
時系列マイニングのためのデータラベル(第4回):ラベルデータを使用した解釈可能性の分解

はじめに
この連載の前回の記事ではNHITSモデルについて触れ、単一の変数入力に対する終値の予測のみを検証しました。今回は、モデルの解釈可能性と、終値を予測するために複数の共変数を使用することについて説明します。より多くの可能性を提供するために、デモンストレーションには別のモデルNBEATSを使用します。 ただし、この記事の焦点はモデルの解釈可能性にあることにご注意ください。共変量の話題も登場する理由もまた示されます。読者はいつでもさまざまなモデルを使用して自分のアイデアを検証することができます。もちろん、これら2つのモデルは本質的に高品質で解釈可能であり、私の記事で紹介したライブラリを使用してご自分のアイデアを検証するために他のモデルに拡張することもできます。この連載は、問題に対する解決策を提供することを目的としています。実際の取引に直接適用する前には慎重に検討してください。実際の取引の実装では、信頼性の高い安定した結果を提供するために、より多くのパラメータ調整と最適化方法が必要になる可能性があることには言及する価値があります。
以前の3つの記事へのリンクは以下の通りです。
- 時系列マイニングのためのデータラベル(第1回):EA操作チャートでトレンドマーカー付きデータセットを作成する
- 時系列マイニングのためのデータラベル(第2回):Pythonを使用してトレンドマーカー付きデータセットを作成する
- 時系列マイニングのためのデータラベル(第3回):ラベルデータの利用例
目次
NBEATSについて
このモデルは、さまざまな雑誌やWebサイトで広く引用され、説明されていますが、異なるWebサイトを常に行き来する手間を省くために、このモデルの簡単な紹介をすることにしました。NBEATSは、任意の長さの入力および出力シーケンスを扱うことができ、時系列の特定の特徴工学や入力スケーリングに依存しません。また、多項式やフーリエ級数を基本関数として使用し、トレンドや季節分解をシミュレートするための解釈可能な設定をおこなうこともできます。さらに、このモデルは二重残差スタッキングトポロジーを採用しており、各構成ブロックは2つの残差分岐を持ち、1つは逆方向予測に沿ったもの、もう1つは順方向予測に沿ったもので、モデルの学習性と解釈性を大幅に向上させています。とても印象的です。具体的な論文のアドレスはhttps://arxiv.org/pdf/1905.10437.pdfです。
1. モデルアーキテクチャ
2. モデルの実装プロセス
入力された時系列(次元はlength)は低次元ベクトル(次元はdim)にマッピングされ、2部目では時系列(長さはlength)にマッピングし直されます。この手順もオートエンコーダと同様で、時系列を低次元ベクトルにマッピングしてコア情報を保存し、それを復元します。このプロセスは単純に次のように表すことができます。 
このモジュールは2組の拡張係数を生成します。1つは未来を予測するためのもの(フォーキャスト)、もう1つは過去を予測するためのもの(バックキャスト)です。このプロセスは以下の式で表すことができます。

3.解釈可能性
具体的には、モデルの分解は解釈可能です。NBEATSモデルは、各層にいくつかの事前知識を導入し、いくつかの層に特定のタイプの時系列特性を学習させ、解釈可能な時系列分解を実現します。その実装方法は、展開係数を出力シーケンスの関数形に制約することです。例えば、ある層ブロックに時系列の季節性を主に予測させたい場合、以下の式を使用して出力を強制的に季節性にすることができます。


4. 共変量
今回は、目標値を予測するための共変量を紹介します。以下は共変量の定義です。- static_categoricals::時間とともに変化しないカテゴリ変数のリスト
- static_reals:時間とともに変化しない連続変数のリスト
- time_varying_known_categoricals:休日情報など、時間とともに変化し、将来既知のカテゴリ変数のリスト
- time_varying_known_reals:日付など、時間とともに変化し、将来既知の連続変数のリスト
- time_varying_unknown_categoricals:トレンドなど、時間とともに変化し、将来未知のカテゴリ変数のリスト
- time_varying_unknown_reals:上昇や下降など、時間とともに変化し、将来未知の連続変数のリスト
5.外部変数
NBEATSモデルは、平たく言えば私たちのデータセットとは無関係な、外部変数を導入することもできますが、モデルはそれに応じて変化します。論文チームはこれをNBEATSxと名付けましたが、本稿では触れません。ライブラリのインポート
言うことは何もありません。やるだけです。
import lightning.pytorch as pl import os from lightning.pytorch.callbacks import EarlyStopping,ModelCheckpoint import matplotlib.pyplot as plt import numpy as np import pandas as pd from pytorch_forecasting import TimeSeriesDataSet,NBeats from pytorch_forecasting.data import NaNLabelEncoder from pytorch_forecasting.metrics import MQF2DistributionLoss from pytorch_forecasting.data.samplers import TimeSynchronizedBatchSampler from lightning.pytorch.tuner import Tuner import MetaTrader5 as mt import warnings import json
TimeSeriesDataSetクラスの書き換え
言うことは何もありません。やるだけです。 なぜこのようなことをするのかについては、本連載の以前の記事をご参照ください。
class New_TmSrDt(TimeSeriesDataSet): ''' rewrite dataset class ''' def to_dataloader(self, train: bool = True, batch_size: int = 64, batch_sampler: Sampler | str = None, shuffle:bool=False, drop_last:bool=False, **kwargs) -> DataLoader: default_kwargs = dict( shuffle=shuffle, # drop_last=train and len(self) > batch_size, drop_last=drop_last, # collate_fn=self._collate_fn, batch_size=batch_size, batch_sampler=batch_sampler, ) default_kwargs.update(kwargs) kwargs = default_kwargs # print(kwargs['drop_last']) if kwargs["batch_sampler"] is not None: sampler = kwargs["batch_sampler"] if isinstance(sampler, str): if sampler == "synchronized": kwargs["batch_sampler"] = TimeSynchronizedBatchSampler( SequentialSampler(self), batch_size=kwargs["batch_size"], shuffle=kwargs["shuffle"], drop_last=kwargs["drop_last"], ) else: raise ValueError(f"batch_sampler {sampler} unknown - see docstring for valid batch_sampler") del kwargs["batch_size"] del kwargs["shuffle"] del kwargs["drop_last"] return DataLoader(self,**kwargs)
データ処理
データの読み込みとデータの前処理については、ここでは繰り返しません。具体的な説明については、私が過去に書いた3つの記事の関連する内容をご参照ください。今回は対応する場所の変更点のみを説明します。
1.データ収集
def get_data(mt_data_len:int): if not mt.initialize(): print('initialize() failed!') else: print(mt.version()) sb=mt.symbols_total() rts=None if sb > 0: rts=mt.copy_rates_from_pos("GOLD_micro",mt.TIMEFRAME_M15,0,mt_data_len) mt.shutdown() # print(len(rts)) rts_fm=pd.DataFrame(rts) rts_fm['time']=pd.to_datetime(rts_fm['time'], unit='s') rts_fm['time_idx']= rts_fm.index%(max_encoder_length+2*max_prediction_length) rts_fm['series']=rts_fm.index//(max_encoder_length+2*max_prediction_length) return rts_fm
2.前処理
以前とは異なり、ここでは共変量について話をします。何故でしょうか。実際、このモデルには他にもNBEATSxとGAGAというバリエーションがあります。これらのモデルや、私たちが使用しているpytorch-forecastingライブラリに含まれている他のモデルに興味があるならば、共変数を理解することが重要です。ここでは簡単にそれについて話をします。
外為データバーに対する特徴として、「始値」、「高値」、「安値」のデータ列を共変量として使用します。もちろん、MACD、ADX、RSI、その他の関連指標など、他のデータを共変量として自由に拡張することもできますが、私たちのデータに関連している必要があることを忘れないでください。連邦準備制度理事会の議事録、金利決定、非農業部門データなどの外部変数を共変量入力として追加することはできません。このモデルにはこれらのデータを解析する機能がないためです。いつか、モデルに外部変数を追加する方法に焦点を当てた記事を書くかもしれません。
それでは、New_TmSrDt()クラスで共変量を追加する方法を説明しましょう。このクラスには以下の変数定義があります。
- static_categoricals (List[str])
- static_reals (List[str])
- timevaryingknown_categoricals (List[str])
- timevaryingknown_reals (List[str])
- timevaryingunknown_categoricals (List[str])
- timevaryingunknown_reals (List[str])
これらの変数の具体的な意味については、以前にも説明しました。では、変数open、high、lowがどのカテゴリに属するかを考えてみましょう。他のものは簡単に見分けがつきますが、紛らわしいのは次のようなものです。
- timevaryingknown_categoricals
- timevaryingknown_reals
- timevaryingunknown_categoricals
- timevaryingunknown_reals
変数open、high、lowはカテゴリではないので、選択できるのはtime_varying_known_realsとtime_varying_unknown_realsだけです。closeを予測したいのであれば、すべてのバーのopen、high、lowをリアルタイムで得ることができるのに、なぜtime_varying_known_realsに追加できないのでしょうか。よくお考えください。1本のバーの値だけを予測するのであれば、この考え方は確立しており、完全にtime_varying_known_realsとして分類することができます。しかし、複数のバーの値を予測したい場合はどうすればよいでしょうか。現在のバーのデータしか知らなくて、その後ろの値は完全に未知である可能性がありため、この記事で取り上げた環境には適していません。time_varying_unknown_realsに追加するべきです。しかし、1つのバーのclose値を予測するだけであれば、間違いなくtime_varying_known_realsに追加できるので、使用例を慎重に検討することが重要です。また、time_varying_known_realsに関する特殊なケースもあります。実際、それぞれのバーにはM15、H1、H4、D1などの決まったサイクルがあり、予測するバーが属する時間を完全に計算することができます。時間をtime_varying_known_realsとして完全に追加することができます。この記事では説明しません。興味のある読者はご自分で追加なさってください。共変量を使用したい場合、「time_varying_unknown_reals=["close"]」を「time_varying_unknown_reals=["close","high","open","low"]」に変更します。もちろん、私たちのNBEATSのバージョンはこの機能をサポートしていません。
コードは次のようになります。
def spilt_data(data:pd.DataFrame, t_drop_last:bool, t_shuffle:bool, v_drop_last:bool, v_shuffle:bool): training_cutoff = data["time_idx"].max() - max_prediction_length #max:95 context_length = max_encoder_length prediction_length = max_prediction_length training = New_TmSrDt( data[lambda x: x.time_idx <= training_cutoff], time_idx="time_idx", target="close", categorical_encoders={"series":NaNLabelEncoder().fit(data.series)}, group_ids=["series"], time_varying_unknown_reals=["close"], max_encoder_length=context_length, max_prediction_length=prediction_length, ) validation = New_TmSrDt.from_dataset(training, data, min_prediction_idx=training_cutoff + 1) train_dataloader = training.to_dataloader(train=True, shuffle=t_shuffle, drop_last=t_drop_last, batch_size=batch_size, num_workers=0,) val_dataloader = validation.to_dataloader(train=False, shuffle=v_shuffle, drop_last=v_drop_last, batch_size=batch_size, num_workers=0) return train_dataloader,val_dataloader,training
学習率の取得
言うことは何もありません。やるだけです。 なぜこのようなことをするのかについては、本連載の以前の記事をご参照ください。
def get_learning_rate(): pl.seed_everything(42) trainer = pl.Trainer(accelerator="cpu", gradient_clip_val=0.1,logger=False) net = NBeats.from_dataset( training, learning_rate=3e-2, weight_decay=1e-2, backcast_loss_ratio=0.0, optimizer="AdamW", ) res = Tuner(trainer).lr_find( net, train_dataloaders=t_loader, val_dataloaders=v_loader, min_lr=1e-5, max_lr=1e-1 ) # print(f"suggested learning rate: {res.suggestion()}") lr_=res.suggestion() return lr_
メモ: この関数とNbitsの間には、NBeats.from_dataset()関数にhidden_sizeパラメータがない点で若干の違いがあります。また、損失パラメータはMQF2DistributionLoss()メソッドを使用できません。
訓練関数の定義
言うことは何もありません。やるだけです。 なぜこのようなことをするのかについては、本連載の以前の記事をご参照ください。
def train():
early_stop_callback = EarlyStopping(monitor="val_loss",
min_delta=1e-4,
patience=10,
verbose=True,
mode="min")
ck_callback=ModelCheckpoint(monitor='val_loss',
mode="min",
save_top_k=1,
filename='{epoch}-{val_loss:.2f}')
trainer = pl.Trainer(
max_epochs=ep,
accelerator="cpu",
enable_model_summary=True,
gradient_clip_val=1.0,
callbacks=[early_stop_callback,ck_callback],
limit_train_batches=30,
enable_checkpointing=True,
)
net = NBeats.from_dataset(
training,
learning_rate=lr,
log_interval=10,
log_val_interval=1,
weight_decay=1e-2,
backcast_loss_ratio=0.0,
optimizer="AdamW",
stack_types = ["trend", "seasonality"],
)
trainer.fit(
net,
train_dataloaders=t_loader,
val_dataloaders=v_loader,
# ckpt_path='best'
)
return trainer メモ: この関数のNBeats.from_dataset()では、解釈可能な分解型変数stack_typesを追加する必要があります。デフォルト値を使用します。これら2つのデフォルトに加えて、「汎用」オプションもあります。
モデルの訓練とテスト
さて、前回解説したモデルの学習予測ロジックを実装していますが、特に変更点はないので、あまり触れないことにします。
if __name__=='__main__': ep=200 __train=False mt_data_len=200000 max_encoder_length = 2*96 max_prediction_length = 30 batch_size = 128 info_file='results.json' warnings.filterwarnings("ignore") dt=get_data(mt_data_len=mt_data_len) if __train: # print(dt) # dt=get_data(mt_data_len=mt_data_len) t_loader,v_loader,training=spilt_data(dt, t_shuffle=False,t_drop_last=True, v_shuffle=False,v_drop_last=True) lr=get_learning_rate() trainer__=train() m_c_back=trainer__.checkpoint_callback m_l_back=trainer__.early_stopping_callback best_m_p=m_c_back.best_model_path best_m_l=m_l_back.best_score.item() # print(best_m_p) if os.path.exists(info_file): with open(info_file,'r+') as f1: last=json.load(fp=f1) last_best_model=last['last_best_model'] last_best_score=last['last_best_score'] if last_best_score > best_m_l: last['last_best_model']=best_m_p last['last_best_score']=best_m_l json.dump(last,fp=f1) else: with open(info_file,'w') as f2: json.dump(dict(last_best_model=best_m_p,last_best_score=best_m_l),fp=f2) best_model = NHiTS.load_from_checkpoint(best_m_p) predictions = best_model.predict(v_loader, trainer_kwargs=dict(accelerator="cpu",logger=False), return_y=True) raw_predictions = best_model.predict(v_loader, mode="raw", return_x=True, trainer_kwargs=dict(accelerator="cpu",logger=False)) for idx in range(10): # plot 10 examples best_model.plot_prediction(raw_predictions.x, raw_predictions.output, idx=idx, add_loss_to_title=True) plt.show() else: with open(info_file) as f: best_m_p=json.load(fp=f)['last_best_model'] print('model path is:',best_m_p) best_model = NHiTS.load_from_checkpoint(best_m_p) offset=1 dt=dt.iloc[-max_encoder_length-offset:-offset,:] last_=dt.iloc[-1] # print(len(dt)) for i in range(1,max_prediction_length+1): dt.loc[dt.index[-1]+1]=last_ dt['series']=0 # dt['time_idx']=dt.apply(lambda x:x.index,args=1) dt['time_idx']=dt.index-dt.index[0] # dt=get_data(mt_data_len=max_encoder_length) predictions = best_model.predict(dt, mode='raw',trainer_kwargs=dict(accelerator="cpu",logger=False),return_x=True) best_model.plot_prediction(predictions.x,predictions.output,show_future_observed=False) plt.show()
メモ: 実行する前に、TensorBoardがインストールされていることを確認してください。これは重要なことで、インストールされていなければ不可解なエラーが起こります。
訓練結果は次の通りです(コードを実行すると10枚の画像が表示されます。ここでは例として無作為なものを示します)。

テスト結果

モデルの解釈
データを解釈する方法はたくさんありますが、NBEATSモデルの特徴は、予測を季節性とトレンドに分解していることです(もちろん、この記事ではこの2つを選択しているため、結果はこの2つにしか分解できませんが、他にもいろいろな組み合わせが考えられます)。
訓練が終了し、予測を分解したい場合は、次のコードを追加することができます。
for idx in range(10): # plot 10 examples best_model.plot_interpretation(x, raw_predictions, idx=idx)
予測を実行する際に予測を分解したい場合は、次ののコードを追加することができます。
best_model.plot_interpretation(predictions.x,predictions.output,idx=0) 次が結果です。
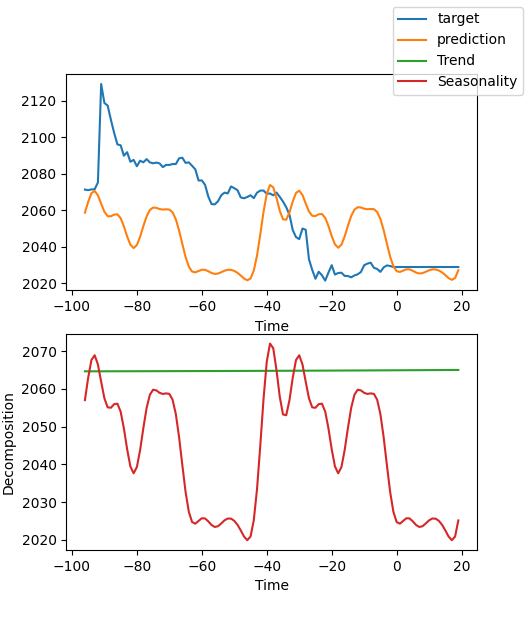
図からは、結果は十分でないように見えます。大まかな例を示しただけで、モデルの最適化を入念におこなっていないし、データの重要な指標もまだ科学的に特定されていないからです。しかも、モデルのパラメータのほとんどはデフォルトで使用されているだけで、チューニングされていません。
結論
この記事では、NBEATSモデルを使用して将来の価格を予測するために、ラベル付けされたデータを使用する方法について説明しました。同時に、NBEATSモデルの特殊な解釈可能性分解機能も実証しました。コードの変更に大きな意味はありませんが、本文中の共変量に関する議論にはご注意ください。さまざまな共変量の使い方を本当に理解していれば、このモデルを他のさまざまな応用シナリオに拡張することができます。これは、EAの精度を向上させ、完了すべきタスクを正確にこなすのに大いに役立つと思います。もちろん、この記事はほんの一例に過ぎません。実際の取引に応用するのであれば、まだ少し荒っぽいです。さらに最適化が必要な箇所がたくさんあるので、取引には直接使用しないでください。同時に、外部変数に関する情報もいくつか挙げました。この方向に興味がある方がいらっしゃるかどうかはわかりません。十分な情報が得られれば、今後、この連載でその導入方法について述べるかもしれません。
というわけで、この記事はここまでです。
次は、すべてのコードです。
# Copyright 2021, MetaQuotes Ltd. # https://www.mql5.com import lightning.pytorch as pl import os from lightning.pytorch.callbacks import EarlyStopping,ModelCheckpoint import matplotlib.pyplot as plt import pandas as pd from pytorch_forecasting import TimeSeriesDataSet,NBeats from pytorch_forecasting.data import NaNLabelEncoder from pytorch_forecasting.data.samplers import TimeSynchronizedBatchSampler from lightning.pytorch.tuner import Tuner import MetaTrader5 as mt import warnings import json from torch.utils.data import DataLoader from torch.utils.data.sampler import Sampler,SequentialSampler class New_TmSrDt(TimeSeriesDataSet): ''' rewrite dataset class ''' def to_dataloader(self, train: bool = True, batch_size: int = 64, batch_sampler: Sampler | str = None, shuffle:bool=False, drop_last:bool=False, **kwargs) -> DataLoader: default_kwargs = dict( shuffle=shuffle, # drop_last=train and len(self) > batch_size, drop_last=drop_last, # collate_fn=self._collate_fn, batch_size=batch_size, batch_sampler=batch_sampler, ) default_kwargs.update(kwargs) kwargs = default_kwargs # print(kwargs['drop_last']) if kwargs["batch_sampler"] is not None: sampler = kwargs["batch_sampler"] if isinstance(sampler, str): if sampler == "synchronized": kwargs["batch_sampler"] = TimeSynchronizedBatchSampler( SequentialSampler(self), batch_size=kwargs["batch_size"], shuffle=kwargs["shuffle"], drop_last=kwargs["drop_last"], ) else: raise ValueError(f"batch_sampler {sampler} unknown - see docstring for valid batch_sampler") del kwargs["batch_size"] del kwargs["shuffle"] del kwargs["drop_last"] return DataLoader(self,**kwargs) def get_data(mt_data_len:int): if not mt.initialize(): print('initialize() failed!') else: print(mt.version()) sb=mt.symbols_total() rts=None if sb > 0: rts=mt.copy_rates_from_pos("GOLD_micro",mt.TIMEFRAME_M15,0,mt_data_len) mt.shutdown() # print(len(rts)) rts_fm=pd.DataFrame(rts) rts_fm['time']=pd.to_datetime(rts_fm['time'], unit='s') rts_fm['time_idx']= rts_fm.index%(max_encoder_length+2*max_prediction_length) rts_fm['series']=rts_fm.index//(max_encoder_length+2*max_prediction_length) return rts_fm def spilt_data(data:pd.DataFrame, t_drop_last:bool, t_shuffle:bool, v_drop_last:bool, v_shuffle:bool): training_cutoff = data["time_idx"].max() - max_prediction_length #max:95 context_length = max_encoder_length prediction_length = max_prediction_length training = New_TmSrDt( data[lambda x: x.time_idx <= training_cutoff], time_idx="time_idx", target="close", categorical_encoders={"series":NaNLabelEncoder().fit(data.series)}, group_ids=["series"], time_varying_unknown_reals=["close"], max_encoder_length=context_length, # min_encoder_length=max_encoder_length//2, max_prediction_length=prediction_length, # min_prediction_length=1, ) validation = New_TmSrDt.from_dataset(training, data, min_prediction_idx=training_cutoff + 1) train_dataloader = training.to_dataloader(train=True, shuffle=t_shuffle, drop_last=t_drop_last, batch_size=batch_size, num_workers=0,) val_dataloader = validation.to_dataloader(train=False, shuffle=v_shuffle, drop_last=v_drop_last, batch_size=batch_size, num_workers=0) return train_dataloader,val_dataloader,training def get_learning_rate(): pl.seed_everything(42) trainer = pl.Trainer(accelerator="cpu", gradient_clip_val=0.1,logger=False) net = NBeats.from_dataset( training, learning_rate=3e-2, weight_decay=1e-2, backcast_loss_ratio=0.1, optimizer="AdamW", ) res = Tuner(trainer).lr_find( net, train_dataloaders=t_loader, val_dataloaders=v_loader, min_lr=1e-5, max_lr=1e-1 ) # print(f"suggested learning rate: {res.suggestion()}") lr_=res.suggestion() return lr_ def train(): early_stop_callback = EarlyStopping(monitor="val_loss", min_delta=1e-4, patience=10, verbose=True, mode="min") ck_callback=ModelCheckpoint(monitor='val_loss', mode="min", save_top_k=1, filename='{epoch}-{val_loss:.2f}') trainer = pl.Trainer( max_epochs=ep, accelerator="cpu", enable_model_summary=True, gradient_clip_val=1.0, callbacks=[early_stop_callback,ck_callback], limit_train_batches=30, enable_checkpointing=True, ) net = NBeats.from_dataset( training, learning_rate=lr, log_interval=10, log_val_interval=1, weight_decay=1e-2, backcast_loss_ratio=0.0, optimizer="AdamW", stack_types=["trend", "seasonality"], ) trainer.fit( net, train_dataloaders=t_loader, val_dataloaders=v_loader, # ckpt_path='best' ) return trainer if __name__=='__main__': ep=200 __train=False mt_data_len=80000 max_encoder_length = 96 max_prediction_length = 20 # context_length = max_encoder_length # prediction_length = max_prediction_length batch_size = 128 info_file='results.json' warnings.filterwarnings("ignore") dt=get_data(mt_data_len=mt_data_len) if __train: # print(dt) # dt=get_data(mt_data_len=mt_data_len) t_loader,v_loader,training=spilt_data(dt, t_shuffle=False,t_drop_last=True, v_shuffle=False,v_drop_last=True) lr=get_learning_rate() # lr=3e-3 trainer__=train() m_c_back=trainer__.checkpoint_callback m_l_back=trainer__.early_stopping_callback best_m_p=m_c_back.best_model_path best_m_l=m_l_back.best_score.item() # print(best_m_p) if os.path.exists(info_file): with open(info_file,'r+') as f1: last=json.load(fp=f1) last_best_model=last['last_best_model'] last_best_score=last['last_best_score'] if last_best_score > best_m_l: last['last_best_model']=best_m_p last['last_best_score']=best_m_l json.dump(last,fp=f1) else: with open(info_file,'w') as f2: json.dump(dict(last_best_model=best_m_p,last_best_score=best_m_l),fp=f2) best_model = NBeats.load_from_checkpoint(best_m_p) predictions = best_model.predict(v_loader, trainer_kwargs=dict(accelerator="cpu",logger=False), return_y=True) raw_predictions = best_model.predict(v_loader, mode="raw", return_x=True, trainer_kwargs=dict(accelerator="cpu",logger=False)) for idx in range(10): # plot 10 examples best_model.plot_prediction(raw_predictions.x, raw_predictions.output, idx=idx, add_loss_to_title=True) plt.show() else: with open(info_file) as f: best_m_p=json.load(fp=f)['last_best_model'] print('model path is:',best_m_p) best_model = NBeats.load_from_checkpoint(best_m_p) offset=1 dt=dt.iloc[-max_encoder_length-offset:-offset,:] last_=dt.iloc[-1] # print(len(dt)) for i in range(1,max_prediction_length+1): dt.loc[dt.index[-1]+1]=last_ dt['series']=0 # dt['time_idx']=dt.apply(lambda x:x.index,args=1) dt['time_idx']=dt.index-dt.index[0] # dt=get_data(mt_data_len=max_encoder_length) predictions = best_model.predict(dt, mode='raw',trainer_kwargs=dict(accelerator="cpu",logger=False),return_x=True) # best_model.plot_prediction(predictions.x,predictions.output,show_future_observed=False) best_model.plot_interpretation(predictions.x,predictions.output,idx=0) plt.show()
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/13218
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索