Diskussion zum Artikel "Entwicklung eines Expertenberaters für mehrere Währungen (Teil 13): Automatisierung der zweiten Phase — Aufteilung in Gruppen"
Vielen Dank für das Feedback, wir werden weitermachen.
Alexander, ich vermute, Sie haben noch nicht ganz herausgefunden, wie Sie static verwenden können. Mit seiner Hilfe kann das Singleton-Entwurfsmuster sowohl in MQL5 als auch in C++ leicht implementiert werden. Ich habe es z. B. für die Klasse CVirtualReceiver im dritten Teil verwendet. Dieser Modifikator ist in keiner Weise mit dem Chart verbunden, auf dem der Expert Advisor ausgeführt wird. Eine Variable oder eine Eigenschaft, die mit diesem Modifikator deklariert wurde, kann in Beziehung stehen, wenn wir ihnen z.B. das Ergebnis des Aufrufs der Funktion Symbol() zuweisen. Dies bedeutet jedoch nicht, dass wir den Wert solcher Variablen nicht nachträglich ändern können
Hallo Victor.
Ich verwende SQLiteStudio. Dieses kostenlose Programm hat in letzter Zeit seine Funktionalität stark erweitert, so dass ich nicht feststellen konnte, dass es an etwas Notwendigem fehlt. In MetaEditor kann man die Datenbank nur durch die Ausführung von SQL-Abfragen bearbeiten. Das ist natürlich weniger bequem.
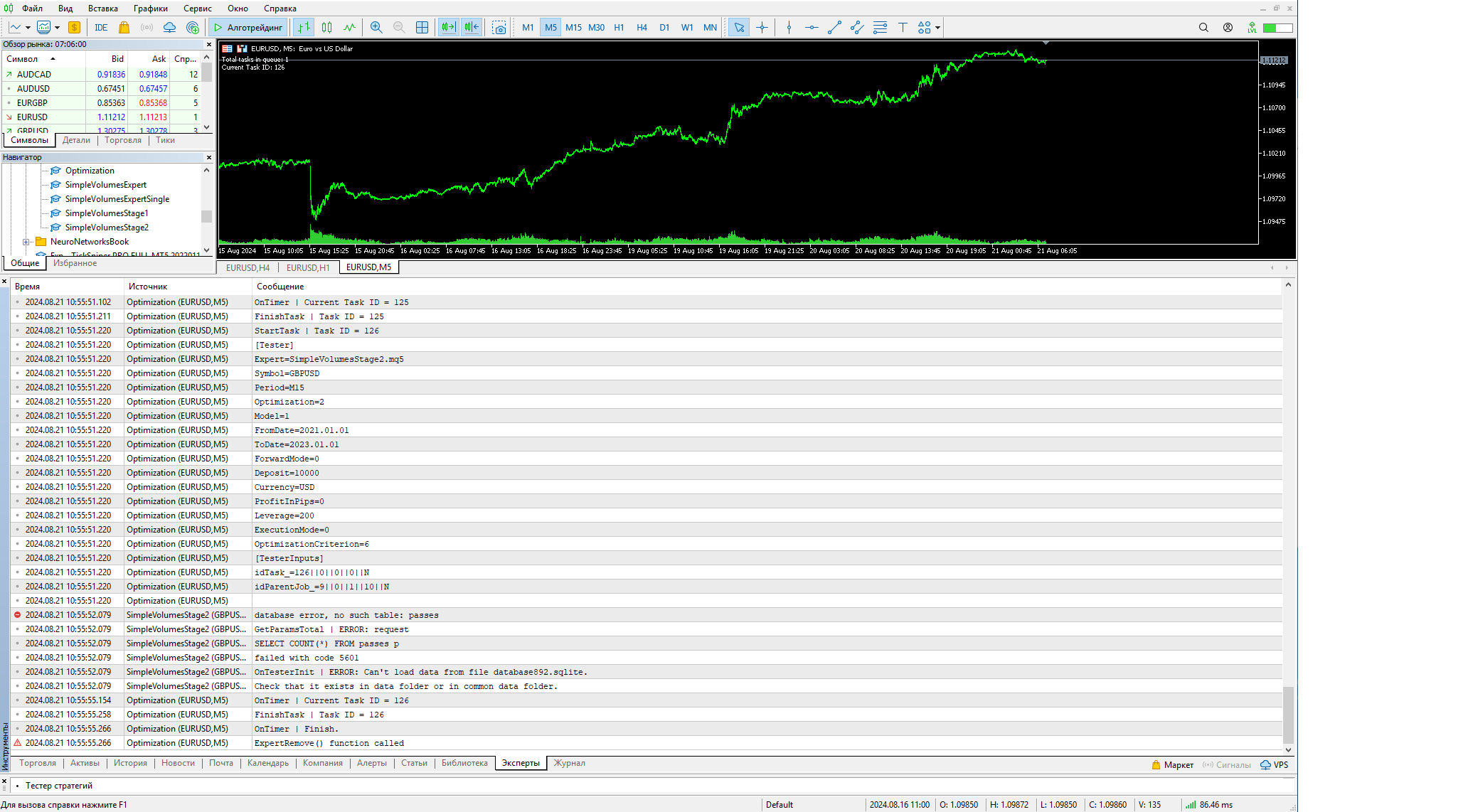
Yuri, danke für das Programm, jetzt kann ich die Datenbank öffnen und bearbeiten. Und ich habe die erste Stufe der Berechnungen durchgeführt, aber die zweite Stufe hat ein Problem - sie startet nicht. Ich habe zuerst die erste Stufe ausgeführt, dann manuell eine Zeile der zweiten Stufe hinzugefügt, wie auf dem Screenshot zu sehen ist, und zwei Abfragen aus Ihrem Artikel ausgeführt. Die Aufgaben und Jobs erschienen in der Datenbank und der Expert Advisor versucht, die zweite Phase auszuführen. Aber aus irgendeinem Grund sieht er die Durchläufe der ersten Phase nicht, obwohl sie in der Datenbank sind. Vielleicht verstehe ich etwas falsch (ich habe nicht mit Basen von jemandem gearbeitet).
Hier sind die Fehler auf den Bildschirmfotos. Wie kann ich es ausführen?
{kind=link}
{kind=link}
Außerdem, so wie ich diese Parameter verstehe:
input int count_ = 16; // - Anzahl der Strategien in der Gruppe (1 ... 16) input int i1_ = 1; // - Strategie-Index #1 input int i2_ = 2; // - Strategie-Index #2 input int i3_ = 3; // - Strategie-Index #3 input int i4_ = 4; // - Strategie-Index #4 input int i5_ = 5; // - Strategie-Index #5 input int i6_ = 6; // - Strategie-Index #6 input int i7_ = 7; // - Strategie-Index #7 input int i8_ = 8; // - Strategie-Index #8 input int i9_ = 9; // - Strategie-Index #9 input int i10_ = 10; // - Strategie-Index #10 input int i12_ = 11; // - Strategie-Index #11 input int i11_ = 12; // - Strategie-Index #12 input int i13_ = 13; // - Strategie-Index #13 input int i14_ = 14; // - Strategie-Index #14 input int i15_ = 15; // - Strategie-Index #15 input int i16_ = 16; // - Strategie-Index #16
in jeder Aufgabe der zweiten Stufe gesucht werden sollen. Aber in welchen Bereichen sollten sie durchsucht werden und mit welchem Schritt? Und der Parameter count_ selbst, wie ich verstehe, sollte nicht durchsucht werden?
Für die zweite Stufe sollte automatisch eine zweite Datenbank erstellt und an die Testagenten gesendet werden. Ihr Name wird in der Richtlinie
#define PARAMS_FILE "database892.stage2.sqlite"
Er muss sich von dem Namen der Hauptdatenbank unterscheiden. Auf dem Screenshot sehen Sie, dass die Tabelle passes nicht in dieser Datenbank enthalten ist, obwohl sie dort erwartet wurde. Versuchen Sie, die Arbeit der Funktion CreateTaskDB() zu verstehen, mit der die zweite Datenbank aus der ursprünglichen Datenbank erstellt wird.
Der Schritt und die Grenzen der Suche nach Parametern des Typs i{N}_ werden vom Expert Advisor Optimisation.mq5 automatisch auf der Grundlage der Informationen aus der zweiten Datenbank festgelegt.
Der Parameter count_ muss nicht durchsucht werden. Er kann auf einen kleineren Wert geändert werden, wenn wir Gruppen nicht aus 16, sondern aus einer kleineren Anzahl von Instanzen auswählen wollen. Zum Beispiel aus 12 oder aus 8. Aber für mich war er immer gleich 16.
Juri, ich kann es nicht zum Laufen bringen.... Die Datei der gemeinsamen Datenbank, die ich habe, ist wie bei Ihnen im Advisor database892.sqlite angegeben, ich habe sie nicht geändert und sie befindet sich wirklich auf der Festplatte, und der Advisor Optimisation.mq5 verbindet sich mit ihr und führt Aufgaben aus. Im Expert Advisor SimpleVolumesStage2.mq5 ist sie auch angegeben. Und die Datenbankdatei des Tasks ist mit database892.stage2.sqlite angegeben. So wie ich das verstehe, sind das unterschiedliche Dateien. Die gemeinsame Datenbankdatei befindet sich im Ordner Common\Files.
Ich habe versucht, Prüfungen in die Funktion GetParamsTotal einzufügen und die Variable fileName in der Funktion DB::Connect anzugeben, hier ist der Code:
//+------------------------------------------------------------------+ //| Anzahl der Strategieparametersätze in der Aufgabendatenbank | //+------------------------------------------------------------------+ int GetParamsTotal(const string fileName) { int paramsTotal = 0; PrintFormat(__FUNCTION__" 1 "); // Wenn die Aufgabendatenbank geöffnet ist, dann if(DB::Connect(fileName, 0)) { PrintFormat(__FUNCTION__" 2 "); // Erstellen Sie eine Abfrage, um die Anzahl der Durchläufe für diese Aufgabe zu ermitteln string query = "SELECT COUNT(*) FROM passes p"; PrintFormat(__FUNCTION__" 3 "); int request = DatabasePrepare(DB::Id(), query); PrintFormat(__FUNCTION__" 4 "); if(request != INVALID_HANDLE) { // Datenstruktur für das Abfrageergebnis PrintFormat(__FUNCTION__" 5 "); struct Row { int total; } row; PrintFormat(__FUNCTION__" 6 "); // Abrufen des Ergebnisses der Abfrage aus der ersten Zeile if (DatabaseReadBind(request, row)) { paramsTotal = row.total; } } else { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } DB::Close(); } PrintFormat(__FUNCTION__" 7 "); return paramsTotal; }
Bei der Ausführung im Protokoll wird dies so ausgegeben:
2024.08.21 22:05:27.964 Optimization (EURUSD,M5) idTask_=124||0||0||0||N 2024.08.21 22:05:27.964 Optimization (EURUSD,M5) idParentJob_=7||0||1||10||N 2024.08.21 22:05:27.964 Optimization (EURUSD,M5) 2024.08.21 22:05:29.096 SimpleVolumesStage2 (GBPUSD,H1) GetParamsTotal 1 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) GetParamsTotal 2 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) GetParamsTotal 3 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) database error, no such table: passes 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) GetParamsTotal 4 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) GetParamsTotal | ERROR: request 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) SELECT COUNT(*) FROM passes p 2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) failed with code 5039 2024.08.21 22:05:29.098 SimpleVolumesStage2 (GBPUSD,H1) GetParamsTotal 7 2024.08.21 22:05:29.098 SimpleVolumesStage2 (GBPUSD,H1) OnTesterInit | ERROR: Can't load data from file database892.sqlite. 2024.08.21 22:05:29.098 SimpleVolumesStage2 (GBPUSD,H1) Check that it exists in data folder or in common data folder. 2024.08.21 22:05:32.900 Optimization (EURUSD,M5) OnTimer | Current Task ID = 124 2024.08.21 22:05:33.008 Optimization (EURUSD,M5) FinishTask | Task ID = 124 2024.08.21 22:05:33.022 Optimization (EURUSD,M5) StartTask | Task ID = 125 2024.08.21 22:05:33.022 Optimization (EURUSD,M5) [Tester]
Wobei die Fehlernummer noch 5602 schreiben kann. So wie ich es verstehe, stolpert er über die Funktion DatabasePrepare.
Ich habe die Datenbank genommen, wie Sie in der Datei zum Artikel 11 gepostet haben. Das einzige, was ich geändert habe, ist der Dateiname von database.sqlite zu database892.sqlite und ich habe den Namen des Beraters der ersten Stufe in der Datenbank in den tatsächlichen in diesem Teil geändert und nachdem ich die erste Stufe ausgeführt habe, habe ich die Zeile der zweiten Stufe zur Tabelle stages hinzugefügt und 2 Sätze von Befehlen aus Ihrem Artikel ausgeführt. Sonst habe ich nichts geändert. Es gibt etwa 388.000 Zeilen mit Pässen in der Tabelle passes.
Der Fehler tritt schon früher auf, er wird nur nicht gemeldet, da aus Sicht der Programmausführung alles in Ordnung ist.
Diese Meldung
2024.08.21 22:05:29.097 SimpleVolumesStage2 (GBPUSD,H1) database error, no such table: passes
besagt direkt, dass es in der zweiten Datenbank keine Pässe-Tabelle gibt, und wir versuchen, Daten daraus zu holen. Deshalb sollten wir uns mit der Funktion befassen, die sie erstellen soll - CreateTaskDB().
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Neuer Artikel Entwicklung eines Expertenberaters für mehrere Währungen (Teil 13): Automatisierung der zweiten Phase — Aufteilung in Gruppen :
Die erste Stufe der automatischen Optimierung haben wir bereits umgesetzt. Wir führen die Optimierung für verschiedene Symbole und Zeiträume nach mehreren Kriterien durch und speichern Informationen über die Ergebnisse jedes Durchgangs in der Datenbank. Nun werden wir die besten Gruppen von Parametersätzen aus den in der ersten Stufe gefundenen auswählen.
Die nächste Stufe ist eine Auswahl von guten Gruppen einzelner Instanzen von Handelsstrategien, die, wenn sie zusammenarbeiten, die Handelsparameter verbessern — den Drawdown reduzieren, die Linearität des Wachstums der Gleichgewichtskurve erhöhen, und so weiter. Wir haben uns bereits im sechsten Teil der Serie angesehen, wie dieser Schritt manuell durchgeführt werden kann. Zunächst haben wir aus den Ergebnissen der Optimierung der Parameter einzelner Handelsstrategien diejenigen ausgewählt, die unsere Aufmerksamkeit verdienen. Dies hätte anhand verschiedener Kriterien geschehen können, aber zu diesem Zeitpunkt beschränkten wir uns darauf, Ergebnisse mit negativem Gewinn einfach zu entfernen. Dann haben wir mit verschiedenen Methoden versucht, verschiedene Kombinationen von acht Instanzen von Handelsstrategien zu nehmen, sie in einem EA zu kombinieren und sie im Tester laufen zu lassen, um die Parameter ihrer gemeinsamen Arbeit zu bewerten.
Ausgehend von der manuellen Auswahl haben wir auch eine automatische Auswahl von Eingabekombinationen einzelner Handelsstrategien implementiert, die aus der Liste der in einer CSV-Datei gespeicherten Parameter ausgewählt wurden. Es zeigt sich, dass selbst im einfachsten Fall das gewünschte Ergebnis erzielt wird, wenn wir einfach eine genetische Optimierung durchführen, die acht Kombinationen auswählt.
Ändern wir nun den EA, der die Gruppenauswahloptimierung durchgeführt hat, so, dass er die Ergebnisse der ersten Stufe aus der Datenbank verwenden kann. Außerdem sollte es seine Ergebnisse in der Datenbank speichern. Wir werden auch die Erstellung von Aufgaben für die Durchführung von Optimierungen der zweiten Stufe in Betracht ziehen, indem wir die erforderlichen Einträge in unsere Datenbank aufnehmen.
Autor: Yuriy Bykov