
Entwicklung eines Multi-Currency Expert Advisors (Teil 26): Informer für Handelsinstrumente
Inhalt
- Einführung
- Den weiteren Weg planen
- Projekt erstellen
- Repository des Bibliotheksmoduls
- Projekt-Repository
- Beschreibung des Projekts
- Umsetzung der ersten Version
- EA-Test
- Schlussfolgerung
Einführung
Im vorangegangenen Artikel haben wir schlussendlich ein umfassendes System entwickelt, das es uns ermöglicht, eine einfache Handelsstrategie automatisch in einen vollwertigen EA umzuwandeln und sicherzustellen, dass diese Strategie gleichzeitig auf verschiedenen Instrumenten und Zeitrahmen funktioniert. Auch Fragen im Zusammenhang mit dem Kapitalmanagementsystem und dem Risikomanager, der es ermöglicht, den Handel zu stoppen, wenn sich ungünstige oder umgekehrt zu günstige Situationen ergeben, wurden nicht außer Acht gelassen.
Im größten Teil dieser Artikelserie haben wir nur mit einer einfachen Handelsstrategie gearbeitet, und erst in den letzten Teilen, als die wichtigsten Funktionen bereits implementiert waren, haben wir darüber nachgedacht, eine neue Handelsstrategie hinzuzufügen und diese als Hauptstrategie zu verwenden. Dieses Beispiel hat gezeigt, dass es möglich ist, das Potenzial fast jeder Handelsstrategie zu erschließen (natürlich nur, wenn dieses Potenzial wirklich vorhanden ist).
Doch auf dem aktuellen Entwicklungsstand eröffnen sich für die weitere Arbeit noch mehr Möglichkeiten. Es gibt nun viele mögliche Richtungen, was die Entscheidung für den nächsten Schritt erschwert. Um dies zu überwinden, wurde versucht, den Ansatz für die Organisation und Ablage der Quellcodes dieses Projekts zu ändern. Die ersten Schritte wurden bereits in Teil 23 unternommen, in dem wir den größten Teil des Codes in den so genannten „Bibliotheksmodul“ aufteilten und den Rest des Codes im „Projektteil“ beließen. Danach haben wir uns den Möglichkeiten des neuen Code-Repositorys zugewandt und die ersten Schritte in einem separaten Artikel Umstellung auf MQL5 Algo Forge (Teil 1): Erstellen des Haupt-Repositorys. Die Strategie für die Nutzung der Möglichkeiten des neuen Repositories befindet sich noch in Ausarbeitung. Insgesamt möchte ich die Möglichkeit schaffen, das Bibliotheksmodul in mehreren Bereichen gleichzeitig zu bearbeiten. Ob dies möglich sein wird, bleibt abzuwarten.
Der Prozess erfordert Übung. Nur so lässt sich feststellen, ob die getroffenen architektonischen Entscheidungen richtig waren. Versuchen wir also, ein neues Projekt mit der entwickelten Bibliothek namens Advisor zu erstellen. Wir werden nicht sofort mit der Arbeit an einem großen Projekt zur Entwicklung eines EA mit einer komplexen Handelsstrategie beginnen. Ganz im Gegenteil. Wir werden ein Projekt erstellen, das nicht darauf abzielt, einen Handels-EA zu entwickeln.
Den weiteren Weg planen
Einer der Leser hat eine interessante Frage zu der neuesten Strategie gestellt – SimpleCandles. Bei dieser Strategie ist einer der Parameter die Anzahl der aufeinanderfolgenden Kerzen in derselben Richtung in einem bestimmten Zeitrahmen. Daher wäre es schön, wenn man die Möglichkeit hätte, zu sehen, welche Reihen solcher Kerzen auf verschiedenen Instrumenten und in verschiedenen Zeitrahmen existieren, um nicht die gesamte Aufgabe der Auswahl geeigneter Werte dem Optimierer zu überlassen.
Selbst bei der automatischen Optimierung muss man wissen, innerhalb welcher Grenzen sich die Eingaben ändern werden. Sie können natürlich auch einfach einen weiten Bereich festlegen, aber das dürfte die Effizienz der Optimierung stark verringern. Schließlich ist die Gesamtzahl der Parameterkombinationen größer, und die Wahrscheinlichkeit, eine Gewinnkombination zu treffen, ist geringer. Es ist schwer zu sagen, wie stark dieser Effekt ausfällt, aber schon ein grundlegendes Verständnis dieses Rückgangs reicht aus, um nach Möglichkeiten zur Effizienzsteigerung zu suchen.
Das Sammeln dieser Art von Informationen über das Preisverhalten der verschiedenen Instrumente wird auch zur Beantwortung der Frage beitragen: „Können die gleichen Parameterbereiche für verschiedene Instrumente verwendet werden?“ Ist dies der Fall, vereinfacht dies die Organisation der ersten Optimierungsphase. Wenn nicht, muss die Erstellung von Optimierungsaufgaben in diesem Stadium etwas komplexer sein.
Im Allgemeinen werden wir versuchen, einen Hilfs-EA oder einen Teil eines EA zu erstellen, der in der Lage ist, uns einige Statistiken über Symbole und Zeitrahmen in geeigneter Form zu zeigen. Vielleicht werden wir sie in Zukunft für unsere Handelsstrategien nutzen können.
Aber das wird die zweite Frage sein. Als Erstes werden wir uns damit befassen, wie wir die Speicherung des Quellcodes im Hinblick auf seine künftige Verwendung in anderen Projekten gestalten können.
Projekt erstellen
Auf den ersten Blick scheint es hier nichts Kompliziertes zu geben. Wir haben den Code vorher irgendwie gespeichert und können das auch weiterhin tun. Aber es gibt immer noch einen Unterschied. Es ist eine Sache, wenn wir den gesamten Projektcode in einem Ordner speichern und für jedes nachfolgende Projekt einfach einen neuen Ordner erstellen und den Code aus dem vorherigen Projekt dorthin kopieren. Dieser Ansatz ist wegen seiner Einfachheit gut und hat seine Berechtigung, wenn es um eine streng konsistente Entwicklung geht, ohne dass man sich um die Rückwärtskompatibilität kümmern muss. In der Anfangsphase, in der es häufig zu bedeutenden Änderungen kommt, ist dies wesentlich günstiger. Anders verhält es sich jedoch, wenn unser Projekt zu wachsen beginnt. In diesem Stadium teilt sich das Projekt eindeutig in Teile, die sich kaum ändern, und Teile, die sich erheblich ändern oder von Grund auf neu erstellt werden können.
In diesem Fall überwiegen unserer Meinung nach die Nachteile der Speicherung des gesamten Codes in einem Ordner die Vorteile dieses Ansatzes. Etwas früher hatten wir bereits den größten Teil des Codes in den Ordner MQL5/Include/antekov/Advisor verschoben und diesen Teil als Bibliothek bezeichnet. Aber jetzt scheint die Nutzung dieses Ortes für das Bibliotheksmodul nicht ganz günstig zu sein.
Stellen wir uns vor, dass wir parallel an zwei Projekten arbeiten, die die Bibliothek Advisor verwenden. Die Änderungen betreffen vor allem den Projektteil, aber auch das Bibliotheksmodul wird in einigen Fällen überarbeitet. Wenn beide Projekte auf ein Bibliotheksmodul verweisen, das sich am gleichen Ort befindet (MQL5/Include/antekov/Advisor), sind Konflikte durchaus möglich. Um dies zu vermeiden, müssen wir beim Wechsel von einem Projekt zu einem anderen zumindest das Bibliotheksmodul auf eine entsprechende Version umstellen, die in einem anderen Zweig des Repositorys gespeichert ist. Das ist zwar nicht kompliziert, aber die Notwendigkeit solcher Manipulationen ist unerwünscht. Vielleicht vergessen Sie eines Tages, umzuschalten, und müssen dann Bearbeitungen, die Sie im falschen Zweig vorgenommen haben, durch Verschieben in einen anderen Zweig bereinigen.
Lassen Sie uns also versuchen, den Ansatz zu ändern. Jedes Projekt wird in einem eigenen Repository geführt. Innerhalb des Projektordners gibt es immer einen Include-Ordner, der Ordner mit den Bibliotheksmodulen enthält. Bitte beachten Sie: nicht mit einem einzigen Bibliotheksmodul, sondern mit mehreren, die auf verschiedene Ordner verteilt sind. Jedes Bibliotheksmodul wird ein Klon eines separaten Code-Repositorys sein.
Repository des Bibliotheksmoduls
Für das Bibliotheksmodul erstellen wir ein neues Repository aufMQL5 Algo Forge oder einem anderen öffentlichen GIT-Repository. Der Name Advisor, den wir für die Bibliothek verwendet haben, erschien uns zu allgemein. Fügen wir etwas Einzigartigkeit hinzu, indem wir es in Adwizard umbenennen. So werden wir unsere Bibliothek auch weiterhin nennen.
Legen wir alle Bibliotheksmoduldateien in diesem Repository ab. Nach der Erstellung des Repositorys enthält es einen einzigen Zweig namens main. Erstellen Sie einen neuen Zweig mit dem Namen develop, aus dem die Artikel und neuen Bibliotheksfunktionen generiert werden sollen. Diese Hilfszweige werden geschlossen, sobald neue Funktionen implementiert sind, und die Bearbeitungen werden in den Zweig develop und anschließend in main zusammengeführt. In der Regel geschieht dies, wenn ich meine Arbeit an einem Artikel abgeschlossen habe.
Um sicherzustellen, dass der Code in diesem Repository funktioniert, wenn er in einen beliebigen Ordner geklont wird, mussten wir einige kleinere Änderungen an einigen Bibliotheksdateien vornehmen. Sie wurden in den Direktiven #include benötigt, wo wir die Pfade zum Include-Ordner mit der Standardbibliothek verwendet haben. Nachdem wir sie durch relative Pfade ersetzt hatten, entfernten wir den Link zu einem bestimmten Bibliotheksort im Ordner MQL5/Include/antekov/Advisor.
In der Datei Optimization.mqh wurde zum Beispiel folgende Ersetzung vorgenommen:
#include <antekov/Advisor/Optimization/Optimizer.mqh> #include "../Optimization/Optimizer.mqh"
In der Datei OptimizerTask.mqh hatten wir noch eine einzelne Datei einer Drittanbieter-Bibliothek von fxsaber verwendet. Wir haben sie auch innerhalb der Bibliothek in den Ordner Utils verschoben:
#include <antekov/Advisor/Database/Database.mqh> #include <fxsaber/MultiTester/MTTester.mqh> // https://www.mql5.com/ru/code/26132 #include "../Database/Database.mqh" #include "../Utils/MTTester.mqh" // https://www.mql5.com/ru/code/26132
Diese Bearbeitungen wurden an die Bibliotheks-Repository weitergeleitet.
Projekt-Repository
Für das Projekt erstellen wir das neue Repository SymbolsInformer. In diesem Repository werden wir neben main auch einen Entwicklungszweig mit dem Namen develop anlegen. Wenn dieses Projekt in mehreren Artikeln behandelt wird, wäre es ratsam, Bearbeitungen, die sich auf verschiedene Artikel beziehen, in verschiedene Zweige aufzuteilen. Sie werden aus develop abgezweigt und in den main und develop zurückgeführt, sobald sie fertig sind.
Wir erstellen einen Ordner, der den Projektordner enthält, zum Beispiel MQL5/Experts/Article/17606, klonen dieses Repository in den ausgewählten Ordner und erstellen darin den Ordner Include. In diesem Ordner werden wir die Repositories anderer Bibliotheken ablegen, von denen das Projekt abhängen wird. Bis auf weiteres wird es nur eine Bibliothek geben – Adwizard. Der Ordner Include enthält das geklonte Adwizard-Bibliotheks-Repository. Wenn wir eine weitere Bibliothek benötigen, klonen wir sie in denselben Include-Ordner.
Nach diesen Vorgängen erhalten wir ungefähr die folgende Ordnerstruktur im Terminalordner:
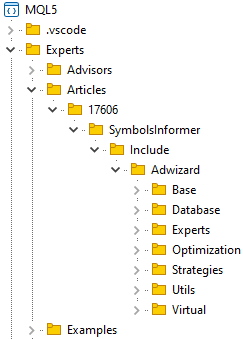
Wechseln wir im geklonten Ordner des Adwizard-Repositorys zum Zweig develop. Dies gilt für alle Artikel. Wenn wir während der Arbeit an diesem Projekt keine Änderungen an der Bibliothek Adwizard vornehmen, bleiben wir im Zweig develop und aktualisieren ihn, sobald bei der Arbeit an anderen Artikeln neue Änderungen vorgenommen werden. Wenn wir etwas in dieser Bibliothek korrigieren müssen, während wir an dem aktuellen Projekt arbeiten, dann erstellen wir einen neuen Zweig.
Danach erstellen wir einen Zweig im Projekt-Repository für die Arbeit an diesem Artikel und beginnen mit der Entwicklung darin. Hier haben wir die Erstellung eines neuen Projekts kurz beschrieben Ich werde die Einzelheiten in einem separaten Artikel vorstellen.
Beschreibung des Projekts
Versuchen wir, eine kurze technische Spezifikation für die Entwicklung des benötigten Werkzeugs zu formulieren. Es wird in Form eines EA implementiert, da es keine Berechnungsparameter enthält, die eine periodische Neuberechnung und Anzeige von sich ändernden Werten über einen bestimmten Zeitraum erfordern.
Um die Anzahl der unidirektionalen Kerzenserien zu zählen, müssen wir zunächst einen bestimmten Zeitraum festlegen, über den wir diese Statistiken erheben wollen. Dies kann auf unterschiedliche Weise geschehen. Sie können z. B. die Anzahl der Tage ab dem aktuellen Datum angeben oder zwei verschiedene Daten, die den Beginn und das Ende angeben. Vielleicht wollen wir zunächst nur Statistiken für das Intervall ab dem aktuellen Datum berechnen. Die Dauer kann durch Auswahl eines Zeitrahmens (z. B. täglich) und der Anzahl seiner Kerzen festgelegt werden. Nennen wir ihn den Hauptzeitrahmen.
Als nächstes müssen wir irgendwie angeben, für welche Handelsinstrumente (Symbole) und für welche Zeitrahmen wir Berechnungen durchführen wollen. Natürlich ist es möglich, Berechnungen nur für das Symbol und den Zeitrahmen durchzuführen, auf dem der entwickelte EA gestartet wird. Aber es ist immer noch besser, gleich die Möglichkeit einzubeziehen, Berechnungen für mehrere Symbole und Zeitrahmen durchzuführen.
Stellen wir auf der Grundlage der obigen Ausführungen eine Liste von EA-Eingaben zusammen:
- Hauptzeitrahmen
- Anzahl der Kerzen auf dem Hauptzeitrahmen
- Liste der Symbole
- Liste der Zeitrahmen
Dieser Satz von Parametern kann in Zukunft erweitert werden. Die Listen der Symbole und Zeitrahmen enthalten die durch Kommas getrennten Namen. Wir werden die Namen der Zeitrahmen so festlegen, wie sie im Terminal benannt sind, z. B. M5, M15, H1 usw.
Für jedes Symbol und jeden Zeitrahmen werden wir die folgenden Werte berechnen:
- Durchschnittliche Kerzengröße:
- bullisch („up“- oder „buy“-Kerze, deren Schlusskurs nicht niedriger als der Eröffnungskurs ist);
- bärisch („down“- oder „sell“-Kerze, deren Schlusskurs nicht höher als der Eröffnungskurs ist);
- alle (sowohl bullisch als auch bärisch);
- Durchschnittliche Länge einer Serie (eine Serie wird als eine Folge von zwei oder mehr Kerzen derselben Richtung betrachtet);
- Anzahl der Serien mit Länge
- 2
- 3
- ...
- 8
- 9
Diese Liste ist ebenfalls offen, d. h. wir können ihr neue Berechnungswerte hinzufügen, wenn wir dies wünschen.
Umsetzung der ersten Version
Lassen Sie uns zunächst versuchen, eine möglichst einfache Version zu erstellen. Wir werden die berechneten Werte in globalen Arrays speichern und die Ergebnisse in irgendeiner Form im Protokoll und im Chart als Kommentar anzeigen. Wir wissen noch nicht genau, welche Daten für uns nützlich und welche bedeutungslos sein werden. Daher verwenden wir die erste Version hauptsächlich, um festzustellen, was wir tatsächlich brauchen. Dabei werden wir der Überprüfung der Konsistenz der Eingaben und der Organisation der Informationsspeicherung nicht viel Aufmerksamkeit schenken.
Die Eingänge können gemäß der erstellten Liste wie folgt eingestellt werden:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Calculation period" sinput ENUM_TIMEFRAMES mainTimeframe_ = PERIOD_D1; // Main timeframe input int mainLength_ = 30; // Number of candles on the main timeframe input group "::: Symbols and timeframes " sinput string symbols_ = ""; // Symbols (comma separated) sinput string timeframes_ = ""; // Timeframes (e.g. M5, H1, H4)
Da die Eingaben mehrere Symbole und Zeitrahmen in einer Zeichenkette angeben, benötigen wir Arrays, die separate Werte für jeden Symbolnamen und jeden Zeitrahmen speichern.
Wir werden zweidimensionale Arrays erstellen, um die berechneten Werte zu speichern. Der erste Index in ihnen wird mit dem Symbol und der zweite mit dem Zeitrahmen verbunden sein. Da es bei der Deklaration von zweidimensionalen Arrays notwendig ist, die Anzahl der Elemente entlang der zweiten Dimension anzugeben, werden wir die Konstante TFN einführen, in der wir die Anzahl aller derzeit existierenden Standardzeitrahmen angeben werden. Insgesamt sind es 21.
// Number of existing timeframes #define TFN (21) // Global variables string g_symbols[]; // Array of all used symbols ENUM_TIMEFRAMES g_timeframes[]; // Array of all used timeframes // Arrays of calculated values. // The first index is a symbol, the second index is a timeframe double symbolAvrCandleSizes[][TFN]; // Array of average sizes of all candles double symbolAvrBuyCandleSizes[][TFN]; // Array of average sizes of bullish candles double symbolAvrSellCandleSizes[][TFN]; // Array of average sizes of bearish candles double symbolAvrSeriesLength[][TFN]; // Array of average series lengths int symbolCountSeries2[][TFN]; // Array of the number of series of length 2 int symbolCountSeries3[][TFN]; // Array of the number of series of length 3 int symbolCountSeries4[][TFN]; // Array of the number of series of length 4 int symbolCountSeries5[][TFN]; // Array of the number of series of length 5 int symbolCountSeries6[][TFN]; // Array of the number of series of length 6 int symbolCountSeries7[][TFN]; // Array of the number of series of length 7 int symbolCountSeries8[][TFN]; // Array of the number of series of length 8 int symbolCountSeries9[][TFN]; // Array of the number of series of length 9
Für Konvertierungen zwischen symbolischen Zeitrahmenkonstanten (wie ENUM_TIMEFRAMES), ihren Stringnamen und Indizes werden wir Hilfsfunktionen im Array aller Zeitrahmen bereitstellen. Mit ihrer Hilfe wird es möglich sein, drei Probleme zu lösen:
- Ermitteln einer Zeitrahmenkonstante anhand eines Namens (StringToTimeframe)
- Ermitteln des Namens des Zeitrahmens aus einer Zeitrahmenkonstante ohne das Präfix PERIOD_ (TimeframeToString) ermitteln
- Ermitteln des Indexes im Zeitrahmen-Array anhand der Zeitrahmenkonstante (TimeframeToIndex)
// Array of all timeframes ENUM_TIMEFRAMES tfValues[] = { PERIOD_M1, PERIOD_M2, PERIOD_M3, PERIOD_M4, PERIOD_M5, PERIOD_M6, PERIOD_M10, PERIOD_M12, PERIOD_M15, PERIOD_M20, PERIOD_M30, PERIOD_H1, PERIOD_H2, PERIOD_H3, PERIOD_H4, PERIOD_H6, PERIOD_H8, PERIOD_H12, PERIOD_D1, PERIOD_W1, PERIOD_MN1 }; //+------------------------------------------------------------------+ //| Convert a string name to a timeframe | //+------------------------------------------------------------------+ ENUM_TIMEFRAMES StringToTimeframe(string s) { // If the string contains the "_" symbol, leave only the characters that follow it int pos = StringFind(s, "_"); if(pos != -1) { s = StringSubstr(s, pos + 1); } // Convert to uppercase StringToUpper(s); // Arrays of corresponding string names of timeframes string keys[] = {"M1", "M2", "M3", "M4", "M5", "M6", "M10", "M12", "M15", "M20", "M30", "H1", "H2", "H3", "H4", "H6", "H8", "H12", "D1", "W1", "MN1" }; // Search for a match and return it if found FOREACH(keys) { if(keys[i] == s) return tfValues[i]; } return PERIOD_CURRENT; } //+------------------------------------------------------------------+ //| Convert a timeframe to a string name | //+------------------------------------------------------------------+ string TimeframeToString(ENUM_TIMEFRAMES tf) { // Get the timeframe name of the 'PERIOD_*' type string s = EnumToString(tf); // Return the part of the name after the '_' symbol return StringSubstr(s, StringFind(s, "_") + 1); } //+------------------------------------------------------------------+ //| Convert a timeframe to an index in an array of all timeframes | //+------------------------------------------------------------------+ int TimeframeToIndex(ENUM_TIMEFRAMES tf) { // Search for a match and return it if found FOREACH(tfValues) { if(tfValues[i] == tf) return i; } return WRONG_VALUE; }
Die Berechnung aller Werte wird in der Funktion Calculate() durchgeführt. In der Funktion verwenden wir eine verschachtelte Schleife, die alle Kombinationen von Symbolen und Zeitrahmen durchläuft. Darin wird geprüft, ob eine neue Bar für dieses bestimmte Symbol und diesen Zeitrahmen entstanden ist. Wenn ja, rufen wir die Hilfsfunktion für die Berechnung auf. Die Angabe, dass alle Werte sofort berechnet werden sollen, ohne auf eine neue Bar zu warten, kann auch über den Force-Parameter übergeben werden. Dieser Modus wird beim Starten des EA verwendet, damit wir die Ergebnisse sofort sehen können.
//+------------------------------------------------------------------+ //| Calculate all values | //+------------------------------------------------------------------+ void Calculate(bool force = false) { string symbol; ENUM_TIMEFRAMES tf; // For each symbol and timeframe FOREACH_AS(g_symbols, symbol) { FOREACH_AS(g_timeframes, tf) { // If a new bar has arrived for the given symbol and timeframe, then if(IsNewBar(symbol, tf) || force) { // Find the number of candles for calculation int n = PeriodSeconds(mainTimeframe_) * mainLength_ / PeriodSeconds(tf); // Calculate the average candle sizes CalculateAvrSizes(symbol, tf, n); // Calculate the lengths of candlestick series CalculateSeries(symbol, tf, n); } } } }
Wir haben die direkten Berechnungen in zwei Hilfsfunktionen untergebracht. Jede dieser Funktionen führt Berechnungen nur für ein Symbol und einen Zeitrahmen durch. Zusätzlich zu diesen beiden Parametern wird ein dritter Parameter übergeben – die Anzahl der Kerzen, für die die Berechnung durchgeführt wird.
Die Durchschnittswerte werden mit der Funktion CalculateAvrSizes() berechnet. Zunächst verwenden wir das Symbol und den Namen des Zeitrahmens, um die Indizes s und t des Elements in den zweidimensionalen Arrays zu definieren, die dieses Ergebnis speichern sollen. Kerzen, deren Eröffnungskurs gleich dem Schlusskurs ist, werden sowohl als Aufwärts- als auch als Abwärtskerze betrachtet. Die errechneten Durchschnittswerte werden auf ganze Punkte gerundet.
//+------------------------------------------------------------------+ //| Calculate average candle sizes | //+------------------------------------------------------------------+ void CalculateAvrSizes(string symbol, ENUM_TIMEFRAMES tf, int n) { // Find the index used for the desired symbol int s; FIND(g_symbols, symbol, s); // Find the index used for the desired timeframe int t = TimeframeToIndex(tf); // Array for candles MqlRates rates[]; // Copy the required number of candles into the array int res = CopyRates(symbol, tf, 1, n, rates); // If everything was copied, then if(res == n) { // Number of up and down candles int nBuy = 0, nSell = 0; // Zero out the elements for the calculated average values symbolAvrCandleSizes[s][t] = 0; symbolAvrBuyCandleSizes[s][t] = 0; symbolAvrSellCandleSizes[s][t] = 0; // For all candles FOREACH(rates) { // Find the candle size double size = rates[i].high - rates[i].low; // Add it to the total size of all candles symbolAvrCandleSizes[s][t] += size; // If this is a bullish candle, then we take it into account if(IsBuyRate(rates[i])) { symbolAvrBuyCandleSizes[s][t] += size; nBuy++; } // If this is a downward candle, take it into account if(IsSellRate(rates[i])) { symbolAvrSellCandleSizes[s][t] += size; nSell++; } } // Get the size of one point for a symbol double point = SymbolInfoDouble(symbol, SYMBOL_POINT); // Find the average values in points symbolAvrCandleSizes[s][t] /= n * point; symbolAvrBuyCandleSizes[s][t] /= nBuy * point; symbolAvrSellCandleSizes[s][t] /= nSell * point; // Round them to whole points symbolAvrCandleSizes[s][t] = MathRound(symbolAvrCandleSizes[s][t]); symbolAvrBuyCandleSizes[s][t] = MathRound(symbolAvrBuyCandleSizes[s][t]); symbolAvrSellCandleSizes[s][t] = MathRound(symbolAvrSellCandleSizes[s][t]); } }
Die Berechnung der Reihenlängen erfolgt in ähnlicher Weise mit der Funktion CalculateSeries(). Sie verwendet das Hilfs-Array seriesLens mit einer Größe von 100 Elementen. Der Index eines Elements dieser Matrix entspricht der Länge einer Reihe, und das Element selbst entspricht der Anzahl der Reihen dieser Länge. Wir gehen also davon aus, dass die überwiegende Mehrheit der Serien weniger als hundert Kerzen lang ist. Wir zeigen nur die Anzahl der Serien mit einer Länge von weniger als 10 Kerzen. Wir schreiben die Anzahl der Serien mit genau der gleichen Länge aus dem Array seriesLens in die entsprechenden Array-Elemente für Ergebnisse mit den Namen vom Typ symbolCountSeries* um.
//+------------------------------------------------------------------+ //| Calculate the lengths of candlestick series | //+------------------------------------------------------------------+ void CalculateSeries(string symbol, ENUM_TIMEFRAMES tf, int n) { // Find the index used for the desired symbol int s; FIND(g_symbols, symbol, s); // Find the index used for the desired timeframe int t = TimeframeToIndex(tf); // Array for candles MqlRates rates[]; // Copy the required number of candles into the array int res = CopyRates(symbol, tf, 1, n, rates); // If everything was copied, then if(res == n) { // Current series length int curLen = 0; // Direction of the previous candle bool prevIsBuy = false; bool prevIsSell = false; // Array of numbers of series of different lengths (index = series length) int seriesLens[]; // Set the size and initialize ArrayResize(seriesLens, 100); ArrayInitialize(seriesLens, 0); // For all candles FOREACH(rates) { // Determine the candle direction bool isBuy = IsBuyRate(rates[i]); bool isSell = IsSellRate(rates[i]); // If the direction is the same as the previous one, then if((isBuy && prevIsBuy) || (isSell && prevIsSell)) { // Increase the series length curLen++; } else { // Otherwise, if the length is within the required range, then if(curLen > 1 && curLen < 100) { // Increase the counter of the length series seriesLens[curLen]++; } // Reset the current series length curLen = 1; } // Save the direction of the current candle as the previous one prevIsBuy = isBuy; prevIsSell = isSell; } // Initialize the array element for the average series length symbolAvrSeriesLength[s][t] = 0; int count = 0; // For all series lengths we find the sum and quantity FOREACH(seriesLens) { symbolAvrSeriesLength[s][t] += seriesLens[i] * i; count += seriesLens[i]; } // Calculate the average length of candlestick series symbolAvrSeriesLength[s][t] /= (count > 0 ? count : 1); // Copy the values of the series lengths into the final arrays symbolCountSeries2[s][t] = seriesLens[2]; symbolCountSeries3[s][t] = seriesLens[3]; symbolCountSeries4[s][t] = seriesLens[4]; symbolCountSeries5[s][t] = seriesLens[5]; symbolCountSeries6[s][t] = seriesLens[6]; symbolCountSeries7[s][t] = seriesLens[7]; symbolCountSeries8[s][t] = seriesLens[8]; symbolCountSeries9[s][t] = seriesLens[9]; } }
Die Funktion Show() ist für die Anzeige der Ergebnisse zuständig. In der ersten Version beschränken wir uns vorerst auf die Ausgabe in das Terminalprotokoll und als Kommentar auf dem Chart, auf dem der EA gestartet wird. Daher reicht es aus, wenn wir die Ergebnisse in Textform darstellen. Eine separate Funktion TextComment() wird diese Darstellung übernehmen.
//+------------------------------------------------------------------+ //| Show results | //+------------------------------------------------------------------+ void Show() { // Get the results as text string text = TextComment(); // Show it in the comment and in the log Comment(text); Print(text); }
In der EA-Initialisierungsfunktion müssen wir nur die Eingabeparameter verarbeiten, indem wir die aufgelisteten Symbolnamen und Zeitrahmen in separate Werte aufteilen und Arrays der erforderlichen Größe für die Aufzeichnung der Ergebnisse vorbereiten. Danach können wir die Funktion zur Berechnung und Anzeige der Ergebnisse aufrufen:
//+------------------------------------------------------------------+ //| Initialize the EA | //+------------------------------------------------------------------+ int OnInit(void) { // Fill in the symbol array for calculations from the inputs SPLIT(symbols_, g_symbols); // If no symbols are specified, use the current single symbol if(ArraySize(g_symbols) == 0) { APPEND(g_symbols, Symbol()); } // Number of symbols for calculations int nSymbols = ArraySize(g_symbols); // Initialize arrays for calculated values Initialize(nSymbols); // Fill the array with timeframe names from the inputs string strTimeframes[]; SPLIT(timeframes_, strTimeframes); ArrayResize(g_timeframes, 0); // If timeframes are not specified, use the current one if(ArraySize(strTimeframes) == 0) { APPEND(strTimeframes, TimeframeToString(Period())); } // Fill the timeframe array from the timeframe names array FOREACH(strTimeframes) { ENUM_TIMEFRAMES tf = StringToTimeframe(strTimeframes[i]); if(tf != PERIOD_CURRENT) { APPEND(g_timeframes, tf); } } // Perform a forced recalculation Calculate(true); // Show the results Show(); return(INIT_SUCCEEDED); }
In der obigen Funktion haben wir ein neues Makro SPLIT verwendet. Es wurde der Datei Utils/Macros.mqh der Bibliothek Adwizard hinzugefügt. Dies ist die einzige Ergänzung der Bibliothek, die bisher für dieses Projekt erforderlich war.
Das Makro selbst ist so konzipiert, dass es eine Zeichenkette unter Verwendung von zwei möglichen Trennzeichen in Teile aufteilt: ein Komma und ein Semikolon.
#define SPLIT(V, A) { string s=V; StringReplace(s, ";", ","); StringSplit(s, ',', A); }
Schauen wir uns nun die Ergebnisse der Arbeit des entwickelten EA an.
EA-Test
Starten wir den EA mit Standardparametern in einem Chart. Das Ergebnis sieht dann etwa so aus:
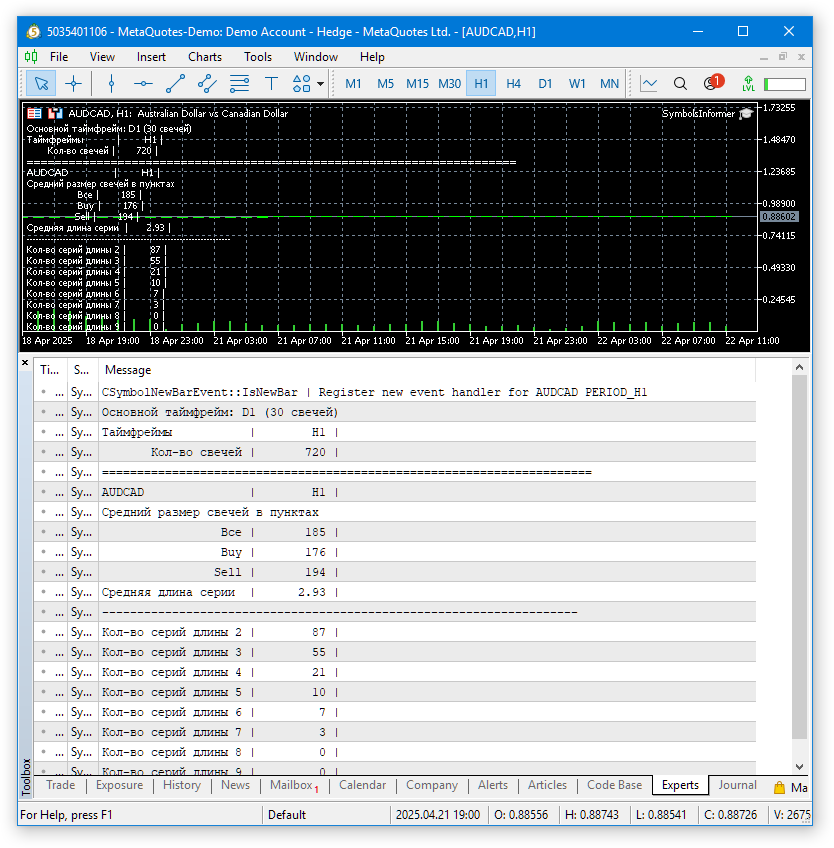
Abb. 1. Ergebnisse der Ausführung des EA mit Standardparametern auf AUDCAD H1
Da bei der Darstellung von Kommentaren in einem Chart eine nicht monospaced Schriftart verwendet wird, ist es nicht besonders praktisch, die ermittelten Werte im Chart abzulesen. Das Terminalprotokoll verwendet eine nichtproportionale Schrift, daher ist die Darstellung dort deutlich besser. Sehen wir uns an, wie die Ergebnisse für verschiedene Symbole und Zeitrahmen aussehen.
Führen wir den EA mit den folgenden Eingaben aus:
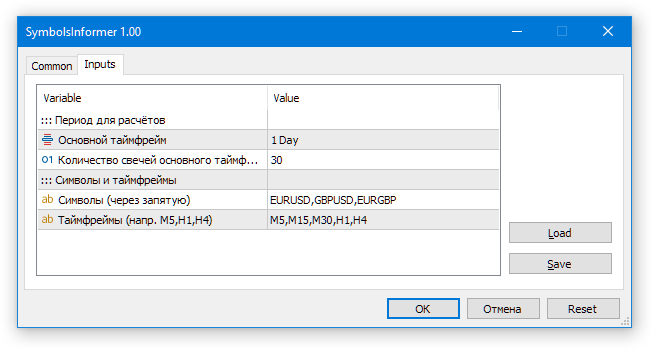
Werfen wir einen Blick auf das Ergebnis.
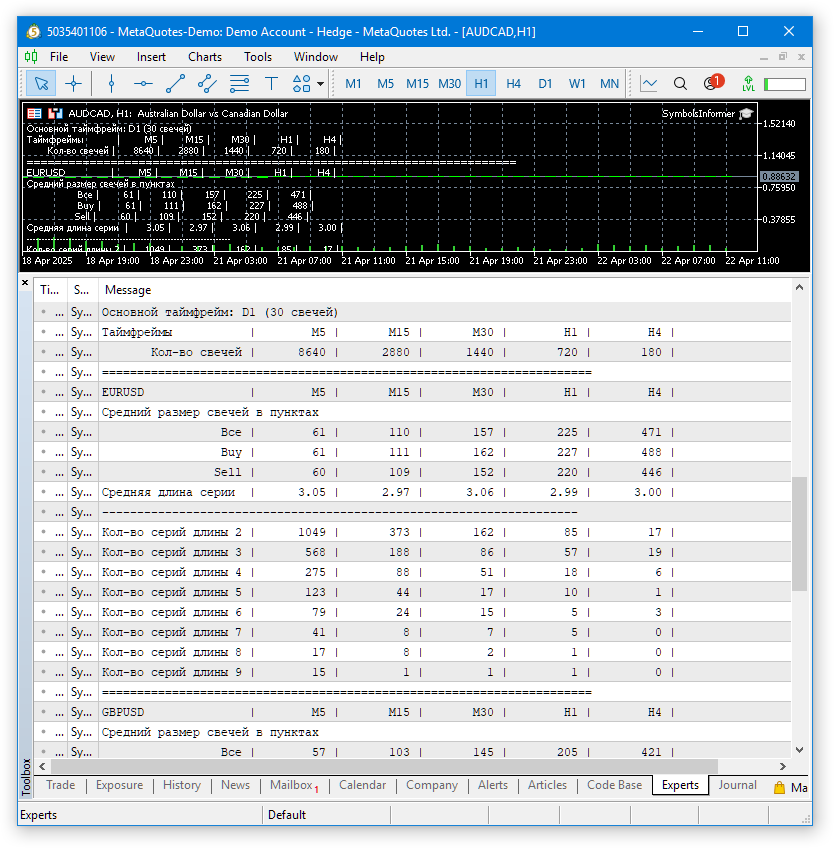
Abb. 2. Ergebnisse des EA für verschiedene Symbole und Zeitrahmen
Die Berechnungen für mehrere Symbole und Zeitrahmen wurden erfolgreich abgeschlossen. Die Ergebnisse sind in der Tabelle aufgeführt. Sie sind noch nicht besonders nutzerfreundlich, aber für eine erste schnelle Analyse reichen sie aus.
Schlussfolgerung
Wir haben die erste Version eines Hilfs-EAs für den Informer erstellt, der Informationen über die durchschnittlichen Kerzengrößen in Punkten und die Länge der Serien von Kerzen, die sich in dieselbe Richtung bewegen, anzeigt. Auf den ersten Blick hat dies einen etwas indirekten Bezug zu unserem Hauptprojekt, der Schaffung eines Systems zur automatischen Optimierung und dem Start von Mehrwährungs-EAs, die eine Vielzahl von einfachen Strategien umsetzen. Dies ist in der Tat der Fall, sodass die Arbeit an diesem EA über den Rahmen dieser Artikelserie hinaus fortgesetzt werden wird. Aber während der Arbeit werden wir viele Dinge ausprobieren und testen, die wir dann hoffentlich im Hauptprojekt erfolgreich anwenden können.
Jetzt haben wir schon eine ganze Menge getan. Die Wahl einer anderen, optimaleren Code-Organisationsstruktur wird die Parallelisierung der Arbeit in verschiedenen Bereichen der weiteren Bibliotheksentwicklung von Adwizard ermöglichen. Ich denke bereits über einige zukünftige Verbesserungsmöglichkeiten nach. Eine davon ist der Aufbau einer visuellen Schnittstelle für die Verwaltung der Arbeit der endgültigen EAs. Das in diesem Artikel besprochene Projekt wird uns helfen, verschiedene mögliche Ansätze auszuprobieren, ohne uns in der Implementierung sehr komplexer Dinge zu verzetteln. Nachdem wir ihre Vor- und Nachteile geprüft und die am besten geeignete ausgewählt haben, können wir uns gezielter auf die Entwicklung des Hauptprojekts konzentrieren.
Vielen Dank für Ihre Aufmerksamkeit! Bis bald!
Wichtige Warnung
Alle in diesem Artikel und in allen vorangegangenen Artikeln dieser Reihe vorgestellten Ergebnisse beruhen lediglich auf historischen Testdaten und sind keine Garantie für zukünftige Gewinne. Die Arbeiten im Rahmen dieses Projekts haben Forschungscharakter. Alle veröffentlichten Ergebnisse können von jedermann auf eigenes Risiko verwendet werden.
Inhalt des Archivs
| # | Name | Version | Beschreibung | Jüngste Änderungen |
|---|---|---|---|---|
| SymbolsInformer | Arbeitsordner des Projekts | |||
| 1 | SymbolsInformer.mq5 | 1.00 | Der EA für die Anzeige von Informationen über die Länge von unidirektionalen Kerzenserien | Teil 26 |
| SymbolsInformer/Include/Adwizard/Base | Basisklassen, von denen andere Projektklassen erben | |||
| 2 | Advisor.mqh | 1.04 | EA-Basisklasse | Teil 10 |
| 3 | Factorable.mqh | 1.05 | Basisklasse von Objekten, die aus einer Zeichenkette erstellt werden | Teil 24 |
| 4 | FactorableCreator.mqh | 1.00 | Klasse von Erzeugern, die Namen und statische Konstruktoren von CFactorable-Nachfolgeklassen binden | Teil 24 |
| 5 | Interface.mqh | 1.01 | Basisklasse zur Visualisierung verschiedener Objekte | Teil 4 |
| 6 | Receiver.mqh | 1.04 | Basisklasse für die Umwandlung von offenen Volumina in Marktpositionen | Teil 12 |
| 7 | Strategy.mqh | 1.04 | Handelsstrategie-Basisklasse | Teil 10 |
| SymbolsInformer/Include/Adwizard/Database | Dateien für den Umgang mit allen Arten von Datenbanken, die von Projekt-EAs verwendet werden | |||
| 8 | Database.mqh | 1.12 | Klasse für den Umgang mit der Datenbank | Teil 25 |
| 9 | db.adv.schema.sql | 1.00 | Endgültige Datenbankstruktur von EA | Teil 22 |
| 10 | db.cut.schema.sql | 1.00 | Struktur der verkürzten Optimierungsdatenbank | Teil 22 |
| 11 | db.opt.schema.sql | 1.05 | Struktur der Optimierungsdatenbank | Teil 22 |
| 12 | Storage.mqh | 1.01 | Klasse zur Handhabung der Schlüssel-Wert-Speicherung für den endgültigen EA in der EA-Datenbank | Teil 23 |
| SymbolsInformer/Include/Adwizard/Experts | Dateien mit gemeinsamen Teilen der verwendeten EAs verschiedener Typen | |||
| 13 | Expert.mqh | 1.22 | Die Bibliotheksdatei für den endgültigen EA. Gruppenparameter können aus der EA-Datenbank übernommen werden | Teil 23 |
| 14 | Optimization.mqh | 1.04 | Bibliotheksdatei für den EA, der den Start von Optimierungsaufgaben verwaltet | Teil 23 |
| 15 | Stage1.mqh | 1.19 | Bibliotheksdatei für die Einzelinstanz der Handelsstrategieoptimierung EA (Stage 1) | Teil 23 |
| 16 | Stage2.mqh | 1.04 | Bibliotheksdatei für den EA, der eine Gruppe von Handelsstrategieinstanzen optimiert (Stage 2) | Teil 23 |
| 17 | Stage3.mqh | 1.04 | Bibliotheksdatei für den EA, die eine generierte standardisierte Gruppe von Strategien in einer EA-Datenbank mit einem bestimmten Namen speichert. | Teil 23 |
| SymbolsInformer/Include/Adwizard/Optimization | Für die automatische Optimierung zuständige Klassen | |||
| 18 | OptimizationJob.mqh | 1.00 | Jobklasse für die Optimierungsphase des Projekts | Teil 25 |
| 19 | OptimizationProject.mqh | 1.00 | Klasse für ein Optimierungsprojekt | Teil 25 |
| 20 | OptimizationStage.mqh | 1.00 | Klasse für eine Optimierungsprojektphase | Teil 25 |
| 21 | OptimizationTask.mqh | 1.00 | Optimierungsaufgabenklasse (Erstellung) | Teil 25 |
| 22 | Optimizer.mqh | 1.03 | Klasse für den Projektautooptimierungsmanager | Teil 22 |
| 23 | OptimizerTask.mqh | 1.03 | Optimierungsaufgabenklasse (Pipeline) | Teil 22 |
| SymbolsInformer/Include/Adwizard/Strategies | Beispiele für Handelsstrategien, die die Funktionsweise des Projekts veranschaulichen | |||
| 24 | HistoryStrategy.mqh | 1.00 | Klasse der Handelsstrategie für die Wiederholung der Handelshistorie | Teil 16 |
| 25 | SimpleVolumesStrategy.mqh | 1.11 | Klasse der Handelsstrategie mit Tick-Volumen | Teil 22 |
| SymbolsInformer/Include/Adwizard/Utils | Hilfsprogramme, Makros zur Code-Reduzierung | |||
| 26 | ExpertHistory.mqh | 1.00 | Klasse für den Export der Handelshistorie in eine Datei | Teil 16 |
| 27 | Macros.mqh | 1.07 | Nützliche Makros für Array-Operationen | Teil 26 |
| 28 | NewBarEvent.mqh | 1.00 | Klasse zur Erkennung einer neuen Bar eines bestimmten Symbols | Teil 8 |
| 29 | SymbolsMonitor.mqh | 1.00 | Klasse zur Beschaffung von Informationen über Handelsinstrumente (Symbole) | Teil 21 |
| SymbolsInformer/Include/Adwizard/Virtual | Klassen zur Erstellung verschiedener Objekte, die durch ein System virtueller Handelsaufträge und -positionen verbunden sind | |||
| 30 | Money.mqh | 1.01 | Basisklasse für das Money-Management | Teil 12 |
| 31 | TesterHandler.mqh | 1.07 | Klasse zur Behandlung von Optimierungsereignissen | Teil 23 |
| 32 | VirtualAdvisor.mqh | 1.10 | Klasse des EA, der virtuelle Positionen (Aufträge) bearbeitet | Teil 24 |
| 33 | VirtualChartOrder.mqh | 1.01 | Grafische virtuelle Positionsklasse | Teil 18 |
| 34 | VirtualHistoryAdvisor.mqh | 1.00 | Die Klasse des EA zur Wiedergabe der Handelshistorie | Teil 16 |
| 35 | VirtualInterface.mqh | 1.00 | EA GUI-Klasse | Teil 4 |
| 36 | VirtualOrder.mqh | 1.09 | Klasse der virtuellen Aufträge und Positionen | Teil 22 |
| 37 | VirtualReceiver.mqh | 1.04 | Klasse für die Umwandlung von offenen Volumina in Marktpositionen (Empfänger) | Teil 23 |
| 38 | VirtualRiskManager.mqh | 1.05 | Klasse Risikomanagement (Risikomanager) | Teil 24 |
| 39 | VirtualStrategy.mqh | 1.09 | Klasse einer Handelsstrategie mit virtuellen Positionen | Teil 23 |
| 40 | VirtualStrategyGroup.mqh | 1.03 | Klasse der Handelsstrategiegruppe(n) | Teil 24 |
| 41 | VirtualSymbolReceiver.mqh | 1.00 | Empfängerklasse für Symbole | Teil 3 |
Der Quellcode ist auch in den öffentlichen Repositories SymbolsInformer und Adwizard verfügbar.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/17606
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Einfach schade(
Ich werde mir morgen Ihren informativen Bericht ansehen
@Rashid Umarov
Hallo
Verfolgen Sie diesen Thread aufmerksam und sind Sie in der Lage, alles zu implementieren und zu optimieren?
Können Sie mir bitte dabei helfen?
Vielen Dank