
Rede neural na prática: Uma questão de escala

Introdução
No artigo anterior Rede neural na prática: Perceptron, foi explicado de forma mais adequada e abrangente, sobre tudo que montamos até o momento. Mas foi principalmente feita uma revisão, a fim de mostrar como as coisas, vão surgir naturalmente. Isto conforme a matemática vai avançar em direção ao que precisamos de fato implementar.
Neste artigo veremos e iremos explorar a necessidade de se modificar a escala dos dados que serão utilizados. O objetivo desta mudança é, de certa forma, um pouco confusa para a maioria das pessoas. Já que muitos fazem tal coisa sem de fato entender a real motivação para que tal coisa precise ser feita. Enquanto outros simplesmente acreditam que tal coisa não precisa ser feita.
Por que mudar a escala dos dados?
Durante este artigo, não daremos tanta atenção ao código, assim como também não iremos mais falar ou mencionar o mínimo quadrado. Salvo em situações bem específicas. Mesmo que ele ainda permaneça presente no código da classe C_Neuron. Ele estará ali, apenas por que será necessário explicar, outra coisa que ainda não abordamos e que faz uso justamente, da função de custo de mínimo quadrado. Com isto o foco principal de agora em diante, de fato será o uso do gradiente. De qualquer forma, não quero que você se apegue em demasia a nenhuma parte do código. Quero que você procure entender, porque usar uma coisa ou outra, e quando usar.
E o motivo é bem simples, não existe uma única e totalmente perfeita forma de se fazer as coisas quando o assunto são redes perceptrons. Existe a forma que funciona e a forma que não funciona. E em muitos casos, a forma que funciona, pode ser um tanto custosa em termos de custo computacional, precisando assim ser adaptada de alguma maneira para um modelo mais adequado, onde você precisa saber como adaptar o código. Conforme formos adicionando cada vez mais e mais entradas ao perceptron, e aumentando o número deles, este tipo de coisa da qual acabei de mencionar começará a fazer cada vez mais sentido, e você entenderá melhor este tipo de coisa, na prática.
Existe uma falsa sensação por parte do grande público, de que uma rede perceptron, ou inteligência artificial, consegue de alguma forma compreender o mundo em que vivemos. Isto em alguns casos pode até ser verdade. Mas você, que deseja fazer com que uma rede perceptron, ou mesmo de um único perceptron, possa conseguir convergir o mais rápido possível, precisará entender que a escala usada nos valores, em muitas das vezes acaba influenciando a velocidade desta mesma convergência.
Isto parece de certa maneira bobagem, e até mesmo contra intuitivo, já que durante a retro propagação, o valor de erro faz com que o perceptron, aparentemente dê saltos relativamente grandes no começo, em direção a um ponto de convergência. E conforme o tempo vai passando, começamos a dar passos cada vez menores nesta mesma correção do erro. Então a primeira vista, mudar a escala dos dados não iria influenciar muito. Bem, isto de fato é verdade em muitas das situações. Porém, existem situações muito específicas em que a mudança de escala dos valores, permite, sim, ajudar a melhorar a velocidade da convergência de forma excepcional. Mas existe outro fator, que também torna a mudança de escala um tanto quanto interessante. Este fator tem a ver com a questão que será explicada quando formos falar de normalização e padronização. Mas adiantando um pouco o assunto. Seria como se tirássemos um pouco do viés do aprendizado. Muitas vezes uma rede, ou mesmo um perceptron isolado, acaba ficando viciado, justamente por conta de que ele está lidando com dados crus.
Novamente não é sempre que precisamos fazer o que será mostrado aqui. Tanto que ainda não tenho certeza se de fato irei manter o que será visto aqui, em algum código futuro. Porém, como ainda não me decidi a este respeito, você precisa entender que dependendo, do propósito a ser dado a sua rede perceptron, ou perceptron. Você precisará efetuar algum tipo de tratamento dos dados, antes mesmo que estes dados passem pelo perceptron, ou por uma rede perceptron. Isto durante a fase de treinamento. Após treinada, pode ser que tal tratamento que os dados estejam sofrendo, possa não ser mais de fato necessário. Mas novamente este tipo de situação precisa ser analisada com calma.
Uma das formas mais simples de tratamento é a mudança na escala dos valores. Para você compreender qual seria a importância deste tratamento. Quero que você procure no mercado financeiro, um ativo que pague proventos. Se você olhar o gráfico passado deste mesmo ativo. Irá notar que o tamanho das barras vai diminuindo gradativamente, assim como também a cotação do ativo. O que nos dá uma falsa impressão de que o movimento percentual mudou ao longo do tempo. Mesmo que a cotação do ativo ao longo do tempo tenha se mantido no mesmo patamar. A nossa percepção grosseira das coisas, nos dirá exatamente o contrário daquilo que seria a realidade. E este tipo de coisa, acaba nos causando um viés.
O mesmo acontece durante o treinamento de uma rede perceptron, ou perceptron. Se os dados estiverem de uma dada maneira. O cálculo feito, irá construir uma equação completamente enviesada. E devido justamente ao fato de que o sistema está sendo levado a usar valores um tanto quanto diferentes. Quando, na verdade, eles estariam em um mesmo range mostrando que o ativo não tem um movimento que acreditamos que esteja acontecendo. Isto acaba forçando o sistema a um falso positivo, ou falso negativo.
Neste momento estou apenas introduzindo este tipo de assunto. Já que isto será melhor explorado, quando formos falar em normatização e padronização. Lá de fato, você notará, como este tratamento faz toda a diferença, podendo tanto ajudar quanto também atrapalhar bastante, caso não sejam tomados todos os cuidados necessários para evitar algo que seria a dispersão de dados. Contudo, aqui e neste momento a ideia será um tanto quanto mais simples de ser compreendida, sendo apenas a base para algo bem mais profundo.
Para que você possa entender um pouco melhor sobre isto. Vamos pensar em um bloco de dados cujo conteúdo serão valores que se encontram distribuídos entre zero e quinze mil. Para o perceptron, ou mesmo uma rede perceptron, esta distribuição pouco importa, pois no final as variáveis internas, que conhecemos como pesos e viés, serão ajustados de maneira a criar uma equação, que represente a dispersão daqueles dados. Então mesmo que mudemos a escala de forma que ela fique entre zero e um, isto a princípio, não fará muita diferença. Desde que mantenhamos a mesma distribuição.
Porém, pelo fato de que a mudança de escala, não faça diferença, ela pode tornar a fatoração um pouco mais eficiente. Lembre-se de que começamos os valores internos, entre zero e um. Isto de forma pseudo randômica. Mesmo que o perceptron, usando o gradiente, procure analisar rapidamente o bloco de dados, convergindo para alguma solução. No começo podemos ter um erro gigantesco. Que irá decair aos poucos. Mas começando em uma escala diferente, este mesmo erro poderá ser consideravelmente menor ou maior. Podendo inclusive ser pequeno o suficiente para que se aproxime do erro estimado.
Assim, quando aumentarmos novamente a escala, o perceptron, ou rede, já não estará mais tão enviesado. Já que existirá uma margem maior no erro entre os cálculos feitos pelo perceptron, ou rede, e os valores estimados. E se tivermos valores estimados muito próximos, acabará que o perceptron, ou rede, não saberá exatamente qual o valor correto. Nos dando assim a chance de estudar, qual seria o valor mais adequado. Uma vez que o perceptron, ou rede, poderia vir a nos dizer, quais seriam os valores mais próximos daquele que seria o correto. E isto não acontece, quando a rede ou perceptron, já se encontra de alguma forma viciado em um conjunto de dados.
Então aqui focaremos justamente nesta questão da escala. Isto antes mesmo de tentar entender por que precisamos fazer a normalização ou padronização dos valores de um banco de dados. De certa maneira, padronizar ou mesmo normalizar dados, nada mais é do que fazer com que uma dispersão de valores fiquem em um range especifico. Com isto, apesar de serem coisas que a princípio parecem diferentes, o objetivo primário é basicamente o mesmo. Então, para começar a ver isto em forma de código, vamos abrir um novo tópico para poder separar melhor as coisas.
Diferença nas escalas
A primeira coisa, na qual precisamos pensar, está diretamente ligada a matemática. Quero que você primeiro entenda isto, para não imaginar que estamos fazendo algo, quando, na verdade, estaremos fazendo outra coisa.
Basicamente existem dois tipos de escalas bastante conhecidas. Uma é a escala aritmética e a outra é a escala logarítmica. Mas qual devemos de fato utilizar? Ou melhor dizendo, quando usar uma e quando usar a outra? Bem, provável que ao ouvir estes nomes de escala, você pense em algo que seria o gráfico de um ativo qualquer. Pois apesar de você não estar errado ao ter este tipo de pensamento. A ideia, mas principalmente o conceito de escala, não está diretamente ligado ao mercado financeiro. Escala, serve para nos ajudar a dimensionar de forma mais adequada valores, que de outra maneira, seriam muito mais complicados de serem mensurarmos.
Por exemplo: Quando usamos uma régua para medir algo, estaremos muito provavelmente usando a escala aritmética. Já que seria muito mais complicado entender e comparar coisas diferentes, se o valor não progredisse de maneira linear. E é justamente neste ponto que mora a grande diferença entre estas duas escalas. A escala logarítmica, não tem uma progressão linear. Mas mesmo que pareça algo insano tentar mensurar algo usando a escala logarítmica. De fato, ela tem muitas aplicações. Como, por exemplo: medir a amplitude de um sinal, ou mesmo a intensidade de força.
Mas veja que nestes casos, não existe a possibilidade de um valor negativo. Sem bem que podemos usar valores negativos em logaritmos. Mas isto nos forçaria a usar números complexos. O que apenas iria complicar toda a explicação, algo que sairia completamente do objetivo deste artigo. Então vamos ficar apenas na parte simples da ideia sobre escala.
Então resumindo: se você precisar medir valores tanto positivos, quanto negativos. E eles precisam progredir de maneira gradual e sempre linear. Usamos a escala aritmética. Se os dados a serem medidos, aumentam muito rapidamente de valor, e não podem assumir valores negativos. É preferível utilizar a escala logarítmica. Basicamente é isto. Mas só a prática, de fato lhe ajudará a fazer a melhor escolha, em cada caso específico.
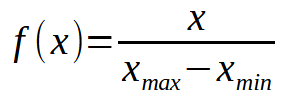
Imagem 01
Isto pode até soar como sendo bobagem. Mas preste atenção a uma coisa: podemos mudar o valor de < x >, apenas mudando o range. Neste caso não iremos forçar um valor. Mas iremos reduzir ele a uma faixa de valores. Talvez esta expressão acima, não faça muito sentido logo de cara. Então vamos abrir um pouco ela, talvez assim ela comece a fazer um pouco mais de sentido para você.
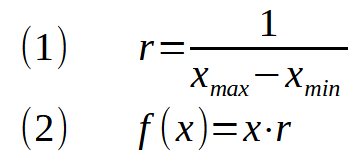
Imagem 02
A expressão (1) indica o quanto estaremos mudando a relação na escala. Se o valor de < r > na expressão (2), for menor que um, teremos a compactação dos valores. Se ele for maior que um, teremos a aplicação dos valores. Com isto seria como se estivéssemos aumentando ou diminuindo o zoom dentro do sistema.
Agora para a escala logarítmica, a expressão é um pouco diferente, como você já deve estar imaginando. O detalhe é que podemos usar qualquer base, para representar os dados. Mas geralmente se usa a base dez ou a base Euler, que neste caso é mais conhecido como logaritmo natural, o famoso ln. Esta parte da escala logarítmica, talvez eu nem explique, pelo ela ser muito parecida em termos de programação, com o que será visto aqui.
Agora para entrar na parte prática, e para que isto que está sendo explicado faça sentido. Vamos pegar o código, que se encontra no artigo anterior, e mudar, apenas e tão somente, os dados de treinamento. Não vamos fazer nada além disto. É importante que você consiga ver isto e perceba que apenas esta mudança estará sendo feita. Então no código original, temos o seguinte fragmento mostrado abaixo:
//+------------------------------------------------------------------+ //Training expression: f(x) = (w0 * 1.8) + (w1 * 2.15) + 2.1 //+------------------------------------------------------------------+ double Train[] { 1, 3, 10.35, 1.5, 3.25, 11.7875, 1.75, 3.94, 13.721, 2.85, 3.46, 14.669 }; //+------------------------------------------------------------------+ #define nColumns 3 #define nLines Train.Size() / nColumns //+------------------------------------------------------------------+
Fragmento 01
Este fragmento será modificado, pelo fragmento mostrado logo a seguir:
//+------------------------------------------------------------------+ //Training expression: f(x) = (w0 * 1.8) + (w1 * 1.254) + (w2 * 2.35) + 4.1258 //+------------------------------------------------------------------+ double Train[] { 5.89, 12.473, 18.452, 73.731142, 8.452, 13.154, 24.2541, 92.831651, 7.512, 14.576, 15.831, 73.128554, 3.452, 8.459, 30.1254, 91.741676 }; //+------------------------------------------------------------------+ #define nColumns 4 #define nLines Train.Size() / nColumns //+------------------------------------------------------------------+
Fragmento 02
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. #property script_show_inputs 04. #property description "Script to compare execution speed\n" \ 05. "Here we are using only the CPU.\n" \ 06. "However, the results are still very interesting." 07. //+------------------------------------------------------------------+ 08. #include <Neural Network\C_Check_Neuron.mqh> 09. //+------------------------------------------------------------------+ 10. enum eFactorization { 11. Minimum_Square, 12. Gradient_Descent, 13. }; 14. //+------------------------------------------------------------------+ 15. input eFactorization user00 = Minimum_Square; //Type of factorization 16. input double user01 = 1e-3; //Estimated error 17. input double user02 = 1e-3; //Learning Rate 18. input C_Neuron::eFnActivate user03 = C_Neuron::Identity; //Activation function 19. input ulong user04 = 5; //Number of interactions 20. //+------------------------------------------------------------------+ 21. //Training expression: f(x) = (w0 * 1.8) + (w1 * 1.254) + (w2 * 2.35) + 4.1258 22. //+------------------------------------------------------------------+ 23. double Train[] { 24. 5.89, 12.473, 18.452, 73.731142, 25. 8.452, 13.154, 24.2541, 92.831651, 26. 7.512, 14.576, 15.831, 73.128554, 27. 3.452, 8.459, 30.1254, 91.741676 28. }; 29. //+------------------------------------------------------------------+ 30. #define nColumns 4 31. #define nLines Train.Size() / nColumns 32. //+------------------------------------------------------------------+ 33. void OnStart() 34. { 35. C_Check_Neuron *neuron; 36. 37. Print("************************************"); 38. Print("Simple Neuron in Class..."); 39. Print("************************************"); 40. Print("Parameters:"); 41. Print("Type of factorization: ", EnumToString(user00)); 42. Print("Estimated error: ", user01); 43. Print("Learning Rate:", user02); 44. Print("Activation function: ", EnumToString(user03)); 45. Print("Number of interactions: ", user04); 46. Print("************************************"); 47. 48. neuron = new C_Check_Neuron(nColumns - 1, user03, user00 == Minimum_Square); 49. 50. (*neuron).View_Training_Data(Train, nColumns); 51. (*neuron).Performs_Training(Train, user01, user02, user04); 52. // (*neuron).Check_Training(Train, nColumns); 53. 54. delete neuron; 55. } 56. //+------------------------------------------------------------------+
Código 01
Observe que além do array de treinamento, que se encontra modificado. Também existe a presença da linha dezenove. Esta será responsável por nos ajudar a configurar o número de interações que o código fará. Por motivos práticos, a linha cinquenta e dois, que é a responsável por apresentar os resultados, foi comentada, assim ela não será mais executada. Contudo, isto pouco importa, já que precisamos de fato é da linha cinquenta e um seja executada. Já que ela irá nos mostra qual o erro que o perceptron está tendo naquele exato número de interações. Agora veja o que acontece, quando executamos este código no terminal do MetaTrader 5. O resultado é visto na imagem abaixo.
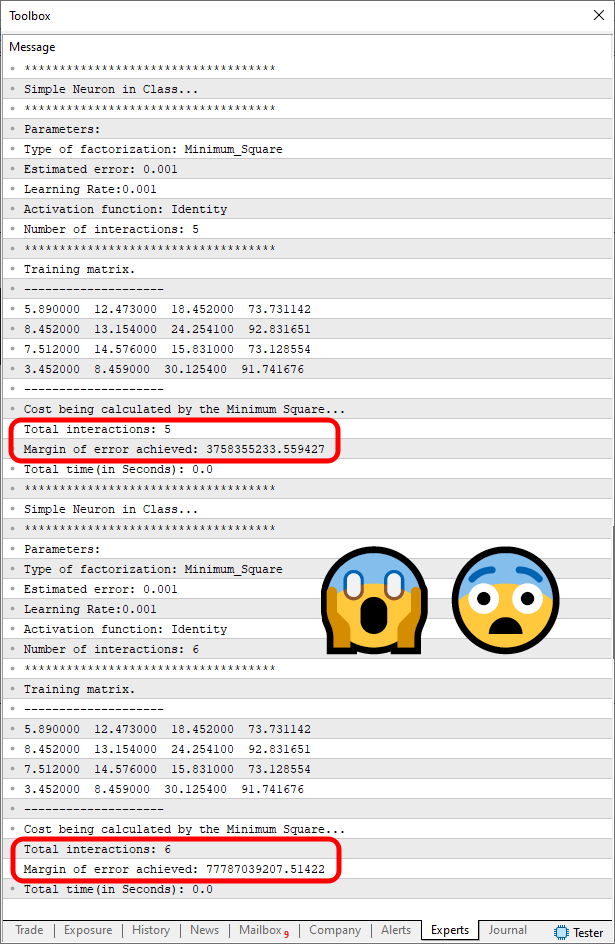
Imagem 03
Para facilitar, marquei o exato ponto onde podemos ver o erro que o perceptron está tendo. E para a sua surpresa, note que o erro não caiu. Mas sim aumentou e bastante. Isto significa que o perceptron, não está conseguindo lidar com os dados presentes no array de treinamento. Mas por quê? Se você mudar os valores, verá que o perceptron funciona. Mas quando extrapolamos, ele simplesmente fica meio alucinado, totalmente perdido, sem saber para onde ir.
Este é um dos problemas que para conseguirmos resolver, precisaremos mexer na escala dos valores. Preste atenção no que acabei de dizer. Não estou dizendo que você tem que procurar valores adequados para serem utilizados. Estou dizendo para você enganar o perceptron, fazendo com que ele pense estar lidando com algo, quando, na verdade, está de fato lidando com outro tipo de coisa.
Existem diversas maneiras de se fazer isto. Cada uma com um propósito diferente e um objetivo bem específico. Mas aqui, como o intuito é ser o mais didático quanto for possível. Vamos usar uma maneira que seja bem mais interessante, pelo ponto de vista didático. Vamos fazer com que a própria aplicação, que no caso é um script para MetaTrader 5. Mude os valores de maneira que o perceptron bobão, não perceba que as coisas estão diferentes. Para fazer isto, vamos ao código da classe C_Check_Neuron.
Um detalhe: No anexo, irei deixar o código original, para você ver os resultados como mostrei na imagem acima. E também o código que estaremos implementando neste momento. Assim você poderá entender na prática como e por que precisamos fazer as coisas de uma certa maneira.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include <Neural Network\C_Neuron.mqh> 05. //+------------------------------------------------------------------+ 06. class C_Check_Neuron : private C_Neuron 07. { 08. //+------------------------------------------------------------------+ 09. private : 10. //+------------------------------------------------------------------+ 11. struct st_0 12. { 13. double Hi, 14. Lo, 15. Reason; 16. uint nColumns, 17. nLines; 18. }m_Limits; 19. double m_arr[]; 20. //+------------------------------------------------------------------+ 21. public : 22. //+------------------------------------------------------------------+ 23. C_Check_Neuron(const double &arr[], uint nInputs = 1, eFnActivate fn = Identity, bool isFx = false) 24. :C_Neuron(nInputs, fn, isFx) 25. { 26. ZeroMemory(m_Limits); 27. m_Limits.nColumns = nInputs + 1; 28. m_Limits.nLines = arr.Size() / m_Limits.nColumns; 29. m_Limits.Lo = m_Limits.Hi = arr[0]; 30. for (ulong c = 1, m = arr.Size(); c < m; c++) 31. { 32. m_Limits.Hi = MathMax(arr[c], m_Limits.Hi); 33. m_Limits.Lo = MathMin(arr[c], m_Limits.Lo); 34. }; 35. ArrayResize(m_arr, arr.Size()); 36. m_Limits.Reason = 1 / (m_Limits.Hi - m_Limits.Lo); 37. for (ulong c = 0, m = arr.Size(); c < m; c++) 38. m_arr[c] = arr[c] * m_Limits.Reason; 39. } 40. //+------------------------------------------------------------------+ 41. ~C_Check_Neuron() 42. { 43. ArrayFree(m_arr); 44. } 45. //+------------------------------------------------------------------+ 46. void View_Training_Data(void) 47. { 48. string sz0; 49. 50. Print("Training matrix."); 51. Print("--------------------"); 52. for (uchar i = 0; i < m_Limits.nLines; i++) 53. { 54. sz0 = ""; 55. for (uchar j = 0; j < m_Limits.nColumns; j++) 56. sz0 += StringFormat("%f ", m_arr[(i * m_Limits.nColumns) + j]); 57. Print(sz0); 58. } 59. Print("--------------------"); 60. } 61. //+------------------------------------------------------------------+ 62. void Performs_Training(double epsilon, double LearningRate, ulong limit) 63. { 64. ulong it0, it1; 65. 66. it0 = GetTickCount(); 67. Print("Margin of error achieved: ", Learning(m_arr, epsilon, LearningRate, limit)); 68. it1 = GetTickCount(); 69. Print("Total time(in Seconds): ", (it1 - it0) / 1000.0); 70. } 71. //+------------------------------------------------------------------+ 72. void Check_Training(const double &arr[]) 73. { 74. string sz0; 75. double mem[]; 76. 77. Print("********** RESULT *************"); 78. ArrayResize(mem, m_Limits.nColumns); 79. for (uchar i = 0; i < m_Limits.nLines; i++) 80. { 81. sz0 = ""; 82. for (uchar j = 0; j < m_Limits.nColumns - 1; j++) 83. sz0 += StringFormat("%f ", mem[j] = arr[(i * m_Limits.nColumns) + j]); 84. sz0 += StringFormat("%f", Perceptron(mem)); 85. Print(sz0); 86. } 87. Print("--------------------"); 88. ArrayFree(mem); 89. View_Variables(); 90. } 91. //+------------------------------------------------------------------+ 92. }; 93. //+------------------------------------------------------------------+
Código 02
Este código ainda não está concluído, e de fato o mesmo ainda tem um pequeno problema. Mas depois veremos isto com mais calma. Primeiro note que foi adicionado uma estrutura na linha onze, esta pretende, criar a manipulação que faremos para enganar o perceptron bobão. Veja que temos um array, declarado na linha dezenove. Agora vem a piada. Na linha vinte e três, onde o constructor, passou a receber um array, deveremos usar este novo array de treinamento.
Agora preste atenção no que será feito. Primeiro na linha vinte e seis limpamos a região de memória onde a estrutura de dados se encontra. Em seguida iniciamos alguns dos valores desta estrutura, e o motivo para limpar a memória, é evitar que trabalhemos com lixo. Mesmo que atribuamos valores depois, é sempre bom garantir que está tudo limpo, pois podemos esquecer de atribuir algum valor, e aí a coisa complica. Agora a parte divertida. Na linha vinte e nove, iniciamos os valores de máximo e mínimo, para logo depois entramos no laço que varrerá todo o array de treinamento, procurando desta forma o maior e menor valor presente no array.
Depois, já na linha trinta e cinco, alocamos memória para o array interno da classe. Na linha trinta e seis, colocamos a equação vista anteriormente neste artigo. Isto para criar uma escala aritmética. Assim na linha trinta e sete entramos em um novo laço. Mas desta vez criaremos um array de treinamento falso. Com base no array de treinamento original. Com isto finalizamos o constructor.
//+------------------------------------------------------------------+ void OnStart() { C_Check_Neuron *neuron; Print("************************************"); Print("Simple Neuron in Class..."); Print("************************************"); Print("Parameters:"); Print("Type of factorization: ", EnumToString(user00)); Print("Estimated error: ", user01); Print("Learning Rate:", user02); Print("Activation function: ", EnumToString(user03)); Print("Number of interactions: ", user04); Print("************************************"); neuron = new C_Check_Neuron(Train, nColumns - 1, user03, user00 == Minimum_Square); (*neuron).View_Training_Data(); (*neuron).Performs_Training(user01, user02, user04); // (*neuron).Check_Training(Train); delete neuron; } //+------------------------------------------------------------------+
Fragmento 03
Estou aqui dando destaque apenas e tão somente a parte que realmente mudou no código. Nada que de fato precise ser explicado, dada a simplicidade da coisa. Mas repare agora o que acontece, quando compilamos e executamos este código no terminal do MetaTrader 5. O resultado é visto na imagem abaixo.
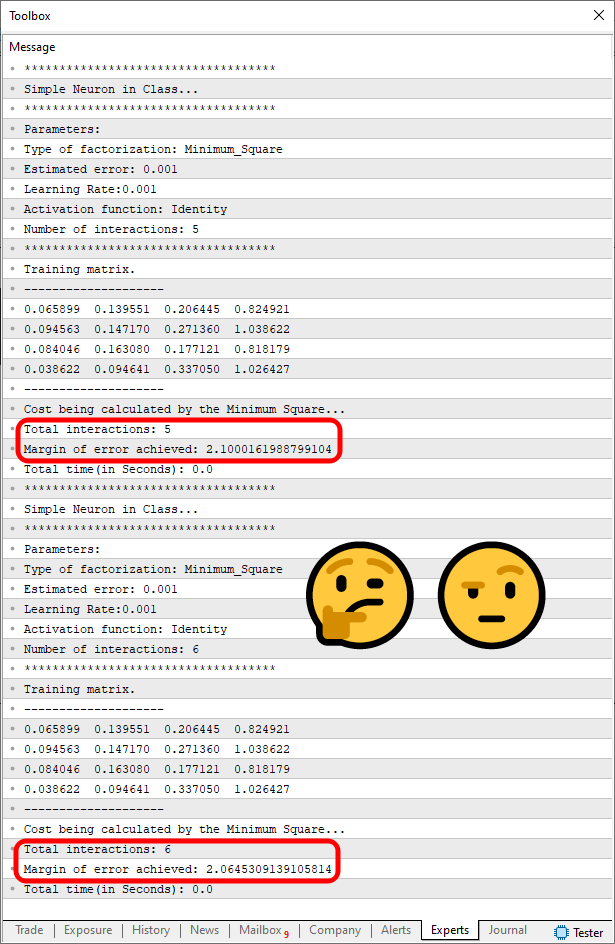
Imagem 04
Mas que coisa do cão. Isto não é de DEUS. Como assim, agora o perceptron conseguiu entender a situação e começou a convergir? Que coisa mais maluca foi esta? De fato, meu amigo, tem coisas que somente vendo para conseguir entender e acreditar. Falando ninguém acreditaria e diriam que você não faz ideia do que estaria sendo explicado, ou no mínimo não sabe o que está fazendo. Mas você pode de forma bastante nítida e bem clara, notar que o perceptron mudou seu comportamento. Apenas pelo simples fato de termos mudado a escala dos valores. É ou não é uma coisa de maluco. E tem gente que acha que já viu de tudo na vida. Eu digo: "Sabe de nada inocente."
45. //+------------------------------------------------------------------+ 46. void View_Training_Data(void) 47. { 48. string sz0; 49. 50. Print("Training matrix."); 51. Print("--------------------"); 52. for (uchar i = 0; i < m_Limits.nLines; i++) 53. { 54. sz0 = ""; 55. for (uchar j = 0; j < m_Limits.nColumns; j++) 56. sz0 += StringFormat("%f ", m_arr[(i * m_Limits.nColumns) + j] / m_Limits.Reason); 57. Print(sz0); 58. } 59. Print("--------------------"); 60. } 61. //+------------------------------------------------------------------+
Fragmento 04
Ok, agora compilamos e executamos novamente o código. Com isto passaremos a ter o seguinte resultado, mostrado na imagem abaixo:
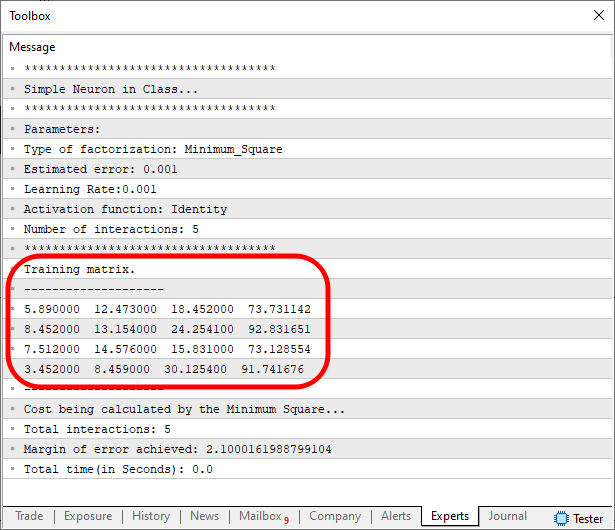
Imagem 05
Agora, sim. Além de estamos enganando o perceptron bobão e estupido. Também estamos mostrando para o usuário inocente que está tudo perfeito. Mas ainda temos outro problema. Para perceber este novo problema é preciso ligar o código que mostra os resultados. Além de deixar o perceptron convergir até um valor de erro mais adequado, já que sabemos que ele agora está de fato convergindo, poderemos remover a possibilidade de ajuste feito pelo usuário. E liberar o código como mostrado abaixo.
//+------------------------------------------------------------------+ void OnStart() { C_Check_Neuron *neuron; Print("************************************"); Print("Simple Neuron in Class..."); Print("************************************"); Print("Parameters:"); Print("Type of factorization: ", EnumToString(user00)); Print("Estimated error: ", user01); Print("Learning Rate:", user02); Print("Activation function: ", EnumToString(user03)); Print("************************************"); neuron = new C_Check_Neuron(Train, nColumns - 1, user03, user00 == Minimum_Square); (*neuron).View_Training_Data(); (*neuron).Performs_Training(user01, user02, ULONG_MAX); (*neuron).Check_Training(Train); delete neuron; } //+------------------------------------------------------------------+
Código 03
E mais uma vez, compilamos e executamos a nova versão do código, e com isto resultado no terminal do MetaTrader 5, será o seguinte:
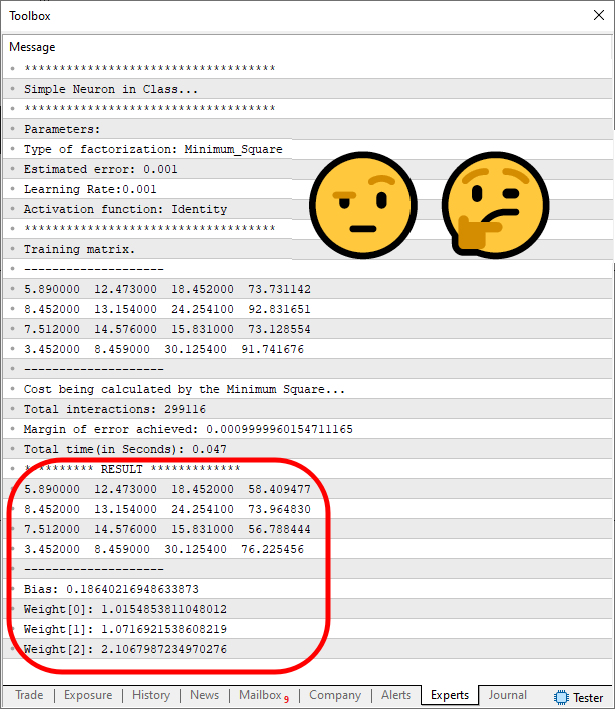
Imagem 06
Mas espere um pouco. Isto não está correto. O que aconteceu para que isto ficasse errado desta maneira? Bem, meu caro leitor, nem tudo é sempre perfeito e tranquilo na vida de um programador. Às vezes, temos que entender o que estamos fazendo, caso contrário, acabamos encontrando uma resposta que não entenderemos. E por não entender a mesma acabamos desistindo da solução, mesmo quando ela não está tão errada, como nos parece à primeira vista. Por conta disto, vamos tentar entender o que aconteceu para que o resultado ficasse tão diferente daquele que era o esperado.
Para isto, precisamos recorrer a um programa de matemática, onde consigamos plotar um gráfico na tela. Assim será mais simples de entender, o que está acontecendo aqui. Usarei o código abaixo no SciLab, que é gratuito, mas também poderia ser no MatLab. Ambos mostraram o mesmo tipo de coisa.
clc; clear; clf; x = [-2:0.01:2]; y = (1.8 * x) + (1.254 * x) + (2.35 * x) + 4.1258; plot(x, y, 'p-'); y = (1.0154853811048012 * x) + (1.0716921538608219 * x) + (2.1067987234970276 * x) + 0.18640216948633873; plot(x, y, 'r-'); xgrid(0, 1);
Script SciLab
O resultado é visto logo abaixo.
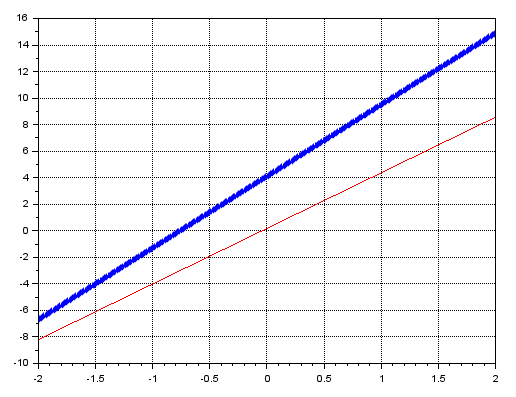
Imagem 07
//+------------------------------------------------------------------+ inline double Learning(const double &train[], double reason, double epsilon, double LearningRate, ulong limit = ULONG_MAX) { double err = (m_Infos.IsFx ? Learning_FX(train, epsilon, LearningRate, limit) : Learning_DX(train, epsilon, LearningRate, limit)); m_Infos.Bias /= reason; return err; } //+------------------------------------------------------------------+
Fragmento 05
//+------------------------------------------------------------------+ void Performs_Training(double epsilon, double LearningRate, ulong limit) { ulong it0, it1; it0 = GetTickCount(); Print("Margin of error achieved: ", Learning(m_arr, m_Limits.Reason, epsilon, LearningRate, limit)); it1 = GetTickCount(); Print("Total time(in Seconds): ", (it1 - it0) / 1000.0); } //+------------------------------------------------------------------+
Fragmento 06
Com isto solucionamos uma parte do problema. Agora executamos novamente o script e veremos o seguinte resultado.
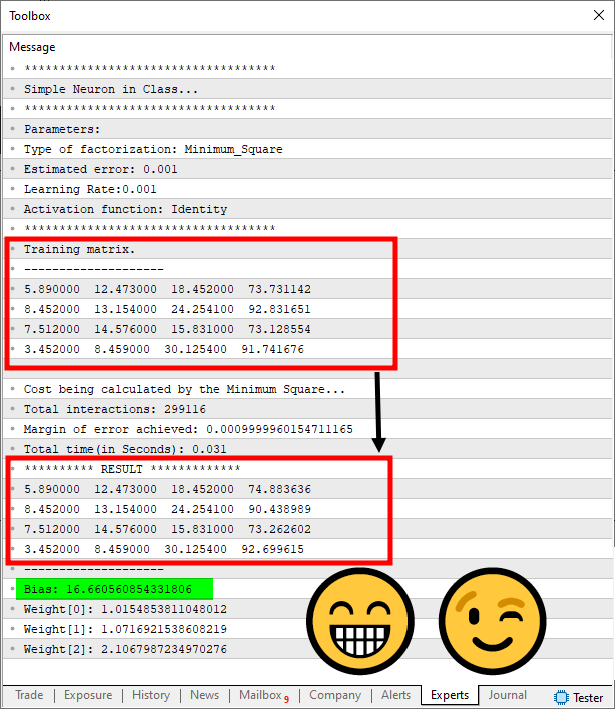
Imagem 08
clc; clear; clf; x = [-2:0.01:2]; y = (1.8 * x) + (1.254 * x) + (2.35 * x) + 4.1258; plot(x, y, 'p-'); y = (1.0154853811048012 * x) + (1.0716921538608219 * x) + (2.1067987234970276 * x) + 0.18640216948633873; plot(x, y, 'r-'); y = (1.0154853811048012 * x) + (1.0716921538608219 * x) + (2.1067987234970276 * x) + 16.660560854331806; plot(x, y, 'g-'); xgrid(0, 1);
Script SciLab
Com isto teremos o seguinte gráfico sendo mostrado.
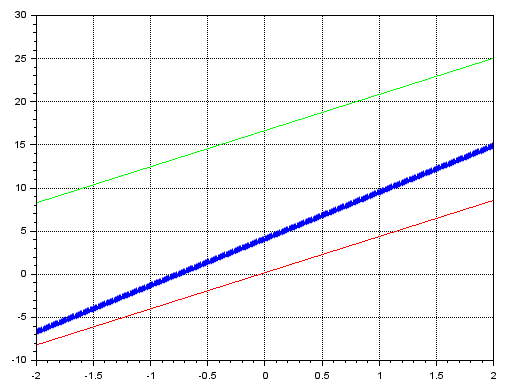
Imagem 09
Veja que a linha em verde, é onde estão os valores por conta de termos ajustado o viés. Mas apesar de eles estarem adequados para algumas situações, pode ser que não esteja para muitas outras. Então para tentar melhorar um pouco mais as coisas, mudamos o valor de erro estimado e a taxa de aprendizagem. Já que os valores default são na ordem de 1e-3, vamos tentar usar um valor de 1e-5, tanto para o erro estimado, quanto para a taxa de aprendizagem. Com isto teremos o seguinte resultado sendo mostrado, na imagem abaixo:
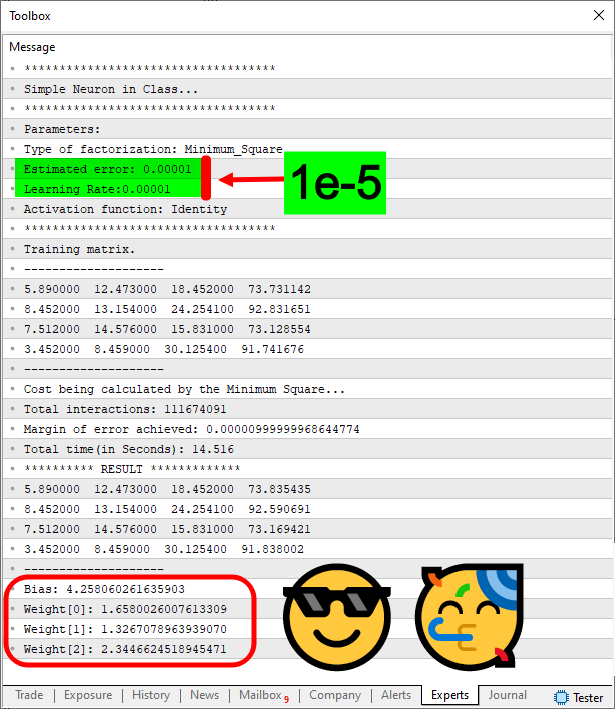
Imagem 10
clc; clear; clf; x = [-2:0.25:2]; y = (1.8 * x) + (1.254 * x) + (2.35 * x) + 4.1258; plot(x, y, 'p-'); y = (1.0154853811048012 * x) + (1.0716921538608219 * x) + (2.1067987234970276 * x) + 0.18640216948633873; plot(x, y, 'r-'); y = (1.0154853811048012 * x) + (1.0716921538608219 * x) + (2.1067987234970276 * x) + 16.660560854331806; plot(x, y, 'g-'); y = (1.6580026007613309 * x) + (1.3267078963939070 * x) + (2.3446624518945471 * x) + 4.258060261635903; plot(x, y, 'mo'); xgrid(0, 1);
Script SciLab
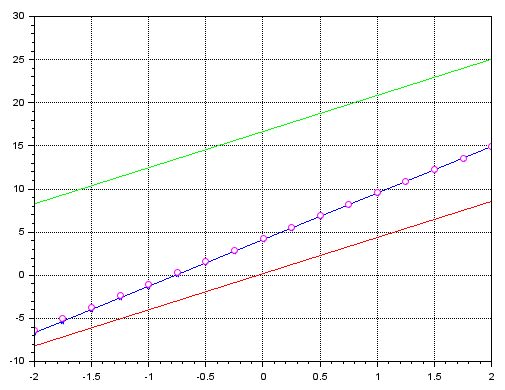
Imagem 11
Observe uma coisa interessante aqui. A linha em azul é onde estão de fato os dados de treinamento. Já a linha em verde representa o erro quando efetuamos um treinamento com erro estimado e taxa de aprendizagem de 1e-3. Os pequenos círculos em púrpura, representa o resultado quando usamos o mesmo código, só que com valores de 1e-5. Este tipo de coisa é algo de fato bastante surpreendente.
Considerações finais
Neste artigo, mostrei que de fato temos muito a ser estudado antes de achar que já sabemos das coisas. Já mencionei diversas vezes que apesar de todo progresso, A HUMANIDADE AINDA NÃO SABE COMO CRIAR UMA REDE PERCEPTRON DEFINITIVA. Tudo que estamos fazendo, é pesquisando e tentando aprender com os nossos próprios erros e acertos.
Não estou aqui para difamar ou ofender ninguém, se quer preciso provar algo para alguém. Estou aqui simplesmente para passar um pouco da minha experiência como programador. E como ficou evidente aqui, neste artigo, não é apenas ter um apanhado de dados sendo coletados que conseguiremos criar algo realmente capaz de simular a mente humana.
Existem detalhes envolvidos dos quais muitos não sabem. Mas agora você após ler este artigo, passou a entender que muitas das vezes precisamos ajustar o código para tornar dados aparentemente difusos em algo realmente utilizável.
| Arquivo MQ5 | Descrição |
|---|---|
| Scripts\Example A | Demonstração básica |
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 WebSocket para MetaTrader 5: conexões assíncronas no lado do cliente usando a API do Windows
WebSocket para MetaTrader 5: conexões assíncronas no lado do cliente usando a API do Windows
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso