
Einsatz spieltheoretischer Ansätze in Handelsalgorithmen

Unter Bedingungen, in denen die Geschwindigkeit der Entscheidungsfindung entscheidend ist und der Markt durch ein hohes Maß an Unsicherheit gekennzeichnet ist, ist ein anderer Ansatz für die Entwicklung von Handelssystemen erforderlich.
AdaptiveQ Enhanced ist ein Expert Advisor, der auf der Grundlage von Methoden des Deep Reinforcement Learning (DQN), der Spieltheorie und der Kausalanalyse entwickelt wurde. Der Expert Advisor analysiert den Markt, indem er 531.441 einzigartige Zustände modelliert und dabei die Wechselbeziehungen zwischen den sieben wichtigsten Währungspaaren berücksichtigt. Das Schlüsselelement des Algorithmus ist das Nash-Gleichgewicht, das dazu dient, die optimale Strategie unter Berücksichtigung der gegenseitigen Einflüsse der Handelssymbole auszuwählen.
Die neue Version des Systems verfügt über einen erweiterten Aktionsraum: Zu den standardmäßigen Kauf- und Verkaufsoperationen sind die Funktionen des Positionsaufbaus sowie das selektive Schließen profitabler Positionen hinzugekommen. Dies gewährleistet Anpassungsfähigkeit und Flexibilität in verschiedenen Marktszenarien. Der Artikel untersucht die praktische Umsetzung dieser Ansätze in MQL5 und zeigt, wie die Kombination aus adaptivem Lernen, Spieltheorie und KI es Ihnen ermöglicht, genauere und nachhaltigere Handelsstrategien zu entwickeln.
Theoretische Grundlagen: vom Verstärkungslernen zum Nash-Gleichgewicht
Tiefes Verstärkungslernen (DQN)
Bevor wir uns mit den technischen Aspekten des Codes befassen, sollten wir eine theoretische Grundlage schaffen. Unser System basiert auf Deep Q-Learning (Deep Q-Network (DQN)), einer modernen Version eines Verstärkungslernalgorithmus, der sich nicht nur bei Spielen, sondern auch bei der Lösung komplexer Finanzprobleme bewährt hat.
Beim klassischen Verstärkungslernen interagiert ein Agent (in unserem Fall ein Handelssystem) mit der Umgebung (Markt), indem er bestimmte Aktionen (Öffnen/Schließen von Positionen) durchführt. Für jede Aktion erhält der Agent eine Belohnung und wechselt in einen neuen Zustand. Das Ziel des Agenten ist es, die kumulierte Belohnung über die Zeit zu maximieren.
Mathematisch wird dies in Form einer Q-Funktion ausgedrückt, die den erwarteten Nutzen einer Aktion in einem bestimmten Zustand bewertet:
Q(s, a) = r + γ max Q(s', a')
wobei r die unmittelbare Belohnung, γ der Abzinsungsfaktor (wie sehr wir künftige Belohnungen schätzen), s' der neue Zustand und a' die möglichen Handlungen im neuen Zustand ist.
Spieltheorie und Nash-Gleichgewicht
Herkömmliche Handelssysteme betrachten jedes Symbol für sich allein. Unser Ansatz ist grundlegend anders: Wir wenden die Spieltheorie an, um die Wechselbeziehungen zwischen den Währungspaaren zu berücksichtigen.
Ein Nash-Gleichgewicht ist ein Zustand, in dem kein Spieler sein Ergebnis durch einseitige Änderung seiner Strategie verbessern kann. Im Zusammenhang mit unserem System bedeutet dies, dass wir die optimale Strategie für jedes Währungspaar unter Berücksichtigung der Strategien aller anderen Paare finden.
Im Code wird dies durch die Funktion DetermineActionNash() umgesetzt, die nun mit einem erweiterten Bereich von sechs möglichen Aktionen arbeitet. Jede Aktion wird nicht nur auf der Grundlage der Daten eines bestimmten Währungspaares bewertet, sondern auch unter Berücksichtigung von Korrelationen mit anderen Symbolen:
void DetermineActionNash(int symbolIdx) { double actionScores[TOTAL_ACTIONS]; // Get basic estimates of actions from Q-matrix for(int action = 0; action < TOTAL_ACTIONS; action++) { actionScores[action] = qMatrix[tradeStates[symbolIdx].currentStateIdx][action][symbolIdx]; } // Correction based on correlation with other symbols (Nash) for(int otherIdx = 0; otherIdx < TOTAL_SYMBOLS; otherIdx++) { if(otherIdx != symbolIdx) { double corr = correlationMatrix[symbolIdx][otherIdx]; for(int action = 0; action < TOTAL_ACTIONS; action++) { double otherScore = qMatrix[tradeStates[otherIdx].currentStateIdx][action][otherIdx]; // Take correlation into account only if there is significant relationship if(MathAbs(corr) > 0.3) { actionScores[action] += corr * otherScore * 0.05; } } } }
Achten Sie auf die Feinabstimmung - eine Korrelation wird nur berücksichtigt, wenn ihr absoluter Wert 0,3 übersteigt. So lässt sich das „Rauschen“ herausfiltern und sich auf die wirklich wichtigen Beziehungen zwischen den Währungspaaren konzentrieren.
Kausale Inferenz in einem mehrdimensionalen Handlungsraum
In der aktualisierten Version von AdaptiveQ Enhanced hat unser System ein erweitertes Arsenal an möglichen Aktionen erhalten:
- Eröffnung einer Kaufposition
- Eröffnung einer Verkaufsposition
- Aufstockung bestehender Kaufpositionen
- Aufstockung bestehender Verkaufspositionen
- Nur profitable Kaufpositionen schließen
- Nur profitable Verkaufspositionen schließen
Dadurch wird das strategische Potenzial des Systems erheblich erweitert. Jetzt können nicht nur Positionen eröffnet und geschlossen werden, sondern auch die Volumina erhöht werden, wenn sich der Trend in die richtige Richtung entwickelt, und es können selektiv Gewinne eingefahren und Verlustpositionen in Erwartung einer Marktumkehr offen gelassen werden.
Es ist von besonderem Interesse, nur profitable Positionen zu schließen. Dieser Mechanismus ermöglicht es dem System, Gewinne zu sichern, ohne Verluste zu realisieren, was die Gesamtrentabilität erheblich verbessert:
void ClosePositionsByTypeIfProfitable(string symbol, ENUM_POSITION_TYPE posType) { CTrade trade; CPositionInfo pos; for(int i = PositionsTotal() - 1; i >= 0; i--) { if(pos.SelectByIndex(i)) { if(pos.Symbol() == symbol && pos.PositionType() == posType) { double profit = pos.Profit(); // Close only if position is in profit if(profit > 0) { trade.PositionClose(pos.Ticket()); } } } } }
Technische Umsetzung: AdaptiveQ Enhanced Anatomie
Großer Zustandsraum und mehrstufige Analyse
Eines der Hauptmerkmale unseres Systems ist sein riesiger Zustandsraum (531.441 eindeutige Zustände). Dies ermöglicht eine detaillierte Analyse der Marktbedingungen und die Anpassung des Systems an ein breites Spektrum von Szenarien.
In der aktualisierten Version sind die einzelnen Zustände noch informativer geworden. Jetzt analysiert das System den Markt nicht nur auf dem aktuellen Zeitrahmen, sondern gleichzeitig auf drei verschiedenen Zeitintervallen: M15, H1 und H4. Dieser Multi-Timeframe-Ansatz ermöglicht es AdaptiveQ Enhanced, ein vollständiges Bild der Marktdynamik zu erhalten - von kurzfristigen Schwankungen bis hin zu mittelfristigen Trends.
Für jeden Zeitrahmen verfolgt das System eine ganze Reihe von Parametern:
- Die Differenz zwischen dem Preis und 20 gleitenden Durchschnitten (von MA10 bis MA200)
- Binäre Flags der Preisposition im Verhältnis zu wichtigen MA-Niveaus
- Werte der technischen Indikatoren RSI und Stochastic
- Momentum der Preisbewegung
Alle diese Daten werden in einen eindeutigen Zustandsindex umgewandelt, der dann für den Zugriff auf die Q-Matrix verwendet wird:
int ConvertToStateIndex(MarketState &state) { double range = state.price_high - state.price_low; if(range == 0) range = 0.0001; // Basic components from prices int o_idx = (int)((state.price_open - state.price_low) / range * 9); int c_idx = (int)((state.price_close - state.price_low) / range * 9); int m_idx = (int)((state.momentum + 0.001) / 0.002 * 9); // Basic index from main components int stateIdx = o_idx * 81 + c_idx * 9 + m_idx; // Add components from difference with MA for current timeframe int ma_idx = 0; for(int i = 0; i < 10; i++) { int diff_idx = (int)((state.ma_diff[i] + 0.01) / 0.02 * 9); diff_idx = MathMin(MathMax(diff_idx, 0), 8); ma_idx += diff_idx * (int)MathPow(9, i % 3); } // Add components from indicators for each timeframe ulong tf_state = 0; for(int tfIdx = 0; tfIdx < TOTAL_TIMEFRAMES; tfIdx++) { // RSI: 0-100 -> 0-9 int rsi_idx = (int)(state.tf_rsi[tfIdx] / 10); rsi_idx = MathMin(MathMax(rsi_idx, 0), 9); tf_state = tf_state * 10 + rsi_idx; // Stochastic %K: 0-100 -> 0-9 int stoch_k_idx = (int)(state.tf_stoch_k[tfIdx] / 10); stoch_k_idx = MathMin(MathMax(stoch_k_idx, 0), 9); tf_state = tf_state * 10 + stoch_k_idx; // Binary flags for MA: selecting key MAs (10, 50, 100, 200) int ma_flags = 0; ma_flags |= state.tf_ma_above[tfIdx][0] << 0; // MA10 ma_flags |= state.tf_ma_above[tfIdx][4] << 1; // MA50 ma_flags |= state.tf_ma_above[tfIdx][9] << 2; // MA100 ma_flags |= state.tf_ma_above[tfIdx][19] << 3; // MA200 tf_state = tf_state * 16 + ma_flags; } // Hash base index and indicators together ulong hash = stateIdx + ma_idx + (ulong)tf_state; // Reduce to range TOTAL_STATES through hash return (int)(hash % TOTAL_STATES); }
Schauen Sie sich diese Funktion genauer an. Hier findet eine erstaunliche Transformation statt: ein mehrdimensionaler Raum von Marktparametern wird in eine eindeutige Zustandskennung umgewandelt. Es ist, als ob wir eine mehrdimensionale Marktkarte erstellen würden, bei der jeder Punkt einer bestimmten Kombination von Preisen und Indikatoren entspricht, und diese dann mithilfe einer Hash-Funktion in einen eindimensionalen Index umwandeln.
Caching und Leistungsoptimierung
Angesichts der Komplexität des Systems haben wir besonderes Augenmerk auf die Optimierung gelegt. In der neuen Version werden nicht nur die Preise und Korrelationen, sondern auch die Werte aller verwendeten Indikatoren gespeichert:
// Cache for prices and correlations (performance optimization) double bidCache[TOTAL_SYMBOLS], askCache[TOTAL_SYMBOLS]; double correlationMatrix[TOTAL_SYMBOLS][TOTAL_SYMBOLS]; double pointCache[TOTAL_SYMBOLS]; // Cache for Point // Cache for indicators double maCache[TOTAL_SYMBOLS][10]; double maTFCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES][20]; int maAboveCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES][20]; double rsiCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; double stochKCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; double stochDCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES];Außerdem speichert das System jetzt Indikator-Handles zwischen Aufrufen, sodass deren wiederholte Erstellung vermieden werden kann:
// Indicator handles to avoid multiple creation int rsiHandles[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; int stochHandles[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES];Und um Rechenressourcen zu sparen, wurde ein Mechanismus zur periodischen Aktualisierung der Indikatoren hinzugefügt:
// Time of last update of indicators datetime lastMAUpdate = 0; datetime lastIndicatorsUpdate = 0; int indicatorUpdateInterval = 60; // Update indicators every minute void UpdateIndicatorsCache() { datetime currentTime = TimeCurrent(); if(currentTime - lastIndicatorsUpdate < indicatorUpdateInterval) return; // ... indicator update code ... lastIndicatorsUpdate = currentTime; }
Diese Technik mag trivial erscheinen, aber in der Praxis bringt sie erhebliche Leistungssteigerungen, was für ein System, das gleichzeitig mit sieben Währungspaaren auf drei Zeitrahmen arbeitet, von entscheidender Bedeutung ist.
Adaptives Lernen mit einem Opportunitätskostenmechanismus
Das Herzstück unseres Systems ist der adaptive Lernmechanismus, der jetzt noch weiter verbessert wurde. Im Gegensatz zum klassischen Q-Learning verwendet AdaptiveQ Enhanced das Konzept der „Opportunitätskosten“, das es dem System ermöglicht, schneller aus seinen Fehlern zu lernen.
Wenn das System eine Entscheidung trifft, bewertet es nicht nur die tatsächliche Belohnung für die gewählte Handlung, sondern modelliert auch ein mögliches Ergebnis alternativer Handlungen. Wenn sich herausstellt, dass eine andere Aktion mehr Gewinn bringen könnte, passt das System seine Strategie aggressiver an:// Check whether an action resulted in a loss and whether it was possible to make a reward with an alternative action bool wasLoss = reward < 0; bool couldProfit = tradeStates[symbolIdx].alternativeReward > 0 && tradeStates[symbolIdx].opportunityCost < 0; // Apply adaptive learning rate for cases of opportunity cost if(wasLoss && couldProfit) { // Increase learning rate to quickly adapt to incorrect decisions double adaptiveLearningRate = MathMin(learningRate * adaptiveMultiplier, 0.9); // Additionally, reduce the Q-value in proportion to the opportunity cost newQ -= adaptiveLearningRate * MathAbs(tradeStates[symbolIdx].opportunityCost) * opportunityCostWeight; }
Dies ist vergleichbar mit der Art und Weise, wie ein erfahrener Händler nicht nur aus seinen Fehlern lernt, sondern auch verpasste Gelegenheiten analysiert und seine Strategie aggressiver anpasst, wenn er sieht, dass eine alternative Lösung wesentlich besser wäre. Dank des Parameters adaptiveMultiplier kann der Nutzer konfigurieren, wie intensiv das System aus verpassten Gelegenheiten lernen soll.
Ein weiterer innovativer Aspekt des Lernens ist die kausale Wirkung zwischen Währungspaaren:
// Update Q-values for other symbols based on correlation (causal learning) for(int otherSymbol = 0; otherSymbol < TOTAL_SYMBOLS; otherSymbol++) { if(otherSymbol != symbolIdx) { double corr = correlationMatrix[symbolIdx][otherSymbol]; // Apply update only if correlation is significant if(MathAbs(corr) > 0.2) { qMatrix[tradeStates[symbolIdx].previousStateIdx][tradeStates[symbolIdx].previousAction][otherSymbol] += learningRate * reward * corr * 0.1; } } }
Wenn das System Erfahrungen mit einem Währungspaar gesammelt hat, kann es diese auf andere verwandte Symbole übertragen, je nach dem Grad ihrer Korrelation. Dadurch entsteht ein „Cross-Learning-Effekt“, der den Prozess der Anpassung des Systems an die Marktbedingungen erheblich beschleunigt.
Praktische Aspekte der Verwendung von AdaptiveQ Enhanced
Erweiterte Anpassungs- und Risikomanagementfunktionen
AdaptiveQ Enhanced bietet eine beeindruckende Reihe von Parametern zur Feinabstimmung des Systems auf die individuellen Präferenzen des Händlers:
input OPERATION_MODE OperationMode = MODE_LEARN_AND_TRADE; // System operating mode input CLOSE_STRATEGY CloseStrategy = STRATEGY_CLOSE_ALL; // Close strategy input POSITION_MODE PositionMode = MODE_MULTI; // Position mode input double TradeVolume = 0.01; // Base volume of trade input double AddVolumePercent = 50.0; // Percentage of base volume to add to position input int TakeProfit = 2500; // Take Profit (points) input int StopLoss = 1500; // Stop Loss (points) input double LearningRate = 0.1; // Learning rate input double DiscountFactor = 0.9; // Discount factor input double AdaptiveMultiplier = 1.5; // Adaptive learning rate multiplier input double OpportunityCostWeight = 0.2; // Opportunity cost weight input int MaxPositionsPerSymbol = 5; // Maximum number of positions per symbol
Das System kann in drei Positionsmodi betrieben werden: MODE_SINGLE ermöglicht es Ihnen, nur eine Position für jedes Symbol zu haben, MODE_MULTI erlaubt das Öffnen von bis zu MaxPositionsPerSymbol gleichgerichteten Positionen, und MODE_OPPOSITE ermöglicht es Ihnen, gleichzeitig Positionen in entgegengesetzten Richtungen zu haben.
Der Parameter AddVolumePercent verdient besondere Aufmerksamkeit. Sie bestimmt, wie viel Volumen zu einer bestehenden Position hinzugefügt wird, wenn ACTION_ADD_BUY und ACTION_ADD_SELL ausgeführt werden. Dies ermöglicht die Umsetzung einer Strategie zum Positionsaufbau, wenn das System Volumen in Richtung eines erfolgreichen Trends hinzufügt.
Intelligentes Positionsmanagement
Eine der interessantesten Neuerungen von AdaptiveQ Enhanced ist die Möglichkeit, selektiv nur profitable Positionen zu schließen. Auf diese Weise kann das System Gewinne festhalten und gleichzeitig Verlustpositionen eine Chance geben, sich zu erholen:
case ACTION_CLOSE_PROFITABLE_BUYS: if(tradeStates[symbolIdx].buyPositions > 0) { // Close only profitable BUY positions ClosePositionsByTypeIfProfitable(symbol, POSITION_TYPE_BUY); tradeStates[symbolIdx].actionSuccessful = true; } break;
In Verbindung mit der Möglichkeit, mehrere Positionen zu eröffnen, ergibt sich eine interessante Dynamik: Das System kann Positionen schrittweise aufbauen, während sich ein Trend entwickelt, und dann bei den ersten Anzeichen einer Trendwende die Gewinne teilweise einbehalten und einige Positionen für eine mögliche Fortsetzung der Bewegung aufheben.
Regelmäßiges Speichern und Laden des trainierten Modells
Das Highlight unseres Systems ist nach wie vor die Möglichkeit, eine trainierte Q-Matrix zu speichern und zu laden. In der neuen Version ist dieser Mechanismus dank der periodischen automatischen Speicherung noch zuverlässiger geworden:
void CheckAndSaveQMatrix() { if(IsNewBar() && OperationMode == MODE_LEARN_AND_TRADE) { Print("Periodic saving of Q-matrix..."); SaveQMatrix(); } }
Das System prüft, ob sich eine neue Kerze gebildet hat und speichert in regelmäßigen Abständen das gesammelte Wissen. Dies schützt vor dem Verlust von Trainingsdaten im Falle einer unerwarteten Abschaltung.
Das gesamte System funktioniert folgendermaßen:
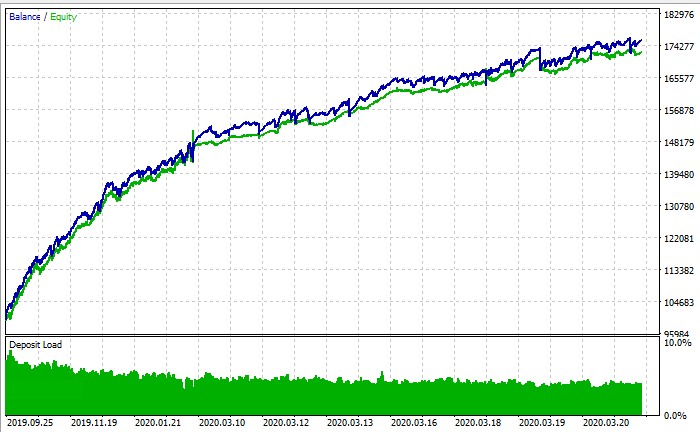
Schlussfolgerung: Neue Horizonte für den algorithmischen Handel
Der Expert Advisor AdaptiveQ Enhanced ist nicht nur ein weiteres algorithmisches Handelsinstrument, sondern ein grundlegend neuer Ansatz zur Analyse und Prognose von Finanzmärkten. Durch die Kombination von Deep Reinforcement Learning, Spieltheorie und kausaler Inferenz mit einem erweiterten Arsenal an Handelsaktionen und Multi-Timeframe-Analyse haben wir ein System geschaffen, das in der Lage ist, komplexe Beziehungen zwischen verschiedenen Währungspaaren zu erfassen und optimale Handelsentscheidungen zu treffen.
Als besonders wirksam erwies sich der Mechanismus einer adaptiven Lernrate, die durch Opportunitätskosten gesteuert wird. Wenn das System eine falsche Entscheidung trifft und eine alternative Aktion einen Gewinn bringen könnte, erhöht es die Lernrate entsprechend dem AdaptiveMultiplier (standardmäßig das 1,5-fache). Dies ist eine Art „High-Intensity-Lektion“ - das System lernt schneller aus seinen Fehlern als aus Erfolgen, was auch der menschlichen Psychologie entspricht.
Die Zukunft des algorithmischen Handels liegt gerade im Bereich der adaptiven Systeme, die mit dem Markt lernen und sich weiterentwickeln können. Und AdaptiveQ Enhanced ist nicht nur ein Experiment, sondern ein einsatzfähiges Werkzeug, das neue Horizonte für Forschung und Entwicklung eröffnet. Der in diesem Artikel enthaltene Code steht für Experimente und weitere Verbesserungen zur Verfügung. Ich lade die MQL5-Gemeinschaft ein, sich an der Entwicklung dieses Konzepts und der Schaffung von noch fortschrittlicheren Handelssystemen auf der Grundlage von künstlicher Intelligenz und Spieltheorie zu beteiligen.
Die Welt der Finanzen wird immer komplexer und vernetzter. Und nur Systeme, die in der Lage sind, diese Komplexität wahrzunehmen und sich ihr anzupassen, werden sich auf den Märkten der Zukunft erfolgreich behaupten können. AdaptiveQ Enhanced ist ein Schritt in diese Richtung, ein Schritt in Richtung eines intelligenteren, anpassungsfähigeren und letztlich profitableren algorithmischen Handels.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/17546
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Guten Tag, ich bin sehr an Ihrem Projekt interessiert, aber ich bin neu auf diesem Gebiet. Ich kann nicht herausfinden, wie ich den Expert Advisor im Strategietester ausführen kann. So wie ich es verstehe, ist es unmöglich, ihn vollständig zu konfigurieren und über den Tester zu trainieren? Oder mache ich etwas falsch? Ich wäre dankbar für die OS
Wo habe ich Verwandte in den Niederlanden 👀?
Wie kommt es, dass ich Verwandte in den Niederlanden habe? 👀
Ahahahahah, nicht in den Niederlanden)))) VPN ist so eine Sache)))))
PS: ist es möglich, im Strategietester ein Training durchzuführen oder nicht? Laut dem Screenshot des Gleichgewichtsdiagramms ist es ein Strategietester, aber egal was ich tue, ich komme nicht einmal in die Nähe von +.
Der Autor stellt "AdaptiveQ Enhanced" vor, einen Multi-Symbol-FX-EA, der angeblich DQN, Nash-Gleichgewicht, Kausalanalyse, sieben Hauptwährungspaare, sechs Aktionen und 531.441 Zustände kombiniert. Der Aktionssatz umfasst Kaufen, Verkaufen, Hinzufügen zum Kaufen, Hinzufügen zum Verkaufen und Schließen nur profitabler Käufe oder Verkäufe.
Mein Hauptproblem: Der Artikel verwendet eher schicke Bezeichnungen als echte Substanz. Das "Nash-Gleichgewicht" ist keine tatsächliche Gleichgewichtslösung, sondern es werden einfach die Q-Werte eines Symbols genommen und mit den Q-Werten anderer Symbole gewichtet, wenn |corr| > 0,3 ist. Das ist keine Spieltheorie in irgendeinem ernsthaften Sinne. Das gleiche Problem besteht bei der "kausalen" Sprache: Die symbolübergreifende Aktualisierung basiert buchstäblich auf Belohnung mal Korrelation, wenn |corr| > 0,2 ist. Korrelation ist keine Kausalität.
Auch das Zustandsdesign sieht wackelig aus. Im Artikel heißt es, dass ein umfangreicher Multi-Zeitrahmen-Status aus Preisen, MA-Differenzen, RSI, Stochastik und MA-Flags erstellt wird, dann werden diese multidimensionalen Informationen gehasht und mit dem Hash % TOTAL_STATES reduziert. So können verschiedene Marktsituationen in denselben Eimer fallen. Die Angabe "531.441 einzigartige Zustände" klingt beeindruckender, als sie tatsächlich ist.
Die Positionslogik ist der hässlichste Teil. Der EA kann im Multipositions- oder Gegenpositionsmodus laufen, Volumen zu bestehenden Positionen hinzufügen, bis zu 5 Positionen pro Symbol zulassen und selektiv nur profitable Positionen schließen, während er Verlierer offen lässt, "um sich zu erholen". Das ist für mich kein intelligentes Bestandsmanagement, sondern ein verkappter Weg zu hässlichen Engagements.
Was gut ist: Die technische Seite ist seriöser als der durchschnittliche MQL5-Flaum. Das Zwischenspeichern von Indikator-Handles, periodische Aktualisierungen und das Speichern/Laden der Q-Matrix sind praktische Implementierungsdetails.
Meiner Meinung nach also ein interessantes Experiment und ein schwaches Handelsdesign. Zu viel Branding rund um "KI/Spieltheorie/Kausalschluss", nicht genug Beweis, dass es einen echten Vorteil hat. Ich würde nicht direkt auf dieser Logik aufbauen.