID)
Embora comumente usado em geração de imagens, o FID também pode ser aplicado a dados financeiros. Ele compara as distribuições de dados reais e sintéticos no espaço de características. Um valor de FID mais baixo implica melhor alinhamento entre os dados sintéticos e reais, apoiando aplicações como testes de estresse de portfólio e estimativa de risco. Por exemplo, auxilia na gestão de portfólios, ajudando a comparar distribuições sintéticas de retornos com os retornos reais de mercado. A Hipótese 3 indica que, como um valor de FID mais baixo significa que os retornos gerados pela GAN são imitações mais próximas das distribuições reais de retorno, isso mostra que o modelo GAN é adequado para o desempenho em testes de estresse de portfólio e estimativas de risco.
3. Divergência de Kullback-Leibler (KL)
A Divergência KL avalia o quão de perto a distribuição de probabilidade dos dados sintéticos corresponde à distribuição dos dados reais. Em finanças, uma Divergência KL baixa sugere que os dados gerados pela GAN capturam propriedades críticas, como agrupamento de volatilidade, tornando-os eficazes para modelagem de risco e trading algorítmico. Por exemplo, os modelos avaliam a capacidade do modelo generativo ou da GAN de reconhecer a distribuição real de retornos de ativos, em termos de riscos de cauda e agrupamento de volatilidade. Uma Divergência KL baixa significa que os dados sintéticos possuem características importantes de riscos realistas de retorno, sendo eficaz aplicar modelos de risco baseados em dados de GAN.
4. Acurácia do Discriminador
O Discriminador mede o quão bem consegue diferenciar entre dados reais e sintéticos. Idealmente, à medida que o treinamento avança, a acurácia do Discriminador deve se aproximar de 50%, indicando que os dados sintéticos são indistinguíveis dos reais. Isso valida a qualidade das saídas da GAN para backtesting e modelagem de cenários futuros. Por exemplo, quando usada em estratégia de trading algorítmico, ajuda no processo de validação de fluxo. Ao observar essa acurácia, os traders estarão bem posicionados para ver se a GAN está criando futuros sintéticos realistas. Um cenário de alta qualidade e indistinguível corresponde ao resultado dos dados de backtest quando a acurácia gira em torno de 50%.
Essas métricas fornecem uma estrutura abrangente para avaliar GANs em modelagem financeira. Elas ajudam os desenvolvedores a melhorar a qualidade dos dados sintéticos e garantir sua aplicabilidade em tarefas como gestão de portfólio, avaliação de risco e validação de estratégias de trading.
Conclusão
As Redes Generativas Adversariais (GANs) permitem que traders e analistas financeiros gerem dados sintéticos, algo benéfico quando os dados reais são limitados, caros ou sensíveis. As GANs fornecem dados confiáveis para modelagem financeira, aprimorando a análise de fluxo de caixa em modelos de negociação. Com conhecimento fundamental de GANs, os traders podem explorar a geração de dados sintéticos de forma independente para fortalecer suas capacidades analíticas.
Tópicos futuros abordarão técnicas avançadas, como GANs de Wasserstein e Crescimento Progressivo, para maior estabilidade das GANs e aplicação em finanças.
| Nome do Arquivo | Descrição |
|---|---|
| GAN_training_code.py | Arquivo de código de treinamento para treinar a GAN |
| GAN_Inspired basic structure.mq5 | Arquivo contendo código para a estrutura da GAN em MQL5 |
| GAN_Model_building.py | Arquivo contendo código para a estrutura da GAN em Python |
| MA Crossover GAN integrated.mq5 | Arquivo contendo o código do Expert Advisor testado em dados reais e falsos |
| EURUSD_historical_synthetic_ comparison.py | Arquivo contendo o código de comparação entre EURUSD histórico e sintético |
| Synthetic EURUSDchart.mq5 | Arquivo contendo o código para criar gráfico sintético no gráfico EURUSD |
| EURUSD_CSV.csv | Arquivo contendo os dados sintéticos que são importados para testar o expert advisor |
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/16214
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso