
Rede neural na prática: Gradiente

Introdução
No artigo anterior Rede neural na prática: Funções de ativação, implementamos uma aplicação cujo propósito era nos permitir estudar o comportamento das derivadas em conjunto com as funções de ativação. Entender o que foi explicado ali lhe ajudará a entender o que será visto aqui.
Neste artigo tentarei explicar como e por que o gradiente começou a ser utilizado durante o treinamento de uma rede perceptron. A matemática envolvida no gradiente pode a princípio ser um tanto quanto confusa e difícil de entender. Contudo, irei utilizar uma metodologia bem mais simples a fim de que você consiga entender definitivamente como o gradiente funciona na prática. Então vamos dar uma pausa nas distrações e focar no que será explicado neste artigo. Pois entender o funcionamento do gradiente é crucial para entender outras coisas que serão vistas no futuro.Por que o gradiente?
Como não sei, de fato, quanta intimidade cada um tem com a parte matemática. Vou tentar ir com calma neste momento. A programação em si é a parte fácil. Difícil é de fato entender e principalmente explicar a parte matemática. Muitos poderiam dizer, que a parte matemática, que basicamente é a parte teórica do que estaremos implementando. Poderia ser até mesmo ignorada e que deveríamos ir direto ao código.
Mas pessoalmente, ao meu entender, se fosse mostrado apenas e somente o código. Você acabaria, em algum momento, ficando totalmente paralisado. Isto porque, já disse e torno a repetir: NÃO EXISTE UM MODELO PADRÃO PARA CRIAÇÃO DE REDES NEURAIS. Cada caso é um caso. E entender como cada parte de um perceptron funciona é primordial, para que você entenda, e consiga estabelecer, algum tipo de conexão para escolher quais operações serão usadas. Não caia nesta de imaginar que uma dada implementação, conseguirá resolver todo e qualquer tipo de estudo. Mesmo que você procure a treinar, a fim de criar um modelo para representar um certo banco de dados. Nem sempre você conseguirá, usar a mesma implementação, em um banco de dados completamente diferente. Pois isto raramente irá de fato dar certo.
Em outro artigo, abordei o tema sobre gradiente. Mas ao meu ver, aquilo ficou muito mal explicado em diversos aspectos. Talvez este seja o motivo pelo qual tanta gente faz uma grande confusão sobre o tema. Mas aqui vou abordar a coisa toda de uma forma bem mais simples. Isto porque, em breve vamos entrar em um assunto bem mais complicado. Então não iremos adicionar, ainda, as funções de ativação a classe C_Neuron. Isto porque não quero complicar desnecessariamente antes da hora.
Bem, o gradiente é uma forma bem mais simples e cômoda, de representar uma derivada. Ou melhor dizendo, de realmente usarmos a reta tangente. Isto quando temos diversas variáveis sendo utilizadas. Ao fazermos isto, podemos de fato encontrar um cálculo que será mais eficiente, para convergir em muitas situações.
O primeiro ponto a ser compreendido, é o fato de que todo gradiente é na verdade um vetor. E o que isto significa na prática? A primeira consequência disto, é que sendo um vetor, ele aponta em alguma direção. No caso ele aponta para a direção de maior incremento possível. Mas se usarmos ele de forma invertida, poderemos ir na direção de menor incremento. Ou no nosso caso, menor custo. Daí, para diferenciá-lo de todos os demais tipos de vetores, chamamo-lo de gradiente descendente.
O segundo ponto, e este é onde muitos começam a confundir as coisas, é que o gradiente é um vetor ortogonal. Por este motivo, ele literalmente, está perpendicular a uma outra reta que passa pelo ponto de origem do vetor. Esta reta que é sim, a reta tangente. Preste atenção a isto, pois este tipo de coisa será importante depois. Diferente do que acontece com o mínimo quadrado, onde temos uma reta secante sendo criada de fato. Muitos dizem de maneira equivocada, que o perceptron utiliza a reta tangente. Mas quando vamos de fato olhar os cálculos que estão sendo feitos, notamos que se trata na realidade da reta secante. Então cuidado ao mencionar que tipo de reta você está usando nos cálculos trigonométricos. Existem outras coisas relacionadas a vetores, mas para o que se propõem estes artigos, o que foi mencionado ha pouco já será mais do que o suficiente, para explicar todo o conteúdo.
Assim sendo, como o gradiente é um vetor, ele é consideravelmente mais prático em diversos cenários. Mas aqui vamos focar na questão mais básica. Pelo menos por hora. Caso contrário, iríamos começar a falar de coisa não relacionadas ao tema principal.
Ok, o código que estaremos modificando, ou melhor dizendo, adicionando novas funcionalidades, foi visto no artigo Rede neural na prática: Surgimento de C_Neuron, lá apenas colocamos o código para mínimo quadrado. Este faz uso da função mostrada abaixo.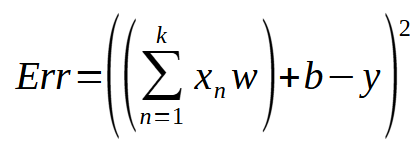
Esta expressão, vista acima, é exatamente o que usamos para calcular o erro de cada uma das linhas de treinamento. Isto usando o mínimo quadrado. Aqui < t > representa o número de entradas no perceptron. < w > representa cada um dos pesos. < b > representa o viés. Assim como < y > o valor estimado como resultado durante o treinamento. Muito bem. A pergunta é: Como podemos tornar esta mesma expressão em um gradiente? A resposta é: Usando um conceito matemático conhecido como derivadas.
Se você olhar esta expressão matemática acima, e ter o mínimo conhecimento de matemática, irá perceber que existe uma outra muito parecida com ela, conhecida como: Regra da cadeia. Isto quando o assunto é derivadas. A tal expressão, é mostrada logo abaixo.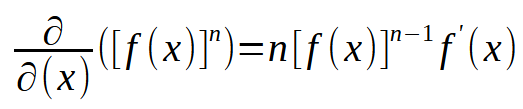
Olhando esta expressão, você deve estar sentindo um arrepio de pavor. Já que parece algo muito complicado. Na verdade, ela é bem simples, e nos diz o que devemos fazer. O valor de x é a expressão que queremos derivar. O n é o expoente, que no caso é dois. Então o valor dois desce multiplicando. O novo expoente é o antigo menos um. E vamos multiplicar esta nova expressão pela derivada de primeira ordem da expressão original. Simples assim. Mas como a nossa expressão original, contém duas variáveis, no mínimo. Que é o peso e o viés. Vamos escrever a nova expressão já usando a notação do gradiente. Desta maneira a expressão fica como mostrada abaixo.
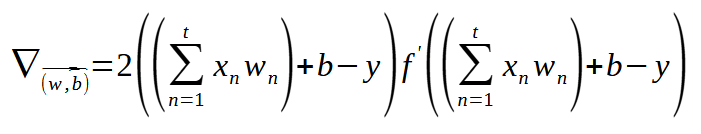
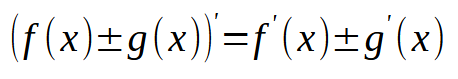
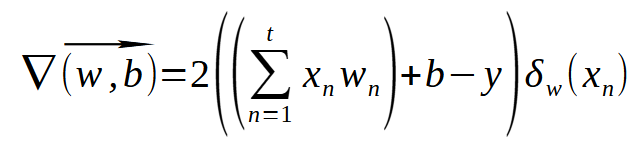
Esta é, de fato, a expressão que deveremos usar. Talvez esta expressão, não esteja escrita da maneira matemática correta. Mas não estou aqui para explicar sobre matemática ou como escrever expressões matemáticas. Estou aqui para mostrar como tornar expressões matemáticas, em código utilizável. E mesmo que esta expressão acima, não esteja 100% correta, dentro do que os matemáticos utilizam para escrever. Ela é suficientemente adequada para que eu consiga explicar o que deverá ser implementado.
Isto porque, aqui estou tanto mostrando o cálculo para o viés, quanto o cálculo para os pesos. E isto quando temos diversas entradas em um perceptron. Talvez fosse melhor escrever em forma matricial boa parte desta expressão. E tornar a derivada parcial no final da expressão, uma notação um tanto quanto diferente. Mas como mencionei a pouco, não tenho interesse em ser 100% correto, quanto a maneira de escrever a expressão matemática. Desde que o código seja corretamente escrito. Pois não queremos ter em nossas mãos, algo que funcione de forma estranha ou extravagante.
Muito bem, com isto chegamos em um ponto chave. E podemos dar uma rápida olhada em como ficou a classe C_Neuron, já com o gradiente sendo devidamente calculado, e já podendo ser utilizado. O código abaixo mostra o que a expressão acima de fato faz, quando colocada em forma de código. Claro que aqui estamos mostrando o código completo. Mas não se preocupe, irei focar a explicação apenas no código do gradiente. Mas isto será feito no próximo tópico.//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) //+------------------------------------------------------------------+ class C_Neuron { private: //+------------------------------------------------------------------+ struct stInfos { bool IsFx; uint nInputs; double Bias, Weight[]; }m_Infos; //+------------------------------------------------------------------+ struct stErr { double weight[], eMaxWeight, bias; }m_Error; //+------------------------------------------------------------------+ inline double Cost_FX(const double &train[]) { double x, err; err = 0; for (uint c0 = 0; c0 < train.Size(); c0++) { x = 0; for(uint c1 = 0; c1 < m_Infos.nInputs; c1++, c0++) x += (train[c0] * m_Infos.Weight[c1]); err += MathPow((x + m_Infos.Bias) - train[c0], 2); } return err; } //+------------------------------------------------------------------+ inline double Learning_FX(const double &train[], const double epsilon, const double LearningRate, const ulong limit) { double err, memT, err_w[]; ulong count; Print("Cost being calculated by the Minimum Square..."); ArrayResize(err_w, m_Infos.nInputs); for (count = 0; (count < limit) && ((err = Cost_FX(train)) > epsilon); count++) { for (uint c = 0, m = m_Infos.Weight.Size(); c < m; c++) { memT = m_Infos.Weight[c]; m_Infos.Weight[c] += LearningRate; err_w[c] = Cost_FX(train) - err; m_Infos.Weight[c] = memT; } memT = m_Infos.Bias; m_Infos.Bias += LearningRate; m_Infos.Bias = memT - (Cost_FX(train) - err); for (uint c = 0, m = m_Infos.Weight.Size(); c < m; c++) m_Infos.Weight[c] -= err_w[c]; } PrintFormat("Total interactions: %I64u", count); ArrayFree(err_w); return err; } //+------------------------------------------------------------------+ inline double Cost_DX(const double &train[]) { double x1, t; ZeroMemory(m_Error); for (uint c0 = 0, cw = 0; c0 < train.Size(); c0++, cw = c0) { x1 = 0; for(uint c1 = 0; c1 < m_Infos.nInputs; c1++, c0++) x1 += (train[c0] * m_Infos.Weight[c1]); t = 2 * ((x1 + m_Infos.Bias) - train[c0]); for(uint c1 = 0; c1 < m_Infos.nInputs; c1++, cw++) { m_Error.weight[c1] += (t * train[cw]); m_Error.eMaxWeight = (MathAbs(m_Error.weight[c1]) > MathAbs(m_Error.eMaxWeight) ? m_Error.weight[c1] : m_Error.eMaxWeight); } m_Error.bias += t; } return (MathAbs(m_Error.bias) > MathAbs(m_Error.eMaxWeight) ? m_Error.bias : m_Error.eMaxWeight); } //+------------------------------------------------------------------+ inline double Learning_DX(const double &train[], const double epsilon, const double LearningRate, const ulong limit) { ulong count; double eRet; Print("Cost being calculated by the Gradient..."); for (count = 0; (count < limit) && (MathAbs(eRet = Cost_DX(train)) > epsilon); count++) { m_Infos.Bias -= (m_Error.bias * LearningRate); for (uint c = 0, m = m_Infos.Weight.Size(); c < m; c++) m_Infos.Weight[c] -= (m_Error.weight[c] * LearningRate); } PrintFormat("Total interactions: %I64u", count); return eRet; } //+------------------------------------------------------------------+ public : //+------------------------------------------------------------------+ C_Neuron(const uint nInputs = 1, const bool isFx = false, double H = 1.0, double L = 0.0) { MathSrand(512); ZeroMemory(m_Infos); m_Infos.IsFx = isFx; m_Infos.Bias = (double)macroRandom; ArrayResize(m_Infos.Weight, m_Infos.nInputs = nInputs); ArrayResize(m_Error.weight, m_Infos.nInputs); for(uint c = 0; c < m_Infos.nInputs; c++) m_Infos.Weight[c] = ((double)macroRandom * (H - L)) + L; } //+------------------------------------------------------------------+ ~C_Neuron() { ArrayFree(m_Infos.Weight); ArrayFree(m_Error.weight); } //+------------------------------------------------------------------+ void View_Variables(void) { Print("Bias: ", m_Infos.Bias); for (uint c = 0, m = m_Infos.Weight.Size(); c < m; c++) PrintFormat("Weight[%d]: %.16f", c, m_Infos.Weight[c]); } //+------------------------------------------------------------------+ inline double Learning(const double &train[], const double epsilon = 1e-3, const double LearningRate = 1e-2, const ulong limit = ULONG_MAX) { return (m_Infos.IsFx ? Learning_FX(train, epsilon, LearningRate, limit) : Learning_DX(train, epsilon, LearningRate, limit)); } //+------------------------------------------------------------------+ }; //+------------------------------------------------------------------+ #undef macroRandom //+------------------------------------------------------------------+
Note como este código está diferente do que foi visto no artigo, onde ele apareceu originalmente. O motivo para isto, se deve justamente ao fato de que agora temos toda uma nova implementação. Cujo objetivo principal é implementar o gradiente, assim como também ter a função de custo de mínimo quadrado. Ambas podem ser selecionadas dentro do perceptron durante a fase onde o construtor é executado. Observe, que depois de termos feito a escolha no construtor. Não precisaremos dizer novamente ao perceptron, se é para ele utilizar o gradiente ou usar o mínimo quadrado no cálculo de custo.
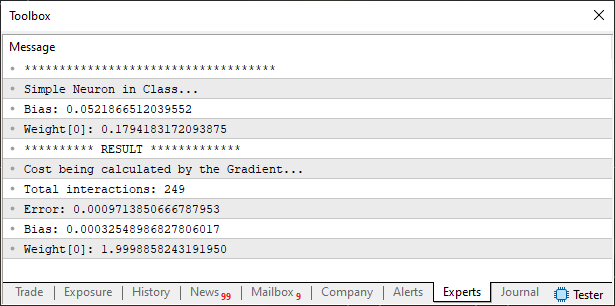
Atenção também ao fato de que foi adicionada uma nova variável na função Learning. Esta nova variável, será bastante útil no futuro. Mas por hora, vamos ver se este perceptron está de fato funcionando. Para isto, usamos o código de script visto logo abaixo.//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #include <Neural Network\C_Neuron.mqh> //+------------------------------------------------------------------+ double Train[] { 0, 0, 1, 2, 2, 4, 3, 6, 4, 8 }; //+------------------------------------------------------------------+ void OnStart() { C_Neuron *neuron; Print("************************************"); Print("Simple Neuron in Class..."); neuron = new C_Neuron(1); (*neuron).View_Variables(); Print("********** RESULT *************"); Print("Error: ", (*neuron).Learning(Train)); (*neuron).View_Variables(); delete neuron; } //+------------------------------------------------------------------+
Ao executar este script no MetaTrader 5, você verá exatamente o que é mostrado na imagem abaixo:
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #include <Neural Network\C_Neuron.mqh> //+------------------------------------------------------------------+ double Train[] { 1, 3, 10.35, 1.5, 3.25, 11.7875, 1.75, 3.94, 13.721, 2.85, 3.46, 14.669 }; //+------------------------------------------------------------------+ void OnStart() { C_Neuron *neuron; Print("************************************"); Print("Simple Neuron in Class..."); neuron = new C_Neuron(2); (*neuron).View_Variables(); Print("********** RESULT *************"); Print("Error: ", (*neuron).Learning(Train)); (*neuron).View_Variables(); delete neuron; } //+------------------------------------------------------------------+
Agora note que temos duas entradas para que o neurônio execute a sua pesquisa. O resultado que será mostrado no MetaTrader 5, pode ser visto na imagem abaixo.
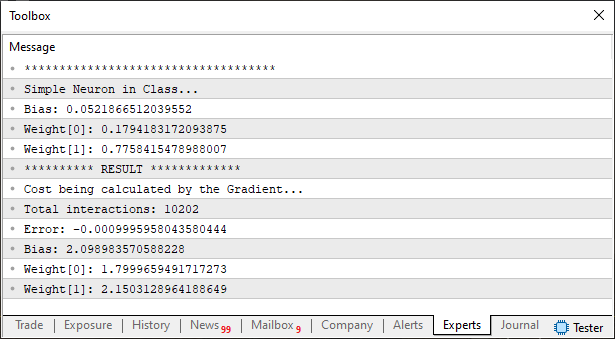
E novamente o resultado é muito, mas muito próximo mesmo do que seriam os valores corretos. Provando desta maneira que o nosso gradiente está de fato funcionando. Conseguindo desta forma, fazer com que o perceptron venha a convergir em direção a uma resposta adequada.
Não se preocupe em criar estes códigos. No anexo, você os terá integralmente. Podendo inclusive criar novos dados a serem usados no treinamento. Mas apesar de tudo está lindo e maravilhoso. Ainda não expliquei como o código funciona. Apesar de ter mostrado as expressões que deram origem a ele. Mas como quero explicar o código do gradiente com calma. Vamos a um novo tópico para que isto seja feito de maneira adequada.
Entendendo o código do gradiente
Para não ficar chato e repetitivo, vamos replicar aqui apenas a parte realmente necessária do código. Com isto focaremos apenas no fragmento mostrado abaixo. A numeração das linhas é voltada a explicar o fragmento, não correspondendo desta maneira a numeração real no arquivo. 01. //+------------------------------------------------------------------+ 02. inline double Cost_DX(const double &train[]) 03. { 04. double x1, t; 05. 06. ZeroMemory(m_Error); 07. for (uint c0 = 0, cw = 0; c0 < train.Size(); c0++, cw = c0) 08. { 09. x1 = 0; 10. for(uint c1 = 0; c1 < m_Infos.nInputs; c1++, c0++) 11. x1 += (train[c0] * m_Infos.Weight[c1]); 12. t = 2 * ((x1 + m_Infos.Bias) - train[c0]); 13. for(uint c1 = 0; c1 < m_Infos.nInputs; c1++, cw++) 14. { 15. m_Error.weight[c1] += (t * train[cw]); 16. m_Error.eMaxWeight = (MathAbs(m_Error.weight[c1]) > MathAbs(m_Error.eMaxWeight) ? m_Error.weight[c1] : m_Error.eMaxWeight); 17. } 18. m_Error.bias += t; 19. } 20. return (MathAbs(m_Error.bias) > MathAbs(m_Error.eMaxWeight) ? m_Error.bias : m_Error.eMaxWeight); 21. } 22. //+------------------------------------------------------------------+ 23. inline double Learning_DX(const double &train[], const double epsilon, const double LearningRate, const ulong limit) 24. { 25. ulong count; 26. double eRet; 27. 28. Print("Cost being calculated by the Gradient..."); 29. for (count = 0; (count < limit) && (MathAbs(eRet = Cost_DX(train)) > epsilon); count++) 30. { 31. m_Infos.Bias -= (m_Error.bias * LearningRate); 32. for (uint c = 0, m = m_Infos.Weight.Size(); c < m; c++) 33. m_Infos.Weight[c] -= (m_Error.weight[c] * LearningRate); 34. } 35. PrintFormat("Total interactions: %I64u", count); 36. 37. return eRet; 38. } 39. //+------------------------------------------------------------------+
Este fragmento contém todo o conteúdo da última expressão matemática, vista no tópico anterior. Esta que tem como objetivo descrever o gradiente, que precisamos implementar em forma de código. Parece um absurdo o que estamos fazendo de fato aqui. Mas por mais que pareça complicado, ao olhar a expressão matemática. Criar o código em si, é muito mais simples do que parece. Desde que, é claro, você respeite exatamente o que está sendo expresso na expressão matemática.
O gradiente basicamente se inicia na linha vinte e três. Uma vez que ele seja chamado, entramos em um laço na linha vinte e nove. Este tem como objetivo, gerar uma série de interações com a função na linha dois. A cada interação que vier a ocorrer, testamos se o erro da função de custo é menor do que o estimado. Caso seja iremos encerrar retornando o erro final, na linha trinta e sete. Agora, caso o erro ainda seja maior do que o estimado, entramos na fase de correção dos valores. Tanto de peso, quanto de viés. Isto é feito usando um ajuste de deslocamento, que estamos chamando aqui de LearningRate. Estes ajustes, que são feitos nas linhas trinta e um, para o viés, e via laço na linha trinta e dois para os pesos. Faz com que venha a ocorrer uma retro propagação dentro do perceptron. Em breve iremos ver em mais detalhes a respeito desta questão da retro propagação. Mas por hora ficamos nisto.
Ok, e como o perceptron sabe o quanto precisa deslocar com base no LearningRate? Bem, para saber isto, o perceptron, conta com a função de custo. Esta é o que se encontra definida na linha dois. Então vamos a ela, para entender como o perceptron sabe o quanto deslocar. A primeira coisa que fazemos é zerar todo o conteúdo da memória onde estará a estrutura contendo os erros internos do perceptron. Isto é feito na linha seis. Uma vez feito isto, entramos em um laço na linha sete. Este tem como objetivo varrer todas as linhas presentes no array de treinamento.
Bem, olhando o código, você nota que existe, uma variável chamada cw. Esta tem o intuito de servir de memória para um outro laço mais interno. Mas o que de fato, é feito dentro deste primeiro laço é a contabilização do erro entre os dados do perceptron e os valores estimados como sendo a saída do perceptron. Preste atenção a isto. Pois depois iremos voltar nesta mesma questão, mas isto em outro artigo, onde precisaremos que você, tenha entendido que neste momento estamos estimando o erro dentro do perceptron. Então não se esqueça deste detalhe.
Ok, na linha dez, entramos em um laço que irá varrer todas as entradas, presentes em uma única linha, do array de treinamento. Neste primeiro momento estamos ajustando o valor de x1, que é a nossa variável de contabilização. Uma vez contabilizado, todo o somatório entre os valores de entrada e os valores de peso para cada uma das entradas. Na linha doze efetuamos a primeira parte do cálculo do gradiente. Atenção ao seguinte fato, que pode ser visto na expressão do gradiente. Quando estamos fazendo o cálculo, tanto os valores para o viés quanto para os valores de peso, passam por uma etapa em comum.
Esta etapa é que está sendo executada nesta linha doze. Feito isto podemos fazer a segunda e última etapa no cálculo do gradiente. Isto porque esta segunda etapa é justamente calcular a derivada parcial. Mas como o valor de viés é uma constante, sua derivada é igual a um. Então neste caso não precisamos fazer coisa alguma com o valor calculado na linha doze. Podemos simplesmente somar o valor calculado para o erro da linha de treinamento, ao valor que já se encontra presente no viés. Isto é feito na linha dezoito. Mas apesar de o valor de viés ter uma derivada constante, o mesmo não se aplica ao peso. Já que se formos olhar a derivada parcial do peso, acabamos por notar que ela é de fato o valor de entrada, para aquele peso específico.
Por conta disto, precisamos de um novo cálculo, que irá varrer novamente toda a linha de treinamento. Só que desta vez iremos multiplicar o valor conseguido no cálculo da linha doze por um outro valor, que no caso é o valor da entrada, que se encontra na linha de treinamento. Este tipo de coisa é feito usando o laço presente na linha treze. Devido ao fato, de já termos deslocado uma determinada quantidade de posições no array, precisamos da variável de memória, criada lá na linha sete. Isto para conseguirmos varrer adequadamente o array novamente. O resultado, de erro para cada um dos pesos é anotado em um outro array. Isto fará diferença depois, quando na linha trinta e três formos ajustar o valor dos pesos baseados no erro que ele contém.
Um detalhe importante aqui. Você pode notar que dentro deste laço na linha treze existem duas coisas sendo feitas. Uma é o que acabamos de mencionar. Que é justamente ajustar o erro de cada um dos pesos em separado. A segunda coisa, é o fato de estamos procurando o maior erro dentre os que estão sendo computados. O motivo desta separação, entre ajustar o erro para cada peso em separado, e ao mesmo tempo buscar o maior erro entre os que foram efetivamente computados. Visa na verdade, forçar o gradiente a não finalizar de forma prematura. E tão pouco, fazer com que todos os pesos, sejam ajustados em um mesmo nível de profundidade. Se você não fizer esta diferenciação, irá mudar a equação de cálculo do gradiente.
Este tipo de mudança, pode até ser benéfica em situações muito específicas. Já que isto fará com que o gradiente, venha a ser calculado de maneira mais rápida. Porém, como foi dito, isto se aplica a situações muito específicas. E como não estamos gerando algo específico, queremos sim que o gradiente seja calculado e ajustado da maneira o mais generalista possível. Por isso está diferenciação e separação entre o valor de maior erro e o valor de erros para cada um dos pesos.
Muito bem, mas apesar de tudo isto, ainda assim temos no final um novo teste antes de retornarmos ao chamador. Este novo teste que está sendo feito na linha vinte, visa garantir que o erro de viés, caso seja maior que o erro nos pesos. Seja de fato o valor retornado para o chamador. Em diversas situações o erro no viés será menor que o erro nos pesos. Porém quando isto não estiver ocorrendo, queremos de fato que o gradiente não finalize. Por conta disto o teste na linha vinte.
E é assim que o gradiente é construído em um perceptron, de modo a poder ter qualquer número de entradas disponíveis. Usando aquela mesma expressão matemática vista no tópico anterior. Onde apesar de parecer bastante confusa e complexa. Ela em forma de código se mostra bem mais simples e amigável do que muitos poderiam de fato imaginar. E tudo isto, faz com que nosso perceptron, seja capaz de executar tarefas, independentemente do tipo de trabalho que vier a lhe ser imposto. Isto sim é algo bonito e divertido de se programar. Porém, ainda não terminamos, falta ainda adicionarmos a função de ativação a este gradiente e a função de mínimo quadrado. Esta é a parte realmente interessante de ser implementada. Mas antes precisamos entender como a matemática será efetivamente desenvolvida. Pois a parte do código é algo até um tanto sem graça de ser feita. Mas a parte matemática. Há esta sim é bem interessante. Então para separar as coisas, vamos a um novo tópico.
Um pouco de matemática não faz mal a ninguém
A parte divertida, não é criar uma forma de adicionar individualmente cada uma das funções de ativação. Isto definitivamente não tem graça alguma. Chega a ser um tédio, de tão chato e simples. Aqui vamos fazer algo um pouco mais elaborado. Vamos desenvolver uma maneira de poder usar qualquer função de ativação, que precisarmos ou desejarmos. Isto apenas, precisando adicionar a mesma na biblioteca de funções de ativação. Isto sim vai ser divertido de ser desenvolvido.
Antes de começarmos deixe-me fazer uma pequena ressalva, com relação ao que foi criado e o que iremos criar. Esta classe C_Neuron, não está sendo de maneira alguma pensada para usar a forma de mínimo quadrado, como função de custo final. Mesmo por que, uma vez que as funções de ativação, estejam devidamente implementadas no gradiente. Este passará a ser bem mais adequado de uma forma geral. Já que ele é consideravelmente muito mais rápido, conforme o número de entradas no perceptron começam a escalar. Ou seja, se você precisar utilizar dez mil entradas em um perceptron. Posso garantir que o gradiente será muito mais rápido do que o mínimo quadrado. Isto durante o treinamento. Já que uma vez que o treinamento foi finalizado. Não precisaremos mais de nenhuma função de custo na implementação final. Tudo que precisaremos será as funções de ativação, os pesos e viés de cada um dos perceptrons envolvidos. Assim como a forma que eles serão ligados. Mas isto será tema para ser melhor explicado em outro artigo no futuro.
Então a forma de adicionarmos a função de ativação ao perceptron, nos forçará a usar um cálculo um pouco diferente. Isto para quando estivermos usando o mínimo quadrado e para quando estivermos usando o gradiente. Mas isto tem um motivo especial. E o motivo é a retro propagação. Quando formos implementar, esta retro propagação, dentro de uma rede. Não quero ter problemas em mover os dados entre os perceptrons. Então a abordagem a ser usada será bem diferente da que muitos podem estar esperando. Mas vamos focar neste momento na retro propagação dentro do perceptron, e não nos preocupar por hora com ligações em rede. Para entender isto, veja a imagem abaixo.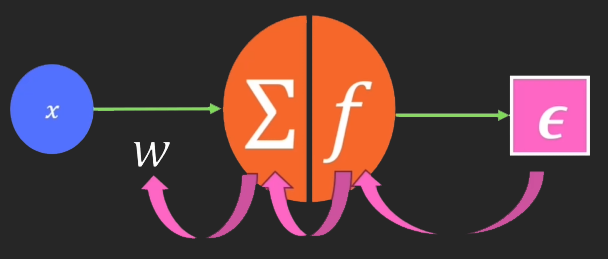
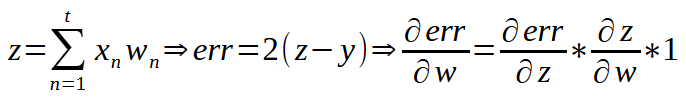
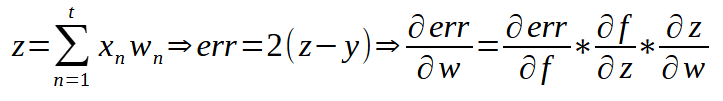
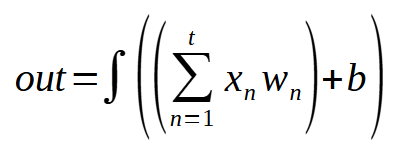
Esta sim é a expressão que de fato usamos. Tanto quando já temos um modelo treinado, como no momento em que estamos treinando um modelo. Um detalhe: O símbolo de integração que você vê nesta expressão, não representa de fato que faremos um cálculo de integral. Ele está aí apenas para indicar a função de ativação. Mas observando esta expressão podemos ver claramente que não existe nenhum tipo de cálculo complexo sendo feito. Tudo se baseia em somas e multiplicações. Além é claro, de uma das funções de ativação, que foi explicada em outro artigo anterior. Esta função deverá ser definida durante a criação do perceptron, para que tudo funcione perfeitamente bem.
Agora vem a parte curiosa, na qual você já deve estar pensando: Então temos duas e não uma saída sendo feita no perceptron? É isto que de fato acabamos de criar? Sim, é isto mesmo que estará acontecendo. Porém ainda não criamos estas duas saídas. Se bem que a retro propagação já é uma saída. Mas da forma como ela está, isto não conta. Uma das saídas é conhecida como FORWARD PROPAGATION, enquanto a outra é conhecida como BACK PROPAGATION. Ambas precisam existir, para que o perceptron seja de fato útil para nós.
Mas como a coisa é muito simples, e aparentemente obvia, dificilmente ouvimos falar da FORWARD PROPAGATION. Mas vemos muitos falarem sobre BACK PROPAGATION, mesmo quando a explicação fica meio que capenga.
Considerações finais
Neste artigo, expliquei com um pouco mais de detalhes, como e por que surgiu o gradiente em redes perceptron. Também começamos a explorar uma outra questão que é a FORWARD PROPAGATION e BACK PROPAGATION. Apesar de ainda não termos colocado as funções de ativação no perceptron, a fim de que possamos ver isto ocorrendo. O que foi explicado aqui, tornará o trabalho a ser mostrado nos próximos artigos um pouco mais simples e fácil de explicar, e por consequência mais adequado de ser devidamente compreendido.
Apesar de tudo parecer um tanto quanto distante, o fato de que estamos caminhando na direção correta. Assim, peço que você estude este material com calma. Pois entender o que foi explicado aqui é primordial para entender o que será visto em breve.| Arquivo MQ5 | Descrição |
|---|---|
| Scripts\Example A | Demonstração básica |
| Scripts\Example B | Demonstração básica |
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso