
基于马尔可夫链的矩阵预测模型

过去十年,我们见证了神经网络与深度学习的成功。但如果我告诉您,市场分析还存在更深层次的方法呢?在该层面,前沿数学结构与经典马尔可夫理论相遇,古老的斐波那契和谐关系被编织进自学习遗传算法之中。
金融市场是混沌与秩序的万花筒,二者交织共舞。传统统计方法常因市场的不可预测性而失效,神经网络尽管复杂,却往往是难以解释的 “黑箱”。在这两种极端之间,存在一条中间道路:概率模型。其核心思想是市场会通过当前状态隐含过往信息。本文要介绍的正是这类模型之一:基于马尔可夫链的矩阵迭代预测模型。
我们的模型将数学概率论的简洁优雅与机器学习的实用性相结合,把市场描述为离散状态间的转移系统。其核心灵感来自这一基本观察:尽管市场看似随机,却隐藏着规律,这些规律通过技术指标、时间周期与成交量的不同组合显现出来。
数学基础:从马尔可夫到华尔街
安德烈・马尔可夫(Andrey Markov)是20世纪初杰出的数学家。他在概率论研究中提出的概念,一个世纪后成为现代金融数学的基石之一。在随机过程理论中,他研究了这样一类事件序列:未来仅取决于系统当前状态,与更早的历史无关。这一核心特性 —— 除当前状态外,不再“记忆”更早的历史 —— 被称为“马尔可夫性”,并成为一整类模型的基础。
马尔可夫链是一个数学系统,它按照概率规则从一种状态转移到另一种状态。如果把系统的可能状态看作空间中的点,马尔可夫链就描述了这些点之间移动的概率。这一概念的惊人简洁之处在于,它能用简单的概率机制,对极其复杂的过程进行建模。
在数学上,马尔可夫链通过转移概率矩阵P来定义,其中元素P(i,j)表示从状态i转移到状态j的概率。马尔可夫链的核心方程可写作:
π(t+1) = π(t) · P 其中π(t)为系统在时刻t处于各状态的概率向量。
从离散状态到连续过程
经典马尔可夫链基于离散状态与离散时间,非常适合对价格区间、市场状态、交易时段等系统进行建模。然而,马尔可夫过程理论并不局限于离散模型。马尔可夫过程理论还包括连续型模型,其中最著名的例子是维纳过程 —— 它是布朗运动的数学描述,也是经典期权定价模型Black-Scholes(布莱克 - 斯科尔斯) 的理论基础。
隐马尔可夫模型(HMMs) 是另一重要扩展。在这类模型中,系统的真实状态无法直接观测,只能通过间接信号推断。这一点与金融市场高度契合:市场真实的 “状态”(如“牛市趋势”或“横盘震荡”)无法直接观察,只能从价格走势与成交量中间接推导。
金融市场是马尔可夫模型极为理想的应用场景。弱式有效市场假说认为,无法通过历史价格预测未来价格,这实际上等价于假定价格序列满足马尔可夫性。尽管市场是否完全符合马尔可夫过程仍存在争议,但实证结果表明,在大量实际问题中,马尔可夫近似能取得出人意料的精准效果。
在交易领域,马尔可夫模型已被应用于多个方向:
- 价格走势预测 —— 利用历史市场状态转移统计,预测未来可能的运行方向。
- 市场状态识别 —— 自动将当前市场划分为趋势、横盘或过渡阶段。
- 交易系统优化 —— 根据识别出的市场状态动态调整策略参数。
- 风险评估 —— 基于当前状态与已知转移概率,计算价格大幅波动的可能。
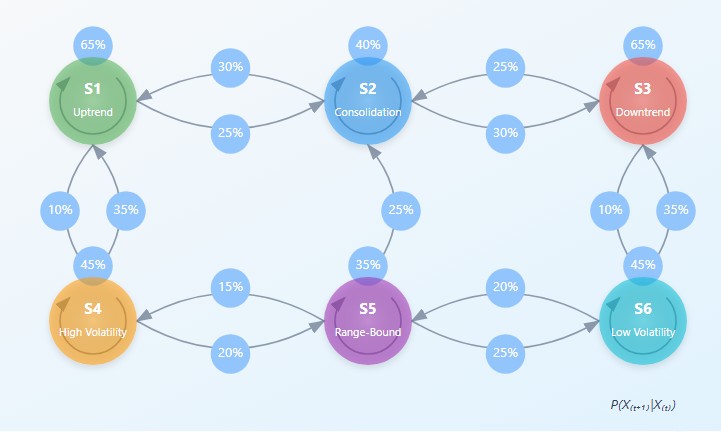
转移矩阵:市场概率的代数表达
马尔可夫模型的核心是转移矩阵:一个以当前状态为行、未来状态为列、元素为对应转移概率的表格。对于划分为n个状态的金融市场,转移矩阵P为n×n阶矩阵,且每一行元素之和为1(系统必然会转移到某个状态)。
马尔可夫方法的优势在于可以迭代应用该矩阵,从而实现多步预测。从状态i经过k步转移到状态j的概率,可通过矩阵P^k(P的k次幂)中对应位置的元素计算得出。这样使我们能够对更远期的未来进行预测,尽管随着预测步长增加,预测精度通常会随之下降。
特别值得关注的是当k→∞时马尔可夫链的极限行为,其描述了状态概率的长期均衡分布。对于遍历链(从任意状态出发,均可在有限步内到达其他任意状态的马尔可夫链),存在唯一的平稳分布π*,满足方程:
π* = π* · P
该平稳分布表明,从长期来看,无论初始状态如何,系统在各个状态上停留的时间占比是固定的。对金融市场而言,这可以理解为在无外部冲击下,市场状态的内在结构。
从理论到实践:马尔可夫模型的训练
将马尔可夫模型应用于金融市场,需要解决两个核心问题:状态定义与转移概率估计。
状态的划分可以通过多种方式实现:
- 专家定义法 —— 由分析师根据技术指标与预设阈值手动划分市场状态。
- 聚类法 —— 使用K-means、层次聚类等算法,在市场特征构成的高维空间中自动识别自然分组。
- 离散化法 —— 将连续型指标划分为若干离散等级,再以这些等级组合形成市场状态。
在我们的方法中,对价格、时间、成交量等各类因子分别使用K-means聚类,既能保证状态具有可解释性,又能高效地从数据中提取特征。
def create_state_clusters(feature_groups, n_clusters_per_group=3): for group_name, group_data in feature_groups.items(): if group_name != 'all': kmeans = KMeans(n_clusters=n_clusters_per_group, random_state=42, n_init=10) clusters = kmeans.fit_predict(group_data['data']) group_clusters[group_name] = clusters kmeans_models[group_name] = kmeans转移概率通过统计历史数据中对应事件的出现频次来估算:
for i in range(len(states) - 1): curr_state = states[i] next_state = states[i + 1] # Increase the transition counter transition_matrix[curr_state, next_state] += 1 # If the next candle is bullish, increase the rise counter if i + 1 < len(labels) and labels[i + 1] == 1: rise_matrix[curr_state, next_state] += 1 # Normalization of the transition matrix for i in range(9): row_sum = np.sum(transition_matrix[i, :]) if row_sum > 0: state_transitions[i, :] = transition_matrix[i, :] / row_sum
此过程需要足够的历史数据,才能得到具有统计显著性的估计结果,对于那些罕见的状态转移尤为如此。针对数据稀疏的问题,可通过多种平滑方法加以解决:从简单地添加伪计数,到对模型参数施加先验分布的贝叶斯方法。
市场三要素:价格、时间、成交量
传统市场分析方法往往只聚焦于价格走势。然而,市场是一个多维系统,价格仅仅是冰山一角。我们的方法将市场数据划分为三类相互关联的因子:
- 价格指标作为经典技术分析工具,包含趋势、移动平均线、震荡指标及K线形态。它们回答了市场正在发生什么。
- 时间周期代表不同程度上市场的季节性,从日内交易时段到月度周期。它们回答了重大行情最可能在何时出现。
- 成交量指标反映市场参与者的交易强度与行为特征,包括分时成交量动态、专用的累积/派发指标等。它们揭示了价格为何变动以及如何变动。
这种对市场的三维刻画,能够捕捉市场不同维度运行之间的微妙联动。代码将通过以下方式提取这些信息:
def add_indicators(df): # --- PRICE INDICATORS --- df['ema_9'] = df['close'].ewm(span=9, adjust=False).mean() df['ema_21'] = df['close'].ewm(span=21, adjust=False).mean() df['ema_50'] = df['close'].ewm(span=50, adjust=False).mean() df['ema_cross_9_21'] = (df['ema_9'] > df['ema_21']).astype(int) df['ema_cross_21_50'] = (df['ema_21'] > df['ema_50']).astype(int) # --- TIME INDICATORS --- df['hour'] = df['time'].dt.hour df['day_of_week'] = df['time'].dt.dayofweek df['hour_sin'] = np.sin(2 * np.pi * df['hour'] / 24) df['hour_cos'] = np.cos(2 * np.pi * df['hour'] / 24) # --- VOLUME INDICATORS --- df['tick_volume'] = df['tick_volume'].astype(float) df['volume_change'] = df['tick_volume'].pct_change(1) df['volume_ma_14'] = df['tick_volume'].rolling(14).mean() df['rel_volume'] = df['tick_volume'] / df['volume_ma_14']
该模型特别强调通过正弦变换对时间数据进行周期性表征。例如,一天中的具体小时数会被转换为一组正弦 / 余弦坐标,这让模型能够自然地捕捉日内周期,而不会在23:59与00:00之间产生断层。
从混沌到秩序:市场状态的量化
模型的核心思想是将连续数据转化为离散的市场状态 —— 即一系列“状态”,其中每种状态都具备自身的特征与概率行为。为此,我们采用K-means聚类算法,对每一组因子分别进行处理:
def create_state_clusters(feature_groups, n_clusters_per_group=3): group_clusters = {} kmeans_models = {} for group_name, group_data in feature_groups.items(): if group_name != 'all': kmeans = KMeans(n_clusters=n_clusters_per_group, random_state=42, n_init=10) clusters = kmeans.fit_predict(group_data['data']) group_clusters[group_name] = clusters kmeans_models[group_name] = kmeans return group_clusters, kmeans_models
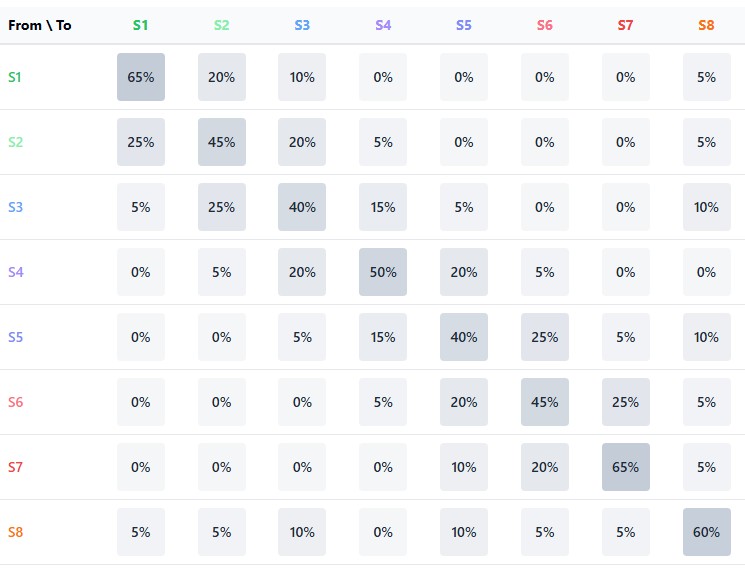
每组特征(价格、时间、成交量)均被划分为三个聚类,理论上可以组合出27种可能的市场状态。为简化起见,当前实现仅使用9种状态,代表最具代表性的市场行情组合。该方案在模型精细度与统计估计稳健性之间取得了平衡。
聚类的独特价值在于,它能够在无先验假设的前提下,自动发现数据中天然存在的分组。例如,模型仅依靠历史数据结构,就能自主识别出高波动期、盘整期或趋势行情阶段。
概率矩阵:预测模型的核心
模型的核心是两个矩阵:状态间的转移概率矩阵和各转移对应的上涨概率矩阵。二者共同构成马尔可夫链,其未来状态仅取决于当前状态,与更早的历史状态无关。
def combine_state_clusters(group_clusters, labels): # Fill the transition matrix and rise matrix for i in range(len(states) - 1): curr_state = states[i] next_state = states[i + 1] # Increase the transition counter transition_matrix[curr_state, next_state] += 1 # If the next candle is bullish, increase the rise counter if i + 1 < len(labels) and labels[i + 1] == 1: rise_matrix[curr_state, next_state] += 1 # Normalization of the transition matrix state_transitions = np.zeros((9, 9)) for i in range(9): row_sum = np.sum(transition_matrix[i, :]) if row_sum > 0: state_transitions[i, :] = transition_matrix[i, :] / row_sum
转移矩阵记录了从一个状态转向另一个状态的概率,反映了市场的动态结构。例如,在盘整状态之后,市场可能会以一定概率进入趋势变动状态,或继续维持横盘。
上涨概率矩阵则更进一步,它为每一种状态转移标注出下一根K线收阳(收盘价高于开盘价)的概率。这让我们不仅能预测市场的下一个状态,还能预判价格的变动方向。
在可视化这些矩阵后,往往会呈现出令人意想不到的市场规律。比如,某些状态表现出强烈的自我延续性,形成稳定的市场格局;而另一些状态则是过渡性的,会迅速切换为新的格局。这种转移结构上的不对称性,是理解市场动态逻辑的关键。
迭代预测:眺望更远的行情
马尔可夫模型的威力体现在迭代预测中 —— 构建所有可能事件路径上的概率加权和作为预测结果:
def predict_with_matrix(state_transitions, rise_probability_matrix, current_state): # Probabilities of transition to the next state next_state_probs = state_transitions[current_state, :] # Calculation of the weighted rise probability taking into account all possible transitions weighted_prob = 0 total_prob = 0 for next_state, prob in enumerate(next_state_probs): weighted_prob += prob * rise_probability_matrix[current_state, next_state] total_prob += prob # Normalization (if necessary) if total_prob > 0: weighted_prob = weighted_prob / total_prob # Forecast prediction = 1 if weighted_prob > 0.5 else 0 confidence = max(weighted_prob, 1 - weighted_prob)
与简单的“上涨/下跌”二分类预测不同,我们的模型提供完整的概率分布,并包含预测的置信度。这对于做出理性交易决策、实施合理的风险管理至关重要。
模型的迭代特性还体现在,它不仅能预测紧邻的下一根K线,还能构建未来多步可能行情的概率树。这种方法能够揭示单步预测无法捕捉的长期趋势。
提炼内涵:可解释性与透明度
相较于神经网络这类“黑箱模型”,马尔可夫模型的核心优势之一,就是完全透明且具备可解释性。每个状态与转移都具备清晰的统计意义,让我们不仅能获得预测结果,还能理解背后的市场逻辑。
通过分析各单独因子对状态分类的影响,可以揭示不同指标的相对重要性:
for group_name in ['price', 'time', 'volume']: features = feature_groups[group_name]['features'] kmeans = kmeans_models[group_name] cluster_centers = kmeans.cluster_centers_ for cluster_idx in range(3): center = cluster_centers[cluster_idx] # We obtain the importance of each feature as its deviation from zero at the center of the cluster importances = np.abs(center) sorted_idx = np.argsort(-importances) top_features = [(features[i], importances[i]) for i in sorted_idx[:3]]
这些信息能让交易者聚焦于当前市场状态下最具显著性的指标,忽略无信息价值的因子带来的噪声。此外,各状态的特征往往对应经典的市场形态:趋势、盘整、反转等,从而在统计建模与传统技术分析之间架起了桥梁。
超越二元判断:置信度分级
在金融领域,预测准确率本身是一个颇具争议的概念。即便是完全随机的模型,在价格方向预测上也能达到50%的准确率。我们模型的真正价值,体现在对预测置信度分级的分析上:
bins = [0.5, 0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95, 1.0] confidence_groups = np.digitize(confidences, bins) accuracy_by_confidence = {} for bin_idx in range(1, len(bins)): bin_mask = (confidence_groups == bin_idx) if np.sum(bin_mask) > 0: bin_accuracy = np.mean([1 if predictions[i] == test_labels[i+1] else 0 for i in range(len(predictions)) if bin_mask[i] and i+1 < len(test_labels)]) accuracy_by_confidence[f"{bins[bin_idx-1]:.2f}-{bins[bin_idx]:.2f}"] = (bin_accuracy, np.sum(bin_mask))
此分析显示,高置信度(>70%)的预测准确率可达68%–70%,显著优于随机猜测。这在实盘交易中具备关键的优势,让您能聚焦最具潜力的信号,过滤不确定行情。
尤为重要的是,高预测置信度与特定市场状态相关,可在行情形成早期就识别出有利的交易机会。
实证结果:欧元兑美元(EURUSD)回测
该模型基于高流动性、技术面复杂的EURUSD货币对历史小时数据进行测试。使用80%历史数据训练,剩余20%时序数据用于验证。
模型在测试集上的整体准确率约为55%,显著高于等仓位交易下的理论盈亏平衡点。此外,高置信度预测(处于第四分位区间)的准确率达到65%–70%。
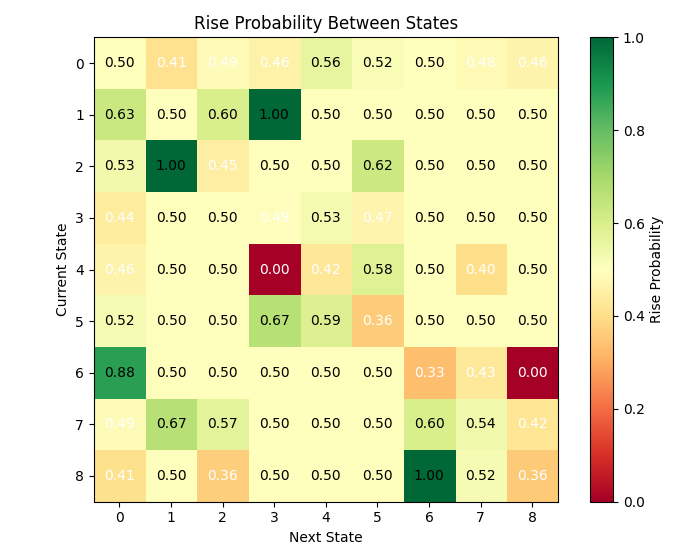
由图可见,许多状态呈现出相对较高的状态转移概率。这是否会对矩阵预测的有效性构成挑战?
对市场状态的分析揭示了一个典型的规律:部分状态具有明确的价格朝特定方向运行的倾向。例如,状态3(特征为相对高波动、欧洲交易时段、成交量下降)的价格上涨概率超过60%。
下图展示了相对强弱指标(RSI)与动量指标的聚类分布:
超越二元预测:实际应用
尽管本文聚焦于价格方向的二元预测,但马尔可夫模型具备更广泛的应用。以下是部分其他应用方向:
- 多分类预测 —— 不仅预测涨跌方向,还能判断波动幅度(大幅上涨、温和上涨、横盘、温和下跌、大幅下跌)。
- 市场状态识别 —— 自动划分当前市场状态,适配调整交易策略。
- 信号过滤 —— 作为传统技术信号的辅助过滤器,提升信号有效性。
- 波动率评估 —— 同时预测价格方向与预期波动率,对仓位管理与止损设置至关重要。
当前模型仅作为起步阶段,未来部分可拓展方向包括:
- 自适应聚类 —— 依据聚类质量指标,动态确定各特征组的最优聚类数量。
- 基本面数据融合 —— 纳入宏观经济指标与市场情绪作为附加因子。
- 分层马尔可夫模型 —— 兼顾不同时间周期的状态关联,实现多周期预测。
- 自适应学习 —— 基于最新市场数据持续更新转换矩阵,适配市场状态变化。
结论:用概率驾驭市场混沌
金融市场处于确定性混沌与随机秩序的平衡之间。马尔可夫链矩阵迭代模型,在统计方法的严谨性与技术分析的细腻性之间提供了一种优雅的折中。
与机器学习的“黑箱”不同,该模型对市场动态的解释完全透明、可追溯,将市场视为离散状态间的概率转换系统。这一理念不仅具备数学严谨性,也符合资深交易者以“市场状态与转换”为核心的思维习惯。
基于EURUSD的测试结果验证了模型的实盘潜力,尤其在高置信度预测场景下表现突出。该方法的持续优化有望进一步提升预测精度与应用广度。
归根结底,马尔可夫模型提示我们:即便市场看似混乱,仍存在内在结构与规律。虽然未来无法完全确定,但是概率思维能帮我们在市场的不确定性中找到方向。
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/18097
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

干得好特别喜欢 你将价格、时间和交易量分开 的做法--这真是一种聪明的方法。欧元/美元测试看起来很有希望。
但 在Covid 等 市场急剧变化时,模型将如何表现?如果转换矩阵是基于历史数据建立的,那么它将如何适应这种极端情况?
我们很想知道该模型是否在欧元/美元以外的货币对 上进行过测试?是否有适应波动性急剧变化的内置机制?你们是否计划考虑宏观新闻等基本面因素?