Science des Données et Apprentissage Automatique (Partie 02) : Régression Logistique

Contrairement à la régression linéaire que nous avons abordée dans la 1ère partie, la régression logistique est une méthode de classification basée sur la régression linéaire.
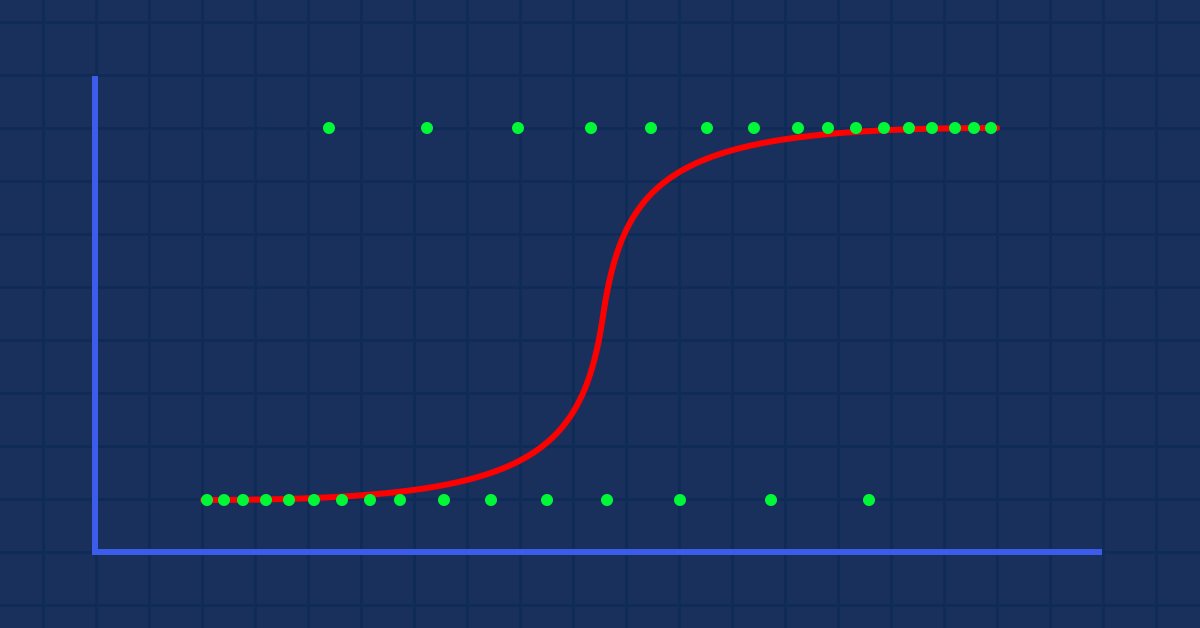
Théorie : Supposons que nous tracions le graphique de la probabilité qu'une personne soit obèse en fonction de son poids.
Dans ce cas, nous ne pouvons pas utiliser un modèle linéaire. Nous allons utiliser une autre technique pour transformer cette ligne en une courbe en S connue sous le nom de Sigmoïde.
Puisque la régression logistique produit des résultats dans un format binaire utilisé pour prédire le résultat de la variable dépendante catégorique, le résultat doit être discret/catégorique, par exemple :
- 0 ou 1
- Oui ou Non
- Vrai ou Faux
- Haut ou Bas
- Acheter ou Vendre
Dans la bibliothèque que nous allons créer, nous allons ignorer les autres valeurs discrètes. Nous nous concentrerons sur les valeurs binaires (0 et 1) uniquement.
Puisque nos valeurs de y sont censées être comprises entre 0 et 1, notre ligne doit également être comprise entre 0 et 1. Cela peut être calculé grâce à la formule suivante :

Ce qui nous donnera ce graphique :

Le modèle linéaire est passé à une fonction logistique (sigmoïde/p) =1/1 + e^t où t est le modèle linéaire dont le résultat est compris entre 0 et 1. Elle représente la probabilité qu'une donnée appartienne à une classe.
Au lieu d'utiliser le y d'un modèle linéaire comme dépendant, sa fonction représentée par "p" est utilisée comme dépendance.
p = 1/1+e^-(c+m1x1+m2x2+....+mnxn), en cas de valeurs multiples
Comme nous l'avons dit précédemment, la courbe sigmoïde a pour but de convertir les valeurs infinies du résultat au format binaire (0 ou 1). Mais si j'ai un point de données situé à 0,8, comment décider que la valeur est 0 ou 1 ? C'est là que les seuils entrent en jeu.

Le seuil indique la probabilité de gagner ou de perdre. Il est situé à 0,5 (milieu entre 0 et 1).
Toute valeur supérieure ou égale à 0,5 sera arrondie à 1, donc considérée comme gagnante. Tandis que toute valeur inférieure à 0,5 sera arrondie à 0, donc considérée comme perdante. À ce stade, il est temps de voir la différence entre les régressions linéaire et logistique.
Régression Linéaire vs Régression Logistique
| Régression Linéaire | Régression Logistique |
|---|---|
| Variable continue | Variable catégorielle |
| Résout les problèmes de régression | Résout les problèmes de classification |
| Le modèle a une équation droite | Le modèle a une équation logistique |
Avant de nous plonger dans le code et dans les algorithmes de classification des données, plusieurs étapes vont nous aider à comprendre les données et faciliter la construction de notre modèle :
- Collecte et Analyse des Données
- Nettoyage des Données
- Vérification de l'Exactitude
01 - Collecte et Analyse des Données
Dans cette section, nous allons devoir écrire beaucoup de code python pour visualiser nos données. Commençons par importer les bibliothèques que nous allons utiliser pour extraire et visualiser les données dans le notebook Jupyter.
Pour les besoins de la construction de notre bibliothèque, nous allons utiliser les données du Titanic. Pour ceux qui ne le connaissent pas, il s'agit des données concernant l'accident du navire Titanic qui a coulé dans l'océan Atlantique Nord le 15 avril 1912 après avoir heurté un iceberg, Wikipedia. Tous les codes python et le jeu de données se trouvent sur mon dépôt GitHub dont le lien figure à la fin de l'article.

Signification des colonnes :
survival - Survivant (0 = Non ; 1 = Oui)
class - Classe du passager (1 = 1er ; 2 = 2e ; 3 = 3e)
name - Nom du passager
sex - Sexe du passager
age - Âge du passager
sibsp - Nombre de frères et sœurs ou conjoints à bord
parch - Nombre de parents ou enfants à bord
ticket - Numéro du ticket du passager
fare - Tarif pour le passager
cabin - Cabine du passager
embarked - Port d'embarquement (C = Cherbourg ; Q = Queenstown ; S = Southampton)
Maintenant que nous avons collecté nos données et que nous les avons stockées dans une variable titanic_data, commençons par les visualiser en colonnes, en commençant par la colonne de survie.
sns.countplot(x="Survived", data = titanic_data)
Sortie :

Cela nous indique que la majorité des passagers n’a pas survécu à l'accident : moins de la moitié des passagers qui se trouvaient sur le navire ont survécu à l'accident.
Visualisation du taux de survie en fonction du sexe
sns.countplot(x='Survived', hue='Sex', data=titanic_data)

Je ne sais pas ce qui est arrivé aux hommes ce jour-là, mais les femmes ont survécu 2 fois plus que les hommes.
Visualisons le nombre de survivants en fonction des groupes de classe.
sns.countplot(x='Survived', hue='Pclass', data=titanic_data)

Traçons l'histogramme des groupes d'âge des passagers qui se trouvaient dans le navire. Ici, nous ne pouvons pas utiliser le mode Count-plots pour visualiser nos données, car il existe de nombreuses valeurs d'âge différentes dans notre ensemble de données et elles ne sont pas organisées.
titanic_data['Age'].plot.hist()Sortie :

Enfin, visualisons l'histogramme des tarifs dans le navire :
titanic_data['Fare'].plot.hist(bins=30, figsize=(10,10))

Voici les principales visualisation des données des colonnes les plus importantes (5 sur 12). Nous devons maintenant nettoyer ces données.
02 - Nettoyage des Données
Nous devons nettoyer nos données en supprimant les valeurs NaN (manquantes), tout en évitant/supprimant les colonnes inutiles dans l'ensemble de données.
En utilisant la régression logistique, vous avez besoin de valeurs entières ou doubles. Vous devez donc éviter les valeurs de chaîne non significatives. Ici, nous allons ignorer les colonnes suivantes :
- name (elle ne contient aucune information significative)
- ticket (n'a pas de sens pour la survie de l'accident)
- cabin (elle comporte trop de valeurs manquantes, même les 5 premières lignes le montrent)
- embarked (je pense que ce n'est pas pertinent)
Pour cela, je vais ouvrir le fichier CSV dans WPS Office et supprimer manuellement les colonnes. Vous pouvez utiliser le tableur de votre choix.
Après avoir supprimé les colonnes, nous pouvons visualiser les nouvelles données.
new_data = pd.read_csv(r'C:\Users\Omega Joctan\AppData\Roaming\MetaQuotes\Terminal\892B47EBC091D6EF95E3961284A76097\MQL5\Files\titanic.csv') new_data.head(5)
Sortie :

Nous avons maintenant des données nettoyées, bien que nous ayons toujours des valeurs manquantes dans la colonne d'âge, sans oublier les valeurs de chaîne dans la colonne du sexe. Corrigeons ces problèmes à l'aide du code. Créons un encodeur d'étiquettes pour convertir les chaînes de caractères ’male’ et ’female’ en 0 et 1 respectivement.
void CLogisticRegression::LabelEncoder(string &src[],int &EncodeTo[],string members="male,female") { string MembersArray[]; ushort separator = StringGetCharacter(m_delimiter,0); StringSplit(members,separator,MembersArray); //convert members list to an array ArrayResize(EncodeTo,ArraySize(src)); //make the EncodeTo array same size as the source array int binary=0; for(int i=0;i<ArraySize(MembersArray);i++) // loop the members array { string val = MembersArray[i]; binary = i; //binary to assign to a member int label_counter = 0; for (int j=0; j<ArraySize(src); j++) { string source_val = src[j]; if (val == source_val) { EncodeTo[j] = binary; label_counter++; } } Print(MembersArray[binary]," total =",label_counter," Encoded To = ",binary); } }
Pour obtenir le tableau source nommé src[], j'ai également programmé une fonction permettant d'obtenir les données d'une colonne spécifique d'un fichier CSV, puis de les copier dans un tableau MembersArray[] :
void CLogisticRegression::GetDatatoArray(int from_column_number, string &toArr[]) { int handle = FileOpen(m_filename,FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI,m_delimiter); int counter=0; if (handle == INVALID_HANDLE) Print(__FUNCTION__," Invalid csv handle err=",GetLastError()); else { int column = 0, rows=0; while (!FileIsEnding(handle)) { string data = FileReadString(handle); column++; //--- if (column==from_column_number) //if column in the loop is the same as the desired column { if (rows>=1) //Avoid the first column which contains the column's header { counter++; ArrayResize(toArr,counter); toArr[counter-1]=data; } } //--- if (FileIsLineEnding(handle)) { rows++; column=0; } } } FileClose(handle); }
Dans notre testcript.mq5, voici comment appeler correctement les fonctions et comment initialiser la bibliothèque :
#include "LogisticRegressionLib.mqh"; CLogisticRegression Logreg; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Logreg.Init("titanic.csv",","); string Sex[]; int SexEncoded[]; Logreg.GetDatatoArray(4,Sex); Logreg.LabelEncoder(Sex,SexEncoded,"male,female"); ArrayPrint(SexEncoded); }
Sortie imprimée, après avoir réussi à exécuter le script :
male total =577 Encoded To = 0
female total =314 Encoded To = 1
[ 0] 0 1 1 1 0 0 0 0 1 1 1 1 0 0 1 1 0 0 1 1 0 0 1 0 1 1 0 0 1 0 0 1 1 0 0 0 0 0 1 1 1 1 0 1 1 0 0 1 0 1 0 0 1 1 0 0 1 0 1 0 0 1 0 0 0 0 1 0 1 0 0 1 0 0 0
[ 75] 0 0 0 0 1 0 0 1 0 1 1 0 0 1 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 1 0 1 0 1 1 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 1 1 0 0 0 0 1 0 0
... ... ... ...
... ... ... ...
[750] 1 0 0 0 1 0 0 0 0 1 0 0 0 1 0 1 0 1 0 0 0 0 1 0 1 0 0 1 0 1 1 1 0 0 0 0 1 0 0 0 0 0 1 0 0 0 1 1 0 1 0 1 0 0 0 0 0 1 0 1 0 0 0 1 0 0 1 0 0 0 1 0 0 1 0
[825] 0 0 0 0 1 1 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 1 1 1 1 1 0 1 0 0 0 1 1 0 1 1 0 0 0 0 1 0 0 1 1 0 0 0 1 1 0 1 0 0 1 0 1 1 0 0
Avant de coder vos valeurs, faites attention aux members="male,female" de votre argument de fonction. La 1ère valeur qui apparaît sur votre chaîne sera codée avec 0. Comme vous pouvez le voir dans la colonne, ’male’ apparaît en premier. Donc tous les ’male’ seront codés à 0 et les ’female’ à 1. Cette fonction n'est pas limitée à deux valeurs. Vous pouvez en coder autant que vous le souhaitez, tant que la chaîne de caractères a un sens pour vos données.
Valeurs Manquantes
Si vous faites attention à la colonne Age, vous remarquerez qu'il y a des valeurs manquantes. Elles peuvent être principalement dues à une raison : le décès, dans notre ensemble de données, ce qui rend impossible l'identification de l'âge d'un individu. Vous pouvez identifier ces lacunes en regardant l'ensemble de données. Mais cela peut prendre du temps, en particulier sur les grands ensembles de données. Puisque nous utilisons également pandas pour visualiser nos données, trouvons les lignes manquantes dans toutes les colonnes.
titanic_data.isnull().sum()
La sortie sera :
PassengerId 0
Survived 0
Pclass 0
Sex 0
Age 177
SibSp 0
Parch 0
Fare 0
dtype : int64
Sur 891 lignes, 177 lignes de notre colonne Age ont des valeurs manquantes (NAN).
Nous allons maintenant remplacer ces valeurs manquantes dans notre colonne par la moyenne de toutes les valeurs.
void CLogisticRegression::FixMissingValues(double &Arr[]) { int counter=0; double mean=0, total=0; for (int i=0; i<ArraySize(Arr); i++) //first step is to find the mean of the non zero values { if (Arr[i]!=0) { counter++; total += Arr[i]; } } mean = total/counter; //all the values divided by their total number Print("mean ",MathRound(mean)," before Arr"); ArrayPrint(Arr); for (int i=0; i<ArraySize(Arr); i++) { if (Arr[i]==0) { Arr[i] = MathRound(mean); //replace zero values in array } } Print("After Arr"); ArrayPrint(Arr); }
Cette fonction trouve la moyenne de toutes les valeurs non nulles, puis elle remplace toutes les valeurs nulles du tableau par cette valeur moyenne.
Comme vous pouvez le voir, toutes les valeurs nulles ont été remplacées par 30.0, qui correspond à l'âge moyen des passagers du Titanic.
moyenne 30,0 - Arr avant
[ 0] 22.0 38.0 26.0 35.0 35.0 0.0 54.0 2.0 27.0 14.0 4.0 58.0 20.0 39.0 14.0 55.0 2.0 0.0 31.0 0.0 35.0 34.0 15.0 28.0 8.0 38.0 0.0 19.0 0.0 0.0
… … … … … … … … …
[840] 20.0 16.0 30.0 34.5 17.0 42.0 0.0 35.0 28.0 0.0 4.0 74.0 9.0 16.0 44.0 18.0 45.0 51.0 24.0 0.0 41.0 21.0 48.0 0.0 24.0 42.0 27.0 31.0 0.0 4.0
[870] 26.0 47.0 33.0 47.0 28.0 15.0 20.0 19.0 0.0 56.0 25.0 33.0 22.0 28.0 25.0 39.0 27.0 19.0 0.0 26.0 32.0
Arr après
[ 0] 22.0 38.0 26.0 35.0 35.0 30.0 54.0 2.0 27.0 14.0 4.0 58.0 20.0 39.0 14.0 55.0 2.0 30.0 31.0 30.0 35.0 34.0 15.0 28.0 8.0 38.0 30.0 19.0 30.0 30.0
… … … … … … … … …
[840] 20.0 16.0 30.0 34.5 17.0 42.0 30.0 35.0 28.0 30.0 4.0 74.0 9.0 16.0 44.0 18.0 45.0 51.0 24.0 30.0 41.0 21.0 48.0 30.0 24.0 42.0 27.0 31.0 30.0 4.0
[870] 26.0 47.0 33.0 47.0 28.0 15.0 20.0 19.0 30.0 56.0 25.0 33.0 22.0 28.0 25.0 39.0 27.0 19.0 30.0 26.0 32.0
Construction du Modèle de Régression Logistique
Construisons tout d’abord notre régression logistique où nous aurons une variable indépendante et une variable dépendante. Nous passerons ensuite à un modèle de solution complète à notre problème.
Construisons le modèle à partir de deux variables : le nombre de survivants et l'âge, afin de déterminer quelles sont les chances de survie d'une personne en fonction de son âge.
Jusqu'à présent, nous savons qu'à la base d’un modèle logistique, il y a un modèle linéaire. Commençons par coder les fonctions qui rendent possible un modèle linéaire :
Coefficient_of_X() et y_intercept() : ces fonctions ne sont pas nouvelles. Nous les avons construites dans le 1er article de cette série. Pensez à le lire pour plus d'informations sur ces fonctions et la régression linéaire en général.
double CLogisticRegression::y_intercept() { // c = y - mx return (y_mean-coefficient_of_X()*x_mean); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ double CLogisticRegression::coefficient_of_X() { double m=0; //--- { double x__x=0, y__y=0; double numerator=0, denominator=0; for (int i=0; i<ArraySize(m_xvalues); i++) { x__x = m_xvalues[i] - x_mean; //right side of the numerator (x-side) y__y = m_yvalues[i] - y_mean; //left side of the numerator (y-side) numerator += x__x * y__y; //summation of the product two sides of the numerator denominator += MathPow(x__x,2); } m = numerator/denominator; } return (m); }
Programmons maintenant le modèle logistique à partir de la formule :

Notez que z est également appelé le logit (ou log-odds) car l'inverse de la sigmoïde stipule que z peut être défini comme le logarithme de la probabilité de l'étiquette 1 (par exemple, "a survécu"), divisée par la probabilité de l'étiquette 0 (par exemple, "n'a pas survécu") :

Dans ce cas, y = mx+c (souvenez-vous du modèle linéaire).
Une fois codé, le résultat est le suivant :
double y_= (m*m_xvalues[i])+c; double z = log(y_)-log(1-y_); //log loss p_hat = 1.0/(MathPow(e,-z)+1);
Faites bien attention à ce qui a été fait ici sur la valeur de z: la formule est log(y/1-y), mais le code est écrit comme log(y_)-log(1-y_). Souvenez-vous des lois des logarithmes en mathématiques ! La division de logarithmes de même base aboutit à la soustraction des exposants, Vous pouvez lire cette page.
Ceci est essentiellement notre modèle lorsque la formule est programmée. Mais beaucoup d’autres choses se passent à l'intérieur de notre fonction LogisticRegression(). Voici tout ce qui se trouve à l'intérieur de la fonction :
double CLogisticRegression::LogisticRegression(double &x[],double &y[],int& Predicted[],double train_size_split = 0.7) { int arrsize = ArraySize(x); //the input array size double p_hat =0; //store the probability //--- int train_size = (int)MathCeil(arrsize*train_size_split); int test_size = (int)MathFloor(arrsize*(1-train_size_split)); ArrayCopy(m_xvalues,x,0,0,train_size); ArrayCopy(m_yvalues,y,0,0,train_size); //--- y_mean = mean(m_yvalues); x_mean = mean(m_xvalues); // Training our model in the background double c = y_intercept(), m = coefficient_of_X(); //--- Here comes the logistic regression model int TrainPredicted[]; double sigmoid = 0; ArrayResize(TrainPredicted,train_size); //resize the array to match the train size Print("Training starting..., train size=",train_size); for (int i=0; i<train_size; i++) { double y_= (m*m_xvalues[i])+c; double z = log(y_)-log(1-y_); //log loss p_hat = 1.0/(MathPow(e,-z)+1); double odds_ratio = p_hat/(1-p_hat); TrainPredicted[i] = (int) round(p_hat); //round the values to give us the actual 0 or 1 if (m_debug) PrintFormat("%d Age =%.2f survival_Predicted =%d ",i,m_xvalues[i],TrainPredicted[i]); } //--- Testing our model if (train_size_split<1.0) //if there is room for testing { ArrayRemove(m_xvalues,0,train_size); //clear our array ArrayRemove(m_yvalues,0,train_size); //clear our array from train data ArrayCopy(m_xvalues,x,0,train_size,test_size); //new values of x, starts from where the training ended ArrayCopy(m_yvalues,y,0,train_size,test_size); //new values of y, starts from where the testing ended Print("start testing...., test size=",test_size); ArrayResize(Predicted,test_size); //resize the array to match the test size for (int i=0; i<test_size; i++) { double y_= (m*m_xvalues[i])+c; double z = log(y_)-log(1-y_); //log loss p_hat = 1.0/(MathPow(e,-z)+1); double odds_ratio = p_hat/(1-p_hat); TrainPredicted[i] = (int) round(p_hat); //round the values to give us the actual 0 or 1 if (m_debug) PrintFormat("%d Age =%.2f survival_Predicted =%d , Original survival=%.1f ",i,m_xvalues[i],Predicted[i],m_yvalues[i]); } }
Maintenant, nous devons entraîner et tester notre modèle dans notre TestScript.mq5.
double Age[]; Logreg.GetDatatoArray(5,Age); Logreg.FixMissingValues(Age); double y_survival[]; int Predicted[]; Logreg.GetDatatoArray(2,y_survival); Logreg.LogisticRegression(Age,y_survival,Predicted);
Voici le résultat d'une exécution réussie du script :
Training starting..., train size=624
0 Age = 22.00 survival_Predicted =0
1 Age = 38.00 survival_Predicted =0
... .... ....
622 Age = 20.00 survival_Predicted =0
623 Age = 21.00 survival_Predicted =0
start testing...., test size=267
0 Age = 21.00 survival_Predicted =0
1 Age = 61.00 survival_Predicted =1
.... .... ....
265 Age = 26.00 survival_Predicted =0
266 Age =32.00 survival_Predicted =0
Très bien. Notre modèle fonctionne maintenant et nous pouvons au moins en obtenir des résultats. Mais le modèle fait-il de bonnes prédictions ?
Nous devons vérifier sa précision.
La Matrice de Confusion

Comme nous le savons tous, chaque modèle, bon ou mauvais, peut faire des prédictions. J'ai créé un fichier CSV pour les prédictions de notre modèle, accompagné des valeurs originales des données de test sur la survie des passagers. Encore une fois, 1 signifie "a survécu", 0 signifie "n'a pas survécu".
Voici quelques colonnes parmi les 10 :
| Original | Prédiction | |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 1 |
| 2 | 0 | 1 |
| 3 | 1 | 0 |
| 4 | 0 | 0 |
| 5 | 0 | 0 |
| 6 | 1 | 1 |
| 7 | 0 | 1 |
| 8 | 1 | 0 |
| 9 | 0 | 0 |
Nous calculons la matrice de confusion en utilisant les valeurs suivantes :
- TP - Vrai Positif
- TN - Vrai Négatif
- FP - Faux Positif
- FN - Faux Négatif
Maintenant, à quoi correspondent ces valeurs ?
TP (Vrai Positif)
C'est lorsque la valeur originale est positive (1), et que le modèle prédit également une valeur positive (1).
TN (Vrai Négatif)
C'est lorsque la valeur originale est négative (0), et que le modèle prédit également une valeur négative (0).
FP (Faux Positif)
C'est lorsque la valeur originale est négative (0), mais que le modèle prédit une valeur positive (1).
FN (Faux Négatif)
C'est lorsque la valeur originale est positive (1), mais que le modèle prédit une valeur négative (0).
Maintenant que vous connaissez ces valeurs, calculons par exemple la matrice de confusion pour l'échantillon ci-dessus.
| Original | Prédiction | TP/TN/FP/FN | |
|---|---|---|---|
| 0 | 0 | 0 | TN |
| 1 | 0 | 1 | FP |
| 2 | 0 | 1 | FP |
| 3 | 1 | 0 | FN |
| 4 | 0 | 0 | TN |
| 5 | 0 | 0 | TN |
| 6 | 1 | 1 | TP |
| 7 | 0 | 1 | FP |
| 8 | 1 | 0 | FN |
| 9 | 0 | 0 | TN |
La matrice de confusion peut être utilisée pour calculer la précision de notre modèle en utilisant la formule suivante.
D’après notre table :
- TN = 4
- TP = 1
- FN = 2
- FP = 3

Précision = 1 + 5/4 + 1 + 2 + 3
Précision = 0,5
Dans ce cas, notre précision est de 50% (0,5*100%, en convertissant en pourcentage).
Maintenant, que vous avez compris comment fonctionne la matrice de confusion 1X1, il est temps de le convertir en code et d'analyser la précision de notre modèle sur l'ensemble du jeu de données.
void CLogisticRegression::ConfusionMatrix(double &y[], int &Predicted_y[], double& accuracy) { int TP=0, TN=0, FP=0, FN=0; for (int i=0; i<ArraySize(y); i++) { if ((int)y[i]==Predicted_y[i] && Predicted_y[i]==1) TP++; if ((int)y[i]==Predicted_y[i] && Predicted_y[i]==0) TN++; if (Predicted_y[i]==1 && (int)y[i]==0) FP++; if (Predicted_y[i]==0 && (int)y[i]==1) FN++; } Print("Confusion Matrix \n ","[ ",TN," ",FP," ]","\n"," [ ",FN," ",TP," ] "); accuracy = (double)(TN+TP) / (double)(TP+TN+FP+FN); }
Revenons maintenant à la fonction principale de notre classe, connue sous le nom de LogisticRegression(). Cette fois-ci, nous allons la transformer en une fonction double qui renvoie la précision du modèle. Je vais également réduire le nombre d’appel à la méthode Print() mais les ajouter dans le ’if’ pour imprimer les valeurs en cas de débogage. Tous les changements sont surlignés en bleu :
double CLogisticRegression::LogisticRegression(double &x[],double &y[],int& Predicted[],double train_size_split = 0.7) { double accuracy =0; //Accuracy of our Train/Testmodel int arrsize = ArraySize(x); //the input array size double p_hat =0; //store the probability //--- int train_size = (int)MathCeil(arrsize*train_size_split); int test_size = (int)MathFloor(arrsize*(1-train_size_split)); ArrayCopy(m_xvalues,x,0,0,train_size); ArrayCopy(m_yvalues,y,0,0,train_size); //--- y_mean = mean(m_yvalues); x_mean = mean(m_xvalues); // Training our model in the background double c = y_intercept(), m = coefficient_of_X(); //--- Here comes the logistic regression model int TrainPredicted[]; double sigmoid = 0; ArrayResize(TrainPredicted,train_size); //resize the array to match the train size Print("Training starting..., train size=",train_size); for (int i=0; i<train_size; i++) { double y_= (m*m_xvalues[i])+c; double z = log(y_)-log(1-y_); //log loss p_hat = 1.0/(MathPow(e,-z)+1); TrainPredicted[i] = (int) round(p_hat); //round the values to give us the actual 0 or 1 if (m_debug) PrintFormat("%d Age =%.2f survival_Predicted =%d ",i,m_xvalues[i],TrainPredicted[i]); } ConfusionMatrix(m_yvalues,TrainPredicted,accuracy); //be careful not to confuse the train predict values arrays printf("Train Model Accuracy =%.5f",accuracy); //--- Testing our model if (train_size_split<1.0) //if there is room for testing { ArrayRemove(m_xvalues,0,train_size); //clear our array ArrayRemove(m_yvalues,0,train_size); //clear our array from train data ArrayCopy(m_xvalues,x,0,train_size,test_size); //new values of x, starts from where the training ended ArrayCopy(m_yvalues,y,0,train_size,test_size); //new values of y, starts from where the testing ended Print("start testing...., test size=",test_size); ArrayResize(Predicted,test_size); //resize the array to match the test size for (int i=0; i<test_size; i++) { double y_= (m*m_xvalues[i])+c; double z = log(y_)-log(1-y_); //log loss p_hat = 1.0/(MathPow(e,-z)+1); TrainPredicted[i] = (int) round(p_hat); //round the values to give us the actual 0 or 1 if (m_debug) PrintFormat("%d Age =%.2f survival_Predicted =%d , Original survival=%.1f ",i,m_xvalues[i],Predicted[i],m_yvalues[i]); } ConfusionMatrix(m_yvalues,Predicted,accuracy); printf("Testing Model Accuracy =%.5f",accuracy); } return (accuracy); //Lastly, the testing Accuracy will be returned }
L'exécution du script produira le résultat suivant :
Training starting..., train size=624
Confusion Matrix
[ 378 0 ]
[ 246 0 ]
Train Model Accuracy =0.60577
start testing...., test size=267
Confusion Matrix
[ 171 0 ]
[ 96 0 ]
Précision du modèle de test = 0,64045
Parfait ! Nous sommes maintenant en mesure d'identifier la qualité de notre modèle à l'aide d’une valeur. La précision de 64,045 % sur les données de test n’est toutefois pas suffisante pour utiliser le modèle dans la réalisation de prédictions (à mon avis). Mais nous disposons au moins maintenant d'une bibliothèque qui pourrait nous aider à classer les données en utilisant la régression logistique.
Quelques explications sur la fonction principale :
double CLogisticRegression::LogisticRegression(double &x[],double &y[],int& Predicted[],double train_size_split = 0.7)
L'entrée train_size_split permet de diviser les données entre l’apprentissage et le test. Par défaut, la division est de 0,7, ce qui signifie que 70% des données seront destinées à l’apprentissage, tandis que les 30% restants seront destinés au test. Le tableau Predicted[] renvoie les données prédites pour le test.
Entropie Croisée Binaire (alias Fonction de Perte)
Tout comme l'erreur quadratique moyenne est la fonction d'erreur de la régression linéaire, l'entropie croisée binaire est la fonction de coût de la régression logistique.
Théorie :
Voyons comment cela fonctionne dans 2 cas d'utilisation de la régression logistique, c'est-à-dire lorsque la sortie réelle est 0 et 1.
01 : Lorsque la valeur réelle de la sortie est 1
Considérons le modèle avec deux échantillons d'entrée p1 = 0,4 et p2 = 0,6. Il est attendu que p1 soit plus pénalisé que p2 car il est plus éloigné de 1 que p1.
D'un point de vue mathématique, le logarithme négatif d'un petit nombre est un grand nombre, et vice versa.
Pour pénaliser les entrées, nous utiliserons la formule suivante :
penalty = -log(p)
Dans ces deux cas :
- penalty = -log(0.4)=0.4 - c'est-à-dire que la pénalité sur p1 est de 0,4
- penalty = -log(0.6)=0.2 - c'est-à-dire que la pénalité sur p2 est de 0,2
02 : Lorsque la valeur réelle de la sortie est 0
Considérons la sortie du modèle pour les 2 échantillons d'entrée, p1 = 0,4 et p2= 0,6 (comme dans le cas précédent). Il est attendu que p2 soit plus pénalisé que p1 parce qu'il est loin de 0. Mais gardez à l'esprit que la sortie du modèle logistique est la probabilité qu'un échantillon soit positif. Pour pénaliser les probabilités d'entrée, nous devons trouver la probabilité qu'un échantillon soit négatif. C'est facile, voici la formule :
Probabilité d'un échantillon négatif = 1 - probabilité d'un échantillon positif
Donc, pour trouver la pénalité dans ce cas, la formule sera la suivante :
penalty = -log(1 - p)
Dans ces deux cas :
- penalty = -log(1 - p) = -log(1 - 0.4) = 0.2 - c'est-à-dire que la pénalité sur p2 est de 0,2
- penalty = -log(1 - p) = -log(1 - 0.6) =0.4 - c'est-à-dire que la pénalité sur p2 est de 0,4
La pénalité sur p2 est plus grande que sur celle sur p1 (fonctionne comme prévu), cool !
Maintenant, la pénalité pour un échantillon d'entrée unique dont la sortie du modèle est p et la vraie valeur de sortie est y, peut être calculée comme suit :
si l'échantillon d'entrée est positif y=1 :
penalty = -log(p)
sinon :
penalty = -log(1 - p)
L’équation à une ligne correspondante à l'instruction du bloc if-else ci-dessus peut être écrite comme suit :
penalty = -( y*log(p) + (1-y)*log(1-p) )
avec
y = valeurs actuelles dans notre jeu de données
p = probabilité brute prédite du modèle (avant arrondi)
Nous pouvons prouver que cette équation est équivalente à l'instruction if-else ci-dessus.
01 - lorsque les valeurs de sortie y = 1
penalty = -( 1*log(p) + (1-1)*log(1-p) ) = -log(p) donc c’est prouvé
02 - lorsque la valeur de sortie y = 0
penalty = -( 0*log(p) + (1-0)* log(1-p) ) = log(1-p) donc c’est prouvé
Enfin, la fonction de perte de logarithme pour N échantillons d'entrée est

La perte de logarithme (log-loss) indique dans quelle mesure la probabilité de prédiction est proche de la valeur réelle/vraie correspondante (0 ou 1 dans le cas de la classification binaire). Plus la probabilité prédite diverge de la valeur réelle, plus la valeur de la perte de logarithme sera élevée.
Les fonctions de coût telles que la perte logarithmique et bien d'autres peuvent être utilisées comme une mesure de la qualité du modèle. Mais la plus grande utilisation est l'optimisation du modèle pour les meilleurs paramètres en utilisant la descente du gradient ou d'autres algorithmes d'optimisation.(nous en parlerons dans une prochaine série, restez à l'écoute).
Vous ne pouvez améliorer ce que vous mesurez. C'est le principal objectif des fonctions de coût.
À partir de notre ensemble de données de test et d'apprentissage, il apparaît que notre perte de logarithme se situe entre 0,64 et 0,68, ce qui n'est pas idéal.
ensemble des données d’apprentissage
Logloss = 0.6858006105398738
jeu de données de test
Logloss = 0.6599503403665642
Voici comment nous pouvons convertir notre fonction de perte de logarithme en code :
double CLogisticRegression::LogLoss(double &rawpredicted[]) { double log_loss =0; double penalty=0; for (int i=0; i<ArraySize(rawpredicted); i++ ) { penalty += -((m_yvalues[i]*log(rawpredicted[i])) + (1-m_yvalues[i]) * log(1-rawpredicted[i])); //sum all the penalties if (m_debug) printf("penalty =%.5f",penalty); } log_loss = penalty/ArraySize(rawpredicted); //all the penalties divided by their total number Print("Logloss =",log_loss); return(log_loss); }
Pour obtenir la sortie prédite brute, nous devons revenir aux boucles principales de test et d'apprentissage et stocker les données dans le tableau prédit brut, juste avant le processus d'arrondi des probabilités.
Défi des Régressions Logistiques Dynamiques Multiples
Le plus grand défi auquel j'ai été confronté lors de la construction des bibliothèques de régression linéaire et logistique (dans cet article et dans le précédent) est la création de fonctions de régression dynamiques multiples que nous pourrions utiliser pour plusieurs colonnes de données sans avoir à coder en dur des choses pour chaque donnée ajoutée à notre modèle. Dans le précédent article, j'ai codé en dur 2 fonctions avec le même nom. La seule différence était le nombre de données avec lesquelles chaque modèle pouvait travailler. L’une était capable de travailler avec 2 variables indépendantes et l'autre avec 4 :
void MultipleRegressionMain(double& predicted_y[],double& Y[],double& A[],double& B[]); void MultipleRegressionMain(double& predicted_y[],double& Y[],double& A[],double& B[],double& C[],double& D[]);
Mais ce n'est pas pratique. Cela donne l'impression d'avoir anticipé le code. Et surtout, cela viole les règles du Code Propre (Clean Code) et du principe DRY (Don't Repeat Yourself - Ne Vous Répétez Pas) que la POO essaie de nous aider à atteindre.
Contrairement à python avec ses fonctions flexibles qui peuvent prendre un grand nombre d'arguments fonctionnels grâce aux *args et **kwargs, en MQL5 cela peut être réalisé en utilisant uniquement des chaînes de caractères, autant que je sache. C’est notre point de départ.
void CMultipleLogisticRegression::MLRInit(string x_columns="3,4,5,6,7,8")
L'entrée x_columns représente toutes les colonnes de variables indépendantes que nous utiliserons dans notre bibliothèque. Ces colonnes nous obligeront à avoir plusieurs tableaux indépendants pour chacune des colonnes. Mais il n'y a aucun moyen de créer des tableaux de façon dynamique, donc l'utilisation des tableaux tombe à plat ici.
Nous pouvons créer plusieurs fichiers CSV de manière dynamique et les utiliser comme des tableaux. Mais cela rendra nos programmes plus coûteux en termes d'utilisation des ressources informatiques par rapport à l'utilisation de tableaux, en particulier lorsqu'il s'agit de données multiples, sans parler des boucles while que nous utiliserons fréquemment pour ouvrir les fichiers, ce qui ralentira l'ensemble du processus. Je ne suis pas sûr à 100%, corrigez-moi si je me trompe.
Mais nous pouvons bien sûr toujours utiliser la méthode mentionnée.
J'ai découvert la façon d'utiliser les tableaux. Nous allons stocker toutes les données de toutes les colonnes dans un tableau, puis utiliser les données séparément depuis ce tableau unique.
int start = 0; if (m_debug) //if we are on debug mode print Each Array vs its row for (int i=0; i<x_columns_total; i++) { ArrayCopy(EachXDataArray,m_AllDataArray,0,start,rows_total); start += rows_total; Print("Array Number =",i," From column number ",m_XColsArray[i]); ArrayPrint(EachXDataArray); }
À l'intérieur de la boucle for, nous pouvons manipuler les données dans les tableaux et effectuer tous les calculs pour le modèle de la manière souhaitée pour toutes les colonnes. J'ai essayé cette méthode mais mes tentatives sont toujours infructueuses. J'ai quand même expliqué cette hypothèse pour permettre à tous ceux qui lisent cet article de comprendre ce défi. J'accueille toutes vos opinions dans les sections de commentaires sur la façon dont nous pouvons coder cette fonction de régression logistique dynamique multiple. Ma tentative complète pour créer cette bibliothèque se trouve sur ici https://www.mql5.com/fr/code/38894.
Cette tentative n'a pas abouti mais je ne perds pas espoir et je crois qu'elle mérite d'être partagée.
Avantages de la Régression Logistique
- Ne présume pas de la distribution de la classe dans l'espace des caractéristiques.
- Extension facile à des classes multiples (régression multinomiale).
- Vue probabiliste naturelle des prédictions de classe
- Rapide à entraîner
- Très rapide dans la classification des enregistrements inconnus
- Bonne précision pour de nombreux ensembles de données simples
- Résistant au sur-apprentissage
- Peut interpréter les coefficients du modèle comme un indicateur de l'importance de la caractéristique
Inconvénients
- Construit des frontières linéaires
Dernières pensées
C'est tout pour cet article. La régression logistique est utilisée dans de nombreux domaines dans la vie réelle, comme par exemple la classification des e-mails en spam et non spam, la détection de l'écriture manuscrite, et bien d'autres choses intéressantes.
Je sais que nous n'allons pas utiliser les algorithmes de régression logistique pour classer les données du Titanic ou tout autre domaine mentionné, en particulier sur la plateforme MetaTrader 5. Comme nous l'avons dit précédemment, l'ensemble de données a été utilisé uniquement pour construire la bibliothèque en comparaison avec le résultat obtenu en python disponible ici > https://github.com/MegaJoctan/LogisticRegression-MQL5-and-python. Dans le prochain article, nous verrons comment utiliser les modèles logistiques pour prédire un krach boursier.
Comme cet article est devenu long, je laisse la régression multiple comme devoir à tous les lecteurs.
Traduit de l’anglais par MetaQuotes Ltd.
Article original : https://www.mql5.com/en/articles/10626
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.


 Apprenez à concevoir un système de trading basé sur l’ADX
Apprenez à concevoir un système de trading basé sur l’ADX
 Science des données et Apprentissage Automatique (Partie 01) : Régression Linéaire
Science des données et Apprentissage Automatique (Partie 01) : Régression Linéaire
 Apprendre à concevoir un système de trading basé sur l’ATR
Apprendre à concevoir un système de trading basé sur l’ATR
 Ce qu’il est possible de faire avec les Moyennes Mobiles
Ce qu’il est possible de faire avec les Moyennes Mobiles
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation