
Neuronale Netze im Handel: Integration der Chaostheorie in die Zeitreihenprognose (letzter Teil)

Einführung
Wir entwickeln unsere eigene Sicht auf die von den Autoren des Attraos-Frameworks vorgeschlagenen Ansätze weiter. Im vorigen Artikel haben wir die theoretischen Aspekte des Frameworks untersucht. Das Framework wendet Prinzipien der Chaostheorie an, um Probleme der Zeitreihenprognose zu lösen.
Die Architektur des Attraos-Frameworks ist ein komplexes, mehrkomponentiges System, das Methoden der nichtlinearen Analyse, des maschinellen Lernens und der rechnergestützten Optimierung kombiniert. Durch den Einsatz der Phasenraum-Rekonstruktionsmethode (PSR) kann Attraos verborgene dynamische Prozesse modellieren und nichtlineare Beziehungen zwischen verschiedenen Marktvariablen berücksichtigen. Dies ermöglicht die Identifizierung stabiler Strukturen in Marktdaten und deren Nutzung zur Verbesserung der Genauigkeit von Prognosen für zukünftige Preisbewegungen.
Eines der wichtigsten Merkmale von Attraos ist die Multi-Resolution Dynamic Memory Unit (MDMU), die es dem Modell ermöglicht, historische Kursbewegungsmuster zu speichern und sich an veränderte Marktbedingungen anzupassen. Dies ist besonders wichtig auf den Finanzmärkten, wo sich Muster in verschiedenen Zeitintervallen mit unterschiedlicher Amplitude und Intensität wiederholen können. Das Modell passt sich dynamisch an die sich entwickelnde Struktur der Finanzmärkte an und liefert genauere Vorhersagen über mehrere Zeithorizonte.
Der Einsatz einer lokalen Evolutionsstrategie im Frequenzbereich ermöglicht die Anpassung an sich ändernde Marktbedingungen und verstärkt gleichzeitig die Unterschiede zwischen den Attraktoren. Dies hilft dem Modell, Fehler zu minimieren und Attraktorabweichungen zu kontrollieren, was sowohl Stabilität als auch eine hohe Prognosegenauigkeit gewährleistet.
Die Originalvisualisierung des Attraos-Frameworks ist unten zu sehen.

Im praktischen Teil des vorherigen Artikels haben wir die grundlegenden Komponenten in OpenCL implementiert. Heute gehen wir dazu über, Objekte im Hauptprogramm zu erstellen.
Konstruktion des Attraos-Objekts
Der Attraos-Algorithmus beginnt mit dem PSR-Modul, das die analysierte Zeitreihe mit einer bestimmten Zeitverzögerung in den Phasenraum transformiert. Dieser Prozess ist ein wichtiger Schritt in der Datenvorverarbeitung, der es ermöglicht, verborgene Abhängigkeiten, Zeitreihenstrukturen und latente dynamische Muster zu erkennen.
Eine mehrdimensionale Zeitreihe wird normalerweise als Matrix dargestellt, wobei jede Zeile die Parameter des analysierten Systems zu einem bestimmten Zeitpunkt t enthält. In unserem Fall werden die Daten jedoch in eindimensionalen Puffern gespeichert, und die Matrixdarstellung ist rein konventionell. Die Daten sind so organisiert, dass Vektoren, die den Systemzustand zu jedem Zeitpunkt beschreiben, nacheinander im Puffer gespeichert werden. Die Größe der einzelnen Vektoren wird durch den Fensterparameter bestimmt. Um Teilsequenzen mit einer bestimmten Zeitverzögerung zu erstellen, genügt es daher, den Fensterwert proportional zu erhöhen und gleichzeitig die Sequenzlänge zu verringern. Die Transformation einer Zeitreihe in den Phasenraum erfordert also keine zusätzlichen Rechenressourcen und wird allein durch die Gestaltung der Modellarchitektur realisiert.
Alle nachfolgenden Operationen des Frameworks sind innerhalb des CNeuronAttraos-Objekts strukturiert, dessen Struktur im Folgenden skizziert wird.
class CNeuronAttraos : public CNeuronBaseOCL { protected: CNeuronBaseOCL cOne; CNeuronBaseOCL cX_norm; CNeuronConvOCL cA; CNeuronConvOCL cX_proj; CNeuronBaseOCL cDelta; CNeuronBaseOCL cB; CNeuronBaseOCL cC; CNeuronConvOCL cD; CNeuronBaseOCL cH; CNeuronConvOCL cDelta_proj; CNeuronBaseOCL cDeltaA; CNeuronBaseOCL cDeltaB; CNeuronBaseOCL cDeltaBX; CNeuronBaseOCL cDeltaH; CNeuronBaseOCL cHS; //--- virtual bool PScan(void); virtual bool PScanCalcGradient(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronAttraos(void) {}; ~CNeuronAttraos(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronAttraos; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
In dieser neuen Klassenstruktur gibt es neben dem Standardsatz überschreibbarer virtueller Methoden auch eine beträchtliche Anzahl interner Objekte. Sie erfüllen verschiedene Funktionen und erleichtern die Interaktion zwischen den Klassenelementen. Die Verwendung interner Objekte ermöglicht eine effizientere Codeorganisation. Jedes Objekt ist für eine bestimmte Aufgabe zuständig, wodurch das System modular aufgebaut und leichter zu ändern ist. Während der Implementierung der Methoden des neuen Objekts werden wir die Funktionalität jeder internen Komponente im Detail untersuchen, um ihren Zweck und ihre Rolle in der Gesamtstruktur zu verstehen.
Alle internen Objekte sind direkt als Klassenmember deklariert, sodass keine dynamische Erzeugung und Löschung erforderlich ist. Folglich bleiben der Konstruktor und der Destruktor der Klasse leer, da die Speicherverwaltung für diese Objekte automatisch erfolgt. Die Initialisierung dieser deklarierten und geerbten Objekte wird in der Methode Init durchgeführt. Die Methode erhält Konstanten als Parameter, um die Architektur des zu erstellenden Objekts eindeutig zu definieren. Die Struktur dieser Parameter sollte selbsterklärend sein.
bool CNeuronAttraos::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false; SetActivationFunction(None);
Im Methodenkörper wird zuerst die gleichnamige Methode der übergeordneten Klasse aufgerufen. Diese Methode richtet minimale Kontrollpunkte ein und initialisiert vererbte Schnittstellen.
Wir deaktivieren in diesem Stadium ausdrücklich die Aktivierungsfunktion für unser Objekt, da alle Prozesse über interne Objekte abgewickelt werden. Vererbte Schnittstellen werden ausschließlich für den Datenaustausch auf globaler Ebene verwendet.
Nachdem die Methode der übergeordneten Klasse erfolgreich ausgeführt wurde, fahren wir mit der Initialisierung der deklarierten Objekte fort. Zu Beginn werden Objekte für zwei Matrizen trainierbarer Parameter initialisiert:
- A – die Übergangsmatrix der Zustände
- D – die Matrix der Residualverbindungen mit den Originaldaten
Da diese Matrizen mit vollständigen Matrizen multipliziert werden, die alle Elemente der analysierten Sequenz enthalten, müssen ihre Werte sofort über die Anzahl der Sequenzelemente wiederholt werden. Dadurch werden zusätzliche Kopiervorgänge vermieden und der Backpropagation-Prozess optimiert.
Wie zuvor organisieren wir die trainierbaren Parameter mithilfe eines kleinen Zwei-Schichten-Modells. Die erste Schicht enthält feste Werte, und die zweite Schicht erzeugt den erforderlichen Tensor durch Multiplikation der internen trainierbaren Parameter mit den festen Werten aus der ersten Schicht. Mit diesem Ansatz können bestehende Algorithmen mit neuronalen Schichten Parameter trainieren, ohne zusätzliche Funktionen zu schaffen. Um die Anzahl der trainierbaren Parameter in der zweiten Schicht zu minimieren, enthält die erste Schicht normalerweise nur ein Element.
In diesem Fall muss die Ausgabe der zweiten Schicht jedoch ein Tensor mit wiederholten Werten sein. Um dies zu erreichen, werden die festen Werte in der ersten Schicht eine bestimmte Anzahl von Malen wiederholt. Die zweite Schicht ist als Faltungsschicht implementiert, wobei die Anzahl der Filter gleich der Anzahl der trainierbaren Parameter ist. Die Größe des Faltungsfensters und die Schrittweite werden auf 1 gesetzt, sodass jedes Ausgangstensorelement von einem einzigen Eingabewert abhängt.
int index = 0; if(!cOne.Init(0, index, OpenCL, units_count, optimization, iBatch)) return false; if(!cOne.getOutput().Fill(1)) return false; cOne.SetActivationFunction(None); //--- index++; if(!cA.Init(0, index, OpenCL, 1, 1, window * window_key, units_count, 1, optimization, iBatch)) return false; cA.SetActivationFunction(MinusSoftPlus); CBufferFloat *w = cA.GetWeightsConv(); if(!w || !w.Fill(0)) return false;
Da die erste Schicht keine trainierbaren Parameter enthält, kann sie auch die zweite trainierbare Parametermatrix erzeugen. Daher initialisieren wir nur das zweite Objekt, um trainierbare Parameter zu erzeugen.
index++; if(!cD.Init(0, index, OpenCL, 1, 1, window, units_count, 1, optimization, iBatch)) return false; cD.SetActivationFunction(None); w = cD.GetWeightsConv(); if(!w || !w.Fill(1)) return false;
Beachten Sie, dass bei der Objektinitialisierung die trainierbaren Parametermatrizen mit festen Werten gefüllt werden. Dies unterscheidet sich etwas von dem allgemeinen Ansatz, die trainierbaren Parameter mit Zufallswerten zu füllen. Eine feste Initialisierung ist nützlich, wenn das Modell bestimmte Eigenschaften in frühen Trainingsphasen beibehalten muss oder wenn die Anfangsbedingungen die endgültige Parameterverteilung stark beeinflussen. Dadurch werden starke anfängliche Schwankungen vermieden und eine sanftere Anpassung an die Daten gefördert.
Die übrigen Parameter des Zustandsraummodells werden in Abhängigkeit von den Eingabedaten generiert, sodass sie sich an die spezifischen Merkmale der analysierten Sequenz anpassen können. Eine Faltungsschicht erzeugt alle Modellelemente parallel. Dieser Ansatz gewährleistet eine effiziente Datenverarbeitung und beschleunigt die Berechnungen erheblich, da die Faltung in der gesamten Sequenz parallel durchgeführt wird.
Bevor die Parameter des Zustandsraummodells generiert werden, werden die Eingaben normalisiert. Durch die Normalisierung werden Skalenunterschiede in den Rohwerten beseitigt, wodurch der Optimierungsprozess reibungsloser und berechenbarer wird.
//--- index++; if(!cX_norm.Init(0, index, OpenCL, window * units_count, optimization, iBatch)) return false; cX_norm.SetActivationFunction(None); index++; if(!cX_proj.Init(0, index, OpenCL, window, window, 4 * window_key, units_count, 1, optimization, iBatch)) return false; cX_proj.SetActivationFunction(None);
Anschließend werden die generierten Modellparameter in einzelne Entitäten aufgeteilt. Außerdem werden zusätzliche Objekte für die Speicherung erstellt, deren Namen die gespeicherten Daten widerspiegeln.
index++; if(!cDelta.Init(0, index, OpenCL, window_key * units_count, optimization, iBatch)) return false; cDelta.SetActivationFunction(None); index++; if(!cB.Init(0, index, OpenCL, window_key * units_count, optimization, iBatch)) return false; cB.SetActivationFunction(None); index++; if(!cC.Init(0, index, OpenCL, window_key * units_count, optimization, iBatch)) return false; cC.SetActivationFunction(None); index++; if(!cH.Init(0, index, OpenCL, window_key * units_count, optimization, iBatch)) return false; cH.SetActivationFunction(None);
Anschließend initialisieren wir das Objekt, das für die Erzeugung der exponentiellen Zerfallsparameter der verborgenen Zustände verantwortlich ist. Diese Komponente ist entscheidend für die Steuerung der Informationsdynamik durch die Sequenz, indem sie den Grad der Beibehaltung oder des Verfalls vergangener Zustände kontrolliert.
index++; if(!cDelta_proj.Init(0, index, OpenCL, window_key, window_key, window, units_count, 1, optimization, iBatch)) return false; cDelta_proj.SetActivationFunction(SoftPlus);
Die Verwendung von SoftPlus als Aktivierungsfunktion stellt sicher, dass am Ausgang nur positive Werte erscheinen.
Mehrere zusätzliche Objekte werden initialisiert, um Zwischenergebnisse von Berechnungen zu speichern, die alle die gleiche Größe haben.
index++; if(!cDeltaA.Init(0, index, OpenCL, window * window_key * units_count, optimization, iBatch)) return false; cDeltaA.SetActivationFunction(None); index++; if(!cDeltaB.Init(0, index, OpenCL, window * window_key * units_count, optimization, iBatch)) return false; cDeltaB.SetActivationFunction(None); index++; if(!cDeltaBX.Init(0, index, OpenCL, window * window_key * units_count, optimization, iBatch)) return false; cDeltaBX.SetActivationFunction(None); index++; if(!cDeltaH.Init(0, index, OpenCL, window * window_key * units_count, optimization, iBatch)) return false; cDeltaH.SetActivationFunction(None); index++; if(!cHS.Init(0, index, OpenCL, window * window_key * units_count, optimization, iBatch)) return false; cHS.SetActivationFunction(None); //--- return true; }
Die Initialisierungsmethode schließt mit der Rückgabe eines logischen Ergebnisses an das aufrufende Programm ab.
Beachten Sie, dass in diesem Objekt die Architekturparameter nicht in separaten lokalen Variablen gespeichert werden. Durch diese Implementierung wird vermieden, dass dauerhafte Duplikate von Werten, die bereits in internen Objekten gespeichert sind, beibehalten werden. Stattdessen werden die lokalen Variablen zu Beginn der Methoden für den Vorwärts- und den Rückwärtsdurchlauf (Backpropagation) gefüllt.
Nach der Objektinitialisierung geht es weiter mit dem Vorwärtsdurchlauf-Algorithmus, der in der Methode feedForward implementiert ist, die einen Zeiger auf das Eingabedatenobjekt erhält.
bool CNeuronAttraos::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- uint window = cX_proj.GetWindow(); uint window_key = cX_proj.GetFilters() / 4; uint units = cD.GetUnits();
Im Methodenrumpf werden zunächst Parameter aus internen Objekten geladen, die bei der Initialisierung nicht gespeichert wurden. Dann erzeugen wir Tensoren für die trainierbaren Parameter des Modells.
if(!cA.FeedForward(cOne.AsObject())) // (Units, Window, WindowKey) return false; if(!cD.FeedForward(cOne.AsObject())) // (Units, Window)) return false;
Anschließend normalisieren wir die Eingabedaten und erstellen kontextabhängige Modellparameter.
if(!NeuronOCL || !SumAndNormilize(NeuronOCL.getOutput(), NeuronOCL.getOutput(), cX_norm.getOutput(), window, true, 0, 0, 0, 0.5f)) return false; if(!cX_proj.FeedForward(cX_norm.AsObject())) // (Units, 4*WindowKey) return false;
Sie werden dann in einzelne Komponenten aufgeteilt.
if(!DeConcat(cDelta.getOutput(), cB.getOutput(), cC.getOutput(), cH.getOutput(), cX_proj.getOutput(), window_key, window_key, window_key, window_key, units)) // 4*(Units, WindowKey) return false;
Wir erzeugen auch adaptive Zeitschrittparameter.
if(!cDelta_proj.FeedForward(cDelta.AsObject())) // (Units, Window) return false;
An diesem Punkt ist die Vorbereitungsphase abgeschlossen, und wir gehen zur Konstruktion des Algorithmus MDMU über, der für die Modellierung der Zeitreihendynamik verantwortlich ist. Der Zustand des Modells wird gemäß der wiederkehrenden Gleichung aktualisiert:
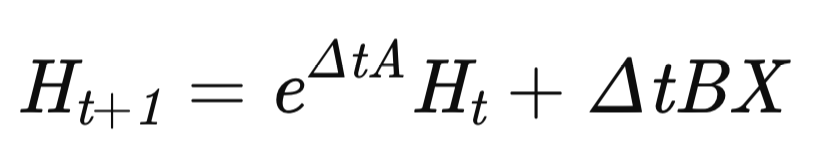
wobei Δt der adaptive Zeitschritt ist.
Zunächst berechnen wir die Exponentialkomponente im ersten Term und ersetzen die Standard-Exponentialfunktion durch SoftPlus, die mehrere Vorteile bietet.
if(!DiagMatMul(cDelta_proj.getOutput(), cA.getOutput(), cDeltaA.getOutput(), window, window_key, units, SoftPlus)) // (Units, Window, WindowKey) return false;
SoftPlus wächst langsamer als die Exponentialfunktion, wodurch die Gefahr eines starken Anstiegs der Übergangsmatrix verringert wird. Dies gewährleistet sanftere Steigungsänderungen und ein stabileres Training.
Die Exponentialfunktion ist sehr empfindlich gegenüber kleinen Änderungen Δ. SoftPlus glättet die Schwankungen und verhindert abrupte Sprünge in verborgenen Zuständen.
Bei verrauschten Daten begrenzt SoftPlus die Auswirkungen von Ausreißern, da das Wachstum logarithmisch begrenzt ist, was die Stabilität des Modells erhöht.
Anschließend werden die Werte des zweiten Terms durch sequenzielle Matrixmultiplikationen berechnet.
if(!MatMul(cDelta_proj.getOutput(), cB.getOutput(), cDeltaB.getOutput(), window, 1, window_key, units)) // (Units, Window, WindowKey) return false; if(!DiagMatMul(cX_norm.getOutput(), cDeltaB.getOutput(), cDeltaBX.getOutput(), window, window_key, units, None)) // (Units, Window, WindowKey) return false;
Anschließend passen wir die Matrix des dynamischen Regulators für Änderungen der verborgenen Zustände entsprechend der Änderungsrate des verborgenen Zustands an.
if(!MatMul(cDelta_proj.getOutput(), cH.getOutput(), cDeltaH.getOutput(), window, 1, window_key, units)) // (Units, Window, WindowKey) return false;
Nachdem wir alle notwendigen Daten vorbereitet haben, korrigieren wir die verborgenen Zustände des Systems mithilfe des parallelen Scan-Algorithmus, der im vorherigen Artikel in OpenCL implementiert wurde. Hier genügt es, den Kernel-Wrapper PScan aufzurufen.
if(!PScan()) return false;
Der Aufruf des Kernels erfolgt nach einem Standardalgorithmus, sodass wir ihn hier nicht im Detail untersuchen werden. Der vollständige Code für diese Methode ist im Anhang enthalten (Datei NeuroNet.cl).
Anschließend wird der prognostizierte Zustand des analysierten Systems durch Multiplikation der aktualisierten verborgenen Zustandsmatrix mit der Projektionsmatrix der verborgenen Zustände erzeugt.
if(!MatMul(cHS.getOutput(), cC.getOutput(), Output, window, window_key, 1, units)) // (Units, Window, 1) return false;
Die normierten Eingangsdaten werden mit den Koeffizienten für die direkte Verbindung multipliziert.
if(!ElementMult(cD.getOutput(), cX_norm.getOutput(), PrevOutput)) // (Units, Window)) return false;
Die Ergebnisse der beiden Operationen werden dann addiert.
if(!SumAndNormilize(Output, PrevOutput, Output, window, false, 0, 0, 0, 1)) // (Units, Window)) return false;
Zusätzlich beziehen wir die ursprünglichen Eingabedaten ein, indem wir eine Residualverbindung hinzufügen.
if(!SumAndNormilize(Output, NeuronOCL.getOutput(), Output, window, false, 0, 0, 0, 1)) // (Units, Window)) return false; //--- return true; }
Bei diesem Ansatz werden Informationen aus verborgenen Zuständen und kurzfristigen Abhängigkeiten in die Eingabedaten integriert.
Damit ist der Algorithmus des Vorwärtsdurchlaufs unserer Attraos-Frameworkimplementierung abgeschlossen. Abschließend gibt die Methode das boolesche Ergebnis an den Aufrufer zurück.
Der nächste Schritt besteht darin, die Algorithmen für die Rückwärtsdurchläufe für unser Objekt zu konstruieren. In diesem Artikel wird die Methode calcInputGradients untersucht, mit der Fehlergradienten verteilt werden. Wie zuvor erhält die Methode einen Zeiger auf das Eingabedatenobjekt, aber dieses Mal nimmt sie auch die Fehlergröße entsprechend dem Einfluss der Eingabedaten auf die endgültige Modellausgabe.
bool CNeuronAttraos::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Die Methode prüft zunächst die Gültigkeit des Zeigers. Wenn die Zeiger ungültig oder veraltet sind, wären alle weiteren Operationen sinnlos.
Anschließend speichern wir die Parameter der Eingabedaten in lokalen Variablen wie beim Vorwärtsdurchlauf.
uint window = cX_proj.GetWindow(); uint window_key = cX_proj.GetFilters() / 4; uint units = cD.GetUnits();
Als Nächstes verteilen wir den Fehlergradienten der Ausgangsebene auf die drei Datenströme. Ich möchte Sie daran erinnern, dass wir während des Vorwärtsdurchlaufs drei Informationsflüsse zur Datenübertragung verwendet haben:
- Zustandsraummodell
- Direkte Verbindungen mit Koeffizienten
- Residualverbindungen
Zunächst wird der Fehlergradient zwischen direkten Verbindungskoeffizienten und normalisierten Eingabedaten verteilt.
if(!ElementMultGrad(cD.getOutput(), cD.getGradient(), cX_norm.getOutput(), cX_norm.getPrevOutput(), Gradient, cD.Activation(), None)) // (Units, Window)) return false;
Anschließend wird der Gradient entlang des zweiten Datenstroms propagiert und auf die verborgenen Zustände und Projektionskoeffizienten verteilt.
if(!MatMulGrad(cHS.getOutput(), cHS.getGradient(), cC.getOutput(), cC.getGradient(), Gradient, window, window_key, 1, units)) // (Units, Window, 1) return false;
Falls erforderlich, werden die Ergebnisse durch Ableitungen der entsprechenden Aktivierungsfunktionen korrigiert.
if(cHS.Activation() != None) { if(!DeActivation(cHS.getOutput(), cHS.getGradient(), cHS.getGradient(), cHS.Activation())) return false; } if(cC.Activation() != None) { if(!DeActivation(cC.getOutput(), cC.getGradient(), cC.getGradient(), cC.Activation())) return false; }
Anschließend verteilen wir den Gradienten über das Parallel-Scan-Modul unter Verwendung des entsprechenden Kernel-Wrappers.
if(!PScanCalcGradient()) return false;
Die resultierenden Werte werden anschließend den entsprechenden Komponenten zugewiesen. Zunächst wird der Gradient an verborgene Zustände und adaptive Zeitschrittparameter weitergegeben.
if(!MatMulGrad(cDelta_proj.getOutput(), cDelta_proj.getGradient(), cH.getOutput(), cH.getGradient(), cDeltaH.getGradient(), window, 1, window_key, units)) // (Units, Window, WindowKey) return false;
Dann wird der Fehlergradient auf die normalisierten Eingangsdaten übertragen.
if(!DiagMatMulGrad(cX_norm.getOutput(), cX_norm.getGradient(), cDeltaB.getOutput(), cDeltaB.getGradient(), cDeltaBX.getGradient(), window, window_key, units)) // (Units, Window, WindowKey) return false; if(!SumAndNormilize(cX_norm.getGradient(), cX_norm.getPrevOutput(), cX_norm.getPrevOutput(), window, false, 0, 0, 0, 1)) return false;
Beachten Sie, dass wir die Werte des Fehlergradienten bereits an das normalisierte Eingabeobjekt übergeben haben. Daher fassen wir in dieser Phase die Daten aus den beiden Informationsströmen zusammen.
In ähnlicher Weise werden Gradienten auf die Koeffizienten verteilt, die den Einfluss der Eingaben auf die verborgenen Zustände und die Parameter der adaptiven Zeitschritte steuern.
if(!MatMulGrad(cDelta_proj.getOutput(), cDelta_proj.getPrevOutput(), cB.getOutput(), cB.getGradient(), cDeltaB.getGradient(), window, 1, window_key, units)) // (Units, Window, WindowKey) return false; if(!SumAndNormilize(cDelta_proj.getGradient(), cDelta_proj.getPrevOutput(), cDelta_proj.getGradient(), window, false, 0, 0, 0, 1)) return false;
Die Gradienten für die adaptiven Zeitschrittparameter werden mit den zuvor erfassten Werten akkumuliert.
Anschließend wird der Fehlergradient auf die Entwicklungsmatrix der verborgene Zustände übertragen, wobei die Werte anhand der Ableitung der Aktivierungsfunktion korrigiert werden.
if(!DeActivation(cDeltaA.getOutput(), cDeltaA.getGradient(), cDeltaA.getGradient(), SoftPlus)) return false;
Dann verteilen wir die Werte auf die Entitäten.
if(!DiagMatMulGrad(cDelta_proj.getOutput(), cDelta_proj.getPrevOutput(), cA.getOutput(), cA.getGradient(), cDeltaA.getGradient(), window, window_key, units)) // (Units, Window, WindowKey) return false; if(!SumAndNormilize(cDelta_proj.getGradient(), cDelta_proj.getPrevOutput(), cDelta_proj.getGradient(), window, false, 0, 0, 0, 1)) return false;
In diesem Stadium summieren wir erneut die Werte des Fehlergradienten auf der Ebene der adaptiven Zeitschrittparameter. Dieses Mal ist dies jedoch der letzte Informationsstrom in diese Richtung. Dann passen wir die akkumulierten Werte durch die Ableitung der entsprechenden Aktivierungsfunktion an.
if(cDelta_proj.Activation() != None) { if(!DeActivation(cDelta_proj.getOutput(), cDelta_proj.getGradient(), cDelta_proj.getGradient(), cDelta_proj.Activation())) return false; }
Danach propagieren wir den Fehlergradienten auf der Ebene der adaptiven Zeitschritte.
if(!cDelta.calcHiddenGradients(cDelta_proj.AsObject())) return false;
In diesem Stadium haben wir Fehlergradienten für alle kontextabhängigen Entitäten erhalten. Diese Werte werden in einem einzigen Tensor zusammengefasst.
if(!Concat(cDelta.getGradient(), cB.getGradient(), cC.getGradient(), cH.getGradient(), cX_proj.getGradient(), window_key, window_key, window_key, window_key, units)) // 4*(Units, WindowKey) return false;
Der Fehlergradient wird dann bis auf die Ebene der normalisierten Eingabedaten zurückpropagiert.
if(!cX_norm.calcHiddenGradients(cX_proj.AsObject())) return false; if(!SumAndNormilize(cX_norm.getGradient(), cX_norm.getPrevOutput(), cX_norm.getGradient(), window, false, 0, 0, 0, 1)) return false;
Erinnern Sie sich, dass das normalisierte Eingabedatenobjekt bereits zweimal den Fehlergradienten erhalten hat? Daher werden die in dieser Phase erhaltenen Werte zu den zuvor akkumulierten Gradienten addiert.
Wir beziehen auch Werte aus dem Verbindungspfad der Residuen ein, bevor wir die akkumulierten Gradienten an die Eingabedatenebene weitergeben, indem wir sie durch die Ableitung der entsprechenden Aktivierungsfunktion anpassen.
if(!SumAndNormilize(cX_norm.getGradient(), Gradient, cX_norm.getGradient(), window, false, 0, 0, 0, 1)) return false; if(!DeActivation(NeuronOCL.getOutput(), NeuronOCL.getGradient(), cX_norm.getGradient(), NeuronOCL.Activation())) return false; //--- return true; }
Damit ist die Methode calcInputGradients abgeschlossen, die ein logisches Ergebnis an das aufrufende Programm zurückgibt.
Was die Methode updateInputWeights betrifft, die für die Aktualisierung der Modellparameter zuständig ist, schlage ich vor, sie unabhängig zu überprüfen. Sie ruft einfach die entsprechenden Aktualisierungsmethoden für die vier internen Objekte auf, die trainierbare Parameter enthalten.
Ich möchte noch ein paar Worte zu den Algorithmen der Methoden sagen, die Objektzustände speichern und wiederherstellen. Unsere neue Klasse enthält eine beträchtliche Anzahl von internen Objekten, aber nur vier davon enthalten trainierbare Parameter. Daher reicht es aus, beim Speichern nur diese vier Objekte auf der Festplatte zu speichern.
bool CNeuronAttraos::Save(const int file_handle) { if(!CNeuronBaseOCL::Save(file_handle)) return false; //--- if(!cA.Save(file_handle)) return false; if(!cD.Save(file_handle)) return false; if(!cX_proj.Save(file_handle)) return false; if(!cDelta_proj.Save(file_handle)) return false; //--- return true; }
Es stellt sich jedoch die Frage, wie die Funktionalität des Objekts wiederhergestellt werden kann. Bei der Methode Load werden die zuvor gespeicherten Daten zunächst von der Festplatte gelesen.
bool CNeuronAttraos::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false; //--- if(!LoadInsideLayer(file_handle, cA.AsObject())) return false; if(!LoadInsideLayer(file_handle, cD.AsObject())) return false; if(!LoadInsideLayer(file_handle, cX_proj.AsObject())) return false; if(!LoadInsideLayer(file_handle, cDelta_proj.AsObject())) return false;
Die Architekturparameter werden dann in lokalen Variablen gespeichert.
uint window = cX_proj.GetWindow(); uint window_key = cX_proj.GetFilters() / 4; uint units_count = cD.GetUnits();
Der restliche Ablauf entspricht der Initialisierung der temporären Speicherobjekte.
if(!cOne.Init(0, 0, OpenCL, units_count, optimization, iBatch)) return false; if(!cOne.getOutput().Fill(1)) return false; cOne.SetActivationFunction(None); int index = 3; if(!cX_norm.Init(0, index, OpenCL, window * units_count, optimization, iBatch)) return false; cX_norm.SetActivationFunction(None); index += 2; if(!cDelta.Init(0, index, OpenCL, window_key * units_count, optimization, iBatch)) return false; cDelta.SetActivationFunction(None); index++; if(!cB.Init(0, index, OpenCL, window_key * units_count, optimization, iBatch)) return false; cB.SetActivationFunction(None); index++; if(!cC.Init(0, index, OpenCL, window_key * units_count, optimization, iBatch)) return false; cC.SetActivationFunction(None); index++; if(!cH.Init(0, index, OpenCL, window_key * units_count, optimization, iBatch)) return false; cH.SetActivationFunction(None); index += 2; if(!cDeltaA.Init(0, index, OpenCL, window * window_key * units_count, optimization, iBatch)) return false; cDeltaA.SetActivationFunction(None); index++; if(!cDeltaB.Init(0, index, OpenCL, window * window_key * units_count, optimization, iBatch)) return false; cDeltaB.SetActivationFunction(None); index++; if(!cDeltaBX.Init(0, index, OpenCL, window * window_key * units_count, optimization, iBatch)) return false; cDeltaBX.SetActivationFunction(None); index++; if(!cDeltaH.Init(0, index, OpenCL, window * window_key * units_count, optimization, iBatch)) return false; cDeltaH.SetActivationFunction(None); index++; if(!cHS.Init(0, index, OpenCL, window * window_key * units_count, optimization, iBatch)) return false; cHS.SetActivationFunction(None); //--- return true; }
Dieser Ansatz optimiert die Datensicherung, die Wiederherstellung von Objekten und die Nutzung des Speicherplatzes.
Damit schließen wir die Diskussion über den Aufbau des Attraos-Frameworks in MQL5 ab. Der vollständige Code für die Klasse CNeuronAttraos und alle ihre Methoden ist im Anhang enthalten.
Modellarchitektur
Nachdem wir die Algorithmen des Attraos-Frameworks implementiert haben, wollen wir die Architektur der trainierbaren Modelle beschreiben. In diesem Experiment werden zwei Modelle mithilfe von Multi-Task-Learning trainiert. Die Architekturen werden in der Methode CreateDescriptions definiert, die Zeiger auf zwei dynamische Arrays erhält, in denen die Beschreibungen der Modellarchitekturen gespeichert werden.
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&probability) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
Innerhalb der Methode prüfen wir zunächst die Gültigkeit der Zeiger und erstellen gegebenenfalls neue Objektinstanzen.
Das erste beschriebene Modell ist das Actor-Modell, der die zuvor implementierten Attraos-Ansätze verwendet. Wie üblich beginnt das Modell mit einer vollständig verbundene Eingabeschicht, gefolgt von einer Batch-Normalisierung. Auf diese Weise können die Rohdaten vom Handelsterminal direkt in das Modell eingespeist werden. In diesem Fall wird ihre primäre Normalisierung intern durch das Modell durchgeführt.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Als Nächstes verwenden wir die erste Schicht der Attraos-Architektur. Die Eingabe wird mit einer Zeitverzögerung von 5 Schritten in den Phasenraum transformiert, was 5 Minuten im einminütigen Zeitrahmen entspricht.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronAttraos; descr.window = BarDescr*5; // 5 min descr.count = HistoryBars/5; // 24 descr.window_out = 256; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Mit der zweiten Schicht wird die Verzögerung auf 15 Schritte erhöht.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronAttraos; descr.window = BarDescr*15; // 15 min descr.count = HistoryBars/15; // 8 descr.window_out = 256; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Und die dritte Schicht erhöht die Verzögerung auf 30 Schritte.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronAttraos; descr.window = BarDescr*30; // 30 min descr.count = HistoryBars/30; // 4 descr.window_out = 256; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Es ist wichtig zu beachten, dass die Ausgabe jedes CNeuronAttraos-Objekts der Dimensionalität der Eingabedaten entspricht. Daher reduziert die nächste Faltungsschicht die Tensordimensionalität um den Faktor drei.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count=descr.count = HistoryBars/3; descr.window = BarDescr*3; descr.step = descr.window; int prev_window=descr.window_out = BarDescr; descr.activation = SoftPlus; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Daran schließt sich der Entscheidungskopf an, der aus drei aufeinanderfolgenden, vollständig vernetzten Schichten besteht.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 512; descr.batch = 1e4; descr.activation = TANH; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = TANH; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = SoftPlus; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Die resultierende Ausgabe wird normalisiert.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Anschließend wird ein Block zum Risikomanagement hinzugefügt.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMacroHFTvsRiskManager; //--- Windows { int temp[] = {3, 15, NActions, AccountDescr}; //Window, Stack Size, N Actions, Account Description if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = 10; descr.window_out = 16; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Das Richtungswahrscheinlichkeitsmodell für die Vorhersage zukünftiger Bewegungen wurde vollständig und ohne Änderungen aus früheren Arbeiten übernommen. Seine Beschreibung wird hier weggelassen. Eine vollständige Beschreibung der Architektur der trainierbaren Modelle findet sich im Anhang, einschließlich der Programme zur Interaktion mit der Umgebung, die ebenfalls unverändert aus früheren Arbeiten übernommen wurden.
Tests
Im Laufe von zwei Artikeln haben wir die Ideen des Attraos-Frameworks in erheblichem Umfang adaptiert und erweitert. Wir kommen nun zu einer entscheidenden Phase: der Bewertung der Funktionalität und Wirksamkeit der implementierten Methoden anhand realer historischer Daten. Dieser Prozess ist wichtig, um die praktische Anwendbarkeit des Modells und seine Fähigkeit zur Erkennung von Mustern zu bewerten und stabile Ergebnisse unter wechselnden Marktbedingungen zu erzielen.
Das Modell wurde auf historischen EURUSD M1-Daten für das gesamte Jahr 2024 trainiert. Alle Indikatorparameter blieben auf den Standardwerten, ohne zusätzliche Optimierung. Bei diesem Ansatz werden externe Faktoren wie die Abstimmung der Parameter auf bestimmte historische Daten eliminiert, sodass man sich auf die grundlegende Leistung des Modells konzentrieren kann. Durch die Verwendung unveränderter Indikatorparameter wird auch die Fähigkeit des Modells bewertet, sich an die reale Marktdynamik anzupassen, ohne dass ein ständiges Eingreifen oder eine Neukonfiguration erforderlich ist.
Das Modelltraining erfolgt in zwei Stufen. In der ersten Stufe wird eine Batch-Größe von 1 verwendet, sodass bei jeder Trainingsiteration ein völlig zufälliger Zustand aus der Trainingsmenge ausgewählt wird. Dadurch kommt das Modell mit möglichst vielen neuen Zuständen in Kontakt. Dies allein reicht jedoch nicht aus, um den Risikomanagement-Block richtig zu trainieren. Daher wird in der zweiten Stufe die Chargengröße auf 60 erhöht, sodass das Modell und der Risikomanagementblock über 60 aufeinanderfolgende Umgebungszustände hinweg angepasst werden können, was einer Stunde im einminütigen Zeitrahmen entspricht.
Für die Tests wurden Daten von Januar – Februar 2025 verwendet. Dieser Zeitraum wurde gewählt, um eine strenge Bewertung von zuvor ungesehenen Daten zu gewährleisten. Alle anderen Versuchsparameter blieben unverändert, um die Reproduzierbarkeit und einen fairen Vergleich zu gewährleisten. Diese Methode eliminiert Zufallsfaktoren und ermöglicht eine objektive Bewertung der Algorithmusleistung.
Die Testergebnisse sind unten dargestellt.



Während des Tests führte das Modell 287 Geschäfte aus, von denen fast 39 % gewinnbringend abgeschlossen wurden. Trotz der relativ geringen Gewinnquote erzielte die Strategie aufgrund des Gewinn-Verlust-Verhältnisses ein positives Gesamtergebnis. Insbesondere war der durchschnittliche Gewinn je profitablem Trade doppelt so hoch wie der durchschnittliche Verlust, was die weniger erfolgreichen Trades ausglich und mit einem Gewinnfaktor von 1,15 zu einem insgesamt positiven Ergebnis führte.
Die durchschnittliche Haltedauer der Positionen betrug mehr als 2 Stunden, was auf eine Tendenz zu kurz- und mittelfristigen Entscheidungen hinweist. Bemerkenswert ist, dass die am längsten gehaltene Position fast zwei Tage andauerte. Diese Tatsache bedarf einer weiteren Analyse.
Schlussfolgerung
Wir haben das Attraos-Framework untersucht, das Konzepte der Chaostheorie für Zeitreihenprognosen verwendet. Das Framework integriert nichtlineare Analyse, Phasenraumrekonstruktion, dynamischen Speicher mit mehreren Auflösungen und adaptive Algorithmen. Diese Technologien ermöglichen genauere Prognosen und adaptive Handelsmodelle.
Im praktischen Teil haben wir unsere Interpretation dieser Ansätze in MQL5 implementiert und Modelle auf historischen Daten erstellt und trainiert. Tests mit Daten, die nicht in der Stichprobe enthalten sind, zeigen, dass das Modell in der Lage ist, auch mit ungesehenen Daten Gewinne zu erzielen. Die Ergebnisse zeigten jedoch auch einige Probleme auf. Insbesondere ist ein längeres Halten von Positionen zu beobachten. Außerdem ist die Saldenkurve weniger glatt als gewünscht. Diese Ergebnisse deuten auf Potenzial hin, machen aber auch deutlich, dass weitere Optimierungen erforderlich sind.
Es ist wichtig zu beachten, dass diese Schlussfolgerungen spezifisch für diese Umsetzung sind. Die Originalversion von Attraos wurde in diesem Artikel nicht getestet.
Liste der Referenzen
- Attractor Memory for Long-Term Time Series Forecasting: A Chaos Perspective
- Andere Artikel dieser Serie
In diesem Artikel verwendete Programme
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Expert Advisor für die Datenerfassung |
| 2 | ResearchRealORL.mq5 | Expert Advisor | Expert Advisor für die Datenerfassung mit der Methode Real-ORL |
| 3 | Study.mq5 | Expert Advisor | Expert Advisor für das Training des Modells |
| 4 | Test.mq5 | Expert Advisor | Expert Advisor für Modelltests |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Beschreibung des Systemzustands und der Modellarchitektur |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code-Bibliothek | OpenCL-Programmcode |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/17371
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.