
データサイエンスとML(第45回):FacebookのPROPHETモデルを用いた外国為替時系列予測

内容
- Prophetモデルとは
- Prophetモデルの理解
- PythonによるProphetモデルの実装
- Prophetモデルへのイベントの追加
- Prophetモデルに基づくMetaTrader 5自動売買ロボットの作成
- 結論
Prophetモデルとは
Prophetモデルは、Meta(旧Facebook)が開発したオープンソースの時系列予測ツールです。このモデルは、特に季節性やトレンドが顕著な時系列データに対して、精度の高い予測をユーザーフレンドリーに提供することを目的としています。
このモデルは、FacebookのS.J. TaylorとB. Lethamによって2018年に発表され、もともとは日次データの週次・年次季節性やイベント効果の予測を想定していましたが、その後、より幅広い季節性データに対応できるよう拡張されています。Prophetモデルは、明確な季節性を持つデータや、複数シーズンにわたる過去データが存在する場合に特に有効です。
以下が主な用語です。
- トレンド:データが長期的に増加または減少する傾向を示します。季節変動を除外して長期的な方向性を捉える指標です。
- 季節性: 短期間で周期的に繰り返される変動を示します。トレンドほど顕著ではないが、一定のパターンを持つ変動です。

本記事では、FXデータを用いてProphetモデルを理解し、実際に実装する方法を紹介します。さらに、このモデルがどのように市場での優位性獲得に役立つかについても考察します。
Prophetモデルの理解
Prophetモデルは、非線形回帰モデルとして理解することができます。モデルの基本式は以下の通りです。
![]()
図01
ここで
-
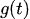 :区分線形トレンド(成長項)
:区分線形トレンド(成長項) -
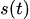 :さまざまな季節パターン
:さまざまな季節パターン -
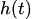 :イベント効果、
:イベント効果、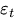 :ホワイトノイズ誤差項
:ホワイトノイズ誤差項
01:トレンドコンポーネント
トレンドコンポーネント![]() では、変化点を考慮することができます。変化点は、トレンドが変化する可能性のある時点を示し、指定がなければモデルが自動的に選択します(例:急激な成長や減少のタイミング)。
では、変化点を考慮することができます。変化点は、トレンドが変化する可能性のある時点を示し、指定がなければモデルが自動的に選択します(例:急激な成長や減少のタイミング)。
線形トレンドの代わりに、ロジスティック成長モデルを使用することも可能です。この場合、上限(cap)パラメータを導入することで、成長が一定の自然上限に達すると緩やかになる飽和効果をモデル化できます。
02:季節性
Prophetモデルでは、季節性![]() をフーリエ級数で表現します。
をフーリエ級数で表現します。
デフォルトの設定では以下の通りです。
- 年次季節性にはフーリエ級数の次数10を使用
- 週次季節性にはフーリエ級数の次数3を使用
これにより、繰り返し発生する季節パターンを捉えることができます。
03:イベント効果の部分
イベント効果![]() は、ダミー変数(One-Hotエンコーディング)としてモデルに組み込まれます。これにより、経済ニュースや祝日など、過去にデータに影響を与えた特定の日付の影響を予測に反映させることが可能です。
は、ダミー変数(One-Hotエンコーディング)としてモデルに組み込まれます。これにより、経済ニュースや祝日など、過去にデータに影響を与えた特定の日付の影響を予測に反映させることが可能です。
モデル全体はベイズ推定を用いて推定されます。これにより、変化点やその他のモデルパラメータが自動的に選択されます。
見た目はシンプルな加法モデルですが、各成分の計算は非常に数学的で高度です。そのため、理解が不十分なまま使用すると、誤った予測をしてしまう可能性があります。
Prophetでは以下の2種類の成長モデルを提供しています。
- 区分線形成長モデル(デフォルト)
- ロジスティック成長モデル
01:区分線形モデル
これはProphetのデフォルトモデルです。データのトレンドが線形で推移すると仮定しつつ、特定の時点(変化点)でトレンドが変化することを許容します。このモデルは、安定した成長または減少パターンを持つデータ、もしくは急な変化が含まれるデータに適しています。
このモデリング手法は図01の式によって表されます。
02:ロジスティック成長モデル
このモデルは、成長が飽和するデータに適しています。初期段階では急速に成長しますが、ある上限値に近づくにつれて成長が緩やかになります。このようなパターンは、現実のシステムでよく見られます。特に、自然的制約やビジネス上の制約がある場合です(例:飽和した市場でのユーザー数の増加など)。
ロジスティック成長モデルは、成長の上限を定義するキャパシティパラメータを組み込んでいます。
このモデリング手法は次の式で表されます。
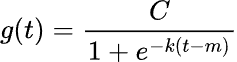
図02
ここで
![]() はキャパシティ(上限)、
はキャパシティ(上限)、![]() は成長率、
は成長率、![]() はオフセットパラメータです。
はオフセットパラメータです。
PythonによるProphetモデルの実装
ここでは、EUR/USDの1時間足データを用いて、Prophetモデルでトレンドや季節性を検出し、将来の値を予測してみます。
まず最初におこなうべきことは、記事末尾に添付されているrequirements.txtファイルからすべての依存ライブラリをインストールすることです。
pip install -r requirements.txt
Import文
import pandas as pd import numpy as np import MetaTrader5 as mt5 import matplotlib.pyplot as plt import seaborn as sns from prophet import Prophet plt.style.use('fivethirtyeight') sns.set_style("darkgrid")
MetaTrader 5からデータを取得しましょう。
if not mt5.initialize(r"c:\Program Files\MetaTrader 5 IC Markets (SC)\terminal64.exe"): print("Failed to initialize MetaTrader5. Error = ",mt5.last_error()) mt5.shutdown() symbol = "EURUSD" timeframe = mt5.TIMEFRAME_H1 rates = mt5.copy_rates_from_pos(symbol, timeframe, 1, 10000) if rates is None: print(f"Failed to copy rates for symbol={symbol}. MT5 Error = {mt5.last_error()}")
Prophetモデルは日時または日付スタンプの特徴量に大きく依存しています。この特徴量はモデルの動作に必須です。
MetaTrader 5からレートデータを取得した後、まずデータをPandasのDataFrameオブジェクトに変換します。次に、秒単位で格納されている時間列を、datetime形式に変換します。
rates_df = pd.DataFrame(rates) # we convert rates object to a dataframe rates_df["time"] = pd.to_datetime(rates_df["time"], unit="s") # we convert the time from seconds to datatime rates_df
以下が出力です。
| time | open | high | low | close | tick_volume | spread | real_volume | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2023-11-10 23:00:00 | 1.06849 | 1.06873 | 1.06826 | 1.06846 | 762 | 0 | 0 |
| 1 | 2023-11-13 00:00:00 | 1.06828 | 1.06853 | 1.06779 | 1.06841 | 1059 | 10 | 0 |
| 2 | 2023-11-13 01:00:00 | 1.06854 | 1.06907 | 1.06854 | 1.06906 | 571 | 0 | 0 |
| 3 | 2023-11-13 02:00:00 | 1.06904 | 1.06904 | 1.06822 | 1.06839 | 1053 | 0 | 0 |
| 4 | 2023-11-13 03:00:00 | 1.06840 | 1.06886 | 1.06811 | 1.06867 | 1204 | 0 | 0 |
Prophetモデルは単変量モデル(英語)であり、PandasのDataFrameから動作させるために必要な特徴量は2つだけです。すなわち、日時を示す特徴量「ds」(datastamp)と目的変数yです。
ここではまず、MetaTrader 5から取得したデータを基に、時間(time)とボラティリティ(volatility)の2つの特徴量を持つ簡単なデータセットを作成します。このデータを後ほどProphetモデルに入力して予測に使用します。
prophet_df = pd.DataFrame({
"time": rates_df["time"],
"volatility": rates_df["high"] - rates_df["low"]
}).set_index("time")
prophet_df ボラティリティ(高値と安値の差として計算)は、本モデルの予測対象(目的変数)です。
ARIMAやVARなどの従来の時系列予測モデル(前回解説済み)では、目的変数が定常変数であることが前提条件となります。一方、Prophetモデルはこの条件に制約されず、非定常データでも動作可能です。ただし、すべての機械学習モデルは、定常変数を扱う方が学習しやすく、性能も安定しやすい傾向があります。これは、定常変数が平均値・分散・標準偏差が一定であるためです。
本記事では、Prophetモデルを扱いやすくするために、目的変数を定常化したデータを使用しています。
次に、DataFrameをプロットして、特徴量の様子を観察してみましょう。
# Color pallete for plotting color_pal = ["#F8766D", "#D39200", "#93AA00", "#00BA38", "#00C19F", "#00B9E3", "#619CFF", "#DB72FB"] prophet_df.plot(figsize=(7,5), color=color_pal, title="Volatility (high-low) against time", ylabel="volatility", xlabel="time")
以下が出力です。
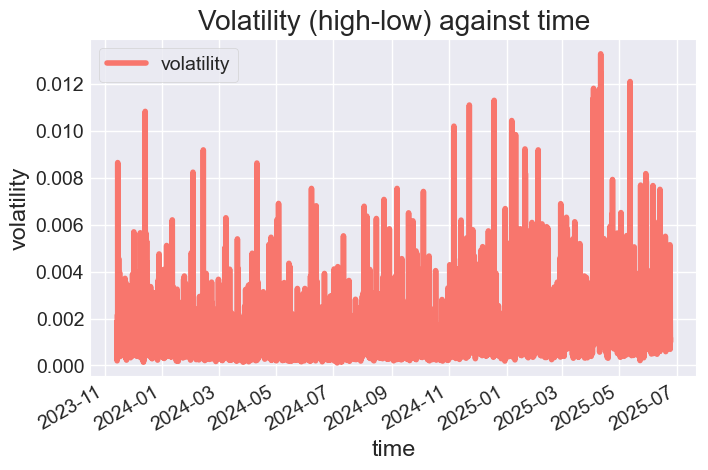
図03
必要に応じて、市場で発生しているボラティリティに対する時間的特徴の影響を評価するために、X特徴量とy特徴量を作成できます。
def create_features(df, label=None): """ Creates time series features from datetime index. """ df = df.copy() df['date'] = df.index df['hour'] = df['date'].dt.hour df['dayofweek'] = df['date'].dt.dayofweek df['quarter'] = df['date'].dt.quarter df['month'] = df['date'].dt.month df['year'] = df['date'].dt.year df['dayofyear'] = df['date'].dt.dayofyear df['dayofmonth'] = df['date'].dt.day df['weekofyear'] = df['date'].dt.isocalendar().week X = df[['hour','dayofweek','quarter','month','year', 'dayofyear','dayofmonth','weekofyear']] if label: y = df[label] return X, y return X X, y = create_features(prophet_df, label='volatility') features_and_target = pd.concat([X, y], axis=1)
以下が出力です。
| hour | dayofweek | quarter | month | year | dayofyear | dayofmonth | weekofyear | volatility | |
|---|---|---|---|---|---|---|---|---|---|
| time | |||||||||
| 2023-11-13 16:00:00 | 16 | 0 | 4 | 11 | 2023 | 317 | 13 | 46 | 0.00122 |
| 2023-11-13 17:00:00 | 17 | 0 | 4 | 11 | 2023 | 317 | 13 | 46 | 0.00179 |
| 2023-11-13 18:00:00 | 18 | 0 | 4 | 11 | 2023 | 317 | 13 | 46 | 0.00186 |
| 2023-11-13 19:00:00 | 19 | 0 | 4 | 11 | 2023 | 317 | 13 | 46 | 0.00125 |
| 2023-11-13 20:00:00 | 20 | 0 | 4 | 11 | 2023 | 317 | 13 | 46 | 0.00150 |
手動で分析するために、これらの特徴量をボラティリティに対してプロットすることができます。
sns.pairplot(features_and_target.dropna(), hue='hour', x_vars=['hour','dayofweek', 'year','weekofyear'], y_vars='volatility', height=5, plot_kws={'alpha':0.45, 'linewidth':0.5} ) plt.suptitle(f"{symbol} close prices by Hour, Day of Week, Year, and Week") plt.show()
以下が出力です。

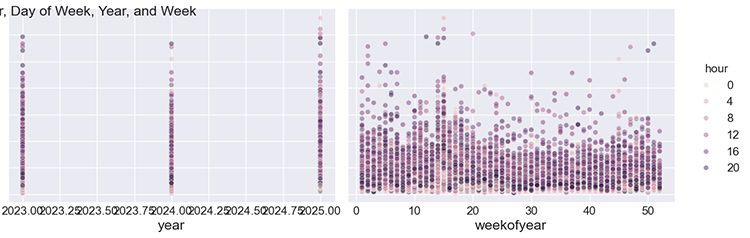
図04
サブプロットからわかるように、時間、曜日、年、週番号はいずれも、チャート上の各時間におけるボラティリティに影響を与えています。このことから、このデータを用いてProphetモデルを適用することに自信を持って進められます。
Prophetモデルの学習プロセス
まず、特定の日付を使用してデータを学習セットとテストセットに分割します。
split_date = '01-Jan-2025' # threshold date between training and testing samples, all values after this date are for testing prophet_df_train = prophet_df.loc[prophet_df.index <= split_date].copy().reset_index().rename(columns={"time": "ds", "volatility": "y"}) prophet_df_test = prophet_df.loc[prophet_df.index > split_date].copy().reset_index().rename(columns={"time": "ds", "volatility": "y"})
学習データを用いてProphetモデルを学習させます。
model = Prophet() model.fit(prophet_df_train)
モデルを学習させた後、私たちはしばしば、モデルがこれまで見たことのないアウトオブサンプルデータに対してどれだけ効果的かを検証したくなります。他のモデルとは異なり、Prophetモデルは予測結果の返し方が少し異なります。
test_fcst = model.predict(df=prophet_df_test)
このモデルは、予測値を含むベクトルを返す代わりに、予測値やモデルの状態を表すさまざまな特徴量を含むDataFrame全体を返します。
test_fcst.head()
以下が出力です。
ds trend yhat_lower yhat_upper trend_lower trend_upper additive_terms additive_terms_lower additive_terms_upper daily daily_lower daily_upper weekly weekly_lower weekly_upper multiplicative_terms multiplicative_terms_lower multiplicative_terms_upper yhat 0 2025-01-02 00:00:00 0.001674 0.000168 0.001993 0.001674 0.001674 -0.000571 -0.000571 -0.000571 -0.000510 -0.000510 -0.000510 -0.000061 -0.000061 -0.000061 0.0 0.0 0.0 0.001102 1 2025-01-02 01:00:00 0.001674 0.000161 0.001977 0.001674 0.001674 -0.000614 -0.000614 -0.000614 -0.000556 -0.000556 -0.000556 -0.000057 -0.000057 -0.000057 0.0 0.0 0.0 0.001060 2 2025-01-02 02:00:00 0.001674 0.000337 0.002123 0.001674 0.001674 -0.000483 -0.000483 -0.000483 -0.000430 -0.000430 -0.000430 -0.000054 -0.000054 -0.000054 0.0 0.0 0.0 0.001191
次の表には、predictメソッドによって返されるいくつかの列(特徴量)の意味が含まれています。
| 列 | 意味 |
|---|---|
| ds | 予測ポイントの日時(タイムスタンプ) |
| yhat | 最終的に予測された値(その時点でProphetが予測する値) |
| yhat_lower、yhat_upper | yhatの80%(または95%)信頼区間の下限および上限 |
| trend | 時点dsにおけるトレンドコンポーネントの値(例:時間経過に伴う緩やかな増加や減少) |
| trend_lower, trend_upper | トレンドコンポーネントの信頼区間 |
| additive_terms | 時点dsにおけるすべての季節性コンポーネントとイベントコンポーネントの合計(例:日次+週次+イベント) |
| additive_terms_lower、additive_terms_upper | 加法コンポーネントの上限と下限 |
| daily | 日次季節性の影響(例:1日の時間帯ごとのパターン) |
| daily_lower、daily_upper | 日次コンポーネントの信頼区間 |
| weekly | 週次季節性の影響(例:週末と平日の違い) |
| weekly_lower、weekly_upper | 週次コンポーネントの信頼区間 |
私たちが最も必要とするのは、yhat、yhat_lower、yhat_upper、trend、季節性パターン(daily、weekly、yearly)、休日(含まれている場合)、およびコンポーネント列のエラー境界(*_lowerおよび*_upper)です。
テストサンプルの実際の値と予測値を、学習サンプルの実際の値と並べてプロットしてみましょう。
f, ax = plt.subplots(figsize=(7,5)) ax.scatter(prophet_df_test["ds"], prophet_df_test['y'], color='r') # plot actual values from the testing sample in red fig = model.plot(test_fcst, ax=ax) # plot the forecasts
以下が出力されます。
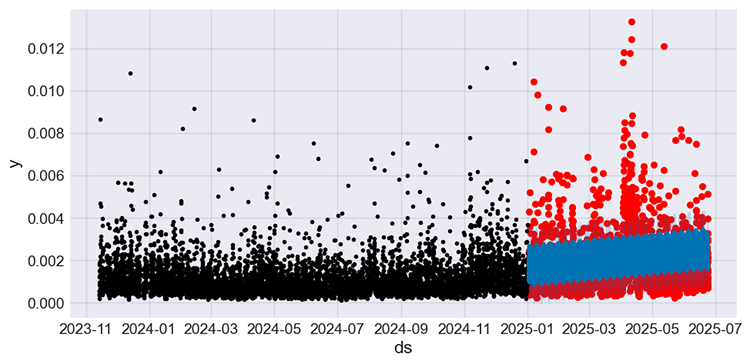
図05
黒色の値は学習サンプルを、赤色の値はテストサンプルの実際の値を、青色の値はテストサンプルに対するモデルの予測値を表しています。
ただし、このプロットだけではモデルの効果を理解するのは難しいです。そこで、テストサンプルの実際の値と予測値を示す小さなプロットを作成してみましょう。
まずは、テストデータの最初の月である2025年1月におけるモデルの評価をおこないます。
f, ax = plt.subplots(figsize=(7, 5)) ax.scatter(prophet_df_test["ds"], prophet_df_test['y'], color='r') fig = model.plot(test_fcst, ax=ax) ax.set_xbound( lower=pd.to_datetime("2025-01-01"), # starting data on the x axis upper=pd.to_datetime("2025-02-01")) # ending data on the x axis ax.set_ylim(0, 0.005) plot = plt.suptitle("January 2025, Actual vs Forecasts")
以下が出力です。
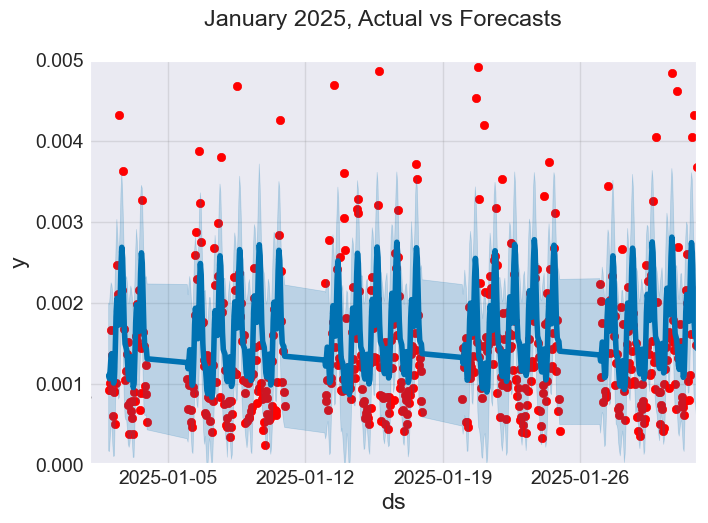
図06
上の画像からわかるように、Prophetモデルはいくつかの予測を正しくおこなっていますが、データ内の外れ値に対してはあまりうまく対応できていないようです。
必要に応じて、1月の最初の週(1月1日から1月8日)における実際の値とモデルの予測値を比較して、予測の詳細をさらに分析することもできます。
f, ax = plt.subplots(figsize=(9, 5)) ax.scatter(prophet_df_test["ds"], prophet_df_test['y'], color='r') fig = model.plot(test_fcst, ax=ax) ax.set_xbound( lower=pd.to_datetime("2025-01-01"), upper=pd.to_datetime("2025-01-08")) ax.set_ylim(0, 0.005) plot = plt.suptitle("January 01-08, 2025. Actual vs Forecasts")
以下が出力です。
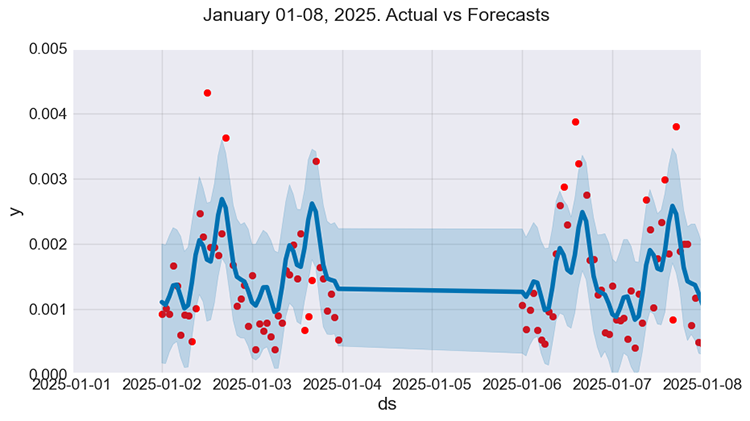
図07
かなり改善されたように見えます。ただし、モデルはいくつかのパターンを捉えているものの、予測値が実際の値にそれほど近くないことがわかります。これは、回帰モデルを使用する際によく直面する状況です。
とはいえ、全体的には良い一般化された予測をおこなっているようです。
次に、いくつかの評価指標を用いてモデルを評価してみましょう。
import sklearn.metrics as metric def forecast_accuracy(forecast, actual): # Convert to numpy arrays if they aren't already forecast = np.asarray(forecast) actual = np.asarray(actual) metrics = { 'mape': metric.mean_absolute_percentage_error(actual, forecast), 'me': np.mean(forecast - actual), # Mean Error 'mae': metric.mean_absolute_error(actual, forecast), 'mpe': np.mean((forecast - actual) / actual), # Mean Percentage Error 'rmse': metric.root_mean_squared_error(actual, forecast), 'minmax': 1 - np.mean(np.minimum(forecast, actual) / np.maximum(forecast, actual)), "r2_score": metric.r2_score(forecast, actual) } return metrics results = forecast_accuracy(test_pred, prophet_df_test["y"]) for metric_name, value in results.items(): print(f"{metric_name:<10}: {value:.6f}")
以下が出力です。
mape : 0.603277 me : 0.000130 mae : 0.000829 mpe : 0.430299 rmse : 0.001221 minmax : 0.339292 r2_score : -4.547775
私が注目しているのは、MAPE(Mean Absolute Percentage Error、平均絶対誤差率)という指標です。おおよそ0.6という値は、モデルの予測が実際の値から平均で60%もずれていることを意味します。簡単に言えば、モデルの予測は非常に不正確で、誤差が大きいことがわかります。
Prophetモデルへのイベントの追加
Prophetモデルは、時系列データにおいて通常とは異なる変化を引き起こすイベントが存在する可能性を理解できるように設計されています。これらは「イベント」と呼ばれます。
現実の世界では、イベントはビジネスデータに不規則な影響を与える可能性があります。たとえば:
- 公的な祝日(例:元日、クリスマス)
- ビジネスイベント(例:ブラックフライデー、製品発売)
- 金融関連イベント(例:中央銀行の発表、四半期末)
- 地域イベント(例:選挙、天候ショック)
これらの日は不規則な季節パターンには従いませんが、通常は年次、四半期、日次などで繰り返されます。
金融(取引)データでは、経済ニュースをイベントとして考慮することができます。これにより、現在のモデルの課題である「極値を捉えられない」という問題に対処する手助けになります。
図01に示されているProphetモデルの公式でもわかるように、イベントがある場合は追加することでモデルがより完全になり、イベントは公式の主要な構成要素のひとつとなります。
そのため、ニュースはMQL5言語を用いて収集する必要があります。
ファイル名: OHLC + News.mq5
input datetime start_date = D'01.01.2023'; input datetime end_date = D'24.6.2025'; input ENUM_TIMEFRAMES timeframe = PERIOD_H1; MqlRates rates[]; struct news_data_struct { datetime time[]; //News release time double open[]; //Candle opening price double high[]; //Candle high price double low[]; //Candle low price double close[]; //Candle close price string name[]; //Name of the news ENUM_CALENDAR_EVENT_SECTOR sector[]; //The sector a news is related to ENUM_CALENDAR_EVENT_IMPORTANCE importance[]; //Event importance double actual[]; //actual value double forecast[]; //forecast value double previous[]; //previous value void Resize(uint size) { ArrayResize(time, size); ArrayResize(open, size); ArrayResize(high, size); ArrayResize(low, size); ArrayResize(close, size); ArrayResize(name, size); ArrayResize(sector, size); ArrayResize(importance, size); ArrayResize(actual, size); ArrayResize(forecast, size); ArrayResize(previous, size); } } news_data; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- if (!ChartSetSymbolPeriod(0, Symbol(), timeframe)) return; SaveNews(StringFormat("%s.%s.OHLC + News.csv",Symbol(),EnumToString(timeframe))); } //+------------------------------------------------------------------+ //| | //| The function which collects news alongsided OHLC values and | //| saves the data to a CSV file | //| | //+------------------------------------------------------------------+ void SaveNews(string csv_name) { //--- get OHLC values first ResetLastError(); if (CopyRates(Symbol(), timeframe, start_date, end_date, rates)<=0) { printf("%s failed to get price information from %s to %s. Error = %d",__FUNCTION__,string(start_date),string(end_date),GetLastError()); return; } uint size = rates.Size(); news_data.Resize(size-1); //--- FileDelete(csv_name); //Delete an existing csv file of a given name int csv_handle = FileOpen(csv_name,FILE_WRITE|FILE_SHARE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON,",",CP_UTF8); //csv handle if(csv_handle == INVALID_HANDLE) { printf("Invalid %s handle Error %d ",csv_name,GetLastError()); return; //stop the process } FileSeek(csv_handle,0,SEEK_SET); //go to file begining FileWrite(csv_handle,"Time,Open,High,Low,Close,Name,Sector,Importance,Actual,Forecast,Previous"); //write csv header MqlCalendarValue values[]; //https://www.mql5.com/ja/docs/constants/structures/mqlcalendar#mqlcalendarvalue for (uint i=0; i<size-1; i++) { news_data.time[i] = rates[i].time; news_data.open[i] = rates[i].open; news_data.high[i] = rates[i].high; news_data.low[i] = rates[i].low; news_data.close[i] = rates[i].close; int all_news = CalendarValueHistory(values, rates[i].time, rates[i+1].time, NULL, NULL); //we obtain all the news with their values https://www.mql5.com/ja/docs/calendar/calendarvaluehistory for (int n=0; n<all_news; n++) { MqlCalendarEvent event; CalendarEventById(values[n].event_id, event); //Here among all the news we select one after the other by its id https://www.mql5.com/ja/docs/calendar/calendareventbyid MqlCalendarCountry country; //The couhtry where the currency pair originates CalendarCountryById(event.country_id, country); //https://www.mql5.com/ja/docs/calendar/calendarcountrybyid if (StringFind(Symbol(), country.currency)>-1) //We want to ensure that we filter news that has nothing to do with the base and the quote currency for the current symbol pair { news_data.name[i] = event.name; news_data.sector[i] = event.sector; news_data.importance[i] = event.importance; news_data.actual[i] = !MathIsValidNumber(values[n].GetActualValue()) ? 0 : values[n].GetActualValue(); news_data.forecast[i] = !MathIsValidNumber(values[n].GetForecastValue()) ? 0 : values[n].GetForecastValue(); news_data.previous[i] = !MathIsValidNumber(values[n].GetPreviousValue()) ? 0 : values[n].GetPreviousValue(); } } FileWrite(csv_handle,StringFormat("%s,%f,%f,%f,%f,%s,%s,%s,%f,%f,%f", (string)news_data.time[i], news_data.open[i], news_data.high[i], news_data.low[i], news_data.close[i], news_data.name[i], EnumToString(news_data.sector[i]), EnumToString(news_data.importance[i]), news_data.actual[i], news_data.forecast[i], news_data.previous[i] )); } //--- FileClose(csv_handle); }
SaveNews関数内でニュースを収集した後、取得したデータは「共通パス(フォルダ)」内のCSVファイルに保存されます。
Pythonスクリプト内では、同じパスからこのデータを読み込みます。
from Trade.TerminalInfo import CTerminalInfo import os terminal = CTerminalInfo() data_path = os.path.join(terminal.common_data_path(), "Files") timeframe = "PERIOD_H1" df = pd.read_csv(os.path.join(data_path, f"{symbol}.{timeframe}.OHLC + News.csv")) df
以下が出力です。
| Time | Open | High | Low | Close | Name | Sector | Importance | Actual | Forecast | Previous | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023.01.02 01:00:00 | 1.06967 | 1.06983 | 1.06927 | 1.06983 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 1 | 2023.01.02 02:00:00 | 1.06984 | 1.07059 | 1.06914 | 1.07041 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 2 | 2023.01.02 03:00:00 | 1.07059 | 1.07069 | 1.06858 | 1.06910 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 3 | 2023.01.02 04:00:00 | 1.06909 | 1.06909 | 1.06828 | 1.06880 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 4 | 2023.01.02 05:00:00 | 1.06881 | 1.07029 | 1.06880 | 1.06897 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
MQL5スクリプトでデータの各行に対してニュースを収集したため、ニュース列に「(null)」という名前が入っている行があります。これは、その時点でニュースがなかったことを示しており、これらの行をフィルタリングする必要があります。
news_df = df[df['Name'] != "(null)"].copy()
以前、このモデル用にデータをdsとyの2列に整形したのと同様に、イベントのデータセットもdsとholidayの2列に整形する必要があります。 holiday列にはニュースの名前を保持します。
holidays = news_df[['Time', 'Name']].rename(columns={ 'Time': 'ds', 'Name': 'holiday' }) holidays['ds'] = pd.to_datetime(holidays['ds']) # Ensure datetime format holidays
以下が出力です。
| ds | holiday | |
|---|---|---|
| 0 | 2023-01-02 01:00:00 | New Year's Day |
| 1 | 2023-01-02 02:00:00 | New Year's Day |
| 2 | 2023-01-02 03:00:00 | New Year's Day |
| 3 | 2023-01-02 04:00:00 | New Year's Day |
| 4 | 2023-01-02 05:00:00 | New Year's Day |
これらの特徴量に加えて、holidaysのDataFrameにはオプションで2つの列(lower_windowとupper_window)を追加することができます。これらの列は、各イベントが発生する前後にモデルへ与える影響を示します。
現実世界のあらゆるイベントは、必ずしもその日だけに影響を与えるわけではなく、発生日の前後にも影響を及ぼすことが多いことがわかっています。
holidays['lower_window'] = 0 holidays['upper_window'] = 1 # Extend effect to 1 hour after
lower_window列は、イベントが発生する前に時系列データにどの程度影響を与えるかを示します。一方、upper_window列は、イベントが発生した後に時系列データにどの程度影響を与えるかを示します。
- lower_window列の値は0以下(<=0)で指定できます。デフォルト値は0で、イベントが時系列の過去の値に影響を与えないことを意味します。値が「-1」の場合、特定のイベントが発生前の直前の1つの値に影響を与えることを意味します。同様に、それ以外の負の値でさらに過去の値に影響を拡張できます。
- upper_window列の値は0以上(>=0)で指定できます。デフォルト値は0で、イベントが発生後の時系列の値に影響を与えないことを意味します。値が1の場合、特定のイベントが発生後の直後の1つの値に影響を与えることを意味します。同様に、それ以上の正の値で影響範囲を拡張できます。
それでは、説明したとおりにこれらの特徴量を追加してみましょう。
holidays['lower_window'] = -1 # The anticipation of the news affect the volatility 1 bar before it's release holidays['upper_window'] = 1 # The news affects the volatility 1 bar after its release holidays
holidays DataFrameは次のようになります。
| ds | holiday | lower_window | upper_window | |
|---|---|---|---|---|
| 0 | 2023-01-02 01:00:00 | New Year's Day | -1 | 1 |
| 1 | 2023-01-02 02:00:00 | New Year's Day | -1 | 1 |
| 2 | 2023-01-02 03:00:00 | New Year's Day | -1 | 1 |
| 3 | 2023-01-02 04:00:00 | New Year's Day | -1 | 1 |
| 4 | 2023-01-02 05:00:00 | New Year's Day | -1 | 1 |
| ... | ... | ... | ... | ... |
| 15369 | 2025-06-20 18:00:00 | Eurogroup Meeting | -1 | 1 |
| 15370 | 2025-06-20 19:00:00 | Eurogroup Meeting | -1 | 1 |
| 15371 | 2025-06-20 20:00:00 | Eurogroup Meeting | -1 | 1 |
| 15372 | 2025-06-20 21:00:00 | Eurogroup Meeting | -1 | 1 |
| 15373 | 2025-06-20 22:00:00 | Eurogroup Meeting | -1 | 1 |
最後に、Prophetモデルにholidays DataFrameと、以前に準備した学習データを提供します。
model_w_holidays = Prophet(holidays=holidays) model_w_holidays.fit(prophet_df_train)
以前と同じように、予測値と実際の値をプロットすることで、イベントに関する学習済みモデルの予測をテストできます。
# Predict on training set with model test_fcst = model_w_holidays.predict(df=prophet_df_test) test_pred = test_fcst.yhat # We get the predictions # Plot the forecast with the actuals f, ax = plt.subplots(figsize=(10,5)) ax.scatter(prophet_df_test["ds"], prophet_df_test['y'], color='r') fig = model_w_holidays.plot(test_fcst, ax=ax)
以下が出力です。
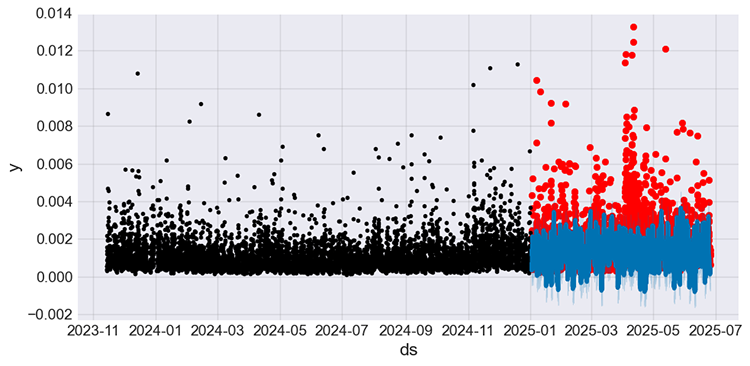
図08
ニュース(イベント)を考慮せずにモデルが行った予測(図05)では、予測が静的に見えたのに対し、ニュース(イベント)を組み込んだ新しいモデルの予測は、以前のモデルが捉えられなかった変動の一部を捉えているように見えます。
改めて、前回のモデルで使用したのと同じ評価指標を用いて、このモデルを評価します。
results = forecast_accuracy(test_pred, prophet_df_test["y"]) for metric_name, value in results.items(): print(f"{metric_name:<10}: {value:.6f}")
以下が出力です。
mape : 0.549152 me : -0.000633 mae : 0.000970 mpe : -0.175082 rmse : 0.001487 minmax : 0.461444 r2_score : -2.793478
MAPEを見ると、モデルの予測は約10%改善されていることがわかります。前回のモデルではおおよそ60%の誤差がありましたが、このモデルでは約55%の誤差となっています。この改善は、r2_scoreにも反映されています。
それでもなお、誤差が55%のモデルは十分とは言えません。理想的なモデルでは、誤差は少なくとも50%未満である必要があります。このモデルをさらに改善するためには、イベント(ニュース)の扱いを見直す余地があります。
今回の例では、lower_windowとupper_windowの値をそれぞれ -1 と 1 に設定しました。つまり、ニュースは公開前後の1バーに市場のボラティリティに影響を与えることになります。これによりモデルは改善しましたが、これが理想的かどうかは疑問です。
異なるニュースは影響の範囲や強さが異なるため、すべてのニュースに同じ定数値を設定するのは根本的に誤りです。また、重要度の低いニュースもすべて使用しており、トレーダーはこうしたニュースをしばしば無視します。なぜなら、こうしたニュースは非常に頻繁に発生し、チャート上での影響を測定・観察することが難しいからです。
この2つの問題を解決するには、lower_windowとupper_windowの値を、ニュースの種類や過去の観察に基づく影響度に応じて動的に設定する必要があります。
以下が擬似コードの例です。
def get_windows(name): if "CPI" in name: return (-1, 4) # CPI news affects one previous bar volatility, and it affects the volatility of four bars ahead (4 hours impact forward) elif "NFP" in name: return (-1, 2) # NFP news affects one previous bar volatility, and it affects the volatility of two bars ahead (2 hours impact afterward) elif "FOMC" in name or "Rate" in name: return (-2, 6) # NFP news affects two previous bar volatility, and it affects the volatility of six bars ahead (6 hours impact afterward) else: return (0, 1) # Default holidays[['lower_window', 'upper_window']] = holidays['holiday'].apply( lambda name: pd.Series(get_windows(name)) )
数万種類ものユニークなニュースが存在し、かつ設定する影響値に確信を持つ必要があることを考えると、このアプローチを実装するのは非常に難しいですが、理想的な方法です。ぜひチャレンジしてみてください。
現時点で私たちができる明らかな対策は、ニュースをある程度フィルタリングし、重要度が高いまたは中程度のニュースのみを残すことです。
news_df = df[ (df['Name'] != "(null)") & # Filter rows without news at all ((df['Importance'] == "CALENDAR_IMPORTANCE_HIGH") | (df['Importance'] == "CALENDAR_IMPORTANCE_MODERATE")) # Filter other news except high importance news ].copy() news_df
以下が出力です。
| Time | Open | High | Low | Close | Name | Sector | Importance | Actual | Forecast | Previous | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 7 | 2023.01.02 08:00:00 | 1.06921 | 1.06973 | 1.06724 | 1.06858 | S&P Global Manufacturing PMI | CALENDAR_SECTOR_BUSINESS | CALENDAR_IMPORTANCE_MODERATE | 47.10 | 47.400 | 47.400 |
| 8 | 2023.01.02 09:00:00 | 1.06878 | 1.06909 | 1.06627 | 1.06784 | S&P Global Manufacturing PMI | CALENDAR_SECTOR_BUSINESS | CALENDAR_IMPORTANCE_MODERATE | 47.80 | 47.800 | 47.800 |
| 31 | 2023.01.03 08:00:00 | 1.06636 | 1.06677 | 1.06514 | 1.06524 | Unemployment | CALENDAR_SECTOR_JOBS | CALENDAR_IMPORTANCE_MODERATE | 2.52 | 2.522 | 2.538 |
| 37 | 2023.01.03 14:00:00 | 1.05283 | 1.05490 | 1.05241 | 1.05355 | S&P Global Manufacturing PMI | CALENDAR_SECTOR_BUSINESS | CALENDAR_IMPORTANCE_HIGH | 46.20 | 46.200 | 46.200 |
| 38 | 2023.01.03 15:00:00 | 1.05353 | 1.05698 | 1.05304 | 1.05602 | Construction Spending m/m | CALENDAR_SECTOR_HOUSING | CALENDAR_IMPORTANCE_MODERATE | 0.20 | 0.200 | -0.300 |
うまくいきました。time列とname列をholidays DataFrameに抽出した後、lower_window値とupper_window値を追加します。
holidays = news_df[['Time', 'Name']].rename(columns={ 'Time': 'ds', 'Name': 'holiday' }) holidays['ds'] = pd.to_datetime(holidays['ds']) # Ensure datetime format holidays['lower_window'] = 0 holidays['upper_window'] = 1 holidays
モデルを学習させた後、以下のプロットは、学習サンプルとテストサンプルの実際の値をそれぞれ黒色と赤色で、テストサンプルに対する予測値を青色で示したものです。
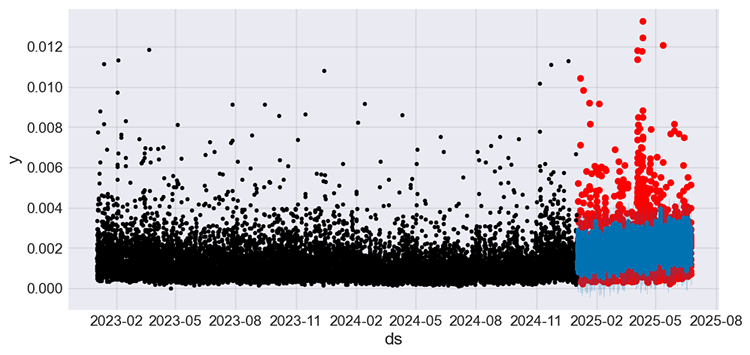
図09
モデルはさらに改善され、MAPEによると誤差はおおよそ50%となりました。これで、この回帰モデルを用いて予測をおこなうことができます。
mape : 0.506827 me : -0.000053 mae : 0.000783 mpe : 0.271597 rmse : 0.001234 minmax : 0.320422 r2_score : -3.318859
お気づきかもしれませんが、ニュースはCSVファイルから別途インポートしましたが、学習データはMetaTrader 5から直接インポートして使用しました。
Prophetモデルは、holidays DataFrameの日付をメインの学習データの日付と同期させます。ただし、holidays DataFrameのタイムスタンプが学習期間や将来予測期間内にある場合に限ります。
このモデルは日付を同期できるものの、両方のデータセットの開始日が同じであることを明示的に確認する必要があります。そうすることで、両方のデータセットを最大限に活用できます。
そのため、main.ipynb内でMetaTrader 5から価格情報を取得する処理を修正し、開始日と終了日をOHLC + News.mq5スクリプトで使用している日付と一致させました。
# set time zone to UTC timezone = pytz.timezone("Etc/UTC") # create 'datetime' objects in UTC-time to avoid the implementation of a local time zone offset utc_from = datetime(2023, 1, 1, tzinfo=timezone) utc_to = datetime(2025, 6, 24, hour = 0, tzinfo=timezone) rates = mt5.copy_rates_range(symbol, timeframe, utc_from, utc_to)
Prophetモデルに基づくMetaTrader 5自動売買ロボットの作成
Prophetモデルをベースにした自動売買ロボットを作成するためには、まず対象変数(今回の場合はボラティリティ)に対してリアルタイム予測をおこなえる必要があります。
これを実現するためには、市場(銘柄)からの最新情報に加えて、最新のニュース更新も含めて一度に取得できるパイプラインが必要です。学習スクリプトであるmain.ipynbでは、MetaTrader 5-Pythonパッケージを使用してMetaTrader 5からデータを収集しましたが、このパッケージではニュースを取得する手段が提供されていません。そのため、このプロセスにはMQL5を使用する必要があります。
基本的なアイデアは、Pythonスクリプト(自動売買ロボット)とMQL5のエキスパートアドバイザー(EA)との間でデータをやり取りすることです。
- 具体的には、MetaTrader 5のチャートにアタッチされたEA (Data for Prophet.mq5)が、MetaTrader 5からニュースやOHLC値を定期的に取得し、共通フォルダ内のCSVファイルに保存します。
- その後、このCSVファイルをPythonスクリプト(Prophet-trading-bot.py)が読み込み、Prophetモデルを定期的に学習させます。
- 学習後、このモデルを用いて予測を行い、その予測結果に基づいてPythonスクリプト内でトレード判断を行います。
ファイル名:Data for Prophet.mq5
input uint collect_news_interval_seconds = 60; input uint training_bars = 1000; input ENUM_TIMEFRAMES timeframe = PERIOD_H1; //... other lines of code //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- create timer EventSetTimer(collect_news_interval_seconds); if (!ChartSetSymbolPeriod(0, Symbol(), timeframe)) return INIT_FAILED; //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- destroy timer EventKillTimer(); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- } //+------------------------------------------------------------------+ //| Timer function | //+------------------------------------------------------------------+ void OnTimer() { //--- MqlDateTime time_struct; TimeToStruct(TimeGMT(), time_struct); SaveNews(StringFormat("%s.%s.OHLC.date=%s.hour=%d + News.csv",Symbol(),EnumToString(timeframe), TimeToString(TimeGMT(), TIME_DATE), time_struct.hour)); }
正しいファイルを使用していることを保証するために、CSVファイルの名前には日付と現在の時刻(UTC時間)が使用されます。
このEAは、OnTimer関数に従ってデフォルトで毎分ニュースやその他の値を収集し、CSVファイルに保存します。
Pythonスクリプト内では、共通フォルダから同じようにCSVファイルを読み込み、データをインポートします。
ファイル名:Prophet-trading-bot.py
def prophet_vol_predict() -> float: # Getting the data with news now_utc = datetime.utcnow() current_date = now_utc.strftime("%Y.%m.%d") current_hour = now_utc.hour filename = f"{symbol}.{timeframe}.OHLC.date={current_date}.hour={current_hour} + News.csv" # the same file naming as in MQL5 script common_path = os.path.join(terminal.common_data_path(), "Files") csv_path = os.path.join(common_path, filename) # Keep trying to read a CSV file until it is found, as there could be a temporary difference in values for the file due to the change in time while True: if os.path.exists(csv_path): try: rates_df = pd.read_csv(csv_path) rates_df["Time"] = pd.to_datetime(rates_df["Time"], unit="s", errors="ignore") # Convert time from seconds to datetime print("File loaded successfully.") break # Exit the loop once file is read except Exception as e: print(f"Error reading the file: {e}") time.sleep(30) else: print("File not found. Retrying in 30 seconds...") time.sleep(30)
volatility列を準備し、学習データとイベントデータのそれぞれにニュース名を抽出します。
# Getting continous variables for the prophet model prophet_df = pd.DataFrame({ "time": rates_df["Time"], "volatility": rates_df["High"] - rates_df["Low"] }).set_index("time") prophet_df = prophet_df.reset_index().rename(columns={"time": "ds", "volatility": "y"}).copy() print("Prophet df\n",prophet_df.head()) # Getting the news data for the model as well news_df = rates_df[ (rates_df['Name'] != "(null)") & # Filter rows without news at all ((rates_df['Importance'] == "CALENDAR_IMPORTANCE_HIGH") | (rates_df['Importance'] == "CALENDAR_IMPORTANCE_MODERATE")) # Filter other news except high importance news ].copy() holidays = news_df[['Time', 'Name']].rename(columns={ 'Time': 'ds', 'Name': 'holiday' }) holidays['ds'] = pd.to_datetime(holidays['ds']) # Ensure datetime format holidays['lower_window'] = 0 holidays['upper_window'] = 1 print("Holidays df\n", holidays)
prophet_vol_pred関数の最後では、受け取った情報を用いてモデルを学習させ、その結果として単一の予測値を返します。これは、モデルが次のバーに市場で発生すると予測するボラティリティを表しています。
# re-training the prophet model prophet_model = Prophet(holidays=holidays) prophet_model.fit(prophet_df) # Making future predictions future = prophet_model.make_future_dataframe(periods=1) # prepare the dataframe for a single value prediction forecast = prophet_model.predict(future) # Predict the next one value return forecast.yhat[0] # return a single predicted value
他の時系列予測で使用される機械学習モデルと同様に、将来の予測に関連する最新情報を反映させるためには、モデルを頻繁に更新する必要があります。これが、新しい予測をおこなう前にモデルを再学習させる主な理由です。
それでは、この関数を実行して結果を確認してみましょう。
print("predicted volatility: ",prophet_vol_predict())
以下が出力です。
File loaded successfully. Prophet df ds y 0 2025.04.29 01:00:00 0.00100 1 2025.04.29 02:00:00 0.00210 2 2025.04.29 03:00:00 0.00170 3 2025.04.29 04:00:00 0.00215 4 2025.04.29 05:00:00 0.00278 Holidays df ds holiday lower_window upper_window 8 2025-04-29 09:00:00 GfK Consumer Climate 0 1 14 2025-04-29 15:00:00 Retail Inventories excl. Autos m/m 0 1 31 2025-04-30 08:00:00 Consumer Spending m/m 0 1 33 2025-04-30 10:00:00 Unemployment 0 1 35 2025-04-30 12:00:00 GDP y/y 0 1 .. ... ... ... ... 978 2025-06-24 19:00:00 FOMC Member Williams Speech 0 1 979 2025-06-24 20:00:00 2-Year Note Auction 0 1 982 2025-06-24 23:00:00 Fed Vice Chair for Supervision Barr Speech 0 1 984 2025-06-25 01:00:00 Jobseekers Total 0 1 994 2025-06-25 11:00:00 Bbk Executive Board Member Mauderer Speech 0 1 [186 rows x 4 columns] 16:01:50 - cmdstanpy - INFO - Chain [1] start processing 16:01:50 - cmdstanpy - INFO - Chain [1] done processing predicted volatility: 0.0013592111956094713
予測値を取得できるようになったので、それを取引戦略に活用できます。
symbol = "EURUSD" timeframe = "PERIOD_H1" terminal = CTerminalInfo() m_position = CPositionInfo() def main(): m_symbol = CSymbolInfo(symbol=symbol) magic_number = 25062025 slippage = 100 m_trade = CTrade(magic_number=magic_number, filling_type_symbol=symbol, deviation_points=slippage) m_symbol.refresh_rates() # Get recent information from the market # we want to open random buy and sell trades if they don't exist and use the predicted volatility to set our stoploss and takeprofit targets predicted_volatility = prophet_vol_predict() print("predicted volatility: ",prophet_vol_predict()) if pos_exists(mt5.POSITION_TYPE_BUY, magic_number, symbol) is False: m_trade.buy(volume=m_symbol.lots_min(), symbol=symbol, price=m_symbol.ask(), sl=m_symbol.ask()-predicted_volatility, tp=m_symbol.ask()+predicted_volatility) if pos_exists(mt5.POSITION_TYPE_SELL, magic_number, symbol) is False: m_trade.sell(volume=m_symbol.lots_min(), symbol=symbol, price=m_symbol.bid(), sl=m_symbol.bid()+predicted_volatility, tp=m_symbol.bid()-predicted_volatility)
上記の関数は、Prophetモデルから予測されたボラティリティを取得し、それを使用して取引のストップロスとテイクプロフィットのターゲットを設定します。ランダムに取引をおこなう際には、同じタイプのポジションが既に存在しないかを確認してから新規にポジションを開きます。
以下が関数呼び出しです。
main()
以下が結果です。
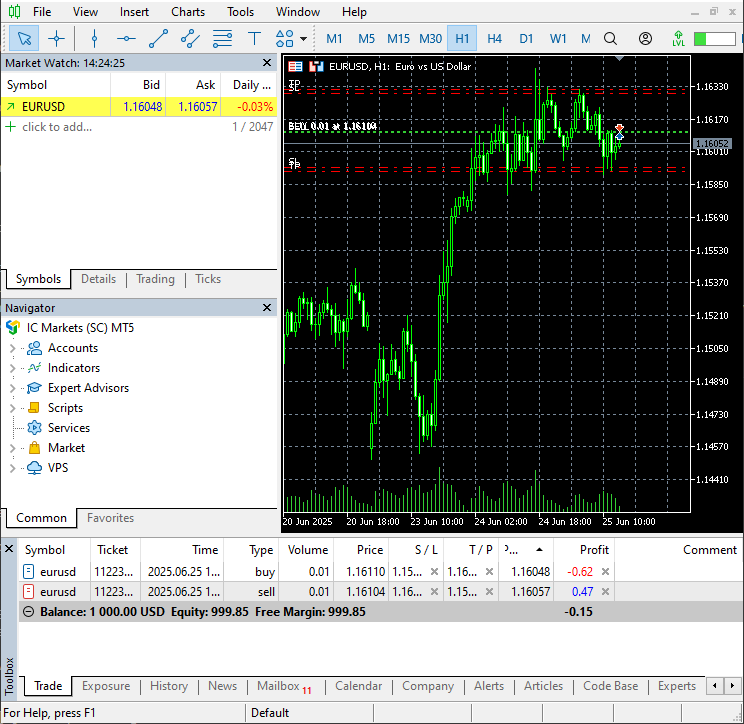
図10
MetaTrader 5上で、モデルが予測したボラティリティをストップロス値およびテイクプロフィット値として設定した、2つの反対方向の取引がおこなわれました。
この学習プロセスを自動化し、取引操作やシグナルを定期的に監視することが可能です。
schedule.every(1).minute.do(main) # train and run trading operations after every one minute while True: schedule.run_pending() time.sleep(1)
結論
一部の記事や投稿、チュートリアルでは、Prophetモデルが時系列予測に優れていると紹介されていますが、本連載で取り上げたモデルの中では最も扱いにくいモデルのひとつであると私は考えます。
Prophetモデルは、天候やイベント、その他の季節的なパターンに依存するビジネス需要の予測など、比較的単純な時系列問題には適しているかもしれません。しかし、金融市場はそれよりもはるかに複雑であり、テストサンプルにおける実測値と予測値を示した図(05、06、07、08、09)からもわかるように、Prophetモデルは大半の予測を実際の値に近づけることができませんでした。
もちろん、改善のためにできることはいくつかあると理解していますが、現時点では単純な問題にのみ使用することをおすすめします。
このモデルの制限事項をまとめると次のようになります。
- 単純なモデル構造であり、複雑な相互作用をサポートしていない
- ボラティリティの扱いが不得意:上記の通り、FXデータでは良い結果を出せない
- 多変量モデリングができない:サポートされているのは「時刻」と「目的変数」の2つの特徴量のみ
- 交差検証やハイパーパラメータチューニングの機能がない:トレンドや季節性、変化点を自分で制御する必要がある
ご一読、誠にありがとうございました。
出典と参考文献
- https://facebook.github.io/prophet/
- https://otexts.com/fpp3/prophet.html
- https://www.geeksforgeeks.org/time-series-analysis-using-facebook-prophet/
- https://www.kaggle.com/code/omegajoctan/time-series-forecasting-with-prophet/edit
添付ファイルの表
| ファイル名 | 説明と使用法 |
|---|---|
| Python code\main.ipynb | Prophetモデルのデータ分析と探索のためのJupyter Notebook |
| Python code\Prophet-trading-bot.py | MetaTrader 5 Pythonベースの自動売買ロボット |
| Python code\requirementx.txt | Pythonの依存関係とそのバージョン番号を含むテキストファイル |
| Python code\error_description.py | MetaTrader 5によって生成されるすべてのエラー コードの説明 |
| Python code\Trade\* | MQL5言語で使用できるクラスと同様の、Python用取引クラス(CTrade、CPositionInfoなど) |
| Experts\Data for Prophet.mq5 | Prophetモデル学習用データを定期的に収集し、CSVファイルに保存するEA |
| Scripts\OHLC + News.mq5 | Prophetモデル学習用データを収集し、CSVファイルに保存するスクリプト |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/18549
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索