
Del básico al intermedio: Operadores

Introducción
El contenido expuesto aquí tiene como único objetivo servir de material didáctico. En ningún caso debe considerarse una aplicación final, a menos que el propósito sea el estudio exclusivo de los conceptos presentados aquí.
En el artículo anterior "Del básico al intermedio: Variables (III)", se explicó un poco sobre las variables predefinidas y se demostró una manera interesante de interpretar funciones. Sin embargo, todo lo explicado hasta este punto se enfrenta a un problema crítico que es precisamente una de las mayores dificultades para los nuevos programadores, especialmente para aquellos que desean realizar pequeños proyectos de uso personal. Esta dificultad surge debido a la existencia de diferentes tipos de datos.
Como se explicó brevemente en el artículo "Del básico al intermedio: Variables (II)", en MQL5 existe una clasificación de datos basada en tipos que pueden utilizarse. No obstante, para poder explicar los tipos de datos de forma adecuada, es necesario hacerlo dentro de un contexto específico. Y precisamente este es el tema principal de este artículo: los operadores básicos, que proporcionan el contexto necesario para hablar sobre los tipos de datos.
Sé que muchos considerarán que el tema que abordaremos aquí es simple y que no tiene ningún sentido discutirlo. Sin embargo, precisamente por ser un tema aparentemente trivial, se vuelve indispensable. Muchos errores en el código se deben a un mal entendimiento del tema en cuestión.
Sin más preámbulos, empecemos con el primer tema de este artículo.
Tipos de datos y operadores
En lenguajes no tipados, hablar sobre operadores y tipos de datos suele ser completamente innecesario. Una operación como 10 dividido por 3 generará un resultado adecuado sin importar el contexto. Sin embargo, en un lenguaje tipado como MQL5, al igual que en C y C++, esta operación de división no tiene una única respuesta, sino dos respuestas completamente diferentes. En algunos casos, pueden existir más de dos respuestas, aunque este aspecto se tratará en su momento. Para lo que abordaremos aquí, podemos centrarnos únicamente en la posibilidad de que haya dos respuestas.
Espera un momento. ¿Cómo que dos respuestas? ¿Estás loco o estás divagando? Porque cada vez que dividimos 10 entre 3, el resultado es 3.3333... Y no cualquier otra. Bueno, querido lector, si piensas así, entonces este artículo definitivamente es para ti. Y por eso se creó: precisamente para explicar que las cosas, cuando se habla de programación, no son como muchos piensan.
Para empezar, haremos algo un poco más sencillo: generar un valor que sea una dízima periódica. Aun así, puede dar dos respuestas completamente diferentes. Para ilustrarlo, veamos un código bastante simple. A continuación se muestra dicho código.
1. //+------------------------------------------------------------------+ 2. #property copyright "Daniel Jose" 3. //+------------------------------------------------------------------+ 4. void OnStart(void) 5. { 6. Print(5 / 2); 7. } 8. //+------------------------------------------------------------------+
Código 01
Este código 01, que es muy sencillo, servirá para ilustrar algo muy interesante, aunque causa una tremenda confusión. Supongo que, querido lector, deberías saber cuál es el resultado de la operación que se realiza en la línea seis. Sin embargo, dudo que sepas cuál es el valor que realmente se mostrará. Esto ocurre porque existe una dependencia del tipo de dato utilizado en la respuesta. Obviamente, el resultado esperado es 2,5. Sin embargo, si ejecutas este código 01, verás que el terminal imprimirá el valor 2. ¿Por qué? ¿Acaso el computador no sabe calcular esta sencilla expresión? Bueno, la respuesta es que no. El computador no sabe hacer cálculos. En realidad, el computador es muy bueno sumando, pero pésimo para todas las demás operaciones.
Amigo, estás intentando tomarnos el pelo, ¿verdad? No puede ser. Sin embargo, aunque parezca una broma, es un hecho real. Los computadores NO saben hacer ninguna operación que no sea sumar. Y aun así, hay un problema. Esto se debe a que, si le pides que sume dos fracciones, lo más probable es que no pueda darte el resultado correcto. Y todo esto tiene que ver con la forma en que los valores se representan en la memoria del computador.
Los computadores solo entienden ceros y unos. O están encendidos o apagados. No saben la diferencia entre dos y tres, ni entre ningún otro número. Solo trabajan con la conocida lógica booleana. Y, al hacerlo de cierta manera, logran realizar los cálculos que les pedimos. De acuerdo, pero si escribo 5 dividido entre 2 en una calculadora, obtengo como resultado 2.5. Sin embargo, no entiendo por qué al hacerlo aquí en MQL5 obtengo como respuesta dos y no 2,5.
Es precisamente en este punto donde entra en juego el tipo de dato, querido lector. En este caso, ambos datos son del tipo entero. Por lo tanto, el compilador considerará que la respuesta que debe generarse también debe ser del tipo entero. Sin embargo, para la calculadora, la respuesta puede ser de tipo entero o de tipo conocido en programación como punto flotante. Es aquí donde la cosa se complica para muchos, ya que en lenguajes no tipados siempre obtendrás la misma respuesta, pero en lenguajes tipados puedes obtener más de una respuesta. Todo depende de ti, como programador, al indicar qué tipo debe utilizarse en la respuesta.
Así que una forma de corregir el código 01 para que la respuesta sea 2,5 es utilizar el siguiente código.
1. //+------------------------------------------------------------------+ 2. #property copyright "Daniel Jose" 3. //+------------------------------------------------------------------+ 4. void OnStart(void) 5. { 6. Print((double)(5 / 2)); 7. } 8. //+------------------------------------------------------------------+
Código 02
Al hacer los cambios que puedes ver en el código 02, la respuesta será única. A este proceso se le conoce como TYPECASTING o conversión de tipo. Encontrarás toda la información al respecto en la documentación de MQL5, así como en otros lenguajes de programación.
En el caso de MQL5, puedes consultar la explicación buscando «Conversión de tipo». Encontrarás imágenes que te ayudarán a entender cómo esta conversión se realiza de forma implícita hacia un tipo más complejo. En este caso, todos tienden hacia el tipo double. Una de estas imágenes se muestra a continuación.
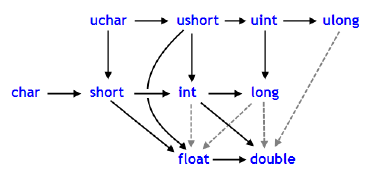
Imagen 01
Como este tema está muy bien explicado en la documentación, al menos en lo que respecta a cómo los datos pueden escalarse entre sí, no es necesario entrar en detalles aquí sobre lo que se describe allí. Sin embargo, es posible que surja una duda en personas más curiosas que deseen entender los detalles de esta conversión de tipos. Esa duda es precisamente: ¿por qué ocurre esto?
Entenderlo te permitirá comprender muchas otras cosas, querido lector. Por ejemplo: ¿por qué, cuando realizamos una operación entre dos valores, a veces no obtenemos la respuesta correcta, sino una respuesta que no tiene mucho sentido? Y otras veces, aunque la respuesta sea correcta, al intentar usarla parece que no lo es.
Este tipo de cosas realmente suceden y están directamente relacionadas con la forma en que los datos se representan en la memoria del computador. Pero, para explicar esto adecuadamente, avancemos al siguiente tema.
Ancho de bits.
Al final del artículo "Del básico al intermedio: Variables (II)", se presentó una pequeña tabla, que muestra el límite de cada valor que puede representarse en la memoria del computador. Sin embargo, hay un detalle: los valores de tipo punto flotante, como double y float, no se representan de la misma manera que los valores enteros, como int o ushort. Por lo tanto, lo que se explicará a continuación se refiere únicamente a los valores de tipo entero. La cuestión relacionada con los valores de punto flotante se tratará en otro momento, ya que requiere una explicación más detallada para comprender realmente cómo funcionan y por qué es peligroso confiar ciegamente en un valor calculado por el computador cuando se trata de este tipo de datos.
Primero, veamos qué son los valores enteros. Todos ellos pueden resumirse a su unidad más básica: los bits. El mayor valor que puede representarse con un tipo de dato es equivalente a dos elevado al número de bits utilizados en su representación. Por ejemplo: si se utilizan cuatro bits, se pueden representar 16 valores diferentes. Si tienes 10 bits, puedes representar 1024 valores, y así sucesivamente.
Sin embargo, esto solo se aplica a valores positivos. A los valores negativos se les aplica un pequeño ajuste en este recuento. En este caso, cuando se trabaja con valores negativos, el rango que puede representarse oscila entre dos elevado al número de bits menos uno y el mismo valor negativo menos uno. Puede parecer un poco confuso, pero es muy sencillo de entender en la práctica. Por ejemplo, con los mismos cuatro bits, pero representando tanto valores positivos como negativos, podríamos ir de -8 a 7. Con 10 bits, podríamos ir de -512 a 511. Pero espera un momento. Si ignoramos que el valor es negativo y sumamos ambos, 8 más 7 no son 15, sino 16, como se mencionó antes. De manera similar, 512 más 511 son 1023 y no 1024. ¿Por qué ocurre esta diferencia? La respuesta está en el cero, querido lector. Cuando sumas 8 con 7, estás considerando únicamente los valores posibles, pero el cero no se cuenta en esa suma, por lo que ocupa una posición por sí mismo.
Para aclarar esto de manera definitiva, necesitamos entender cómo se representan los valores negativos en la memoria. Para ello, utilizaremos la imagen que se presenta a continuación, que nos permitirá explicar este concepto con mayor claridad.
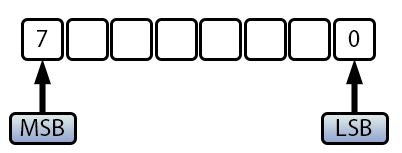
Imagen 02
Aquí tenemos un valor del tipo uchar o char, ya que se muestran 8 bits. Sin embargo, la diferencia entre un valor uchar y un valor char radica precisamente en lo que se representa en el bit MSB, o bit más significativo. En el caso de los valores uchar, donde todos los valores son positivos (gracias al prefijo u que indica unsigned o sin signo), el MSB no supone ningún problema, ya que los valores siempre serán positivos. Por tanto, podemos contar de 0 a 255, lo que totaliza 256 valores posibles. Por otro lado, cuando usamos un tipo char, el MSB indica si el valor es negativo o positivo. Si el MSB es igual a uno, el valor es negativo. Si el MSB es cero, el valor es positivo. Por esta razón, podemos contar de 0 a 127 los valores positivos. Sin embargo, como el cero no tiene signo y el único caso en que el MSB está activado sin otros bits presentes se interpreta como -128, no existe el «cero negativo». Esto también explica por qué, en los valores negativos, la cuenta siempre tiene un valor adicional en comparación con la mitad de los valores posibles.
Interesante, ¿verdad, querido lector? Pero esto aún mejora. Si has comprendido la explicación anterior, ya puedes entender cómo la función ABS o MathAbs, presente en muchos lenguajes de programación, puede transformar un valor negativo en positivo y viceversa. Basta con cambiar el estado del MSB para realizar esa transformación.
Sin embargo, si no prestas atención a lo que estás haciendo, puede ocurrirte. Por ejemplo, si sumas dos valores positivos, como 100 y 40, podrías obtener un valor negativo. ¿Qué locura me estás diciendo? ¿Cómo puede ser posible que al sumar dos valores positivos obtengamos un resultado negativo? Eso es absurdo, la lógica dicta que la respuesta siempre debería ser positiva. Nunca podríamos obtener un valor negativo como resultado de esa suma. En el mundo de la informática, la verdad a veces no coincide con el sentido común. Para dejar esto claro, observa el siguiente código:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. char value1 = 100, 07. value2 = 40, 08. Result; 09. 10. Result = value1 + value2; 11. Print(value1, " + ", value2, " = ", Result); 12. } 13. //+------------------------------------------------------------------+
Código 03
Al ejecutar este código, se muestra el resultado que se ve más abajo.

Imagen 03
¡Por la santa virgen María! ¿Qué clase de extraña es esta? ¡Esto es IMPOSIBLE. No, querido lector, definitivamente no es imposible. Esto tiene todo que ver con el motivo por el que este artículo era necesario. Debes comprender que, en lenguajes tipados, la elección correcta del tipo de dato influirá directamente en el resultado del cálculo. Muchas personas tienen serias dificultades a la hora de programar precisamente por no entender lo que estoy explicando aquí. Y muchas son engañadas por desconocer estos temas, que, aunque aparentemente simples, sin el conocimiento adecuado te exponen a falsas promesas de seguridad.
De acuerdo. En este caso, podrías estar pensando: está bien, estamos usando un tipo que puede representar hasta 127 para valores positivos y -128 para valores negativos. ¿No sería ideal usar un tipo más grande, como por ejemplo un tipo int, que en lugar de 8 bits utiliza 32 bits? Sí, querido lector. Pero ese no es el problema aquí. El problema es que, en algún momento, se alcanzará el límite de valores que puede representarse. Y cuando eso ocurra, la cuenta fallará de alguna manera. Y eso que aún estamos trabajando únicamente con tipos enteros. Los valores de punto flotante son incluso más complicados de entender.
Por esta razón, es fundamental que comprendas bien los enteros antes de pasar a los de punto flotante. Sin embargo, hay una cuestión que merece la pena mencionar: la imposibilidad de trabajar siempre con un tipo de mayor capacidad. Esto es muy común cuando trabajamos con cadenas de texto o strings. Precisamente aquí es donde las cosas se complican. Las cadenas de texto, o secuencias de caracteres, pueden utilizar tanto 16 bits como 8 bits. Normalmente, salvo en casos específicos, los computadores utilizan lo que se conoce como la tabla ASCII. Esta tabla de 8 bits se creó en los inicios de la informática. Sin embargo, como no era adecuada para representar ciertos caracteres, fue necesario desarrollar otros tipos de tablas. Por este motivo, algunos programas utilizan 16 bits para escribir textos. Sin embargo, usar 16 bits solo cambia el MSB al bit número 15, pero no crea un número infinito de posibilidades. Simplemente permite pasar de 256 valores a 65 536 valores diferentes.
En cualquier caso, una string no es más que un arreglo de valores más simples, pero con la posibilidad de representar un rango mayor de valores. Por ejemplo, puedes crear un valor de 128 bits utilizando MQL5, aunque el mayor valor posible de forma nativa es de 64 bits con el tipo ulong. ¿Cómo se hace algo así? Es muy sencillo, querido lector. Si conoces los valores que representan cada bit activado o desactivado dentro de una secuencia de bits, solo tienes que sumar los valores de los bits activados. Al hacer esto, ocurre algo mágico: puedes representar cualquier valor imaginable.
Por eso, al sumar 100 con 40, como se hizo en el código 03, obtenemos el valor -116. Esto se debe a que este valor, -116, es en realidad una representación del valor positivo 140, lo que parece bastante absurdo al principio. Pero si observas los valores en binario, verás lo siguiente:
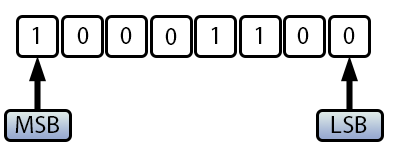
Imagen 04
Es decir, el mismo valor que en un caso se interpreta como positivo, en otro se interpreta como negativo, precisamente por el MSB. Por eso, debes tener cuidado, especialmente al crear bucles. Esto es por esta situación que puede producirse. Sin la atención adecuada, tanto los cálculos como los bucles pueden hacer que tu programa se comporte de manera errática. Incluso si aparentemente todo está siendo calculado correctamente, la elección incorrecta del tipo de datos o de los límites máximos que este soporta puede hacer que todo se salga de control.
Muy bien, pero en algún momento se mencionó que podríamos usar un tipo mayor para resolver este mismo problema. ¿Por qué este tipo de solución funciona en algunos casos y en otros no? Esto se debe a que el MSB se estaría desplazando. Como puedes ver en la imagen siguiente.
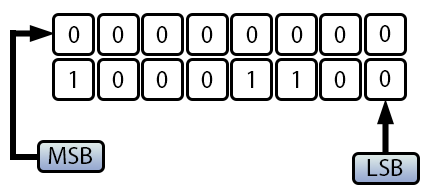
Imagen 05
Es bastante sencillo de entender, ¿verdad? De acuerdo. En lo que respecta a las operaciones básicas, de momento podemos mencionar lo siguiente. Sin embargo, todo lo que se ha discutido hasta ahora está relacionado con el uso de operadores aritméticos. No obstante, existe otra categoría de operadores: los operadores lógicos. Para explicar estos conceptos y separarlos adecuadamente, pasaremos a un tema nuevo.
Operadores lógicos
Un operador lógico trabaja con bits. Aunque, en ocasiones, podemos utilizar bytes o conjuntos completos de bits en operaciones lógicas. Generalmente este tipo de operador debe concebirse, al menos al principio, como enfocado en trabajar con bits y no con bytes. Puede parecer un tanto confuso. Pero con el tiempo notarás que tiene sentido. Esto se debe a que, a diferencia de los operadores aritméticos, que están diseñados para calcular algo, los operadores lógicos están destinados a probar algo. Por lo general, estas pruebas se realizan para verificar si los valores cumplen o no alguna condición. Dado que estos operadores tienen más sentido cuando se usan junto con otros comandos, aquí solo haremos un repaso rápido para que estés preparado para lo que veremos en breve.
No obstante, aunque tengan más sentido junto a otros comandos, es posible realizar pequeñas operaciones con operadores lógicos. De hecho, cualquier operación en una CPU implica más lógica que aritmética. Aunque la parte principal y más importante de una CPU se llama ALU (unidad aritmética y lógica). Esto se debe a que es la encargada de que la CPU funcione.
Básicamente, dentro de los operadores lógicos tenemos la operación AND, la operación OR, la operación NOT y, en muchos lenguajes (aunque no en todos), la operación XOR. Además de estas, contamos con las operaciones de desplazamiento hacia la derecha y hacia la izquierda. Con estas simples operaciones podemos hacer muchas cosas. Para ser sinceros, podemos hacer cualquier cosa que se nos ocurra. De hecho, la ALU, que es el núcleo de la CPU, se basa en estas operaciones.
En este momento, podrías estar revisando la documentación de MQL5 u otro lenguaje y pensando: «Pero existen más operadores lógicos, como mayor que y menor que, entre otros, presentes en ciertos lenguajes». Sí, querido lector. Algunos lenguajes implementan más tipos de operadores o funciones de comparación lógica. Sin embargo, a nivel de ALU, muchas de estas operaciones son mucho más simples de lo que parecen en las implementaciones de alto nivel de los lenguajes. Y no me malinterpretes. No es que considere que sea incorrecto o innecesario implementarlas. Todo lo contrario. Se implementan precisamente para simplificar ciertos aspectos del trabajo de programación. Por ejemplo: si quieres comparar un valor con otro, la forma más sencilla de hacerlo sería restar uno del otro. Pero hay otra manera: aplicar la operación XOR bit a bit. Si todos los bits son iguales, el resultado final será igual a cero. Si algún bit es diferente, entonces uno de los valores podría ser mayor o menor que el otro. Sin embargo, cuando realizamos la resta y analizamos el MSB, podemos determinar si el resultado es cero, es menor que cero o es mayor que cero. Según este resultado, sabremos si el valor es mayor, menor o igual que el otro.
Para que quede más claro, veamos un ejemplo sencillo de comparación para determinar si un valor es mayor, menor o igual que otro. Para ello, utilizaremos el código que aparece a continuación.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. short value1 = 230, 07. value2 = 250; 08. 09. Print("Result #1: ", value1 - value2); 10. Print("Result #2: ", value2 - value1); 11. Print("Result #3: ", value2 ^ value1); 12. } 13. //+------------------------------------------------------------------+
Código 04
Este es un sistema típico y sencillo para analizar valores. Cuando se ejecute este código, se obtendrá el siguiente resultado en el terminal:
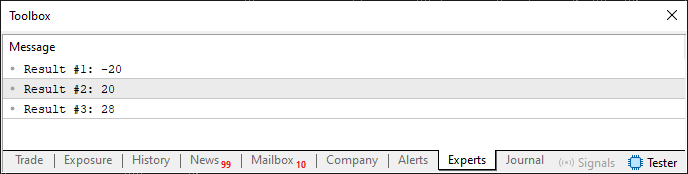
Imagen 06
Ahora presta atención para comprender cómo se explica anteriormente determinar si un valor es mayor, menor o igual. Para hacerlo más interesante, estamos utilizando un tipo de dato de 16 bits. Esto nos permite manejar 65 536 valores diferentes. Sin embargo, como es un valor con signo, es decir, que admite valores negativos y positivos, el rango es de -32 768 a 32 767. Si nos limitamos a analizar valores dentro de un rango de 8 bits, no tendríamos problemas para determinar si un valor es mayor, menor o igual al otro. Sin embargo, a diferencia de lo que sería posible usando solo 8 bits, aquí podemos trabajar con valores que van de -255 a 255, lo cual es excelente. No obstante, existen formas de optimizar esta capacidad aún más. No entraremos en detalles por ahora, ya que necesitarías conocer algunos conceptos que aún no se han explicado. Aun así, este código 04 es bastante interesante y entretenido.
Ahora veremos qué ocurrió aquí. Dado que value1 es claramente menor que value2, al restar uno del otro, el resultado inicial es negativo, lo que indica que efectivamente value1 es menor. Esto se hace en la línea nueve del código 04. Sin embargo, al restar value2 de value1, como se hace en la línea diez, el resultado es positivo, lo que indica que value2 es mayor que value1. Lo mismo ocurre en la línea once, pero en este caso se comprueba si los valores son iguales. Como el resultado es diferente de cero, sabemos con certeza que los valores no son iguales.
Este tipo de ejercicios resulta muy interesante. Y se vuelve aún más fascinante cuando comprendes que la ALU no contiene una operación de resta. En realidad, cualquier operación que se realice en ella será siempre una suma. Combinada con otras operaciones lógicas. Incluso la propia operación de suma se reduce, en su esencia más profunda, a operaciones lógicas.
Sin embargo, para demostrarlo necesitaríamos emplear algunas funciones de control. Y como aún no se ha explicado ninguna función de control de código, no mostraremos en este artículo cómo se realiza este proceso en la unidad de procesamiento aritmético y lógico (ALU). Pero pronto podremos hacerlo. Ya que entender cómo lograrlo te permitirá usar MQL5 para algo aún más espectacular que crear indicadores, scripts y Expert Advisors.
Todavía no estoy seguro de si mostraré cómo implementar algo de este tipo. Ya que el objetivo es puramente didáctico. Pero lo tendré en cuenta.
De acuerdo, aún falta presentar adecuadamente los operadores de desplazamiento, ya que en la documentación de MQL5 apenas se mencionan. Sin embargo, estos operadores tienen un propósito muy específico y están enfocados en tareas concretas. Por eso, no se utilizan mucho en la mayoría de los códigos comunes en MQL5, especialmente en los destinados a trabajar con indicadores y Expert Advisors. Sin embargo, cuando trabajamos con imágenes dentro de una aplicación hecha en MQL5, estos operadores se utilizan mucho más.
Sin embargo, aunque estén orientados a actividades muy específicas, existen formas de utilizarlos para otras cosas. Una de ellas la exploraremos tan pronto como se explique cómo trabajar con funciones de control.
Consideraciones finales
En este artículo, abordamos ciertos detalles de la programación que marcan la diferencia a la hora de trabajar con un lenguaje que utiliza tipos para clasificar los datos. Sin embargo, aunque hemos tratado conceptos que para muchos podrían ser novedosos, aquí solo hemos rozado la superficie de lo que hay disponible sobre este tema. Por lo tanto, querido lector, te recomiendo que estudies la documentación básica de MQL5 para comprender mejor algunos de los conceptos explicados aquí. También es muy recomendable que estudies un poco sobre lógica booleana. Aunque pueda parecer algo complejo, comprenderla te ayudará a simplificar muchos de los cálculos que normalmente necesitarás realizar en tus códigos. Entender cuándo un valor es positivo o negativo y saber trabajar con esas sutilezas marcará una gran diferencia a largo plazo.
En el anexo, incluiré tres de los cuatro códigos que hemos visto aquí para que puedas estudiarlos con más calma. En el próximo artículo, comenzaremos a tratar las funciones o operadores de control. Entonces, la cosa se pondrá mucho más interesante y la diversión comenzará a tomar forma y sentido. ¡Hasta pronto!
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/15305
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso