Entwicklung des Price Action Analysis Toolkit (Teil 35): Training und Einsatz von Vorhersagemodellen

Einführung
Im vorangegangenen Artikel haben wir eine zuverlässige Pipeline für das Streaming historischer Daten aus einem MQL5-Skript in Python und deren Speicherung auf der Festplatte eingerichtet. Wir haben bewiesen, dass die Balken des Marktes erfasst, serialisiert und neu geladen werden können, aber wir haben nicht mit der Modellanpassung begonnen.
Diese Folge macht genau da weiter, wo wir aufgehört haben. Wir gehen über die Lagerung hinaus und zeigen, wie es geht:
- Vorhersagemodelle anhand der eingegebenen Daten zu trainieren,
- diese Modelle pro Symbol verpacken und zwischenlagern und
- sie als Hintergrund einer leichtgewichtigen REST-API einsetzen, die ein MQL5 Expert Advisor in Echtzeit abfragen kann.
Um dies zu erreichen, kombinieren wir die Stärken des Python-Ökosystems für maschinelles Lernen mit der Ausführungsgeschwindigkeit des MetaTrader 5. Der EA kümmert sich um die Interaktion mit dem Markt, während der Python-Dienst das Feature-Engineering, die Modellinferenz und – optional – das periodische Retraining übernimmt.
Ein „trainierbares Modell“ ist in diesem Zusammenhang jeder Algorithmus, dessen interne Parameter anhand von Daten optimiert werden können. Klassische Techniken (über scikit-learn) wie Gradient Boosting oder Support-Vector Machines sind für tabellarische Merkmalsätze geeignet, während Deep-Learning-Frameworks (TensorFlow, PyTorch) bei Bedarf komplexere Architekturen unterstützen. Die umfangreiche Bibliotheksunterstützung, die klare Syntax und die aktive Community machen Python zur Sprache der Wahl für diese Phase der Pipeline.
In der nachstehenden Tabelle sind die jeweiligen Zuständigkeiten im fertigen System zusammengefasst:
| Komponente | Rolle im Arbeitsablauf |
|---|---|
| MQL5 Expert Advisor | Sammelt Live-Balken und den Kontostatus; sendet Funktionsanfragen; führt Handelssignale aus, die von der API zurückgegeben werden. |
| Python-Ingestion-Skript | Empfängt Stücke (chunks) der Historie von MetaTrader 5, bereinigt und speichert sie (Parquet). |
| Modul für das Feature-Engineering | Konvertiert OHLC-Rohdaten in technische und statistische Merkmale. |
| Modultraining | Passt Modelle pro Symbol an oder aktualisiert sie; serialisiert sie mit joblib. |
| Flask-REST-Dienste | Bedient /predict, /upload_history usw.; verwaltet einen speicherinternen Modell-Cache für Antworten auf Millisekundenebene. |
Dieser Artikel ist wie folgt gegliedert:
- Einführung
- Rekapitulation der Ingestion Pipeline
- MQL5 und Python-Implementierung
- Modelltraining in Python
- Modellbereitstellung und Echtzeit-Inferenz
- Schlussfolgerung
Lassen Sie uns eintauchen.
Rekapitulation der Ingestion Pipeline
Wie im vorangegangenen Artikel beschrieben, rationalisiert unser „history ingestion“ Skript zum Abrufen der Historie den gesamten MetaTrader 5-Python-Workflow: Es zieht zunächst die gewünschten historischen Balken über CopyRates, parst dann Zeitstempel, Höchst- und Tiefstwerte sowie Schlussstände in Arrays, bevor es jeden Teil mit BuildJSON zu einer JSON-Nutzlast zusammensetzt. Um die Größenbeschränkungen von MetaTrader 5 für WebRequests einzuhalten, werden die Daten automatisch in überschaubare Stücke (chunks) aufgeteilt – wobei die Stückgrößen je nach Bedarf auf ein definiertes Minimum reduziert werden – und jedes Teil mit PostChunk an unseren Python-Endpunkt gesendet, komplett mit Wiederholungslogik und Timeout-Steuerung. Auf dem Weg dorthin protokolliert es jeden Schritt und jeden Fehler auf der Registerkarte „Experten“ und beendet sich bei Fehlern oder bestätigt die Fertigstellung, sobald alle Daten hochgeladen sind, und legt damit eine solide Grundlage für unsere Pipeline zur Spike-Erkennung.
Schauen wir uns das folgende Diagramm an, um jede Funktion innerhalb des MQL5-Skripts zu untersuchen.
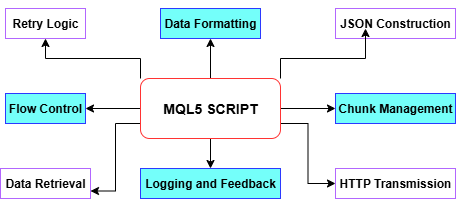
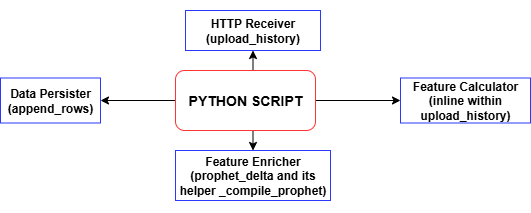
Jedes Mal, wenn das MQL5-Skript ein Stück historischer Balken sendet, berechnet der upload_history-Handler des Python-Endpunkts alle technischen Merkmale und Beschriftungen und ruft dann append_rows auf, um diese Datensätze in training_set.csv zu schreiben – wobei die Datei und die Kopfzeile erstellt werden, falls sie noch nicht existieren. Mit jedem weiteren Upload erstellen Sie einen vollständigen Datensatz mit Zeitstempel, der für das Modelltraining bereit ist. Mit dieser training_set.csv werden wir zweifellos unser Modell zur Spike-Erkennung trainieren.
MQL5 und Python-Implementierung
In diesem Artikel gehen wir von der Verwendung eines einfachen Skripts zur Entwicklung eines vollständigen Expert Advisors (EA) über, um eine kontinuierliche Überwachung und Echtzeitkommunikation mit einem Python-Backend zu ermöglichen – etwas, das ein eigenständiges Skript nicht effizient bewältigen kann. Der Spike Detector EA auf MetaTrader 5 arbeitet in einem Client-Server-Setup, bei dem er als Client und ein Python Flask Server als Backend fungiert. Der EA beobachtet kontinuierlich die Bildung neuer Kerzen. In festgelegten Intervallen sammelt es eine konfigurierte Anzahl historischer Kerzen (OHLCV-Daten und Zeitstempel), serialisiert diese im JSON-Format und sendet sie über eine HTTP-POST-Anfrage an den Python-Server.
Das Python-Backend, das in der Regel entweder ein maschinelles Lernmodell oder eine regelbasierte Logik enthält, analysiert die eingehenden Marktdaten und liefert ein Signal: BUY, SELL, CLOSE, oder WAIT. Nach Erhalt dieser Antwort interpretiert der EA das Signal und reagiert entsprechend – er zeichnet Pfeile auf dem Chart, eröffnet Handelsgeschäfte oder schließt bestehende Positionen, je nach den Einstellungen des Nutzers. Diese Rückkopplungsschleife ermöglicht es MetaTrader, seine nativen Fähigkeiten mit externer analytischer Intelligenz in Echtzeit zu erweitern, indem die Ausführungsengine von MetaTrader 5 mit der Verarbeitungsleistung von Python kombiniert wird.
MQL5-Implementierung
Skript-Metadaten und strikter Modus
Ganz oben in Ihrer MQL5-Datei deklarieren Sie Metadaten-Eigenschaften wie #property copyright, #property link und #property version, um Informationen zur Urheberschaft und Version direkt in den kompilierten EA einzubetten. Die Aktivierung von #property strict erzwingt die strengsten Überprüfungen zur Kompilierzeit und hilft Ihnen, Syntax- oder Typfehler frühzeitig zu erkennen und sicherzustellen, dass Ihr Code die Best Practices einhält.
#property copyright "Copyright 2025, MetaQuotes Ltd." #property link "https://www.mql5.com/en/users/lynnchris" #property version "1.0" #property strict
Importieren der Handelsbibliothek
Indem wir <Trade.mqh> einbinden und ein CTrade-Objekt instanziieren, erhalten wir Zugriff auf die systemeigene Handelsmanagement-API von MetaTrader. Diese integrierte Bibliothek stellt Methoden für Market Orders, Stop Orders, Positionsschließungen und andere wichtige Operationen zur Verfügung, sodass Sie Handelsgeschäfte als Reaktion auf die Signale Ihres Servers programmatisch eröffnen, ändern und schließen können.
#include <Trade\Trade.mqh> static CTrade trade;
Definieren von Eingabeparametern
Alle vom Nutzer konfigurierbaren Einstellungen – von der REST-Endpunkt-URL (InpServerURL) und der Anzahl der zu sendenden Balken (InpBufferBars) bis hin zu den Optionen für die Chart-Erstellung und den Flaggen für die Handelsausführung – werden im Voraus mit Eingabeanweisungen deklariert. Jeder Parameter enthält einen Inline-Kommentar, der seinen Zweck erklärt. Dadurch ist der EA selbstdokumentierend und ermöglicht Händlern die Feinabstimmung des Verhaltens direkt in der MetaTrader 5-GUI, ohne den Code zu berühren.
// REST endpoint & polling input string InpServerURL = "http://127.0.0.1:5000/analyze"; input int InpBufferBars = 200; input int MinSecsBetweenReq = 10; // Visual & trading options input color ColorBuy = clrLime; input color ColorSell = clrRed; input bool DrawSLTPLines = true; input bool EnableTrading = true; input double FixedLots = 0.10; // Debug & retry controls input int MaxRetry = 3; input bool DebugPrintJSON = true; input bool DebugPrintReply = true;
Globale Zustandsvariablen
Sie pflegen mehrere Globals, z. B. lastBarTime und lastReqTime zur Drosselung von Anfragen, retryCount für Ihre HTTP-Wiederholungslogik und _digits plus tickSize für die präzise Preisformatierung. Eine objPrefix-Zeichenkette, die mit der ID des aktuellen Charts versehen ist, gibt allen von diesem EA erstellten Chart-Objekten (Pfeile und Linien) einen Namen, sodass sie später eindeutig identifiziert und entfernt werden können.
datetime lastBarTime = 0; datetime lastReqTime = 0; int retryCount = 0; int _digits; double tickSize; string objPrefix;
Initialisierung in OnInit
Wenn der EA startet, wird OnInit() einmal ausgeführt, um Eingaben zu validieren (z. B. um sicherzustellen, dass mindestens zwei Balken angefordert werden), Symboleigenschaften (SYMBOL_DIGITS und SYMBOL_POINT) zwischenzuspeichern und einen eindeutigen Objekt-Präfix zu erzeugen. Eine Startmeldung protokolliert die Anzahl der zu sendenden Balken und die URL des Zielservers und bestätigt, dass der EA bereit ist, seinen Abfragezyklus zu beginnen.
int OnInit() { if(InpBufferBars < 2) return INIT_FAILED; _digits = (int)SymbolInfoInteger(_Symbol, SYMBOL_DIGITS); tickSize = SymbolInfoDouble(_Symbol, SYMBOL_POINT); objPrefix = StringFormat("SpikeEA_%I64d_", ChartID()); PrintFormat("[SpikeEA] Initialized: posting %d bars → %s", InpBufferBars, InpServerURL); return INIT_SUCCEEDED; }
Aufräumen bei OnDeinit
Beim Entfernen oder Beenden iteriert OnDeinit() rückwärts durch alle Chart-Objekte und löscht diejenigen, deren Namen mit Ihrem objPrefix beginnen. Dadurch wird sichergestellt, dass nach der Deaktivierung des EA keine verirrten Pfeile oder SL/TP-Linien auf dem Chart verbleiben und Ihr Arbeitsbereich sauber bleibt.
void OnDeinit(const int reason) { for(int i = ObjectsTotal(0) - 1; i >= 0; --i) { string name = ObjectName(0, i); if(StringFind(name, objPrefix) == 0) ObjectDelete(0, name); } }
Polling und Payload-Konstruktion in OnTick
Bei jedem Tick prüft der EA, ob sich ein neuer Balken gebildet hat (wenn PollOnNewBarOnly aktiviert ist) und stellt sicher, dass seit der letzten Anfrage ein Mindestintervall (MinSecsBetweenReq) verstrichen ist. Anschließend werden die letzten InpBufferBars über CopyRates gezogen, in eine Reihenfolge gebracht und BuildJSON() aufgerufen, um Closures und Zeitstempel in die JSON-Nutzdaten zu serialisieren. Wenn das Debugging aktiviert ist, wird das rohe JSON in das Expertenprotokoll gedruckt, bevor es gesendet wird.
void OnTick() { datetime barTime = iTime(_Symbol, _Period, 0); if(barTime == lastBarTime) return; lastBarTime = barTime; if(TimeCurrent() - lastReqTime < MinSecsBetweenReq) return; MqlRates rates[]; if(CopyRates(_Symbol, _Period, 0, InpBufferBars, rates) != InpBufferBars) return; ArraySetAsSeries(rates, true); string payload = BuildJSON(rates); if(DebugPrintJSON) PrintFormat("[SpikeEA] >>> %s", payload); SServerMsg msg; if(CallServer(payload, msg)) ActOnSignal(msg); lastReqTime = TimeCurrent(); }
Erstellung von JSON in BuildJSON
Die Hilfsfunktion BuildJSON() nimmt das Array von MqlRates und konstruiert einen kompakten JSON-String, der den Namen Ihres Symbols, ein Array von Schlusskursen (mit der richtigen Anzahl von Dezimalstellen formatiert) und ein paralleles Array von Zeitstempeln im UNIX-Stil enthält. Die Zeichenkettenumwandlung wird angewendet, um alle Sonderzeichen im Symbolnamen zu behandeln und eine gültige JSON-Ausgabe zu gewährleisten.
string BuildJSON(const MqlRates &r[]) { string j = StringFormat("{\"symbol\":\"%s\",\"prices\":[", _Symbol); for(int i = 0; i < InpBufferBars; i++) j += DoubleToString(r[i].close, _digits) + (i+1<InpBufferBars?",":""); j += "],\"timestamps\":["; for(int i = 0; i < InpBufferBars; i++) j += IntegerToString(r[i].time) + (i+1<InpBufferBars?",":""); j += "]}"; return j; }
Server-Kommunikation im CallServer
CallServer() konvertiert die JSON-Zeichenfolge in einen uchar[]-Puffer und führt dann mit WebRequest() einen HTTP-POST an InpServerURL durch. Es behandelt Timeouts und Nicht-200-Statuscodes mit einer Wiederholungslogik bis zu MaxRetry und gibt Fehler aus, wenn Anfragen fehlschlagen. Bei Erfolg wird die Rohtextantwort erfasst – optional protokolliert – und zur Interpretation an ParseJSONLite() übergeben.
bool CallServer(const string &payload, SServerMsg &out) { uchar body[]; int len = StringToCharArray(payload, body, 0, WHOLE_ARRAY, CP_UTF8); ArrayResize(body, len); string hdr = "Content-Type: application/json\r\n"; uchar reply[]; string resp_hdr; int status = WebRequest("POST", InpServerURL, hdr, InpTimeoutMs, body, reply, resp_hdr); if(status <= 0) { PrintFormat("WebRequest error %d (retry %d/%d)", GetLastError(), retryCount+1, MaxRetry); ResetLastError(); if(++retryCount >= MaxRetry) retryCount = 0; return false; } retryCount = 0; string resp = CharArrayToString(reply); if(DebugPrintReply) PrintFormat("[SpikeEA] <<< HTTP %d – %s", status, resp); if(status != 200) return false; return ParseJSONLite(resp, out); }
Leichtes JSON-Parsing in ParseJSONLite
Anstelle einer vollständigen JSON-Bibliothek verwendet ParseJSONLite() eine einfache Zeichenkettensuche (StringFind), um Schlüsselwörter wie „signal“: „BUY“ und numerische Schlüssel wie „conf“:, „sl“: und „tp“: zu erkennen.
bool ParseJSONLite(const string &txt, SServerMsg &o) { o.code = SIG_WAIT; o.conf = o.sl = o.tp = 0.0; if(StringFind(txt, "\"signal\":\"BUY\"") >= 0) o.code = SIG_BUY; if(StringFind(txt, "\"signal\":\"SELL\"") >= 0) o.code = SIG_SELL; if(StringFind(txt, "\"signal\":\"CLOSE\"") >= 0) o.code = SIG_CLOSE; // extract numeric values ParseJSONDouble(txt, "\"conf\":", o.conf); ParseJSONDouble(txt, "\"sl\":", o.sl); ParseJSONDouble(txt, "\"tp\":", o.tp); return true; }Er extrahiert und konvertiert diese Teilstrings in die Struktur SServerMsg und setzt den Signalcode des EA, den Konfidenzwert, den Stop-Loss und das Take-Profit-Niveau.
void ParseJSONDouble(const string &txt, const string &key, double &out) { int p = StringFind(txt, key); if(p >= 0) out = StringToDouble(StringSubstr(txt, p + StringLen(key))); }
Einwirkung auf Signale in ActOnSignal
Wenn ein neues Signal eintrifft, löscht ActOnSignal() zunächst alle vorherigen Pfeile oder Linien, indem es Ihren objPrefix abgleicht. Anschließend wird ein neuer Pfeil am aktuellen Geldkurs gezeichnet – je nach Signaltyp werden Symbolcode, Farbe und Größe ausgewählt – und, falls aktiviert, werden horizontale SL- und TP-Linien mit Beschriftungen hinzugefügt. Wenn der Live-Handel aktiviert ist, wird das Handelsobjekt verwendet, um Positionen entsprechend dem Signal zu öffnen oder zu schließen: Buy(), Sell(), oder PositionClose().
void ActOnSignal(const SServerMsg &m) { static ESignal last = SIG_WAIT; if(m.code == SIG_WAIT || m.code == last) return; last = m.code; // remove old objects for(int i=ObjectsTotal(0)-1;i>=0;--i) if(StringFind(ObjectName(0,i),objPrefix)==0) ObjectDelete(0,ObjectName(0,i)); // draw arrow int arrow = (m.code==SIG_BUY ? 233 : m.code==SIG_SELL ? 234 : 158); color clr = (m.code==SIG_BUY ? ColorBuy : m.code==SIG_SELL ? ColorSell : ColorClose); string id = objPrefix + "Arr_" + TimeToString(TimeCurrent(),TIME_SECONDS); double y = SymbolInfoDouble(_Symbol, SYMBOL_BID); if(ObjectCreate(0,id,OBJ_ARROW,0,TimeCurrent(),y)) { ObjectSetInteger(0,id,OBJPROP_ARROWCODE,arrow); ObjectSetInteger(0,id,OBJPROP_COLOR,clr); ObjectSetInteger(0,id,OBJPROP_WIDTH,ArrowSize); PlaySound("alert.wav"); } // draw SL/TP lines if(DrawSLTPLines && m.sl>0) ObjectCreate(0,objPrefix+"SL_"+id,OBJ_HLINE,0,0,m.sl); if(DrawSLTPLines && m.tp>0) ObjectCreate(0,objPrefix+"TP_"+id,OBJ_HLINE,0,0,m.tp); // execute trade if(EnableTrading) { bool hasPos = PositionSelect(_Symbol); if(m.code==SIG_BUY && !hasPos) trade.Buy(FixedLots,_Symbol,0,m.sl,m.tp); if(m.code==SIG_SELL && !hasPos) trade.Sell(FixedLots,_Symbol,0,m.sl,m.tp); if(m.code==SIG_CLOSE&& hasPos) trade.PositionClose(_Symbol,SlippagePoints); } }
Kompilieren und Einsetzen
Zum Abschließen fügen Sie den EA-Code in MetaEditor ein, speichern ihn unter Experten und drücken F7. Nachdem Sie „0 Fehler, 0 Warnungen“ bestätigt haben, wechseln Sie zurück zu MetaTrader 5, suchen Ihren EA im Navigator, ziehen ihn auf einen Chart und konfigurieren die Eingaben im Popup-Dialog. Auf den Registerkarten Experten und Journal werden dann Echtzeitprotokolle von JSON POSTs, geparsten Signalen, gezeichneten Objekten und Handelsausführungen angezeigt.
Python-Implementierung
Datei-Header & Anforderungen
Ganz oben in engine.py fügen wir einen Unix-Shebang (#!/usr/bin/env python3) und einen beschreibenden Kommentarblock ein, der die Fähigkeiten des Back-Ends zusammenfasst – vektorisierte History-Ingestion, CSV-Normalisierung, Prophet-Caching, Training, Backtesting und CLI-Modi – sowie den Pip-Install-Befehl für alle erforderlichen Abhängigkeiten. Diese Kopfzeile dokumentiert nicht nur auf einen Blick, was das Skript tut, sondern liefert jedem Entwickler auch die genaue Liste der Bibliotheken, die für den Betrieb des Systems erforderlich sind.
#!/usr/bin/env python3 # engine.py – Boom/Crash/Vol-75 ML back-end # • vectorised /upload_history # • /upload_spike_csv # • Prophet cache (1h) # • robust CSV writer # • train() drops bad rows # • SL/TP with ATR or fallback # • backtest defaults to 30 days # • CLI: collect · history · train · backtest · serve · info # # REQS: pip install numpy pandas ta prophet cmdstanpy pykalman \ # scikit-learn flask MetaTrader5 joblib pytz
Nutzerkonfigurierbare Einstellungen
Unmittelbar nach dem Header definieren wir Konstanten für die Anmeldedaten des Terminals (TERM_PATH, LOGIN, PASSWORD, SERVER) und ein Array von SYMBOLEN, die unser System verarbeiten wird. Wir legen auch Parameter fest, die die Vorausschau für die Kennzeichnung (LOOKAHEAD, THRESH_LABEL), die Abfrageintervalle (STEP_SECONDS), die Schwellenwerte für das Öffnen und Schließen von Handelsgeschäften (THR_BC_OPEN, THR_O_OPEN, THR_O_CLOSE) und die ATR-basierten Stop-Loss/Take-Profit-Multiplikatoren (ATR_PERIOD, SL_MULT, TP_MULT, ATR_FALLBACK_P) steuern. Durch die Zentralisierung dieser Werte können die Nutzer die Risikoparameter, Datenfenster und die Symbolliste der Strategie schnell anpassen, ohne in die Codelogik einzutauchen.
TERM_PATH = r"" LOGIN = 123456 PASSWORD = "passwd" SERVER = "DemoServer" SYMBOLS = [ "Boom 900 Index", "Crash 1000 Index", "Volatility 75 (1s) Index" ] LOOKAHEAD = 10 # minutes THRESH_LABEL = 0.0015 # 0.15 % STEP_SECONDS = 60 # live collect interval ATR_PERIOD = 14 SL_MULT = 1.0 TP_MULT = 2.0 ATR_FALLBACK_P = 0.002
Dateipfade & CSV-Kopfzeile
Als Nächstes legen wir Konstanten für das Dateisystem fest: BASE_DIR als Stammordner für die Analyse, CSV_FILE, das auf unseren aggregierten Trainingsdatensatz verweist, MODEL_DIR für die Artefakte des Modells für jedes einzelne Symbol und GLOBAL_PKL für das übergreifende Modell. Wir definieren auch CSV_HEADER, eine feste Liste von Spaltennamen, die sicherstellen, dass jede geschriebene Zeile dieselben 12 Felder enthält. In diesem Abschnitt wird der Speicherort der Daten standardisiert und die Konsistenz der gespeicherten CSV-Dateien sichergestellt, was für eine nahtlose nachfolgende Training und Analyse entscheidend ist.
BASE_DIR = r"C:\Analysis EA" CSV_FILE = rf"{BASE_DIR}\training_set.csv" MODEL_DIR = rf"{BASE_DIR}\models" GLOBAL_PKL = rf"{MODEL_DIR}\_global.pkl" CSV_HEADER = [ "timestamp","symbol","price","spike_mag","macd","rsi", "atr","slope","env_low","env_up","delta","label" ]
Einrichtung von Importen und Protokollierung
Wir importieren Standardbibliotheken (os, sys, time, threading, etc.), datenwissenschaftliche Pakete (numpy, pandas, ta, joblib), die Prophet- und Kalman-Filter-Module, Flask für unsere API und den MetaTrader 5 Python-Wrapper. Warnungen werden aus Gründen der Sauberkeit unterdrückt, und die Protokollierung ist so konfiguriert, dass Zeitstempel, Protokollstufen und Meldungen in einem für Menschen lesbaren Format ausgegeben werden. Schließlich stellen wir sicher, dass das Modellverzeichnis existiert und ändern das Arbeitsverzeichnis in BASE_DIRum, damit alle relativen Dateioperationen an einem bekannten Ort stattfinden.
import os,sys,time,logging,warnings,argparse,threading,io import datetime as dt from pathlib import Path import numpy as np, pandas as pd, ta, joblib, pytz from flask import Flask, request, jsonify, abort from prophet import Prophet from pykalman import KalmanFilter import MetaTrader5 as mt5 warnings.filterwarnings("ignore") logging.basicConfig(level=logging.INFO, format="%(asctime)s %(levelname)-7s %(message)s", datefmt="%H:%M:%S") Path(MODEL_DIR).mkdir(parents=True, exist_ok=True) os.chdir(BASE_DIR)
MetaTrader 5 Initialisierungshilfen
Die Funktion init_mt5() initialisiert die MetaTrader 5-Verbindung auf sichere Weise, indem sie zunächst einen Standardaufruf versucht und bei Bedarf auf die Anmeldeinformationen zurückgreift; ein Fehlschlag löst einen sauberen Abbruch mit einer Fehlermeldung aus. sicher_symbol(sym) wickelt einfach mt5.symbol_select um sicherzustellen, dass jedes Instrument aktiv ist, bevor Datenanforderungen gestellt werden. Eine Threading-Sperre (_mt5_lock) schützt alle Multi-Thread-Aufrufe an MetaTrader 5, um die Thread-Sicherheit zu gewährleisten, wenn unser Server Hintergrundaufgaben ausführt.
_mt5_lock = threading.Lock() def init_mt5(): if mt5.initialize(): return if not mt5.initialize(path=TERM_PATH, login=LOGIN, password=PASSWORD, server=SERVER): sys.exit(f"MT5 init failed {mt5.last_error()}") def ensure_symbol(sym): return mt5.symbol_select(sym, True)
Prophet Cache & Vorhersage Delta
Um zu vermeiden, dass das Prophet-Modell bei jeder Anfrage neu kompiliert wird, führen wir ein thread-sicheres Wörterbuch _PROP, das Symbole entweder auf None (Kompilierung ausstehend) oder auf ein Tupel (Modell, Zeitstempel) abbildet. _compile_prophet(df, sym) trainiert ein neues Prophet-Modell auf historischen Daten und zeichnet die Zeit auf. prophet_delta(preise, zeiten, sym) prüft den Cache: wenn er fehlt oder veraltet ist (mehr als eine Stunde), wird eine Hintergrundkompilierung gestartet; wenn er bereits verfügbar ist, wird eine Sekunde vorausgesagt und das vorhergesagte Delta zurückgegeben. Dieses Design sorgt dafür, dass die Vorhersage schnell reagiert und eingehende Anfragen nicht blockiert werden.
_PROP_LOCK = threading.Lock()
_PROP = {} # sym -> (model, timestamp) or None
def _compile_prophet(df, sym):
mdl = Prophet(daily_seasonality=False, weekly_seasonality=False)
mdl.fit(df)
with _PROP_LOCK:
_PROP[sym] = (mdl, time.time())
def prophet_delta(prices, times, sym):
if len(prices) < 20: return 0.0
with _PROP_LOCK:
entry = _PROP.get(sym)
if entry is None:
_PROP[sym] = None
df = pd.DataFrame({"ds": pd.to_datetime(times, unit='s'),
"y": prices})
threading.Thread(target=_compile_prophet, args=(df, sym), daemon=True).start()
return 0.0
mdl, ts = entry
if time.time() - ts > 3600:
with _PROP_LOCK: _PROP[sym] = None
return 0.0
fut = mdl.make_future_dataframe(periods=1, freq='s')
return float(mdl.predict(fut).iloc[-1]["yhat"] - prices[-1])
Hilfsfunktionen für Merkmale
Wir definieren eine Reihe von kleinen Funktionen – z_spike, macd_div, rsi_val, combo_spike und andere – die einzelne technische Signale berechnen, z. B. Standard-Score-Spikes, MACD-Divergenz, RSI und einen kombinierten „Spike-Score“. Jeder Helfer prüft vor der Berechnung, ob genügend Daten vorhanden sind, und gibt einen Standardwert zurück, wenn die Daten nicht ausreichen. Indem wir diese Berechnungen isolieren, halten wir unsere Hauptlogik für die Aufnahme sauber und erleichtern die Einheitstests der einzelnen Indikatoren.
def z_spike(prices, win=20): if len(prices) < win: return False, 0.0 r = np.diff(prices[-win:]) z = (r[-1] - r.mean())/(r.std()+1e-6) return abs(z) > 2.5, float(z) def macd_div(prices): if len(prices) < 35: return 0.0 return float(ta.trend.macd_diff(pd.Series(prices)).iloc[-1]) def rsi_val(prices, l=14): if len(prices) < l+1: return 50.0 return float(ta.momentum.rsi(pd.Series(prices), l).iloc[-1]) def combo_spike(prices): _, z = z_spike(prices) m = macd_div(prices) v = prices[-1] - prices[-4] if len(prices) >= 4 else 0.0 s = abs(z) + abs(m) + abs(v)/(np.std(prices[-20:])+1e-6) return s > 3.0, s
CSV Append Helper & gen_row
append_rows(rows) nimmt eine Liste von 12-Element-Listen und schreibt sie in training_set.csv, wobei die Datei beim ersten Schreiben mit Kopfzeilen erstellt und danach angehängt wird. gen_row(i, closes, times, sym, highs=None, lows=None) erstellt eine einzelne Trainingszeile: Sie berechnet die Merkmale aus der Kurshistorie bis zum Index i (einschließlich ATR und Envelope-Bänder, wenn High/Low-Arrays angegeben sind), ruft prophet_delta für die Vorhersage auf und weist eine der Kennzeichnungen „BUY/SELL/WAIT“ auf der Grundlage der zukünftigen Preisbewegung zu. Durch die Trennung von Zeilengenerierung und Ingestion verwenden wir erneut gen_row sowohl bei Live- als auch bei historischen Importen.
def append_rows(rows): if not rows: return pd.DataFrame(rows, columns=CSV_HEADER)\ .to_csv(CSV_FILE, mode="a", index=False, header=not Path(CSV_FILE).exists()) def gen_row(i, closes, times, sym, highs=None, lows=None): if i < LOOKAHEAD or i+LOOKAHEAD >= len(closes): return None seq = closes[:i] _, mag = combo_spike(seq) atr = ta.volatility.average_true_range(pd.Series(highs[:i+1]), pd.Series(lows[:i+1]), pd.Series(seq)).iloc[-1] if highs else 0.0 row = [ times[i], sym, closes[i], mag, macd_div(seq), rsi_val(seq), atr, 0.0, 0.0, 0.0, prophet_delta(seq, times[:i], sym) ] ch = (closes[i+LOOKAHEAD] - closes[i]) / closes[i] row.append("BUY" if ch > THRESH_LABEL else "SELL" if ch < -THRESH_LABEL else "WAIT") return row
Schleife sammeln (Live-Daten)
In collect_loop() stellen wir sicher, dass die CSV-Datei existiert, und starten dann eine Endlosschleife, die für jedes Symbol die letzten LOOKAHEAD+1-Balken über mt5.copy_rates_from_pos anfordert, Duplikate nach Zeitstempel überspringt und gen_row aufruft, um eine neue beschriftete Beobachtung zu erstellen und anzuhängen. Ein Sleep von STEP_SECONDS erzwingt eine kontrollierte Abfragerate. Diese Live-Daten-Schleife erweitert unsere Trainingsmenge kontinuierlich um neue Beobachtungen, bis der Nutzer sie unterbricht.
def collect_loop(): if not Path(CSV_FILE).exists(): append_rows([]) last = {} print("Collecting… CTRL-C to stop") init_mt5() while True: for sym in SYMBOLS: if not ensure_symbol(sym): continue bars = mt5.copy_rates_from_pos(sym, mt5.TIMEFRAME_M1, 0, LOOKAHEAD+1) if bars is None or len(bars) < LOOKAHEAD+1: continue if last.get(sym) == bars[-1]['time']: continue last[sym] = bars[-1]['time'] closes = bars['close'].tolist() times = bars['time'].tolist() row = gen_row(len(closes)-LOOKAHEAD-1, closes, times, sym) if row: append_rows([row]) time.sleep(STEP_SECONDS)
Historie importieren (MetaTrader 5 & Datei)
history_from_mt5(sym, start, end) und history_from_file(sym, path) ermöglichen es, die CSV-Datei entweder aus der gespeicherten Historie von MetaTrader 5 oder aus einer lokalen Datei auszufüllen. Beide Funktionen durchlaufen eine Schleife durch jeden mit einem Zeitstempel versehenen Balken, rufen gen_row auf, um Merkmale und eine Beschriftung zu erzeugen, stapeln die Zeilen in Stücken (z. B. 5.000 auf einmal) und fügen sie mit append_rows an. Der Wrapper history_cli(args) analysiert Kommandozeilenargumente (--days, --from, --to oder --file), um die Aufnahme des gesamten Datensatzes für bestimmte Symbole und Datumsbereiche zu automatisieren.
def history_from_mt5(sym, start, end): init_mt5() r = mt5.copy_rates_range(sym, mt5.TIMEFRAME_M1, start.replace(tzinfo=UTC), end.replace(tzinfo=UTC)) if r is None or len(r)==0: return closes, times = r['close'].tolist(), r['time'].tolist() highs, lows = r['high'].tolist(), r['low'].tolist() rows = [gen_row(i, closes, times, sym, highs, lows) for i in range(len(closes)-LOOKAHEAD) if gen_row(i, closes, times, sym, highs, lows)] append_rows([rw for rw in rows if rw]) print(sym, "imported", len(rows), "rows")
Training der Modelle
train_models() liest training_set.csv ein, wandelt die Merkmalsspalten in numerische Werte um (wobei alle fehlerhaften Zeilen entfernt werden) und durchläuft dann die Teilmenge jedes Symbols: Wenn mindestens 400 Zeilen vorhanden sind, wird eine scikit‑learn-Pipeline erstellt (Standard-Skalierung + Gradient Boosting), an die gekennzeichneten Daten angepasst und das Modell als .pkl gespeichert. Es trainiert und speichert auch ein globales Modell für alle Symbole. Das Ergebnis ist ein Verzeichnis mit einsatzbereiten Klassifikatoren.
def build_pipe(X, y): pipe = Pipeline([ ("sc", StandardScaler()), ("gb", GradientBoostingClassifier(n_estimators=400, learning_rate=0.05, max_depth=3, random_state=42)) ]) return pipe.fit(X, y) def train_models(): df = pd.read_csv(CSV_FILE) df = df.dropna(subset=FEATURES) for sym in SYMBOLS: d = df[df.symbol == sym] if len(d) < 400: continue model = build_pipe(d[FEATURES], d.label.map({"WAIT":0,"BUY":1,"SELL":2})) joblib.dump(model, Path(MODEL_DIR)/f"{sym.replace(' ','_')}.pkl") global_model = build_pipe(df[FEATURES], df.label.map({"WAIT":0,"BUY":1,"SELL":2})) joblib.dump(global_model, GLOBAL_PKL)
Flask-Server-Endpunkte
Wir erstellen eine Flask-App mit drei primären Routen:
/upload_history parst JSON-Balkenstücke, berechnet die gleichen Merkmale wie gen_row, beschriftet jede Zeile und ruft append_rows auf.
/upload_spike_csv akzeptiert rohe EA-Protokolle (entweder CSV-Text oder JSON-Arrays), überträgt sie in unser 12-Spalten-Format und hängt sie an.
/analyze lädt das entsprechende Modell über load_model(), berechnet Live-Merkmale aus geposteten Kursen und Zeitstempeln, prognostiziert Klassenwahrscheinlichkeiten, wendet Open/Close-Schwellenwerte an und gibt ein JSON-Objekt zurück, das das Signal, die Konfidenz, SL/TP und die Positionsstärke enthält.
app = Flask(__name__) app.config["MAX_CONTENT_LENGTH"] = 32*1024*1024 @app.route("/upload_history", methods=["POST"]) def upload_history(): j = request.get_json(force=True) close, ts = np.array(j["close"]), np.array(j["time"],dtype=int) high = np.array(j.get("high", close)) low = np.array(j.get("low", close)) df = pd.DataFrame({"timestamp": ts, "price": close}) # compute features as in gen_row… append_rows(df.assign(symbol=j["symbol"]).values.tolist()) return jsonify(status="ok", rows_written=len(df)) @app.route("/upload_spike_csv", methods=["POST"]) def upload_spike_csv(): j = request.get_json(force=True) df_ea = pd.read_csv(io.StringIO(j.get("csv","")), sep=",") # map EA columns → CSV_HEADER append_rows(mapped_rows) return jsonify(status="ok", rows_written=len(mapped_rows)) @app.route("/analyze", methods=["POST"]) def api_analyze(): j = request.get_json(force=True) mdl = load_model(j["symbol"]) feats = [...] # compute from j["prices"], j["timestamps"] proba = mdl.predict_proba([feats])[0] signal = decide_open(proba[1], proba[2], j["symbol"]) # build sl, tp, manage _trades… return jsonify(signal=signal, sl=sl, tp=tp, strength=max(proba))
Diese Endpunkte ermöglichen Ingestion, Backfill und Entscheidungsfindung in Echtzeit für den MQL5 EA.
Backtest & Info Utilities
backtest_one(sym, df) verwendet die Offline-Feature-Helfer und die Modellinferenzlogik, um Handelsgeschäfte über den historischen DataFrame df zu simulieren und die P&L aufzuzeichnen, wenn Stop-Loss-, Take-Profit- oder Early-Close-Bedingungen erfüllt sind. backtest_cli(args) aggregiert die Ergebnisse über alle Symbole und druckt eine Zusammenfassung der P&L. Die Funktion info() meldet einfach die Anzahl der CSV-Zeilen, die Verteilungen der Bezeichnungen und die Anzahl der Merkmale jedes Modells – praktisch für eine schnelle Überprüfung des Datenzustands.
def backtest_one(sym, df): mdl = load_model(sym) for i in range(len(df)): feats = [...] # offline feature calcs pr = mdl.predict_proba([feats])[0] # open/close logic identical to /analyze return trades def info(): df = pd.read_csv(CSV_FILE) print("Rows:", len(df), "Labels:", df.label.value_counts()) for pkl in Path(MODEL_DIR).glob("*.pkl"): mdl = joblib.load(pkl) print(pkl.name, "features", mdl.named_steps["sc"].n_features_in_)
Befehlszeilenschnittstelle
Schließlich definiert der Block if __name__ == "__main__": eine „argparse-CLI“ mit sechs Unterbefehlen – collect, history, train, backtest, serve und info – die jeweils die entsprechende Funktion aufrufen. Dieses Muster liefert ein einziges, zusammenhängendes Skript, in dem Sie zum Beispiel python engine.py history --days 180 ausführen können, um sechs Monate an Daten zurückzufüllen, oder python engine.py serve, um die Live-API für Ihren EA zu starten.
if __name__ == "__main__": parser = argparse.ArgumentParser() subs = parser.add_subparsers(dest="mode", required=True) subs.add_parser("collect") subs.add_parser("history") subs.add_parser("train") subs.add_parser("backtest") subs.add_parser("serve") subs.add_parser("info") args = parser.parse_args() if args.mode == "collect": init_mt5(); collect_loop() elif args.mode == "history": history_cli(args) elif args.mode == "train": train_models() elif args.mode == "backtest": backtest_cli(args) elif args.mode == "serve": init_mt5(); app.run("0.0.0.0", 5000, threaded=True) elif args.mode == "info": info()
Modelltraining in Python
Da wir nun genügend historische Daten in unserer CSV-Datei gesammelt haben (die über unsere MQL5-Historienabfrage-Routine und den Python-Empfänger gefüllt wurde), ist der nächste Schritt das Modelltraining. Stellen Sie sicher, dass wir Daten für alle in unseren MQL5- und Python-Skripten definierten Symbole aufgenommen haben. Sobald die Einnahme abgeschlossen ist, können wir fortfahren:- Trainieren der Machine-Learning-Modelle
- Backtesting ihrer Leistung über einen historischen Zeitraum
- Einsatz der resultierenden Modelle für Live-Inferenz
In diesem Schritt trainieren wir einen Gradient-Boosting-Klassifikator für jedes Symbol (und ein globales Modell), um vorherzusagen, ob der Preis nach unserem Vorausschauzeitraum BUY, SELL, oder WAIT wird. Gradient Boosting baut nacheinander ein Ensemble von Entscheidungsbäumen auf, wobei jeder neue Baum die Fehler der vorangegangenen korrigiert. Dadurch ist es robust gegenüber verrauschten Finanzdaten und in der Lage, nichtlineare Muster in unserer Merkmalsgruppe zu erfassen. Wir verpacken es in eine scikit‑learn-Pipeline mit einem StandardScaler zur Normalisierung der Merkmale vor dem Training.
# 3) TRAIN MODELS def build_pipe(X, y): """ Construct and fit a pipeline: StandardScaler → GradientBoostingClassifier. """ pipe = Pipeline([ ("sc", StandardScaler()), ("gb", GradientBoostingClassifier( n_estimators=400, # number of boosting rounds learning_rate=0.05, # shrinkage factor per tree max_depth=3, # depth of each tree random_state=42 # reproducibility )) ]) pipe.fit(X, y) return pipe def train_models(): """ Load the CSV, clean it, train per-symbol and global Gradient Boosting models, and save to disk. """ if not Path(CSV_FILE).exists(): sys.exit("No training_set.csv") # Read and sanitize df = pd.read_csv(CSV_FILE) if "symbol" not in df.columns: sys.exit("CSV missing 'symbol' column") # Ensure numeric features for col in FEATURES: df[col] = pd.to_numeric(df[col], errors="coerce") bad = df[FEATURES].isna().any(axis=1).sum() if bad: print(f"Discarding {bad} malformed rows") df = df.dropna(subset=FEATURES) # Train a Gradient Boosting model for each symbol for sym in SYMBOLS: d = df[df.symbol == sym] if len(d) < 400: print("Skip", sym, "(few rows)") continue model = build_pipe( d[FEATURES], d.label.map({"WAIT": 0, "BUY": 1, "SELL": 2}) ) joblib.dump(model, Path(MODEL_DIR) / f"{sym.replace(' ', '_')}.pkl") print("model", sym, "saved") # Train and save a global Gradient Boosting model global_model = build_pipe( df[FEATURES], df.label.map({"WAIT": 0, "BUY": 1, "SELL": 2}) ) joblib.dump(global_model, GLOBAL_PKL) print("global model saved")Rufen wir auch das Training auf:
python engine.py trainNach dem Aufrufen unserer Trainingsroutine haben wir diese Konsolenausgabe beobachtet:
C:\Users\hp\Pictures\Saved Pictures\Analysis EA>python engine.py train Discarding 1152650 malformed rows model Boom 900 Index saved model Boom 1000 Index saved model Boom 500 Index saved model Crash 500 Index saved model Boom 300 Index saved .................................... .................................... All models saved
Sobald das Training abgeschlossen ist und alle Modelle gespeichert wurden – was angesichts der Datenmenge eine Weile dauern kann – sind wir bereit für die nächsten Schritte. Wir können die neu trainierten Modelle entweder anhand historischer Daten einem Backtest unterziehen oder direkt mit dem Einsatz beginnen. In meinem Fall bin ich direkt zur Modellbereitstellung übergegangen, die ich im nächsten Abschnitt behandeln werde.
Modellbereitstellung und Echtzeit-Interferenz
Um den Trainingsprozess zu beenden, muss nur Strg+C. Dann starten Sie den Echtzeit-Inferenzserver mit:python engine.py serve
Dieser Befehl setzt die trainierten Modelle ein und beginnt mit der Ausgabe von Live-Handelssignalen.
In MetaTrader 5 fügen Sie den Expert Advisor jedem Symbol zu, für das Sie ein Modell trainiert haben. Dann, in MetaTrader 5 Extras → Optionen → Expert Advisors aktivieren Sie WebRequest zulassen für die aufgelistete URL, und fügen Sie die Adresse Ihres Servers zur Whitelist hinzu.
Der HTTP-Statuscode 200 bedeutet „OK“ – die Anfrage wurde empfangen, verstanden und erfolgreich verarbeitet.
Während unserer Live-Server-Tests erreichte jede EA-Instanz erfolgreich das Python-Backend (HTTP 200) und gab ihre Handelsempfehlung in weniger als 50 ms zurück. Das sagen uns die Protokolle:
Crash 1000 Index (M1)
Um 00:31:59.717 Uhr meldete das Modell eine KAUF-Wahrscheinlichkeit von 0 % und eine VERKAUFS-Wahrscheinlichkeit von 2,6 %, was eine kombinierte Konfidenz (Stärke) von nur 3 % ergibt. Da keiner der beiden Schwellenwerte überschritten wurde, entschied sich der EA korrekt für das WAIT-Signal.
Boom 1000 Index (M1)
Nur 37 ms später (um 00:31:59.754) ergab das Modell dieses Symbols eine KAUF-Wahrscheinlichkeit von 99,4 % und einen VERKAUF von 0 %. Dieses hohe Vertrauen löste sofort ein OPEN BUY-Signal aus.
Diese Protokolle bestätigen, dass unsere Bereitstellungs-Pipeline durchgängig funktioniert.
2025.07.30 00:31:59.717 Spike DETECTOR (Crash 1000 Index,M1) [SpikeEA] <<< HTTP 200 – {"Pbuy":0.0,"Psell":0.026,"scale_in":null ,"side":"NONE","signal":"WAIT","strength":0.03 2025.07.30 00:31:59.754 Spike DETECTOR (Boom 1000 Index,M1) [SpikeEA] <<< HTTP 200 – {"Pbuy":0.994,"Psell":0.0,"scale_in":null ,"side":"BUY","signal":"OPEN" , "strength":0.99
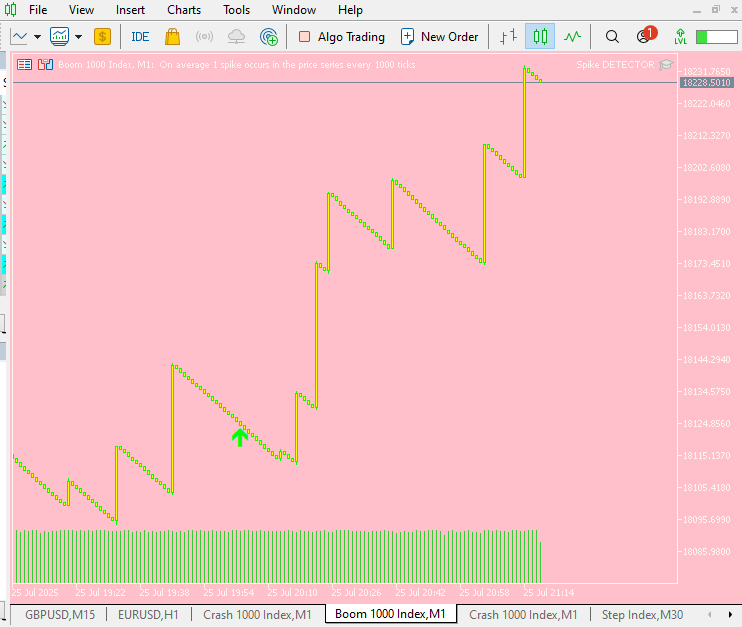
Hier ist ein früherer Testlauf des Systems. Gelegentlich signalisiert der EA einen Einstieg – diese „OPEN“-Anweisungen erscheinen in den Protokollen des MetaTrader 5, obwohl kein Pfeil auf dem Chart angezeigt wird. Ob eine visuelle Markierung erscheint, hängt von der Stärke des Signals ab.
MetaTrader 5 Protokolle
2025.07.25 19:55:01.445 Spike DETECTOR (Boom 1000 Index,M1) [SpikeEA] <<< HTTP 200 – {"Pbuy":0.999,"Psell":0.0,"scale_in":null ,"side":"BUY","signal":"OPEN","strength":1.0
MetaTrader 5 Chart
Schlussfolgerung
Durch die Verbindung von MQL5 und Python haben wir einen leistungsstarken, flexiblen Handelsrahmen geschaffen, der das Beste aus beiden Welten nutzt. Auf der MQL5-Seite erfasst unser EA nahtlos Spikes, MACD-Divergenz, RSI, ATR, Kalman-gefilterte Steigungen und Prophet-Deltas und leitet diese Metriken dann direkt in Python weiter. Auf der Python-Seite übernimmt ein einziges engine.py-Skript (mit den Befehlen collect, history, train, backtest, serve) die schwere Arbeit des Modelltrainings und des Live-Serving. In unserem Setup stützten wir uns auf den EA von MQL5, um alle erforderlichen Merkmalsdaten zu liefern, sodass wir ihn nur einmal ausführen mussten:
python engine.py train python engine.py serve
Wir überspringen „collect“ und „history“, weil unser EA bereits den gesamten Datensatz für uns verwaltet und bereitstellt.
Das Ergebnis? Unsere Gradient-Boosting-Modelle liefern innerhalb weniger Augenblicke nach dem Aufschlagen von Serve Echtzeit-Kauf-/Verkaufs-/WAIT-Signale in weniger als 50 ms pro Balken an den MetaTrader 5 zurück – bereit, von der Auftragslogik unseres EAs verarbeitet zu werden. Egal, ob Sie gerade erst mit der reichhaltigen Bibliothek der MQL5-Website und den Community-Beispielen beginnen oder ob Sie ein erfahrener Quant sind, der neue Feature-Generatoren oder Algorithmen einfügen möchte, diese End-to-End-Pipeline lässt sich mühelos über Symbole und Strategien hinweg skalieren.
Vielen Dank an die MQL5-Gemeinschaft und die Fülle an Codebeispielen und Foreneinblicken, die auf mql5.com zur Verfügung stehen, Ihre Ressourcen haben diese Integration unkompliziert gemacht. Ich möchte jeden ermutigen, weiter zu forschen: Hyperparameter zu optimieren, neue Indikatoren hinzuzufügen oder sogar Ihren Python-Server für die Produktion zu containerisieren. Am wichtigsten ist jedoch, dass Sie Ihre Erkenntnisse mit der Community teilen, damit wir alle gemeinsam den datengesteuerten algorithmischen Handel weiter vorantreiben können.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/18985
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.


- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.