
Von der Grundstufe bis zur Mittelstufe: Vererbung

Einführung
Im vorigen Artikel, „Von der Grundstufe bis zur Mittelstufe: Struktur (VII)“ haben wir mit einem strukturierten Programm gearbeitet, das zwar auf den ersten Blick recht komplex erscheint, sich aber letztendlich als sehr spannend und interessant erweist. Ich weiß das, weil es mir zu Beginn meiner Reise sehr schwer fiel, zu verstehen, warum manche Codes funktionieren und andere nicht. Nach vielen Jahren des Kampfes und der Beharrlichkeit habe ich schließlich die Konzepte verstanden, die ich Ihnen in diesen Artikeln zu vermitteln versuche. Viele Menschen glauben, dass man Programmieren lernen kann, indem man einen Kurs besucht oder einfach den Code anderer Programmierer studiert.
Um das Programmieren wirklich zu lernen, ist jedoch leider Übung erforderlich. Und erst nach einiger Zeit, wenn man ein Problem nach dem anderen gelöst hat, wird man ein guter Fachmann. Aber, ich wiederhole, das braucht Zeit. Aber wenn ich den Prozess ein wenig beschleunigen kann, warum sollte ich dieses Wissen nicht mit denen teilen, die wirklich lernen wollen? Nun, wir sind an einem entscheidenden Punkt angelangt.
Hier werden die Dinge noch interessanter. Es ist sehr wichtig, eine solide Grundlage zu schaffen und alles zu verstehen, was in den vorangegangenen Artikeln erläutert wurde. Wenn Sie das, was Sie zuvor gesehen haben, nicht studiert und in die Praxis umgesetzt haben, wird es Ihnen sehr schwer fallen, diesem und den folgenden Artikeln zu folgen.
Einfache Vererbung
Eines der häufigsten Missverständnisse ist, dass Vererbung nur im Klassencode oder, wie es oft genannt wird, in der objektorientierten Programmierung existiert. Was also ist Vererbung? Einfach ausgedrückt handelt es sich um die Erstellung eines einfachen Datentyps und, darauf aufbauend, die Erstellung anderer, komplexerer Datentypen, ohne dass Elemente, Funktionen und Prozeduren erstellt werden müssen, die bereits in diesem einfacheren Datentyp implementiert waren.
Zum besseren Verständnis sollten wir uns Folgendes vor Augen führen: In der Natur gibt es viele Arten von Tieren, Pflanzen und Mineralien. Nehmen wir an, wir müssen einen Code erstellen, um alle Eingabedaten nach den in der Natur vorkommenden Kategorien zu ordnen, die wir in diesem Fall als Tiere, Pflanzen und Mineralien bezeichnen werden. Wie würden Sie dies tun? Höchstwahrscheinlich müssten Sie drei verschiedene Strukturen erstellen, um die Eingabedaten in einen dieser drei vordefinierten Typen zu unterteilen.
Wenn Sie solche Strukturen erstellen, werden Sie feststellen, dass Sie durch die Einhaltung eines vollständig strukturierten Programmierstils den Code leichter manipulieren und verstehen können. Dies wurde bereits in früheren Artikeln erwähnt. Tiere und Pflanzen haben jedoch etwas gemeinsam. Beide sind lebende Organismen, im Gegensatz zu Mineralien. Daher haben Pflanzen und Tiere die gleichen Strukturelemente.
Diese Elemente können entfernt und in ein neues Hauptkonstrukt eingefügt werden. Auf diese Weise haben wir etwas mit den Lebewesen gemeinsam, was eine Verdoppelung des Codes innerhalb der Datenstruktur selbst vermeidet und ihre künftige Wartung, Implementierung und Verbesserung vereinfacht.
In der Regel erfordert der meiste Code, der auf die Arbeit auf dem Finanzmarkt ausgerichtet ist und für den MetaTrader 5 und folglich MQL5 verwendet wird, nicht die Abstraktionsebene, die ich in diesem Artikel vorstelle. Für unsere Zwecke ist es auch nicht notwendig, strukturierte oder objektorientierte Programmierung zu verwenden.
Aufgrund der Natur der Programmierung und der Arten von Problemen, denen wir begegnen können, ist es jedoch äußerst nützlich und notwendig, dass Sie die Mechanismen und Konzepte verstehen, die ich hier vorstelle. Es geht nicht darum, dass Sie sie brauchen, sondern darum, dass Sie, um mit weniger Aufwand arbeiten zu können, verstehen müssen, wie bestimmte Dinge funktionieren. Um unsere Ziele zu erreichen, wird das Verständnis dieser Konzepte trotz ihrer scheinbaren Komplexität in Zukunft alles wesentlich vereinfachen.
Ich wiederhole: Um einen Expert Advisor oder einen Indikator zu erstellen, ist es nicht notwendig, die strukturierte Programmierung zu verstehen, da dies mithilfe der traditionellen Programmierung erfolgen kann. Wenn Sie an meinen Worten zweifeln, können Sie meinen ersten Artikel lesen: „Entwicklung eines Trading Expert Advisors von Grund auf“. Darin haben wir untersucht, wie man einen einfachen Expert Advisor erstellen kann, der es ermöglicht, Aufträge direkt an den Chart zu senden, ohne strukturierte oder objektorientierte Programmiertechniken zu verwenden.
Das Gleiche gilt für Indikatoren. In dem Artikel „Von der Grundstufe bis zur Mittelstufe: Indikator (IV)“ haben wir gezeigt, wie man einen Indikator im Chart anzeigt. All dies ist einfach und erfordert keine besonderen Kenntnisse. Um die gewünschte Anwendung zu erstellen, brauchen Sie nur gesunden Menschenverstand und ein Verständnis der MQL5-Dokumentation.
Sobald die Unterscheidung zwischen dem, was man wissen muss, um Dinge zu schaffen, und dem, was man nicht unbedingt wissen muss, getroffen ist, können wir zu unserem hypothetischen Beispiel zurückkehren. Da wir wissen, dass es gemeinsame Elemente zwischen lebenden und nicht lebenden Objekten gibt, können wir sie logisch und konsequent voneinander trennen, sowohl was die Umsetzung als auch was die Benutzerfreundlichkeit und die Wartung von Funktionen und Verfahren betrifft.
Um dies zu verdeutlichen, wollen wir uns einem der im vorigen Artikel besprochenen Codes zuwenden. Ein ähnliches Ergebnis ist unten zu sehen.
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. struct st_Reg 005. { 006. //+----------------+ 007. private: 008. //+----------------+ 009. string h_value; 010. uint k_value; 011. //+----------------+ 012. public: 013. //+----------------+ 014. void Set(const uint arg1, const string arg2) 015. { 016. k_value = arg1; 017. h_value = arg2; 018. } 019. //+----------------+ 020. uint Get_K(void) { return k_value; } 021. //+----------------+ 022. string Get_H(void) { return h_value; } 023. //+----------------+ 024. }; 025. //+------------------------------------------------------------------+ 026. struct st_Bio 027. { 028. //+----------------+ 029. private: 030. //+----------------+ 031. string h_value; 032. string b_value; 033. uint k_value; 034. //+----------------+ 035. public: 036. //+----------------+ 037. void Set(const uint arg1, const string arg2, const string arg3) 038. { 039. k_value = arg1; 040. h_value = arg2; 041. b_value = arg3; 042. } 043. //+----------------+ 044. uint Get_K(void) { return k_value; } 045. //+----------------+ 046. bool Get_Bio(string &arg1, string &arg2) 047. { 048. arg1 = h_value; 049. arg2 = b_value; 050. 051. return true; 052. } 053. //+----------------+ 054. }; 055. //+------------------------------------------------------------------+ 056. template <typename T> 057. struct st_Data 058. { 059. //+----------------+ 060. private: 061. //+----------------+ 062. T Values[]; 063. //+----------------+ 064. public: 065. //+----------------+ 066. bool Set(const T &arg) 067. { 068. if (ArrayResize(Values, Values.Size() + (Values.Size() == 0 ? 2 : 1)) == INVALID_HANDLE) 069. return false; 070. 071. Values[Values.Size() - 1] = arg; 072. 073. return true; 074. } 075. //+----------------+ 076. T Get(const uint index) 077. { 078. for (uint c = 0; c < Values.Size(); c++) 079. if (Values[c].Get_K() == index) 080. return Values[c]; 081. 082. return Values[0]; 083. } 084. //+----------------+ 085. }; 086. //+------------------------------------------------------------------+ 087. #define PrintX(X) Print(#X, " => [", X, "]") 088. //+------------------------------------------------------------------+ 089. void CheckBio(st_Data <st_Bio> &arg) 090. { 091. string sz[2]; 092. 093. Print("Checking data in the structure..."); 094. for (uint i = 7; i < 11; i += 3) 095. { 096. Print("Index: ", i, " Result: "); 097. if (arg.Get(i).Get_Bio(sz[0], sz[1])) 098. ArrayPrint(sz); 099. else 100. Print("Failed."); 101. } 102. } 103. //+------------------------------------------------------------------+ 104. void OnStart(void) 105. { 106. const string T = "possible loss of data due to type conversion"; 107. const string M[] = {"2", "cool", "4", "zero", "mad", "five", "what", "xoxo"}; 108. const uint K[] = {2, 1, 4, 0, 7, 5, 3, 6}; 109. 110. st_Data <st_Reg> Info_1; 111. st_Data <st_Bio> Info_2; 112. 113. string H[]; 114. 115. StringSplit(T, ' ', H); 116. for (uint c = 0; c < H.Size(); c++) 117. { 118. st_Reg reg; 119. st_Bio bio; 120. 121. reg.Set(K[c], H[c]); 122. bio.Set(K[c], M[c], H[c]); 123. 124. Info_1.Set(reg); 125. Info_2.Set(bio); 126. } 127. 128. PrintX(Info_1.Get(3).Get_H()); 129. PrintX(Info_1.Get(13).Get_H()); 130. CheckBio(Info_2); 131. } 132. //+------------------------------------------------------------------+
Code 01
Wenn wir Code 01 ausführen, erhalten wir das in der folgenden Abbildung gezeigte Ergebnis.
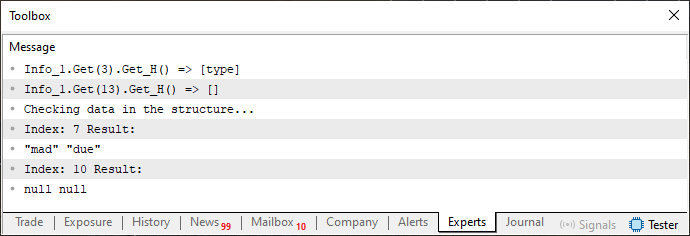
Abbildung 01
Kommen wir nun zum Kern der Sache. So wie Tiere und Pflanzen gemeinsame Elemente haben, ist k_value in Code 01 ein gemeinsames Element für st_Reg und st_Bio. Diese Strukturen interagieren jedoch nicht miteinander und sind völlig unterschiedlich. Dies wird im Folgenden visuell dargestellt.
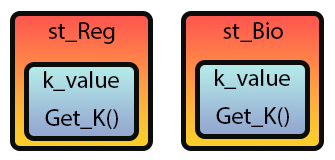
Abbildung 02
Mit anderen Worten: Es handelt sich um zwei unterschiedliche Einheiten, die jedoch gemeinsame Merkmale aufweisen. Eine solche Code-Duplizierung tritt auf, wenn mehrere Strukturen Elemente teilen, auf die auf die gleiche Weise zugegriffen wird und die auf die gleiche Weise gehandhabt werden, da in diesem Fall keine Notwendigkeit bestünde, sie zu trennen. Dies verkompliziert den Code nur auf völlig unnötige Weise.
Um dies zu verdeutlichen, stellen Sie sich vor, dass Sie aus irgendeinem Grund beschließen, die in der Struktur st_Reg vorhandene Funktion Get_K zu verbessern. Sie stellen also fest, dass sich der allgemeine Code erheblich verbessert hat, aber Sie tun nicht dasselbe in st_Bio. Wenn Sie beide Strukturen gleichzeitig verwenden, werden Sie feststellen, dass sich st_Bio trotz der Verwendung von Get_K anders verhält als st_Reg.
Und genau hier beginnen die Probleme. Der in der Struktur st_Reg vorhandene Code Get_K wird in die Struktur st_Bio kopiert, und nach einiger Zeit muss der Code Get_K erneut geändert werden, was bedeutet, dass dieser Vorgang an beiden Strukturen durchgeführt werden muss.
Abgesehen davon, dass dies eine enorme Zeitverschwendung ist, erschweren solche Aktionen die Verbesserung des Codes. Und wir verwenden hier nur zwei Strukturen. In echtem Code kann es Dutzende oder sogar Hunderte von Strukturen geben, die etwas gemeinsam haben. Können Sie sich vorstellen, wie es wäre, einen solchen Code zu debuggen und zu pflegen? Ein Albtraum. Es gibt jedoch eine einfache Möglichkeit, all diese Arbeit zu vereinfachen. Diese Methode ist genau die Verwendung der Vererbung.
Bei der Vererbung wird dieser gemeinsame Teil einfach aus den beiden Strukturen herausgenommen und in eine andere Struktur eingefügt. Dann muss man irgendwie dafür sorgen, dass die Struktur den Code, den sie erbt, verwenden kann. Ich verstehe, dass dies kompliziert erscheint. Aber in der Praxis werden Sie sehen, dass es viel einfacher ist, als Sie es sich vorstellen.
Wenden wir dies nun in der Praxis an, indem wir im Code 01 die Vererbung nutzen. Der erste Schritt, um unser Ziel zu erreichen, ist in dem nachstehenden Codeschnipsel dargestellt.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Base 05. { 06. private: 07. uint KeyValue; 08. public: 09. //+----------------+ 10. void SetKey(const uint arg) { KeyValue = arg; } 11. //+----------------+ 12. uint GetKey(void) { return KeyValue; } 13. }; 14. //+------------------------------------------------------------------+ 15. struct st_Reg 16. { 17. private: 18. string Value; 19. public: 20. //+----------------+ 21. void SetValue(const uint arg1, const string arg2) 22. { 23. Value = arg2; 24. } 25. //+----------------+ 26. string GetValue(void) { return Value; } 27. }; 28. //+------------------------------------------------------------------+ 29. struct st_Bio 30. { 31. private: 32. string Value[2]; 33. public: 34. //+----------------+ 35. void SetValue(const uint arg1, const string arg2, const string arg3) 36. { 37. Value[0] = arg2; 38. Value[1] = arg3; 39. } 40. //+----------------+ 41. bool GetValue(string &arg1, string &arg2) 42. { 43. arg1 = Value[0]; 44. arg2 = Value[1]; 45. 46. return true; 47. } 48. //+----------------+ 49. }; 50. //+------------------------------------------------------------------+ . . .
Code 02
Im Codeschnipsel von Code 02 sehen wir, dass eine neue Struktur angelegt wurde. Sie wird st_Base genannt. Und jetzt aufgepasst. Obwohl wir die Organisation der Variablen in diesem Ausschnitt (Code 02) verbessert haben, enthält er immer noch die gleiche Anzahl und Art von Variablen wie Code 01. Sie ist jedoch besser organisiert. Aber das Wichtigste ist hier im Wesentlichen die Struktur st_Base. Das führt zu folgendem Ergebnis.
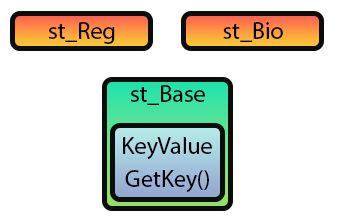
Abbildung 03
Bitte beachten Sie, dass sie der Abbildung 02 sehr ähnlich ist. In Abbildung 03 wird jedoch keine Vererbung verwendet. Das liegt daran, dass auch Codeschnipsel 02 keine Vererbung verwendet wird. Wenn wir also versuchen, Code 01 unter Verwendung von Codeschnipsel 02 zu kompilieren, wird der Compiler mehrere Fehler erzeugen. Um dies zu beheben, müssen wir Bild 03 in Bild 04 umwandeln, wie unten gezeigt.
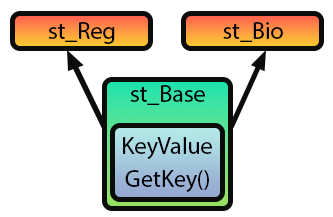
Abbildung 04
In Abbildung 04 zeigen die Pfeile an, wie die Vererbung umgesetzt wird. Mit anderen Worten, wir werden den Inhalt der Struktur st_Base in die Strukturen st_Bio und st_Reg aufnehmen, ohne den Code wesentlich zu ändern. Dazu ändern wir einfach den Code 02 in den unten stehenden Code.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Base 05. { 06. private: 07. uint KeyValue; 08. public: 09. //+----------------+ 10. void SetKey(const uint arg) { KeyValue = arg; } 11. //+----------------+ 12. uint GetKey(void) { return KeyValue; } 13. }; 14. //+------------------------------------------------------------------+ 15. struct st_Reg : public st_Base 16. { 17. private: 18. string Value; 19. public: 20. //+----------------+ 21. void SetValue(const uint arg1, const string arg2) 22. { 23. Value = arg2; 24. } 25. //+----------------+ 26. string GetValue(void) { return Value; } 27. }; 28. //+------------------------------------------------------------------+ 29. struct st_Bio : public st_Base 30. { 31. private: 32. string Value[2]; 33. public: 34. //+----------------+ 35. void SetValue(const uint arg1, const string arg2, const string arg3) 36. { 37. Value[0] = arg2; 38. Value[1] = arg3; 39. } 40. //+----------------+ 41. bool GetValue(string &arg1, string &arg2) 42. { 43. arg1 = Value[0]; 44. arg2 = Value[1]; 45. 46. return true; 47. } 48. //+----------------+ 49. }; 50. //+------------------------------------------------------------------+ . . .
Code 03
Sehen Sie sich an, wie schwierig es war, die Vererbung in den Code zu implementieren. Wie in Code-Snippet 03 zu sehen ist, gibt es jedoch Verweise auf Werte, die noch nicht aufgelöst wurden. Das liegt daran, dass wir in diesem Schnipsel nur die Vererbung implementiert haben. In der Praxis verwenden wir sie noch nicht in einer Weise, die die KeyValue-Informationen anwendet. Unser Ziel ist es, st_Data zu ermöglichen, eine Verbindung zwischen den Daten herzustellen, um das zu konstruieren, was in Abbildung 01 zu sehen ist.
Um diese Probleme zu lösen, müssen wir den Code erneut ändern. Das Ergebnis sieht dann so aus:
001. //+------------------------------------------------------------------+ 002. #property copyright "Daniel Jose" 003. //+------------------------------------------------------------------+ 004. struct st_Base 005. { 006. private: 007. uint KeyValue; 008. public: 009. //+----------------+ 010. void SetKey(const uint arg) { KeyValue = arg; } 011. //+----------------+ 012. uint GetKey(void) { return KeyValue; } 013. }; 014. //+------------------------------------------------------------------+ 015. struct st_Reg : public st_Base 016. { 017. private: 018. string Value; 019. public: 020. //+----------------+ 021. void SetValue(const uint arg1, const string arg2) 022. { 023. SetKey(arg1); 024. Value = arg2; 025. } 026. //+----------------+ 027. string GetValue(void) { return Value; } 028. }; 029. //+------------------------------------------------------------------+ 030. struct st_Bio : public st_Base 031. { 032. private: 033. string Value[2]; 034. public: 035. //+----------------+ 036. void SetValue(const uint arg1, const string arg2, const string arg3) 037. { 038. SetKey(arg1); 039. Value[0] = arg2; 040. Value[1] = arg3; 041. } 042. //+----------------+ 043. bool GetValue(string &arg1, string &arg2) 044. { 045. arg1 = Value[0]; 046. arg2 = Value[1]; 047. 048. return true; 049. } 050. //+----------------+ 051. }; 052. //+------------------------------------------------------------------+ 053. template <typename T> 054. struct st_Data 055. { 056. private: 057. T Values[]; 058. public: 059. //+----------------+ 060. bool Set(const T &arg) 061. { 062. if (ArrayResize(Values, Values.Size() + (Values.Size() == 0 ? 2 : 1)) == INVALID_HANDLE) 063. return false; 064. 065. Values[Values.Size() - 1] = arg; 066. 067. return true; 068. } 069. //+----------------+ 070. T Get(const uint index) 071. { 072. for (uint c = 0; c < Values.Size(); c++) 073. if (Values[c].GetKey() == index) 074. return Values[c]; 075. 076. return Values[0]; 077. } 078. }; 079. //+------------------------------------------------------------------+ 080. #define PrintX(X) Print(#X, " => [", X, "]") 081. //+------------------------------------------------------------------+ 082. void CheckBio(st_Data <st_Bio> &arg) 083. { 084. string sz[2]; 085. 086. Print("Checking data in the structure..."); 087. for (uint i = 7; i < 11; i += 3) 088. { 089. Print("Index: ", i, " Result: "); 090. if (arg.Get(i).GetValue(sz[0], sz[1])) 091. ArrayPrint(sz); 092. else 093. Print("Failed."); 094. } 095. } 096. //+------------------------------------------------------------------+ 097. void OnStart(void) 098. { 099. const string T = "possible loss of data due to type conversion"; 100. const string M[] = {"2", "cool", "4", "zero", "mad", "five", "what", "xoxo"}; 101. const uint K[] = {2, 1, 4, 0, 7, 5, 3, 6}; 102. 103. st_Data <st_Reg> Info_1; 104. st_Data <st_Bio> Info_2; 105. 106. string H[]; 107. 108. StringSplit(T, ' ', H); 109. for (uint c = 0; c < H.Size(); c++) 110. { 111. st_Reg reg; 112. st_Bio bio; 113. 114. reg.SetValue(K[c], H[c]); 115. bio.SetValue(K[c], M[c], H[c]); 116. 117. Info_1.Set(reg); 118. Info_2.Set(bio); 119. } 120. 121. PrintX(Info_1.Get(3).GetValue()); 122. PrintX(Info_1.Get(13).GetValue()); 123. CheckBio(Info_2); 124. } 125. //+------------------------------------------------------------------+
Code 04
Code 04 hat die gleiche Wirkung wie Code 01. In Code 04 verwenden wir jedoch die Vererbung zwischen Strukturen. Jede Verbesserung, die wir an der st_Base-Struktur vornehmen, wirkt sich also automatisch auf den gesamten Code aus. Mit anderen Worten: Jede noch so kleine Änderung, die an der Struktur st_Base vorgenommen wird, ist automatisch auch für st_Reg und st_Bio verfügbar.
Voraussetzung ist natürlich, dass die Prozedur, Funktion oder Variable im öffentlichen Teil des Codes enthalten ist. Dies gilt natürlich nur für Mitglieder, die über die öffentliche Schnittstelle zugänglich sind. Wenn ein Mitglied in stBase nicht öffentlich zugänglich ist, dann können stReg und stBio es nicht direkt verwenden.
Ein Punkt, den wir in Code 04 nicht erwähnt haben, der aber wichtig sein könnte, ist, dass in den Zeilen 15 und 30 die Vererbung öffentlich erfolgt. Dadurch kann jede Variable eines der beiden Strukturtypen, die auf die öffentlichen Mitglieder von st_Base zugreift, auch auf jedes öffentliche Element der Struktur st_Base zugreifen. Hätten wir anstelle des reservierten Wortes public in diesen Zeilen das Wort private verwendet, dann hätte jede Variable, die diese Struktur verwendet, ob st_Bio oder st_Reg, keinen Zugriff auf den Inhalt der Struktur st_Base. Ich schlage vor, dass Sie dies später mit der Datei im Anhang ausprobieren, um es besser zu verstehen.
Da das Hauptthema dieses Artikels die Vererbung ist, lassen Sie uns ein wenig mit diesem Thema „spielen“, aber in einer etwas unterhaltsameren Form. Zu diesem Zweck werden wir uns einem neuen Thema zuwenden. Ich möchte nicht, dass Sie sich erschrecken und denken, dass ich Ihnen etwas zeige, was nur einem hochqualifizierten Spezialisten möglich ist. Das ist in der Tat nicht der Fall. Jeder von Ihnen, der diese Artikelserie studiert und verfolgt, kann etwas Ähnliches tun.
Dazu ist es jedoch notwendig, bestimmte Konzepte anzuwenden, die in früheren Artikeln vorgestellt wurden. Lassen Sie uns nun mit unserer Pyjamaparty weitermachen, denn der Spaß fängt gerade erst an.
Strukturen, Vorlagen und Vererbung: eine wilde Kombination
Viele sind sich der Möglichkeiten von MQL5 nicht bewusst, auch wenn es nicht alle Funktionen von C und C++ besitzt. Das liegt daran, dass die Programmierung in MQL5 im Vergleich zu C und C++ wesentlich einfacher ist. Wenn es in diesen Artikeln um C und C++ ginge, hätten viele von Ihnen sicher schon längst aufgegeben. Da wir uns hier aber nur auf die Programmierung in MQL5 konzentrieren werden, werden die Artikel meist aus sehr einfachen Dingen bestehen. Da sie jedoch wenig erforscht sind, bekommen sie einen fast mystischen Charakter.
Ein solcher Faktor ist die Kombination aus allem, was wir bisher beobachtet haben. Mit anderen Worten: Können wir strukturierte Programmierung mit der Fähigkeit kombinieren, Strukturen mit Vorlagen und Vererbung in einem einzigen Code zu kombinieren? Ja, lieber Leser. Und obwohl dieses Material komplex erscheinen mag, ist es für mich immer noch recht einfach, nur etwas komplexer als alles, was ich bisher gezeigt habe.
Wenn Sie jedoch die Konzepte, die wir behandelt haben, studieren und darüber nachdenken, werden Sie irgendwann darüber nachdenken, wie Sie all dies zu wirklich interessantem Code kombinieren können, denn wir können nutzen, was für viele das Schreiben einer großen Menge an Code erfordern würde. Wir werden dies jedoch mit sehr einfachem Code tun und die ganze Arbeit dem Compiler überlassen.
Da ich Sie nicht mit dem Code aus dem vorigen Thema erschrecken möchte, wenn Sie alle diese Ressourcen gleichzeitig verwenden, werden wir schrittweise beginnen. Auf diese Weise werden Sie sich an die Idee gewöhnen und die Bedeutung der Konzepte verstehen, anstatt zu versuchen, beliebige Codes auswendig zu lernen und zu kopieren, damit sie später funktionieren.
Unser Code wird also wie folgt beginnen:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Base 05. { 06. private : 07. uint KeyValue; 08. public : 09. //+----------------+ 10. void SetKey(const uint arg) 11. { 12. KeyValue = arg; 13. } 14. //+----------------+ 15. uint GetKey(void) 16. { 17. return KeyValue; 18. } 19. //+----------------+ 20. }; 21. //+------------------------------------------------------------------+
Code 05
Nun gut, ich denke, jeder wird Code 05 verstehen. Dann können wir zur nächsten Stufe übergehen.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Base 05. { 06. private : 07. uint KeyValue; 08. public : 09. //+----------------+ 10. void SetKey(const uint arg) 11. { 12. KeyValue = arg; 13. } 14. //+----------------+ 15. uint GetKey(void) 16. { 17. return KeyValue; 18. } 19. //+----------------+ 20. }; 21. //+------------------------------------------------------------------+ 22. struct st_Dev01 : public st_Base 23. { 24. private : 25. string ValueInfo; 26. public : 27. //+----------------+ 28. void SetKeyInfo(uint arg1, string arg2) 29. { 30. SetKey(arg1); 31. ValueInfo = arg2; 32. } 33. //+----------------+ 34. string GetInfo(void) 35. { 36. return ValueInfo; 37. } 38. //+----------------+ 39. } 40. //+------------------------------------------------------------------+
Code 06
Ausgezeichnet, wir haben jetzt den Vererbungsmechanismus implementiert. Wir haben zwei sehr einfache und ziemlich grundlegende Strukturen. Nun ist es Zeit für den nächsten Schritt. In diesem Stadium werden wir etwas implementieren, das als Liste bezeichnet werden kann. Auch dies ist sehr einfach, wie unten zu sehen ist.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Base 05. { 06. private : 07. uint KeyValue; 08. public : 09. //+----------------+ 10. void SetKey(const uint arg) 11. { 12. KeyValue = arg; 13. } 14. //+----------------+ 15. uint GetKey(void) 16. { 17. return KeyValue; 18. } 19. //+----------------+ 20. }; 21. //+------------------------------------------------------------------+ 22. struct st_Dev01 : public st_Base 23. { 24. private : 25. string ValueInfo; 26. public : 27. //+----------------+ 28. void SetKeyInfo(uint arg1, string arg2) 29. { 30. SetKey(arg1); 31. ValueInfo = arg2; 32. } 33. //+----------------+ 34. string GetInfo(void) 35. { 36. return ValueInfo; 37. } 38. //+----------------+ 39. }; 40. //+------------------------------------------------------------------+ 41. struct st_List 42. { 43. private : 44. st_Dev01 List[]; 45. uint nElements; 46. public : 47. //+----------------+ 48. void Clear(void) 49. { 50. ArrayFree(List); 51. nElements = 0; 52. } 53. //+----------------+ 54. bool AddList(const st_Dev01 &arg) 55. { 56. nElements += (nElements == 0 ? 2 : 1); 57. ArrayResize(List, nElements); 58. List[nElements - 1] = arg; 59. 60. return true; 61. 62. } 63. //+----------------+ 64. st_Dev01 SearchKey(const uint arg) 65. { 66. for (uint c = 1; c < nElements; c++) 67. if (List[c].GetKey() == arg) 68. return List[c]; 69. 70. return List[0]; 71. } 72. //+----------------+ 73. }; 74. //+------------------------------------------------------------------+
Code 07
Wie Sie sehen können, haben wir im Vergleich zu früher nichts verändert. Alles bleibt so einfach und didaktisch. Jetzt werden wir eine kurze Liste von Daten erstellen, um sicherzustellen, dass alles richtig funktioniert. Wir werden dies in dem Code tun, der unten zu sehen ist.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. #define PrintX(X) Print(#X, " => [", X, "]") 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. const string Names[] = 11. { 12. "Daniel Jose", 13. "Edimarcos Alcantra", 14. "Carlos Almeida", 15. "Yara Alves" 16. }; 17. 18. st_List list; 19. 20. for (uint c = 0; c < Names.Size(); c++) 21. { 22. st_Dev01 info; 23. 24. info.SetKeyInfo(c, Names[c]); 25. list.AddList(info); 26. } 27. 28. PrintX(list.SearchKey(2).GetInfo()); 29. } 30. //+------------------------------------------------------------------+
Code 08
Bitte beachten Sie, dass der gesamte Code aus Code 07 eigentlich eine Header-Datei war. Sie wird von Code 08 in Zeile 04 eingebunden. In Zeile 10 haben wir ein kleines Array erstellt, das einige Namen enthält. In Zeile 18 wird eine Datenstruktur vorgestellt. In Zeile 25 haben wir die Struktur selbst erstellt. In Zeile 28 wird anhand des Schlüssels nach Informationen gesucht, die sich auf diesen speziellen Schlüssel beziehen. Nach der Ausführung des Codes erhalten wir das unten dargestellte Ergebnis.

Abbildung 05
Kurzum, nichts Besonderes. Alles entspricht den Erwartungen und dem, was bis jetzt gezeigt und untersucht wurde. Aber jetzt ist es an der Zeit, etwas Neues zu zeigen, das wirklich Spaß macht. Das Neue daran ist, dass wir nun Überladungen in dieses Listensystem einbauen werden. Um den Ablauf so reibungslos wie möglich zu gestalten, beginnen wir in den hinteren Reihen und bewegen uns nach vorne. Daher werden wir den Code der Header-Datei so ändern, dass er wie unten dargestellt aussieht. Erinnern wir uns, dass der ursprüngliche Code der Header-Datei Code 07 war.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Base 05. { 06. private : 07. uint KeyValue; 08. public : 09. //+----------------+ 10. void SetKey(const uint arg) 11. { 12. KeyValue = arg; 13. } 14. //+----------------+ 15. uint GetKey(void) 16. { 17. return KeyValue; 18. } 19. //+----------------+ 20. }; 21. //+------------------------------------------------------------------+ 22. struct st_Dev01 : public st_Base 23. { 24. private : 25. string ValueInfo; 26. public : 27. //+----------------+ 28. void SetKeyInfo(uint arg1, string arg2) 29. { 30. SetKey(arg1); 31. ValueInfo = arg2; 32. } 33. //+----------------+ 34. string GetInfo(void) 35. { 36. return ValueInfo; 37. } 38. //+----------------+ 39. }; 40. //+------------------------------------------------------------------+ 41. template <typename T> 42. struct st_List 43. { 44. private : 45. T List[]; 46. uint nElements; 47. public : 48. //+----------------+ 49. void Clear(void) 50. { 51. ArrayFree(List); 52. nElements = 0; 53. } 54. //+----------------+ 55. bool AddList(const T &arg) 56. { 57. nElements += (nElements == 0 ? 2 : 1); 58. ArrayResize(List, nElements); 59. List[nElements - 1] = arg; 60. 61. return true; 62. 63. } 64. //+----------------+ 65. T SearchKey(const uint arg) 66. { 67. for (uint c = 1; c < nElements; c++) 68. if (List[c].GetKey() == arg) 69. return List[c]; 70. 71. return List[0]; 72. } 73. //+----------------+ 74. }; 75. //+------------------------------------------------------------------+
Code 09
Damit der Code 08 weiterhin funktioniert, müssen wir ihn nun auf das unten abgebildete Formular aktualisieren.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. #define PrintX(X) Print(#X, " => [", X, "]") 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. const string Names[] = 11. { 12. "Daniel Jose", 13. "Edimarcos Alcantra", 14. "Carlos Almeida", 15. "Yara Alves" 16. }; 17. 18. st_List <st_Dev01> list; 19. 20. for (uint c = 0; c < Names.Size(); c++) 21. { 22. st_Dev01 info; 23. 24. info.SetKeyInfo(c, Names[c]); 25. list.AddList(info); 26. } 27. 28. PrintX(list.SearchKey(2).GetInfo()); 29. } 30. //+------------------------------------------------------------------+
Code 10
Bitte beachten Sie, dass wir in Code 10 nur Zeile 18 gegenüber dem ursprünglichen Code 08 geändert haben.
Perfekt. Wir haben jetzt eine Vorlage für eine Liste. Da dies genau die Situationen sind, die wir in den letzten Artikeln aufgezeigt haben, gibt es keinen Grund zur Panik. Der nächste Schritt ist etwas komplexer. Da es jedoch keine einfache Möglichkeit gibt, dies Schritt für Schritt zu erklären, müssen wir alles auf einmal betrachten. Oder besser gesagt, in zwei Schritten. Der erste Schwerpunkt liegt auf der Header-Datei, der zweite auf der Hauptdatei. Lassen Sie sich also nicht beunruhigen, aber versuchen Sie, sich nicht ablenken zu lassen.
Zunächst die Header-Datei. Dies wird nun im nachstehenden Code angezeigt.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename KEY> 05. struct st_Base 06. { 07. private : 08. KEY KeyValue; 09. public : 10. //+----------------+ 11. void SetKey(const KEY arg) 12. { 13. KeyValue = arg; 14. } 15. //+----------------+ 16. KEY GetKey(void) 17. { 18. return KeyValue; 19. } 20. //+----------------+ 21. }; 22. //+------------------------------------------------------------------+ 23. template <typename KEY> 24. struct st_Dev01 : public st_Base <KEY> 25. { 26. private : 27. string ValueInfo; 28. public : 29. //+----------------+ 30. void SetKeyInfo(KEY arg1, string arg2) 31. { 32. SetKey(arg1); 33. ValueInfo = arg2; 34. } 35. //+----------------+ 36. string GetInfo(void) 37. { 38. return ValueInfo; 39. } 40. //+----------------+ 41. }; 42. //+------------------------------------------------------------------+ 43. template <typename T, typename KEY> 44. struct st_List 45. { 46. private : 47. T List[]; 48. uint nElements; 49. public : 50. //+----------------+ 51. void Clear(void) 52. { 53. ArrayFree(List); 54. nElements = 0; 55. } 56. //+----------------+ 57. bool AddList(const T &arg) 58. { 59. nElements += (nElements == 0 ? 2 : 1); 60. ArrayResize(List, nElements); 61. List[nElements - 1] = arg; 62. 63. return true; 64. 65. } 66. //+----------------+ 67. T SearchKey(const KEY arg) 68. { 69. for (uint c = 1; c < nElements; c++) 70. if (List[c].GetKey() == arg) 71. return List[c]; 72. 73. return List[0]; 74. } 75. //+----------------+ 76. }; 77. //+------------------------------------------------------------------+
Code 11
Beachten Sie, was in der Header-Datei von Code 11 passiert ist, und vergleichen Sie sie mit den vorherigen Dateien, die wir in diesem Artikel untersucht haben. Sie werden sehen, dass der Code 11 viel interessanter ist als die vorherigen. Es gibt jedoch keinen Grund zur Panik. Es gibt keinen Grund zur Beunruhigung, zumindest nicht so, wie wir es erklärt haben. Als ich vor einigen Jahren lernte, dies in C und C++ zu tun, verstand ich es nicht auf Anhieb, da es schwierig war, jemanden zu finden, der mir erklären konnte, wie es funktioniert. Aber hier werden Sie verstehen, wie es funktioniert, liebe Leserinnen und Leser.
Bitte beachten Sie: In Zeile 04 führt der Compiler eine Überladung durch. Dies geschieht genau deshalb, weil wir eine Vodevorlage für diese Struktur definieren. Wie Sie vielleicht schon wissen, erstellt der Compiler für jeden Datentyp, der erstellt werden muss, eine Version. Dies ist der einfachste Teil. Jetzt kommt der verwirrende Teil, zumindest meiner Meinung nach.
Da die Struktur st_Dev01 von der Struktur st_Base erbt, die eine Vorlage ist, MUSS die Struktur st_Dev01 ebenfalls als Vorlagenstruktur definiert werden. Wie auch immer wir darüber denken: Die Tatsache, dass eine Datenstruktur eine Vorlagedatenstruktur erbt, zwingt die Struktur, die sie erbt, ebenfalls eine Vorlage zu sein. Dies ist nicht sehr kompliziert, da wir nur die Zeile 23 definieren müssen.
Allerdings, und hier wird es am schwierigsten, müssen wir diesen Typ, der in Zeile 23 definiert ist, in die Basisstruktur verschieben. Mit anderen Worten: st_Base muss diesen Wert erhalten, der später im Code definiert wird. Es scheint einfach zu sein, aber glauben Sie mir, es hat lange gedauert, bis ich begriffen habe, dass ich die Erklärung in Zeile 22 von Code 09 in die Erklärung in Zeile 24 von Code 11 ändern muss.
Sie haben keine Ahnung, wie sehr ich gelitten habe, bis ich das erfahren habe, denn damals hat es mir niemand erklärt. Ich nehme an, Sie stellen sich immer vor, dass Sie zuerst definieren müssen, was in Zeile 23 steht, und dann definieren, was in Zeile 30 steht. Wenn jedoch die Definition in Zeile 24 nicht korrigiert wird, lässt sich der Code ÜBERHAUPT NICHT KOMPILIEREN..
Da unsere Liste eine Datenstruktur verwenden wird, die je nach Fall überladen wird, müssen wir auch den Deklarationscode der st_List-Struktur ändern. Aber das lässt sich leicht lösen, indem man einfach Zeile 43 ändert und dann Zeile 57 anpasst. Ja. Unser Header ist fast fertig. Das Einzige, was dies noch an einen bestimmten Datentyp bindet, ist die Deklaration in Zeile 27, aber das werden wir später ändern. Sehen wir uns nun an, was aus der Hauptdatei geworden ist. Es ist unten zu sehen:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. #define PrintX(X) Print(#X, " => [", X, "]") 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. #define def_TypeKey uint 11. 12. const string Names[] = 13. { 14. "Daniel Jose", 15. "Edimarcos Alcantra", 16. "Carlos Almeida", 17. "Yara Alves" 18. }; 19. 20. st_List <st_Dev01 <def_TypeKey>, def_TypeKey> list; 21. 22. for (uint c = 0; c < Names.Size(); c++) 23. { 24. st_Dev01 <def_TypeKey> info; 25. 26. info.SetKeyInfo(c, Names[c]); 27. list.AddList(info); 28. } 29. 30. PrintX(list.SearchKey(2).GetInfo()); 31. 32. #undef def_TypeKey 33. } 34. //+------------------------------------------------------------------+
Code 12
„Oh Gott! Habt Erbarmen mit uns! Dieser Typ ist verrückt. Wie kann er es wagen, hierher zu kommen und uns den obigen Code zu zeigen? Interessieren Sie sich nicht für uns Programmieranfänger? Willst du uns umbringen, indem du so einen verrückten Code zeigst?“
Beruhigen Sie sich, liebe Leser. Regen Sie sich nicht auf. Code 12 ist so einfach, dass es fast langweilig erscheint, obwohl es durchaus Spaß macht. Aber aufgepasst. Da wir bestimmte Aktionen an verschiedenen Stellen des Codes wiederholen müssen, verwenden wir eine Direktive in Zeile 10, um eine Definition zu erstellen, mit der wir schnell und sicher Änderungen an all diesen Stellen vornehmen können. In Code 12 müssen wir nur zwei Dinge ändern. Die erste ist Zeile 20. Vergleichen Sie die Deklaration dieser Variable mit der Deklaration der gleichen Variable in Code 10.
Da sich das Überladen auch auf die Datenstruktur auswirkt, die wir erstellen, müssen wir die Deklaration in Zeile 24 ändern, in der wir die Struktur deklarieren, die in der Liste gespeichert werden soll. Alles andere im Code bleibt unverändert. Das Ergebnis wird dasselbe sein wie in Abbildung 05 dargestellt.
Aber wir sind noch nicht fertig mit der Diskussion über dieses Thema, denn wir haben noch die Möglichkeit, eine weitere Verbesserung vorzunehmen, was wir jetzt tun werden. So können wir eine nahezu perfekte Liste von Strukturen erstellen. Ich sage „fast“, weil es ein kleines Problem gibt, das ohne die Verwendung von Klassen, d.h. ohne die Verwendung von OOP, nicht gelöst werden kann. Aber das wird später klar werden, wenn wir zeigen, was das Problem ist und wie es mit OOP gelöst wird.
Kurzum, atmen Sie tief durch, denn wir werden noch tiefer in das Thema einsteigen. Wir kehren zum Code der Header-Datei zurück und ändern ihn erneut wie unten gezeigt.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. template <typename KEY> 05. struct st_Base 06. { 07. private : 08. KEY KeyValue; 09. public : 10. //+----------------+ 11. void SetKey(const KEY arg) 12. { 13. KeyValue = arg; 14. } 15. //+----------------+ 16. KEY GetKey(void) 17. { 18. return KeyValue; 19. } 20. //+----------------+ 21. }; 22. //+------------------------------------------------------------------+ 23. template <typename KEY, typename INFO> 24. struct st_Dev01 : public st_Base <KEY> 25. { 26. private : 27. INFO ValueInfo; 28. public : 29. //+----------------+ 30. void SetKeyInfo(KEY arg1, INFO arg2) 31. { 32. SetKey(arg1); 33. ValueInfo = arg2; 34. } 35. //+----------------+ 36. INFO GetInfo(void) 37. { 38. return ValueInfo; 39. } 40. //+----------------+ 41. }; 42. //+------------------------------------------------------------------+ 43. template <typename T, typename KEY> 44. struct st_List 45. { 46. private : 47. T List[]; 48. uint nElements; 49. public : 50. //+----------------+ 51. void Clear(void) 52. { 53. ArrayFree(List); 54. nElements = 0; 55. } 56. //+----------------+ 57. bool AddList(const T &arg) 58. { 59. nElements += (nElements == 0 ? 2 : 1); 60. ArrayResize(List, nElements); 61. List[nElements - 1] = arg; 62. 63. return true; 64. 65. } 66. //+----------------+ 67. T SearchKey(const KEY arg) 68. { 69. for (uint c = 1; c < nElements; c++) 70. if (List[c].GetKey() == arg) 71. return List[c]; 72. 73. return List[0]; 74. } 75. //+----------------+ 76. }; 77. //+------------------------------------------------------------------+
Code 13
Wie Sie sehen können, habe ich in diesem Code 13 nur die Zeile 23 geändert, das ist alles. Jetzt können wir jeden Datentyp als Schlüssel und jeden Datentyp als die mit diesem Schlüssel verbundenen Informationen verwenden. Nachdem wir dies verstanden haben, können wir nun sehen, wie der Hauptcode aussieht. Sie ist unten abgebildet.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. #define PrintX(X) Print(#X, " => [", X, "]") 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. #define def_TypeKey string 11. #define def_TypeInfo string 12. 13. const string Names[][2] = 14. { 15. "Daniel Jose" , "Chief Programmer", 16. "Edimarcos Alcantra", "Programmer", 17. "Carlos Almeida" , "Junior Programmer", 18. "Yara Alves" , "Accounting" 19. }; 20. 21. st_List <st_Dev01 <def_TypeKey, def_TypeInfo>, def_TypeKey> list; 22. 23. for (int c = 0; c < ArrayRange(Names, 0); c++) 24. { 25. st_Dev01 <def_TypeKey, def_TypeInfo> info; 26. 27. info.SetKeyInfo(Names[c][1], Names[c][0]); 28. list.AddList(info); 29. } 30. 31. PrintX(list.SearchKey("Chief Programmer").GetInfo()); 32. PrintX(list.SearchKey("Guest").GetInfo()); 33. 34. #undef def_TypeKey 35. #undef def_TypeInfo 36. } 37. //+------------------------------------------------------------------+
Code 14
Bitte beachten Sie, dass sich der Code kaum verändert hat. Diese wenigen Unterschiede reichen jedoch aus, um einen sehr einfachen Code zu erhalten, der sowohl in praktischer Hinsicht als auch in Bezug auf seine Fähigkeiten interessante Ergebnisse liefern kann. Da die Änderungen sehr einfach sind, werden wir Ihnen die Möglichkeit geben, die Funktionsweise des Codes zu verstehen. Auf jeden Fall werden wir Ihnen das Ergebnis zeigen. Dies ist auf dem folgenden Bild zu sehen.

Abbildung 06
Wie schön! Bild 06 ist ein echtes Juwel, denn es zeigt, wie scheinbar komplexe Dinge unglaublich einfach werden können, wenn man sich die Mühe macht, das in den Artikeln vorgestellte Material zu verarbeiten.
Abschließende Überlegungen
Zweifellos kann ich Ihnen versichern, dass dieser Artikel einige Zeit in Anspruch nehmen wird, bis Sie das Material verdaut haben. Das liegt daran, dass alles, was hier gezeigt wird, zunächst auf OOP ausgerichtet ist. Viele halten es für unwahrscheinlich, etwas zu entwickeln, das als eine Art der Programmierung angepriesen wird, in Wirklichkeit aber auf den Grundsätzen der vollständig strukturierten Programmierung beruht.
Wie wir bereits gesagt haben, müssen wir, bevor wir erklären, was OOP ist, verstehen, was als ursprüngliche Grundlage dieses Programmiermodells diente, da es entstand, um eine der Schwierigkeiten der strukturierten Programmierung zu lösen. Viele Dinge, die als ausschließliches Vorrecht der OOP gelten, werden jedoch nicht innerhalb der OOP, sondern innerhalb der strukturierten Programmierung durchgeführt.
Versuchen Sie also, liebe Leserinnen und Leser, alle in diesen Artikeln vorgestellten Punkte zu studieren. Verwenden Sie die Codes im Anhang, um zu lernen, zu üben und zu verstehen, wie man richtig programmiert. Und im nächsten Artikel wird der Spaß weitergehen. Auf Wiedersehen!
Übersetzt aus dem Portugiesischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/pt/articles/15922
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.