
Redes generativas antagónicas (GAN) para datos sintéticos en modelos financieros (Parte 1): Introducción a las GAN y los datos sintéticos en modelos financieros

El trading algorítmico se basa en datos financieros de calidad, pero problemas como muestras pequeñas o desequilibradas pueden perjudicar la fiabilidad del modelo. Las redes generativas antagónicas (GAN) ofrecen una solución mediante la generación de datos sintéticos, lo que mejora la diversidad de los conjuntos de datos y la solidez de los modelos.
Las GAN, introducidas en 2014 por Ian Goodfellow, son modelos de aprendizaje automático que simulan distribuciones de datos para crear copias realistas, ampliamente utilizadas en finanzas para abordar la escasez de datos y el ruido. Por ejemplo, las GAN pueden generar secuencias sintéticas de precios de acciones, lo que enriquece los conjuntos de datos limitados para una mejor generalización en los modelos. Sin embargo, el entrenamiento de las GAN requiere un gran esfuerzo computacional, y los datos sintéticos deben validarse cuidadosamente para garantizar su relevancia y evitar discrepancias con las condiciones reales del mercado.
La estructura de una GAN
Las GAN son simplemente dos redes neuronales (el generador y el discriminador), que juegan un juego competitivo: A continuación se ofrece un desglose de estos componentes.
- Generador: Por «generador» se entiende aquí el entrenamiento de un algoritmo para imitar datos reales. Funciona con ruido aleatorio como entrada y, con el tiempo, tiende a producir muestras de datos más realistas. En términos bursátiles, el generador proporcionaría secuencias falsas de movimientos de precios o volúmenes de negociación que se asemejan a secuencias reales.
- Discriminador: La función del discriminador es decidir qué datos de los datos estructurados y sintetizados son auténticos. A continuación, se evalúa cada muestra de datos en función de su probabilidad de ser datos originales o datos sintetizados. Como resultado, en un proceso de entrenamiento, el discriminador aumenta su capacidad para clasificar la entrada como datos reales, lo que anima al generador a avanzar en la generación de datos.
Veamos ahora el proceso adversarial, ya que es precisamente el aspecto adversarial de las GAN lo que las hace tan poderosas. Así es como interactúan las dos redes durante el proceso de entrenamiento:
- Paso 1: El generador crea un lote de muestras de datos sintéticos a través del ruido.
- Paso 2: El discriminador toma los datos reales, así como los datos sintéticos del generador. Asigna posibilidades, o en otras palabras, «emite un juicio» sobre la autenticidad de cada muestra.
- Paso 3: En las siguientes interacciones, basándose en la retroalimentación del discriminador, se ajusta el peso del generador para generar datos más realistas.
- Paso 4: El discriminador también cambia su peso para distinguir mejor los datos reales de los falsos.
Este ciclo continuo continúa hasta que los datos sintéticos del generador son muy precisos y el discriminador ya no puede distinguirlos de los datos reales. En este punto, se considera que la GAN está entrenada, ya que el generador está generando datos sintéticos de gran calidad..
La pérdida del generador se reduce a medida que se acerca a generar datos más realistas, y la pérdida del discriminador varía a medida que este intenta adaptarse a la mejora en la salida del generador.
A continuación se muestra una estructura simplificada de una GAN en Python utilizando TensorFlow para ilustrar cómo interactúan el generador y el discriminador:
import tensorflow as tf from tensorflow.keras import layers # Define the Generator model def build_generator(): model = tf.keras.Sequential([ layers.Dense(128, activation='relu', input_shape=(100,)), layers.Dense(256, activation='relu'), layers.Dense(512, activation='relu'), layers.Dense(1, activation='tanh') # Output size to match the data shape ]) return model # Define the Discriminator model def build_discriminator(): model = tf.keras.Sequential([ layers.Dense(512, activation='relu', input_shape=(1,)), layers.Dense(256, activation='relu'), layers.Dense(128, activation='relu'), layers.Dense(1, activation='sigmoid') # Output is a probability ]) return model # Compile GAN with Generator and Discriminator generator = build_generator() discriminator = build_discriminator() # Combine the models in the adversarial network discriminator.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) gan = tf.keras.Sequential([generator, discriminator]) gan.compile(optimizer='adam', loss='binary_crossentropy')
En esta estructura:
El generador transforma el ruido aleatorio en datos sintéticos realistas, luego el discriminador clasifica la entrada como real o falsa, y la GAN combina ambos modelos, lo que les permite aprender entre sí de forma iterativa.
Entrenamiento de una GAN
Hasta ahora hemos conocido la estructura de una GAN, ahora podemos pasar al entrenamiento de una GAN, que es un proceso iterativo, en el que las redes generadora y discriminadora se entrenan simultáneamente por turnos para mejorar su rendimiento. El proceso de formación consiste en una serie de pasos en los que cada una de las redes actúa de manera que la otra pueda aprender de ella, lo que les permite ofrecer mejores resultados. Ahora analizaremos las partes principales del proceso de entrenamiento de una GAN eficaz. El núcleo del entrenamiento de las GAN es un proceso alternativo de dos pasos en el que cada red se actualiza de forma independiente en cada ciclo:
- Paso 1: Entrenar el discriminador.
En primer lugar, el discriminador recibe muestras de datos reales y estima la probabilidad de que cada una de ellas sea real, luego recibe datos sintéticos generados por el generador. A continuación, la pérdida del discriminador se determina por su capacidad para clasificar las muestras reales y sintéticas. Sus pesos se ajustan para minimizar esta pérdida, mejorando su capacidad para identificar datos reales de los falsos.
- Paso 2: Entrenar al generador.
El generador genera muestras sintéticas a partir de ruido aleatorio y luego las envía al discriminador. A continuación, las predicciones del discriminador se utilizan para calcular la pérdida del generador, ya que el generador «quiere» que el discriminador diga que estaba generando datos realistas. Los pesos del generador se ajustan para reducir su pérdida, de modo que pueda generar datos más realistas que engañen al discriminador.
Este proceso de alternancia entre las predicciones de cada uno se repite muchas veces, y las redes se van adaptando gradualmente a los cambios de las demás.
El siguiente código muestra el núcleo de un bucle de entrenamiento GAN en Python utilizando TensorFlow:
import numpy as np import tensorflow as tf from tensorflow.keras import layers, Model from tensorflow.keras.optimizers import Adam tf.get_logger().setLevel('ERROR') # Only show errors # Generator model def create_generator(): input_layer = layers.Input(shape=(100,)) x = layers.Dense(128, activation="relu")(input_layer) x = layers.Dense(256, activation="relu")(x) x = layers.Dense(512, activation="relu")(x) output_layer = layers.Dense(784, activation="tanh")(x) model = Model(inputs=input_layer, outputs=output_layer) return model # Discriminator model def create_discriminator(): input_layer = layers.Input(shape=(784,)) x = layers.Dense(512, activation="relu")(input_layer) x = layers.Dense(256, activation="relu")(x) output_layer = layers.Dense(1, activation="sigmoid")(x) model = Model(inputs=input_layer, outputs=output_layer) return model # GAN model to combine generator and discriminator def create_gan(generator, discriminator): discriminator.trainable = False # Freeze discriminator during GAN training gan_input = layers.Input(shape=(100,)) x = generator(gan_input) gan_output = discriminator(x) gan_model = Model(inputs=gan_input, outputs=gan_output) return gan_model # Function to train the GAN def train_gan(generator, discriminator, gan, data, epochs=10000, batch_size=64): half_batch = batch_size // 2 for epoch in range(epochs): # Train Discriminator noise = np.random.normal(0, 1, (half_batch, 100)) generated_data = generator.predict(noise, verbose=0) real_data = data[np.random.randint(0, data.shape[0], half_batch)] # Train discriminator on real and fake data d_loss_real = discriminator.train_on_batch(real_data, np.ones((half_batch, 1))) d_loss_fake = discriminator.train_on_batch(generated_data, np.zeros((half_batch, 1))) d_loss = 0.5 * np.add(d_loss_real, d_loss_fake) # Train Generator noise = np.random.normal(0, 1, (batch_size, 100)) g_loss = gan.train_on_batch(noise, np.ones((batch_size, 1))) # Print progress every 100 epochs if epoch % 100 == 0: print(f"Epoch {epoch} | D Loss: {d_loss[0]:.4f} | G Loss: {g_loss[0]:.4f}") # Prepare data data = np.random.normal(0, 1, (1000, 784)) # Initialize models generator = create_generator() discriminator = create_discriminator() discriminator.compile(optimizer=Adam(), loss="binary_crossentropy", metrics=["accuracy"]) gan = create_gan(generator, discriminator) gan.compile(optimizer=Adam(), loss="binary_crossentropy") # Train GAN train_gan(generator, discriminator, gan, data, epochs=10000, batch_size=64)
Este código entrena al discriminador básicamente con datos reales del conjunto de datos dado, así como con datos falsos/recreados por el generador real. Los datos reales se clasifican como «1», mientras que los datos generados se clasifican como «0» en el entrenamiento del discriminador. A continuación, el generador se entrena a partir del discriminador mediante un sistema de retroalimentación, de manera que el generador cree datos que sean realistas.
A partir de la respuesta del discriminador, el generador puede perfeccionar aún más su capacidad para crear datos realistas. El código también imprime las pérdidas del discriminador y el generador cada cien épocas, como se explicará más adelante. Esto constituye un medio para evaluar el progreso del entrenamiento de la GAN y valorar en qué medida cada parte de la GAN está desempeñando la función prevista en un momento determinado.
GAN en el modelado financiero
Las GAN se han vuelto muy útiles para la modelización financiera, especialmente en la generación de nuevos datos. En los mercados financieros, la falta de datos o los problemas relacionados con la privacidad de los datos hacen que los datos de alta calidad para entrenar y probar los modelos predictivos sean escasos. Las GAN ayudan a resolver este problema, ya que producen datos sintéticos con estadísticas similares a las de los conjuntos de datos financieros reales.
Una de las áreas de aplicación que podemos identificar es el campo de la evaluación de riesgos, donde las GAN pueden modelar condiciones de mercado extremas y ayudar a realizar pruebas de estrés a las carteras sin utilizar datos históricos. Además, las GAN son útiles para aumentar la robustez del modelo, ya que generan conjuntos de datos de entrenamiento diversos, lo que evita el sobreajuste del modelo. También se utilizan para la generación de valores atípicos, donde se desarrollan modelos complejos para crear conjuntos de datos sintéticos que señalan valores atípicos como transacciones fraudulentas o anomalías del mercado.
En general, el uso de GAN en la modelización financiera permite a las instituciones abordar los problemas de baja calidad de los datos, simular la ocurrencia de eventos que no se observan con frecuencia y aumentar la capacidad predictiva de los modelos, lo que convierte a las GAN en herramientas importantes para el análisis financiero moderno y la toma de decisiones.
Implementación de una GAN simple en MQL5
Ahora que ya estamos familiarizados con las GAN, pasemos a la generación de datos sintéticos como resultado del entrenamiento de una red generativa antagónica (GAN) en MQL5, que ofrece una forma novedosa de abordar el concepto de datos sintéticos en el contexto del trading. Una GAN básica consta de dos componentes: un generador que genera datos falsos (por ejemplo, tendencias de precios) y un discriminador que determina si un punto de datos es auténtico o falso. Así es como podemos aplicar una GAN simple en MQL5 para modelar precios de cierre artificiales que imitan la dinámica real del mercado.
- Definición del generador y el discriminador
double GenerateSyntheticPrice() { return NormalizeDouble(MathRand() / 1000.0, 5); // Simple random price } double Discriminator(double price, double threshold) { if (MathAbs(price - threshold) < 0.001) return 1; // Real return 0; // Fake }
El ejemplo presentado sobre el uso de GAN en MQL5 muestra cómo se pueden utilizar para crear datos sintéticos para la modelización y las pruebas financieras, ampliando así las posibilidades de mejora de los algoritmos de trading.
A continuación se muestra la prueba de un asesor experto con datos reales y sintéticos:
Según estos resultados, los datos reales han dado lugar a beneficios más realistas, pero potencialmente más bajos, debido a la naturaleza impredecible de las condiciones reales del mercado.


Según estos resultados, los datos sintéticos han demostrado generar mayores beneficios si los datos se deben a las condiciones ideales para su EA.
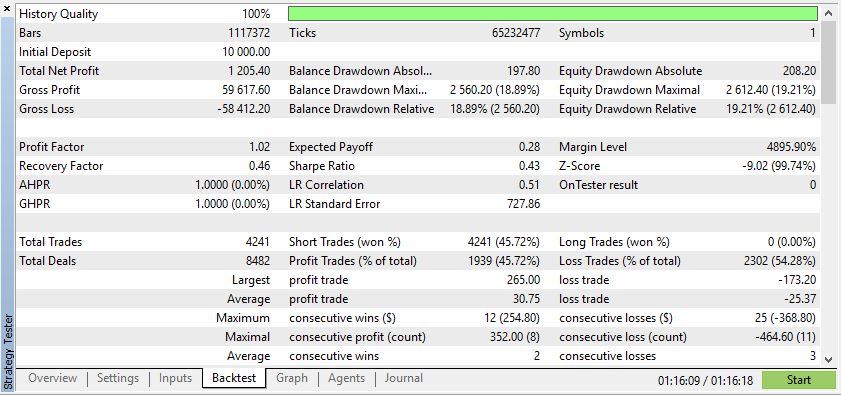

Sin embargo, los datos reales le permitirán comprender mucho mejor cómo funcionará el EA en condiciones reales de negociación. Confiar en datos sintéticos a menudo puede llevar a resultados engañosos en las pruebas retrospectivas, que podrían no ser reproducibles en un mercado real.
La percepción del entrenamiento de las GAN es crucial, ya que proporciona información sobre el proceso de aprendizaje y la estabilidad del modelo. En el modelado financiero, la visualización se utiliza para ayudar a los modeladores a comprender si los datos sintéticos tienen el patrón adecuado, como los datos reales capturados por la GAN. Los resultados generados en las diferentes etapas de entrenamiento pueden mostrarse a los desarrolladores para detectar posibles problemas, como el colapso del modo o la mala calidad de los datos sintéticos. Esta evaluación es continua, lo que permite establecer los parámetros de formación de forma adecuada, al tiempo que se promueve el rendimiento de la GAN para generar datos que reflejen los patrones financieros deseados.
A continuación se muestra un código sobre cómo crear un instrumento sintético basado en datos del EURUSD de los últimos tres años:
import pandas as pd import numpy as np import matplotlib.pyplot as plt import os # Download data using the terminal # Replace 'your-api-key' with an actual API key from a data provider # Here, we simulate this with a placeholder for clarity api_key = "your-api-key" symbol = "EURUSD" output_csv = "EURUSD_3_years.csv" # Command to download the data from Alpha Vantage or any similar service # Example using Alpha Vantage (Daily FX data): https://www.alphavantage.co command = f"curl -o {output_csv} 'https://www.alphavantage.co/query?function=FX_DAILY&from_symbol=EUR&to_symbol=USD&outputsize=full&apikey={api_key}&datatype=csv'" os.system(command) # Read the downloaded CSV file data = pd.read_csv(output_csv) # Ensure the CSV is structured correctly for further processing # Rename columns if necessary to match yfinance format data.rename(columns={"close": "Close"}, inplace=True) # Print the first few rows to confirm print(data.head()) # Extract the 'Close' prices from the data prices = data['Close'].values # Normalize the prices for generating synthetic data min_price = prices.min() max_price = prices.max() normalized_prices = (prices - min_price) / (max_price - min_price) # Example: Generating some mock data def generate_real_data(samples=100): # Real data following a sine wave pattern time = np.linspace(0, 4 * np.pi, samples) data = np.sin(time) + np.random.normal(0, 0.1, samples) # Add some noise return time, data def generate_fake_data(generator, samples=100): # Fake data generated by the GAN noise = np.random.normal(0, 1, (samples, 1)) generated_data = generator.predict(noise).flatten() return generated_data # Mock generator function (replace with actual GAN generator model) class MockGenerator: def predict(self, noise): # Simulate GAN output with a cosine pattern (for illustration) return np.cos(np.linspace(0, 4 * np.pi, len(noise))).reshape(-1, 1) # Instantiate a mock generator for demonstration generator = MockGenerator() # Generate synthetic data: Let's use a simple random walk model as a basic example # (this is a placeholder for a more sophisticated method, like using GANs) np.random.seed(42) # Set seed for reproducibility synthetic_prices_normalized = normalized_prices[0] + np.cumsum(np.random.normal(0, 0.01, len(prices))) # Denormalize the synthetic prices back to the original scale synthetic_prices = synthetic_prices_normalized * (max_price - min_price) + min_price # Configure font sizes plt.rcParams.update({ 'font.size': 12, # General font size 'axes.titlesize': 16, # Title font size 'axes.labelsize': 14, # Axis labels font size 'legend.fontsize': 12, # Legend font size 'xtick.labelsize': 10, # X-axis tick labels font size 'ytick.labelsize': 10 # Y-axis tick labels font size }) # Plot both historical and synthetic data on the same graph plt.figure(figsize=(14, 7)) plt.plot(prices, label="Historical EURUSD", color='blue') plt.plot(synthetic_prices, label="Synthetic EURUSD", linestyle="--", color='red') plt.xlabel("Time Steps", fontsize=14) # Adjust fontsize directly if needed plt.ylabel("Price", fontsize=14) # Adjust fontsize directly if needed plt.title("Comparison of Historical and Synthetic EURUSD Data", fontsize=16) plt.legend() plt.show()

Esta visualización ayuda a realizar un seguimiento de la coincidencia entre los datos sintéticos y los datos reales, lo que ofrece información sobre el progreso de la GAN y destaca las áreas susceptibles de mejora durante el entrenamiento.
A continuación se muestra un código que crea un par de divisas sintético basado en el EURUSD y muestra su gráfico de velas japonesas en el gráfico EURUSD.
//+------------------------------------------------------------------+ //| Sythetic EURUSDChart.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property indicator_separate_window // Display in a seperate window #property indicator_buffers 4 //Buffers for Open, High,Low,Close #property indicator_plots 1 //Plot a single series(candlesticks) //+------------------------------------------------------------------+ //| Indicator to generate and display synthetic currency data | //+------------------------------------------------------------------+ double openBuffer[]; double highBuffer[]; double lowBuffer[]; double closeBuffer[]; //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { //---Set buffers for synthetic data SetIndexBuffer(0, openBuffer); SetIndexBuffer(1, highBuffer); SetIndexBuffer(2, lowBuffer); SetIndexBuffer(3, closeBuffer); //---Define the plots for candle sticks IndicatorSetString(INDICATOR_SHORTNAME, "Synthetic Candlestick"); //---Set the plot type for the candlesticks PlotIndexSetInteger(0, PLOT_DRAW_TYPE, DRAW_CANDLES); //---Setcolours for the candlesticks PlotIndexSetInteger(0, PLOT_COLOR_INDEXES, clrGreen); PlotIndexSetInteger(1, PLOT_COLOR_INDEXES, clrRed); //---Set the width of the candlesticks PlotIndexSetInteger(0, PLOT_LINE_WIDTH, 2); //---Set up the data series(buffers as series arrays) ArraySetAsSeries(openBuffer, true); ArraySetAsSeries(highBuffer, true); ArraySetAsSeries(lowBuffer, true); ArraySetAsSeries(closeBuffer, true); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Custom indicator iteration function | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { //--- int start = MathMax(prev_calculated-1, 0); //start from the most recent data double price =close[rates_total-1]; // starting price MathSrand(GetTickCount()); //initialize random seed //---Generate synthetic data for thechart for(int i = start; i < rates_total; i++) { double change = (MathRand()/ 32768.0)* 0.0002 - 0.0002; //Random price change price += change ; // Update price with the random change openBuffer[i]= price; highBuffer[i]= price + 0.0002; //simulated high lowBuffer[i]= price - 0.0002; //simulated low closeBuffer[i]= price; } //--- return value of prev_calculated for next call return(rates_total); } //+------------------------------------------------------------------+

Análisis de métricas populares para evaluar las GAN en el modelado financiero
La evaluación de las redes generativas antagónicas (GAN) es fundamental para determinar si sus datos sintéticos reproducen con precisión los datos financieros reales. A continuación se presentan las métricas clave utilizadas para la evaluación:
1. Error cuadrático medio (Mean Squared Error, MSE)
El MSE mide la diferencia cuadrática media entre los puntos de datos reales y sintéticos. Un MSE más bajo indica que los datos sintéticos se asemejan mucho al conjunto de datos reales, lo que los hace adecuados para tareas como la predicción de precios o la gestión de carteras. Los operadores pueden utilizar el MSE para validar si los datos generados por GAN reflejan los movimientos reales del mercado. Por ejemplo, un operador que utilice una red generativa adversaria (GAN) para generar datos falsos sobre el precio de las acciones puede medir la entropía frente a la utilización de los precios reales registrados en el historial para calcular el error cuadrático medio (Mean Squared Error, MSE). Un MSE bajo demuestra la solidez de los datos sintetizados, ya que coinciden con los movimientos reales del mercado, lo que permite utilizarlos para entrenar modelos de IA para predecir futuras interacciones de precios.
2. Distancia de inicio de Fréchet (Fréchet Inception Distance, FID)
Aunque se utiliza habitualmente en la generación de imágenes, el FID también se puede aplicar a los datos financieros. Compara distribuciones de datos reales y sintéticos en el espacio de características. Una puntuación FID más baja implica una mejor alineación entre los datos sintéticos y los reales, lo que respalda aplicaciones como las pruebas de estrés de carteras y la estimación de riesgos. Por ejemplo, gestiona una cartera ayudando a comparar las distribuciones sintéticas de los rendimientos con los rendimientos reales del mercado. La hipótesis 3 indica que, dado que una puntuación FID más baja significa que los rendimientos generados por GAN se acercan más a las distribuciones de rendimientos reales, esto demuestra que el modelo GAN es muy adecuado para realizar pruebas de estrés de carteras y estimaciones de riesgo.
3. Divergencia de Kullback-Leibler (KL)
La divergencia de Kullback-Leibler evalúa en qué medida la distribución de probabilidad de los datos sintéticos se ajusta a la distribución de los datos reales. En finanzas, una divergencia KL baja sugiere que los datos generados por GAN capturan propiedades críticas como la agrupación de volatilidad, lo que los hace eficaces para el modelado de riesgos y el comercio algorítmico. Por ejemplo, los modelos evalúan la capacidad del modelo generativo o GAN para reconocer la distribución real del rendimiento de los activos, en términos de riesgos extremos y agrupamiento de la volatilidad. Una divergencia KL baja significa que los datos sintéticos tienen características importantes de riesgos de rentabilidad realistas, por lo que resulta eficaz aplicar modelos de riesgo basados en datos GAN.
4. Precisión del discriminador
El discriminador mide su capacidad para diferenciar entre datos reales y sintéticos. Lo ideal es que, a medida que avanza el entrenamiento, la precisión del discriminador se acerque al 50%, lo que indicaría que los datos sintéticos son indistinguibles de los datos reales. Esto valida la calidad de los resultados de las GAN para el backtesting y la modelización de escenarios futuros. Por ejemplo, cuando se utiliza en estrategias de trading algorítmico, ayuda en el proceso de validación del flujo. Al observar esta precisión, los operadores estarán en una buena posición para determinar si la GAN está creando futuros sintéticos realistas. Un escenario de alta calidad e indistinguible coincide con el resultado de los datos retroactivos, con una precisión que ronda el 50%.
Estas métricas proporcionan un marco integral para evaluar las GAN en el modelado financiero. Ayudan a los desarrolladores a mejorar la calidad de los datos sintéticos y garantizan su aplicabilidad en tareas como la gestión de carteras, la evaluación de riesgos y la validación de estrategias comerciales.
Conclusión
Las redes generativas adversarias (GAN) permiten a los operadores bursátiles y analistas financieros generar datos sintéticos, lo que resulta beneficioso cuando los datos reales son limitados, costosos o confidenciales. Las GAN proporcionan datos fiables para la modelización financiera, lo que mejora el análisis del flujo de caja en los modelos de negociación. Con conocimientos básicos sobre las GAN, los operadores pueden explorar la generación de datos sintéticos de forma independiente para reforzar sus capacidades analíticas.
Los temas futuros abarcarán técnicas avanzadas como las GAN de Wasserstein y el crecimiento progresivo para mejorar la estabilidad de las GAN y su aplicación en las finanzas.
| Nombre del archivo | Descripción |
|---|---|
| GAN_training_code.py | Código de entrenamiento de archivos para entrenar la GAN. |
| GAN_Inspired basic structure.mq5 | Archivo que contiene el código para la estructura GAN en MQL5. |
| GAN_Model_building.py | Archivo que contiene el código para la estructura GAN en Python. |
| MA Crossover GAN integrated.mq5 | Archivo que contiene el código del Asesor Experto probado con datos reales y ficticios. |
| EURUSD_historical_synthetic_ comparison.py | Archivo que contiene el código de comparación entre el EURUSD histórico y sintético. |
| Synthetic EURUSDchart.mq5 | Archivo que contiene el código para crear un gráfico sintético en el gráfico EURUSD. |
| EURUSD_CSV.csv | Archivo que contiene los datos sintéticos que se importan para probar el Asesor Experto. |
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/16214
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso