
取引におけるニューラルネットワーク:周波数領域における異常検出(CATCH)

はじめに
現代の金融市場では、膨大な量のデータがリアルタイムで処理されています。株価、為替レート、取引量、金利などは、いずれも複雑かつ高次元な時系列データを構成しています。こうしたデータを分析することは、トレーダーや投資家にとって極めて重要です。市場変動を予測し、潜在的なパターンを発見するうえで欠かせないためです。
時系列解析における主要な課題の1つが、異常検知です。急激な価格変動、流動性の急変、不審な取引活動などは、相場操縦やインサイダー取引を示唆している可能性があります。こうした兆候を見逃した場合、巨額損失だけでなく、金融機関そのものの破綻につながるおそれもあります。
異常は一般に、「点異常」と「部分時系列異常」の2種類に分類されます。点異常とは、単一銘柄における出来高の急増のような、突発的な外れ値を指します。これらは比較的明確な異常であるため、従来手法でも検出しやすい傾向があります。一方、部分時系列異常はより複雑です。一見すると正常に見えるものの、既存の市場パターンから逸脱しています。たとえば、資産間相関の長期的な変化や、ボラティリティの高い市場環境にもかかわらず不自然なほど滑らかに続く価格上昇などが挙げられます。この種の異常は、潜在的なリスクを示唆することが多いため、特に重要です。
こうしたパターンを検出する有効な方法の1つが、データを周波数領域へ変換して解析するアプローチです。周波数領域では、異常の種類ごとに異なる周波数帯に特徴が現れます。たとえば、短期的なボラティリティ急騰は高周波成分に現れやすく、一方で大局的なトレンド変化は低周波成分に反映されます。しかし、従来手法では重要な情報が失われることが多く、特に高周波領域に存在する微細かつ重要なシグナルを十分に捉えられない場合があります。
また、異なる金融商品間の関係性を考慮することも重要です。たとえば、原油先物が急落しているにもかかわらず、石油関連株が安定したままである場合、市場に何らかの不整合が存在している可能性があります。しかし、従来モデルの多くはこうした依存関係を無視するか、あるいは過度に厳しい仮定を置いてしまうため、予測精度の低下を招いていました。
これらの問題に対する解決策の1つとして提案されているのが、論文「CATCH:Channel-Aware Multivariate Time Series Anomaly Detection via Frequency Patching」です。本論文で提案されているCATCHフレームワークは、フーリエ変換を利用して市場データを周波数領域で解析します。さらに、複雑な異常を高精度に検出するため、正常な資産の挙動を詳細にモデル化する周波数パッチング機構を導入しています。また、適応的関係性モジュールにより、金融商品間の有意な相関関係を自動的に抽出しつつ、ノイズの影響を抑制します。
CATCHアルゴリズム
CATCHのアーキテクチャは、以下の3つの主要モジュールで構成されています。
- Forward Module
- Channel Fusion Module (CFM)
- Time-Frequency Reconstruction Module (TFRM)
最初の段階はForward Moduleです。このモジュールでは、データを正規化した後、高速フーリエ変換(FFT)を用いて時系列データを周波数領域へ変換し、その結果を周波数パッチへ分割します。フーリエ変換は時系列を直交三角関数の集合として表現し、スペクトルの実部と虚部の両方を保持します。
次に、スペクトルはサイズP、ステップ幅SのL個の周波数パッチに分割されます。実部と虚部は同一のパラメータでパッチ化され、その後、1つの統一テンソルとして結合されます。
これらのパッチは、以下の投射層を通じて潜在空間に射影されます。
![]()
このステップは、次元削減をおこないながらも、最も情報量の多い特徴を保持する点で重要です。これによりモデルの汎化性能が向上し、異常検知精度の改善につながります。
2つ目の構成要素はChannel Fusion Module (CFM)であり、各周波数帯におけるチャネル間依存関係を捉えます。これはChannel-Masked Transformer (CMT)を用いて実現されます。チャネルマスクMはMask Generator (MG)によって生成されます。MGは確率行列Dを構築し、それをベルヌーイ再サンプリングによって二値化します。Dにおける高い値はM内の1に対応し、チャネル間の依存関係を示します。
CMTはマスク付きアテンションを用いてパッチを処理します。この処理は以下の式で表されます。

マスク生成およびアテンション機構の調整を効果的に最適化するためには、明確な最適化目的を設定することが重要です。これにより、生成されるマスクの品質が向上します。重要なのは、マスクによって重要と判断されたチャネル間のアテンション重みを強調し、アテンション機構が有意な相関関係に集中できるようにする点です。この仕組みにより、アテンション機構は最も重要な相関関係に整合し、モデル全体の性能が向上します。
このアプローチの大きな利点は、アテンション処理から無関係なチャネルを除外することで、不要な影響を抑えられる点です。最も情報量の多いチャネルのみに注目することで、マスク付きアテンション機構はノイズや歪みを低減します。この方法により、アテンション機構の安定性を維持でき、動的な環境においてモデルの堅牢性と精度を向上させます。
次のステップでは、チャネル間の相関関係をさらに洗練させるために、マスク生成器を反復的に最適化します。これには、マスク付きTransformer層内のアテンション機構を微調整し、チャネル間の文脈においてより多くの関連するチャネル間関係を正確に捉えることが含まれます。
マスキングを最適化するために、著者らはClusteringLoss関数を導入します。
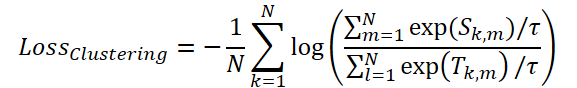
最後に、Time-Frequency Reconstruction Module (TFRM)は、逆フーリエ変換(iFFT)を適用して時系列を再構成します。
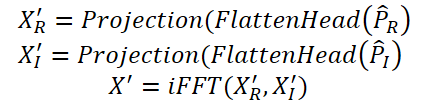
異常は再構成誤差に基づいて検出されます。
時間領域と周波数領域の分析を組み合わせた統合的な解析により、CATCHモデルは堅牢で信頼性の高い異常検知を実現します。
CATCHフレームワークの構成図を以下に示します。

MQL5での実装
CATCH手法の理論的な側面を確認した後は、実践部分に移ります。本記事では、提案されたアプローチをMQL5を用いて実装した例を示します。
まず最初に重要なのは、このフレームワーク内のほぼすべての処理が周波数領域で実行されるという点です。これは本手法の本質的な特徴であり、データ処理のアプローチと数理的手法の選択の両方を規定します。
周知の通り、信号を周波数領域で表現する際には複素数が用いられます。そのため、演算処理を含む複素データの効率的な取り扱いは、システムを正しく動作させる上で不可欠です。
以前、ATFNetフレームワークの開発において同様の課題に対処しました。その際、スペクトルデータ処理の原理を確立し、現在再利用可能な方法論的アプローチを構築しています。これらの既存実装により、今回の実装は大幅に簡略化されています。
複素畳み込み層
まず、複素値を扱うことができる畳み込み層を設計します。実務上、畳み込み層は多変量時系列処理において最も有効な手法の一つであるため、このコンポーネントの構築を優先します。
通常通り、OpenCL側でコアアルゴリズムの実装から開始します。主要な処理をGPUレベルで実装することで最大限の並列性を確保でき、多変量データ処理において極めて重要となります。CPUによる逐次処理とは異なり、GPUコアはタスクの異なる部分を同時並列に処理するため、学習時および本番環境の両方で大幅な高速化が可能になります。
順伝播はFeedForwardComplexConvカーネルに実装されています。このカーネルは3つのデータバッファへのポインタと、データ構造を定義するいくつかの定数を受け取ります。
ここで重要なのは、すべてのバッファがfloat2型を使用している点です。これは複素数を効率的に扱うための選択であり、各値が実部と虚部の2要素から構成されます。
float2を使用する利点は以下の通りです。
- メモリアクセスの最適化:2値を同時に読み書きできるため、メモリ操作が削減される
- ハードウェアアクセラレーション:OpenCLがベクトル型をハードウェアレベルでサポートし、演算が高速化される
- データ表現の明確化:float2を使用すると、各変数が複素数に直接対応し、コードの可読性が向上する
__kernel void FeedForwardComplexConv(__global const float2 *matrix_w, __global const float2 *matrix_i, __global float2 *matrix_o, const int inputs, const int step, const int window_in, const int activation ) { const size_t i = get_global_id(0); const size_t units = get_global_size(0); const size_t out = get_global_id(1); const size_t w_out = get_global_size(1); const size_t var = get_global_id(2); const size_t variables = get_global_size(2);
このカーネルは3次元の実行空間で動作します。第1次元はシーケンス要素数、第2次元はフィルタ数、第3次元は入力テンソル内の独立したユニットシーケンス数を表します。カーネル開始時に各スレッドはこの空間内での位置を特定し、インデックスとして保持します。
次に、これらのインデックスに基づいて、データバッファ内のオフセットが計算されます。この処理は、実数値畳み込み層で用いたロジックと同様であり、複素数をfloat2として扱うことで実現されています。
int w_in = window_in; int shift_out = w_out * (i + units * var); int shift_in = step * i + inputs * var; int shift = (w_in + 1) * (out + var * w_out); int stop = (w_in <= (inputs - shift_in) ? w_in : (inputs - shift_in)) + inputs * var;
これで前処理は完了し、畳み込み演算に進みます。入力データとフィルタパラメータはともに複素数であり、結果も複素数となります。すべての数学演算は、既に実装済みの複素数演算関数を用いて行われます。
まず、ローカル変数を宣言し、中間結果を格納するために用意します。この変数はフィルタのバイアス項で初期化されます。
float2 sum = ComplexMul((float2)(1, 0), matrix_w[shift + w_in]); #pragma unroll for(int k = 0; k <= stop; k ++) sum += IsNaNOrInf2(ComplexMul(matrix_i[shift_in + k], matrix_w[shift + k]), (float2)0);
次に、入力データベクトルと対応するフィルタベクトルを要素ごとに乗算するループを実行し、その結果を局所変数に累積していきます。
その後、適切な活性化関数を適用し、変換後の最終値を出力バッファへ書き込みます。
switch(activation) { case 0: sum = ComplexTanh(sum); break; case 1: sum = ComplexDiv((float2)(1, 0), (float2)(1, 0) + ComplexExp(-sum)); break; case 2: if(sum.x < 0) { sum.x *= 0.01f; sum.y *= 0.01f; } break; default: break; } matrix_o[out + shift_out] = sum; }
次のステップはバックプロパゲーション(逆伝播)の実装です。ここでは、誤差勾配を伝播させる役割を持つCalcHiddenGradientComplexConvカーネルを考えます。この処理でも、複素数はベクトル形式で表現されます。メソッドのパラメータには、各対応段階における誤差勾配を格納するためのバッファが含まれます。
__kernel void CalcHiddenGradientComplexConv(__global const float2 * matrix_w, __global const float2 * matrix_g, __global const float2 * matrix_o, __global float2 * matrix_ig, const int outputs, const int step, const int window_in, const int window_out, const int activation, const int shift_out ) { const size_t i = get_global_id(0); const size_t inputs = get_global_size(0); const size_t var = get_global_id(1); const size_t variables = get_global_size(1);
この操作の目的は、モデルの出力に対する入力データの寄与度に応じて、誤差勾配を入力データに逆伝播させることであることに注意することが重要です。この要件により、カーネルの実行空間の構成も変更されます。実装では2次元の実行空間を使用しています。第1次元は入力シーケンスの要素に対応し、第2次元は多変量系列内の各単変量系列に対応します。
これまでと同様に、カーネルはまず実行空間の各次元における現在のスレッド位置を取得します。取得されたインデックスはローカル定数として保存されます。
続いて、データバッファ内のオフセットを計算します。ここで重要なのは、畳み込みウィンドウのストライドによっては、単一の入力要素が複数の畳み込み演算に関与する可能性があるという点です。そのため、勾配はそれらすべての演算にわたって集約する必要があります。これを実現するために、勾配を累積する範囲を定義します。
float2 sum = (float2)0; float2 out = matrix_o[i]; int start = i - window_in + step; start = max((start - start % step) / step, 0) + var * inputs; int stop = (i + step - 1) / step; if(stop > (outputs / window_out)) stop = outputs / window_out; stop += var * outputs;
準備が完了すると、指定されたステップ幅でこれらの範囲を走査するループが実行されます。このループでは、対応するフィルタ重みを考慮しながら勾配を加算していきます。
#pragma unroll for(int h = 0; h < window_out; h ++) { for(int k = start; k < stop; k++) { int shift_g = k * window_out + h; int shift_w = (stop - k - 1) * step + i % step + h * (window_in + 1); if(shift_g >= outputs || shift_w >= (window_in + 1) * window_out) break; sum += ComplexMul(matrix_g[shift_out + shift_g], matrix_w[shift_w]); } } sum = IsNaNOrInf2(sum, (float2)0);
その後、得られた値に対して、入力データに適用された活性化関数の導関数を用いて補正されます。
switch(activation) { case 0: sum = ComplexMul(sum, (float2)1.0f - ComplexMul(out, out)); break; case 1: sum = ComplexMul(sum, ComplexMul(out, (float2)1.0f - out)); break; case 2: if(out.x < 0.0f) { sum.x *= 0.01f; sum.y *= 0.01f; } break; default: break; } matrix_ig[i] = sum; }
最終的な結果は、グローバルデータバッファ内の対応する要素に保存されます。
以上で示したカーネルの完全なコードは添付ファイルに含まれています。また、添付ファイルには学習可能なフィルタパラメータを最適化するためのカーネル実装もすべて含まれているため、そちらについては各自で確認していただきたいと思います。ここからは、メインプログラム側でのワークフローの構成へ進みます。
この段階で、新しいオブジェクトCNeuronComplexConvOCLを導入します。その構造は以下のとおりです。
class CNeuronComplexConvOCL : public CNeuronConvOCL { protected: //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronComplexConvOCL(void) { activation = None; } ~CNeuronComplexConvOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronComplexConvOCL; } };
このクラスは、実数値用の畳み込み層オブジェクトを継承しています。これにより、内部オブジェクトやインターフェースを含む既存のインフラストラクチャを再利用することが可能になります。ただし、継承したメソッドの一部には依然として調整が必要です。
特に重要なのは、順伝播およびバックプロパゲーションのメソッドです。これらは、前述した新しいOpenCLカーネルに対応するようオーバーライドされています。これらのカーネルを実行キューへ登録する処理自体は標準的な手順に従うため、ここでは詳細な説明は省略します。完全な実装は添付ファイルに含まれています。
一方で、新しいオブジェクトの初期化メソッドについては詳しく見ておく価値があります。というのも、複素数を扱うことでデータバッファの管理方法に影響が生じるためです。MQL5はネイティブに複素数をサポートしていますが、私たちは新しいバッファ型を導入しませんでした。その代わり、既存バッファのサイズを拡張しています。このアプローチにより、ソリューションをより汎用的に保つことができ、既存メソッドに大規模な変更を加える必要も回避できます。
初期化メソッドのパラメータ構成は、親クラスから完全に継承されています。
bool CNeuronComplexConvOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, 2 * units_count * window_out * variables, optimization_type, batch)) return false;
メソッド内部では、まず全結合層の対応するメソッドを呼び出します。この全結合層は、畳み込み層を含むライブラリ内のすべてのニューラルネットワーク層の基底クラスとして機能しています。バッファサイズが異なるため、直近の親クラスのメソッドをそのまま使用することはできません。
なお、親クラスのメソッドを通じて生成されるオブジェクトのサイズを指定する際には、計算されたサイズの2倍を設定しています。これは当然ながら、複素値の実部と虚部の両方を格納するために必要です。
続いて、オブジェクトのアーキテクチャ定数を内部変数へ保存します。
iWindow = (int)window; iStep = MathMax(step, 1); activation = None; iWindowOut = window_out; iVariables = variables;
続いて、継承されたデータバッファを初期化します。まず、学習可能パラメータ用バッファが有効であるかを確認し、必要に応じて新しいバッファを生成します。
if(CheckPointer(WeightsConv) == POINTER_INVALID) { WeightsConv = new CBufferFloat(); if(CheckPointer(WeightsConv) == POINTER_INVALID) return false; }
このバッファのサイズを決定する際にも、複素値を考慮します。そのため、必要となるサイズは想定値の2倍として確保されます。
int count = (int)(2 * (iWindow + 1) * iWindowOut * iVariables); if(!WeightsConv.Reserve(count)) return false;
その後、このバッファはランダム値を用いて初期化されます。
float k = (float)(1 / sqrt(iWindow + 1)); for(int i = 0; i < count; i++) { if(!WeightsConv.Add((GenerateWeight() * 2 * k - k)*WeightsMultiplier)) return false; } if(!WeightsConv.BufferCreate(OpenCL)) return false;
最後に、選択された最適化手法に応じて、オプティマイザの状態であるモメンタム項を保存するために必要な数のバッファを確保します。これらのバッファは、初期状態ではすべてゼロで埋められます。
if(optimization == SGD) { if(CheckPointer(DeltaWeightsConv) == POINTER_INVALID) { DeltaWeightsConv = new CBufferFloat(); if(CheckPointer(DeltaWeightsConv) == POINTER_INVALID) return false; } if(!DeltaWeightsConv.BufferInit(count, 0.0)) return false; if(!DeltaWeightsConv.BufferCreate(OpenCL)) return false; } else { if(CheckPointer(FirstMomentumConv) == POINTER_INVALID) { FirstMomentumConv = new CBufferFloat(); if(CheckPointer(FirstMomentumConv) == POINTER_INVALID) return false; } if(!FirstMomentumConv.BufferInit(count, 0.0)) return false; if(!FirstMomentumConv.BufferCreate(OpenCL)) return false; //--- if(CheckPointer(SecondMomentumConv) == POINTER_INVALID) { SecondMomentumConv = new CBufferFloat(); if(CheckPointer(SecondMomentumConv) == POINTER_INVALID) return false; } if(!SecondMomentumConv.BufferInit(count, 0.0)) return false; if(!SecondMomentumConv.BufferCreate(OpenCL)) return false; } //--- return true; }
そして最後に、このメソッドは、各処理が正常に実行されたかどうかを示す真偽値を返して完了します。
以上で、複素数データに対する畳み込み層アルゴリズムについての説明を終わります。このクラスおよびそのすべてのメソッドの完全な実装は、添付資料に含まれています。
複素マスク付きアテンションモジュール
次に構築する主要コンポーネントは、複素数データ用のマスク付きアテンションモジュールです。これは、Channel Fusion Moduleの中核を構成する要素となります。
これまでに、実数値データに対するマスク付きアテンション機構を実装してきました。ここでの課題は、この手法を複素数へ拡張するとともに、CATCHフレームワーク特有のいくつかの重要な機能を組み込むことです。
通常どおり、開発はOpenCL側から開始します。フィードフォワード処理はMaskAttentionComplexカーネル内で実装されます。このカーネルは、5つのデータバッファへのポインタと、入力データ構造を定義する2つの定数を受け取ります。複素数を扱うため、入力データおよび出力データ用のバッファにはfloat2ベクトル型を使用します。一方で、マスク行列およびアテンション係数を格納するバッファには、実数値のまま保持されます。これらは確率分布を表現するためです。
__kernel void MaskAttentionComplex(__global const float2 *q, __global const float2 *kv, __global float2 *scores, __global const float *masks, __global float2 *out, const int dimension, const int heads_kv ) { //--- init const int q_id = get_global_id(0); const int k = get_local_id(1); const int h = get_global_id(2); const int qunits = get_global_size(0); const int kunits = get_local_size(1); const int heads = get_global_size(2);
このカーネルは、3次元の実行空間内で動作します。第1次元はQueryテンソルのサイズに対応しており、解析対象となる要素数を表します。第2次元はKeyテンソルのサイズに対応しており、依存関係の計算に使用される要素数を示します。この次元に沿って、スレッドはワークグループへとまとめられます。第3次元はアテンションヘッドの数を表します。実行開始時に、各スレッドはこの空間内での自身の位置を特定し、そのインデックスをローカル定数へ保存します。
これらのインデックスを用いて、すべてのデータバッファに対するオフセットが計算されます。
const int h_kv = h % heads_kv; const int shift_q = dimension * (q_id * heads + h); const int shift_k = dimension * (2 * heads_kv * k + h_kv); const int shift_v = dimension * (2 * heads_kv * k + heads_kv + h_kv); const int shift_s = kunits * (q_id * heads + h) + k;
マスク値はローカル変数に読み込まれます。
const float mask = IsNaNOrInf(masks[shift_s], 0);
ここで重要なのは、このカーネルが、すでにアテンションヘッドを考慮したマスクテンソルを前提としている点です。言い換えると、各アテンションヘッドは、それぞれ独自のチャネルマスク行列を持っています。
次に、OpenCLのローカルメモリ内に配列を宣言します。この配列は、ワークグループ内でのデータ交換に使用されます。
const uint ls = min((uint)kunits, (uint)LOCAL_ARRAY_SIZE); float2 koef = (float2)(fmax((float)sqrt((float)dimension), (float)1), 0); __local float2 temp[LOCAL_ARRAY_SIZE];
これにより準備作業は完了し、計算処理へと直接進みます。まず、アテンション係数を算出する必要があります。そのために、対応するQueryベクトルとKeyベクトルに対してループ処理を実行します。それらの積に対する指数関数を計算し、その結果にマスクを乗算します。
//--- Score float score = 0; float2 score2 = (float2)0; if(ComplexAbs(mask) >= 0.01) { for(int d = 0; d < dimension; d++) score2 = IsNaNOrInf2(ComplexMul(q[shift_q + d], kv[shift_k + d]), (float2)0); score = IsNaNOrInf(ComplexAbs(ComplexExp(ComplexDiv(score, koef))) * mask, 0); }
なお、この演算は、マスク値があらかじめ定義された閾値を超えている場合にのみ実行されます。これにより、無関係なチャネルの影響が効果的に除去されます。
次に、得られた値はSoftMax関数を用いて正規化され、適切な確率分布へと変換される必要があります。そのために、ワークグループ全体にわたって値の総和を計算します。まず、ローカル配列の各要素内で部分和が計算されます。
//--- sum of exp #pragma unroll for(int i = 0; i < kunits; i += ls) { if(k >= i && k < (i + ls)) temp[k % ls].x = (i == 0 ? 0 : temp[k % ls].x) + score; barrier(CLK_LOCAL_MEM_FENCE); }
その後、これらの部分和は統合され、最終的な総和が得られます。
uint count = ls; #pragma unroll do { count = (count + 1) / 2; if(k < ls) temp[k].x += (k < count && (k + count) < kunits ? temp[k + count].x : 0); if(k + count < ls) temp[k + count].x = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
すべての反復処理が完了すると、ローカル配列の先頭要素にはワークグループ全体の総和が格納されます。各スレッドは、この総和で自身のアテンション係数を割ることで正規化された値を取得します。最終的に、その結果がグローバル出力バッファへ書き込まれます。
//--- score if(temp[0].x > 0) score = score / temp[0].x; scores[shift_s] = score;
次に、各要素の最終的な表現を計算します。この際、他のチャネルからの寄与も考慮します。そのために、アテンション係数ベクトルとValue行列を掛け合わせます。各スレッドは単一のアテンション係数しか保持していないため、この処理ではワークグループ内のスレッド間で並列演算をおこなう必要があり、実装が複雑になります。そのため、この処理にはネストしたループ構造が必要となります。外側のループは、Value行列の対応する行の要素を反復処理します。
//--- out #pragma unroll for(int d = 0; d < dimension; d++) { float2 val = (score > 0 ? ComplexMul(kv[shift_v + d], (float2)(score,0)) : (float2)0);
ループ内では、各スレッドがグローバルメモリから該当する値を読み込み、それに自身のアテンション係数を掛けて、その結果をローカル変数に格納します。グローバルメモリアクセスのコストを削減するため、この処理はアテンション係数が0より大きい場合にのみ実行されます。それ以外の場合は、グローバルメモリへアクセスすることなく、安全に変数を0で初期化します。
次のステップでは、これらの中間結果をワークグループ内のスレッド間で加算します。ここでは、アテンション係数の総和を計算した際と同様の手法を用います。まず、ローカル配列内で部分結果の総和を計算します。
#pragma unroll for(int i = 0; i < kunits; i += ls) { if(k >= i && k < (i + ls)) temp[k % ls] = (i == 0 ? (float2)0 : temp[k % ls]) + val; barrier(CLK_LOCAL_MEM_FENCE); }
そして、ローカル配列要素の総和を計算します。
uint count = ls; #pragma unroll do { count = (count + 1) / 2; if(k < ls) temp[k] += (k < count && (k + count) < kunits ? temp[k + count] : (float2)0); if((k + count) < ls) temp[k + count] = (float2)0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
最終結果をグローバルバッファに書き込むには、単一のスレッドのみが必要です。
//--- if(k == 0) out[shift_q + d] = temp[0]; barrier(CLK_LOCAL_MEM_FENCE); } }
次の反復処理に進む前に、ワークグループ内のすべてのスレッドが同期されます。
すべての反復処理が完了すると、カーネルの実行が終了します。
次の段階では、複素マスク付きアテンション機構を通じたバックプロパゲーションを実装します。この処理はMaskAttentionGradientsComplexカーネル内で実装します。
__kernel void MaskAttentionGradientsComplex(__global const float2 *q, __global float2 *q_g, __global const float2 *kv, __global float2 *kv_g, __global const float *scores, __global const float *mask, __global float *mask_g, __global const float2 *gradient, const int kunits, const int heads_kv ) { //--- init const int q_id = get_global_id(0); const int d = get_global_id(1); const int h = get_global_id(2); const int qunits = get_global_size(0); const int dimension = get_global_size(1); const int heads = get_global_size(2);
このカーネルの構造は、フォワードパスとほぼ同様です。ただし、誤差勾配を保存するためのグローバルバッファが追加されます。しかし、実行空間はわずかに変更されます。依然として3次元構造である点は同じですが、第2次元は内部ベクトルのサイズを表すようになり、スレッドはもはやワークグループにグループ化されません。
カーネル本体では、タスク空間の全次元にわたって現在のスレッドを特定し、得られた値をローカル定数として保存します。これまでと同様に、それらを用いてグローバルデータバッファへのオフセットを決定します。
const int h_kv = h % heads_kv; const int shift_q = dimension * (q_id * heads + h) + d; const int shift_s = (q_id * heads + h) * kunits; const int shift_g = h * dimension + d; float2 koef = (float2)(fmax(sqrt((float)dimension), (float)1), 0);
準備作業が完了した後、誤差勾配の収集処理へと直接進みます。まず、Valueテンソルレベルでの誤差を定義します。
ここで思い出すべき点として、Valueテンソルはアテンション行列との乗算を通じて出力シーケンスのすべての要素を生成するために使用されます。したがって、アテンション出力からの勾配は、対応するアテンション係数によって重み付けされながらValueテンソルへと逆伝播されます。この処理はループ構造を用いて実装されます。
//--- Calculating Value's gradients int step_score = kunits * heads; if(h < heads_kv) { #pragma unroll for(int v = q_id; v < kunits; v += qunits) { float2 grad = (float2)0; for(int hq = h; hq < heads; hq += heads_kv) { int shift_score = hq * kunits + v; for(int g = 0; g < qunits; g++) { float sc = IsNaNOrInf(scores[shift_score + g * step_score], 0); if(sc > 0) grad += ComplexMul(gradient[shift_g + dimension * (hq - h + g * heads)], (float2)(sc, 0)); } } int shift_v = dimension * (2 * heads_kv * v + heads_kv + h) + d; kv_g[shift_v] = grad; } }
次に、誤差勾配をQueryテンソルのレベルへと伝播させます。Queryテンソルの各要素は、単一の出力要素のみに影響を与えます。そのため、対応する勾配はローカル変数に格納することで、グローバルメモリアクセスを最小化できます。
//--- Calculating Query's gradients float2 grad = 0; float2 out_g = IsNaNOrInf2(gradient[shift_g + q_id * dimension], (float2)0); int shift_val = (heads_kv + h_kv) * dimension + d; int shift_key = h_kv * dimension + d; #pragma unroll for(int k = 0; (k < kunits && ComplexAbs(out_g) != 0); k++) { float2 sc_g = 0; float2 sc = (float2)(scores[shift_s + k], 0); for(int v = 0; v < kunits; v++) sc_g += IsNaNOrInf2(ComplexMul( ComplexMul((float2)(scores[shift_s + v], 0), out_g * kv[shift_val + 2 * v * heads_kv * dimension]), ((float2)(k == v, 0) - sc)), (float2)0); float m = mask[shift_s + k]; mask_g[shift_s + k] = IsNaNOrInf(sc.x / m * sc_g.x + sc.y / m * sc_g.y, 0); grad += IsNaNOrInf2(ComplexMul(sc_g, kv[shift_key + 2*k*heads_kv*dimension]), (float2)0); } q_g[shift_q] = IsNaNOrInf2(ComplexDiv(grad, koef), (float2)0);
ただし、最終的な値を生成する際には、KeyテンソルおよびValueテンソルの多数の要素と相互作用します。そのため、必要な誤差を得るには、まず勾配をアテンション係数行列へと伝播させ、その後でQueryテンソルへと転送します。
なお、この過程ではチャネルマスク行列にも誤差勾配が伝播される点に注意します。
最後にKeyテンソルへも勾配が伝播されます。このアルゴリズムはQueryの場合とほぼ同様ですが、アテンション行列の列方向に沿って計算が進行する点が異なります。
//--- Calculating Key's gradients if(h < heads_kv) { #pragma unroll for(int k = q_id; k < kunits; k += qunits) { int shift_k = dimension * (2 * heads_kv * k + h_kv) + d; grad = 0; for(int hq = h; hq < heads; hq++) { int shift_score = hq * kunits + k; float2 val = IsNaNOrInf2(kv[shift_k + heads_kv * dimension], (float2)0); for(int scr = 0; scr < qunits; scr++) { float2 sc_g = (float2)0; int shift_sc = scr * kunits * heads; float2 sc = (float2)(IsNaNOrInf(scores[shift_sc + k], 0), 0); if(ComplexAbs(sc) == 0) continue; for(int v = 0; v < kunits; v++) sc_g += IsNaNOrInf2( ComplexMul( ComplexMul((float2)(scores[shift_sc + v], 0), gradient[shift_g + scr * dimension]), ComplexMul(val, ((float2)(k == v, 0) - sc))), (float2)0); grad += IsNaNOrInf2(ComplexMul(sc_g, q[shift_q + scr * dimension]), (float2)0); } } kv_g[shift_k] = IsNaNOrInf2(ComplexDiv(grad, koef), (float2)0); } } }
これにより、OpenCL環境における複素数値マスク付きアテンションのアルゴリズムの概要は完了します。完全なカーネル実装は添付ファイルに含まれています。
次のステップでは、メインプログラム側でマスク付きアテンションのロジックを実装します。これは次回の記事で解説します。
結論
本記事では、時系列多変量データにおける異常検知のために、フーリエ変換と周波数パッチングを組み合わせたCATCHフレームワークの理論的基盤について解説しました。その主な利点は、時間領域のみのデータ解析では捉えにくい複雑な市場パターンを明らかにできる点にあります。
周波数領域での表現を用いることで市場ダイナミクスに対するより深い洞察が得られ、さらに周波数パッチングによって変化する市場条件に適応した解析が可能になります。またCATCHは資産間の関係性も捉えるため、システム的な異常に対してより高い感度を持ちます。従来手法とは異なり、単なる明確なスパイクや外れ値の検出にとどまらず、市場トレンドの変化を示唆するような微細で隠れた依存関係までも検出することができます。
実践セクションでは、MQL5を用いて本フレームワークの独自解釈による実装を開始しました。次回の記事ではこの作業を継続し、最終的には実際の過去データを用いて実装した手法の性能評価をおこないます。
関連リンク
記事で使用されたプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | データセット収集用EA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法を用いたデータセット収集用EA |
| 3 | Study.mq5 | EA | モデル学習用EA |
| 4 | Test.mq5 | EA | モデルテスト用EA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態とモデルアーキテクチャ記述構造 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | ライブラリ | OpenCLプログラムコード |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/17649
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索