
Von der Grundstufe bis zur Mittelstufe: Struktur (IV)

Einführung
Im vorigen Artikel, „Von der Grundstufe zur Mittelstufe: Struktur (III)“ haben wir uns mit einem Thema beschäftigt, das bei Anfängern große Verwirrung stiftet: dem Unterschied zwischen strukturiertem und organisiertem Code. Viele verwechseln die Tatsache, dass der Code gut organisiert ist, mit der Tatsache, dass er strukturiert ist. Auch wenn die Konzepte ähnlich erscheinen mögen, sind sie nicht genau dasselbe. Dieser Artikel dient jedoch lediglich als Ausgangspunkt für etwas Komplexeres, Eleganteres und Faszinierenderes im Bereich der strukturierten Programmierung.
Da es mehrere Konzepte gibt, die je nach Vorkenntnissen mehr oder weniger schwierig zu verstehen sind, werden wir uns bemühen, jedes Konzept auf klare und objektive Weise zu präsentieren. Das Ziel ist es, dass Sie verstehen, was strukturierter Code ist und wie man damit fast alles bauen kann. Ich sage „fast“, weil es eine Beschränkung gibt, was strukturierter Code regeln kann. Wenn wir uns dieser Einschränkung nähern, wird es notwendig sein, ein weiteres Konzept einzuführen: die Klasse. An diesem Punkt werden wir die strukturierte Programmierung hinter uns lassen und zur objektorientierten Programmierung (OOP) übergehen. Im Moment können wir jedoch viele Dinge erforschen und eine Menge Spaß dabei haben, verschiedene Beispiele für strukturierten Code zu erstellen, um die Konzepte und Grenzen der strukturierten Programmierung wirklich zu verstehen.
Also gut, machen wir dort weiter, wo wir im letzten Artikel aufgehört haben. Dort haben wir erwähnt und gezeigt, wie die öffentlichen und privaten Bereiche des Codes verwendet werden. Wir haben zwar nicht erklärt, warum das so ist, aber wir werden jetzt von diesem Punkt ausgehen.
Der private Bereich des Codes innerhalb einer Struktur
Da jedes in einer Struktur definierte Element standardmäßig öffentlich ist, sehe ich keine Notwendigkeit, den öffentlichen Bereich zu erklären, da er nicht im Code deklariert werden muss – er ist implizit, da er innerhalb der Struktur deklariert wird. Der private Bereich des Codes ist jedoch anders. In diesem Fall muss der Bereich ausdrücklich angegeben werden. Dies hat jedoch bestimmte Auswirkungen auf den Code und die Art und Weise, wie wir mit ihm arbeiten. Lassen Sie uns mit etwas Einfachem beginnen. Und da das Ziel ein pädagogisches ist, versuchen Sie nicht, die Logik dahinter zu finden, warum der Code auf eine bestimmte Weise implementiert werden sollte. Versuchen Sie, das Konzept zu begreifen, denn das ist es, was für uns wirklich zählt.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. double Values[]; 08. //+----------------+ 09. void Set(const double &arg[]) 10. { 11. ArrayCopy(Values, arg); 12. } 13. //+----------------+ 14. double Average(void) 15. { 16. double sum = 0; 17. 18. for (uint c = 0; c < Values.Size(); c++) 19. sum += Values[c]; 20. 21. return sum / Values.Size(); 22. } 23. //+----------------+ 24. double Median(void) 25. { 26. double Tmp[]; 27. 28. ArrayCopy(Tmp, Values); 29. ArraySort(Tmp); 30. if (!(Tmp.Size() & 1)) 31. { 32. int i = (int)MathFloor(Tmp.Size() / 2); 33. 34. return (Tmp[i] + Tmp[i - 1]) / 2.0; 35. } 36. return Tmp[Tmp.Size() / 2]; 37. } 38. //+----------------+ 39. }; 40. //+------------------------------------------------------------------+ 41. #define PrintX(X) Print(#X, " => ", X) 42. //+------------------------------------------------------------------+ 43. void OnStart(void) 44. { 45. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 46. st_Data Info; 47. 48. Info.Set(H); 49. PrintX(Info.Average()); 50. PrintX(Info.Median()); 51. } 52. //+------------------------------------------------------------------+
Code 01
Code 01 macht etwas sehr Einfaches, Praktisches und Verständliches. Das Ziel ist es, einen konsequent strukturierten Code zu erstellen. Zu diesem Zweck müssen wir zunächst unsere eigene Struktur definieren. Dies geschieht in Zeile 04. Achtung: Das Einzige, was in dieser Struktur normalerweise gemacht wird, ist die Deklaration in Zeile 07. Denn das ist genau das, was in den Artikeln über Strukturen erklärt und untersucht wurde. Im vorigen Artikel haben wir jedoch begonnen, über strukturierten Code zu sprechen, und um dies zu erreichen, haben wir der Struktur noch etwas hinzugefügt. In diesem Fall werden wir mit dem Hinzufügen von Funktionen und/oder Prozeduren fortfahren. Innerhalb der Struktur werden also interne Unterprogramme erscheinen, die den strukturierten Code definieren.
Diese Unterprogramme, ob Funktionen oder Prozeduren, müssen jedoch in einen Kontext eingebettet sein, der mit den in der Struktur vorhandenen Variablen oder dem Zweck, für den die Struktur konzipiert und implementiert wurde, zusammenhängt. Ich denke, Sie haben jetzt alles verstanden. Sobald die Struktur definiert ist, können wir sie verwenden. Um die Verwendung dieser spezifischen Struktur zu veranschaulichen, werden wir die OnStart-Prozedur in Zeile 43 verwenden.
Zunächst definieren wir in Zeile 45 ein Array mit numerischen Konstanten. Es spielt keine Rolle, wofür diese Werte stehen; sie müssen lediglich existieren. In Zeile 46 deklarieren wir nun eine Variable, um auf die in Zeile 04 definierte Struktur zuzugreifen. Danach gibt es zwei Wege, die wir einschlagen können. Die erste Möglichkeit sehen wir in Zeile 48; auf die zweite kommen wir später zurück. Nach der Ausführung von Zeile 48 wird das in Zeile 07 deklarierte Array innerhalb der Struktur mit den Werten gefüllt, die uns im Moment interessieren. An dieser Stelle werden die Dinge interessant.
Verfolgen Sie die Argumentation, um zu verstehen, wie strukturierter Code es einfacher macht, den Zweck einer Variablen zu verstehen. Wenn wir Info in Zeile 46 deklarieren, wissen wir nicht, wofür diese Deklaration ist; wir brauchen einfach eine Variable dieses bestimmten Typs. Da die Struktur jedoch interne Funktionen und Prozeduren enthält, die den in ihr enthaltenen Werten einen Kontext geben, wissen wir, welche Art von Aktivitäten wir durchführen können, wenn wir sie verwenden. Wären diese Funktionen und Prozeduren nicht deklariert, könnte unsere Struktur jeden beliebigen Zweck erfüllen (und kann es immer noch). Dies bezieht sich auf eine Frage, die noch offen ist. Aus den Zeilen 49 und 50 geht jedoch hervor, dass unsere Struktur darauf abzielt, den Durchschnitt und den Median genau der Daten zu berechnen, die wir eingeben.
Dinge wie diese schaffen das, was wir als Kontext kennen. Mit anderen Worten: Etwas ist nur dann sinnvoll, wenn wir verstehen, warum es existiert. Ohne sie könnte jede Variable, Funktion oder Prozedur alles Mögliche bedeuten und jedem Zweck dienen. Bei der Ausführung von Code 01 wird also folgendes Ergebnis angezeigt:
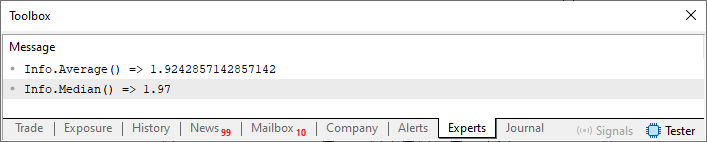
Abbildung 01
Mit anderen Worten, wir sind nicht daran interessiert, was die in Zeile 45 angegebenen Werte bedeuten oder wie sie sich auf die reale Welt beziehen. Wir können jedoch behaupten, dass das Ergebnis in dem von der Wertestruktur vorgegebenen Kontext wie folgt aussehen sollte: Solche Dinge können auf vielfältige Weise erweitert werden, denn wann immer wir etwas brauchen, das mit den Daten in der Struktur zusammenhängt, können wir den Kontext nutzen, um das Verständnis des Ergebnisses selbst zu unterstreichen und zu vereinfachen, da die Struktur selbst den Kontext für diese Art von Informationen liefert.
Bitte beachten Sie, dass wir einen ähnlichen Code für den gleichen Zweck hätten erstellen können, aber uns würde ein echter Kontext fehlen, der die Daten in der Struktur mit der generierten Antwort verbindet. Und nun kommen wir zu dem Bereich, der für viele Anfänger oft schwer zu begreifen ist. Sie weist darauf hin, dass, da in der Struktur kein Bereich angegeben ist, alles innerhalb der Struktur als öffentlich gilt. Mit anderen Worten: Wir können die Informationen völlig willkürlich manipulieren. Um dies zu demonstrieren und die Komplexität des Prozesses zu verstehen, ändern wir den Code wie folgt:
. . . 40. //+------------------------------------------------------------------+ 41. #define PrintX(X) Print(#X, " => ", X) 42. //+------------------------------------------------------------------+ 43. void OnStart(void) 44. { 45. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 46. const double K[] = {12, 4, 7, 23, 38}; 47. 48. st_Data Info; 49. 50. Info.Set(H); 51. PrintX(Info.Average()); 52. 53. ArrayPrint(Info.Values, 2); 54. ZeroMemory(Info); 55. ArrayCopy(Info.Values, K); 56. 57. PrintX(Info.Median()); 58. 59. ArrayPrint(Info.Values, 2); 60. } 61. //+------------------------------------------------------------------+
Code 02
In Code 02, der nur ein Fragment des vollständigen Codes ist (der im Anhang zu finden sein wird), können wir sehen, dass nur der Bereich, der sich auf die OnStart-Prozedur bezieht, geändert wurde. Diese Änderung änderte zwar nicht den Kontext der Struktur, zerstörte aber letztlich jede Aussicht auf korrekte Ergebnisse. Dies geschieht, weil die interne Variable innerhalb der Struktur geändert werden kann – oder genauer gesagt, auf sie kann zugegriffen werden. Und das ist in der Tat sehr gefährlich. Man könnte meinen: „Natürlich werden die Werte anders sein, wenn wir diesen Code ausführen“. Das ist offensichtlich, denn in Zeile 55 werden der in Zeile 04 definierten Variablen neue Werte zugewiesen, die sich wiederum innerhalb der Struktur befinden.
Ich verstehe nicht, was hier das Problem ist, denn wir können deutlich sehen, was passiert. Das ist richtig, liebe Leserin, lieber Leser, aber ich muss Sie daran erinnern, dass es sich um didaktische Codebeispiele handelt, und aus diesem Grund sind Fehler in ihnen leicht zu erkennen. In echtem Code wäre dies nur schwer zu erreichen, da der verwendete Kontext erhalten bleibt und in der Struktur vorhanden ist. Die Tatsache, dass wir in Zeile 55 die Änderung der in der Struktur vorhandenen Variablen erzwingen, ohne dass die Struktur davon weiß, verkompliziert die Situation jedoch erheblich und macht es schwierig zu verstehen, warum die Ergebnisse falsch sind und nicht den Erwartungen entsprechen.
Diese Art von Fehler wird als „Kapselungsfehler“ bezeichnet, weil Code, der etwas nicht sehen sollte, es doch sieht, oder, noch schlimmer, es schafft, eine Variable zu ändern, die nicht geändert werden sollte. Das Problem ist jedoch noch viel gravierender. Um dies zu verstehen, müssen wir das Ergebnis der Ausführung von Code 02 kennen. Dieser Bereich ist unten zu sehen:
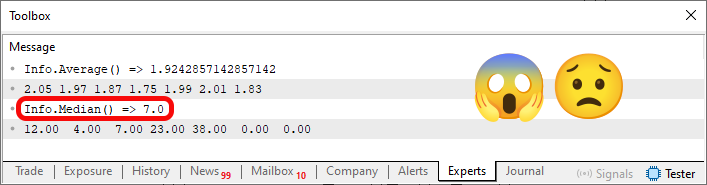
Abbildung 02
Seien Sie vorsichtig, denn dies ist ein Grund für das Scheitern in einem Programmierertest, denn wenn ein Arbeitgeber Ihren Wissensstand über mögliche Fehler im Code beurteilen will, werden Sie sich in einer unangenehmen Lage befinden. Bei der Ausführung von Zeile 50 wird genügend Speicherplatz für die Werte aus Zeile 45 zugewiesen. So weit, so gut. Wenn also Zeile 53 ausgeführt wird, sehen wir die in Zeile 45 deklarierten Werte. Das heißt, der Code funktioniert wie erwartet, und die Struktur ist korrekt definiert. Wenn jedoch Zeile 54 ausgeführt wird, werden alle in der Struktur vorhandenen Variablen zurückgesetzt. Dies ist kein Fehler. In vielen Fällen ist dies sogar zulässig und wünschenswert, da eine Struktur mehrere vordefinierte Elemente enthalten kann, die wir alle entfernen wollen.
Bei der Ausführung von Zeile 55 tritt jedoch ein Fehler im Code auf. Dies geschieht, weil der zugewiesene Speicher NICHT FREIGEGEBEN wurde; er wurde lediglich zurückgesetzt. Daher wird der tatsächliche Inhalt des Speichers in Zeile 59 angezeigt. Der in Bild 02 hervorgehobene Median K ist also falsch. „Aber warum ist es falsch? Ich verstehe das nicht“. Um dies zu verstehen, müssen Sie wissen, wie hoch der Median K sein sollte. Wenn Sie sich den Code 02 ansehen und wissen, wie man den Median ermittelt, werden Sie feststellen, dass der richtige Wert 12 und nicht 7 ist. Der Grund für den falschen Wert ist, dass in der Struktur, die aufgrund von Zeile 59 sichtbar ist, Nullen oder Elemente vorhanden sind, die NICHT vorhanden sein SOLLTEN.
Genau aus diesem Grund müssen wir den privaten Bereich des Codes verwenden. Damit sind wir bei der Frage angelangt, die den Ausgangspunkt für dieses Thema bildete: Warum und wann sollte man den privaten Bereich nutzen? Aber man könnte meinen: „Mal ehrlich: Was wäre, wenn ich, anstatt alles wie in Code 02 gezeigt zu verwenden, versehentlich Zeile 50 in Zeile 55 wiederhole und nur H durch K ersetze? Wäre das nicht die Lösung des Problems?“. In diesem Fall – nein. Der Strukturcode enthält einen kleinen Fehler, aber darauf werden wir später zurückkommen. Es geht darum, zu verstehen, dass wir bestimmte Fehler machen können, ohne uns dessen bewusst zu sein. Durch die Anwendung der richtigen Konzepte können solche Fehler jedoch vermieden werden, und der Code lässt sich viel leichter korrigieren.
Um das erste Problem zu lösen, das darin besteht, dass wir direkt auf die in der Struktur deklarierte Variable zugreifen können, müssen wir den Code wie unten gezeigt ändern:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayCopy(Values, arg); 16. } 17. //+----------------+ 18. double Average(void) 19. { 20. double sum = 0; 21. 22. for (uint c = 0; c < Values.Size(); c++) 23. sum += Values[c]; 24. 25. return sum / Values.Size(); 26. } 27. //+----------------+ 28. double Median(void) 29. { 30. double Tmp[]; 31. 32. ArrayCopy(Tmp, Values); 33. ArraySort(Tmp); 34. if (!(Tmp.Size() & 1)) 35. { 36. int i = (int)MathFloor(Tmp.Size() / 2); 37. 38. return (Tmp[i] + Tmp[i - 1]) / 2.0; 39. } 40. return Tmp[Tmp.Size() / 2]; 41. } 42. //+----------------+ 43. }; 44. //+------------------------------------------------------------------+ 45. #define PrintX(X) Print(#X, " => ", X) 46. //+------------------------------------------------------------------+ 47. void OnStart(void) 48. { 49. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 50. const double K[] = {12, 4, 7, 23, 38}; 51. 52. st_Data Info; 53. 54. Info.Set(H); 55. PrintX(Info.Average()); 56. 57. ArrayPrint(Info.Values, 2); 58. ZeroMemory(Info); 59. ArrayCopy(Info.Values, K); 60. 61. PrintX(Info.Median()); 62. 63. ArrayPrint(Info.Values, 2); 64. } 65. //+------------------------------------------------------------------+
Code 03
Passen Sie jetzt gut auf, denn genau aus dem folgenden Grund verwenden viele Programmierer in Strukturen keinen privaten Bereich.
Erinnern Sie sich, dass wir sagten, das ganze Problem sei durch Zeile 59 verursacht worden? In Code 03 teilen wir dem Compiler mit, dass die innerhalb der Struktur deklarierte Variable vom Typ privat ist, was bedeutet, dass sie außerhalb des Körpers der Struktur nicht mehr sichtbar sein wird. Dies geschieht genau wegen der Linie 07. Aber wir brauchen Zeile 11, damit andere Elemente außerhalb des Strukturkörpers zugänglich sind, in diesem Fall die Funktionen und Prozeduren. Andernfalls würde das Konstrukt völlig nutzlos werden.
Wenn wir versuchen, Code 03 zu kompilieren, gibt der Compiler Warnmeldungen aus, die auf Fehler im Code hinweisen. Dies gehört zum Prozess, da wir die Art und Weise, wie die Struktur genutzt wird, geändert haben. Diese Fehler sind weiter unten zu sehen:
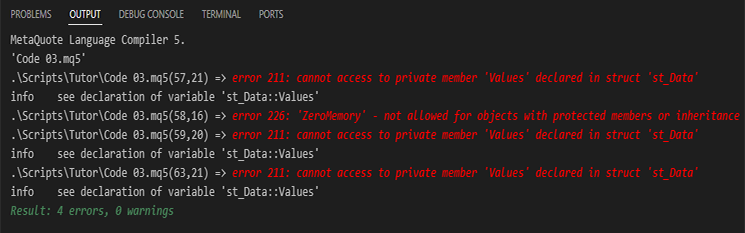
Abbildung 03
Man könnte erwarten, dass der Fehler nur in Zeile 59 von Code 03 auftritt, da wir dort der Variablen etwas zuweisen. Es traten jedoch vier Fehler auf. Warum? Der Grund dafür ist einfach. Die Fehler in den Zeilen 57, 59 und 63, die in Abbildung 03 zu sehen sind, hängen genau damit zusammen, dass wir versuchen, auf etwas zuzugreifen, das nun nicht mehr zugänglich ist, weil die Variable innerhalb der Struktur privat ist. Aus diesem Grund kann nur innerhalb der Struktur, in der sie deklariert ist, auf sie zugegriffen werden, wodurch der Kontext der Existenz der Struktur und der Variablen selbst geschaffen und aufrechterhalten wird.
Aber was ist mit dem Fehler in Zeile 58, wo wir die Bibliotheksfunktion ZeroMemory verwenden, um die Daten in der Struktur vollständig zu löschen? Warum ist dieser Fehler jetzt aufgetreten? Der Grund dafür ist, dass wir einen Kontext für die Struktur und die darin enthaltenen Daten schaffen.
Folglich können wir nicht mehr direkt auf die Datenstruktur zugreifen oder sie verändern, da dies die Kapselung aufheben und den internen Datenkontext beeinflussen könnte. Es sind genau diese Konzepte – Kapselung und Kontext –, die dafür sorgen, dass die Daten in der Struktur immer intakt und sicher bleiben. Dies zwingt uns, eine Reihe von neuen Lösungen zu implementieren, um diese Konzepte zu erhalten. Auf diese Weise beginnen wir, eine vollständig strukturierte Programmierung aufzubauen.
„Aber warte mal kurz. Wenn wir nicht mehr alles so machen können wie früher, wie sollen wir dann den Code in Betrieb halten? Kapselung und Kontext scheinen nur geschaffen worden zu sein, um uns das Leben schwer zu machen. Ich ziehe es vor, so zu programmieren, wie es früher gemacht wurde – das ist viel einfacher“. Nun, ich stimme Ihnen und vielen Programmierern zu, die bei der ersten Begegnung mit etwas Neuem genau dasselbe denken. Das dachte ich auch, als ich mit dem Programmieren begann. Und ich hasste die Notwendigkeit, strukturierten Code zu erstellen, weil ich keinen Sinn darin sah, da wir dadurch oft gezwungen sind, alles bis ins Detail zu durchdenken, wie es eigentlich funktionieren sollte. Aber mit der Zeit habe ich mich daran gewöhnt, vor allem, weil die Codes immer komplexer werden. Da merkt man, dass die strukturierte Programmierung einen großen Unterschied macht.
Kehren wir nun zum eigentlichen Code zurück. Da Code 03 keine ausführbare Datei erzeugen kann, müssen wir ihn reparieren, damit er funktioniert. Zu diesem Zweck werden wir sie erneut wie unten dargestellt ändern:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ . . . 43. //+----------------+ 44. }; 45. //+------------------------------------------------------------------+ 46. #define PrintX(X) Print(#X, " => ", X) 47. //+------------------------------------------------------------------+ 48. void OnStart(void) 49. { 50. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 51. const double K[] = {12, 4, 7, 23, 38}; 52. 53. st_Data Info; 54. 55. Info.Set(H); 56. PrintX(Info.Average()); 57. 58. Info.Set(K); 59. PrintX(Info.Median()); 60. } 61. //+------------------------------------------------------------------+
Code 04
In Code 04 haben wir eine mögliche Umsetzung dessen, was zuvor in Code 02 gemacht wurde, wo wir den Durchschnittswert H und dann den Median der K-Werte erzeugen wollten. Aber Achtung, wir sind nicht daran interessiert, den internen Inhalt der Struktur zu untersuchen, da wir wissen, welche Werte für die Analyse verwendet werden. Sehen Sie sich jedoch Zeile 15 in Code 04 an. Hier wird der Fehler behoben, der beim Versuch auftrat, der Struktur neue interne Werte zuzuweisen. Deshalb sage ich, dass dies nur eine der möglichen Lösungen ist – je nach Einzelfall kann diese Bereinigung anders gehandhabt werden.
Nehmen wir zum Beispiel an, wir brauchen den Code, um genau das zu tun, was in Code 02 getan wurde. Mit anderen Worten, wir wollen die Werte der Struktur löschen, wie es in Zeile 54 von Code 02 geschehen ist, und auch in der Lage sein, den Inhalt der Variablen auszugeben. Wie können wir dieses Problem lösen und gleichzeitig die Konzepte der Kapselung und des Kontexts beibehalten? Zu diesem Zweck wird im Folgenden ein möglicher Vorschlag unterbreitet. Dies ist der interessanteste Bereich des Spiels, denn jeder Programmierer kann sich verschiedene Wege ausdenken und entwickeln, um dieselbe Aufgabe zu lösen.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ 19. void ZeroMemory(void) 20. { 21. Print(__FUNCTION__); 22. ArrayFree(Values); 23. } 24. //+----------------+ 25. void ArrayPrint(void) 26. { 27. Print(__FUNCTION__); 28. ArrayPrint(Values, 2); 29. } 30. //+----------------+ 31. double Average(void) 32. { 33. double sum = 0; 34. 35. for (uint c = 0; c < Values.Size(); c++) 36. sum += Values[c]; 37. 38. return sum / Values.Size(); 39. } 40. //+----------------+ 41. double Median(void) 42. { 43. double Tmp[]; 44. 45. ArrayCopy(Tmp, Values); 46. ArraySort(Tmp); 47. if (!(Tmp.Size() & 1)) 48. { 49. int i = (int)MathFloor(Tmp.Size() / 2); 50. 51. return (Tmp[i] + Tmp[i - 1]) / 2.0; 52. } 53. return Tmp[Tmp.Size() / 2]; 54. } 55. //+----------------+ 56. }; 57. //+------------------------------------------------------------------+ 58. #define PrintX(X) Print(#X, " => ", X) 59. //+------------------------------------------------------------------+ 60. void OnStart(void) 61. { 62. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 63. const double K[] = {12, 4, 7, 23, 38}; 64. 65. st_Data Info; 66. 67. Info.Set(H); 68. Info.ArrayPrint(); 69. PrintX(Info.Average()); 70. Info.ZeroMemory(); 71. 72. Info.Set(K); 73. PrintX(Info.Median()); 74. Info.ArrayPrint(); 75. } 76. //+------------------------------------------------------------------+
Code 05
Wenn Sie Code 05 in MetaTrader 5 ausführen, sieht das Ergebnis wie folgt aus:
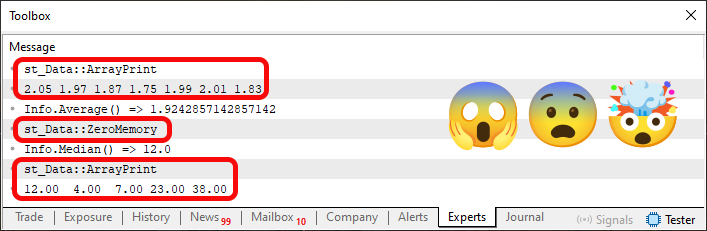
Abbildung 04
Bitte beachten Sie, dass wir in Abbildung 04 bestimmte Aspekte hervorheben. Aber natürlich könnten Sie fragen: Warum heben Sie diese Dinge hervor? Der Grund dafür ist in Code 05 zu finden. „Schau dir die Zeilen 19 und 25 an. Welchen Wahnsinn begehen Sie hier? Ist das überhaupt erlaubt?“
Wie ich kürzlich erwähnte, besteht der interessanteste Bereich gerade darin, dass jeder Programmierer unterschiedliche Wege zur Lösung derselben Aufgabe entwickeln kann. In der strukturierten Programmierung können Sie die Namen von Funktionen oder Bibliotheksprozeduren frei verwenden, wie ich es hier in Code 05 tue. Sie müssen jedoch darauf achten, dass Sie nicht ungewollt einen rekursiven Aufruf erzeugen, wie es hier geschieht, wo wir die Standardfunktionen der MQL5-Bibliothek überladen.
Und wir tun dies innerhalb des durch die Struktur vorhandenen Kontextes. Dieses Konstrukt bereitet keine Probleme, zumal der Code in den Zeilen 68, 70 und 74 deutlich leichter verständlich ist, als dafür eine spezielle Bezeichnung einzuführen, da klar erkennbar ist, welche Prozedur oder Funktion ausgeführt werden soll. Es gibt jedoch ein kleines Detail: Wie bereits erwähnt, ist bei der Umsetzung Vorsicht geboten. Um zu demonstrieren, wie dies in der Praxis funktioniert, habe ich die Zeilen 21 und 27 dem Code hinzugefügt, damit Sie den Ablauf der Ausführung nachvollziehen und verstehen können, dass wir nicht von Anfang an Standardbibliotheksaufrufe verwenden. Der Compiler verwendet zunächst die in der Struktur deklarierten Prozeduren und fährt erst dann mit weiteren Aktionen fort.
Im Falle des Aufrufs von ArrayPrint verwendet der Compiler zunächst das, was in der Struktur deklariert ist. Dies geschieht, weil wir ihm in den Zeilen 68 und 74 mitteilen, dass sich der auszuführende Code innerhalb der Struktur befindet. Erst wenn dieses Problem gelöst ist, kann der Compiler das zweite Problem angehen – den Aufruf in Zeile 28. Dieser Aufruf leitet den Ausführungsfluss zu dem in der MQL5-Standardbibliothek vorhandenen Code.
Bitte beachten Sie, dass wir auch ohne die Deklaration eines privaten Bereichs, der die in Zeile 9 deklarierte Variable exklusiv für die Struktur und vor dem Rest des Codes verborgen machen würde, Code 05 leicht in Code 02 umwandeln könnten, da wir nur ein paar Änderungen vornehmen müssten. Dasselbe lässt sich auch in umgekehrter Richtung tun: Code 02 in Code 05 umwandeln. In diesem Fall wäre die Umwandlung jedoch nicht sehr reibungslos, und zwar wegen der Zeile 55 in Code 02. Wenn das Ausführungsproblem in Code 02 jedoch kein Problem für Sie darstellt, kann eine Lösung implementiert werden, die zu 100 % mit dem übereinstimmt, was Code 02 im Rahmen einer 100 % strukturierten Programmierung tut. Um dies zu erreichen, müssen wir Folgendes tun:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. struct st_Data 05. { 06. //+----------------+ 07. private: 08. //+----------------+ 09. double Values[]; 10. //+----------------+ 11. public: 12. //+----------------+ 13. void Set(const double &arg[]) 14. { 15. ArrayFree(Values); 16. ArrayCopy(Values, arg); 17. } 18. //+----------------+ 19. void ArrayCopy(const double &arg[]) 20. { 21. ArrayCopy(Values, arg); 22. } 23. //+----------------+ 24. void ZeroMemory(void) 25. { 26. ZeroMemory(Values); 27. } 28. //+----------------+ 29. void ArrayPrint(void) 30. { 31. ArrayPrint(Values, 2); 32. } 33. //+----------------+ 34. double Average(void) 35. { 36. double sum = 0; 37. 38. for (uint c = 0; c < Values.Size(); c++) 39. sum += Values[c]; 40. 41. return sum / Values.Size(); 42. } 43. //+----------------+ 44. double Median(void) 45. { 46. double Tmp[]; 47. 48. ArrayCopy(Tmp, Values); 49. ArraySort(Tmp); 50. if (!(Tmp.Size() & 1)) 51. { 52. int i = (int)MathFloor(Tmp.Size() / 2); 53. 54. return (Tmp[i] + Tmp[i - 1]) / 2.0; 55. } 56. return Tmp[Tmp.Size() / 2]; 57. } 58. //+----------------+ 59. }; 60. //+------------------------------------------------------------------+ 61. #define PrintX(X) Print(#X, " => ", X) 62. //+------------------------------------------------------------------+ 63. void OnStart(void) 64. { 65. const double H[] = {2.05, 1.97, 1.87, 1.75, 1.99, 2.01, 1.83}; 66. const double K[] = {12, 4, 7, 23, 38}; 67. 68. st_Data Info; 69. 70. Info.Set(H); 71. PrintX(Info.Average()); 72. Info.ArrayPrint(); 73. 74. Info.ZeroMemory(); 75. Info.ArrayCopy(K); 76. 77. PrintX(Info.Median()); 78. Info.ArrayPrint(); 79. } 80. //+------------------------------------------------------------------+
Code 06
Wenn wir den Code 06 ausführen, erhalten wir genau das gleiche Ergebnis wie in Abbildung 02. Es ist jedoch zu beachten, dass sich Code 06 von Code 02 unterscheidet.
Zunächst einmal hält sich Code 02 nicht an die Kapselung, und aus diesem Grund wird der Kontext der Struktur gefährdet, denn irgendwann besteht die Gefahr, dass der interne Inhalt der Struktur geändert wird, ohne dass die Struktur dies merkt.
Zweitens: Da Code 06 vollständig mit strukturiertem Code arbeitet, können Probleme oder Fehler nicht auf ein einfaches Versehen zurückgeführt werden, da wir uns bei der Erstellung von Strukturprozeduren bewusst sind, was wir schaffen. Wenn also ein Fehler auftritt, ist er genau auf eine falsche Verwendung oder den Versuch zurückzuführen, den Kontext der Struktur zu ändern, ohne ihren ursprünglichen Zweck zu verstehen.
Solche Dinge sorgen für viel Verwirrung, wenn wir von der strukturierten Programmierung zur OOP übergehen, denn dort können wir die Bedeutung eines Objekts – das theoretisch eine Struktur sein sollte – vollständig in etwas ändern, das nichts mit dem ursprünglichen Objekt zu tun hat. Wir werden in Zukunft, wenn wir über OOP sprechen, auf diese Frage des Kontextes zurückkommen.
Deshalb ist es sehr wichtig, keine Schritte zu überspringen und nicht zu schnell voranzukommen. Der Versuch, etwas zu verstehen, ohne zuerst die einfacheren Konzepte zu begreifen, die seine Implementierung kompliziert machen, wird Ihnen als Programmierer nicht helfen. Je besser ein Konzept verstanden wird, desto einfacher ist es, es in einer Vielzahl von Situationen anzuwenden.
„Ich glaube, ich beginne, den Zweck der strukturierten Programmierung zu verstehen. Im Wesentlichen hilft es uns, sichereren und effizienteren Code zu erstellen. Aber ich habe eine Frage: Alles, was wir bisher gemacht haben, musste manuell gemacht werden. Das heißt, wir haben vom Compiler nicht viel Hilfe zu Themen wie denjenigen bekommen, die bei der Erklärung des Überladens und der Verwendung von Funktions- und Prozedurtemplates besprochen wurden. Können wir ein Überladen vermeiden und mithilfe des Compilers Funktions- und Prozedur-Templates einsetzen, um strukturierten Code zu erstellen? Wäre das noch strukturierte Programmierung?“
Das ist sicherlich eine ausgezeichnete Frage. Ich werde Sie jedoch mit dem Wunsch zurücklassen, zu lernen, wie man es macht, zumindest bis zur Veröffentlichung des nächsten Artikels.
Abschließende Gedanken
In diesem Artikel haben wir untersucht, wie man sogenannten strukturierten Code erstellt, bei dem der gesamte Kontext und die Methoden zur Manipulation von Variablen und Informationen in eine Struktur eingebettet sind, um einen geeigneten Kontext für die Implementierung jedes benötigten Codes zu schaffen. Wir haben gesehen, dass es notwendig ist, einen privaten Bereich zu verwenden, um zu trennen, was öffentlich ist und was nicht, um so die Regel der Kapselung einzuhalten und die Integrität, Sicherheit und Zuverlässigkeit des Kontextes zu bewahren, für den die Datenstruktur erstellt wurde. Wir haben auch festgestellt, dass selbst in strukturiertem Code Fehler gemacht werden können – oder besser gesagt, eine Kaskade von Fehlern ausgelöst werden kann -, und zwar genau dadurch, dass Funktionen oder Prozeduren eingeführt werden, die den ursprünglich beabsichtigten Kontext verletzen und dadurch einen einfachen Code in etwas Komplexes verwandeln, das schwer zu warten und zu verwenden ist.
Es wurde auch die Frage der Verwendung von Templates bei dieser Art der Umsetzung aufgeworfen. Da es sich hierbei um ein sehr viel komplexeres Thema handelt und dieser Artikel bereits reichlich Material zum Verständnis und zur Übung bietet, werden wir im nächsten Artikel mit dem Thema der Templates in strukturiertem Code beginnen. Aber Sie können jetzt damit anfangen, indem Sie die hier bereitgestellten Codes verwenden. Dies wird Ihnen helfen, die Hypothese der Verwendung von Konzepten für Dinge, die Sie noch nicht in Betracht gezogen oder erforscht haben, in die Praxis umzusetzen.
Übersetzt aus dem Portugiesischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/pt/articles/15860
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.