
Quantisierung beim maschinellen Lernen (Teil 2): Datenvorverarbeitung, Tabellenauswahl, Training von CatBoost-Modellen

Einführung
Der Artikel befasst sich mit der praktischen Anwendung der Quantisierung bei der Konstruktion von Baummodellen. Es werden keine komplexen mathematischen Gleichungen verwendet. Dies ist der zweite Teil des Artikels „Quantisierung und andere Methoden der Vorverarbeitung von Eingabedaten beim maschinellen Lernen“, sodass ich Ihnen dringend empfehle, sich mit ihm vertraut zu machen. Hier werden wir über Folgendes sprechen:
- Im ersten Teil werden wir die in MQL5 implementierten Methoden zur Vorverarbeitung von Beispieldaten betrachten.
- Im zweiten Teil werden wir ein Experiment durchführen, das Aufschluss über die Durchführbarkeit der Datenquantisierung geben wird.
1. Zusätzliche Methoden der Datenvorverarbeitung
Betrachten wir die Methoden der Datenvorverarbeitung, die ich am Beispiel der Beschreibung der Funktionsweise des Skripts Q_Error_Selection implementiert habe.
Kurz gesagt besteht das Ziel des Skripts „Q_Error_Selection“ darin, eine Stichprobe aus der Datei „train.csv“ zu laden, den Inhalt in die Matrix zu übertragen, die Daten vorzuverarbeiten, abwechselnd Quantentabellen zu laden und den Fehler der wiederhergestellten Daten im Vergleich zu den ursprünglichen Daten für jeden Prädiktor zu bewerten. Die Bewertungsergebnisse jeder Quantentabelle sind in dem Array zu speichern. Nach der Prüfung aller Optionen erstellen wir eine zusammenfassende Tabelle mit Fehlern für jeden Prädiktor und wählen die besten Optionen für Quantentabellen für jeden Prädiktor nach einem bestimmten Kriterium aus. Erstellen und speichern wir eine zusammenfassende Quantentabelle, eine Datei mit CatBoost-Einstellungen, in die Prädiktoren, die aus der Liste für das Training ausgeschlossen wurden, mit den Seriennummern ihrer Spalten aufgenommen werden. Außerdem werden je nach den gewählten Skripteinstellungen Begleitdateien erstellt.
Schauen wir uns die Skripteinstellungen, die ich unten nach Gruppen aufgelistet habe, genauer an.
Laden von Daten
- Musterverzeichnis1
- Quantisierungsverzeichnis2
1 Geben Sie den Pfad zu dem Verzeichnis an, in dem sich das Setup-Verzeichnis befindet, in dem sich die csv-Dateien mit dem Muster befinden. Das Verzeichnis wird im Folgenden als „project directory“ (Projektverzeichnis) bezeichnet.
2 Geben Sie den Pfad zu dem Verzeichnis an, in dem sich das Q-Verzeichnis befindet, in dem die csv-Dateien mit den Quantentabellen gespeichert sind.
Konfigurieren der Spike-Behandlung
- Verwendung von Spike-Check1
- Spike-Umrechnungsmethode2
- Der Spike-Wert wird in den Wert nahe der Teilung umgerechnet 2.1
- Der Spike-Wert wird in einen Zufallswert außerhalb des Spike-Bereichs umgewandelt2.2
- Ersetzen von Daten nach der Behandlung von Spikes3
- Speichern/Nicht speichern der „Trainings“-Stichprobe mit transformierten Spikes4
- Hinzufügen von Informationen zu Unterstichproben über Spikes5
- Zeilen mit einer großen Anzahl von Stacheln entfernen5.1
- Maximaler Prozentsatz der Zeilen mit Prädiktorausreißer in der Stichprobe5.2
1 Bei Auswahl von „true“ ist die Spike-Behandlung aktiviert. Seltene Werte von Prädiktoren werden hier als Spikes betrachtet. Seltene Werte können statistisch unbedeutend sein, aber die Modelle berücksichtigen dies normalerweise nicht, was zu fragwürdigen Regeln für die Schätzung der Klassifizierungswahrscheinlichkeit führen kann. Die Abbildung 1 zeigt einen solchen Spike. Durch die Festlegung von Grenzen zwischen Spikes und normalen Daten können wir Ausreißer zu einem einzigen Ganzen zusammenfassen, wodurch sich die statistische Zuverlässigkeit erhöht und wir versuchen können, mit den Daten wie mit normalen Daten zu arbeiten oder sie ganz vom Training auszuschließen.
2 Auswahl einer der Spike-Transformationsmethoden, mit deren Hilfe der Wert des Prädiktors so verändert wird, dass dieses Beispiel in der Trainingsstichprobe berücksichtigt und nicht als anormales Beispiel ausgeschlossen wird. Um die Spitzen zu bestimmen, habe ich 2,5 % der Daten für jede Seite der Zahlenreihe verwendet. Die zuvor gefundenen identischen Zahlenwerte wurden gruppiert und den Gruppen wurden Ränge zugeordnet. Wenn der nächste Rang 2,5 % übersteigt, gilt der vorherige Rang als letzter Rang mit Spikes. Prädiktoren mit wenigen Rängen gelten als kategorisch und verarbeiten keine Spikes. Informationen in Form einer Liste kategorialer Prädiktoren werden unter dem folgenden Pfad relativ zum Projektverzeichnis „..\CB\Categ.txt“ gespeichert. Eine gängige Methode zur Identifizierung von Spikes ist die Drei-Sigma-Regel, bei der eine Einkerbung von drei Standardabweichungen vom Durchschnittswert links und rechts des Datenbereichs vorgenommen wird und alles, was außerhalb dieser Grenze liegt, als Spike gilt. In den nachstehenden Grafiken sind drei horizontale Linien in schwarzer Farbe zu sehen - der Mittelpunkt, die Differenz und die Summe der drei Sigmas vom Mittelpunkt. Die blauen Linien in der Grafik zeigen die Grenzen an, innerhalb derer sich häufig vorkommende Daten nach dem von mir vorgeschlagenen Algorithmus befinden.
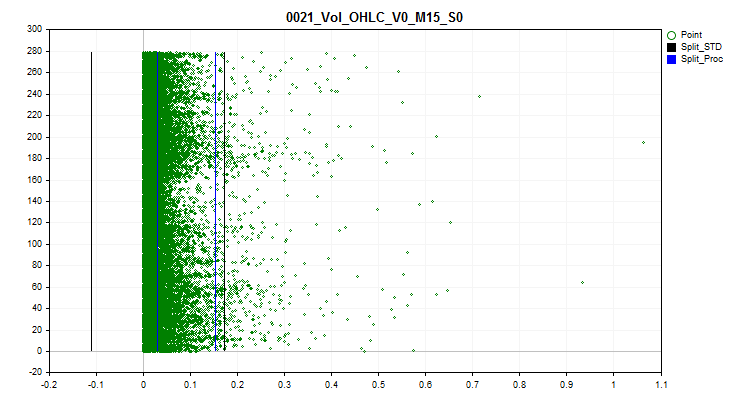
Bild 1. Bestimmung der Grenzen der Spike-Definition
2.1 Bei dieser Methode werden alle Spike-Werte durch einen Wert nahe der Grenze (split) ersetzt. Dieser Ansatz ermöglicht es, die Schätzung der Annäherung durch die Quantentabelle innerhalb der Spike-Grenzen nicht zu verfälschen.
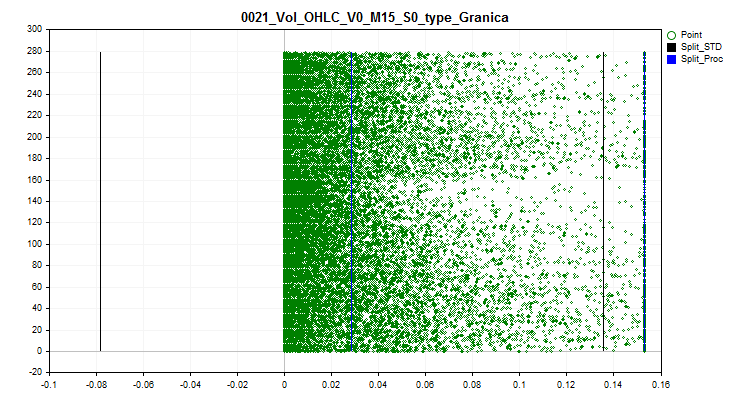
Bild 2. Der Spike-Wert wird in den Wert nahe der Teilung umgerechnet
2.2 Bei dieser Methode werden alle Spike-Werte durch Zufallswerte ersetzt, die den Rängen innerhalb der Grenzen normaler Daten entsprechen. Dieser Ansatz ermöglicht es, den Fehler bei der Schätzung der Annäherung durch eine Quantentabelle zu beseitigen.
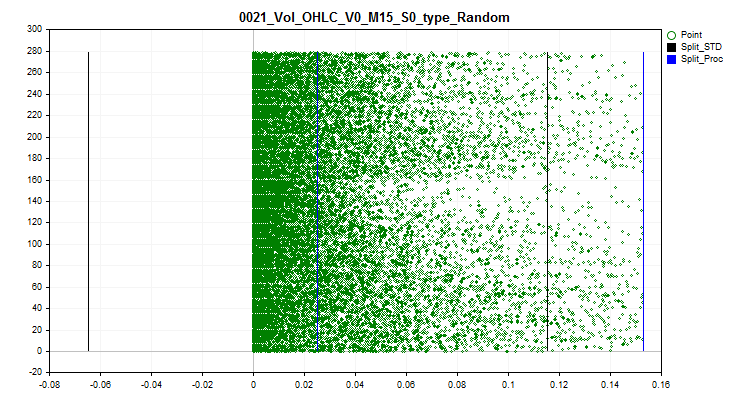
Abb. 3. Der Spike-Wert wird in einen Zufallswert außerhalb des Spike-Bereichs umgewandelt
3 Wenn es notwendig ist, Quantentabellen unter Berücksichtigung von konvertierten Spikes auszuwerten und auszuwählen, dann wählen Sie „true“. Wenn diese Funktion aktiviert ist, wird das Array in Form einer Matrix mit den Originaldaten geändert, die Werte der Prädiktoren mit Spikes werden auf die Werte gesetzt, die gemäß der Spike-Transformationsmethode ausgewählt wurden.
4 Sie können das Beispiel train.csv speichern. Es wird im Verzeichnis „..\CB\Q_Vibros_Viborka“ gespeichert. Dies kann notwendig sein, um die Quantisierung mit CatBoost durchzuführen. Da die Daten bereits in transformierte Daten umgewandelt werden, können sich die Quantisierungstabellen unterscheiden, und dies kann auch eine Verringerung der Anzahl der Trennungen (Splits) ermöglichen, um eine minimale Fehlerschwelle bei der Bewertung der Qualität der Annäherung durch eine Quantentabelle zu erreichen.
5 Wenn Sie diesen Parameter aktivieren und die Variable auf „true“ setzen, werden die Dateien mit den Teilstichproben train.csv, test.csv und exam.csv nacheinander geladen. In jeder Zeile der Teilstichprobe wird die Anzahl der Prädiktorwerte in der Spike-Region gezählt, und das Gesamtergebnis wird in der zusätzlich angelegten Spalte „Proc_Vibros“ festgehalten. Die geänderte Auswahl wird im Verzeichnis „..\CB\ADD_Drop_Info_Viborka“ gespeichert.
Unabhängig davon, ob diese Einstellung aktiviert ist, wird eine separate Datei im Projektverzeichnis unter „..\CB\Proc_Vibros_Train.csv“ angelegt. Die Datei enthält nur Informationen über die Spikes in der Probe „train“.
5.1 Wenn Sie diese Einstellung aktivieren, werden Zeilen mit den Ausreißern bzw. Spikes aus der Selektion entfernt. Manchmal lohnt sich der Versuch, ein Modell auf Daten ohne Spikes zu trainieren.
5.2 Wenn Sie sich entschließen, Zeilen mit Ausreißern zu löschen, dann lohnt es sich, den Prozentsatz der Prädiktoren zu bewerten, deren Wert im Bereich der Spike-Definition lag.
Konfigurieren der Korrelationsschätzung
- Korrelationsschätzung verwenden, um Prädiktoren zu eliminieren 1
- Methode zum Ausschluss korrelierter Prädiktoren legt die Auswahlmethode (Ausschluss von Prädiktoren) fest, die zur Auswahl steht2
- Rückwärtsauswahl von Prädiktoren2.1
- Auswahl von verallgemeinernden Prädiktoren2.2
- Auswahl seltener Prädiktoren2.3
- Korrelationsverhältnis3
1 Wenn Sie „true“ wählen, wird die Schätzung der Pearson-Korrelation aktiviert. Das Ergebnis dieser Funktion ist eine Prädikator-Korrelationstabelle unter „../CB“, wobei der Dateiname aus dem Namen „Corr_Matrix_“ und der Korrelationsverhältnisgröße „Corr_Matrix_70.csv“ besteht. Stark korrelierte Prädiktoren werden ausgeschlossen.
2 Es stehen drei Methoden zum Ausschluss von Prädiktoren zur Auswahl.
2.1 Bei dieser Methode wird in umgekehrter Reihenfolge nach korrelierten Prädiktoren gesucht, und wenn es einen früheren Prädiktor gibt, wird die aktuelle Spalte mit diesem Prädiktor vom Training ausgeschlossen.
2.2 Die Methode schätzt die Anzahl der Prädiktoren, die mit jedem Prädiktor korrelieren, und wählt iterativ denjenigen aus, der mit einer großen Anzahl von Prädiktoren korreliert, wobei andere Prädiktoren, die mit ihm korrelieren, eliminiert werden. Die Logik dabei ist, dass wir Prädiktoren mit Informationen auswählen, die die meisten Informationen über andere Prädiktoren enthalten. So erhalten wir eine Generalisierung der Daten.
2.3 Diese Methode ähnelt der vorherigen, aber hier werden die Prädiktoren ausgewählt, die den anderen am wenigsten ähnlich sind. Hier wird versucht, das Gegenteil zu tun - einen Prädiktor mit einzigartigen Daten zu finden.
3 Hier sollte das Pearson-Korrelationsverhältnis angegeben werden. Erst wenn der angegebene Verhältniswert erreicht oder überschritten wird, werden die Prädiktoren als ähnlich für eine Manipulation angesehen, um sie aus der Stichprobe auszuschließen.
Konfigurieren des Umgangs mit zeitinstabilen Prädiktoren
- Verwendung der Prüfung auf den Mittelwert in jedem Teil der Stichprobe1
- Teilstichprobe Mittelwert der Streuung in Prozent2
1 Wenn „true“, wird eine Prüfung auf Schwankungen des Durchschnittswerts des Prädiktorindikators in jedem der 1/10 Teile der Stichprobe aktiviert. Dieser Test ermöglicht den Ausschluss von Prädiktoren, deren Indikatoren im Zeitverlauf stark verschoben sind. Solche Prädiktoren behindern theoretisch das Training. Ein Beispiel für einen solchen Prädiktor ist in Abbildung 4 zu sehen, während eine visuelle Bewertung in Abbildung 5 zu sehen ist. Der Beispielprädiktor wurde auf der Grundlage des Indikators Variabler Index Dynamischer Durchschnitt (iVIDyA) erstellt, der in der Tat den durchschnittlichen Preiswert anzeigt, und seine Verwendung im Modell wird zu einem Trainingsverhalten bei einem bestimmten absoluten Preis führen.
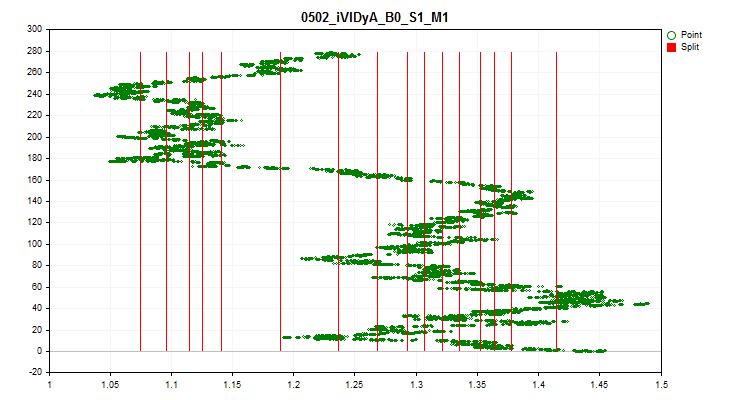
Abb. 4. Der iVIDyA_B0_S1_M1 Prädiktor zeigt eine deutliche Verschiebung
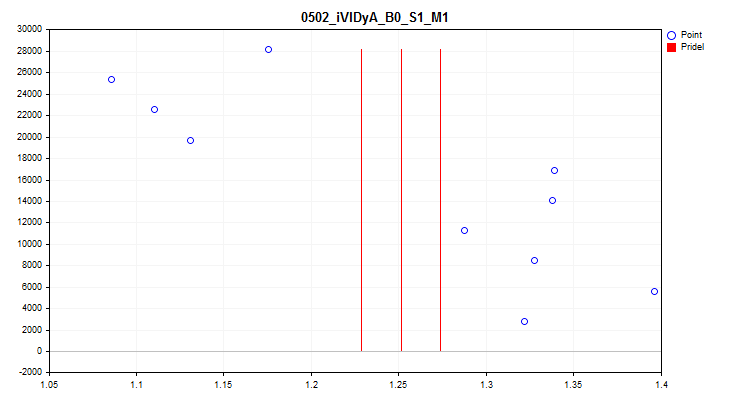
Abbildung 5. Der iVIDyA_B0_S1_M1 Prädiktor (mittlere Streuung)
2 Hier wird die Breite der Spanne als Prozentsatz für jede Grenze angegeben, die sich aus der gesamten Spanne der Prädiktorenwerte im Verhältnis zum Durchschnittswert über den gesamten Zeitraum ergibt.
Konfigurieren der Erstellung einer einheitlichen Quantentabelle
- Erstellen einer einheitlichen quantisierten Tabelle1
- Die Anzahl der Intervalle, in die die Originaldaten unterteilt (quantisiert) werden sollen2
1 Wenn „true“, wird der Algorithmus zur Erstellung einer einheitlichen Quantentabelle für alle Prädiktoren in der Stichprobe aktiviert. Die Tabelle wird im Unterverzeichnis des Q_Bit-Projekts gespeichert.
2 Legen Sie die Anzahl der Intervalle fest, in die der Prädiktor unterteilt werden soll.
Konfigurieren der Erstellung einer Quantentabelle mit einem Zufallselement
- Erstellen einer zufälligen Quantentabelle1
- Anfangszahl für den Zufallszahlengenerator 2
- Anzahl der Iterationen, um die beste Option zu finden3
- Die Anzahl der Intervalle, in die die Originaldaten unterteilt (quantisiert) werden sollen4
1 Wenn „true“, wird der Algorithmus zur Erstellung einer Zufallsquantentabelle für alle Prädiktoren in der Stichprobe aktiviert. Die Tabelle wird in dem Projekt Q_Random gespeichert.
2 Die Zahl macht es möglich, das Ergebnis der Zufallsgenerierung wiederholbar zu machen. Indem wir die Zahl ändern, können wir die Reihenfolge der erzeugten Zahlen ändern.
3 Der Algorithmus bewertet den Approximationsfehler nach jeder Generierung einer Zufallstabelle und wählt die beste Option aus. Je mehr Versuche, desto größer ist die Chance, die erfolgreichste Option zu finden.
4 Festlegung der Anzahl der Intervalle, in die der Prädiktor unterteilt werden soll.
Konfigurieren der Auswahl von Quantentabellen
- Start der Auswahl von Quantentabellen1
- Auswahl eines Prädiktors anhand eines Schwellenwerts2
- Maximal zulässiger Quantisierungsfehler3
1 Bei Auswahl von „true“ wird der Algorithmus zum Suchen und Auswerten von Quantentabellen aus dem Unterverzeichnis Q des Projekts aktiviert, andernfalls stellt das Programm seine Arbeit ein. Das Ergebnis der Ausführung dieser Skriptfunktion ist die Erstellung von zwei Verzeichnissen:
Das Verzeichnis „..\CB\Setup“ soll 3 Dateien enthalten:
- Auxiliary.txt – Hilfsdatei mit Indexnummern von Prädiktoren, die ausgeschlossen wurden
- Quant_CB.csv – Datei mit Quantentabellen für Prädiktoren, die an der Training teilnehmen werden
- Test_CB_Setup_0_000000000 – Datei mit Informationen für CatBoost – Spalten, die vom Training ausgeschlossen werden sollen, und eine Spalte, die als Zielspalte betrachtet werden soll.
Das Verzeichnis Test_Error enthält die Datei arr_Svod.csv. Sie enthält die zusammenfassenden Ergebnisse der Berechnung des Rekonstruktionsfehlers (Näherungsfehlers) für jeden Prädiktor bei Verwendung verschiedener Quantisierungstabellen. Die erste Spalte enthält eine Liste von Prädiktoren, die nachfolgenden Ergebnisse bei Anwendung einer bestimmten Quantentabelle, während die letzte Spalte den Index der Quantentabelle enthält, die das beste Ergebnis zeigte. Das beste Ergebnis wurde zur Erstellung der zusammenfassenden Quantentabelle Quant_CB.csv verwendet.
2 Wenn „false“, wird nur der Rekonstruktionsfehler (Näherungsfehler) zur Bewertung der Quantentabellen herangezogen, und die Tabelle mit dem kleinsten Fehler wird ausgewählt.
Wenn „true“, dann wird der Rekonstruktionsfehler (Approximationsfehler) geteilt durch die Anzahl der Splits in der Quantentabelle zur Auswertung der Quantentabellen verwendet. Dieser Ansatz ermöglicht es uns, die Anzahl der Quantentabellen bei der Schätzung zu berücksichtigen, um eine übermäßige Quantisierung zu vermeiden. Die Tabellen nehmen nur dann an der Auswahl teil, wenn ihr Fehler kleiner ist als der im nächsten Einstellungsparameter angegebene.
3 Hier geben wir den maximal akzeptablen Fehler bei der Rekonstruktion (Annäherung) von Prädiktorwerten an.
Konfigurieren des Speicherns der transformierten Auswahl
- Konvertieren und Speichern der Probe1
- Option Datenkonvertierung:2
- Als Indizes speichern2.1
- Speichern als Zentroide2.2
1 Wenn „true“, wird das Beispiel (drei csv-Dateien) konvertiert und im Projektunterverzeichnis „..\CB\Index_Viborka“ gespeichert. Diese Einstellung ermöglicht die Verwendung von Quantentabellen in Algorithmen für das Maschinentraining, für die sie ursprünglich nicht vorgesehen waren. Ein weiterer Anwendungsfall ist die öffentliche Weitergabe von Modell-Trainingsdaten ohne Offenlegung der Prädiktorenwerte, um die Offenlegung von Wettbewerbsinformationen über die verwendeten Datenquellen zu verhindern. Darüber hinaus kann durch das Speichern in Form von Indizes der von den Beispieldateien belegte Festplattenspeicher erheblich reduziert werden, und es wird weniger Arbeitsspeicher für die Bearbeitung der Probe benötigt.
2 Auswahl einer von zwei Optionen für die Konvertierung von Prädiktorwerten nach Anwendung der endgültigen Quantisierungsübersichtstabelle.
2.1 Speichern der Indizes der Segmente der Quantentabelle, in die die Prädikatornummer fällt.
2.2 Speichern des Wertes zwischen zwei Grenzen, in die die Prädiktorzahl fällt.
Konfigurieren der Grafikspeicherung
- Speichern Sie der Grafik1
- Breite der Grafik2
- Höhe der Grafik3
- Schriftgröße der Legende4
1 Wenn „true“, ist die Funktion zum Erstellen und Speichern von Grafiken aktiviert. Grafikdateien mit Informationen über jeden Prädiktor in der Stichprobe werden im Verzeichnis Graphics erstellt. Der Dateiname beginnt mit der Prädiktorennummer, gefolgt vom Namen des Prädiktors aus der Spaltenüberschrift der Stichprobe und dem Namen der bedingten Grafik. Schauen wir uns die Grafiken an, die für den iCCI_B0_S1_M1 Prädiktor erstellt wurden:
- Die erste Grafik zeigt die Dichte der Prädiktorwerte in einem bestimmten Intervall - je höher die Dichte, desto stärker steigt die Kurve in diesem Intervall an. Die X-Achse ist der Prädiktorwert, und die Y-Achse ist die Anzahl der Beobachtungen, geordnet nach ihrem Wert. Anhand der Grafik können wir die Dichte der Beobachtungen in der Stichprobe, die auf bestimmte Intervalle fallen, schätzen und die Spitzen erkennen.
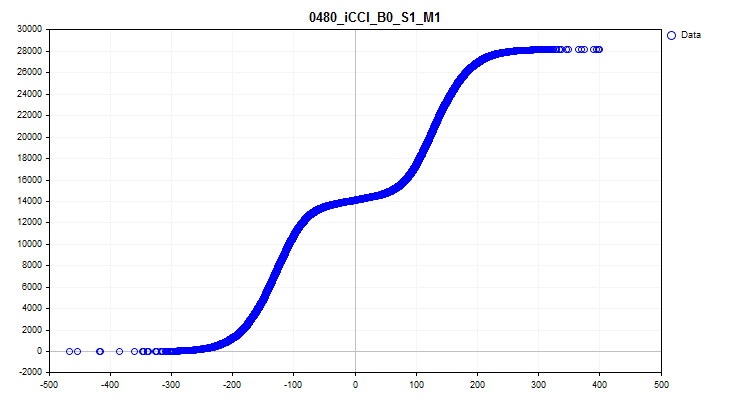
Abbildung 6. Dichte der Prädiktorwerte
- Die zweite Grafik zeigt, in welchen Abständen die Werte der Prädiktoren am Ziel „0“ und „1“ beobachtet wurden. Daher werden die Werte für Null in blau und die Werte für Eins in rot dargestellt. So lässt sich erkennen, bei welchen Prädiktorintervallen der Zielwert stärker vertreten ist. Ich empfehle, eine Grafik zu erstellen, das breiter ist als das hier gezeigte.
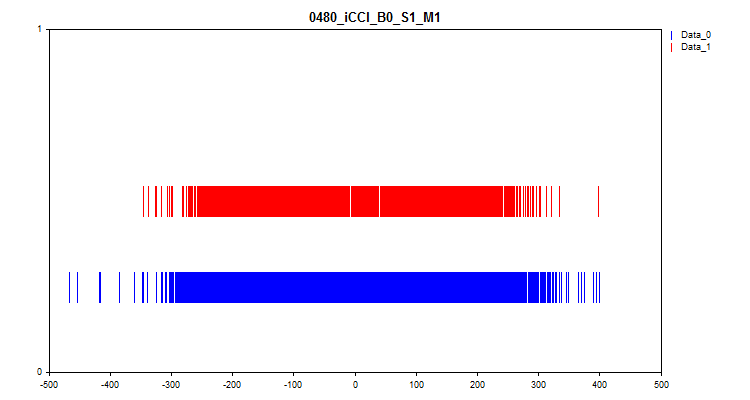
Abbildung 7. Übereinstimmung des Vorhersagewertes mit der Zielmarkierung
- Die dritte Grafik stellt ein Histogramm dar, bei dem auf der Y-Achse der prozentuale Anteil der Beobachtungen an allen Beobachtungen in der Stichprobe aufgetragen wird. Anhand der Grafik können wir Spikes bewerten und eine Annahme über die Verteilungsdichte treffen.
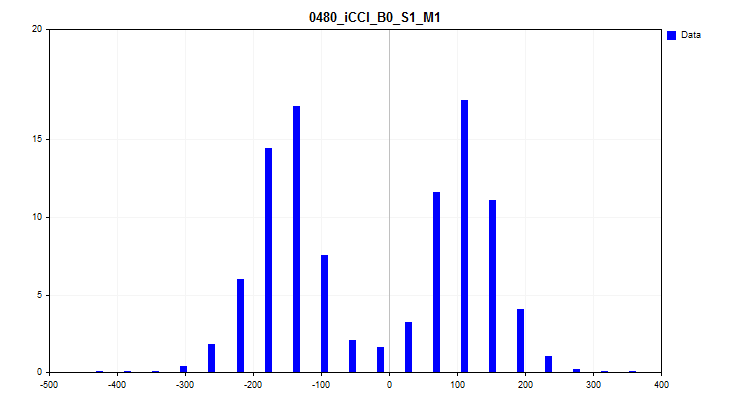
Abbildung 8. Histogramm der Verteilungsdichte
- Die vierte Grafik zeigt die Ausfüllung des Prädiktorskalenbereichs mit seinen Werten in chronologischer Reihenfolge und zeigt auch die für die endgültige Quantisierung ausgewählten Stufen. Die X-Achse ist der Wert des Prädiktors und die Y-Achse ist die Anzahl der Gruppe von 100 Beobachtungen.
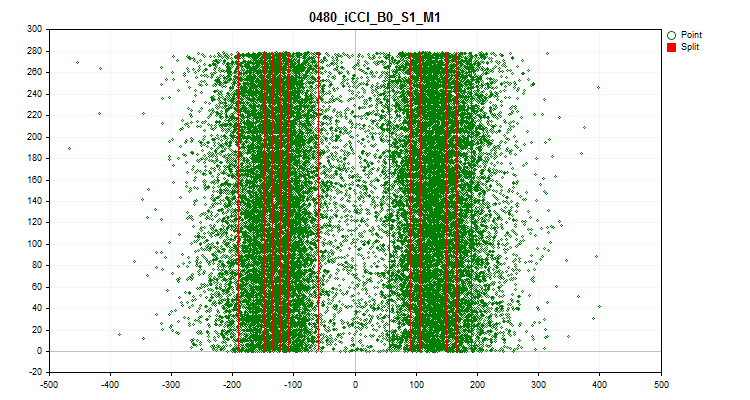
Abbildung 9. Quantentisch
- Die fünfte Grafik zeigt den durchschnittlichen Prädiktorwert über 10 Stichprobenintervalle. Bei starken Streuungen empfiehlt es sich, den Prädiktor auszuschließen. Die X-Achse ist der Wert des Prädiktors, und die Y-Achse ist die Anzahl der Gruppe von N Beobachtungen.
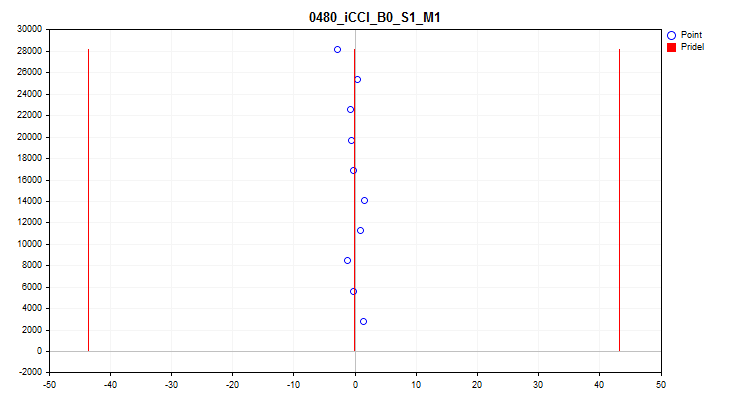
Abbildung 10. Durchschnittsspanne der Wert
- Die sechste Grafik zeigt die geschätzten Spikes. Auf der Grafik sind 3 schwarze Linien zu sehen - dies ist der Durchschnittswert, sowie plus und minus drei Standardabweichungen. Die blauen Grenzen sind diejenigen, die in der Nähe von 2,5 % der Beobachtungen liegen, gemessen am Anfang und am Ende des Stichprobenbereichs. Die X-Achse ist der Wert des Prädiktors, und die Y-Achse ist die Anzahl der Gruppe mit einer festen Anzahl von Beobachtungen.
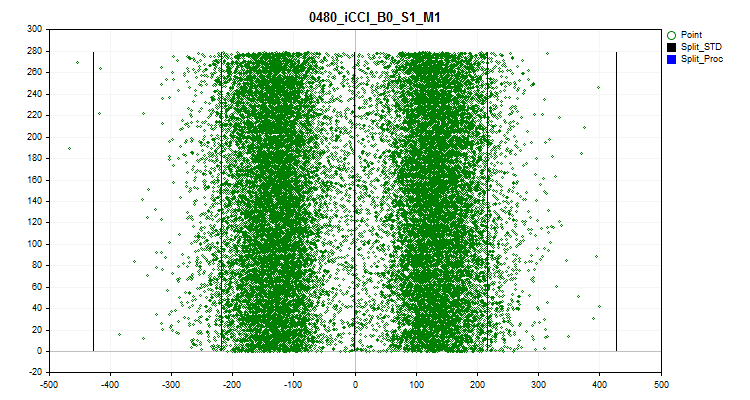
Abbildung 11. Spikes
2 Breite der Grafik in Pixel.
3 Höhe der Grafik in Pixel.
4 Schriftgröße und Größe der Kurvensymbole in der Legende der Grafik.
Konfigurieren der Suche nach Einstellungsszenarien
- Einstellungsszenarien durchspielen1
1 Aktiviert die Suche nach Einstellungen gemäß dem eingebetteten Algorithmus. Nachstehend finden Sie die Einzelheiten.
2. Durchführung eines vergleichenden Experiments zur Bewertung der Auswirkungen der Quantisierung
Aufbau des Experiments - Ziele
Wir haben ein Werkzeug mit beträchtlicher Funktionalität, es ist an der Zeit, seine Fähigkeiten zu bewerten! Führen wir ein Experiment durch, das Antworten auf folgende drängende Fragen geben wird:
- Haben all diese Maßnahmen und Manipulationen bei der Auswahl von Quantentabellen für Prädiktoren einen Sinn? Vielleicht wäre es einfacher, die Standardeinstellungen von CatBoost zu verwenden?
- Wie viele minimale Splits (Grenzen) werden benötigt, um ein ähnliches Ergebnis wie mit den Standardeinstellungen von CatBoost zu erzielen?
- Sollten wir Quantisierungsmethoden wie „uniform“ und „random“ verwenden?
- Gibt es einen signifikanten Unterschied zwischen den Auswahlmethoden für Quantentische?
Um diese Fragen zu beantworten, müssen wir ein Training mit verschiedenen Quantentabellen durchführen, die mit unterschiedlichen Einstellungen des Skripts Q_Error_Selection gewonnen wurden. Ich schlage vor, die folgenden Einstellungen auszuprobieren:
Auswahlverfahren:
- Nur der Rekonstruktionsfehler (Näherungsfehler) wird zur Bewertung von Quantentabellen herangezogen.
- Der Rekonstruktionsfehler (Approximationsfehler) geteilt durch die Anzahl der Splits in der Quantentabelle wird zur Bewertung von Quantentabellen verwendet. Der maximale Fehler liegt bei 1 %.
- Der Rekonstruktionsfehler (Approximationsfehler) geteilt durch die Anzahl der Splits in der Quantentabelle wird zur Bewertung von Quantentabellen verwendet. Der maximale Fehler liegt bei 0,5 %.
Quelle der Quantentabellen:
- Mit CatBoost erstellte Tabellen.
- Tabellen, die nach der Methode der einheitlichen Quantisierung erstellt wurden.
- Tabellen, die nach der Methode der zufälligen Aufteilung erstellt wurden.
Quantum Tabelleneinstellung:
- Einstellen von „1“ - alle verfügbaren Quantentabellen im Quellverzeichnis werden verwendet.
- Einstellen von „2“ - es werden nur Quantentabellen mit 16 Splits oder Intervallen verwendet.
- Einstellen von „3“ - es werden nur Quantentabellen mit 32 Splits oder Intervallen verwendet.
- Einstellen von „4“ - es werden nur Quantentabellen mit 64 Splits oder Intervallen verwendet.
- Einstellen von „5“ - es werden nur Quantentabellen mit 128 Splits oder Intervallen verwendet.
- Einstellen von „6“ - es werden nur Quantentabellen mit 256 Splits oder Intervallen verwendet.
Alle Einstellungskombinationen sind in der Tabelle in Form von Abbildung 12 dargestellt. Im Code ist diese Aufgabe in Form von drei verschachtelten Schleifen implementiert, die die entsprechenden Einstellungen ändern, indem sie eine Variable in den Einstellungen mit der Bezeichnung „Iterate through settings scenarios“ auf „true“ setzen.
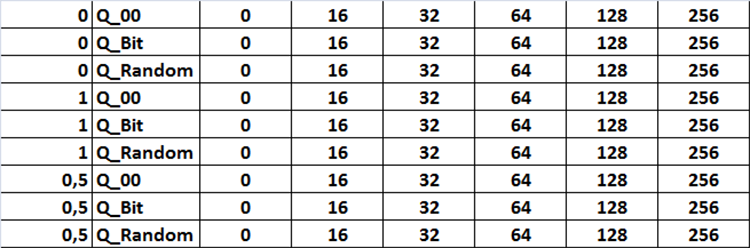
Abbildung 12. Tabelle der Kombinationen von Sucheinstellungen
Wir werden 101 Modelle mit jeder Einstellungskombination trainieren, indem wir den Seed-Parameter von 0 bis 800 mit einem Schritt von 8 durchlaufen, was uns erlaubt, den Durchschnitt des Ergebnisses zu ermitteln, um die Einstellungen zu bewerten und ein Zufallsergebnis auszuschließen.
Dies sind die Parameter, die ich für die vergleichende Analyse verwenden möchte:
- Profit_Avr - durchschnittlicher Gewinn aller Modelle;
- MO_Avr - durchschnittliche mathematische Erwartung der Modelle;
- Precision_Avr - durchschnittliche Klassifizierungsgenauigkeit der Modelle;
- Recall_Avr - durchschnittliche Vollständigkeit der Modellrückrufe;
- N_Exam_Model - durchschnittliche Anzahl der Modelle, die einen Gewinn von mehr als 3000 Einheiten aufweisen;
- Profit_Max - durchschnittlicher maximaler Gewinn aller Modelle.
Nach der Berechnung der Indikatoren schlage ich vor, diese zu summieren und durch die Anzahl der Indikatoren zu teilen. So erhalten wir einen allgemeinen Indikator für die Qualität der Auswahl von Quantentabellen - nennen wir ihn einfach Q_Avr.
Aufbereitung der Daten für das Experiment
Um ein Beispiel zu erhalten, werden wir denselben EA und dieselben Skripte verwenden, die wir bereits beim Kennenlernen von CatBoost im Artikel: „Der Algorithmus CatBoost von Yandex für das maschinelle Lernen, Kenntnisse von Python- oder R sind nicht erforderlich“ verwendet haben.
Ich habe die folgenden Einstellungen verwendet:
A. Tester-Einstellungen:
- Symbol: EURUSD
- Zeitrahmen: M1
- Intervall vom 01.01.2010 bis 01.09.2023
B. CB_Exp EA-Strategieeinstellungen:
- Period: 104
- Timeframe: 2 Minuten
- MA method: Smoothed
- Basis der Preisberechnung: Close-Preise
Nachdem wir die Stichprobe erhalten und in drei Teile geteilt haben (train, test, exam), müssen wir Quantentabellen auf ähnliche Weise erhalten, wie ich sie in meinem Artikel beschrieben habe. Um dies zu erreichen, habe ich das Skript CB_Bat (im Anhang zu diesem Artikel) geändert. Wenn Sie nun Brut_Quantilization_grid in der Einstellung „Suchobjekt“ auswählen, erstellt das Skript die Datei _01_Quant_All.txt. Die Einstellungen für die Suche nach dem Bereich sind gleich geblieben - die Anfangs- und Endwerte der Variablen sowie der Änderungsschritt sind festgelegt. Ich habe die Suche von 8 bis 256 mit einem Schritt von 8 verwendet. Als Ergebnis der Skript-Operation werden Befehle zum Erhalt von Quantisierungstabellen mit allen Typen mit einer bestimmten Anzahl von Grenzen vorbereitet. Die Quantisierungstabellendatei hat folgende Namensstruktur: der Dateiname in Form des semantischen Dateinamens „quant“, die Anzahl der Trennzeichen und die Seriennummer der Teilungsart. Die Parameter werden mit einem Unterstrich verknüpft, die Dateien selbst werden im Verzeichnis Q gespeichert, das mit dem Projekt-Setup-Verzeichnis identisch ist.
quant_"+IntegerToString(Seed,3,'0')+"_"+IntegerToString(ENUM_feature_border_type_NAME(Q),0)+".csv";
Nachdem Sie das Skript ausgeführt haben, ändern Sie die Dateierweiterung der resultierenden Datei _01_Quant_All.txt in *.bat, legen Sie die zuvor im Skript angegebene CatBoost-Version in das Verzeichnis mit der Datei und führen Sie die Datei durch Doppelklick aus.
Wenn das Skript seine Arbeit beendet hat, erscheint eine Reihe von Dateien im Unterverzeichnis Q - dies sind die Quantisierungstabellen, mit denen wir weiterarbeiten werden.
Abbildung 13. Inhalt des Unterverzeichnisses Q
Mit dem Skript Q_Error_Otbor werden einheitliche und zufällige Quantentabellen mit der Anzahl der Intervalle 16, 32, 64, 128 und 256 erzeugt. Die entsprechenden Dateien werden in den Verzeichnissen Q_Bit und Q_Random angezeigt. Wir erstellen eine Kopie des Verzeichnisses Q in das Projektverzeichnis und nennen das neue Verzeichnis Q_00.
Jetzt haben wir alles, was wir brauchen, um das Paket mit den Trainingsaufgaben zu erstellen. Starten Sie das Skript Q_Error_Otbor, setzen Sie den Parameter „Suche in den Einstellungen der Szenarien“ auf „true“ und klicken Sie auf „Ok“. Das Skript erstellt Dateien mit einer Quantentabelle und Trainingseinstellungen entsprechend dem im Code angegebenen Szenario.
Um Quantentabellen für jede Konfiguration von CatBoost-Einstellungen während des Trainings zu verwenden, fügt das Skript den Namen der Einstellungsdatei zum Namen der Quantentabelle „Quant_CB.csv“ hinzu.
Holen wir uns die Dateien für das Training mit dem Skript CB_Bat_v_02. Ich habe Seed von 0 bis 800 mit einem Schritt von 8 gewählt und das Projektverzeichnis angegeben.
Nun müssen wir die Trainingsdatei leicht bearbeiten und den Dateinamen Quant_CB.csv durch Quant_CB_%%a.csv ersetzen. Diese Änderung ermöglicht es uns, den Namen der Einstellungen als Variable zu verwenden, deren Nummer die Anzahl der Trainingszyklen bestimmt. Kopieren Sie die erstellten Dateien in das Projektverzeichnis Setup und starten Sie das Training, indem Sie die Datei _00_Start.txt in _00_Start.bat umbenennen und auf die Datei _00_Start.bat doppelklicken.
Auswertung der Versuchsergebnisse
Nach Abschluss des Trainings wird das Skript CB_Calc_Svod verwendet, um die Metriken für jedes Modell zu berechnen. Die Skripteinstellungen wurden bereits in einem früheren Artikel ausführlich beschrieben, sodass ich das nicht wiederholen werde.
Außerdem habe ich 101 Modelle mit den Standardeinstellungen der Quantentabelle trainiert. Hier sind die Ergebnisse:
- Profit_Avr=2810.17;
- МО_Avr=28.33;
- Precision _Avr=0.3625;
- Recall_Avr=0.023;
- N_Exam_Model=43;
-
Profit_Max=8026.
Schauen wir uns die Ergebnistabellen und -grafiken für jeden Parameter genauer an, bevor wir allgemeine Schlussfolgerungen ziehen.
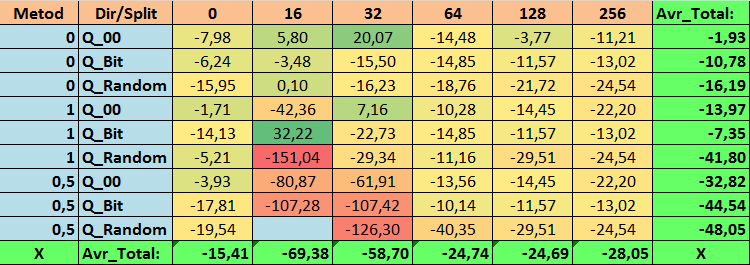
Tabelle 14. Zusammengefasste Werte des Parameters Profit_Avr
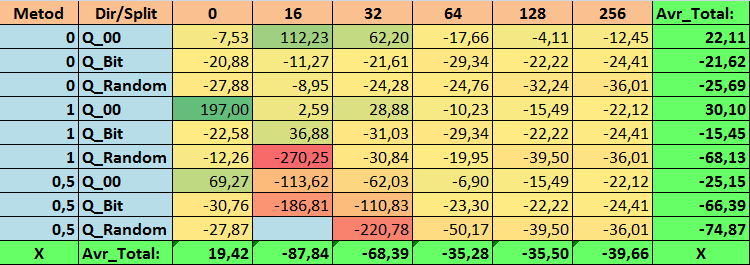
Tabelle 15. Zusammengefasste Werte des Parameters MO_Avr
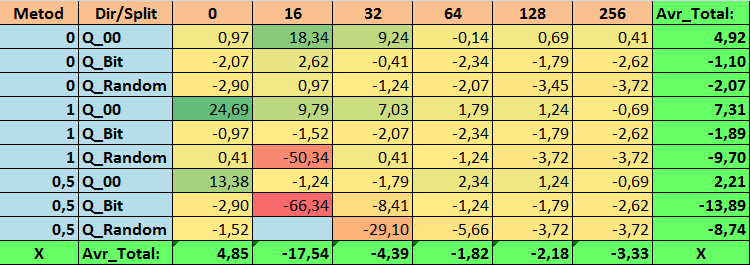
Tabelle 16. Zusammengefasste Werte des Parameters Precision_Avr
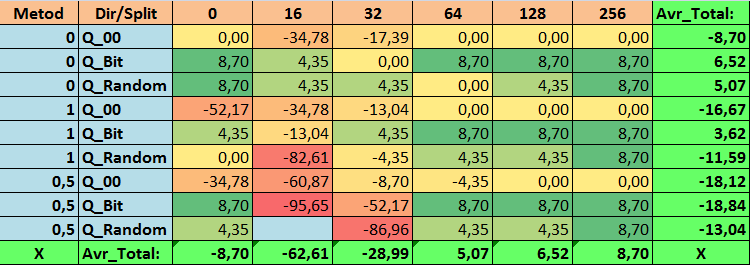
Tabelle 17. Zusammengefasste Werte des Parameters Recall_Avr
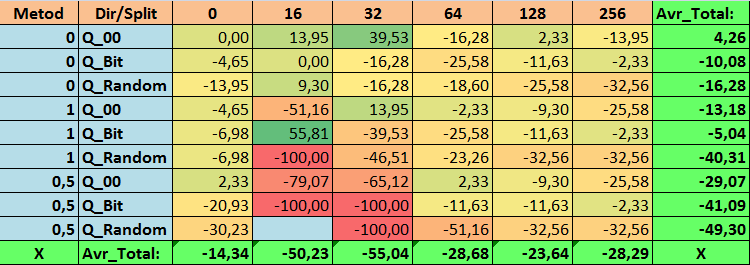
Tabelle 18. Zusammengefasste Werte des Parameters N_Exam_Model
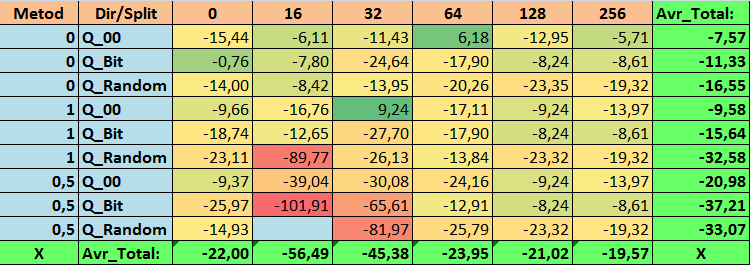
Tabelle 19. Zusammengefasste Werte des Parameters Profit_Max

Tabelle 20. Zusammengefasste Werte des Q_Avr-Parameters
Bei der Durchsicht unserer informativen Tabellen konnten wir feststellen, dass die Streuung der Parameter recht groß ist, was auf die Auswirkungen der Einstellungen insgesamt auf das Trainingsergebnis hinweist. Es zeigt sich, dass die Tabellen, die durch eine zufällige Aufteilung (Q_Random) erstellt wurden, die schwächsten Ergebnisse im Vergleich zu den mit anderen Methoden erstellten Quantentabellen aufweisen. Interessant ist, dass eine Erhöhung der Anzahl der Splits im Allgemeinen zu einer Verschlechterung der Leistung unserer Metriken führt, mit Ausnahme der Metrik Recall_Avr. Dies ist wahrscheinlich auf die Tatsache zurückzuführen, dass die Informationen in den Quantensegmenten stark verstreut sind, was nicht nur zu mathematischen Manipulationen während des Trainings führt (was mit einem Anstieg des Modellvertrauens endet), sondern auch zu einem Rückgang der Genauigkeit und damit des durchschnittlichen Gewinns. Sie fragen sich vielleicht: „Und wie wird das Modell mit 254 Standardsplits erfolgreich trainiert?“ Ich verwende nämlich die Standardmethode zur Gitterkonstruktion namens GreedyLogSum, die, wie wir bereits gesehen haben, das Gitter nicht mit einem einheitlichen Schritt konstruiert. Da das Gitter nicht gleichmäßig aufgebaut ist, zeigt die Metrik, die wir häufig zur Bewertung der Qualität der Gitterkonstruktion wählen, ein schlechteres Ergebnis als ein gleichmäßiges Gitter. Daher wählen wir bei der Auswahl von Quantisierungstabellen aus der Menge aller CatBoost-Methoden selten eine Methode wie GreedyLogSum. Wir können uns sogar Statistiken darüber ansehen, wie oft diese Methode gewählt wurde. Im Falle der Kombination (0;Q_00;256) gilt dies beispielsweise für nur 121 von 2408 Prädiktoren. Warum erweisen sich die extremen Bereiche der Prädiktoren als so signifikant? Schreiben Sie Ihre Vermutungen in die Kommentare!
Die Tabellen mit einer großen Anzahl von Splits und mit der Zufallsmethode für die Festlegung der Splits haben keine sehr guten Ergebnisse gezeigt. Aber was lässt sich über die Unterschiede in den Methoden zur Auswahl von Quantentabellen sagen? Beginnen wir mit der schlechten Nachricht. Die Forderung nach einem Fehler von 0,5 % erwies sich für Tabellenwerte von 16 bis 64 als zu hoch. Dies hatte zur Folge, dass deutlich weniger Prädiktoren am Training teilnahmen als ursprünglich, aber gleichzeitig konnten Tabellen mit einer großen Anzahl von Splits diese Schwelle erfolgreich überwinden, was aber, wie wir bereits angedeutet haben, nicht effizient war. Wenn man jedoch aus allen verfügbaren Tabellen auswählt, ergeben sich relativ ausgewogene Tabellen (insbesondere die CatBoost-Tabelle). Gleichzeitig hat sich die Auswahlmethode für Prädiktoren mit weniger strengen Anforderungen (mindestens 1 % Approximationsfehler) als eine Lösung erwiesen, die mehr Aufmerksamkeit verdient.
Kommen wir nun zur Beantwortung der gestellten Fragen, denn die Beantwortung dieser Fragen ist ja das Ziel dieses Experiments.
Antworten:
1. Die Standard-Quantisierungstabelle in CatBoost zeigt objektiv ein gutes Ergebnis für unsere Daten, aber es stellt sich heraus, dass sie erheblich verbessert werden kann! Schauen wir uns unsere Metriken für die besten Methoden zur Gewinnung von Quantentabellen an:
- Profit_Avr - (1;Q_Bit;16) Kombination, die die Grundeinstellungen um 32,22% übersteigt.
- MO_Avr - (1;Q_00;0) Kombination, die die Grundeinstellungen um 197,00 % überschreitet.
- Precision_Avr - (1;Q_00;0) Kombination, die die Grundeinstellungen um 24,69 % überschreitet.
- Recall_Avr – hier gibt es eine Fülle von Kombinationen. Sie alle übertreffen die Grundeinstellungen um 8,7 %.
- N_Exam_Model - (1;Q_Bit;16) Kombination, die die Grundeinstellungen um 55,81 % übersteigt.
- N_Profit_Max - (1;Q_00;32) Kombination, die die Grundeinstellungen um 9,24 % übersteigt.
Wir können diese Frage also objektiv positiv beantworten. Es lohnt sich, die besten Quantentabellen auszuwählen, die die Ergebnisse bei den für uns wichtigen Metriken verbessern können.
2. Es hat sich gezeigt, dass für unsere Stichprobe nur 16 Splits ausreichen, um einen guten Wert für den Parameter Q_Avr zu erhalten. Im Falle von (1;Q_Bit;16) ist er beispielsweise gleich 16,28, während er im Falle von (0;Q_00;16) 18,24 beträgt.
3. Die einheitliche Methode hat sich als recht effizient erwiesen. Besonders interessant ist die Tatsache, dass wir mit der Kombination (1;Q_Bit;16) die meisten Modelle erhalten haben, die die Grundeinstellungen um 55,81 % übertreffen. Angesichts der Tatsache, dass es eines der besten Ergebnisse in Bezug auf die mathematische Erwartung zeigte und die Grundeinstellungen um 36,88 % übertraf, denke ich, dass es sich lohnt, diese Methode bei der Auswahl von Quantisierungstabellen zu verwenden und sie in anderen Projekten im Zusammenhang mit maschinellem Lernen zu implementieren. Wie bei den Tabellen, die durch die Methode der zufälligen Aufteilung erhalten wurden, sollte dieser Ansatz mit Vorsicht (vielleicht selektiv) verwendet werden, wenn es nicht möglich ist, die Schwelle eines bestimmten Kriteriums für die Auswahl von Quantentabellen zu überschreiten. 10000 Optionen reichen möglicherweise nicht aus, um die beste Aufteilung des Prädiktors in Quantensegmente zu finden.
4. Wie die Versuchsergebnisse zeigen, hat die Methode der Auswahl von Quantentabellen einen erheblichen Einfluss auf die Ergebnisse. Ein einziges Experiment reicht jedoch nicht aus, um mit Sicherheit die Anwendung nur einer der Methoden zu empfehlen. Verschiedene Methoden und ihre Einstellungen ermöglichen es dem Modell, seine Aufmerksamkeit auf verschiedene Teile der Daten in der Stichprobe zu richten, indem es verschiedene Quantentabellen auswählt, was dazu beitragen kann, die optimale Lösung zu finden.
Schlussfolgerung
In diesem Artikel haben wir uns mit dem Algorithmus zur Auswahl von Quantentabellen vertraut gemacht und ein großes Experiment durchgeführt, um die Durchführbarkeit der Auswahl von Quantentabellen zu bewerten. Andere Methoden der Datenvorverarbeitung wurden nur oberflächlich geprüft, ohne den Code zu analysieren und ohne die Effizienz dieser Methoden zu bewerten. Die Durchführung einer Reihe von Experimenten und die Beschreibung ihrer Ergebnisse ist eine arbeitsintensive Aufgabe. Wenn dieser Artikel für die Leser von Interesse ist, führe ich vielleicht Experimente durch und beschreibe sie in anderen Artikeln.
Ich habe in dem Artikel keine Saldentabellen verwendet. Es gibt zwar einige schöne Beispiele für Modelle, aber ich würde empfehlen, mehr Prädiktoren für die Auswahl und anschließende Erstellung von Modellen für den realen Handel auf den Finanzmärkten zu verwenden.
Für die Auswahl der Quantentabellen wurde der Näherungswert verwendet, aber es lohnt sich, andere Werte auszuprobieren, mit denen die Homogenität und Nützlichkeit der Daten bewertet werden kann.
| # | Anwendung | Beschreibung |
|---|---|---|
| 1 | Q_Error_Otbor.mq5 | Skript, das für die Vorverarbeitung der Daten und die Auswahl der Quantentabellen für jeden Prädiktor zuständig ist. |
| 2 | CB_Bat_v_02.mq5 | Skript für die Erzeugung von Aufgaben für das Training von Modellen mit CatBoost - neue Version 2.0 |
| 3 | CSV fast.mqh | Klasse für die Arbeit mit CSV-Dateien, alle Urheberrechte am Programmcode liegen bei Aliaksandr Hryshyn. Sie müssen die fehlenden Dateien von hier herunterladen. |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/13648
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.