
Generative Adversarial Networks (GANs) für synthetische Daten in der Finanzmodellierung (Teil 1): Einführung in GANs und synthetische Daten für die Finanzmodellierung

Der algorithmische Handel ist auf qualitativ hochwertige Finanzdaten angewiesen, aber Probleme wie kleine oder unausgewogene Stichproben können die Zuverlässigkeit der Modelle beeinträchtigen. Generative Adversarial Networks (GANs) bieten eine Lösung, indem sie synthetische Daten generieren und so die Vielfalt der Datensätze und die Robustheit der Modelle verbessern.
GANs, die 2014 von Ian Goodfellow eingeführt wurden, sind Modelle des maschinellen Lernens, die Datenverteilungen simulieren, um realistische Kopien zu erstellen, die im Finanzwesen häufig eingesetzt werden, um Datenknappheit und Rauschen zu beseitigen. GANs können beispielsweise synthetische Aktienkurssequenzen generieren und so begrenzte Datensätze für eine bessere Verallgemeinerung in Modellen anreichern. Das Training von GANs ist jedoch rechenintensiv, und synthetische Daten sollten sorgfältig auf ihre Relevanz hin überprüft werden, um Abweichungen von den realen Marktbedingungen zu vermeiden.
Die Struktur eines GAN
GANs sind einfach die beiden neuronalen Netze - der Generator und der Diskriminator - die ein gegnerisches Spiel spielen: Hier ist eine Aufschlüsselung dieser Komponenten.
- Generator: Mit dem Wort „Generator“ wird hier beabsichtigt, einen Algorithmus zu trainieren, der die tatsächlichen Daten nachahmt. Es arbeitet mit Zufallsrauschen als Input und erzeugt mit der Zeit eher realistische Datenproben. In Bezug auf den Handel würde der Generator gefälschte Kursbewegungen oder Handelsvolumensequenzen ausgeben, die echten Sequenzen ähneln.
- Diskriminator: Die Aufgabe des Diskriminators besteht darin, zu entscheiden, welche Daten aus den strukturierten und synthetisierten Daten echt sind. Jede Datenprobe wird dann auf ihre Wahrscheinlichkeit hin bewertet, ob es sich um Originaldaten oder synthetisierte Daten handelt. In einem Trainingsprozess verbessert sich daher die Fähigkeit des Diskriminators, die Eingaben als echte Daten zu klassifizieren, was den Generator ermutigt, bei der Generierung der Daten voranzukommen.
Betrachten wir nun den gegnerischen Prozess, denn gerade der gegnerische Aspekt der GANs macht sie so leistungsfähig. So interagieren die beiden Netze während des Trainingsprozesses:
- Schritt 1: Der Generator erzeugt einen Stapel synthetischer Datenproben durch Rauschen.
- Schritt 2: Der Discriminator nimmt sowohl die realen Daten als auch die synthetischen Daten des Generators auf. Er ordnet Möglichkeiten zu, oder anders gesagt, es „urteilt“ über die Echtheit jeder Probe.
- Schritt 3: In den nächsten Interaktionen wird die Gewichtung des Generators auf der Grundlage des Feedbacks des Diskriminators angepasst, um realistischere Daten zu erzeugen.
- Schritt 4: Der Diskriminator ändert auch seine Gewichtung, um echte Daten besser von gefälschten Daten unterscheiden zu können.
Dieser Zyklus wird so lange fortgesetzt, bis die synthetischen Daten des Generators sehr genau sind und vom Diskriminator nicht mehr von den echten Daten unterschieden werden können. Zu diesem Zeitpunkt gilt das GAN als trainiert, da der Generator synthetische Daten von hoher Qualität erzeugt.
Der Verlust des Generators verringert sich, je näher er an die Erzeugung realistischerer Daten herankommt, und der Verlust des Diskriminators ändert sich, wenn der Diskriminator versucht, sich an die verbesserte Ausgabe des Generators anzupassen.
Hier ist eine vereinfachte Struktur für ein GAN in Python unter Verwendung von TensorFlow, um zu veranschaulichen, wie der Generator und der Diskriminator zusammenwirken:
import tensorflow as tf from tensorflow.keras import layers # Define the Generator model def build_generator(): model = tf.keras.Sequential([ layers.Dense(128, activation='relu', input_shape=(100,)), layers.Dense(256, activation='relu'), layers.Dense(512, activation='relu'), layers.Dense(1, activation='tanh') # Output size to match the data shape ]) return model # Define the Discriminator model def build_discriminator(): model = tf.keras.Sequential([ layers.Dense(512, activation='relu', input_shape=(1,)), layers.Dense(256, activation='relu'), layers.Dense(128, activation='relu'), layers.Dense(1, activation='sigmoid') # Output is a probability ]) return model # Compile GAN with Generator and Discriminator generator = build_generator() discriminator = build_discriminator() # Combine the models in the adversarial network discriminator.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) gan = tf.keras.Sequential([generator, discriminator]) gan.compile(optimizer='adam', loss='binary_crossentropy')
In dieser Struktur:
Der Generator wandelt zufälliges Rauschen in realistische synthetische Daten um, dann klassifiziert der Discriminator die Eingabe als echt oder gefälscht, und das GAN kombiniert beide Modelle, sodass sie iterativ voneinander lernen können.
Training eines GAN
Nachdem wir nun die Struktur eines GANs kennengelernt haben, können wir zum Training eines GANs übergehen, das ein interaktiver Prozess ist, bei dem das Generator- und das Diskriminatornetz gleichzeitig trainiert werden, um ihre Leistung zu verbessern. Der Trainingsprozess besteht aus einer Reihe von Schritten, bei denen jedes der Netze eine Leistung erbringt, von der das andere lernen kann, sodass sie bessere Ergebnisse liefern können. Im Folgenden werden wir die Hauptbestandteile des Trainingsprozesses eines effektiven GAN erörtern. Der Kern des GAN-Trainings ist ein alternativer, zweistufiger Prozess, bei dem jedes Netz in jedem Zyklus unabhängig aktualisiert wird:
- Schritt 1: Trainieren des Diskriminators.
Zunächst empfängt der Diskriminator reale Datenproben und schätzt die Wahrscheinlichkeit, dass jede von ihnen real ist, dann empfängt er vom Generator erzeugte synthetische Daten. Anschließend wird der Verlust des Diskriminators durch seine Fähigkeit bestimmt, die realen und synthetischen Proben zu klassifizieren. Die Gewichte werden angepasst, um diesen Verlust zu minimieren und die Fähigkeit zu verbessern, echte Daten von gefälschten zu unterscheiden.
- Schritt 2: Training des Generators.
Der Generator erzeugt synthetische Proben aus Zufallsrauschen und leitet sie dann an den Diskriminator weiter. Dann werden die Vorhersagen des Diskriminators verwendet, um den Verlust des Generators zu berechnen, denn der Generator „will“, dass der Diskriminator sagt, dass er realistische Daten erzeugt hat. Die Gewichte des Generators werden angepasst, um seinen Verlust zu verringern, damit er realistischere Daten erzeugen kann, die den Diskriminator täuschen würden.
Dieser Prozess des gegenseitigen Wechsels der Vorhersagen wird viele Male wiederholt, wobei sich die Netze allmählich an die Änderungen der jeweils anderen anpassen.
Der folgende Code demonstriert den Kern einer GAN-Trainingsschleife in Python mit TensorFlow:
import numpy as np import tensorflow as tf from tensorflow.keras import layers, Model from tensorflow.keras.optimizers import Adam tf.get_logger().setLevel('ERROR') # Only show errors # Generator model def create_generator(): input_layer = layers.Input(shape=(100,)) x = layers.Dense(128, activation="relu")(input_layer) x = layers.Dense(256, activation="relu")(x) x = layers.Dense(512, activation="relu")(x) output_layer = layers.Dense(784, activation="tanh")(x) model = Model(inputs=input_layer, outputs=output_layer) return model # Discriminator model def create_discriminator(): input_layer = layers.Input(shape=(784,)) x = layers.Dense(512, activation="relu")(input_layer) x = layers.Dense(256, activation="relu")(x) output_layer = layers.Dense(1, activation="sigmoid")(x) model = Model(inputs=input_layer, outputs=output_layer) return model # GAN model to combine generator and discriminator def create_gan(generator, discriminator): discriminator.trainable = False # Freeze discriminator during GAN training gan_input = layers.Input(shape=(100,)) x = generator(gan_input) gan_output = discriminator(x) gan_model = Model(inputs=gan_input, outputs=gan_output) return gan_model # Function to train the GAN def train_gan(generator, discriminator, gan, data, epochs=10000, batch_size=64): half_batch = batch_size // 2 for epoch in range(epochs): # Train Discriminator noise = np.random.normal(0, 1, (half_batch, 100)) generated_data = generator.predict(noise, verbose=0) real_data = data[np.random.randint(0, data.shape[0], half_batch)] # Train discriminator on real and fake data d_loss_real = discriminator.train_on_batch(real_data, np.ones((half_batch, 1))) d_loss_fake = discriminator.train_on_batch(generated_data, np.zeros((half_batch, 1))) d_loss = 0.5 * np.add(d_loss_real, d_loss_fake) # Train Generator noise = np.random.normal(0, 1, (batch_size, 100)) g_loss = gan.train_on_batch(noise, np.ones((batch_size, 1))) # Print progress every 100 epochs if epoch % 100 == 0: print(f"Epoch {epoch} | D Loss: {d_loss[0]:.4f} | G Loss: {g_loss[0]:.4f}") # Prepare data data = np.random.normal(0, 1, (1000, 784)) # Initialize models generator = create_generator() discriminator = create_discriminator() discriminator.compile(optimizer=Adam(), loss="binary_crossentropy", metrics=["accuracy"]) gan = create_gan(generator, discriminator) gan.compile(optimizer=Adam(), loss="binary_crossentropy") # Train GAN train_gan(generator, discriminator, gan, data, epochs=10000, batch_size=64)
Dieser Code trainiert den Discriminator grundsätzlich sowohl mit tatsächlichen Daten aus dem gegebenen Datensatz als auch mit den gefälschten/erstellten Daten durch den aktuellen Generator. Die realen Daten werden als „1“ klassifiziert, während die generierten Daten beim Training des Diskriminators als „0“ klassifiziert werden. Dann wird der Generator vom Diskriminator durch ein Feedback-System so trainiert, dass der Generator Daten erzeugt, die der Realität entsprechen.
Anhand der Antwort des Diskriminators kann der Generator seine Fähigkeit zur Erstellung realistischer Daten weiter verbessern. Der Code gibt auch die Verluste für den Diskriminator und den Generator alle hundert Epochen aus, wie später noch erläutert wird. Auf diese Weise kann der Trainingsfortschritt des GAN bewertet und beurteilt werden, wie gut jeder Teil des GAN zu einem bestimmten Zeitpunkt die ihm zugedachte Funktion erfüllt.
GANs in der Finanzmodellierung
GANs sind für die Finanzmodellierung sehr nützlich geworden, insbesondere bei der Generierung neuer Daten. Auf den Finanzmärkten sind qualitativ hochwertige Daten zum Trainieren und Testen von Prognosemodellen aufgrund mangelnder Daten oder aus Datenschutzgründen rar. GANs helfen bei der Lösung dieses Problems, da sie synthetische Daten erzeugen, die ähnliche Statistiken aufweisen wie die tatsächlichen Finanzdatensätze.
Einer der Anwendungsbereiche, die wir identifizieren können, ist der Bereich der Risikobewertung, wo GANs extreme Marktbedingungen modellieren und bei Stresstests von Portfolios helfen können, ohne historische Daten zu verwenden. Darüber hinaus sind GANs nützlich, um die Robustheit des Modells zu erhöhen, indem sie verschiedene Trainingsdatensätze erzeugen und so eine Überanpassung des Modells vermeiden. Sie werden auch für die Generierung von Ausreißern verwendet, wobei komplexe Modelle entwickelt werden, um synthetische Datensätze zu erstellen, die auf Ausreißer wie betrügerische Transaktionen oder Marktanomalien hinweisen.
Insgesamt ermöglicht der Einsatz von GANs in der Finanzmodellierung den Instituten, das Problem der geringen Datenqualität zu lösen, das Auftreten von Ereignissen zu simulieren, die nicht oft beobachtet werden, und die Vorhersagekraft von Modellen zu erhöhen, was GANs zu wichtigen Instrumenten für die moderne Finanzanalyse und Entscheidungsfindung macht.
Implementierung eines einfachen GAN in MQL5
Nachdem wir nun mit dem GAN vertraut sind, wollen wir uns nun der Erzeugung synthetischer Daten als Ergebnis des Trainings eines Generative Adversarial Network (GAN) in MQL5 zuwenden, das einen neuartigen Ansatz für das Konzept der synthetischen Daten im Handelskontext bietet. Ein grundlegendes GAN besteht aus zwei Komponenten: einem Generator, der gefälschte Daten (z. B. Preistrends) erzeugt, und einem Diskriminator, der feststellt, ob ein Datenpunkt echt oder gefälscht ist. So können wir ein einfaches GAN in MQL5 anwenden, um künstliche Schlusskurse zu modellieren, die die reale Marktdynamik nachahmen.
- Definieren des Generators und des Diskriminators
double GenerateSyntheticPrice() { return NormalizeDouble(MathRand() / 1000.0, 5); // Simple random price } double Discriminator(double price, double threshold) { if (MathAbs(price - threshold) < 0.001) return 1; // Real return 0; // Fake }
Das vorgestellte Beispiel für die Verwendung von GANs in MQL5 zeigt, wie man damit synthetische Daten für die Finanzmodellierung und das Testen erstellen und so die Möglichkeiten zur Verbesserung von Handelsalgorithmen erweitern kann.
Nachfolgend finden Sie den Test für einen Expertenberater sowohl für reale als auch für synthetische Daten:
Diesen Ergebnissen zufolge hat Real Data zu realistischeren, aber potenziell niedrigeren Gewinnen geführt, da die tatsächlichen Marktbedingungen nicht vorhersehbar sind.
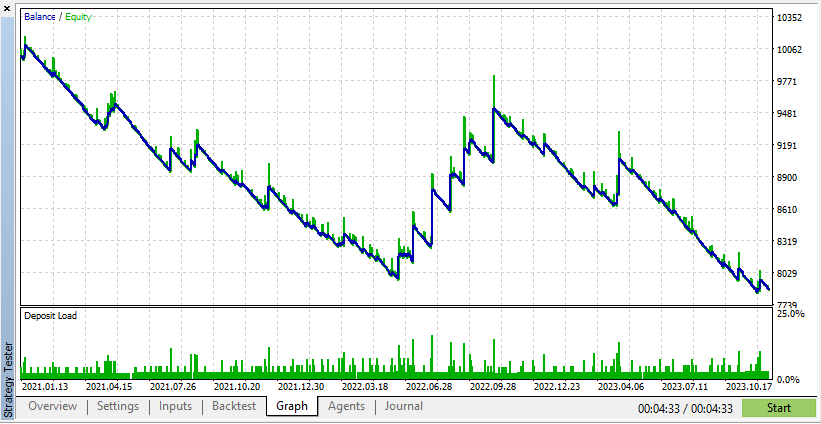
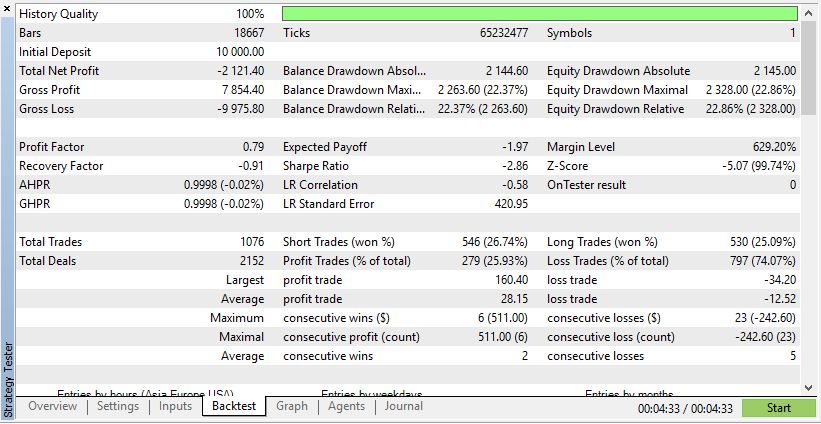
Diesen Ergebnissen zufolge zeigen synthetische Daten höhere Gewinne, wenn die Daten auf den idealen Bedingungen für Ihren EA beruhen.
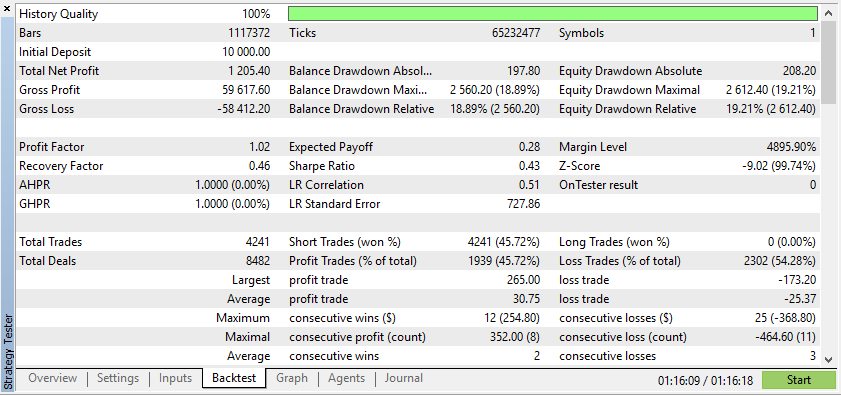
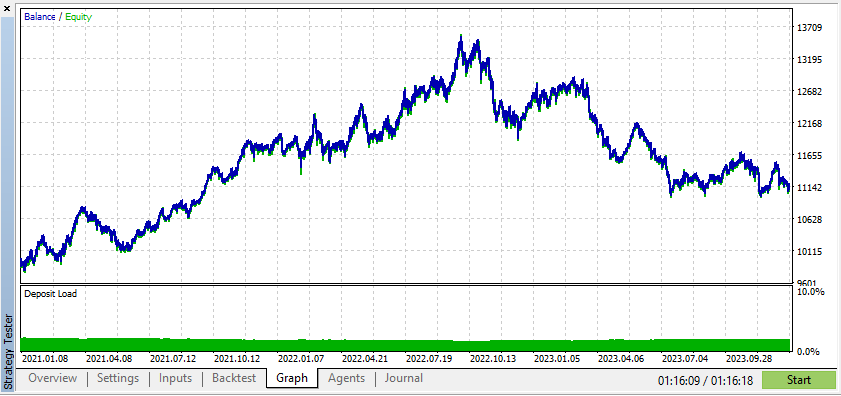
Echte Daten geben Ihnen jedoch ein viel klareres Bild davon, wie sich der EA unter tatsächlichen Handelsbedingungen verhalten wird. Der Rückgriff auf synthetische Daten kann oft zu irreführenden Backtest-Ergebnissen führen, die auf einem Live-Markt nicht reproduzierbar sind.
Die Wahrnehmung des Trainings von GANs ist entscheidend, da sie Einblicke in den Lernprozess und die Stabilität des Modells bietet. Bei der Finanzmodellierung wird die Visualisierung verwendet, um den Modellierern zu helfen, zu verstehen, ob die synthetischen Daten das richtige Muster wie die realen Daten haben, die vom GAN erfasst werden. Die in den verschiedenen Trainingsphasen erzeugten Ergebnisse können den Entwicklern angezeigt werden, um mögliche Probleme wie z. B. einen Moduszusammenbruch oder eine schlechte Qualität der synthetischen Daten zu erkennen. Eine solche Bewertung erfolgt kontinuierlich, was es ermöglicht, beim Training die Parameter angemessen einzustellen und gleichzeitig die GAN-Leistung zu fördern, um Daten zu erzeugen, die die angestrebten Finanzmuster widerspiegeln.
Nachfolgend finden Sie einen Code, mit dem Sie ein synthetisches Instrument auf der Grundlage von EURUSD-Daten aus 3 Jahren erstellen können:
import pandas as pd import numpy as np import matplotlib.pyplot as plt import os # Download data using the terminal # Replace 'your-api-key' with an actual API key from a data provider # Here, we simulate this with a placeholder for clarity api_key = "your-api-key" symbol = "EURUSD" output_csv = "EURUSD_3_years.csv" # Command to download the data from Alpha Vantage or any similar service # Example using Alpha Vantage (Daily FX data): https://www.alphavantage.co command = f"curl -o {output_csv} 'https://www.alphavantage.co/query?function=FX_DAILY&from_symbol=EUR&to_symbol=USD&outputsize=full&apikey={api_key}&datatype=csv'" os.system(command) # Read the downloaded CSV file data = pd.read_csv(output_csv) # Ensure the CSV is structured correctly for further processing # Rename columns if necessary to match yfinance format data.rename(columns={"close": "Close"}, inplace=True) # Print the first few rows to confirm print(data.head()) # Extract the 'Close' prices from the data prices = data['Close'].values # Normalize the prices for generating synthetic data min_price = prices.min() max_price = prices.max() normalized_prices = (prices - min_price) / (max_price - min_price) # Example: Generating some mock data def generate_real_data(samples=100): # Real data following a sine wave pattern time = np.linspace(0, 4 * np.pi, samples) data = np.sin(time) + np.random.normal(0, 0.1, samples) # Add some noise return time, data def generate_fake_data(generator, samples=100): # Fake data generated by the GAN noise = np.random.normal(0, 1, (samples, 1)) generated_data = generator.predict(noise).flatten() return generated_data # Mock generator function (replace with actual GAN generator model) class MockGenerator: def predict(self, noise): # Simulate GAN output with a cosine pattern (for illustration) return np.cos(np.linspace(0, 4 * np.pi, len(noise))).reshape(-1, 1) # Instantiate a mock generator for demonstration generator = MockGenerator() # Generate synthetic data: Let's use a simple random walk model as a basic example # (this is a placeholder for a more sophisticated method, like using GANs) np.random.seed(42) # Set seed for reproducibility synthetic_prices_normalized = normalized_prices[0] + np.cumsum(np.random.normal(0, 0.01, len(prices))) # Denormalize the synthetic prices back to the original scale synthetic_prices = synthetic_prices_normalized * (max_price - min_price) + min_price # Configure font sizes plt.rcParams.update({ 'font.size': 12, # General font size 'axes.titlesize': 16, # Title font size 'axes.labelsize': 14, # Axis labels font size 'legend.fontsize': 12, # Legend font size 'xtick.labelsize': 10, # X-axis tick labels font size 'ytick.labelsize': 10 # Y-axis tick labels font size }) # Plot both historical and synthetic data on the same graph plt.figure(figsize=(14, 7)) plt.plot(prices, label="Historical EURUSD", color='blue') plt.plot(synthetic_prices, label="Synthetic EURUSD", linestyle="--", color='red') plt.xlabel("Time Steps", fontsize=14) # Adjust fontsize directly if needed plt.ylabel("Price", fontsize=14) # Adjust fontsize directly if needed plt.title("Comparison of Historical and Synthetic EURUSD Data", fontsize=16) plt.legend() plt.show()
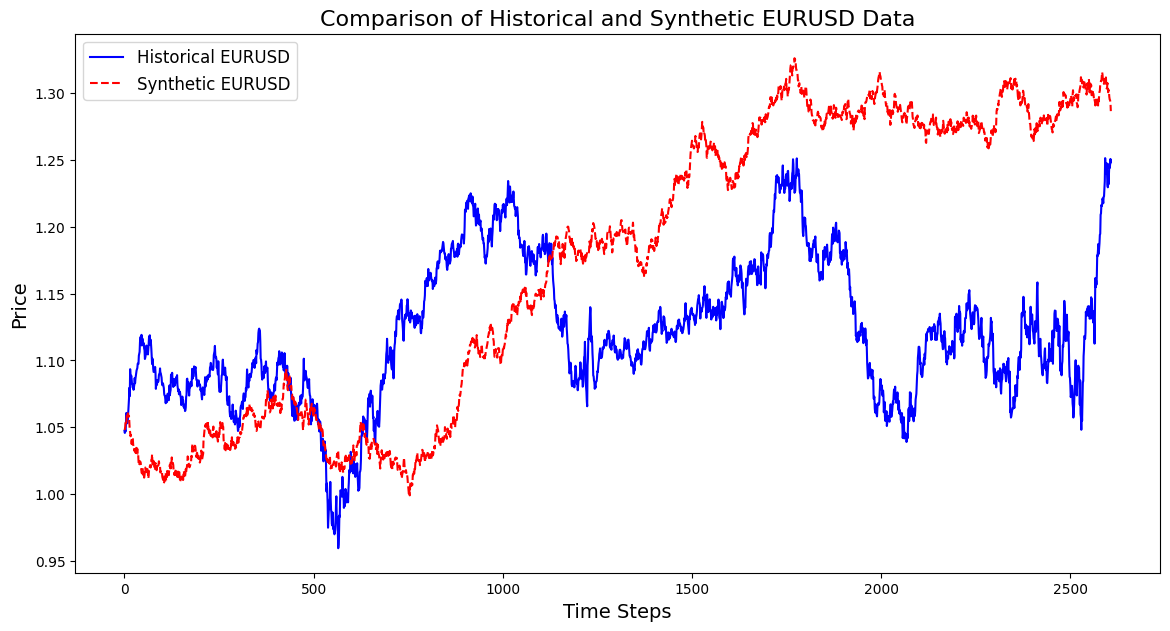
Anhand dieser Visualisierung lässt sich nachvollziehen, wie gut die synthetischen Daten mit den realen Daten übereinstimmen. Sie bietet Einblicke in den Fortschritt des GAN und zeigt Bereiche auf, die beim Training verbessert werden können.
Im Folgenden finden Sie einen Code, der ein synthetisches Währungspaar auf der Basis von EURUSD erstellt und dessen Kerzen-Chart auf dem EURUSD-Chart anzeigt
//+------------------------------------------------------------------+ //| Sythetic EURUSDChart.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property indicator_separate_window // Display in a seperate window #property indicator_buffers 4 //Buffers for Open, High,Low,Close #property indicator_plots 1 //Plot a single series(candlesticks) //+------------------------------------------------------------------+ //| Indicator to generate and display synthetic currency data | //+------------------------------------------------------------------+ double openBuffer[]; double highBuffer[]; double lowBuffer[]; double closeBuffer[]; //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { //---Set buffers for synthetic data SetIndexBuffer(0, openBuffer); SetIndexBuffer(1, highBuffer); SetIndexBuffer(2, lowBuffer); SetIndexBuffer(3, closeBuffer); //---Define the plots for candle sticks IndicatorSetString(INDICATOR_SHORTNAME, "Synthetic Candlestick"); //---Set the plot type for the candlesticks PlotIndexSetInteger(0, PLOT_DRAW_TYPE, DRAW_CANDLES); //---Setcolours for the candlesticks PlotIndexSetInteger(0, PLOT_COLOR_INDEXES, clrGreen); PlotIndexSetInteger(1, PLOT_COLOR_INDEXES, clrRed); //---Set the width of the candlesticks PlotIndexSetInteger(0, PLOT_LINE_WIDTH, 2); //---Set up the data series(buffers as series arrays) ArraySetAsSeries(openBuffer, true); ArraySetAsSeries(highBuffer, true); ArraySetAsSeries(lowBuffer, true); ArraySetAsSeries(closeBuffer, true); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Custom indicator iteration function | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { //--- int start = MathMax(prev_calculated-1, 0); //start from the most recent data double price =close[rates_total-1]; // starting price MathSrand(GetTickCount()); //initialize random seed //---Generate synthetic data for thechart for(int i = start; i < rates_total; i++) { double change = (MathRand()/ 32768.0)* 0.0002 - 0.0002; //Random price change price += change ; // Update price with the random change openBuffer[i]= price; highBuffer[i]= price + 0.0002; //simulated high lowBuffer[i]= price - 0.0002; //simulated low closeBuffer[i]= price; } //--- return value of prev_calculated for next call return(rates_total); } //+------------------------------------------------------------------+
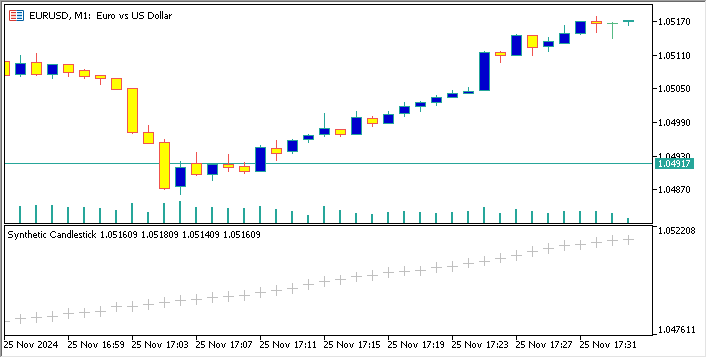
Die Analyse gängiger Metriken zur Bewertung von GANs in der Finanzmodellierung
Die Bewertung von Generative Adversarial Networks (GANs) ist von entscheidender Bedeutung, um festzustellen, ob ihre synthetischen Daten die realen Finanzdaten genau wiedergeben. Hier sind die wichtigsten Kriterien für die Bewertung:
1. Mittlerer quadratischer Fehler (MSE)
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/16214
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.