
Redes neuronales en el trading: Modelo multivariado de extremo a extremo para la predicción de series temporales (GinAR)

Introducción
La previsión de series temporales multivariadas (MTSF, por sus siglas en inglés) se ha convertido en una parte integral del análisis en diversas industrias, desde el transporte y la ecología hasta, por supuesto, los mercados financieros. En nuestro campo, esto significa la capacidad de predecir el comportamiento de varios instrumentos financieros interconectados (acciones, índices, divisas) usando como base su dinámica histórica. Estos modelos permiten tomar decisiones de inversión más informadas, gestionar el riesgo y descubrir relaciones ocultas entre los activos.
Formalmente, una serie temporal multivariada (MTS) puede representarse como un grafo espacio-temporal, donde cada variable (ya sea un tipo de cambio, un volumen de negociación o la rentabilidad) se observa a lo largo del tiempo y se relaciona con otras variables a través de dependencias ocultas. Estas dependencias se dividen en dos tipos clave: temporales (relaciones de causa y efecto entre eventos) y espaciales (interacciones entre activos o sectores del mercado).
Para predecir con eficacia MTS, es vital poder identificar y aprovechar estas dependencias espacio-temporales. Esto resulta especialmente crítico en condiciones de alta volatilidad y perturbaciones del mercado, cuando los modelos tradicionales simplemente no pueden adaptarse. Y aquí es donde las redes neuronales gráficas vienen al rescate. Estos modelos combinan las ventajas de las redes neuronales convolucionales sobre grafos y los modelos recurrentes, lo que permite realizar predicciones más precisas basadas en relaciones complejas entre variables.
Pero en la práctica, las cosas no son tan sencillas, pues los datos financieros suelen estar incompletos. Algunas métricas no están disponibles o solo se observa una parte del intervalo temporal. Dichas ausencias pueden deberse a diversos factores, como interrupciones en la entrega de datos, cambios en las políticas de cálculo de indicadores o errores técnicos por parte de los intermediarios. Y si no disponemos de datos sobre los activos clave, la precisión del pronóstico disminuye drásticamente. En estos casos, los modelos de grafos suelen perder la capacidad de estimar adecuadamente las dependencias, lo cual conlleva una acumulación de errores en cadena y una disminución de la calidad de las previsiones.
Algunos intentos por sortear este problema se basan simplemente en excluir las variables no disponibles, pero esto representa un enfoque poco sólido: la falta de datos sobre un activo importante puede destruir toda la estructura lógica del modelo y llevar a conclusiones erróneas. Los enfoques más sofisticados utilizan técnicas de restauración de omisiones (imputación), combinando el contexto temporal y las relaciones espaciales fijas (por ejemplo, correlaciones o estructuras de red entre activos). Sin embargo, estos métodos suelen fallar cuando hay un alto porcentaje de datos faltantes o cuando no existe una relación fiable entre las variables observadas y las faltantes. Y de nuevo, los errores se acumulan y el pronóstico deja de ser fiable.
¿Qué debemos hacer, entonces? La solución reside en construir modelos que puedan usar información sobre las variables disponibles para reconstruir los datos faltantes directamente durante el proceso de previsión, sin dividir el entrenamiento en pasos de “Recuperación → Pronóstico”. Así es exactamente como se presenta el nuevo framework Graph Interpolation Attention Recursive Network (GinAR), en el artículo " GinAR: An End-To-End Multivariate Time Series Forecasting Model Suitable for Variable Missing". Se trata de una nueva arquitectura end-to-end diseñada para gestionar variables faltantes en series temporales multivariadas.
GinAR se basa en una red recursiva simple (SRU) con dos componentes clave incorporados:
- La atención por interpolación (Interpolation Attention o IA), un mecanismo que reconstruye las variables faltantes aplicando algoritmos de atención a los datos disponibles. Evita los errores causados por intentar indagar en ceros y valores atípicos.
- La convolución gráfica adaptativa (Adaptive Graph Convolution o AGCN), una convolución gráfica adaptativa que recompone la estructura de relaciones entre variables después de la reconstrucción, lo que le permite tener en cuenta tanto las correlaciones directas como las indirectas entre los activos.
De este modo, GinAR predice y corrige simultáneamente el modelo de dependencia, evitando que los errores se propaguen. Y lo que es especialmente importante es que funciona incluso en condiciones extremas. En las pruebas realizadas con datos reales por los autores del framework, el modelo ha mantenido una alta precisión incluso cuando hasta el 90% de las variables no están disponibles. Imagine una situación en la que solo tiene datos sobre unos pocos activos de su cartera, mientras que el resto permanecen sin datos; aun así, GinAR realiza una previsión para todo el sistema.
Resumiendo, los principales logros de GinAR son:
- Este es el primer modelo dirigido a MTSF con variables faltantes que funciona sin un paso de imputación previo.
- La nueva arquitectura (IA + AGCN) reemplaza las capas SRU totalmente conectadas, minimizando las distorsiones de dependencia.
- Según los resultados experimentales presentados en el artículo del autor, GinAR ha superado a otros 11 modelos en cinco conjuntos de datos diferentes, mostrando resultados fiables incluso con niveles críticamente altos de datos faltantes.
Para los mercados financieros, esto significa solo una cosa: incluso en ausencia parcial de datos, se pueden realizar pronósticos de forma sistemática y precisa. Esto significa que las estrategias adaptativas, las pruebas de estrés y la gestión de riesgos pueden implementarse de forma fiable sin depender de datos iniciales perfectos. Al fin y al cabo, en realidad, el mercado nunca es perfecto, y GinAR se creó precisamente para su uso en esas condiciones.
El algoritmo GinAR
La arquitectura del framework GinAR está construida según el esquema clásico Codificador → Decodificador. El Codificador es una pila de capas GinAR, mientras que el Decodificador se implementa usando como base un perceptrón multicapa (MLP). El elemento clave del sistema es la celda GinAR, un módulo construido sobre el principio del modelado recursivo. Cuando se le proporcionan datos incompletos, es decir, series temporales con variables faltantes, el modelo es capaz de predecir valores futuros de todas las variables simultáneamente, incluso aquellas para las que falta una historia completa.
Al diseñar la lógica interna de GinAR, los autores del framework propusieron reemplazar todas las capas totalmente conectadas en la estructura SRU recursiva clásica con dos componentes especializados: la IA (Interpolation Attention) y la AGCN (Adaptive Graph Convolution Network).
El primer componente reconstruye las variables faltantes usando información de los vecinos disponibles. En los mercados financieros, esto resulta especialmente importante: si faltan datos sobre activos clave, aunque sea parcialmente, el modelo puede perder precisión drásticamente. El mecanismo IA evita esto reconstruyendo representaciones significativas de las series temporales faltantes partiendo de las existentes y minimizando la influencia del ruido.
El segundo componente, AGCN, abandona los grafos de dependencia fijos (por ejemplo, relaciones predefinidas entre activos, índices y sectores) y aprende una estructura gráfica adaptativa directamente durante el entrenamiento. Esto nos permite captar de forma flexible las relaciones espaciales entre variables, incluso si son variables o no evidentes.
El Codificador GinAR se implementa usando un esquema recursivo en el que, en cada paso de tiempo, la entrada son las características del momento actual y el estado interno del paso anterior. La celda GinAR los procesa, actualiza el estado y forma una representación oculta del paso de tiempo actual. Este enfoque nos permite recuperar simultáneamente los datos que faltan, reconstruir el grafo de dependencias y extraer patrones dinámicos, todo ello en un único módulo. Gracias a las conexiones residuales (skip connections), el modelo puede ser profundo sin perder estabilidad en el entrenamiento. Esto resulta especialmente importante en tareas de predicción de señales de mercado complejas, donde tanto las fluctuaciones a corto plazo como las tendencias a largo plazo son importantes.
El siguiente paso es la previsión. Para lograr esto, debemos añadir correctamente las representaciones ocultas obtenidas. Por un lado, cada estado oculto final de una celda GinAR contiene información completa sobre la estructura temporal de los datos de origen; esto se debe a la naturaleza recursiva del modelo. Por otro lado, debido a su naturaleza multicapa y a la presencia de conexiones skip, cada representación oculta refleja diferentes niveles de abstracción: desde micromovimientos hasta correlaciones globales. Por ello, las características de todas las capas se combinan en un solo tensor y se introducen en la entrada del Decodificador. El Decodificador es un perceptrón multicapa entrenado mediante la estrategia de predicción directa de múltiples pasos (Direct Multi-Step Forecasting o DMSF). Este enfoque permite pronosticar de inmediato el horizonte objetivo completo (por ejemplo, el movimiento del precio durante las próximas 5-10 barras), sin recurrir a pronósticos iterativos paso a paso, que son propensos a la acumulación de errores.
Como resultado, GinAR conforma una arquitectura robusta que puede afrontar eficazmente las tareas de previsión en presencia de datos faltantes, relaciones dinámicas y alta correlación entre series temporales. El modelo combina la recuperación de datos, el entrenamiento de grafos y la previsión, todo ello en una única solución end-to-end capaz de adaptarse a la incertidumbre del mercado real.
El mecanismo de atención por interpolación (Interpolation Attention o IA) está diseñado para reconstruir representaciones de variables con datos históricos completamente faltantes. Para cada variable faltante, debemos determinar un conjunto de variables normales sobre cuya base se realizará la reconstrucción, así como los pesos de influencia correspondientes de estas variables. Este proceso consta de dos pasos clave: primero, se establecen correspondencias entre las variables faltantes y las disponibles, y luego se aplica un mecanismo de atención para agregar la información y recuperarla.
En la primera etapa, se construye una matriz de correspondencias entre variables. Luego se inicializa la matriz diagonal IN ∈ Rᴺ*ᴺ, así como dos incorporaciones matriciales de variables: EIA1 ∈ Rᴺ*ᵈ y EIA2 ∈ Rᵈ*ᴺ. Estas incorporaciones se entrenan conjuntamente con el modelo. La matriz de correlación entre variables se calcula usando la fórmula:
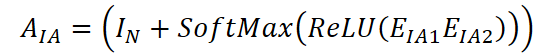
El elemento (i, j) de la matriz AIA ∈ Rᴺ*ᴺ refleja el grado de conexión entre las variables i y j. Si el valor es positivo, indica que la variable normal j puede utilizarse para reconstruir la variable faltante i. Por consiguiente, para cada variable faltante i, se puede identificar un conjunto de variables normales asociadas N(i) ⊆ {1,…,N}.
Una vez determinadas las correspondencias, las representaciones de las variables faltantes se reconstruyen usando mecanismos de atención. Para ello, se calculan los coeficientes de atención aij, que reflejan la importancia de la variable normal j en la reconstrucción de la variable i :
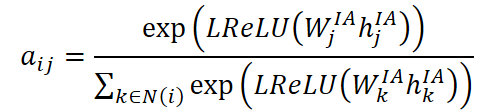
donde hᴵᴬj es la representación oculta actual de la variable j, mientras que Wᴵᴬj es la matriz de pesos entrenable. La activación se realiza mediante la función LReLU, que evita que los gradientes se desvanezcan para activaciones débiles.
Los coeficientes obtenidos se usan para agregar información de variables normales. La representación de la variable faltante i se reconstruye usando la fórmula:
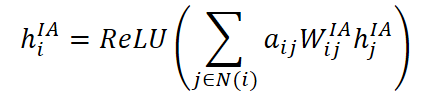
donde Wᴵᴬij es la matriz de pesos individuales que se pueden aprender para cada par de variables i y j, mientras que la agregación final se normaliza utilizando ReLU para mejorar la robustez frente a valores atípicos.
Este proceso se repite para todas las variables faltantes hasta que se hayan reconstruido las representaciones de los M componentes faltantes. Después de esto, se obtiene un nuevo tensor XᴵᴬM ∈ Rᴺ*ᴴ*ᶜ′, en el que todas las variables (incluidas las que faltaban anteriormente) tienen representaciones ocultas completas. Cabe señalar que, en la práctica, para mejorar la eficiencia de la recuperación, los pasos 2 y 3 se implementan usando multiplicación de matrices y computación paralela.
De este modo, el mecanismo de atención por interpolación permite una recuperación de datos flexible en series temporales multidimensionales con variables faltantes, sin necesidad de fijar rígidamente la estructura de las relaciones entre variables de antemano. Esto resulta particularmente importante para las tareas de previsión financiera, donde las estructuras de correlación entre activos pueden ser volátiles y los datos históricos pueden ser incompletos o presentar ruido.
En los problemas de predicción de series temporales multivariadas, a menudo se usa una estructura gráfica predefinida para captar las dependencias espaciales entre las variables. Para ello, se define una matriz de adyacencia A que permite al modelo capturar las relaciones subyacentes. Sin embargo, en situaciones donde hay una cantidad significativa de datos faltantes, sobre todo cuando no se dispone de información completa sobre varias variables, una estructura gráfica predefinida de este tipo puede resultar insuficiente. Para superar esta limitación, los autores del framework introducen la convolución gráfica adaptativa, que combina una estructura predefinida y un grafo formado a partir de datos.
La estructura gráfica predefinida se basa en información de distancia (por ejemplo, para redes de transporte) o en el coeficiente de correlación de Pearson entre variables si los datos no contienen información topológica. La matriz de adyacencia para la convolución de grafos en este caso se calcula de la forma que sigue:
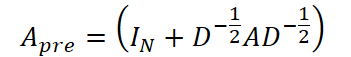
donde IN ∈ Rᴺ*ᴺ es la matriz diagonal identidad, D es la matriz de grados de los vértices del grafo y A es la matriz de adyacencia original. Esta normalización nos permite estabilizar la escala de los pesos durante el entrenamiento.
No obstante, cuando faltan algunas variables o se desconocen sus relaciones, es necesario identificar dinámicamente las dependencias espaciales. Para ello, se construye un grafo adaptativo que se entrena según los datos. Este proceso comienza con la inicialización de la matriz diagonal unitaria IN ∈ Rᴺ*ᴺ y la inicialización aleatoria de las incorporaciones de variables EA ∈ Rᴺ*ᵈ. Estas incorporaciones se actualizan durante el entrenamiento del modelo.
Después de restaurar las variables usando el mecanismo IA, obtenemos el tensor de representación oculta XᴵᴬM ∈ Rᴺ*ᴴ*ᶜ′. A continuación, se calcula una representación actualizada de las variables En ∈ Rᴺ*ᵈ, combinando incorporaciones y representaciones temporales:
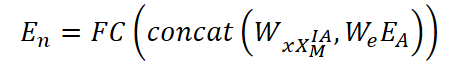
donde Wx y We son las matrices de pesos entrenables para las características temporales y las incorporaciones, respectivamente, y concat(⋅) es la operación de concatenación a lo largo del último eje. Esta representación se usa para construir la matriz de adyacencia adaptativa:
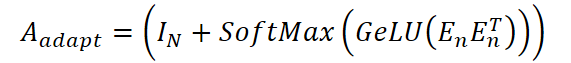
El último paso consiste en agregar la información de ambos grafos mediante convolución gráfica adaptativa que combina dos canales: uno que utiliza una estructura predefinida y otro adaptativo. La representación final de las variables se calcula utilizando la fórmula:
![]()
Este diseño permite la integración de información espacial estática y dinámica, lo cual resulta particularmente importante al pronosticar series temporales multivariadas con variables parcialmente faltantes.
Al combinar ambos grafos, el modelo obtiene una estructura robusta y adaptativa, lo que permite una identificación más precisa de las dependencias entre variables y, como resultado, mejora la exactitud de las previsiones a corto y medio plazo.
La idea principal de la arquitectura GinAR consiste en integrar el mecanismo de atención de interpolación (IA) y la convolución gráfica adaptativa (AGCN) en un modelo recursivo simple. Esta combinación permite no solo restaurar las variables faltantes, sino también considerar de manera efectiva las dependencias espaciotemporales.
Vamos a analizar más de cerca la estructura de la celda de GinAR y el proceso paso a paso de la predicción de datos.
A nivel de un único paso de tiempo, una celda GinAR representa una unidad computacional básica. Utiliza IA para reconstruir los valores de origen que faltan y AGCN para manejar las relaciones espaciales entre variables. La entrada es un tensor xT, que primero se transforma utilizando el mecanismo de atención de interpolación:
![]()
A continuación, las puertas de control de olvido fT y reinicio rT se calculan agregando información del grafo predefinido Apre y del grafo adaptativo Aadapt :
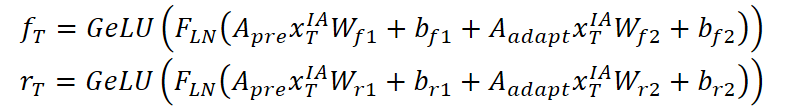
El nuevo estado cT se forma como una combinación de la entrada transformada actual y el estado anterior cT-1, ponderado por la puerta de olvido:
![]()
Finalmente, el estado oculto hT se calcula mediante una mezcla no lineal del estado de la celda actualizado y la entrada:
![]()
De este modo, cada celda GinAR realiza un ciclo completo de actualización de sus estados internos, que incluye la recuperación de datos y la agregación de información espacial.
A nivel global, el codificador GinAR consta de varias capas GinAR. Cada capa incluye celdas H conectadas en serie. Los datos de entrada originales X∈ Rᴺ*ᴴ*ᶜ se prenormalizan y enmascaran, formando un tensor X M ∈ Rᴺ*ᴴ*ᶜ, donde los valores de las variables M se establecen en cero.
A continuación, XM se transmite a la entrada de la primera capa de GinAR, en la que cada celda es responsable de procesar un paso temporal. El proceso comienza con la inicialización del estado c₀, después de lo cual x₁ y c₀ se transmiten a la primera celda, formando h¹₁ y c₁. Estos valores luego se mueven a la siguiente celda junto con x₂ y así sucesivamente. El resultado es una secuencia de estados ocultos de la primera capa h¹ = [h¹₁, h¹₂, …, h¹H].
Este tensor se convierte en la entrada de la siguiente capa. El proceso se repite hasta que se hayan pasado todas las n capas. Luego, el último estado oculto hH ⁱ se extrae de cada capa y se combinan en el vector final halln.
La representación final halln se introduce en un decodificador de perceptrón multicapa (MLP), que genera valores predichos:
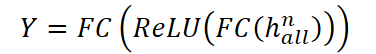
De este modo, GinAR implementa un procesamiento completo end-to-end de series temporales con valores faltantes, combinando la reconstrucción de datos y el modelado de dependencias espaciotemporales en un único framework recursivo-convolucional.
A continuación le presentamos la visualización del framework GinAR realizada por el autor.

Implementación con MQL5
Tras repasar los aspectos teóricos del framework GinAR, podemos pasar a la parte práctica, donde demostraremos una de las opciones para implementar los enfoques descritos, propuestos por los autores del framework, utilizando herramientas MQL5.
Sin embargo, antes de comenzar a construir el algoritmo principal, necesitamos realizar un trabajo preparatorio. Como podemos observar en la descripción anterior de GinAR, el algoritmo original aplica repetidamente la normalización de datos utilizando la función SoftMax. En este sentido, hemos decidido implementarlo como una función independiente en el programa OpenCL, garantizando así flexibilidad y alto rendimiento al trabajar con datos multidimensionales.
Trabajo preparatorio
Para una mejor organización, hemos dividido la implementación del algoritmo en bloques funcionales separados. Comenzaremos con el primero: la búsqueda del valor máximo entre los flujos del grupo de trabajo. La función LocalMax realiza esta tarea.
La función LocalMax toma dos parámetros: el valor calculado en el flujo actual y el número de dimensión en el espacio de tareas (loc) por el cual los flujos se agrupan en grupos de trabajo.
#define BarrierLoc barrier(CLK_LOCAL_MEM_FENCE) float LocalMax(const float value, const int loc) { const size_t id = get_local_id(loc); const size_t total = get_local_size(loc); //--- __local float Temp[LOCAL_ARRAY_SIZE]; const uint ls = min((uint)total, (uint)LOCAL_ARRAY_SIZE);
En el primer paso, se determina el ID del flujo en el grupo local y el tamaño total del grupo de trabajo. A continuación, se crea un array Temp, que se ubica en la memoria local del dispositivo y que se usará para intercambiar valores intermedios entre flujos del mismo grupo de trabajo.
Luego se inicia una búsqueda en todos los subgrupos formados dentro del grupo de trabajo, con el objetivo de encontrar los máximos locales. Los valores se escriben en los elementos del array Temp.
//--- Look Max for(int d = 0; d < total; d += ls) { if(id >= d && id < (d + ls) && (d == 0 || Temp[id - d] < value)) Temp[id - d] = IsNaNOrInf(value, MIN_VALUE); BarrierLoc; }
Después de esto, se inicia un proceso iterativo para reducir (colapsar) el array Temp a un único valor: el máximo entre todos los elementos.
int count = ls; do { count = (count + 1) / 2; if(id < count && (id + count) < ls && Temp[id] < Temp[id + count]) Temp[id] = Temp[id + count]; BarrierLoc; } while(count > 1); //--- return IsNaNOrInf(Temp[0], MIN_VALUE); }
El resultado de las operaciones se devuelve al programa que realiza la llamada.
De forma similar a la función LocalMax anterior, creamos otro componente básico: una función para sumar elementos dentro de un grupo de trabajo local. Esta tarea la realiza la función LocalSum, que se basa en el mismo principio que LocalMax, pero con una operación de suma en lugar de encontrar el máximo.
float LocalSum(const float value, const int loc) { const size_t id = get_local_id(loc); const size_t total = get_local_size(loc); //--- __local float Temp[LOCAL_ARRAY_SIZE]; const uint ls = min((uint)total, (uint)LOCAL_ARRAY_SIZE);
En la fase inicial, como antes, se determinan el ID del flujo y el tamaño del grupo de trabajo. También se crea un array local llamado Temp, donde se almacenarán las sumas intermedias.
A continuación, recorremos todos los flujos del grupo local y acumulamos valores intermedios. Nótese el uso de la condición d == 0, que permite que el array Temp se inicialice correctamente en la primera iteración.
//--- Sum float result = IsNaNOrInf(value, 0); for(int d = 0; d < total; d += ls) { if(id >= d && id < (d + ls)) Temp[id - d] = (d == 0 ? result : Temp[id - d] + result); BarrierLoc; }
Después de ello, se implementa la conocida reducción mediante una división doble del número de elementos; aquí, en lugar de una comparación, se realiza una simple suma de los elementos del array Temp.
int count = ls; do { count = (count + 1) / 2; if(id < count && (id + count) < ls) Temp[id] += Temp[id + count]; BarrierLoc; } while(count > 1); result = IsNaNOrInf(Temp[0], 0); //--- return result; }
El valor final (la suma de todos los elementos del grupo de trabajo) se devuelve al programa que realiza la llamada.
En la fase final del trabajo preparatorio, combinaremos las funciones auxiliares LocalMax y LocalSum, implementadas previamente, en un único algoritmo, la función LocalSoftMax, que efectúa una normalización numéricamente estable de los valores dentro de un grupo de trabajo.
float LocalSoftMax(const float value, const int loc) { //--- Look Max const float max = LocalMax(value, loc); BarrierLoc;
Dentro de la función LocalSoftMax, primero se llama a LocalMax, que encuentra el valor máximo entre todos los flujos del grupo de trabajo. Esto es necesario para estabilizar los cálculos: restar el valor máximo de cada valor nos permite evitar desbordamientos y mejorar la estabilidad numérica de las operaciones exponenciales.
Después de esto, considerando el desplazamiento, se calcula el exponente de cada valor. El resultado de esta operación se almacena temporalmente en la variable result, después de lo cual llamamos a la función LocalSum para calcular la suma total de los exponentes dentro del grupo.
//--- SoftMax float result = IsNaNOrInf(exp(value - max), 0); const float sum = LocalSum(result, loc); result = IsNaNOrInf(result / (sum == 0 ? 1 : sum), 0); //--- return result; }
A continuación, se realiza la normalización: el valor result se divide por la suma de todos los exponentes. Además, se ofrece protección contra la división por cero: si la suma es cero, se usa uno en el denominador. El último paso consiste en devolver el valor normalizado.
Esta estructura permite que SoftMax se use como un componente flexible para futuros núcleos de OpenCL. Esto hace que el código sea más limpio, simplifica la depuración y mejora la legibilidad de toda la arquitectura, especialmente en el contexto de los modelos de grafos y los mecanismos de atención utilizados en la implementación de GinAR mediante MQL5.
Sin embargo, una pasada directa a través de SoftMax todavía no es suficiente para entrenar el modelo. Para actualizar correctamente los pesos durante la propagación inversa, es necesario implementar una función de distribución de gradiente adecuada. Esta función permite que el modelo tenga en cuenta cómo afectará al error resultante el cambio del valor de entrada.
Vamos a implementar esta funcionalidad en la función LocalSoftMaxGrad, que determinará el gradiente de la función SoftMax con respecto al valor de entrada. Los parámetros de entrada son: el valor value correspondiente a la salida de SoftMax; el gradiente grad pasado desde una capa posterior de la red y el valor del índice de la dimensión del espacio de tareas loc a lo largo de la cual se forman los grupos de trabajo.
float LocalSoftMaxGrad(const float value, const float grad, const int loc) { const size_t id = get_local_id(loc); const size_t total = get_local_size(loc); //--- __local float Temp[LOCAL_ARRAY_SIZE]; const uint ls = min((uint)total, (uint)LOCAL_ARRAY_SIZE);
Al inicio de la función, determinamos el número del flujo actual y el número total de flujos en el grupo local. Luego creamos una matriz Temp local para almacenar valores intermedios, de forma similar a como se hacía en LocalMax y LocalSum. La variable val representa una versión saneada.
float result = 0; float val = IsNaNOrInf(value, 0); for(uint d = 0; d < total; d += ls) { if(id >= d && id < (d + ls)) Temp[id - d] = IsNaNOrInf(val * grad, 0); BarrierLoc; for(uint l = 0; l < min(ls, (uint)(total - d)); l++) result += Temp[l] * ((float)((d + l) == id) - val); BarrierLoc; } //--- return result; }
A continuación, iniciamos una iteración en todos los subgrupos dentro del grupo de trabajo completo. En cada bloque, llenamos un búfer temporal con los valores del producto val * grad y, usando la expresión clásica para la derivada SoftMax, acumulamos el resultado en la variable result. La expresión en sí utiliza la comprobación lógica (d + l) == id, que garantiza que los elementos diagonales y no diagonales del jacobiano se manejen correctamente.
El resultado de la función es el valor final del gradiente correspondiente al elemento de entrada dado. Este resultado se devuelve al núcleo que realiza la llamada, lo que garantiza la correcta implementación del pasada inversa en la arquitectura del modelo.
De este modo, esta función completa la implementación del ciclo completo de procesamiento SoftMax dentro del módulo OpenCL, desde el cálculo directo hasta la propagación inversa correcta del gradiente.
Interpolation Attention
Tras completar el trabajo preparatorio relacionado con la implementación de operaciones básicas como SoftMax y su distribución de gradiente, vamos a construir el mecanismo de atención por interpolación, que desempeña un papel clave en la arquitectura de GinAR. En la primera etapa, nuestro objetivo consiste en implementar una pasada directa de este algoritmo utilizando OpenCL, lo que garantiza un procesamiento paralelo eficiente en el lado del acelerador gráfico.
El núcleo InterpositionAttention toma como entrada varios arrays:
- la matriz de características de entrada matrix_in,
- los parámetros entrenables W y A,
- las representaciones latentes de GL,
- las matrices de adyacencia Adj,
- las representaciones intermedias H,
- el valor de atención Atten,
- la matriz resultante matrix_out.
Además, se transmite la dimensionalidad del espacio de características dimension.
__kernel void InterpositionAttention(__global const float* matrix_in, __global const float* W, __global const float* A, __global const float* GL, __global float* Adj, __global float* H, __global float* Atten, __global float* matrix_out, const int dimension ) { const size_t i = get_global_id(0); const size_t j = get_local_id(1); const size_t total = get_global_size(0); const size_t total_loc = get_local_size(1);
Al inicio del trabajo, definimos los índices de flujo globales y locales i y j, que se usarán para iterar sobre los elementos de los arrays de entrada y salida. A continuación, calculamos los desplazamientos correspondientes para garantizar el acceso correcto a los subconjuntos dentro del búfer global.
const int shift_i = i * dimension; const int shift_j = j * dimension; const int shift_adj = i * total_loc + j;
El primer paso consiste en calcular los pesos de adyacencia entre dos nodos i y j multiplicando por pares sus representaciones latentes del array GL.
float adj = 0; for(int d = 0; d < dimension; d++) adj += IsNaNOrInf(GL[shift_i + d] * GL[shift_j + d], 0); adj = max(IsNaNOrInf(adj, 0), 0); adj = LocalSoftMax(adj, 1); Adj[shift_adj] = adj; adj += (float)(i == j);
El resultado se acumula en la variable adj, se normaliza utilizando la función LocalSoftMax y se almacena en la matriz de adyacencia Adj. Luego se suma uno al valor de adj si i es igual a j, asegurando así que se conserve el elemento diagonal.
A continuación comenzamos la formación de la representación intermedia H. Para ello, las características de entrada del nodo actual se multiplican paso a paso por la matriz de pesos entrenada W. Cada valor se almacena en una matriz H, y se utiliza una barrera BarrierLoc para sincronizar entre flujos.
for(int id_h = 0; id_h < dimension; id_h += total_loc) { if(j >= (dimension - id_h)) break; float h = 0; for(int w = 0; w < dimension; w++) h += IsNaNOrInf(matrix_in[shift_i + w] * W[(id_h + j) * dimension + w], 0); H[shift_i + id_h + j] = h; BarrierLoc; }
Una vez formada H, se calcula un valor de atención e, que determina la importancia de la interacción entre los nodos i y j. El valor se inicializa con un pequeño valor positivo para evitar la división por cero. En caso de correlación positiva entre elementos, se acumulan productos escalares ponderados entre las filas correspondientes de H y el vector de aprendizaje A. El resultado se normaliza nuevamente mediante la función LocalSoftMax y se almacena en el array Atten.
float e = 1e-12f; if(adj > 0) { e = 0; for(int a = 0; a < dimension; a++) e += IsNaNOrInf(H[shift_i + a] * A[a], 0) + IsNaNOrInf(H[shift_j + a] * A[dimension + a], 0); } e = LocalSoftMax(e, 1); Atten[shift_adj] = e;
La etapa final consiste en la reconstrucción del valor de la variable analizada a partir de la información obtenida de otras variables observadas. El valor de la variable i faltante (o recuperable) se agrega mediante la suma ponderada de las representaciones de las variables j, mientras que las representaciones mismas se multiplican por los valores del coeficiente de atención correspondientes. Esta agregación permite transferir información útil de los vecinos a la variable objetivo.
for(int d = 0; d < dimension; d += total_loc) { if(j >= (dimension - d)) break; float out = 0; int shift_h = d + j; int shift_att = i * total_loc; int shift_out = i * dimension + shift_h; for(int n = 0; n < total_loc; n++) out += IsNaNOrInf(H[shift_h + n * dimension] * Atten[shift_att + n], 0); matrix_out[shift_out] = Activation(out, ActFunc_LReLU); } }
Para mejorar la robustez frente a los valores atípicos y mitigar su impacto, el resultado obtenido se normaliza usando la función de activación LReLU. Esto favorece un entrenamiento del modelo más estable, especialmente en presencia de datos inestables o ruidosos.
Este paso completa la pasada directa de la atención de interpolación y produce una representación final de la variable i que tiene en cuenta tanto las relaciones internas entre las variables como los parámetros de correlación aprendidos.
De este modo, el kernel de OpenCL descrito implementa la pasada directa de la atención de interpolación, utilizando eficazmente el paralelismo para procesar elementos de la estructura del grafo. El kernel permite la construcción de un modelo adaptativo de interacción entre elementos de series temporales basado en características latentes, lo que posibilita un análisis sensible al contexto y una adaptación flexible a la estructura de los datos.
El siguiente paso de nuestro trabajo es la implementación del algoritmo de pasada inversa Interpolation Attention, que también implementaremos como un kernel de OpenCL. Esta función calcula los gradientes para todos los parámetros y datos de origen involucrados en la pasada directa.
La idea principal del código es que para cada elemento calculamos derivadas parciales del error con respecto a variables intermedias: características ocultas H, coeficientes de atención Atten, matrices de entrada, pesos y la matriz de características GL.
__kernel void InterpositionAttentionGrad(__global const float* matrix_in, __global float* matrix_in_gr, __global const float* W, __global float* W_gr, __global const float* A, __global float* A_gr, __global const float* GL, __global float* GL_gr, __global float* Adj, __global float* H, __global float* H_gr, __global float* Atten, __global float* matrix_out_gr, const int dimension ) { const size_t i = get_global_id(0); const size_t j = get_local_id(1); const size_t total = get_global_size(0); const size_t total_loc = get_local_size(1);
Dentro del kernel, para cada flujo (identificado por los índices i y j ), se produce un cálculo secuencial:
- Los gradientes de características latentes H grad se calculan en función de los gradientes de salida y los pesos de atención, teniendo en cuenta la función de activación LeakyReLU.
const int shift_i = i * dimension; const int shift_j = j * dimension; const int shift_adj = i * total_loc + j; //--- H Gradient for(int d = 0; d < dimension; d += total_loc) { if(j >= (dimension - d)) break; float h_grad = 0; int shift_h = shift_i + d + j; int shift_att = i; int shift_out = d + j; for(int n = 0; n < total_loc; n++) { float gr = matrix_out_gr[shift_out + n * dimension]; h_grad += IsNaNOrInf( Deactivation(gr, gr, ActFunc_LReLU) * Atten[shift_att + n * total_loc], 0); } H_gr[shift_h] = h_grad; BarrierLoc; }
- Luego, se calcula el gradiente sobre los coeficientes de atención Att grad y se pasa a través de la función SoftMax inversa para propagar correctamente los errores en la distribución de atención.
//--- Attention Gradient float att_grad = 0; for(int d = 0; d < dimension; d++) { float gr = matrix_out_gr[shift_i + d]; gr = Deactivation(gr, gr, ActFunc_LReLU); att_grad += IsNaNOrInf(gr * H[shift_j + d], 0) } att_grad = LocalSoftMaxGrad(Atten[shift_adj], att_grad, 1);
- Este gradiente se usa luego para actualizar los gradientes de las características latentes H dados los pesos de la matriz A, y para acumular gradientes en la propia matriz A.
for(int d = 0; d < dimension; d++) { float h_grad = att_grad * A[d]; h_grad = LocalSum(h_grad, 1); if(j == 0) H_gr[shift_i + d] += h_grad; h_grad = att_grad * A[dimension + d]; h_grad = LocalSum(h_grad, 1); if(j == 0) H_gr[shift_j + d] += h_grad; float a_grad = att_grad * H[shift_i + d]; a_grad = LocalSum(a_grad, 1); A_gr[d] += a_grad; a_grad = att_grad * H[shift_j + d]; a_grad = LocalSum(a_grad, 1); A_gr[dimension + d] += a_grad; }
- Los gradientes para las características de entrada se obtienen usando los gradientes de las características ocultas y las matrices de pesos W, lo que permite una correcta actualización de los datos de entrada durante el proceso de entrenamiento.
//--- Inputs' Gradient for(int d = 0; d < dimension; d += total_loc) { if(j >= (dimension - id_h)) break; float grad = 0; for(int w = 0; w < dimension; w++) grad += IsNaNOrInf(H_gr[shift_i + w] * W[(id_h + j) + dimension * w], 0); matrix_in_gr[shift_i + d + j] = grad; BarrierLoc; }
- Finalmente, los gradientes sobre la matriz adaptativa GL se calculan mediante la función SoftMax inversa sobre la adyacencia y se acumulan para ambas variables i y j.
//--- Adj Gradient float grad = LocalSoftMaxGrad(Adj[shift_adj], att_grad, 1); for(int d = 0; d < dimension; d++) { GL_gr[shift_i + d] += IsNaNOrInf(grad * GL[shift_j + d], 0); GL_gr[shift_j + d] += IsNaNOrInf(grad * GL[shift_i + d], 0); } }
La estructura general de la función se construye utilizando la sincronización de flujos locales (BarrierLoc), lo que garantiza la corrección del intercambio de datos entre ellos y evita las condiciones de carrera.
Este enfoque garantiza una actualización precisa y estable de todos los parámetros del modelo durante el entrenamiento, lo cual permite un ajuste eficiente de los pesos y una mejor imputación de los valores faltantes en series temporales multivariadas.
En esta etapa, completamos la implementación de los componentes clave en el lado del programa OpenCL. El siguiente paso lógico será organizar todo el proceso en el programa principal: integración, gestión de cálculos y entrenamiento del modelo utilizando MQL5. Sin embargo, el volumen de material ya ha aumentado considerablemente y, para mantener la claridad y la calidad de la presentación, les propongo hacer una pausa.
Continuaremos con este importante trabajo en el próximo artículo, donde examinaremos con detalle la implementación práctica del algoritmo en MQL5, las complejidades de la interacción con OpenCL y la optimización del rendimiento. De esta forma, podemos centrarnos en cada etapa sin prisas, manteniendo la profundidad y la exhaustividad del tema.
Conclusión
Como conclusión, cabe destacar que el framework GinAR presentado demuestra un enfoque potente para la predicción de series temporales multivariadas con valores faltantes. La integración de la atención por interpolación y la convolución gráfica adaptativa en una arquitectura recursiva permite la reconstrucción eficiente de datos faltantes y la consideración de dependencias espaciotemporales complejas.
La implementación práctica de componentes clave en el lenguaje OpenCL presentada en el artículo abre amplias posibilidades para su posterior optimización e implementación en sistemas de negociación reales.
Sin duda, dedicaremos más esfuerzos a integrar estos avances en el programa principal MQL5, lo que nos permitirá aprovechar todo el potencial de los métodos propuestos. Les invito a continuar explorando este tema en el próximo artículo.
Enlaces
- GinAR: An End-To-End Multivariate Time Series Forecasting Model Suitable for Variable Missing
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos offline |
| 2 | StudyOnline.mq5 | Asesor | Asesor de entrenamiento de modelos online |
| 3 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 4 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema y la arquitectura del modelo |
| 5 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/18854
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso