
Criação de Previsões de Séries Temporais Usando Redes Neurais LSTM: Normalizando Preço e Tokenizando o Tempo
Introdução
Eu queria explorar o uso de Redes Neurais no desenvolvimento de uma estratégia de negociação, então comecei a investigar o assunto assistindo alguns vídeos no YouTube. A maioria deles era relativamente confusa, pois começavam em um nível muito básico, como programar em Python: usar strings, arrays, POO e outros conceitos básicos. Quando o educador finalmente chegava ao ponto principal do curso, Redes Neurais e Aprendizado de Máquina, você percebia que eles apenas explicavam como usar uma biblioteca específica ou um modelo pré-treinado, sem realmente explicar como funcionam. Depois de muita pesquisa, finalmente encontrei vídeos de Andrej Karpathy, que foram bastante esclarecedores. Particularmente, o vídeo "Vamos construir o GPT: do zero, em código, passo a passo" me permitiu ver como conceitos matemáticos simples, combinados com código, podem dar vida à inteligência artificial com apenas algumas centenas de linhas de código. O vídeo meio que desvendou o mundo das redes neurais para mim de uma forma relativamente intuitiva e prática, permitindo-me experimentar seu poder em primeira mão. Combinando um entendimento básico do canal dele com a ajuda de centenas de consultas ao ChatGPT para entender como funcionam, como escrevê-las em Python, etc. Fui capaz de desenvolver uma metodologia para usar Redes Neurais na criação de previsões e consultores especializados. Neste artigo, gostaria não apenas de documentar essa jornada, mas também mostrar o que aprendi e como uma rede neural simples como a LSTM pode ser usada para fazer previsões de mercado.
Visão Geral do LSTM
Quando comecei a pesquisar na internet, me deparei com alguns artigos descrevendo o uso de LSTMs para previsões de séries temporais. Especificamente, encontrei uma postagem no blog de Christopher Olah, "Understanding LSTM Networks" no blog do colah. Em seu blog, Olah explica a estrutura e função dos LSTMs, compara-os com RNNs padrão e discute várias variantes de LSTM, como aquelas com conexões de peephole ou Unidades Recorrentes Gated (GRUs). Olah conclui destacando o impacto significativo dos LSTMs nas aplicações de RNN e apontando para avanços futuros, como mecanismos de atenção.
Em essência, redes neurais tradicionais têm dificuldade com tarefas que exigem contexto de entradas anteriores devido à falta de memória. As RNNs resolvem isso com laços que permitem a persistência da informação, mas ainda enfrentam dificuldades com dependências de longo prazo. Por exemplo, prever a próxima palavra em uma frase onde o contexto relevante está muitas palavras atrás pode ser desafiador para RNNs padrão. Redes de Memória de Longo Curto Prazo (LSTM) são um tipo de rede neural recorrente (RNN) projetada para lidar melhor com dependências de longo prazo ausentes em RNNs.
Os LSTMs resolvem isso usando uma arquitetura mais complexa, que inclui um estado de célula e três tipos de portas (entrada, esquecimento e saída) que regulam o fluxo de informações. Esse design permite que os LSTMs lembrem informações por longos períodos, tornando-os altamente eficazes para tarefas como modelagem de linguagem, reconhecimento de fala e legendagem de imagens. O que me interessava explorar era se os LSTMs poderiam ajudar a prever a ação de preço hoje com base na ação de preço anterior em dias com ação de preço semelhante, devido à sua capacidade natural de lembrar informações por longos períodos. Encontrei outro artigo útil de Adrian Tam, intitulado astutamente "LSTM para Previsão de Séries Temporais no PyTorch", que desmistificou a matemática e os aspectos de programação para mim com um exemplo prático. Senti-me confiante o suficiente para enfrentar o desafio de aplicá-los na tentativa de prever a ação de preço futura para qualquer par de moedas.
Processo de Tokenização e Normalização
Desenvolvi um método para tokenizar o tempo dentro de um dia e normalizar o preço para um determinado intervalo de tempo dentro do dia para treinar a rede neural; depois, encontrei uma maneira de usar a rede neural treinada para fazer previsões e, finalmente, desnormalizar a previsão para obter a previsão do preço futuro. Essa abordagem foi inspirada no vídeo do ChatGPT que mencionei na introdução. Uma estratégia semelhante é usada por LLMs para converter strings de texto em representações numéricas e vetoriais para treinar redes neurais para processamento de linguagem e geração de respostas. No meu caso, para o preço, queria que os dados de entrada na minha rede neural fossem relativos ao máximo ou mínimo do dia de forma contínua para o dia em questão. A estratégia de normalização e tokenização que usei é fornecida no script abaixo e resumida da seguinte forma:
Tokenização do Tempo
-
Conversão para Segundos: O script pega a coluna de tempo (que está no formato datetime) e a converte no número total de segundos decorridos desde o início do dia. Esse cálculo inclui horas, minutos e segundos.
-
Normalização para Fração do Dia: O número resultante de segundos é então dividido pelo número total de segundos em um dia (86400). Isso cria um "time_token" que representa o tempo como uma fração de um dia. Por exemplo: Meio-dia seria 0,5 ou 50% do dia concluído.
Normalização de Preço Diária e Contínua
-
Agrupamento por Data: Os dados são agrupados pela coluna de data para garantir que a normalização ocorra de forma independente para cada dia de negociação.
-
Cálculo do Máximo/Mínimo Contínuo:
- Para cada grupo (dia), o script calcula o máximo expansivo (máximo_contínuo) e o mínimo expansivo (mínimo_contínuo) dos preços máximos e mínimos, respectivamente. Isso significa que o máximo/mínimo contínuo só aumenta/diminui à medida que novos dados chegam ao longo do dia.
-
Normalização:
- Os preços de abertura, máximo, mínimo e fechamento são normalizados usando a seguinte fórmula: preço_normalizado = (preço - mínimo_contínuo) / (máximo_contínuo - mínimo_contínuo)
- Isso escala cada preço para um intervalo entre 0 e 1 em relação aos preços mais altos e mais baixos observados até então naquele dia.
- A normalização é feita de forma contínua diária, garantindo que os relacionamentos de preços dentro de cada dia sejam capturados enquanto evita que a normalização seja afetada por movimentos de preços em vários dias.
-
Tratamento de NaNs: Valores NaN podem ocorrer no início de um dia antes de o máximo/mínimo contínuo ser estabelecido. Considerei três abordagens diferentes para lidar com eles. A primeira abordagem foi descartá-los, a segunda foi preenchê-los com o valor anterior e a terceira foi substituí-los por zeros. Decidi substituí-los por zeros após muitos testes e dificuldades em descartá-los, pois, em última análise, meu objetivo é converter esse processo em um pipeline de processamento de dados ONNX que possa ser usado diretamente com MQL5 para fazer previsões sem replicar o código. Percebi que o ONNX é relativamente rígido quando se trata de formatos de entrada e saída, e descartar valores NaN altera a forma do vetor de saída, o que causa erros inesperados ao usar o ONNX no MQL. Também tentei usar o método de preenchimento com o valor anterior para substituir os NaNs, mas este é um método do Pandas/NumPy e não se traduz convenientemente para o torch, que é a biblioteca que usei principalmente para converter meu modelo de rede neural para ONNX. Por fim, decidi simplesmente substituir os NaNs por zeros, o que pareceu funcionar melhor, permitindo evitar o problema das formas variáveis, criar um pipeline para todo o processamento de dados e implementá-lo no MQL por meio do ONNX, simplificando todo o processo de obter uma previsão no MQL.
Em resumo, a normalização é feita de forma contínua diária, garantindo que os relacionamentos de preços dentro de cada dia sejam capturados enquanto evita que a normalização seja afetada por movimentos de preços em vários dias. Fazer isso coloca os preços em uma escala semelhante, evitando que o modelo seja tendencioso em relação a características com magnitudes maiores. Isso também ajuda a se adaptar à volatilidade em mudança dentro de cada dia.
O código abaixo ajuda a visualizar o processo descrito acima. Se você baixar o arquivo zip que acompanha este artigo, poderá encontrar este código na pasta intitulada: "Visualizando o Processo de Normalização e Tokenização". O arquivo é chamado: "visualizing.py"
import torch import torch.nn as nn import numpy as np import pandas as pd from sklearn.preprocessing import MinMaxScaler import MetaTrader5 as mt5 import matplotlib.pyplot as plt import joblib # Connect to MetaTrader 5 if not mt5.initialize(): print("Initialize failed") mt5.shutdown() # Load market data symbol = "EURUSD" timeframe = mt5.TIMEFRAME_M15 rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 96) # Note: 96 represents 1 day or 15*96= 1440 minutes of data (there are 1440 minutes in a day) mt5.shutdown() # Convert to DataFrame data = pd.DataFrame(rates) data['time'] = pd.to_datetime(data['time'], unit='s') data.set_index('time', inplace=True) # Tokenize time data['time_token'] = (data.index.hour * 3600 + data.index.minute * 60 + data.index.second) / 86400 # Normalize prices on a rolling basis resetting at the start of each day def normalize_daily_rolling(data): data['date'] = data.index.date data['rolling_high'] = data.groupby('date')['high'].transform(lambda x: x.expanding(min_periods=1).max()) data['rolling_low'] = data.groupby('date')['low'].transform(lambda x: x.expanding(min_periods=1).min()) data['norm_open'] = (data['open'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_high'] = (data['high'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_low'] = (data['low'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_close'] = (data['close'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) # Replace NaNs with zeros data.fillna(0, inplace=True) return data # Visualize the price before normalization plt.figure(figsize=(15, 10)) plt.subplot(3, 1, 1) data['close'].plot() plt.title('Close Prices') plt.xlabel('Time') plt.ylabel('Price') data = normalize_daily_rolling(data) # Check for NaNs in the data if data.isnull().values.any(): print("Data contains NaNs") print(data.isnull().sum()) # Drop unnecessary columns data = data[['time_token', 'norm_open', 'norm_high', 'norm_low', 'norm_close']] # Visualize the normalized price plt.subplot(3, 1, 2) data['norm_close'].plot() plt.title('Normalized Close Prices') plt.xlabel('Time') plt.ylabel('Normalized Price') # Visualize Time After Tokenization plt.subplot(3, 1, 3) data['time_token'].plot() plt.title('Time Token') plt.xlabel('Time') plt.ylabel('Time Token') plt.tight_layout() plt.show()
Se você executar o código acima, verá a abordagem que desenvolvi em ação. No gráfico abaixo, preços de 12/06/2024, todo o dia de negociação, sobrepondo-se em 13/06/2024. Esse também foi um dia de divulgação do CPI e uma reunião do Fed, dois eventos de notícias importantes no mesmo dia, o que é relativamente raro. Você pode ver que o token de tempo é reiniciado no final de cada dia e aumenta linearmente ao longo do dia. O preço também é reiniciado, mas isso é um pouco mais difícil de ver nos gráficos. Sempre que um novo máximo se forma, o valor dos preços de fechamento normalizados vai para 1. Quando um novo mínimo se forma, o valor dos preços de fechamento normalizados vai para 0.

Resumo dos Passos de Treinamento e Validação
O código abaixo treina um modelo LSTM (Memória de Longo Curto Prazo) para prever preços, focando especificamente no par de moedas EURUSD. O usuário pode alterar "EURUSD" para qualquer outro par que desejar trabalhar.
Preparação de Dados
- Recupera Dados: Conecta-se à plataforma MetaTrader 5 para buscar dados históricos de preços (máximo, mínimo, abertura, fechamento) para EURUSD em intervalos de 15 minutos. Novamente, você pode escolher o período de tempo preferido: 1 min, 5 min, 15 min, etc., dependendo do seu estilo pessoal.
- Pré-processa os Dados:
- Converte os dados para um DataFrame do Pandas, definindo o timestamp como índice.
- Cria uma funcionalidade 'time_token' que representa o tempo como uma fração do dia.
- Normaliza os preços dentro de cada dia com base em máximos/mínimos contínuos para considerar as flutuações diárias.
- Lida com valores ausentes (NAN) substituindo-os por zeros.
- Descarta colunas desnecessárias, como volumes de tick, volume real e spread.
- Cria Sequências: Estrutura os dados em sequências de 60 passos de tempo, onde cada sequência se torna uma entrada (X) e o preço de fechamento seguinte é o alvo (y).
- Divide os Dados: Separa as sequências em conjuntos de treinamento (80%) e teste (20%).
- Converte para Tensores: Transforma os dados em tensores PyTorch para compatibilidade com o modelo.
Definição e Treinamento do Modelo
- Define o Modelo LSTM: Cria uma classe para o modelo LSTM com:
- Uma camada LSTM que processa os dados de sequência.
- Uma camada linear que produz a previsão final.
- Variáveis de estado internas para o LSTM.
- Configura o Treinamento:
- Define o Erro Quadrático Médio (MSE) como a função de perda a ser minimizada.
- Usa o otimizador Adam para ajustar os pesos do modelo.
- Define uma semente aleatória para reprodutibilidade.
- Treina o Modelo:
- Itera por 100 épocas (passagens completas pelos dados de treinamento).
- Para cada sequência no conjunto de treinamento:
- Reinicia o estado oculto do LSTM.
- Passa a sequência pelo modelo para obter uma previsão.
- Calcula a perda MSE entre a previsão e o valor verdadeiro.
- Realiza retropropagação para atualizar os pesos do modelo.
- Imprime a perda a cada 10 épocas.
- Salva o Modelo: Preserva os parâmetros do modelo treinado. O arquivo é salvo como "lstm_model.pth" na mesma pasta onde foi executado o arquivo LSTM_model_training.py. Também converte o modelo para o formato ONNX para uso direto com MQL5. O arquivo ONNX é chamado "lstm_model.onnx". Nota: a forma do vetor necessário para previsão é seq_length, 1, input_size, que é 60, 1, 5, indicando que 60 barras anteriores de dados de 15 minutos são necessárias como 1 lote, com 5 valores (time_token, norm_open, norm_high, norm_low e norm_close), todos entre 0 e 1. Usaremos isso mais tarde neste artigo para criar um pipeline de processamento de dados em ONNX para uso com nosso modelo.
Avaliação
- Gera Previsões:
- Muda o modelo para o modo de avaliação.
- Itera sobre as sequências no conjunto de teste e gera previsões.
- Visualiza os Resultados:
- Plota os preços normalizados reais e os preços normalizados previstos.
- Calcula e plota a variação percentual dos preços para os valores reais e previstos.
Seleção de Parâmetros do Modelo:
- A maior parte desse código foi escrita para encontrar tendências intradiárias. No entanto, ele pode ser facilmente adaptado para outros períodos de tempo, como semanal, mensal, etc. O único problema para mim foi a disponibilidade de dados. Caso contrário, eu poderia ter expandido o código para incluir alguns desses outros períodos também.
- Escolhi trabalhar com o intervalo de 15 minutos porque consegui obter aproximadamente 80.000 barras de dados para alimentar minha rede neural. Isso equivale a aproximadamente 3 anos de dados de negociação (excluindo finais de semana), o que pareceu suficiente para construir uma rede neural LSTM decente que tenta prever a ação de preço intradiária.
- A base geral para o modelo é os seguintes 5 parâmetros: time_token, norm_open, norm_high, norm_low, norm_close. Portanto, input_size = 5. Há três parâmetros adicionais que escolhi ignorar: volumes de tick, volumes reais e spread. Excluí os volumes de tick porque não consegui encontrar uma fonte de dados suficientemente confiável. Excluí os volumes reais porque meu corretor não os disponibiliza e eles sempre são relatados como zero. Por fim, excluí o spread porque extraí os dados de uma conta demo, então eles não correspondem aos spreads de uma conta real.
- As Camadas Ocultas foram escolhidas para ser 100. Esse é um valor arbitrário que escolhi e que pareceu funcionar bem.
- O valor para output_size = 1 porque, da forma como este modelo é projetado, só nos interessa a previsão para a próxima barra de 15 minutos.
- Escolhi uma divisão de 80% para treinamento e 20% para teste. Esta também é uma escolha arbitrária. Algumas pessoas preferem divisão 50:50, outras preferem 70:30. Eu simplesmente decidi ir com 80:20 para minha divisão.
- Escolhi um valor de semente de 42. Meu principal objetivo era ter alguma reprodutibilidade nos resultados de teste em teste. Portanto, especifiquei o valor da semente para poder comparar os resultados de forma justa, caso decida alterar algum parâmetro no futuro.
- Escolhi um valor de taxa de aprendizado de 0.001. Esta é, novamente, uma escolha arbitrária. O usuário é livre para definir a taxa de aprendizado como achar melhor.
- Selecionei o comprimento da sequência (seq_length) de 60. Basicamente, é o número de barras de "contexto" que o modelo LSTM precisa para fazer a previsão sobre a próxima barra. Esta também foi uma escolha arbitrária. 60 * 15 min = 900 minutos ou 15 horas. Isso é muito tempo para obter contexto e prever uma barra de 15 minutos, o que pode ser um pouco excessivo. Não tenho uma justificativa muito boa para escolher este valor; no entanto, o modelo é flexível e os usuários são livres para alterar esses valores conforme desejarem.
- Não tenho uma justificativa muito boa para escolher este valor; no entanto, o modelo é flexível e os usuários são livres para alterar esses valores conforme desejarem. Usei CPU para treinamento. Enquanto escrevia este artigo, fiz várias refinamentos no código e tive que re-executar o modelo várias vezes. Então, 8 horas de tempo de treinamento era o que eu podia dispor para o modelo.
import torch import torch.nn as nn import numpy as np import pandas as pd import MetaTrader5 as mt5 import matplotlib.pyplot as plt import torch.onnx import torch.nn.functional as F # Connect to MetaTrader 5 if not mt5.initialize(): print("Initialize failed") mt5.shutdown() # Load market data symbol = "EURUSD" timeframe = mt5.TIMEFRAME_M15 rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 80000) mt5.shutdown() # Convert to DataFrame data = pd.DataFrame(rates) data['time'] = pd.to_datetime(data['time'], unit='s') data.set_index('time', inplace=True) # Tokenize time data['time_token'] = (data.index.hour * 3600 + data.index.minute * 60 + data.index.second) / 86400 # Normalize prices on a rolling basis resetting at the start of each day def normalize_daily_rolling(data): data['date'] = data.index.date data['rolling_high'] = data.groupby('date')['high'].transform(lambda x: x.expanding(min_periods=1).max()) data['rolling_low'] = data.groupby('date')['low'].transform(lambda x: x.expanding(min_periods=1).min()) data['norm_open'] = (data['open'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_high'] = (data['high'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_low'] = (data['low'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_close'] = (data['close'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) # Replace NaNs with zeros data.fillna(0, inplace=True) return data data = normalize_daily_rolling(data) # Check for NaNs in the data if data.isnull().values.any(): print("Data contains NaNs") print(data.isnull().sum()) # Drop unnecessary columns data = data[['time_token', 'norm_open', 'norm_high', 'norm_low', 'norm_close']] # Create sequences def create_sequences(data, seq_length): xs, ys = [], [] for i in range(len(data) - seq_length): x = data.iloc[i:(i + seq_length)].values y = data.iloc[i + seq_length]['norm_close'] xs.append(x) ys.append(y) return np.array(xs), np.array(ys) seq_length = 60 X, y = create_sequences(data, seq_length) # Split data split = int(len(X) * 0.8) X_train, X_test = X[:split], X[split:] y_train, y_test = y[:split], y[split:] # Convert to tensors X_train = torch.tensor(X_train, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.float32) X_test = torch.tensor(X_test, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.float32) # Set the seed for reproducibility seed_value = 42 torch.manual_seed(seed_value) # Define LSTM model class class LSTMModel(nn.Module): def __init__(self, input_size, hidden_layer_size, output_size): super(LSTMModel, self).__init__() self.hidden_layer_size = hidden_layer_size self.lstm = nn.LSTM(input_size, hidden_layer_size) self.linear = nn.Linear(hidden_layer_size, output_size) def forward(self, input_seq): h0 = torch.zeros(1, input_seq.size(1), self.hidden_layer_size).to(input_seq.device) c0 = torch.zeros(1, input_seq.size(1), self.hidden_layer_size).to(input_seq.device) lstm_out, _ = self.lstm(input_seq, (h0, c0)) predictions = self.linear(lstm_out.view(input_seq.size(0), -1)) return predictions[-1] print(f"Seed value used: {seed_value}") input_size = 5 # time_token, norm_open, norm_high, norm_low, norm_close hidden_layer_size = 100 output_size = 1 model = LSTMModel(input_size, hidden_layer_size, output_size) #model = torch.compile(model) loss_function = nn.MSELoss() optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # Training epochs = 100 for epoch in range(epochs + 1): for seq, labels in zip(X_train, y_train): optimizer.zero_grad() y_pred = model(seq.unsqueeze(1)) # Ensure both are tensors of shape [1] y_pred = y_pred.view(-1) labels = labels.view(-1) single_loss = loss_function(y_pred, labels) # Print intermediate values to debug NaN loss if torch.isnan(single_loss): print(f'Epoch {epoch} NaN loss detected') print('Sequence:', seq) print('Prediction:', y_pred) print('Label:', labels) single_loss.backward() optimizer.step() if epoch % 10 == 0 or epoch == epochs: # Include the final epoch print(f'Epoch {epoch} loss: {single_loss.item()}') # Save the model's state dictionary torch.save(model.state_dict(), 'lstm_model.pth') # Convert the model to ONNX format model.eval() dummy_input = torch.randn(seq_length, 1, input_size, dtype=torch.float32) onnx_model_path = "lstm_model.onnx" torch.onnx.export(model, dummy_input, onnx_model_path, input_names=['input'], output_names=['output'], dynamic_axes={'input': {0: 'sequence'}, 'output': {0: 'sequence'}}, opset_version=11) print(f"Model has been converted to ONNX format and saved to {onnx_model_path}") # Predictions model.eval() predictions = [] for seq in X_test: with torch.no_grad(): predictions.append(model(seq.unsqueeze(1)).item()) # Evaluate the model plt.plot(y_test.numpy(), label='True Prices (Normalized)') plt.plot(predictions, label='Predicted Prices (Normalized)') plt.legend() plt.show() # Calculate percent changes with a small value added to the denominator to prevent divide by zero error true_prices = y_test.numpy() predicted_prices = np.array(predictions) true_pct_change = np.diff(true_prices) / (true_prices[:-1] + 1e-10) predicted_pct_change = np.diff(predicted_prices) / (predicted_prices[:-1] + 1e-10) # Plot the true and predicted prices plt.figure(figsize=(12, 6)) plt.subplot(2, 1, 1) plt.plot(true_prices, label='True Prices (Normalized)') plt.plot(predicted_prices, label='Predicted Prices (Normalized)') plt.legend() plt.title('True vs Predicted Prices (Normalized)') # Plot the percent change plt.subplot(2, 1, 2) plt.plot(true_pct_change, label='True Percent Change') plt.plot(predicted_pct_change, label='Predicted Percent Change') plt.legend() plt.title('True vs Predicted Percent Change') plt.tight_layout() plt.show()
Resultados da Avaliação do Modelo
O tempo de treinamento foi de aproximadamente 8 horas para 100 épocas. O modelo não foi treinado usando uma GPU. Usei meu próprio PC, que é um computador de jogos de 4 anos com as seguintes especificações: AMD Ryzen 5 4600H com gráficos Radeon 3.00 GHz e 64 GB de RAM instalada.
O Valor da Semente e a Perda do Erro Quadrático Médio para Cada 10 Épocas são impressos no console
- Valor da semente usado: 42
- Epoch 0 loss: 0.01435865368694067
- Epoch 10 loss: 0.014593781903386116
- Epoch 20 loss: 0.02026239037513733
- Epoch 30 loss: 0.017134636640548706
- Epoch 40 loss: 0.017405137419700623
- Epoch 50 loss: 0.004391830414533615
- Epoch 60 loss: 0.0210900716483593
- Epoch 70 loss: 0.008576949127018452
- Epoch 80 loss: 0.019675739109516144
- Epoch 90 loss: 0.008747504092752934
- Epoch 100 loss: 0.033280737698078156
Ao final do treinamento, também recebi um aviso mostrado abaixo. O aviso sugere especificar o modelo de uma maneira diferente. Fiquei tentando consertar. mas devido ao longo tempo de treinamento, decidi ignorar o aviso, pois as sequências em nosso lote não terão comprimentos diferentes.

Além disso, os seguintes gráficos são gerados:
")
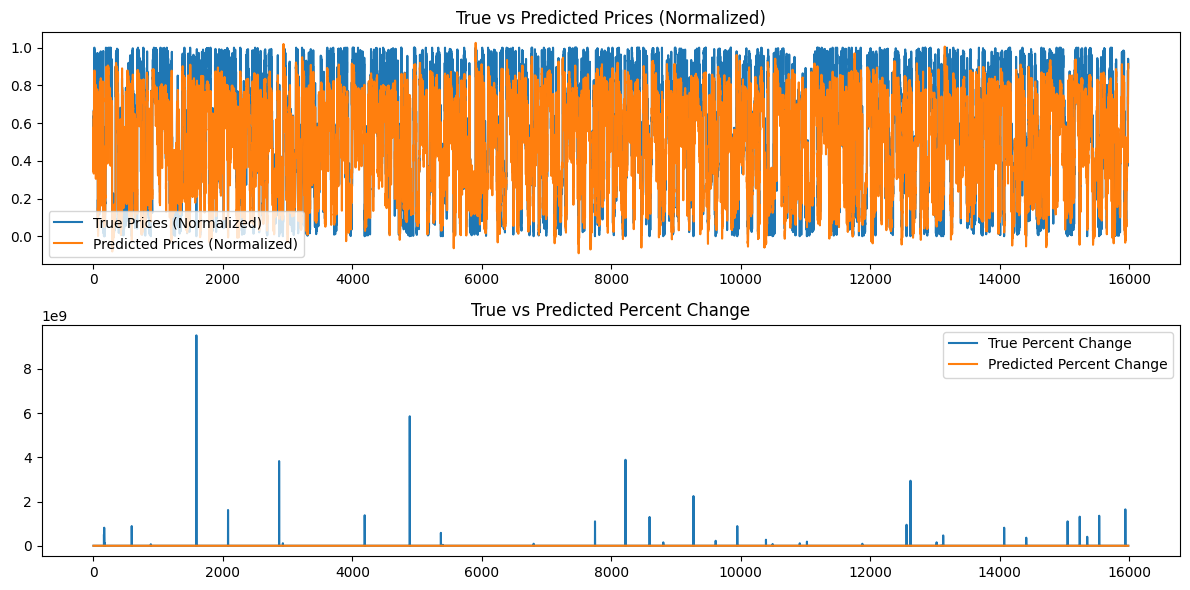
Análise dos Resultados do Modelo
As perdas por época para um valor de semente de 42 parecem diminuir de forma irregular. Como não são monotônicas, talvez o modelo possa se beneficiar de mais treinamento. Alternativamente, o usuário pode considerar fornecer um valor de semente diferente ou usar um valor de semente aleatório gerado automaticamente pela biblioteca Torch em Python e imprimir esse valor usando o comando torch.seed(). Além disso, o desempenho do modelo também pode melhorar se a quantidade de dados disponíveis for aumentada; no entanto, ao fazer isso, o usuário pode enfrentar custos computacionais adicionais associados a tempos de treinamento mais longos e maiores requisitos de memória de hardware.
Os gráficos gerados tentam resumir mais de 16.000 barras de dados de 15 minutos. Portanto, o sistema de gráficos que usei não é muito eficaz porque a maioria dos dados fica comprimida e difícil de avaliar. Esses gráficos são representações mais "globais" do treinamento geral que ocorreu. Como estão, não adicionam valor. Incluí-os para referência porque treinei o modelo com conjuntos de dados menores também, e eles foram úteis; no entanto, para 80.000 barras, não são muito úteis. Abordaremos esse problema na próxima seção, quando tentaremos fazer previsões com base em nosso modelo gerado e os dados serão uma representação "local", ou seja, a ação de preço dia a dia. Criaremos uma previsão contínua com base em nosso modelo na próxima seção, utilizando nosso comprimento de sequência de 60 e adicionando mais 100 barras (160 barras totais de dados de 15 minutos) e faremos previsões continuamente da barra 100 até 0 e representaremos isso em um gráfico que talvez seja mais esclarecedor.
Fazendo Previsões Usando o Modelo Treinado (Usando Python)
Para criar um script de previsão, idealmente usaríamos os últimos 60 valores dos dados do EURUSD em um intervalo de 15 minutos para fazer uma previsão usando o modelo LSTM salvo. No entanto, achei melhor obter uma previsão contínua juntamente com um gráfico em Python para validar rapidamente o modelo antes de usá-lo. Aqui estão os principais recursos do script de previsão para o caso de uso em Python. Um resumo do script é fornecido abaixo:
-
Definição do Modelo LSTM: O script define a estrutura do modelo LSTM. O modelo consiste em uma camada LSTM seguida por uma camada linear. Isso é idêntico ao que usamos para treinar o modelo no script de treinamento acima.
-
Preparação de Dados
- Conecta-se ao MetaTrader 5 para recuperar as últimas 160 barras (intervalos de 15 minutos) de dados do EURUSD. Observe que, embora precisemos apenas de 60 barras de dados de 15 minutos para fazer uma previsão, extrairemos 160 barras para prever e comparar as últimas 100 previsões. Isso nos dará uma ideia da tendência subjacente dos preços previstos em relação aos reais.
- Os dados são convertidos para um DataFrame do pandas e normalizados usando a mesma técnica de normalização contínua utilizada durante o treinamento.
- A tokenização de tempo é aplicada para converter o tempo em uma representação numérica.
-
Carregamento do Modelo:
- O modelo LSTM treinado (do arquivo 'lstm_model.pth') é carregado. Este é o modelo que treinamos durante a fase de treinamento.
-
Avaliação:
- O script itera pelos últimos 100 passos dos dados.
- Para cada passo, ele pega as 60 barras anteriores como entrada e usa o modelo para prever o preço de fechamento normalizado.
- Os preços reais e previstos são armazenados para comparação.
-
Próxima Previsão:
- Faz uma previsão para o próximo passo usando as 60 barras mais recentes.
- Calcula a variação percentual para essa previsão.
- Mostra a previsão como um ponto vermelho no gráfico.
-
Visualização:
- São gerados dois gráficos:
- Preços Reais vs. Preços Previstos (Normalizados) com a próxima previsão destacada.
- Variação Percentual do Preço Real vs. Preço Previsto com a próxima previsão destacada.
- Os eixos Y são limitados a 100% para melhor visualização.
- São gerados dois gráficos:
O código abaixo pode ser encontrado no arquivo "LSTM_model_prediction.py", localizado na raiz do arquivo LSTM_Files.zip anexado a este artigo.
import torch import torch.nn as nn import numpy as np import pandas as pd import MetaTrader5 as mt5 import matplotlib.pyplot as plt # Define LSTM model class (same as during training) class LSTMModel(nn.Module): def __init__(self, input_size, hidden_layer_size, output_size): super(LSTMModel, self).__init__() self.hidden_layer_size = hidden_layer_size self.lstm = nn.LSTM(input_size, hidden_layer_size) self.linear = nn.Linear(hidden_layer_size, output_size) self.hidden_cell = (torch.zeros(1, 1, self.hidden_layer_size), torch.zeros(1, 1, self.hidden_layer_size)) def forward(self, input_seq): lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq), 1, -1), self.hidden_cell) predictions = self.linear(lstm_out.view(len(input_seq), -1)) return predictions[-1] # Normalize prices on a rolling basis resetting at the start of each day def normalize_daily_rolling(data): data['date'] = data.index.date data['rolling_high'] = data.groupby('date')['high'].transform(lambda x: x.expanding(min_periods=1).max()) data['rolling_low'] = data.groupby('date')['low'].transform(lambda x: x.expanding(min_periods=1).min()) data['norm_open'] = (data['open'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_high'] = (data['high'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_low'] = (data['low'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) data['norm_close'] = (data['close'] - data['rolling_low']) / (data['rolling_high'] - data['rolling_low']) # Replace NaNs with zeros data.fillna(0, inplace=True) return data[['norm_open', 'norm_high', 'norm_low', 'norm_close']] # Load the saved model input_size = 5 # time_token, norm_open, norm_high, norm_low, norm_close hidden_layer_size = 100 output_size = 1 model = LSTMModel(input_size, hidden_layer_size, output_size) model.load_state_dict(torch.load('lstm_model.pth')) model.eval() # Connect to MetaTrader 5 if not mt5.initialize(): print("Initialize failed") mt5.shutdown() # Load the latest 160 bars of market data symbol = "EURUSD" timeframe = mt5.TIMEFRAME_M15 bars = 160 # 60 for sequence length + 100 for evaluation steps rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, bars) mt5.shutdown() # Convert to DataFrame data = pd.DataFrame(rates) data['time'] = pd.to_datetime(data['time'], unit='s') data.set_index('time', inplace=True) # Normalize the new data data[['norm_open', 'norm_high', 'norm_low', 'norm_close']] = normalize_daily_rolling(data) # Tokenize time data['time_token'] = (data.index.hour * 3600 + data.index.minute * 60 + data.index.second) / 86400 # Drop unnecessary columns data = data[['time_token', 'norm_open', 'norm_high', 'norm_low', 'norm_close']] # Fetch the last 100 sequences for evaluation seq_length = 60 evaluation_steps = 100 # Initialize lists for storing evaluation results all_true_prices = [] all_predicted_prices = [] model.eval() for step in range(evaluation_steps, 0, -1): # Get the sequence ending at 'step' seq = data.values[-step-seq_length:-step] seq = torch.tensor(seq, dtype=torch.float32) # Make prediction with torch.no_grad(): model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size), torch.zeros(1, 1, model.hidden_layer_size)) prediction = model(seq).item() all_true_prices.append(data['norm_close'].values[-step]) all_predicted_prices.append(prediction) # Calculate percent changes and convert to percentages true_pct_change = (np.diff(all_true_prices) / np.array(all_true_prices[:-1])) * 100 predicted_pct_change = (np.diff(all_predicted_prices) / np.array(all_predicted_prices[:-1])) * 100 # Make next prediction next_seq = data.values[-seq_length:] next_seq = torch.tensor(next_seq, dtype=torch.float32) with torch.no_grad(): model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size), torch.zeros(1, 1, model.hidden_layer_size)) next_prediction = model(next_seq).item() # Calculate percent change for the next prediction next_true_price = data['norm_close'].values[-1] next_price_pct_change = ((next_prediction - all_predicted_prices[-1]) / all_predicted_prices[-1]) * 100 print(f"Next predicted close price (normalized): {next_prediction}") print(f"Percent change for the next prediction based on normalized price: {next_price_pct_change:.5f}%") print("All Predicted Prices: ", all_predicted_prices) # Plot the evaluation results with capped y-axis plt.figure(figsize=(12, 8)) plt.subplot(2, 1, 1) plt.plot(all_true_prices, label='True Prices (Normalized)') plt.plot(all_predicted_prices, label='Predicted Prices (Normalized)') plt.scatter(len(all_true_prices), next_prediction, color='red', label='Next Prediction') plt.legend() plt.title('True vs Predicted Prices (Normalized, Last 100 Steps)') plt.ylim(min(min(all_true_prices), min(all_predicted_prices))-0.1, max(max(all_true_prices), max(all_predicted_prices))+0.1) plt.subplot(2, 1, 2) plt.plot(true_pct_change, label='True Percent Change') plt.plot(predicted_pct_change, label='Predicted Percent Change') plt.scatter(len(true_pct_change), next_price_pct_change, color='red', label='Next Prediction') plt.legend() plt.title('True vs Predicted Price Percent Change (Last 100 Steps)') plt.ylabel('Percent Change (%)') plt.ylim(-100, 100) # Cap the y-axis at -100% to 100% plt.tight_layout() plt.show()
Abaixo está a saída que obtemos no console e os gráficos que geramos. Esta previsão foi gerada no início do dia em 14/06/2024 (aproximadamente às 00:45 UTC + 3, horário do corretor).
Saída do Console:
Próximo preço de fechamento previsto (normalizado): 0.9003118872642517
Variação percentual para a próxima previsão com base no preço normalizado: 73.64274%
All Predicted Prices: [0.6229779124259949, 0.6659790277481079, 0.6223553419113159, 0.5994003415107727, 0.565409243106842, 0.5767043232917786, 0.5080181360244751, 0.5245669484138489, 0.6399291753768921, 0.5184902548789978, 0.6269711256027222, 0.6532717943191528, 0.7470211386680603, 0.6783792972564697, 0.6942530870437622, 0.6399927139282227, 0.5649009943008423, 0.6392825841903687, 0.6454082727432251, 0.4829435348510742, 0.5231367349624634, 0.17141318321228027, 0.3651347756385803, 0.2568517327308655, 0.41483253240585327, 0.43905267119407654, 0.40459558367729187, 0.25486069917678833, 0.3488359749317169, 0.41225481033325195, 0.13895493745803833, 0.21675345301628113, 0.04991495609283447, 0.28392884135246277, 0.17570143938064575, 0.34913408756256104, 0.17591500282287598, 0.33855849504470825, 0.43142321705818176, 0.5618296265602112, 0.0774659514427185, 0.13539350032806396, 0.4843936562538147, 0.5048894882202148, 0.8364744186401367, 0.782444417476654, 0.7968958616256714, 0.7907949686050415, 0.5655181407928467, 0.6196668744087219, 0.7133172750473022, 0.5095566511154175, 0.3565239906311035, 0.2686333656311035, 0.3386841118335724, 0.5644893646240234, 0.23622554540634155, 0.3433009088039398, 0.3493557274341583, 0.2939424216747284, 0.08992069959640503, 0.33946871757507324, 0.20876094698905945, 0.4227801263332367, 0.4044940173625946, 0.654332160949707, 0.49300187826156616, 0.6266812086105347, 0.807404637336731, 0.5183461904525757, 0.46170246601104736, 0.24424996972084045, 0.3224128782749176, 0.5156376957893372, 0.06813174486160278, 0.1865384578704834, 0.15443122386932373, 0.300825834274292, 0.28375834226608276, 0.4036571979522705, 0.015333771705627441, 0.09899216890335083, 0.16346102952957153, 0.27330827713012695, 0.2869266867637634, 0.21237093210220337, 0.35913240909576416, 0.4736405313014984, 0.3459511995315552, 0.47014304995536804, 0.3305799663066864, 0.47306257486343384, 0.4134630858898163, 0.4199170768260956, 0.5666837692260742, 0.46681761741638184, 0.35662856698036194, 0.3547590374946594, 0.5447400808334351, 0.5184851884841919]

Análise dos Resultados da Previsão
A saída do console é 0.9003118872642517, o que indica que o próximo movimento de preço provavelmente será 0,9 do intervalo diário atual, que está aproximadamente entre 1.07402 e 1.07336, ou ~8 pips. Isso pode não ser uma mudança de preço significativa, o que é compreensível, pois, no momento em que escrevo, tivemos apenas cerca de 45 minutos de negociação em 14/06/2024. No entanto, o modelo prevê que o preço fechará próximo ao limite superior do intervalo diário atual.
A próxima linha é: Variação percentual para a próxima previsão com base no preço normalizado: 73.64274%. Isso sugere que a próxima mudança de preço provavelmente será cerca de +74% acima do preço anterior, o que, quando colocado em contexto com o intervalo diário de 8 pips, pode não oferecer um número suficiente de pips para realizar uma negociação.
Em vez de trabalhar com números e frações, o usuário pode considerar adicionar uma linha que pegue o intervalo diário (máximo - mínimo) e multiplique pelo preço de fechamento previsto normalizado para obter um valor real de pips que possam ser antecipados. Faremos isso não apenas ao converter nosso script para MQL, mas também obteremos uma previsão de preço exata.
Como você pode ver na saída acima, uma lista de 100 previsões também é impressa no console. Podemos usar esses valores para validação, especialmente quando fizermos a transição para o MQL5 e começarmos a usar o script lá.
Por fim, também obtemos um gráfico da biblioteca Matplotlib em Python que nos mostra as últimas 100 previsões, as plota e as compara com as mudanças reais nos preços de fechamento em uma base normalizada (escala de 0 a 1). O ponto vermelho mostra o próximo preço mais provável em uma base normalizada, dando-nos uma indicação da possível direção do próximo preço. Com base nos dados deste dia específico, nossa previsão parece estar atrasada em relação ao mercado, indicando que os resultados previstos podem não estar bem alinhados com a ação de preço real do dia. Em um dia como esse, um trader discricionário ou usuário deve considerar ficar à margem e não negociar, pois o modelo não está fazendo previsões com precisão. Isso não significa necessariamente que as previsões do modelo estejam incorretas em todo o conjunto de dados, portanto, o re-treinamento pode não ser necessário.
Transição de Python para ONNX e Usando o Modelo Treinado com MQL5 Diretamente
Criação de um Pipeline de Processamento de Dados
A ideia de criar um pipeline de processamento de dados foi para não replicar o código de normalização e tokenização que criei em Python. Eu não queria reescrever esse código em MQL. Então, decidi converter o script em um pipeline de dados, convertê-lo para ONNX e usar o ONNX diretamente para processamento de dados em MQL. Levei vários dias para descobrir o código para fazer isso devido à minha falta de experiência prévia com a criação de pipelines de processamento de dados. A razão pela qual tive dificuldades é porque o Python é relativamente flexível quando se trata de tipos de dados. Mas, ao converter para ONNX, você precisa ser muito mais rígido e específico. Encontrei inúmeros erros ao longo do caminho. Finalmente, quando consegui resolver, fiquei muito feliz e estou contente em compartilhar o script abaixo. Aqui está um resumo rápido de como o script funciona:
Como observamos em nossa discussão anterior, o pré-processamento consiste em duas etapas cruciais:
-
Tokenização de Tempo: Transforma a hora do dia bruta (por exemplo, 15:45) em um valor fracionário entre 0 e 1, representando a porção do dia de 24 horas que já passou.
-
Normalização Contínua Diária: Esse processo padroniza os dados de preços (abertura, máxima, mínima, fechamento) em uma base diária. Calcula os preços mínimos e máximos contínuos dentro de cada dia e normaliza os preços em relação a esses valores. Essa normalização ajuda no treinamento do modelo, garantindo que os dados de preços tenham uma escala consistente.
Componentes:
-
TimeTokenizer (Transformador Personalizado): Essa classe lida com a tokenização de tempo. Ela extrai a coluna de tempo do tensor de entrada, converte em uma representação fracionária do dia e, em seguida, combina de volta com os outros dados de preços.
-
DailyRollingNormalizer (Transformador Personalizado): Essa classe executa a normalização contínua diária. Ela itera pelos dados de preços, acompanhando o máximo e mínimo contínuos para cada dia. Os preços são então normalizados usando esses valores dinâmicos. Também inclui uma etapa para substituir quaisquer valores NaN que possam surgir durante o cálculo.
-
ReplaceNaNs (Transformador Personalizado): Substitui todos os valores NaN do cálculo por zeros.
-
Pipeline (nn.Sequential): Combina os três transformadores personalizados acima em um fluxo de trabalho sequencial. Os dados de entrada passam pelo TimeTokenizer, depois pelo DailyRollingNormalizer e, por último, pelo ReplaceNaNs, nessa ordem.
-
Conexão MetaTrader5: O script estabelece uma conexão com o MetaTrader 5 para recuperar dados históricos de preços EUR/USD.
Execução:
-
Carregamento de Dados: O script busca 160 barras (pontos de dados de preços) do MetaTrader 5 para o par EURUSD no intervalo de 15 minutos.
-
Conversão de Dados: Os dados brutos são convertidos em um tensor PyTorch para processamento posterior.
-
Processamento do Pipeline: O tensor é passado pelo pipeline definido, aplicando os passos de tokenização de tempo e normalização contínua diária.
-
Exportação para ONNX: Os dados finais pré-processados são impressos no console para mostrar os resultados antes e depois do processamento. Além disso, todo o pipeline de pré-processamento é exportado para um arquivo ONNX. ONNX é um formato aberto que permite que modelos de aprendizado de máquina sejam facilmente transferidos entre diferentes frameworks e ambientes, garantindo maior compatibilidade para a implantação e uso do modelo.
Pontos Principais:
- Modularidade: O uso de transformadores personalizados torna o código modular e reutilizável. Cada transformador encapsula uma etapa específica de pré-processamento.
- PyTorch: O script utiliza o PyTorch, um popular framework de aprendizado profundo, para operações de tensor e gerenciamento de modelo.
- Exportação para ONNX: A exportação para ONNX garante que as etapas de pré-processamento possam ser integradas perfeitamente a diferentes plataformas ou ferramentas onde o modelo treinado é implantado.
import torch import torch.nn as nn import pandas as pd import MetaTrader5 as mt5 # Custom Transformer for tokenizing time class TimeTokenizer(nn.Module): def forward(self, X): time_column = X[:, 0] # Assuming 'time' is the first column time_token = (time_column % 86400) / 86400 time_token = time_token.unsqueeze(1) # Add a dimension to match the input shape return torch.cat((time_token, X[:, 1:]), dim=1) # Concatenate the time token with the rest of the input # Custom Transformer for daily rolling normalization class DailyRollingNormalizer(nn.Module): def forward(self, X): time_tokens = X[:, 0] # Assuming 'time_token' is the first column price_columns = X[:, 1:] # Assuming 'open', 'high', 'low', 'close' are the remaining columns normalized_price_columns = torch.zeros_like(price_columns) rolling_max = price_columns.clone() rolling_min = price_columns.clone() for i in range(1, price_columns.shape[0]): reset_mask = (time_tokens[i] < time_tokens[i-1]).float() rolling_max[i] = reset_mask * price_columns[i] + (1 - reset_mask) * torch.maximum(rolling_max[i-1], price_columns[i]) rolling_min[i] = reset_mask * price_columns[i] + (1 - reset_mask) * torch.minimum(rolling_min[i-1], price_columns[i]) denominator = rolling_max[i] - rolling_min[i] normalized_price_columns[i] = (price_columns[i] - rolling_min[i]) / denominator time_tokens = time_tokens.unsqueeze(1) # Assuming 'time_token' is the first column return torch.cat((time_tokens, normalized_price_columns), dim=1) class ReplaceNaNs(nn.Module): def forward(self, X): X[torch.isnan(X)] = 0 X[X != X] = 0 # replace negative NaNs with 0 return X # Connect to MetaTrader 5 if not mt5.initialize(): print("Initialize failed") mt5.shutdown() # Load market data (reduced sample size for demonstration) symbol = "EURUSD" timeframe = mt5.TIMEFRAME_M15 rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 160) #intialize with maximum number of bars allowed by your broker mt5.shutdown() # Convert to DataFrame and keep only 'time', 'open', 'high', 'low', 'close' columns data = pd.DataFrame(rates)[['time', 'open', 'high', 'low', 'close']] # Convert the DataFrame to a PyTorch tensor data_tensor = torch.tensor(data.values, dtype=torch.float32) # Create the updated pipeline pipeline = nn.Sequential( TimeTokenizer(), DailyRollingNormalizer(), ReplaceNaNs() ) # Print the data before processing print('Data Before Processing\n', data[:100]) # Process the data processed_data = pipeline(data_tensor) print('Data After Processing\n', processed_data[:100]) # Export the pipeline to ONNX format dummy_input = torch.randn(len(data), len(data.columns)) torch.onnx.export(pipeline, dummy_input, "data_processing_pipeline.onnx", input_names=["input"], output_names=["output"])
A saída do código fornece os dados antes e depois do processamento, impressos no console. Não reproduzirei essa saída porque não é importante, mas o usuário pode considerar executar o script para ver a saída por si mesmo. Além disso, a saída cria um arquivo: data_processing_pipeline.onnx. Para validar a forma usada por este modelo ONNX, criei um script conforme mostrado abaixo:
Este script pode ser encontrado na pasta ONNX Data Pipeline e é chamado de "shape_check.py". Esses arquivos estão localizados no LSTM_Files.zip anexado a este artigo.
import onnx
model = onnx.load("data_processing_pipeline.onnx")
onnx.checker.check_model(model)
for input in model.graph.input:
print(f'Input name: {input.name}')
print(f'Input type: {input.type}')
for dim in input.type.tensor_type.shape.dim:
print(dim.dim_value) Isso gera o seguinte resultado:
- 160
- 5
Portanto, a forma exigida pelo nosso modelo é 160 - barras de 15 minutos, e 5 valores (valor do tempo como Inteiro UNIX, Abertura, Máxima, Mínima, Fechamento). Após o processamento dos dados, o resultado será os dados normalizados como time_token, norm_open, norm_high, norm_low e norm_close.
Para testar o processamento de dados no MQL, também criei um script específico chamado "LSTM Data Pipeline.mq5", localizado na pasta raiz do arquivo zip anexado para validar se os dados estão sendo transformados da forma que eu originalmente pretendia. Esse script pode ser encontrado abaixo. Os principais recursos são resumidos da seguinte forma:
-
Inicialização (OnInit):
- Carrega o modelo ONNX dos dados binários ("data_processing_pipeline.onnx") incorporados como um recurso. Nota: O modelo ONNX está armazenado dentro de uma pasta chamada "LSTM", que é uma subpasta dentro da pasta "Experts" conforme mostrado abaixo.
- Em seguida, configuramos as formas de entrada e saída do modelo com base no nosso código ONNX. Portanto, o "LSTM Data Pipeline Test.ex5" deve ser armazenado dentro da pasta Experts, pois estamos usando o seguinte caminho. Se você decidir armazenar o arquivo de outra forma, atualize esta linha para garantir que o código funcione corretamente.
-
#resource "\LSTM\data_processing_pipeline.onnx" as uchar ExtModel[]

-
Tratamento de Dados de Tick (OnTick):
- Esta função é acionada a cada atualização de preço.
- Aguarda até que a próxima barra (vela de 15 minutos, neste caso) se forme.
- Chama a função ProcessData para lidar com o processamento de dados e a previsão.
-
Processamento de Dados (ProcessData):
- Busca as últimas SAMPLE_SIZE (160 neste caso) barras de dados EURUSD M15.
- Extrai o tempo, abertura, máxima, mínima e fechamento dos dados obtidos.
- Normaliza o componente de tempo para representar uma fração do dia (entre 0 e 1).
- Prepara os dados de entrada para o modelo ONNX como um vetor unidimensional.
- Executa o modelo ONNX (OnnxRun) com o vetor de entrada preparado.
- Recebe a saída processada do modelo.
- Imprime os dados processados, que incluem o token de tempo e os preços normalizados.
//+------------------------------------------------------------------+ //| ONNX Test | //| Copyright 2023 | //| Your Name Here | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Your Name Here" #property link "https://www.mql5.com" #property version "1.00" static vectorf ExtOutputData(1); vectorf output_data(1); #include <Trade\Trade.mqh> CTrade trade; #resource "\\LSTM\\data_processing_pipeline.onnx" as uchar ExtModel[] #define SAMPLE_SIZE 160 // Adjusted to match the model's expected input size long ExtHandle=INVALID_HANDLE; datetime ExtNextBar=0; // Expert Advisor initialization int OnInit() { // Load the ONNX model ExtHandle = OnnxCreateFromBuffer(ExtModel, ONNX_DEFAULT); if (ExtHandle == INVALID_HANDLE) { Print("Error creating model OnnxCreateFromBuffer ", GetLastError()); return(INIT_FAILED); } // Set input shape const long input_shape[] = {SAMPLE_SIZE, 5}; // Adjust based on your model's input dimensions if (!OnnxSetInputShape(ExtHandle, ONNX_DEFAULT, input_shape)) { Print("Error setting the input shape OnnxSetInputShape ", GetLastError()); return(INIT_FAILED); } // Set output shape const long output_shape[] = {SAMPLE_SIZE, 5}; // Adjust based on your model's output dimensions if (!OnnxSetOutputShape(ExtHandle, 0, output_shape)) { Print("Error setting the output shape OnnxSetOutputShape ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } // Expert Advisor deinitialization void OnDeinit(const int reason) { if (ExtHandle != INVALID_HANDLE) { OnnxRelease(ExtHandle); ExtHandle = INVALID_HANDLE; } } // Process the tick function void OnTick() { if (TimeCurrent() < ExtNextBar) return; ExtNextBar = TimeCurrent(); ExtNextBar -= ExtNextBar % PeriodSeconds(); ExtNextBar += PeriodSeconds(); // Fetch new data and run the ONNX model if (!ProcessData()) { Print("Error processing data"); return; } } // Function to process data using the ONNX model bool ProcessData() { MqlRates rates[SAMPLE_SIZE]; int copied = CopyRates(_Symbol, PERIOD_M15, 1, SAMPLE_SIZE, rates); if (copied != SAMPLE_SIZE) { Print("Failed to copy the expected number of rates. Expected: ", SAMPLE_SIZE, ", Copied: ", copied); return false; } else if(copied == SAMPLE_SIZE) { Print("Successfully copied the expected number of rates. Expected: ", SAMPLE_SIZE, ", Copied: ", copied); } double min_time = rates[0].time; double max_time = rates[0].time; for (int i = 1; i < copied; i++) { if (rates[i].time < min_time) min_time = rates[i].time; if (rates[i].time > max_time) max_time = rates[i].time; } float input_data[SAMPLE_SIZE * 5]; int count; for (int i = 0; i < copied; i++) { count++; // Normalize time to be between 0 and 1 within a day input_data[i * 5 + 0] = (float)((rates[i].time)); // normalized time input_data[i * 5 + 1] = (float)rates[i].open; // open input_data[i * 5 + 2] = (float)rates[i].high; // high input_data[i * 5 + 3] = (float)rates[i].low; // low input_data[i * 5 + 4] = (float)rates[i].close; // close } Print("Count of copied after for loop: ", count); // Resize input vector to match the copied data size vectorf input_vector; input_vector.Resize(copied * 5); for (int i = 0; i < copied * 5; i++) { input_vector[i] = input_data[i]; } vectorf output_vector; output_vector.Resize(copied * 5); if (!OnnxRun(ExtHandle, ONNX_NO_CONVERSION, input_vector, output_vector)) { Print("Error running the ONNX model: ", GetLastError()); return false; } // Process the output data as needed for (int i = 0; i < copied; i++) { float time_token = output_vector[i * 5 + 0]; float norm_open = output_vector[i * 5 + 1]; float norm_high = output_vector[i * 5 + 2]; float norm_low = output_vector[i * 5 + 3]; float norm_close = output_vector[i * 5 + 4]; // Print the processed data PrintFormat("Time Token: %f, Norm Open: %f, Norm High: %f, Norm Low: %f, Norm Close: %f", time_token, norm_open, norm_high, norm_low, norm_close); } return true; }
A saída deste script é a seguinte: valida que o pipeline de dados está funcionando conforme o esperado.

Para verificar novamente a saída acima, criei um script adicional em Python chamado "LSTM Data Pipeline Test.py", que basicamente fornece a mesma saída. Este script também está incluído no arquivo zip anexado no final deste artigo (localizado na pasta "ONNX Data Pipeline") e é fornecido abaixo para inspeção rápida.
import torch import onnx import onnxruntime as ort import MetaTrader5 as mt5 import pandas as pd import numpy as np # Load the ONNX model onnx_model = onnx.load("data_processing_pipeline.onnx") onnx.checker.check_model(onnx_model) # Initialize MT5 and fetch new data if not mt5.initialize(): print("Initialize failed") mt5.shutdown() symbol = "EURUSD" timeframe = mt5.TIMEFRAME_M15 rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 160) mt5.shutdown() # Convert the new data to a DataFrame data = pd.DataFrame(rates)[['time', 'open', 'high', 'low', 'close']] data_tensor = torch.tensor(data.values, dtype=torch.float32) # Prepare the input for ONNX input_data = data_tensor.numpy() # Run the ONNX model ort_session = ort.InferenceSession("data_processing_pipeline.onnx") input_name = ort_session.get_inputs()[0].name output_name = ort_session.get_outputs()[0].name processed_data = ort_session.run([output_name], {input_name: input_data})[0] # Convert the output back to DataFrame for easy viewing processed_df = pd.DataFrame(processed_data, columns=['time_token', 'norm_open', 'norm_high', 'norm_low', 'norm_close']) print('Processed Data') print(processed_df)
A saída ao executar o script acima é mostrada abaixo. O formato e a forma da saída correspondem ao que vimos na saída do MQL acima.

Usando o Modelo Treinado para Fazer Previsões no MQL
Nesta seção, finalmente quero conectar as diferentes partes deste artigo - processamento de dados e previsão - em um único script que permite ao usuário obter uma previsão após treinar o modelo. Vamos revisar brevemente o que é necessário para obter uma previsão no MQL e criar um consultor especializado:
- Treine o modelo executando o LSTM_model_training.py. Sinta-se à vontade para ajustar os parâmetros conforme necessário. Executar este arquivo criará o lstm_model.onnx.
- Copie o arquivo lstm_model.onnx que foi gerado ao executar o LSTM_model_training.py para a pasta Experts do MQL, dentro da subpasta chamada "LSTM".
- Crie o Pipeline de Processamento de Dados executando o LSTM Data Pipeline.py. Este arquivo está localizado dentro da pasta "ONNX Data Pipeline" no arquivo zip anexado.
- Executar o arquivo produzirá um arquivo ONNX para processamento de dados. Copie o data_processing_pipeline.onnx para a pasta Experts do MQL, dentro da subpasta chamada LSTM.
- Armazene o script fornecido abaixo na pasta principal "Experts" e anexe-o ao gráfico de EURUSD de 15 minutos para obter uma previsão:
//+------------------------------------------------------------------+ //| ONNX Test | //| Copyright 2023 | //| Your Name Here | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Your Name Here" #property link "https://www.mql5.com" #property version "1.00" static vectorf ExtOutputData(1); vectorf output_data(1); #include <Trade\Trade.mqh> //#include <Chart\Chart.mqh> CTrade trade; #resource "\\LSTM\\data_processing_pipeline.onnx" as uchar DataProcessingModel[] #resource "\\LSTM\\lstm_model.onnx" as uchar PredictionModel[] #define SAMPLE_SIZE_DATA 160 // Adjusted to match the model's expected input size #define SAMPLE_SIZE_PRED 60 long DataProcessingHandle = INVALID_HANDLE; long PredictionHandle = INVALID_HANDLE; datetime ExtNextBar = 0; // Expert Advisor initialization int OnInit() { // Load the data processing ONNX model DataProcessingHandle = OnnxCreateFromBuffer(DataProcessingModel, ONNX_DEFAULT); if (DataProcessingHandle == INVALID_HANDLE) { Print("Error creating data processing model OnnxCreateFromBuffer ", GetLastError()); return(INIT_FAILED); } // Set input shape for data processing model const long input_shape[] = {SAMPLE_SIZE_DATA, 5}; // Adjust based on your model's input dimensions if (!OnnxSetInputShape(DataProcessingHandle, ONNX_DEFAULT, input_shape)) { Print("Error setting the input shape OnnxSetInputShape for data processing model ", GetLastError()); return(INIT_FAILED); } // Set output shape for data processing model const long output_shape[] = {SAMPLE_SIZE_DATA, 5}; // Adjust based on your model's output dimensions if (!OnnxSetOutputShape(DataProcessingHandle, 0, output_shape)) { Print("Error setting the output shape OnnxSetOutputShape for data processing model ", GetLastError()); return(INIT_FAILED); } // Load the prediction ONNX model PredictionHandle = OnnxCreateFromBuffer(PredictionModel, ONNX_DEFAULT); if (PredictionHandle == INVALID_HANDLE) { Print("Error creating prediction model OnnxCreateFromBuffer ", GetLastError()); return(INIT_FAILED); } // Set input shape for prediction model const long prediction_input_shape[] = {SAMPLE_SIZE_PRED, 1, 5}; // Adjust based on your model's input dimensions if (!OnnxSetInputShape(PredictionHandle, ONNX_DEFAULT, prediction_input_shape)) { Print("Error setting the input shape OnnxSetInputShape for prediction model ", GetLastError()); return(INIT_FAILED); } // Set output shape for prediction model const long prediction_output_shape[] = {1}; // Adjust based on your model's output dimensions if (!OnnxSetOutputShape(PredictionHandle, 0, prediction_output_shape)) { Print("Error setting the output shape OnnxSetOutputShape for prediction model ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } // Expert Advisor deinitialization void OnDeinit(const int reason) { if (DataProcessingHandle != INVALID_HANDLE) { OnnxRelease(DataProcessingHandle); DataProcessingHandle = INVALID_HANDLE; } if (PredictionHandle != INVALID_HANDLE) { OnnxRelease(PredictionHandle); PredictionHandle = INVALID_HANDLE; } } // Process the tick function void OnTick() { if (TimeCurrent() < ExtNextBar) return; ExtNextBar = TimeCurrent(); ExtNextBar -= ExtNextBar % PeriodSeconds(); ExtNextBar += PeriodSeconds(); // Fetch new data and run the data processing ONNX model vectorf input_data = ProcessData(DataProcessingHandle); if (input_data.Size() == 0) { Print("Error processing data"); return; } // Make predictions using the prediction ONNX model double predictions[SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED + 1]; for (int i = 0; i < SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED + 1; i++) { double prediction = MakePrediction(input_data, PredictionHandle, i, SAMPLE_SIZE_PRED); //if (prediction < 0) //{ // Print("Error making prediction"); // return; //} // Print the prediction //PrintFormat("Predicted close price (index %d): %f", i, prediction); double min_price = iLow(Symbol(), PERIOD_D1, 0); //price is relative to the day's price therefore we use low of day for min price double max_price = iHigh(Symbol(), PERIOD_D1, 0); //high of day for max price double price = prediction * (max_price - min_price) + min_price; predictions[i] = price; PrintFormat("Predicted close price (index %d): %f", i, predictions[i]); } // Get the actual prices for the last 60 bars double actual_prices[SAMPLE_SIZE_PRED]; for (int i = 0; i < SAMPLE_SIZE_PRED; i++) { actual_prices[i] = iClose(Symbol(), PERIOD_M15, SAMPLE_SIZE_PRED - i); Print(actual_prices[i]); } // Create a label object to display the predicted and actual prices string label_text = "Predicted | Actual\n"; for (int i = 0; i < SAMPLE_SIZE_PRED; i++) { label_text += StringFormat("%.5f | %.5f\n", predictions[i], actual_prices[i]); } label_text += StringFormat("Next prediction: %.5f", predictions[SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED]); Print(label_text); //int label_handle = ObjectCreate(OBJ_LABEL, 0, 0, 0); //ObjectSetText(label_handle, label_text, 12, clrWhite, clrBlack, ALIGN_LEFT); //ObjectMove(label_handle, 0, ChartHeight() - 20, ChartWidth(), 20); } // Function to process data using the data processing ONNX model vectorf ProcessData(long data_processing_handle) { MqlRates rates[SAMPLE_SIZE_DATA]; vectorf blank_vector; int copied = CopyRates(_Symbol, PERIOD_M15, 1, SAMPLE_SIZE_DATA, rates); if (copied != SAMPLE_SIZE_DATA) { Print("Failed to copy the expected number of rates. Expected: ", SAMPLE_SIZE_DATA, ", Copied: ", copied); return blank_vector; } float input_data[SAMPLE_SIZE_DATA * 5]; for (int i = 0; i < copied; i++) { // Normalize time to be between 0 and 1 within a day input_data[i * 5 + 0] = (float)((rates[i].time)); // normalized time input_data[i * 5 + 1] = (float)rates[i].open; // open input_data[i * 5 + 2] = (float)rates[i].high; // high input_data[i * 5 + 3] = (float)rates[i].low; // low input_data[i * 5 + 4] = (float)rates[i].close; // close } vectorf input_vector; input_vector.Resize(copied * 5); for (int i = 0; i < copied * 5; i++) { input_vector[i] = input_data[i]; } vectorf output_vector; output_vector.Resize(copied * 5); if (!OnnxRun(data_processing_handle, ONNX_NO_CONVERSION, input_vector, output_vector)) { Print("Error running the data processing ONNX model: ", GetLastError()); return blank_vector; } return output_vector; } // Function to make predictions using the prediction ONNX model double MakePrediction(const vectorf& input_data, long prediction_handle, int start_index, int size) { vectorf input_subset; input_subset.Resize(size * 5); for (int i = 0; i < size * 5; i++) { input_subset[i] = input_data[start_index * 5 + i]; } vectorf output_vector; output_vector.Resize(1); if (!OnnxRun(prediction_handle, ONNX_NO_CONVERSION, input_subset, output_vector)) { Print("Error running the prediction ONNX model: ", GetLastError()); return -1.0; } // Extract the normalized close price from the output data double norm_close = output_vector[0]; return norm_close; }
Se você estiver usando uma estrutura de pastas diferente do que foi descrito neste artigo, considere alterar as seguintes linhas de código para corresponder aos caminhos de arquivo desejados.
#resource "\\LSTM\\data_processing_pipeline.onnx" as uchar DataProcessingModel[] #resource "\\LSTM\\lstm_model.onnx" as uchar PredictionModel[]
Para revisar, veja como o script funciona. Ele trabalha com EURUSD em um intervalo de 15 minutos.
-
Modelo de Pré-processamento de Dados: Este modelo ("data_processing_pipeline.onnx") lida com tarefas como tokenização de tempo (convertendo o tempo em uma representação numérica) e normalização dos dados de preços, preparando-os para uso com nosso modelo LSTM treinado.
-
Modelo de Previsão: Este modelo ("lstm_model.onnx") é a rede LSTM (Memória de Longo Curto Prazo) treinada para analisar as últimas 60 barras de ação de preço de 15 minutos e nos fornecer uma previsão do próximo preço de fechamento provável.
Funcionalidade:
-
Inicialização (OnInit):
- Carrega ambos os modelos ONNX (pré-processamento de dados e previsão) dos recursos incorporados.
- Configura as formas de entrada e saída para ambos os modelos com base em seus requisitos.
-
Tratamento de Dados de Tick (OnTick):
- Esta função é acionada a cada novo tick de preço.
- Aguarda até que a próxima barra de 15 minutos (vela) seja formada.3
- Chama a função ProcessData para pré-processar os dados.
- Itera através dos dados pré-processados, gerando previsões de preços usando a função MakePrediction.
- Converte as previsões normalizadas de volta para valores reais de preço. NOTA: No MQL, para a previsão, agora estamos usando as seguintes linhas de código. Essas linhas de código convertem a previsão obtida, que foi normalizada em relação ao máximo e mínimo diários entre 0 e 1, e a convertem de volta para um valor de preço real.
-
double min_price = iLow(Symbol(), PERIOD_D1, 0); //price is relative to the day's price therefore we use low of day for min price double max_price = iHigh(Symbol(), PERIOD_D1, 0); //high of day for max price double price = prediction * (max_price - min_price) + min_price;
- Imprime os preços de fechamento previstos e reais para comparação. Os valores podem ser visualizados na aba "Journal".
- Formata uma string com as informações de preço previsto vs. real.
- Nota: A seção de código comentada parece ter sido projetada para criar uma etiqueta no gráfico para exibir as previsões e os valores reais. Isso seria um bom auxílio visual para avaliar o desempenho do modelo em tempo real. Mas, eu ainda não consegui completar o código porque ainda estou pensando em como usar melhor as previsões - como um indicador ou como um EA.
-
Processamento de Dados (ProcessData):
- Busca as últimas 160 barras de dados EURUSD M15.
- Prepara os dados de entrada para o modelo de processamento de dados (tempo, abertura, máxima, mínima, fechamento).
- Executa o modelo de processamento de dados para normalizar e tokenizar os dados de entrada.
-
Previsão (MakePrediction):
- Toma um subconjunto dos dados pré-processados (uma sequência de 60 pontos de dados) como entrada.
- Executa o modelo de previsão para obter o preço de fechamento previsto normalizado de forma contínua.
- Imprime a previsão -> pode ser visualizada na aba "Experts".
Observe o formato de saída mostrado abaixo:

Como podemos ver, obtemos algumas coisas diferentes como saídas. Primeiro estão os valores previstos e reais na coluna acima do "Próxima Previsão". No formato Previsão | Real de acordo com as linhas do código acima.
for (int i = 0; i < SAMPLE_SIZE_PRED; i++) { label_text += StringFormat("%.5f | %.5f\n", predictions[i], actual_prices[i]); }
A linha "Próxima previsão: 1.07333" vem das seguintes linhas no código acima:
label_text += StringFormat("Next prediction: %.5f", predictions[SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED]); Print(label_text);
Aplicação de Modelos Treinados: Criando Consultores Especializados
Criação de Consultores Especializados
A abordagem que adotei para converter a previsão em um consultor especializado foi inspirada em um artigo de Yevgeniy Koshtenko, intitulado "Python, ONNX e MetaTrader 5: Criando um modelo RandomForest com RobustScaler e Pré-processamento de Dados com PolynomialFeatures". É um EA relativamente simples que serve de base para a criação de EAs. Os usuários, é claro, podem expandir a abordagem que descrevi abaixo para incluir parâmetros adicionais, como trailing stop losses ou combinar previsões da rede neural LSTM com outras ferramentas que já utilizam no desenvolvimento de seus Consultores Especializados.
Usamos a estrutura geral para processar os dados e fazer a previsão, como fizemos acima. No entanto, no script do EA, usamos as seguintes modificações adicionais:
-
Determinação de Sinal (DetermineSignal):
- Compara o último preço de fechamento previsto com o preço de fechamento atual e spread para determinar o sinal de negociação.
- Considera um pequeno limite de spread para filtrar sinais ruidosos.
-
Gestão de Negociação (CheckForOpen, CheckForClose):
- CheckForOpen : Se nenhuma posição estiver aberta e um sinal válido (compra ou venda) for recebido, abre uma nova posição com o tamanho de lote configurado, stop loss e take profit.
- CheckForClose : Se uma posição estiver aberta e um sinal na direção oposta for recebido, fecha a posição. Isso só acontecerá se InpUseStops for "False" por causa das seguintes linhas de código:
// Check position closing conditions void CheckForClose(void) { if (InpUseStops) return; //...rest of code }Caso contrário, se InpUseStops estiver definido como verdadeiro, a posição só será fechada quando o stop-loss ou take profit for acionado. O código completo para o EA com tudo implementado pode ser encontrado na pasta raiz dentro do LSTM_Files.zip anexado a este artigo. O arquivo é chamado LSTM_Simple_EA.mq5.
//+------------------------------------------------------------------+ //| ONNX Test | //| Copyright 2023 | //| Your Name Here | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Your Name Here" #property link "https://www.mql5.com" #property version "1.00" static vectorf ExtOutputData(1); vectorf output_data(1); #include <Trade\Trade.mqh> CTrade trade; input double InpLots = 1.0; // Lot volume to open a position input bool InpUseStops = true; // Trade with stop orders input int InpTakeProfit = 500; // Take Profit level input int InpStopLoss = 500; // Stop Loss level #resource "\\LSTM\\data_processing_pipeline.onnx" as uchar DataProcessingModel[] #resource "\\LSTM\\lstm_model.onnx" as uchar PredictionModel[] #define SAMPLE_SIZE_DATA 160 // Adjusted to match the model's expected input size #define SAMPLE_SIZE_PRED 60 long DataProcessingHandle = INVALID_HANDLE; long PredictionHandle = INVALID_HANDLE; datetime ExtNextBar = 0; int ExtPredictedClass = -1; #define PRICE_UP 1 #define PRICE_SAME 2 #define PRICE_DOWN 0 // Expert Advisor initialization int OnInit() { // Load the data processing ONNX model DataProcessingHandle = OnnxCreateFromBuffer(DataProcessingModel, ONNX_DEFAULT); if (DataProcessingHandle == INVALID_HANDLE) { Print("Error creating data processing model OnnxCreateFromBuffer ", GetLastError()); return(INIT_FAILED); } // Set input shape for data processing model const long input_shape[] = {SAMPLE_SIZE_DATA, 5}; // Adjust based on your model's input dimensions if (!OnnxSetInputShape(DataProcessingHandle, ONNX_DEFAULT, input_shape)) { Print("Error setting the input shape OnnxSetInputShape for data processing model ", GetLastError()); return(INIT_FAILED); } // Set output shape for data processing model const long output_shape[] = {SAMPLE_SIZE_DATA, 5}; // Adjust based on your model's output dimensions if (!OnnxSetOutputShape(DataProcessingHandle, 0, output_shape)) { Print("Error setting the output shape OnnxSetOutputShape for data processing model ", GetLastError()); return(INIT_FAILED); } // Load the prediction ONNX model PredictionHandle = OnnxCreateFromBuffer(PredictionModel, ONNX_DEFAULT); if (PredictionHandle == INVALID_HANDLE) { Print("Error creating prediction model OnnxCreateFromBuffer ", GetLastError()); return(INIT_FAILED); } // Set input shape for prediction model const long prediction_input_shape[] = {SAMPLE_SIZE_PRED, 1, 5}; // Adjust based on your model's input dimensions if (!OnnxSetInputShape(PredictionHandle, ONNX_DEFAULT, prediction_input_shape)) { Print("Error setting the input shape OnnxSetInputShape for prediction model ", GetLastError()); return(INIT_FAILED); } // Set output shape for prediction model const long prediction_output_shape[] = {1}; // Adjust based on your model's output dimensions if (!OnnxSetOutputShape(PredictionHandle, 0, prediction_output_shape)) { Print("Error setting the output shape OnnxSetOutputShape for prediction model ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } // Expert Advisor deinitialization void OnDeinit(const int reason) { if (DataProcessingHandle != INVALID_HANDLE) { OnnxRelease(DataProcessingHandle); DataProcessingHandle = INVALID_HANDLE; } if (PredictionHandle != INVALID_HANDLE) { OnnxRelease(PredictionHandle); PredictionHandle = INVALID_HANDLE; } } // Process the tick function void OnTick() { if (TimeCurrent() < ExtNextBar) return; ExtNextBar = TimeCurrent(); ExtNextBar -= ExtNextBar % PeriodSeconds(); ExtNextBar += PeriodSeconds(); // Fetch new data and run the data processing ONNX model vectorf input_data = ProcessData(DataProcessingHandle); if (input_data.Size() == 0) { Print("Error processing data"); return; } // Make predictions using the prediction ONNX model double predictions[SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED + 1]; for (int i = 0; i < SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED + 1; i++) { double prediction = MakePrediction(input_data, PredictionHandle, i, SAMPLE_SIZE_PRED); double min_price = iLow(Symbol(), PERIOD_D1, 0); // price is relative to the day's price therefore we use low of day for min price double max_price = iHigh(Symbol(), PERIOD_D1, 0); // high of day for max price double price = prediction * (max_price - min_price) + min_price; predictions[i] = price; PrintFormat("Predicted close price (index %d): %f", i, predictions[i]); } // Determine the trading signal DetermineSignal(predictions); // Execute trades based on the signal if (ExtPredictedClass >= 0) if (PositionSelect(_Symbol)) CheckForClose(); else CheckForOpen(); } // Function to determine the trading signal void DetermineSignal(double &predictions[]) { double spread = GetSpreadInPips(_Symbol); double predicted = predictions[SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED]; // Use the last prediction for decision making if (spread < 0.000005 && predicted > iClose(Symbol(), PERIOD_M15, 1)) { ExtPredictedClass = PRICE_UP; } else if (spread < 0.000005 && predicted < iClose(Symbol(), PERIOD_M15, 1)) { ExtPredictedClass = PRICE_DOWN; } else { ExtPredictedClass = PRICE_SAME; } } // Check position opening conditions void CheckForOpen(void) { ENUM_ORDER_TYPE signal = WRONG_VALUE; if (ExtPredictedClass == PRICE_DOWN) signal = ORDER_TYPE_SELL; else if (ExtPredictedClass == PRICE_UP) signal = ORDER_TYPE_BUY; if (signal != WRONG_VALUE && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { double price, sl = 0, tp = 0; double bid = SymbolInfoDouble(_Symbol, SYMBOL_BID); double ask = SymbolInfoDouble(_Symbol, SYMBOL_ASK); if (signal == ORDER_TYPE_SELL) { price = bid; if (InpUseStops) { sl = NormalizeDouble(bid + InpStopLoss * _Point, _Digits); tp = NormalizeDouble(ask - InpTakeProfit * _Point, _Digits); } } else { price = ask; if (InpUseStops) { sl = NormalizeDouble(ask - InpStopLoss * _Point, _Digits); tp = NormalizeDouble(bid + InpTakeProfit * _Point, _Digits); } } trade.PositionOpen(_Symbol, signal, InpLots, price, sl, tp); } } // Check position closing conditions void CheckForClose(void) { if (InpUseStops) return; bool tsignal = false; long type = PositionGetInteger(POSITION_TYPE); if (type == POSITION_TYPE_BUY && ExtPredictedClass == PRICE_DOWN) tsignal = true; if (type == POSITION_TYPE_SELL && ExtPredictedClass == PRICE_UP) tsignal = true; if (tsignal && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { trade.PositionClose(_Symbol, 3); CheckForOpen(); } } // Function to get the current spread double GetSpreadInPips(string symbol) { double spreadPoints = SymbolInfoInteger(symbol, SYMBOL_SPREAD); double spreadPips = spreadPoints * _Point / _Digits; return spreadPips; } // Function to process data using the data processing ONNX model vectorf ProcessData(long data_processing_handle) { MqlRates rates[SAMPLE_SIZE_DATA]; vectorf blank_vector; int copied = CopyRates(_Symbol, PERIOD_M15, 1, SAMPLE_SIZE_DATA, rates); if (copied != SAMPLE_SIZE_DATA) { Print("Failed to copy the expected number of rates. Expected: ", SAMPLE_SIZE_DATA, ", Copied: ", copied); return blank_vector; } float input_data[SAMPLE_SIZE_DATA * 5]; for (int i = 0; i < copied; i++) { // Normalize time to be between 0 and 1 within a day input_data[i * 5 + 0] = (float)((rates[i].time)); // normalized time input_data[i * 5 + 1] = (float)rates[i].open; // open input_data[i * 5 + 2] = (float)rates[i].high; // high input_data[i * 5 + 3] = (float)rates[i].low; // low input_data[i * 5 + 4] = (float)rates[i].close; // close } vectorf input_vector; input_vector.Resize(copied * 5); for (int i = 0; i < copied * 5; i++) { input_vector[i] = input_data[i]; } vectorf output_vector; output_vector.Resize(copied * 5); if (!OnnxRun(data_processing_handle, ONNX_NO_CONVERSION, input_vector, output_vector)) { Print("Error running the data processing ONNX model: ", GetLastError()); return blank_vector; } return output_vector; } // Function to make predictions using the prediction ONNX model double MakePrediction(const vectorf& input_data, long prediction_handle, int start_index, int size) { vectorf input_subset; input_subset.Resize(size * 5); for (int i = 0; i < size * 5; i++) { input_subset[i] = input_data[start_index * 5 + i]; } vectorf output_vector; output_vector.Resize(1); if (!OnnxRun(prediction_handle, ONNX_NO_CONVERSION, input_subset, output_vector)) { Print("Error running the prediction ONNX model: ", GetLastError()); return -1.0; } // Extract the normalized close price from the output data double norm_close = output_vector[0]; return norm_close; }
Testando o Consultor Especializado
Depois de criar o consultor especializado, executei o otimizador com as seguintes configurações:

Cheguei aos seguintes parâmetros de otimização em menos de 1 hora. Para fins de demonstração, estou mostrando apenas o primeiro resultado que apareceu. Não completei o ciclo completo de otimização porque queria apenas ilustrar o quão bem as previsões funcionam, mesmo com pouca otimização e um EA relativamente simples que criamos acima:

Os resultados ao longo do período de teste usando as configurações especificadas podem ser vistos abaixo. O relatório completo de backtesting também está anexado como um arquivo zip para revisão adicional.

Conclusão
Neste artigo, compartilhei toda a minha jornada, desde a extração de dados do MetaTrader para o Python até a criação de um Consultor Especializado usando uma rede neural LSTM treinada que pode ser utilizada no MQL. Ao longo do caminho, documentei como abordei a tokenização de tempo, normalização de preços, validação de dados e obtenção de previsões tanto usando Python quanto MQL. Tive que fazer mais de 200 revisões neste artigo à medida que aprendia coisas novas e decidia incorporá-las. Minha única esperança é que os leitores possam usar meu trabalho e rapidamente se familiarizar com o uso das poderosas redes neurais disponíveis em Python e implementá-las no MQL usando ONNX. Também quis permitir que os usuários aproveitassem pipelines de processamento de dados para transformar os dados da maneira que considerassem adequada e implementassem essa funcionalidade em seus scripts MQL usando ONNX. Espero que os leitores gostem deste artigo e estou ansioso para quaisquer perguntas e recomendações que possam ter para mim.
Notas Adicionais:
- O arquivo LSTM_Files.zip inclui um arquivo requirements.txt com os pacotes Python necessários. Basta usar o comando pip install -r requirements.txt no terminal. Isso instalará todos os pacotes listados no arquivo requirements.txt.
- Se você examinar este código com um pouco de cuidado, perceberá que a escala é baseada no máximo e mínimo do dia atual, enquanto o array de previsão pode conter dados do dia anterior, pois usa 60 contínuos de previsão, como vimos, o que pode se sobrepor ao dia anterior, especialmente durante a sessão asiática.
for (int i = 0; i < SAMPLE_SIZE_DATA - SAMPLE_SIZE_PRED + 1; i++) { double prediction = MakePrediction(input_data, PredictionHandle, i, SAMPLE_SIZE_PRED); double min_price = iLow(Symbol(), PERIOD_D1, 0); // price is relative to the day's price therefore we use low of day for min price double max_price = iHigh(Symbol(), PERIOD_D1, 0); // high of day for max price double price = prediction * (max_price - min_price) + min_price; predictions[i] = price; PrintFormat("Predicted close price (index %d): %f", i, predictions[i]); }
Portanto, seria mais preciso usar o preço do dia anterior para uma parte da previsão para obter os preços reais previstos.
double min_price = iLow(Symbol(), PERIOD_D1, 1 ); // previous day's low double max_price = iHigh(Symbol(), PERIOD_D1, 1 ); // previous day's high
- Mesmo o código acima não é muito preciso, pois seria necessário considerar os máximos e mínimos contínuos até o ponto do dia para obter uma previsão precisa.
- Deixei assim porque meu objetivo era converter meu código em um EA, que fará principalmente previsões futuras com base nos valores tokenizados mais recentes do dia atual, que é o que o data_processing_pipeline.onnx faz. Mas para aqueles que estão desenvolvendo um indicador, devem considerar a implementação do uso dos máximos/mínimos do dia anterior com intervalos contínuos para escalar as previsões passadas que se sobrepõem ao dia anterior. Talvez criar um inverso do data_processing_pipeline.onnx que faça isso de forma reversa seja uma escolha lógica.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/15063
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso