
金融建模中合成数据的生成式对抗网络(GAN)(第 1 部分):金融建模中的 GAN 与合成数据概述

算法交易依赖高品质的财经数据,但样本太小、或不平衡等问题可能会损害模型的可靠性。生成式对抗网络(GAN)提供了一种解决方案,通过生成合成数据,强化数据集多样性、及模型稳健性。
GAN 由 Ian Goodfellow 于 2014 年提出,是一种机器学习模型,即模拟数据分布来创建逼真的副本,已在金融领域广泛运用,来解决数据稀缺、和噪音问题。例如,GAN 能够产生合成股票价格序列,丰富有限的数据集,使之模型能更好地普适。然而,训练 GAN 的计算需求很高,应仔细验证合成数据的相关性,从而避免与真实市场条件不匹配。
GAN 的结构
GAN 简单说是两个神经网络 — 生成器和鉴别器,两者玩对抗游戏:以下是这些部件的细分。
- 生成器(Generator):字面上,其意向是训练一种算法,来模拟实际数据。它配以随机噪声作为输入进行操作,随时间推移,往往会产生更真实的数据样本。在交易术语中,生成器会给出虚假价格走势、或交易量序列,幻似真实序列。
- 鉴别器(Discriminator):鉴别器的角色是判定结构化数据、即合成数据中哪些数据是可信赖的。然后甄别每个数据样本是原始数据、或合成数据的似然性。如是结果,在训练过程中,鉴别器提升了把输入归类到真实数据的能力,从而鼓励生成器在生成数据方面取得进展。
现在我们看看对抗过程,因为正是 GAN 的对抗性层面,令它们如此强大。以下是两个网络在训练过程中的交互方式:
- 步骤 1:生成器遍历噪声,创建一批合成数据样本。
- 步骤 2:鉴别器从生成器中获取真实数据,以及合成数据。它赋予了可能性,或者换言之,它对每个样本的真实性“通盘判断”。
- 步骤 3:在接下来的交互中,根据鉴别器的反馈,调整生成器的权重,从而生成更真实的数据。
- 步骤 4:鉴别器还会改变其权重,以便更好地区分真实数据和虚假数据。
这个循环会不断持续,直至生成器的合成数据高度准确,且鉴别器不再能与真实数据区分开来。此刻,可认定 GAN 已受训练,因为生成器正在生成高品质的合成数据。
因生成器产生的的数据更接近真实,故生成器的损失会降低,而鉴别器的损失会随着鉴别器尝试适应由生成器改进的输出而变化。
以下是以 Python 定义的 GAN 简化结构,并用 TensorFlow 概括生成器和鉴别器如何交互:
import tensorflow as tf from tensorflow.keras import layers # Define the Generator model def build_generator(): model = tf.keras.Sequential([ layers.Dense(128, activation='relu', input_shape=(100,)), layers.Dense(256, activation='relu'), layers.Dense(512, activation='relu'), layers.Dense(1, activation='tanh') # Output size to match the data shape ]) return model # Define the Discriminator model def build_discriminator(): model = tf.keras.Sequential([ layers.Dense(512, activation='relu', input_shape=(1,)), layers.Dense(256, activation='relu'), layers.Dense(128, activation='relu'), layers.Dense(1, activation='sigmoid') # Output is a probability ]) return model # Compile GAN with Generator and Discriminator generator = build_generator() discriminator = build_discriminator() # Combine the models in the adversarial network discriminator.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) gan = tf.keras.Sequential([generator, discriminator]) gan.compile(optimizer='adam', loss='binary_crossentropy')
在该结构中:
生成器把随机噪声转换为可靠的合成数据,然后鉴别器把输入归类到真实、或虚假,GAN 将两个模型组合在一起,令它们能够相互迭代学习。
训练 GAN
迄今为止,我们已知道了 GAN 的结构,我们现在可以转向 GAN 的训练,这是一个交互式过程,其中生成器和鉴别器网络同时进行训练,从而提升其性能。训练过程是一连串步骤,其中每个网络的执行方式,都能让另一个网络可从中学习,如此令它们能够提供强化的结果。现在我们将讨论训练一个有效 GAN 的主要过程部分。GAN 训练的核心是一个交替两步过程,其中每个网络在每次循环中独立更新:
- 步骤 1:训练鉴别器。
首先,鉴别器接收真实数据样本,并估测每个样本的真实性概率,然后接收生成器产生的合成数据。接下来,鉴别器的损失取决于其对真实样本、及合成样本进行分类的能力。调整其权重,以便最大限度地降低损失,从而提高其识别真实数据、及虚假数据的能力。
- 步骤 2:训练生成器。
生成器自随机噪声产生合成样本,然后将它们带给鉴别器。然后,Discriminator 的预测用于计算 Generator 损失,因为 Generator“希望”Discriminator 说它正在生成真实数据。调整生成器的权重,以便减少其损失,如此它就能生成更真实的数据,从而欺骗鉴别器。
这种在彼此的预测之间交替的过程会一遍又一遍地重复,网络逐渐适应彼此的变化。
以下代码演示了使用 TensorFlow,以 Python 编写的 GAN 训练循环核心:
import numpy as np import tensorflow as tf from tensorflow.keras import layers, Model from tensorflow.keras.optimizers import Adam tf.get_logger().setLevel('ERROR') # Only show errors # Generator model def create_generator(): input_layer = layers.Input(shape=(100,)) x = layers.Dense(128, activation="relu")(input_layer) x = layers.Dense(256, activation="relu")(x) x = layers.Dense(512, activation="relu")(x) output_layer = layers.Dense(784, activation="tanh")(x) model = Model(inputs=input_layer, outputs=output_layer) return model # Discriminator model def create_discriminator(): input_layer = layers.Input(shape=(784,)) x = layers.Dense(512, activation="relu")(input_layer) x = layers.Dense(256, activation="relu")(x) output_layer = layers.Dense(1, activation="sigmoid")(x) model = Model(inputs=input_layer, outputs=output_layer) return model # GAN model to combine generator and discriminator def create_gan(generator, discriminator): discriminator.trainable = False # Freeze discriminator during GAN training gan_input = layers.Input(shape=(100,)) x = generator(gan_input) gan_output = discriminator(x) gan_model = Model(inputs=gan_input, outputs=gan_output) return gan_model # Function to train the GAN def train_gan(generator, discriminator, gan, data, epochs=10000, batch_size=64): half_batch = batch_size // 2 for epoch in range(epochs): # Train Discriminator noise = np.random.normal(0, 1, (half_batch, 100)) generated_data = generator.predict(noise, verbose=0) real_data = data[np.random.randint(0, data.shape[0], half_batch)] # Train discriminator on real and fake data d_loss_real = discriminator.train_on_batch(real_data, np.ones((half_batch, 1))) d_loss_fake = discriminator.train_on_batch(generated_data, np.zeros((half_batch, 1))) d_loss = 0.5 * np.add(d_loss_real, d_loss_fake) # Train Generator noise = np.random.normal(0, 1, (batch_size, 100)) g_loss = gan.train_on_batch(noise, np.ones((batch_size, 1))) # Print progress every 100 epochs if epoch % 100 == 0: print(f"Epoch {epoch} | D Loss: {d_loss[0]:.4f} | G Loss: {g_loss[0]:.4f}") # Prepare data data = np.random.normal(0, 1, (1000, 784)) # Initialize models generator = create_generator() discriminator = create_discriminator() discriminator.compile(optimizer=Adam(), loss="binary_crossentropy", metrics=["accuracy"]) gan = create_gan(generator, discriminator) gan.compile(optimizer=Adam(), loss="binary_crossentropy") # Train GAN train_gan(generator, discriminator, gan, data, epochs=10000, batch_size=64)
这段代码配以给定数据集中的实际数据、以及来自生成器的虚假/重建数据来进行鉴别器的基础训练。在训练鉴别器时,真实数据被归类为 “1”,而生成的数据则被归类为 “0”。然后,生成器再次依据鉴别器反馈而来的数据进行训练,生成器按此方式来创建仿真数据。
据来自鉴别器的响应,生成器能够进一步磨练其创建可信赖数据的能力。该代码每 100 局次打印一遍鉴别器和生成器的损失,稍后将讨论。这种举措形式,能够估测 GAN 训练进度、及评估 GAN 每个部分在任何特定时间执行其预期功能的优异度。
GAN 在金融建模中的应用
GAN 在金融建模中已变得非常实用,尤其是在生成新数据方面。在金融市场中,数据匮乏、或数据隐私问题,意味着能用来训练和测试预测模型的高品质数据稀缺。GAN 有助于解决这个问题,因为它们生成的合成数据与真实金融数据集拥有相似的统计数据。
我们可以辨别的应用领域之一,是风险评估领域,GAN 可在无历史数据的情况下针对极端市场条件进行建模,并帮助对投资组合进行压力测试。进而,实用的 GAN 依据产生的合成训练数据集来提升模型健壮性,从而避免模型过度拟合。它们还用于超纲值生成,其中开发的复杂模型,创建指代欺诈交易、或市场异动等超纲值的合成数据集。
总体而言,在金融建模中应用 GAN,令机构能够解决数据品质低下的问题,模拟不常观察到的事件的发生,并提高模型的预测能力,这令 GAN 成为现代金融分析和决策的重要工具。
利用 MQL5 实现简单的 GAN
现在我们已经熟悉了 GAN,如此转向利用 MQL5 训练生成式对抗网络(GAN),并生成合成数据,其为交易环境中处理合成数据概念,提供了一种新颖方式。一个基本的 GAN 由两部分组成:生成虚假数据(例如价格趋势)的生成器,和盘定数据点是真实、亦或虚假的鉴别器。这就是我们如何在 MQL5 中应用简单 GAN,为人造收盘价建模,从而模拟真实市场动态。
- 定义生成器和鉴别器
double GenerateSyntheticPrice() { return NormalizeDouble(MathRand() / 1000.0, 5); // Simple random price } double Discriminator(double price, double threshold) { if (MathAbs(price - threshold) < 0.001) return 1; // Real return 0; // Fake }
在 MQL5 中使用 GAN 的示例,展现如何使用它们来创建用于金融建模和测试的合成数据,进而拓展改进交易算法的视野。
以下是一款智能交易系统,基于真实数据和合成数据的测试:
根据这些结果,真实数据得到的成果更现实,但可能盈利更低,这是由于实际市场条件的不可预测性。
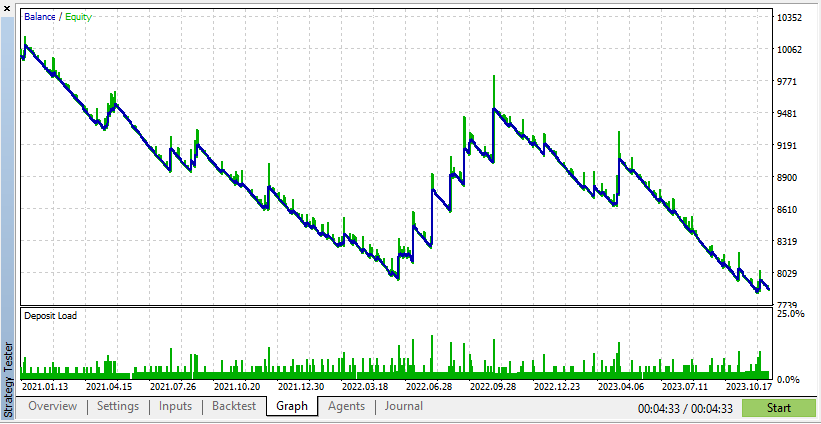
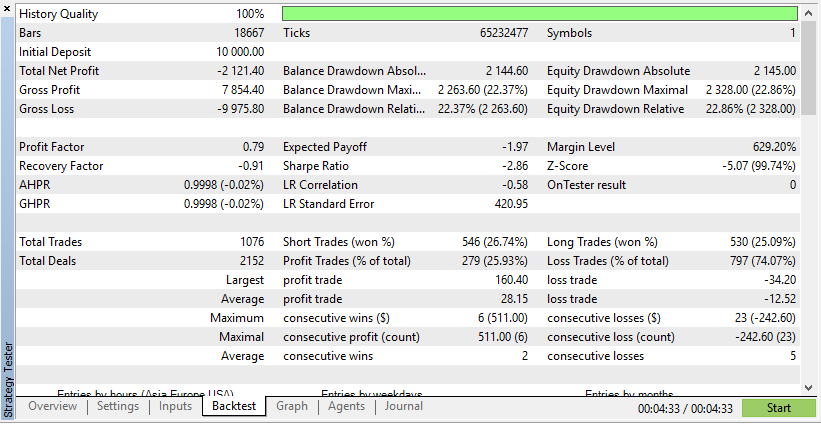
根据这些结果,合成数据会展现出更高的利润,这是由于数据更符合您的 EA 理想条件。
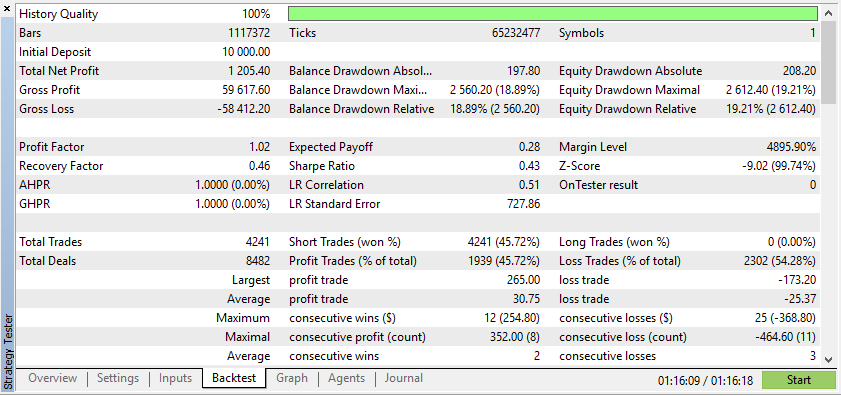
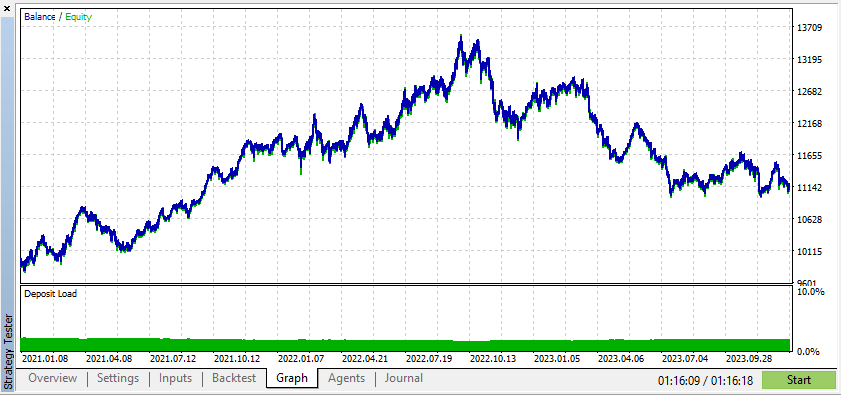
不过,真实数据将令您更清晰地了解 EA 在实际交易条件下的性能。依赖合成数据通常会导致误导性的回测结果,这或许在实时市场中无法重现。
GAN 的训练感知至关重要,因为它提供了直入学习过程和模型稳定性的洞察。在金融建模中,可视化被用来帮助建模者了解合成数据是否具有正确的形态,就如同 GAN 捕获的真实数据。不同训练阶段生成的输出能显示给开发人员,来检测可能出现的问题,譬如形态崩溃、或合成数据的品质太差。这样的评估是连续的,这令训练能够相应地设置参数,同时提高 GAN 性能,从而生成反映目标金融形态的数据。
以下是如何基于 3 年的 EURUSD 数据创建合成金融产品的代码:
import pandas as pd import numpy as np import matplotlib.pyplot as plt import os # Download data using the terminal # Replace 'your-api-key' with an actual API key from a data provider # Here, we simulate this with a placeholder for clarity api_key = "your-api-key" symbol = "EURUSD" output_csv = "EURUSD_3_years.csv" # Command to download the data from Alpha Vantage or any similar service # Example using Alpha Vantage (Daily FX data): https://www.alphavantage.co command = f"curl -o {output_csv} 'https://www.alphavantage.co/query?function=FX_DAILY&from_symbol=EUR&to_symbol=USD&outputsize=full&apikey={api_key}&datatype=csv'" os.system(command) # Read the downloaded CSV file data = pd.read_csv(output_csv) # Ensure the CSV is structured correctly for further processing # Rename columns if necessary to match yfinance format data.rename(columns={"close": "Close"}, inplace=True) # Print the first few rows to confirm print(data.head()) # Extract the 'Close' prices from the data prices = data['Close'].values # Normalize the prices for generating synthetic data min_price = prices.min() max_price = prices.max() normalized_prices = (prices - min_price) / (max_price - min_price) # Example: Generating some mock data def generate_real_data(samples=100): # Real data following a sine wave pattern time = np.linspace(0, 4 * np.pi, samples) data = np.sin(time) + np.random.normal(0, 0.1, samples) # Add some noise return time, data def generate_fake_data(generator, samples=100): # Fake data generated by the GAN noise = np.random.normal(0, 1, (samples, 1)) generated_data = generator.predict(noise).flatten() return generated_data # Mock generator function (replace with actual GAN generator model) class MockGenerator: def predict(self, noise): # Simulate GAN output with a cosine pattern (for illustration) return np.cos(np.linspace(0, 4 * np.pi, len(noise))).reshape(-1, 1) # Instantiate a mock generator for demonstration generator = MockGenerator() # Generate synthetic data: Let's use a simple random walk model as a basic example # (this is a placeholder for a more sophisticated method, like using GANs) np.random.seed(42) # Set seed for reproducibility synthetic_prices_normalized = normalized_prices[0] + np.cumsum(np.random.normal(0, 0.01, len(prices))) # Denormalize the synthetic prices back to the original scale synthetic_prices = synthetic_prices_normalized * (max_price - min_price) + min_price # Configure font sizes plt.rcParams.update({ 'font.size': 12, # General font size 'axes.titlesize': 16, # Title font size 'axes.labelsize': 14, # Axis labels font size 'legend.fontsize': 12, # Legend font size 'xtick.labelsize': 10, # X-axis tick labels font size 'ytick.labelsize': 10 # Y-axis tick labels font size }) # Plot both historical and synthetic data on the same graph plt.figure(figsize=(14, 7)) plt.plot(prices, label="Historical EURUSD", color='blue') plt.plot(synthetic_prices, label="Synthetic EURUSD", linestyle="--", color='red') plt.xlabel("Time Steps", fontsize=14) # Adjust fontsize directly if needed plt.ylabel("Price", fontsize=14) # Adjust fontsize directly if needed plt.title("Comparison of Historical and Synthetic EURUSD Data", fontsize=16) plt.legend() plt.show()
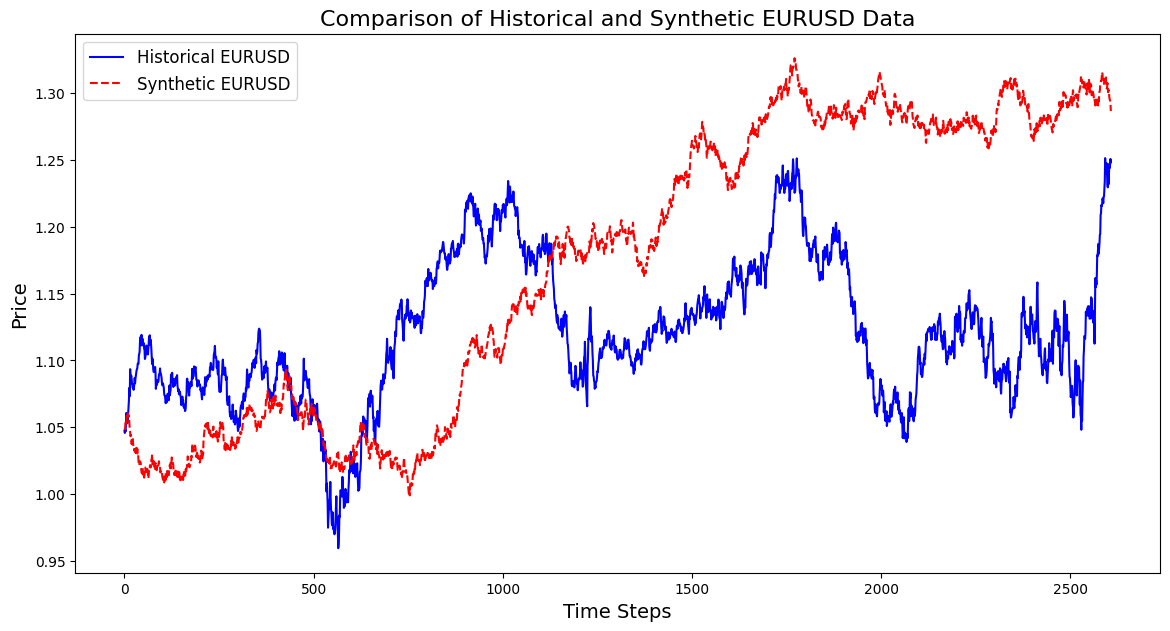
这种可视化有助于跟踪合成数据与真实数据的匹配程度,从而深入了解 GAN 的进度,并高亮示意训练期间潜在改进的区域。
下面是一段代码,创建基于 EURUSD 的合成货币对,并在 EURUSD 图表上显示其烛条图表
//+------------------------------------------------------------------+ //| Sythetic EURUSDChart.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property indicator_separate_window // Display in a seperate window #property indicator_buffers 4 //Buffers for Open, High,Low,Close #property indicator_plots 1 //Plot a single series(candlesticks) //+------------------------------------------------------------------+ //| Indicator to generate and display synthetic currency data | //+------------------------------------------------------------------+ double openBuffer[]; double highBuffer[]; double lowBuffer[]; double closeBuffer[]; //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { //---Set buffers for synthetic data SetIndexBuffer(0, openBuffer); SetIndexBuffer(1, highBuffer); SetIndexBuffer(2, lowBuffer); SetIndexBuffer(3, closeBuffer); //---Define the plots for candle sticks IndicatorSetString(INDICATOR_SHORTNAME, "Synthetic Candlestick"); //---Set the plot type for the candlesticks PlotIndexSetInteger(0, PLOT_DRAW_TYPE, DRAW_CANDLES); //---Setcolours for the candlesticks PlotIndexSetInteger(0, PLOT_COLOR_INDEXES, clrGreen); PlotIndexSetInteger(1, PLOT_COLOR_INDEXES, clrRed); //---Set the width of the candlesticks PlotIndexSetInteger(0, PLOT_LINE_WIDTH, 2); //---Set up the data series(buffers as series arrays) ArraySetAsSeries(openBuffer, true); ArraySetAsSeries(highBuffer, true); ArraySetAsSeries(lowBuffer, true); ArraySetAsSeries(closeBuffer, true); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Custom indicator iteration function | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { //--- int start = MathMax(prev_calculated-1, 0); //start from the most recent data double price =close[rates_total-1]; // starting price MathSrand(GetTickCount()); //initialize random seed //---Generate synthetic data for thechart for(int i = start; i < rates_total; i++) { double change = (MathRand()/ 32768.0)* 0.0002 - 0.0002; //Random price change price += change ; // Update price with the random change openBuffer[i]= price; highBuffer[i]= price + 0.0002; //simulated high lowBuffer[i]= price - 0.0002; //simulated low closeBuffer[i]= price; } //--- return value of prev_calculated for next call return(rates_total); } //+------------------------------------------------------------------+
评估 GAN 在金融建模中应用的流行量值分析
评估生成式对抗网络(GAN),这对于判定其合成数据是否准确复现真实金融数据至关重要。以下是用来评估的关键量值:
1. 均方误差(MSE)
MSE 衡量真实数据点和合成数据点之间的均方差。较低的 MSE 表明合成数据与真实数据集非常近似,令其适合价格预测、或投资组合管理等任务。交易者可用 MSE 来验证 GAN 生成的数据是否反映了实际的市场走势。例如,使用生成式对抗网络(GAN)产生虚假股价数据的交易者,能够衡量熵与利用历史记录的实际价格来计算均方误差(MSE)。较低的 MSE 证明了合成数据的可靠性,因为它们与真实的市场走势相匹配,允许用它们来训练 AI 模型,预测未来的价格互动。
2. Fréchet 起始距离(FID)
虽然 FID 常用于图像生成,但也可应用于金融数据。它在特征空间中比较真实数据与合成数据分布。较低的 FID 分数意味着合成数据和真实数据之间的一致性更好,支持投资组合压力测试、和风险评估等应用。例如,它借助将合成回报分布、与实际市场回报进行比较,来管理投资组合。假设 3 表明,由于较低的 FID 分数意味着 GAN 产生的回报更接近实际回报分布,这展示出 GAN 模型非常适合投资组合压力测试、及风险评估等业绩。
3. 库尔巴克-莱布勒(Kullback-Leibler)背离
KL 背离评估的是合成数据的概率分布、与真实数据分布的匹配程度。在金融领域,较低 KL 背离表明 GAN 生成的数据捕获了波动率聚类等关键属性,令其在风险建模、和算法交易方面行之有效。例如,就尾段风险和波动率聚类而言,评估生成式模型、或 GAN 识别实际资产回报分布的能力。较低 KL 背离意味着合成数据具有现实收益风险的重要特征,因此把基于 GAN 的数据应用于风险模型是有效的。
4. 鉴别器精度
鉴别器衡量的是它区分真实数据和合成数据的能力。理想情况下,随着训练的推进,鉴别器的准确率应接近 50%,这表明合成数据与真实数据没有区别。这验证了 GAN 输出的品质,可用于回测和未来场景建模。例如,当用在算法交易策略当中时,有助于流程验证过程。通过观察这种准确性,交易者就能够很好地明白 GAN 是否正在创建可依赖的未来合成数据。高品质且难以区分的场景、与回测数据相匹配,准确率徘徊在 50% 左右。
这些量值为评估 GAN 在金融建模中的应用,提供了一个综合性的框架。它们帮助开发人员提高合成数据品质,并确保其在投资组合管理、风险评估、和交易策略验证等任务中的适用性。
结束语
生成式对抗网络(GAN)允许交易者和金融分析师产生合成数据,这在真实数据有限、昂贵、或敏感时非常实用。GAN 为金融建模提供可依赖的数据,强化交易模型中的现金流分析。凭借 GAN 的基础知识,交易者可独立探索合成数据生成,从而增强他们的分析能力。
未来的主题将涵盖 Wasserstein GAN、和渐进式增长等先进技术,是为提高 GAN 稳定性,及在金融中的应用。
| 文件名 | 描述 |
|---|---|
| GAN_training_code.py | 训练 GAN 的训练代码文件 |
| GAN_Inspired basic structure.mq5 | 包含 GAN 结构的 MQL5 代码文件 |
| GAN_Model_building.py | 包含 GAN 结构的 Python 代码文件 |
| MA Crossover GAN integrated.mq5 | 包含依据真实和虚假数据进行测试的智能系统代码的文件 |
| EURUSD_historical_synthetic_ comparison.py | 包含比较 EURUSD 历史、及合成 EURUSD 的代码文件 |
| Synthetic EURUSDchart.mq5 | 包含在 EURUSD 图表上创建合成图表的代码文件 |
| EURUSD_CSV.csv | 包含测试智能系统时导入的合成数据文件 |
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/16214
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
