
Rede neural na prática: Surgimento de C_Neuron

Introdução
No artigo anterior Rede neural na prática: Quando usar um neurônio artificial e entender sua função em MQL5, mencionei e demonstrei de forma clara, que você usando os códigos no anexo. Também pode observar, que um neurônio, nem sempre consegue lidar com certos tipos de situação. Apesar de que o senso comum diz exatamente o contrário, do que pode ser observado. Os experimentos não deixam dúvidas. Nem sempre usar neurônios, ou mesmo uma rede neural, será de fato o melhor caminho.
No entanto existe uma série enorme de situações, em que um neurônio, ou mesmo uma rede neural, é de fato a solução ideal. Isto para que possamos, de forma bastante rápida e eficaz, conseguir uma representação adequada, para um dado conjunto de informações, ou registros. No geral, muitas das vezes podemos estar usando simplesmente um banco de dados. E este já terá todas as informações das quais precisaremos, ou queremos lidar. Outras vezes, estes dados serão alimentados em tempo real. Com relação a este segundo modelo, onde os dados serão alimentados na rede neural, em tempo real. Iremos deixar para ver isto em um outro momento no futuro.
Isto por que, pretendo mostrar um tipo de aplicação bastante interessante. Na qual, permitirá que você, meu caro leitor, possa de fato compreender como o sistema, ou rede neural, conseguirá aprender a lidar com uma situação bem específica. Porém é algo que de fato irá despertar a sua curiosidade e interesse em buscar mais e mais conhecimento sobre o tema. Porém neste momento, vamos nos concentrar no presente.
Bem, se você está acompanhando estes artigos sobre rede neural. Deve ter notado que muitas das vezes, temos usado apenas uma única entrada. Isto para facilitar a parte da programação e a didática dos códigos a serem explicados. No entanto, raramente de fato usamos em casos reais, apenas uma única entrada. É bem comum termos no mínimo de duas ou mais entradas no neurônio. Ainda mais se desejarmos implementar uma pequena rede neural. Mesmo durante a fase inicial, você, meu caro leitor, deve ter notado, que foi necessário usarmos mais de uma entrada. Isto quando criamos um neurônio para representar portas lógicas. E durante este processo, tivemos de utilizar uma pequena rede neural para conseguirmos representar uma porta XOR e sua inversa.
Muito bem, neste ponto da conversa, você já deve estar imaginando uma coisa: Mas adicionar novas entradas é algo relativamente simples. Tudo que precisamos é indicar isto ao neurônio, adicionarmos um peso a esta entrada e pronto. Mas é claro, que não devemos nos esquecer de modificar a função de custo. Caso contrário a nova entrada não terá nenhuma serventia. De fato, você está correto quanto a isto, meu caro leitor. Porém existe um pequeno agravante. Para adicionarmos poucas entradas, a coisa é bem simples. Assim como também para remover as mesmas.
No entanto, pensar em alguns detalhes relacionados a isto. Você não quer de forma alguma precisar ficar codificando ou modificando o código a todo momento. Isto simplesmente para poder adicionar ou remover entradas do neurônio. E pior, se for necessário usar uma rede neural, você não vai querer codifica-la a mão. É muito mais simples e adequado, simplesmente anunciarmos como ela deverá ser arquitetada, e deixar que o código implemente isto para nós. Futuramente veremos como isto pode ser feito. Mas vamos voltar ao caso das entradas.
Uma outra questão é que, suponhamos que um dado problema venha a exigir mil entradas. Daí você, desanda a adicionar código a fim de criar as tais mil entradas. Em um dado momento, alguém pega e lhe diz: "Cara acabamos de perceber que serão necessárias dez mil entradas". Logo você sente vontade de chorar. Mas aceita a tarefa, quando já está com quase dez mil entradas criadas. Outra pessoa volta e diz. Notamos que dez mil entradas, não são necessárias, podemos usar apenas duas mil. Aí você sente vontade de pegar um porrete e ensinar alguém uma lição.
Não é raro um iniciante cair nesta pegadinha do malandro. Mas de qualquer forma, se ele não fosse assim tão iniciante, teria alguma malandragem. E saberia como resolver a coisa de forma a reduzir o seu trabalho. Bem, é justamente esta a proposta inicial deste artigo. Mostrar como podemos criar uma implementação, na qual podemos controlar o número de entradas, de maneira muito, mas muito simples mesmo. Então vamos arregaçar as mangas e vamos ao código.
O nascimento da classe C_Neuron
Um detalhe, do qual precisamos deixar claro para você, meu caro leitor, antes mesmo de começarmos. Esta classe que iremos criar, cujo objetivo é comportar um neurônio, será neste momento uma classe bem simples e direta. Não iremos colocar absolutamente nada, que não seja extremamente necessário dentro da mesma. O código a ser usado, será o mais simples e didático quanto for possível ser feito. Mesmo que ele não seja de fato eficiente em termos de tempo de fatoração. Entenda este tempo de fatoração, como sendo o tempo de execução.
O objetivo aqui não será criar um código eficiente, mas sim funcional e que possa ser perfeitamente compreendido por qualquer pessoa. Mesmo quem esteja começando a programar em MQL5, e venha a demonstrar interesse sobre redes neurais. Isto por que o código usará MQL5 puro. Talvez eu venha no futuro colocar um pouco de SQL nele. Mas vou tentar ao máximo evitar sair do MQL5 puro e simples.
Dito tais coisas, e explicado o que será visto. Podemos começar. E vamos fazer isto, pela implementação mais simples de todas, a que usa o mínimo quadrado como função de custo. Novamente a ideia, não é ser eficiente e sim didático. Mas antes de vermos o código, vamos ver uma coisa, que é mostrada logo abaixo:

Talvez possamos estar parecendo um tanto quanto repetitivo. Mas redes neurais é isto mesmo. Mas ignorando isto. Note algo curioso nesta equação acima. Olhando para ela e entendendo o que se passa, você logo percebe que precisamos multiplicar cada entrada por um peso, somar tudo e depois subtrair do valor que seria o correto. Elevando o resultado ao quadrado, temos o que seria o erro final daquela posição testada. Um detalhe, existem outras funções para efetuar o cálculo do erro. Mas como esta vista a cima é a que nos permite derivar de forma mais simples, usaremos ela.
Muito bem, agora vamos isolar apenas a parte da entrada, que é representado como < X > e o peso que é representado como < W >. Isto nos dá o que é visto logo abaixo.

Hum, interessante. Mas o que isto quer nos dizer? Bem, meu caro leitor, ao fazermos as coisas assim, estamos dizendo que o valor de < k > é na verdade a quantidade de entradas que o neurônio terá. Se um algum treinamento por ventura vier a exigir que tenhamos mil entradas, tudo que precisamos fazer é tornar o valor de k igual a mil. Simples assim. Desta forma teríamos algo equivalente ao que é visto abaixo
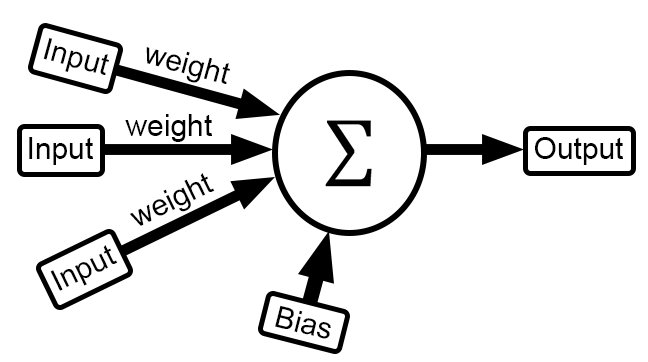
Agora vem a parte realmente interessante, e que está diretamente envolvida no que precisamos fazer no código. Ao olhar o somatório de x e w. Você talvez não consiga notar, mais este nada mais é do que uma operação de matrizes. Mas como assim, não entendi. Calma meu caro leitor, vamos transformar a notação do somatório em algo mais claro. Assim você conseguirá entender. Isto é visto na imagem abaixo.

Agora sim temos algo realmente bonito em nossa frente. Pois apesar de ser complicado implementar em código o conteúdo no lado esquerdo. Implementar o conteúdo do lado direito é muito fácil e simples. Isto por que podemos usar arrays para tal implementação. Assim podemos de forma extremamente simples e rápida mudar o número de entradas no neurônio. Cara isto é muito legal, então como isto fica em termos de código? Bem, meu caro leitor, logo abaixo, você pode ver como ficou isto dentro do código da classe.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define macroRandom (rand() / (double)SHORT_MAX) 05. //+------------------------------------------------------------------+ 06. class C_Neuron 07. { 08. private: 09. uint m_Inputs; 10. double m_bias, 11. m_weight[]; 12. //+------------------------------------------------------------------+ 13. inline double Cost(const double &train[]) 14. { 15. double x, err; 16. 17. err = 0; 18. for (uint c0 = 0; c0 < train.Size(); c0++) 19. { 20. x = 0; 21. for(uint c1 = 0; c1 < m_Inputs; c1++, c0++) 22. x += (train[c0] * m_weight[c1]); 23. err += MathPow((x + m_bias) - train[c0], 2); 24. } 25. 26. return err; 27. } 28. //+------------------------------------------------------------------+ 29. public : 30. //+------------------------------------------------------------------+ 31. C_Neuron(const uint nInputs = 1, double H = 1.0, double L = 0.0) 32. { 33. MathSrand(512); 34. m_Inputs = nInputs; 35. ArrayResize(m_weight, m_Inputs); 36. for(uint c = 0; c < m_Inputs; c++) 37. m_weight[c] = ((double)macroRandom * (H - L)) + L; 38. m_bias = (double)macroRandom; 39. } 40. //+------------------------------------------------------------------+ 41. ~C_Neuron() 42. { 43. ArrayFree(m_weight); 44. } 45. //+------------------------------------------------------------------+ 46. void View_Variables(void) 47. { 48. Print("Bias: ", m_bias); 49. for (uint c = 0, m = m_weight.Size(); c < m; c++) 50. PrintFormat("Weight[%d]: %.16f", c, m_weight[c]); 51. } 52. //+------------------------------------------------------------------+ 53. inline double Learning(const double &train[], const double epsilon = 1e-3, const ulong limit = ULONG_MAX) 54. { 55. double err, 56. mem_b, 57. err_w[], 58. mem_w[]; 59. 60. ArrayResize(err_w, m_Inputs); 61. ArrayResize(mem_w, m_Inputs); 62. for (ulong count = 0; (count < limit) && ((err = Cost(train)) > epsilon); count++) 63. { 64. ArrayCopy(mem_w, m_weight); 65. for (uint c = 0, m = m_weight.Size(); c < m; c++) 66. { 67. m_weight[c] += epsilon; 68. err_w[c] = Cost(train) - err; 69. m_weight[c] = mem_w[c]; 70. } 71. mem_b = m_bias; 72. m_bias += epsilon; 73. m_bias = mem_b - (Cost(train) - err); 74. for (uint c = 0, m = m_weight.Size(); c < m; c++) 75. m_weight[c] -= err_w[c]; 76. } 77. ArrayFree(err_w); 78. ArrayFree(mem_w); 79. 80. return err; 81. } 82. //+------------------------------------------------------------------+ 83. }; 84. //+------------------------------------------------------------------+ 85. #undef macroRandom 86. //+------------------------------------------------------------------+
Bem, por conta de algumas diferenças entre o C/C++ e o MQL5. O código ficou um pouco diferente, do que seria um código, que ao meu entender seria mais legível. Mas mesmo assim não é algo complicado de se entender. Aqui temos o básico do básico sendo implementado. De forma que este neurônio, usará o mínimo quadrado como função de custo. E também, este mesmo neurônio, poderá ter tantas entradas quantas forem necessárias. Mas existe um pequeno detalhe, e é justamente este detalhe que fará a diferença na forma de se trabalhar com esta classe. Mas isto será visto um pouco mais a frente.
Então vamos começar entendendo o que temos como código implementado aqui. Vamos começar pelo constructor da classe. Este se encontra na linha 31. Repare que ele é bem simples, claro e direto. Como argumentos, podemos dizer a classe, quantas entradas o neurônio irá conter. E quais serão os limites superiores e inferiores dentro do que seria colocado, como valores pseudo aleatórios, durante a inicialização.
Perceba que agora começamos a tornar a coisa bem mais séria. Então, na linha 33, dizemos como o gerador de números pseudos aleatórios irá começar. Como o intuito aqui é ser didático. Estaremos usando um valor fixo. Mas em situações reais, esta linha 33 seria ligeiramente diferente. Na verdade, em todo o código da classe, esta seria a única linha que precisaria ser modificada.
Ok, então nos próximos passos, iremos inicializar os valores internos da classe. Começando com a memória de quantidade de entradas, que é feito na linha 34. Logo depois na linha 35 alocamos memória suficiente para comportar o array com todos os pesos. Um para cada entrada. Para inicializar estes pesos, usamos o laço na linha 36. E para finalizar na linha 38, inicializamos o valor do viés. Com isto nosso neurônio já se encontrará pronto para o treinamento.
Muito bem, na linha 41, temos o destructor, cujo único objetivo é devolver a memória alocada para comportar os valores de peso. Como nosso neurônio pode ter diversas entradas, e podemos querer visualizar o conteúdo, temos na linha 46 um procedimento bastante simples. Porém bem útil. Seu único objetivo, é permitir imprimir os valores de todas as variáveis contidas no neurônio, no terminal do MetaTrader 5. Na linha 48, pedimos para imprimir o valor do viés. Já na linha 49, pedimos para que todos os valores de peso sejam impressos. Ou seja, não precisamos novamente dizer quantas entradas o neurônio precisa nos mostrar. Ele sabendo quantas ele tem, irá nos mostrar todas elas. Algo bem direto, simples e prático.
Agora vem a parte tão esperada. As funções que são usadas no treinamento do neurônio. Primeiramente vamos usar a função de mínimo quadrado. Porém como ela exige mais poder computacional, logo iremos mudar isto para algum outro tipo. Muito provavelmente para um dos gradientes. Mas isto irá ficar para um outro momento. Primeiro vamos ver como esta do mínimo quadrado funciona.
A primeira coisa da qual você deve entender, e a seguinte meu caro leitor. Não importa onde você irá usar este neurônio. Se ele conseguir entender os dados usados no treinamento. Você o conseguirá utilizar, sem de fato entender qual tipo de função está sendo usada para o aprendizado. Isto talvez possa soar um tanto quanto abstrato. Mas pelo fato de que estamos fazendo uso de uma classe. Qualquer coisa dentro da classe, poderá ser modificada, sem que precisemos notificar o código que a está usando, sobre as mudanças feitas internamente na classe. Isto permite que tenhamos uma função de custo mais eficiente, sem que a aplicação que esteja usando a classe, saiba disto. O que é muito bom, já que podemos mudar para uma função de gradiente, sem dizer nada a aplicação que esteja usando a classe.
Mas para que isto ocorra, precisamos de uma interface adequada. Por conta isto, a única função a ser usada no treinamento é a que se encontra declarada na linha 53. Note que ela é bastante simples contando com pouco argumentos a serem informados. O primeiro argumento, são os dados de treinamento. O segundo argumento é o erro estimado e esperado, para que a função encerre o treinamento. Já o último argumento, diz quantas interações poderão ocorrer. Este é o argumento que nos permite testar o treinamento, para verificar se ele está ou não convergindo para uma solução. Pois como foi mostrado nos outros artigos, pode acontecer de o neurônio, ou melhor, a função procurada não conseguir convergir.
Muito bem, dentro desta função da linha 53, temos algumas variáveis internas, que estão sendo declaradas na linha 55. Na linha 60 e 61, alocamos memória para ser utilizada temporariamente. Já na linha 62, entramos no laço que irá interagir um dado número de vezes. Este laço, já foi explicado em outros artigos. Porém o conteúdo interno dele é um pouco diferente. Observe que na linha 64, copiamos os dados de peso, para uma região temporária da memória. Este tipo de coisa não é muito eficiente, mas por hora servirá ao nosso propósito.
Já na linha 65, entramos em um novo laço interno. Este tem como objetivo varrer e encontrar os valores de erro, para cada uma das entradas. Uma a uma. Os novos valores de erro, para cada uma das entradas é armazenado de forma temporária na memória, isto pode ser visto na linha 68. Depois que todas as entradas, terem os valores de erro calculados, com base na variação desejada, precisamos ajustar o valor de erro do viés. Isto é feito na linha 73. Agora finalmente podemos corrigir, cada um dos pesos, com base no valor de erro que foi calculado anteriormente. Isto é feito pelo laço na linha 74.
Com tudo isto efetivamente executado, o código volta a linha 62, onde uma nova interação acontecerá. E ficará dentro deste laço, até que o limite informado de interações, ou o erro esperado seja alcançado. Quando qualquer uma das duas condições for conseguida, o laço se encerrará e teremos a execução das linhas 77 e 78, para liberar a memória alocada. Como as vezes é interessante ser feito, na linha 80 retornaremos o valor de erro que o treinamento atingiu. Assim podemos analisar se ele está ou não dentro do esperado. Isto quando estivermos usando um pequeno número de interações para testar o treinamento.
Ok, agora vamos para a linha 13. Pois como você pode ver, nesta função de treinamento, chamamos por diversas vezes a função que faz o cálculo de custo. E esta função, como você observa na linha 13, recebe um único argumento, como este é um array, podemos passar muito mais informações do que seria possível via outro tipo de construção. Porém existe um pequeno cuidado a ser tomado aqui. Então preste atenção, meu caro leitor, pois se você não entender o que vou explicar, você terá problemas ao tentar treinar o neurônio, fazendo uso de mais ou menos entradas.
Então vamos com calma. Na linha 18, iniciamos um laço que irá percorrer todo o array. Como você pode notar, esta varredura é feita de maneira indiscriminada. Ou seja, a função não irá de maneira alguma checar se o valor é uma entrada ou o valor esperado. Mas, porém, toda via e, entretanto, se você fizer as coisas da forma correta, não terá problemas aqui. Então vamos entender, como não ter problemas com este array.
Durante o processo de criação do neurônio, dizemos a ele, quantas entradas ele deverá ter. Então, no momento em que o laço da linha 21 for se executado, a função de custo, irá pegar cada um dos valores do array de treinamento e multiplicar pelo peso correspondente da entrada. Esta é a parte do cálculo matricial. Multiplicamos os valores e o somamos com o valor anterior. Como o array de treinamento, assim como array de pesos, é uma matriz de uma dimensão, ou seja, ela contém apenas linhas, ou apenas colunas. O resultado é um valor escalar, este valor é depois somado com o valor de viés, e subtraído do valor esperado.
Tendo este resultado sido calculado, o elevamos ao quadrado e somamos com os valores anteriores. Dando assim um erro de mínimo quadrado. Isto que acabo de explicar, é feito na linha 23. No final da interação com os valores de treinamento, retornamos na linha 26 o valor de erro total calculado.
Agora se você olhar esta função de custo, prestando atenção ao que acontece nos laços. Talvez pense que ela está um tanto quanto estranha. E que talvez ela não funcione. Mas vamos ver se isto de fato acontece. Fazendo uso do seguinte código mostrado abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include <Neural Network\C_Neuron.mqh> 05. //+------------------------------------------------------------------+ 06. double Train[] { 07. 0, 0, 08. 1, 2, 09. 2, 4, 10. 3, 6, 11. 4, 8 12. }; 13. //+------------------------------------------------------------------+ 14. void OnStart() 15. { 16. C_Neuron *neuron; 17. 18. Print("************************************"); 19. Print("Simple Neuron in Class..."); 20. 21. neuron = new C_Neuron(1); 22. 23. (*neuron).View_Variables(); 24. Print("********** RESULT *************"); 25. Print("Error: ", (*neuron).Learning(Train)); 26. (*neuron).View_Variables(); 27. 28. delete neuron; 29. } 30. //+------------------------------------------------------------------+
O resultado da execução é visto a imagem abaixo.
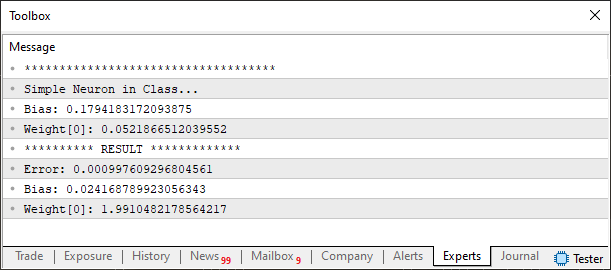
Note que o resultado está dentro do esperado, mostrando que de fato o neurônio está funcionando perfeitamente. Bem, mas espere um pouco como este código visto a pouco funciona? Ele parece um tanto quanto estranho. Bem meu caro leitor. Como foi mencionado, tudo que for feito aqui, terá como objetivo ser o mais didático quanto é possível ser. Então neste código existem dois pontos, dos quais você deve prestar atenção quando for usar a classe neurônio. O primeiro ponto, são dos dados de treinamento. Porém estes dados, devem ser pensados, observando qual será o número de entradas no neurônio. Uma coisa estará intimamente ligada a outra. Se você mudar uma sem pensar na outra irá fazer besteira. Ou terá um neurônio completamente louco, sem saber o que fazer com os dados.
Então preste atenção. Na linha seis, temos declarados os dados de treinamento. Aqui eles foram pensados, de maneira que o neurônio terá apenas uma entrada. Por conta disto, na linha 21, dizemos que o neurônio terá uma entrada. Mas vamos voltar aos dados de treinamento. Note que estou montando o array, de modo que ele se pareça com uma matriz, de duas colunas e diversas linhas. Como forma de organizar as coisas, lhe aconselho a montar o array de treinamento da mesma forma.
Ou seja, você deverá colocar tantas colunas quanto forem a entradas para o neurônio. Só que, a última coluna, deverá corresponder ao valor esperado. Ou estimado, caso o valor não seja exato. Ou deixando de forma mais clara, se você desejar que o neurônio tenha duas entradas, deverá montar o array com três colunas. Sendo que a terceira, deverá ser o valor para dizer e permitir que o neurônio, possa analisar o quanto ele está errado. Assim ele conseguirá ajustar o valor de custo da função. Permitindo desta forma que ele possa ser treinado.
Porém neste momento, você deve trabalhar com este neurônio com uma certa calma. Isto por que ele pode acabar encontrando um ponto de estagnação, do qual ele não conseguirá progredir no seu treinamento. Isto por conta da falta de uma função de ativação.
Você pode ver isto ocorrer, no artigo ##>>Rede neural na prática: A prática leva a perfeição<<https://www.mql5.com/pt/articles/13748## onde mostrei que poderíamos fazer uso de um neurônio. A fim de conseguir gerar uma representação de uma porta lógica. Porém devido ao fato de que ele não continha uma função de ativação. Vez ou outra, o neurônio acabava encontrando um ponto de estagnação, no qual a taxa de aprendizado ou caia muito, ou simplesmente o aprendizado deixava de acontecer.
Porém, lembre-se de que estamos apenas começando uma nova fase. Na qual irei explicar diversas coisas. Mas para este primeiro momento, de fato já temos algo por onde começar e estudar. Mas mesmo assim você pode usar este neurônio para resolver alguns tipos de polinômios simples. Como por exemplo, se você modificar o código, a fim de usar uma outra base de treinamento, poderá notar que ele ainda assim consegue gerar dados bem aceitáveis. Mesmo que não sejam exatos. Já que tudo irá depender do fato da equação usada para gerar os dados, poder ou não ser representada por uma reta, ou função afim. Por exemplo, vamos modificar o código para o que é visto logo abaixo.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include <Neural Network\C_Neuron.mqh> 05. //+------------------------------------------------------------------+ 06. double Train[] { 07. 1, 3, 10.35 , 08. 1.5, 3.25, 11.7875, 09. 1.75, 3.94, 13.721 , 10. 2.85, 3.46, 14.669 , 11. }; 12. //+------------------------------------------------------------------+ 13. void OnStart() 14. { 15. C_Neuron *neuron; 16. 17. Print("************************************"); 18. Print("Simple Neuron in Class..."); 19. 20. neuron = new C_Neuron(2); 21. 22. (*neuron).View_Variables(); 23. Print("********** RESULT *************"); 24. Print("Error: ", (*neuron).Learning(Train)); 25. (*neuron).View_Variables(); 26. 27. delete neuron; 28. } 29. //+------------------------------------------------------------------+
Agora vemos algo, um pouco diferente. Temos na linha seis, novos dados para o treinamento. Aqui as coisas, são baseadas no fato de que iremos usar duas e não mais uma entrada no neurônio. Note que ao executarmos este novo código, poderemos ver o seguinte resultado nos sendo mostrados. Isto conforme pode ser visto na imagem abaixo.
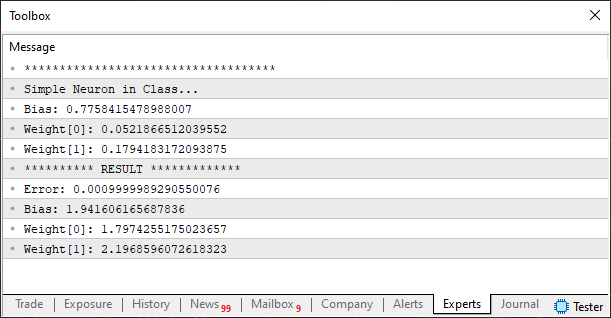
Simples não é mesmo? Mas você, meu caro leitor, deve se lembrar do que foi dito anteriormente. Devemos olhar e montar o array de treinamento, pensando que cada coluna representa uma entrada. Porém a última coluna irá de fato, representar os valores a serem usados para que o neurônio, procure analisar o quanto ele está errado. Isto com relação aos dos parâmetros internos de pesos e viés que foram construídos de maneira pseudo aleatória. Por isto temos uma organização de três colunas neste segundo exemplo de treinamento. Então por consequência disto, precisamos que na linha 20, o antigo valor, que era de um, passe a ser dois. Desta maneira o neurônio irá conseguir compreender, que ele terá de ajustar, ou melhor, observar dois valores como sendo de entrada. E deverá usar o terceiro valor como sendo o resultado estimado, no qual ele deverá usar para conseguir ajustar o erro, a cada interação.
Como todo o código foi pensado de maneira que não precisamos nos preocupar, em mudar nada nele. O neurônio, automaticamente irá criar espaço suficiente para que duas entradas possam ser analisadas. E com isto temos finalmente uma implementação da qual não precisamos ficar codificando, ou modificando as coisas a todo momento. Sempre que precisarmos mudar o número de entradas no neurônio.
Considerações finais
Neste artigo, começamos a sair daquela onda de codificação que estava sendo feita anteriormente. Onde a cada nova mudança, ajuste, ou carga a ser imposta ao neurônio, nos exigia, precisar mexer no código. De agora em diante, começando a encapsular a implementação, de forma que podemos usar, melhorar e modificar as coisas, sem grandes problemas. Visto que conforme novas coisas vão sendo adicionadas ao neurônio, todo e qualquer código que use a classe, passará a se beneficiar de tais mudanças.
Neste momento, fizemos a implementação mais simples de todas. Visto que o neurônio ainda está usando uma função de custo, baseada no mínimo quadrado, e ainda não tem nenhuma função de ativação presente nele. Além destes fatores, ainda temos um outro, que será também implementado futuramente, que é um mecanismo de back propagation mais profundo. O mecanismo atual, está limitado a um único neurônio. No entanto, para treinamentos mais complexos, precisamos que este mecanismo seja aperfeiçoado, de maneira que possamos colocar os neurônios em forma de cascata. Ou para que você, meu caro leitor, consiga compreender o que acabou se ser falado. Precisamos criar um mecanismo de back propagation, que consiga estabelecer uma comunicação de erro, quando os neurônios forem colocados, um após o outro. Da forma como o mecanismo se encontra atualmente, se você tentar fazer isto, criando assim uma pequena rede neural. Chegará um momento em que ela simplesmente irá encontrar um ponto de estagnação. Não conseguindo assim progredir em seu aprendizado.
Mas como falei anteriormente, a forma como faremos isto será visto no futuro. Até lá, comece a estudar e experimentar o código visto neste artigo. No anexo, você terá acesso a ambos neurônios visto aqui. Assim como também terá acesso a classe inicial. Então no vemos no próximo artigo.
| Arquivo MQ5 | Descrição |
|---|---|
| Scripts\Example A | Demonstração básica |
| Scripts\Example B | Demonstração básica |
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso