使用Python和MQL5进行特征工程(第四部分):基于UMAP回归的K线模式识别

K线模式被我们社区中的大多数算法交易者广泛应用于许多不同的交易策略和风格中。然而,我们对这些模式的理解仅限于我们已经发现的那些K线,而事实上,可能还有许多其他我们尚未意识到的、能够盈利的K线模式。由于覆盖大多数现代市场的信息量巨大,交易者很难自信地确定他们总是在市场中使用了最可靠的K线模式。
为了缓解这个问题,我们将提出一个解决方案,让计算机能够识别我们未曾意识到的新K线模式。我们提出的框架在某种程度上可以与一个大多数人应该都很熟悉的童年游戏相比较。这个游戏有不同的名字。但其基本前提是相同的。游戏要求玩家使用不包含名词本身的形容词来描述一个名词。因此,举个例子,如果给定的名词是香蕉,那么主持游戏的玩家会给他的朋友们提供最能描述香蕉的线索,比如“黄色且弯曲的”,希望读者能直观地理解这一点。
这个童年游戏在逻辑上与我们将要求计算机执行的任务相同,这样我们就能发现那些因数据集往往具有高维度而被隐藏起来的新K线模式。与我们刚刚描述的游戏类似——玩家被要求用3个或更少的词来描述一根香蕉——我们将向计算机提供包含10列描述当前K线的数据,然后要求计算机用8列或更少的“词”(嵌入)来描述原始的市场数据。这就叫做降维。
有许多读者可能已经熟知的著名降维技术,例如主成分分析(PCA)。这些技术很有帮助,因为它们引导我们的计算机专注于转换后数据最重要的方面。今天,我们将采用一种称为“统一流形逼近与投影”(UMAP)的技术。这是一个较新的算法,正如读者很快将看到的,它可以通过一种新颖的方式揭示市场数据中的非线性关系,从而为我们服务。
我们的目标是在原始数据集中精心设计和构建列,从而对当前K线进行详细描述。这样做,可以让UMAP算法转换我们的数据,将相似的K线分组,并用更少的“词”(嵌入)来描述它们。这反过来可能有助于我们的计算机识别那些由于我们需要准确描述每根K线的高维度而对我们隐藏的K线模式。
为了测试UMAP算法的优越性,我们训练了两个相同的统计模型来预测EURGBP(欧元兑英镑)日汇率的回报率。第一个模型使用其原始形式的原始市场数据进行训练。在这个特定的例子中,原始市场数据有10个维度,这些维度直接从我们的MetaTrader 5终端的市场数据中创建。使用UMAP算法,我们能够将原始市场数据降至仅3个维度,而这足以超越我们开始时使用的原始市场数据所产生的错误。
最后,我们将不讨论如何在MQL5中从零开始原生实现UMAP算法。原因是,该算法相当复杂,尝试以数值稳定性和计算效率来实现它并非易事。如果读者有信心自己具备必要的解析几何和代数拓扑技能,那么他们可以追求自己的兴趣,在MQL5中原生实现该算法。我在这里提供了指向原始研究论文的链接,其中解释了该算法精确的数学规范。
否则,对于可能不具备所有必要数值技能的读者(包括我自己),我们将演示如何通过运用我们在函数逼近方面的技能,来替代从零开始实现算法的需求。
为什么选择UMAP?
鉴于有如此多有用且更知名的降维技术,一些读者可能会自然地问自己:“我们为什么应该有兴趣学习UMAP?我真的需要再学习一个库吗?”UMAP的主要优势之一是,随着我们数据集规模的增加,该库转换数据所需的时间几乎保持不变。此外,UMAP算法专门用于揭示数据中的非线性效应,同时仍试图保留数据的原始全局结构。换句话说,这意味着该算法明确地尽力不扭曲数据,不创建可能引入额外噪声的误导性伪影。这在大多数降维算法中并不常见。
UMAP算法相对较新,我们今天将要考虑的实现是使用Python和Numba构建的。Numba是一个将Python代码转换为机器代码的编译器。这种Python和机器代码的结合,使我们在大型数据集上也能体验到极高的速度和数值稳定的计算。UMAP算法的这个特定实现是由Leland McInnes等人设计的。该库最初于2018年发布。

图1:Leland McInnes是UMAP研究论文的主要作者之一,并帮助维护该Python库
然而,读者应该注意,如果他们用的是我们今天讨论所使用的库之外的UMAP算法,那么其质量将无法得到保证。同一算法的不同实现方式,其数值特性可能会有所不同。
在 MQL5 中实现
我们从获取描述当前K线的量化数据出发。我们想知道在一定时期内(本例中称为“horizon”)开盘价、最高价、最低价和收盘价水平的变化。除此之外,我们希望跟踪从开盘价到最高价、开盘价到最低价以及开盘价到收盘价的涨幅。对MetaTrader 5终端中可用的4个价格源分别重复此计算。这总共为我们提供了10列数据,不包括前两列:时间和真实收盘价。这10列数据可以有效地描述任何K线模式,例如十字星K线或锤子线。然而,我们当前的技术对于识别由多于1根K线形成的模式将没有用处。
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ #define HORIZON 24 //+------------------------------------------------------------------+ //| File name | //+------------------------------------------------------------------+ string file_name = Symbol() + " UMAP Candlestick Recognition.csv"; //+------------------------------------------------------------------+ //| User inputs | //+------------------------------------------------------------------+ input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time","True Close","Open","High","Low","Close","O - H","O - L","O - C","H - L","H - C","L - C"); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON
在 Python 中分析数据
我们的目标有两个方面:
- 展示使用UMAP转换代替原始形式价格数据的优势。
- 使用我们的函数逼近技术获得UMAP算法的副本,以便可以回测该算法的有效性。
我们将展示使用UMAP相对于原始形式价格数据的优势,以确保我们的目标是清晰的,并且其好处对读者来说是显而易见的。在展示了采用UMAP的优势之后,将使用UMAP库提供给我们的转换来训练我们的第一个神经网络,以估计给定市场数据的UMAP嵌入。
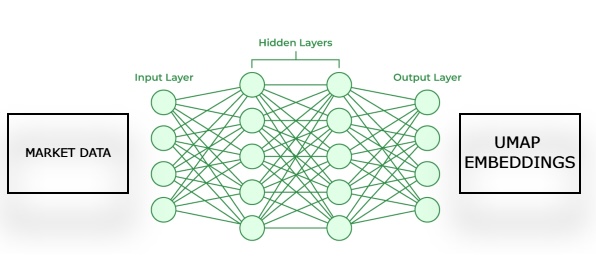
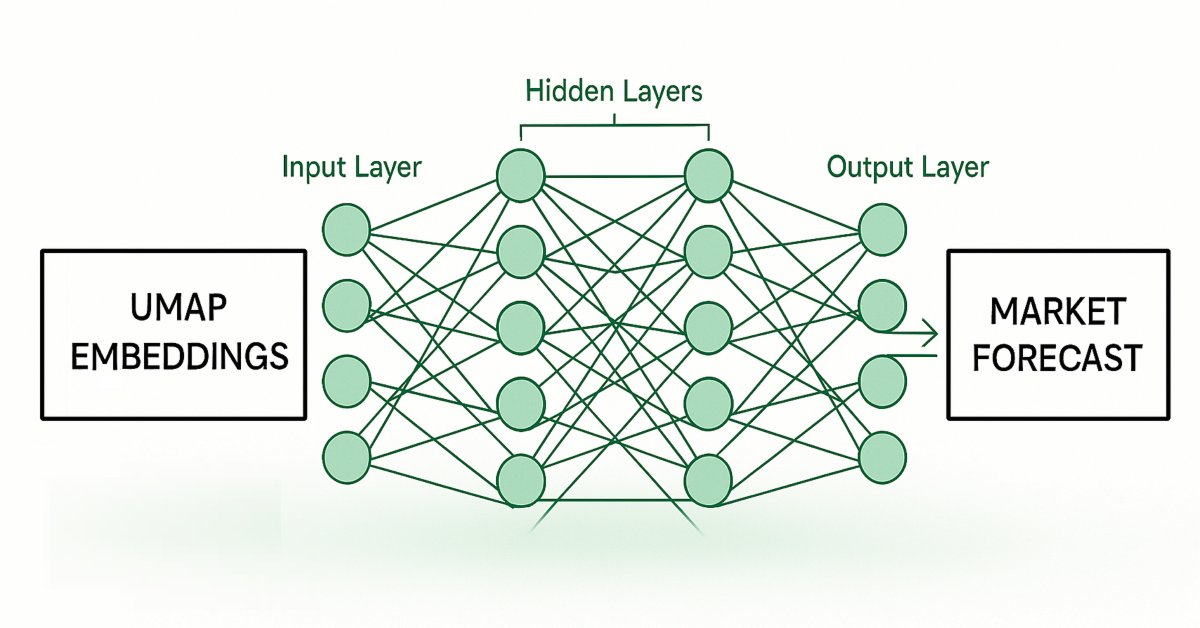
图2:可视化我们从给定市场数据中估计UMAP嵌入的框架。
随后,我们将训练第二个模型,该模型学习在给定我们第一个模型对其UMAP嵌入的估计的情况下,预测市场中的未来价格变动。我们的目标是让这两个统计模型以链式方式工作。第一个模型从给定的市场数据中估计UMAP嵌入,第二个模型接收第一个模型的输出来预测我们正在交易市场的未来回报。这个框架最终将比从头实现UMAP算法快得多,并且可能同样有效。
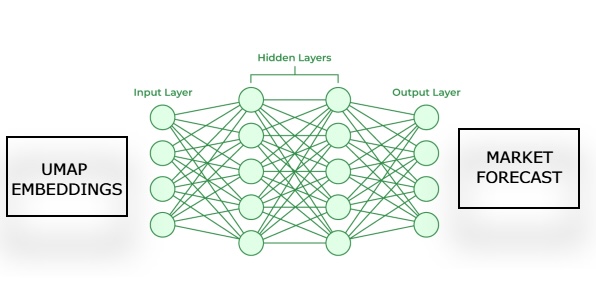
图3:可视化我们从估计的UMAP嵌入生成市场预测的框架。
既然已经清楚了我们的目的和将要遵循的方法,让我们开始在Python中进行操作。我们首先导入需要的库。如果读者希望跟随操作,可能需要先通过输入命令“pip install umap-learn”将UMAP库安装到他们的机器上。
import pandas as pd import numpy as np import matplotlib.pyplot as plt import umap import seaborn as sns
之后,如果读者准备好跟随操作,我们要采取的下一步是读取我们使用MQL5脚本生成的市场数据。
HORIZON = 24 data = pd.read_csv("..\EURGBP UMAP Candlestick Recognition.csv") data['Target'] = data['True Close'].shift(-HORIZON) - data['True Close'] data['Class'] = 0 data.loc[data['Target'] > 0,'Class'] = 1 data.dropna(inplace=True) data
我们的市场数据已成功读入,但如果你查看Time列,你会观察到我们的CSV文件中包含了最近的市场数据。我们希望从CSV文件中删除最近5年的市场数据,以确保我们的策略回测不会被那些模型无法获得的历史信息所污染。
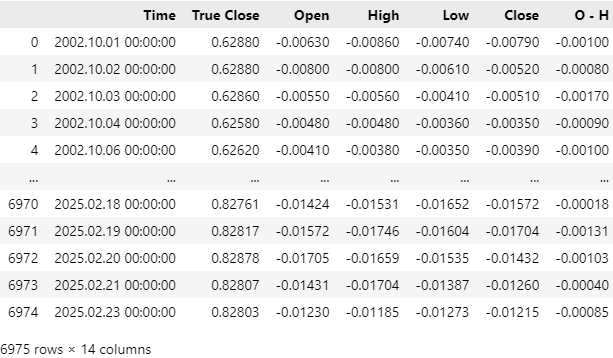
图 4:我们使用MQL5脚本获取的历史市场数据
让我们从CSV文件中删除最近5年的市场数据。请注意,我们CSV文件中的最近日期现在是2019年10月16日。我们的回测将从2020年1月1日开始。训练期结束和测试期开始之间的这个间隔是必要的,以确保我们的测试是稳健的。
#Delete all the data that overlaps with our back test data = data.iloc[:(-(365 * 5) + (31 * 5)),:] data
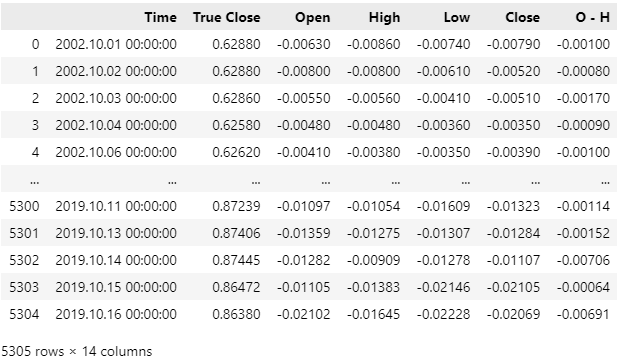
图 5:确保删除所有与您希望回测的时期重叠的数据
让我们可视化用于训练的列的效果。“H - L”列代表当日最高价与最低价之间的差额。这是每一天的有效交易区间。另一方面,“O - C”列是当日的净价格变化。通过绘制这两列的散点图,我们希望了解当日的交易区间和当日净价格变化之间是否存在任何关系。不幸的是,这种关系看起来很复杂且非线性。这可能是UMAP可以帮助我们分析的数据类型。
sns.scatterplot(
data=data,
y='O - C',
x='H - L',
hue='Class'
)
plt.grid()
plt.title("Visualizing Our Custom Columns on EURUSD Market Data")
plt.axhline(0,color='black',linestyle='--')
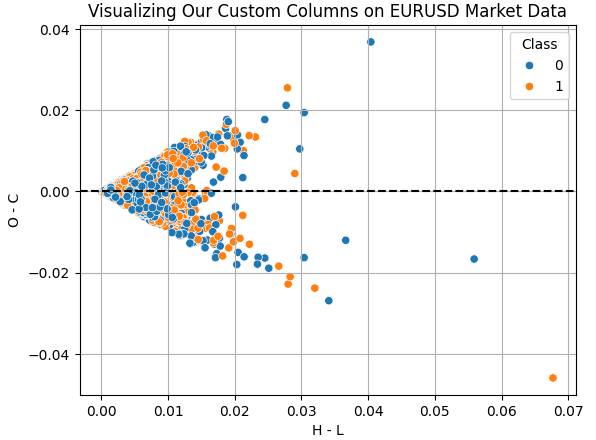
图 6:可视化当日交易区间与当日净价格变化之间的关系
应用UMAP变换相当简单。我们首先需要创建一个UMAP对象。然后,我们将UMAP对象拟合到我们的数据上,并获得变换后的数据。默认情况下,我们的UMAP对象会将数据缩减到2列。随着讲解的深入,我们将演示如何指定所需的列数。我们最初使用MQL5脚本获取的10列数据,被缩减为图7中观察到的2个维度。
在下面的代码示例中,我们向读者展示了UMAP库的某些调优参数:
- n_neighbors: 这个调优参数指示算法应尝试确保多少个数据点位于同一邻域内。
- metric: 有多种不同的度量标准可用于衡量两个点之间的“接近”程度,以及它们是否符合同一邻域的条件。更改距离度量标准将显著改变投影数据的结构。
reducer = umap.UMAP(n_neighbors=100,metric="euclidean") embedding = reducer.fit_transform(data.iloc[:,2:-2]) embedding = pd.DataFrame(embedding,columns=['X1','X2']) embedding['Class'] = data['Class'] sns.scatterplot( data=embedding, x='X1', y='X2', hue='Class' ) plt.grid() plt.title("Visualizing the effects of UMAP on our EURUSD Market Data")
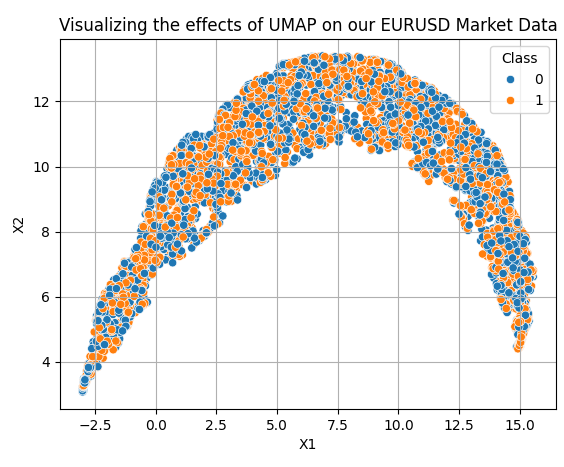
图 7:可视化应用了UMAP算法后的变换数据
我们的新数据表示并不完美。然而,它确实有以橙色点为主的区域和以蓝色点为主的区域。这可能使我们的统计模型更容易学习我们试图区分的两个类别之间的差异。然而,我们只是随意选择了2列,以让读者了解入门是多么容易。事实上,我们不知道需要多少维度才能有效地转换数据。因此,我们将在1到9之间进行线性搜索。以下函数接受一个指定所需维度数的参数,并返回相应的变换后数据。
def return_transformed_data(n_components): HORIZON = 24 data = pd.read_csv("..\EURGBP UMAP Candlestick Recognition.csv") data['Target'] = data['True Close'].shift(-HORIZON) - data['True Close'] data.dropna(inplace=True) data = data.iloc[:(-(365 * 5) + (31 * 5)),:] reducer = umap.UMAP(n_neighbors=100,metric="euclidean",n_components=n_components,n_jobs=-1) embedding = reducer.fit_transform(data.iloc[:,2:-1]) cols = [] for i in np.arange(n_components): s = 'X' + ' ' + str(i) cols.append(s) embedding = pd.DataFrame(embedding,columns=cols) return embedding.copy()
现在让我们准备模型。
from sklearn.ensemble import GradientBoostingRegressor from sklearn.model_selection import TimeSeriesSplit,cross_val_score
定义时间序列分割对象,以进行适当的时间序列交叉验证。
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON) 现在让我们执行线性搜索,以找出表示原始数据所需的最优维度数。
LEVELS = 8 res = pd.DataFrame(columns=['X'],index=np.arange(LEVELS)) for i in range(LEVELS): new_data = return_transformed_data(i+1) res.iloc[i,0] = np.mean(np.abs(cross_val_score(GradientBoostingRegressor(),new_data.iloc[:,0:],data['Target'],cv=tscv)))
获取最小索引和最小值。
res['X'] = pd.to_numeric(res['X'], errors='coerce') min_value = min(res.iloc[:,0]) min_index = res['X'].idxmin()
当我们使用3列来表示原始的10列时,得到了最佳结果。读者应该理解,这些不应被视为我们开始的10列中最好的3列。而是,这10列被转换成了3列,
plt.plot(res,color='black') plt.grid() plt.title('Finding The Optimal Number of U-MAP Components') plt.ylabel('RMSE Validation Error') plt.xlabel('Training Iteration') plt.scatter(min_index,min_value,color='red')
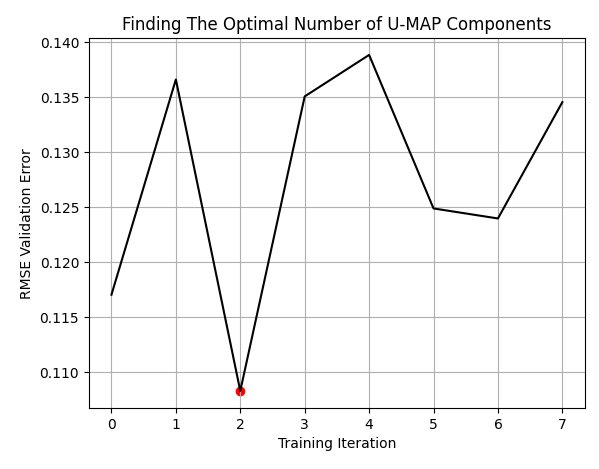
图 8:我们的最优列数为3,是从开始的10列中得出的
现在让我们记录在使用原始形式的市场数据时的误差水平。
classic_error = np.mean(np.abs(cross_val_score(GradientBoostingRegressor(),data.iloc[:,2:-2],data['Target'],cv=tscv)))
现在我们将比较使用变换后的UMAP数据产生的误差与使用未经任何变换的市场数据产生的误差。正如我们所看到的,UMAP变换已将误差水平降低到使用原始形式的价格数据无法达到的最优区域。
results = [min(res.iloc[:,0]),classic_error] sns.barplot(results,color='black') plt.axhline(results[0],color='red',linestyle='--') plt.ylabel('RMSE Validation Error') plt.xlabel('0: UMAP Transformed Data | 1: Original OHLC Data') plt.title("UMAP Transformations Are Helping Us Reduce Our Error Rates")
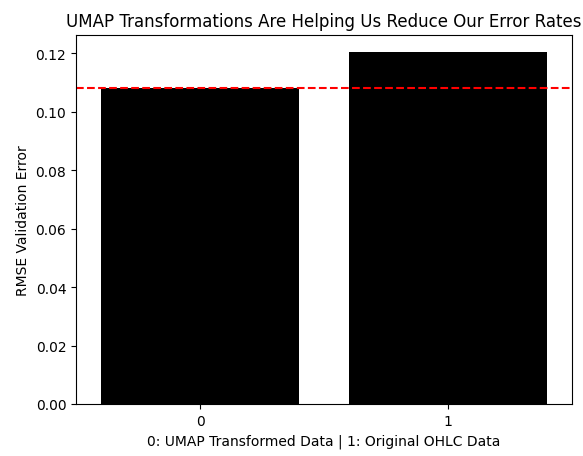
图 9:UMAP变换降低了我们的误差水平,并且表现优于原始形式的数据
既然我们已经确立了使用UMAP变换的原因,现在可以开始构建图2和3中描述的架构。我们将首先评估当神经网络学习如何将原始市场数据有效地转换为其UMAP嵌入时,需要多少次训练迭代。
from sklearn.neural_network import MLPRegressor
获取所需的数据。
new_data = return_transformed_data(3) 执行线性搜索以观察模型误差与允许的训练周期数之间的关系。
LEVELS = 18 NN_ERROR = pd.DataFrame(columns=['Error'],index=np.arange(LEVELS)) for i in range(LEVELS): model = MLPRegressor(hidden_layer_sizes=(data.iloc[:,2:-2].shape[1],10,5),max_iter=(2 ** i),solver='adam') NN_ERROR.iloc[i,0] = np.mean(np.abs(cross_val_score(model,new_data,data['Target'],cv=tscv)))
让我们绘制结果。我们的最佳结果是在模型执行65,536次训练迭代(即2的16次方)时获得的。
NN_ERROR['Error'] = pd.to_numeric(NN_ERROR['Error'], errors='coerce') min_idx = NN_ERROR.idxmin() min_value = NN_ERROR.min() plt.plot(NN_ERROR,color='black') plt.grid() plt.ylabel('5 Fold CV RMSE') plt.xlabel('Max Iterations As Powers of 2') plt.scatter(min_idx,min_value,color='red') plt.title('Minimizing The Error of Our Neural Network')
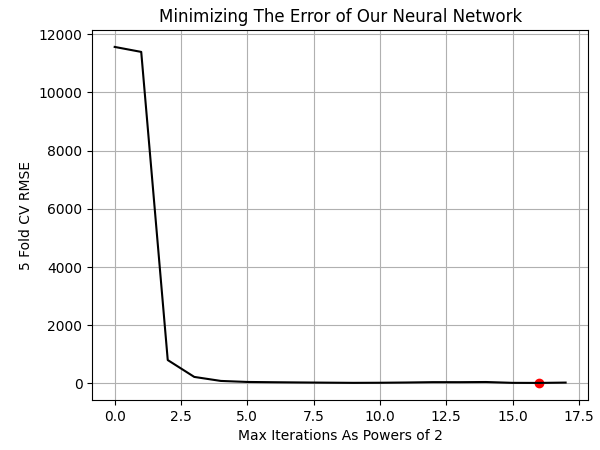
图 10:可视化学习UMAP嵌入所需模型的最优训练迭代次数
现在我们可以拟合两个模型了。
#The first model will transform the given market data into its UMAP embeddings umap_transform_model = MLPRegressor(hidden_layer_sizes=(data.iloc[:,2:-2].shape[1],10,5),max_iter=int(2 ** min_idx),solver='adam') umap_transform_model.fit(data.iloc[:,2:-2],new_data) #The second model will forecast the future EURGBP returns, given UMAP embeddings forecast_model = MLPRegressor(hidden_layer_sizes=(new_data.shape[1],10,5),max_iter=int(2 ** min_idx),solver='adam') forecast_model.fit(new_data,data['Target'])
让我们准备将模型导出为ONNX格式。
import onnx import netron from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
负责估计我们UMAP嵌入的模型具有独特的输入和输出形状。它接收10个参数作为输入,并返回3个参数作为输出。我们将使用ONNX API中的initial_types和final_types来设定。
umap_transform_shape = [("float_input",FloatTensorType([1,data.iloc[:,2:-2].shape[1]]))] umap_transform_output_shape = [("float_output",FloatTensorType([new_data.shape[1],1]))]
另一方面,负责根据给定的UMAP嵌入预测价格变化的模型,具有简单的输入和输出形状。它将第一个模型的3个输出作为其输入,并只有1个输出。
forecast_shape = [("float_input",FloatTensorType([1,new_data.shape[1]]))]
定义模型的输入/输出形状。请注意,我们必须多用一步来指定第一个模型是多输出的,然后我们提供多输出模型的形状。
umap_model_proto = convert_sklearn(umap_transform_model,initial_types=umap_transform_shape,final_types=umap_transform_output_shape,target_opset=12) forecast_model_proto = convert_sklearn(forecast_model,initial_types=forecast_shape,target_opset=12)
保存模型。
onnx.save(umap_model_proto,"EURGBP UMAP.onnx") onnx.save(forecast_model_proto,"EURGBP UMAP Forecast.onnx")
在 MQL5 中实现
我们现在可以开始编写MQL5代码来测试UMAP回归的盈利能力。回想一下,在图5中,我们删除了从2020年至今的所有数据。因此,今天获得的回测结果,公平地代表了我们的策略在未曾见过的真实条件下的表现。让我们加载ONNX模型。
//+------------------------------------------------------------------+ //| UMAP Regression.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/en/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System resources | //+------------------------------------------------------------------+ #resource "\\Files\\EURGBP UMAP.onnx" as uchar umap_onnx_buffer[]; #resource "\\Files\\EURGBP UMAP Forecast.onnx" as uchar umap_forecast_onnx_buffer[];
此外,我们还需要一些全局变量。因为我们的策略是算法驱动的,因此并不需要很多全局变量。
//+------------------------------------------------------------------+ //| Global Variables | //+------------------------------------------------------------------+ long umap_onnx_model,umap_forecast_onnx_model; vectorf umap_onnx_output(3),umap_forecast_onnx_output(1); double trade_sl;
为技术指标定义句柄和缓冲区。
//+------------------------------------------------------------------+ //| Technical indicators | //+------------------------------------------------------------------+ int ma_o_handler,ma_c_handler; double ma_o[],ma_c[];
加载交易库。
//+------------------------------------------------------------------+ //| Technical indicators | //+------------------------------------------------------------------+ int ma_o_handler,ma_c_handler; double ma_o[],ma_c[];
为了保持我们的代码设计易于阅读,选择为每个事件处理程序都分配一个专用的函数。这使得我们程序的主体从头到尾都易于阅读。如果用户希望添加更多功能,我建议遵循相同的设计原则,将您想要的功能封装到一个方法中,然后从主体中调用它。与另一种可能需要在一个事件处理程序中解析数百行代码的方案相比,这使代码库处于一种更易于维护的状态。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!setup()) return(INIT_FAILED); //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- release(); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- update(); } //+------------------------------------------------------------------+
release 函数在我们的EA被完全停用前进行资源清理工作。
//+------------------------------------------------------------------+ //| Custom functions | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Free up system memory | //+------------------------------------------------------------------+ void release(void) { IndicatorRelease(ma_c_handler); IndicatorRelease(ma_o_handler); OnnxRelease(umap_onnx_model); OnnxRelease(umap_forecast_onnx_model); }
setup 函数负责初始化我们的 ONNX 模型和其他重要的系统变量。它返回一个布尔类型,如果在初始化过程中出现错误,则返回 false。否则,该函数应返回 true。ONNX 模型的形状是成对的输入和输出,它们的调用也是成对的。
//+------------------------------------------------------------------+ //| Setup system variables | //+------------------------------------------------------------------+ bool setup(void) { umap_onnx_model = OnnxCreateFromBuffer(umap_onnx_buffer,ONNX_DATA_TYPE_FLOAT); umap_forecast_onnx_model = OnnxCreateFromBuffer(umap_forecast_onnx_buffer,ONNX_DATA_TYPE_FLOAT); ma_c_handler = iMA(_Symbol,PERIOD_CURRENT,2,0,MODE_EMA,PRICE_CLOSE); ma_o_handler = iMA(_Symbol,PERIOD_CURRENT,2,0,MODE_EMA,PRICE_OPEN); if(umap_onnx_model == INVALID_HANDLE) { Comment("Failed to create EURGBP UMAP Transformer ONNX model"); return(false); } if(umap_forecast_onnx_model == INVALID_HANDLE) { Comment("Failed to create EURGBP UMAP Forecast ONNX model"); return(false); } ulong umap_input_shape[] = { 1 , 10 }; ulong umap_forecast_input_shape[] = { 1 , 3 }; ulong umap_output_shape[] = { 3 , 1 }; ulong umap_forecast_output_shape[] = { 1 , 1 }; if(!OnnxSetInputShape(umap_onnx_model,0,umap_input_shape)) { Comment("Failed to specify ONNX model input shape"); Print("Actual shape: ",OnnxGetInputCount(umap_onnx_model)); return(false); } if(!OnnxSetInputShape(umap_forecast_onnx_model,0,umap_forecast_input_shape)) { Comment("Failed to specify EURGBP Forecast ONNX model input shape"); Print("Actual shape: ",OnnxGetInputCount(umap_onnx_model)); return(false); } if(!OnnxSetOutputShape(umap_onnx_model,0,umap_output_shape)) { Comment("Failed to specify ONNX model output shape"); Print("Actual shape: ",OnnxGetOutputCount(umap_onnx_model)); return(false); } if(!OnnxSetOutputShape(umap_forecast_onnx_model,0,umap_forecast_output_shape)) { Comment("Failed to specify EURGBP Forecast ONNX model output shape"); Print("Actual shape: ",OnnxGetOutputCount(umap_onnx_model)); return(false); } trade_sl = 2e-2; return(true); }
我们的 update 函数将帮助我们把指标读数复制到它们的缓冲区,并以周期性的方式(每天一次)执行我们的既定交易。
//+------------------------------------------------------------------+ //| Update our system variables | //+------------------------------------------------------------------+ void update(void) { static datetime time_stamp; datetime current_time = iTime(_Symbol,PERIOD_CURRENT,0); if(current_time != time_stamp) { time_stamp = current_time; CopyBuffer(ma_c_handler,0,0,1,ma_c); CopyBuffer(ma_o_handler,0,0,1,ma_o); if(PositionsTotal() == 0) { GetModelForecast(); FindSetup(); } } }
forecast 函数用于获取我们的预测链。第一个预测将是对原始市场数据的 UMAP 嵌入的近似。第二个预测是我们的交易信号,即在其 UMAP 嵌入的近似值给定的情况下,预测出的 EURGBP 市场回报。
//+------------------------------------------------------------------+ //| Get a forecast from our models | //+------------------------------------------------------------------+ void GetModelForecast(void) { vectorf model_inputs = GetUmapModelInputs(); OnnxRun(umap_onnx_model,ONNX_DATA_TYPE_FLOAT,model_inputs,umap_onnx_output); OnnxRun(umap_forecast_onnx_model,ONNX_DATA_TYPE_FLOAT,umap_onnx_output,umap_forecast_onnx_output); Print("Model Inputs: \n",model_inputs); Print("Umap Transformer Forecast: \n",umap_onnx_output); Print("EURUSD Return UMAP Forecast: \n",umap_forecast_onnx_output); }
在从我们的模型获得预测之前,需要为其准备输入。回想一下,我们必须准备第一个模型的输入,而它的输出将作为第二个模型的输入。
//+------------------------------------------------------------------+ //| Get our model's input data | //+------------------------------------------------------------------+ vectorf GetUmapModelInputs(void) { vectorf umap_model_inputs(10); umap_model_inputs[0] = (float)(iOpen(_Symbol,PERIOD_CURRENT,1) - iOpen(_Symbol,PERIOD_CURRENT,11)); umap_model_inputs[1] = (float)(iHigh(_Symbol,PERIOD_CURRENT,1) - iHigh(_Symbol,PERIOD_CURRENT,11)); umap_model_inputs[2] = (float)(iLow(_Symbol,PERIOD_CURRENT,1) - iLow(_Symbol,PERIOD_CURRENT,11)); umap_model_inputs[3] = (float)(iClose(_Symbol,PERIOD_CURRENT,1) - iClose(_Symbol,PERIOD_CURRENT,11)); umap_model_inputs[4] = (float)(iOpen(_Symbol,PERIOD_CURRENT,1) - iHigh(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[5] = (float)(iOpen(_Symbol,PERIOD_CURRENT,1) - iLow(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[6] = (float)(iOpen(_Symbol,PERIOD_CURRENT,1) - iClose(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[7] = (float)(iHigh(_Symbol,PERIOD_CURRENT,1) - iLow(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[8] = (float)(iHigh(_Symbol,PERIOD_CURRENT,1) - iClose(_Symbol,PERIOD_CURRENT,1)); umap_model_inputs[9] = (float)(iLow(_Symbol,PERIOD_CURRENT,1) - iClose(_Symbol,PERIOD_CURRENT,1)); return(umap_model_inputs); } //+------------------------------------------------------------------+
回想一下,在图4和图5中,我们删除了所有与下图11中所用日期重叠的历史数据。这使我们能够看到模型在处理样本外数据时可能的表现如何,并作为对该策略盈利能力的真实估计。

图 11:我们用于评估UMAP模型组合的回测期
现在,我们将决定测试策略的条件。为了获得最可靠的结果,我们将在具有挑战性的条件下对智能交易(EA)进行压力测试,在回测中,通过在订单执行和订单成交之间设置随机延迟来实现。

图 12:上述模拟的条件,模仿了真实的交易场景
在策略测试器的日志中,我们可以看到ONNX模型的输入,并且UMAP模型链正在产生有效的输出。第一个模型正确地将我们从市场数据记录的10个输入减少到3个输入,随后这3个输入被用来获得市场预测。

图 13:一切似乎都运行良好
从权益曲线来看,我们的系统似乎正在给予积极的反馈。这是令人鼓舞的,因为读者应该记得,我们只是近似了UMAP算法及其嵌入。

图 14:到目前为止,我们的策略似乎是有利可图的
让我们更详细地检查我们策略的表现。我们系统的夏普比率为0.42,预期回报为7.05,这些都是积极的统计数据。我们的盈利交易比例为64%,而总共进行了25笔交易。

图 15:使用UMAP回归对我们历史表现的详细分析
平均而言,我们的每笔交易持仓时间为1274小时,约54天。这表明我们的EA必定是在捕捉市场趋势,因为平均持仓时间在54天左右。

图 16:可视化我们交易持续时间的分布
在检查回测后,我们发现EA确实捕捉到了市场中持续的趋势。在下面的截图中,垂直的白线代表1天的时间段,观察到的交易是由我们的UMAP回归EA在其回测期间执行的。我们可以观察到,第一笔交易在2020年4月开仓,并在次月(5月)平仓。而随后的交易从5月底一直持续到9月初。
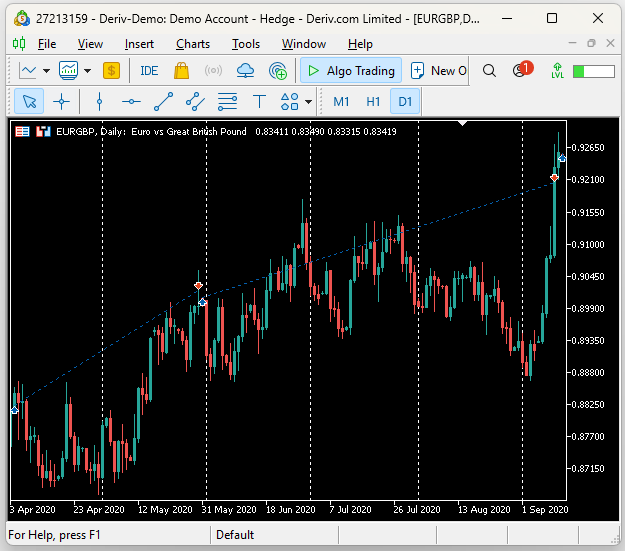
图 17:可视化我们EA所做的单
结论
在本文中,我们演示了读者如何运用降维技术来帮助他们的统计模型学习其数据中的主导市场特征。我们展示了与在未经UMAP变换的原始市场数据上训练的相同模型相比,当使用统计模型时,UMAP算法可以将我们的错误率降低多达40%。最后,读者学习了一个新的框架,该框架允许他们安全地近似无法原生实现的算法。这应该能让您在决定交易的任何市场中都拥有竞争优势。 | 文件名 | 说明 |
|---|---|
| EURGBP UMAP Forecast.onnx | 该ONNX文件将我们近似的UMAP嵌入作为其输入,以预测未来的EURGBP回报。 |
| EURGBP UMAP.onnx | 该ONNX文件负责将我们的市场数据作为其输入,并近似正确的UMAP嵌入。 |
| UMAP Candlestick Recognition.ipynb | 我们用来分析MetaTrader 5市场数据并构建ONNX文件的Jupyter Notebook。 |
| UMAP Candlestick Recognition.mq5 | 我们构建的用于获取详细市场数据的MQL5脚本文件。 |
| UMAP Regression.mq5 | 我们构建的EA,使用双模型架构来交易EURGBP。 |
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/17631
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

谢谢,这是一款非常有趣的应用程序。如果出现 NameError: name 'FloatTensorType' is not defined ,则需要通过 !pip install onnxmltools 安装或更新 onnixxmltools。我的数据结果与此处显示的数据大相径庭,我很想知道其他人是如何使用该代码的。
我需要 MT5 的 EA,并使用 Exness 经纪商