
Auf Markov-Ketten basierendes Matrix-Prognosemodell

In den letzten zehn Jahren haben wir den Siegeszug von neuronalen Netzen und Deep Learning erlebt. Aber was wäre, wenn ich Ihnen sagen würde, dass es eine noch tiefere Ebene der Marktanalyse gibt? Auf dieser Ebene treffen fortschrittliche mathematische Konstrukte auf die klassische Markov-Theorie, und uralte Fibonacci-Harmonien werden mit selbstlernenden genetischen Algorithmen verwoben.
Die Finanzmärkte sind ein Kaleidoskop aus Chaos und Ordnung, die in einem einzigen Tanz miteinander verwoben sind. Klassische statistische Ansätze scheitern oft an der Unvorhersehbarkeit der Märkte, und neuronale Netze bleiben bei aller Raffinesse allzu oft geheimnisvolle „Black Boxes“. Zwischen diesen beiden Extremen gibt es einen Mittelweg: probabilistische Modelle, die auf der Vorstellung beruhen, dass die Märkte durch ihren aktuellen Zustand Informationen über ihre Vergangenheit behalten. Eines dieser Modelle – ein auf Markov-Ketten basierendes iteratives Matrix-Prognosemodell – wird in dieser Studie erörtert.
Unser Modell verbindet die Eleganz der mathematischen Wahrscheinlichkeitstheorie mit der praktischen Anwendbarkeit des maschinellen Lernens und stellt den Markt als ein System von Übergängen zwischen diskreten Zuständen dar. Es basiert auf der grundlegenden Beobachtung, dass der Markt trotz seiner scheinbaren Zufälligkeit versteckte Muster enthält, die sich in verschiedenen Kombinationen von technischen Indikatoren, Zeitzyklen und Volumen manifestieren.
Mathematische Grundlagen: Von Markov zur Wall Street
Andrey Markov, ein prominenter Mathematiker des frühen 20. Jahrhunderts, entwickelte bei seiner Arbeit an der Wahrscheinlichkeitstheorie ein Konzept, das ein Jahrhundert später zu einem der Eckpfeiler der modernen Finanzmathematik wurde. Bei der Entwicklung der Theorie der stochastischen Prozesse untersuchte er Ereignisfolgen, bei denen die Zukunft nur vom aktuellen Zustand des Systems, nicht aber von der Vorgeschichte abhängt. Diese grundlegende Eigenschaft – das Fehlen eines „Gedächtnisses“ der Vergangenheit über den aktuellen Zustand hinaus – wurde als „Markov-Eigenschaft“ bezeichnet und bildete die Grundlage für eine ganze Klasse von Modellen.
Eine Markov-Kette ist ein mathematisches System, das in Abhängigkeit von probabilistischen Regeln von einem Zustand in einen anderen übergeht. Stellt man sich die möglichen Zustände eines Systems als Punkte im Raum vor, so beschreibt die Markov-Kette die Wahrscheinlichkeiten der Bewegung zwischen diesen Punkten. Die verblüffende Eleganz dieses Konzepts liegt in seiner Fähigkeit, unglaublich komplexe Prozesse durch einfache probabilistische Gesetzmäßigkeiten zu modellieren.
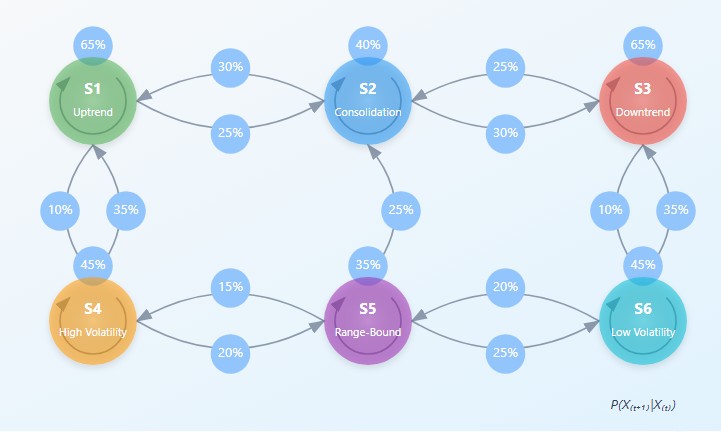
Mathematisch wird eine Markov-Kette durch eine Matrix von Übergangswahrscheinlichkeiten P definiert, wobei das Element P(i,j) die Wahrscheinlichkeit des Übergangs vom Zustand i zum Zustand j darstellt. Die Grundgleichung einer Markov-Kette kann wie folgt geschrieben werden:
π(t+1) = π(t) · P wobei π(t) der Vektor der Wahrscheinlichkeiten ist, dass sich das System zum Zeitpunkt t in jedem der Zustände befindet.
Von diskreten Zuständen zu kontinuierlichen Prozessen
Klassische Markov-Ketten arbeiten mit diskreten Zuständen und diskreter Zeit, was sie ideal für die Modellierung von Systemen wie Preisniveaus, Marktregimes oder Handelssitzungen macht. Die Theorie der Markov-Prozesse ist jedoch nicht auf diskrete Modelle beschränkt. Es gibt kontinuierliche Markov-Prozesse, von denen der berühmteste der Wiener-Prozess ist, ein mathematisches Modell der Brownschen Bewegung, das dem berühmten Black-Scholes-Modell für die Optionsbewertung zugrunde liegt.
Hidden Markov Models (HMMs) stellen eine weitere wichtige Erweiterung dar, bei der der wahre Zustand des Systems nicht direkt beobachtbar ist, sondern nur indirekte Beobachtungen zur Verfügung stehen. Dies ist besonders wichtig für Finanzmärkte, auf denen echte „Marktregimes“ (z. B. „Aufwärtstrend“ oder „Konsolidierung“) nicht direkt beobachtbar sind, sondern nur aus beobachteten Preisbewegungen und Volumina abgeleitet werden können.
Die Finanzmärkte bieten ein ideales Testfeld für die Anwendung von Markov-Modellen. Die Hypothese des effizienten Marktes in ihrer schwachen Form besagt, dass künftige Preise nicht aus vergangenen Preisen vorhergesagt werden können, was die Markov-Eigenschaft für Preisreihen postuliert. Obwohl die vollständige Übereinstimmung der Märkte mit einem Markov-Prozess umstritten ist, bestätigt die Empirie, dass Markov-Näherungen für viele praktische Probleme erstaunlich genaue Ergebnisse liefern.
Im Zusammenhang mit dem Handel haben Markov-Modelle in verschiedenen Bereichen Anwendung gefunden:
- Vorhersage von Kursbewegungen – Verwendung historischer Statistiken über Marktübergänge zur Vorhersage wahrscheinlicher künftiger Bewegungen.
- Erkennung von Marktregimen – automatische Klassifizierung des aktuellen Marktzustands als Trend, Seitwärtsbewegung oder Übergang.
- Optimierung von Handelssystemen – Anpassung der Strategieparameter an den erkannten Marktzustand.
- Risikobewertung – Berechnung der Wahrscheinlichkeiten großer Kursbewegungen auf der Grundlage des aktuellen Zustands und bekannter Übergangsstatistiken.
Übergangsmatrix: Algebra der Marktwahrscheinlichkeiten
Das zentrale Element eines Markov-Modells ist die Übergangsmatrix – eine Tabelle, in der die Zeilen den aktuellen Zuständen und die Spalten den zukünftigen Zuständen entsprechen und die Elemente die Wahrscheinlichkeiten der entsprechenden Übergänge darstellen. Für einen Finanzmarkt, der in n Zustände unterteilt ist, hat die Übergangsmatrix P die Größe n×n, wobei jede Zeile die Summe eins ergibt (da das System in einen bestimmten Zustand übergehen sollte).
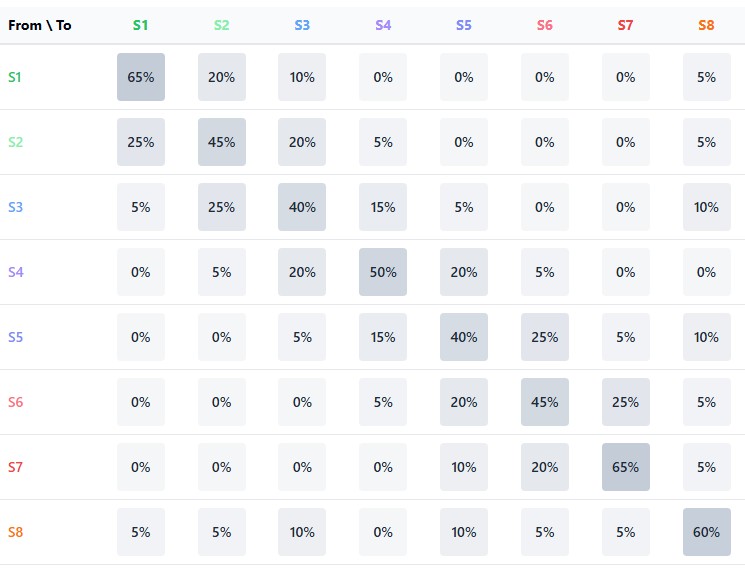
Die Stärke des Markov-Ansatzes liegt in der Möglichkeit, diese Matrix iterativ anzuwenden, um mehrstufige Prognosen zu erhalten. Die Wahrscheinlichkeit des Übergangs vom Zustand i zum Zustand j nach k Schritten kann als das entsprechende Element der P^k-Matrix (P hoch k) berechnet werden. Dadurch können wir weiter in die Zukunft blicken, obwohl die Genauigkeit der Vorhersagen in der Regel mit zunehmendem Prognosehorizont abnimmt.
Von besonderem Interesse ist das Grenzverhalten der Markov-Kette bei k→∞, das die langfristige Gleichgewichtsverteilung der Zustandswahrscheinlichkeiten beschreibt. Für ergodische Ketten (bei denen man von jedem Zustand aus jeden anderen in einer endlichen Anzahl von Schritten erreichen kann) gibt es eine einzige stationäre Verteilung π*, die die Gleichung erfüllt:
π* = π* · P
Diese stationäre Verteilung zeigt, welchen Anteil der Zeit das System langfristig in jedem seiner Zustände verbringt, unabhängig vom Ausgangszustand. Für die Finanzmärkte kann dies als die grundlegende Struktur von Marktregimen in Abwesenheit von externen Schocks interpretiert werden.
Von der Theorie zur Praxis: Lernen von Markov-Modellen
Die Implementierung eines Markov-Modells für Finanzmärkte erfordert die Lösung von zwei Schlüsselproblemen: die Bestimmung von Zuständen und die Schätzung von Übergangswahrscheinlichkeiten.
Die Bestimmung der Zustände kann auf verschiedene Weise erfolgen:
- Expertenbasierte Definition – wenn Zustände auf der Grundlage von technischen Indikatoren und Schwellenwerten definiert werden, die von einem Expertenanalysten festgelegt wurden.
- Clustering – Einsatz von Algorithmen wie K-Means oder hierarchischem Clustering zur automatischen Erkennung natürlicher Gruppierungen in einem mehrdimensionalen Merkmalsraum.
- Quantisierung – Unterteilung kontinuierlicher Indikatoren in diskrete Stufen, aus deren Kombination Zustände gebildet werden.
In unserem Ansatz verwenden wir das K-Means-Clustering separat für jede Gruppe von Faktoren (Preis, Zeit, Volumen), wodurch wir die Interpretierbarkeit der Zustände erhalten und sie gleichzeitig effizient aus den Daten extrahieren können:
def create_state_clusters(feature_groups, n_clusters_per_group=3): for group_name, group_data in feature_groups.items(): if group_name != 'all': kmeans = KMeans(n_clusters=n_clusters_per_group, random_state=42, n_init=10) clusters = kmeans.fit_predict(group_data['data']) group_clusters[group_name] = clusters kmeans_models[group_name] = kmeansDie Übergangswahrscheinlichkeiten werden auf der Grundlage der Häufigkeit der entsprechenden Ereignisse in historischen Daten geschätzt:
for i in range(len(states) - 1): curr_state = states[i] next_state = states[i + 1] # Increase the transition counter transition_matrix[curr_state, next_state] += 1 # If the next candle is bullish, increase the rise counter if i + 1 < len(labels) and labels[i + 1] == 1: rise_matrix[curr_state, next_state] += 1 # Normalization of the transition matrix for i in range(9): row_sum = np.sum(transition_matrix[i, :]) if row_sum > 0: state_transitions[i, :] = transition_matrix[i, :] / row_sum
Dieses Verfahren erfordert ausreichende historische Daten, um statistisch signifikante Schätzungen zu erhalten, insbesondere für seltene Übergänge. Das Problem der spärlichen Daten wird durch verschiedene Glättungsmethoden angegangen, vom einfachen Hinzufügen von Pseudo-Zählern bis hin zu einem bayesschen Ansatz mit Priorverteilungen für die Modellparameter.
Die Dreifaltigkeit der Marktkräfte: Preis, Zeit, Volumen
Der traditionelle Ansatz der Marktanalyse konzentriert sich häufig ausschließlich auf die Preisdynamik. Der Markt ist jedoch ein multidimensionales Phänomen, bei dem der Preis nur die Spitze des Eisbergs ist. Unsere Methode basiert auf der Unterteilung der Marktdaten in drei miteinander verbundene Gruppen von Faktoren:
- Preisindikatoren sind klassische Instrumente der technischen Analyse, zu denen Trends, gleitende Durchschnitte, Oszillatoren und Kerzenmuster gehören. Sie beantworten die Frage, was auf dem Markt passiert.
- Zeitzyklen stellen die Marktsaisonalität auf verschiedenen Ebenen dar, von Intraday-Sitzungen bis hin zu monatlichen Zyklen. Sie beantworten die Frage, wann bedeutende Bewegungen am wahrscheinlichsten sind.
- Volumenindikatoren spiegeln die Intensität und die Art der Aktivitäten der Marktteilnehmer wider, einschließlich der Dynamik des Tick-Volumens und spezieller Akkumulations-/Verteilungsindikatoren. Sie zeigen auf, wie und warum es zu Preisänderungen kommt.
Diese dreidimensionale Darstellung des Marktes ermöglicht es, subtile Interaktionen zwischen verschiedenen Aspekten der Marktdynamik zu erfassen. Der Code extrahiert diese Informationen wie folgt:
def add_indicators(df): # --- PRICE INDICATORS --- df['ema_9'] = df['close'].ewm(span=9, adjust=False).mean() df['ema_21'] = df['close'].ewm(span=21, adjust=False).mean() df['ema_50'] = df['close'].ewm(span=50, adjust=False).mean() df['ema_cross_9_21'] = (df['ema_9'] > df['ema_21']).astype(int) df['ema_cross_21_50'] = (df['ema_21'] > df['ema_50']).astype(int) # --- TIME INDICATORS --- df['hour'] = df['time'].dt.hour df['day_of_week'] = df['time'].dt.dayofweek df['hour_sin'] = np.sin(2 * np.pi * df['hour'] / 24) df['hour_cos'] = np.cos(2 * np.pi * df['hour'] / 24) # --- VOLUME INDICATORS --- df['tick_volume'] = df['tick_volume'].astype(float) df['volume_change'] = df['tick_volume'].pct_change(1) df['volume_ma_14'] = df['tick_volume'].rolling(14).mean() df['rel_volume'] = df['tick_volume'] / df['volume_ma_14']
Das Modell legt besonderen Wert auf die zyklische Darstellung von Zeitdaten durch sinusförmige Transformationen. So wird zum Beispiel die Stunde des Tages in ein Paar von sin/cos-Koordinaten umgewandelt, was es dem Modell ermöglicht, den Tageszyklus auf natürliche Weise zu erfassen, ohne Lücken zwischen 23:59 und 00:00 Uhr zu haben.
Vom Chaos zur Ordnung: Quantisierung der Marktzustände
Der Kerngedanke des Modells ist der Übergang von kontinuierlichen Daten zu diskreten Marktzuständen – eine Art „Regime“, von denen jedes seine eigenen Merkmale und sein eigenes probabilistisches Verhalten hat. Zu diesem Zweck wird das Clustering nach der K-Means-Methode für jede Gruppe von Faktoren getrennt durchgeführt:
def create_state_clusters(feature_groups, n_clusters_per_group=3): group_clusters = {} kmeans_models = {} for group_name, group_data in feature_groups.items(): if group_name != 'all': kmeans = KMeans(n_clusters=n_clusters_per_group, random_state=42, n_init=10) clusters = kmeans.fit_predict(group_data['data']) group_clusters[group_name] = clusters kmeans_models[group_name] = kmeans return group_clusters, kmeans_models
Jede Merkmalsgruppe (Preis, Zeit, Volumen) wird in drei Cluster unterteilt, was theoretisch 27 mögliche Marktzustände ergibt. Der Einfachheit halber werden bei der derzeitigen Umsetzung nur 9 Zustände verwendet, die die wichtigsten Kombinationen von Marktbedingungen darstellen. Dieser Ansatz ermöglicht ein Gleichgewicht zwischen der Detailgenauigkeit des Modells und der Robustheit seiner statistischen Schätzungen.
Der besondere Wert des Clustering liegt in seiner Fähigkeit, automatisch und ohne vorherige Annahmen natürliche Gruppierungen in Daten zu entdecken. So kann das Modell beispielsweise Phasen hoher Volatilität, eine Konsolidierung oder einen Richtungstrend allein auf der Grundlage der Struktur historischer Daten selbstständig erkennen.
Wahrscheinlichkeitsmatrix: Das Herzstück der Prognosen
Die zentralen Elemente des Modells sind zwei Matrizen: die Matrix der Übergänge zwischen den Zuständen und die Matrix der Anstiegswahrscheinlichkeiten für jeden Übergang. Zusammen bilden sie eine Markov-Kette, bei der der zukünftige Zustand nur vom aktuellen Zustand, nicht aber von der Vorgeschichte abhängt:
def combine_state_clusters(group_clusters, labels): # Fill the transition matrix and rise matrix for i in range(len(states) - 1): curr_state = states[i] next_state = states[i + 1] # Increase the transition counter transition_matrix[curr_state, next_state] += 1 # If the next candle is bullish, increase the rise counter if i + 1 < len(labels) and labels[i + 1] == 1: rise_matrix[curr_state, next_state] += 1 # Normalization of the transition matrix state_transitions = np.zeros((9, 9)) for i in range(9): row_sum = np.sum(transition_matrix[i, :]) if row_sum > 0: state_transitions[i, :] = transition_matrix[i, :] / row_sum
Die Übergangsmatrix enthält die Wahrscheinlichkeiten für den Übergang von einem Zustand in einen anderen und spiegelt die dynamische Struktur des Marktes wider. Beispielsweise kann der Markt nach einer Konsolidierungsphase mit einer gewissen Wahrscheinlichkeit in eine Richtungsbewegung übergehen oder sich weiterhin seitwärts bewegen.
Die Matrix der Aufwärtswahrscheinlichkeiten geht noch weiter, indem sie für jeden Übergang die Wahrscheinlichkeit angibt, dass die nächste Kerze bullisch sein wird (der Schlusskurs ist höher als der Eröffnungskurs). So können wir nicht nur die nächste Marktlage vorhersagen, sondern auch die Richtung der Kursbewegung.
Die Visualisierung dieser Matrizen offenbart überraschende Marktmuster. Einige Zustände weisen beispielsweise eine starke Tendenz zur Selbstreproduktion auf und bilden stabile Regime, während andere vorübergehend sind und schnell in neue Regime übergehen. Diese Asymmetrie in der Struktur der Übergänge ist der Schlüssel zum Verständnis der Marktdynamik.
Iterative Vorhersage: Blick über den Horizont hinaus
Die Leistungsfähigkeit des Markov-Modells zeigt sich bei der iterativen Vorhersage, wenn die Vorhersage als gewichtete Summe von Wahrscheinlichkeiten über alle möglichen Ereignistrajektorien konstruiert wird:
def predict_with_matrix(state_transitions, rise_probability_matrix, current_state): # Probabilities of transition to the next state next_state_probs = state_transitions[current_state, :] # Calculation of the weighted rise probability taking into account all possible transitions weighted_prob = 0 total_prob = 0 for next_state, prob in enumerate(next_state_probs): weighted_prob += prob * rise_probability_matrix[current_state, next_state] total_prob += prob # Normalization (if necessary) if total_prob > 0: weighted_prob = weighted_prob / total_prob # Forecast prediction = 1 if weighted_prob > 0.5 else 0 confidence = max(weighted_prob, 1 - weighted_prob)
Im Gegensatz zu binären Vorhersagen liefert unser Modell ein vollständiges probabilistisches Bild, das auch den Grad des Vertrauens in die Vorhersage umfasst. Dies ist entscheidend, um fundierte Handelsentscheidungen mit angemessenem Risikomanagement zu treffen.
Der iterative Charakter des Modells zeigt sich auch in seiner Fähigkeit, nicht nur die unmittelbar nächste Kerze vorherzusagen, sondern auch einen Wahrscheinlichkeitsbaum möglicher Szenarien mehrere Schritte voraus zu konstruieren. Dieser Ansatz zeigt langfristige Trends auf, die mit einer einstufigen Vorhersage nicht zugänglich sind.
Bedeutung sichtbar machen: Interpretierbarkeit und Transparenz
Einer der Hauptvorteile des Markov-Modells gegenüber den „Black Boxes“ der neuronalen Netze ist seine vollständige Transparenz und Interpretierbarkeit. Jeder Zustand und jeder Übergang hat eine klare statistische Bedeutung, die es nicht nur ermöglicht, Prognosen zu erstellen, sondern auch die Marktlogik zu verstehen.
Eine Analyse des Einflusses einzelner Faktoren auf die Klassifizierung von Staaten zeigt die relative Bedeutung verschiedener Indikatoren:
for group_name in ['price', 'time', 'volume']: features = feature_groups[group_name]['features'] kmeans = kmeans_models[group_name] cluster_centers = kmeans.cluster_centers_ for cluster_idx in range(3): center = cluster_centers[cluster_idx] # We obtain the importance of each feature as its deviation from zero at the center of the cluster importances = np.abs(center) sorted_idx = np.argsort(-importances) top_features = [(features[i], importances[i]) for i in sorted_idx[:3]]
Diese Informationen ermöglichen es dem Händler, sich auf die wichtigsten Indikatoren für das aktuelle Marktregime zu konzentrieren und das Rauschen der uninformativen Faktoren zu ignorieren. Darüber hinaus entsprechen die Merkmale der Zustände oft den klassischen Marktmustern: Trend, Konsolidierung, Umkehrung, was eine Brücke zwischen statistischer Modellierung und traditioneller technischer Analyse schlägt.
Jenseits des Binären: Abstufungen des Vertrauens
Die Vorhersagegenauigkeit im Finanzwesen ist ein umstrittenes Konzept. Sogar ein Zufallsmodell kann 50 % korrekte Vorhersagen über die Kursrichtung liefern. Der wahre Wert unseres Modells zeigt sich bei der Analyse der Abstufungen des Prognosevertrauens:
bins = [0.5, 0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95, 1.0] confidence_groups = np.digitize(confidences, bins) accuracy_by_confidence = {} for bin_idx in range(1, len(bins)): bin_mask = (confidence_groups == bin_idx) if np.sum(bin_mask) > 0: bin_accuracy = np.mean([1 if predictions[i] == test_labels[i+1] else 0 for i in range(len(predictions)) if bin_mask[i] and i+1 < len(test_labels)]) accuracy_by_confidence[f"{bins[bin_idx-1]:.2f}-{bins[bin_idx]:.2f}"] = (bin_accuracy, np.sum(bin_mask))
Diese Analyse zeigt, dass Vorhersagen mit hohem Vertrauen (>70 %) eine Genauigkeit von bis zu 68-70 % erreichen und damit deutlich über dem zufälligen Raten liegen. Dies ist ein entscheidender Vorteil im realen Handel, da Sie sich auf die vielversprechendsten Signale konzentrieren und unsichere Situationen überspringen können.
Von besonderer Bedeutung ist, dass eine hohe Prognosezuversicht mit bestimmten Marktzuständen korreliert, was es uns ermöglicht, günstige Handelssituationen in einem frühen Stadium ihrer Entstehung zu erkennen.
Empirische Ergebnisse: EURUSD-Test
Das Modell wurde an historischen Stundendaten des Währungspaares EURUSD getestet, einem der liquidesten und technisch komplexesten Instrumente. Das Training wurde mit 80 % der historischen Daten durchgeführt, gefolgt von einer Validierung mit den verbleibenden 20 % der Zeitreihen.
Die Gesamtgenauigkeit des Modells bei der Teststichprobe lag bei etwa 55 %, was den theoretischen Breakeven beim Handel mit gleichen Positionsgrößen deutlich übersteigt. Bei Prognosen mit hohem Vertrauen (oberes Quartil der Verteilung) erreichte die Genauigkeit 65-70 %.
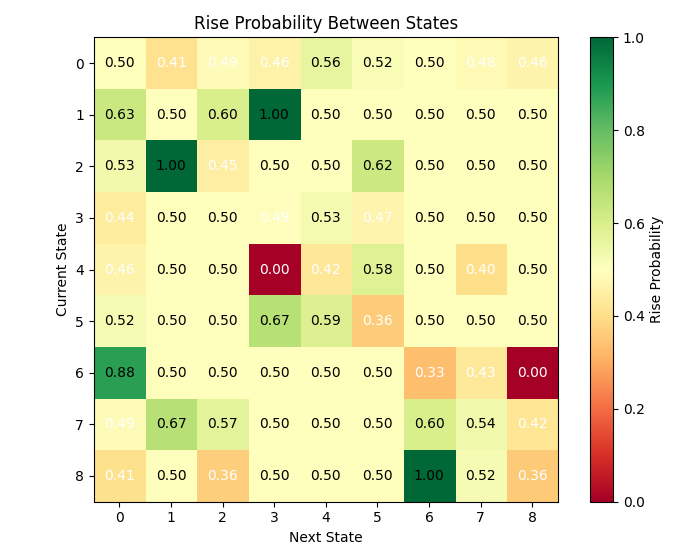
Wie wir sehen können, gibt es viele Zustände, die relativ hohe Übergangswahrscheinlichkeiten aufweisen. Kann dies als Herausforderung für eine erfolgreiche Matrixprognose betrachtet werden?
Die Analyse der Zustände ergab ein interessantes Muster: Einige Zustände zeichnen sich durch eine ausgeprägte Tendenz der Preisentwicklung in eine bestimmte Richtung aus. So wies beispielsweise der Zustand 3 (gekennzeichnet durch hohe relative Volatilität, eine europäische Handelssitzung und ein sinkendes Volumen) eine Wahrscheinlichkeit von mehr als 60 % für einen Kursanstieg auf.
Das folgende Diagramm zeigt das Clustering von RSI und Momentum:
Jenseits binärer Prognosen: Praktische Anwendungen
Obwohl wir uns in diesem Artikel auf die Vorhersage der binären Preisrichtung konzentrieren, bietet das Markov-Modell viel breitere Möglichkeiten. Hier sind einige der alternativen Verwendungsmöglichkeiten:
- Mehrklassen-Klassifizierung – Vorhersage nicht nur der Richtung, sondern auch des Ausmaßes der Bewegung (starker Anstieg, moderater Anstieg, Seitwärtsbewegung, moderater Rückgang, starker Rückgang).
- Erkennung von Marktregimen – automatische Klassifizierung der aktuellen Marktzustände zur Anpassung der Handelsstrategie.
- Signalfilterung – Verwendung des Modells als zusätzlicher Filter für traditionelle technische Signale, um deren Spezifität zu erhöhen.
- Volatilitätseinschätzung – Vorhersage nicht nur der Richtung, sondern auch der erwarteten Volatilität, die für die korrekte Positionsgröße und Stop-Loss-Einstellungen entscheidend ist.
Die derzeitige Umsetzung des Modells ist erst der Anfang. Einige vielversprechende Entwicklungsbereiche sind:
- Adaptives Clustering – dynamische Bestimmung der optimalen Anzahl von Clustern für jede Merkmalsgruppe anhand interner Qualitätsmetriken.
- Integration mit Fundamentaldaten – Einbeziehung von makroökonomischen Indikatoren und Nachrichtenstimmung als zusätzliche Faktorengruppen.
- Hierarchische Markov-Modelle – Berücksichtigung der Abhängigkeiten zwischen Zuständen verschiedener Zeitrahmen zur Erstellung einer multiskaligen Prognose.
- Adaptives Lernen – kontinuierliche Aktualisierung der Übergangsmatrizen unter Berücksichtigung aktueller Marktdaten zur Anpassung an sich ändernde Marktbedingungen.
Schlussfolgerung: Das Chaos durch Wahrscheinlichkeit nutzen
Die Finanzmärkte balancieren auf der Grenze zwischen deterministischem Chaos und stochastischer Ordnung. Das iterative Markov-Ketten-Matrix-Modell stellt einen eleganten Kompromiss zwischen der Strenge des statistischen Ansatzes und den Feinheiten der technischen Analyse dar.
Im Gegensatz zu den „Black Boxes“ des maschinellen Lernens bietet es eine völlig transparente und interpretierbare Sicht auf die Marktdynamik, indem es den Markt als ein System von probabilistischen Übergängen zwischen diskreten Zuständen darstellt. Dieses Konzept ist nicht nur mathematisch rigoros, sondern auch intuitiv ansprechend für erfahrene Händler, die von Natur aus in Marktregimen und den Übergängen zwischen diesen denken.
Die Ergebnisse, die für das Währungspaar EURUSD erzielt wurden, zeigen das Potenzial des Modells für den realen Handel, insbesondere bei Prognosen mit hoher Sicherheit. Die Weiterentwicklung des Ansatzes verspricht eine noch größere Genauigkeit und Vielseitigkeit in der Anwendung.
Letztlich erinnern uns die Markov-Modelle daran, dass es selbst im scheinbaren Chaos des Marktes Strukturen und Muster gibt. Und obwohl die Zukunft nie völlig sicher ist, gibt uns das probabilistische Denken ein Instrument an die Hand, mit dem wir durch den Ozean der Marktunsicherheit navigieren können.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/18097
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Gute Arbeit!!! Besonders gut hat mir gefallen, wie Sie in Preis, Zeit und Volumen aufgeteilt haben - das ist ein wirklich intelligenter Ansatz. Die Tests an EUR/USD sehen vielversprechend aus.
Aber wie wird sich das Modell bei starken Marktveränderungen wie bei Covid verhalten? Wenn die Übergangsmatrix auf historischen Daten aufgebaut wurde, wie wird sie sich dann an solche extremen Bedingungen anpassen können?
Es wäre interessant zu wissen, ob das Modell an anderen Paaren als EUR/USD getestet wurde? Gibt es eingebaute Mechanismen zur Anpassung an starke Veränderungen der Volatilität? Planen Sie, fundamentale Faktoren wie makroökonomische Nachrichten zu berücksichtigen?