
Генеративно-состязательные сети (GAN) для синтетических данных в сфере финансового моделирования (Часть 1): Введение в GAN и синтетические данные в сфере финансового моделирования

Алгоритмическая торговля опирается на качественные финансовые данные, но такие проблемы, как небольшие или несбалансированные выборки, могут снизить надежность модели. Генеративно-состязательные сети (GAN) предлагают решение путем генерирования синтетических данных, повышения разнообразия наборов данных и надежности моделей.
GAN, представленные Иэном Гудфеллоу (Ian Goodfellow) в 2014 году, представляют собой модели машинного обучения, которые имитируют распределение данных для создания реалистичных копий, широко используемые в финансовой сфере для устранения дефицита данных и помех. Например, GAN могут генерировать синтетические последовательности биржевых цен, обогащая ограниченные наборы данных для лучшего обобщения в моделях. Однако обучение GAN требует больших вычислительных затрат, а синтетические данные необходимо тщательно проверять на релевантность во избежание несоответствия реальным рыночным условиям.
Структура GAN
GAN - это просто две нейронные сети - генератор и дискриминатор, которые играют в состязательную игру: Разбивка этих компонентов ниже.
- Генератор: Под словом Генератор здесь понимается цель обучить алгоритм имитации реальных данных. Он работает со случайным шумом в качестве входных данных и со временем приводит к получению более реалистичных выборок данных. С точки зрения трейдинга, генератор выдавал бы фальшивые движения цены или последовательности торговых объемов, которые напоминают реальные последовательности.
- Дискриминатор: Роль дискриминатора заключается в том, чтобы решить, какие данные из структурированных и синтезированных являются подлинными. Затем каждая выборка данных оценивается с точки зрения вероятности того, что она является исходными или синтезированными данными. В результате в процессе обучения у дискриминатора повышается способность классифицировать входные данные как реальные, тем самым стимулируя генератор продвигаться вперед в генерировании данных.
Теперь рассмотрим состязательный процесс, поскольку именно состязательный аспект GAN делает их такими мощными. Вот как эти две сети взаимодействуют в процессе обучения:
- Шаг 1: Генератор создает пакет выборок синтетических данных с помощью шума.
- Шаг 2: Дискриминатор принимает как реальные, так и синтетические данные от генератора. Он определяет возможности, или, другими словами, "выносит суждение" о подлинности каждого образца.
- Шаг 3: В следующих взаимодействиях, основанных на обратной связи дискриминатора, вес генератора корректируется для получения более реалистичных данных.
- Шаг 4: Дискриминатор также изменяет свой вес, чтобы лучше отличать реальные данные от ложных.
Этот непрерывный цикл продолжается до тех пор, пока синтетические данные генератора не станут высокоточными и дискриминатор больше не сможет отличить их от реальных данных. На этом этапе GAN считается обученным, поскольку генератор генерирует синтетические данные отличного качества.
Потери генератора уменьшаются по мере приближения к генерированию более реалистичных данных, а потери дискриминатора изменяются по мере того, как дискриминатор пытается адаптироваться к улучшенным результатам работы генератора.
Вот упрощенная структура для GAN на Python с использованием TensorFlow, чтобы проиллюстрировать, как взаимодействуют генератор и дискриминатор:
import tensorflow as tf from tensorflow.keras import layers # Define the Generator model def build_generator(): model = tf.keras.Sequential([ layers.Dense(128, activation='relu', input_shape=(100,)), layers.Dense(256, activation='relu'), layers.Dense(512, activation='relu'), layers.Dense(1, activation='tanh') # Output size to match the data shape ]) return model # Define the Discriminator model def build_discriminator(): model = tf.keras.Sequential([ layers.Dense(512, activation='relu', input_shape=(1,)), layers.Dense(256, activation='relu'), layers.Dense(128, activation='relu'), layers.Dense(1, activation='sigmoid') # Output is a probability ]) return model # Compile GAN with Generator and Discriminator generator = build_generator() discriminator = build_discriminator() # Combine the models in the adversarial network discriminator.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) gan = tf.keras.Sequential([generator, discriminator]) gan.compile(optimizer='adam', loss='binary_crossentropy')
В данной структуре:
Генератор преобразует случайный шум в реалистичные синтетические данные, затем дискриминатор классифицирует входные данные как реальные или ложные, а GAN объединяет обе модели, позволяя им итеративно обучаться друг у друга.
Обучение GAN
До сих пор мы знали структуру GAN, теперь мы можем перейти к обучению GAN, которое представляет собой интерактивный процесс, в котором сети генератора и дискриминатора обучаются одновременно, по очереди, для улучшения эффективности. Процесс обучения представляет собой серию этапов, на которых каждая из сетей выполняет свою работу таким образом, чтобы другая могла учиться у нее, что позволяет им предлагать улучшенные результаты. Теперь мы обсудим основные составляющие процесса обучения эффективной GAN. Основой обучения GAN является альтернативный двухэтапный процесс, где каждая сеть обновляется независимо в каждом цикле :
- Шаг 1: Обучаем дискриминатор.
Сначала дискриминатор получает реальные образцы данных и оценивает вероятность того, что каждая из них является реальной, затем он получает синтетические данные, сгенерированные генератором. Далее, потери дискриминатора определяются его способностью классифицировать реальные и синтетические образцы. Его веса скорректированы таким образом, чтобы свести к минимуму эти потери, улучшая его способность отличать реальные данные от ложных.
- Шаг 2: Обучаем генератор.
Генератор генерирует синтетические образцы из случайного шума и затем передает их в дискриминатор. Затем прогнозы дискриминатора используются для вычисления потерь генератора, поскольку генератор "хочет", чтобы дискриминатор сказал, что он генерирует реалистичные данные. Веса генератора регулируются таким образом, чтобы уменьшить его потери и он мог генерировать более реалистичные данные, которые могли бы обмануть дискриминатор.
Этот процесс чередования прогнозов друг друга повторяется снова и снова, и сети постепенно адаптируются к изменениям друг друга.
Следующий код демонстрирует ядро обучающего цикла GAN на Python с использованием TensorFlow:
import numpy as np import tensorflow as tf from tensorflow.keras import layers, Model from tensorflow.keras.optimizers import Adam tf.get_logger().setLevel('ERROR') # Only show errors # Generator model def create_generator(): input_layer = layers.Input(shape=(100,)) x = layers.Dense(128, activation="relu")(input_layer) x = layers.Dense(256, activation="relu")(x) x = layers.Dense(512, activation="relu")(x) output_layer = layers.Dense(784, activation="tanh")(x) model = Model(inputs=input_layer, outputs=output_layer) return model # Discriminator model def create_discriminator(): input_layer = layers.Input(shape=(784,)) x = layers.Dense(512, activation="relu")(input_layer) x = layers.Dense(256, activation="relu")(x) output_layer = layers.Dense(1, activation="sigmoid")(x) model = Model(inputs=input_layer, outputs=output_layer) return model # GAN model to combine generator and discriminator def create_gan(generator, discriminator): discriminator.trainable = False # Freeze discriminator during GAN training gan_input = layers.Input(shape=(100,)) x = generator(gan_input) gan_output = discriminator(x) gan_model = Model(inputs=gan_input, outputs=gan_output) return gan_model # Function to train the GAN def train_gan(generator, discriminator, gan, data, epochs=10000, batch_size=64): half_batch = batch_size // 2 for epoch in range(epochs): # Train Discriminator noise = np.random.normal(0, 1, (half_batch, 100)) generated_data = generator.predict(noise, verbose=0) real_data = data[np.random.randint(0, data.shape[0], half_batch)] # Train discriminator on real and fake data d_loss_real = discriminator.train_on_batch(real_data, np.ones((half_batch, 1))) d_loss_fake = discriminator.train_on_batch(generated_data, np.zeros((half_batch, 1))) d_loss = 0.5 * np.add(d_loss_real, d_loss_fake) # Train Generator noise = np.random.normal(0, 1, (batch_size, 100)) g_loss = gan.train_on_batch(noise, np.ones((batch_size, 1))) # Print progress every 100 epochs if epoch % 100 == 0: print(f"Epoch {epoch} | D Loss: {d_loss[0]:.4f} | G Loss: {g_loss[0]:.4f}") # Prepare data data = np.random.normal(0, 1, (1000, 784)) # Initialize models generator = create_generator() discriminator = create_discriminator() discriminator.compile(optimizer=Adam(), loss="binary_crossentropy", metrics=["accuracy"]) gan = create_gan(generator, discriminator) gan.compile(optimizer=Adam(), loss="binary_crossentropy") # Train GAN train_gan(generator, discriminator, gan, data, epochs=10000, batch_size=64)
Этот код обучает дискриминатор в основном фактическим данным из представленного набора данных, а также ложным/воссозданным данным, созданным фактическим генератором. Реальные данные классифицируются как "1 ", в то время как сгенерированные данные классифицируются как "0 " при обучении дискриминатора. Затем генератор обучается от дискриминатора через систему обратной связи таким образом, что генератор будет создавать данные, похожие на реальные.
Основываясь на реакции дискриминатора, генератор может еще больше отточить свою способность создавать реалистичные данные. Код также выводит данные о потерях для дискриминатора и генератора каждые сто эпох, о чем будет рассказано позже. Это является средством, с помощью которого можно оценить прогресс в обучении GAN и сделать вывод о том, насколько хорошо каждая часть GAN выполняет назначенную функцию в любой конкретный момент времени.
GAN в сфере финансового моделирования
GAN стали весьма полезными для финансового моделирования, особенно при генерировании новых данных. На финансовых рынках нехватка данных или проблемы с их конфиденциальностью означают нехватку высококачественных данных для обучения и тестирования прогностических моделей. GAN помогают решить эту проблему, поскольку создают синтетические данные, которые содержат статистику, аналогичную фактическим финансовым наборам данных.
Одной из областей применения, которую мы можем выделить, является оценка рисков, где GAN могут моделировать экстремальные рыночные условия и помогать в стресс-тестировании портфелей без использования исторических данных. Кроме того, GAN полезны для повышения надежности модели за счет создания разнообразных наборов обучающих данных, что позволяет избежать переобучения модели. Они также используются для генерации выбросов, когда разрабатываются сложные модели для создания синтетических наборов данных, указывающих на такие выбросы, как мошеннические операции или рыночные аномалии.
В целом, использование GAN в финансовом моделировании позволяет учреждениям решать проблемы низкого качества данных, моделировать возникновение событий, которые нечасто наблюдаются, и повышать прогностическую силу моделей, что делает GAN важными инструментами для современного финансового анализа и принятия решений.
Реализация простых GAN на MQL5
Теперь, когда мы познакомились с GAN, перейдем к генерации синтетических данных в результате обучения генеративно-состязательной сети (GAN) на MQL5, которая предлагает инновационный подход к концепции синтетических данных в контексте торговли. Базовая GAN состоит из двух компонентов: генератора, генерирующего ложные данные (например, ценовые тренды), и дискриминатора, определяющего, являются ли данные подлинными или ложными. Вот как мы можем применить простую GAN на MQL5 для моделирования искусственных цен закрытия, которые имитируют реальную динамику рынка.
- Определение генератора и дискриминатора
double GenerateSyntheticPrice() { return NormalizeDouble(MathRand() / 1000.0, 5); // Simple random price } double Discriminator(double price, double threshold) { if (MathAbs(price - threshold) < 0.001) return 1; // Real return 0; // Fake }
Представленный пример использования GAN в MQL5 показывает, как с их помощью можно создавать синтетические данные для финансового моделирования и тестирования и, тем самым, расширять горизонты совершенствования торговых алгоритмов.
Ниже приведен тест для одного советника как на реальных, так и на синтетических данных:
Согласно этим результатам, реальные данные привели к получению более реалистичной, но потенциально более низкой прибыли из-за непредсказуемости реальных рыночных условий.
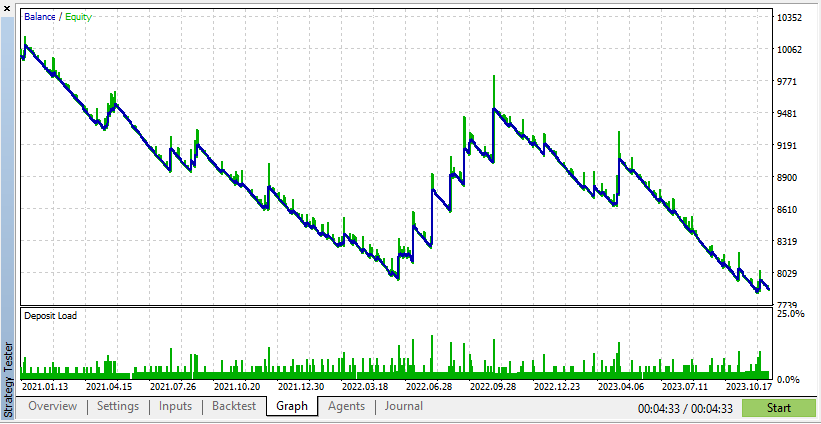
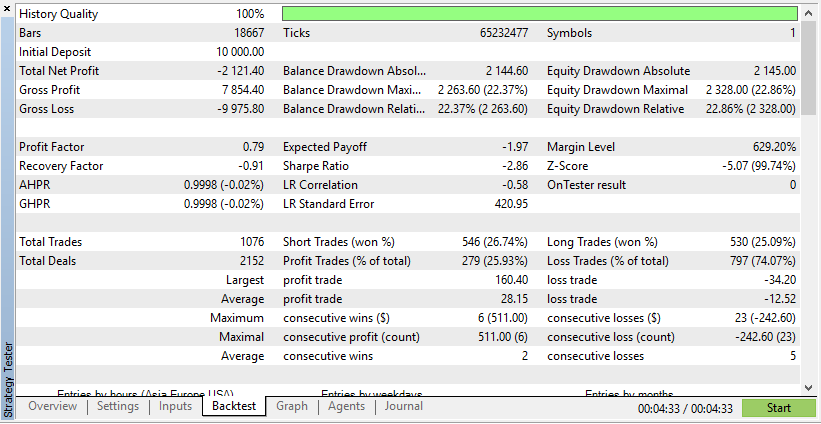
Согласно этим результатам, синтетические данные показали более высокую прибыль, если данные будут получены благодаря идеальным условиям для вашего советника.
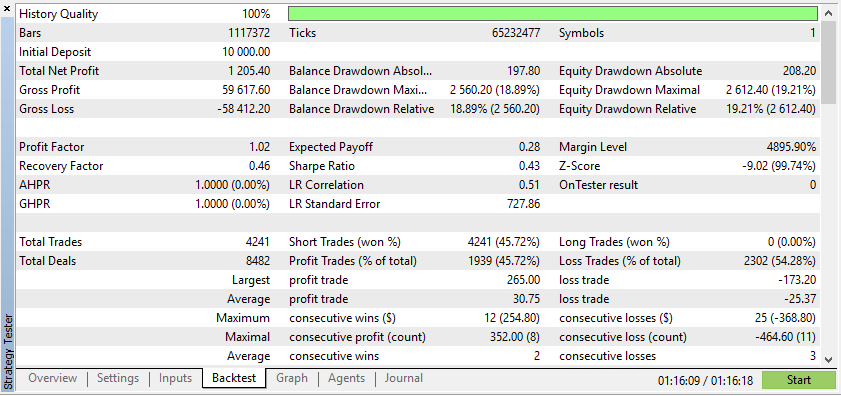
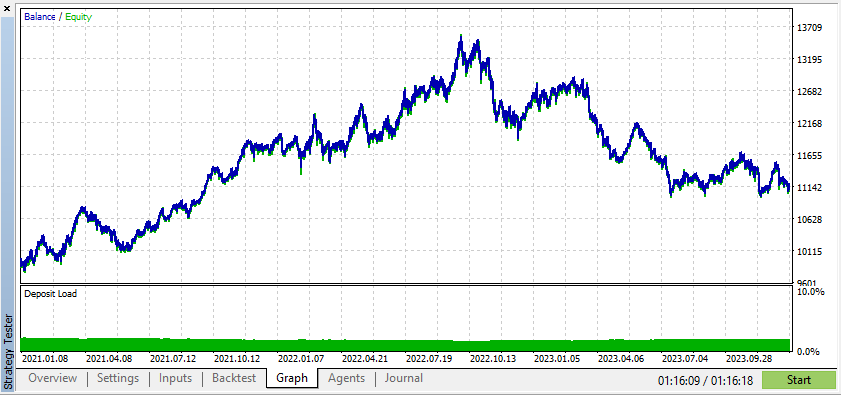
Однако реальные данные дадут вам гораздо более четкое представление о том, как советник будет работать в реальных торговых условиях. Использование синтетических данных часто может привести к ошибочным результатам бэк-тестирования, которые могут оказаться невоспроизводимыми на реальном рынке.
Восприятие процесса обучения GAN имеет решающее значение, поскольку дает ценную информацию о процессе обучения и стабильности модели. В финансовом моделировании визуализация используется для того, чтобы помочь разработчикам моделей понять, есть ли у синтетических данных верный паттерн, например, реальные данные, полученные с помощью GAN. Сгенерированные выходные данные на различных этапах обучения могут быть показаны разработчикам для выявления возможных проблем, таких как сбой режима или низкое качество синтетических данных. Такая оценка является непрерывной, что позволяет обучать надлежащему установлению параметров, одновременно повышая эффективность GAN для генерирования данных, отражающих целевые финансовые паттерны.
Ниже приведен код создания синтетического инструмента на основе данных по паре EURUSD за 3 года:
import pandas as pd import numpy as np import matplotlib.pyplot as plt import os # Download data using the terminal # Replace 'your-api-key' with an actual API key from a data provider # Here, we simulate this with a placeholder for clarity api_key = "your-api-key" symbol = "EURUSD" output_csv = "EURUSD_3_years.csv" # Command to download the data from Alpha Vantage or any similar service # Example using Alpha Vantage (Daily FX data): https://www.alphavantage.co command = f"curl -o {output_csv} 'https://www.alphavantage.co/query?function=FX_DAILY&from_symbol=EUR&to_symbol=USD&outputsize=full&apikey={api_key}&datatype=csv'" os.system(command) # Read the downloaded CSV file data = pd.read_csv(output_csv) # Ensure the CSV is structured correctly for further processing # Rename columns if necessary to match yfinance format data.rename(columns={"close": "Close"}, inplace=True) # Print the first few rows to confirm print(data.head()) # Extract the 'Close' prices from the data prices = data['Close'].values # Normalize the prices for generating synthetic data min_price = prices.min() max_price = prices.max() normalized_prices = (prices - min_price) / (max_price - min_price) # Example: Generating some mock data def generate_real_data(samples=100): # Real data following a sine wave pattern time = np.linspace(0, 4 * np.pi, samples) data = np.sin(time) + np.random.normal(0, 0.1, samples) # Add some noise return time, data def generate_fake_data(generator, samples=100): # Fake data generated by the GAN noise = np.random.normal(0, 1, (samples, 1)) generated_data = generator.predict(noise).flatten() return generated_data # Mock generator function (replace with actual GAN generator model) class MockGenerator: def predict(self, noise): # Simulate GAN output with a cosine pattern (for illustration) return np.cos(np.linspace(0, 4 * np.pi, len(noise))).reshape(-1, 1) # Instantiate a mock generator for demonstration generator = MockGenerator() # Generate synthetic data: Let's use a simple random walk model as a basic example # (this is a placeholder for a more sophisticated method, like using GANs) np.random.seed(42) # Set seed for reproducibility synthetic_prices_normalized = normalized_prices[0] + np.cumsum(np.random.normal(0, 0.01, len(prices))) # Denormalize the synthetic prices back to the original scale synthetic_prices = synthetic_prices_normalized * (max_price - min_price) + min_price # Configure font sizes plt.rcParams.update({ 'font.size': 12, # General font size 'axes.titlesize': 16, # Title font size 'axes.labelsize': 14, # Axis labels font size 'legend.fontsize': 12, # Legend font size 'xtick.labelsize': 10, # X-axis tick labels font size 'ytick.labelsize': 10 # Y-axis tick labels font size }) # Plot both historical and synthetic data on the same graph plt.figure(figsize=(14, 7)) plt.plot(prices, label="Historical EURUSD", color='blue') plt.plot(synthetic_prices, label="Synthetic EURUSD", linestyle="--", color='red') plt.xlabel("Time Steps", fontsize=14) # Adjust fontsize directly if needed plt.ylabel("Price", fontsize=14) # Adjust fontsize directly if needed plt.title("Comparison of Historical and Synthetic EURUSD Data", fontsize=16) plt.legend() plt.show()
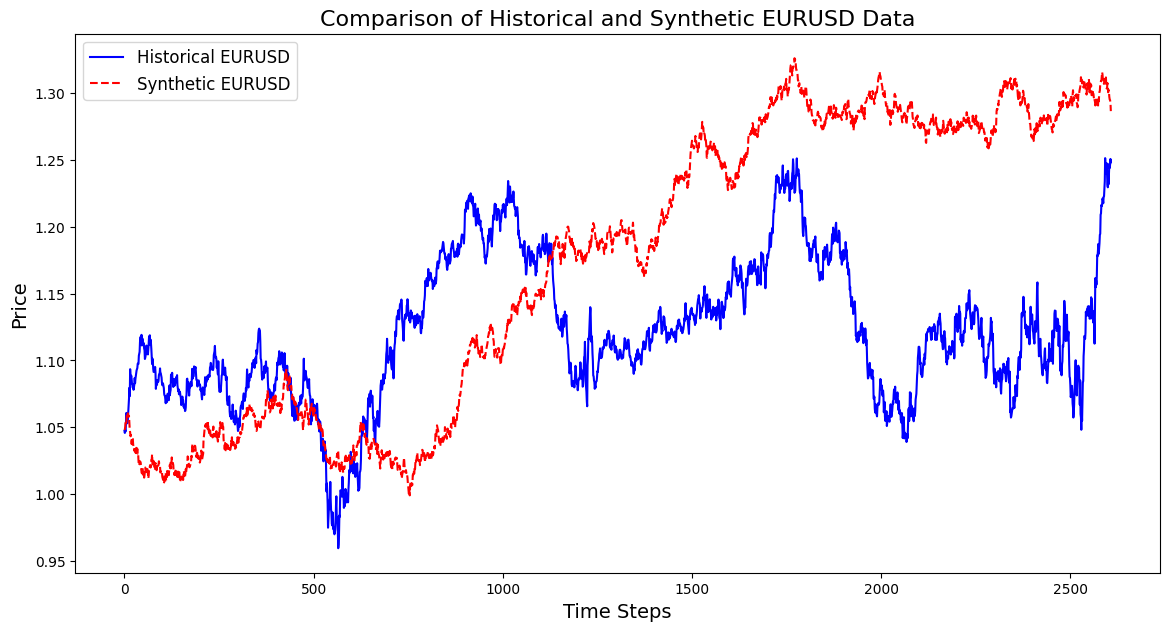
Эта визуализация помогает отслеживать, насколько точно синтетические данные соответствуют реальным, позволяя получить представление о прогрессе GAN и выявляя области для потенциального улучшения во время обучения.
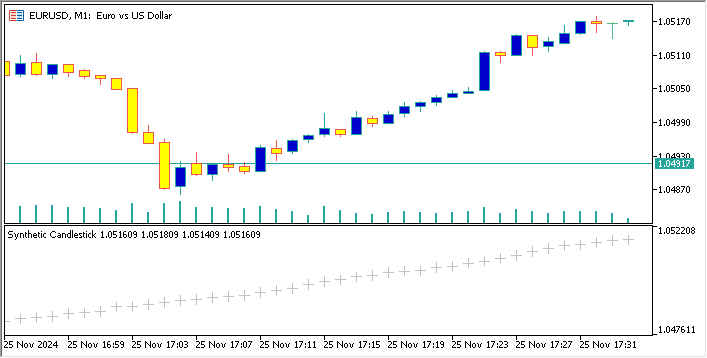
Ниже приведен код, который создает синтетическую валютную пару на основе EURUSD и отображает график ее свечей на графике EURUSD
//+------------------------------------------------------------------+ //| Sythetic EURUSDChart.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property indicator_separate_window // Display in a seperate window #property indicator_buffers 4 //Buffers for Open, High,Low,Close #property indicator_plots 1 //Plot a single series(candlesticks) //+------------------------------------------------------------------+ //| Indicator to generate and display synthetic currency data | //+------------------------------------------------------------------+ double openBuffer[]; double highBuffer[]; double lowBuffer[]; double closeBuffer[]; //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { //---Set buffers for synthetic data SetIndexBuffer(0, openBuffer); SetIndexBuffer(1, highBuffer); SetIndexBuffer(2, lowBuffer); SetIndexBuffer(3, closeBuffer); //---Define the plots for candle sticks IndicatorSetString(INDICATOR_SHORTNAME, "Synthetic Candlestick"); //---Set the plot type for the candlesticks PlotIndexSetInteger(0, PLOT_DRAW_TYPE, DRAW_CANDLES); //---Setcolours for the candlesticks PlotIndexSetInteger(0, PLOT_COLOR_INDEXES, clrGreen); PlotIndexSetInteger(1, PLOT_COLOR_INDEXES, clrRed); //---Set the width of the candlesticks PlotIndexSetInteger(0, PLOT_LINE_WIDTH, 2); //---Set up the data series(buffers as series arrays) ArraySetAsSeries(openBuffer, true); ArraySetAsSeries(highBuffer, true); ArraySetAsSeries(lowBuffer, true); ArraySetAsSeries(closeBuffer, true); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Custom indicator iteration function | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { //--- int start = MathMax(prev_calculated-1, 0); //start from the most recent data double price =close[rates_total-1]; // starting price MathSrand(GetTickCount()); //initialize random seed //---Generate synthetic data for thechart for(int i = start; i < rates_total; i++) { double change = (MathRand()/ 32768.0)* 0.0002 - 0.0002; //Random price change price += change ; // Update price with the random change openBuffer[i]= price; highBuffer[i]= price + 0.0002; //simulated high lowBuffer[i]= price - 0.0002; //simulated low closeBuffer[i]= price; } //--- return value of prev_calculated for next call return(rates_total); } //+------------------------------------------------------------------+
Анализ популярных показателей для оценки GAN в сфере финансового моделирования
Оценка генеративно-состязательных сетей (GAN) имеет решающее значение для определения того, точно ли их синтетические данные воспроизводят реальные финансовые данные. Вот ключевые показатели, используемые для оценки:
1. Среднеквадратичная ошибка (Mean Squared Error, MSE)
MSE измеряет среднюю квадратичную разницу между реальными и синтетическими точками данных. Более низкий MSE указывает на то, что синтетические данные очень похожи на реальный набор данных, что делает их подходящими для таких задач, как прогнозирование цен или управление портфелем. Трейдеры могут использовать MSE для проверки того, отражают ли данные, сгенерированные GAN, фактические движения на рынке. Например, трейдер, использующий генеративно-состязательную сеть (GAN) для генерации ложных данных о биржевых ценах, может измерить энтропию по сравнению с использованием фактических цен, зафиксированных в истории, для вычисления среднеквадратичной ошибки (MSE). Низкая MSE доказывает достоверность синтезированных данных, поскольку они соответствуют реальным рыночным движениям, что позволяет использовать их для обучения моделей ИИ для прогнозирования будущих ценовых взаимодействий.
2. Начальное расстояние Фреше (FID)
Несмотря на то, что FID обычно используется для создания изображений, оно также может применяться к финансовым данным. Оно сравнивает распределение реальных и синтетических данных в пространстве признаков. Более низкий показатель FID означает лучшее соответствие между синтетическими и реальными данными, поддерживая такие типы применения, как стресс-тестирование портфеля и оценка рисков. Например, оно управляет портфелем, помогая сравнивать синтетическое распределение доходности с фактической рыночной доходностью. Гипотеза 3 указывает на то, что, поскольку более низкий показатель FID означает, что доходность, генерируемая GAN, более точно соответствует фактическому распределению доходности, это показывает, что модель GAN хорошо подходит для проведения стресс-тестов портфеля и оценки рисков.
3. Дивергенция Кульбака—Лейблера (КЛ) (Kullback-Leibler (KL) Divergence)
Дивергенция КЛ оценивает, насколько близко распределение вероятностей синтетических данных соответствует распределению реальных данных. В финансовой сфере низкая дивергенция КЛ предполагает, что данные, сгенерированные GAN, отражают такие важные свойства, как кластеризация волатильности, что делает их эффективными для моделирования рисков и алгоритмической торговли. Например, модели оценивают генеративную модель или способность GAN распознавать фактическое распределение доходности активов с точки зрения побочных рисков и кластеризации волатильности. Низкая дивергенция КЛ означает, что синтетические данные обладают важными характеристиками реалистичных рисков доходности, поэтому эффективно применять модели риска, основанные на данных GAN.
4. Точность дискриминатора
Дискриминатор измеряет, насколько хорошо он может различать реальные и синтетические данные. В идеале, по мере обучения точность дискриминатора должна приближаться к 50%, указывая на то, что синтетические данные неотличимы от реальных. Это подтверждает качество выходных данных GAN для бэк-тестирования и моделирования будущих сценариев. Например, при использовании в алгоритмической торговле стратегия помогает в процессе проверки потока. Соблюдая эту точность, трейдеры смогут лучше понять, создает ли GAN реалистичные синтетические фьючерсы или нет. Высококачественный и неразличимый сценарий соответствует результатам данных, прошедших бэк-тестирование, с точностью около 50%.
Эти показатели обеспечивают комплексную основу для оценки GAN в сфере финансового моделирования Они помогают разработчикам повысить качество синтетических данных и обеспечить их применимость в таких задачах, как управление портфелем, оценка рисков и проверка торговой стратегии.
Заключение
Генеративно-состязательные сети (GAN) позволяют трейдерам и финансовым аналитикам генерировать синтетические данные, что полезно в тех случаях, когда реальные данные ограничены, являются дорогостоящими или конфиденциальными. GAN предоставляют надежные данные для финансового моделирования, улучшая анализ денежных потоков в торговых моделях. Обладая базовыми знаниями о GAN, трейдеры могут самостоятельно освоить генерирование синтетических данных для укрепления своих аналитических возможностей.
В будущих темах будут рассмотрены такие передовые методы, как GAN Вассерштейна (Wasserstein GANs) и Прогрессивный рост (Progressive Growing) для повышения стабильности GAN и их применения в финансовой сфере.
| Название файла | Описание |
|---|---|
| GAN_training_code.py | Файл обучающего кода для обучения GAN |
| GAN_Inspired basic structure.mq5 | Файл, содержащий код для структуры GAN на MQL5 |
| GAN_Model_building.py | Файл, содержащий код для структуры GAN на Python |
| MA Crossover GAN integrated.mq5 | Файл, содержащий код для советника, протестированный на реальных и ложных данных |
| EURUSD_historical_synthetic_ comparison.py | Файл, содержащий код сравнения исторической и синтетической пары EURUSD |
| Synthetic EURUSDchart.mq5 | Файл, содержащий код для создания синтетического графика на графике EURUSD |
| EURUSD_CSV.csv | Файл, содержащий синтетические данные, импортируемых для тестирования советника |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/16214
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Клиент в Connexus (Часть 7): Добавление клиентского уровня
Клиент в Connexus (Часть 7): Добавление клиентского уровня
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования