
Rede neural na prática: Perceptron

Introdução
No artigo anterior Rede neural na prática: Gradiente, falamos um pouco sobre como o gradiente surgiu a partir da utilização de uma derivação da função de custo.
Apesar de não ser uma das tarefas mais simples, dividir este conteúdo em partes. Já que o tema, é de fato um conteúdo no qual você precisa ver, e ser apresentado a uma série enorme de coisas e conceitos. Sendo muitos deles completamente abstratos, enquanto outros são um tanto quanto complicados, por serem termos iguais, mas utilizados em contextos diferentes. Tenho tentando deixar o material o mais fácil possível de ser compreendido.
Entre estas coisas está o uso dos termos BACK PROPAGATION e a FORWARD PROPAGATION. Que normalmente são usados de forma indiscriminada sem serem devidamente explicados. Para entender de forma correta tudo que está sendo feito dentro do código de uma rede perceptron, precisamos entender como as coisas foram surgindo.
Não entraremos em certos detalhes neste momento. Contudo, precisamos entender como o termo rede neural surgiu. E para isto precisamos entender a base por trás da mesma, sendo esta base conhecida como perceptron. Sendo este o tema principal deste artigo.
Perceptron
Quando se fala em perceptron, muitos já logo começam a pensar em inteligência artificial. Na verdade, o termo foi proposto por McCulloch e Pitts, sendo implementado por Frank Rosenblatt em 1958, quando trabalhava no laboratório Aeronáutico Cornell. Rosenblatt, se inspirou em um neurônio biológico e no que ele é capaz de fazer. Basicamente um perceptron, consistiria em uma ou mais entradas.
Um sistema de processamento e uma saída como resultado do processamento. Porém, a primeira implementação prática foi feita em um IBM 704. Onde Rosenblatt, usando software, tentou criar um sistema capaz de efetuar reconhecimento facial. O curioso foi a frase usada ao se referirem ao tal perceptron: "O perceptron é o embrião de um computador eletrônico que a Marinha espera que seja capaz de andar, falar, ver, escrever, reproduzir-se e ter consciência de sua existência". Cara este povo é uma piada. Imagino quanto dinheiro receberam para as pesquisas depois desta demonstração.
Porém, devida a dificuldades técnicas, o sistema não funcionou como esperado. Se mostrando capaz de apenas trabalhar com padrões lineares. E por conta disto, não faria reconhecimento de padrões distintos, como era o esperado. Isto fez com que o interesse pela pesquisa de inteligência artificial desaparecesse por um tempo.
Contudo, porque um perceptron, utiliza diversas entradas. E usando coisas como pesos e viés, conseguindo fazer somas e multiplicações ponderadas. O nome de fato, acabou sendo bastante interessante. Já que a função que seria criada, seria capaz de fazer justamente este mesmo tipo de trabalho. Ou seja, ao enviamos para uma função, diversos valores, que seriam as entradas, e com base em um conhecimento prévio adquirido.
Esta mesma função, conseguia fazer todo o trabalho de somas e multiplicações conseguindo gerar um certo tipo de padrão de identidade. Assim, quando passamos a saída por uma função, que ficou sendo definida como sendo: função de ativação, justamente para diferenciar a função de saída da função interna do perceptron. Acabávamos por assim gerar uma saída que poderia ser entregue a novos perceptrons ou reportadas a nós humanos.
Em um artigo futuro, irei mostrar como conseguiram chegar nesta que seria a ideia inicial da função perceptron. Que seria justamente aquela cadeia de somas e multiplicações ponderadas. Mas isto ficará para o futuro, justamente por envolver o entendimento de coisas das quais para muitos pode não ser interessante ser vista aqui e agora.
Assim vamos voltar a questão, onde vamos observar o perceptron de maneira mais moderna. Contudo, para simplificar, vamos focar em um único perceptron, neste momento. Apesar de que em artigos anteriores temos começado a fazer a ligação de perceptrons em cadeia, justamente para simular portas lógicas. Aqui o foco será tentar levar você a uma modelagem um pouco mais elaborada.
Basicamente um perceptron, faz uso de uma expressão matemática, que vimos no artigo anterior. Esta pode ser revista logo abaixo.
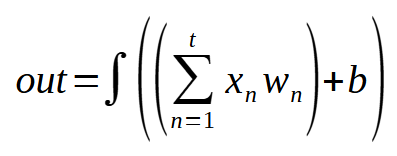
//+------------------------------------------------------------------+ inline double Perceptron(const double &inputs[]) { double value = m_Infos.Bias; for (uint c = 0; c < m_Infos.nInputs; c++) value += (inputs[c] * m_Infos.Weight[c]); return fnActivation(true, value); } //+------------------------------------------------------------------+
Este fragmento contém praticamente tudo que já foi implementado até aqui na classe C_Neuron. Com uma única ressalva para a função fnActivation. Que até o momento ainda não foi definitivamente construída. Fora este detalhe, você claramente nota que, estamos fazendo simplesmente somas e multiplicações. Nada além disto.
Diferente do que possa ter dado a entender no artigo anterior, um perceptron nada mais é do que somas e multiplicações simples. Porém, uma vez que definimos as constantes dentro da expressão matemática, conseguimos estabelecer um tipo de resposta que pode ser interessante. Estas mesmas constantes, que são os valores de peso e viés, são ajustas graças aquilo que ficou conhecido como treinamento. Assim o objetivo primário de toda rede, é justamente o de ajustar tais constantes. Sendo este o propósito da função que chamamos de perceptron.
Bem agora que entendemos isto, podemos ver aquela que seria a função que está faltando no código. Ou seja, a fnActivation, e esta pode ser observada logo seguir.
//+------------------------------------------------------------------+ inline double fnActivation(const bool isFx, const double value) { switch (m_Infos.Activate) { case Sigmoid: return (isFx ? 1 / (1 + MathExp(-value)) : MathExp(-value) / MathPow(1 + MathExp(-value), 2)); case Tangh: return (isFx ? (2 / (1 + MathExp(-2 * value))) - 1 : (4 / MathPow(MathExp(-value) + MathExp(value), 2))); case ReLU: return (isFx ? MathMax(0, value) : (value <= 0 ? 0 : 1)); case eLU: return (isFx ? (value <= 0 ? (m_Infos.Alpha * (MathExp(value) - 1)) : value) : (value <= 0 ? (m_Infos.Alpha * MathExp(value)) : 1)); case SoftSign: return (isFx ? value / (1 + MathAbs(value)) : value / MathPow(1 + MathAbs(value), 2)); case SoftPlus: return (isFx ? MathLog(1 + MathExp(value)) : 1 / (1 + MathExp(-value))); case Identity: default: return (isFx ? value : 1); } } //+------------------------------------------------------------------+
Agora temos ideia uma ideia geral do que seria o perceptron inteiro e do que ele consegue fazer. Isto por que, estas funções de ativação mostradas aqui, são as mesmas que foram mostradas e comentadas em um artigo onde explicamos graficamente as mesmas. Mas observe uma coisa, apesar de termos todas aquelas funções mostradas antes, você pode observar, que o perceptron, não faz uso das derivadas. Isto por que em nenhum momento o parâmetro isFx é falso. Mas então, por que derivamos aqui? Bem, o motivo é o gradiente. Mas antes de falarmos sobre isto, quero que você entenda uma coisa antes.
Função de ativação no mínimo quadrado
Para entender como de fato as coisas funcionam. Precisamos ver elas funcionando na sua forma mais simples. Como nossa classe C_Neuron, já contém alguma funcionalidade, vamos voltar nossa atenção ao código completo da classe. Desta forma, será mais simples explicar, mas principalmente entender, o que estará acontecendo. O código em, sim, pode ser visto abaixo.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #define macroRandom (rand() / (double)SHORT_MAX) //+------------------------------------------------------------------+ class C_Neuron { protected: //+------------------------------------------------------------------+ enum eFnActivate { Identity, Sigmoid, Tangh, SoftSign, ReLU, eLU, SoftPlus, }; //+------------------------------------------------------------------+ private: //+------------------------------------------------------------------+ struct stInfos { bool IsFx; uint nInputs; double Bias, Weight[], Alpha; eFnActivate Activate; }m_Infos; //+------------------------------------------------------------------+ struct stErr { double weight[], eMaxWeight, bias; }m_Error; //+------------------------------------------------------------------+ inline double fnActivation(const bool isFx, const double value) { switch (m_Infos.Activate) { case Sigmoid: return (isFx ? 1 / (1 + MathExp(-value)) : MathExp(-value) / MathPow(1 + MathExp(-value), 2)); case Tangh: return (isFx ? (2 / (1 + MathExp(-2 * value))) - 1 : (4 / MathPow(MathExp(-value) + MathExp(value), 2))); case ReLU: return (isFx ? MathMax(0, value) : (value <= 0 ? 0 : 1)); case eLU: return (isFx ? (value <= 0 ? (m_Infos.Alpha * (MathExp(value) - 1)) : value) : (value <= 0 ? (m_Infos.Alpha * MathExp(value)) : 1)); case SoftSign: return (isFx ? value / (1 + MathAbs(value)) : value / MathPow(1 + MathAbs(value), 2)); case SoftPlus: return (isFx ? MathLog(1 + MathExp(value)) : 1 / (1 + MathExp(-value))); case Identity: default: return (isFx ? value : 1); } } //+------------------------------------------------------------------+ inline double Cost_FX(const double &train[]) { double x, err; err = 0; for (uint c0 = 0; c0 < train.Size(); c0++) { x = 0; for(uint c1 = 0; c1 < m_Infos.nInputs; c1++, c0++) x += (train[c0] * m_Infos.Weight[c1]); err += MathPow((x + m_Infos.Bias) - train[c0], 2); } return err; } //+------------------------------------------------------------------+ inline double Learning_FX(const double &train[], const double epsilon, const double LearningRate, const ulong limit) { double err, memT, err_w[]; ulong count; Print("Cost being calculated by the Minimum Square..."); ArrayResize(err_w, m_Infos.nInputs); for (count = 0; (count < limit) && ((err = Cost_FX(train)) > epsilon); count++) { for (uint c = 0, m = m_Infos.Weight.Size(); c < m; c++) { memT = m_Infos.Weight[c]; m_Infos.Weight[c] += LearningRate; err_w[c] = Cost_FX(train) - err; m_Infos.Weight[c] = memT; } memT = m_Infos.Bias; m_Infos.Bias += LearningRate; m_Infos.Bias = memT - (Cost_FX(train) - err); for (uint c = 0, m = m_Infos.Weight.Size(); c < m; c++) m_Infos.Weight[c] -= err_w[c]; } PrintFormat("Total interactions: %I64u", count); ArrayFree(err_w); return err; } //+------------------------------------------------------------------+ inline double Cost_DX(const double &train[]) { double x1, t; ZeroMemory(m_Error); for (uint c0 = 0, cw = 0; c0 < train.Size(); c0++, cw = c0) { x1 = 0; for(uint c1 = 0; c1 < m_Infos.nInputs; c1++, c0++) x1 += (train[c0] * m_Infos.Weight[c1]); t = 2 * ((x1 + m_Infos.Bias) - train[c0]); for(uint c1 = 0; c1 < m_Infos.nInputs; c1++, cw++) { m_Error.weight[c1] += (t * train[cw]); m_Error.eMaxWeight = (MathAbs(m_Error.weight[c1]) > MathAbs(m_Error.eMaxWeight) ? m_Error.weight[c1] : m_Error.eMaxWeight); } m_Error.bias += t; } return (MathAbs(m_Error.bias) > MathAbs(m_Error.eMaxWeight) ? m_Error.bias : m_Error.eMaxWeight); } //+------------------------------------------------------------------+ inline double Learning_DX(const double &train[], const double epsilon, const double LearningRate, const ulong limit) { ulong count; double eRet; Print("Cost being calculated by the Gradient..."); for (count = 0; (count < limit) && (MathAbs(eRet = Cost_DX(train)) > epsilon); count++) { m_Infos.Bias -= (m_Error.bias * LearningRate); for (uint c = 0, m = m_Infos.Weight.Size(); c < m; c++) m_Infos.Weight[c] -= (m_Error.weight[c] * LearningRate); } PrintFormat("Total interactions: %I64u", count); return eRet; } //+------------------------------------------------------------------+ public : //+------------------------------------------------------------------+ C_Neuron(uint nInputs = 1, eFnActivate fn = Identity, bool isFx = false, double alpha = 0.75, double H = 1.0, double L = 0.0) { MathSrand(512); ZeroMemory(m_Infos); m_Infos.Activate = fn; m_Infos.IsFx = isFx; m_Infos.Alpha = alpha; m_Infos.Bias = (double)macroRandom; ArrayResize(m_Infos.Weight, m_Infos.nInputs = nInputs); ArrayResize(m_Error.weight, m_Infos.nInputs); for(uint c = 0; c < m_Infos.nInputs; c++) m_Infos.Weight[c] = ((double)macroRandom * (H - L)) + L; } //+------------------------------------------------------------------+ ~C_Neuron() { ArrayFree(m_Infos.Weight); ArrayFree(m_Error.weight); } //+------------------------------------------------------------------+ void View_Variables(void) { Print("Bias: ", m_Infos.Bias); for (uint c = 0, m = m_Infos.Weight.Size(); c < m; c++) PrintFormat("Weight[%d]: %.16f", c, m_Infos.Weight[c]); } //+------------------------------------------------------------------+ inline double Learning(const double &train[], const double epsilon = 1e-3, const double LearningRate = 1e-2, const ulong limit = ULONG_MAX) { return (m_Infos.IsFx ? Learning_FX(train, epsilon, LearningRate, limit) : Learning_DX(train, epsilon, LearningRate, limit)); } //+------------------------------------------------------------------+ inline double Perceptron(const double &inputs[]) { double value = m_Infos.Bias; for (uint c = 0; c < m_Infos.nInputs; c++) value += (inputs[c] * m_Infos.Weight[c]); return fnActivation(true, value); } //+------------------------------------------------------------------+ }; //+------------------------------------------------------------------+ #undef macroRandom //+------------------------------------------------------------------+
Sei que pode parece bobagem, mostrar todo o código, mas quero mostrar algo aqui. No anexo, você terá um código já finalizado. Mas ver como ele era antes, é tão ou em alguns casos até mais importante do que ver o código pronto. Preste atenção para entender como ele precisará ser modificado. Isto irá lhe ajudar a entender, porque ele passará a ter um determinado comportamento futuro.
Aqui apenas e somente o perceptron está usando a função de ativação. Tanto a função de custo, que faz uso do mínimo quadrado, quanto a que utiliza o gradiente, não estão recebendo uma chamada para serem utilizadas.
Agora preste atenção, antes de mexer nesta classe C_Neuron, vamos criar outra classe, esta servirá para reduzir o código durante os testes, concentrando tudo em um único arquivo de cabeçalho. A tal classe que será criada é vista na íntegra logo abaixo.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" //+------------------------------------------------------------------+ #include <Neural Network\C_Neuron.mqh> //+------------------------------------------------------------------+ class C_Check_Neuron : private C_Neuron { //+------------------------------------------------------------------+ private : //+------------------------------------------------------------------+ public : //+------------------------------------------------------------------+ C_Check_Neuron(uint nInputs = 1, eFnActivate fn = Identity, bool isFx = false) :C_Neuron(nInputs, fn, isFx) {} //+------------------------------------------------------------------+ void View_Training_Data(const double &arr[], uint nColumns) { string sz0; uint nLines = arr.Size() / nColumns; Print("Training matrix."); Print("--------------------"); for (uchar i = 0; i < nLines; i++) { sz0 = ""; for (uchar j = 0; j < nColumns; j++) sz0 += StringFormat("%f ", arr[(i * nColumns) + j]); Print(sz0); } Print("--------------------"); } //+------------------------------------------------------------------+ void Performs_Training(const double &arr[], double epsilon, double LearningRate, ulong limit) { ulong it0, it1; it0 = GetTickCount(); Print("Margin of error achieved: ", Learning(arr, epsilon, LearningRate, limit)); it1 = GetTickCount(); Print("Total time(in Seconds): ", (it1 - it0) / 1000.0); } //+------------------------------------------------------------------+ void Check_Training(const double &arr[], uint nColumns) { string sz0; double mem[]; uint nLines = arr.Size() / nColumns; Print("********** RESULT *************"); ArrayResize(mem, nColumns); for (uchar i = 0; i < nLines; i++) { sz0 = ""; for (uchar j = 0; j < nColumns - 1; j++) sz0 += StringFormat("%f ", mem[j] = arr[(i * nColumns) + j]); sz0 += StringFormat("%f", Perceptron(mem)); Print(sz0); } Print("--------------------"); ArrayFree(mem); View_Variables(); } //+------------------------------------------------------------------+ }; //+------------------------------------------------------------------+
Esta classe C_Check_Neuron, pretende, nos permitir, imprimir, treinar e verificar o que está ocorrendo. Como ela conta apenas e tão somente com o essencial para termos o que será utilizado depois, fica mais simples entender as coisas sem nos perdermos no meio da explicação. Agora, vamos ver o primeiro dos códigos que será usado para testar o perceptron. O código pode ser observado a seguir.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" #property script_show_inputs #property description "Script to compare execution speed\n" \ "Here we are using only the CPU.\n" \ "However, the results are still very interesting." //+------------------------------------------------------------------+ #include <Neural Network\C_Check_Neuron.mqh> //+------------------------------------------------------------------+ enum eFactorization { Minimum_Square, Gradient_Descent, }; //+------------------------------------------------------------------+ input eFactorization user00 = Minimum_Square; //Type of factorization input double user01 = 1e-3; //Estimated error input double user02 = 1e-3; //Learning Rate input C_Neuron::eFnActivate user03 = C_Neuron::Identity; //Activation function //+------------------------------------------------------------------+ double Train[] { 0, 0, 1, 2, 2, 4, 3, 6, 4, 8 }; //+------------------------------------------------------------------+ #define nColumns 2 #define nLines Train.Size() / nColumns //+------------------------------------------------------------------+ void OnStart() { C_Check_Neuron *neuron; Print("************************************"); Print("Simple Neuron in Class..."); Print("************************************"); Print("Parameters:"); Print("Type of factorization: ", EnumToString(user00)); Print("Estimated error: ", user01); Print("Learning Rate:", user02); Print("Activation function: ", EnumToString(user03)); Print("************************************"); neuron = new C_Check_Neuron(nColumns - 1, user03, user00 == Minimum_Square); (*neuron).View_Training_Data(Train, nColumns); (*neuron).Performs_Training(Train, user01, user02, ULONG_MAX); (*neuron).Check_Training(Train, nColumns); delete neuron; } //+------------------------------------------------------------------+
Por conta que a maior complexidade, foi jogada para dentro da classe C_Check_Neuron. Este código mostrado acima, permite que tenhamos todos os testes sendo feitos e, ao mesmo tempo, nos permite imprimir diversas informações necessárias para sabermos o que o perceptron está fazendo. Isto a ponto de podemos analisar se de fato ocorreu ou não uma convergência para um ponto conhecido como ponto de menor custo. Ao executar exatamente este código acima, você poderá ver algo como mostrado na imagem abaixo.
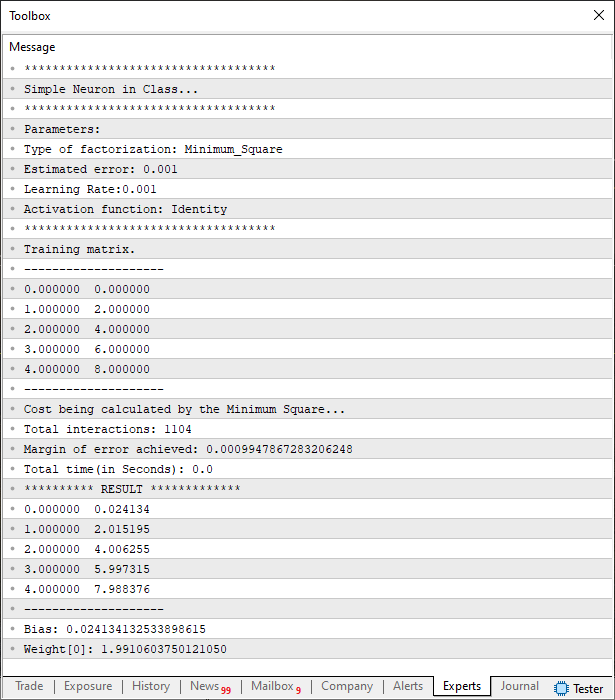
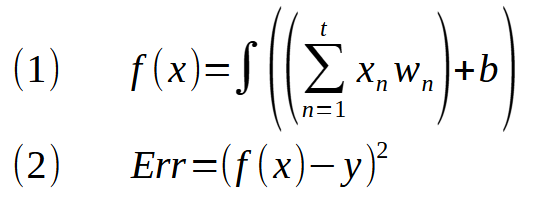
E aqui está a função de ativação sendo aplicada no mínimo quadrado. Lembre-se de que o símbolo de integração, na verdade, representa a função de ativação sendo fatorada. Agora quero que você compare esta expressão (1) com a expressão do perceptron. Note como são idênticas. Então você se pergunta: Como isto é possível? Existe algum motivo especial, para que isto tenha acontecido? Sim, meu amigo. O motivo é que todo o sistema de rede perceptron, foi e é primeiramente pensado para resolver regressões lineares. Se você não sabe do que estou falando, veja meus primeiros artigos sobre este tema.
Lá foi explicado como esta ideia começou a surgir. Mas o ponto aqui, não é a equação (1) mas sim a equação (2). Pois a expressão (1) representa o FORWARD PROPAGATION. Porém, a expressão (2) é justamente a BACK PROPAGATION, que estará sendo aplicada no perceptron. Note que não tem tanta diferença com relação ao que já estava sendo mostrado. Mas se você olhar isto no código, ainda mais da forma como eu o escrevo. Dará a impressão de que a coisa toda funciona de uma forma diferente da que estou mostrando nas expressões matemáticas. Por conta disto, estou mostrando as expressões. Para que você consiga compreender de maneira adequada, de onde está vindo este ou aquele código. Agora colocando isto em forma de código, passamos a ter o seguinte fragmento sendo incorporado no código da classe C_Neuron.
//+------------------------------------------------------------------+ inline double Cost_FX(const double &train[]) { double x, err; err = 0; for (uint c0 = 0; c0 < train.Size(); c0++) { x = 0; for(uint c1 = 0; c1 < m_Infos.nInputs; c1++, c0++) x += (train[c0] * m_Infos.Weight[c1]); err += MathPow(fnActivation(true, x + m_Infos.Bias) - train[c0], 2); } return err; } //+------------------------------------------------------------------+
A diferença é muito sutil, sendo preciso prestar atenção para que se possa notar o momento em que a função de ativação passa a ser chamada. Tanto que ao executar novamente o código de testagem, você verá a imagem mostrada abaixo.
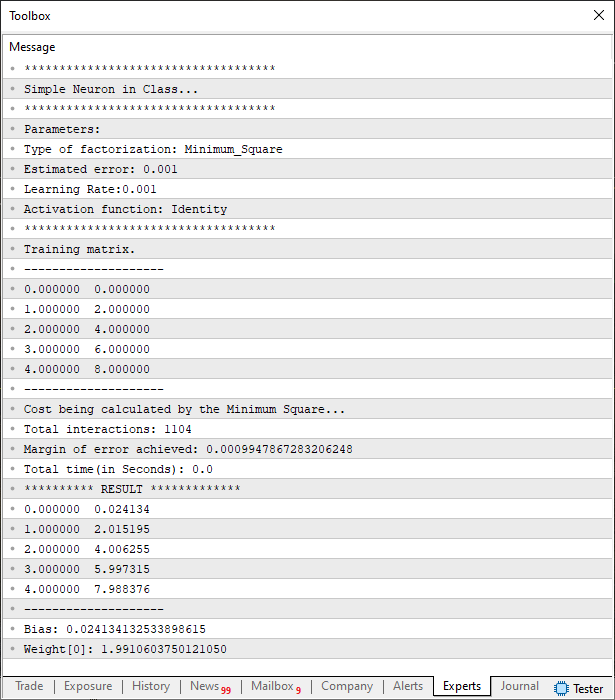
Parece uma cópia aquilo que estava sendo feito antes, mas não, são momentos diferentes para o mesmo código sendo executado. Uma hora com a função de ativação e outra sem a função de ativação. Mas preste ainda mais atenção ao fato de estarmos usando a função de ativação identidade. Isto por que, neste caso estamos de fato lidando com uma regressão linear. Não fazendo o mínimo sentido usar outra função de ativação.
Muito bem, mas será que este mesmo perceptron, consegue lidar com um número diferente de entradas? Bem, podemos facilmente testar este tipo de coisa. Para isto, vamos usar o código mostrado abaixo.
//+------------------------------------------------------------------+ #property copyright "Daniel Jose" #property script_show_inputs #property description "Script to compare execution speed\n" \ "Here we are using only the CPU.\n" \ "However, the results are still very interesting." //+------------------------------------------------------------------+ #include <Neural Network\C_Check_Neuron.mqh> //+------------------------------------------------------------------+ enum eFactorization { Minimum_Square, Gradient_Descent, }; //+------------------------------------------------------------------+ input eFactorization user00 = Minimum_Square; //Type of factorization input double user01 = 1e-3; //Estimated error input double user02 = 1e-3; //Learning Rate input C_Neuron::eFnActivate user03 = C_Neuron::Identity; //Activation function //+------------------------------------------------------------------+ //Training expression: f(x) = (w0 * 1.8) + (w1 * 2.15) + 2.1 //+------------------------------------------------------------------+ double Train[] { 1, 3, 10.35, 1.5, 3.25, 11.7875, 1.75, 3.94, 13.721, 2.85, 3.46, 14.669 }; //+------------------------------------------------------------------+ #define nColumns 3 #define nLines Train.Size() / nColumns //+------------------------------------------------------------------+ void OnStart() { C_Check_Neuron *neuron; Print("************************************"); Print("Simple Neuron in Class..."); Print("************************************"); Print("Parameters:"); Print("Type of factorization: ", EnumToString(user00)); Print("Estimated error: ", user01); Print("Learning Rate:", user02); Print("Activation function: ", EnumToString(user03)); Print("************************************"); neuron = new C_Check_Neuron(nColumns - 1, user03, user00 == Minimum_Square); (*neuron).View_Training_Data(Train, nColumns); (*neuron).Performs_Training(Train, user01, user02, ULONG_MAX); (*neuron).Check_Training(Train, nColumns); delete neuron; } //+------------------------------------------------------------------+
Ao executar este código, você verá o seguinte resultado sendo mostrado no terminal.
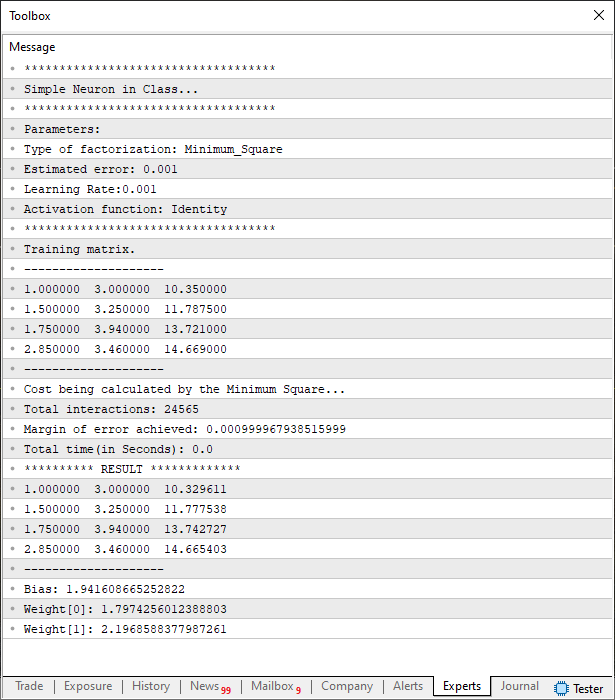
Não sei se você está conseguindo de fato acompanhar a linha de raciocínio. Mas note que entre este código e o anterior, voltados para testar o perceptron. Basicamente foram necessárias poucas mudanças. Em especial, as mudanças foram feitas na definição que diz quantas colunas nos temos naquele que é o array de treinamento. Assim como também os dados que estão sendo usado no treinamento. Então caso você queira fazer uso de dados, completamente diferentes, não terá dificuldades em experimentar este perceptron. Mas como foi mencionado, existem alguns cuidados a serem tomados. Talvez o maior deles é com relação ao valor informado no campo da taxa de aprendizagem.
Você não deve usar valores muito altos, pois isto acaba deixando o perceptron meio louco. Assim como também não deverá usar valores muito pequenos, pois eles tornam o perceptron muito lento para conseguir convergir a um valor de erro abaixo do estimado e desejado. Ou seja, moderação é a palavra de ordem aqui.
Esta questão de mencionar que o perceptron fica meio louco, se deve a um fator matemático. Não por conta que o programa contenha uma falha, que o faça entrar em um loop muito longo. Mas sim pelo motivo matemático da convergência de valores. Para entender veja a imagem abaixo.
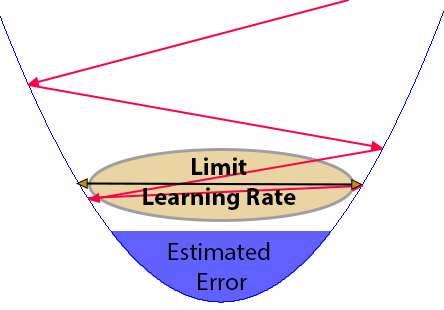
Esta imagem acima, que aparentemente é confusa à primeira vista, está nos mostrando justamente o problema de se usar um valor inadequado para a taxa de aprendizagem. Normalmente gosto de definir o valor como sendo igual ou um pouco menor que o erro estimado. Justamente para evitar esta situação mostrada na imagem acima.
Conforme o perceptron vai convergindo para alcançar o erro estimado, e isto está sendo mostrado pelas linhas em vermelho. Ele em algum momento pode acabar por atingir um vale, cuja distância entre os extremos está muito perto do valor de taxa de aprendizagem. Mesmo que o valor de erro estimado, esteja corretamente definido. A distância entre as paredes do vale, faz com que o perceptron pare de convergir, fazendo com que ele nunca de fato encerre por atingir o erro previamente definido. Isto por que a taxa de aprendizagem, pode fazer com que o perceptron vá de um lado a outro, sem ao menos conseguir continuar descendo. Este talvez seja o pior dos cenários que podemos experimentar. Já que você pensa que a aplicação travou. Daí a necessidade de termos algum tipo de mecanismo para sair de tal condição constrangedora.
Um dos mecanismos adotados, é o de ajustar o valor máximo para interações com os dados de treinamento. Pessoalmente gosto de deixar como ULONG_MAX. Mas pode acontecer de isto ser tempo demais. Então é bom você ponderar no momento de ajustar a taxa de aprendizagem, o erro estimado e até mesmo quem sabe a quantidade máxima de interações do perceptron com os dados de treinamento. Estas alternativas podem ser feitas, sem você precisar mudar nada no código aqui apresentado. Bastando apenas, ajustar o código na aplicação final.
Se você achou tudo isto interessante. E conseguiu entender e compreender como a função de ativação é utilizada quando selecionamos o mínimo quadrado. Chegou a hora de ver a coisa de maneira ainda mais interessante. Pois agora veremos como as coisas se dão quando selecionamos o gradiente. Mas para separar as coisas, vamos ver isto em um novo tópico.
Função de ativação no gradiente
Agora a coisa ficará muito mais divertida. Pois o que foi visto no tópico anterior, é doce nas mãos de uma criança. Mas o que será visto aqui, poderia ser considerado. Fogo no parquinho. Pois aqui é onde as crianças começam a chorar, sem saber como resolver a parada. Esperando que um adulto venha ao seu socorro.
Brincadeiras à parte, aplicar a função de ativação no gradiente, não é tão simples quanto aplicar na função de mínimo quadrado. Isto devido justamente ao fato de que o gradiente é uma derivada da função de mínimo quadrado. Mas existe um porém, e é este o motivo de que muitos ficam confusos quando tentam entender o gradiente. Ainda mais quando parte de um princípio equivocado, sem antes entender a própria forma de trabalhar do mínimo quadrado.
Diferente das expressões usadas no mínimo quadrado, onde as expressões praticamente se parecem com a expressão vista no perceptron. No gradiente, temos duas expressões. Uma para a saída dos dados, e outra para a retro propagação. Por isto que muitos acabam ficando confusos. Mas isto não é motivo para alarde ou pânico. Apenas tente entender o que explicarei. Pois você verá que, na prática, as coisas são muito mais simples do que possa parecer. No artigo anterior, mostrei a seguinte expressão:
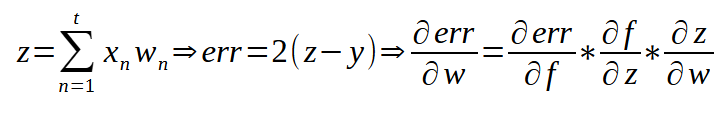
Ou seja, o erro, na verdade, é um conjunto de derivadas, isto quando nosso foco é o uso do gradiente. Então tudo que precisamos fazer é multiplicar o valor do gradiente pela derivada da função de ativação, para começar a corrigir o erro. Simples assim. Na forma de código, você pode ver isto sendo usado no fragmento logo a seguir.
//+------------------------------------------------------------------+ inline double Cost_DX(const double &train[]) { double x1, t; ZeroMemory(m_Error); for (uint c0 = 0, cw = 0; c0 < train.Size(); c0++, cw = c0) { x1 = 0; for(uint c1 = 0; c1 < m_Infos.nInputs; c1++, c0++) x1 += (train[c0] * m_Infos.Weight[c1]); t = 2 * ((x1 + m_Infos.Bias) - train[c0]) * fnActivation(false, x1 + m_Infos.Bias); for(uint c1 = 0; c1 < m_Infos.nInputs; c1++, cw++) { m_Error.weight[c1] += (t * train[cw]); m_Error.eMaxWeight = (MathAbs(m_Error.weight[c1]) > MathAbs(m_Error.eMaxWeight) ? m_Error.weight[c1] : m_Error.eMaxWeight); } m_Error.bias += t; } return (MathAbs(m_Error.bias) > MathAbs(m_Error.eMaxWeight) ? m_Error.bias : m_Error.eMaxWeight); } //+------------------------------------------------------------------+
Mas é só isto? Sim, meu caro leitor, é somente isto que precisamos fazer. Agora temos tanto um perceptron que faz utiliza o gradiente, como também é capaz de fazer uso do mínimo quadrado. A grosso modo, podemos dizer que o perceptron está completo. Ou seja, temos entradas, uma função de custo, uma função de ativação, uma retro propagação e uma saída. Estas coisas já estão implementadas dentro do nosso perceptron, que está sendo implementado na classe C_Neuron. Toda aquela complicação, que muitos fazem em torno do tema. É apenas para tentar deixar a coisa parecendo mais complicada do que realmente são.
Resumo da opera
Talvez você ainda possa estar um tanto quanto incrédulo, sobre se de fato precisamos usar a derivada da função de ativação, quando usamos o gradiente. Para compreender a necessidade da derivada, precisaremos entrar na parte matemática da coisa. Então, o restante deste artigo, será voltado a explicar como chegamos a tal conclusão e necessidade do uso das derivadas. Você pode pular o resto do artigo, se assim desejar. Mas garanto que será uma bela revisão de tudo visto até aqui. E isto lhe ajudará a entender os próximos passos que serão dados.
Muito bem, a primeira coisa é darmos alguns passos para trás, voltarmos para a origem do gradiente. Já expliquei isto antes, mas aqui vamos reforçar o que foi explicado, mas de uma forma um pouco mais profunda. Tudo começa com a função afim. Ela tem como expressão, o que é visto na imagem abaixo.
![]()
O < a > é o coeficiente angular e o <b> é o ponto de intersecção. Já o valor de <x> é o valor de entrada. Tanto <a> como <b> são constantes. Esta expressão acima, quando montada em forma de um polinômio, dá origem a outra expressão muito parecida com ela. E quando resolvemos o polinômio gerado. Temos o que é conhecido como regressão linear. O detalhe é que muitas das vezes os valores usados, não tocam exatamente na reta que será construída, pela função afim. E esta diferença entre o valor estimado e o valor obtido pela função afim, é conhecido como erro. Então usando um pouco de astúcia matemática, podemos gerar algumas funções que tentam fazer com que este erro tenda a zero. Isto nos leva a expressão mostrada abaixo.
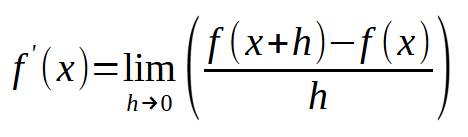
Esta expressão, é a base geral para a criação da regressão linear, onde temos um banco de dados com diversos valores, e queremos fazer com que a função afim, que será construída, tenha o menor valor de erro possível. Fazemos isto, forçando o valor de <h> a zero. Porém, existe um detalhe aqui. Esta expressão não nos permite corrigir os valores de <a> e <b> da função afim, com base no erro que está sendo gerado. Para isto, fazemos algumas manipulações matemáticas, e chegamos a seguinte expressão mostrada a seguir.
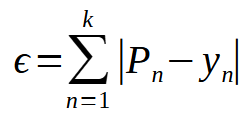
Esta é a expressão original para encontrar o erro. O valor <P> é o valor que estamos calculando com base na função afim. Já o valor de <y> é o valor estimado, ou esperado como resultado. Note que estamos usando o modulo do valor. Isto para que valores negativos não cancelem valores positivos. Dando assim a falsa impressão de que os valores de <a> e <b> estão corretos, quando, na verdade, continuam errados. Porém, esta expressão mostrada acima, não nos força a nos mover muito rápido em direção ao menor erro possível. Para fazer isto, substituímos o modulo, por uma potência de dois. Surgindo assim a seguinte expressão, mostrada na sequência.
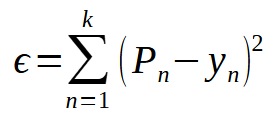
Note que ela é praticamente igual à expressão vista anteriormente. Mas o fato de estamos usando uma potência no lugar do módulo. Faz com que este erro, mude de um gráfico assim:
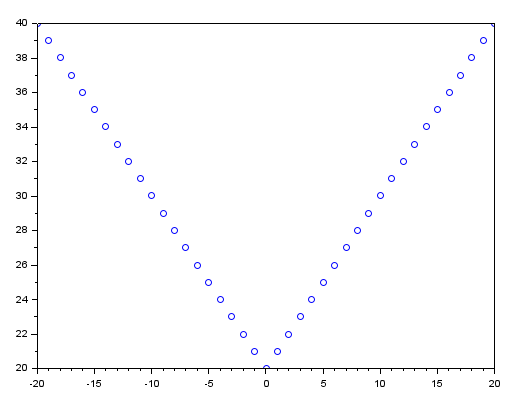
Para um assim:
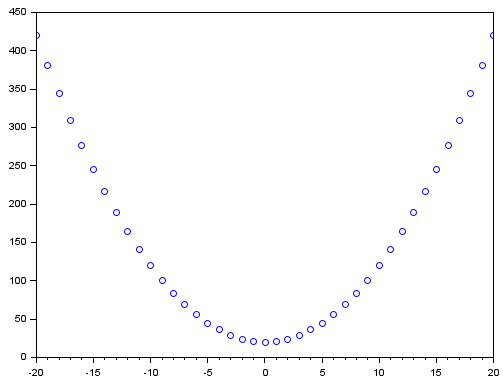
Apesar de não parecer, isto faz muita diferença na velocidade de decaimento. Tanto que se você mudar para uma potência ainda maior, verá que a velocidade irá aumentar ainda mais. Só tome o cuidado de usar potências pares. Pois valores impares na potência, permitem valores negativo na saída. E isto cai naquela questão de não podermos ter valores positivos e negativos sendo somados ao erro final.
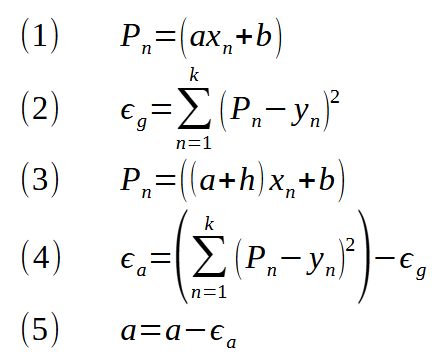
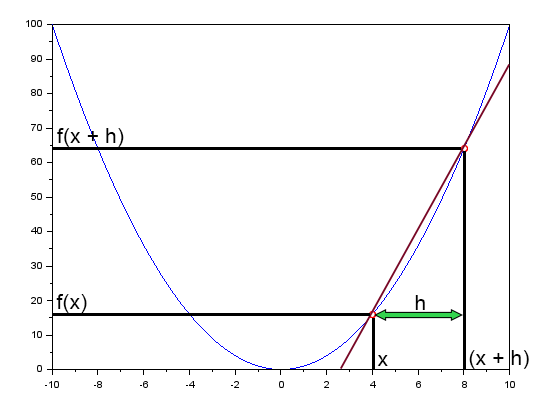
Esta reta em vermelho não é uma tangente, ela é uma secante, e conforme h se aproxima de zero, esta mesma reta tende a se tornar, uma reta tangente, isto quando <h> for igual a zero. Ok, então de onde vem a ideia de reta tangente? Bem, ela vem justamente do gradiente, e não do uso de outra coisa. Mas calma, se você está chegando agora, você verá como isto ocorre. Voltando ao assunto. Por conta de que a expressão mostrada acima, de fato gera uma reta, e esta é uma regressão linear. Não conseguimos representar outros tipos de distribuição de dados. Por isto surge a necessidade de se usar o que é conhecida como função de ativação. Isto será melhor entendido depois. Por hora você precisa entender apenas que sem a função de ativação teríamos de fato uma regressão linear sendo representada, o que limita bastante as coisas.
Porém, conforme a quantidade de entradas, começa a aumentar. O número de vezes que precisamos executar os passos de três a cinco, também começa a aumentar muito rapidamente. Para solucionar isto, pegamos o cálculo de mínimo quadrado, e o derivamos, criando assim uma nova expressão. Esta expressão é mostrada logo abaixo.
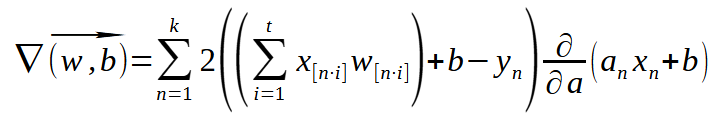
Sei que esta expressão acima, parece assustadora. Mas ela representa todos aqueles passos para tentar buscar o valor para o erro a ser corrigido. Mas como você pode notar o gradiente é, na verdade, um vetor. Este vetor é ortogonal a reta tangente, em um dado ponto da curva. Diferente do que estávamos usando antes, este gradiente consegue de fato, usar a reta tangente para buscar o valor de mínimo erro. Então como derivamos a expressão de mínimo quadrado, e na expressão de mínimo quadrado, temos a função de ativação incrustada nele. Ao procurarmos o valor para o gradiente, também precisaremos derivar a função de ativação. Por isto, usamos a derivada das funções de ativação. Mas isto apenas durante a fase de retro propagação, já que nesta fase estamos tentando fazer com que a saída do perceptron passe a ser vista como uma entrada.
Uma última observação. Aqui você pode ter notado que não usei, os famosos valores <w> e <b>. Mas sim <a> e <b>, fiz isto intencionalmente, para mostrar que no final das contas, tudo se resume a expressão original. Que é a função afim, que apenas sofreu uma série de manipulações para se tornar uma função gradiente.
Considerações finais
Neste artigo você aprendeu como e por que o perceptron começou a deixar de usar o recurso de mínimo quadrado para ajustar o erro das constantes internas e passou a utilizar o gradiente para isto. Fizemos isto, mediante uma transição relativamente suave e simples. Onde você começou a perceber que um perceptron nada mais é do que uma coleção de funções e expressões matemáticas, cujo objetivo é justamente o de permitir que consigamos gerar uma regressão linear mais adequada em um banco de dados.
Então procure estudar com calma os códigos presentes no anexo, pois isto irá lhe ajudar a entender o que irá ser feito nos próximos artigos. Já que estamos chegando em um momento crucial. Onde você irá começar a ver que existem detalhes a serem observados no treinamento de um sistema perceptron.
| Arquivo MQ5 | Descrição |
|---|---|
| Scripts\Example A | Demonstração básica |
| Scripts\Example B | Demonstração básica |
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso