Artículos con ejemplos de programación de robots comerciales en el lenguaje MQL5
En el ámbito del trading automático los Asesores Expertos es la cima de la programación y objetivo deseable de cada desarrollador. Usted puede escribir su propio Asesor Experto utilizando los artículos de esta sección. Paso a paso los principiantes podrán pasar todas las fases de creación, depuración y simulación de los sistemas automáticos de trading.
Los artículos no sólo enseñarán a programar en el lenguaje MQL5, sino mostrarán cómo implementar cualquier idea y técnica comercial. Usted conocerá cómo programar el Trailing Stop, cómo realizar la gestión del capital, cómo obtener el valor del indicador y muchas cosas más.
Nuevo artículo

Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese

Redes neuronales: así de sencillo (Parte 84): Normalización reversible (RevIN)
Hace tiempo que sabemos que el preprocesamiento de los datos de origen desempeña un papel fundamental en la estabilidad del entrenamiento de los modelos. Y para el procesamiento en línea de datos de origen "brutos" solemos utilizar una capa de normalización por lotes. Pero a veces tenemos que invertir el procedimiento. En este artículo analizaremos un posible enfoque para resolver este tipo de problemas.

Redes neuronales: así de sencillo (Parte 16): Uso práctico de la clusterización
En el artículo anterior, creamos una clase para la clusterización de datos. En este artículo, queremos compartir con el lector diferentes opciones de uso de los resultados obtenidos para resolver problemas prácticos en el trading.

Cómo construir un EA que opere automáticamente (Parte 05): Gatillos manuales (II)
Aprenda a crear un EA que opere automáticamente de forma sencilla y segura. Al final del artículo anterior, pensé que sería apropiado permitir el uso del EA de forma manual, al menos durante un tiempo.

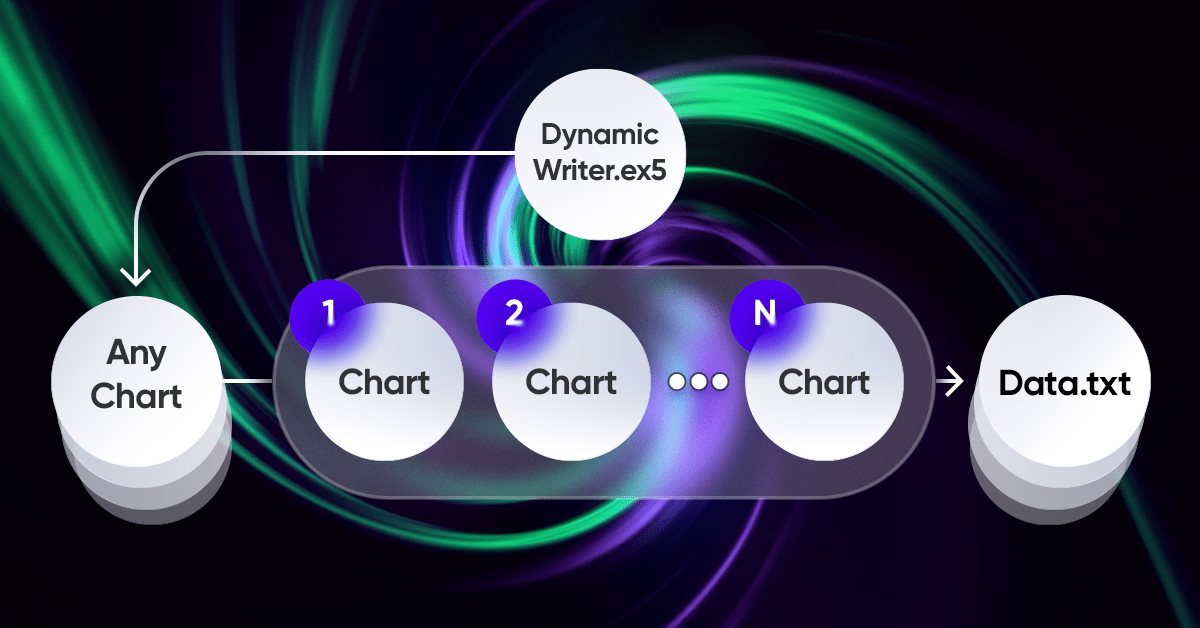
Formulación de un Asesor Experto Multipar Dinámico (Parte 1): Correlación de divisas y correlación inversa
El asesor experto dinámico de múltiples pares aprovecha las estrategias de correlación y correlación inversa para optimizar el rendimiento comercial. Al analizar datos del mercado en tiempo real, identifica y explota la relación entre pares de divisas.
Aproximación por fuerza bruta a la búsqueda de patrones (Parte VI): Optimización cíclica
En este artículo mostraremos la primera parte de las mejoras que nos permitieron no solo cerrar toda la cadena de automatización para comerciar en MetaTrader 4 y 5, sino también hacer algo mucho más interesante. A partir de ahora, esta solución nos permitirá automatizar completamente tanto el proceso de creación de asesores como el proceso de optimización, así como minimizar el gasto de recursos a la hora de encontrar configuraciones comerciales efectivas.


Interfaces gráficas XI: Controles dibujados (build 14.2)
En la nueva versión de la librería, todos los controles van a dibujarse en los objetos gráficos separados tipo OBJ_BITMAP_LABEL. Además, seguiremos describiendo la optimización del código: es decir, analizaremos los cambios en las clases que representan el núcleo de la librería.

Redes neuronales: así de sencillo (Parte 33): Regresión cuantílica en el aprendizaje Q distribuido
Continuamos explorando el aprendizaje Q distribuido. Hoy analizaremos este enfoque desde un ángulo diferente. Vamos a hablar de la posibilidad de utilizar la regresión cuantílica para resolver el problema de la previsión de los movimientos de precio.

Redes neuronales: así de sencillo (Parte 18): Reglas asociativas
Como continuación de esta serie, hoy presentamos otro tipo de tarea relacionada con los métodos de aprendizaje no supervisado: la búsqueda de reglas asociativas. Este tipo de tarea se usó por primera vez en el comercio minorista para analizar las cestas de la compra. En este artículo, hablaremos de las posibilidades que ofrece el uso de dichos algoritmos en el trading.

Creación de un Asesor Experto MQL5 basado en la estrategia PIRANHA utilizando las Bandas de Bollinger
En este artículo, creamos un Asesor Experto (Expert Advisor, EA) en MQL5 basado en la estrategia PIRANHA, utilizando Bandas de Bollinger para mejorar la efectividad comercial. Discutimos los principios clave de la estrategia, la implementación de la codificación y los métodos de prueba y optimización. Este conocimiento le permitirá implementar el EA en sus escenarios comerciales de manera efectiva.

Desarrollando un EA comercial desde cero (Parte 09): Un salto conceptual (II)
Colocación del Chart Trade en una ventana flotante. En el artículo anterior creamos el sistema base para utilizar templates dentro de una ventana flotante.

Redes neuronales: así de sencillo (Parte 83): Algoritmo de convertidor espacio-temporal de atención constante (Conformer)
El algoritmo de Conformer que le mostraremos hoy se desarrolló para la previsión meteorológica, una esfera del saber que, por su constante variabilidad, puede compararse con los mercados financieros. El Conformer es un método completo que combina las ventajas de los modelos de atención y las ecuaciones diferenciales ordinarias.

Introducción a MQL5 (Parte 3): Estudiamos los elementos básicos de MQL5
En este artículo, seguiremos estudiando los fundamentos de la programación MQL5. Hoy veremos los arrays, las funciones definidas por el usuario, los preprocesadores y el procesamiento de eventos. Para una mayor claridad, todos los pasos de cada explicación irán acompañado de un código. Esta serie de artículos sienta las bases para el aprendizaje de MQL5, prestando especial atención a la explicación de cada línea de código.

Construya Asesores Expertos Auto-Optimizables con MQL5 y Python (Parte II): Ajuste de redes neuronales profundas
Los modelos de aprendizaje automático vienen con varios parámetros ajustables. En esta serie de artículos, exploraremos cómo personalizar sus modelos de IA para que se adapten a su mercado específico utilizando la biblioteca SciPy.

Desarrollo de un kit de herramientas para el análisis de la acción del precio (Parte 2): Script de comentarios analíticos
En línea con nuestra visión de simplificar la acción del precio, nos complace presentar otra herramienta que puede mejorar significativamente su análisis de mercado y ayudarle a tomar decisiones bien informadas. Esta herramienta muestra indicadores técnicos clave, como los precios del día anterior, los niveles significativos de soporte y resistencia, y el volumen de operaciones, al tiempo que genera automáticamente señales visuales en el gráfico.

Experimentos con redes neuronales (Parte 6): El perceptrón como herramienta autosuficiente de predicción de precios
Ejemplo de utilización de un perceptrón como herramienta autónoma de predicción de precios. En el artículo exploraremos los conceptos generales y veremos un sencillo asesor experto ya preparado, así como los resultados de su optimización.

Cómo construir un EA que opere automáticamente (Parte 13): Automatización (V)
¿Sabes lo que es un diagrama de flujo? ¿Sabes cómo utilizarlo? ¿Cree que los diagramas de flujo son sólo cosas de aprendiz de programador? Pues echa un vistazo a este artículo y aprende a trabajar con diagramas de flujo.

Redes neuronales: así de sencillo (Parte 35): Módulo de curiosidad intrínseca (Intrinsic Curiosity Module)
Seguimos analizando los algoritmos de aprendizaje por refuerzo. Todos los algoritmos que hemos estudiado hasta ahora requerían la creación de una política de recompensas tal que el agente pudiera evaluar cada una de sus acciones en cada transición de un estado del sistema a otro, pero este enfoque resulta bastante artificial. En la práctica, existe cierto tiempo de retraso entre la acción y la recompensa. En este artículo, le sugerimos que se familiarice con un algoritmo de entrenamiento de modelos que puede funcionar con varios retrasos de tiempo desde la acción hasta la recompensa.
Indicadores alternativos de riesgo y rentabilidad en MQL5
En este artículo, presentaremos una aplicación de varias medidas de rentabilidad y riesgo consideradas alternativas al ratio de Sharpe e investigaremos diferentes curvas de capital hipotéticas para analizar sus características.

Cómo implementar la optimización automática en los asesores expertos de MQL5
Guía paso a paso para la optimización automática en MQL5 para Asesores Expertos. Cubriremos la lógica de optimización robusta, las mejores prácticas para la selección de parámetros y cómo reconstruir estrategias con pruebas retrospectivas. Además, se discutirán métodos de nivel superior, como la optimización del avance, para mejorar su enfoque comercial.

Análisis cuantitativo en MQL5: implementamos un algoritmo prometedor
Hoy veremos qué es el análisis cuantitativo, cómo lo utilizan los grandes jugadores y crearemos uno de los algoritmos de análisis cuantitativo en MQL5.

Creación de un asesor experto MQL5 basado en la estrategia de ruptura del rango diario (Daily Range Breakout)
En este artículo, creamos un Asesor Experto MQL5 basado en la estrategia de ruptura del rango diario (Daily Range Breakout). Cubrimos los conceptos clave de la estrategia, diseñamos el plano del EA e implementamos la lógica de ruptura en MQL5. Al final, exploramos técnicas para realizar pruebas retrospectivas y optimizar el EA con el fin de maximizar su eficacia.

Cómo construir y optimizar un sistema de trading basado en la volatilidad (Chaikin Volatility - CHV)
En este artículo, proporcionaremos otro indicador basado en la volatilidad llamado Chaikin Volatility. Entenderemos cómo construir un indicador personalizado después de identificar cómo se puede utilizar y construir. Compartiremos algunas estrategias sencillas que se pueden utilizar y luego las pondremos a prueba para entender cuál puede ser mejor.

Trading bursátil con cuadrícula usando un asesor con órdenes stop pendientes en la Bolsa de Moscú (MOEX)
Hoy utilizaremos un enfoque comercial de cuadrícula con órdenes stop pendientes en un asesor experto en el lenguaje de estrategias comerciales MQL5 para MetaTrader 5 en la Bolsa de Moscú (MOEX). Al comerciar en el mercado, una de las estrategias más simples consiste en colocar una cuadrícula de órdenes diseñada para "atrapar" el precio del mercado.

Redes neuronales: así de sencillo (Parte 15): Clusterización de datos usando MQL5
Continuamos analizando el método de clusterización. En este artículo, crearemos una nueva clase CKmeans para implementar uno de los métodos de clusterización de k-medias más extendidos. Según los resultados de la prueba, el modelo ha podido identificar alrededor de 500 patrones.

Redes neuronales: así de sencillo (Parte 17): Reducción de la dimensionalidad
Seguimos analizando modelos de inteligencia artificial, y en particular, los algoritmos de aprendizaje no supervisado. Ya nos hemos encontrado con uno de los algoritmos de clusterización. Y en este artículo queremos compartir con ustedes una posible solución a los problemas de la reducción de la dimensionalidad.

Gestión de Riesgo (Parte 5): Integrando la Gestión de Riesgo en un Asesor Experto
En este artículo implemento la gestión de riesgo desarrollada en publicaciones anteriores e incorporo el indicador de order blocks presentado en otros artículos. Además, realizaré un backtest para comparar los resultados con la aplicación de la gestión de riesgo y evaluaré el impacto del riesgo dinámico.

Redes neuronales: así de sencillo (Parte 85): Predicción multidimensional de series temporales
En este artículo presentaremos un nuevo método complejo de previsión de series temporales que combina armoniosamente las ventajas de los modelos lineales y los transformadores.

Desarrollando un EA comercial desde cero (Parte 21): Un nuevo sistema de órdenes (IV)
Finalmente el sistema visual funcionará... aún no del todo. Aquí terminaremos de hacer los cambios básicos, y no serán pocos, serán muchos, y todos ellos necesarios, y todo el trabajo será bastante interesante.
Ejemplo de nuevo Indicador y LSTM condicional
Este artículo explora el desarrollo de un Asesor Experto (Expert Advisor, EA) para trading automatizado que combina el análisis técnico con predicciones de aprendizaje profundo.

Redes neuronales: así de sencillo (Parte 48): Métodos para reducir la sobreestimación de los valores de la función Q
En el artículo anterior, presentamos el método DDPG, que nos permite entrenar modelos en un espacio de acción continuo. Sin embargo, al igual que otros métodos de aprendizaje Q, el DDPG tiende a sobreestimar los valores de la función Q. Con frecuencia, este problema provoca que entrenemos los agentes con una estrategia subóptima. En el presente artículo, analizaremos algunos enfoques para superar el problema mencionado.
Preparación de indicadores de símbolo/periodo múltiple
En este artículo analizaremos los principios de la creación de los indicadores de símbolo/periodo múltiple y la obtención de datos de ellos en asesores e indicadores. Asimismo, veremos los principales matices de uso de los indicadores múltiples en asesores e indicadores, y su representación a través de los búferes del indicador personalizado.

Experimentos con redes neuronales (Parte 3): Uso práctico
Las redes neuronales lo son todo. Vamos a comprobar en la práctica si esto es así. MetaTrader 5 como herramienta autosuficiente para el uso de redes neuronales en el trading. Una explicación sencilla.

Cómo construir un EA que opere automáticamente (Parte 11): Automatización (III)
Un sistema automatizado sin seguridad no tendrá éxito. Sin embargo, la seguridad no se consigue sin entender bien algunas cosas. En este artículo, comprenderemos por qué es tan difícil lograr la máxima seguridad en los sistemas automatizados.

Cómo construir un EA que opere automáticamente (Parte 07): Tipos de cuentas (II)
Aprenda a crear un EA que opere automáticamente de forma sencilla y segura. Uno siempre debe estar al tanto de lo que está haciendo un EA automatizado, y si se descarrila, eliminarlo lo más rápido posible del gráfico, para poner fin a lo que él estaba haciendo y evitar que las cosas se salgan de control.

Previsión y apertura de órdenes basadas en aprendizaje profundo (Deep Learning) con el paquete Python MetaTrader 5 y el archivo modelo ONNX
El proyecto consiste en utilizar Python para realizar previsiones basadas en el aprendizaje profundo en los mercados financieros. Exploraremos los entresijos de la comprobación del rendimiento del modelo utilizando métricas clave como el error medio absoluto (MAE, Mean Absolute Error), el error medio cuadrático (MSE, Mean Squared Error) y R-cuadrado (R2), y aprenderemos a envolverlo todo en un ejecutable. También haremos un fichero modelo ONNX con su EA.
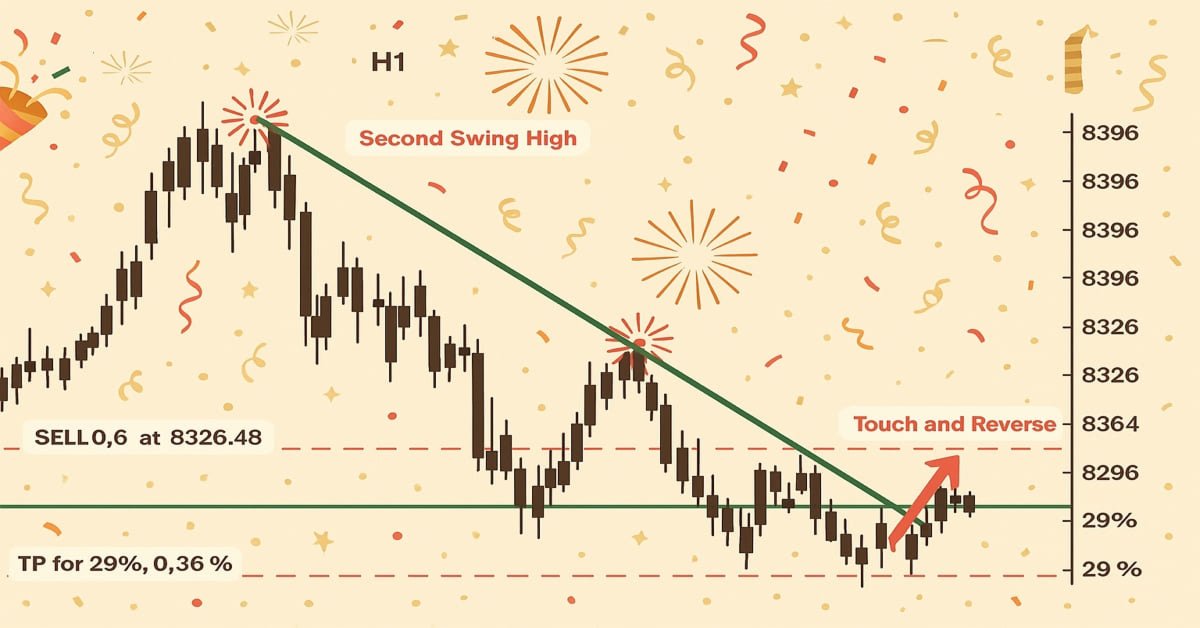
Introducción a MQL5 (Parte 17): Creación de asesores expertos para reversiones de tendencias
Este artículo enseña a los principiantes cómo crear un Asesor Experto (EA) en MQL5 que opera basándose en el reconocimiento de patrones gráficos utilizando rupturas y reversiones de líneas de tendencia. Al aprender a recuperar dinámicamente los valores de las líneas de tendencia y compararlos con la evolución de los precios, los lectores podrán desarrollar EA capaces de identificar y operar con patrones gráficos como líneas de tendencia ascendentes y descendentes, canales, cuñas, triángulos y mucho más.

Desarrollamos un Asesor Experto multidivisas (Parte 4): Órdenes pendientes virtuales y guardado del estado
Tras empezar a desarrollar un EA multidivisa, ya hemos obtenido algunos resultados y hemos conseguido realizar varias iteraciones de mejora del código. Sin embargo, nuestro EA fue incapaz de trabajar con órdenes pendientes y reanudar la operación después del reinicio del terminal. Añadamos estas características.
Interfaces gráficas X: Actualizaciones para la tabla dibujada y optimización del código (build 10)
Continuamos completar la tabla dibujada (CCanvasTable) con nuevas funcionalidades. Ahora la tabla va a contener las siguientes funciones: resalto de las filas al situar el cursor encima; posibilidad de agregar el array de imágenes para cada celda y el método para su conmutación; posibilidad de establecer y editar el texto de las cceldas durante la ejecución del programa, y muchas cosas más.

Redes neuronales: así de sencillo (Parte 46): Aprendizaje por refuerzo dirigido a objetivos (GCRL)
En el artículo de hoy, nos familiarizaremos con otra tendencia en el campo del aprendizaje por refuerzo. Se denomina aprendizaje por refuerzo dirigido a objetivos (Goal-conditioned reinforcement learning, GCRL). En este enfoque, el agente se entrenará para alcanzar diferentes objetivos en determinados escenarios.

Redes neuronales: así de sencillo (Parte 30): Algoritmos genéticos
En el artículo de hoy, hablaremos de un método de aprendizaje ligeramente distinto. Podríamos decir que lo hemos tomado de la teoría de la evolución de Darwin. Probablemente resulte menos controlable que los métodos anteriormente mencionados, pero también nos permite entrenar modelos indiferenciados.