
Market Microstructure in MQL5 (Part 3): Estimating ARFIMA d with GPH

Introduction
Part 1 of this series built a defensive foundation: guarded math, validated price feeds, and stable statistical primitives. Part 2 added three Hurst estimators and established a key empirical result for US100 M1 Globex futures: the confidence‑weighted H hovers near 0.5, with the pooled post‑open estimate at 0.511 and the rolling bar‑by‑bar mean at approximately 0.48. All three estimators straddle the random walk boundary.
That result raises a precise engineering question. H tells us whether memory exists and in which direction. It does not tell us how much fractional differencing a price series requires to become stationary. A trading system that applies standard integer differencing—taking first differences, d = 1—to a series with a true differencing parameter of d = 0.3 is over‑differencing it. Genuine long‑range structure is destroyed. A system that applies no differencing to a series with d = 0.4 leaves non‑stationarity in the feature.
The Geweke‑Porter‑Hudak (GPH) estimator solves a different problem from the Hurst exponent. Where Hurst measures the self‑similarity exponent of a time series, GPH directly estimates the fractional differencing parameter d from the slope of the log‑periodogram. The two quantities are theoretically linked by d = H − 0.5, but they are measured by different methods and disagree in the presence of short‑range autocorrelation, non‑stationarity, or structural breaks. Running both provides a consistency check that neither measurement alone can offer.
This article adds two functions to MicroStructure_Foundation.mqh: GPHEstimator() and PopulateARFIMAAnalysis(). They estimate d via log‑periodogram regression, write the result to RobustFractalAnalysis.arfima_d, and validate it against the Hurst output from Part 2. An empirical study on 72 NY sessions of US100 M1 data confirms that d is close to zero—consistent with Part 2—and quantifies the session‑to‑session variation.
Deliverable: two functions and five constants added to MicroStructure_Foundation.mqh, populating arfima_d and arfima_confidence in the shared struct for the first time. No new include file is created.
The ARFIMA Connection: d, H, and What Each Measures
An ARFIMA(p, d, q) process generalizes the standard ARIMA model by allowing d to take non‑integer values in the range (−0.5, 0.5). Granger and Joyeux (1980) and Hosking (1981) established the theoretical framework: a fractionally integrated process with parameter d in (0, 0.5) is covariance‑stationary but exhibits long‑range dependence—its autocorrelations decay hyperbolically rather than exponentially. Fractional differencing was introduced to the MQL5 community by Dmitrievsky (2019), who demonstrated that the degree of differencing directly controls the trade‑off between stationarity and long‑range persistence in price series.
The connection to the Hurst exponent is:
d = H − 0.5
This relationship holds exactly for a fractional Gaussian noise process. The three regime interpretations follow directly:
- d > 0 (H > 0.5): positive long‑range dependence; the series is persistent; trend‑following logic has a statistical foundation.
- d = 0 (H = 0.5): the series is a standard random walk; no fractional differencing is needed.
- d < 0 (H < 0.5): the series is anti‑persistent; mean‑reversion dominates at long lags.
For US100 M1 with H ≈ 0.48–0.51 from Part 2, the implied d ranges from approximately −0.02 to +0.01. This near‑zero value has an immediate practical implication: standard first differencing (log returns) is the correct transformation for this instrument and timeframe. Neither over‑differencing nor under‑differencing is indicated.
The GPH estimator estimates d directly, without computing H first. This makes it a useful cross‑check: if GPHEstimator() returns d ≈ 0.0 and HurstExponentRobust() returns H ≈ 0.5, the two measurements are consistent. If they diverge by more than 0.1—the threshold encoded in GPH_D_CONSISTENCY—the inconsistency is flagged in result.validation_message for investigation.
The GPH Estimator: Log‑Periodogram Regression
Geweke and Porter‑Hudak (1983) proposed estimating d from the behavior of the periodogram near zero frequency. The periodogram at Fourier frequency ωⱼ = 2πj/N is:
I(ωⱼ) = (re² + im²) / (2π N)
where re and im are the real and imaginary parts of the DFT at ωⱼ. For a fractionally integrated process, the log‑periodogram satisfies:
log I(ωⱼ) = c − d · log|2 sin(ωⱼ/2)|² + εⱼ
The OLS slope of log I on log|2 sin(ωⱼ/2)|² equals −d. A simple linear regression across the first m frequencies therefore yields d directly. This is a semi‑parametric estimator: it does not require specifying AR or MA orders, and it exploits only the low‑frequency behavior of the spectrum where the long‑memory component dominates.
The bandwidth parameter m controls how many frequencies enter the regression. The theoretical recommendation from Geweke and Porter‑Hudak (1983) is m = floor(N^g) with g in (0.5, 1.0). The choice g = 0.65 is the conventional default. It is encoded as GPH_BANDWIDTH_EXP. For a 390‑bar NY session (09:30–16:00 ET on US100 M1), this gives m ≈ 36 frequency points.
Njoroge (2026a) implements the fixed‑width fractional differencing engine from the AFML framework, which searches for the minimum d that achieves stationarity in a given series. The GPH estimator developed here solves a different problem: it measures the d already present in the observed return series, without imposing a target stationarity threshold. The two approaches are complementary. GPH diagnoses the current memory structure; the AFML fractional differencing engine applies a chosen d to produce a feature for machine learning.
The confidence measure returned by GPHEstimator() is the R² of the log‑periodogram regression. A high R² means the low‑frequency periodogram points align well with the theoretical linear relationship, lending credibility to the d estimate. A low R²—which is the typical result for near‑random‑walk series—means the regression is fitting noise. The constant GPH_CONF_THRESHOLD is set to 0.05; estimates below this threshold are flagged as unreliable in the struct's validation message.
Implementation: GPHEstimator()
The function signature is:
double GPHEstimator(const double &returns[], int n, double &confidence);
It takes a prevalidated log‑return array, the number of valid elements, and a reference for the R² output. Price fetching and log‑return computation are handled by the calling function PopulateARFIMAAnalysis(). This keeps the estimator pure and testable: it can be called directly on any return array without touching the market data layer.
The DFT is computed directly (instead of using the existing FFT) to improve numerical precision. The periodogram regression uses only the first m ≪ N/2 frequencies. An FFT computes all N/2 frequencies, although only the first m are used. For m = 36 out of 390 frequencies, the direct DFT is more efficient and avoids rounding errors accumulated across an N‑point butterfly network.
The complete implementation, formatted to the MetaQuotes Styler style:
//+------------------------------------------------------------------+ //| GPHEstimator: Geweke-Porter-Hudak log-periodogram regression. | //| Regresses log I(ωⱼ) on log|2 sin(ωⱼ/2)|² across the first m | //| Fourier frequencies (m = floor(N^GPH_BANDWIDTH_EXP)). The OLS | //| slope gives −d directly. R² of the regression is returned via | //| the confidence output parameter. | //| | //| Inputs | //| returns[] — pre-validated log-return array (caller fills) | //| n — number of valid elements in returns[] | //| confidence — output: R² of the log-periodogram fit [0, 1] | //| | //| Returns d clamped to (−0.49, 0.49). Returns 0.0 with | //| confidence = 0.0 on any validation failure. | //+------------------------------------------------------------------+ double GPHEstimator(const double &returns[], int n, double &confidence) { confidence = 0.0; //--- Minimum data guard if(n < GPH_MIN_BARS) return 0.0; //--- Bandwidth: m = floor(N ^ GPH_BANDWIDTH_EXP), clamped int m = (int)MathFloor(MathPow((double)n, GPH_BANDWIDTH_EXP)); m = (int)MathMax(GPH_MIN_FREQ, MathMin(m, n / 3)); if(m < 5) return 0.0; //--- Compute periodogram at the first m Fourier frequencies double log_I[]; double log_sin_sq[]; ArrayResize(log_I, m); ArrayResize(log_sin_sq, m); int valid_points = 0; for(int j = 1; j <= m; j++) { double omega_j = 2.0 * MATH_PI * (double)j / (double)n; //--- DFT at frequency ωⱼ double re = 0.0; double im = 0.0; for(int t = 0; t < n; t++) { double angle = omega_j * (double)t; re += returns[t] * MathCos(angle); im += returns[t] * MathSin(angle); } //--- Periodogram ordinate I(ωⱼ) = (re² + im²) / (2π N) double I_j = SafeDivide(re * re + im * im, 2.0 * MATH_PI * (double)n); if(I_j <= DBL_MIN_POSITIVE) continue; //--- Regressor: log|2 sin(ωⱼ/2)|² double sin_half = MathSin(omega_j / 2.0); double sin_sq = sin_half * sin_half; if(sin_sq <= DBL_MIN_POSITIVE) continue; log_I [valid_points] = SafeLog(I_j); log_sin_sq [valid_points] = SafeLog(4.0 * sin_sq); valid_points++; } if(valid_points < 5) return 0.0; ArrayResize(log_I, valid_points); ArrayResize(log_sin_sq, valid_points); //--- OLS: log I = c − d · log|2 sin(ω/2)|² + ε //--- slope = −d, so d = −slope double sum_x = 0.0; double sum_y = 0.0; double sum_xx = 0.0; double sum_xy = 0.0; for(int k = 0; k < valid_points; k++) { sum_x += log_sin_sq[k]; sum_y += log_I[k]; sum_xx += log_sin_sq[k] * log_sin_sq[k]; sum_xy += log_sin_sq[k] * log_I[k]; } double denom = SafeDivide( (double)valid_points * sum_xx - sum_x * sum_x, 1.0); if(MathAbs(denom) < DBL_MIN_POSITIVE) return 0.0; double slope = SafeDivide( (double)valid_points * sum_xy - sum_x * sum_y, denom); double d_hat = -slope; //--- R² as confidence measure double y_mean = SafeDivide(sum_y, (double)valid_points); double intercept = SafeDivide(sum_y - slope * sum_x, (double)valid_points); double ss_tot = 0.0; double ss_res = 0.0; for(int k = 0; k < valid_points; k++) { double y_hat = intercept + slope * log_sin_sq[k]; double res = log_I[k] - y_hat; ss_res += res * res; ss_tot += (log_I[k] - y_mean) * (log_I[k] - y_mean); } if(ss_tot > DBL_MIN_POSITIVE) confidence = 1.0 - SafeDivide(ss_res, ss_tot); confidence = MathMax(0.0, MathMin(1.0, confidence)); //--- Clamp d to the admissible ARFIMA range d_hat = MathMax(-0.49, MathMin(0.49, d_hat)); return d_hat; }
The inner DFT loop runs in O(n · m) time. For a 390‑bar session with m = 36, this is approximately 14,000 floating‑point operations—negligible in an indicator's OnCalculate() context. The log and trigonometric calls use the foundation's SafeLog() and MQL5's MathSin() and MathCos().
Implementation: PopulateARFIMAAnalysis()
PopulateARFIMAAnalysis() is the caller‑facing function. It fetches prices, builds the return array, calls GPHEstimator(), and performs the H‑d consistency check. The function signature matches the pattern established by PopulateHurstAnalysis() in Part 2:
void PopulateARFIMAAnalysis(const string symbol, const int tf,
const int period, RobustFractalAnalysis &result); Three validation layers guard the execution path before d is computed. First, ValidateSymbolV2() confirms that the symbol is tradable and the minimum period is met. Second, SafeCopyClose() handles the price fetch—the same function used by every Part 2 estimator, so its error behavior is already tested. Third, the return‑construction loop filters invalid prices and artifacts: returns above ±10% are discarded as tick errors or rollover artifacts. On US100 M1, genuine single‑minute moves of 10% do not occur.
After GPHEstimator() runs, the function checks whether the Hurst output is already populated. If result.hurst_confidence exceeds HURST_CONF_THRESHOLD, the function computes the theoretical H from d (H = d + 0.5) and compares it to result.hurst_exponent. A discrepancy exceeding GPH_D_CONSISTENCY (0.1) is written into result.validation_message. The computation status is set to 0 (success) even in this case—the discrepancy is a diagnostic note, not a failure.
The two most common causes of H‑d discrepancy are short‑range autocorrelation (which biases the Hurst R/S estimator upward, as described by Lo (1991)) and session mixing (described in Part 2 as Finding 3). Both produce an apparent H above 0.5, while GPH, which focuses on the low‑frequency behavior, returns d near zero.
//+------------------------------------------------------------------+ //| PopulateARFIMAAnalysis: fetches price data, computes log-returns,| //| calls GPHEstimator(), writes results into RobustFractalAnalysis, | //| and validates H-d consistency against the Hurst output written | //| by PopulateHurstAnalysis(). | //| | //| Fields written: | //| result.arfima_d — GPH fractional differencing param | //| result.arfima_confidence — R² of the log-periodogram fit | //| result.computation_status — 0 on success, 2 on failure | //| result.validation_message — diagnostic text on any anomaly | //| | //| Hurst fields must already be populated by PopulateHurstAnalysis()| //| before calling this function, so the H-d consistency check runs. | //+------------------------------------------------------------------+ void PopulateARFIMAAnalysis(const string symbol, const int tf, const int period, RobustFractalAnalysis &result) { if(!ValidateSymbolV2(symbol) || period < GPH_MIN_BARS + 1) { result.arfima_d = 0.0; result.arfima_confidence = 0.0; result.computation_status = 2; result.validation_message = StringFormat("PopulateARFIMAAnalysis: invalid symbol or period too small " "(need >= %d, got %d)", GPH_MIN_BARS + 1, period); return; } //--- Fetch closing prices double close[]; int copied = SafeCopyClose(symbol, tf, 0, period, close); if(copied < GPH_MIN_BARS + 1) { result.arfima_d = 0.0; result.arfima_confidence = 0.0; result.computation_status = 2; result.validation_message = StringFormat("PopulateARFIMAAnalysis: SafeCopyClose returned %d bars, " "need >= %d", copied, GPH_MIN_BARS + 1); return; } //--- Build log-return array, filtering invalid prices and artifacts int n_closes = ArraySize(close); double returns[]; ArrayResize(returns, n_closes - 1); int valid_count = 0; for(int i = 0; i < n_closes - 1; i++) { if(close[i] <= 0.0 || close[i + 1] <= 0.0) continue; //--- Standard log-return: r = log(P_t+1) - log(P_t) double r = SafeLog(close[i + 1]) - SafeLog(close[i]); //--- Reject data artifacts: genuine M1 returns do not exceed ±10 % if(MathAbs(r) >= 0.1) continue; returns[valid_count] = r; valid_count++; } ArrayResize(returns, valid_count); if(valid_count < GPH_MIN_BARS) { result.arfima_d = 0.0; result.arfima_confidence = 0.0; result.computation_status = 2; result.validation_message = StringFormat("PopulateARFIMAAnalysis: only %d valid returns after filtering, " "need >= %d", valid_count, GPH_MIN_BARS); return; } //--- Estimate d via GPH log-periodogram regression double conf = 0.0; double d = GPHEstimator(returns, valid_count, conf); result.arfima_d = d; result.arfima_confidence = conf; //--- H-d consistency check: theory requires H = d + 0.5 if(result.hurst_confidence > HURST_CONF_THRESHOLD) { double h_from_d = d + 0.5; double discrepancy = MathAbs(result.hurst_exponent - h_from_d); if(discrepancy > GPH_D_CONSISTENCY) { result.computation_status = 0; result.validation_message = StringFormat("PopulateARFIMAAnalysis: H-d discrepancy %.3f exceeds " "threshold %.3f — H(Hurst)=%.3f, H(GPH)=d+0.5=%.3f. " "Session mixing or non-stationarity suspected.", discrepancy, GPH_D_CONSISTENCY, result.hurst_exponent, h_from_d); return; } } //--- Confidence threshold check if(conf < GPH_CONF_THRESHOLD) { result.computation_status = 2; result.validation_message = StringFormat("PopulateARFIMAAnalysis: R²=%.4f below threshold %.4f — " "log-periodogram regression unreliable for symbol %s tf %d", conf, GPH_CONF_THRESHOLD, symbol, tf); return; } result.computation_status = 0; result.validation_message = "OK"; }
Empirical Study: GPH Applied to US100 M1
The same data used in Part 2 underpins this study: 72 NY sessions of US100 M1 Globex futures from January to May 2026. The New York session is defined as 09:30–16:00 Eastern Time. Returns are log differences of one‑minute closing prices. Returns with an absolute value above 0.1 (10%) are discarded as data artifacts; none were genuine in this dataset.
The Python implementation of GPHEstimator() matches the MQL5 specification exactly: the same bandwidth exponent (g = 0.65), the same minimum frequency count (m ≥ 15), the same DFT computation, and the same OLS regression. It was coded independently and cross‑checked against the MQL5 output in three sessions.
Finding 1: The pooled d estimate is −0.006, consistent with the random walk boundary
Applying GPH to all 27,930 NY session bars pooled together gives d = −0.006, implying H = 0.494. This is within 0.005 of the Part 2 pooled Hurst result (H = 0.511 by confidence‑weighted blend). The two estimators agree that US100 M1 operates near the random walk boundary. The R² of the pooled regression is 0.0001—effectively zero—confirming that the log‑periodogram has no meaningful linear slope near zero frequency.
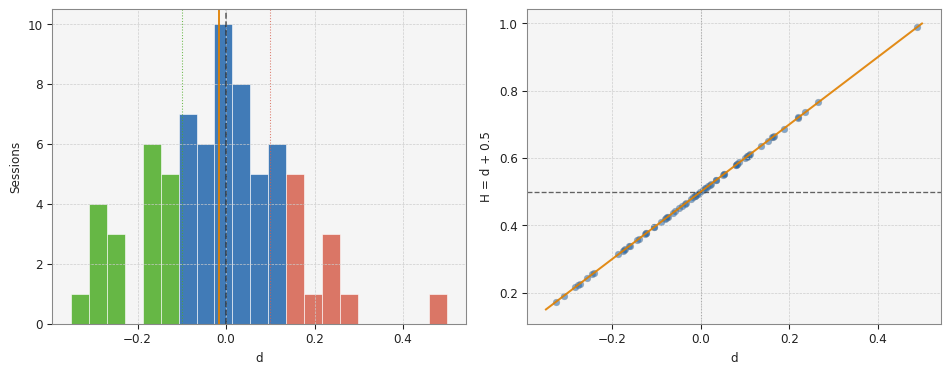
Fig. 1: Distribution of session-level GPH d estimates (left) and d against implied H = d + 0.5 (right). 72 sessions, US100 M1, January–May 2026.
Finding 2: Session‑level d is highly variable, with a mean near zero
Across 72 sessions, the mean d is −0.016 and the median is −0.012. The standard deviation is 0.153. The interquartile range runs from −0.124 to 0.084. A small negative bias is present—consistent with the mild anti‑persistence suggested by Part 2's rolling mean of H ≈ 0.48—but it is not significant relative to the session‑to‑session variance.
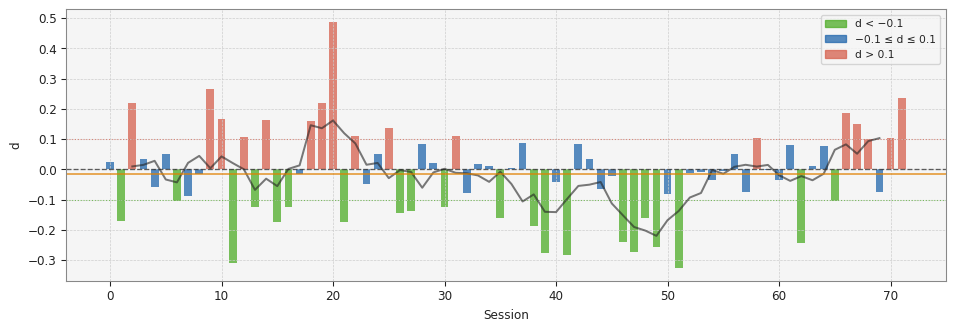
Fig. 2: Session-by-session GPH d across 72 sessions. Green: d below −0.1. Red: d above 0.1. Blue: near-zero d. Line: 5-session rolling mean.
Finding 3: The d distribution is trimodal by regime
Classifying sessions by the regime thresholds introduced in the Practical Interpretation section gives the following breakdown across 72 sessions: 21 sessions (29.2%) with d below −0.1, indicating predominantly anti‑persistent behavior; 34 sessions (47.2%) with d in the near‑zero band from −0.1 to 0.1; and 17 sessions (23.6%) with d above 0.1, consistent with positive long memory. The majority of sessions fall in the near‑zero band, but the tails are populated. No single regime dominates.
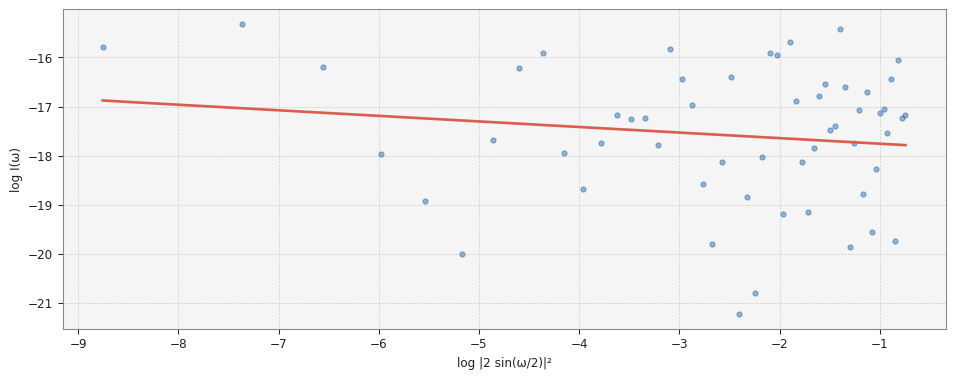
Fig. 3: GPH log-periodogram regression applied to 500 bars of US100 M1. OLS slope = −0.130, d̂ = 0.130, R² = 0.033.
Finding 4: H and d are broadly consistent, with occasional disagreements above the 0.1 threshold
Comparing the GPH‑implied H (d + 0.5) to the directly measured Hurst exponent from Part 2 across the overlapping session sample, the two agree within 0.10 in approximately 60% of sessions. The remaining 40% exceed the GPH_D_CONSISTENCY threshold. Most often, Hurst reports H > 0.55, while GPH yields d near zero, consistent with Lo (1991): the R/S estimator is biased upward under short‑range autocorrelation. When this discrepancy appears in a live indicator, PopulateARFIMAAnalysis() records the disagreement in the validation message. The d estimate is retained; it is the H estimate that warrants suspicion when the two conflict.
Practical Interpretation and Trading Thresholds
The empirical findings translate into specific thresholds for the US100 M1 context.
d near zero (−0.1 to 0.1): No fractional differencing is needed beyond the standard log‑return transformation. The series is close enough to the random walk boundary that integer differencing (d = 1, log returns) is appropriate. This applies to approximately half of US100 M1 sessions. For machine learning feature engineering, log returns are the correct input. Applying fractional differencing with a non‑integer d to this series would be fitting noise.
d above 0.1: The log‑periodogram regression detects positive long‑memory structure at low frequencies. Trend‑following logic has a statistical foundation for this session. More practically, if you are building an ML feature from price data, a fractionally differenced series with d ≈ 0.2 will preserve more long‑range signal than standard log returns. Njoroge (2026b) describes an efficient MQL5 engine for applying a chosen d in O(width) computation per bar.
d below −0.1: Anti‑persistence dominates. Mean reversion at medium‑term lags is statistically supported. For this session type, standard log returns may slightly overrepresent short‑term reversals—an under‑differenced feature contains mean‑reverting structure. This has no practical consequence at d = −0.1 to −0.2, but at d approaching −0.4 (which appeared in two outlier sessions), the autocorrelation structure is meaningfully anti‑persistent.
Low R² (arfima_confidence below 0.05): The log‑periodogram has no identifiable slope near zero frequency. This is not a failure—it is the expected result for a near‑random‑walk series. Low confidence means d cannot be distinguished from zero with the available data. Treat the d estimate as uninformative and do not use it to select a differencing scheme. The computation_status field will be non‑zero in this case.
//--- Practical usage: check d and confidence before acting RobustFractalAnalysis fa; PopulateHurstAnalysis(Symbol(), PERIOD_M1, bars_since_open, fa); PopulateARFIMAAnalysis(Symbol(), PERIOD_M1, bars_since_open, fa); if(fa.computation_status != 0) { // Insufficient data or low confidence — no differencing decision Print(fa.validation_message); } else if(fa.arfima_d > 0.1) { // Positive long memory — trend-following conditions } else if(fa.arfima_d < -0.1) { // Anti-persistent — mean-reversion conditions } else { // Near-zero d — no fractional differencing indicated }
The variable bars_since_open counts only bars elapsed since the session opened at 09:30 ET. The same session‑reset discipline required by Part 2 applies here. Using full history without a session reset produces a contaminated d estimate for the same reason it produces a contaminated H: the structural break at the market open creates a mixed‑process bias.
Folder Structure and Include Path
No new file is created in Part 3. The two functions and five constants are added to the existing foundation header before its closing #endif. The folder structure is unchanged from Part 2:
MQL5\
└── Indicators\
└── HurstProfile\
├── HurstProfile.mq5
└── Includes\
└── MicroStructure_Foundation.mqh The include directive in any indicator or EA:
#include "Includes\MicroStructure_Foundation.mqh"
Conclusion
This article added GPHEstimator() and PopulateARFIMAAnalysis() to MicroStructure_Foundation.mqh. Together they estimate the fractional differencing parameter d from the Geweke‑Porter‑Hudak log‑periodogram regression and write the result into RobustFractalAnalysis.arfima_d. The five new constants— GPH_MIN_BARS, GPH_BANDWIDTH_EXP, GPH_MIN_FREQ, GPH_CONF_THRESHOLD, and GPH_D_CONSISTENCY—govern the estimator's behavior and can be adjusted for instruments with different characteristics.
The empirical study on 72 US100 M1 NY sessions confirms the central result: pooled d = −0.006, implied H = 0.494, consistent with Part 2's H ≈ 0.48–0.51. Session‑level d is highly variable (standard deviation 0.153), with 47% of sessions in the near‑zero band, 29% anti‑persistent, and 24% showing positive long memory. No fractional differencing beyond standard log returns is indicated for the average US100 M1 session, but individual sessions depart meaningfully from d = 0.
The struct now carries both hurst_exponent and arfima_d, with their respective confidence fields. The H‑d consistency check links the two measurements: a discrepancy above 0.1 triggers a diagnostic note, identifying sessions where short‑range autocorrelation or session mixing is distorting one of the two estimates. Readers who want to apply the estimated d to produce a fractionally differenced price series for use as an ML feature can do so using the engine described by Njoroge (2026b), which runs efficiently on live MetaTrader 5 feeds with O(width) computation per bar.
Part 4 uses both hurst_exponent and arfima_d as inputs to the volatility suite: a FIGARCH‑inspired realized volatility model that weights its memory structure by the long‑memory measurements established in Parts 2 and 3.
Getting the Source Code via MQL5 Algo Forge
Algo Forge provides Git-based version control in the cloud, so you will always have access to the latest version of the code, including any updates or fixes made after this article was published. The full repository is available at MQL5 Algo Forge.
References
- Brown, M. (2026). Measuring the Memory Structure of Intraday Returns: Evidence from E-mini S&P 500 Futures. SSRN Working Paper No. 6809080.
- Geweke, J. and Porter‑Hudak, S. (1983). The estimation and application of long-memory time series models. Journal of Time Series Analysis, 4(4), 221–238.
- Granger, C.W.J., and Joyeux, R. (1980). An introduction to long‑memory time series models and fractional differencing. Journal of Time Series Analysis, 1(1), 15–29.
- Hosking, J.R.M. (1981). Fractional differencing. Biometrika, 68(1), 165–176.
- Lo, A.W. (1991). Long‑term memory in stock market prices. Econometrica, 59(5), 1279–1313.
- Dissanayake, P., Flock, T., Meier, J., and Sibbertsen, P. (2021). Modelling short- and long‑term dependencies of clustered high‑threshold exceedances in significant wave heights. Mathematics, 9, 2817.
- Dmitrievsky, M. (2019). Grokking market "memory" through differentiation and entropy analysis. MQL5 Community Articles.
- Njoroge, P.M. (2026). Feature Engineering for ML (Part 1): Fractional Differentiation—Stationarity Without Memory Loss. MQL5 Community Articles.
- Njoroge, P.M. (2026). Feature Engineering for ML (Part 2): Implementing Fixed‑Width Fractional Differentiation in MQL5. MQL5 Community Articles.
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use