
取引におけるニューラルネットワーク:市場異常の適応型検出(DADA)

はじめに
技術の進歩とプロセスの自動化に伴い、時系列データは金融市場分析において不可欠な要素となっています。市場データにおける異常を効果的に検出することで、急激な価格変動、資産操作、流動性の変化といった潜在的なリスクを迅速に特定することが可能になります。これは特に、アルゴリズム取引、リスク管理、そして金融システムの安定性評価において重要です。ボラティリティの急上昇、取引量の異常な変動、あるいは資産間の通常とは異なる相関関係は、システム障害、投機的活動、さらには市場危機の兆候である可能性があります。
深層学習に基づく近年の異常検知手法は大きな成功を収めていますが、一方でいくつかの限界も存在します。多くの場合、このような手法では新しいデータセットごとに個別の学習が必要となり、実運用環境への適用を難しくしています。金融データは常に変化しており、過去のパターンが必ずしも繰り返されるとは限りません。
主な問題の一つは、市場ごとにデータ構造が異なる点です。現代のアルゴリズムは通常、オートエンコーダを用いて正常な市場挙動を「学習」します。これは異常が稀にしか発生しないためです。しかし、モデルが過剰な情報を保持すると、市場ノイズまでも再現してしまい、異常検知の精度が低下します。一方で、圧縮を強くしすぎると重要なパターンが失われる可能性があります。多くの手法では圧縮率が固定されているため、さまざまな市場環境への適応性が制限されます。
もう一つの課題は、異常の多様性です。多くのモデルは正常データのみで学習されますが、異常そのものを理解していなければ検出は困難になります。たとえば、急激な価格上昇はある市場では異常ですが、別の市場では通常の現象である場合もあります。資産によっては、異常が急激な流動性の増加として現れる一方で、別の資産では予期しない相関関係として現れることもあります。その結果、モデルは重要なシグナルを見逃したり、過剰な誤検知を生じたりする可能性があります。
これらの問題に対処するため、「Towards a General Time Series Anomaly Detector with Adaptive Bottlenecks and Dual Adversarial Decoders」の著者らは、適応的な情報圧縮と2つの独立したデコーダを用いる新しいフレームワークDADAを提案しています。従来の方法とは異なり、DADAはさまざまなデータに柔軟に適応します。固定された圧縮レベルを用いるのではなく、複数の選択肢を採用し、各ケースに最も適したものを選択します。これにより、市場データの特性をより適切に捉え、重要なパターンを保つことができます。
モデルの出力では、2つのデコーダが使用されます。一方のデコーダは正常データの再構成に使用され、もう一方は異常データの識別に使用されます。前者は時系列データの再構成を学習し、後者は異常サンプルを用いて学習されます。この構造により、正常状態と異常状態を明確に区別できるだけでなく、誤検知の発生を抑えることができます。
DADAアルゴリズム
時系列データとは、時間の経過とともに変化するデータの系列を指します。通常とは異なる振る舞いは、危機、システム障害、あるいは不正行為の兆候である可能性があります。こうした異常を効果的に検出するために、DADA(Detector with Adaptive Bottlenecks and Dual Adversarial Decoders)フレームワークは、深層学習を用いた適応的な時系列解析と異常パターン検出をおこないます。DADAの大きな特徴の一つは汎用性です。特定のドメインに事前適応する必要がなく、幅広い入力データに適用することができます。
DADAフレームワークは、マスキングを用いたデータ再構成の考え方に基づいており、時間的依存関係の解析や正常状態からの逸脱検出に有効です。この手法により、モデルは単にデータパターンを記憶するのではなく、欠損または破損した部分を再構成することでデータ構造そのものを学習します。
学習プロセスでは、正常系列と異常系列の2種類のデータを扱います。従来手法のように異常データの手動ラベル付けを必要とするのではなく、DADAでは生成的アプローチが採用されており、元の時系列データに人工的なノイズを加えます。この方法により、手作業によるラベリングを不要としつつ、モデルの汎用性が向上します。モデルは、スパイク、外れ値、トレンドの変化、ボラティリティの変動など、さまざまな種類の異常を学習します。
最初の段階では、元のデータはパッチ(区間)に分割され、それぞれにランダムなマスキングが適用されます。これは、欠損部分の再構成を学習させるために必要な処理です。これにより、異常検出能力や潜在的なパターンの抽出能力が強化されます。
次に、各パッチはエンコーダに入力され、圧縮された潜在表現へと変換されます。エンコーダは、ノイズや不要な情報を除外しながら、時系列データの重要な特徴を抽出するように学習します。この仕組みにより、金融市場の価格データ、取引量の時系列、その他の指標など、さまざまな性質のデータに対して高い汎化性能を発揮できます。
モデルの重要な構成要素の一つが、データの構造や品質に応じて情報圧縮の度合いを調整するアダプティブボトルネック機構です。データ内に有意な信号が含まれている場合にはより多くの情報を保持し、冗長またはノイズが多い場合には圧縮を強めることで、干渉を抑えつつ異常検出性能を向上させます。
Adaptive Bottleneck Module (AdaBN)は、データ圧縮の程度を動的に調整します。この仕組みは、オートエンコーダに類似した複数の小規模モデル群で構成されており、それぞれが異なる次元の潜在表現を持ちます。
![]()
ここでDownNet i (•) は分析済みのデータを圧縮し、UpNet i(•) はそれを再構築します。
また、適応型ルーターは入力データの入力データの解析結果に基づいて最適な経路を選択します。
![]()
ここで、WrouterとWnoiseは学習可能な行列です。
各パッチの圧縮には、R(z)の値が高い上位k個の経路が使用されます。
エンコーディング後、潜在表現は2つの並列デコーダへと入力されます。一方のデコーダは正常データの再構成を目的としており、再構成誤差の最小化を学習します。もう一方のデコーダは異常検出を目的としており、再構成結果と元データとの差を最大化するように学習されます。この敵対的な学習プロセスにより、モデルは正常パターンと異常パターンを効果的に区別できるようになります。
テスト時および実運用時には、異常検出用デコーダは無効化され、正常デコーダのみを用いて評価がおこなわれます。モデルが高精度でデータを再構成できる場合、その時系列は正常であると判断されます。一方で、再構成誤差が大きい場合には、異常の可能性が示唆されます。
著者らが作成したDADAフレームワークの可視化を以下に示します。

MQL5を使用した実装
DADAフレームワークの理論的な側面を確認した後、ここからは実践的な部分に移ります。このセクションでは、提案されたアプローチを基にした独自の解釈をMQL5で実装する方法について検討します。本フレームワークにおいて中心的な要素となるのが適応型ボトルネックモジュールです。まずはこの構築から作業を開始します。
おそらく、これが以前に実装したMixture of Expertsモジュールと類似していることに気づいた方も多いと思います。しかし、重要な違いが一つあります。これまで構築してきたCNeuronMoEオブジェクトでは、同一アーキテクチャを持つ複数のミニモデルを使用することを前提としていました。一方で今回のケースでは、各モデルごとに潜在状態レイヤーのサイズを変化させ、データの特性に応じて適応させる必要があります。このような設計は、従来のような畳み込みレイヤーのオブジェクトを用いる方法では実現できません。もちろん、各モデルを個別に作成し、それらにデータを順次通過させる方法も考えられます。しかし、この方法ではハードウェア効率が低下し、学習および運用にかかるコストが増加してしまいます。
これらの問題を解決するために、新たにマルチウィンドウ畳み込みレイヤーのオブジェクトを設計することにしました。この手法は、異なるサイズの畳み込みウィンドウを同時に使用するという考え方に基づいています。これにより、モデルは異なる粒度のデータを並列的な計算ストリームで同時に解析できるようになります。このアプローチにより、アーキテクチャはより柔軟になり、入力データの処理品質が向上するとともに、計算資源をより効率的に活用できるようになります。その結果、モデルは入力データに含まれるさまざまな時間的構造により適応できるようになり、高い精度と性能が実現されます。
OpenCLプログラム側でのアルゴリズムの構築
通常通り、計算負荷の大きい数学的処理の大部分はOpenCLコンテキストへ移譲されます。ここでは、新しいレイヤーの順伝播処理を実装するためにFeedForwardMultWinConvカーネルを作成します。
__kernel void FeedForwardMultWinConv(__global const float *matrix_w, __global const float *matrix_i, __global float *matrix_o, __global const int *windows_in, const int inputs, const int windows_total, const int window_out, const int activation ) { const size_t i = get_global_id(0); const size_t v = get_global_id(1); const size_t outputs = get_global_size(0);
カーネルのパラメータは、4つのデータバッファへのポインタと、入力データおよび結果の構造を定義する4つの定数から構成されます。
ここで注意すべき点として、グローバルバッファの1つであるwindows_inには整数値が含まれています。これは畳み込みウィンドウのサイズを保持するためのものです。入力データバッファ(matrix_i)にはセグメント列が格納されており、各セグメント内では各畳み込みウィンドウのデータが順番に配置されていることを前提としています。
カーネルは2次元の計算空間で実行される設計です。第1次元は単変量時系列における結果バッファの要素数を示し、第2次元はその単変量系列の数を表します。
ここで重要なのは、第1次元が「時系列の要素数」ではなく、「結果バッファ上の出力値の数」であるという点です。つまり第1次元のサイズは、1つのセグメント内の処理対象数と、使用するフィルタ数および畳み込みウィンドウ数の積として定義されます。また、各ウィンドウサイズに対して同一数のフィルタを適用することで、圧縮表現から再構成されるデータ形式の整合性を保証しています。
カーネル内部ではまず、2次元空間上の各スレッド位置を特定します。
次に、必要な要素へアクセスするために各グローバルバッファのオフセットを計算します。第1次元のスレッドIDは結果バッファの要素を指しますが、他のバッファのオフセットは追加の計算が必要です。
まず、現在のセグメント内での位置を特定するために、第1次元インデックスを単一セグメントの出力サイズで剰余演算します。
const int id = i % (window_out * windows_total);
その後、補助変数を用いて中間値を保持します。
int step = 0; int shift_in = 0; int shift_weight = 0; int window_in = 0; int window = 0;
次に、すべての畳み込みウィンドウを走査するループを構成します。
#pragma unroll for(int w = 0; w < windows_total; w++) { int win = windows_in[w]; step += win;
このループ内では、全ウィンドウサイズの総和を計算し、それによって1セグメントの入力サイズを求めます。また、対象ウィンドウへの入力オフセット(shift_in)、ウィンドウサイズ(window_in)、および重みバッファへのオフセット(shift_weight)を同時に決定します。
if((w * window_out) < id) { shift_in = step; window_in = win; shift_weight += (win + 1) * window_out; } }
次に、結果バッファ内で現在の要素の前に存在する完全なセグメント数(steps)を求め、それに対応する入力データバッファのオフセットを加算して、目的のセグメントへ到達します。
int steps = (int)(i / (window_out * windows_total)); shift_in += steps * step + v * inputs;
重みバッファのオフセットについては補正をおこないます。そのために、まず結果バッファの現在のセグメント内における解析対象要素の位置を用いて剰余を計算します。これにより、現在の畳み込みウィンドウにおける結果内での要素インデックスが得られます。本質的には、この値が対応するフィルタを特定します。各フィルタにおける訓練可能パラメータの数は、畳み込みウィンドウのサイズにバイアス要素を加えたものに等しくなります。したがって、フィルタインデックスにそのパラメータ数を乗算することで、必要なオフセットを求めることができます。
shift_weight += (id % window_out) * (window_in+1);
準備ステップが完了した後、現在の要素の値を計算し、ローカル変数に格納するためのループを構成します。
float sum = matrix_w[shift_weight + window_in]; #pragma unroll for(int w = 0; w < window_in; w++) if((shift_in + w) < inputs) sum += IsNaNOrInf(matrix_i[shift_in + w], 0) * matrix_w[shift_weight + w];
得られた値は、その後活性化関数によって調整され、グローバルな結果バッファの対応する要素に格納されます。
matrix_o[v * outputs + i] = Activation(sum, activation); }
順伝播アルゴリズムの構築が完了した後、逆伝播処理の構成に進みます。ここではまず、入力データレベルまで誤差勾配を伝播させるために、CalcHiddenGradientMultWinConvカーネルを作成します。このカーネルのパラメータ構造は、基本的に順伝播カーネルの構造を踏襲しています。追加されるのは、対応する勾配バッファへのポインタのみです。
__kernel void CalcHiddenGradientMultWinConv(__global const float *matrix_w, __global const float *matrix_i, __global float *matrix_ig, __global const float *matrix_og, __global const int *windows_in, const int outputs, const int windows_total, const int window_out, const int activation ) { const size_t i = get_global_id(0); const size_t v = get_global_id(1); const size_t inputs = get_global_size(0);
このカーネルも2次元のタスク空間で動作します。ただし今回は、第1次元が入力データバッファ内のオフセットを示します。これは、入力データレベルにおいて、すべてのフィルタからの勾配値を集約する必要があるためです。
通常通り、カーネルはまずタスク空間全体におけるスレッド位置を特定します。その後、入力データバッファ内の単一セグメントのサイズを決定するために、すべての畳み込みウィンドウを合計するループを構成します。
int step = 0; #pragma unroll for(int w = 0; w < windows_total; w++) step += windows_in[w];
これにより、対象要素が属するセグメントのインデックスと、そのセグメント内におけるオフセットを特定することができます。
int steps = (int)(i / step); int id = i % step;
次に、一時データを保持するためのローカル変数をいくつか宣言し、別のループを構成します。このループ内では、解析対象となる畳み込みウィンドウのサイズ(window_in)、畳み込みウィンドウのインデックス(window)、および現在のセグメント内における当該畳み込みウィンドウの先頭までのオフセット(before)を決定します。
int window = 0; int before = 0; int window_in = 0; #pragma unroll for(int w = 0; w < windows_total; w++) { window_in = windows_in[w]; if((before + window_in) >= id) break; window = w + 1; before += window_in; }
これらの値により、結果バッファ(shift_out)とパラメータテンソル(shift_weight)のオフセットを決定できます。
int shift_weight = (before + window) * window_out + id - before; int shift_out = (steps * windows_total + window) * window_out + v * outputs;
この時点で準備段階は完了し、誤差勾配を蓄積するのに十分な情報が得られました。別のループを構成し、対応する重みを考慮に入れながら、すべてのフィルターから勾配値を収集します。
float sum = 0; #pragma unroll for(int w = 0; w < window_out; w++) sum += IsNaNOrInf(matrix_og[shift_out + w], 0) * matrix_w[shift_weight + w * (window_in + 1)];
得られた値は、入力層の活性化関数の導関数を用いて調整され、その結果はグローバル勾配バッファの対応する要素に格納されます。
matrix_ig[v * inputs + i] = Deactivation(sum, matrix_i[v * inputs + i], activation); }
研究の第三段階では、誤差勾配を重み係数のレベルへと分配し、モデル全体の誤差を最小化するようにそれらを更新する処理を構築します。UpdateWeightsMultWinConvAdamカーネル内においてAdam最適化アルゴリズムを実装します。
このアルゴリズムを正しく構築するために、カーネルのパラメータ数を拡張し、追加の定数およびモーメント用の2つのグローバルバッファを導入します。
__kernel void UpdateWeightsMultWinConvAdam(__global float *matrix_w, __global const float *matrix_og, __global const float *matrix_i, __global float *matrix_m, __global float *matrix_v, __global const int *windows_in, const int windows_total, const int window_out, const int inputs, const int outputs, const float l, const float b1, const float b2 ) { const size_t i = get_global_id(0); // weight shift const size_t v = get_local_id(1); // variable const size_t variables = get_local_size(1);
このカーネルも2次元のタスク空間で使用することを想定しています。今回は、第1次元が訓練可能パラメータのグローバルバッファ内における最適化対象要素を示します。ただし重要な点として、多次元時系列を扱う場合、各単変量系列は共有された訓練可能パラメータによって解析されるという制約があります。そのためこの段階では、すべての単変量系列からの誤差勾配を集約する必要があります。個々の単変量系列の並列処理を構成するために、それらをタスク空間の第2次元に沿って分散し、さらにワークグループ単位でまとめることでデータ交換を可能にします。このワークグループ内でのデータ交換を実現するために、OpenCLコンテキストのローカルメモリ上に配列を確保します。
__local float temp[LOCAL_ARRAY_SIZE];
次に、準備段階へ進み、データバッファ内のオフセットを決定します。最も単純なステップは、結果バッファにおけるストライド(step_out)を求めることです。これは、1セグメントあたりの畳み込みウィンドウ数とフィルタ数の積に等しくなります。
int step_out = window_out * windows_total;
残りのパラメータを取得するためには追加の処理が必要です。まず、中間結果を保持するためのローカル変数を宣言します。
int step_in = 0; int shift_in = 0; int shift_out = 0; int window = 0; int number_w = 0;
その後、グローバルバッファに格納された畳み込みウィンドウサイズの値を走査するループを構成します。
#pragma unroll for(int w = 0; w < windows_total; w++) { int win = windows_in[w]; if((step_in + w)*window_out <= i && (step_in + win + w + 1)*window_out > i) { shift_in = step_in; shift_out = (step_in + w + 1) * window_out; window = win; number_w = w; } step_in += win; }
このループ内では、入力データバッファにおける対象畳み込みウィンドウへのオフセット(shift_in)、結果バッファへのオフセット(shift_out)、畳み込みウィンドウのサイズ(window)、およびそのインデックス(number_w)を決定します。また、すべての畳み込みウィンドウの合計(step_in)を計算し、これをセグメントサイズとして使用します。この値は入力データバッファのストライドとしても利用されます。
重要な点として、バイアス要素の存在により、すべての学習可能パラメータが入力データバッファに対応しているわけではありません。そのため、バイアス要素を判定するためのフラグを導入します。
bool bias = ((i - (shift_in + number_w) * window_out) % (window + 1) == window);
次に、結果バッファ内の該当要素へのオフセットを補正します。
int t = (i - (shift_in + number_w) * window_out) / (window + 1); shift_out += t + v * outputs;
同様の処理を用いて、グローバル入力データバッファのオフセットも補正します。
shift_in += (i - (shift_in + number_w) * window_out) % (window + 1) + v * inputs;
この時点で準備段階は完了し、分析対象パラメータの勾配を決定する作業に直接進みます。そのためには、現在のスレッドで最適化されているパラメータの計算に関わった結果バッファのすべての要素から勾配値を収集するループを構成します。
float grad = 0; int total = (inputs + step_in - 1) / step_in; #pragma unroll for(int t = 0; t < total; t++) { int sh_out = t * step_out + shift_out; if(bias && sh_out < outputs) { grad += IsNaNOrInf(matrix_og[sh_out], 0); continue; }
バイアス要素については、勾配値を単純に合計しますが、その他のパラメータについては、入力データの対応する要素に基づいて調整します。
int sh_in = t * step_in + shift_in; if(sh_in >= inputs) break; grad += IsNaNOrInf(matrix_og[sh_out] * matrix_i[sh_in], 0); }
なお、このループ内では、単一の単変量系列における誤差値のみを収集している点に注意が必要です。しかし前述の通り、最適化対象のパラメータは多次元時系列に含まれるすべての系列で共有されて使用されます。そのため、パラメータ更新を行う前に、ワークグループ内で計算されたすべての単変量系列からの値を集約する必要があります。これを実現するために、まず第一段階として、各スレッドで得られた個々の値をローカル配列の要素へ加算していきます。
//--- sum const uint ls = min((uint)variables, (uint)LOCAL_ARRAY_SIZE); #pragma unroll for(int s = 0; s < (int)variables; s += ls) { if(v >= s && v < (s + ls)) temp[v % ls] = (i == 0 ? 0 : temp[v % ls]) + grad; barrier(CLK_LOCAL_MEM_FENCE); }
次に、ローカル配列の要素に蓄積された値を合計します。
uint count = ls; #pragma unroll do { count = (count + 1) / 2; if(v < ls) temp[v] += (v < count && (v + count) < ls ? temp[v + count] : 0); if(v + count < ls) temp[v + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
ワークグループ内のすべてのスレッドから合計誤差勾配を取得した後、分析対象パラメータの値を更新できます。この操作には単一のスレッドのみが必要です。
if(v == 0) { grad = temp[0]; float mt = IsNaNOrInf(clamp(b1 * matrix_m[i] + (1 - b1) * grad, -1.0e5f, 1.0e5f), 0); float vt = IsNaNOrInf(clamp(b2 * matrix_v[i] + (1 - b2) * pow(grad, 2), 1.0e-6f, 1.0e6f), 1.0e-6f); float weight = clamp(matrix_w[i] + IsNaNOrInf(l * mt / sqrt(vt), 0), -MAX_WEIGHT, MAX_WEIGHT); matrix_w[i] = weight; matrix_m[i] = mt; matrix_v[i] = vt; } }
これらの操作の結果、分析対象のパラメータの値と、グローバルデータバッファ内の対応するモーメントが更新されます。
これで、OpenCLプログラムにおけるマルチウィンドウ畳み込み層アルゴリズムの構築が完了しました。ソースコード全文は付録に記載されています。
マルチウィンドウ畳み込み層オブジェクト
次の段階は、以前に構築したマルチウィンドウ畳み込み層のアルゴリズムをメインプログラムに統合することです。この目的のために、OpenCLコンテキスト内で作成されたカーネルを管理するためのプロセスを整理するための新しいオブジェクトCNeuronMultiWindowsConvOCLを作成します。新しいオブジェクトの構造を以下に示します。
class CNeuronMultiWindowsConvOCL : public CNeuronConvOCL { protected: int aiWindows[]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronMultiWindowsConvOCL(void) { activation = SoftPlus; iWindow = -1; } ~CNeuronMultiWindowsConvOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &windows[], uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronMultiWindowsConvOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual void SetOpenCL(COpenCLMy *obj); };
基本的に、新しいCNeuronMultiWindowsConvOCLオブジェクトは、標準的な畳み込み層の改良版を表しています。したがって、親クラスから派生させるのが論理的です。そうすれば、基本的な畳み込みロジックを継承し、コードの重複を回避することができます。
提示された構造では、おなじみのオーバーライドされた仮想メソッドのセットが見られます。しかし、新しいオブジェクトの主な違いは、複数の畳み込みウィンドウサイズを同時に使用できる点にあります。そのためには、追加のデータストレージ要素と、それらをOpenCLコンテキストに転送するためのインターフェースを作成する必要があります。追加の配列aiWindowsを宣言し、オブジェクト初期化メソッドInitのパラメータを変更します。
bool CNeuronMultiWindowsConvOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &windows[], uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(windows.Size() <= 0 || ArrayCopy(aiWindows, windows) < int(windows.Size())) return false;
CNeuronMultiWindowsConvOCLアルゴリズムに対して多くの変更を加えていますが、親クラスのロジックおよび機能は可能な限り維持するよう努めている点を強調しておきます。これにより、新しいオブジェクトを既存のアーキテクチャへ容易に統合できるだけでなく、すでに検証・デバッグ済みの仕組みを再利用することが可能になります。
オブジェクトの初期化アルゴリズムは、まずパラメータとして受け取った畳み込みウィンドウ配列のサイズを確認し、その値を内部に用意した専用配列へコピーすることから始まります。
次に、各畳み込みウィンドウに対してバイアス要素を加えた上で、すべてのウィンドウサイズの合計を算出します。
int window = 0; for(uint i = 0; i < aiWindows.Size(); i++) window += aiWindows[i] + 1;
一見すると直感的ではない処理に見えますが、これは必要な操作です。というのも、各畳み込みウィンドウに対してサイズが(Windowi + 1) * Filtersの重み行列を生成する必要があるためです。その結果、パラメータバッファ全体のサイズは次のように表されます。
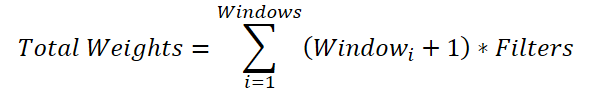
ここで、フィルタ数は共通の変数であるため、総和の外にくくり出すことができます。
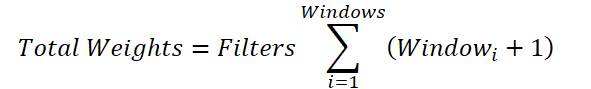
さらに、各ウィンドウサイズの総和を1つの値として置き換えることで、単一の畳み込みウィンドウにおける訓練可能パラメータ数を求める式へと帰着させることができます。しかし、親クラスでは各ウィンドウごとではなく、全体で1つのバイアス要素しか追加できないという制約があります。実装では各ウィンドウごとにバイアスを持たせる必要があるため、まず全ウィンドウに対してバイアスを加えた合計値を求め、その後1を減算した値をウィンドウサイズおよび畳み込みストライドとして親クラスの初期化メソッドへ渡します。
window--; if(!CNeuronConvOCL::Init(numOutputs, myIndex, open_cl, window, window, window_out, units_count * aiWindows.Size()*variables, 1, ADAM, batch)) return false;
すべての単変量系列に対して同一のパラメータを使用する予定であるため、その数は1に設定します。一方で、系列内の要素数については、畳み込みウィンドウ数および単変量系列数を掛け合わせることで拡張します。
このアプローチにより、継承されたすべてのデータバッファを必要なサイズで初期化でき、学習可能パラメータのバッファについてもランダム値で初期化することができます。
次に、畳み込みウィンドウの配列をOpenCLコンテキストへ転送するためのグローバルデータバッファを作成します。このバッファの値はオブジェクト初期化時に設定され、その後の学習およびモデル実行中には変更されません。そのため、このバッファはOpenCLコンテキスト内にのみ作成され、オブジェクト側ではそのポインタのみを保持します。
iVariables = variables; iWindow = OpenCL.AddBufferFromArray(aiWindows, 0, aiWindows.Size(), CL_MEM_READ_ONLY); if(iWindow < 0) return false; //--- return true; }
返されたハンドルを用いてグローバルバッファが正しく作成されたかを検証し、その結果に基づいて新しいオブジェクトの初期化メソッドを完了します。そして、処理の成否を示すブール値を呼び出し元へ返します。
新しいオブジェクトを初期化した後、フィードフォワードパスメソッドCNeuronMultiWindowsConvOCL::feedForwardをオーバーライドします。既にお察しの通り、ここで以前に作成したFeedForwardMultWinConvカーネルをキューに投入して実行します。ただし、この種の処理としては一般的な手順に従っているとはいえ、いくつか注意すべき点があります。
bool CNeuronMultiWindowsConvOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!OpenCL || !NeuronOCL) return false;
メソッドの引数には入力データオブジェクトへのポインタが含まれており、その有効性は最初に直ちに確認されます。
検証チェックを問題なく通過した後、タスク空間を定義する配列を初期化します。
uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {Neurons() / iVariables, iVariables};
前述のカーネルの説明の通り、第2次元は入力データ内の単変量系列の数に対応します。一方、第1次元のスレッド数は、本オブジェクトの結果バッファに含まれる総要素数を単変量系列数で割ることで決定されます。
続いて、データをカーネルのパラメータへ渡します。
ResetLastError(); int kernel = def_k_FeedForwardMultWinConv; if(!OpenCL.SetArgumentBuffer(kernel, def_k_ffmwc_matrix_i, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(kernel, def_k_ffmwc_matrix_o, getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(kernel, def_k_ffmwc_matrix_w, WeightsConv.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(kernel, def_k_ffmwc_windows_in, iWindow)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
あらかじめ保存しておいたハンドルが、畳み込みウィンドウサイズのバッファとして渡される点に注意が必要です。一方で、入力データ系列の次元数は、入力データバッファのサイズを単変量系列の数で割ることによって求められます。
if(!OpenCL.SetArgument(kernel, def_k_ffmwc_inputs, NeuronOCL.Neurons() / iVariables)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(kernel, def_k_ffmwc_window_out, iWindowOut)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(kernel, def_k_ffmwc_windows_total, (int)aiWindows.Size())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(kernel, def_k_ffmwc_activation, (int)activation)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(kernel, 2, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
すべてのパラメータの設定が正常に完了した後、カーネルを実行キューに登録し、本メソッドを終了します。その際、呼び出し元プログラムには処理結果を示すブール値を返します。
同様の手順で、バックプロパゲーション処理を構成するための各カーネルも実行キューに登録されます。相違点としては、誤差勾配を分配する際には入力層の活性化関数を指定すること、またパラメータ最適化処理においてはタスク空間の第2次元にワークグループが生成されるように設定する点が挙げられます。
bool CNeuronMultiWindowsConvOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!OpenCL || !NeuronOCL) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {WeightsConv.Total(), iVariables}; uint local_work_size[2] = {1, iVariables}; //--- ......... ......... ......... //--- if(!OpenCL.Execute(kernel, 2, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
以上で、マルチウィンドウ畳み込み層を構築するアルゴリズムの解説を終えます。CNeuronMultiWindowsConvOCLオブジェクトおよびそのすべてのメソッドの完全なコードは、付録に掲載しています。
記事もいよいよ終盤に差しかかりましたが、作業はまだ完了していません。ここでひとまず区切りとし、次回の記事でDADAフレームワークの著者が提案した手法の実装(本記事での解釈)を引き続き進めていきます。
結論
現代の金融市場は、膨大なデータ量だけでなく、高い変動性という特徴も持っています。そのため、異常検知は特に困難な課題となっています。DADAフレームワークは、適応型ボトルネックと2つの並列デコーダを組み合わせることで、時系列データのより高精度な分析を可能にする、根本的に新しいアプローチを提案しています。その最大の利点は、事前の個別調整を必要とせず、さまざまなデータ構造に動的に適応できる点にあり、汎用的なツールとして利用できることです。
記事の実践パートでは、DADAフレームワークの著者が提案した手法について、MQL5を用いた独自の解釈による実装を開始しました。しかし、作業はまだ完了しておらず、次回の記事で引き続き取り組んでいきます。
参照文献
- Towards a General Time Series Anomaly Detector with Adaptive Bottlenecks and Dual Adversarial Decoders
- 本連載の他の記事
記事で使用されたプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | サンプル収集用EA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法を用いたサンプル収集用EA |
| 3 | Study.mq5 | EA | モデル学習用EA |
| 4 | Test.mq5 | EA | モデルテスト用EA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態とモデルアーキテクチャ記述構造 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードライブラリ | OpenCLプログラムコード |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/17549
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索