
Usando planilhas para construir estratégias de negociação

Introdução
As planilhas são uma invenção bastante antiga. Programas modernos desse tipo têm um poder tremendo e permitem analisar visualmente dados em tabelas. Além disso, tal análise é possível em diferentes planos, de ângulos diferentes, acontecendo muito rapidamente. Gráficos, tabelas dinâmicas, análise de hipóteses, formatação condicional de células e muito mais: tudo isso que é escrito em livros grossos e que são lidos em longos cursos.
Aqui está um pouco desse poder e proponho testá-lo para analisar nossas estratégias.
Pessoalmente, eu uso o Libre Office Calc porque é gratuito e funciona onde quer que eu trabalho 😀. No entanto, a mesma abordagem funciona para outras planilhas: Microsoft Excel, Planilhas Google, etc. Atualmente, todas elas permitem a conversão entre elas, além disso, os princípios de construção de fórmulas para todos também são semelhantes.
Sendo assim, presumo que você tenha algum tipo de programa para trabalhar com planilhas. Além disso, talvez você tenha dados em formato de arquivo de texto (*.txt ou *.csv) que deseja analisar. Este artigo descreve resumidamente como importar esses arquivos. Vou usar o histórico do terminal MetaTrader, mas quaisquer outros dados servirão, sejam eles de Dukas Copy ou Finam. Também espero que esteja claro que você deve ter uma ideia de estratégia para poder configurar sinais. Isso é tudo o que é necessário para por em prática os materiais do artigo.
Espero que o artigo seja útil para diferentes categorias de traders, por isso, tentarei escrevê-lo de uma forma que seja compreensível mesmo para pessoas que nunca viram programas desse tipo antes, além disso, farei o esforço para abranger um leque de problemas que não são conhecidos por todos os usuários/traders experientes...
Uma rápida olhada nas tabelas: para iniciantes
A Figura 1 mostra uma aparência típica de uma planilha.
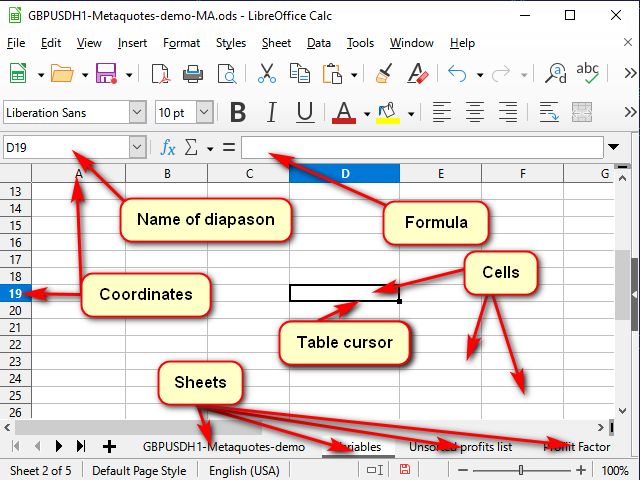
Figura 1. Aparência típica de um programa para trabalhar com planilhas.
Qualquer tabela é apresentada como um conjunto de planilhas. Podemos pensar nelas como "guias" separadas para tarefas diferentes.
Cada planilha consiste em "células". Cada célula é essencialmente uma calculadora pequena, mas muito poderosa.
Para que o programa possa entender qual célula queremos processar agora, cada uma delas recebe coordenadas, como num tabuleiro de xadrez ou numa "batalha naval". Essas coordenadas juntas definem o "endereço" único de uma célula. O endereço consiste no número ou nome da coluna e no número da linha (por exemplo, na imagem 1, o cursor da tabela destaca a célula "D19". Isso pode ser visto nos nomes das coordenadas destacadas e na linha do nome.
Além das próprias coordenadas, o endereço pode conter o nome da planilha e até mesmo o nome do arquivo da tabela. Como regra, o mesmo endereço também é o nome desta célula. Mas, se desejarmos, podemos definir seus próprios nomes para que fique claro o que exatamente essa célula ou intervalo de células armazena. Esses nomes podem ser visualizados (e alterados) na linha do nome.
A célula pode conter dados simples (por exemplo, cotações ou volumes) ou "fórmulas" que calculam seu valor.
Na "barra de fórmulas" podemos visualizar o que exatamente está na célula selecionada e, se necessário, podemos alterar esses valores ou fórmulas.
Para editar o valor numa célula, precisamos clicar duas vezes nela ou corrigir o que precisamos na barra de fórmulas. Alternativamente, podemos selecionar uma célula e pressionar "F2". E se precisarmos criar um novo texto, podemos selecionar uma célula e digitar algo imediatamente. Somente neste caso é necessário levar em consideração que todos os dados desta célula serão deletados.
Podemos cancelar a edição sem salvá-la pressionando "ESC" (canto superior direito do teclado). Podemos confirmar com a tecla "Enter" (transição para abaixo) ou pressionando "Tab" (transição para um lado).
Se várias células forem selecionadas, "Enter" e "Tab" só funcionam na seleção. Isso pode ser usado para acelerar o processo.
Quanto ao resto dos botões e menus, acho que será fácil descobrir por conta própria como usar.
Primeiros passos: importando cotações
Vamos começar a preparar os dados para testar nossas estratégias. Como eu disse, pegarei dados do terminal. Para fazer isso, em qualquer janela de gráfico, podemos pressionar o atalho de teclado Ctrl+S ou selecionar no menu do terminal "Arquivo" -> "Salvar". O terminal oferecerá a janela normal do sistema, na qual precisaremos inserir o nome e o caminho do arquivo.
Se a extensão do arquivo for *.csv, geralmente não há problemas. Se *.txt, então, como regra, podemos clicar no arquivo com o botão direito do mouse e selecionar "Abrir com" -> "Escolher outro aplicativo" ou primeiro abrir um aplicativo para trabalhar com tabelas e, em seguida, abrir um arquivo a partir dele, pois por padrão o sistema tenta abrir arquivos com esta extensão usando o bloco de notas ou algum outro processador de texto.
Para converter números, na janela de conversão, precisamos selecionar a coluna apropriada, e então indicar ao programa o separador das partes inteiras e fracionárias, bem como, se necessário, o separador dos grupos de dígitos (para volumes). No Excel, isso é feito através do botão "Mais...", no Calc da lista "Tipo de coluna", selecione o item "Inglês dos Estados Unidos".
E há outra nuance. Após a importação bem-sucedida, faz sentido deixar de 5 a 7 mil linhas na tabela com dados. Acontece que quanto mais dados houver, mais difícil será para o programa calcular o resultado de cada célula. Ao mesmo tempo, a precisão da estimativa aumenta ligeiramente: por exemplo, ao comparar os resultados da verificação para dados de 5 000 linhas e 100 000 linhas, os resultados diferiram em cerca de 1% e o tempo de cálculo diferiu de maneira muito significativa.
Alguns atalhos de teclado para trabalhar com tabelas
| Atalho de teclado | Ação executada |
|---|---|
| Ctrl + setas | Transição para o limite mais próximo de uma série contínua de dados |
| Tab | Confirmação de entrada e transição para a célula da direita |
| Shift + Tab | Confirmação de entrada e transição para a célula da esquerda |
| Enter | Confirmação de entrada e transição para a célula de baixo |
| Shift + Enter | Confirmação de entrada e transição para a célula de entrada de cima |
| Ctrl + D | Preencher colunas selecionadas de cima para baixo |
| Shift + Cttrl + setas | Realce desde a posição atual até o final de um intervalo contínuo |
Como podemos preencher uma coluna longa com a mesma fórmula
Para intervalos pequenos, podemos usar o método mostrado na Figura 2: movemos o mouse até a "alça de seleção" (o quadrado no canto inferior direito do cursor de tabela) e, quando o cursor do mouse se transformar numa cruz pequenina, arrastamos este marcador para a linha ou coluna desejada.
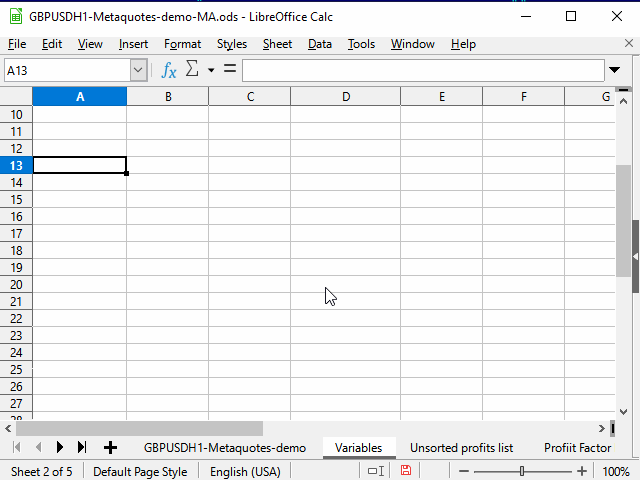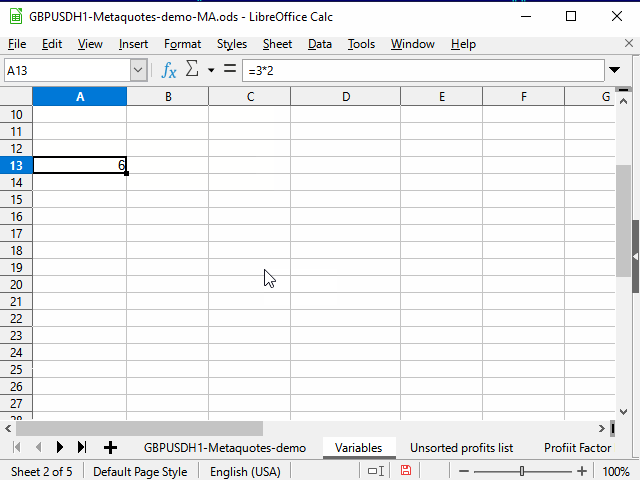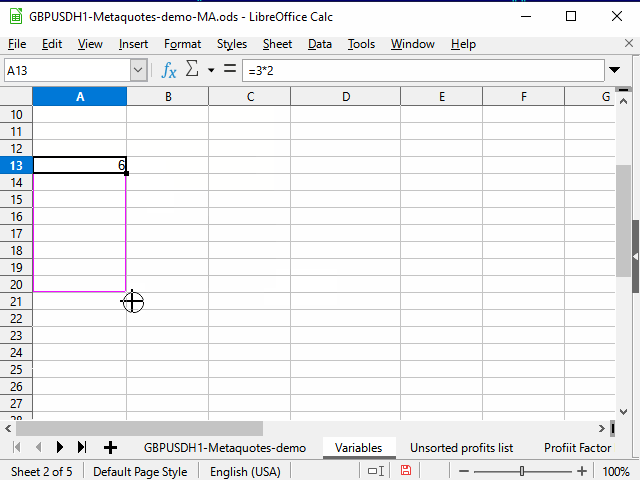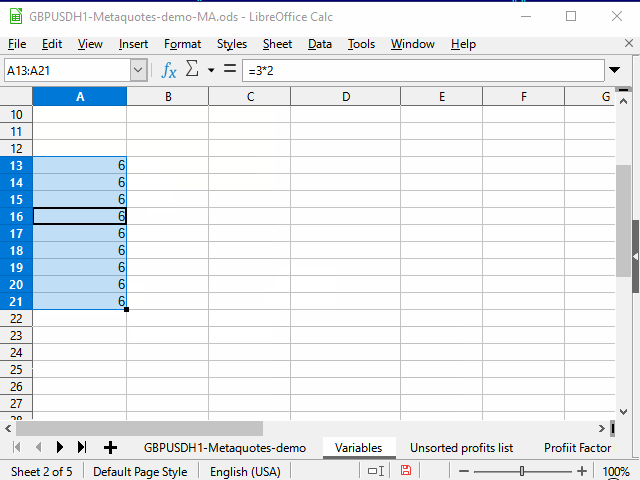
Figura 2. Recheio esticando
No entanto, para grandes quantidades de dados, isso é altamente inconveniente.
Por isso, podemos usar qualquer um dos métodos abaixo.
Método 1. Limitando o intervalo
A sequência de ações é mostrada na Figura 3.
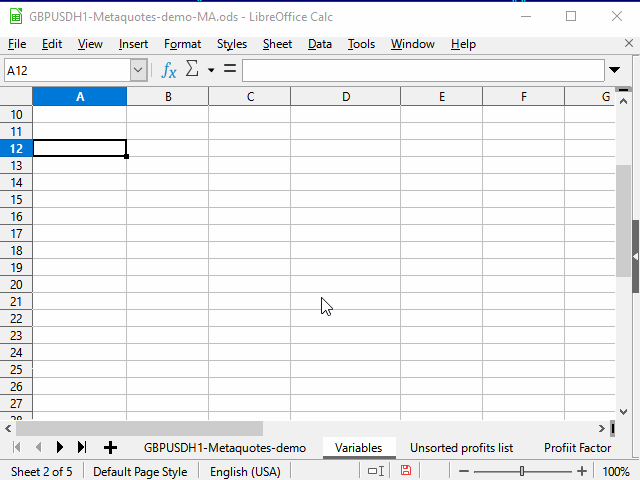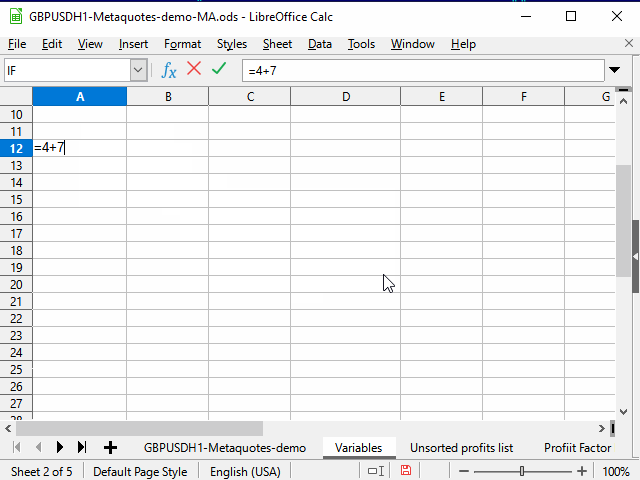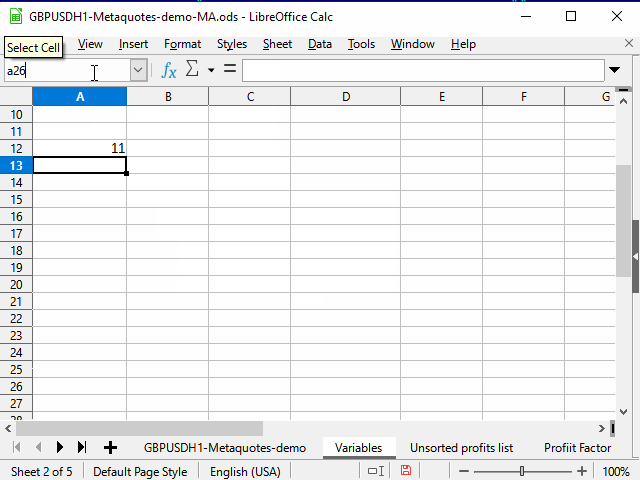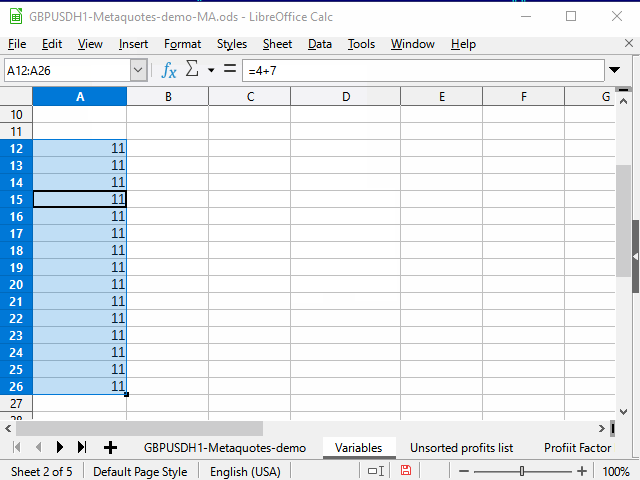
Figura 3. Preenchendo com uma restrição de intervalo
- Inserimos a fórmula desejada na célula superior do intervalo e confirmamos a entrada.
- Vamos para a célula inferior do intervalo usando o campo de nome.
- Pressionamos as teclas Ctrl + Shift + seta para cima para irpara a célula superior do intervalo e selecionar todas as células intermediárias.
- Pressionamos a combinação Ctrl + D para preencher células com dados.
Uma pequena desvantagem do método para mim é que precisamos saber o número da linha mais baixa do intervalo.
Método 2. Usando um intervalo contínuo adjacente
A sequência de ações é mostrada na Figura 4.
Figura 4. Preenchendo com um intervalo adjacente.
- Selecionamos a célula com a fórmula desejada.
- Usando a combinação Shift + seta para a esquerda selecionamos a célula adjacente.
- Pressionamos a tecla Tab para mover o cursor da tabela para a célula à esquerda. Aqui, usamos a capacidade do cursor tabular de se mover apenas dentro da seleção.
- Ctrl + Shift + seta para baixo — selecionamos duas colunas para a linha mais baixa do intervalo contínuo.
- Shift + seta para a direita — desmarcamos a partir da coluna da esquerda. A da direita permanece destacada.
- Ctrl + D — preenchemos a coluna com dados.
Na figura, observamos o conteúdo da barra de fórmulas. Podemos ver que, ao copiar uma fórmula contendo uma referência de célula, essa referência muda automaticamente dependendo da posição do cursor. Por isso, essa referência é chamada de "relativa".
Se quisermos que ao copiar a referência de célula permaneça constante, precisamos selecionar esta referência e pressionar a tecla F4. Um $ aparece antes do número da linha e do nome da coluna, e o valor não será alterado quando copiarmos a fórmula.
Às vezes, é útil não alterar a referência inteira, mas, sim, apenas a coluna ou apenas a linha. Por isso, devemos deixar o cifrão só na parte imutável (podemos pressionar F4 mais uma ou duas vezes).
Bem, e agora que os métodos básicos para acelerar o trabalho foram dominados, podemos prosseguir diretamente para a descrição da estratégia.
Descrição da estratégia
Por exemplo, pegarei a estratégia implementada no Expert Advisor padrão "Examples\Moving Average".
Uma posição é aberta se:
- Não há posições abertas e
- O corpo do candle cruza a média móvel (Open — de um lado do MA, Close — do outro).
A posição é fechada se:
- Há uma posição aberta e
- O candle cruza o MA na direção oposta à abertura.
Adicionando dados do indicador
A peculiaridade de calcular usando planilhas é que os subtotais dos cálculos, via de regra, precisam ser salvos separadamente. Isso torna mais fácil entender fórmulas e localizar erros, e também torna mais fácil construir fórmulas com base em dados de células vizinhas. Bem, e as boas ideias surgem às vezes precisamente por causa dessa "fragmentação".
Mas voltando ao nosso problema.
Após a importação e alguma formatação, minhas cotações de partida ficam assim (Figura 5):
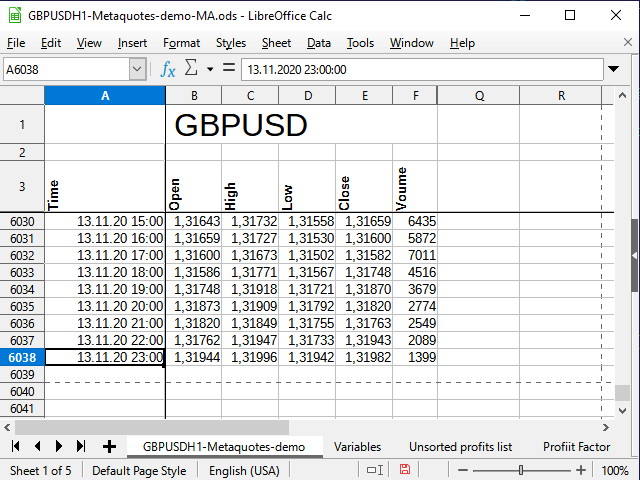
Figura 5. A aparência das cotações de partida.
Observe a linha em branco entre todo o nome da tabela e os nomes das colunas. Esta linha permite que o processador de planilha trate os dois blocos como tabelas separadas e, portanto, posso concatenar as células para a faixa superior, mas ainda usar filtros diferentes para a faixa inferior - elas não interferirão entre si. Se esta linha não for deixada, poderá haver repercussões.
Corrigi as primeiras linhas e colunas para ocultar as informações que são desnecessárias no momento, mesmo assim, todos os dados ainda estão presentes nesta tabela (consulte a ajuda do seu processador de planilha para saber como fazer isso).
A hora e a data estão na coluna A, preços de abertura na coluna B, etc. A última linha da tabela tem o número 6038.
O primeiro passo para construir uma estratégia é construir um indicador. Para que o indicador seja personalizável, vamos adicionar outra planilha e criar uma tabela de variáveis. Com a ajuda de uma linha de nome, atribuiremos um nome próprio a cada variável, para que, ao escrever fórmulas, fique claro de onde vem.
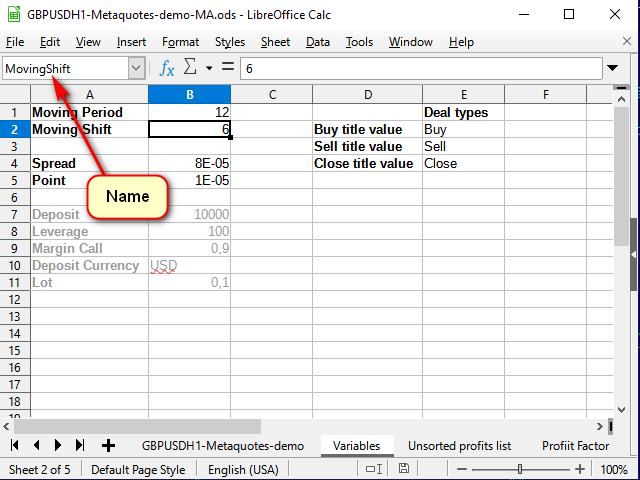
Figura 6. Planilha de variáveis
Agora vamos voltar para a planilha de dados. Para simplificar um pouco a fórmula final, primeiro na coluna G anotamos o número da cotação na lista. É igual ao número da linha menos 3:
=ROW()-3
Após descrever esta fórmula na célula G4, iremos estendê-lo a todas as células inferiores.
Isso é necessário para que a fórmula de cálculo do MA seja universal. Se o (deslocamento + período) MA é mais do que os nossos dados, o cálculo da média se torna sem sentido.
A própria fórmula para o cálculo da média móvel (SMA) será escrita na célula H4 da planilha com dados básicos e será assim:
=IF( G4>(MovingPeriod+MovingShift), AVERAGE( INDIRECT( "E" & ( ROW()-MovingShift-MovingPeriod) & ":" & "E" & ( ROW()-MovingShift) ) ), "" )
Ao inserir fórmulas que requerem referências a outras células, podemos simplesmente apontar as células com o mouse.
A fórmula atual começa com uma chamada da função IF(). Essa é, como podemos imaginar, a função de verificar a condição. A propósito, todas as expressões booleanas como And, Or, Not, se forem necessárias no futuro, também serão funções.
Ao chamar funções, os argumentos são especificados entre parênteses e separados por vírgulas (como neste caso) ou ponto e vírgula.
Função IF recebe três argumentos: condição, valor, se a condição for verdadeira, valor, se a condição for falsa.
Nesse caso, usei-a para verificar se há dados suficientes para calcular um ponto completo para a curva MA. Se não houver dados suficientes, simplesmente mantemos a linha em branco, de outra forma contamos a média do valor a partir de algum intervalo.
A função Indirect retorna um valor (ou vários valores) a partir do intervalo da linha de texto definida. É exatamente disso que preciso, pois os endereços dos intervalos necessárias para o cálculo da média devem ser formados com base nos valores das variáveis de entrada.
O símbolo "&" em programas de planilha denota a concatenação, em outras palavras, a concatenação de duas linhas. Assim, "colei" o endereço desde muitas partes. A primeira parte é o nome da coluna que contém os preços de fechamento ("E"), a segunda é o endereço "distante" calculado como o número da linha atual menos o comprimento médio e menos o deslocamento. A terceira parte dessa expressão é o sinal de dois pontos, que indica a continuidade do intervalo. E, em seguida, novamente o nome da coluna e o número da linha, levando em consideração o deslocamento. Eu não os pintei com muito brilho, espero que quebras ampersand ajudem a entender isso.
É claro que essa fórmula precisará ser estendida a todas as linhas abaixo.
Como resultado, obtemos algo assim:
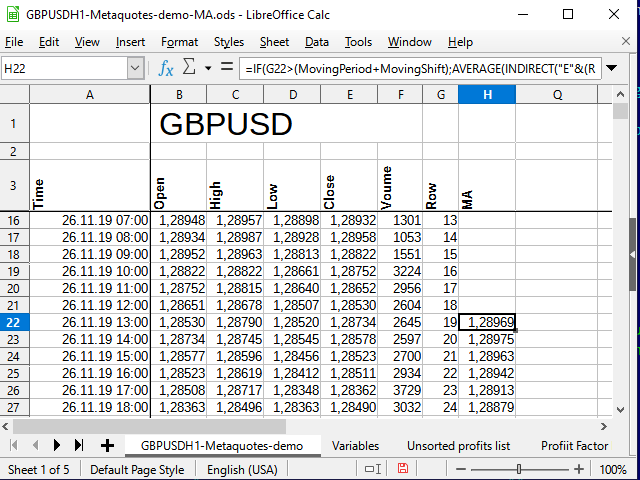
Figura 7. Tabela após adicionar cálculos do MA.
Pode-se ver que os números na coluna H só começaram a aparecer na linha 22 (19 entradas). Veja a razão para isso na Figura 6.
Assim, temos os dados iniciais, temos os dados do indicador. Podemos começar a implementar a estratégia.
Implementação da estratégia
A estratégia será implementada na forma de sinais simples. Se MA cruzar para baixo, escreveremos o valor "-1" na célula, se para cima, "1". Se não houver interseções, a célula conterá o valor de uma linha em branco.
Vamos para a célula I4. A fórmula básica para esta célula será assim:
=IF( AND( B4>H4,E4<H4 ),-1 , IF( AND( B4<H4,E4>H4 ), 1 , "") )
Podemos verificar no gráfico, funciona. Mas esta é a fórmula de uma reversão simples. Ela torna impossível rastrear o status do trade. Podemos experimentar e obter resultados interessantes, mas nossa tarefa agora é implementar a estratégia descrita no início deste artigo. Por isso, precisamos registrar o estado do trade em cada barra (ou seja, em cada linha).
A coluna J, para esses fins, é bastante adequada. A fórmula na célula J4 ficaria assim:
=IF(AND(I4=-1,J3=""), -1 ,IF(AND(I4=1,J3=""), 1 ,IF(OR(AND(I4="",J3=1),AND(I4="",J3=-1),I4=J3), J3 ,"")))
Se um evento (interseção) ocorrer, então verificamos o status do trade anterior. Se um trade estiver aberto e a interseção estiver na direção oposta, fechamo-lo; se estiver fechada, abrimo-lo. Em todos os outros casos, simplesmente salvamos o status.
E para ver claramente onde compraríamos e venderíamos se implementássemos esta estratégia no período a que correspondem os nossos dados, e também para tornar conveniente a análise da estratégia, introduziremos uma outra coluna, uma com sinais.
Os nomes dos sinais podem ser retirados do livro de referência, que pode ser criado na planilha de variáveis.
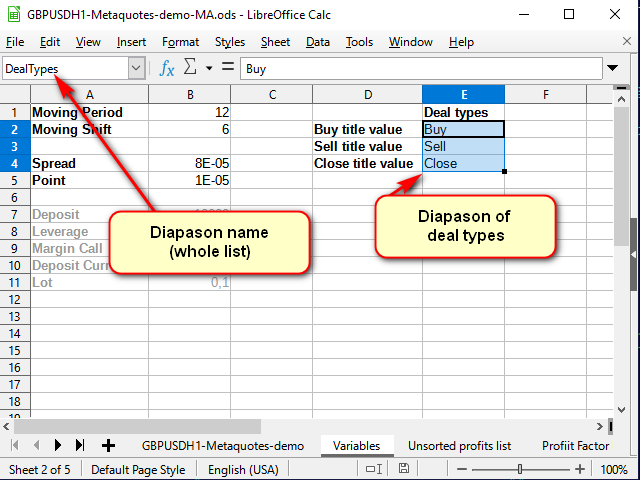
Figura 8. Planilha de "Variáveis" após adicionar o livro de referência de nomes de trades
Preste atenção na linha do nome: aqui eu dei um nome a todo o intervalo selecionado, não a uma única célula.
Agora na célula K4 da planilha principal (com dados), podemos escrever o seguinte:
=IF(AND(J3=1,J2=""),INDEX(DealTypes,1),IF(AND(J3=-1,J2=""),INDEX(DealTypes,2),IF(OR(AND(J3="",J2=1),AND(J3="",J2=-1)),INDEX(DealTypes,3),"")))
O trade aberto é aberto após o sinal na abertura do próximo. Por isso, preste atenção à mudança dos índices nesta fórmula.
Se não houve trade (a célula anterior na coluna de status está vazia) e um sinal chegou, indicamos que tipo de transação precisa ser feita. Se o trade foi aberto, então o fechamos pelo o sinal.
A função Index, como primeiro parâmetro, recebe o intervalo em que a pesquisa ocorrerá. No nosso caso, é dado por um nome. O segundo parâmetro é o número da linha neste intervalo. Se necessário - se o intervalo consistir em várias colunas - podemos especificar a coluna desejada, e se vários intervalos forem especificados separados por ponto-e-vírgula, então o número do intervalo, começando em 1 (o terceiro e o quarto parâmetros, respectivamente).
Como resultado, depois de estender essa fórmula a todas as células abaixo e aplicar a formatação condicional (para fins estéticos, a formatação não é necessária durante a análise), obtemos algo assim:
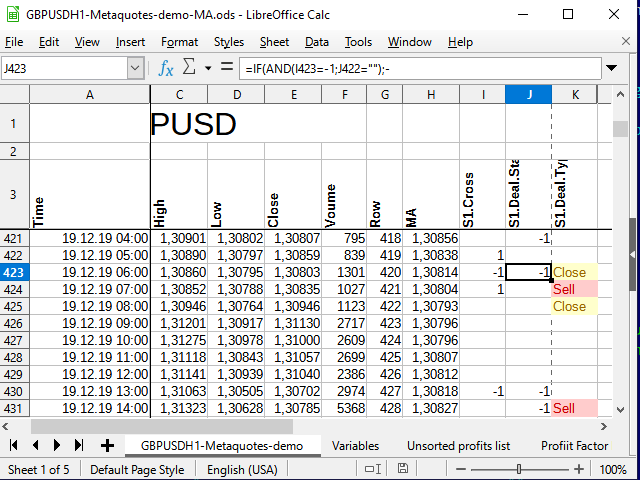
Figura 9. Sinais para trades.
Análise da estratégia
Para analisar a lucratividade da estratégia, eu preciso calcular a distância percorrida pelo preço durante o período da transação. A maneira mais fácil de fazer isso é em vários estágios.
Primeiro, vamos selecionar o preço do trade. Se uma transação for aberta, escrevemos o preço na coluna ao lado do sinal (L) e copiamo-lo para cada célula a seguir até que o trade seja fechado. Se não houver trade, uma linha em branco será registrada na célula. Fórmula na célula L4:
=IF(K4=INDEX(DealTypes;1);B4+Spread;IF(K4=INDEX(DealTypes;2); B4 ;IF(OR(K4=INDEX(DealTypes;3);N(L3)=0); "" ;L3)))
Se na célula de sinal (K4) estivar a palavra "Buy", o preço de abertura do trade será igual ao preço de abertura do candle mais o spread. Se o sinal for a palavra "Sell", simplesmente anotaremos o preço de abertura do candle, se for "Close" (ou a célula anterior da coluna não contém um número) será uma linha em branco, e se a célula anterior de a mesma coluna contém um número e a coluna de sinal não contém nenhuma palavra, simplesmente copiamos a célula anterior.
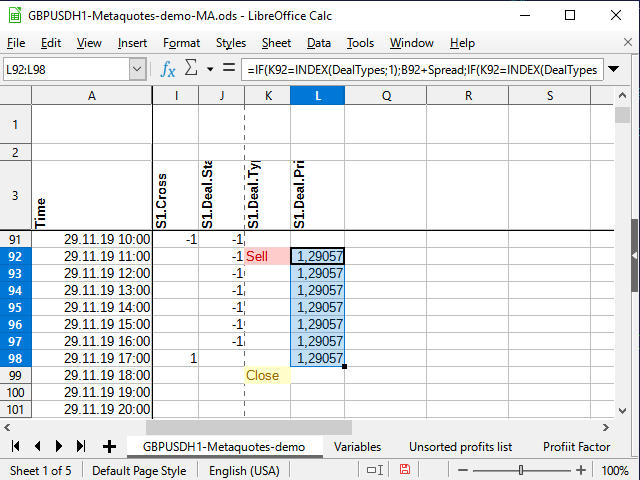
Figura 10. Preço de abertura da transação
Assim, poderemos calcular o lucro da transação na hora do fechamento com um mínimo de esforço.
Certifique-se estender a fórmula abaixo.
Na próxima coluna, pode-se calcular imediatamente a diferença entre os preços de abertura e fechamento, mas faremos isso com mais astúcia. Vamos calcular essa diferença na coluna N para poder filtrar apenas dados exclusivos e, em seguida, calcular sua frequência.
Em este caso simples de avaliação, não usarei nenhum método de gerenciamento de capital, pois estou interessado, em princípio, em entender a eficiência da estratégia. Por isso, basta calcular a diferença de preço em pips. Por exemplo, assim:
=IF(K4=INDEX(DealTypes;3);IF(I3=-1;ROUND((B4-L3)/Point);ROUND((L3-B4)/Point)); "" )
É claro que em vez de verificar a condição média, podemos simplesmente multiplicar (B3-L3)*I3, mas, na minha opinião, isso seria um pouco menos ilustrativo para iniciantes.
E agora esse mesmo truque. Na coluna M vamos numerar todos os registros únicos sobre o intervalo do trade, deixando os não exclusivos sem números.
=IF(N4<>"";IF(COUNTIF(N$3:N4;N4)=1;MAX(M3:M$4)+1;"");"")
Tudo fica claro com a condição externa: se na célula à direita (N4) não está vazio, verificamos se há exclusividade e numeramos, se necessário, caso contrário, deixamos uma linha em branco.
Mas como funciona a numeração?
A função Countif conta a quantidade de números no intervalo especificado, desde que o valor da célula atenda à condição especificada no segundo parâmetro. Digamos que a fórmula é calculada para a célula M71, e na célula N71 é encontrado o número 531 (veja Figura 11). Este número nunca foi visto antes.
Se na célula com a condição não for especificado o sinal de ação, presume-se que queremos verificar se dois valores são iguais. O número é igual a si mesmo (N71=N71), portanto, tentamos calcular. O cálculo sempre começa a partir da célula N$3 (conforme indicado pelo cifrão na frente dos três) e para a célula atual (não há cifrão na fórmula). Vemos todo o intervalo N$3:N71 e tentamos contar o número total de números 531 neste intervalo. Como não existiam esses números antes, o total é 1 (exatamente o que foi encontrado agora). Isso significa que a condição foi atendida: o resultado da função é 1. Por isso, tomamos o seguinte intervalo: a coluna na qual esta fórmula está localizada, começando desde a primeira célula com números (M$4) para a célula anterior à atual (M70) Se houver algum número antes, pegamos o maior e adicionamos 1. Caso contrário, o maior será igual a 0 e, consequentemente, o primeiro número de sequência estará pronto!
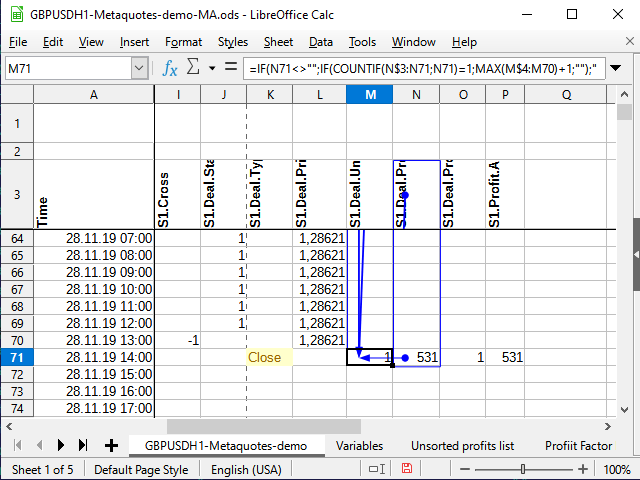
Figura 11. Numeração. Células precedentes (ponto final do intervalo)
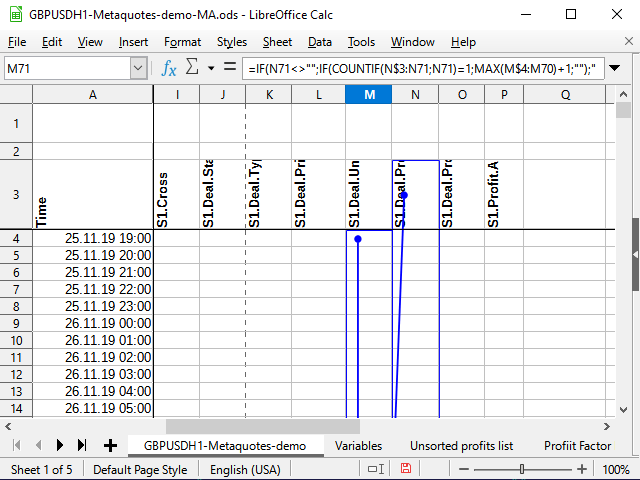
Figura 12. Numeração (ponto inicial do intervalo)
Na Figura 11, tentei usar a ferramenta de análise integrada que mostra as células que afetam uma determinada célula. O ponto com a seta indica o início dos intervalos ou células "exatas", os retângulos indicam os intervalos. A Figura 12 é anexada para maior clareza, de modo que pode ser visto que a seta é contínua e começa exatamente em N$3, e para que o início dos intervalos nos quais a comparação ocorre sejam visíveis.E a tudo isso acrescentarei mais duas colunas de valores: o tipo de resultado e o "módulo" do trade.
Para o tipo de resultado, uso números: se o trade for uma compra, o tipo será 1, se for uma venda, 2. Nesse caso, o resultado pode ser positivo ou negativo, dependendo de se recebemos lucro ou prejuízo como resultado da transação. Isso tornará as fórmulas de análise finais mais curtas.
Aqui está uma fórmula escrita na célula О4:=IF(AND(N(N4)>0;I3=-1); 1 ;IF(AND(N(N4)<0;I3=-1); -1 ;IF(AND(N(N4)>0;I3=1); 2 ;IF(AND(N(N4)<0;I3=1); -2 ;""))))
"Módulo" é simplesmente a quantidade de lucro ou perda sem levar em conta o sinal, uma descrição de quão longe o preço foi numa direção até que o sinal para fechar o trade apareceu. Isso pode ajudar a escolher stops e takes (mesmo que não sejam necessários para a estratégia original).
=IF(N4<>"";ABS(N4);"")
Para construir um gráfico de frequência (probabilístico), é melhor classificar os dados sobre a rentabilidade/não rentabilidade dos trades em ordem crescente. Para fazer isso, eles precisam ser copiados para outra planilha, uma vez que os dados originais são classificados por tempo e não podem ser classificados de outra forma.
Após levar em consideração que cada resultado de lucro único tem seu próprio número único (coluna M), existem pelo menos duas maneiras de copiar dados não classificados para uma nova planilha.
Uma delas é, usando um filtro padrão, simplesmente selecionar células "não vazias" na coluna M e, em seguida, copiar os dados da coluna N e colar em outra planilha usando inserção especial (somente valores).
A segunda maneira é usar uma fórmula. A vantagem é que os próprios dados mudam quando os dados de partida (as mesmas variáveis, ou se você decidir usar um intervalo de teste diferente) mudam, mas a desvantagem é que de qualquer maneira classificá-los não funcionará geralmente, e para classificar tudo você irá ainda precisa fazer Copy / Paste.
É mais conveniente para mim quando os dados classificados e não classificados estão na mesma planilha, porque leva um pouco menos de movimentos para copiar os dados. Por isso, mostrarei uma opção com que os dados não classificados são copiados por uma fórmula e, em seguida, são copiados manualmente novamente para classificação.
Numa nova planilha com o título Profit data vamos criar uma fórmula na célula A2:
=VLOOKUP( ROW(1:1);'GBPUSDH1-Metaquotes-demo'.$M$3:$N$6038; 2 )
A função Row(1:1) retorna o número da primeira linha. Ao preencher as células, o número da linha mudará e, consequentemente, será exibido o número da segunda linha, terceira linha, etc.
Vlookup procura por algum significado (primeiro parâmetro) na primeira coluna do intervalo (segundo parâmetro), e então retorna o valor que está na mesma linha encontrada, apenas na coluna especificada no terceiro parâmetro (no nosso caso, na coluna com o número 2 do intervalo especificado). Ou seja, sequencialmente, a partir do número 1, da coluna N todos os números numerados (únicos) serão copiados.
Tendo olhado com a ajuda de um filtro padrão o último número na planilha principal, podemos através do método de limitação de intervalo copiar todos os outros dados.
Depois, procedemos como na animação da Figura 13.
Figura 13. Copiando dados para classificação.
Agora precisamos descrever a frequência de trades lucrativos e não lucrativos, ou seja, construir uma série de probabilidades.
Na célula D2 da mesma planilha (Profit dada) podemos escrever a seguinte fórmula:
=COUNTIF('GBPUSDH1-Metaquotes-demo'.$N$4:$N$6038;C2)/COUNT('GBPUSDH1-Metaquotes-demo'.$N$4:'GBPUSDH1-Metaquotes-demo'.$N$6038)
Ela descreve a frequência (ou probabilidade) de ocorrência de cada valor de lucro.
A função Count conta a quantidade de números no intervalo, Countif faz o mesmo se atendida a condição (neste caso, são contadas apenas aquelas células cujo valor é igual ao valor na célula da coluna C).
Os livros recomendam fazer uma série de variações de intervalo. Em teoria, é possível dizer que o número de transações pode ser bastante grande?
Os livros sugerem calcular o tamanho do intervalo usando a fórmula:
=(MAX($'Profit data'.C2:$'Profit data'.C214)-MIN($'Profit data'.C2:$'Profit data'.C214))/(1+3,222*LOG10(COUNT('GBPUSDH1-Metaquotes-demo'.$N$4:'GBPUSDH1-Metaquotes-demo'.$N$6038)))
Eu coloquei esta fórmula na célula 'Variables'.E7 e chamei esse valor de "Interval". O intervalo acabou sendo muito grande, não estava claro para mim como - em geral - as probabilidades eram distribuídas, então eu o dividi por mais 4. O número final - 344 - acabou sendo mais aceitável para meus propósitos.
Na planilha 'Profit data' na célula F2 copiei o primeiro número da lista classificada:
=C2
Todas as outras células são preenchidas com a fórmula:
=F2+Interval
As células foram preenchidas até que o último valor ultrapassasse o valor máximo do tamanho do trade.
A célula G2 contém a seguinte fórmula:
=COUNTIFS('GBPUSDH1-Metaquotes-demo'.$N$4:$N$6038;">="&F2;'GBPUSDH1-Metaquotes-demo'.$N$4:$N$6038;"<"&F3)/COUNT('GBPUSDH1-Metaquotes-demo'.$N$4:$N$6038)
CountifS, ao contrário de Countif, permite receber várias condições combinando-as com o operador "AND". O resto é o mesmo.
E quando essas duas linhas são construídas, dá vontade de olhar imediatamente para elas. Felizmente, qualquer processador de planilhas permite isso.
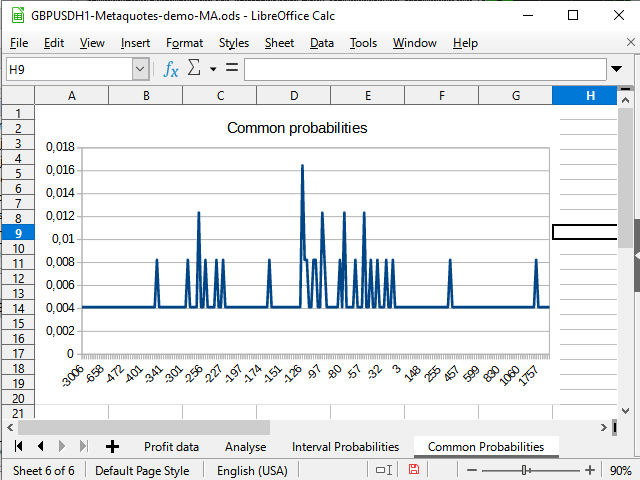
Figura 14. Gráfico de distribuição de probabilidades "imediatas"
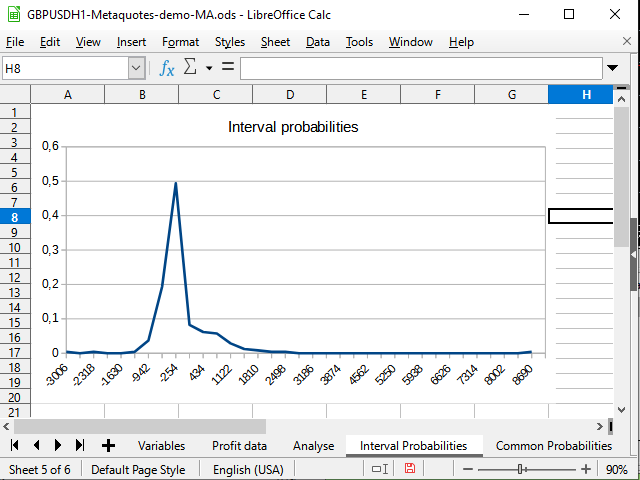
Figura 15. Gráfico de distribuições de probabilidades de intervalo para trades concluídos
Na Figura 14, vejo uma mudança negativa na densidade de probabilidade. A Figura 15 mostra um pico pronunciado de -942 a 2154 e um pico (1 trade) em 8944.
Bem, eu acho que a planilha de análise (considerando tudo o que foi analisado) não vai causar nenhuma dificuldade particular.
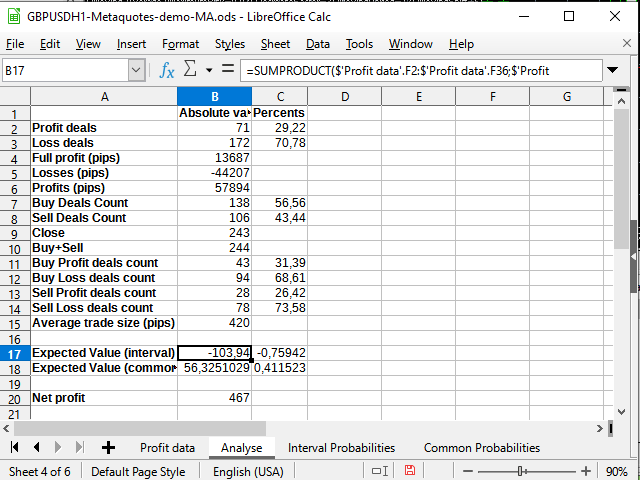
Figura 16. Alguns cálculos estatísticos
A única coisa nova aqui é usar a função Sumproduct que usa dois intervalos como parâmetros e retorna a soma dos produtos dos membros desses intervalos (digamos, a primeira linha para a primeira linha, a segunda para a segunda e assim por diante). Foi com esta função que tentei calcular o valor esperado. Decidi não me envolver com métodos mais complexos de integração.
Percebe-se que o valor esperado é significativamente menor do que o lucro recebido e, em termos percentuais, oscila em torno de 0.
Assim, posso concluir por mim mesmo: a estratégia está funcionando, mas pode ter rebaixamentos muito grandes. Provavelmente, pode funcionar perfeitamente durante uma tendência muito forte (um aumento de ~9000 pips, em princípio, pareceria interessante se não fosse tão solitária), no entanto, a lateralização provavelmente cobrará o que lhe é devido. A estratégia precisa de melhorias sérias por causa das ordens pendentes, por exemplo, considerando lucros (em cerca de 420-500 pips) ou alguns filtros de tendência. As melhorias requerem pesquisas adicionais.
Estratégia executada no testador
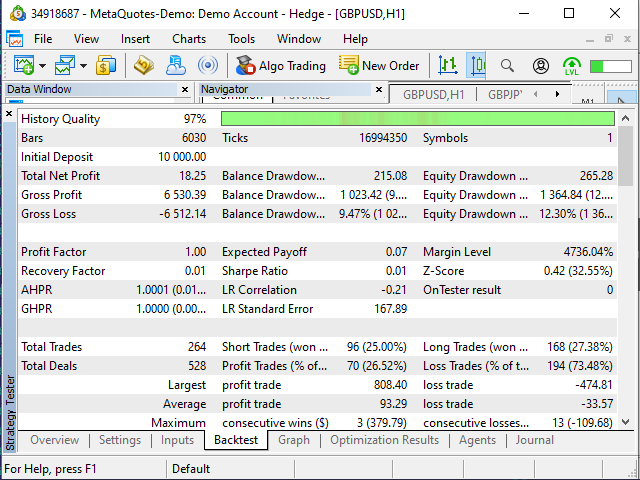
Figura 17. Resultados do teste do EA "Examples\Moving Average"
Para ser sincero, os resultados do Expert Advisor me surpreenderam. Bem, o fato de ele ter aberto trades onde a tabela sugeria fechamento e vice-versa, a princípio, é normal, quiçá. Pode ser baseado em mais ou menos dados (digamos, na minha tabela em 25/11/2019 começa às 19:00, e dei ao Expert Advisor a tarefa de começar desde o início do dia).
Mas o fato de que alguns de seus trades eram mais ou menos assim...
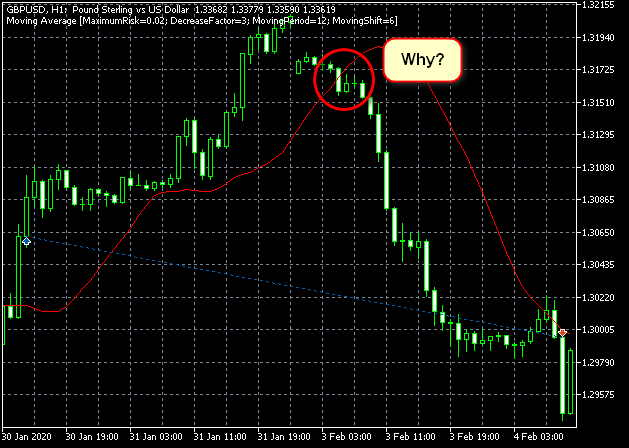
Figura 18. Um erro na minha compreensão do algoritmo? Ou do testador?
Provavelmente, eu simplesmente procurei mal, por isso, não encontrei uma descrição do motivo desse comportamento no algoritmo.
O segundo fato estranho foi que o EA fez 20 trades a mais do que minha tabela sugeria. Mesmo assim, os resultados, paradoxalmente, são próximos aos meus.
Logo:
| Expert Advisor no testador | Tabela |
|---|---|
| Retorno esperado — +0,07 (quase 0) | Retorno esperado — -0,76 — +0,41 (flutua em torno de 0) |
| Trades lucrativos/não lucrativos — 26,52%/73,48% | Trades lucrativos/não lucrativos — 29,22%/70,78% (neste caso posso considerar insignificante a diferença de 3% - levando em consideração a diferença de 8% no número de trades) |
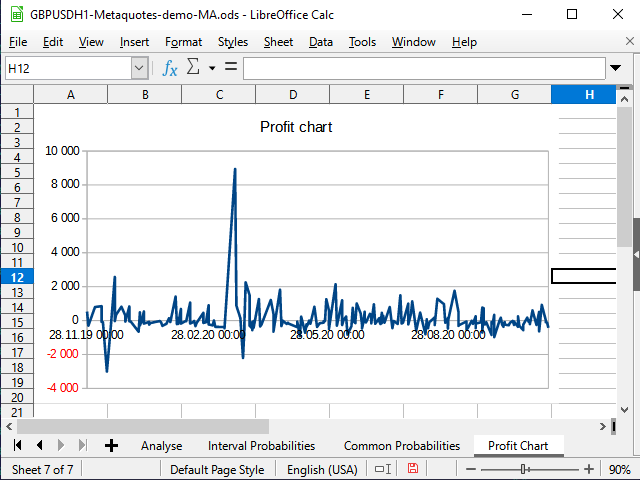
Figura 19. Gráfico de lucratividade na tabela
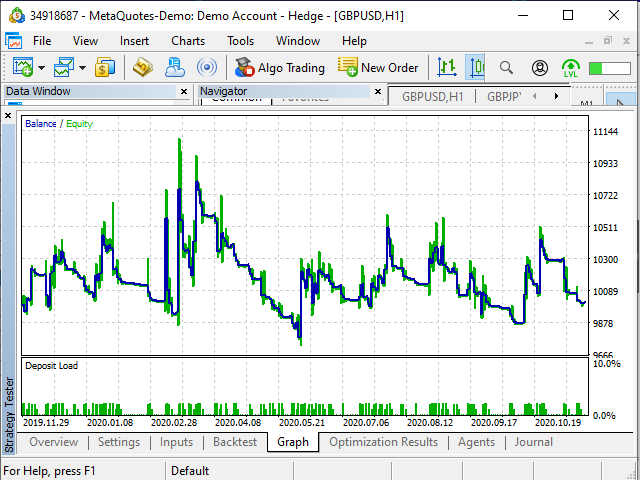
Figura 20. Gráfico de lucro no testador
O tempo de preparação da tabela e do “jogo” com os números é cerca de meia hora. E quanto ao tempo de escrita do Expert Advisor... Não escrevi, peguei um pronto. Demorei cerca de 10 minutos para ter uma ideia aproximada do algoritmo. No entanto, não vou escrever o novo Expert Advisor para entender que provavelmente não vou usá-lo... Eu teria preguiça de fazer isso. Depois de entender que a estratégia vale a pena, eu procedo. E por enquanto - para você - é melhor afastar as mãos disso 😁
Fim do artigo
Na minha opinião, as planilhas são uma ferramenta muito boa para testar e desenvolver estratégias próprias, principalmente para quem não sabe ou não gosta de programar, ou quem quer criar rapidamente um protótipo e depois traduzi-lo para linguagem MQL.
As fórmulas do processador de planilha, é claro, às vezes se parecem muito com código de programa e a formatação não é a exceção... É menos óbvio, digamos.
No entanto, a visibilidade das próprias tabelas, a validação instantânea de novas ideias, o destaque de células de influência, a capacidade de construir diagramas de qualquer tipo, etc. torna as tabelas uma ferramenta indispensável.
E se você mantém um registro de transações numa tabela ou pode importá-lo, então usando processadores de planilha, você pode facilmente melhorar sua estratégia e ver se há erros em sua negociação.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/8699
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Redes Neurais de Maneira Fácil (Parte 9): Documentação do trabalho
Redes Neurais de Maneira Fácil (Parte 9): Documentação do trabalho
 Desenvolvendo um algoritmo auto-adaptável (Parte I): encontrando um padrão básico
Desenvolvendo um algoritmo auto-adaptável (Parte I): encontrando um padrão básico
 Gradient boosting no aprendizado de máquina transdutivo e ativo
Gradient boosting no aprendizado de máquina transdutivo e ativo
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Oleh Fedorov,
Muito obrigado por escrever este artigo. Tenho mais de 75 anos e conhecimentos básicos de Excel. Mas, devido aos mais de 35 anos de negociação, entendo os conjuntos de dados e como usá-los para fazer um estudo de probabilidade.
Somos um grupo de pessoas idosas que negociam em pequenas contas por diversão e para manter o cérebro vivo. Criar e implementar ideias a partir de um estudo de probabilidade nos mantém ativos e felizes.
Por isso, dou as boas-vindas ao seu artigo. Parabéns a você.
1. Por favor, você pode me fornecer uma ferramenta para gerar dados históricos do MT5 em um formato que eu possa usar e gerar dados de acordo com a planilha projetada.
Atualmente, se o indicador tiver um botão de exportação, posso gerar um arquivo csv que salvo como uma planilha do Excel e faço a análise.
Disseram-me que existe um indicador mql de criação de csv que pode usar a lógica de qualquer outro indicador e gerar dados csv em um arquivo de formato pré-fabricado que pode ser modificado para criar novas colunas de planilha.
Você poderia informar onde posso comprar esse indicador?
2. Quero realizar estudos de probabilidades criando mapas de calor como esse no Excel. Você pode ensinar isso em seu novo artigo?
Exemplo: Quero criar um mapa de calor como este. Depois de gerar um arquivo csv por meio de um indicador, como posso fazer isso passo a passo, convertê-lo em um Excel, filtrá-lo e produzir mapas de calor ou outros relatórios como este arquivo anexado?
Mais uma vez, obrigado