
Neuronale Netze im Trading: Duales Clustering multivariater Zeitreihen (Abschlussteil)

Einführung
Wir arbeiten weiter an der Umsetzung der von den Autoren des DUET-Frameworks vorgeschlagenen Ansätze für das duale Clustering von multivariaten Zeitreihen, das ein leistungsstarkes Instrument für die Finanzmarktprognose darstellt. DUET kombiniert zeitliches und kanalbasiertes Clustering. Dadurch kann sich das Modell an komplexe und sich verändernde Muster der Marktdynamik anpassen und zugleich die Grenzen traditioneller, zu Überanpassung neigender Verfahren überwinden.
DUET umfasst mehrere Schlüsselmodule, von denen jedes eine äußerst wichtige Aufgabe erfüllt. Die erste Stufe der Datenverarbeitung umfasst die Normalisierung und die Entfernung von Ausreißern, was die Robustheit des Modells verbessert.
Darauf folgt das zeitliche Clustering, das die Zeitreihen in Gruppen mit ähnlicher Dynamik unterteilt. Dadurch kann das Modell Phasenverschiebungen im Marktgeschehen berücksichtigen, was besonders bei der Analyse hochvolatiler Vermögenswerte wichtig ist.
Das Channel-Clustering-Modul dient dazu, unter den zahlreichen Marktfaktoren die wichtigsten Variablen zu identifizieren. Finanzdaten enthalten eine beträchtliche Menge an Rauschen und redundanten Informationen, die eine genaue Prognose erschweren. DUET analysiert die Korrelationen zwischen den Parametern und eliminiert unbedeutende Komponenten, um die Rechenressourcen auf die wichtigsten Merkmale zu konzentrieren. Die Signalanalyse im Frequenzbereich und Mechanismen zur Extraktion latenter Merkmale machen das Modell weniger anfällig für zufällige Marktschwankungen.
Das Datenfusionsmodul synchronisiert die vom zeitlichen und kanalbasierten Clustering erhaltenen Informationen und bildet eine einheitliche Darstellung des analysierten Umgebungszustands. Diese Phase basiert auf einem Mechanismus der maskierten Attention, der es dem Modell ermöglicht, sich auf die wichtigsten Merkmale zu konzentrieren und gleichzeitig den Einfluss nicht repräsentativer Daten zu minimieren. Infolgedessen weist DUET eine hohe Robustheit gegenüber dynamischen Veränderungen auf und verbessert die langfristige Prognoseleistung.
Das abschließende Prognosemodul verwendet aggregierte Merkmale, um zukünftige Werte von Zeitreihen zu berechnen. In dieser Phase werden fortgeschrittene Verfahren neuronaler Netze eingesetzt, die in der Lage sind, nichtlineare Abhängigkeiten zwischen Marktindikatoren zu erfassen. Die Flexibilität der DUET-Architektur ermöglicht eine dynamische Anpassung an verschiedene Bedingungen, sodass eine manuelle Einstellung der Parameter nicht mehr erforderlich ist.
Nachfolgend ist die originale Darstellung des DUET-Frameworks zu sehen.

Im praktischen Teil des vorangegangenen Artikels haben wir das Temporal-Clustering-Modul implementiert. Wir setzen diese Arbeit mit der Konstruktion des Channel-Clustering-Moduls fort.
Channel-Clustering-Modul
Das Channel-Clustering-Modul (CCM) befasst sich mit dem Problem der korrekten Berücksichtigung von Beziehungen zwischen den Kanälen bei der Vorhersage multivariater Zeitreihen. Hier verwenden die Autoren des DUET-Frameworks metrisches Lernen, um Kanäle im Frequenzbereich zu gruppieren.
Ein wichtiger Aspekt von CCM ist die Darstellung von Daten im Frequenzbereich. Um dies zu erreichen, werden die Zeitreihen mit Hilfe der Fast Fourier Transformation (FFT) in Frequenzkomponenten zerlegt. Infolgedessen werden die Signale im Spektralbereich analysiert, wo die Beziehungen zwischen den Kanälen deutlicher werden. Viele verborgene Abhängigkeiten, die bei der traditionellen Analyse nicht sichtbar sind, treten erst nach der Transformation in den Frequenzbereich zutage, was diesen Ansatz für komplexe Zeitreihen besonders wertvoll macht.
Die Beziehungen zwischen den Kanälen werden anhand einer erlernbaren Distanzmetrik bewertet. Die Amplitudendarstellung des Frequenzspektrums wird als Basismaß verwendet, und der Abstand wird mit einer modifizierten Mahalanobis-Metrik berechnet. Diese Methode berücksichtigt nicht nur die paarweisen Abstände zwischen den Kanälen, sondern auch ihre Korrelationen im Spektralraum.
Nach der Berechnung der Abstände zwischen den Kanälen wird eine Beziehungsmatrix gebildet, deren Koeffizienten auf den Bereich [0, 1] normiert sind. Diese Normalisierung ermöglicht die Identifizierung der wichtigsten Verbindungen und eliminiert gleichzeitig schwache und verrauschte Schwankungen.
Für die endgültige Informationsfilterung wird eine binäre Maskenmatrix für Kanäle erstellt. Dieses Verfahren basiert auf einem probabilistischen Sampling, bei dem jedem Kanal eine Wahrscheinlichkeit zugewiesen wird, mit der er für die Vorhersage geeignet ist. Ein solcher Mechanismus ermöglicht es, die Unsicherheit in den Daten zu berücksichtigen und eine starre Schwellenwertbildung zu vermeiden. Infolgedessen schließt das Modell automatisch unbedeutende Kanäle aus, was die Interpretierbarkeit erheblich verbessert und die Informationsredundanz verringert.
Im Rahmen dieser Arbeit implementieren wir eine leicht vereinfachte Version des Channel-Clustering-Moduls. Der Algorithmus der diskreten Fourier-Transformation wurde zuvor als Teil des Frameworks FITS implementiert und ist bereits in unserer Bibliothek verfügbar. Anstelle der Mahalanobis-Metrik wird eine einfachere Methode verwendet, die auf Vektorabständen zwischen Frequenzamplitudenkomponenten basiert. Auf diese Weise bleiben die Vorteile der Frequenzanalyse erhalten, während der Rechenaufwand verringert und der Algorithmus vereinfacht wird.
Nach der Umwandlung der Zeitreihen in den Frequenzbereich werden die Normen der Amplitudenspektren für jeden Kanal berechnet. Anschließend werden die paarweisen Abstände berechnet, um eine Beziehungsmatrix zwischen den Kanälen zu erstellen. Um schwache Abhängigkeiten von der weiteren Analyse auszuschließen, wird eine Normalisierung vorgenommen, wodurch Rauschen unterdrückt und die Abstände skaliert werden. Es werden also nur signifikante Korrelationen zwischen den Kanälen berücksichtigt. Auf der Grundlage dieser Matrix wird ein probabilistisches Modell der Beziehungen erstellt. Jedem Kanal wird ein Signifikanzgewicht zugewiesen, das seinen Einfluss auf andere Reihen widerspiegelt.
Der beschriebene Algorithmus ist im MaskByDistance-Kernel in OpenCL implementiert. Die Kernelparameter enthalten Zeiger auf drei Datenpuffer. Die ersten beiden enthalten die Eingabedaten in Form des Real- und Imaginärteils der analysierten Signale, während der dritte zur Speicherung der Ergebnisse verwendet wird. In diesem Fall enthält sie die Kanalmaskierungsmatrix.
__kernel void MaskByDistance(__global const float *buf_real, __global const float *buf_imag, __global float *mask, const int dimension ) { const size_t main = get_global_id(0); const size_t slave = get_local_id(1); const int total = (int)get_local_size(1);
Innerhalb des Kernelkörpers wird zunächst der aktuelle Thread in einem zweidimensionalen Ausführungsraum identifiziert. Die erste Dimension entspricht dem analysierten Kanal, die zweite dem zu vergleichenden Kanal. Arbeitsgruppen werden entlang der zweiten Dimension gebildet.
Anschließend wird ein lokales Speicherfeld für den Datenaustausch zwischen Threads innerhalb derselben Arbeitsgruppe erstellt.
__local float Temp[LOCAL_ARRAY_SIZE]; int ls = min((int)total, (int)LOCAL_ARRAY_SIZE);
Anschließend werden die Offsets in den globalen Datenpuffern bestimmt.
const int shift_main = main * dimension; const int shift_slave = slave * dimension; const int shift_mask = main * total + slave;
Nach den vorbereitenden Schritten beginnt die Berechnung mit einer Schleife, in der der Abstand zwischen zwei Vektoren der Frequenzamplituden berechnet wird.
//--- calc distance float dist = 0; if(main != slave) { #pragma unroll for(int d = 0; d < dimension; d++) dist += pow(ComplexAbs((float2)(buf_real[shift_main + d], buf_imag[shift_main + d])) - ComplexAbs((float2)(buf_real[shift_slave + d], buf_imag[shift_slave + d])), 2.0f); dist = sqrt(dist); }
Zu beachten ist, dass in der Threadmatrix diagonale Elemente vorhanden sind. Wie erwartet, berechnet der Algorithmus in solchen Fällen den Abstand zwischen zwei identischen Vektoren, der offensichtlich gleich Null ist. Daher wird die Schleife zur Abstandsberechnung übersprungen und direkt ein Nullwert zugewiesen.
Als Nächstes müssen wir die Werte normalisieren. Zu diesem Zweck implementieren wir einen Algorithmus zur Bestimmung des maximalen Abstands innerhalb einer Arbeitsgruppe. Zunächst sammelt eine Schleife die Maximalwerte der einzelnen Untergruppen von Threads in Elementen des lokalen Arrays.
//--- Look Max #pragma unroll for(int i = 0; i < total; i += ls) { if(i <= slave && (i + ls) > slave) Temp[slave % ls] = fmax((i == 0 ? 0 : Temp[slave % ls]), IsNaNOrInf(dist, 0)); barrier(CLK_LOCAL_MEM_FENCE); }
Dann ermitteln wir den Maximalwert unter den Elementen des lokalen Arrays.
int count = ls; do { count = (count + 1) / 2; if(slave < count && (slave + count) < ls) { if(Temp[slave] < Temp[slave + count]) Temp[slave] = Temp[slave + count]; Temp[slave + count] = 0; } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
Danach werden die Abstände zwischen den Frequenzamplitudenvektoren innerhalb der Arbeitsgruppe normalisiert, indem sie durch den Maximalwert dividiert werden.
//--- Normalize if(Temp[0] > 0) dist /= Temp[0];
Wie erwartet liegen nun alle normierten Abstände im Bereich [0, 1]. Der Wert 1 entspricht der größten normierten Distanz zwischen Kanälen. Da solche Kanäle jedoch nur einen minimalen Einfluss haben sollten, wird der inverse Wert des normierten Abstands im Ausgabepuffer gespeichert.
//--- result mask[shift_mask] = 1 - IsNaNOrInf(dist, 1); }
Und damit ist die Kernel-Implementierung abgeschlossen.
Ein wichtiges Merkmal dieser Implementierung sollte beachtet werden. Der beschriebene Algorithmus enthält keine erlernbaren Parameter, da der Abstand zwischen Frequenzamplitudenvektoren eine feste, von anderen Faktoren unabhängige Größe ist. Dadurch können wir den Backpropagation-Prozess eliminieren und den Optimierungsaufwand verringern.
Der nächste Schritt besteht darin, die Funktionalität des Channel-Clustering-Moduls im Hauptprogramm zu implementieren. Zu diesem Zweck erstellen wir eine neue Klasse CNeuronChanelMask, deren Struktur nachfolgend aufgeführt ist.
class CNeuronChanelMask : public CNeuronBaseOCL { //--- protected: uint iUnits; uint iFFTdimension; CBufferFloat cbFFTReal; CBufferFloat cbFFTImag; //--- virtual bool FFT(CBufferFloat *inp_re, CBufferFloat *inp_im, CBufferFloat *out_re, CBufferFloat *out_im, bool reverse = false); virtual bool Mask(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return true; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) { return true; } public: CNeuronChanelMask(void) {}; ~CNeuronChanelMask(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronChanelMask; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
In dieser Struktur gibt es neben einer kleinen Anzahl von internen numerischen Objekten nur zwei Puffer für die Speicherung der Real- und Imaginärteile der Frequenzkomponenten des analysierten Signals. Auf ihre Verwendung wird bei der Implementierung der virtuellen Methoden der Klasse näher eingegangen.
Diese Objekte sind statisch in der Klasse deklariert, sodass Konstruktor und Destruktor leer bleiben können. Die Initialisierung dieser deklarierten und geerbten Objekte wird in der Methode Init durchgeführt.
bool CNeuronChanelMask::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(window <= 0) return false; if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, units_count * units_count, optimization_type, batch)) return false;
Die Methodenparameter enthalten mehrere Konstanten, die die Architektur des Objekts definieren:
- window – Länge der analysierten Sequenz
- units_count – Anzahl der Kanäle
Es ist zu beachten, dass die Ausgabe des Objekts als quadratische Kanalmaskierungsmatrix erwartet wird. Deren Abmessungen hängen von der Anzahl der Kanäle ab und sind unabhängig von der Sequenzlänge. Die Sequenzlänge ist jedoch für die korrekte Vorverarbeitung der Eingabedaten erforderlich. Daher wird der Parameter zunächst validiert und dann die entsprechende Methode der übergeordneten Klasse aufgerufen, in der die Initialisierung der geerbten Schnittstellen bereits implementiert ist.
Nach erfolgreicher Ausführung der übergeordneten Methode werden die Konstanten gespeichert.
//--- Save constants
iUnits = units_count;
activation = None;
Es ist wichtig, daran zu erinnern, dass der zuvor implementierte FFT-Algorithmus nur Sequenzen unterstützt, deren Länge eine Potenz von zwei ist. Im Allgemeinen ist dies kein Problem, da die Sequenz mit Nullen aufgefüllt werden kann. Zunächst müssen wir jedoch die nächsthöhere Zweierpotenz bestimmen.
//--- Calculate FFT dimension int power = int(MathLog(window) / M_LN2); if(MathPow(2, power) != window) power++; iFFTdimension = uint(MathPow(2, power));
Erst danach werden die Puffer für die Zwischenspeicherung der realen und imaginären Frequenzkomponenten mit ausreichender Größe initialisiert.
if(!cbFFTReal.BufferInit(iFFTdimension * iUnits, 0) || !cbFFTReal.BufferCreate(OpenCL)) return false; if(!cbFFTImag.BufferInit(iFFTdimension * iUnits, 0) || !cbFFTImag.BufferCreate(OpenCL)) return false; //--- return true; }
Nachdem die Initialisierung abgeschlossen ist, wird der Algorithmus für den Forward-Pass in der Methode CNeuronChanelMask::feedForward implementiert. Diese Phase ist relativ einfach.
bool CNeuronChanelMask::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; if(!FFT(NeuronOCL.getOutput(), NULL, GetPointer(cbFFTReal), GetPointer(cbFFTImag), false)) return false; //--- return Mask(); }
Die Methode erhält einen Zeiger auf das Eingabedatenobjekt, das sofort validiert wird. Die Eingabedaten werden dann in Frequenzkomponenten umgewandelt, und es wird eine Wrapper-Funktion für den zuvor beschriebenen Kernel aufgerufen. Das Ergebnis der Ausführung wird an das aufrufende Programm zurückgegeben.
Die Kernel-Aufrufe folgen dem zuvor beschriebenen Muster und werden hier nicht weiter behandelt.
Wie bereits erwähnt, ist die Backpropagation in diesem Fall ausgeschlossen. Die entsprechenden Methoden werden mit Platzhalterimplementierungen ersetzt, die immer true zurückgeben. So lässt sich das neue Objekt ohne zusätzliche Anpassungen in die bestehende Modellarchitektur integrieren.
Damit ist die Implementierung der Algorithmen des Channel-Clustering-Moduls abgeschlossen. Der vollständige Quellcode der Klasse und ihrer Methoden ist in den Anhängen des Artikels verfügbar.
Der DUET-Block
In diesem Stadium haben wir bereits die Module für das zeitliche und das kanalbasierte Clustering erstellt. Diese beiden Module arbeiten parallel und analysieren multivariate Zeitreihen in zwei Darstellungen: in der zeitlichen und in der frequenzbasierten Domäne. Im Fusionsmodul werden die Ergebnisse zusammengeführt; dabei werden Informationen über Kanalabhängigkeiten mittels maskierter Attention integriert. Dies ermöglicht den Abgleich der einzelnen Kanalprognosen unter Berücksichtigung der festgestellten Korrelationen. Bei der Fusion wird der Einfluss der einzelnen Kanäle auf der Grundlage der Gewichtung der Abhängigkeiten zwischen den Kanälen angepasst. Dadurch wird die endgültige Vorhersage robuster, und das Modell ist weniger anfällig für Überanpassung und Zufallsrauschen.
In der Praxis verwenden wir einen modifizierten Self-Attention-Mechanismus, bei dem die aus dem Temporal-Clustering-Modul gewonnenen Abhängigkeitskoeffizienten mit der vom Channel-Clustering-Modul generierten Maske multipliziert werden. Erst danach werden die Gewichte mit Hilfe der Softmax-Funktion normalisiert.
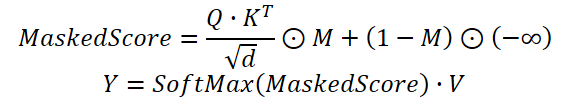
Der vorgeschlagene Algorithmus ist im Objekt CNeuronDUET implementiert, das die Funktionen der drei oben beschriebenen Module vereint. Die Struktur der neuen Klasse ist unten dargestellt.
class CNeuronDUET : public CNeuronTransposeOCL { protected: uint iWindowKey; uint iHeads; //--- CNeuronTransposeOCL cTranspose; CNeuronMoE cExperts; CNeuronConvOCL cQKV; CNeuronBaseOCL cQ; CNeuronBaseOCL cKV; CNeuronChanelMask cMask; CBufferFloat cbScores; CNeuronBaseOCL cMHAttentionOut; CNeuronConvOCL cPooling; CNeuronBaseOCL cResidual; CNeuronMHFeedForward cFeedForward; //--- virtual bool AttentionOut(void); virtual bool AttentionInsideGradients(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); public: CNeuronDUET(void) {}; ~CNeuronDUET(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint units_out, uint experts, uint top_k, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronDUET; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual void TrainMode(bool flag) { bTrain = flag; cExperts.TrainMode(bTrain); } };
Es ist wichtig zu beachten, dass in diesem Fall die übergeordnete Klasse eine Transpositionsschicht ist. Dies ist auf die Struktur der Quelldaten zurückzuführen.
Das Modell erhält als Eingabe eine multivariate Zeitreihe in Form einer Matrix, wobei jede Zeile einem separaten Zeitschritt des analysierten Systems entspricht. Alle oben beschriebenen Module arbeiten jedoch mit univariaten Zeitreihen. Dies gilt auch für das Datenfusionsmodul. Um eine korrekte Datenverarbeitung zu gewährleisten, werden die Eingabedaten in ein für die Analyse geeignetes Format transponiert. Nachdem alle Operationen abgeschlossen sind, werden die Ergebnisse in die ursprüngliche Darstellung zurückverwandelt. Dieser letzte Schritt wird von der übergeordneten Klasse übernommen, was die Konsistenz der Datenstruktur gewährleistet und die Integration der Module vereinfacht.
In der oben dargestellten Klassenstruktur kann man eine ziemlich große Anzahl interner Objekte beobachten, die eine wichtige Rolle bei der Konstruktion des Algorithmus spielen. Ihre Funktionalität wird bei der Implementierung der virtuellen Methoden der Klasse genauer untersucht. Zunächst ist es wichtig zu wissen, dass alle Objekte direkt in der Klasse deklariert werden, sodass der Konstruktor und der Destruktor leer bleiben können. Die Initialisierung aller Objekte, auch der geerbten, erfolgt in der Methode Init.
bool CNeuronDUET::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint units_out, uint experts, uint top_k, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronTransposeOCL::Init(numOutputs, myIndex, open_cl, window, units_out, optimization_type, batch)) return false;
Die Initialisierungsmethode erhält eine Reihe von Konstanten, die die Architektur des Objekts definieren. Die Struktur dieser Parameter ist bereits bekannt. Einige wurden bei der Konstruktion der Module für zeitliches und kanalbasiertes Clustering verwendet, während andere mit den Attention-Blöcken zusammenhängen. Besondere Aufmerksamkeit sollte dem Parameter units_out gewidmet werden, der die gewünschte Länge der Ausgabesequenz festlegt.
Innerhalb des Methodenkörpers rufen wir zunächst die entsprechende Methode der übergeordneten Klasse auf, in der die Validierung einiger Parameter und die Initialisierung der geerbten Schnittstellen bereits implementiert sind.
Anschließend werden die erforderlichen Parameter in internen Variablen gespeichert.
iWindowKey = MathMax(window_key, 1); iHeads = MathMax(heads, 1);
Dann fahren wir mit der Initialisierung der internen Objekte fort. Wie bereits erwähnt, müssen die Eingangsdaten vor der Analyse transponiert werden. Diese Funktion wird von einem speziellen Objekt übernommen.
int index = 0; if(!cTranspose.Init(0, index, OpenCL, units_count, window, optimization, iBatch)) return false;
Danach werden die Module des zeitlichen und kanalbasierten Clustering initialisiert.
index++; if(!cExperts.Init(0, index, OpenCL, units_count, units_out, window, experts, top_k, optimization, iBatch)) return false; index++; if(!cMask.Init(0, index, OpenCL, units_count, window, optimization, iBatch)) return false;
Als Nächstes haben wir die Objekte des Datenfusionsmoduls. Es handelt sich im Wesentlichen um ein modifiziertes Attention-Modul. Zunächst initialisieren wir das Objekt, das für die Erzeugung der Entitäten Query, Key und Value verantwortlich ist. In diesem Fall wird eine einzige Faltungsschicht für die parallele Erzeugung aller drei Entitäten verwendet.
index++; if(!cQKV.Init(0, index, OpenCL, units_out, units_out, iHeads * iWindowKey * 3, window, 1, optimization, iBatch)) return false;
Wir fügen auch zwei Objekte für die Aufteilung dieser Entitäten in separate Tensoren hinzu.
index++; if(!cQ.Init(0, index, OpenCL, cQKV.Neurons() / 3, optimization, iBatch)) return false; index++; if(!cKV.Init(0, index, OpenCL, cQ.Neurons() * 2, optimization, iBatch)) return false;
Die Attention-Koeffizienten werden in einem Datenpuffer gespeichert.
if(!cbScores.BufferInit(cMask.Neurons()*iHeads, 0) || !cbScores.BufferCreate(OpenCL)) return false;
Zu beachten ist, dass in allen Fällen die Objektdimensionen unter Berücksichtigung der transponierten Eingabematrix angegeben werden.
Als Nächstes initialisieren wir das Multi-Head-Attention-Ausgabeobjekt.
index++; if(!cMHAttentionOut.Init(0, index, OpenCL, cQ.Neurons(), optimization, iBatch)) return false;
Dann initialisieren wir eine Faltungsschicht für die Dimensionalitätsreduktion und die Zusammenführung der Ergebnisse von verschiedenen Attention-Köpfen.
index++; if(!cPooling.Init(0, index, OpenCL, iWindowKey * iHeads, iWindowKey * iHeads, units_out, window, 1, optimization, iBatch)) return false; cPooling.SetActivationFunction(None);
Dann fügen wir ein Objekt hinzu, um die Ergebnisse der Residualverbindung zu speichern.
index++; if(!cResidual.Init(0, index, OpenCL, cPooling.Neurons(), optimization, iBatch)) return false; cResidual.SetActivationFunction(None);
Entsprechend der ursprünglichen Architektur wird ein Block mit dem standardmäßigen Forward-Pass erwartet. Wir ersetzen ihn jedoch durch eine Variante mit mehreren Köpfen, die aus dem StockFormer-Framework entlehnt wurde.
index++; if(!cFeedForward.Init(0, index, OpenCL, units_out, 4 * units_out, window, 1, heads, optimization, iBatch)) return false; //--- return true; }
Die Methode endet mit der Rückgabe des logischen Ergebnisses der Operation an die aufrufende Funktion.
Der nächste Schritt ist die Implementierung des Forward-Pass‘ in der Methode CNeuronDUET::feedForward.
bool CNeuronDUET::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cTranspose.FeedForward(NeuronOCL)) return false;
Die Methode erhält einen Zeiger auf das Eingangsdatenobjekt, der sofort an die entsprechende Methode des internen Objekts zur Datentransposition übergeben wird. Alle weiteren Operationen werden mit den transponierten Daten durchgeführt.
Zunächst werden die Daten an das Temporal-Clustering-Modul weitergeleitet, um Prognosen für univariate Sequenzen zu erhalten.
if(!cExperts.FeedForward(cTranspose.AsObject())) return false;
Anschließend wird die transponierte Eingabe an das Channel-Clustering-Modul weitergeleitet.
if(!cMask.FeedForward(cTranspose.AsObject())) return false;
Anschließend erfolgt der Forward-Pass des Datenfusionsmoduls. Die Entitäten Query, Key und Value werden aus den Ergebnissen des Moduls für temporales Clustering generiert.
if(!cQKV.FeedForward(cExperts.AsObject())) return false;
Die Ausgabe wird dann in zwei Tensoren aufgeteilt.
if(!DeConcat(cQ.getOutput(), cKV.getOutput(), cQKV.getOutput(), iWindowKey, 2 * iWindowKey, cQKV.GetUnits())) return false;
Anschließend wird die Wrapper-Funktion der maskierten mehrköpfigen Self-Attention aufgerufen.
if(!AttentionOut()) return false;
Die Ausgaben der mehrköpfigen Self-Attention werden so projiziert, dass sie der Dimensionalität der Ausgaben des Moduls für die zeitliche Clusterung entsprechen.
if(!cPooling.FeedForward(cMHAttentionOut.AsObject())) return false;
Anschließend werden die Residualverbindungen zu den erhaltenen Werten addiert.
if(!SumAndNormilize(cExperts.getOutput(), cPooling.getOutput(), cResidual.getOutput(), iWindow, true, 0, 0, 0, 1)) return false;
Der mehrköpfige FeedForward-Block ist als separates Modul mit eingebauten Residualverbindungen implementiert. Daher reicht es aus, die entsprechende Methode aufzurufen und die Ergebnisse der vorherigen Operationen als Eingabe zu übergeben.
if(!cFeedForward.FeedForward(cResidual.AsObject())) return false;
Schließlich werden die Ergebnisse in die ursprüngliche Datendarstellung zurückverwandelt. Hier nutzen wir die Funktionalität der übergeordneten Klasse.
return CNeuronTransposeOCL::feedForward(cFeedForward.AsObject());
}
Wir geben das logische Ergebnis der durchgeführten Operationen an das aufrufende Programm zurück und schließen die Ausführung der Methode ab.
Nach Abschluss der Implementierung des Forward-Pass‘ gehen wir zu den Algorithmen für Backpropagation über. Wie bereits erwähnt, gibt es dafür zwei Methoden:
- Verteilung des Fehlergradienten auf interne Objekte und Eingabedaten entsprechend ihrem Beitrag zum Endergebnis – calcInputGradients
- Optimierung der Modellparameter zur Minimierung des Gesamtfehlers – updateInputWeights
Alle trainierbaren Parameter des DUET-Blocks in dieser Implementierung sind in internen Objekten enthalten, sodass wir nur die entsprechenden Methoden dieser Objekte aufrufen. Der kritischere Punkt ist die korrekte Verteilung des Fehlergradienten auf die internen Objekte und die Eingabedaten.
Die Methode calcInputGradients erhält einen Zeiger auf das Eingabedatenobjekt. Es handelt sich um dasselbe Objekt, das auch beim Forward-Pass verwendet wird. Diesmal muss er jedoch mit den entsprechenden Gradientenwerten gefüllt werden.
bool CNeuronDUET::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
Es ist klar, dass Daten nur an ein gültiges Objekt übergeben werden können, also überprüfen wir sofort die Gültigkeit des Zeigers. Andernfalls wären weitere Maßnahmen sinnlos.
Wie bereits erwähnt, folgt die Gradientenverteilung strikt dem Informationsfluss des Forward-Pass‘, allerdings in umgekehrter Reihenfolge. Da der Forward-Pass mit einem Aufruf der Methode der Elternklasse abgeschlossen wurde, beginnt der Backpropagation-Durchgang mit einem Aufruf der Methode der Elternklasse. Diesmal rufen wir die Methode zur Verteilung des Fehlergradienten auf.
if(!CNeuronTransposeOCL::calcInputGradients(cFeedForward.AsObject())) return false;
Anschließend wird der Gradient durch das FeedForward-Modul mit mehreren Köpfen weitergegeben.
if(!cPooling.calcHiddenGradients(cFeedForward.AsObject())) return false;
Anschließend werden die resultierenden Gradienten auf die Attention-Köpfe verteilt.
if(!cMHAttentionOut.calcHiddenGradients(cPooling.AsObject())) return false;
Der nächste Schritt ist der Aufruf der Wrapper-Funktion zur Verteilung von Fehlern auf Query, Key und Value innerhalb des maskierten Self-Attention-Mechanismus.
if(!AttentionInsideGradients()) return false;
Die Ergebnisse werden zu einem einzigen Tensor zusammengefasst.
if(!Concat(cQ.getGradient(), cKV.getGradient(), cQKV.getGradient(), iWindowKey, 2 * iWindowKey, iCount)) return false;
Falls erforderlich, werden die Werte mit Hilfe der Ableitung der Aktivierungsfunktion angepasst.
if(cQKV.Activation() != None) if(!DeActivation(cQKV.getOutput(), cQKV.getGradient(), cQKV.getGradient(), cQKV.Activation())) return false;
Der Gradient wird dann an das Temporal-Clustering-Modul weitergeleitet.
if(!cExperts.calcHiddenGradients(cQKV.AsObject()) || !DeActivation(cExperts.getOutput(), cExperts.getPrevOutput(), cPooling.getGradient(), cExperts.Activation()) || !SumAndNormilize(cExperts.getGradient(), cExperts.getPrevOutput(), cExperts.getGradient(), iWindow, false, 0, 0, 0, 1)) return false;
Es ist wichtig zu erwähnen, dass die Ergebnisse des Moduls für zeitliches Clustering auch für Residualverbindungen verwendet wurden. Daher wird der Gradient ebenfalls über diesen Pfad weitergeleitet. Dazu wird zunächst der Gradient am Ausgang des Attention-Blocks mit Hilfe der Ableitung der Aktivierungsfunktion des Temporal-Clustering-Moduls angepasst, und dann werden die Gradienten beider Pfade summiert.
Anschließend wird der Gradient durch das Modul für die zeitliche Clusterbildung weitergegeben.
if(!cTranspose.calcHiddenGradients(cExperts.AsObject())) return false;
Schließlich wird der Gradient an die Ebene der Eingangsdaten weitergegeben.
return prevLayer.calcHiddenGradients(cTranspose.AsObject());
}
Wir geben das logische Ergebnis der durchgeführten Operationen an das aufrufende Programm zurück und schließen die Ausführung der Methode ab.
Zu beachten ist, dass während der Gradientenfortpflanzung kein Informationsfluss durch das Channel-Clustering-Modul stattfindet. Wie bereits erwähnt, enthält dieses Modul keinen Backpropagation-Durchgang, und in diesem Stadium schließen wir einfach unnötige Operationen aus.
Damit ist die Implementierung der Algorithmen abgeschlossen, die unsere Interpretation der von den Autoren des DUET-Frameworks vorgeschlagenen Ansätze umsetzen. Der vollständige Quellcode aller beschriebenen Objekte und ihrer Methoden ist in den Anhängen des Artikels verfügbar.
Modellarchitektur
In der nächsten Phase werden die entwickelten Komponenten in die Architektur trainierbarer Modelle integriert. Zu diesem Zweck wird im Folgenden der architektonische Aufbau der Modelle beschrieben.
Wie in früheren Arbeiten verwenden wir einen Multi-Task-Learning-Ansatz und trainieren zwei Modelle gleichzeitig: das Actor-Modell und ein Modell der Wahrscheinlichkeitsberechnung künftiger Kursrichtungen. Die Architektur des letzteren ist vollständig aus früheren Arbeiten entlehnt, sodass wir uns in diesem Artikel auf die Architektur des Actors konzentrieren. Die Architekturen der beiden Modelle werden in der Methode CreateDescriptions dargestellt.
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&probability) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
In den Methodenparametern erhalten wir Zeiger auf zwei dynamische Objekte, die zur Speicherung der Beschreibungen der Modellarchitekturen bestimmt sind. Innerhalb des Methodenkörpers validieren wir sofort die empfangenen Zeiger und erstellen gegebenenfalls neue Instanzen der Objekte.
Die Architektur des Actor-Modells beginnt mit einer vollständig vernetzten Schicht, die als Eingangsdatenschnittstelle dient. Sie muss groß genug sein, um die gesamte Menge der analysierten Informationen aufnehmen zu können.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Wie von den Autoren des DUET-Frameworks vorgeschlagen, folgt darauf eine Batch-Normalisierungsschicht, die dazu dient, die Eingabedaten zu standardisieren und die Auswirkungen von Ausreißern zu minimieren.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Als Nächstes verwenden wir zwei aufeinanderfolgende DUET-Blöcke, die zuvor konstruiert wurden. Der Ansatz für die Datensegmentierung wurde jedoch geändert. Anstelle der traditionellen Segmentierung wird bei diesem Experiment eine Darstellung der Daten in einem mehrdimensionalen Phasenraum verwendet. Diese Methode, inspiriert von Attraos, ermöglicht eine genauere Modellierung komplexer Abhängigkeiten in Zeitreihen und verbessert die Interpretierbarkeit. In der ersten Schicht wird ein Schritt von 5 Minuten verwendet.
Innerhalb des Temporal-Clustering-Moduls werden 16 parallele Encoder initialisiert. Für jeden Cluster werden die 4 am besten geeigneten ausgewählt.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDUET; descr.window = BarDescr * 5; // 5 min { int temp[] = {HistoryBars / 5, HistoryBars / 5, 16, 4}; // {Units in (24), Units out (24), Experts, Top K} if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.window_out = 256; descr.step = 4; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Im zweiten DUET-Block wird der Phasendarstellungsschritt auf 15 erhöht, während alle anderen Parameter unverändert bleiben.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDUET; descr.window = BarDescr * 15; // 15 min { int temp[] = {HistoryBars / 15, HistoryBars / 15, 16, 4}; // {Units in (8), Units out (8), Experts, Top K} if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.window_out = 256; descr.step = 4; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Zu beachten ist, dass während der Datenverarbeitung die Tensorgröße unverändert bleibt. Die nachfolgende Faltungsschicht reduziert jedoch die Sequenzlänge um den Faktor drei.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = HistoryBars / 3; descr.window = BarDescr * 3; descr.step = descr.window; int prev_window = descr.window_out = BarDescr; descr.activation = SoftPlus; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Als Nächstes kommt der Entscheidungsblock mit 3 vollständig verbundenen Schichten.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.batch = 1e4; descr.activation = TANH; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = TANH; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = SoftPlus; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Dann folgt eine Batch-Normalisierungsschicht.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Am Ausgang des Actors fügen wir einen Block zum Risikomanagement hinzu.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMacroHFTvsRiskManager; //--- Windows { int temp[] = {3, 15, NActions, AccountDescr}; //Window, Stack Size, N Actions, Account Description if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = 10; descr.window_out = 64; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Die vollständige Architektur der beiden Modelle finden Sie in den Anhängen. Die Anhänge enthalten auch Programme zur Interaktion mit der Umgebung und zum Modelltraining, die ohne Änderungen aus früheren Arbeiten übernommen wurden.
Tests
Damit sind die Voraussetzungen geschaffen, um unsere Interpretation der im DUET-Framework vorgeschlagenen Ansätze mit Hilfe von MQL5 zu implementieren und sie in trainierbare Modelle zu integrieren. Wir können nun zur entscheidenden Phase übergehen: dem Testen der implementierten Lösungen mit realen historischen Daten.
Für das Modelltraining verwenden wir einen Datensatz mit historischen Daten für das Währungspaar EURUSD auf dem Zeitrahmen M1 für das gesamte Jahr 2024. Während der Datenerfassung werden die Indikatorparameter auf ihren Standardwerten belassen.
Das Modelltraining wird in zwei Phasen durchgeführt. Zunächst wird die Batchgröße auf 1 gesetzt, sodass bei jeder Iteration ein zufälliger Zustand aus dem Trainingsdatensatz ausgewählt wird. Dadurch kann sich das Modell an unterschiedliche Bedingungen anpassen. Für ein stabiles Funktionieren des Risikomanagement-Blocks ist dies jedoch nicht ausreichend. Daher wird in der zweiten Stufe die Batchgröße auf 60 erhöht, sodass Sequenzen von 60 Umgebungszuständen und entsprechenden Aktionen des Actors berücksichtigt werden können. Dadurch wird der Trainingsprozess stabiler und effizienter.
Das trainierte Modell wird anhand historischer Daten von Januar bis Februar 2025 getestet. Alle Einstellungen bleiben erhalten, sodass eine objektive Bewertung der Prognosequalität gewährleistet ist. Die Testergebnisse sind unten dargestellt.


Während des Testzeitraums führte das Modell 53 Trades aus, von denen mehr als 56 % mit einem Gewinn abgeschlossen wurden. Bemerkenswert ist, dass der durchschnittliche Gewinn pro profitablem Trade fast doppelt so hoch ist wie bei den Verlustpositionen. Daraus ergibt sich ein Profit-Faktor von 2,44.
Schlussfolgerung
In dieser Arbeit haben wir das DUET-Framework untersucht, dessen Autoren die Analyse im Frequenzbereich, metrisches Lernen und probabilistische Filterung für die multivariate Zeitreihenanalyse kombinieren. Diese Komponenten verbessern die Prognosequalität und erhöhen die Robustheit des Modells gegenüber Störungen.
Im praktischen Teil haben wir unsere Interpretation der vorgeschlagenen Ansätze mit MQL5 umgesetzt und in ein Modell integriert. Wir haben das Modell mit realen historischen Daten trainiert und anhand von Out-of-Sample-Daten getestet. Die erzielten Ergebnisse zeigen das Potenzial des Modells. Bevor es jedoch unter realen Handelsbedingungen eingesetzt werden kann, muss das Modell anhand eines repräsentativeren Datensatzes trainiert und anschließend umfassend getestet werden.
Referenzen
In diesem Artikel verwendete Programme
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Expert Advisor für die Datenerfassung |
| 2 | ResearchRealORL.mq5 | Expert Advisor | Expert Advisor für die Datenerfassung mit der Methode Real-ORL |
| 3 | Study.mq5 | Expert Advisor | Expert Advisor für das Modelltraining |
| 4 | Test.mq5 | Expert Advisor | Expert Advisor für die Modelltests |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Beschreibung des Systemzustands und der Modellarchitektur |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Codebibliothek | OpenCL-Programmcode |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/17487
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.