
Rede neural na prática: Quando usar um neurônio artificial e entender sua função em MQL5

Introdução
No artigo anterior Rede neural na prática: Gradiente Descendente Estocástico, fizemos uma modificação, a fim de criamos um pequeno neurônio de gradiente descendente. Este passou a conter algumas mudanças, cujo objetivo visa tornar mais simples explicar algumas coisas a respeito de como um neurônio funciona. Mas principalmente explicar um conceito do qual muitos fazem uma grande confusão, ou muitas das vezes, acabam falando coisas, sem ao menos entende-las de fato. A partir de agora, vamos começar a entender, por que as funções de ativação são necessárias em alguns casos e em outros não. Por que nem sempre uma rede neural é a melhor escolha. Mas principalmente vamos entender, por que existem diferentes arquiteturas de redes neurais. E como você pode dimensionar adequadamente uma rede neural. Além é claro de outras coisas que veremos nos próximos artigos.
Sei que está chamada, parece ser bastante interessante. E algo bastante ousado em colocar em um único artigo. De fato, explicar diversas coisas assim, em um único artigo, seria algo impraticável, já que o mesmo teria um número considerável de páginas. Bem, mas vamos entender por que somente agora, depois de ter mostrado diversas coisas antes, estou dizendo que vamos começar a ver tais detalhes sobre redes neurais. O motivo é simples: Foi preciso, mostrar toda uma gama de coisas, antes de que você, meu caro leitor pudesse finalmente entender do que iremos de fato tratar.
Basicamente, eu poderia dizer, que este seria o artigo zero. Onde de fato começaremos a falar de maneira séria sobre o assunto. Isto por que, neste ponto, você que possivelmente leu os demais artigos. Experimentou dos códigos presentes neles, e tentou mudar o conjunto usado no treinamento dos neurônios. Ou até mesmo, procurou comparar o conteúdo dos primeiros artigos sobre este tema com os últimos artigos. Deve ter notado que existe uma certa lógica no que irei começar a explicar de agora em diante.
Se você está caindo de paraquedas neste artigo. Porém não tem nenhuma noção sobre redes neurais. Mas está cheio de dúvidas sobre o tema. Sugiro que comece olhando os artigos anteriores para compreender o que será explicado deste momento em diante. Dito isto podemos começar.
Será que preciso de fato criar um neurônio?
Com tudo que a mídia, influencies, etc. Tem dito e falado de uns tempos para cá. Dá realmente a impressão de que não conseguiremos viver sem redes neurais. De que ela é a oitava maravilha do mundo moderno. Mas as coisas não é bem assim. Redes neurais, como você pode ter visto nos artigos anteriores, é um ramo de pesquisa bastante interessante. Mas no geral elas são limitadas e falhas. Não conseguem entender certos tipos de coisas, e não são tão versáteis como muitos dizem por aí.
Muitas das vezes um programa voltado para resolver um dado problema, será consideravelmente mais eficiente do que qualquer rede neural, que possa ser construída ou desenvolvida. Isto por conta de diversos fatores. Entre eles o simples fato, de que se você, meu caro leitor, optar em usar uma rede neural, para fazer algo, terá de treiná-la para que ela consiga fazer aquilo. Fora o fato de que pode acontecer, de ela nem se quer conseguir entender os dados que você esteja utilizando para treiná-la.
Até o momento, eu nem expliquei, ou havia mencionado tal coisa. Mas apesar de nem sempre ser necessário, na maior parte das vezes, você terá que normatizar os valores a serem usados pela rede neural. O motivo disto será visto no futuro. Mas você precisa estar ciente deste fato. Às vezes, você precisará normatizar, ou colocar os valores de entrada dentro de um range. Caso você não faça isto, a rede neural simplesmente não conseguirá convergir. Se negando completamente em produzir uma representação adequada para as informações de treinamento.
Mas mesmo que ainda assim você consiga, fazer com que sua rede neural funcione. Você precisará analisar um outro fato. A questão do custo de processamento. Esta questão é um tanto quanto complicada de explicar. Já que envolve diversas coisas, nas quais ainda não expliquei aqui nos artigos. Porém devido ao que já foi mostrado, podemos já considerar algumas coisas aqui. Isto de maneira que você meu caro leitor consiga entender de que nem sempre uma rede neural é o melhor caminho.
Para entender isto, vamos fazer o seguinte teste. Vamos pegar o neurônio visto no artigo anterior, e vamos fornecer a ele alguns dados que foram usados em artigos bem lá no começo desta sequência. Então o novo código do neurônio ficará como mostrado abaixo:
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. #include <Canvas\Canvas.mqh> 005. //+------------------------------------------------------------------+ 006. #define PrintEx(A) Print(#A, " => ", A) 007. #define macroRandom (rand() / (double)SHORT_MAX) 008. #define _SizeLine 300 009. #define nColuns 2 010. //+------------------------------------------------------------------+ 011. CCanvas canvas; 012. //+------------------------------------------------------------------+ 013. double Train[][nColuns] { 014. {-100, -150}, 015. { -80, -50}, 016. { 30, 80}, 017. { 100, 120}, 018. }; 019. //+------------------------------------------------------------------+ 020. const double epsilon = 1e-3; 021. //+------------------------------------------------------------------+ 022. struct stErr 023. { 024. double Weight, 025. Bias; 026. }; 027. //+------------------------------------------------------------------+ 028. stErr Cost(const double w, const double b, const uint p1 = 0, const uint p2 = Train.Size() / nColuns) 029. { 030. double x, y, t; 031. stErr err; 032. 033. ZeroMemory(err); 034. for (uint c = p1; c < p2; c++) 035. { 036. x = Train[c][0]; 037. y = Train[c][1]; 038. t = 2 * ((x * w + b) - y); 039. err.Weight += (t * x); 040. err.Bias += t; 041. } 042. 043. return err; 044. } 045. //+------------------------------------------------------------------+ 046. void PlotText(const int x, const int y, const uchar line, const string sz0) 047. { 048. uint w, h; 049. 050. TextGetSize(sz0, w, h); 051. canvas.TextOut(x - (w / 2), y + _SizeLine + (line * h) + 5, sz0, ColorToARGB(clrBlack)); 052. } 053. //+------------------------------------------------------------------+ 054. inline double CallZoom(void) 055. { 056. double d1 = 0; 057. 058. for (uint c = 0; c < Train.Size() / nColuns; c++) 059. { 060. d1 = MathMax(d1, MathAbs(Train[c][0])); 061. d1 = MathMax(d1, MathAbs(Train[c][1])); 062. } 063. 064. return _SizeLine / d1; 065. } 066. //+------------------------------------------------------------------+ 067. void Plot_Train2D(const int x, const int y, const double weight, double bias) 068. { 069. int vx, vy; 070. double zoom; 071. uint n = Train.Size() / nColuns; 072. 073. zoom = CallZoom(); 074. canvas.LineVertical(x, y - _SizeLine, y + _SizeLine, ColorToARGB(clrRoyalBlue, 255)); 075. canvas.LineHorizontal(x - _SizeLine, x + _SizeLine, y, ColorToARGB(clrRoyalBlue, 255)); 076. for (uint c = 0; c < n; c++) 077. { 078. vx = (int)(Train[c][0] * zoom); 079. vy = (int)(Train[c][1] * zoom); 080. canvas.FillCircle(x + vx, y - vy, 5, ColorToARGB(clrRed, 255)); 081. } 082. canvas.LineAA( 083. x + (int)(Train[0][0] * zoom), 084. y - (int)((Train[0][0] * weight + bias) * zoom), 085. x + (int)(Train[n - 1][0] * zoom), 086. y - (int)((Train[n - 1][0] * weight + bias) * zoom), 087. ColorToARGB(clrForestGreen)); 088. PlotText(x, y, 1, StringFormat("Zoom: %.2fx", zoom)); 089. PlotText(x, y, 2, StringFormat("f(x) = %.4fx %c %.4f", weight, (bias < 0 ? '-' : '+'), MathAbs(bias))); 090. } 091. //+------------------------------------------------------------------+ 092. void OnStart() 093. { 094. double weight, bias; 095. int x, y; 096. ulong it0, it1, count; 097. stErr err; 098. 099. Print("************************************"); 100. Print("Stochastic Gradient Descent Neuron..."); 101. Print("************************************"); 102. MathSrand(512); 103. weight = (double)macroRandom; 104. bias = (double)macroRandom; 105. 106. it0 = GetTickCount(); 107. for(count = 0; count < 5; count++) 108. { 109. err = Cost(weight, bias); 110. if ((MathAbs(err.Weight) <= epsilon) && (MathAbs(err.Bias) <= epsilon)) 111. break; 112. weight -= (err.Weight * epsilon); 113. bias -= (err.Bias * epsilon); 114. PrintFormat("%I64u > w0: %.4f %.4f || b: %.4f %.4f", count, weight, err.Weight, bias, err.Bias); 115. } 116. it1 = GetTickCount(); 117. Print("Time: ", (it1 - it0) / 1000.0, " seconds."); 118. PrintEx(count); 119. PrintEx(weight); 120. PrintEx(bias); 121. PrintEx(err.Weight); 122. PrintEx(err.Bias); 123. Print("Press ESC to close...."); 124. Print("************************************"); 125. 126. x = (int)ChartGetInteger(0, CHART_WIDTH_IN_PIXELS, 0); 127. y = (int)ChartGetInteger(0, CHART_HEIGHT_IN_PIXELS, 0); 128. canvas.CreateBitmapLabel("BL", 0, 0, x, y, COLOR_FORMAT_ARGB_NORMALIZE); 129. canvas.Erase(ColorToARGB(clrWhite, 255)); 130. x /= 2; 131. y /= 2; 132. 133. Plot_Train2D(x, y, weight, bias); 134. 135. canvas.Update(true); 136. 137. while(!IsStopped()) 138. if (TerminalInfoInteger(TERMINAL_KEYSTATE_ESCAPE) !=0) 139. break; 140. 141. canvas.Destroy(); 142. } 143. //+------------------------------------------------------------------+
Ao compilar e rodar este código, você verá as seguintes informações no terminal sendo mostradas:
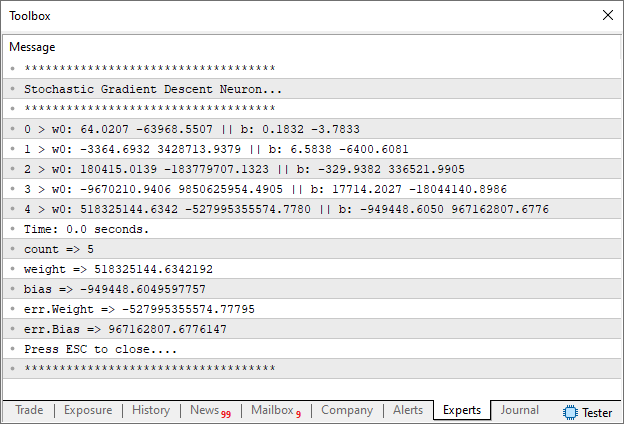
E no gráfico onde o script for executado, você verá a seguinte imagem:
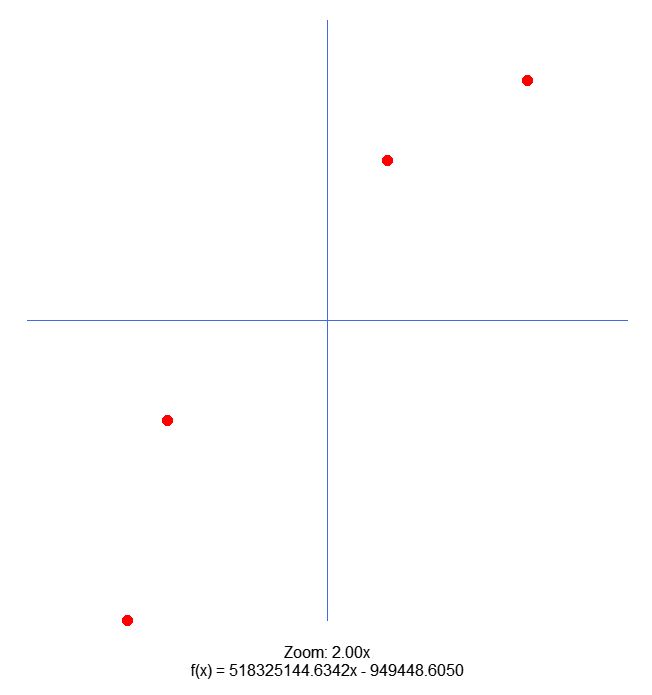
Muito bem, agora você deve estar ser perguntando: Mas o que aconteceu aqui? Não estou entendendo absolutamente nada. Bem meu caro leitor, nem você, tão pouco o neurônio artificial está entendendo o que está se passando. Visto que ele não conseguiu convergir em busca de uma solução. Talvez você esteja pensando o seguinte: Bem, mas você está trapaceado. Só pode ser uma trapaça isto que acabou de acontecer. Como assim o neurônio não conseguiu entender os dados de treinamento? É trapaça. Bem meu caro leitor, pensar assim é algo prudente. Não devemos acreditar em algo, apenas por que alguém nos mostrou ou disse. Devemos experimentar nos mesmos, e ver se aquilo é de fato verdadeiro ou não. Mas devemos fazer isto de forma bem cautelosa. Então vamos entender o que se passou, para que as informações mostradas nas imagens acima viessem a surgir.
Primeiro, vamos olhar no código. Note que na linha 13, mudei os valores de treinamento. Depois irei falar mais a este respeito. Mas vamos ao próximo ponto que foi modificado. Na linha 107, mudamos o número de interações que o laço for iria fazer de ULONG_MAX para cinco. E fazer, isto é, de fato prudente. Assim como o fato de adicionarmos a linha 114, a fim de verificar o que o neurônio estaria fazendo internamente. E diferente do que muitos querem dizer. NÃO, VOCÊ NUNCA DEIXA UM CÓDIGO GERAR COISAS SEM SABER O QUE ELE ESTÁ GERANDO. A um tempo atras ouvi uma pessoa dizer, que em breve não saberíamos o que a rede estaria aprendendo. Isto é a maior das besteiras já ditas por uma pessoa. Com toda a certeza não se trata de um programador. Mas de um digitador de código.
Mas voltando ao assunto, deixamos uma quantidade baixa, de apenas cinco interações. Para ver se o neurônio, iria começar a convergir em direção a uma solução. Mas olhando os dados, nitidamente você percebe que ele não irá fazer isto. Na verdade, os valores de erro estão aumentando exponencialmente. O que indica que o neurônio não sabe o que está fazendo. Ou o que deveria fazer com os dados. Lembre-se, tudo que foi modificado no código foram estes pontos. Você pode pegar o código no anexo do artigo anterior e experimentar. Irá notar que o código original dará uma solução, mas que ao modificar o código o neurônio irá ficar mais perdido, do que uma barata que tomou uma sapatada. Mas por que isto aconteceu? Será que os dados não fazem sentido? Bem, vamos ver de onde estes dados de treinamento saíram.
Se você olhar o artigo Rede neural na prática: Mínimos Quadrados. verá estes mesmos dados sendo usados. No entanto, lá assim como em outros artigos onde não usávamos neurônios, conseguíamos uma solução. Mas o neurônio não está conseguindo. Bem, mas antes de explicar o motivo, vamos ver a equação que foi obtida usando outros métodos. Ela pode ser vista logo abaixo:

Você não precisa acreditar em mim. Mostrei como usar a pseudo inversa, em dois artigos, sendo o segundo: Rede neural na prática: Pseudo Inversa (II), de forma que você pode experimentar e verá que funciona. Mas então, o que existe de errado aqui? Será que é o mesmo caso de quando usamos um neurônio nas portas lógicas? Ou será um caso parecido com a da porta XOR? Bem, não é nenhum destes casos. Mas para tentar esclarecer um pouco as coisas, vamos a um novo tópico.
A essência de um neurônio artificial
Desde que começamos a esboçar um neurônio, tenho mostrado como ele funciona, e por que de ele fazer o que ele faz. Se você não está entendendo, procure ler com calma os artigos anteriores. Pois aqui vamos ver a coisa de uma maneira um pouco mais aprofundada.
Vou repetir algo, que já mencionei antes: TODO NEURÔNIO APRENDE COM BASE NA RETA SECANTE. Muitos gostam de falar da reta tangente no aprendizado de máquina. Mas ao meu ver das duas uma. Ou esta pessoa está confundindo as coisas. Ou ela não sabe do que está falando. O neurônio base, ou seja, aquele que originou todos os demais. Nasceu da seguinte função mostrada abaixo:

Esta função representa justamente a função de custo. Não importa qual seja a metodologia usada. Tudo irá se resumir a esta única função. Porém esta função não representa a reta tangente, mas sim a reta secante. Tendo isto em vista, e entendendo que uma reta é resumida a seguinte função mostrada logo abaixo:

Podemos começar a entender por que de uma rede neural, ou mesmo um único neurônio ser construído da maneira como ele é construído. Muitos de vocês podem, neste momento estar pensando: Este cara não sabe do que está falando. Caro que o neurônio não conseguiria entender os dados de treinamento. Está faltando a função de ativação para ele conseguir aprender como criar a representação dos dados. O neurônio não está em uma rede, e tão pouco está fazendo a back propagation. Bem, se você pensou isto, ou mesmo indagou a este respeito. Sugiro, respeitosamente, que você pare de ler este artigo, e todos os demais, que eu vier a escrever sobre o tema. Pois o conteúdo dele ou de qualquer outro, não irá agregar em nada ao que você já tem, como sendo um pre conceito sobre o tema. Até breve e passar bem.
Enfim, continuando. Todo e qualquer neurônio tem como objetivo traçar uma reta secante, cujo valor de h, venha a ser o mais próximo possível de zero. Este é o tal valor de erro que consideramos aceitável. Nos meus códigos estes mesmos valores de erro, também é usado como taxa de aprendizagem. Ou seja, o quanto o neurônio irá usar o valor de erro, para dar como sendo o próximo passo, a fim de procurar um valor de erro menor. No caso de um neurônio, que utiliza a regressão linear, ou uma derivada da mesma. O valor na equação que é o coeficiente angular é tido como sendo o peso. Já o valor do ponto de intersecção é considerado como sendo o viés. Normalmente, você ao olhar uma imagem de um neurônio sendo vista em qualquer lugar, verá algo mais ou menos, como o que pode ser visto abaixo.
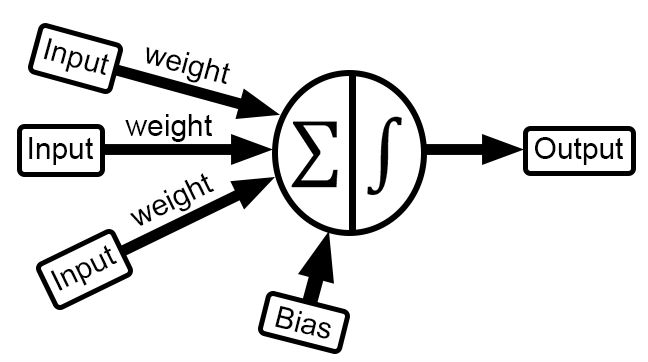
Mas o que esta imagem representa? Para alguns algo mágico. Para outros um resumo do que precisa ser implementado. Mas para outros absolutamente nada. Mas vamos entender o que o nosso código tem implementado nele. Para isto a imagem acima deverá ser modificada para a imagem abaixo.
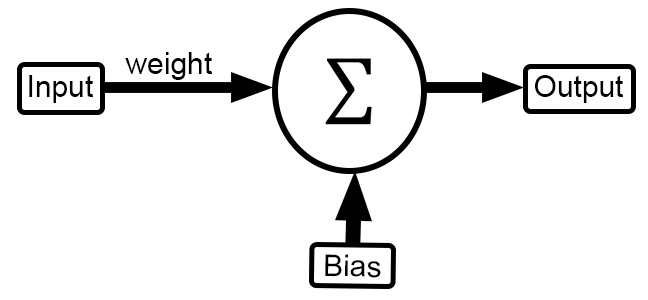
Ok, ele se parece bastante com a imagem vista anteriormente. Mas como podemos saber se isto é verdade, ou algum tipo de pegadinha? Bem, para isto é preciso ver o código. Basicamente olhar o que está acontecendo dentro do fragmento mostrado abaixo.
. . . 012. //+------------------------------------------------------------------+ 013. double Train[][nColuns] { 014. {-100, -150}, 015. { -80, -50}, 016. { 30, 80}, 017. { 100, 120}, 018. }; 019. //+------------------------------------------------------------------+ 020. const double epsilon = 1e-3; 021. //+------------------------------------------------------------------+ 022. struct stErr 023. { 024. double Weight, 025. Bias; 026. }; 027. //+------------------------------------------------------------------+ 028. stErr Cost(const double w, const double b, const uint p1 = 0, const uint p2 = Train.Size() / nColuns) 029. { 030. double x, y, t; 031. stErr err; 032. 033. ZeroMemory(err); 034. for (uint c = p1; c < p2; c++) 035. { 036. x = Train[c][0]; 037. y = Train[c][1]; 038. t = 2 * ((x * w + b) - y); 039. err.Weight += (t * x); 040. err.Bias += t; 041. } 042. 043. return err; 044. } 045. //+------------------------------------------------------------------+ . . . 091. //+------------------------------------------------------------------+ 092. void OnStart() 093. { 094. double weight, bias; 095. int x, y; 096. ulong it0, it1, count; 097. stErr err; 098. 099. Print("************************************"); 100. Print("Stochastic Gradient Descent Neuron..."); 101. Print("************************************"); 102. MathSrand(512); 103. weight = (double)macroRandom; 104. bias = (double)macroRandom; 105. 106. it0 = GetTickCount(); 107. for(count = 0; count < 5; count++) 108. { 109. err = Cost(weight, bias); 110. if ((MathAbs(err.Weight) <= epsilon) && (MathAbs(err.Bias) <= epsilon)) 111. break; 112. weight -= (err.Weight * epsilon); 113. bias -= (err.Bias * epsilon); 114. PrintFormat("%I64u > w0: %.4f %.4f || b: %.4f %.4f", count, weight, err.Weight, bias, err.Bias); 115. } 116. it1 = GetTickCount();
Claro que nossa função de custo, está um tanto quanto estranha. Visto que ela é na verdade uma derivada de primeira ordem, da função original. Por isto ela não se parece com a função da reta. Mas olhando o código, você pode notar que na linha 13 temos o nosso input. Na linha 94, temos o weight e o bias. Estes recebem valores arbitrários, nas linhas 103 e 104 respectivamente. Apesar de tudo, o valor não é 100% aleatório. Já que na linha 102, estamos dizendo em qual patamar o valor deverá iniciar. Mas isto é devido ao fato de que este código tem como objetivo ser didático.
Em um código real, esta linha 102 teria um código ligeiramente diferente. Sendo que ela se ligaria ao relógio ou contador do computador. Forçando assim que a cada nova execução os valores fossem aleatórios. Quando a linha 116 for alcançada teríamos o nosso output. Bem mais isto parece um pouco confuso. Já que a função de custo, não é uma regressão linear, como seria o esperado, se estivéssemos e fato usando a reta secante.
Muito bem, se este é o caso, podemos voltar ao artigo ##>>Rede neural na prática: O primeiro neurônio<<https://www.mql5.com/pt/articles/13745##, pois ali o código é o de uma regressão linear. Você pode ver isto ao olhar o código, abaixo que replica justamente o código visto lá.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define macroRandom (rand() / (double)SHORT_MAX) 05. //+------------------------------------------------------------------+ 06. double Train[][2] { 07. {0, 0}, 08. {1, 2}, 09. {2, 4}, 10. {3, 6}, 11. {4, 8}, 12. }; 13. //+------------------------------------------------------------------+ 14. const uint nTrain = Train.Size() / 2; 15. const double eps = 1e-3; 16. //+------------------------------------------------------------------+ 17. double Cost(const double w, const double b) 18. { 19. double err, fx, a; 20. 21. err = 0; 22. for (uint c = 0; c < nTrain; c++) 23. { 24. a = Train[c][0]; 25. fx = a * w + b; 26. err += MathPow(fx - Train[c][1], 2); 27. } 28. 29. return err / nTrain; 30. } 31. //+------------------------------------------------------------------+ 32. void OnStart() 33. { 34. double weight, ew, eb, e1, bias; 35. int f = FileOpen("Cost.csv", FILE_COMMON | FILE_WRITE | FILE_CSV); 36. 37. Print("The first neuron..."); 38. MathSrand(512); 39. weight = (double)macroRandom; 40. bias = (double)macroRandom; 41. 42. for(ulong c = 0; (c < ULONG_MAX) && ((e1 = Cost(weight, bias)) > eps); c++) 43. { 44. ew = (Cost(weight + eps, bias) - e1) / eps; 45. eb = (Cost(weight, bias + eps) - e1) / eps; 46. weight -= (ew * eps); 47. bias -= (eb * eps); 48. if (f != INVALID_HANDLE) 49. FileWriteString(f, StringFormat("%I64u;%f;%f;%f;%f;%f\n", c, weight, ew, bias, eb, e1)); 50. } 51. if (f != INVALID_HANDLE) 52. FileClose(f); 53. Print("Weight: ", weight, " Bias: ", bias); 54. Print("Error Weight: ", ew); 55. Print("Error Bias: ", eb); 56. Print("Error: ", e1); 57. } 58. //+------------------------------------------------------------------+
Pois bem, temos a mesma sendo implementada aqui neste código acima. Só que ao a função de custo é uma reta. Você pode ver isto na linha 25. Note que é a mesma equação mostrada mais no início do tópico. E mesmo este último código, sendo uma regressão linear, clara e evidente. Este mesmo neurônio, não consegue resolver os dados usados em programas anteriores. Por que? O motivo é a função de custo. Ela é o problema aqui. Epá. Espere um pouco aí. Você está me dizendo que a função de custo, não permite o neurônio aprender como representar os dados? Sim, é isto mesmo meu caro leitor. A função de custo, não permite que o neurônio aprenda como representar certos tipos de dados. Fazendo com que ele simplesmente não consiga convergir a uma solução. Isto parece ser uma afirmação absolutamente absurda. Mas devido a minha experiência, posso literalmente afirmar tal coisa.
Bem, mas você pode neste exato momento está pensado o seguinte: Mas estes neurônios não estão fazendo back propagation. Estão apenas fazendo forward propagation. Por isto não estão conseguindo aprender como representar os dados. Ok, meu caro leitor, agora você me pegou. Então vamos a um novo tópico para entender melhor isto.
Back Propagation: Que negócio é este?
Uma das coisas que mais me faz rir, são estes termos usados em redes neurais. A maior parte, surgiu de uns tempos para cá. Quando comecei a estudar sobre o assunto. Isto lá no começo de meus estudos em C / C++, tais termos não existiam. E se existiam, eram poucas as pessoas que os usavam. De qualquer forma, grande parte dos termos, usados em rodas de conversa sobre redes neurais, não passam de pura besteira. Bobagens criadas para confundir os iniciantes, e para dar a impressão de que a coisa é muito mais complicada do que realmente é.
Esta tal de back propagation, ainda não temos um termo em português que possa ser usado. Nada mais é do que o que está acontecendo dentro do laço for no código OnStart. Talvez isto tenha soado meio abstrato. Mas vamos ver isto nos códigos vistos no tópico anterior. Para facilitar, estou replicando o exato ponto em que a tal back propagation está ocorrendo. No caso do código do neurônio de gradiente, ela pode ser vista no fragmento abaixo.
107. for(count = 0; count < 5; count++) 108. { 109. err = Cost(weight, bias); 110. if ((MathAbs(err.Weight) <= epsilon) && (MathAbs(err.Bias) <= epsilon)) 111. break; 112. weight -= (err.Weight * epsilon); 113. bias -= (err.Bias * epsilon); 114. PrintFormat("%I64u > w0: %.4f %.4f || b: %.4f %.4f", count, weight, err.Weight, bias, err.Bias); 115. }
Mas onde, não estou vendo. Bem, olhe as linhas 112 e 113. Ali está a back propagation para o neurônio de gradiente. Já para o de regressão, ela está acontecendo no fragmento mostrado abaixo.
42. for(ulong c = 0; (c < ULONG_MAX) && ((e1 = Cost(weight, bias)) > eps); c++) 43. { 44. ew = (Cost(weight + eps, bias) - e1) / eps; 45. eb = (Cost(weight, bias + eps) - e1) / eps; 46. weight -= (ew * eps); 47. bias -= (eb * eps); 48. if (f != INVALID_HANDLE) 49. FileWriteString(f, StringFormat("%I64u;%f;%f;%f;%f;%f\n", c, weight, ew, bias, eb, e1)); 50. }
Neste caso você tem que olhar nas linhas 46 e 47. Viu, meu caro e estimado leitor. Estamos fazendo back propagation. Mas diferente do que muitos dizem ou querem fazer uma verdadeira confusão em cima do termo. A tal back propagation, é algo bem simples. Ela simplesmente ajuda o código a tentar convergir. Não é nada de mágico. Sem ela o neurônio não seria capaz de ficar tentando reduzir o erro observado.
Então definitivamente não é a tal da back propagation o que impede o neurônio de não aprender a representar as coisas. O que o impende, é que ele de fato não consegue lidar com qualquer tipo de cenário. Mas neste caso e neste momento, você já pode estar um tanto quanto apreensivo. Já que estou desta forma destruindo completamente todos seus sonhos e ilusões. Visto que cada um dos pontos, que muitos dizem ser necessário para que o neurônio consiga representar, ou aprender, não são de fato como eles dizem ser ou funcionar. Mas ainda resta uma esperança. A função de ativação. Já que os neurônios mostrados aqui não têm a tal função, quem sabe seja ela a responsável por fazer o neurônio convergir para uma resposta.
Ok, meu caro leitor, isto sim que é se apegar em algo. Ter uma esperança que as coisas possam de fato melhorar. Ou quem sabe, ainda exista uma oportunidade para que aquele seu sonho, possa se tornar realidade. Já que temos programas, que conseguem fazer reconhecimento de escrita, fala, imagens e etc, etc. Mas estou pensando: Como poderei fazer tamanha maldade. Não gosto de ser o vilão da história. Mas também não gosto de passar uma falsa ideia sobre algo. Se é para dizer, que diga logo. Se vou destruir os sonhos, irei fazer isto logo de uma vez.
Então, meu caro leitor, sinto lhe informar, mas a função de ativação, não é algo mágico. Algo na qual, fará o neurônio conquistar o mundo, e tornar seus sonhos realidade. A função de ativação serve para um outro propósito. Que neste momento, tentar explicar o proposito dela, é um tanto quanto complicado. É preciso que venhamos a criar algumas coisas, e implementar alguns códigos para que você, meu caro e estimado leitor. Consiga de fato entender, na prática, o que a função de ativação faz.
E diferente do que vejo muitos dizendo, use esta ou aquela função. As funções de ativação devem ser devidamente escolhidas. Isto para que o neurônio ou rede neural possa funcionar adequadamente. Na verdade, a função de ativação, somente tem uma maior relevância no caso de estarmos usando uma rede neural. Ou usando certos tipos de dados como base para treinamento. Isto foi visto, pela primeira vez quando mostrei como um neurônio poderia ser usado para representar portas lógicas. Mesmo que tentássemos usar um sistema de regressão, ou qualquer outra implementação. Sem a função de ativação o neurônio logo acabaria encontrando um ponto de estagnação. E ao atingir este ponto, ele iria parar de aprender. Consequentemente não conseguiria convergir para uma representação mais adequada, dos dados contidos no treinamento.
Mas de qualquer forma, não precisa ficar preocupado, ou apreensivo, meu caro leitor. Em breve, iremos ver de forma prática, como a função de ativação funciona. E você conseguirá compreender melhor como escolher adequadamente a mesma. Bem, talvez, você demore um pouco para dominar a questão. Mas estou pensando em uma forma que seja bem didática de apresentar o tema. Nada de apenas mostrar o cálculo ou a formula. Quero explicar e fazer com que você entenda por que, e quando usar uma função de ativação. Assim como também existe um outro problema. Que na verdade, em muitos dos casos, não se trata de um problema. Mas sim se um cuidado a ser tomado. Que é os dados de entrada. Existem diversos casos em que o neurônio, simplesmente fica sem saber como lidar com as informações fornecidas. Mas este não é o caso que foi mostrado neste artigo. O problema, do qual estou mencionando é de uma outra natureza. Para que você entenda, vou dar uma rápida passada pela questão. Mas isto será melhor compreendido no futuro.
Vamos supor que você queira treinar uma rede neural, para reconhecimento de faces. Para que a rede neural possa nos dizer, se é homem, mulher, velho, criança, animal ou outra coisa qualquer. Como por exemplo, saber qual a expressão o rosto tem naquele momento. Enfim, o que nos importa aqui, é que a rede neural, precisa reconhecer algo na face do indivíduo. Muito bem, como se faz isto? Bem, em tese, é algo muito simples. Você diz a um programa para procurar uma dada região na imagem. Depois você esquadrinha a imagem em determinados pontos.
A distância, e esta é a parte importante, entre estes pontos é enviada para a rede neural. Ela não tem noção do que de fato está sendo analisando. Pode ser qualquer coisa. Tudo que ela de fato estará vendo, é a distância entre os pontos fornecidos por um outro programa. Passados os dados pela rede neural, ela irá emitir um resultado em termos de percentual. Este nunca será de 100%, isto por conta de que ela não está tentando acertar a equação. Mas sim, tentando dizer o quanto aqueles valores estão percentualmente longe ou próximos dos valores que ela reconhece. Isto com base em uma equação previamente calculada.
Neste ponto muitos fazem uma baita de uma confusão. Acreditando que a rede neural reconhece o indivíduo ou a expressão. Mas não. Ela apenas observa uma equação, ou polinômio previamente carregado. Feito isto ela analisa, e diz, qual é a margem de erro entre os valores informados na entrada e os que seriam obtidos ao executar o polinômio, previamente calculado.
Considerações finais
O que foi visto neste artigo, pode parecer extremamente confuso, disperso e fora de qualquer conceito. Mas quero lembrar novamente a você, meu caro leitor, de que o intuito destes artigos é mostrar a coisa em sua forma mais clara. Sem pegadinhas, sem caixa preta, ou métodos obscuros. Tudo e absolutamente tudo que estou mostrando pode ser replicado por qualquer programador. Não existem segredos aqui. E diferente do que muitos influencies dizem e querem lhe fazer acreditar. Redes neurais não é um assunto simples e tão pouco direcionado. Cada caso é um caso. Muitas das vezes, é feito o uso de uma programação mais direta a fim de conseguir gerar um polinômio para representar os dados. Uma vez que fazemos isto, podemos dizer que qualquer predição baseada naquele polinômio previamente gerado. Pode ser um tipo de interação com uma inteligência artificial. Mas isto nem sempre é verdade. Lembre-se dos artigos em que falei sobre inteligência artificial. E como algumas coisas conseguem dar a impressão de serem inteligentes, ou ter algum tipo de mecanismo inteligente.
Porém de qualquer maneira, deste momento em diante, você já deverá estar um tanto quanto vacinado. Isto para conseguir entender alguns detalhes sobre redes neurais e inteligência artificial. Ainda não exploramos tudo que se tem para ver. Já que até o momento, tivemos apenas o vislumbre das possibilidades de implementação. No decorrer dos próximos artigos veremos outras coisas que lhe ajudaram a entender melhor este tema. Assim como também veremos outras que você notará que estranhamente não se parecem com um neurônio. Tal pouco com qualquer modelo de arquitetura de rede neural. No entanto, mesmo assim conseguem se comportar como tal. Nos dando a ilusão de que conseguem aprender, ou criar uma representação para ser usado como inteligência artificial ou rede neural.
Para quem tiver curiosidade sobre o que foi explicado no tópico anterior, sobre reconhecimento de imagens. Mas principalmente o fato, de que uma imagem pode ser representada com base em um polinômio. Vou deixar na referência dois links para serem visualizados. Trata-se de um material bem antigo, que foi postado em 2013. Mas mesmo assim continua bastante atual. Assim como também um site, voltado para quem deseja estudar, de forma um pouco mais profunda a matemática. Já que ali o material estará todo organizado e de forma a ser fácil pesquisar sobre determinado assunto.
Referência de material
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso