
Kategorientheorie (Teil 9): Monoid-Aktionen
Einführung
In einem früheren Artikel haben wir Monoide vorgestellt und gesehen, wie sie beim überwachten Lernen zur Klassifizierung und Information von Handelsentscheidungen verwendet werden können. Im weiteren Verlauf werden wir uns mit den Monoid-Aktionen befassen und untersuchen, wie sie auch beim unüberwachten Lernen eingesetzt werden können, um die Dimensionen der Eingabedaten zu reduzieren. Die Ausgaben von Monoiden aus ihren Operationen ergeben immer Elemente ihrer Menge, das heißt, sie sind nicht transformativ. Es sind also Monoide Aktionen, die die Fähigkeit der Transformation hinzufügen, da die Aktionsmenge keine Teilmenge der monoiden Menge sein muss. Unter Transformation verstehen wir die Fähigkeit, Aktionsausgänge zu haben, die nicht Elemente der Monoidmenge sind.
Formal ist die monoide Wirkung a eines Monoids M (e, *) auf eine Menge S ist definiert als:
a: M x S - - > S ; (1)
e a s - - > s; (2)
m * (n * s) - - > (m * n) a s (3)
Dabei sind m, n Elemente des Monoids M, und s ist ein Elemente der Menge S.
Illustration und Methoden
Das Verständnis der relativen Bedeutung der verschiedenen Merkmale im Entscheidungsprozess eines Modells ist wertvoll. In unserem Fall, wie in einem früheren Artikel beschrieben, waren unsere „Merkmale“:
- Rückblickzeitraum
- Zeitrahmen
- Angewandter Preis
- Indikator
- Handelsentscheidung für Spanne oder Trend.
Wir werden uns einige Techniken ansehen, die zur Gewichtung der Merkmale unseres Modells geeignet sind und dazu beitragen, die für die Genauigkeit unserer Vorhersage empfindlichsten Merkmale zu ermitteln. Wir werden eine Technik auswählen und auf der Grundlage ihrer Empfehlung versuchen, an diesem Knoten eine Transformation zum Monoid hinzuzufügen, indem wir die Monoid-Menge durch Monoid-Aktionen erweitern, um zu sehen, wie sich dies auf unsere Fähigkeit auswirkt, Trailing Stops genau zu platzieren, wie in der Anwendung, die wir im vorherigen Artikel betrachtet haben.
Für die Bestimmung der relativen Bedeutung jeder Datenspalte in einem Trainingssatz gibt es verschiedene Werkzeuge und Methoden, die eingesetzt werden können. Diese Techniken helfen dabei, den Beitrag jedes Merkmals (jeder Datenspalte) zu den Vorhersagen des Modells zu quantifizieren, und geben uns Hinweise darauf, welche Datenspalte möglicherweise ausgearbeitet werden muss und welchen weniger Aufmerksamkeit geschenkt werden sollte. Hier sind einige häufig verwendete Methoden:
Ranking der Wichtigkeit von Merkmalen
Dieser AnsatzAnsatz ordnet die Merkmale nach ihrer Wichtigkeit, indem er die Auswirkungen auf die Modellleistung berücksichtigt. In der Regel bieten verschiedene Algorithmen wie Random Forests, Gradient Boosting Machines (GBMs, Gradientenverstärkung) oder Extra Trees integrierte Merkmalsbedeutungsmaße, die nicht nur bei der Erstellung von Bäumen helfen, sondern auch nach dem Modelltraining extrahiert werden können.
Betrachten wir zur Veranschaulichung ein Szenario, in dem wir, wie im vorangegangenen Artikel, Änderungen in der Preisspanne prognostizieren und dies zur Anpassung des Trailing-Stops offener Positionen nutzen wollen. Wir werden daher die Entscheidungspunkte, die wir damals hatten (Merkmale oder Datenspalten), als Bäume betrachten. Wenn wir für diese Aufgabe einen Random Forest Klassifikator verwenden, indem wir jeden unserer Entscheidungspunkte als Baum betrachten, können wir nach dem Trainings-Modell eine Rangfolge der Merkmalsbedeutung erstellen.
Zur Verdeutlichung: Unser Datensatz wird folgende Bäume enthalten:
- Länge des Rückblickzeitraums der Analyse (ganzzahliger Typ)
- Für den Handel gewählter Zeitrahmen (Enumeration: 1 Stunde, 2 Stunden, 3 Stunden, usw.)
- In der Analyse verwendeter Preis (Enumeration: Eröffnungspreis, Medianpreis, typischer Preis, Schlusskurs)
- Auswahl des in der Analyse verwendeten Indikators (Enumeration von RSI-Oszillator oder den Bollinger Bändern)
Nach dem Training mit dem Random-Forest-Klassifikator können wir eine Rangfolge der Merkmalsbedeutung mit Hilfe von Gini-Fremdbestandteilsgewichten (Gini impurity weights) erstellen. Die Werte für die Bedeutung der Merkmale geben die relative Bedeutung (Gewichtung) jeder Datenspalte im Entscheidungsprozess des Modells an.
Nehmen wir an, das Ranking der Merkmalswichtigkeit ergab Folgendes:
- Wahl des in der Analyse verwendeten Indikators: 0.45
- Länge des Rückblicks-Analysezeitraums: 0.30
- Angewandter Preis für die Analyse: 0.20
- Beim Handel gewählter Zeitrahmen: 0.05
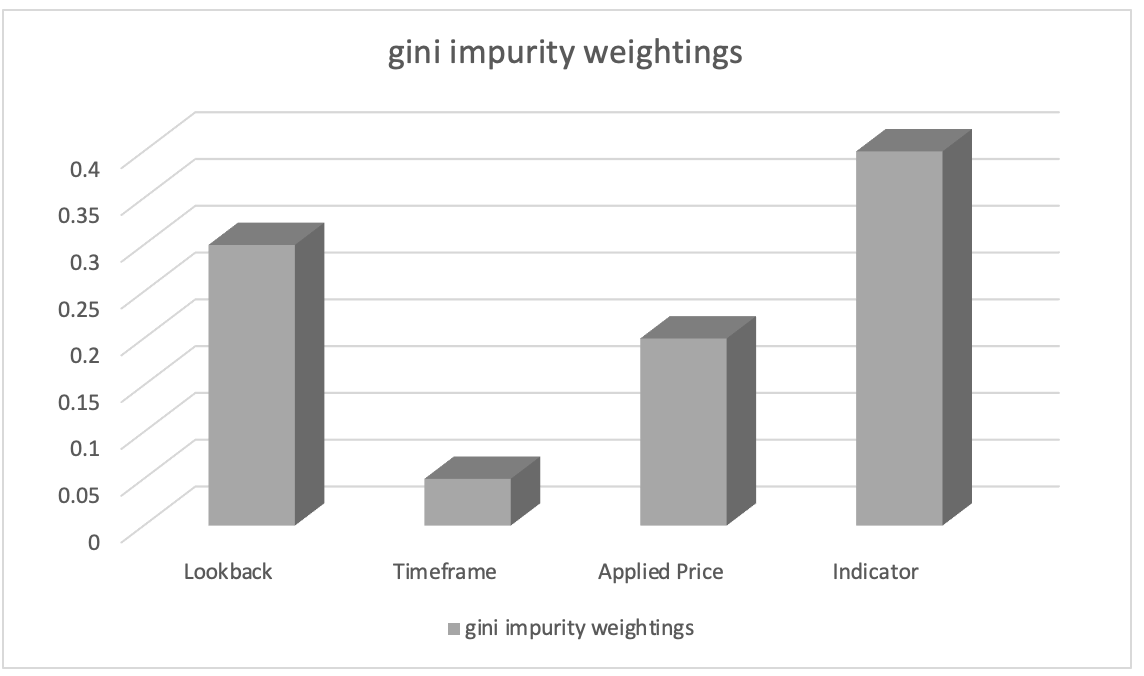
Daraus lässt sich ableiten, dass das Merkmal „Wahl des in der Analyse verwendeten Indikators“ die größte Bedeutung hat, gefolgt von dem Merkmal „Länge des Rückblicks-Analysezeitraums“. Das Merkmal „Angewandter Preis für die Analyse“ steht an dritter Stelle, während das Merkmal „Zeitrahmen für den Handel“ die geringste Bedeutung hat.
Diese Informationen können uns helfen zu verstehen, welche Merkmale die Vorhersagen des Modells am stärksten beeinflussen. Mit diesem Wissen können wir uns bei der Entwicklung von Merkmalen auf wichtigere Merkmale konzentrieren, bei der Auswahl von Merkmalen Prioritäten setzen oder weitere domänenspezifische Erkenntnisse in Bezug auf diese Merkmale erforschen. In unserem Fall könnten wir die monoide Menge von Indikatoren durch die Einführung von monoiden Aktionsmengen anderer Indikatoren umwandeln und untersuchen, wie dies unsere Prognosen beeinflusst. Unsere Aktionssets würden also alternative Indikatoren zum RSI-Oszillator und Bollinger Bänder hinzufügen. Welchen Indikator wir auch immer hinzufügen, wie bei den Bollinger Bändern im vorherigen Artikel, müssen wir seine Ausgabe regulieren und sicherstellen, dass er sich in einem Bereich von 0 bis 100 befindet, wobei 0 eine abnehmende Preisspanne und 100 eine zunehmende Spanne anzeigt.
Bedeutung der Permutation
Die Bedeutung der Permutation bewertet den Einfluss der Reihenfolge von Merkmalen (oder Datenspalten), indem ihre Reihenfolge zufällig vertauscht wird und die anschließende Änderung der Modellleistung bei der Erstellung von Prognosen gemessen wird. Denken Sie daran, dass die Reihenfolge bisher Rückblickzeitraum (lookback), dann Zeitrahmen, dann angewandter Preis, dann Indikator und schließlich Art der Handelsentscheidung war. Was würde passieren, wenn wir unsere Entscheidungen in eine andere Reihenfolge bringen würden? Dazu müssten wir jeweils nur eine Datenspalte (Merkmal) umstellen. Ein größerer Rückgang der Vorhersagegenauigkeit für eine dieser Datenspalten würde auf eine höhere Bedeutung hinweisen. Diese Methode ist modellunabhängig und kann auf jeden maschinellen Lernalgorithmus angewendet werden.
Betrachten wir zur Veranschaulichung ein Szenario mit demselben Datensatz von fünf Spalten wie oben und im vorigen Artikel, und wir möchten Änderungen in der Preisspanne prognostizieren. Entscheiden wir uns für die Verwendung des Klassifikators Gradient Boosting für diese Aufgabe. Um die Signifikanz jeder Datenspalte anhand der Permutationsbedeutung zu bewerten, trainieren wir im Wesentlichen unser Modell. Beim Training des Gradientenverstärkungs-Klassifikators mit monoiden Operatorfunktionen und Identitätseinstellungen, die wir in unserem vorherigen Artikel verwendet haben, wird unser Datensatz der folgenden Tabelle ähneln:

Um einen Gradientenverstärkungs-Klassifikator mit unserem Datensatz zu trainieren, können wir dieser 4-Schritte-Anleitung folgen:
Daten vorverarbeiten:
Dieser Schritt beginnt mit der Umwandlung unserer diskreten Daten (d.h. Enumerationen; Zeitrahmen des Preisdiagramms, angewandter Preis, Wahl des Indikators, Handelsentscheidung) in numerische Darstellungen unter Verwendung von Techniken wie der 1-aus-n-Code. Anschließend teilen Sie den Datensatz in Merkmale (Datenspalten 1-5) und Modellprognosen plus tatsächliche Werte (Datenspalten 6-7) auf.
Daten aufteilen: Nach der Vorverarbeitung müssen wir den Datensatz in Zeilen für die Trainingsmenge und Zeilen für die Testmenge unterteilen. Auf diese Weise können Sie die Leistung des Modells bei unbekannten Daten bewerten und dabei die Einstellungen verwenden, die bei Ihren Trainingsdaten am besten funktioniert haben. In der Regel wird eine Aufteilung von 80:20 verwendet, aber Sie können das Verhältnis je nach Größe und Eigenschaften der Zeilen in Ihrem Datensatz anpassen. Für die in diesem Artikel verwendeten Datenspalten würde ich eine Aufteilung von 60:40 empfehlen.
Einen Gradientenverstärkungs-Klassifikator erstellen: Anschließend binden wir die notwendigen Bibliotheken ein oder implementieren die erforderlichen Funktionen für den Gradientenverstärkungs-Klassifikator in C/MQL5. Dies bedeutet, dass in die Initialisierungsfunktion des Experten erstellte Instanzen des Gradientenverstärkungs-Klassifikatormodells aufgenommen werden, bei denen wir auch Hyperparameter wie die Anzahl der Schätzer, die Lernrate und die maximale Tiefe angeben.
Trainingsmodell: Durch Iteration über die Trainingsdaten und Variation der Reihenfolge der einzelnen Datenspalten während des Entscheidungsprozesses wird der Trainingssatz zum Trainieren des Gradientenverstärkungs-Klassifikators verwendet. Die Modellergebnisse werden dann protokolliert. Um die Genauigkeit der Vorhersagen für die Anpassung der Preisspanne zu erhöhen, können Sie auch die Parameter des Modells variieren, wie z. B. die Identitätselemente der einzelnen Monoide oder die Art der Operationen (aus der Liste der im vorherigen Artikel verwendeten Operationen).
System auswerten: Das Modell wird an Testdatenreihen (40 % bei der Aufteilung getrennt) mit den besten Einstellungen aus dem Training getestet. So können wir feststellen, wie gut trainierte Modelleinstellungen auf untrainierten Daten funktionieren. Dabei würden wir alle Datenzeilen außerhalb der Stichprobe in den Daten (Testdatenzeilen) durchlaufen, um die Fähigkeit des Modells zur Vorhersage von Änderungen in der Zielkursspanne zu bewerten. Die Ergebnisse der Testläufe könnten dann mit Methoden wie F-Score usw. ausgewertet werden.
Wir können auch eine Feinabstimmung des Modells vornehmen, wenn die Leistung verbessert werden muss, indem wir die Hyperparameter des Gradientenverstärkungs-Klassifikators ändern. Um die besten Hyperparameter zu ermitteln, müssen wir Methoden wie die Rastersuche und die Kreuzvalidierung anwenden. Nachdem Sie ein erfolgreiches Modell entwickelt haben, können Sie es verwenden, um Annahmen über neue, unvorhergesehene Daten zu treffen, indem Sie die kategorialen Variablen in den neuen Daten vorverarbeiten und kodieren, um sicherzustellen, dass sie dasselbe Format wie die Trainingsdaten haben. Damit würden wir dann unsere Preisbalkenänderungen für neue Daten mit Hilfe des trainierten Modells vorhersagen.
Beachten Sie, dass die Implementierung der Gradientenverstärkungsklassifikation in MQL5 von Grund auf schwierig und zeitaufwändig sein kann. Daher ist die Verwendung von in C geschriebenen Bibliotheken für maschinelles Lernen, wie XGBoost oder LightGBM die effektive Implementierungen einer Gradientenverstärkung mit C-APIs bieten, sehr zu empfehlen.
Stellen wir uns zur Veranschaulichung vor, dass wir nach dem Vertauschen unserer Datenspalten folgende Ergebnisse erhalten:
- Wenn der Rückblickzeitraum geändert wird, sinkt die Prognoseleistung um 0,062.
- Der Zeitrahmen für die Permutation führt zu einem Leistungsrückgang von 0,048.
- Die Anwendung der Permutation auf den angewandten Preis führt zu einem Leistungsverlust von 0,027.
- Die Leistung sinkt um 0,014, wenn der Indikator für die Position der Datenspalten gemischt wird.
- Performanceverlust nach Permutation der Handelsentscheidung führt zu 0,009.
Diese Ergebnisse lassen den Schluss zu, dass der „Rückblickzeitraum“ bei der Vorhersage von Veränderungen in der Preisspanne die größte Bedeutung hat, da die Vertauschung seiner Werte die größte Verringerung der Modellleistung verursacht. Das zweitwichtigste Merkmal ist „Zeitrahmen“, gefolgt von „angewandter Preis“, „Indikator“ und schließlich „Handelsentscheidung“.
Durch die Quantifizierung der Auswirkungen der einzelnen Datenspalten auf die Leistung des Modells ermöglicht diese Methode die Bestimmung ihrer relativen Bedeutung. Durch die Bewertung der relativen Bedeutung jedes Merkmals (Datenspalte) sind wir besser in der Lage, Merkmale auszuwählen, Merkmale zu entwickeln und vielleicht sogar Bereiche hervorzuheben, in denen unser Vorhersagemodell mehr Forschung und Entwicklung benötigt.
Wir könnten daher monoide Aktionen für die Rückblick-Monoidmenge vorschlagen, die sie durch Hinzufügen zusätzlicher Rückblick-Perioden, die nicht bereits in der Monoidmenge enthalten sind, verändern, um eine weitere Verbesserung zu erklären. Auf diese Weise können wir untersuchen, ob diese zusätzlichen Zeiträume einen Einfluss darauf haben, wie gut unser Modell Veränderungen in der Preisspanne vorhersagt, wenn überhaupt. Die Monoidmenge besteht derzeit aus Werten von 1 bis 8, die jeweils ein Vielfaches von 4 sind. Was wäre, wenn wir einen Multiplikator von 3 oder 2 hätten? Welche Auswirkungen hätte dies (wenn überhaupt) auf die Leistung? Da wir nun wissen, welchen Platz die Rückblicksperiode im Entscheidungsprozess einnimmt und dass sie sich am stärksten auf die Gesamtleistung des Systems auswirkt, können diese und vergleichbare Probleme angegangen werden.
SHAP -Wert
SHAP (SHapley Additive exPlanations) ist ein einheitlicher Rahmen, der jeder Datenspalte auf der Grundlage von spieltheoretischen Prinzipien Wichtigkeitswerte zuweist. Die SHAP-Werte bieten eine faire Verteilung der Merkmalsbeiträge unter Berücksichtigung aller Möglichkeiten. Sie bieten ein umfassendes Verständnis der Bedeutung von Merkmalen in komplexen Modellen wie XGBoost, LightGBM oder Deep-Learning-Modellen.
Rekursive Merkmaleliminierung (RFE)
Die Merkmalsauswahl ist eine iterative Methode zur Auswahl von Merkmalen, bei der weniger wichtige Merkmale auf der Grundlage ihrer Gewichtung oder Wichtigkeit rekursiv eliminiert werden. Der Prozess wird fortgesetzt, bis die gewünschte Anzahl von Merkmalen erreicht oder ein Leistungsschwellenwert erreicht ist. Zur Veranschaulichung können wir ein ähnliches Szenario wie oben verwenden, bei dem wir einen Datensatz mit fünf Spalten vom Rückblickzeitraum bis zur Art der Handelsentscheidung haben und Änderungen in der Preisspanne auf der Grundlage von 5 Merkmalen (Datenspalten) vorhersagen möchten. Wir verwenden für diese Aufgabe einen Support Vector Machine (SVM) Klassifikator. Die rekursive Merkmalseliminierung (RFE) würde also wie folgt angewendet werden:
- Modell mit SVM-Klassifikator unter Verwendung aller Datenspalten im Datensatz trainieren. Am Anfang steht die Ausbildung mit allem.
- Als Nächstes werden die Merkmale in eine Rangfolge gebracht, wobei wir Gewichte oder Wichtigkeitswerte erhalten, die jedem Merkmal vom SVM-Klassifikator zugewiesen werden. Sie zeigen die relative Bedeutung der einzelnen Elemente für die Klassifizierung an.
- Die Eliminierung des am wenigsten wichtigen Merkmals erfolgt als Nächstes, wobei die am wenigsten wichtige Datenspalte auf der Grundlage der SVM-Gewichte weggelassen wird. Dies kann durch Entfernen des Merkmals mit dem geringsten Gewicht geschehen.
- Als Nächstes wird das Modell mit reduzierten Datenspalten neu trainiert, wobei der SVM-Klassifikator nur auf die verbleibenden Merkmale angewendet wird.
- Die Leistungsbewertung ohne ausgelassene Datenspalte erfolgt anhand einer geeigneten Bewertungskennzahl, wie z. B. Genauigkeit oder F-Score.
- Der Prozess wird von Schritt 2 bis 5 wiederholt, bis die gewünschte Anzahl von Spalten erreicht ist, wobei in jeder Iteration die am wenigsten wichtigen Merkmale (oder Datenspalten) eliminiert und das Modell mit einem reduzierten Merkmalssatz neu trainiert wird.
Nehmen wir zum Beispiel an, wir beginnen mit fünf Merkmalen und wenden RFE an, und wir haben ein Ziel von 3 Merkmalen. Bei Iteration 1 nehmen wir an, dass es sich um eine Rangfolge der Merkmale auf der Grundlage absteigender Wichtigkeitswerte handelt:
- Rückblickzeitraum
- Zeitrahmen
- Angewandter Preis
- Indikator
- Handelsentscheidung
Das Merkmal mit der geringsten Wichtigkeit, die Handelsentscheidung, wird eliminiert. Retraining des SVM-Klassifikators mit den verbleibenden Merkmalen: Rückblickszeitraum, Zeitrahmen, angewandter Preis und Indikator würden dann folgen. Nehmen wir an, dass dies die Rangfolge bei Iteration 2 ist:
- Rückblickzeitraum
- Indikator
- Zeitrahmen
- Angewandter Preis
Eliminieren wir das Merkmal mit der geringsten Wichtigkeit, das wäre der angewandte Preis. Da keine weiteren Merkmale mehr zu eliminieren sind, da wir die gewünschte Anzahl von Merkmalen erreicht haben, würde die Iteration anhalten. Der iterative Prozess stoppt, wenn die gewünschte Anzahl von Merkmalen (oder ein anderes vordefiniertes Stoppkriterium wie ein F-Score-Schwellenwert) erreicht ist. Das endgültige Modell wird daher anhand ausgewählter Merkmale trainiert: Rückblickzeitraum, Indikator und Zeitrahmen. RFE hilft dabei, die wichtigsten Merkmale für die Klassifizierungsaufgabe zu identifizieren, indem weniger relevante Merkmale iterativ entfernt werden. Durch die Auswahl einer Teilmenge von Merkmalen, die am meisten zur Leistung des Modells beitragen, kann RFE die Modelleffizienz verbessern, die Überanpassung reduzieren und die Interpretierbarkeit erhöhen.
L1-Regularisierung (Lasso)
Die L1 Regularisierung wendet einen Strafterm auf die Zielfunktion des Modells an, wodurch spärliche Merkmalsgewichte gefördert werden. Infolgedessen haben weniger wichtige Merkmale in der Regel eine Gewichtung von Null oder nahezu Null, sodass eine Merkmalsauswahl auf der Grundlage der Größe der Gewichte möglich ist. Stellen Sie sich ein Szenario vor, in dem ein Händler sein Engagement in Immobilien und REITs abschätzen möchte. Wir verfügen über einen Datensatz von Immobilienpreisen, mit dem wir die Preisentwicklung von Wohnhäusern auf der Grundlage verschiedener Merkmale wie Fläche, Anzahl der Schlafzimmer, Anzahl der Badezimmer, Lage und Alter vorhersagen möchten. Wir können die L1-Regularisierung, insbesondere den Lasso-Algorithmus, verwenden, um die Bedeutung dieser Merkmale zu bewerten. Und so funktioniert es:
- Wir beginnen mit dem Training eines linearen Regressionsmodells mit L1-Regularisierung (Lasso) unter Verwendung aller Merkmale des Datensatzes. Der L1-Regularisierungsterm fügt der Zielfunktion des Modells eine Strafe hinzu.
- Nach dem Training des Lasso-Modells erhalten wir geschätzte Gewichte für jedes Merkmal. Diese Gewichte stehen für die Bedeutung jedes Merkmals bei der Vorhersage der Immobilienpreise. Die L1-Regularisierung fördert spärliche Merkmalsgewichte, was bedeutet, dass weniger wichtige Merkmale in der Regel null oder nahezu null Gewichte haben.
- Rangmerkmale: Wir können die Merkmale anhand der Größe der Gewichte einstufen. Merkmale mit höheren absoluten Gewichten werden als wichtiger angesehen, während Merkmale mit Gewichten nahe Null als weniger wichtig gelten.
Nehmen wir zum Beispiel an, wir trainieren ein Lasso-Modell für den Datensatz der Immobilienpreise und erhalten folgende Merkmalsgewichte:
- Gebiet: 0.23
- Anzahl der Schlafzimmer: 0.56
- Anzahl der Bäder: 0.00
- Standort: 0.42
- Alter: 0.09
Auf der Grundlage dieser Merkmalsgewichte können wir die Merkmale nach ihrer Bedeutung für die Vorhersage der Hauspreise einstufen:
- Anzahl der Schlafzimmer: 0.56
- Standort: 0.42
- Gebiet: 0.23
- Alter: 0.09
- Anzahl der Bäder: 0.00
In diesem Beispiel hat die Anzahl der Schlafzimmer das höchste absolute Gewicht, was darauf hindeutet, dass ihre Bedeutung für die Vorhersage der Immobilienpreise hoch ist. Ort und Gebiet folgen dicht dahinter, während das Alter eine relativ geringe Bedeutung hat. Die Anzahl der Bäder hat in diesem Fall eine Gewichtung von Null, was darauf hindeutet, dass sie als unwichtig erachtet wird und aus dem Modell ausgeschlossen wurde.
Durch Anwendung der L1-Regularisierung (Lasso) können wir die wichtigsten Merkmale für die Vorhersage von Immobilienpreisen ermitteln und auswählen. Die Regularisierungsstrafe fördert die Sparsamkeit der Merkmalsgewichte und ermöglicht eine Merkmalsauswahl auf der Grundlage der Größe der Gewichte. Diese Technik hilft zu verstehen, welche Merkmale den größten Einfluss auf die Zielvariable (Entwicklung der Wohnungspreise) haben, und kann für die Entwicklung von Merkmalen, die Modellinterpretation und die potenzielle Verbesserung der Modellleistung durch Verringerung der Überanpassung nützlich sein.
Die Hauptkomponentenanalyse (PCA)
Die Hauptkomponentenanalyse (eng. Principal Component Analysis, PCA) ist eine Technik zur Dimensionalitätsreduzierung, mit der die Bedeutung von Merkmalen indirekt bewertet werden kann, indem die ursprünglichen Merkmale in einen niedriger-dimensionalen Raum umgewandelt werden. PCA identifiziert die Richtungen maximaler Varianz. Die Hauptkomponenten mit der höchsten Varianz können als wichtiger angesehen werden.
Die Korrelationsanalyse
Die Korrelationsanalyse untersucht die lineare Beziehung zwischen Merkmalen und Zielvariablen. Merkmale mit höheren absoluten Korrelationswerten werden oft als wichtiger für die Vorhersage der Zielvariablen angesehen. Es ist jedoch zu beachten, dass die Korrelation keine nicht-linearen Beziehungen erfasst.
Transinformation
Die Transinformation (engl. mutual information, gegenseitige Information) misst die statistische Abhängigkeit zwischen Variablen. Sie gibt an, wie viele Informationen über eine Variable aus einer anderen gewonnen werden können. Höhere Werte für die wechselseitige Information weisen auf eine stärkere Beziehung hin und können zur Bewertung der relativen Bedeutung von Merkmalen verwendet werden.
Zur Veranschaulichung können wir uns ein Szenario vorstellen, in dem ein Händler/Investor auf der Grundlage eines Datensatzes mit Kundeninformationen eine Position in einem aufstrebenden Private-Equity-Startup eröffnen möchte, mit dem Ziel, die Kundenabwanderung auf der Grundlage verschiedener verfügbarer Merkmale (unserer Datenspalten) wie Alter, Geschlecht, Einkommen, Abonnementtyp und Gesamtkäufe vorherzusagen. Wir können die Transinformation nutzen, um die Wichtigkeit dieser Informationen zu beurteilen. Das würde folgendermaßen funktionieren:
- Wir beginnen mit der Berechnung der Transinformation zwischen jedem Merkmal und der Zielvariablen (Kundenabwanderung). Die Transinformation misst den Umfang der Informationen, die eine Variable über eine andere Variable enthält. In unserem Fall quantifiziert sie, wie viele Informationen über die Kundenabwanderung aus jedem Merkmal in unseren verfügbaren Datenspalten gewonnen werden können.
- Nachdem wir die Werte für die Transinformation ermittelt haben, ordnen wir diese nach ihren Werten. Höhere Werte für die Transinformation weisen auf eine stärkere Beziehung zwischen Merkmal und Kundenabwanderung hin, was auf eine höhere Bedeutung schließen lässt.
Nehmen wir zum Beispiel an, dass die Transinformationswerte für die Datenspalten gleich sind:
- Alter: 0.08
- Geschlecht: 0.03
- Einkommen: 0.12
- Art des Abonnements: 0.10
- Käufe insgesamt: 0.15
Auf dieser Grundlage können wir die Merkmale nach ihrer Bedeutung für die Vorhersage der Kundenabwanderung einstufen:
- Käufe insgesamt: 0.15
- Einkommen: 0.12
- Art des Abonnements: 0.10
- Alter: 0.08
- Geschlecht: 0.03
In diesem Beispiel hat „Gesamtkäufe“ die höchste Transinformationsbewertung, was bedeutet, dass es die meisten Informationen über die Kundenabwanderung enthält. Einkommen und Abonnementtyp folgen dicht dahinter, während Alter und Geschlecht relativ niedrige Werte für die Transinformation aufweisen.
Mit Hilfe der Transinformation können wir jede Datenspalte gewichten und herausfinden, welche Spalten durch Hinzufügen von monoiden Aktionen weiter untersucht werden können. Dieser Datensatz ist völlig neu und nicht vergleichbar mit dem, den wir in einem früheren Artikel hatten. Zur Veranschaulichung ist es daher hilfreich, zunächst Monoide für jede Datenspalte zu konstruieren, indem man die entsprechenden Mengen definiert. Die Käufe insgesamt der Datenspalte mit der vermeintlich höchsten Transinformation sind kontinuierliche Daten und nicht diskret, was bedeutet, dass wir die monoide Menge nicht so einfach erweitern können, indem wir Enumerationen einführen, die im Basismonoid nicht möglich sind. Um die Gesamtkäufe im Monoid weiter zu untersuchen oder zu erweitern, könnten wir also die Dimension des Kaufdatums hinzufügen. Das bedeutet, dass unser Aktionssatz fortlaufende Daten von datetime enthalten wird. Bei einer Verknüpfung (über eine Aktion) mit einem Monoid über die Gesamtkäufe könnten wir für jeden Kauf das Kaufdatum erhalten, was uns erlauben würde, die Bedeutung von Kaufdaten und -beträgen für die Kundenabwanderung zu untersuchen. Dies könnte zu genaueren Prognosen führen.
Modellspezifische Techniken
Einige Algorithmen für maschinelles Lernen verfügen über spezielle Methoden zur Bestimmung der Bedeutung von Merkmalen. Algorithmen, die auf Entscheidungsbäumen basieren, können beispielsweise die Wichtigkeit eines Merkmals anhand der Anzahl der Verwendungen eines Merkmals zur Aufteilung von Daten auf verschiedene Bäume bewerten.
Betrachten wir ein Szenario, in dem wir einen Datensatz mit Kundeninformationen haben und vorhersagen möchten, ob ein Kunde ein Produkt kaufen wird, basierend auf verschiedenen Merkmalen wie Alter, Geschlecht, Einkommen und Verlauf der Seitenaufrufe (browsing history). Wir beschließen, für diese Aufgabe den Klassifikator Random Forest zu verwenden, einen Algorithmus, der auf Entscheidungsbäumen basiert. So können wir mit diesem Klassifikator die Wichtigkeit von Merkmalen bestimmen:
- Wir beginnen mit dem Training eines Random-Forest-Klassifikators unter Verwendung aller Merkmale des Datensatzes. Random Forest ist ein Ensemble-Algorithmus, der mehrere Entscheidungsbäume kombiniert.
- Nach dem Training des Random-Forest-Modells können wir die für diesen Algorithmus spezifischen Werte für die Bedeutung der Merkmale extrahieren. Die Bewertung der Wichtigkeit der Merkmale zeigt die relative Wichtigkeit der einzelnen Merkmale bei der Klassifizierung an.
- Anschließend ordnen wir die Merkmale nach ihrer Wichtigkeit. Merkmale mit höheren Punktzahlen werden als wichtiger angesehen, da sie einen größeren Einfluss auf die Leistung des Modells haben.
Nach dem Training des Random-Forest-Klassifikators erhalten wir beispielsweise die folgenden Werte für die Bedeutung der Merkmale:
- Alter: 0.28
- Geschlecht: 0.12
- Einkommen: 0.34
- Verlauf der Seitenaufrufe: 0.46
Auf der Grundlage dieser Merkmalsbewertungen können wir die Merkmale nach ihrer Bedeutung für die Vorhersage von Kundenkäufen einstufen:
- Verlauf der Seitenaufrufe: 0.46
- Einkommen: 0.34
- Alter: 0.28
- Geschlecht: 0.12
In diesem Beispiel hat der Verlauf der Seitenaufrufe die höchste Wichtigkeit, was bedeutet, dass es das einflussreichste Merkmal für die Vorhersage von Kundenkäufen ist. Das Einkommen folgt dicht dahinter, während Alter und Geschlecht eine relativ geringe Bedeutung haben. Durch die Nutzung spezifischer Methoden des Random Forest Algorithmus können wir die Wichtigkeit von Merkmalen auf der Grundlage der Häufigkeit, mit der jedes Merkmal verwendet wird, um Daten auf verschiedene Bäume im Ensemble aufzuteilen, ermitteln. Anhand dieser Informationen können wir die wichtigsten Merkmale ermitteln, die am stärksten zur Vorhersage beitragen. Sie hilft bei der Auswahl von Merkmalen, beim Verständnis der zugrunde liegenden Muster in den Daten und bei der potenziellen Verbesserung der Modellleistung.
Expertenwissen und spezifische Kompetenzen
Zusätzlich zu den quantitativen Methoden ist die Einbeziehung von Expertenwissen und Fachwissen entscheidend für die Bewertung der Bedeutung von Merkmalen. Fachexperten können aufgrund ihres Fachwissens und ihrer Erfahrung stets Einblicke in die Relevanz und Bedeutung bestimmter Merkmale geben. Es ist auch wichtig zu beachten, dass verschiedene Methoden zu leicht unterschiedlichen Ergebnissen führen können und die Wahl der Technik von den spezifischen Eigenschaften des Datensatzes und des verwendeten Algorithmus für maschinelles Lernen abhängen kann. Es wird oft empfohlen, mehrere Techniken anzuwenden, um ein umfassendes Verständnis der Bedeutung von Merkmalen zu erhalten.
Umsetzung
Um die Gewichtung unserer Datenspalten/Merkmale zu implementieren, werden wir die Korrelation verwenden. Da wir mit denselben Merkmalen arbeiten wie im vorigen Artikel, vergleichen wir die Korrelation zwischen den Werten der Monoidsätze und den Veränderungen in der Preisspanne, um die Gewichtung der einzelnen Datenspalten zu ermitteln. Jede Datenspalte ist ein Monoid mit einer Menge, wobei die Werte der Menge die Spaltenwerte sind. Da wir testen, wissen wir zu Beginn nicht, ob die am stärksten korrelierte Spalte erweitert (durch monoide Aktionen transformiert) oder die Datenspalte mit der geringsten Korrelation sein soll. Zu diesem Zweck fügen wir einen zusätzlichen Parameter hinzu, der die Auswahl bei verschiedenen Testläufen erleichtern wird. Außerdem haben wir zusätzliche globale Parameter eingeführt, um den Monoid-Aktionen gerecht zu werden:
//+------------------------------------------------------------------+ //| TrailingCT.mqh | //| Copyright 2009-2013, MetaQuotes Software Corp. | //| http://www.mql5.com | //+------------------------------------------------------------------+ #include <Math\Stat\Math.mqh> #include <Expert\ExpertTrailing.mqh> #include <ct_9.mqh> // wizard description start //+------------------------------------------------------------------+ //| Description of the class | //| Title=Trailing Stop based on 'Category Theory' monoid-action concepts | //| Type=Trailing | //| Name=CategoryTheory | //| ShortName=CT | //| Class=CTrailingCT | //| Page=trailing_ct | //|.... //| Parameter=IndicatorIdentity,int,0, Indicator Identity | //| Parameter=DecisionOperation,int,0, Decision Operation | //| Parameter=DecisionIdentity,int,0, Decision Identity | //| Parameter=CorrelationInverted,bool,false, Correlation Inverted | //+------------------------------------------------------------------+ // wizard description end //+------------------------------------------------------------------+ //| Class CTrailingCT. | //| Appointment: Class traling stops with 'Category Theory' | //| monoid-action concepts. | //| Derives from class CExpertTrailing. | //+------------------------------------------------------------------+ int __LOOKBACKS[8] = {1,2,3,4,5,6,7,8}; ENUM_TIMEFRAMES __TIMEFRAMES[8] = {PERIOD_H1,PERIOD_H2,PERIOD_H3,PERIOD_H4,PERIOD_H6,PERIOD_H8,PERIOD_H12,PERIOD_D1}; ENUM_APPLIED_PRICE __APPLIEDPRICES[4] = { PRICE_MEDIAN, PRICE_TYPICAL, PRICE_OPEN, PRICE_CLOSE }; string __INDICATORS[2] = { "RSI", "BOLLINGER_BANDS" }; string __DECISIONS[2] = { "TREND", "RANGE" }; #define __CORR 5 int __LOOKBACKS_A[10] = {1,2,3,4,5,6,7,8,9,10}; ENUM_TIMEFRAMES __TIMEFRAMES_A[10] = {PERIOD_H1,PERIOD_H2,PERIOD_H3,PERIOD_H4,PERIOD_H6,PERIOD_H8,PERIOD_H12,PERIOD_D1,PERIOD_W1,PERIOD_MN1}; ENUM_APPLIED_PRICE __APPLIEDPRICES_A[5] = { PRICE_MEDIAN, PRICE_TYPICAL, PRICE_OPEN, PRICE_CLOSE, PRICE_WEIGHTED }; //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class CTrailingCT : public CExpertTrailing { protected: //--- adjusted parameters double m_step; // trailing step ... // CMonoidAction<double,double> m_lookback_act; CMonoidAction<double,double> m_timeframe_act; CMonoidAction<double,double> m_appliedprice_act; bool m_correlation_inverted; int m_lookback_identity_act; int m_timeframe_identity_act; int m_appliedprice_identity_act; int m_source_size; // Source Size public: //--- methods of setting adjustable parameters ... void CorrelationInverted(bool value) { m_correlation_inverted=value; } ... };
Ferner wurden auch die Funktionen „Operate_X“ zu einer einzigen Funktion namens „Operate“ zusammengefasst. Darüber hinaus wurden die 'Get'-Funktionen für die Datenspalten erweitert, um Monoid-Aktionen unterzubringen, und es wurde eine Überladung für jede dieser Funktionen hinzugefügt, um bei der Indizierung der jeweiligen globalen Variablen-Arrays zu helfen.
Auf diese Weise entwickeln wir also unsere Trailing-Klasse.
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void CTrailingCT::Operate(CMonoid<double> &M,EOperations &O,int &OutputIndex) { OutputIndex=-1; // double _values[]; ArrayResize(_values,M.Cardinality());ArrayInitialize(_values,0.0); // ... // if(O==OP_LEAST) { OutputIndex=0; double _least=_values[0]; for(int i=0;i<M.Cardinality();i++) { if(_least>_values[i]){ _least=_values[i]; OutputIndex=i; } } } else if(O==OP_MOST) { OutputIndex=0; double _most=_values[0]; for(int i=0;i<M.Cardinality();i++) { if(_most<_values[i]){ _most=_values[i]; OutputIndex=i; } } } else if(O==OP_CLOSEST) { double _mean=0.0; for(int i=0;i<M.Cardinality();i++) { _mean+=_values[i]; } _mean/=M.Cardinality(); OutputIndex=0; double _closest=fabs(_values[0]-_mean); for(int i=0;i<M.Cardinality();i++) { if(_closest>fabs(_values[i]-_mean)){ _closest=fabs(_values[i]-_mean); OutputIndex=i; } } } else if(O==OP_FURTHEST) { double _mean=0.0; for(int i=0;i<M.Cardinality();i++) { _mean+=_values[i]; } _mean/=M.Cardinality(); OutputIndex=0; double _furthest=fabs(_values[0]-_mean); for(int i=0;i<M.Cardinality();i++) { if(_furthest<fabs(_values[i]-_mean)){ _furthest=fabs(_values[i]-_mean); OutputIndex=i; } } } } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ int CTrailingCT::GetLookback(CMonoid<double> &M,int &L[]) { m_close.Refresh(-1); int _x=StartIndex(); ... int _i_out=-1; // Operate(M,m_lookback_operation,_i_out); if(_i_out==-1){ return(4); } return(4*L[_i_out]); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ ENUM_TIMEFRAMES CTrailingCT::GetTimeframe(CMonoid<double> &M, ENUM_TIMEFRAMES &T[]) { ... int _i_out=-1; // Operate(M,m_timeframe_operation,_i_out); if(_i_out==-1){ return(INVALID_HANDLE); } return(T[_i_out]); }
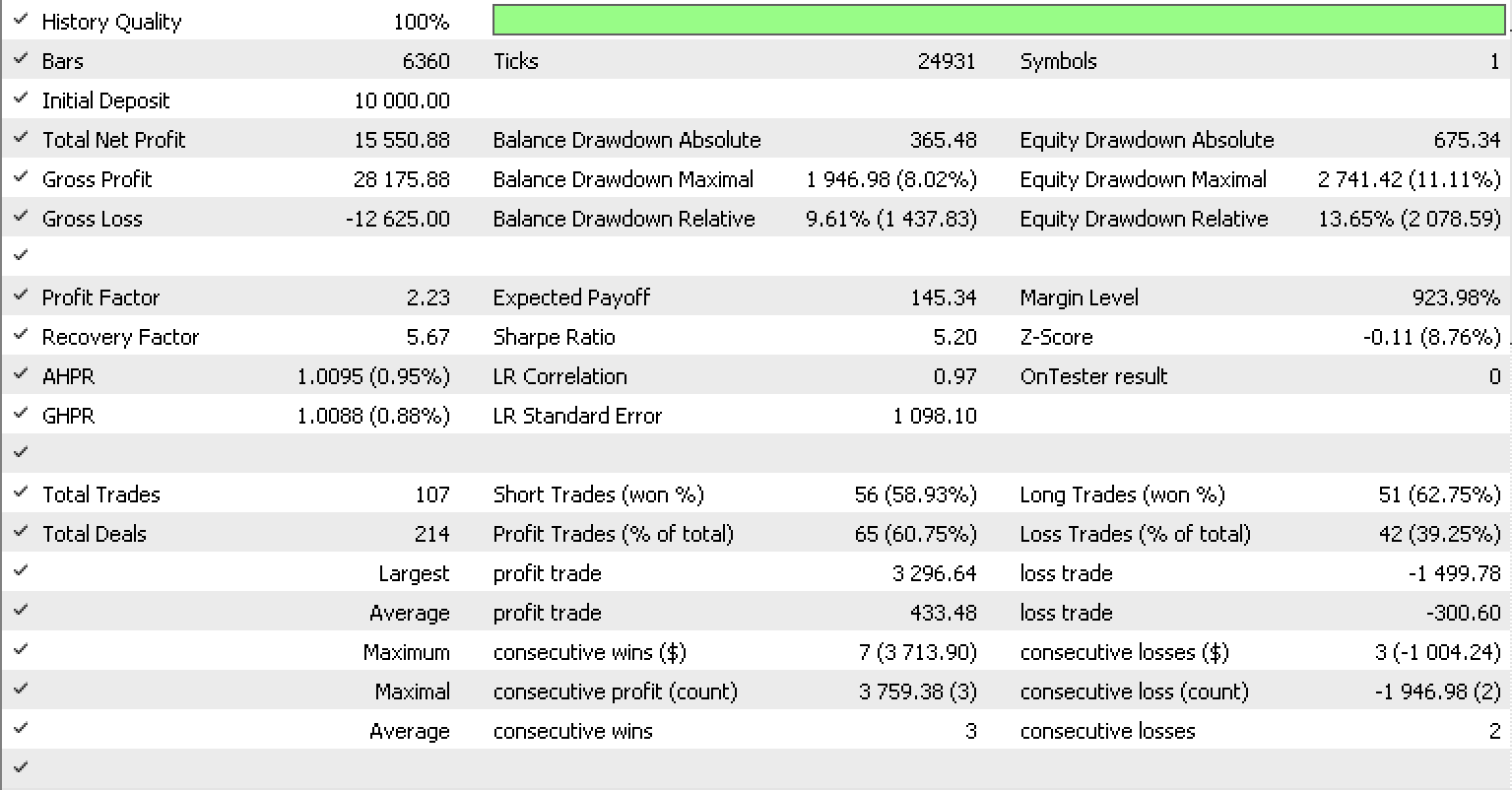
Wenn wir Tests wie im vorherigen Artikel für EURUSD auf dem einstündigen Zeitrahmen vom 2022.05.01 bis 2023.05.15 unter Verwendung der in der Bibliothek eingebauten RSI-Signalklasse durchführen, sehen wir folgenden Testbericht.
Schlussfolgerung
Zusammenfassend haben wir untersucht, wie transformierte Monoide, auch bekannt als Monoid-Aktionen, ein Trailing-Stop-System, das Prognosen zur Volatilität erstellt, weiter verfeinern können, um den Stop-Loss von offenen Positionen genauer anzupassen. Dies wurde zusammen mit verschiedenen Methoden untersucht, die üblicherweise bei der Gewichtung von Modellmerkmalen (in unserem Fall Datenspalten) verwendet werden, um das Modell und seine Empfindlichkeiten besser zu verstehen und festzustellen, welche Merkmale gegebenenfalls erweitert werden müssen, um die Genauigkeit des Modells zu verbessern. Ich hoffe, es hat euch gefallen und danke fürs Lesen.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/12739
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.